1. Introduction
Obstacle detection is a crucial component of space exploration to assure rover patrol safety of deep space probes. Particularly, on the surface of most celestial bodies, rocks are the main obstacle that interfere with landing probes and rover missions [
1,
2,
3]. To obtain suitable path planning and ensure the safe driving of planetary rovers, it is important for planetary rovers to perceive and avoid these rock hazards when carrying out a deep space exploration mission. However, the deep space environment is complex and unknown; some rocks have irregular morphology and different size on the surface of the planet. Compared to other nearby targets such as sand, soil, or gravel, they have no distinct distinguishing features, and some rocks may also be affected by changes in illumination, different lighting angles, and the resulting shadow causing a false visual perception. These conditions undoubtedly increase planetary rovers’ difficulty in perceiving and understanding the surroundings. Therefore, the exploration of autonomous rock detection on the surface of planets still faces great challenges [
4,
5].
Recently, autonomous technology has been used for a range of planetary scientific missions, including autonomous landing location [
6,
7,
8], rover navigation [
2,
3,
9], and autonomous path planning [
1,
10]. As the distance of deep space exploration increases, autonomous technology becomes the key and necessary technology to support deep space exploration in the future [
11]. In deep space environments, edge-based digital image processing methods [
12,
13,
14] are a common method to achieve rock autonomous detection. Most of them use the local strength gradient operator or the gradient difference in illumination direction to detect the target boundary, which is sensitive to noise and illumination conditions. In order to deal with the influence of sunlight and noise, some studies [
15,
16,
17] try to classify regional objects by using a super-pixel segmentation region method based on pixel clustering to improve the performance in rock detection. In addition, some machine learning classifiers [
18,
19] are also used to classify planetary terrain. However, the complexity of super-pixel segmentation increases with the size of the input image, and how to adjust its convergence and detection performance is a challenge. Although most machine-learning techniques are successful at terrain classification, they fall short in accurately identifying rock boundaries and locations.
Convolutional neural network (CNN)-based deep learning technology has achieved great success in the semantic segmentation of 2D images [
20,
21]. Some efforts towards semantic segmentation-based methods have been made to achieve automatic rock detection. For the deep space autonomous rock segmentation network, when the rover captures an image, it is passed to a semantic segmentation network and the network output is the classification at the pixel level, which is fed back to the detector to sense the surrounding environment information. In order to realize high-precision rock detection in the deep space environment, acquiring multiscale context information of rock images is essential in a semantic segmentation network. Some studies propose convolution pooling, dilated convolution [
22], spatial pyramid pooling (SPP) [
23], pyramid pooling module (PPM) [
24], and atrous spatial pyramid pooling (ASPP) [
25] to obtain a larger receptive field and integrate multiscale context information [
26]. A U-shape network [
27] is a common multiscale semantic segmentation network widely applied to medical image segmentation and analysis, which uses upsampling in the decoder to expand the feature map to the same size as the original image. In addition, there has recently been increased focus on other multiscale semantic segmentation networks, such as FCN [
28], PSPNet [
24], and DeepLabV3+ [
25], for planet rock detection [
4,
5,
29,
30].
Convolutional pool operation is a common operation in the encoder of semantic segmentation networks, which is used to obtain the multiscale feature map, expand the field of perception, and reduce the amount of calculation to some extent. However, using convolutional pool operations may cause a loss of information, which causes blurry output results in the process of the network decoder. It is very important to consider how to reduce information loss to restore the clarity output feature mapping for improving the accuracy of rock semantic segmentation. Some works [
24,
25] use a direct upsampling operation in the network decoder to obtain the output feature map. Although this approach is easy to implement, some details may be lost, resulting in blurred segmentation boundaries. To enhance the clarity of the rock detection boundary, other researchers [
5,
29,
30,
31,
32] recommend fusing low-level feature details and using skip connections and stepwise sampling to generate more rich feature output in the upsampling process. These strategies can improve the clarity of the rock segmentation boundary to a certain extent. However, some overlaps and redundant information may be added to the output feature map in the upsampling process, which affects the accuracy of network segmentation [
11]. In addition, the multiple sampling and connection process may increase unnecessary network parameters and computational complexity [
33,
34]. Most rock detection methods do not consider how to balance accuracy and complexity.
