1. Introduction
With the rapid development of microelectronics technology, the increasing maturity of the integrated circuit process, and the continuous exploration of the depths of satellite communications, radar aerospace, and other fields, the application and development of RF semiconductor devices at microwave millimeter-wave frequencies have gradually occupied an important position in high-speed communications [
1,
2]. In order to reduce the cost and improve the performance, some key dimensions of the process have been continuously reduced. Accordingly, the electric field strength and current density to which the device is subjected are also increasing, which exacerbates the probability and randomness of the occurrence of various failure mechanisms and poses a serious challenge to the reliability of integrated circuits and the improvement of electronic design automation (EDA) [
3].
High-reliability EDA tools need to fit, cope with, and correct real-world physical and process problems in software with a systematic approach and predictive margins as high as possible and ultimately ensure that the circuit design simulation results are consistent with the degradation results of the flow test in the reliability environment to achieve the optimal end-of-life performance/power consumption/area (EOL-PPA). The device model, as an important bridge between process and circuit design, is a key link in the DTCO flow under the new architecture, and its accuracy directly determines the accuracy and efficiency of circuit design [
4]. Through the establishment of reliability models for key components in integrated systems, on the one hand, the internal physical mechanism of the device can be explored in depth, laying a foundation for the realization of the device reliability degradation simulation. On the other hand, a better prediction of the characteristic degradation can be obtained in the large-scale simulation of the electrical characteristics of circuits as well as reliability degradation effects. In addition to providing guidance for process improvement, device-level reliability models also play a key role in the reliability-aware design of integrated circuits. The establishment of efficient and accurate reliability models can be used to guide the reliability design and optimization of circuits in order to reduce the time and cost of high-reliability circuit design [
5].
In recent years, research on the conventional small-signal model has focused on the characterization of non-ideal effects corresponding to ultra-high frequency rates and severe parasitics [
6,
7,
8]. The reliability modeling-related research on this basis has been insufficient, still focusing mainly on the physical level of the device, with constraints such as long R&D cycle time, slow modeling, and incompatibility with EDA softwares [
9,
10]. A reliability compact model based on semi-empirical and semi-physical approaches may lack accuracy when actually characterizing degradation in time and frequency domains due to some approximations or simplifications [
11,
12]. Therefore, in addition to the ongoing in-depth study of the physical nature of RF microwave transistor aging and the associated reliability of compact models, we believe that there is another approach worth exploring. This method involves the use of an artificial neural network (ANN) methodology based on machine learning-assisted behavioral-level modeling [
13] to achieve degradation prediction of RF devices in harsh reliability environments. The method can be trained on the degradation behavior of the device under specific reliability conditions, and then the trained network can be used to make predictions. Although the data-driven reliability-based artificial neural network model can achieve higher accuracy, it strongly relies on a large number of reliability test samples for training and learning [
14]. Even if the TCAD numerical simulation tool is used to obtain the training data, a large amount of reliable experimental data is still needed to perform the complex calibration of the degradation of the amount of marching associated with aging as a time-correlated process [
15]. While microwave devices involve a variety of complex combinations of conditions such as materials, geometries, frequencies, processes, etc., reliability data are more difficult to obtain and costly, and reliability experiments require strict requirements on environment, equipment, samples, etc., which require a large amount of cost investment. It can be seen that improving the traditional reliability artificial neural network model with limited reliability test samples in order to achieve efficient, accurate, and high generalization ability modeling is particularly important. Therefore, we hope to use physical/semi-physical degradation laws or formulas to guide this behavioral model and adopt a simple and effective knowledge injection to improve the reliability of the black box model.
In this paper, a prior knowledge-based neural network approach for device reliability modeling is proposed. A dual-extreme learning machine (D-ELM) is used to decompose the aging and fresh features of the device into two sub-networks to simplify the complex nonlinear mapping of the original problem. The established degradation function of the key parameters of the device is introduced into the aging equivalent-circuit model to obtain the degradation of each component of the S-parameters. Then, the S-parameter degradation information obtained from the coarse model is injected into the degradation sub-network as prior knowledge. In addition to the reliability parameter inputs of the original aging problem, the coarse model outputs are also used as additional inputs. At this point, the input–output mapping to be learned by the neural network is the mapping between the existing approximate reliability model outputs and the original problem, thus weakening the complex mapping relationship between reliability parameters and S-parameter degradation and improving the quality of the mapping. This, in turn, reduces the dependence on reliable training samples and improves accuracy with the high generalization ability of the model. Moreover, we have utilized an adaptive evolutionary algorithm to optimize the model and improve the stability of network training. Finally, the proposed PKNN-based reliability model is validated by applying it to 0.7 μm InGaAs/InP HBTs.
