
Monitoring Hydrological Patterns of Temporary Lakes Using Remote Sensing and Machine Learning Models: Case Study of La Mancha Húmeda Biosphere Reserve in Central Spain


 , ,
, ,  ,
,
Abstract
:
1. Introduction
2. Materials and Methods
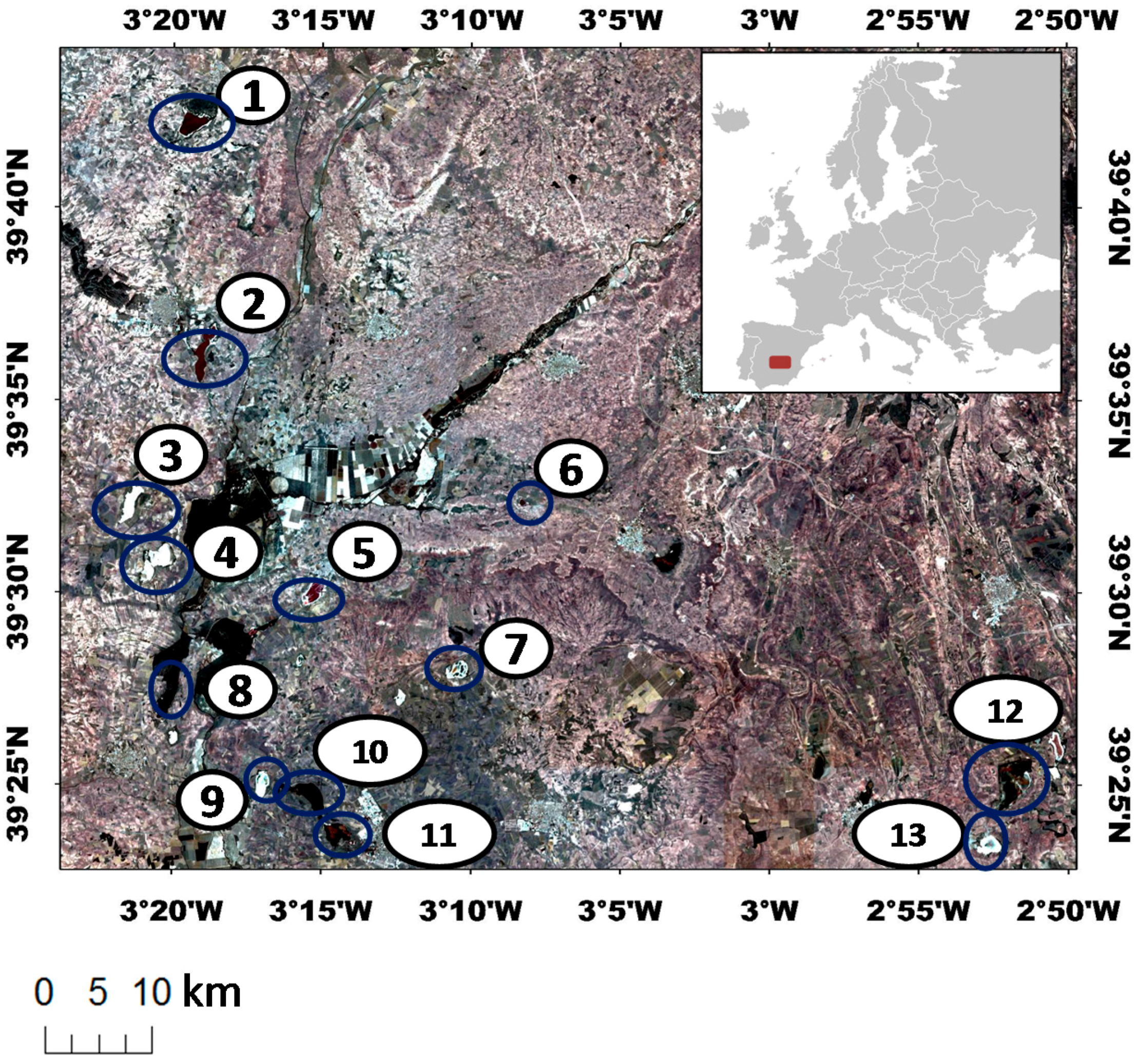
2.1. Study Area
2.2. Reference Datasets
2.3. Remote Sensing Data Collection and Pre-Processing
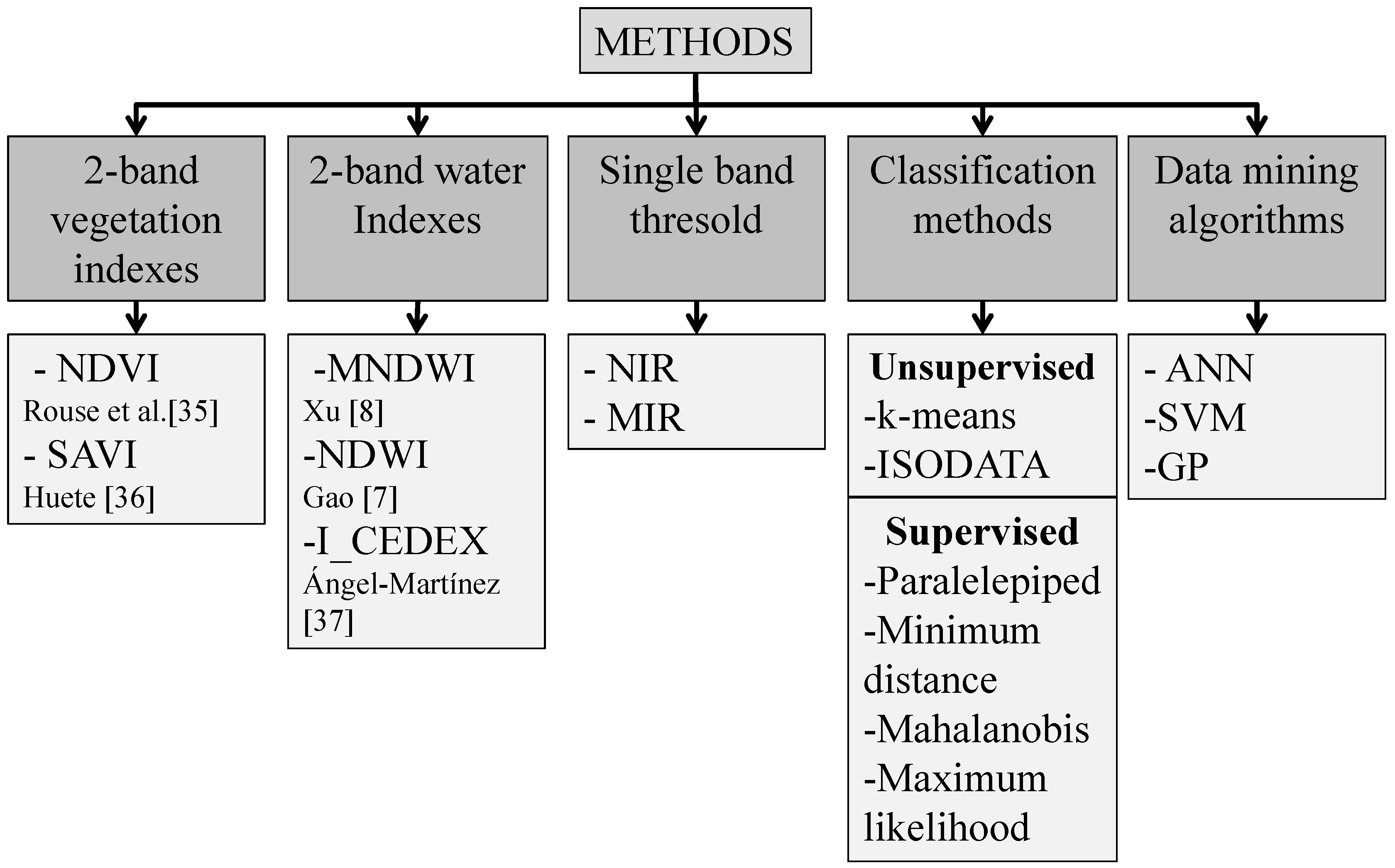
2.4. Water Mapping Methods
3. Results and Discussion
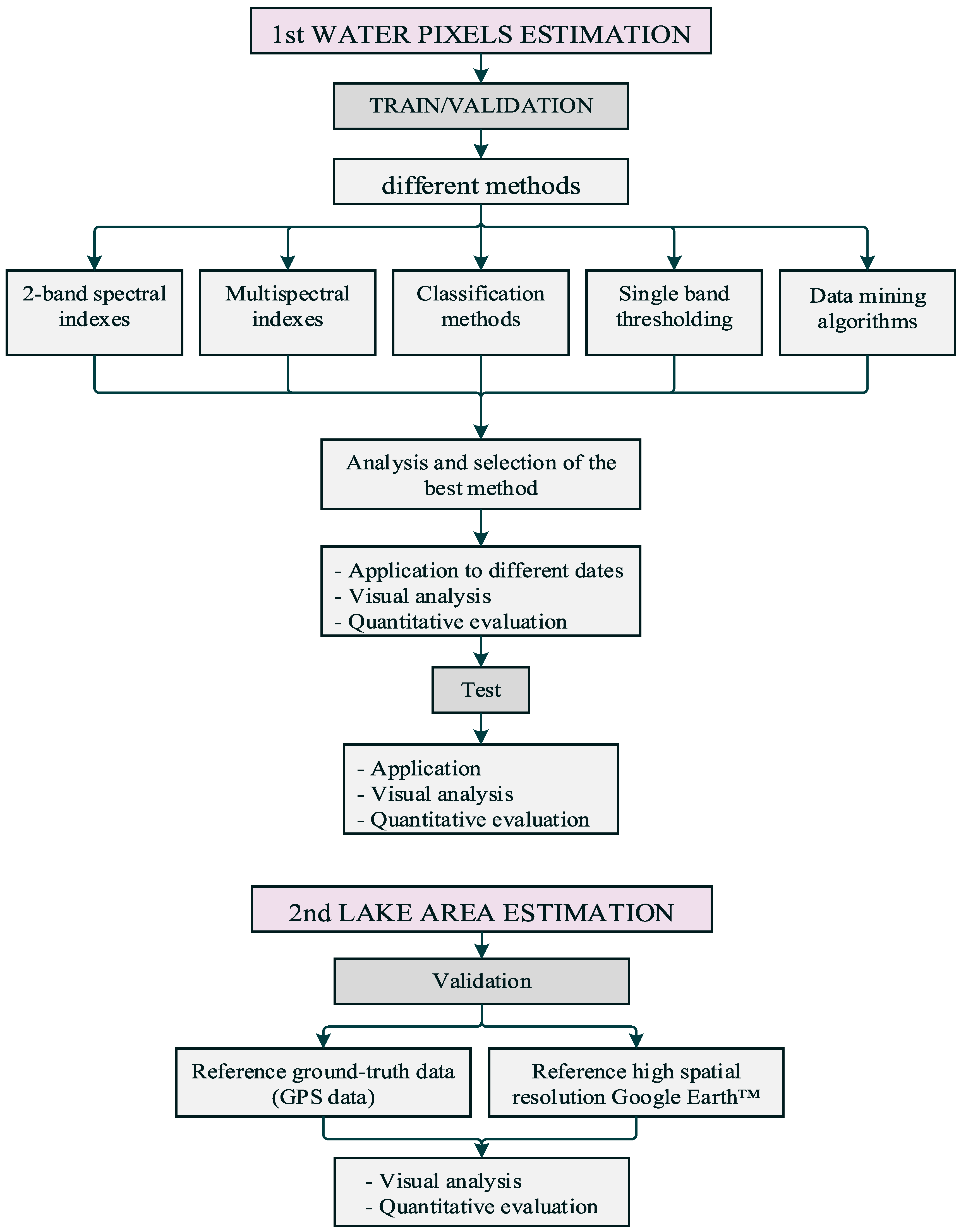
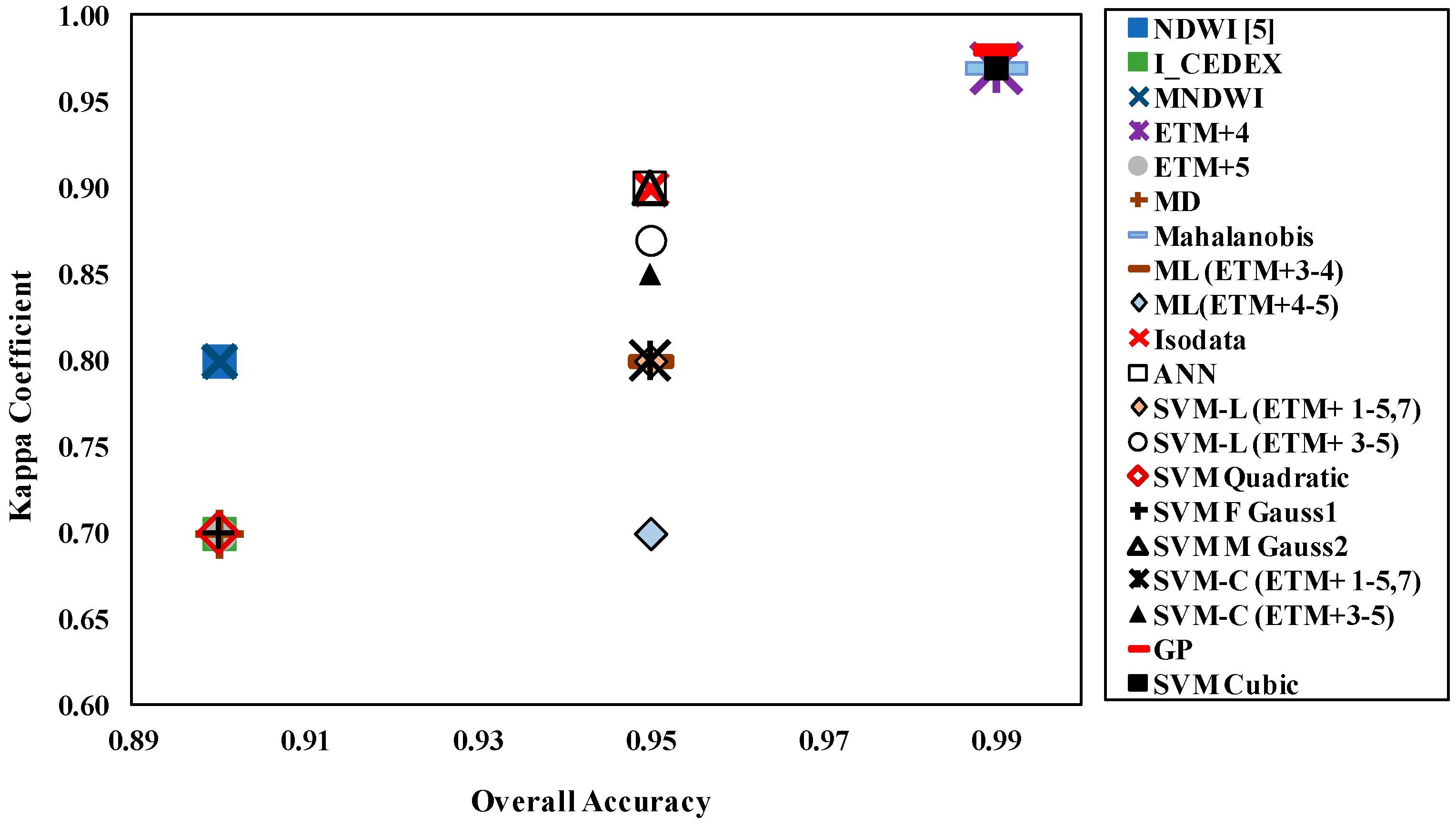
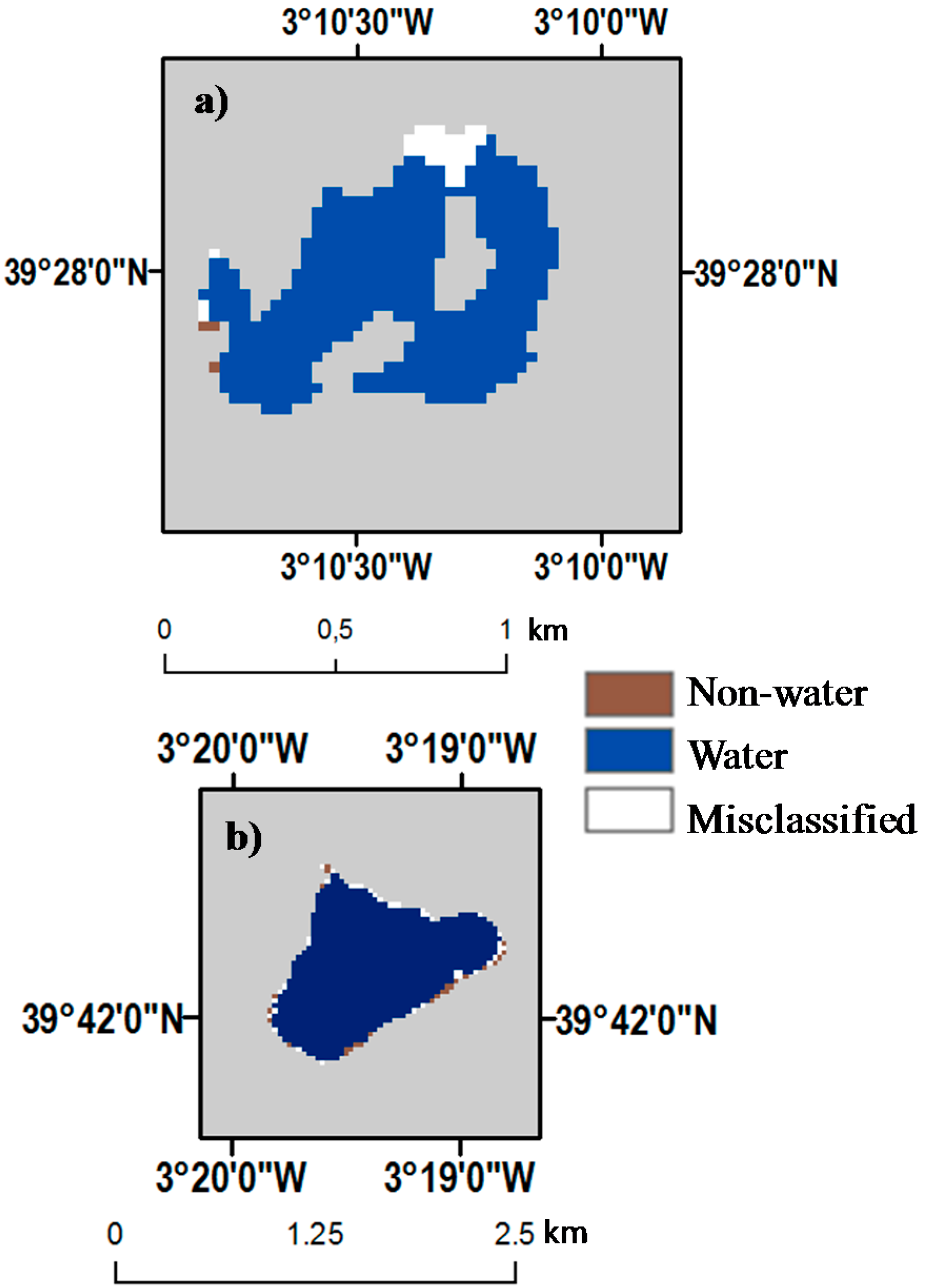
3.1. Water Pixel Estimation
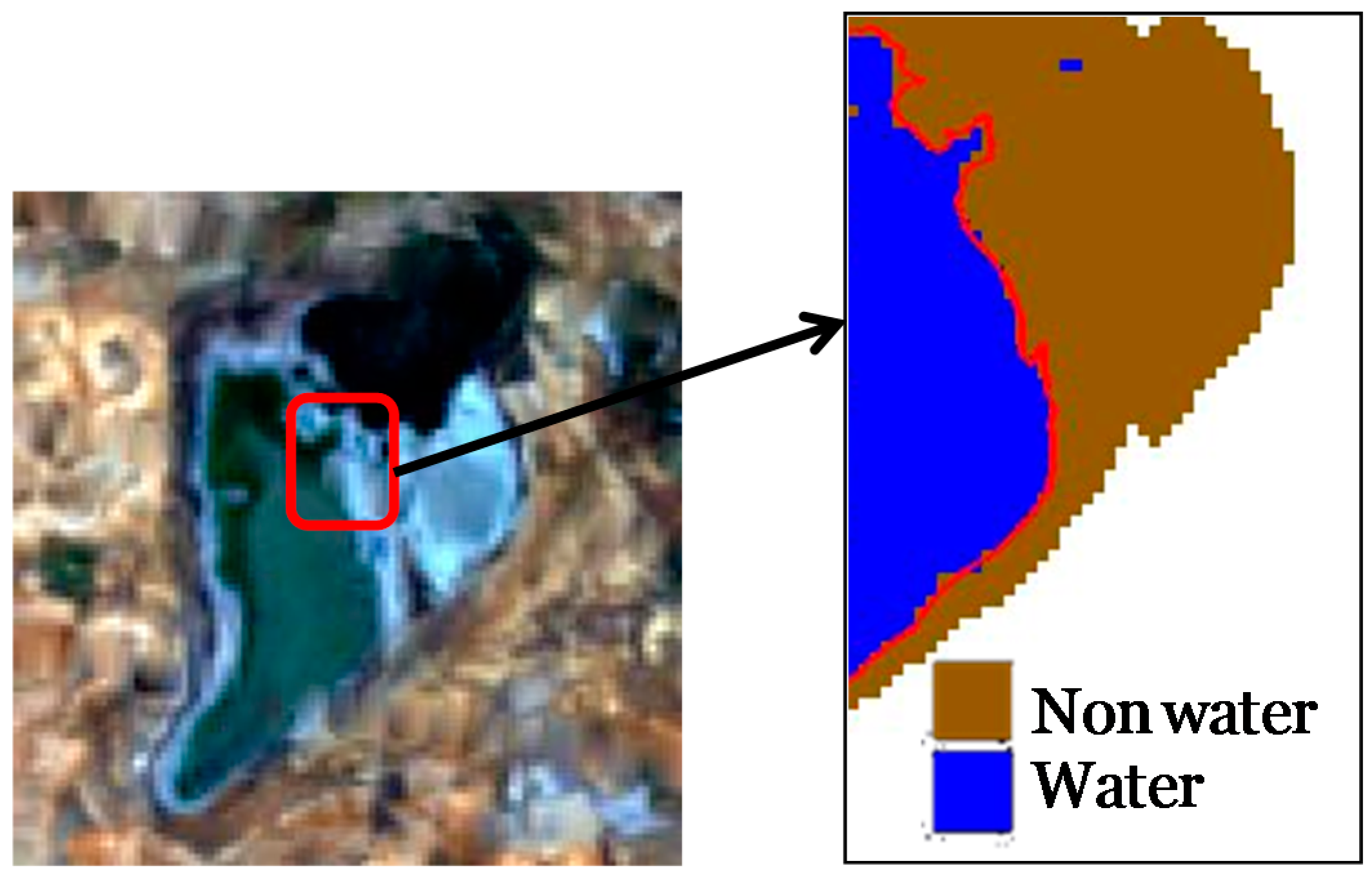
3.2. Sub-Pixel Extraction
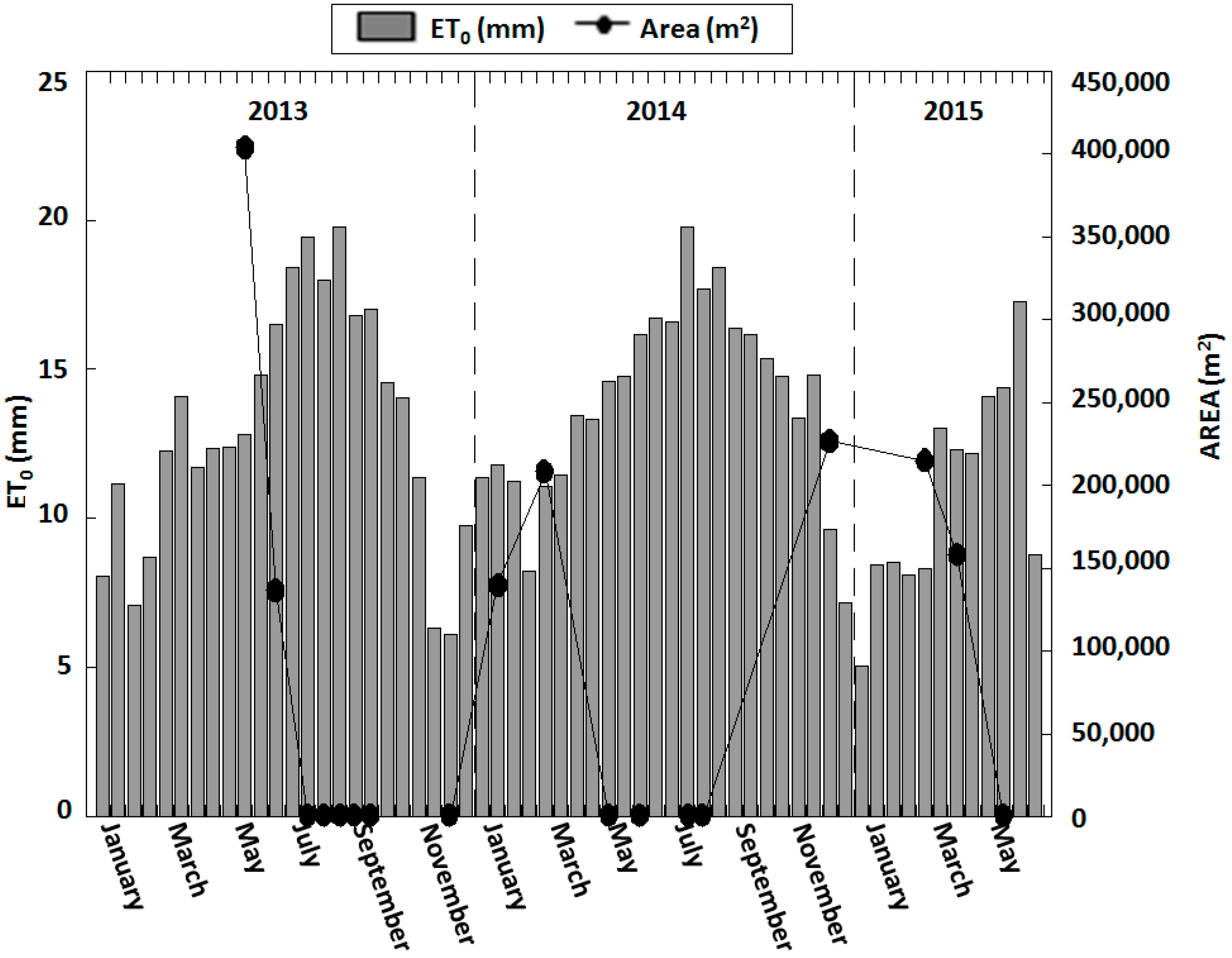
3.3. Water Area Variation
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Florín, M.; Montes, C.; Rueda, F. Origin, hydrologic functioning, and morphometric characteristics of small, shallow, semiarid lakes (lagunas) in La Mancha, central Spain. Wetlands 1993, 13, 247–259. [Google Scholar] [CrossRef]
- Gosálvez, R.; Gil-Delgado, J.A.; Vives-Ferrándiz, C.; Sánchez, G.; Florín, M. Seguimiento de aves acúaticas amenazadas en lagunas dela Reserva de la Biosfera de La Mancha Húmeda (España central). Polígonos 2012, 22, 89–122. [Google Scholar] [CrossRef]
