1. Introduction
Wetlands provide many ecosystem services such as filtering polluted water [
1], mitigating flood damage [
2–
4], recharging groundwater storage [
5,
6], and providing habitat for diverse flora and fauna [
7–
9]. Wetland quality and quantity are particularly important in light of the increasing impacts of climate change, a growing human population, and changing land cover and land use practices [
10,
11]. It is therefore essential that wetlands are managed appropriately and monitored frequently.
The US Army Corps of Engineers defines wetlands as: “areas that are inundated or saturated by surface or ground water at a frequency and duration sufficient to support, and that under normal circumstances do support, a prevalence of vegetation typically adapted for life in saturated soil conditions” [
12]. The Corps identifies potential wetland areas using three broad categories: soils, vegetation, and hydrology, where the classification is specifically based on geological substrate (soil type, drainage), the presence and type of hydrophytic vegetation, and topographic features that influence the hydrological movement and storage of water.
Characteristics of wetland structure and position are not the only influential factors on the permanence and duration of a wetland’s capacity to store water. Regional and local climate conditions are the main driving forces behind a wetland’s hydroperiod. Hydroperiod can be defined as the seasonal pattern of water level, duration and frequency in a wetland, akin to a “hydrologic signature”. The hydroperiod of a wetland has been described by Wissinger [
13] as the single most important aspect of the biodiversity within a wetland habitat, because the duration between dry and wet periods directly influences complex biological interactions and communities. The phenology of a wetland has a major influence on its classification and changes in the hydroperiod over time can thus alter a wetland’s classification.
Accurate landscape-scale wetland maps are important for stakeholders that represent many different interests in wetland ecosystems. Accurate wetland maps are needed to: better respond to and prepare for natural disasters and invasive species mediation [
14,
15], conserve and restore wetland areas following policy and regulation changes [
16,
17], address water quality and quantity concerns [
18,
19], and better understand the linkages and seasonality of these ecosystems to biodiversity and other natural resources [
20,
21]. However, many existing wetland maps are out of date and efforts for updating them tend to happen over small geographic extents or at intervals too infrequent for appropriate environmental mitigation [
22]. Furthermore, traditional wetland mapping methods often rely on optical imagery and manual photo interpretation or classification using single date imagery. These maps typically under-represent ephemeral and forested wetlands, due to their possible absence during time of data acquisition and because of obscuration by vegetative canopy [
18]. Even if the temporal coverage is appropriate, optical imagery alone may not reveal wetlands obscured by clouds or haze, or a dense vegetated canopy.
The integration of multi-source (multi-platform and multi-frequency) and multi-temporal remotely sensed data can provide information for mapping wetlands in addition to the use of single date optical imagery traditionally used for wetland classification. Surface features, such as extent of inundation, vegetation structure, and likelihood of wetlands can be better resolved with the addition of longer wavelength radiometric responses, topographic derivatives [
23], and ancillary data about the geological substrate [
24,
25]. Long-wave radar signals, such as C-band (5.6 cm) or L-band (23 cm), have been found to improve land cover classification accuracy because these wavelengths have deeper canopy penetration and are sensitive to soil moisture and inundation [
26–
28]. These active sensors are not as sensitive to atmospheric effects, penetrate clouds, and are operational at night, thereby increasing the temporal coverage of wetland mapping. Research has shown that data from multiple sources and over multiple seasons capture greater variation in hydroperiod and vegetative condition and thus have the potential to increase both classification accuracy and confidence [
29–
31].
Given the wealth of remotely sensed and ancillary data, a robust wetland classification method applied to large geographic areas needs to be computationally fast, require no assumptions about data distribution, handle nonlinearity in relations between input variables, and be capable of using numeric and categorical data. In addition, the assessment of results will be improved if the classification method identifies outliers in the training data, provides rankings of the importance of the input variables, and produces internal estimates of error and confidence of the output classification. Many decision tree classifiers fulfill all these requirements and have been used in land cover mapping for years [
32–
35], including several that use the meta-classifier random forest [
36–
38].
Our goal was to identify an optimal selection of input data from multiple sources and time periods of remotely sensed and ancillary data for accurate wetland mapping using random forest decision tree classification in a forested region of Northern Minnesota. We assessed ways of increasing classification accuracy, confidence, and practicality by assessing results from several combinations of input data. Our main questions for this study site in Northern Minnesota were: (1) how does classification accuracy and confidence of wetland mapping compare using different remote sensing platforms and ancillary data from different periods of the growing season; (2) what are the key input variables for accurate differentiation of upland, water, and wetlands, including wetland type; and (3) which datasets and seasonal imagery yield the best accuracy for wetland classification.
