1. Introduction
Deeper and wider architectures of convolutional neural networks (CNNs) have achieved great success in the field of computer vision and have been widely used in both academia and industry [
1,
2,
3,
4,
5,
6]. Nevertheless, they also impose high requirements for computing power and memory footprint, resulting in a significant challenge in deploying most state-of-the-art CNNs on mobile or edge devices. Therefore, reducing the parameters and calculations of existing models is still a research hot spot, where an effective technique is model compression. This technique can achieve a balanced trade-off between accuracy and model size.
Conventional compression strategies consist of network pruning [
7,
8,
9,
10,
11], quantization [
12,
13,
14], low-rank approximation [
15,
16], knowledge distillation [
17,
18,
19,
20] and lightweight neural framework design [
21,
22,
23]. Network pruning has become the most popular model compression technique. Recent pruning strategies in this category can be roughly divided into weight pruning [
8,
24,
25] and filter pruning [
26,
27,
28], according to the granularity of pruning. Weight pruning directly removes the selected weights from a filter, resulting in unstructured sparsity. Despite the irregular structure having a high compression ratio, real acceleration cannot be achieved on general hardware platforms or Basic Linear Algebra Subprogram (BLAS) libraries [
29]. Filter pruning directly discards the selected filters, leaving a regular network structure, which makes it hardware friendly. CNNs have exerted a great influence on remote sensing classification tasks with their powerful feature representation capability. Zhang et al. [
30] and Volpi [
31] constructed relatively small networks and trained them using satellite images from scratch. Xia et al. [
32] and Marmanis et al. [
33] extracted features from the middle layer of the pre-training network, formed global feature representation and realized remote sensing classification. Nogueira et al. [
34] used a remote sensing dataset for fine-tuning and obtained a superior classification performance. Zhu et al. [
35] proposed a knowledge-guided land pattern depicting (KGLPD) framework for urban land-use mapping. Ref. [
36] constructed a new remote sensing knowledge graph (RSKG) from scratch to support the inference recognition of unseen remote sensing image scenes. Zhang et al. [
37] made full use of the advantages of CNNs and CapsNet models to propose an effective framework for remote sensing image scene classification. Ref. [
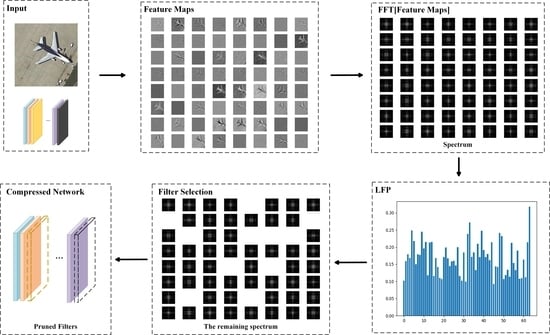
38] proposed a CNN pre-training method guided by the human visual attention mechanism to improve the land-use scene classification accuracy. However, the success of CNNs comes with expensive computing costs and a high memory footprint. However, the classification task of remote sensing images often needs to be carried out on the airborne or satellite-borne equipment with limited computing resources. Insufficient computing resources hinder the application of CNNs in remote sensing imaging. Therefore, model pruning technology can alleviate this resource constraint and enable CNNs to develop in the field of remote sensing. It is worth noting that the scale of public remote sensing image datasets is usually smaller than the scale of natural image datasets, which contain hundreds of thousands or even millions of images. This leads to a lot of parameter redundancy and structural redundancy in the network model, so pruning techniques are needed to reduce these redundancies and avoid overfitting of the model. Therefore, pruning technology has a great application demand and prospect in real-time remote sensing image classification (as shown in
Figure 1) for resource-constrained devices such as spaceborne or airborne devices [
39,
40].
To achieve both network speedup (reduction in FLOPs) and a model size reduction (reduction in parameters), we focus on filter pruning aiming to provide a general solution (as shown in
Figure 2) for devices with a low computational power.
Inherent Attribute Constraint. The pruning operation on a filter can be regarded as decreasing the constraints generated by different inherent attributes in CNNs. Li et al. [
26] calculated the
-norm of parameters or features to judge the degree of attribute constraints. The conclusion was that the smaller norm, the less useful the information, which indicates that a smaller norm is a weak constraint for the network and should be pruned first. Hu et al. [
41] measured the constraint of each filter by counting the Average Percentage of Zeros (APoZ) in the activation values output by the filter. The sparser the activation feature map, the weaker the constraints of the feature map. Molchanov et al. [
42] used a first-order Taylor expansion to approximate the contribution of feature maps to the network output to estimate the importance of filters. He et al. [
43] calculated the geometric median of filters in the same layer, in this case, the filter closest to the geometric median is considered as a weak constraint that should be pruned first. Lin et al. [
44] proposed that feature maps with a lower rank have fewer constraints on the network. Therefore, the corresponding filters can be removed first. Sui et al. [
45] proposed to estimate the independence of channels by calculating the nuclear norm of the feature map. Channels with a lower independence have weaker constraints and can be deleted first. In brief, these methods follow the principle of “weak constraints are pruned, strong constraints are retained” to achieve fast pruning. Nevertheless, they cannot make up for the loss in the network training process while merely improving the performance by fine-tuning in the later stage.
