Deformable ConvNet with Aspect Ratio Constrained NMS for Object Detection in Remote Sensing Imagery


Abstract
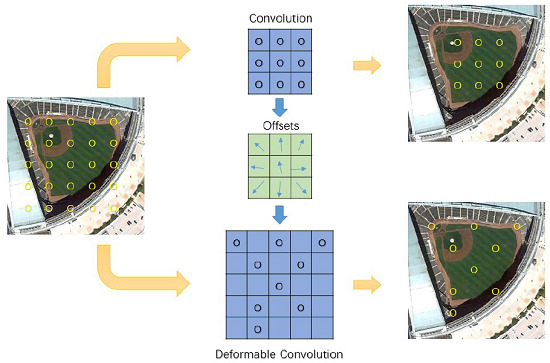
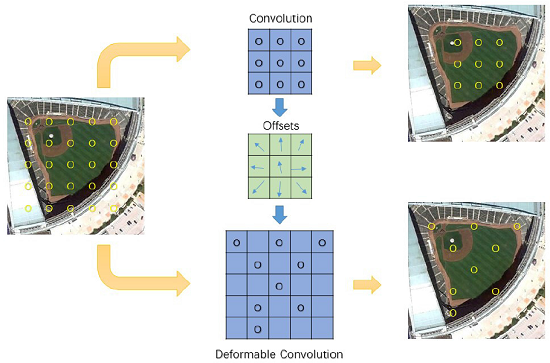
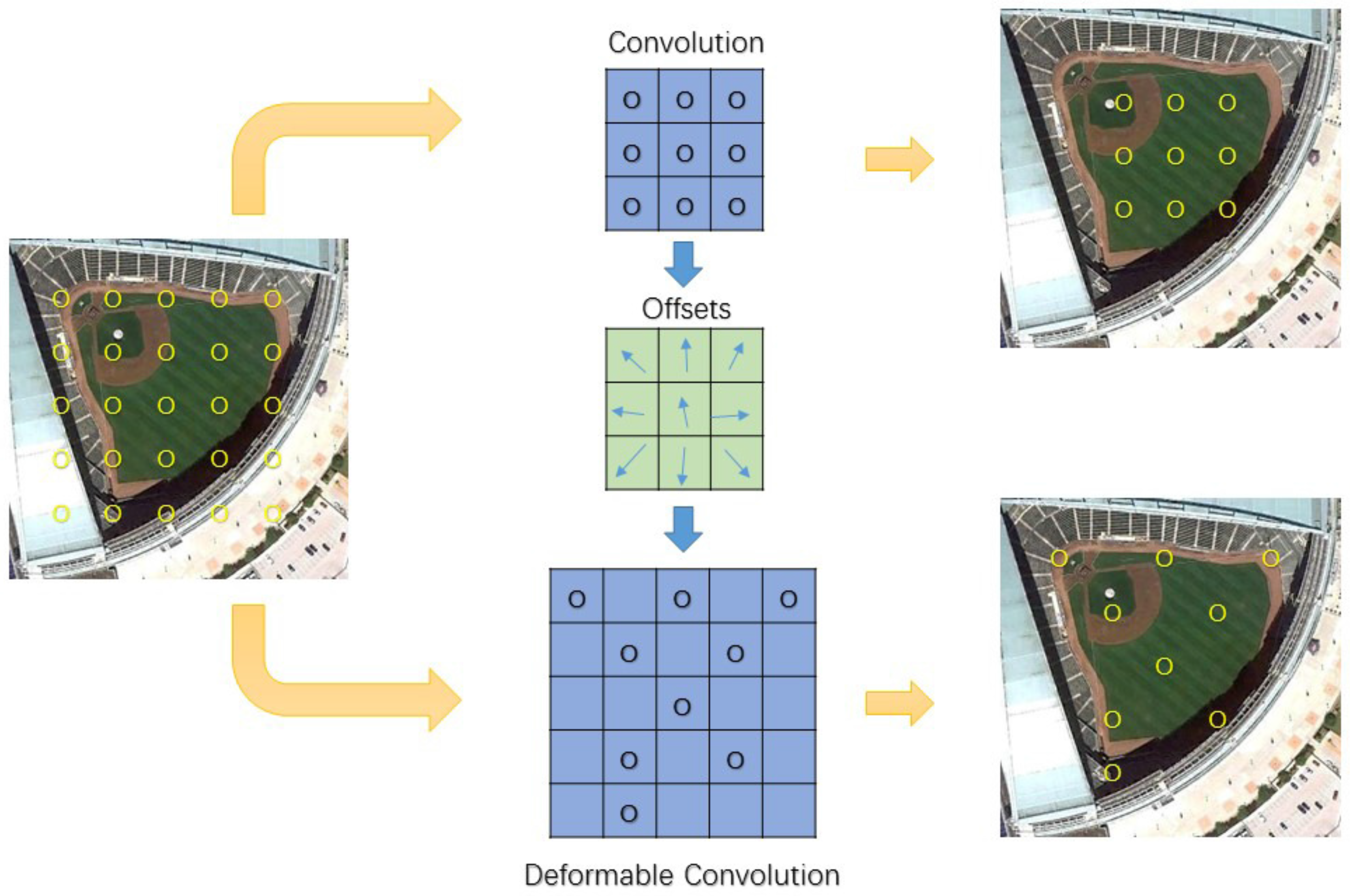
:
1. Introduction
2. Proposed Method
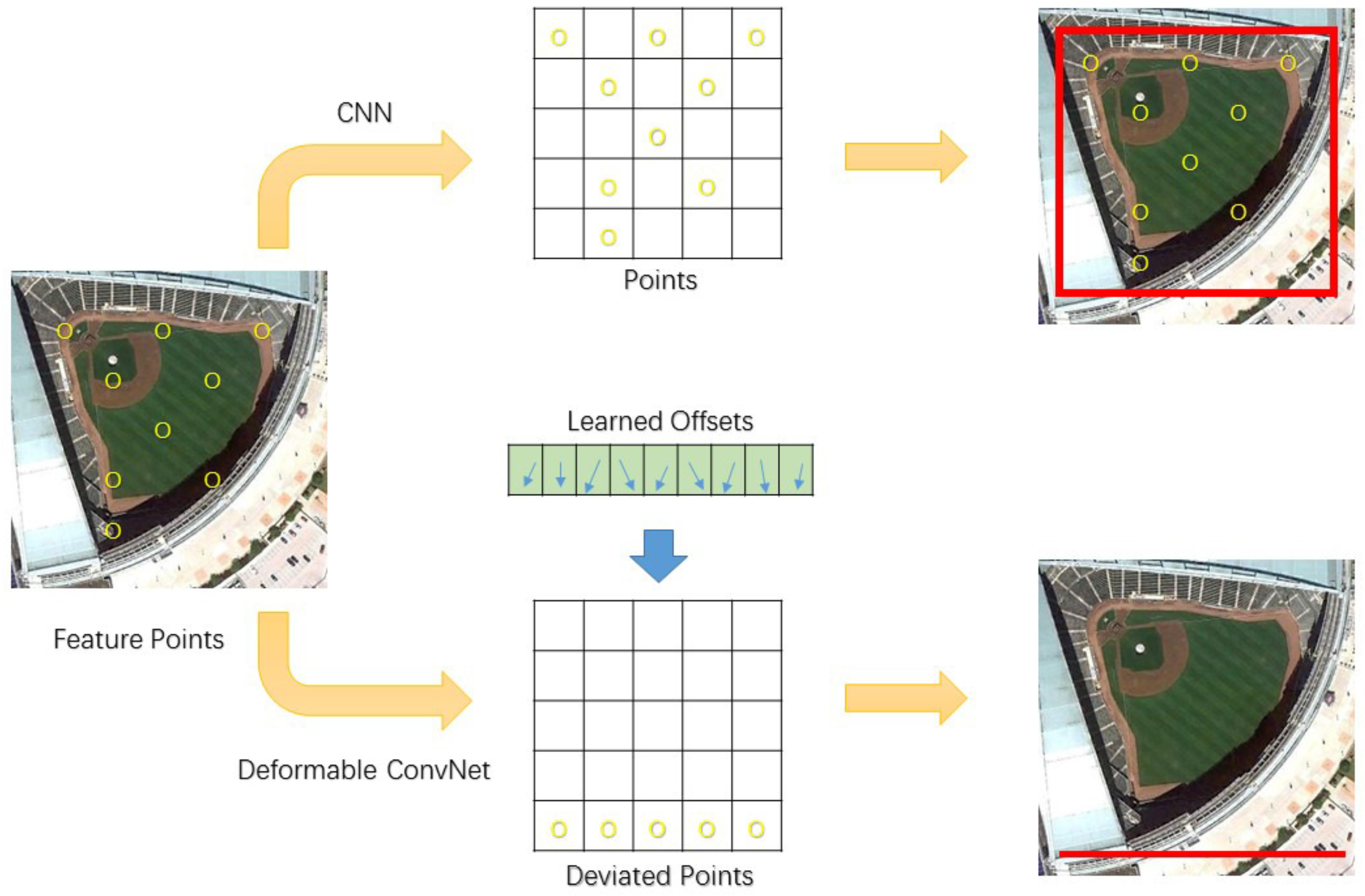
2.1. Deformable Convolution
