
Improved Class-Specific Codebook with Two-Step Classification for Scene-Level Classification of High Resolution Remote Sensing Images


Abstract
:
1. Introduction
- (1)
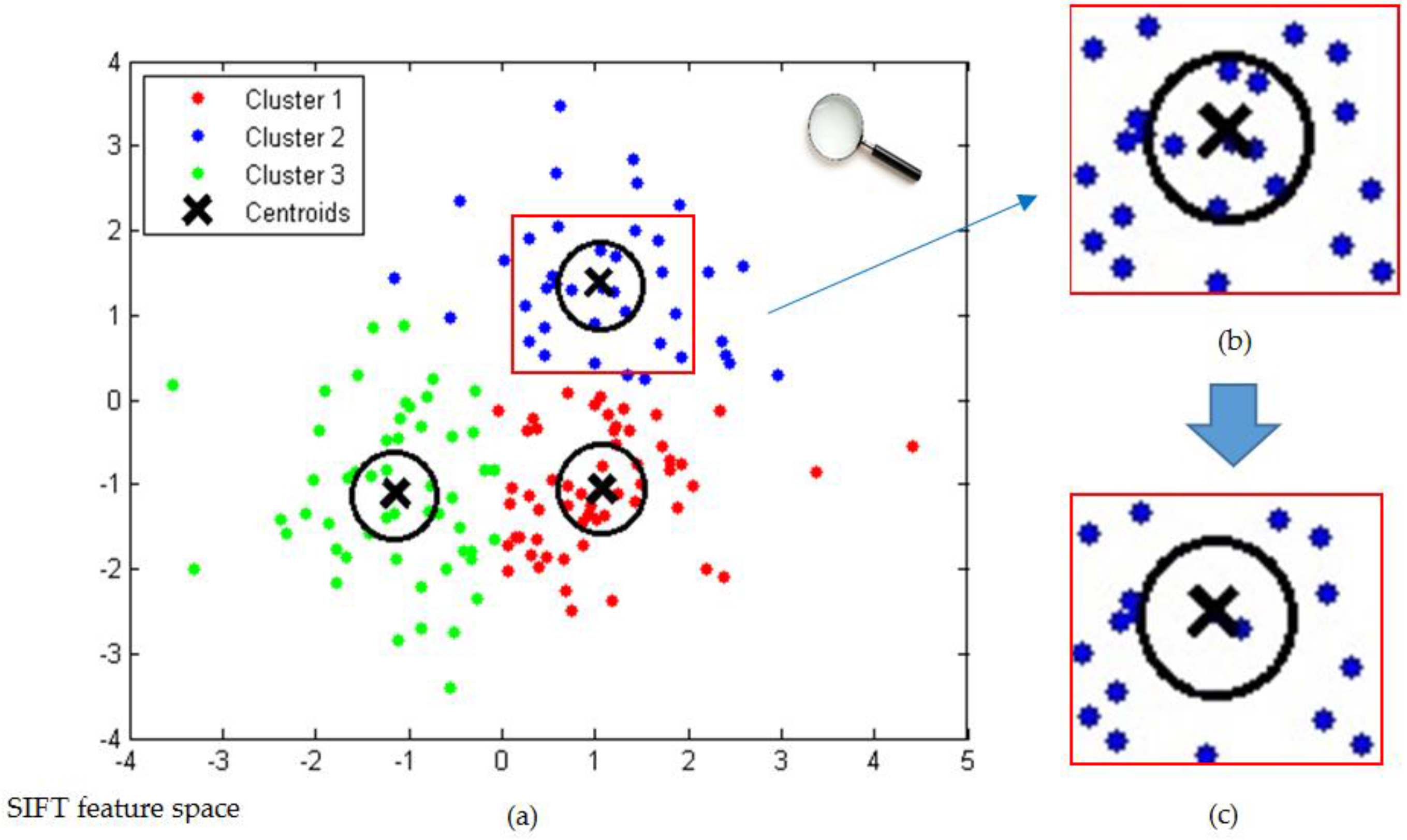
- Some extracted keypoints are unhelpful for land-use classification, which may have a negative effect on computational efficiency and image representation [20].
- (2)
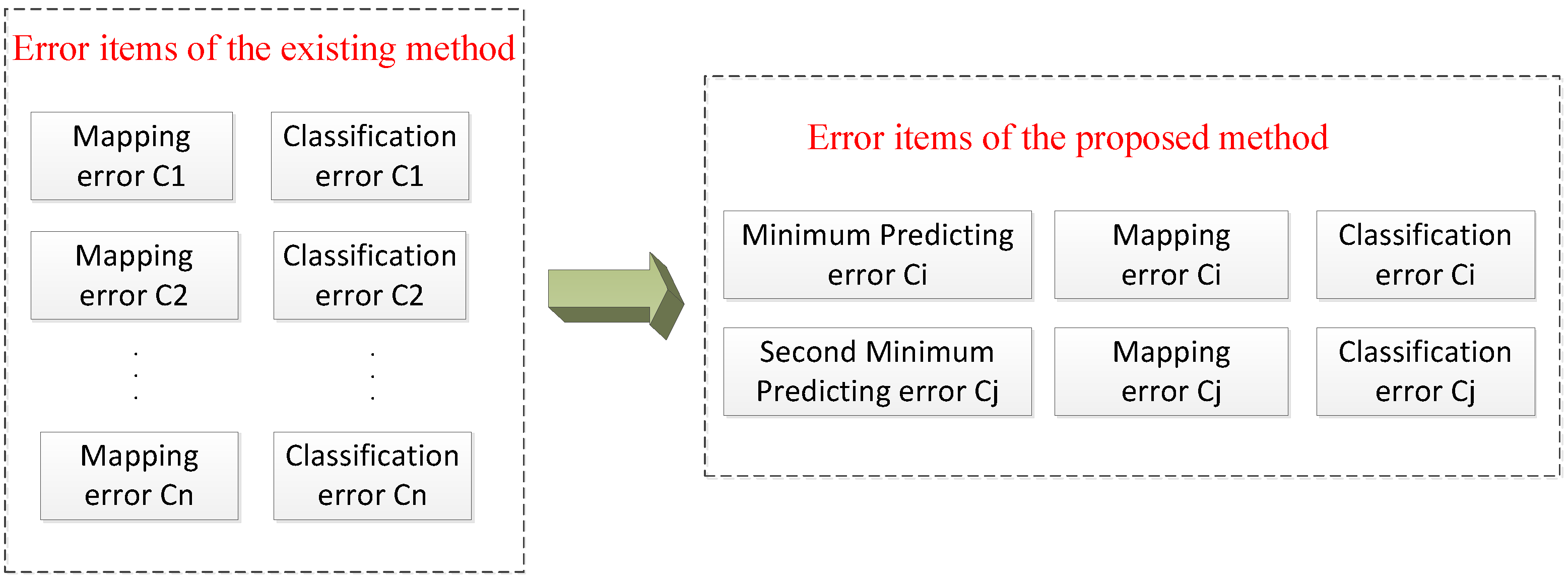
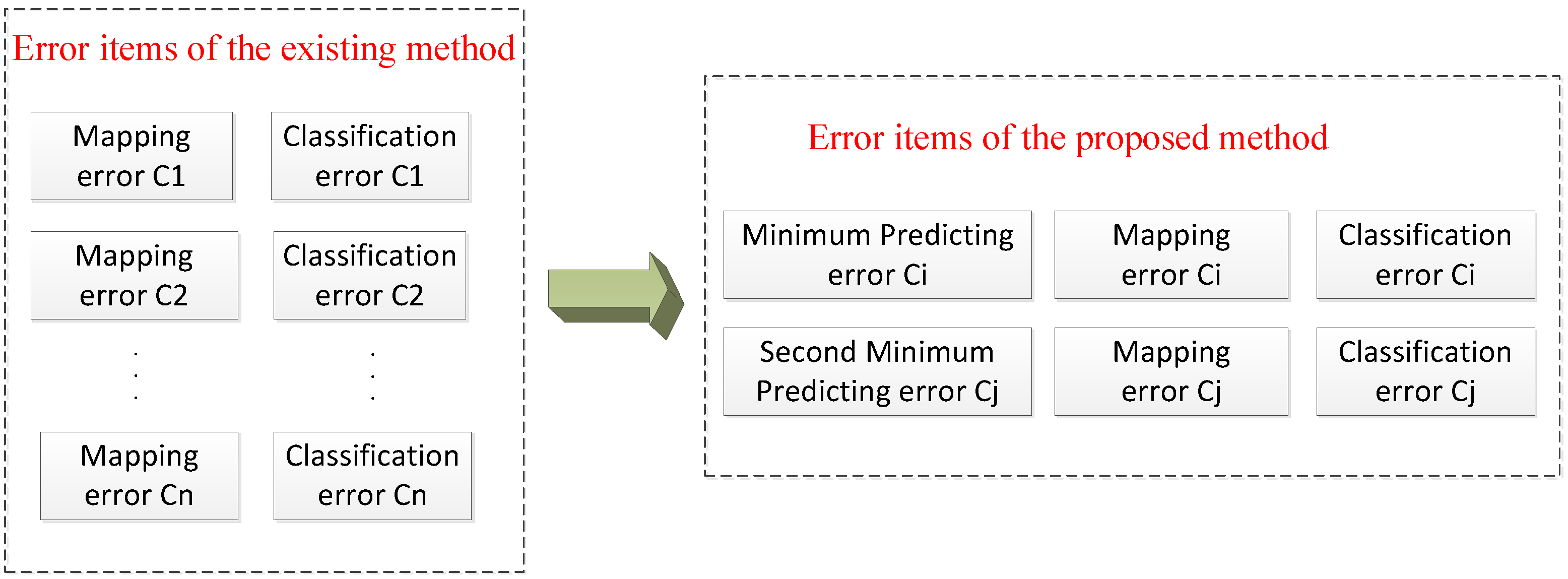
- The traditional BOW model uses a universal codebook for all categories without incorporating information of specific scene labels into it [21], which may result in misclassification in categories with similar backgrounds.
- (3)
- Existing methods incorporating information of labels into BOW model code a testing image with a number of class-specific image representations in each category rather than just one specific representation [21], leading to a large error in mapping universal BOW representation to some inaccurate categories.
- (1)
- We modify an iterative keypoint selection algorithm with the filter by keypoints’ response values, which enables us to reduce the computational complexity by filtering out indiscriminative keypoints and select representative keypoints for better image representation.
- (2)
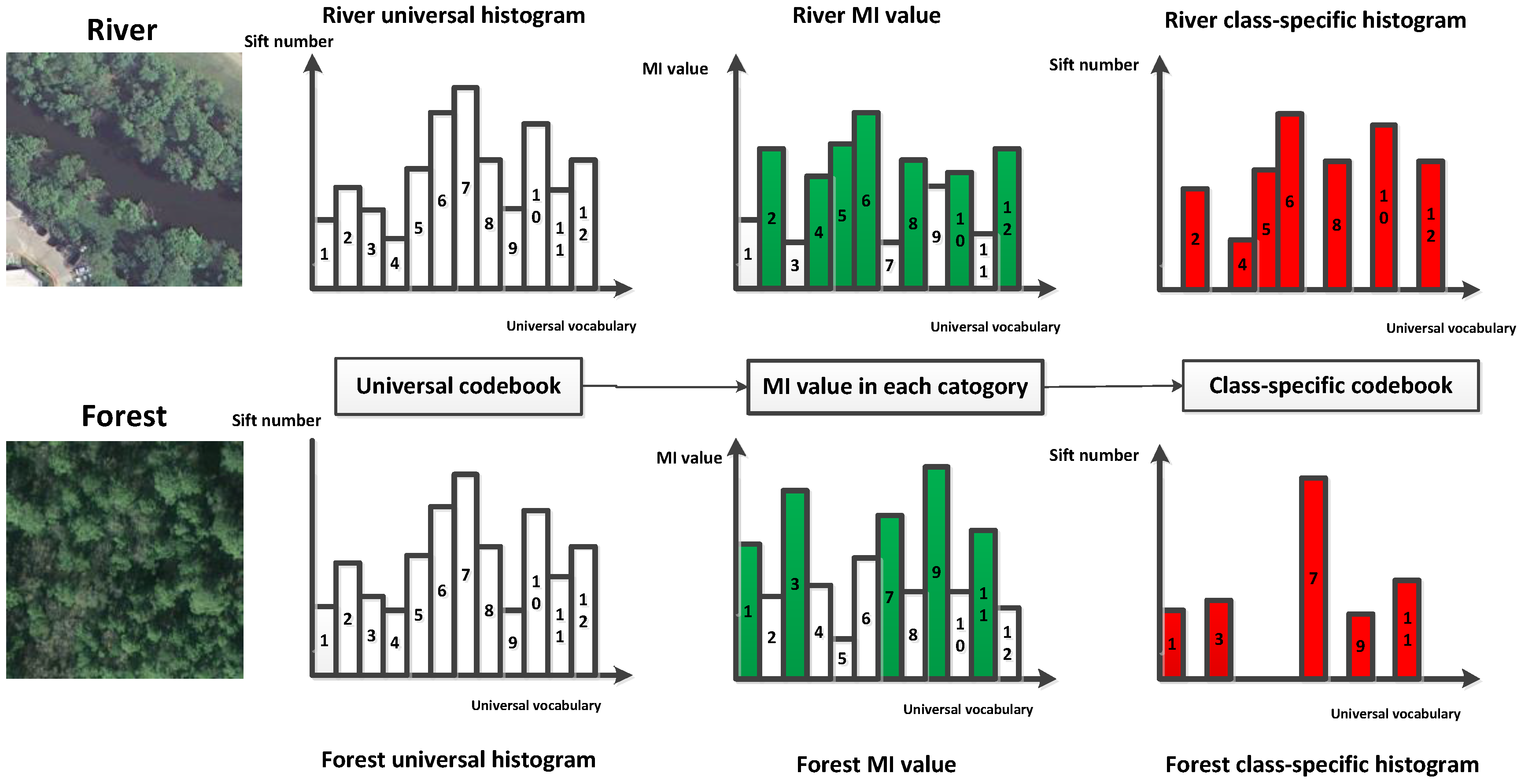
- We propose a class-specific codebook designed for HRIs based on feature selection using MI to allocate vocabularies in the universal codebook for each category in order to expand differences between locality-constrained linear coding (LLC) codes of various land use categories.
