Flash Flood Risk Analysis Based on Machine Learning Techniques in the Yunnan Province, China

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data
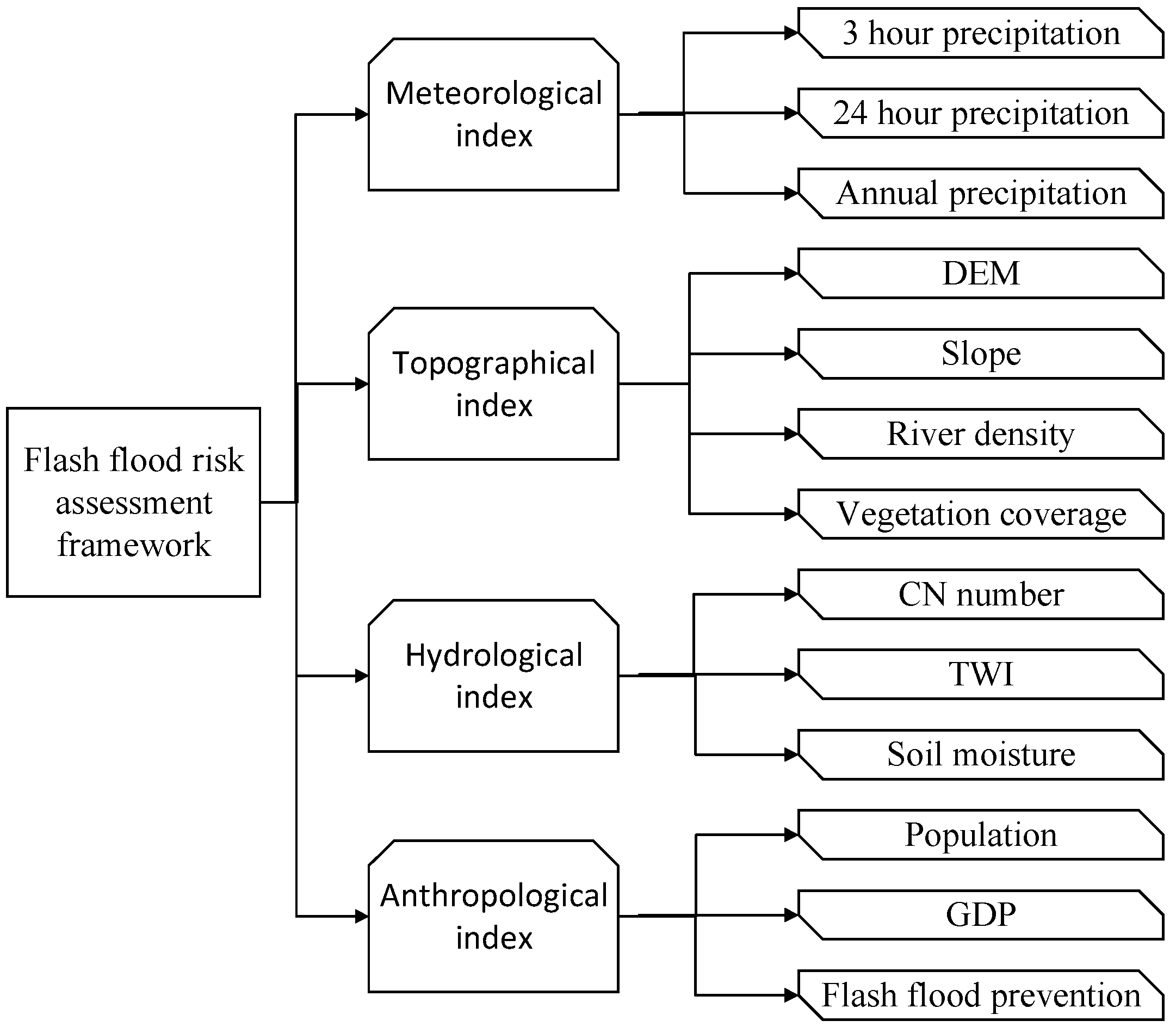
2.3. Flash Flood Triggering Factors
2.4. Methodology
3. Results and Discussion
3.1. Comparison of Results Obtained by Four Models
3.2. Flash Flood Risk Map Comparison
4. Conclusions
- (1)
- LSSVM can provide a more accurate risk assessment than LR and LSSVM with RBF kernel evaluates best.