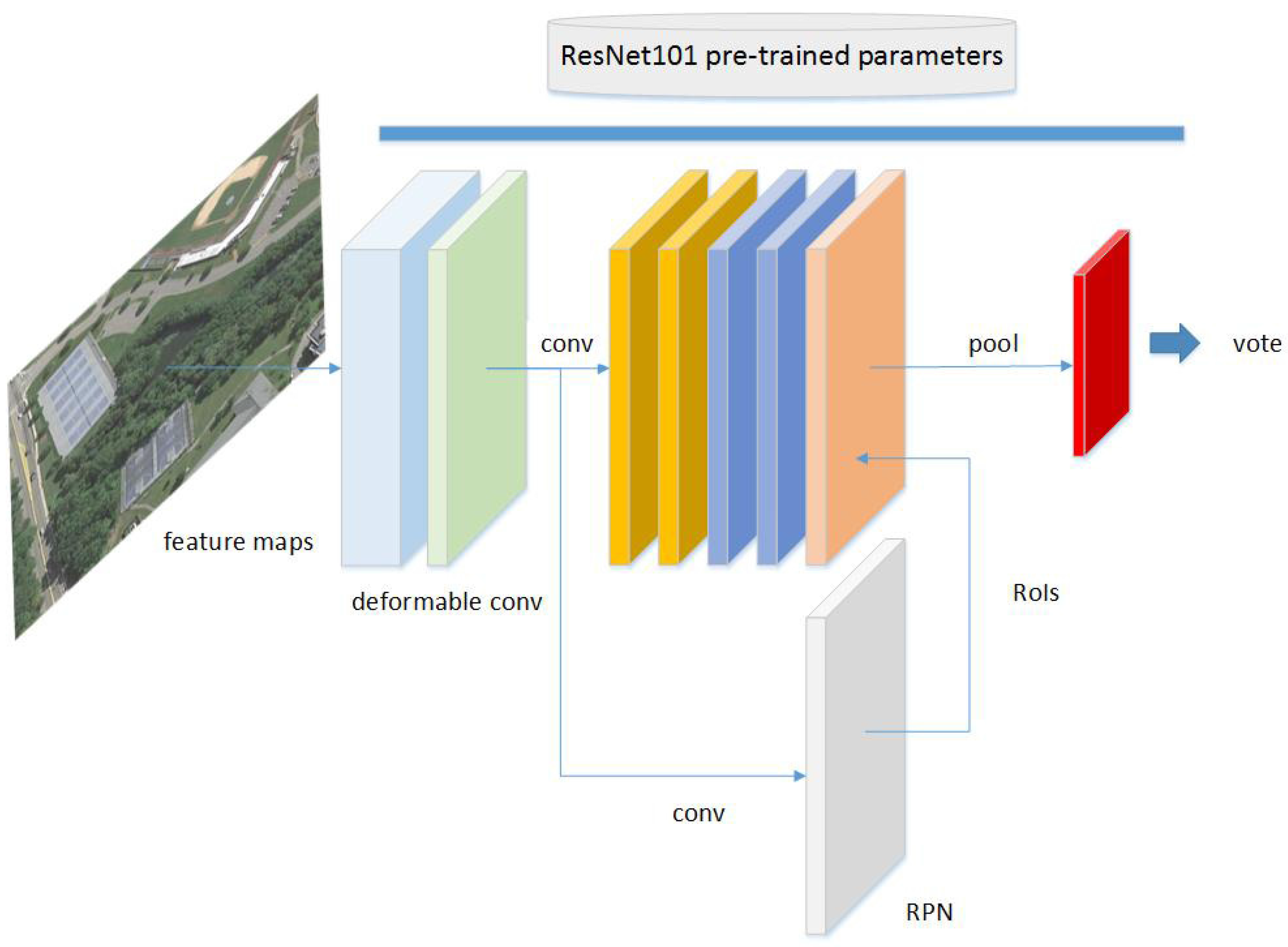
2.2. Deformable R-FCN
2.3. Aspect Ratio Constrained NMS
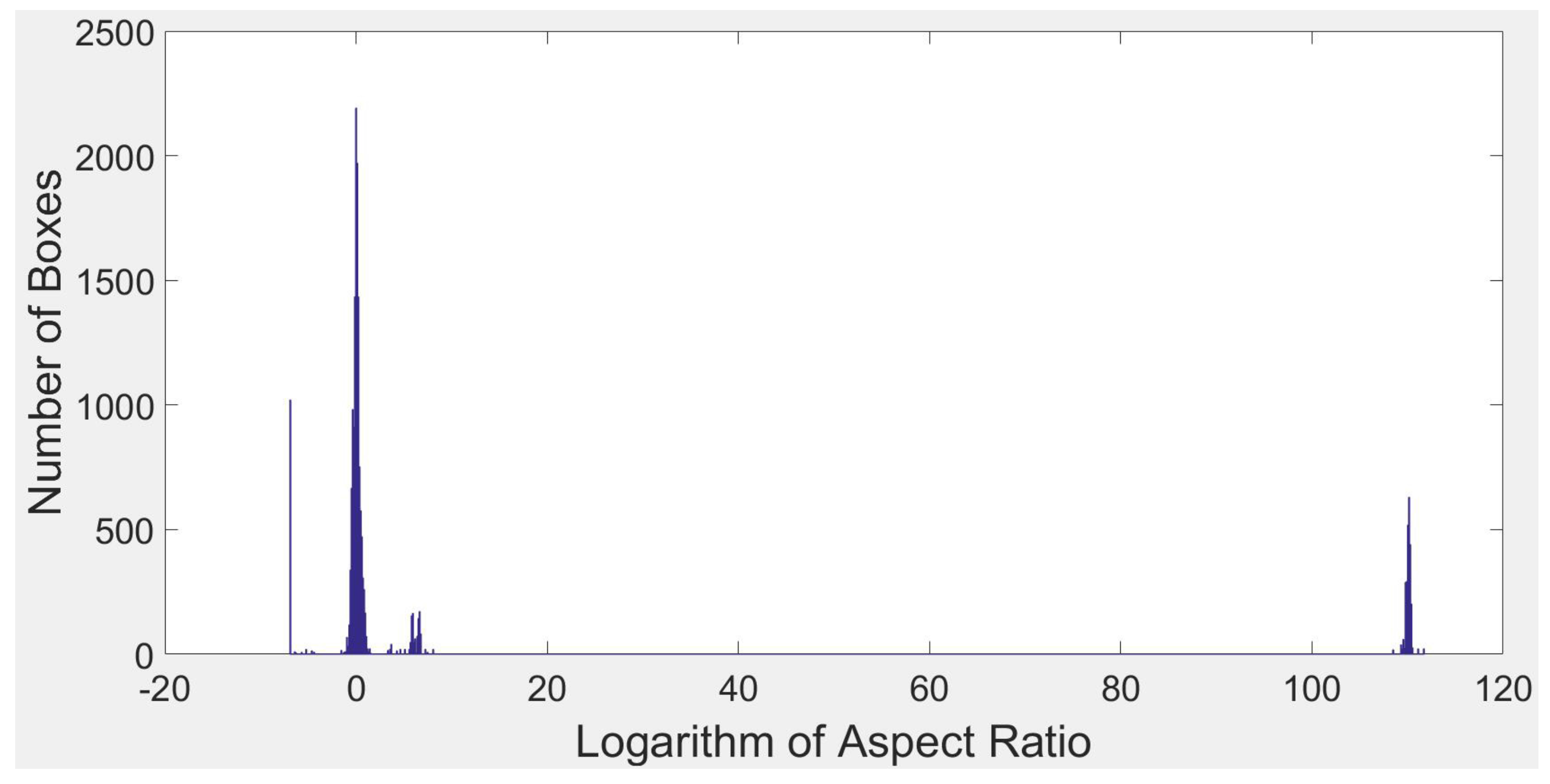
2.3.1. Lines like False Region Proposals
2.3.2. Aspect Ratio Constrained NMS
3. Dataset and Experimental Settings
3.1. Dataset and Implementation Details
- Source and resolution diversity. NWPU VHR-10 dataset not only contains optical remote sensing images, but also includes pan-sharped color infrared images. In addition, 715 images were downloaded from Google Earth Pro (Version 7.3, Google, Mountainview, California, US) with spatial resolutions from 0.5 m to 2.0 m. Meanwhile, 85 pan-sharpened color infrared images were acquired from the Vaihingen data with a 0.08 m spatial resolution.