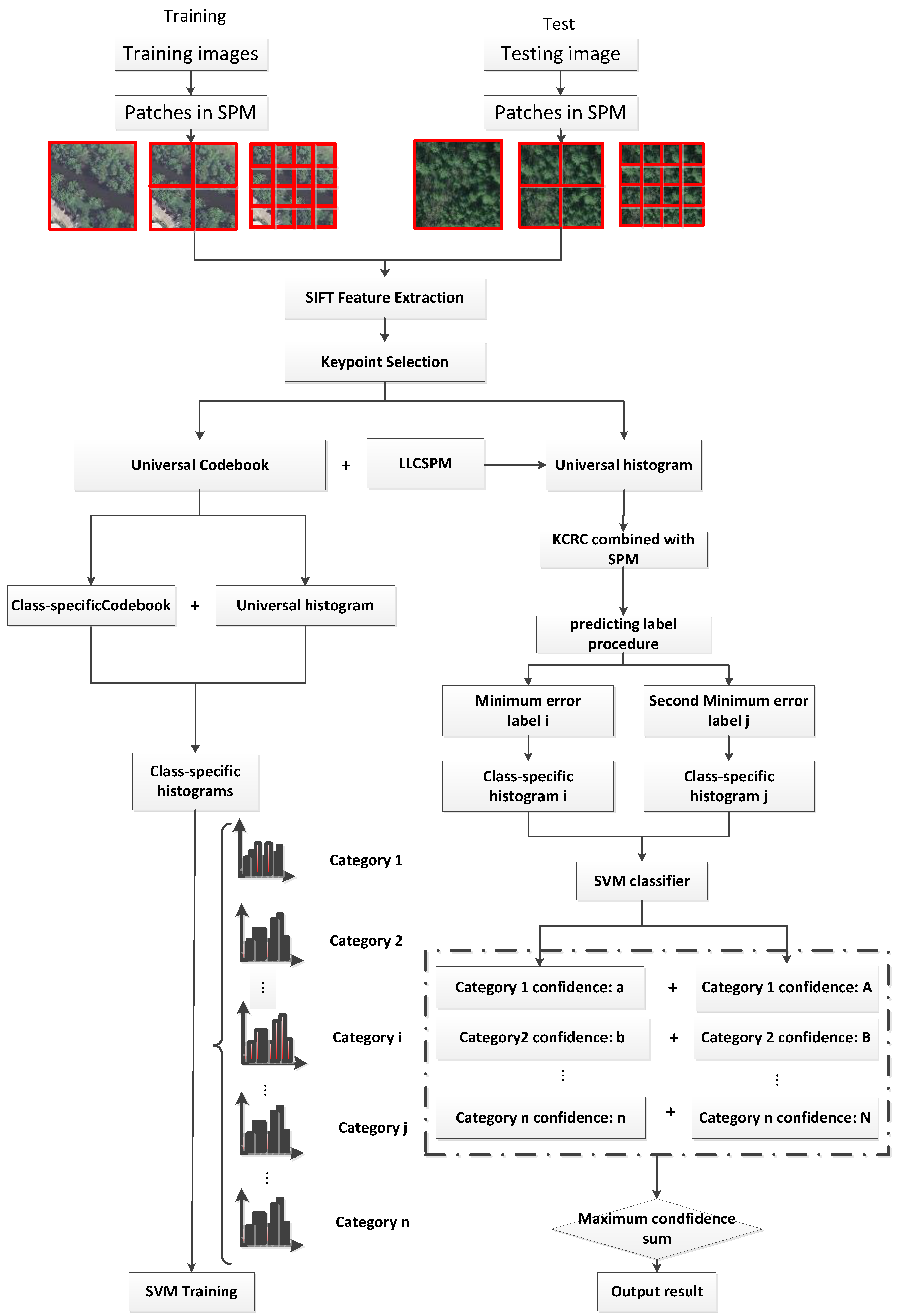
- (3)
- In the testing period, we classify the testing image in two steps. We introduce the KCRC algorithm to obtain two comparatively accurate predicting results of testing samples to make sure the testing sample may be mapped to their unique class-specific codebook and decrease the prediction error by putting these two class-specific histograms respectively into SVM classifiers to output the confidence in each label. The testing image will be assigned to the label with the largest sum of confidence.
2. Materials and Methods
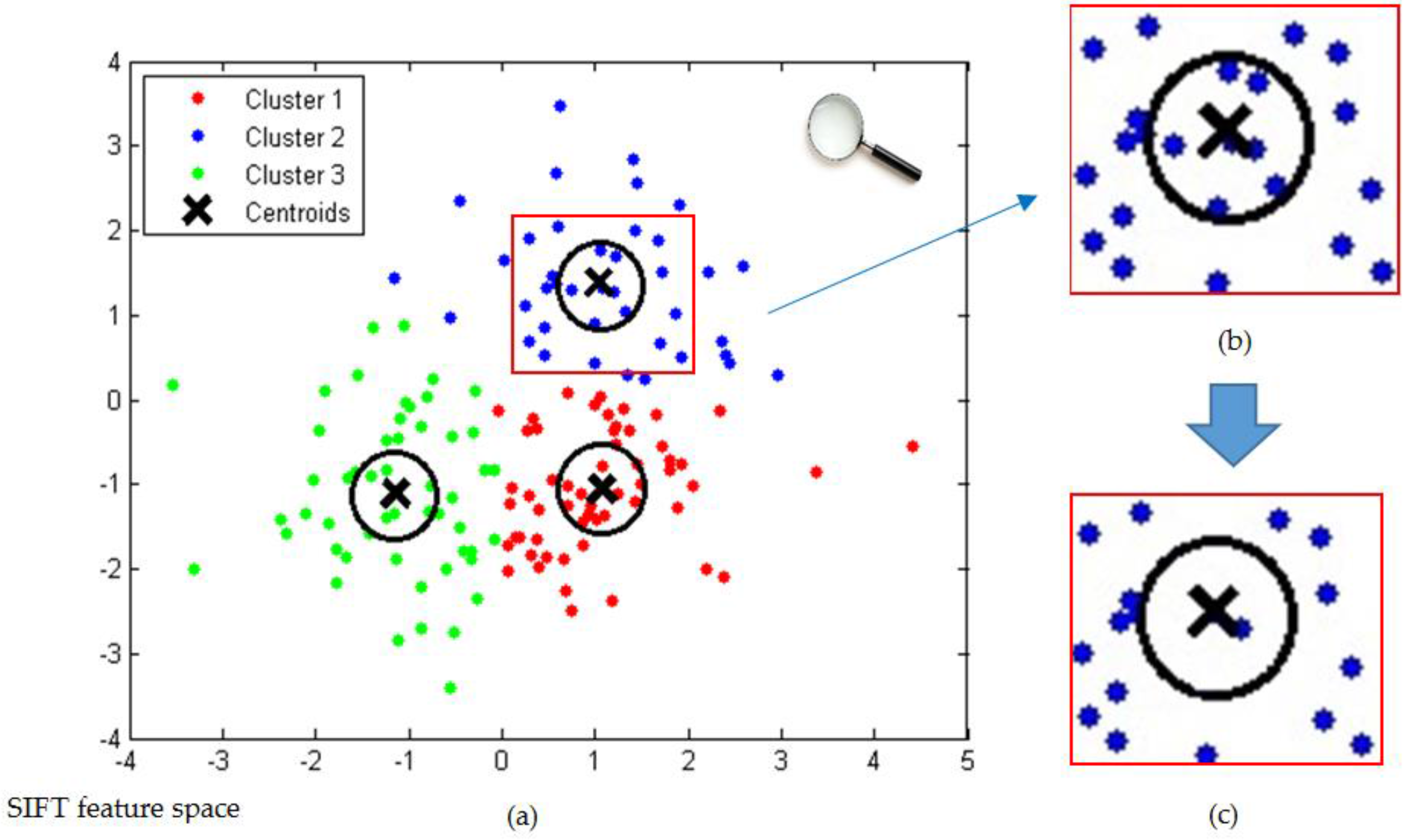
2.1. Iterative Keypoint Selection with the Filter by Keypoints’ Response Values
2.2. LLC Coding
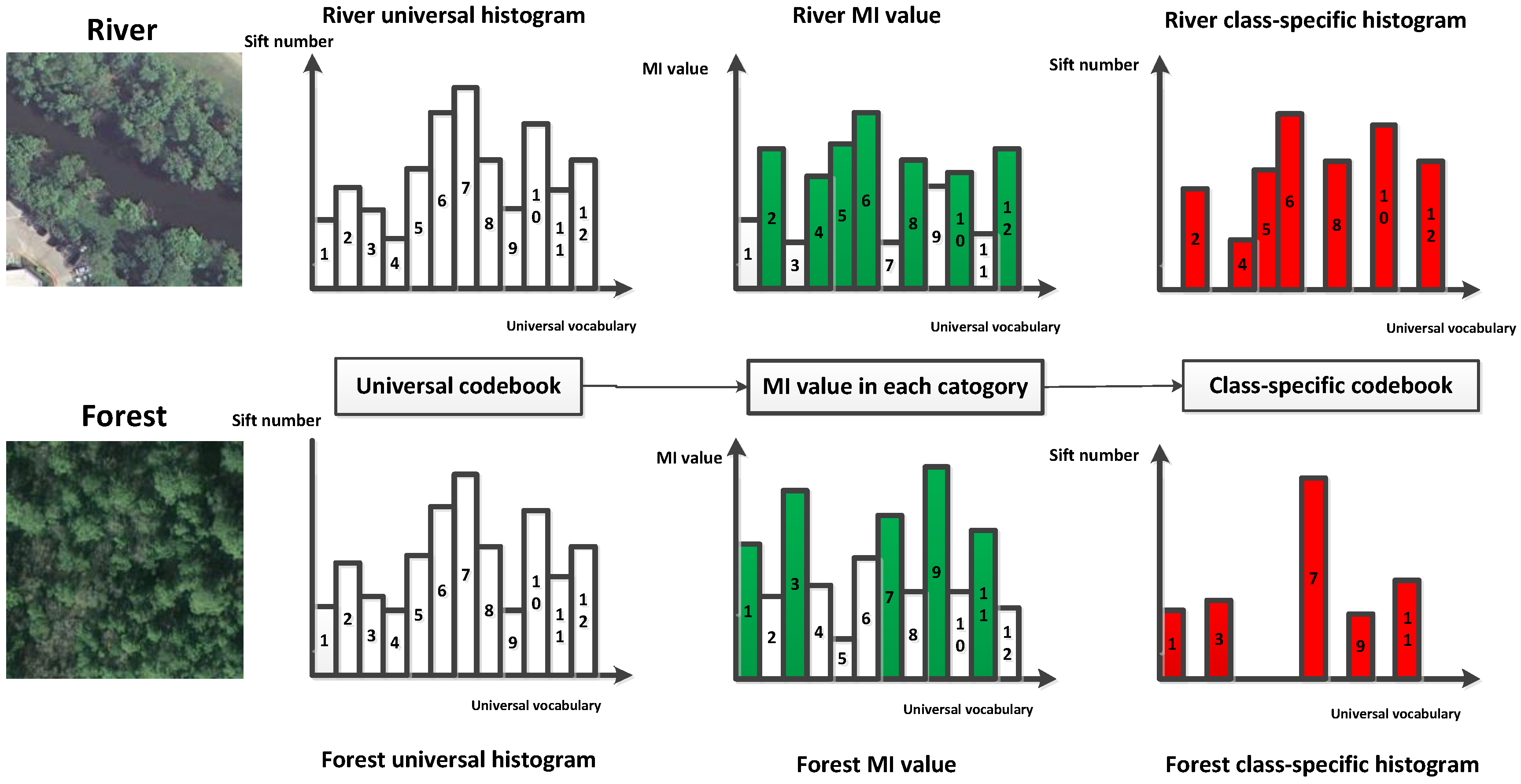
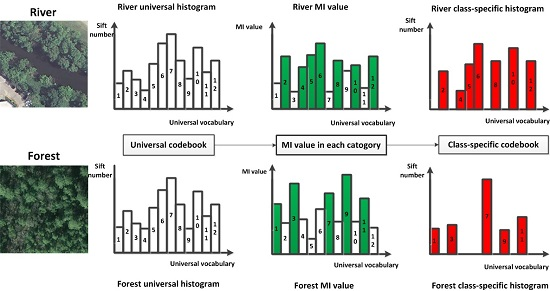
2.3. Generation of Class-Specific Codebook Using MI
2.4. KCRC Combined with SPMPpredicting Method and Two-Step Classification
3. Experiments and Results
3.1. Experimental Data and Setup
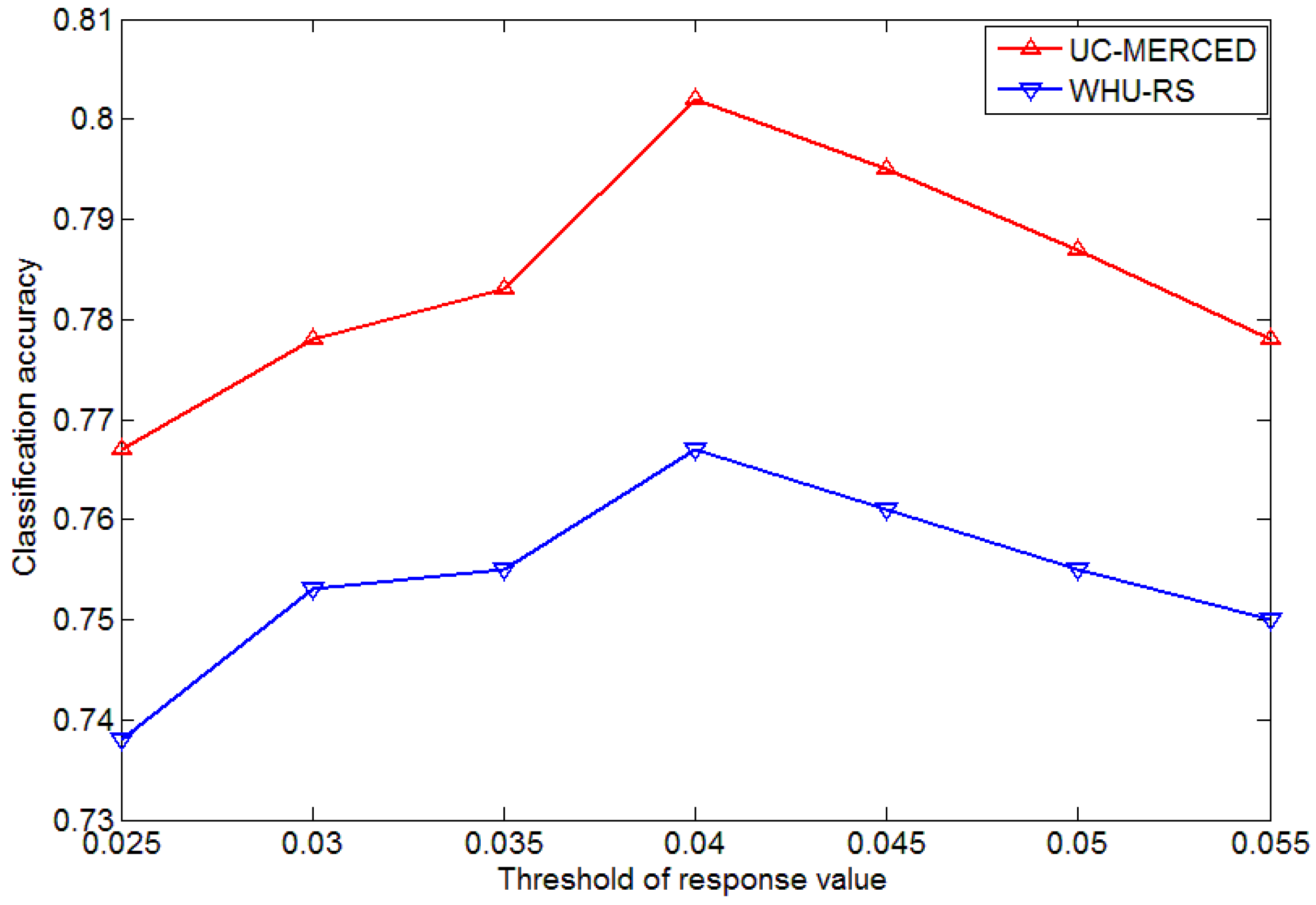
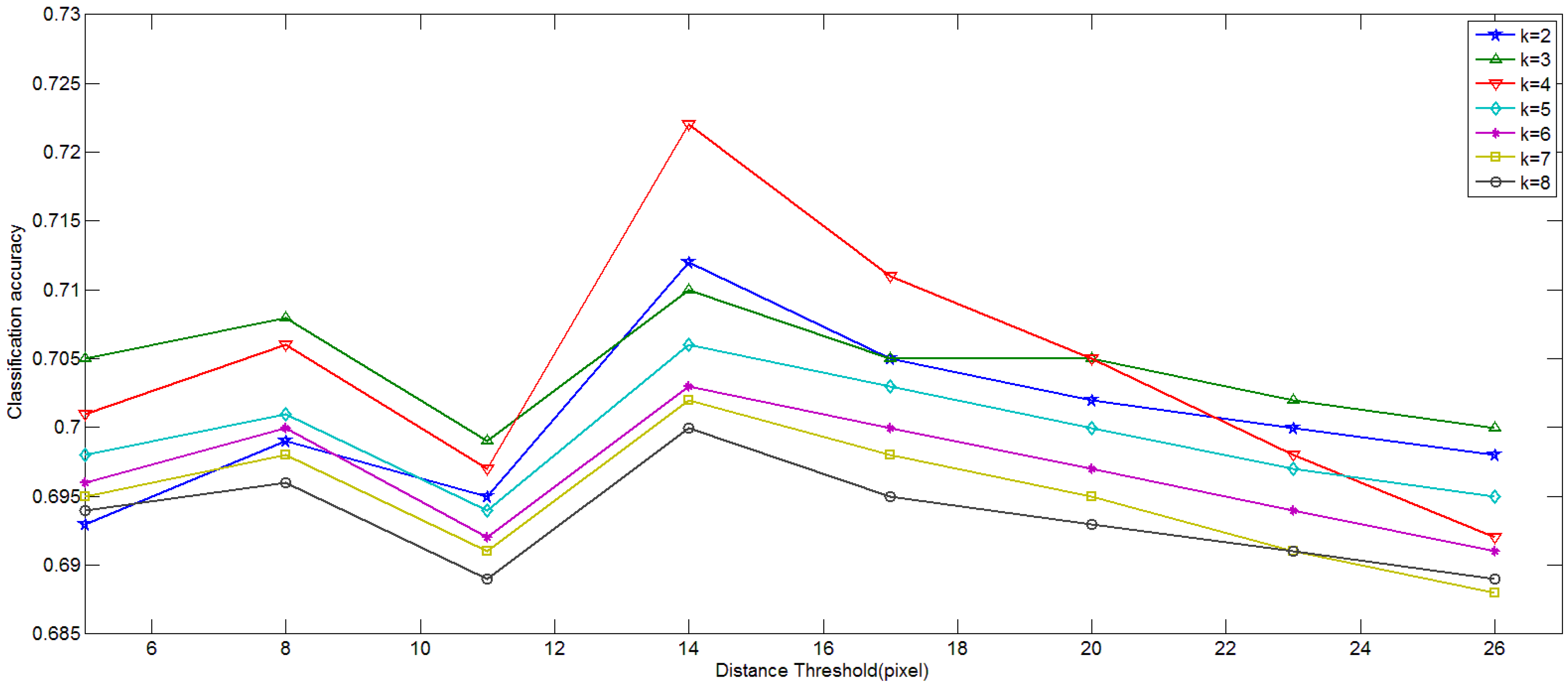
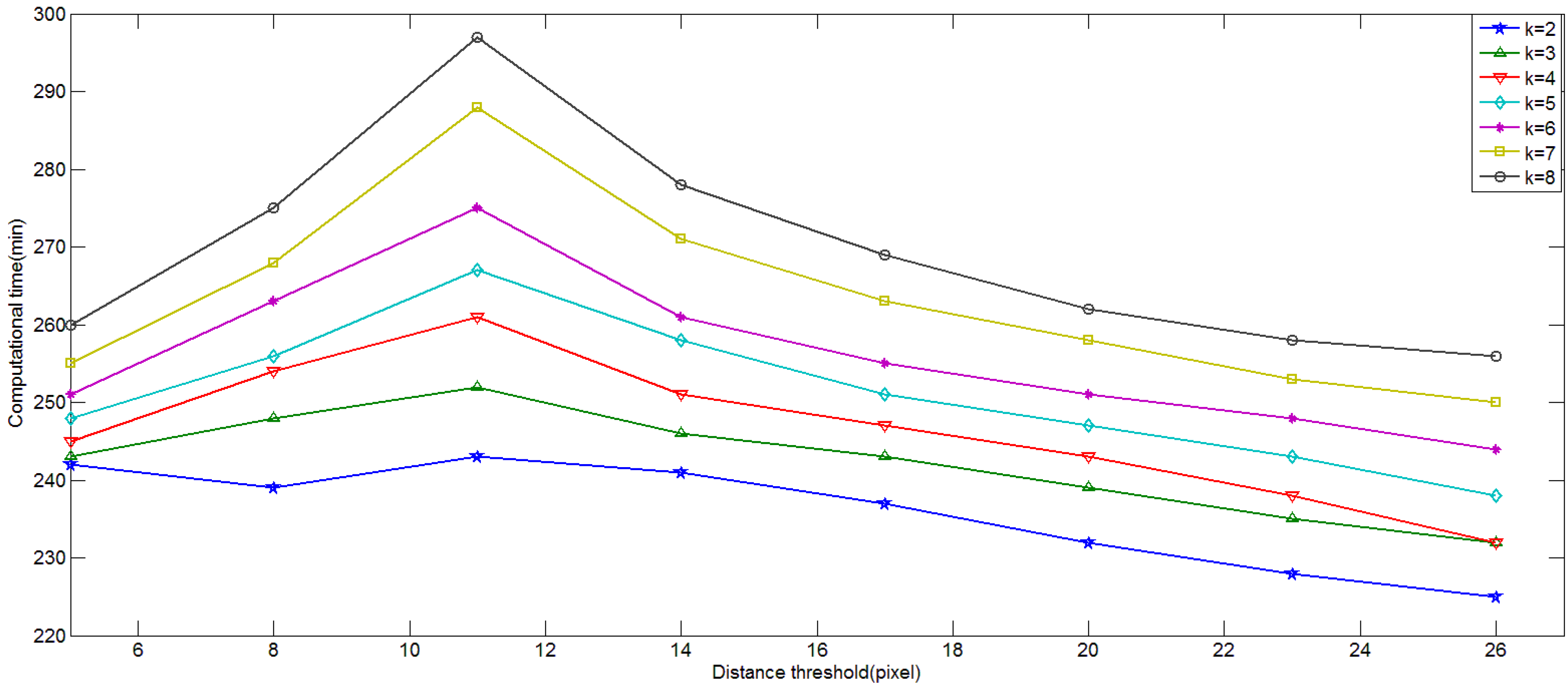
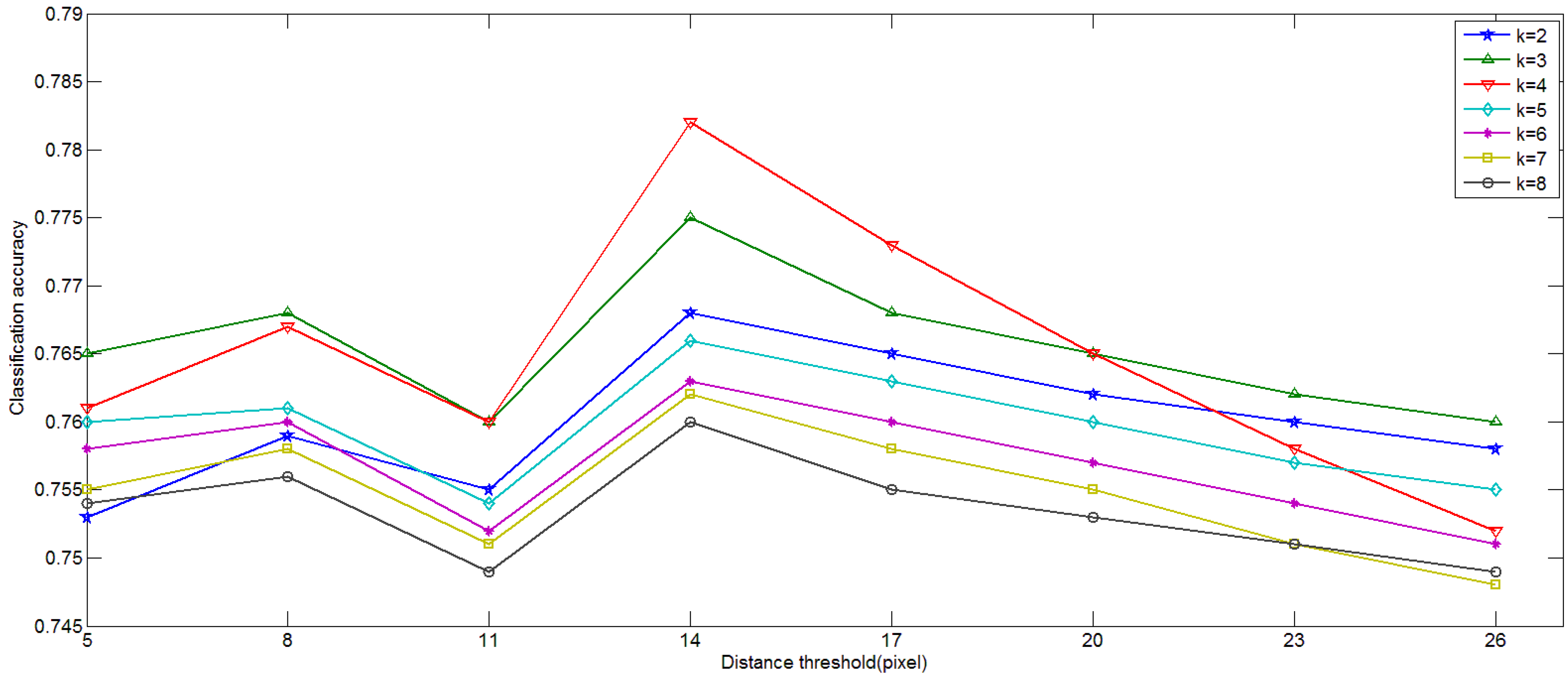
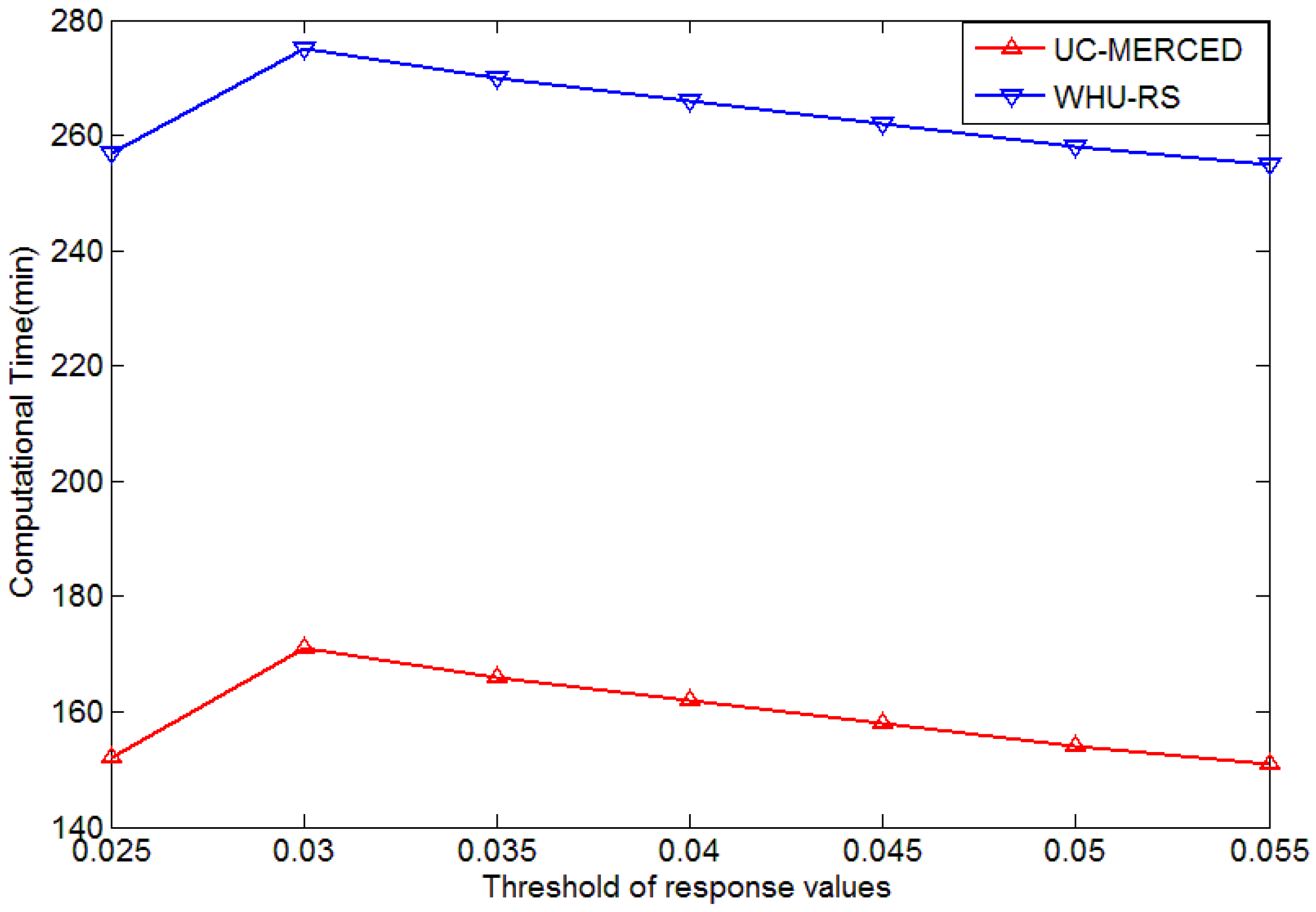
3.2. Results of the Keypoint Selection Algorithm
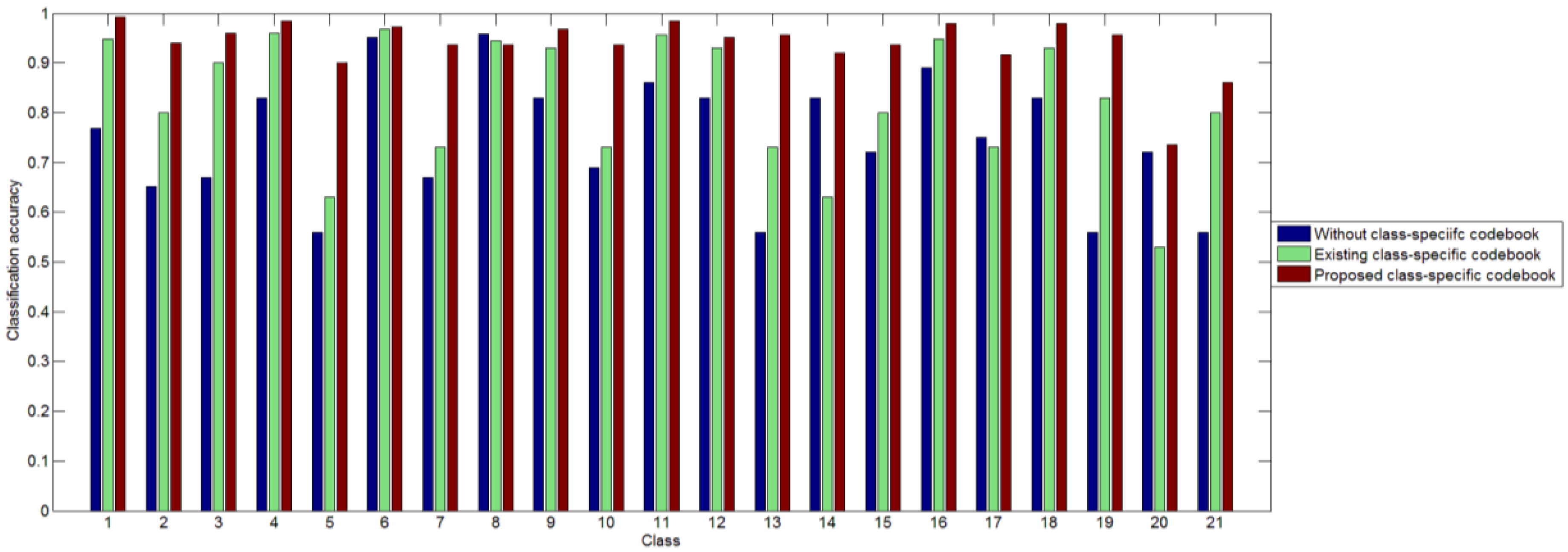
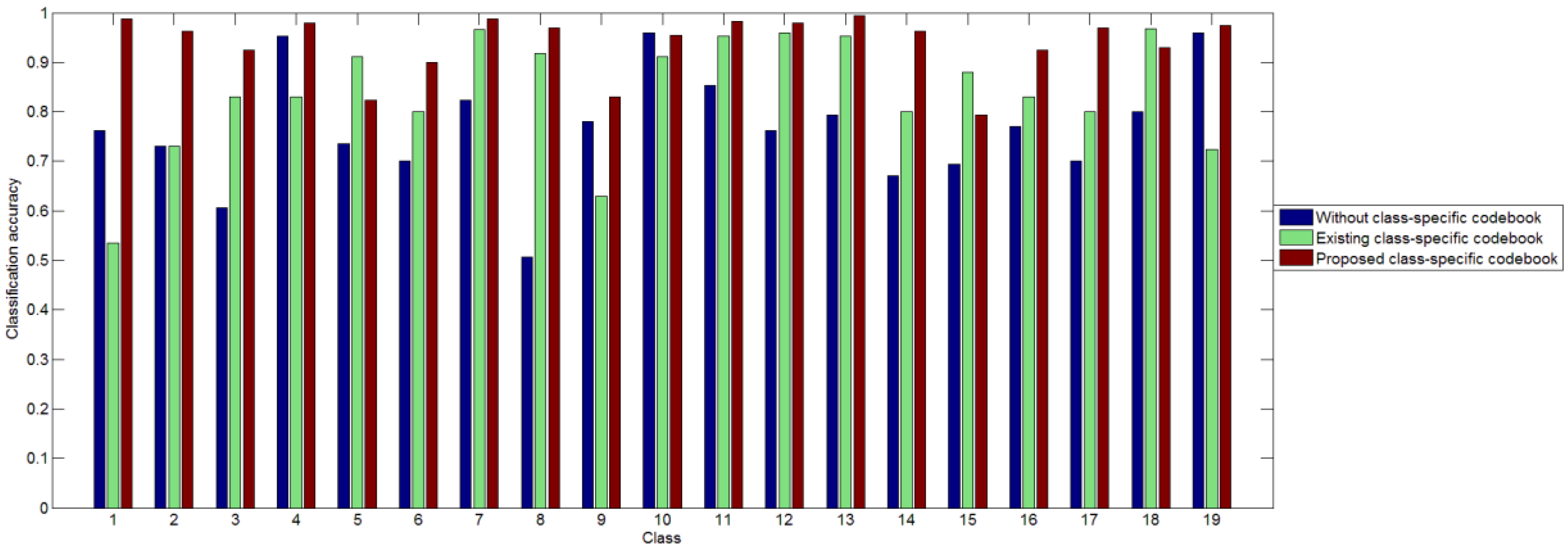
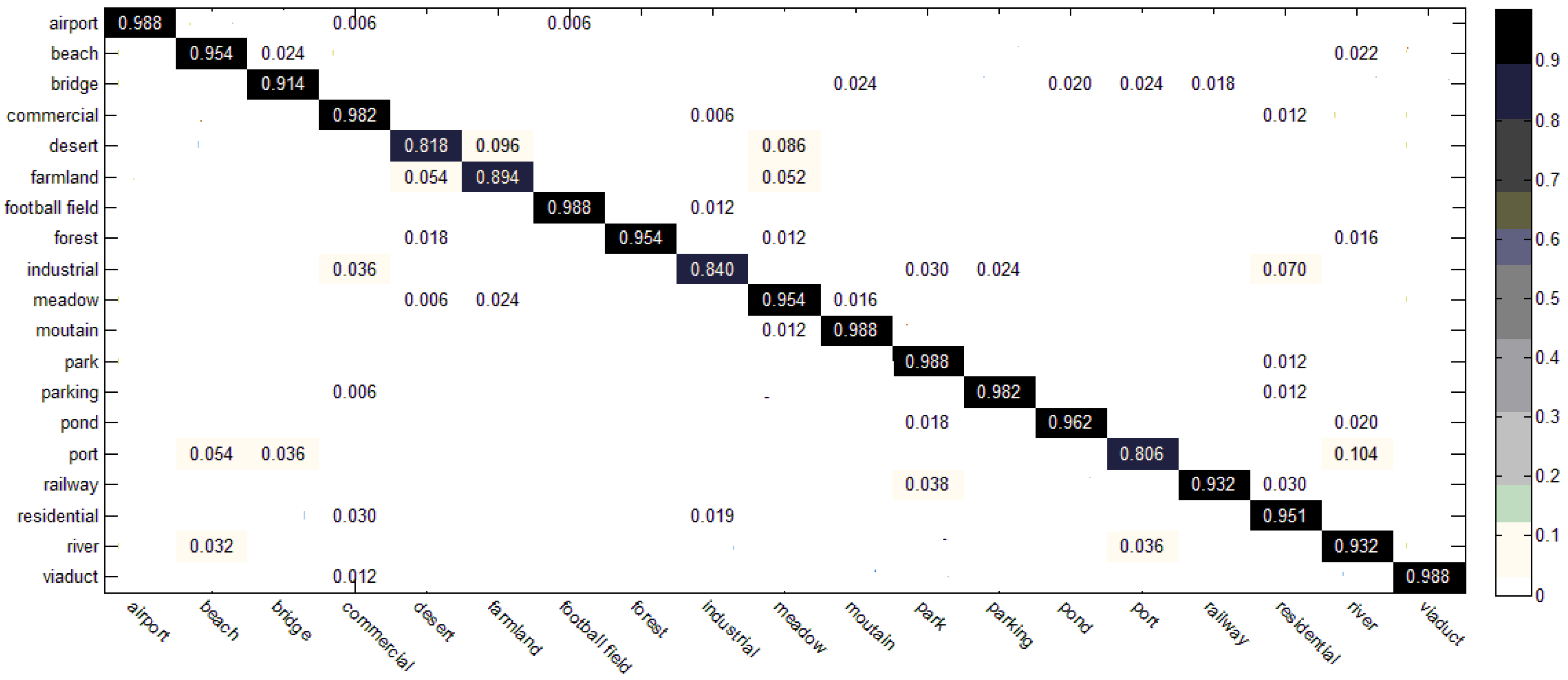
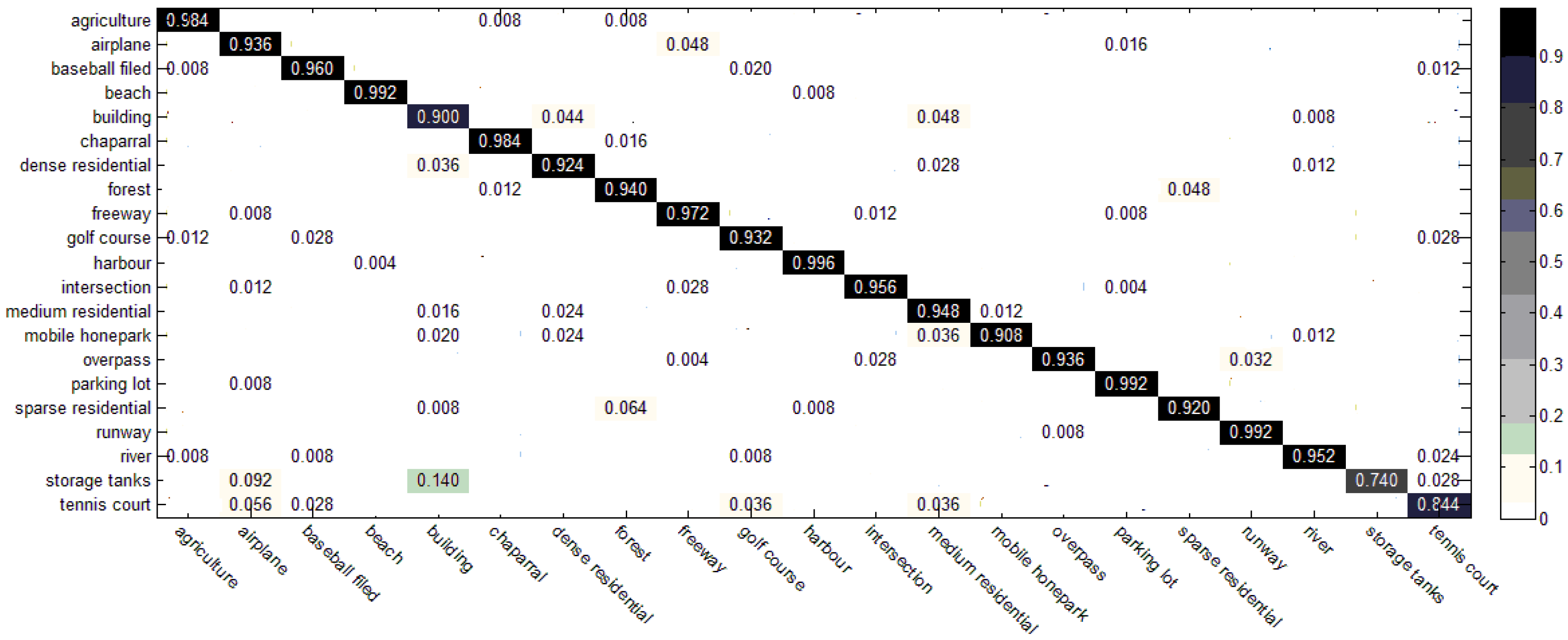
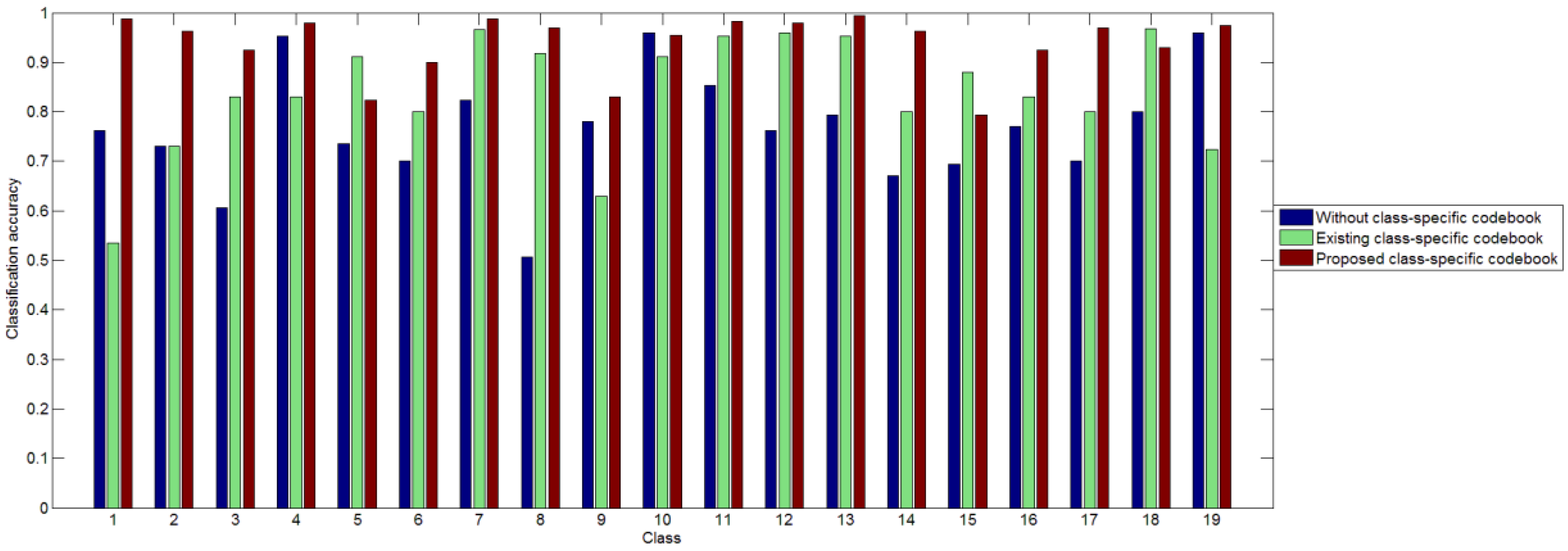
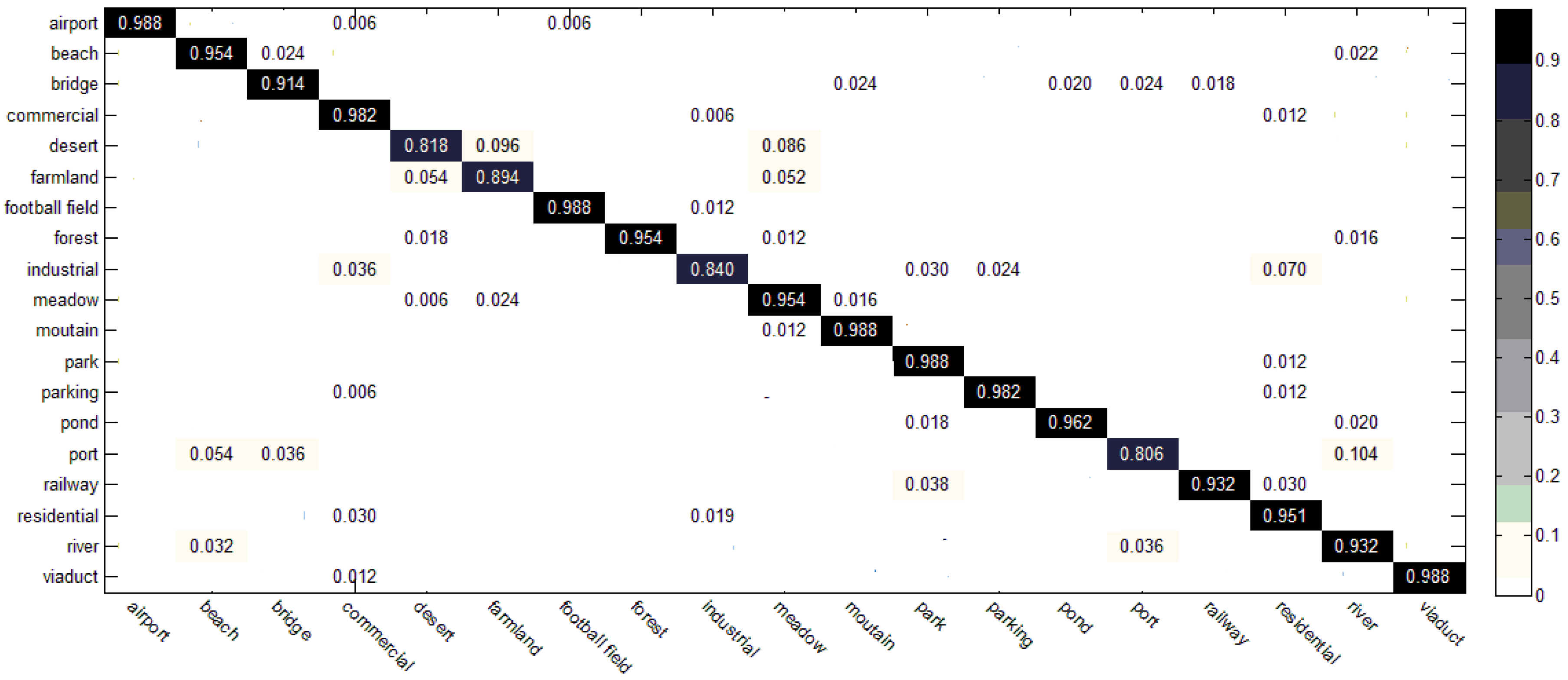
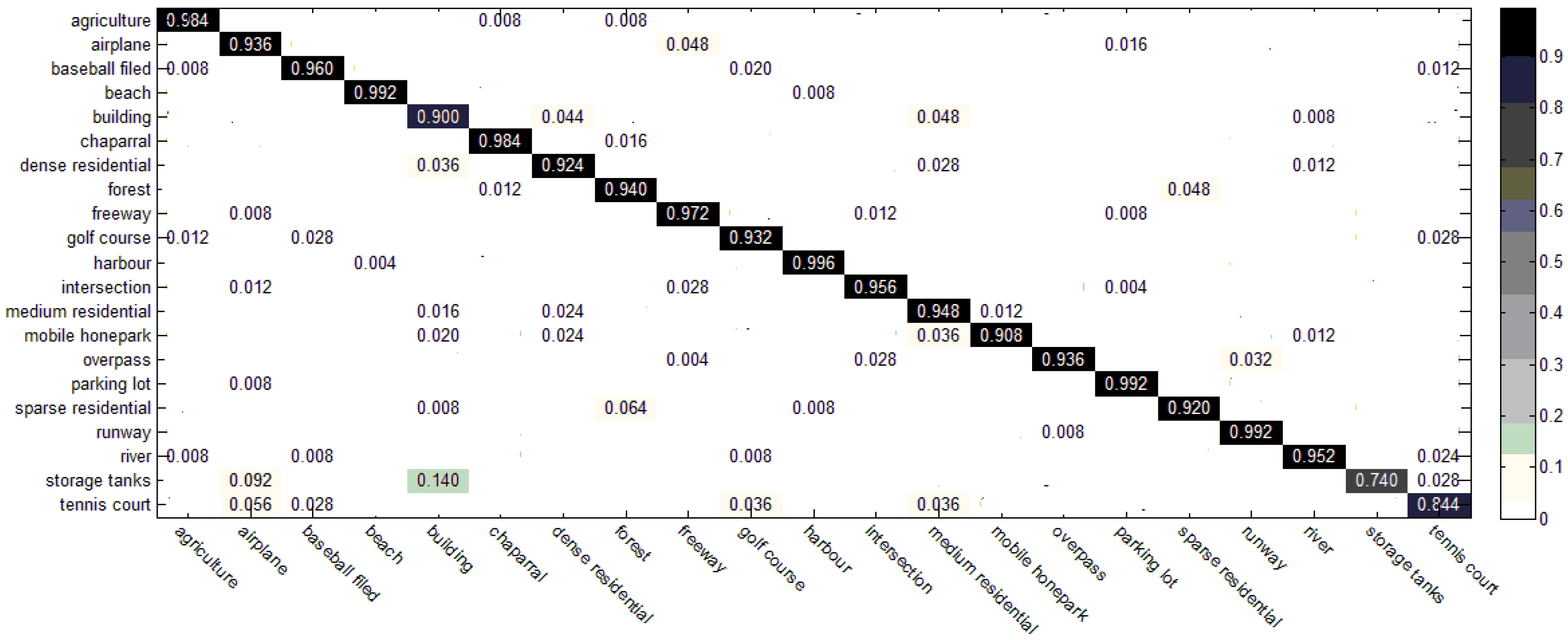
3.3. Results of the Two-Step Classification Method
3.4. Comparison with the State-of-the-Art
4. Discussion
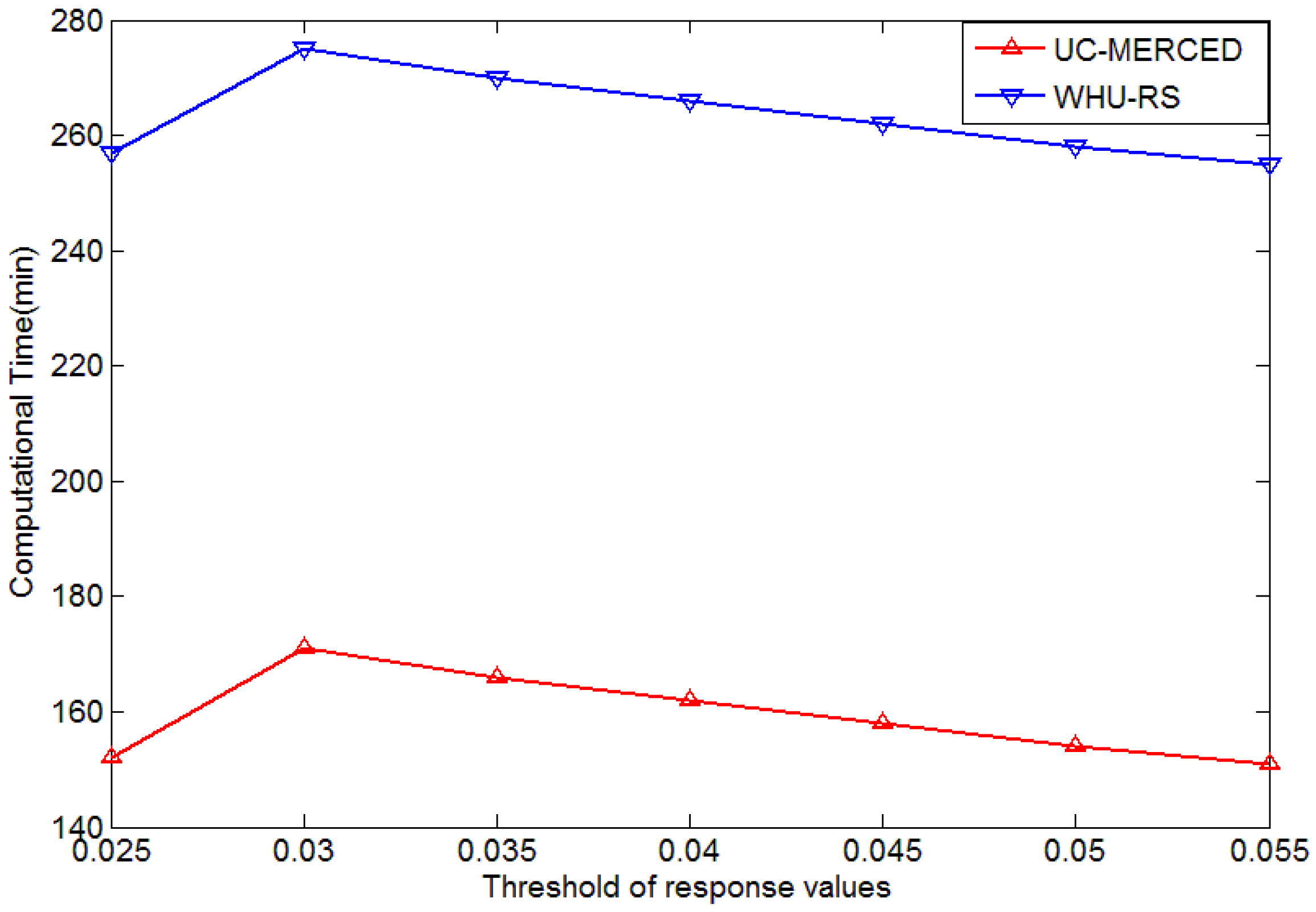
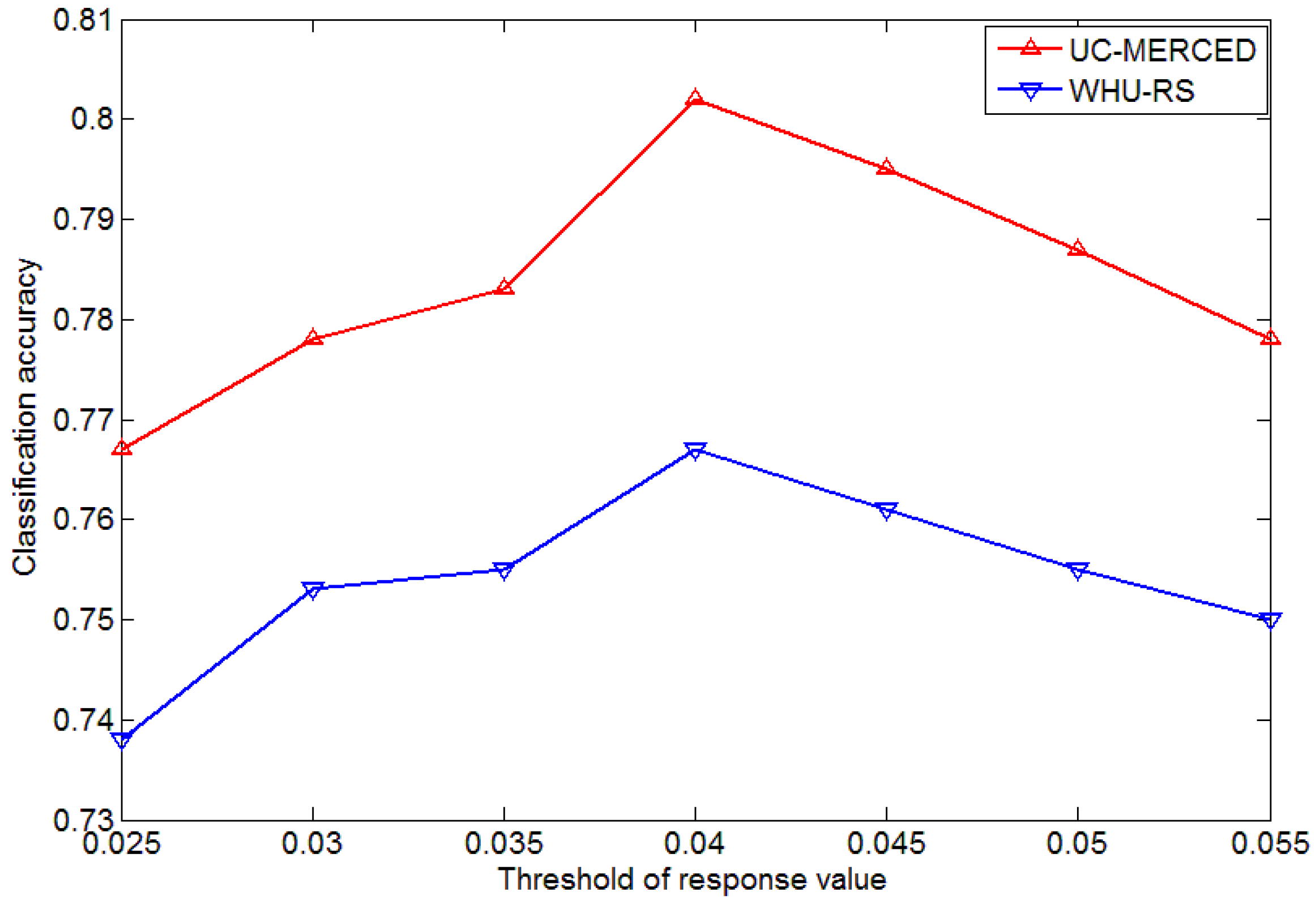