Obtaining local and global context dependencies is the key to extracting the target object [
35,
36]. CNN can obtain the local context dependencies using multiscale context information in semantic segmentation networks. However, the local feature of the convolution layer of the CNN limits the ability of the network to capture global information. Recently, a transformer network based on a multi-headed attention mechanism has been successful in the field of computer vision. Vision Transformer (ViT) can effectively obtain global information using a self-attention mechanism and enhance the model expression through the multi-head spaces map. Some researchers have applied vision transformers (ViT) in image classification and segmentation [
5,
29,
37]. The VIT model often relies on powerful computing resources and a pre-training model, which limits its use in many tasks. To apply the strong global feature extraction ability of the transformer, some studies propose a new combination of CNN and transformer networks to fuse both advantages for capturing local and global contextual information. Hybrid networks combining CNN and transformer have been attempted in some fields, such as image change detection [
38,
39], medical image segmentation [
35,
36], person re-identification [
40], and image super-resolution [
41].
In previous work, we have proposed [
31] an onboard rock detection algorithm based on a spiking neural network to reduce the calculation energy consumption. In this paper, we explore a novel network based on a hybrid framework combining CNN and vision transformer for deep space rock images to improve the efficiency and accuracy of rock detection; the proposed model contains an efficient backbone feature extraction block and a multiscale low-level feature fusion module. Firstly, to efficiently extract rock features, we propose a new backbone (Resnet-T), which utilizes part of the Resnet backbone and combines it with a visual transformer block to capture the global context information of the rock. Secondly, a simple and effective multiscale low-level feature fusion (MSF) module is designed to obtain more rich semantic features, and they are fused into the output feature map in the upsampling process to improve the quality of the output feature map. Last, we use two deep space rock image datasets (MoonData and RockData) to verify the performance of the proposed model. The experimental results show that our model has higher detection accuracy and faster model reasoning speed than other methods when the model parameters and computational complexity are lower.
In summary, our main contributions are as follows.
We propose a novel semantic segmentation network (RockSeg) based on the combined CNN and transformer framework, which contains an efficient feature extraction backbone and a multiscale low-level feature fusion module to effectively detect rocks on the surface of celestial bodies.
We combine Resnet blocks and visual transformer blocks to construct an efficient Resnet-T backbone network to extract the global context information. In addition, we design MSF to obtain rich multiscale fusion features and fuse them into the output feature map to improve the segmentation clarity of the target boundary.
The experiment is conducted on the PyTorch platform with two rock datasets to verify the performance of the RockSeg. The results show that our method outperforms the state-of-the-art rock detection models in terms of detection accuracy and inference speed.
The rest of this paper is organized as follows:
Section 2 describes related work.
Section 3 describes the proposed network architecture, the design of the feature extraction backbone, and the multiscale low-level feature fusion module. The experimental results and analysis are provided in
Section 4. In
Section 5, we conclude our work.
4. Experiments
In this section, we describe the experimental setup, including the experimental environment and parameter settings, experimental datasets, evaluation measures, comparison algorithms, and experiment results and analysis.
4.1. Experiment Setting
We conducted the experiments on a single GPU (GeForce RTX 3080Ti, 12 GB RAM, 8 CPU/4 core) with Pytorch 1.8.1 + CUDA 11.1. During network training, we set the initial learning rate to
, and used the Adam [
52] optimizer and cross-entropy loss function to train the network model. The size of the network training batch was set to 16 and the maximum number of training iterations was 200 epochs. The sign of the end of network training is that the training reaches the maximum number of iterations, or the network is stagnant in 20 epochs. In the experiment, the network input is an RGB image; the image is normalized and processed by a resizing method without distortion to 256 × 256 pixels. All the image label is transformed into gray labels with linear pixel mapping and the output of the network is a grayscale image with different category values.
4.2. Datasets
MoonData: This lunar rock dataset is a sample of artificial yet realistic lunar landscapes, which was used to train rock detection algorithms. The Moon rock dataset contains 9766 realistic renders of rocky lunar landscapes, which are labeled into four classes: background, sky, smaller rocks, and bigger rocks. MoonData is an RGB image with 480 × 720 pixels and the label is also a three-channel RGB image. In this experiment, we convert the three-channel RGB label to grayscale by linear pixel mapping, and we partition the dataset 8:1:1 into 7812 training images, 977 validation images, and 977 testing images. The details of the Mars dataset are described in
Table 3.
MarsData: The Martian rock dataset (
https://dominikschmidt.xyz/mars32k/ (accessed on 13 September 2021)) consists of about 32,000 color images collected by the Curiosity rover on Mars with a Mastcam camera between August 2012 and November 2018. All images have been scaled down using linear interpolation to 560 × 500 pixels; unfortunately, they don’t have semantic segmentation labels. In previous work, the paper [
17] completed a total of 405 labeled rock images of more than 20,000 rocks and the data were augmented to 30,912 images by cropping and rotating. In our experiment, we use the augmented Mars rock dataset to train and evaluate rock segmentation methods. Moreover, we repartitioned the dataset 9:1 according to the train–validation images with 22,279 training images, 5541 validation images, and 3092 testing images.