2. Methods
2.1. Study Area
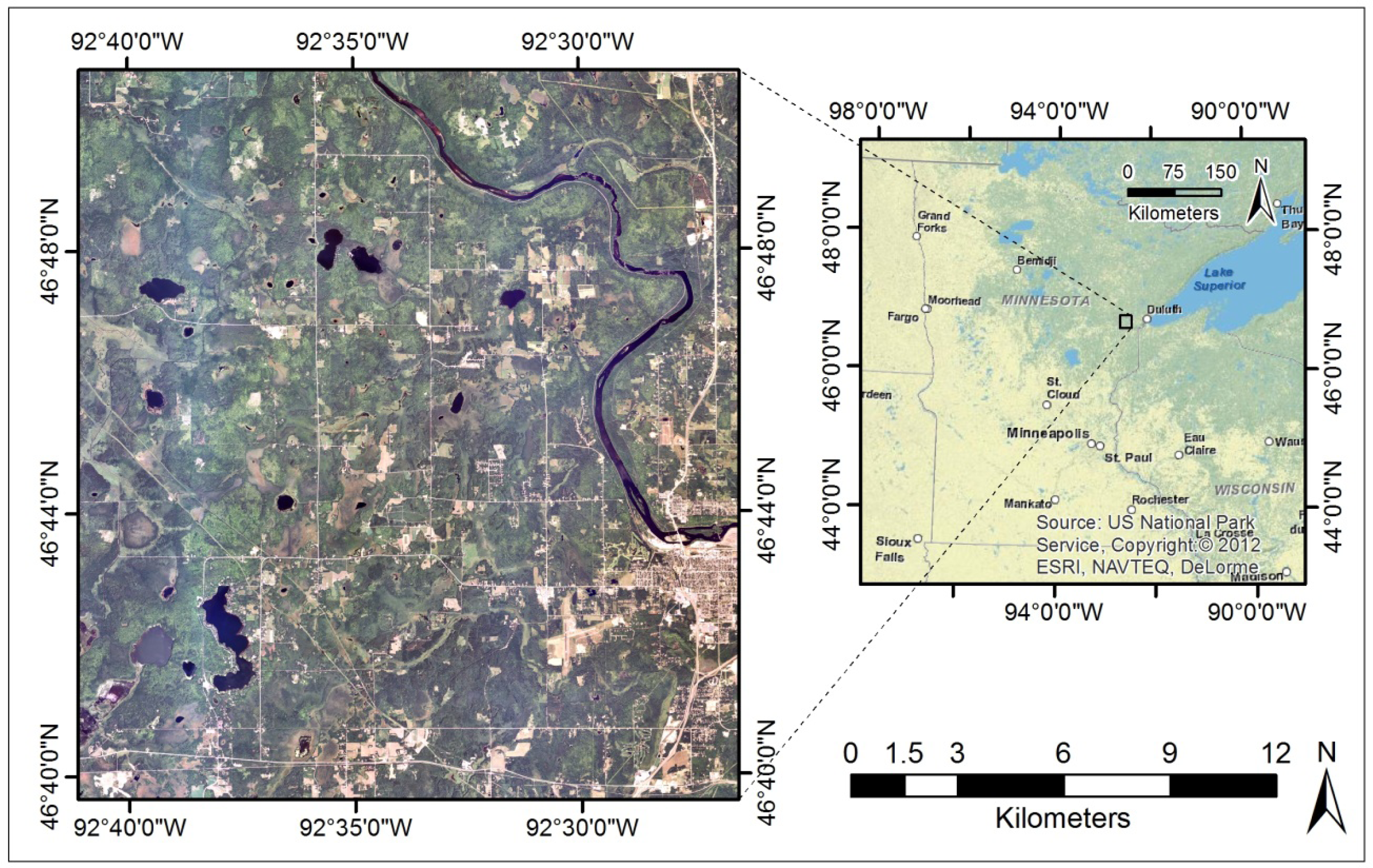
Much of northern Minnesota (MN) is forested. The hydrographic patterns of the landscape have been influenced heavily by glacial advances and retreats over the millennia [
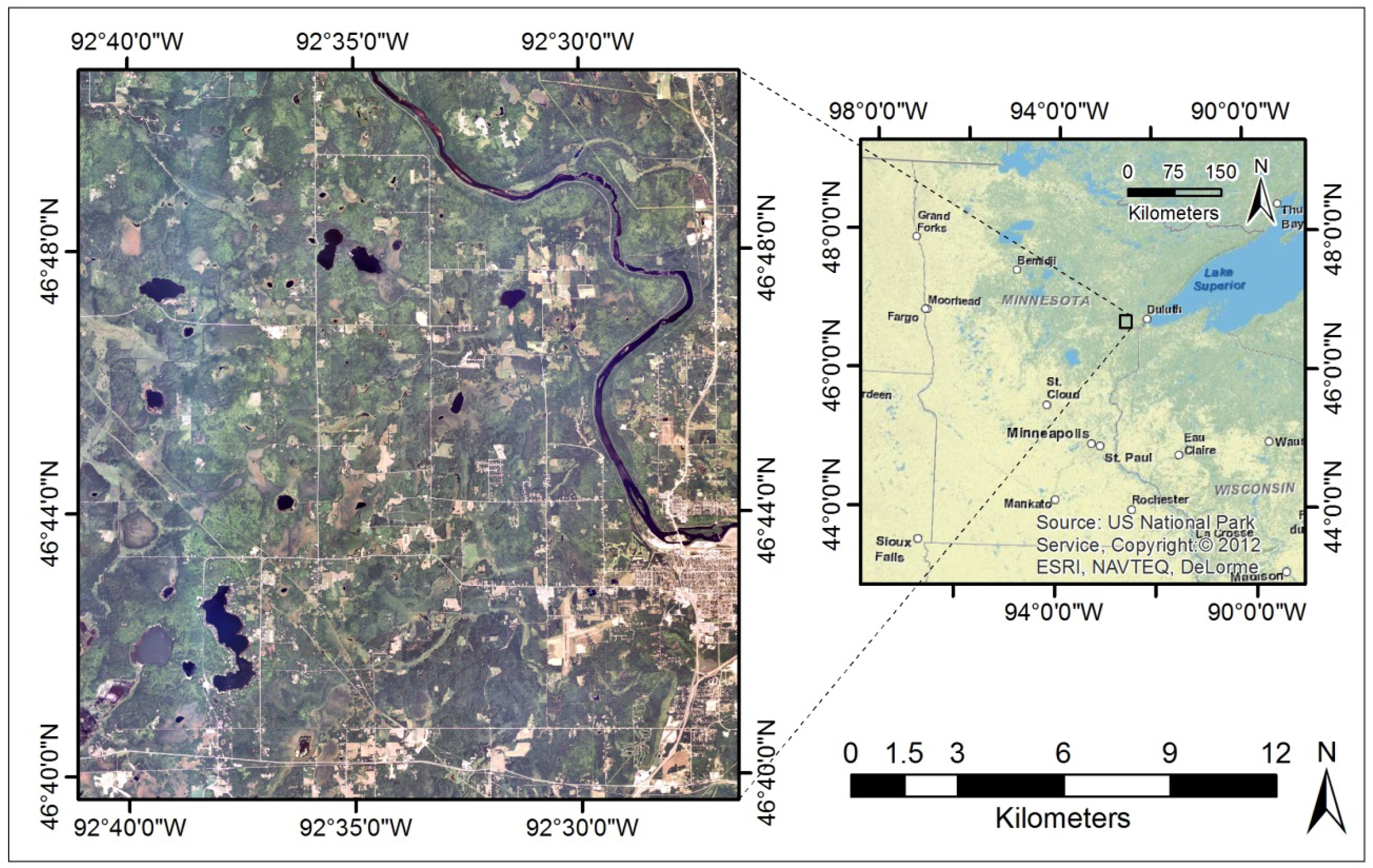
39]. Our study centered on Cloquet, MN (
Figure 1), which lies in the sparsely populated “Arrowhead” region of northeastern Minnesota. This study area is dominated by managed and natural hardwood and conifer forests, woody and herbaceous wetlands [
40], and low density residential housing with a small city center (population 12,000) [
41]. The elevation across the study area is 330–450 m above sea level (mean of 392 m), with the slope of the landscape averaging less than 1.7 degrees.
Given the variable nature of hydroperiod in space and over time, the weather during remotely sensed and field data acquisition is especially relevant when mapping wetlands. We collected field data in the summers of 2009 and 2010 and acquired remotely sensed data for several dates from 2008 to 2010. The 30-year normal total annual precipitation for the nearest major NOAA weather station in Duluth, MN (about 35 km away from the study site) measures between 5 and 10 cm in the spring, about 10 cm in the summer, and between 5 and 10 cm in the fall, for a total of about 79 cm annually [
42]. The 30-year normal minimum precipitation in the spring is between 0.6 and 1.25 cm, with a maximum between 18 and 20 cm. In the summer the minimum precipitation is between 1.75 and 2 cm, with a maximum between 20 and 25 cm. The minimum precipitation in the fall is around 0.25 cm, with a maximum between 18 and 23 cm. Hydrologists in the northern hemisphere use the term water year to describe the period of time between 1 October and 30 September of the next calendar year. The lowest level of precipitation is in general during the fall and the landscape is typically replenished during the winter and spring of that water year. Precipitation over the study site during the 2008 water year (October 2007–September 2008) was slightly above normal, whereas the rest of that summer and well into the 2009 water year the trend was slightly below normal. Precipitation during the first part of the 2010 water year was slightly above normal around the study site and trended more towards normal throughout the north east region, whereas in the latter part of that year the trend was slightly below average [
43].