- Comprehensive object types. NWPU VHR-10 dataset contains 10 different types of objects, including airplane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, and vehicle.
- Abundant object annotations.The NWPU VHR-10 dataset contains 650 annotated images, within each image containing at least one target to be recognized. For the image set in VOC 2007 formula, 757 airplanes, 302 ships, 655 storage tanks, 390 baseball diamonds, 524 tennis courts, 150 basketball courts, 163 ground track fields, 224 harbors, 124 bridges, and 477 vehicles have been manually annotated with rectangular bounding boxes, and were utilized as the training samples and testing ground truth.
3.2. Evaluation Indicators
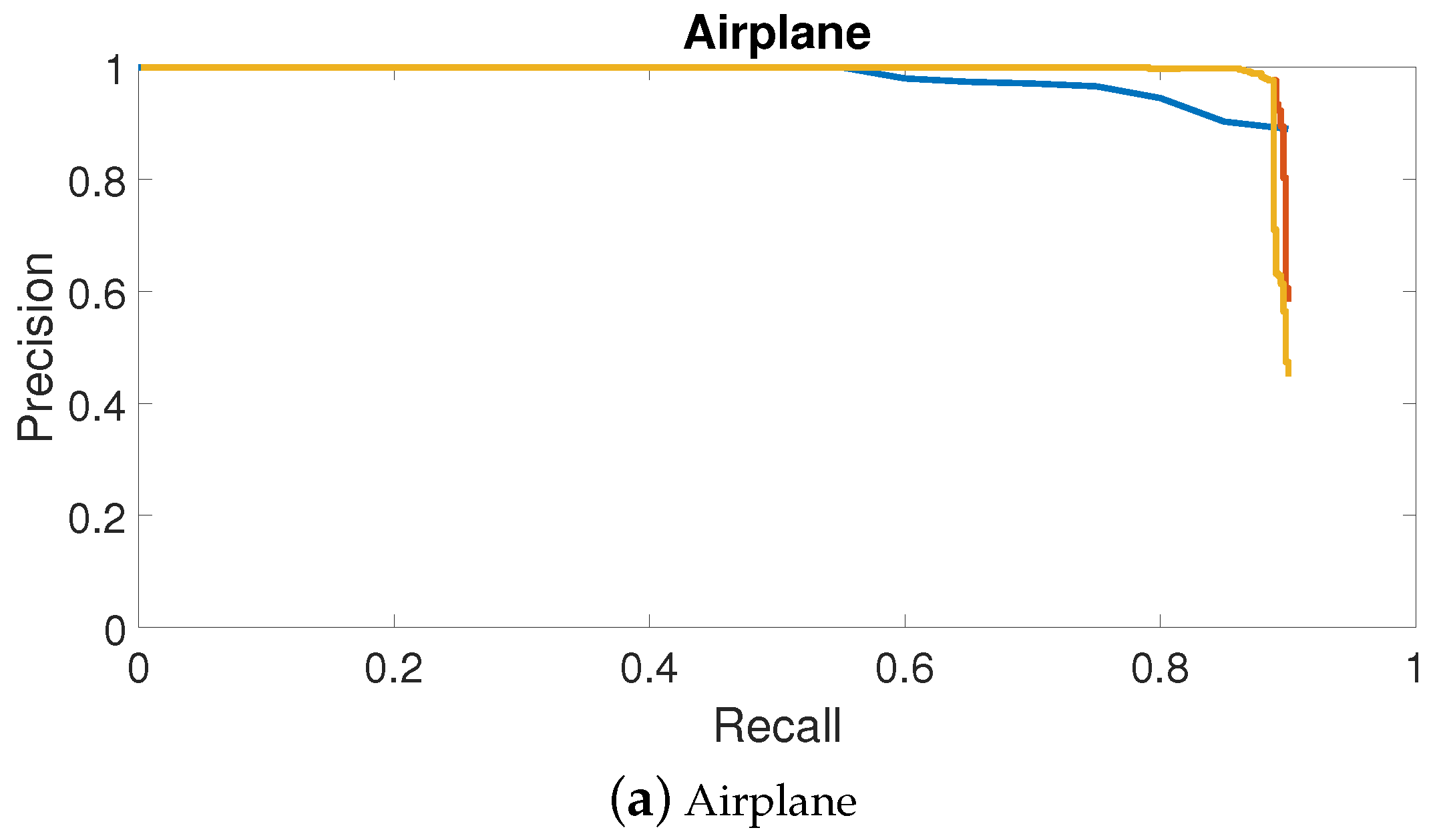
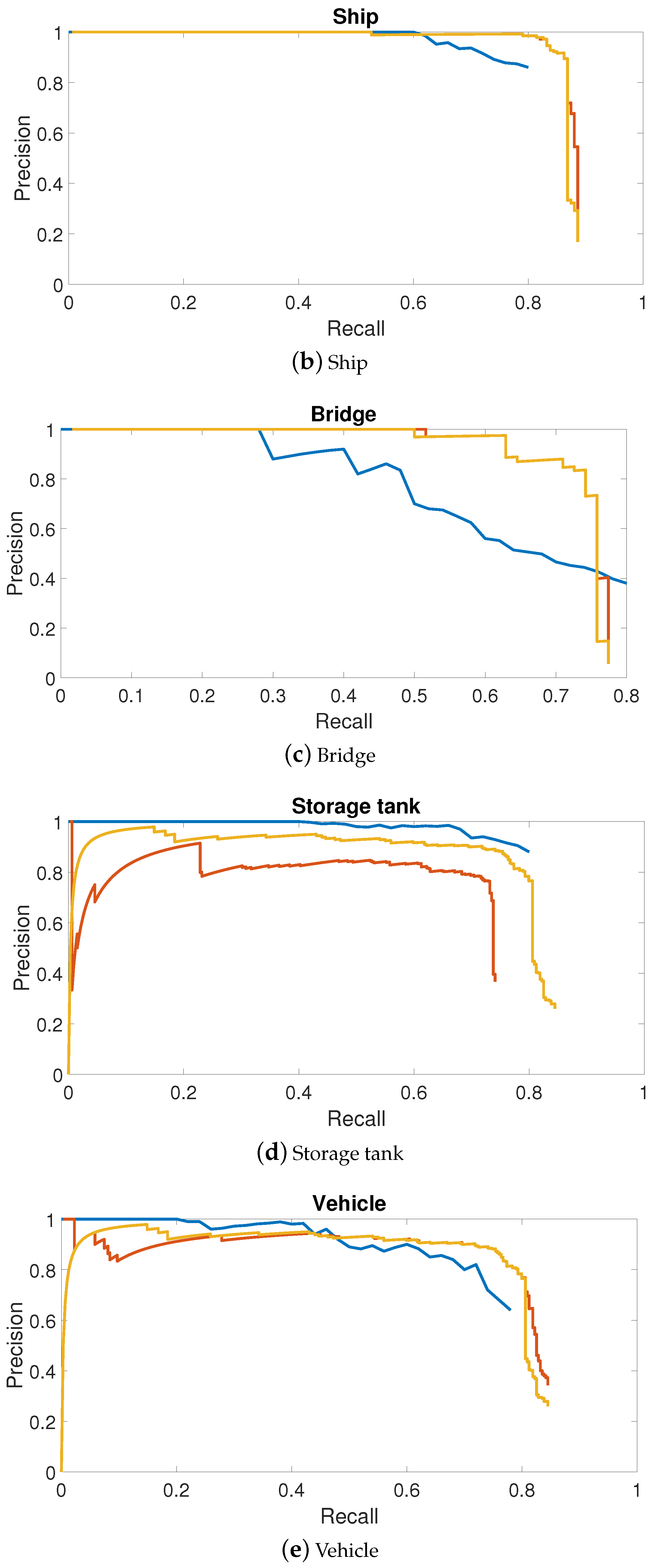
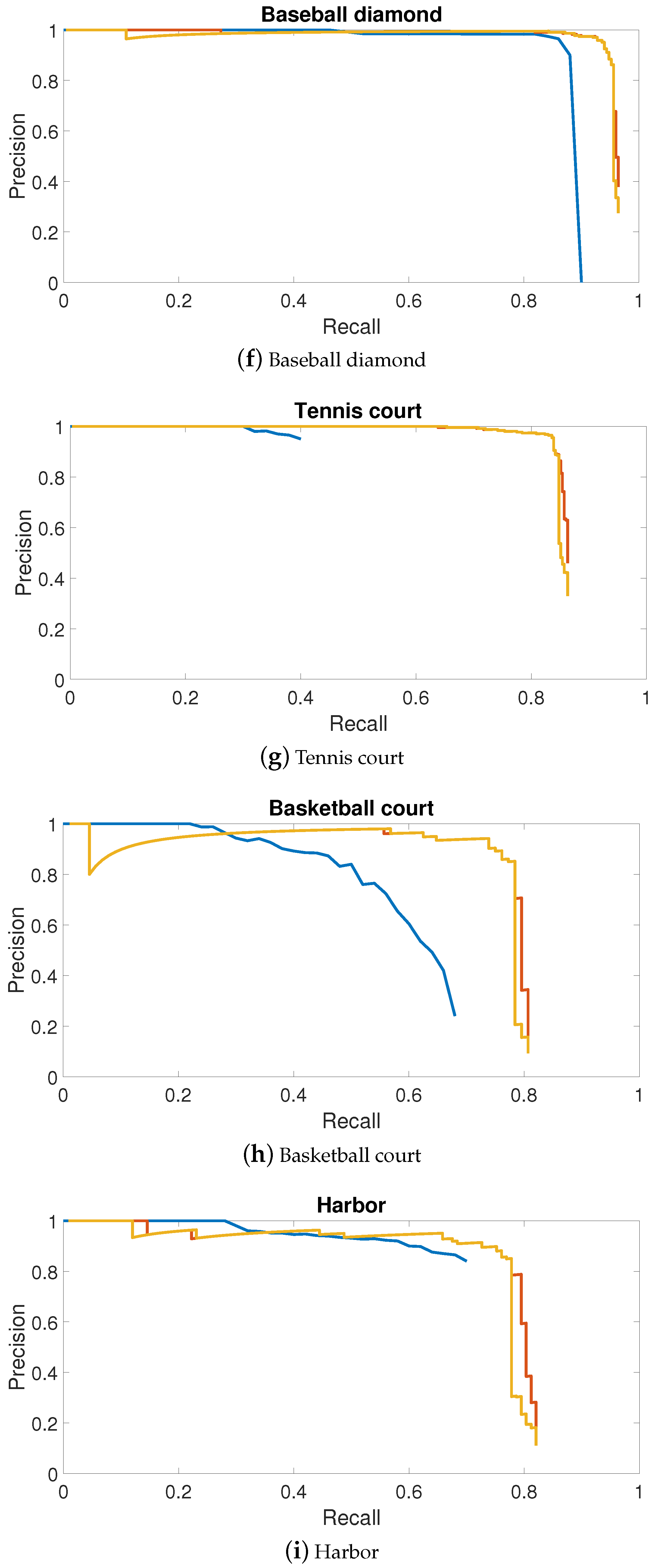
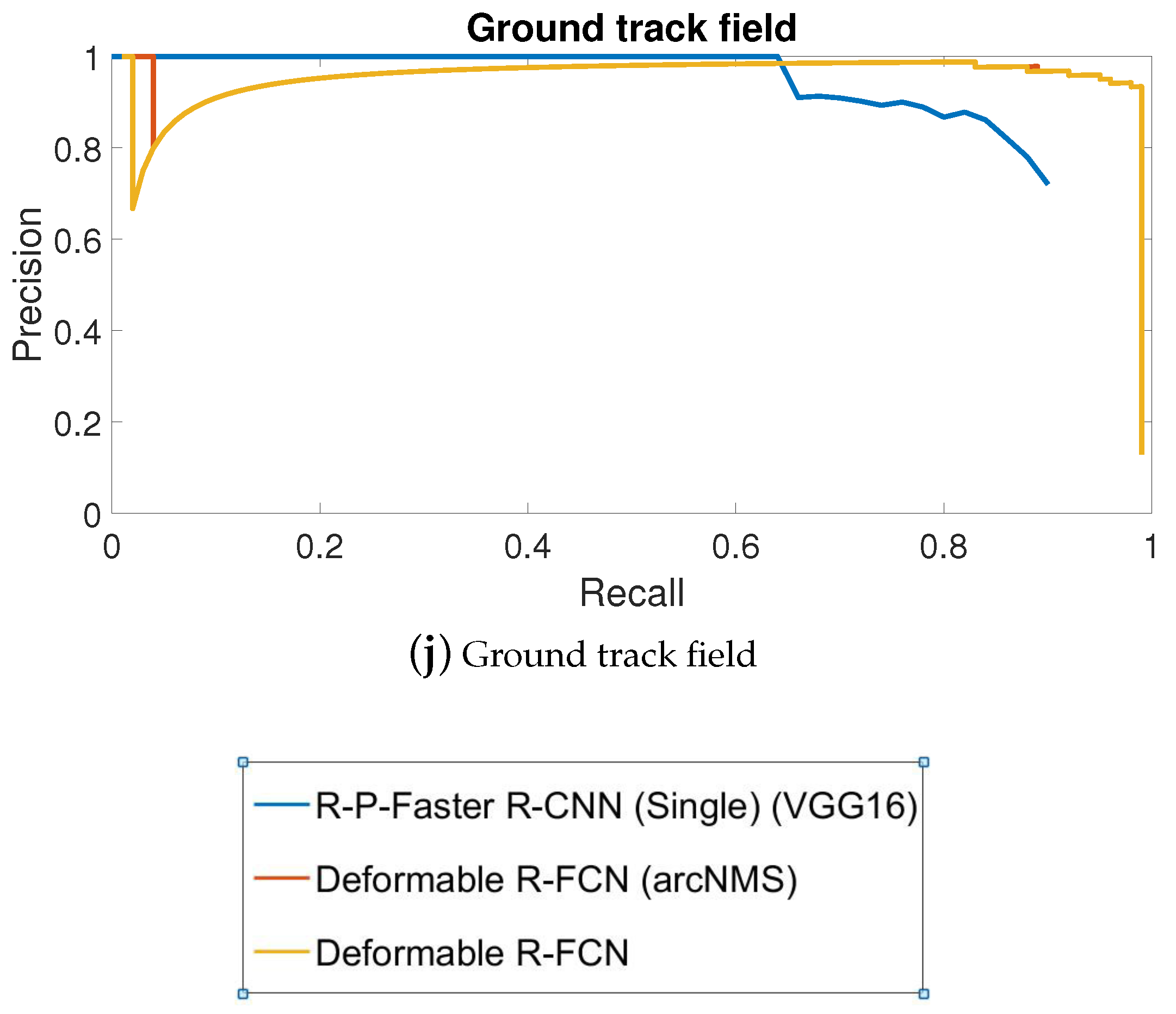
3.2.1. Precision—Recall Curve
3.2.2. Average Precision
4. Results
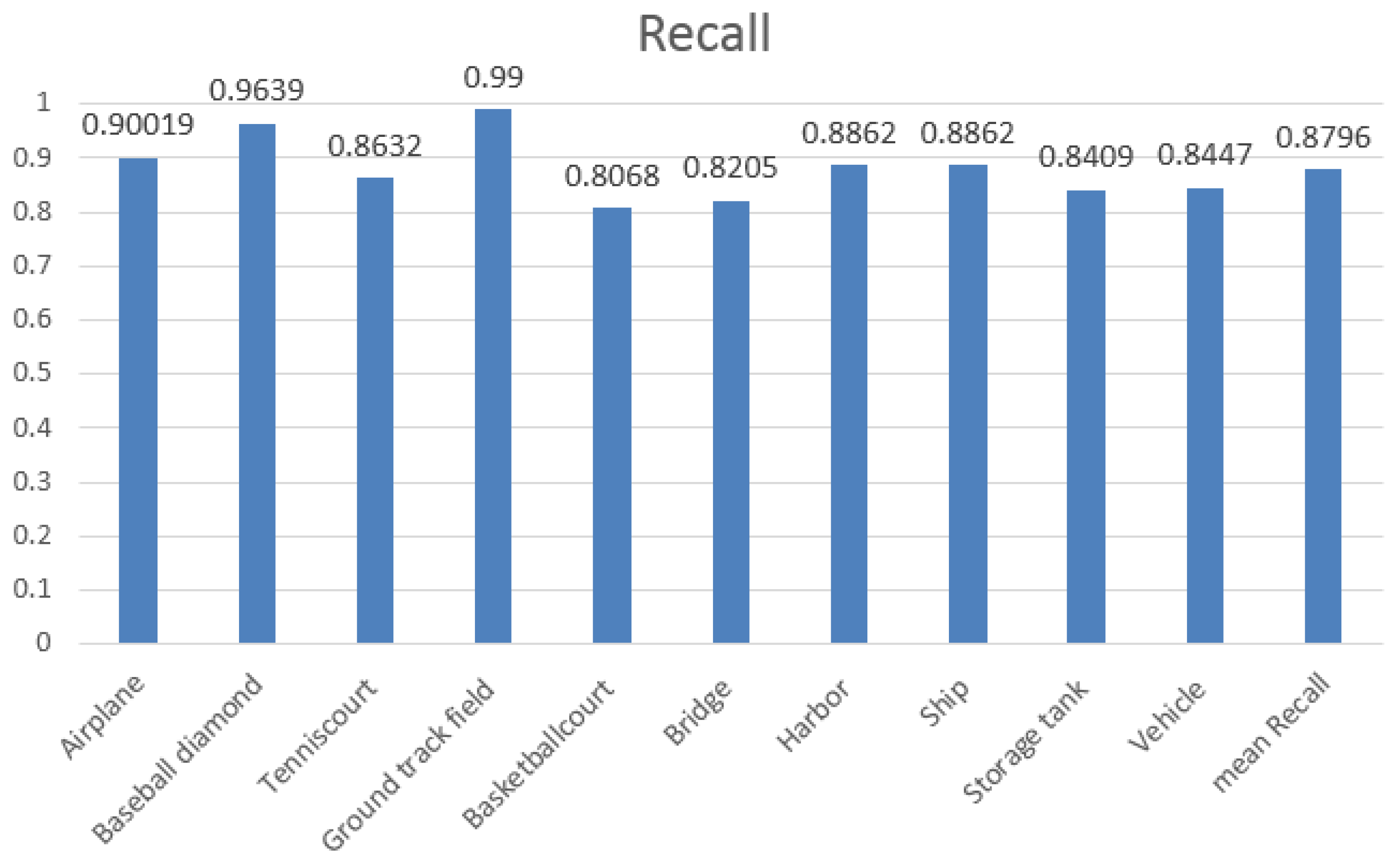
4.1. Quantitative Evaluation of NWPU VHR-10 Dataset
4.2. PRC Evaluation of NWPU VHR-10 Dataset
4.3. Evaluation on RSOD Dataset
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kamusoko, C. Importance of Remote Sensing and Land Change Modeling for Urbanization Studies. In Urban Development in Asia and Africa; Springer: Berlin, Germany, 2017; pp. 3–10. [Google Scholar]
- Barrett, E.C. Introduction to Environmental Remote Sensing; Routledge: Abingdon, UK, 2013. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly Supervised Learning Based on Coupled Convolutional Neural Networks for Aircraft Detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Colomina, I.; Molina, P. Unmanned aerial systems for photogrammetry and remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2014, 92, 79–97. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Yuan, Y.; Hu, X. Bag-of-Words and Object-Based Classification for Cloud Extraction From Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4197–4205. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Liu, T. Learning coarse-to-fine sparselets for efficient object detection and scene classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1173–1181. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Xu, S.; Fang, T.; Li, D.; Wang, S. Object Classification of Aerial Images with Bag-of-Visual Words. IEEE Geosci. Remote Sens. Lett. 2010, 7, 366–370. [Google Scholar]
- Sun, H.; Sun, X.F.; Wang, H.; Li, Y.; Li, X. Automatic Target Detection in High-Resolution Remote Sensing Images Using Spatial Sparse Coding Bag-of-Words Model. IEEE Geosci. Remote Sens. Lett. 2012, 9, 109–113. [Google Scholar] [CrossRef]
- Han, J.; Zhou, P.; Zhang, D.; Cheng, G.; Guo, L.; Liu, Z.; Bu, S.; Wu, J. Efficient, simultaneous detection of multi-class geospatial targets based on visual saliency modeling and discriminative learning of sparse coding. ISPRS J. Photogramm. Remote Sens. 2014, 89, 37–48. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Chen, C.; Gong, W.; Hu, Y.; Chen, Y.; Ding, Y. Learning Oriented Region-based Convolutional Neural Networks for Building Detection in Satellite Remote Sensing Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-1/W1, 461–464. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Wegner, J.D.; Branson, S.; Hall, D.; Schindler, K.; Perona, P. Cataloging public objects using aerial and street-level images-urban trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 6014–6023. [Google Scholar]