4.3. Evaluation Criteria
In order to report the research results in the field of semantic segmentation, most researchers used simple and representative measures of pixel accuracy (PA), class pixel accuracy (CPA), mean pixel accuracy (MPA), intersection and union (IoU), and mean intersection and union (MIoU). In this paper, we employ the standard evaluation standards for semantic segmentation to confirm the effectiveness of our model. We computed PA, MPA, Recall, and MIoU based on the corresponding confusion matrix to evaluate the quality of network predictions.
In the confusion matrix, the PA denotes the sum of the true positives and true negatives divided by the total number of queried individuals. The PA is computed as follow:
where true positive (TP) represents the number of positive samples that are correctly predicted as positive ones. True negative (TN) denotes the number of negative samples that are correctly determined as negative ones. False positive (FP) represents the number of negative objects that are incorrectly predicted as positive samples and false negative (FN) is the number of positive samples that are incorrectly classified as negative samples.
The class pixel accuracy is the percentage of the total predicted value that is correct for a category and MPA is the mean of CPA; CPA is represented as follow:
where TP is the prediction accuracy of the category and TP + FP is all predictions in this category.
, where
n denotes the number of categories and
is the value of CPA in the
i-th class. The recall is the probability that a category is predicted correctly, which is calculated by TP divided by TP + FN as follows:
The IoU is the ratio of the intersection and union of the predicted results and the true values for a given classification. The IoU is computed as follows:
where TP denotes the intersection set and TP + FN + FP is the union set of the predicted results and true values for a category. Moreover, MIoU is the mean of the IoU of the
n classes;
, where
represents the value of
in the
i-th class.
4.4. Compared Methods
In our experiment, we compared with the six latest semantic segmentation networks for rock detection, DeeplabV3+ [
25], FCN [
28], CCNet [
53], DANet [
54], PSPNet [
24], and Swin-Unet [
29]. Simple descriptions of these compared methods are as follows. FCN [
28] is a basic model of classical semantic segmentation with the first full convolution network. PSPNet [
24] used a pyramid pooling module (PPM) and dilated convolutions to integrate contextual information from different regions and embed it in FCN. DeeplabV3+ [
25] used the ASPP module to obtain multiscale context information. DANet [
54] and CCNet [
53] employed a dual attention (DA) mechanism and criss-cross attention (CCA) mechanism to improve the accuracy of segmentation. Swin-Unet [
29] is a novel vision transformer network-based semantic segmentation used to compare.
The main parameter settings of the compared methods are in
Table 4, which contains the network backbone, downsampling multiple (dm), network encoder, and decoder. The
represents the downsampling multiple of the input image in a network encoder; FCN8 denotes using an eight-fold sampling to obtain the output feature map. The network decoder is divided into three methods to restore the output feature map: (1) the
method employing upsampling once, (2) the
method fusing fine-grained shallow features once and upsampling, and (3) the
method utilizing multiple-fusion and upsampling. Resnet-34-2 is a combination of the proposed model, which consists of two Resnet-34 blocks and a transformer block (T). It utilizes MSF to fuse more shallow features to obtain a finer-grained output.
4.5. Experiment Results
In this section, we compared the state-of-the-art methods for deep space rock detection. All compared networks used the Resnet-50 backbone to extract the feature, and the input image was processed to a uniform size of 256 × 256 pixels by image resize, padding, and scale technology. In experiments, we not only used the evaluation metrics of PA, CPA, MPA, Recall, IoU, and MIoU mentioned in
Section 4.3, but we also calculated the network parameters (Params) to evaluate the spatial complexity of the network, evaluated the time complexity of the model by floating-point operations (FLOPs), and computed the inference speed of the network in frames per second (FPS) to evaluate the performance of the networks.
4.5.1. Results on MoonData
The rock detection results on the MoonData dataset are shown in
Table 5; the bold data represents the best prediction results. We can see that the proposed RockSeg obtained the best prediction results in the PA, MPA, Recall, and MIoU indicators, and it achieved a faster inference speed with fewer network parameters. Specifically, it improved by about 5.3% and 11.2% on the PSPNet model in MPA and Recall evaluation indicators, respectively. In the MIoU indicator, the proposed RockSeg improved about 2.2%, 6.1%, 1.4%, 6.7%, 10.5%, and 6.1% on DeeplabV3+, FCN, CCNet, DANet, PSPNet, and Swin-Unet, respectively. Moreover, we found that RockSeg not only obtained a high detection precision but the network also had a fast inference speed; the FPS was up to 52.90 HZ. The network parameters of the proposed model were reduced by about seven times compared to the CCNet model.