Induction of sparsity. These methods learn sparse structure pruning by imposing sparsity constraints on the target function in the network. Wen et al. [
28] proposed a compression method based on structured sparse learning, which learns different compact structures by regularizing various network structures. Huang et al. [
46] also introduced a new scaling factor, which scales the output of various structures, such as neurons, group convolutions or residual blocks, and then safely removes structures whose corresponding scaling factor is close to zero. In contrast to [
46], Liu et al. [
47] utilized the scaling parameter in the batch normalization layer to control the output of the corresponding channel without introducing any additional parameters. Zhao et al. [
48] further extended the scaling parameters in the batch normalization layer to include bias terms and estimated their probability distributions by variational inference. These methods are not based on deterministic values but on the distribution of the corresponding scaling parameters to prune redundant channels, which makes them more interpretable. Lin et al. [
49] studied important filters by incorporating two different regularizations of structural sparsity into the original loss function, achieving a superior performance on a variety of state-of-the-art network frameworks. Chen et al. [
50] imposed regularizations on both filter weights and BN scaling factors and then evaluated the filter importance by their combination. Compared with the inherent attribute constraint method, the induction of sparsity achieves better compression and acceleration results. Nevertheless, the sparsity requirement must be embedded into the training process, so it is expensive with regard to training time and manpower.
In general, it is desirable to pursue a higher compression ratio and speedup ratio without losing too much accuracy. In recent years, pruning models according to the constraints provided by different inherent attributes in CNNs has become a popular filter pruning strategy. Instead of directly selecting filters, important feature maps are first determined and then the corresponding channels are retained. As reported in [
44,
45,
51,
52,
53], feature maps can inherently reflect rich and important information about the input data and filters. Therefore, calculating the importance of feature maps could provide better pruning guidance for filters/channels. For example, the feature-oriented pruning concept [
45] can provide richer knowledge of filter pruning than the intra-channel information when considering the correlation of multiple filter/channel feature information. The importance of a filter that is merely determined by its corresponding feature map could be easily affected by the input data. On the contrary, cross-channel feature information leads to more stable and reliable measurements, as well as a deeper exploitation of the underlying correlations between different feature maps (and corresponding filters). The results in [
45] also show that the proposed inter-channel and feature-guided strategy outperforms the state-of-the-art filter-guided methods in terms of task performance (e.g., accuracy) and compression performance (e.g., model size and floating-point operation reduction).
Preference and Frequency Perspective. In previous work, both the feature-map-based strategy and the filter-guided strategy passively formulate the pruning strategy according to the inherent internal structure of CNNs in the spatial domain. Specifically, some theories, such as optimal brain damage [
54] and the lottery ticket hypothesis [
55,
56], propose that there is parameter redundancy inside the model. Therefore, only if the parameters of the filter or feature maps are calculated in the spatial domain can their importance be determined according to experience and mathematical knowledge. Considering the “preference” of the model from the perspective of frequency domain, it can be found that the neural network often learns low-frequency information first, and then slowly learns high-frequency information [
57,
58] in the process of fitting the data (and some high-frequency information cannot be perfectly fitted). At the same time, the human visual system is sensitive to the representation of low-frequency information [
59,
60], while the representation of low-frequency information in the spatial domain is not prominent enough. We can observe from
Figure 3 that after discarding part of the high-frequency information, the category of the image can still be identified through the retained low-frequency information.
In order to maintain the consistency between the model characteristics and the human visual system, it is necessary to explore new methods in the frequency domain. Experiments in [
61] show that, after adding a low-frequency filter in the test image, the robustness of the whole model is enhanced. In addition, adding low-frequency information can efficiently improve the accuracy and gradually achieve a performance similar to the original image. Considering that most real scenario images are predominantly low frequency, the influence of noise is relatively negligible on the low-frequency images but enormous on the high-frequency images, which easily leads to overfitting of the model. Therefore, a better task and compression performance can be obtained by discarding the learning of high-frequency information (the feature maps with more high-frequency components are pruned).