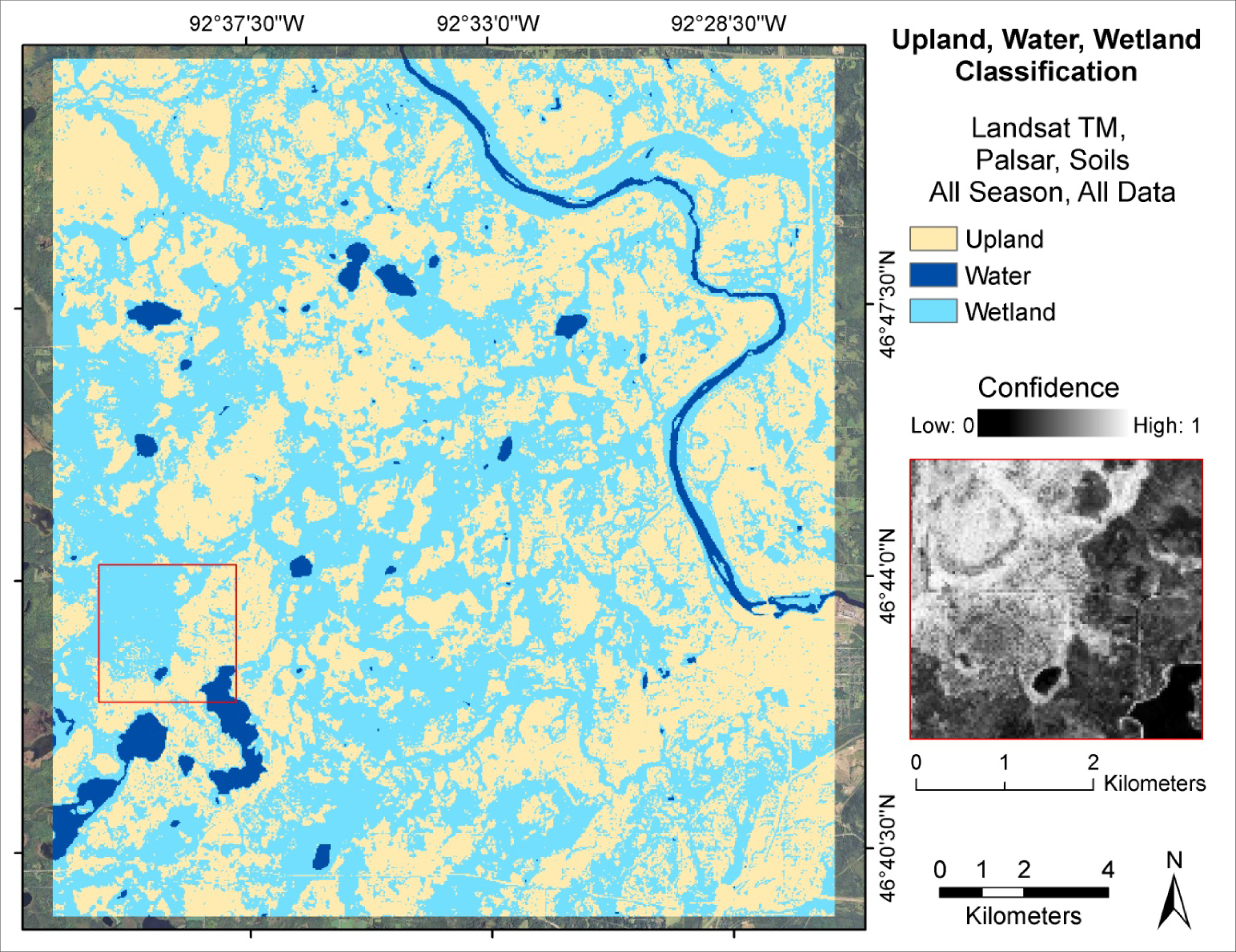
2.2. Land Cover Classification Schemes
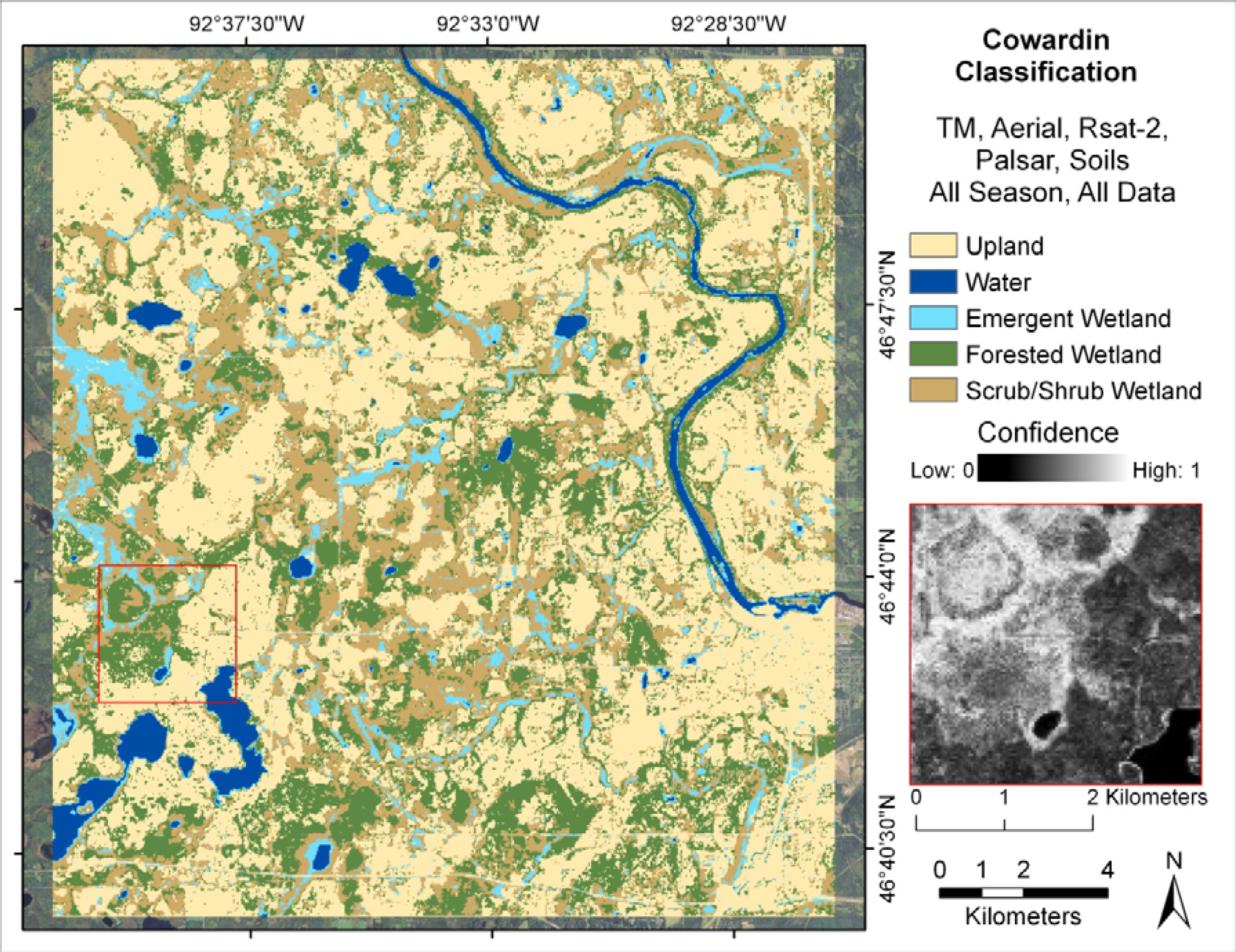
Two levels of classification were performed. The land cover classification schemes we used differentiated between upland, water, and wetland areas (Level 1) and sub-classified wetlands into wetland type (Level 2). Upland areas included all non-wetland classes, for example: urban, forest, grassland, agriculture, and barren land cover classes. Areas classified as wetland were sub-classified into a modified version of the Cowardin classification scheme [
44], including the three most common wetland classes in the study area according to the National Wetlands Inventory (NWI) [
45]: emergent, forested, and scrub/shrub wetlands. We merged the palustrine unconsolidated bottom class with the emergent wetland class and the riverine unconsolidated bottom class with the water class, based on visual assessment of the landscape variability in the study area (
Table 1).
Any errors present in the initial Level 1 classification result prior to sub-classifying the wetland class can be propagated to the Level 2 classification [
46–
49]. We tested whether classification accuracy could be improved by developing a Level 2 classification directly from the full set of input data without first producing a Level 1 classification, but the results were too poor for further consideration. Thus, all subsequent Level 2 classification results and discussion represent a hierarchical sub-classification of the wetland class from the results of the corresponding Level 1 land cover classification.
2.3. Decision Tree Classification
We used random forest as the decision tree classifier for our study [
50]. Generating decision trees was an efficient means of using our point reference training data to establish relations between our independent (remotely sensed and ancillary data) and dependent (field determined land cover class) variables to produce a land cover classification [
51,
52]. Random forest is a meta-classifier that consists of a collection (forest) of decision trees using training data. The decision trees were constructed with a random sample of input variables selected to split at each node [
53]. The default number of variables selected equals the square root of the total number of input variables, which we held as a constant during forest growing. The decision trees were fully grown without pruning using a sample (with replacement) of about one-third of the training data. The cross-validation accuracy was calculated using the remaining training data (out-of-bag) and was used to evaluate the relative accuracy of each model prior to a formal accuracy assessment. Each tree produced a ‘vote’ for the final classification, where the final result was the class which had the highest number of votes [
53]. The classification confidence, or probability, equals the ratio of the number of votes for a given class out of the total number of trees generated, with a resulting value range of 0–1. For each model tested we ran 500 decision trees.