- Castañeda, C.; Herrero, J. Teledeección de cambios en la Laguna de Gallocanta. Memorias Real Soc. Española Hist. Nat. 2009, 7, 103–126. [Google Scholar]
- Camacho, A.; Miracle, M.R.; Vicente, E. Which factors determine the abundance and distribution of picocyanobacteria in inland waters? A comparison among different types of lakes and ponds. Arch. Hydrobiol. 2003, 157, 321–338. [Google Scholar] [CrossRef]
- Work, E.A.; Gilmer, D.S. Utilization of satellite data for inventorying prairie ponds and lakes. J. Photogramm. Eng. Remote Sens. 1976, 42, 685–694. [Google Scholar]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Gao, B.C. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Bai, J.; Chen, X.; Li, J.; Yang, L.; Fang, H. Changes in the area of inland lakes in arid regions of central Asia during the past 30 years. Environ. Monit. Assess. 2011, 178, 247–256. [Google Scholar] [CrossRef] [PubMed]
- McFeeters, S.K. Using the normalized difference water index (NDWI) within a geographic information system to detect swimming pools for mosquito abatement: A practical approach. Remote Sens. 2013, 5, 3544–3561. [Google Scholar] [CrossRef]
- Sakamoto, T.; Van Nguyen, N.; Kotera, A.; Ohno, H.; Ishitsuka, N.; Yokozawa, M. Detecting temporal changes in the extent of annual flooding within the Cambodia and the Vietnamese Mekong Delta from MODIS time-series imagery. Remote Sens. Environ. 2007, 109, 295–313. [Google Scholar] [CrossRef]
- Li, W.; Du, Z.; Ling, F.; Zhou, D.; Wang, H.; Gui, Y.; Sun, B.; Zhang, X. A comparison of land surface water mapping using the normalized difference water index from TM, ETM+ and ALI. Remote Sens. 2013, 5, 5530–5549. [Google Scholar] [CrossRef]
- El-Asmar, H.M.; Hereher, M.E. Change detection of the coastal zone east of the Nile Delta using remote sensing. Environ. Earth Sci. 2011, 62, 769–777. [Google Scholar] [CrossRef]
- Campos, J.C.; Sillero, N.; Brito, J.C. Normalized difference water indexes have dissimilar performances in detecting seasonal and permanent water in the Sahara-Sahel transition zone. J. Hydrol. 2012, 464-465, 438–446. [Google Scholar] [CrossRef]
- Maglione, P. Coastline extraction using high resolution WorldView-2 satellite imagery. Eur. J. Remote Sens. 2014, 685–699. [Google Scholar] [CrossRef]