2. Device Structure and Experiment
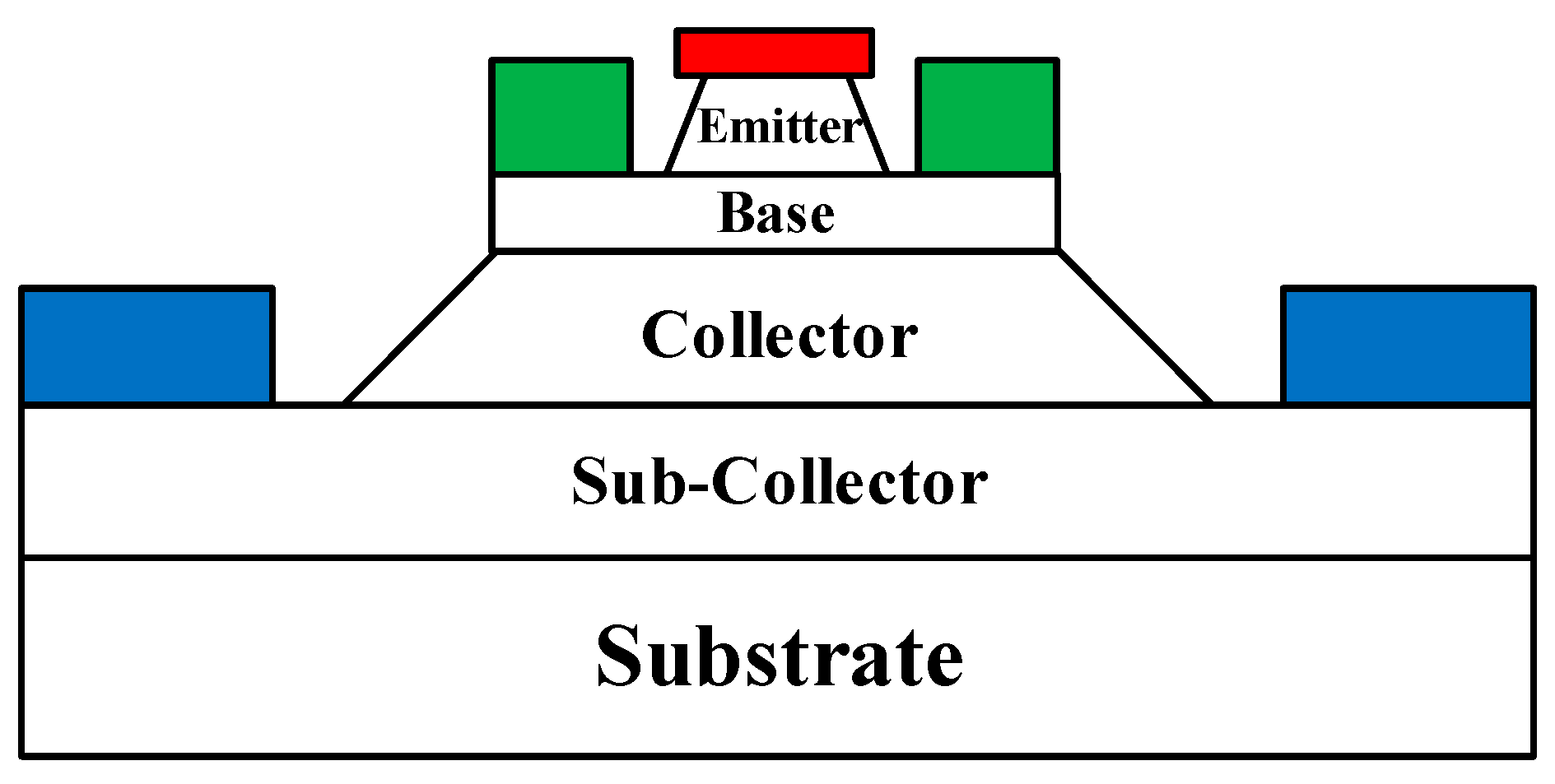
The InP DHBT device used in this paper adopts a three mesa-structure, and its structural schematic is shown in
Figure 1, in which the non-alloyed Ti/Pt/Au and Pt/Ti/Pt/Au are used for N-type and P-type ohmic contacts, respectively. Base self-alignment technology, non-contact exposure, and wet etching technology are used in the fabrication of the device.