- Han, X.; Zhong, Y.; Zhang, L. An Efficient and Robust Integrated Geospatial Object Detection Framework for High Spatial Resolution Remote Sensing Imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Girshick, R.; Iandola, F.; Darrell, T.; Malik, J. Deformable Part Models are Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. arXiv, 2017; arXiv:1703.06211. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing (3rd Edition); Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2006. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Li, B.; Wu, T.; Shao, S.; Zhang, L.; Chu, R. Object Detection via End-to-End Integration of Aspect Ratio and Context Aware Part-based Models and Fully Convolutional Networks. arXiv, 2016; arXiv:1612.00534. [Google Scholar]
- Rothe, R.; Guillaumin, M.; Van Gool, L. Non-Maximum Suppression for Object Detection by Passing Messages between Windows. In Proceedings of the 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Springer: Berlin, Germany, 2014; Volume 9003, pp. 290–306. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefevre, S. Segment-before-Detect: Vehicle Detection and Classification through Semantic Segmentation of Aerial Images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef]
- Benedek, C.; Descombes, X.; Zerubia, J. Building Development Monitoring in Multitemporal Remotely Sensed Image Pairs with Stochastic Birth-Death Dynamics. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 33–50. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Das, S.K.; Mirnalinee, T.T.; Varghese, K. Use of Salient Features for the Design of a Multistage Framework to Extract Roads From High-Resolution Multispectral Satellite Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BoW | SSC BoW | FDDL | CPOD | Transfered AlexNet | Newly Trained AlexNet | RICNN without