- (2)
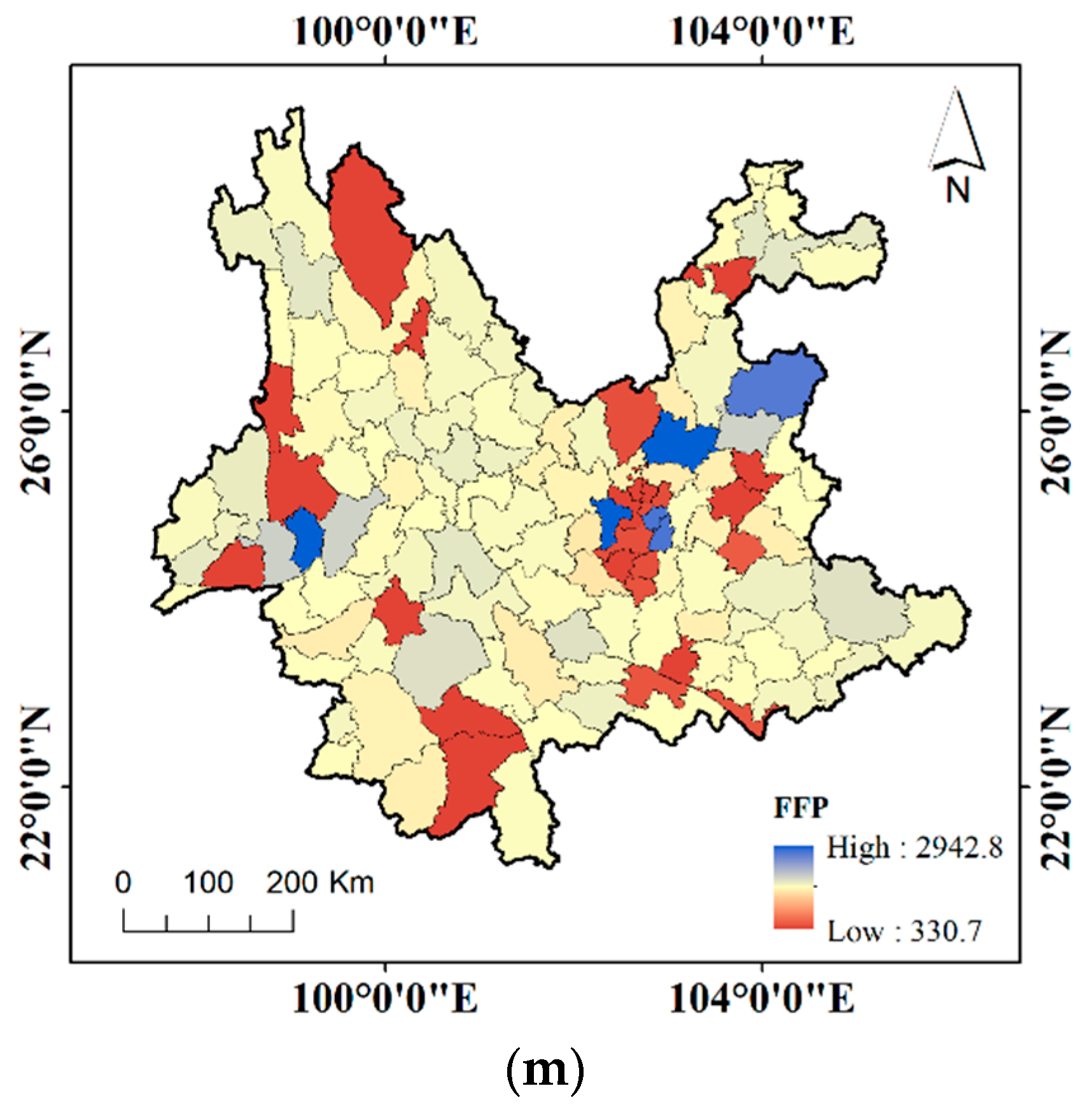
- The risk of flash flood in Yunnan Province is shown as a normal distribution. The highest risk areas are mainly concentrated in the central and western regions and the lowest risk areas are distributed in the northwest regions.