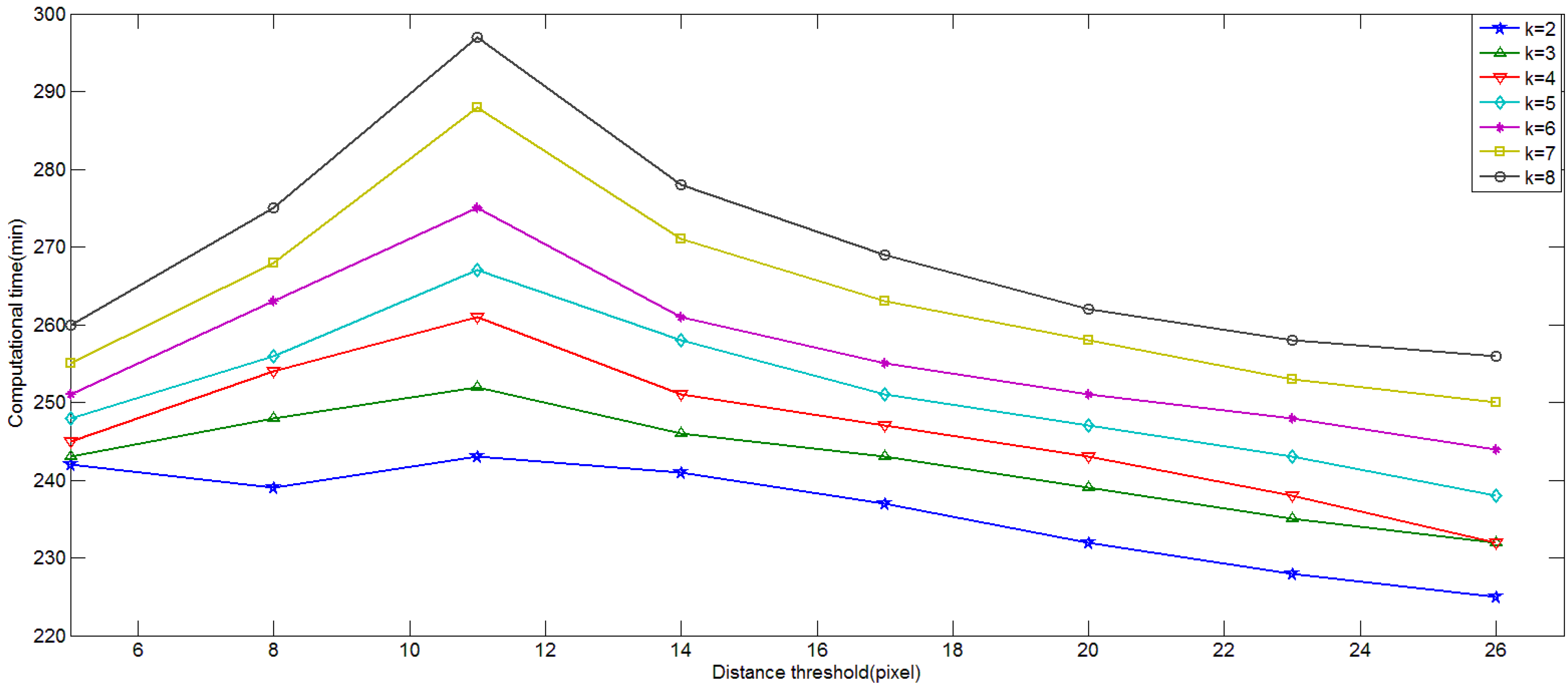
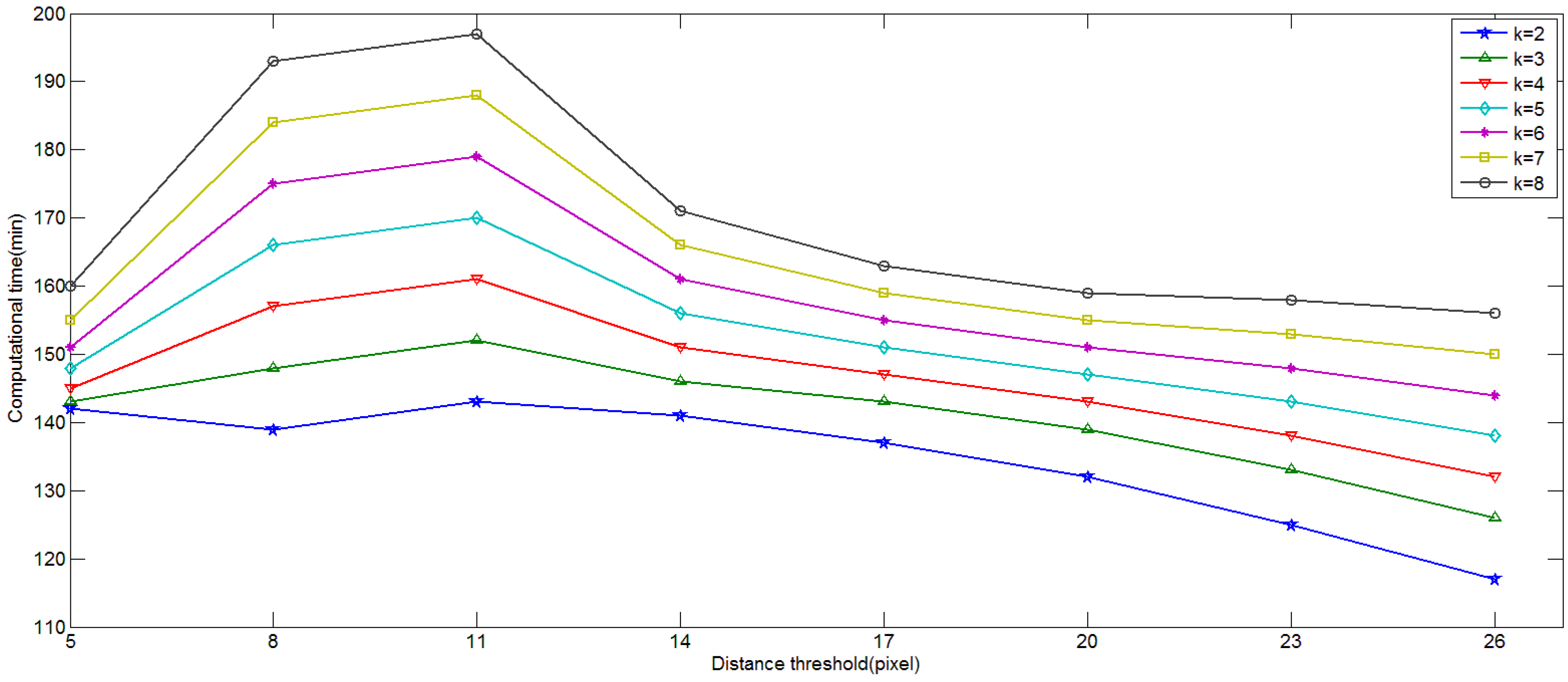
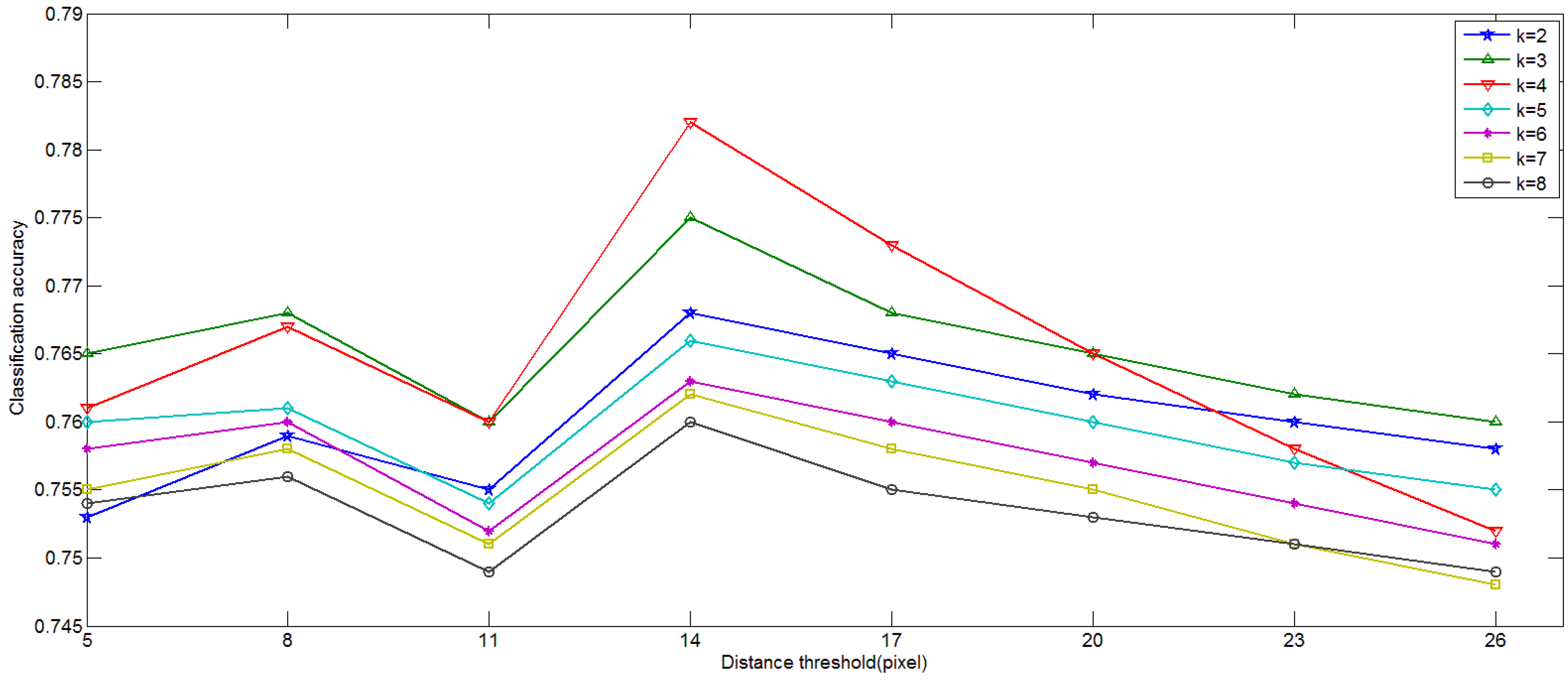
4.1. Influence of Parameters in Keypoint Selection Algorithm
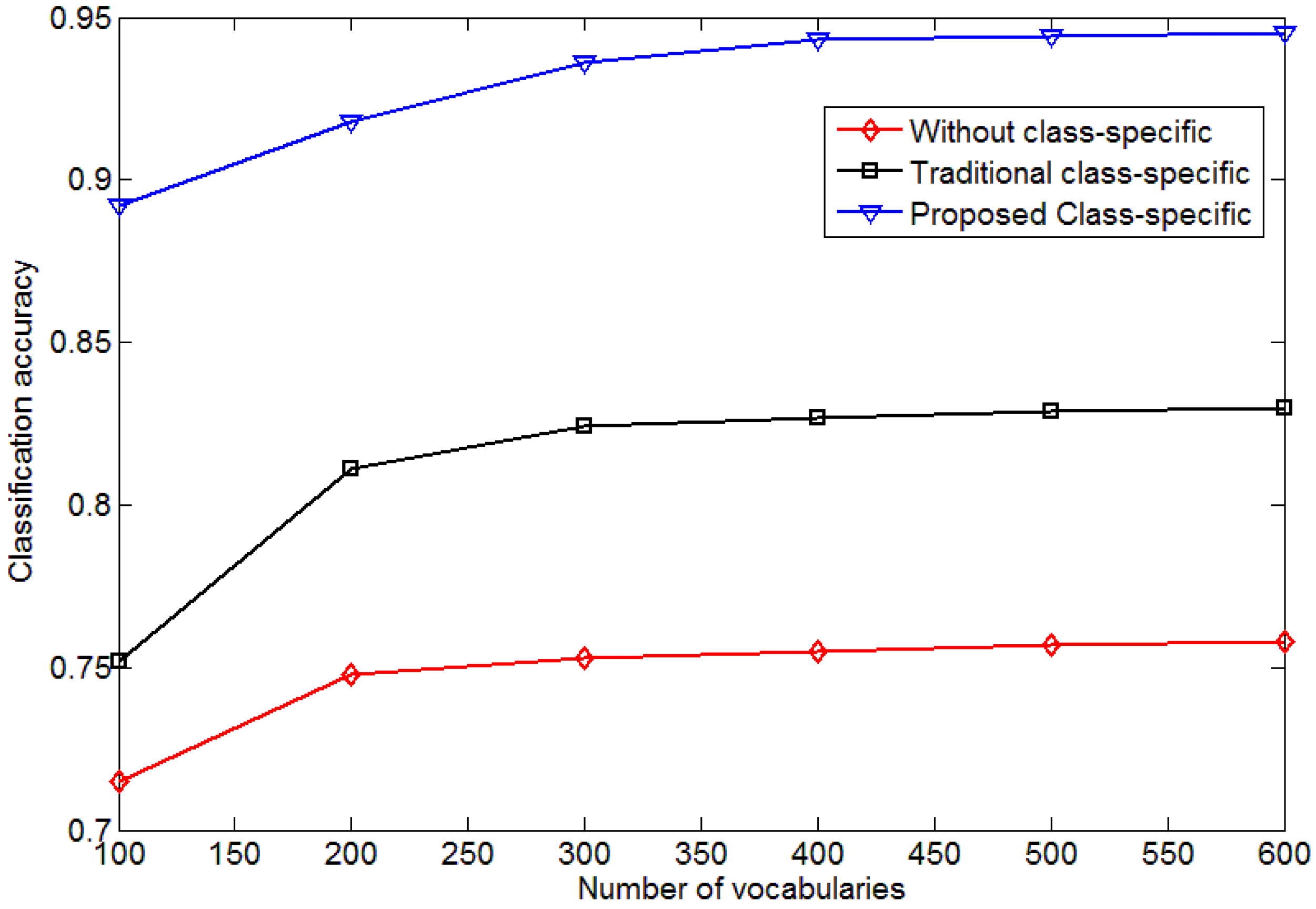
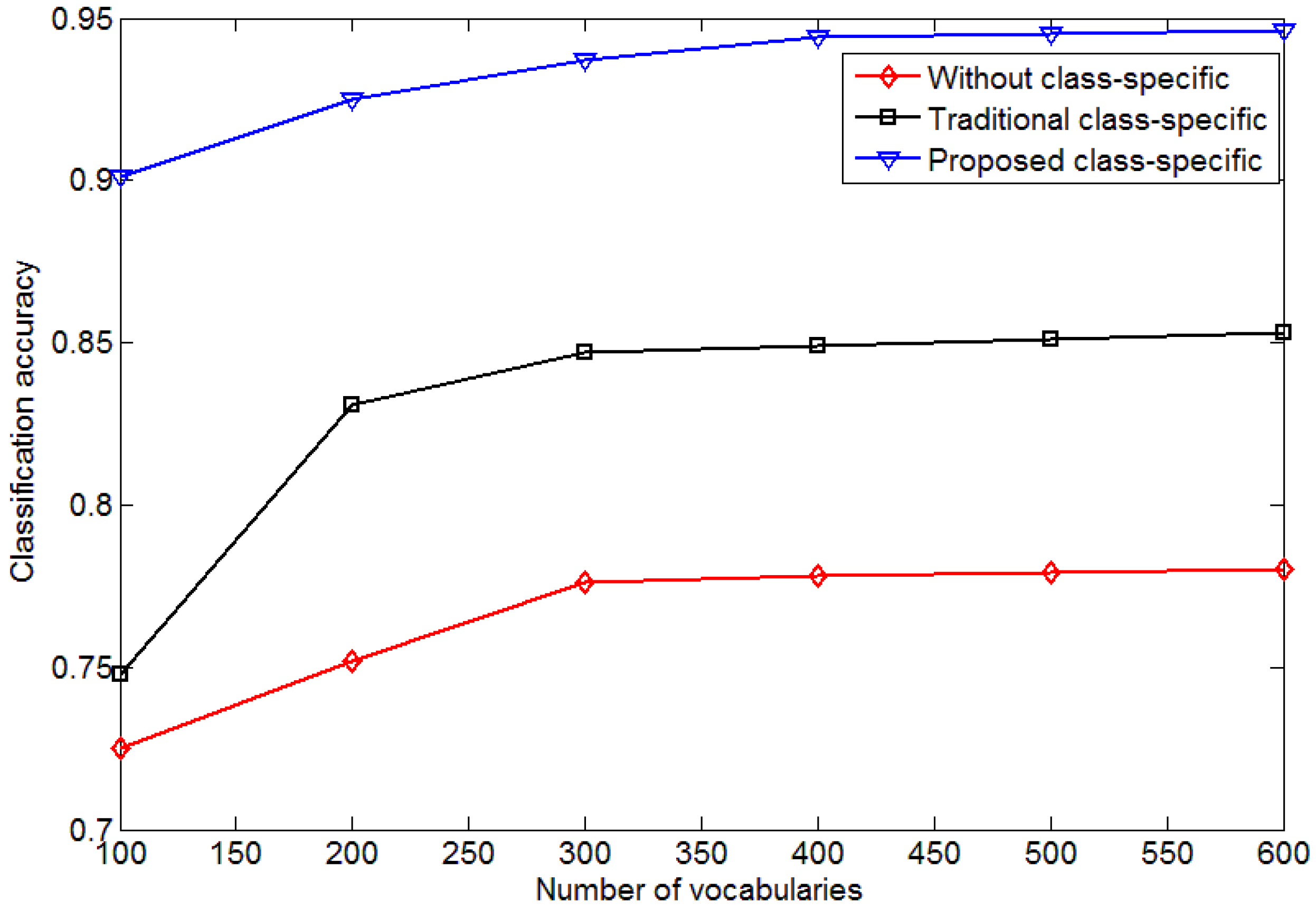
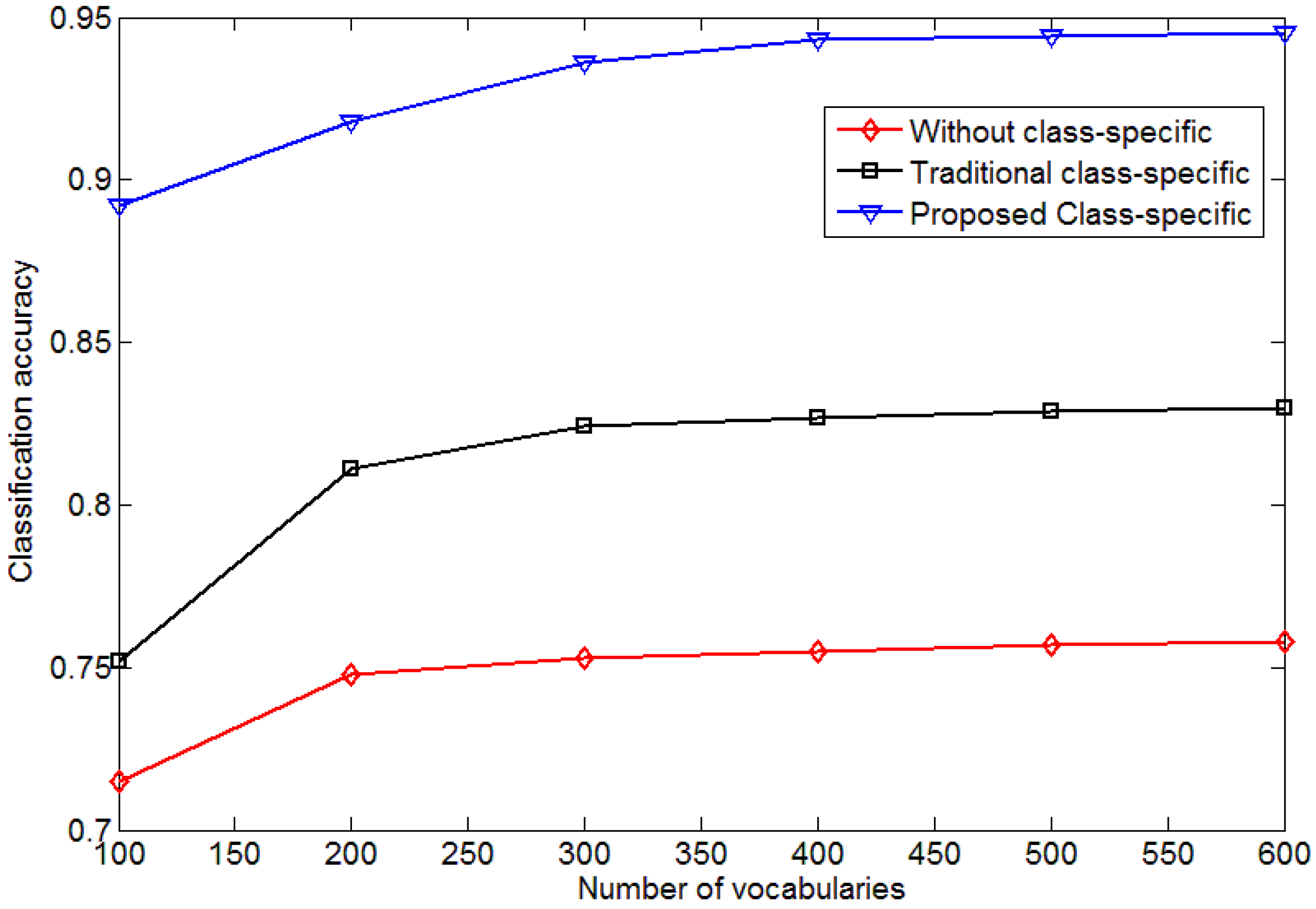
4.2. Influence of the Size of Vocabulary
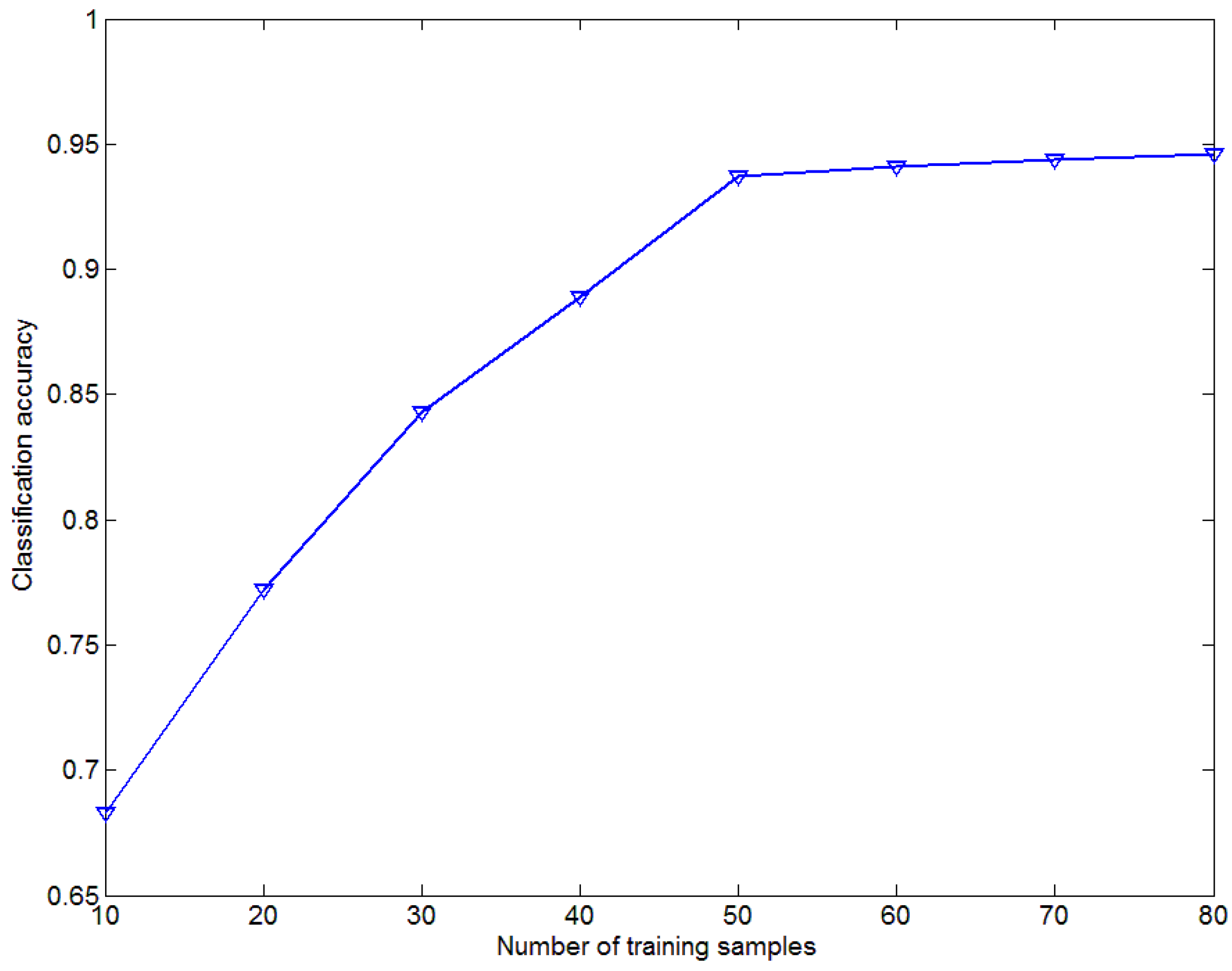
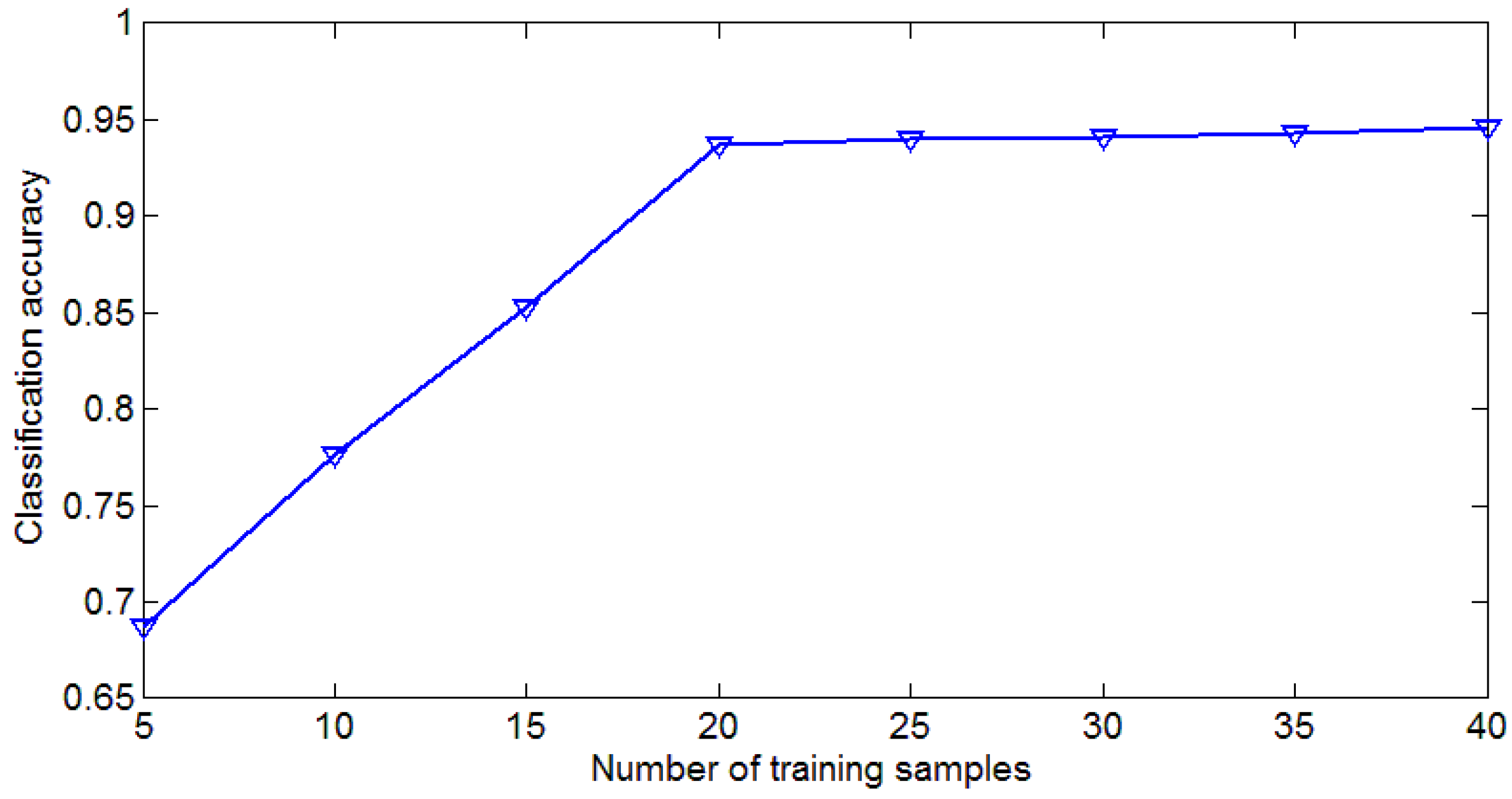
4.3. Influence of Number of Training Samples
4.4. Influence of Two-Step Classification
4.5. Strengths and Limitations
5. Conclusions
- (1)
- Modified keypoint selection method is a useful and efficient way to select the discriminative keypoints from extracted descriptors. This method demonstrates lower computational cost and higher classification accuracy.
- (2)
- We proposed a method for generating class-specific codebook using MI. Vocabularies in the universal codebook will exist in only one specific class-specific codebook. This class-specific codebook will better reflect the information of a specific category.
- (3)
- By classifying the testing image in two steps, we can decrease the error caused by KCRC. Mapping universal histograms to relatively true labels can help to enlarge the differences between different categories. The proposed two-step classification method outperforms the state-of-the-art methods, in terms of the classification accuracy.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhou, V.; Troy, A. An object-oriented approach for analyzing and characterizing urban landscape at the parcel level. Int. J. Remote Sens. 2008, 29, 3119–3135. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Xia, G.