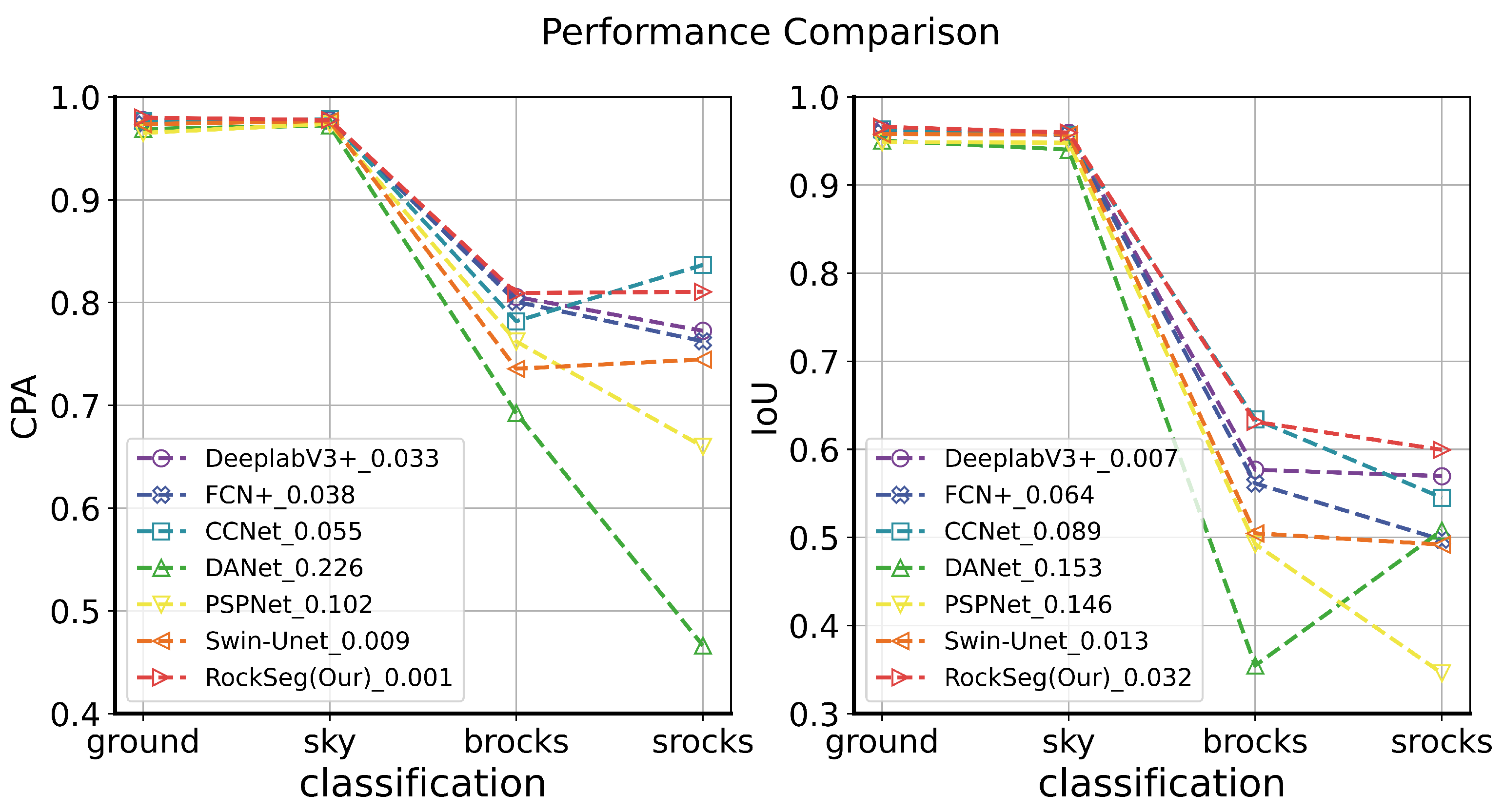
Furthermore, we used the CPA and IoU indicators to evaluate the different category detection results shown in
Figure 4. The MoonData dataset has four categories including ground, sky, bigger rocks simplified “brocks”, and smaller rocks simplified “srocks”. In
Figure 4, the horizontal axis represents four different categories and the vertical axis is the value of CPA and IoU, respectively. The legend represents different methods and ranges (R) in two categories of brocks and srocks;
R is defined as
where
and
denote the accuracy score in brocks and srocks classes and
R represents the difference between the two categories; the larger
R, the more difficult it is to distinguish between the two categories; otherwise, the easier it is to distinguish between the two categories.