- Ji, L.; Zhang, L.; Wylie, B. Analysis of dynamic thresholds for the normalized difference water index. Photogramm. Eng. Remote Sens. 2009, 75, 1307–1317. [Google Scholar] [CrossRef]
- Jain, S.K.; Singh, R.D.; Jain, M.K.; Lohani, A.K. Delineation of flood-prone areas using remote sensing techniques. Water Resour. Manag. 2005, 19, 333–347. [Google Scholar] [CrossRef]
- Ouma, Y.O.; Tateishi, R. A water index for rapid mapping of shoreline changes of five East African Rift Valley lakes: An empirical analysis using Landsat TM and ETM+ data. Int. J. Remote Sens. 2006, 27, 3153–3181. [Google Scholar] [CrossRef]
- Lira, J. Segmentation and morphology of open water bodies from multispectral images. Int. J. Remote Sens. 2006, 27, 4015–4038. [Google Scholar] [CrossRef]
- Fisher, A.; Danaher, T. A water index for SPOT5 HRG satellite imagery, New South Wales, Australia, determined by linear discriminant analysis. Remote Sens. 2013, 5, 5907–5925. [Google Scholar] [CrossRef]
- Gardelle, J.; Hiernaux, P.; Kergoat, L.; Grippa, M. Less rain, more water in ponds: A remote sensing study of the dynamics of surface waters from 1950 to present in pastoral Sahel (Gourma region, Mali). Hydrol. Earth Syst. Sci. Discuss. 2009, 6, 5047–5083. [Google Scholar] [CrossRef]
- Soliman, G.; Soussa, H. Wetland change detection in Nile swamps of southern Sudan using multitemporal satellite imagery. J. Appl. Remote Sens. 2011, 5, 053517. [Google Scholar] [CrossRef]
- Sun, F.; Sun, W.; Chen, J.; Gong, P. Comparison and improvement of methods for identifying waterbodies in remotely sensed imagery. Int. J. Remote Sens. 2012, 33, 6854–6875. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated water extraction index: A new technique for surface water mapping using Landsat imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Klein, I.; Dietz, A.J.; Gessner, U.; Galayeva, A.; Myrzakhmetov, A.; Kuenzer, C. Evaluation of seasonal water body extents in Central Asia over the past 27 years derived from medium-resolution remote sensing data. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 335–349. [Google Scholar] [CrossRef]
- Moser, L.; Voigt, S.; Schoepfer, E. Monitoring of critical water and vegetation anomalies of Sub-Saharan West-African wetlands. In Proceedings of the IEEE International Conference on Geoscience and Remote Sensing Symposium, Québec City, QC, Canada, 13–18 July 2014; pp. 3842–3845.
