Change Detection Using High Resolution Remote Sensing Images Based on Active Learning and Markov Random Fields



Abstract

1. Introduction
- An interactive object-based change detection framework is proposed, which uses active learning with Gaussian processes to update the change detection results iteratively. After the comprehensive analysis of the sample selection strategy in change detection, a new sample selection method is introduced by choosing the easiest one from several candidate samples with the consideration of the representativeness and the convenience of labelling.
- The integration of attribute information (including color and texture) and contextual information. The contextual information is introduced to remove the “superpixel-noise” in the detection results of active learning. It is formulated as MRFs and can be efficiently solved by the min-cut-based integer optimization algorithm.
2. Background
2.1. Active Learning
2.2. Gaussian Processes
2.3. Markov Random Fields
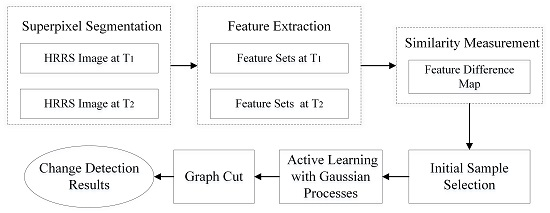
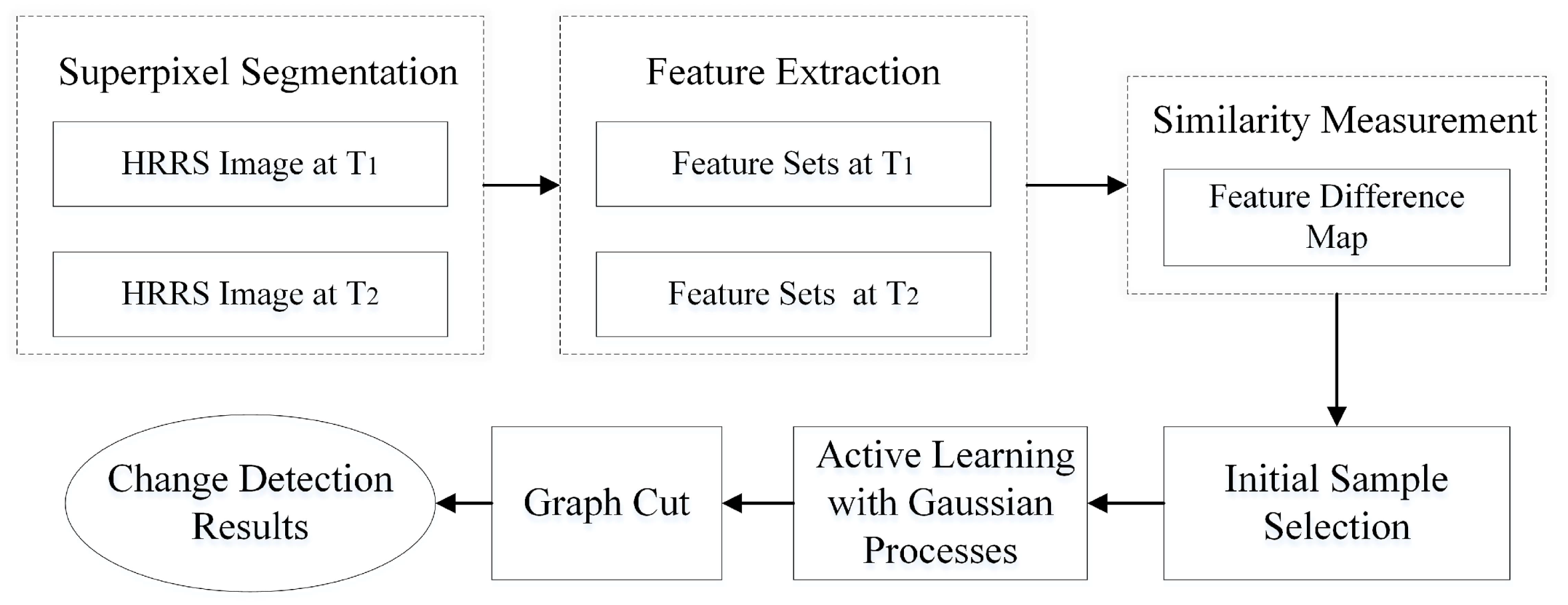
3. Methodology
3.1. Superpixel Segmentation
3.2. Feature Extraction
3.3. Similarity Measurement
3.4. Initial Sample Selection
3.5. Interactive Change Detection Based on Active Learning
3.5.1. Sample Selection Criteria
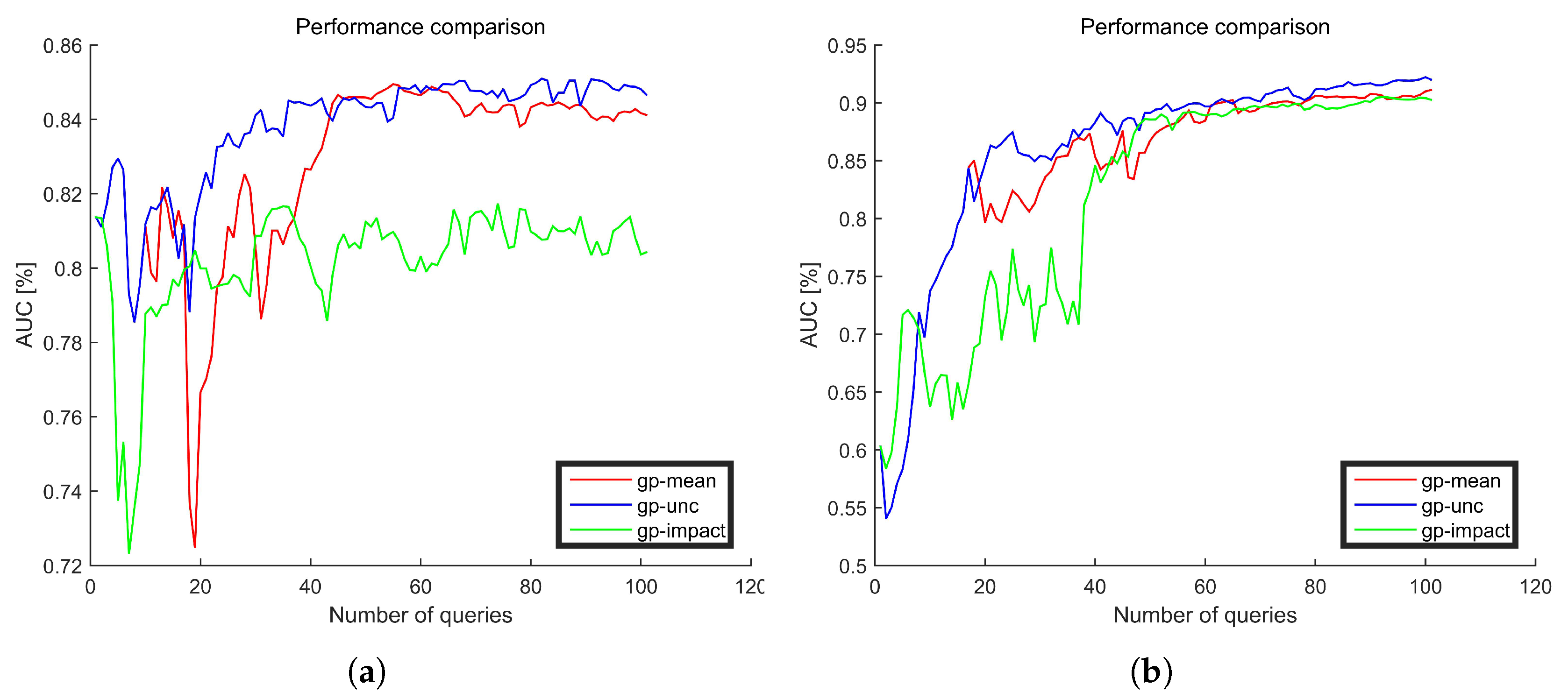
- The predictive meanThe predictive mean tries to select samples close to the current decision boundary, which belongs to exploitative methods. The predictive mean is given bywhere U is the feature set of unlabelled testing samples.