Fine-Tuning | RICNN with Fine-Tuning | R-P-Faster R-CNN (ZF) | R-P-Faster R-CNN (Double) (VGG16) | R-P-Faster R-CNN (Single) (VGG16) | R-FCN (ResNet-101) | Deformable R-FCN (ResNet-101) | Deformable R-FCN (ResNet-101) with arcNMS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Airplane | 0.025 | 0.506 | 0.292 | 0.623 | 0.661 | 0.701 | 0.860 | 0.884 | 0.803 | 0.906 | 0.904 | 0.817 | 0.861 | 0.873 |
| Ship | 0.585 | 0.508 | 0.376 | 0.689 | 0.569 | 0.637 | 0.760 | 0.773 | 0.681 | 0.762 | 0.750 | 0.806 | 0.816 | 0.814 |
| Storage tank | 0.632 | 0.334 | 0.770 | 0.637 | 0.843 | 0.843 | 0.850 | 0.853 | 0.359 | 0.403 | 0.444 | 0.662 | 0.626 | 0.636 |
| Baseball diamond | 0.090 | 0.435 | 0.258 | 0.833 | 0.816 | 0.836 | 0.873 | 0.881 | 0.906 | 0.908 | 0.899 | 0.903 | 0.904 | 0.904 |
| Tennis court | 0.047 | 0.003 | 0.028 | 0.321 | 0.350 | 0.355 | 0.396 | 0.408 | 0.715 | 0.797 | 0.79 | 0.802 | 0.816 | 0.816 |
| Basketball court | 0.032 | 0.150 | 0.036 | 0.363 | 0.459 | 0.468 | 0.579 | 0.585 | 0.677 | 0.774 | 0.776 | 0.697 | 0.724 | 0.741 |
| Ground track field | 0.078 | 0.101 | 0.201 | 0.853 | 0.800 | 0.812 | 0.855 | 0.867 | 0.892 | 0.880 | 0.877 | 0.898 | 0.898 | 0.903 |
| Harbor | 0.530 | 0.583 | 0.254 | 0.553 | 0.620 | 0.623 | 0.665 | 0.686 | 0.769 | 0.762 | 0.791 | 0.786 | 0.722 | 0.753 |
| Bridge | 0.122 | 0.125 | 0.215 | 0.148 | 0.423 | 0.454 | 0.585 | 0.615 | 0.572 | 0.575 | 0.682 | 0.478 | 0.714 | 0.714 |
| Vehicle | 0.091 | 0.336 | 0.045 | 0.440 | 0.429 | 0.448 | 0.680 | 0.711 | 0.646 | 0.666 | 0.732 | 0.783 | 0.757 | 0.755 |
| mean AP | 0.246 | 0.308 | 0.245 | 0.546 | 0.597 | 0.618 | 0.710 | 0.726 | 0.702 | 0.743 | 0.765 | 0.763 | 0.784 | 0.791 |