-S.; Zhang, L. Dirichlet-derived multiple topic scene classification model fusing heterogeneous features for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2108–2123. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Zhang, L.; Huang, B. The fisher kernel coding framework for high spatial resolution scene classification. Remote Sens. 2016, 8, 157. [Google Scholar] [CrossRef]
- Akçay, H.G.; Aksoy, S. Automatic detection of geospatial objects using multiple hierarchical segmentations. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2097–2111. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L. AID: A benchmark dataset for performance evaluation of aerial scene classification. ArXiv preprint 2016. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multi-resolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Building the gist of a scene: The role of global image features in recognition. Prog. Brain Res. 2006, 155, 23–36. [Google Scholar] [PubMed]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision, Washington, DC, USA, 28 June 2004.
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Bosch, A.; Zisserman, A.; Muñoz, X. Scene classification via pLSA. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 517–530.
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.S.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Luus, F.P.S.; Salmon, B.P.; Van Den Bergh, F.; Maharaj, B.T.J. Multiview deep learning for land-use classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2448–2452. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; Lecun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. ArXiv preprint 2013. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678.
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, Y.; Reed, S.; Anguelov, D.; Dumitru, E.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9.
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 270–279.
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2013, 34, 45–59. [Google Scholar] [CrossRef]
- Turcot, P.; Lowe, D. Better matching with fewer features: The selection of useful features in large database recognition problems. In Proceedings of the ICCV Workshop on Emergent Issues in Large Amounts of Visual Data (WS-LAVD), Kyoto, Japan, 4 October 2009.
- Perronnin, F. Universal and adapted vocabularies for generic visual categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1243–1256. [Google Scholar] [CrossRef] [PubMed]
- Dorko, G.; Schmid, C. Selection of scale-invariant parts for object class recognition. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 634–639.
- Vidal-Naquet, M.; Ullman, S. Object recognition with informative features and linear classification. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 281–288.
- Agarwal, S.; Roth, D. Learning a sparse representation for object detection. In Proceedings of the European Conference on Computer Vision, Copenhagen, Denmark, 28–31 May 2002; pp. 113–130.
- Chin, T.-J.; Suter, D.; Wang, H. Boosting histograms of descriptor distances for scalable multiclass specific scene recognition. Image Vis. Comput. 2011, 29, 2. [Google Scholar] [CrossRef]
- Opelt, A.; Pinz, M.; Fussenegger, P. Auer, Generic object recognition with boosting. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 416–431. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.C.; Tsai, C.F.L.; Chen, Z.Y.; Ke, S. Keypoint selection for efficient bag-of-words feature generation and effective image classification. Inf. Sci. 2016, 329, 33–51. [Google Scholar] [CrossRef]