- The uncertaintyThe uncertainty tries to use the predictive mean and variance to select the most representative samples by making trade-offs between exploitative and explorative methods, which is given by
- Impact on the overall model changeThe impact [42] tries to choose the samples that will affect the current model heavily even with the most plausible label, which is given by
3.5.2. Labelling the Easiest Sample
3.6. Refinement with MRF Via Graph Cuts
4. Experiments
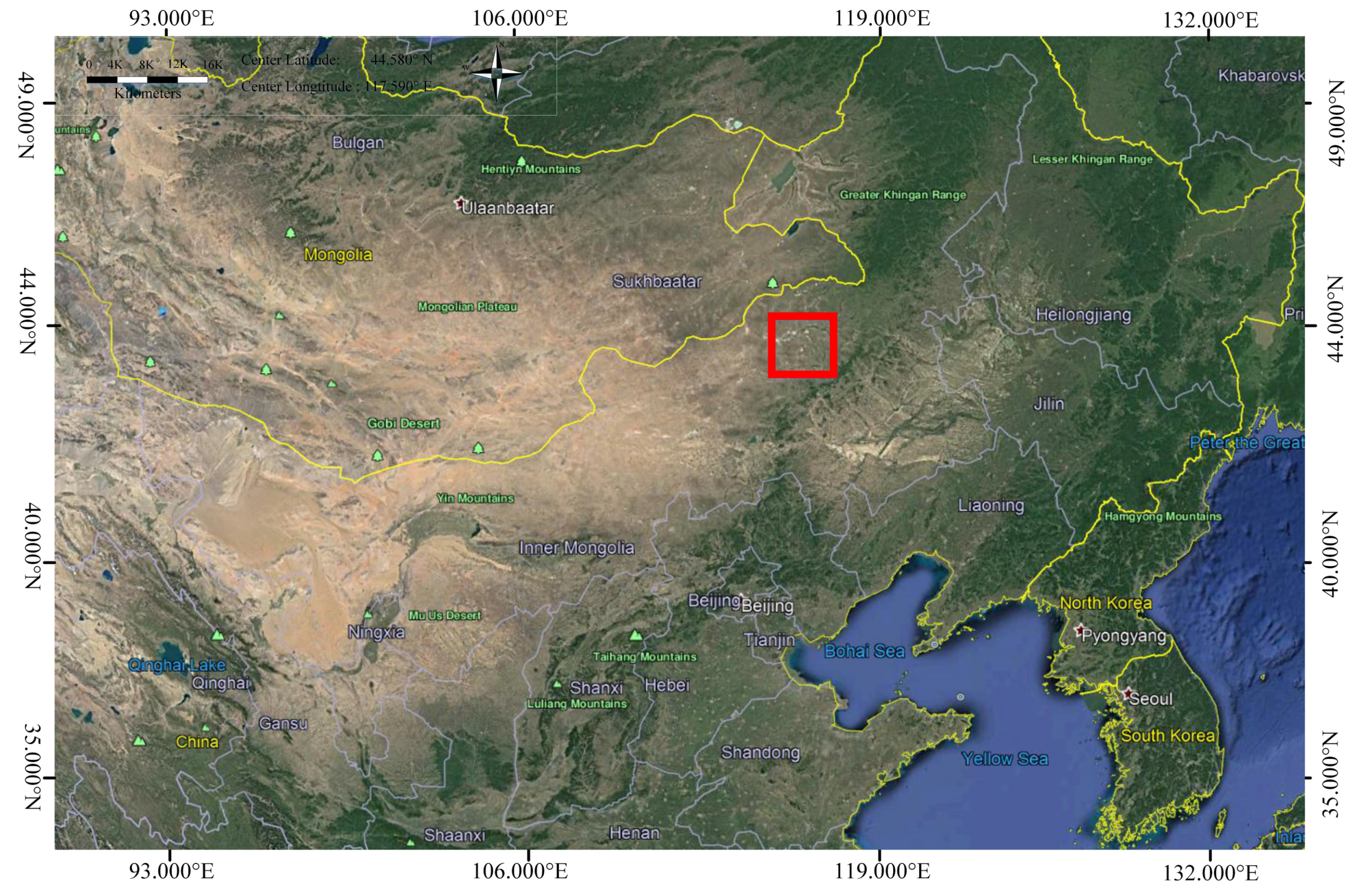
4.1. The Experimental Datasets
4.2. The Experimental Setup
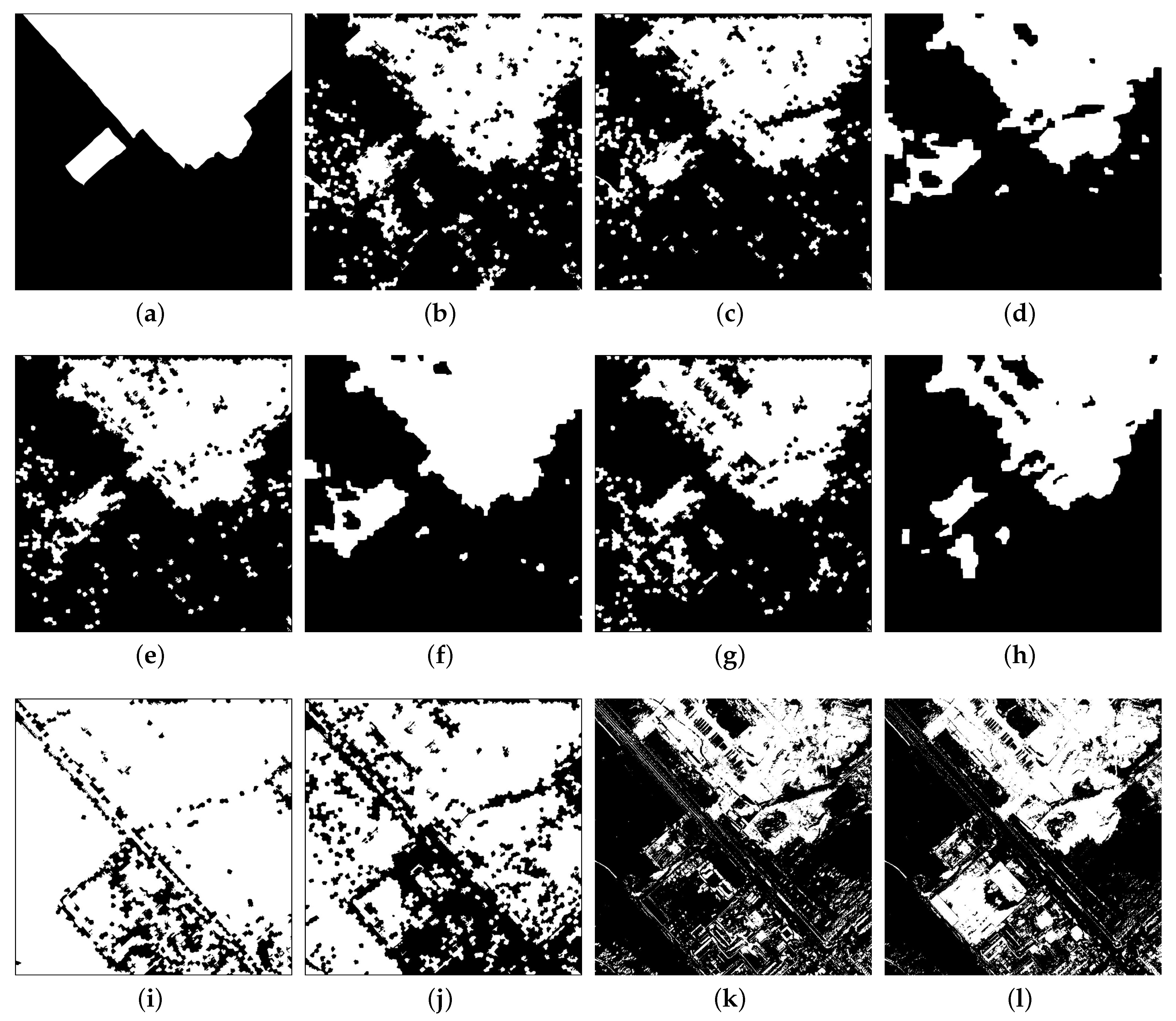
4.3. Experimental Results
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| HRRS | High resolution remote sensing |
| BOVW | Bag of visual words |
| DCD | Discriminate color descriptor |
| SIFT | Scale-invariant feature transform |
| SLIC | Simple linear iteration clustering |
| MRF | Markov random field |
| MAP | Maximum a posteriori |
| MLL | multilevel logistic |
| SVM | Support vector machine |
| IR-MAD | Iteratively reweighted multivariate alteration detection |
| CVA | Change vector analysis |
| PCA | Principal component analysis |
| AL | Active learning |
| AUC | Area under curve |
References
- Singh, A. Digital change detection techniques using remotely sensed data. Int. J. Remote Sens. 1988, 10, 989–1003. [Google Scholar] [CrossRef]
- Büttner, G. Corine land cover and land cover change products. In Land Use and Land Cover Mapping in Europe; Springer: Houten, The Netherlands, 2014; pp. 55–74. [Google Scholar]
- Ma, Y.; Chen, F.; Liu, J.; He, Y.; Duan, J.; Li, X. An automatic procedure for early disaster change mapping based on optical remote sensing. Remote Sens. 2016, 8, 272. [Google Scholar] [CrossRef]
- Schroeder, T.A.; Healey, S.P.; Moisen, G.G.; Frescino, T.S.; Cohen, W.B.; Huang, C.; Kennedy, R.E.; Yang, Z. Improving estimates of forest disturbance by combining observations from Landsat time series with US Forest Service Forest Inventory and Analysis data. Remote Sens. Environ. 2014, 154, 61–73. [Google Scholar] [CrossRef]
- Dewi, R.S.; Bijker, W.; Stein, A.; Marfai, M.A. Fuzzy classification for shoreline change monitoring in a part of the northern coastal area of Java, Indonesia. Remote Sens. 2016, 8, 190. [Google Scholar] [CrossRef]
- Liu, D.; Cai, S. A spatial-temporal modeling approach to reconstructing land-cover change trajectories from multi-temporal satellite imagery. Ann. Assoc. Am. Geogr. 2012, 102, 1329–1347. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B. Detecting trends in forest disturbance and recovery using yearly Landsat time series: 1. LandTrendr—Temporal segmentation algorithms. Remote Sens. Environ. 2010, 114, 2897–2910. [Google Scholar] [CrossRef]