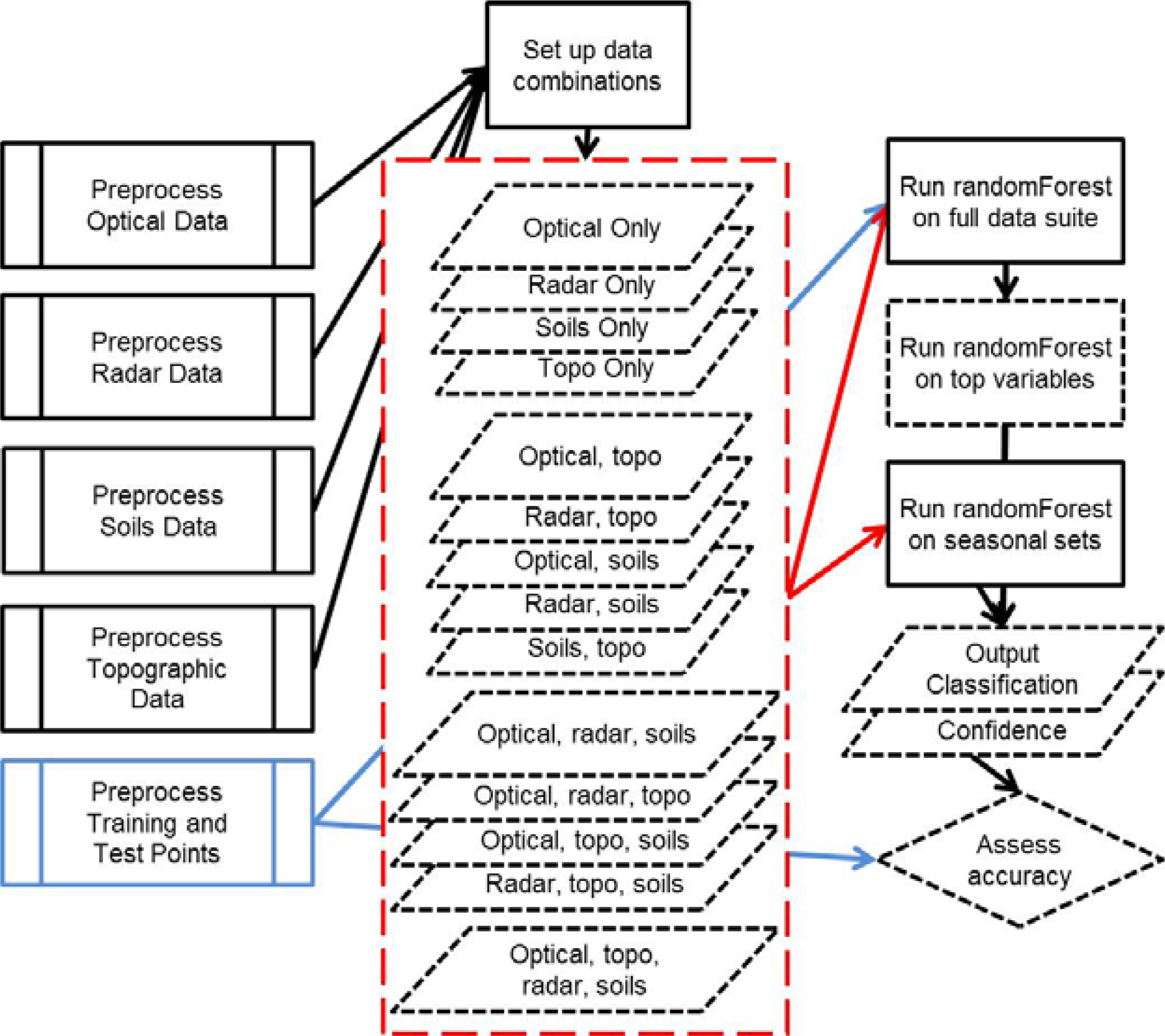
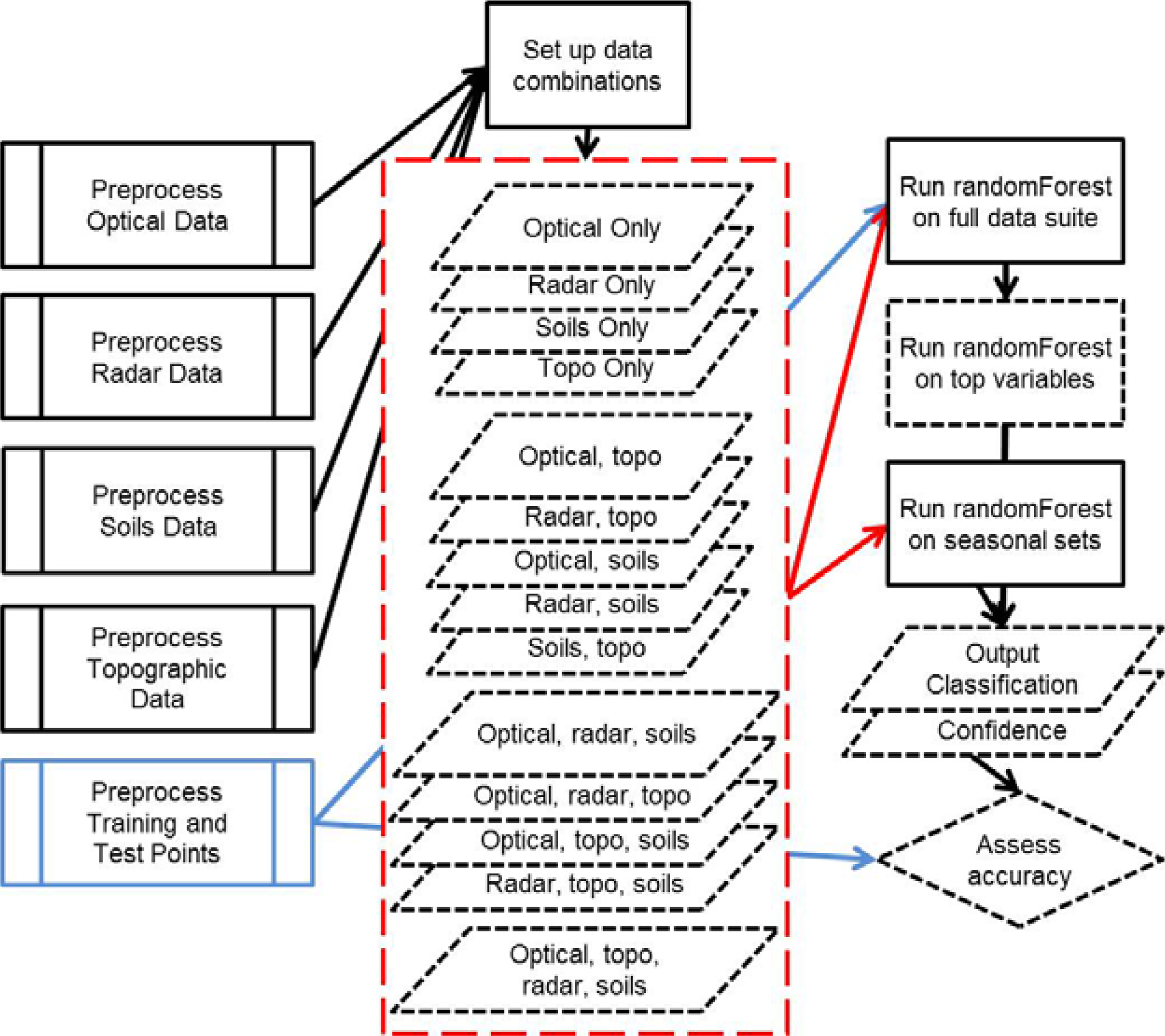
We built several random forest models per classification level by integrating different combinations of remotely sensed and ancillary input data to determine: (1) the most important data sources (corresponding to platform and wavelength of optical or radar data, and ancillary topographic and soils data derivatives), (2) the most significant input variables for mapping wetlands and classifying wetland type, and (3) the most effective temporal period (all data or only spring, summer, or fall season). Pre-defined combinations of input data are shown in
Figure 2. We reviewed the top three models with highest overall accuracy for each classification level.
To determine if reducing the data load significantly changed the accuracy of the classification, we re-ran the top random forest models having the highest overall accuracy using only a selection of important variables-referred to as Reduced Data Load (RDL) models from this point forward. We used a combination of assessment measures from random forest (i.e., mean decrease in accuracy and Gini index for the overall model and per class, explained in the Accuracy Assessment section below) and expert knowledge to assess variable importance. In the selection of important variables for the RDL, we thought it was valuable to have fair representation from all data sources and seasons, to incorporate both remote sensing and wetland science knowledge, and to utilize the measures of variable importance produced by the random forest classifier. For example, if a radar data variable was within the top 20 variables for either the Gini index or the mean decrease in accuracy, that variable was included in the RDL model based on our knowledge of the sensitivity of the radar signal to saturated conditions. Selection for the Level 2 RDL was complex. We considered variable importance measures for the overall model and for each of the three wetland classes, and we incorporated expert knowledge of specific input data layers for our final selection of the RDL. We selected 10 important variables for the Level 1 classification. We increased our selection to 15 variables for the Level 2 classification to accommodate anticipated overlap in the input data distributions between different classes.