- (3)
- Flash floods are caused by the combination of various factors and the rank of various factors affecting flash floods is as follows: CN > DEM > SL > RD > FFP > TWI > 24-H-P > 3-H-P > AP > POP > SM > GDP > VC.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Baker, V.R.; Kochel, R.C.; Patton, P.C. Flood Geomorphology; John Wiley and Sons: New York, NY, USA, 1987; ISBN 978-0-12-394846-5. [Google Scholar]
- Gruntfest, E.; Handmer, J. Coping with Flash Floods; Nato Science: Washington, DC, USA, 2001. [Google Scholar]
- Gourley, J.J.; Flamig, Z.L.; Vergara, H.; Kirstetteret, P.E.; Argyle, E.; Terti, G.; Erlingis, J.M.; Hong, Y.; Howard, K.W.; Arthur, A.; et al. The flooded locations and simulated hydrographs (FLASH) project: Improving the tools for flash flood monitoring and prediction across the United States. Bull. Am. Meteorol. Soc. 2016, 98, 361–372. [Google Scholar] [CrossRef]
- Mousavi, M.E.; Irish, J.L.; Frey, A.E.; Olivera, F.; Edge, B.L. Global warming and hurricanes: The potential impact of hurricane intensification and sea level rise on coastal flooding. Clim. Change 2011, 104, 575–597. [Google Scholar] [CrossRef]
- Creutin, J.D.; Borga, M.; Gruntfest, E.; Lutoff, C.; Zoccatelli, D.; Ruin, I. A space and time framework for analyzing human anticipation of flash floods. J. Hydrol. 2013, 482, 14–24. [Google Scholar] [CrossRef]
- Klijn, F.; Kreibich, H.; Moel, H.D.; Penning-Rowsell, E.C. Adaptive flood risk management planning based on a comprehensive flood risk conceptualization. Mitig. Adapt. Strateg. Glob. Chang. 2015, 20, 845–864. [Google Scholar] [CrossRef] [PubMed]
- Dutta, D.; Herath, S.; Musiake, K. A mathematical model for flood loss estimation. J. Hydrol. 2003, 277, 24–49. [Google Scholar] [CrossRef]
- Dottori, F.; Baldassarre, G.D.; Todini, E. Detailed data is welcome, but with a pinch of salt: Accuracy, precision, and uncertainty in flood inundation modeling. Water Resour. Res. 2014, 49, 6079–6085. [Google Scholar] [CrossRef]
- Alfieri, L.; Salamon, P.; Bianchi, A.; Neal, J.C.; Bates, P.; Feyen, L. Advances in pan-European flood hazard mapping. Hydrol. Process. 2014, 28, 4067–4077. [Google Scholar] [CrossRef]
- Sampson, C.C.; Smith, A.M.; Bates, P.D.; Neal, J.C.; Alfieri, L.; Freer, J.E. A high-resolution global flood hazard model. Water Resour. Res. 2015, 51, 7358–7381. [Google Scholar] [CrossRef] [Green Version]
- Mcmillan, H.K.; Brasington, J. Reduced complexity strategies for modelling urban floodplain inundation. Geomorphology 2007, 90, 226–243. [Google Scholar] [CrossRef]
- Bao, H.; Wang, L.; Zhang, K.; Li, Z. Application of a developed distributed hydrological model based on the mixed runoff generation model and 2D kinematic wave flow routing model for better flood forecasting. Atmos. Sci. Lett. 2017, 18, 284–293. [Google Scholar] [CrossRef] [Green Version]
- Huang, P.N.; Li, Z.J.; Li, Q.L.; Zhang, K.; Zhang, H.C. Application and comparison of coaxial correlation diagram and hydrological model for reconstructing flood series under human disturbance. J. Mt. Sci. 2016, 13, 1245–1264. [Google Scholar] [CrossRef]