- Klonus, S.; Tomowski, D.; Ehlers, M.; Reinartz, P.; Michel, U. Combined edge segment texture analysis for the detection of damaged buildings in crisis areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1118–1128. [Google Scholar] [CrossRef]
- Simard, M.; Saatchi, S.S.; De Grandi, G. The use of decision tree and multiscale texture for classification of JERS-1 SAR data over tropical forest. IEEE Trans. Geosci. Remote Sens. 2000, 38, 2310–2321. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Leichtle, T.; Geiß, C.; Wurm, M.; Lakes, T.; Taubenböck, H. Unsupervised change detection in VHR remote sensing imagery – An object-based clustering approach in a dynamic urban environment. Int. J. Appl. Earth Obs. Geoinf. 2017, 54, 15–27. [Google Scholar] [CrossRef]
- Yousif, O.; Ban, Y. Improving SAR-based urban change detection by combining MAP-MRF classifier and nonlocal means similarity weights. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4288–4300. [Google Scholar] [CrossRef]
- Castellana, L.; D’Addabbo, A.; Pasquariello, G. A composed supervised/unsupervised approach to improve change detection from remote sensing. Pattern Recognit. Lett. 2007, 28, 405–413. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L. The time variable in data fusion: A change detection perspective. IEEE Geosci. Remote Sens. Mag. 2015, 3, 8–26. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gómez-Chova, L.; Munoz-Marí, J.; Rojo-Álvarez, J.L.; Martínez-Ramón, M. Kernel-based framework for multitemporal and multisource remote sensing data classification and change detection. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1822–1835. [Google Scholar] [CrossRef]
- Pons, X. Post-classification change detection with data from different sensors: Some accuracy considerations. Int. J. Remote Sens. 2003, 24, 4975–4976. [Google Scholar]
- Ling, F.; Li, W.; Du, Y.; Li, X. Land cover change mapping at the subpixel scale with different spatial-resolution remotely sensed imagery. IEEE Geosci. Remote Sens. Lett. 2010, 8, 182–186. [Google Scholar] [CrossRef]
- Molina, I.; Martinez, E.; Morillo, C.; Velasco, J.; Jara, A. Assessment of data fusion algorithms for earth observation change detection processes. Sensors 2016, 16, 1621. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Zhang, L.; Zhang, L. A scene change detection framework for multi-temporal very high resolution remote sensing images. Sign. Process. 2016, 124, 184–197. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Bruzzone, L.; Serpico, S.B. An iterative technique for the detection of land-cover transitions in multitemporal remote-sensing images. IEEE Trans. Geosci. Remote Sens. 1997, 35, 858–867. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D.; Bovolo, F.; Kanevski, M.; Bruzzone, L. Supervised change detection in VHR images using contextual information and support vector machines. Int. J. Appl. Earth Obs. Geoinf. 2013, 20, 77–85. [Google Scholar] [CrossRef]