- Altintakan, U.L.; Yazici, A. Towards effective image classification using class-specific codebooks and distinctive local features. IEEE Trans. Multimed. 2015, 17, 323–332. [Google Scholar] [CrossRef]
- Li, H.; Yang, L.; Guo, C. Improved piecewise vector quantized approximation based on normalized time subsequences. Measurement 2013, 46, 3429–3439. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.; Sastry, S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Suykens, J.A.K.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 17–22 June 2006; Volume 2, pp. 2169–2178.
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T.; Gong, T. Locality-constrained linear coding for image classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367.
- Yang, J.; Yu, K.; Gong, Y.; Huang, T. Linear spatial pyramid matching using sparse coding for image classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009.
- Yuan, Q.; Zhang, L.; Shen, H. Hyperspectral image denoising employing a spectral-spatial adaptive total variation model. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3660–3677. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, M.; Feng, X. Sparse representation or collaborative representation: Which helps face recognition? In Proceedings of the IEEE 2011 International Conference on Computer Vision, Colorado Springs, CO, USA, 20–25 June 2011; pp. 471–478.
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2011, 33, 2395–2412. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for Support Vector Machines. 2001. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 30 May 2013).
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef]
- Wilson, D.R.; Martinez, T.R. Reduction techniques for instance-based learning algorithms. Mach. Learn. 2000, 38, 257–286. [Google Scholar] [CrossRef]
- Brighton, H.; Mellish, C. Advances in instance selection for instance-based learning algorithms. Data Min. Knowl. Discov. 2002, 6, 153–172. [Google Scholar] [CrossRef]
- Perronnin, F.; Sánchez, J.; Mensink, T. Improving the fisher kernel for large-scale image classification. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 143–156.
- Negrel, R.; Picard, D.; Gosselin, P.H. Evaluation of second-order visual features for land-use classification. In Proceedings of the 2014 12th International Workshop on Content-Based Multimedia Indexing (CBMI), Klagenfurt, Austria, 18–20 June 2014; pp. 1–5.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | WHU-RS Dataset | UC_MERCED Dataset |
|---|---|---|
| BOW without keypoint selection | 1,513,532 ± 21,888 | 939,657 ± 17,339 |
| Filter with response value (First step) | 862,745 ± 16,411 | 554,310 ± 13,517 |
| Proposed Keypoint Selection Method | 635,497 ± 14,227 | 403,857 ± 11,259 |
| IKS | 575,168 ± 29,110 | 356,952 ± 10,403 |
| Method | BOW without Keypoint Selection | Filter with Response Value | Proposed Keypoint Selection Method | IKS | |
|---|---|---|---|---|---|
| Dataset | |||||
| UC_MER CED | time | 252 ± 1.9 min | 222 ± 2.8 min | 135 ± 2.5 min | 478 ± 3.3 min |
| accuracy | 0.715 ± 0.0036 | 0.736 ± 0.0033 | 0.7780 ± 0.0028 | 0.721 ± 0.0045 | |
| WHU-RS | time | 387 ± 4.5 min | 316 ± 3.3 min | 221 ± 2.9 min | 630 ± 5.1min |