- Sethre, P.; Rundquist, B.; Todhunter, P. Remote detection of prairie pothole ponds in the Devils Lake Basin, North Dakota. GISci. Remote Sens. 2005, 42, 277–296. [Google Scholar] [CrossRef]
- Laguna, C.; Gosálvez, R.; Sánchez, G.; Falomir, J.; Velasco, A.; Florín, M.; Gil-Delgado, J.; Chicote, A. Climate change footprint in the Mancha húmeda biosphere reserve. In Proceedings of the Energy and Environment Knowledge Week, Toledo, Spain, 28–29 October 2013; pp. 183–185.
- Vidal, D.; Anza, I.; Taggart, M.A.; Pérez-ramírez, E.; Crespo, E.; Hofle, U.; Mateo, R. Environmental factors influencing the prevalence of a Clostridium botulinum type C/D mosaic strain in nonpermanent Mediterranean wetlands. Appl. Environ. Microbiol. 2013, 79, 4264–4271. [Google Scholar] [CrossRef] [PubMed]
- Florín, M.; Montes, C. Functional analysis and restoration of Mediterranean lagunas in the Mancha Húmeda Biosphere Reserve ( Central Spain). Plant Ecol. 1999, 109, 97–109. [Google Scholar]
- Schroeder, T.A.; Wulder, M.A.; Healey, S.P.; Moisen, G.G. Mapping wildfire and clearcut harvest disturbances in boreal forests with Landsat time series data. Remote Sens. Environ. 2011, 115, 1421–1433. [Google Scholar] [CrossRef]
- Yang, J.; Weisberg, P.J.; Bristow, N.A. Landsat remote sensing approaches for monitoring long-term tree cover dynamics in semi-arid woodlands: Comparison of vegetation indices and spectral mixture analysis. Remote Sens. Environ. 2012, 119, 62–71. [Google Scholar] [CrossRef]
- Canty, M.J.; Nielsen, A.A. Automatic radiometric normalization of multitemporal satellite imagery with the iteratively re-weighted MAD transformation. Remote Sens. Environ. 2008, 112, 1025–1036. [Google Scholar] [CrossRef]
- Scaramuzza, P.; Micijevic, E.; Chander, G. SCL Gap-Filled Products. Phase One Methodology; USGS-United States Geology Survey: USA, 2004. Available online: https://landsat.usgs.gov/documents/SLC_Gap_Fill_Methodology.pdf (accessed on 17 September 2014).
- Rouse, J.W.; Haas, R.H.; Deering, D.W.; Sehell, J.A. Monitoring the Vernal Advancement and Retrogradation (Green Wave Effect) of Natural Vegetation; Remote Sensing Center. Report RSC 1978-4; Texas A&M University: College Station, TX, USA, 1974. [Google Scholar]
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Ángel-Martínez, M.C. Aplicación de la Teledetección en la Localización de Superficies de Agua; CEDEX: Madrid, Spain, 1994. [Google Scholar]
- Bustamante, J.; Díaz-Delgado, R.; Aragonés, D.; Pacios, F. Determining water body characteristics of Doñana shallow marshes through remote sensing. In Proceedings of the IEEE International Conference on Geoscience and Remote Sensing Symposium, Denver, CO, USA, 31 July–4 August 2006; pp. 3662–3663.
- Doña, C.; Sanchez, J.M.; Caselles, V.; Dominguez, J.A.; Camacho, A. Empirical Relationships for Monitoring Water Quality of Lakes and Reservoirs Through Multispectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1632–1641. [Google Scholar] [CrossRef]
- Srivastava, P.K.; Han, D.; Rico-Ramirez, M.A.; Bray, M.; Islam, T. Selection of classification techniques for land use/land cover change investigation. Adv. Sp. Res. 2012, 50, 1250–1265. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Seifert, J.W. Data mining: An overview. In National Security Issues; Pegarkov, D.D., Ed.; Nova Science Publishers, Inc.: New York, NY, USA, 2006; pp. 201–217. [Google Scholar]