- Shao, P.; Shi, W.; He, P.; Hao, M.; Zhang, X. Novel approach to unsupervised change detection based on a robust semi-supervised FCM clustering algorithm. Remote Sens. 2016, 8, 264. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, Z.; Huo, C.; Sun, X.; Fu, K. A semisupervised context-sensitive change detection technique via gaussian process. IEEE Geosci. Remote Sens. Lett. 2013, 10, 236–240. [Google Scholar] [CrossRef]
- An, L.; Li, M.; Zhang, P.; Wu, Y.; Jia, L.; Song, W. Discriminative random fields based on maximum entropy principle for semisupervised SAR image change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3395–3404. [Google Scholar] [CrossRef]
- Nielsen, A.A. The regularized iteratively reweighted MAD method for change detection in multi- and hyperspectral data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [PubMed]
- Marpu, P.R.; Gamba, P.; Canty, M.J. Improving change detection results of IR-MAD by eliminating strong changes. IEEE Geosci. Remote Sens. Lett. 2011, 8, 799–803. [Google Scholar] [CrossRef]
- Liu, S.; Bruzzone, L.; Bovolo, F.; Du, P. Hierarchical unsupervised change detection in multitemporal hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 244–260. [Google Scholar]
- Byun, Y.; Han, Y.; Chae, T. Image fusion-based change detection for flood extent extraction using bi-temporal very high-resolution satellite images. Remote Sens. 2015, 7, 10347–10363. [Google Scholar] [CrossRef]
- Shah-Hosseini, R.; Homayouni, S.; Safari, A. A hybrid kernel-based change detection method for remotely sensed data in a similarity space. Remote Sens. 2015, 7, 12829–12858. [Google Scholar] [CrossRef]
- Sinha, P.; Kumar, L.; Reid, N. Rank-based methods for selection of landscape metrics for land cover pattern change detection. Remote Sens. 2016, 8, 107. [Google Scholar] [CrossRef]
- Zhu, G.; Wang, Q.; Yuan, Y.; Yan, P. Learning saliency by MRF and differential threshold. IEEE Trans. Cybern. 2013, 43, 2032–2043. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Lin, J.; Wang, Q. Hyperspectral image classification via multitask joint sparse representation and stepwise MRF optimization. IEEE Trans. Cybern. 2016, 46, 2966–2977. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral-spatial hyperspectral image segmentation using subspace multinomial logistic regression and markov random fields. IEEE Trans. Geosc. Remote Sens. 2012, 50, 809–823. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Seo, S.; Wallat, M.; Graepel, T.; Obermayer, K. Gaussian Process Regression: Active Data Selection and Test Point Rejection; Springer: Berlin/Heidelberg, Germany, 2000; Volume 3, pp. 241–246. [Google Scholar]