2.4. Training and Test Reference Point Data
Reference training and test point data (
Table 2) were compiled from randomly generated field sites visited in the summers of 2009 and 2010, from study sites of an existing wetland monitoring program (centroids from polygons of the 2006–2008 MN Department of Natural Resources Wetland Status and Trends Monitoring Program [
19]), and from our expert knowledge in photo interpretation. The protocol for reference data collection in 2009 and 2010 involved several steps in the field: two different field crews were sent to locate random ground reference points with a GPS unit; crew members identified the dominant Cowardin wetland type [
44] within a reasonable visual distance; crew members recorded basic observations about the site’s characteristics; 2–5 photographs were taken per site; and crew members recorded the point ID, photo ID, Cowardin classification, and GPS coordinates in a back-up field book. Each field point represents a spatial area equal to the ground resolution of the input raster data used in the model (30 m). If the landscape surrounding the field point was not homogeneous within a reasonable visual distance, the field crew would use their discretion and move the GPS point to a new location which was more homogeneous. Empirical comparison of accuracies of results using different subdivisions of training and testing data [
45] led us to use a stratified random sample of 75% of the reference point data for training the random forest classifier and 25% of the reference point data for testing the accuracy of the results. Reference points were added to the training dataset via photo interpretation to maintain appropriate representation of land cover classes and to preserve a suitable spatial distribution of training points. Assessment of outliers in the training dataset integrated the proximity measure from random forest (described in more detail below), aerial and field photo interpretation, and expert knowledge to determine whether training sites were appropriate reference for their respective classes. We filtered only training sites; all testing sites were maintained in the reference set (
Table 2). Spatial autocorrelation in either reference dataset was not formally addressed in this study.