- Doña, C.; Chang, N.B.; Caselles, V.; Sánchez, J.M.; Camacho, A.; Delegido, J.; Vannah, B.W. Integrated satellite data fusion and mining for monitoring lake water quality status of the Albufera de Valencia in Spain. J. Environ. Manag. 2015, 151, 416–426. [Google Scholar]
- Francone, D. Discipulus Software Owner’s Manual, Version 3.0 DRAFT; Machine Learning Technologies, Inc.: Littleton, CO, USA, 1998. [Google Scholar]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Allen, R.G.; Pereira, L.S.; Raes, D.; Smith, M.; Ab, W. Crop Evapotranspiration—Guidelines for Computing Crop Water Requirements—FAO Irrigation and Drainage Paper 56; FAO: Rome, Italy, 1998; pp. 1–15. [Google Scholar]
- Sankarasubramanian, A.; Vogel, R.M.; Limbrunner, J.F. Climate elasticity of stream ow in the United States. Water Resour. 2001, 37, 1771–1781. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lake *1 | Coordinates °N | Coordinates °W | Altitude (masl) | Max Area *2 (km2) | Seasonality |
|---|---|---|---|---|---|
| Alcahozo (13) | 39.38 | 2.85 | 660 | 0.19 | High |
| Camino de Villafranca (10) | 39.41 | 3.26 | 638 | 1.4 | Moderate |
| Grande de Quero (5) | 39.50 | 3.24 | 664 | 0.9 | High |
| Grande de Villafranca (8) | 39.46 | 3.33 | 645 | 0.9 | Low |
| La Veguilla (11) | 39.39 | 3.24 | 638 | 0.19 | Low+ |
| Larga de Villacañas (2) | 39.62 | 3.34 | 660 | 1.4 | Low+ |
| Las Yeguas (9) | 39.41 | 3.28 | 638 | 0.6 | High |
| El Longar (1) | 39.70 | 3.32 | 690 | 0.3 | High |
| Manjavacas (12) | 39.41 | 2.86 | 670 | 1.4 | Moderate+ |
| Mermejuela (6) | 39.54 | 3.13 | 660 | 0.09 | High |
| Peñahueca (4) | 39.51 | 3.34 | 650 | 1.6 | High |
| Salicor (7) | 39.47 | 3.17 | 668 | 0.6 | High |
| Tírez (3) | 39.54 | 3.36 | 650 | 1.3 | High |
| Landsat Image Date (Day/Month/Year) | Reference Data Date (Day/Month/Year) | Source | Lakes |
|---|---|---|---|
| 3 February 2011 | 9 February 2011 | C | LO/YE/CA/VE/LAR/PE/QUE/SAL |
| 29 June 2012 | 29 June 2012 | C | VE/LAR/PE |
| 7 July 2012 | 15 July 2012 | C | CA/SAL |
| 24 February 2013 | 28 February 2013 | A | AL/CA/MAN |
| 31 May 2013 | 29 May 2013 | A | AL/CA/LO/VE/MAN/GRAN/LAR/MER/PE/QUE/TI |
| 25 July 2013 | 23 July 2013 | A | CA/VE/YE/QUE/TI |
| 29 October 2013 | 28 October 2013 | A | PE/TI |
| 23 November 2013 | 25 November 2013 | A | AL/CA/LO/LAR/SAL |
| 16 December 2013 | 16 December 2013 | A | CA/LO/GRAN/LAR/PE/TI |
| 26 January 2014 | 27 January 2014 | A | CA/VE/MAN/YE/PE/TI |
| 5 February 2014 | 29 April 2014 | A | CA/MER |
| 26 June 2014 | 24 June 2014 | A | LO/VE/YE/GRAN/LAR/MER/QUE/SAL |
| 21 July 2014 | 23 July 2014 * | A | AL/CA/LO/VE/MAN/YE/MER/PE/TI |
| 2 March 2015 | 22 February 2015 | B | AL/MAN |
| 21 May 2015 | 21 May 2015 | B | AL/MAN |
| Method | Overall Accuracy (%) | Kappa | Commission Error (%) | Omission Error (%) | Producer Accuracy (%) | User Accuracy (%) | Total Error (%) | |
|---|---|---|---|---|---|---|---|---|
| MNDWI | Xu [8] | 90 | 0.80 | 30 | 3 | 95 | 70 | 30 |
| NDWI | Gao [7] | 90 | 0.60 | 40 | 15 | 85 | 60 | 60 |
| NDWI | McFeeters [6] | 90 | 0.80 | 25 | 3 | 95 | 75 | 30 |
| I_CEDEX | Ángel-Martínez [37] | 90 | 0.70 | 40 | 10 | 90 | 60 | 50 |
| NDVI | Rouse et al. [35] | 70 | 0.40 | 60 | 30 | 70 | 40 | 90 |
| SAVI | Huete [36] | 70 | 0.40 | 60 | 30 | 70 | 40 | 90 |
| ETM+4 | 99 | 0.97 | 2 | 2 | 98 | 98 | 4 | |
| ETM+5 | 90 | 0.70 | 40 | 0 | 100 | 60 | 40 |
| Method | Overall Accuracy (%) | Kappa | Commission Error (%) | Omission Error (%) | Producer Accuracy (%) | User Accuracy (%) | Total Error (%) | |
|---|---|---|---|---|---|---|---|---|