- MacKay, D.J.C. Information-based objective functions for active data selection. Neural Comput. 1992, 4, 590–604. [Google Scholar] [CrossRef]
- Cohn, D.; Atlas, L.; Ladner, R. Improving generalization with active learning. Mach. Learn. 1994, 15, 201–221. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A survey of active learning algorithms for supervised remote sensing image classification. IEEE J. Sel. Top. Sign. Process. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Sun, L.L.; Wang, X.Z. A survey on active learning strategy. In Proceedings of the International Conference on Machine Learning & Cybernetics, Qingdao, China, 11–14 July 2010; pp. 161–166. [Google Scholar]
- Rodner, E.; Freytag, A.; Bodesheim, P.; Denzler, J. Large-scale gaussian process classification with flexible adaptive histogram kernels. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 85–98. [Google Scholar]
- Freytag, A.; Rodner, E.; Bodesheim, P.; Denzler, J. Labeling examples that matter: Relevance-based active learning with gaussian processes. In Proceedings of the German Conference on Pattern Recognition, Saarbrücken, German, 3–6 September 2013; pp. 282–291. [Google Scholar]
- Christoph, K.; Alexander, F.; Erik, R.; Paul, B.; Joachim, D. Active learning and discovery of object categories in the presence of unnamable instances. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4343–4352. [Google Scholar]
- Rodner, E.; Freytag, A.; Bodesheim, P.; Fröhlich, B.; Denzler, J. Large-scale gaussian process inference with generalized histogram intersection kernels for visual recognition tasks. Int. J. Comput. Vis. 2017, 121, 235–280. [Google Scholar] [CrossRef]
- Freytag, A.; Rodner, E.; Bodesheim, P.; Denzler, J. Rapid uncertainty computation with gaussian processes and histogram intersection kernels. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; pp. 511–524. [Google Scholar]
- Yang, W.; Dai, D.; Triggs, B.; Xia, G.S. SAR-based terrain classification using weakly supervised hierarchical Markov aspect models. IEEE Trans. Image Process. 2012, 21, 4232–4243. [Google Scholar] [CrossRef] [PubMed]
- Jarecki, J.B.; Meder, B.; Nelson, J.D. Naïve and robust: Class-conditional independence in human classification learning. Cogn. Sci. 2017, 3, 1–39. [Google Scholar] [CrossRef] [PubMed]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Yu, H.; Yan, T.; Yang, W.; Zheng, H. An integrative object-based image analysis workflow for uav images. ISPRS Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B1, 1085–1091. [Google Scholar] [CrossRef]