| BoW | SSC BoW | FDDL | CPOD | Transfered CNN | Newly Trained CNN | RICNN without Fine-Tuning | RICNN with Fine-Tuning | R-P-Faster R-CNN (ZF) | R-P-Faster R-CNN (Double) (VGG16) | R-P-Faster R-CNN (Single) (VGG16) | R-FCN (ResNet-101) | Deformable R-FCN (ResNet-101) | Deformable R-FCN (ResNet-101) with arcNMS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Average running time per image (second) | 5.32 | 40.32 | 7.17 | 1.06 | 5.24 | 8.77 | 8.77 | 8.77 | 0.005 | 0.155 | 0.155 | 0.156 | 0.201 | 0.201 |
| R-P-Faster R-CNN (Single) (VGG16) | R-FCN (ResNet-101) | Deformable R-FCN (ResNet-101) | Deformable R-FCN (ResNet-101) with arcNMS | |
|---|---|---|---|---|
| Aircraft | 0.7084 | 0.7148 | 0.7150 | 0.7187 |
| Oiltank | 0.9019 | 0.9023 | 0.9026 | 0.9035 |
| Overpass | 0.7874 | 0.7684 | 0.8148 | 0.8959 |
| Playground | 0.9809 | 0.9770 | 0.9953 | 0.9988 |
| mean AP | 0.8447 | 0.8407 | 0.8570 | 0.8792 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Xu, X.; Wang, L.; Yang, R.; Pu, F. Deformable ConvNet with Aspect Ratio Constrained NMS for Object Detection in Remote Sensing Imagery. Remote Sens. 2017, 9, 1312. https://doi.org/10.3390/rs9121312
Xu Z, Xu X, Wang L, Yang R, Pu F. Deformable ConvNet with Aspect Ratio Constrained NMS for Object Detection in Remote Sensing Imagery. Remote Sensing. 2017; 9(12):1312. https://doi.org/10.3390/rs9121312
Chicago/Turabian StyleXu, Zhaozhuo, Xin Xu, Lei Wang, Rui Yang, and Fangling Pu. 2017. "Deformable ConvNet with Aspect Ratio Constrained NMS for Object Detection in Remote Sensing Imagery" Remote Sensing 9, no. 12: 1312. https://doi.org/10.3390/rs9121312
APA StyleXu, Z., Xu, X., Wang, L., Yang, R., & Pu, F. (2017). Deformable ConvNet with Aspect Ratio Constrained NMS for Object Detection in Remote Sensing Imagery. Remote Sensing, 9(12), 1312. https://doi.org/10.3390/rs9121312