- Ma, Z.; Shi, Z.; Zhou, Y.; Xu, J.; Yu, W.; Yang, Y. A spatial data mining algorithm for downscaling TMPA 3B43 V7 data over the Qinghai-Tibet Plateau with the effects of systematic anomalies removed. Remote Sens. Environ. 2017, 200, 378–395. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood susceptibility assessment using GIS-based support vector machine model with different kernel types. Catena 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Kalteh, A.M. Improving forecasting accuracy of streamflow time series using least squares support vector machine coupled with data-preprocessing techniques. Water Resour. Manag. 2016, 30, 747–766. [Google Scholar] [CrossRef]
- Pradhan, B. Flood susceptible mapping and risk area delineation using logistic regression, GIS and remote sensing. J. Sp. Hydrol. 2010, 9, 1–18. [Google Scholar]
- Zeng, Z.; Tang, G.; Long, D.; Zeng, C.; Ma, M.; Hong, Y.; Xu, J. A cascading flash flood guidance system: Development and application in Yunnan Province, China. Nat. Hazards 2016, 84, 2071–2093. [Google Scholar] [CrossRef]
- Duan, C.C.; Zhu, Y.; You, W.H. Characteristic and formation cause of drought and flood in Yunnan province rainy season. Plateau Meteorol. 2007, 26, 402–408. [Google Scholar]
- Lindsay, J.B.; Rothwell, J.J.; Davies, H. Mapping outlet points used for watershed delineation onto DEM-derived stream networks. Water Resour. Res. 2008, 44, 370–380. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Yue, J.; Tu, T. Mapping flood susceptibility in mountainous areas on a national scale in China. Sci. Total Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef]
- Pettorelli, N.; Ryan, S.; Mueller, T.; Bunnefeld, N.; Jędrzejewska, B.; Lima, M.; Kausrud, K. The normalized difference vegetation index (NDVI): Unforeseen successes in animal ecology. Clim. Res. 2011, 46, 15–27. [Google Scholar] [CrossRef]
- Zeng, Z.; Tang, G.; Hong, Y.; Zeng, C.; Yang, Y. Development of an NRCS curve number global dataset using the latest geospatial remote sensing data for worldwide hydrologic applications. Remote Sens. Lett. 2017, 8, 528–536. [Google Scholar] [CrossRef]
- Sørensen, R.; Zinko, U.; Seibert, J. On the calculation of the topographic wetness index: Evaluation of different methods based on field observations. Hydrol. Earth Syst. Sci. 2005, 10, 101–112. [Google Scholar] [CrossRef]
- Abelen, S.; Seitz, F.; Abarca-del-Rio, R.; Güntner, A. Droughts and floods in the La Plata basin in soil moisture data and GRACE. Remote Sens. 2015, 7, 7324–7349. [Google Scholar] [CrossRef]
- Jongman, B.; Kreibich, H.; Apel, H.; Barredo, J.I.; Bates, P.D.; Feyen, L.; Ward, P.J. Comparative flood damage model assessment: Towards a European approach. Nat. Hazards Earth Syst. Sci. 2012, 12, 3733–3752. [Google Scholar] [CrossRef]
- Guo, L.; He, B.; Ma, M.; Chang, Q.; Li, Q.; Zhang, K.; Hong, Y. A comprehensive flash flood defense system in China: Overview, achievements, and outlook. Nat. Hazards 2018, 92, 1–14. [Google Scholar] [CrossRef]
- He, B.; Huang, X.; Ma, M.; Chang, Q.; Tu, Y.; Li, Q.; Hong, Y. Analysis of flash flood disaster characteristics in China from 2011 to 2015. Nat. Hazards 2017, 90, 1–14. [Google Scholar] [CrossRef]
- Dos Santos, G.S.; Luvizotto, L.G.J.; Mariani, V.C.; Dos Santos Coelho, L. Squares support vector machines with tuning based on chaotic differential evolution approach applied to the identification of a thermal process. Expert Syst. Appl. 2012, 39, 4805–4812. [Google Scholar] [CrossRef]