On the whole, we discovered that all compared methods could obtain better detection accuracy in the ground and sky categories, but the detection results of different models have a large gap in the brocks and srocks categories. For an input rock image of the Moon, the pixel ratio of the ground and sky is large, and the pixel ratio of the rocks is relatively small; there is an imbalance of categories in the MoonData data. In semantic segmentation, category objects with different pixel proportions in an image have different detection difficulties [
55,
56]. Category objects with small proportion pixels are difficult to distinguish, while category objects with multi-proportion pixels are relatively easy to distinguish [
7]. So the ground and sky categories have a higher accuracy than the brocks and srocks categories in CPA and IoU evaluation.
From
Figure 4, we can see that the DANet model had the worst classification results; the proposed model and the CCNet model had better detection accuracy than other methods. The DANet and PSPNet models obtained a large
R between the brocks and srocks classifications; the accuracy range was 0.226 and 0.102 in CPA, and 0.153 and 0.146 in IoU, respectively. In the IoU evaluation, we found that RockSeg obtained the best scores in each classification; in particular, it achieved 63.11% and 59.94% IoU scores in brocks and srocks classifications, respectively. In the CPA evaluation, the RockSeg obtained high CPA values in ground, sky, and brocks classification, in which the brocks and srocks were 63.11% and 59.94%, respectively. The CCNet network also achieved the highest accuracy in the srocks class using the CPA evaluation, in which the brocks and srocks accuracy were 78.17% and 83.65%, respectively. However, RockSeg obtained a smaller
R in CPA and IoU than the CCNet model. The accuracy range of RockSeg was only 0.001 compared to 0.055 for CCNet in the CPA evaluation and, in the IoU, the accuracy range of RockSeg was 0.032 and the
R was lower than CCNet in the CPA and IoU evaluations. Thus, the proposed RockSeg is more robust than the CCNet model.
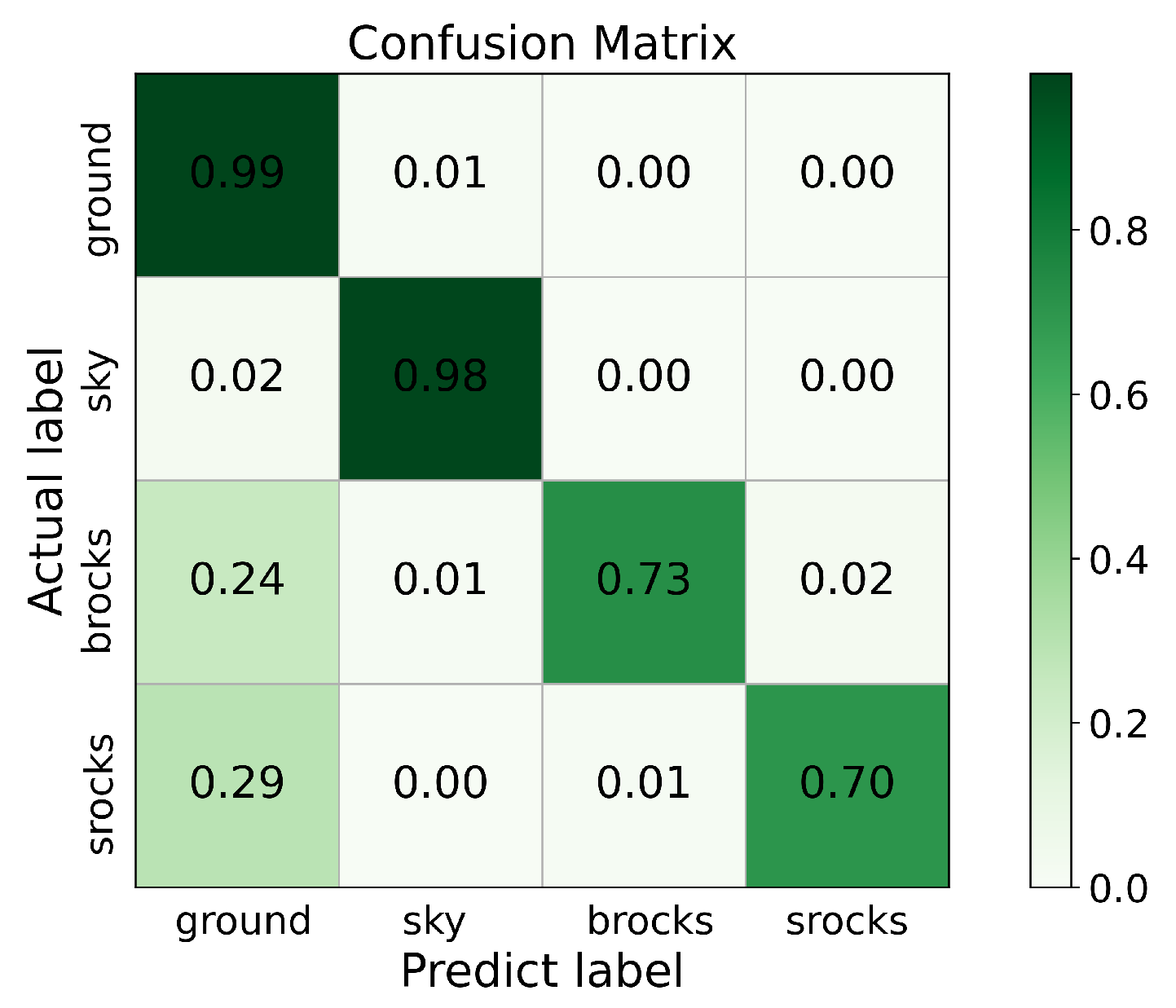
In addition, we show the confusion matrix of the probability of different categories being predicted in
Figure 5. We can see that most pixels with ground and sky categories can be correctly classified; the probability of brocks being incorrectly classified as the ground category was 0.24 and the probability was only 0.02 of them being incorrectly classified as the srocks category. In the srocks category, there was only a probability of 0.29 and 0.01 of being incorrectly classified as the ground and brocks categories, respectively. Therefore, RockSeg has strong robustness for detecting deep space rocks; both large and small rocks can be detected correctly. Last, we show the visualization segmentation results of different methods on MarsData in
Figure 6. There are five visualization segmentation results with different angles of sunlight and shadows in
Figure 6. The yellow rectangle represents the contrast of the local details.