| accuracy | 0.686 ± 0.0029 | 0.698 ± 0.0032 | 0.754 ± 0.0036 | 0.695 ± 0.0033 |
| Different Conditions | UC_MERCED Dataset | WHU-RS Dataset |
|---|---|---|
| Total testing samples | 1050 | 570 |
| KCRC right | 0.843 ± 0.0036 | 0.851 ± 0.0033 |
| KCRC wrong but proposed right | 0.116 ± 0.0029 | 0.109 ± 0.0028 |
| KCRC right but proposed wrong | 0.019 ± 0.0013 | 0.019 ± 0.0015 |
| Method | LDA | IFK | VLAD | GoogLe Net | Proposed Method | |
|---|---|---|---|---|---|---|
| Dataset | ||||||
| UC_MERCED | 0.642 ± 0.0019 | 0.826 ± 0.0028 | 0.778 ± 0.0036 | 0.925 ± 0.0049 | 0.938 ± 0.0058 | |
| WHU-RS | 0.708 ± 0.0015 | 0.835 ± 0.0025 | 0.805 ± 0.0033 | 0.923 ± 0.0045 | 0.937 ± 0.0057 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, L.; Zhu, R.; Mo, N.; Liu, Y. Improved Class-Specific Codebook with Two-Step Classification for Scene-Level Classification of High Resolution Remote Sensing Images. Remote Sens. 2017, 9, 223. https://doi.org/10.3390/rs9030223
Yan L, Zhu R, Mo N, Liu Y. Improved Class-Specific Codebook with Two-Step Classification for Scene-Level Classification of High Resolution Remote Sensing Images. Remote Sensing. 2017; 9(3):223. https://doi.org/10.3390/rs9030223
Chicago/Turabian StyleYan, Li, Ruixi Zhu, Nan Mo, and Yi Liu. 2017. "Improved Class-Specific Codebook with Two-Step Classification for Scene-Level Classification of High Resolution Remote Sensing Images" Remote Sensing 9, no. 3: 223. https://doi.org/10.3390/rs9030223
APA StyleYan, L., Zhu, R., Mo, N., & Liu, Y. (2017). Improved Class-Specific Codebook with Two-Step Classification for Scene-Level Classification of High Resolution Remote Sensing Images. Remote Sensing, 9(3), 223. https://doi.org/10.3390/rs9030223