The set of reference training data were evaluated for outliers using the proximity measure from the random forest classifier. Proximity was calculated by running the training dataset down each tree in the forest a second time, increasing the proximity value by one each time the training site occupied the same terminal node of the decision tree in the first and second run. The proximity measure was normalized by dividing by the total number of trees generated by random forest. Training sites with a low proximity measure may be outliers in the training data. For this study, the proximity measure was used to guide the selection and evaluation of training sites that were considered outliers. Each of the identified sites was evaluated and, subsequently, some of the sites were removed.
2.6. Accuracy Assessment
We reserved a stratified random subset of 25% of the reference point data and implemented traditional methods to assess accuracy and evaluate results. We constructed error matrices with overall accuracy, 95% confidence intervals (CI), User’s and Producer’s accuracies, kappa statistic (k-hat), and ran significance tests of error matrix k-hat values [
80] for all random forest classification models. We performed two error matrix significance tests for each of the land cover classification levels: (1) between the most accurate random forest model with the full data suite to the same model with only a selection of the most important variables (RDL), and (2) between the most accurate random forest model with the full data suite to the most accurate random forest model using only data from a seasonal snapshot. Asterisks were used next to table values that were significant at an alpha of 0.05. We also conducted an accuracy assessment of the original NWI for comparison to our accuracy results.
Outputs from random forest provide unique complements to traditional accuracy assessment, including: (1) cross-validation, using the out-of-bag sample of training data to evaluate relative accuracy of each model prior to a formal accuracy assessment; (2) classification confidence, or probability, calculated by the number of times a given class was designated as the final class out of the total number of trees, with a resulting value range of 0–1; (3) mean decrease in accuracy, calculated per input data layer, giving insight to how influential a layer was on the overall accuracy; and (4) Gini index, which aids in evaluating the influence of input layers on the structure of the decision trees.
To calculate mean decrease in accuracy, the sample of reference data that was retained during the growth of each decision tree (out-of-bag) was used to determine the relative change in accuracy by including or excluding a particular variable. The normalized change in cross-validation accuracy was totaled after all decision trees were run and represents the relative importance of that variable [
53]. The Gini index is calculated by, starting with an index value of 1, reducing the index value per variable every time that variable was used to make a dichotomous split in each decision tree. This index value was totaled per variable and represents the relative influence of that variable on the structure of each decision tree [
53]. The most important variables in the random forest model can be inferred by evaluating both the mean decrease in accuracy and Gini index.
5. Conclusions
One of our main goals was to identify an optimal selection of input data from various sources of remotely sensed and ancillary data to accurately map wetland areas in Northern Minnesota. We accomplished this goal by rigorously testing the results from several combinations of data at two classification levels. We found that the key input variables for accurately differentiating between upland, water, and wetland areas include satellite red, near infrared (NIR), and middle infrared (MIR1) bands and normalized vegetation index (NDVI), elevation and curvature, hydric soils ancillary data, and L-band horizontal-vertical (HV) polarization. We conclude that, in addition to the variables used for the Level 1 classification, the key input variables for a Level 2 classification of wetlands include Tasseled Cap Greenness and Wetness, satellite thermal band, and L-band horizontal-horizontal (HH) polarization. Our sound methods have generated an important set of results for the remote sensing community, describing in detail the differences in accuracy of wetland mapping in a forested region using specific data sources and combinations.
Weather conditions over the study site during the water years October 2007–September 2010 were relevant to conclusions made regarding seasonal data importance. This is because precipitation, and any subsequent deviation from the 30 year normal, influences the site’s hydrologic characteristics prior to data acquisition. The important spring datasets identified in
Tables 5 and
9 all correspond to above normal precipitation conditions. With the exception of the summer of 2008, the rest of the important summer and fall datasets were acquired during below normal precipitation conditions. Though it is possible to plan spring data acquisition knowing the water year trends from the fall and winter before, it is difficult to fully anticipate precipitation events that will obscure optical data acquisition.
To accurately identify wetland areas in a forested region, such as Northern Minnesota, we found accuracy is improved when incorporating only spring season data for both Level 1 and Level 2 classifications. We conclude that, provided multi-temporal satellite optical, L-band radar (PALSAR), topographic, and soils data are included, identifying wetland areas in this region is more accurate when quad-polarization C-band radar (RADARSAT-2) and higher resolution aerial orthophotos are left out of the random forest model. However, we found that once wetland areas are identified, classifying wetland type is more accurate when C-band radar and broader temporal coverage of optical data are included. These findings are unique because through rigorous testing of different sources of remotely sensed data, a task that has not been done before in this region, we found that different wavelengths of radar data are beneficial for different levels of land cover classification.
The results of this study suggest that wetland mapping in a forested region such as Northern Minnesota can be improved by targeting the selection of important input variables from essential data platforms (such as L-band PALSAR) and by allocating more complete spectral coverage during the spring season. The way forward for further improvements to wetland classification in a forested region may include: analysis and utilization of classification confidence to target areas for future field reference data collection, using additional topographic information derived from light detection and ranging (lidar) such as canopy height and other parameters that relate to vegetation structure (e.g., standard deviation of height and number of returns within a grid cell, intensity), and incorporating spatial context and geometry of features through use of image segmentation and object based image analysis.



{kind=link}
{kind=link}
{kind=link}
{kind=link}