| Parallelepiped | All combinations | <40 | <0.20 | >50 | >50 | <50 | <50 | >60 |
| Minimum distance | ETM+ 4,5 | 90 | 0.67 | 40 | 0 | 100 | 60 | 60 |
| Mahalanobis | ETM+ 3,4 | 99 | 0.97 | 5 | 0 | 100 | 95 | 5 |
| Maximum Likelihood | ETM+ 3,4 | 95 | 0.80 | 0 | 30 | 70 | 100 | 30 |
| Maximum Likelihood | ETM+ 4,5 | 95 | 0.70 | 0 | 40 | 60 | 100 | 40 |
| K-means | ETM+ 4,5 | 80 | 0.60 | 10 | 30 | 90 | 75 | 40 |
| K-means | ETM+ 4 | 80 | 0.60 | 10 | 30 | 90 | 75 | 40 |
| ISODATA | ETM+ 3,4 | 95 | 0.90 | 10 | 5 | 100 | 80 | 15 |
| Method | Overall Accuracy (%) | Kappa | Commission Error (%) | Omission Error (%) | Producer Accuracy (%) | User Accuracy (%) | Total Error (%) | |
|---|---|---|---|---|---|---|---|---|
| ANN | ETM+ 1–5,7 | 95 | 0.90 | 4 | 15 | 85 | 95 | 19 |
| SVM linear | ETM+ 1–5,7 | 95 | 0.80 | 0 | 15 | 100 | 85 | 15 |
| SVM linear | ETM+ 3–5 | 95 | 0.87 | 0 | 18 | 100 | 80 | 18 |
| SVM Quadratic | ETM+ 3–5 | 90 | 0.70 | 0 | 40 | 100 | 65 | 40 |
| SVM Cubic | ETM+ 1–5,7 | 99 | 0.97 | 0 | 6 | 100 | 94 | 6 |
| SVM F Gauss1 | ETM+ 3–5 | 90 | 0.70 | 0 | 40 | 100 | 59 | 40 |
| SVM M Gauss2 | ETM+ 3–5 | 95 | 0.90 | 0 | 20 | 100 | 80 | 20 |
| SVM Course | ETM+ 1–5,7 | 95 | 0.80 | 0 | 30 | 100 | 75 | 30 |
| SVM Course | ETM+ 3–5 | 95 | 0.85 | 0 | 20 | 100 | 79 | 20 |
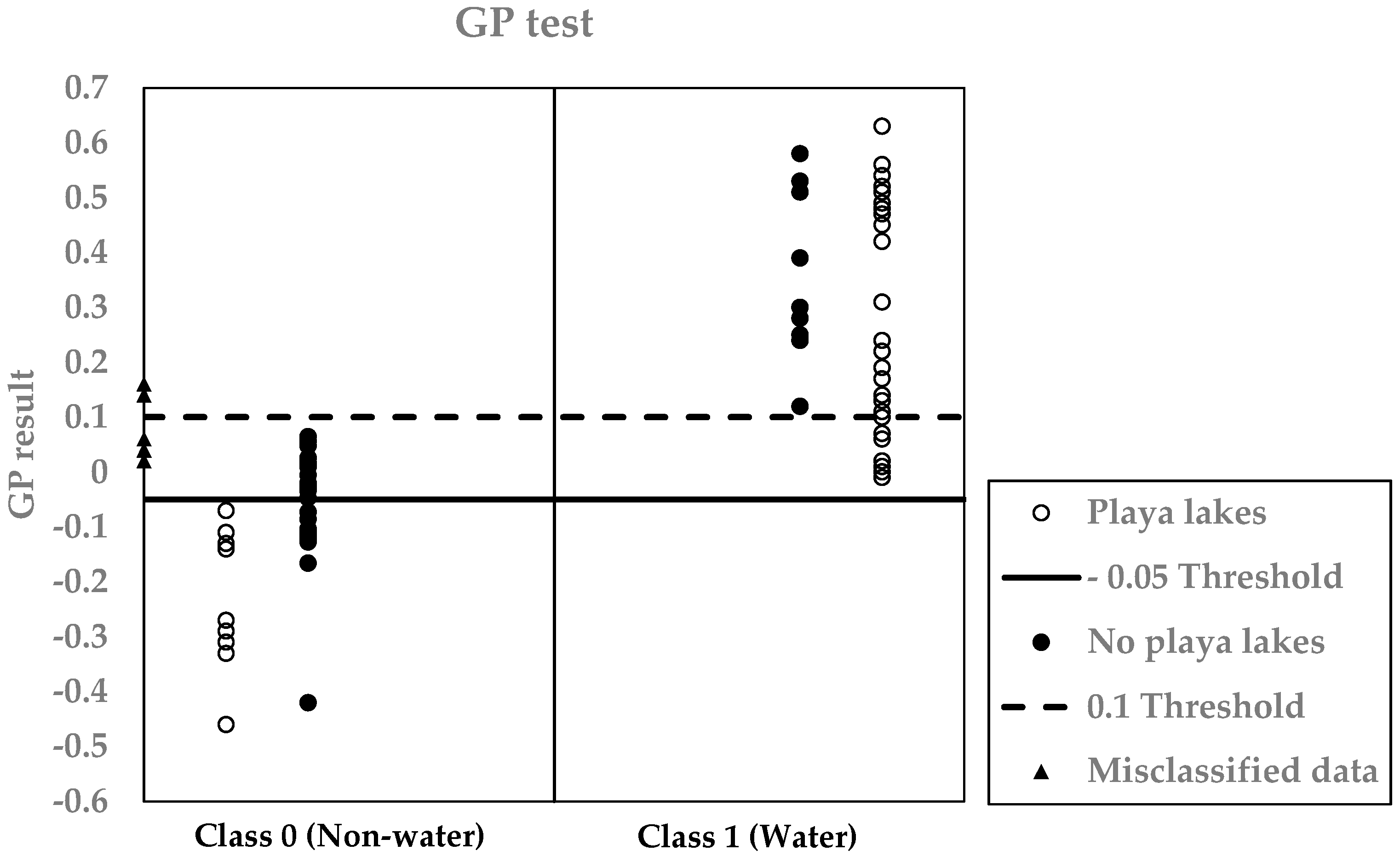
| GP | ETM+ 4 | 99 | 0.98 | 2 | 0 | 100 | 97 | 2 |
| Lake *1 | Threshold | Overall Accuracy (%) | Kappa |
|---|---|---|---|
| Alcahozo (13) | −0.05 | 70 | 0.45 |
| Camino de Villafranca (10) | −0.05 | 94 | 0.62 |
| Grande de Quero (5) | −0.05 | 99 | 0.85 |
| * La Veguilla (11) | 0.10 | 86 | 0.68 |
| Larga de Villacañas (2) | 0.10 | 90 | 0.61 |
| * Larga de Villacañas (2) | 0.10 | 80 | 0.80 |
| Las Yeguas (9) | −0.05 | 97 | 0.76 |
| El Longar (1) | −0.05 | 96 | 0.53 |
| Manjavacas (12) | 0.10 | 96 | 0.92 |
| Manjavacas (12) | 0.10 | 86 | 0.73 |
| * Peñahueca (4) | −0.05 | 95 | 0.82 |
| Salicor (7) | −0.05 | 94 | 0.15 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Doña, C.; Chang, N.-B.; Caselles, V.; Sánchez, J.M.; Pérez-Planells, L.; Bisquert, M.D.M.; García-Santos, V.; Imen, S.; Camacho, A. Monitoring Hydrological Patterns of Temporary Lakes Using Remote Sensing and Machine Learning Models: Case Study of La Mancha Húmeda Biosphere Reserve in Central Spain. Remote Sens. 2016, 8, 618. https://doi.org/10.3390/rs8080618
Doña C, Chang N-B, Caselles V, Sánchez JM, Pérez-Planells L, Bisquert MDM, García-Santos V, Imen S, Camacho A. Monitoring Hydrological Patterns of Temporary Lakes Using Remote Sensing and Machine Learning Models: Case Study of La Mancha Húmeda Biosphere Reserve in Central Spain. Remote Sensing. 2016; 8(8):618. https://doi.org/10.3390/rs8080618
Chicago/Turabian StyleDoña, Carolina, Ni-Bin Chang, Vicente Caselles, Juan Manuel Sánchez, Lluís Pérez-Planells, Maria Del Mar Bisquert, Vicente García-Santos, Sanaz Imen, and Antonio Camacho. 2016. "Monitoring Hydrological Patterns of Temporary Lakes Using Remote Sensing and Machine Learning Models: Case Study of La Mancha Húmeda Biosphere Reserve in Central Spain" Remote Sensing 8, no. 8: 618. https://doi.org/10.3390/rs8080618
APA StyleDoña, C., Chang, N.-B., Caselles, V., Sánchez, J. M., Pérez-Planells, L., Bisquert, M. D. M., García-Santos, V., Imen, S., & Camacho, A. (2016). Monitoring Hydrological Patterns of Temporary Lakes Using Remote Sensing and Machine Learning Models: Case Study of La Mancha Húmeda Biosphere Reserve in Central Spain. Remote Sensing, 8(8), 618. https://doi.org/10.3390/rs8080618