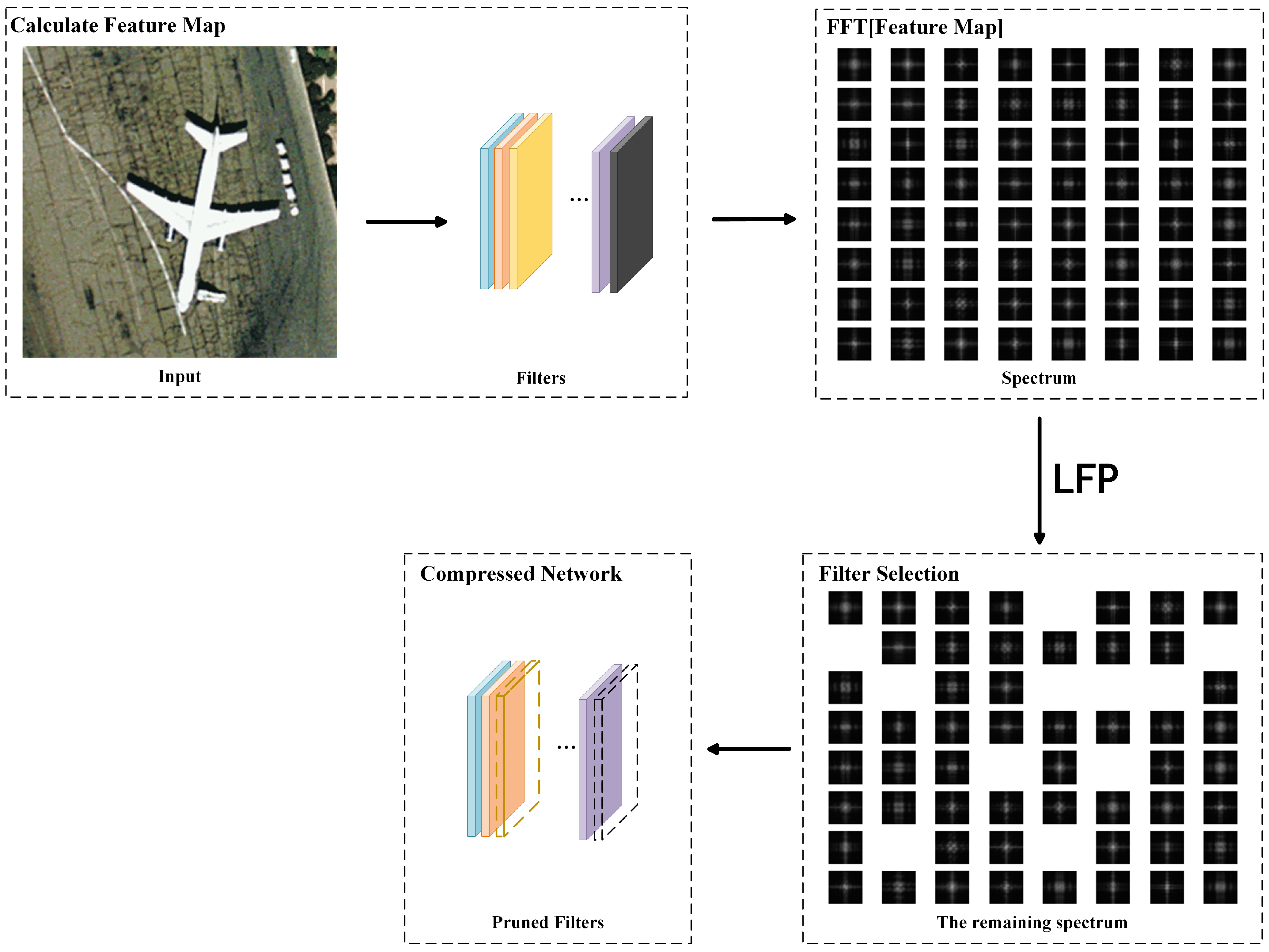
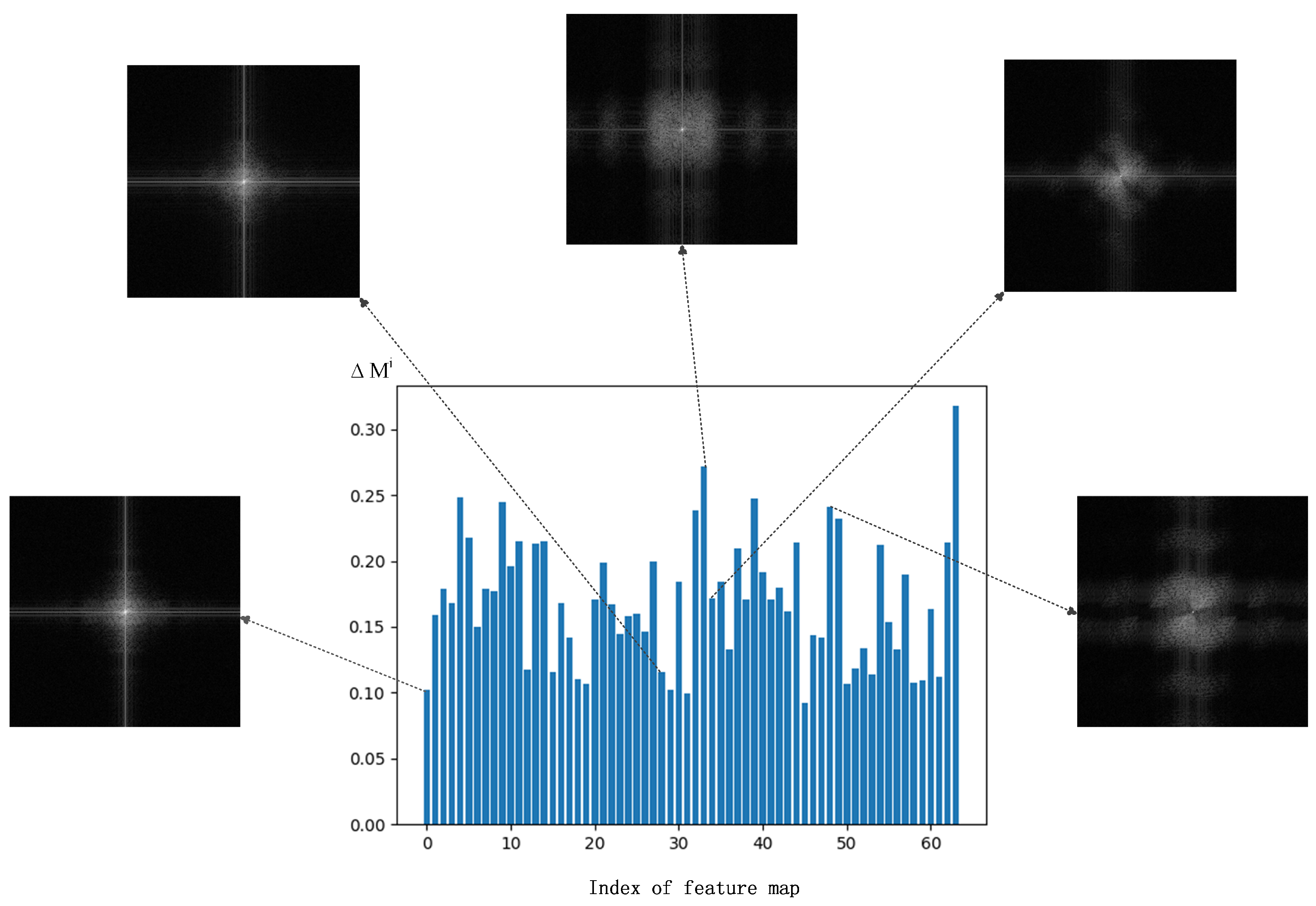
Technical Preview and Contributions. Motivated by these promising potential benefits, in this paper, we exploit the frequency information of cross-channel features for efficient filter pruning. We propose a novel metric termed Low Frequency Preference (LFP) to determine the importance of filters based on the relative frequency components across channels. It can be intuitively understood as a measurement of the “low frequency component”. Specifically, if the feature map of a filter is measured with a larger proportion of low-frequency components compared with other feature maps of the layer, the feature map is more important than that in other channels, which needs to be preserved during pruning. On the contrary, feature maps with more high-frequency components are less preferred by the model, which indicates that they contain very limited information or knowledge. Therefore, the corresponding filters are treated as unimportant and can be safely removed without affecting the model capacity.
To sum up, the contributions of this paper can be summarized as follows:
We analyze the properties of a model from the new perspective of the frequency domain and associate the characteristics of an image with the frequency domain preference characteristics of the model. Similar to the “smaller-norm-less-important” hypothesis, we come up with a novel “lower-frequency-more-important” metric. On this basis, a low-cost, high-robustness, low-frequency component analysis scheme is proposed.
We propose a novel metric that measures the relative low-frequency components of multiple feature maps to determine the importance of filters, termed LFP. It originates from an inter-channel perspective to determine the importance of filters more globally and precisely, thus providing better guidelines for filter pruning.
We apply the LFP-based importance determination method to different filter pruning tasks. Extensive experiments show that the proposed method achieves good results while maintaining high precision. Notably, on the CIFAR-10 dataset, our method improves the accuracy by 0.96% and 0.95% over the baseline ResNet-56 and ResNet-110 models, respectively. Meanwhile, the model size and FLOPs are reduced by 44.7% and 48.4% (for ResNet-56) and 39.0% and 47.8% (for ResNet-110), respectively. On the ImageNet dataset, it achieves 40.8% and 46.7% storage and computation reductions, respectively, for ResNet-50 and the accuracy of Top-1 and Top-5 is 1.21% and 1.26% higher than the baseline model, respectively.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}