Figure 6a,d,e denote the vision that follows the sunlight and
Figure 6b,c are the visual angle against the sunlight on the surface of the Moon. When the sun’s rays shine perpendicular to the surface of the Moon, the rock shadows are small as shown in
Figure 6d,e; otherwise, the rock shadows are big as shown in
Figure 6a–c. We can see that the proposed RockSeg could accurately obtain segmentation results with different sunlight shadows and angles. Specifically, our model could clearly detect the boundary of the object compared to the other models and some small rock objects could also be accurately detected.
4.5.2. Results on MarsData
The comparison results with other methods on MarsData are shown in
Table 6; the bold denotes the best prediction accuracy. The MarsData has two categories, the background and rock objects. The pixel ratio of rocks and background is not much different, so it is relatively easy to segment them. We can see that the compared methods are all above 96% accuracy in the PA, Recall, and MIoU indicators. From
Table 6, the FCN model obtained the best inference speed compared with other models and the precision of the PSPNet model was relatively low. Our proposed model obtained the best accuracy in each indicator compared to the other methods. Moreover, the proposed model achieved a high inference speed with low network parameters and computation complexity. Furthermore, we evaluated the CPA and IoU of different categories on MarsData; the results of different methods are shown in
Table 7. We found that
R was small in the CPA and IoU evaluations for all compared models. Due to the classes being relatively balanced on MarsData data, they could be very well detected. We can see that the RockSeg model achieved the best score in the IoU evaluation and obtained the best PA value in ground classification compared to the other models. In deep space rock detection, our proposed model had excellent portability and robustness.
By comprehensive feature extraction and rich semantic feature fusion, the proposed model could realize high-precision detection. The proposed RockSeg network used combining the CNN and vision transformer to extract the rock features, in which the CNN network is advantageous in obtaining local multiscale context features and the vision transformer block is more suitable for capturing global features. The local and global rock features were fused to achieve a comprehensive feature extraction by the proposed hybrid network, which is beneficial for the detection of objects of different sizes. Moreover, the designed MSF module fused multiscale low-layer features to the output feature map which could improve the accuracy of the segmentation results. Furthermore, we eliminated the feature redundancy and overlap by manually adjusting the network parameters to achieve a lightweight network; see
Section 4.6 for details of model parameters. Using the above policies, the proposed model could achieve high accuracy and inference speed under low computation complexity.