- Barla, A.; Odone, F.; Verri, A. Histogram intersection kernel for image classification. In Proceedings of the IEEE International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; pp. 513–516. [Google Scholar]
- Khan, R.; Van de Weijer, J.; Shahbaz Khan, F.; Muselet, D.; Ducottet, C.; Barat, C. Discriminative color descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2866–2873. [Google Scholar]
- Xiao, J.; Peng, H.; Zhang, Y.; Tu, C.; Li, Q. Fast image enhancement based on color space fusion. Color Res. Appl. 2016, 41, 22–31. [Google Scholar] [CrossRef]
- Maji, S.; Berg, A.C.; Malik, J. Classification using intersection kernel support vector machines is efficient. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- Ru, H.; Yu, H.; Huang, P.; Yang, W. Interactive change detection using high resolution remote sensing images based on active learning with gaussian processes. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 141–147. [Google Scholar] [CrossRef]
- Lee, Y.J.; Grauman, K. Learning the easy things first: Self-paced visual category discovery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1721–1728. [Google Scholar]
- Yang, W.; Yang, X.; Yan, T.; Song, H.; Xia, G.S. Region-based change detection for polarimetric SAR images using Wishart mixture models. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6746–6756. [Google Scholar] [CrossRef]
- Kittler, J.; Illingworth, J. Minimum error thresholding. Pattern Recognit. 1986, 19, 41–47. [Google Scholar] [CrossRef]
- Scharsich, V.; Mtata, K.; Hauhs, M.; Lange, H.; Bogner, C. Analysing land cover and land use change in the Matobo National Park and surroundings in Zimbabwe. Remote Sens. Environ. 2017, 194, 278–286. [Google Scholar] [CrossRef]
- Manandhar, R.; Odeh, I.O.; Ancev, T. Improving the accuracy of land use and land cover classification of Landsat data using post-classification enhancement. Remote Sens. 2009, 1, 330–344. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | OA | Pc | Pu | Kappa |
|---|---|---|---|---|
| SVM | 0.7459 | 0.6296 | 0.8116 | 0.4448 |
| AL Mean | 0.7593 | 0.6795 | 0.8043 | 0.4811 |
| AL Mean MRF | 0.7921 | 0.7405 | 0.8213 | 0.5550 |
| AL Uncertainty | 0.7764 | 0.7222 | 0.8070 | 0.5220 |
| AL Uncertainty MRF | 0.8040 | 0.7572 | 0.8304 | 0.5803 |
| AL Impact | 0.7527 | 0.6579 | 0.8062 | 0.4640 |
| AL Impact MRF | 0.7134 | 0.3209 | 0.9352 | 0.2920 |
| KI Threshold | 0.6285 | 0.6418 | 0.6209 | 0.2460 |
| Otsu Threshold | 0.6728 | 0.2036 | 0.9379 | 0.1663 |
| CVA | 0.7664 | 0.5136 | 0.9092 | 0.4550 |
| IR-MAD | 0.7613 | 0.7006 | 0.7956 | 0.4895 |
| Strategy | OA | Pc | Pu | Kappa |
|---|---|---|---|---|
| SVM | 0.8717 | 0.8603 | 0.8771 | 0.7153 |