- Zhu, B.; Wei, Y. Carbon price forecasting with a novel hybrid ARIMA and least squares support vector machines methodology. Omega Intern. J. Manag. Sci. 2013, 41, 517–524. [Google Scholar] [CrossRef]
- Budimir, M.E.A.; Atkinson, P.M.; Lewis, H.G. A systematic review of landslide probability mapping using logistic regression. Landslides 2015, 12, 419–436. [Google Scholar] [CrossRef] [Green Version]
- He, J. Assessment and Regionalization of Drought Disaster Risk in Yunnan Province[D]; Yunnan University: Kunming, China, 2016. [Google Scholar]
- Wang, L.; Wang, S.; Wang, X.; Wang, F.; Fan, C. Risk zoning of drought disaster based on AHP and GIS in Yunnan province. Water Sav. Irrig. 2017, 10, 100–103, 106. [Google Scholar]
- Smith, G.E. Development of a Flash Flood Potential Index Using Physiographic Data Sets within a Geographic Information System. Ph.D. Thesis, The University of Utah, Salt Lake City, UT, USA, 2010. [Google Scholar]
- Minea, G. Assessment of the flash flood potential of Basca River Catchment (Romania) based on physiographic factors. Cent. Eur. J. Geosci. 2013, 5, 344–353. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Source | Time | |
|---|---|---|---|
| Abbreviation | Meaning | ||
| 3-H-P | Annual maximum 3 h precipitation | China Meteorological Forcing Dataset | 2011–2015 |
| 24-H-P | Annual maximum 24 h precipitation | China Meteorological Forcing Dataset | 2011–2015 |
| AP | Annual precipitation | China Meteorological Forcing Dataset | 2011–2015 |
| DEM | Digital elevation model | Shuttle Radar Topography Mission (SRTM) | 2000 |
| SL | Slope | Shuttle Radar Topography Mission (SRTM) | 2000 |
| RD | River density | Basic vector format dataset of China | - |
| VC | Vegetation coverage | MODIS products | 2011–2015 |
| CN | Curve number | NRCS CN global dataset | 2011–2015 |
| TWI | Topographic wetness index | Shuttle Radar Topography Mission (SRTM) | 2000 |
| SM | Soil moisture | ESA’s SMOS dataset | 2011–2015 |
| Pop | Population | Data Center for Resources and Environmental Sciences Chinese Academy of Sciences (RESDC) | 2010 |
| GDP | Gross domestic product | Data Center for Resources and Environmental Sciences Chinese Academy of Sciences (RESDC) | 2010 |
| FFP | Flash flood preventions | Statistic bulletin from the Ministry of Water Resources and local governments | 2012–2015 |
| Index | Model 1 | Model 2 | Model 3 | Model 4 |
|---|---|---|---|---|
| Accuracy | 0.78 | 0.79 | 0.76 | 0.75 |
| Precision | 0.81 | 0.82 | 0.79 | 0.76 |
| Recall | 0.74 | 0.77 | 0.74 | 0.74 |
| F-score | 0.78 | 0.79 | 0.76 | 0.75 |
| Kappa | 0.56 | 0.59 | 0.53 | 0.50 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, M.; Liu, C.; Zhao, G.; Xie, H.; Jia, P.; Wang, D.; Wang, H.; Hong, Y. Flash Flood Risk Analysis Based on Machine Learning Techniques in the Yunnan Province, China. Remote Sens. 2019, 11, 170. https://doi.org/10.3390/rs11020170
Ma M, Liu C, Zhao G, Xie H, Jia P, Wang D, Wang H, Hong Y. Flash Flood Risk Analysis Based on Machine Learning Techniques in the Yunnan Province, China. Remote Sensing. 2019; 11(2):170. https://doi.org/10.3390/rs11020170
Chicago/Turabian StyleMa, Meihong, Changjun Liu, Gang Zhao, Hongjie Xie, Pengfei Jia, Dacheng Wang, Huixiao Wang, and Yang Hong. 2019. "Flash Flood Risk Analysis Based on Machine Learning Techniques in the Yunnan Province, China" Remote Sensing 11, no. 2: 170. https://doi.org/10.3390/rs11020170