The visualization segmentation results of our model and the state-of-the-art methods on MarsData are shown in
Figure 7. In the label image, we labeled the object rock as green and the other compared segment results as yellow for visual distinction. In the four image visualization segmentations, we discovered that all of the comparison models could accurately detect large rock objects. But, for some small gravel with burning in the soil and some dense rocks, it is relatively more difficult to distinguish and identify them than big rocks. In terms of accuracy and clarity of the border segmentation, the RockSeg results were finer and closer to the label image than the other model, and we used the red box in our model to show the finer boundary segmentation results. From the visualization segmentation results, we can see that the Swin-Unet, PSPNet, DANet, CCNet, and FCN models had poor detection results in small object detection; their segmentation results show that the target boundary was blurred and rough. In
Figure 7b,d, we can see that the proposed model achieved accurate detection in big rocks, and also obtained accurate segmentation in some dense small rocks or small rocks buried in the soil.
4.5.3. Ablation Study
In this section, we ablated our network to validate the performance of the proposed model. The results of the ablation study are shown in
Table 8 and the best value in each column is in bold. The MSF represents the multiscale low-level feature fusion module, the transformer block is simplified as T, the ✓ flag represents the module being used, and the – flag denotes the module not being used. In
Table 8, we can see that our model obtained the best PA, MPA, and MioU compared to the other ablation models. The T module with a multi-headed attention mechanism could capture the global context information of the rock to improve the rock’s object detection accuracy. Thus, we discovered that RockSeg-T and the RockSeg-MSF-T achieved a higher accuracy in PA, MPA, Recall, and MIoU than RockSeg-no-MSF-T. Specifically, RockSeg-T obtained the best accuracy in Recall. The multiscale feature fusion module obtained the rich fusion feature maps
and
; they were added to the output feature map using the upsampling process to accurately enhance the clarity of the semantic segmentation object boundary and improve the accuracy of segmentation. In
Table 8, we found the RockSeg-MSF and RockSeg-MSF-T models also achieved an improvement over the RockSeg-no-MSF-T in the four evaluation indicators. On the whole, our model with T and MSF modules obtained the best performance in rock detection.
Furthermore, we show the visual ablation results of the MSF and T modules with the heatmap output shown in
Figure 8. We compared the different channel activation statuses with the different models of RockSeg-no-MSF-T, RockSeg-T, RockSeg-MSF, and RockSeg-MSF-T. We used a blue–red color scheme to show the difference; the smaller the value, the closer it is to blue, the larger the value, the closer it is to red. In
Figure 8, the top is the original rock image and label;
Figure 8(1–6) show the two low-level feature maps
and
, where
Figure 8(1–3) denote the output results of
and
Figure 8(4–6) are the output results of
with RockSeg-no-MSF-T, RockSeg-MSF, and RockSeg-MSF-T (our model).
Figure 8a–c show the feature map output results of the transformer block using RockSeg-no-MSF-T, RockSeg-T, and RockSeg-MSF-T.
For the whole network structure,
is closer to the input network and
is relatively far from the network input. We can see that most information of the original image was retained in the activation output
. From the activation output
and
, we discovered that, as the number of layers increased, the activation output became more and more abstract. The density of activation decreased with the deepening of layers and the information about categories was increased. For example, the density of activation contrast,
Figure 8(3) >
Figure 8(6). In
and
, we can see that RockSeg-MSF and RockSeg-MSF-T had more channel activation statuses than RockSeg-no-MSF-T; the proposed MSF module obtained more rich semantic information from the context. Due to the T module being far from the network input in the whole network structure, the activation output is very sparse and abstract as shown in
Figure 8a–c. The RockSeg-T and RockSeg-MSF-T used multiple attention mechanisms to activate important information by setting different weights of attention. Thus, they had more red feature signatures than the RockSeg-no-MSF-T model in
Figure 8. On the whole, from different output feature heatmaps, we found that the proposed semantic segmentation network based on a hybrid framework combining CNN and vision transformer, using an efficient feature extraction backbone and multiscale low-level feature fusion, had an excellent presentation of features to achieve good performance in rock detection.
4.6. Impact of Different Backbones and Parameters on Models
In this section, we discuss the parameter impact on our model and tune them with the MoonData data. The parameters contain the different backbone networks, the number of backbone layers, and the number of layers and heads of the T block. The tuning process is divided into three groups, denoted
,
. In the three groups, we kept the same decoder process, normalized the size of the feature map in downsampling to an input size of 1/16 times, and evaluated them by the indicators described in
Section 4.3. The tuning results are shown in
Table 9. In
Table 9,
is the number of Resnet blocks. The backbone represents the network encoder with different modules and parameters, where MSF and T denote the multiscale low-level feature fusion module and vision transformer in the backbone, respectively. The T module has two import parameters, the number of heads represented by
h and the depth of the transformer layer denoted
d. The – represents the process of adjusting their parameters and the ✓ denotes using this module.