| AL Mean | 0.8623 | 0.7657 | 0.9176 | 0.6967 |
| AL Mean MRF | 0.9276 | 0.8909 | 0.9451 | 0.8347 |
| AL Uncertainty | 0.8748 | 0.7889 | 0.9240 | 0.7251 |
| AL Uncertainty MRF | 0.9442 | 0.9538 | 0.9396 | 0.8750 |
| AL Impact | 0.8505 | 0.7615 | 0.9015 | 0.6725 |
| AL Impact MRF | 0.9291 | 0.8409 | 0.9713 | 0.8337 |
| KI Threshold | 0.4736 | 0.9678 | 0.1907 | 0.1223 |
| Otsu Threshold | 0.6122 | 0.8570 | 0.4721 | 0.2821 |
| CVA | 0.8139 | 0.6676 | 0.8837 | 0.5644 |
| IR-MAD | 0.7997 | 0.7471 | 0.8249 | 0.5554 |
| Strategy | OA | Pc | Pu | Kappa | |
|---|---|---|---|---|---|
| Dataset 1 | Original AL | 0.7609 | 0.7280 | 0.7795 | 0.4947 |
| Improved AL | 0.7764 | 0.7222 | 0.8070 | 0.5220 | |
| Improved AL MRF | 0.8040 | 0.7572 | 0.8304 | 0.5803 | |
| Dataset 2 | Original AL | 0.8658 | 0.7921 | 0.9079 | 0.7072 |
| Improved AL | 0.8748 | 0.7889 | 0.9240 | 0.7251 | |
| Improved AL MRF | 0.9442 | 0.9538 | 0.9396 | 0.8750 |
| Method | p | |||||
|---|---|---|---|---|---|---|
| SVM | 1.1465 | 1.1408 | 0.6182 | 6.0944 | 0.1553 | <0.001 |
| AL Uncertainty | 1.2969 | 0.7583 | 0.4678 | 6.4769 | 0.0688 | <0.001 |
| AL Mean MRF | 1.3771 | 0.4938 | 0.3877 | 6.7414 | 0.0128 | <0.001 |
| AL Impact MRF | 1.0087 | 1.5700 | 0.7560 | 5.6652 | 0.2848 | <0.001 |
| IR-MAD | 0.8803 | 1.2680 | 0.8844 | 5.9673 | 0.0683 | <0.001 |
| Method | p | |||||
|---|---|---|---|---|---|---|
| SVM | 0.2702 | 1.0165 | 0.2872 | 8.4261 | 0.4079 | <0.001 |
| AL Uncertainty | 0.3306 | 0.8939 | 0.2269 | 8.5486 | 0.3970 | <0.001 |
| AL Mean MRF | 0.3553 | 0.3626 | 0.2022 | 9.0799 | 0.0456 | <0.001 |
| AL Impact MRF | 0.2181 | 0.4818 | 0.3393 | 8.9607 | 0.0247 | <0.001 |
| IR-MAD | 0.1798 | 1.8189 | 0.3777 | 7.6237 | 0.9456 | <0.001 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, H.; Yang, W.; Hua, G.; Ru, H.; Huang, P. Change Detection Using High Resolution Remote Sensing Images Based on Active Learning and Markov Random Fields. Remote Sens. 2017, 9, 1233. https://doi.org/10.3390/rs9121233
Yu H, Yang W, Hua G, Ru H, Huang P. Change Detection Using High Resolution Remote Sensing Images Based on Active Learning and Markov Random Fields. Remote Sensing. 2017; 9(12):1233. https://doi.org/10.3390/rs9121233
Chicago/Turabian StyleYu, Huai, Wen Yang, Guang Hua, Hui Ru, and Pingping Huang. 2017. "Change Detection Using High Resolution Remote Sensing Images Based on Active Learning and Markov Random Fields" Remote Sensing 9, no. 12: 1233. https://doi.org/10.3390/rs9121233
APA StyleYu, H., Yang, W., Hua, G., Ru, H., & Huang, P. (2017). Change Detection Using High Resolution Remote Sensing Images Based on Active Learning and Markov Random Fields. Remote Sensing, 9(12), 1233. https://doi.org/10.3390/rs9121233