In , we compared the impact of different Resnet backbones with four Resnet blocks on deep space rock detection. We combined Resnet-50, Resnet-34, and Resnet-18 with the T module as the backbone network separately, and used the same MSF module to decode the network. In , we found Resnet-50 obtained the best PA and MPA with maximum parameters and a large amount of computation; Resnet-18 had low parameters, small amounts of computation, and high FPS. Resnet-34 achieved the best MIoU compared to Resnet-50 and Resnet-18; the detection accuracy in PA and MPA indicators was close to Resnet-50, and the model parameters and computations were close to Resnet-18. In order to balance the calculation complexity and accuracy of the rock detection model in a deep space environment with limited resources, we chose Resnet-34 as the backbone for our model. Too many feature extraction layers may cause feature redundancy and overlap. To obtain an efficient and lightweight feature extraction backbone network, after obtaining the Resnet-34 backbone, we tuned the number of Resnet blocks in the backbone to optimize our model. In , Resnet-34-n represents the backbone with different numbers of Resnet blocks n, where . We discovered that Resnet-34-2 with two Resnet blocks achieved better performance than the Resnet-34-4 and Resnet-34-3 models. In , the Resnet-34-4 backbone network may have over-representation; the Resnet-34-2 backbone network achieved the appropriate representation for rock feature extraction. The Resnet-34-2 backbone could obtain the best PA, MPA, Recall, and MIoU score under low computation and parameters, and fast inference speed.
Last, in , we test the impact on the proposed model by tuning the parameters of h and d in the T block. Resnet-34-2- is composed of the Resnet-34-2 backbone network and the T module with h heads and d layers, where h is the number of heads, h = ; corresponding to the number of transformer layer d denotes d = . In , we found the parameter of h and d had little effect on the precision of the model, but the complexity of different parameters was different. In deep space, the probe carries limited resources, and onboard computation needs to satisfy not only high precision requirements but also low complexity requirements. We can see that Resnet-34-2-44 achieved a higher PA, MPA, and MIoU than other models with a faster inference speed. Thus, in this paper, in order to create a high accuracy and low complexity rock detection model, we chose the final Resnet-34-244 as the hybrid framework combining CNN and transformer for deep space rock images, which is based on the Resnet-34-2 backbone and the T module containing four heads and transformer layers.
5. Conclusions
In this paper, we proposed an efficient deep space rock detection network, named RockSeg, which is a novel semantic segmentation network based on a hybrid framework combining CNN and vision transformer for deep space rock images. The novel model contains an efficient backbone feature extraction block and a multiscale low-level feature fusion module for deep space rock detection. Firstly, to enhance the feature extraction, we used part of the Resnet-34 backbone and combined it with the visual transformer block as a new backbone network Resnet-T to extract the global context information of the rock. In addition, we proposed a simple and efficient multiscale low-level feature fusion module to obtain more rich detailed feature information. These rich features were fused to the output feature map in the network decoder to obtain a more fine-grained output result and improve the clarity of the semantic segmentation object boundary. Furthermore, the proposed model was applied to two rock segmentation datasets (lunar and Martian rock data) compared with six state-of-the-art segmentation models for deep space rock detection. The results demonstrated that the RockSeg model outperforms the state-of-the-Art rock detection methods; our model achieved good performance in deep space rock detection. In particular, on MoonData data, our model achieved accuracy up to 97.25% in the PA and 78.97% in the MIoU indicators with low parameters, smaller amount of computation, and high inference speeds.
In tuning the network process, we found the deeper network may not be a good choice to achieve the best performance; too many deep network structures may be redundant for feature extraction. The proposed hybrid network combines CNN and transformer; they need to play to their strengths to complement and integrate local and global context information. To obtain the best appropriate network structure, we manually adjust the network backbone structure and optimize the parameter configuration with coarse-grained parameter tuning. We employed a conventional backbone to achieve network feature extraction and used evaluation measures and visual heatmaps simultaneously to decide whether the network feature extraction is insufficient or redundant. Then, the network structure was suitably decreased and increased based on the qualitative and quantitative assessment results to meet the specific detection task. In the future, we need to further study how to integrate CNN and transformer network structures adaptively to remove redundant features and enhance the ability to capture local and global context information. Moreover, we will transplant and expand our work to the detection of deep space multi-category terrain segmentation, further improving the availability of the model in deep space.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}