In this paper, we use a Keysight B1500A semiconductor device parameter analyzer to apply high-field electrical stress to the device by means of a DC probe. The B1500A has a very sophisticated cycling control module for DC probes to precisely apply the electrical stress, and this test module can also monitor whether the junction of the InP HBT device is broken during the test. The schematic diagram of high-field electrical stress application is shown in
Figure 2, in which the base and collector of the device are connected to the SMU1 and SMU2 ports of Keysight B1500A, respectively. We set the two ports to voltage input mode and used the EasyEXPERT group+ 2015 software for the control of the electrical stress. The selection of stresses needs to be carried out before conducting the high-field stress aging test. Applying a reverse high-field stress of about 80% of the device breakdown voltage
BVCBO to the BC junction can allow the device to operate properly without breakdown and cause non-negligible degradation [
16]. We have chosen about 70–90% of the breakdown voltage for high-field stress aging. The breakdown voltage of the InP HBT device used is about 4.7 V; thus, we apply constant reverse bias voltages of 3.4–4.3 V to the BC junction of the device and select four stress biases in steps of 0.3 V to perform
S-parameter tests after up to 300 minutes of stress application while keeping the BE junction open. To accurately assess the effect of high-field electrical stress on device RF characteristics, a Rohde & Schwarz ZVA 50 Network Analyzer controlled by IC-CAP 2018 software is employed for
S-parameter testing, and the ground–signal–ground (GSG) microwave probe was used in the on-chip measuring process. In addition, to correct the error terms introduced by the test equipment itself, a system error calibration is required before testing with VNA. In this paper, the on-chip test of InP HBT
S-parameters is a two-port network test system, and to obtain the actual
S-parameters of the DUT, the TOSM (Through, Open, Short, Match) system error calibration method [
17,
18] is used to remove the parasitic elements introduced by the equipment components such as test cables and probe tips before the reliability test. It is worth noting that the calibration of the RF on-chip test platform is performed before the electrical stress is applied. Also, attention is paid to maintaining a stable test environment during the test to ensure that the calibration conditions do not deviate. All of the above on-chip tests are performed on the CASCADE MICROTECH Summit 11000 Prober, as shown in
Figure 3.
4. Results and Discussion
In order to more intuitively represent the modeling process in this paper, we use the PKNN-based aging small-signal modeling flowchart shown in
Figure 9 to briefly summarize the above steps of device small-signal aging knowledge construction, knowledge injection, D-ELM network training, and network optimization. In the first stage, we use NETWORK1 to train and predict the
S-parameter samples in the fresh state of the device. Then, we transform the degradation trend of the key parameters into the degradation information of the
S-parameters after applying stress to the device through the aging compact model in the second stage. In the third stage, we inject the rough aging information obtained in the second stage into the degradation NETWORK2, then train and optimize this network. Finally, the aging
S-parameters of the device are obtained by accumulating the predicted outputs of the two networks under the corresponding degradation conditions. The proposed aging modeling technique is evaluated and validated by modeling the aging
S-parameters of different batches of InP HBTs degraded under different stress magnitudes and times in the frequency range of 0.1–40 GHz.
Trained artificial neural network models are usually evaluated using the prediction error of the test sample sets. For the reliability of the ANN model in this paper, the main factors affecting its network training in terms of dataset sample requirements are the total reliability sample size and the percentage of the training sample sets. Therefore, we set up seven groups of training experiments, as summarized in
Table 2, to verify the validity and accuracy of the proposed model. The first, second, and third groups keep the same total sample size (2412 sets) and 50% training set share. These three experiments were conducted to model the degradation of each component of the
S-parameters using the traditional ELM structure and the proposed PKNN structure, respectively, to compare the degradation prediction ability of the two networks under the same sample size and the same training conditions with different amounts of knowledge injection. Additionally, to further illustrate the superiority of the aging modeling approach proposed in the paper, keeping the same conditions as the first three sets of experiments, the widely used backpropagation (BP) and radial basis function (RBF) algorithms are applied for additional comparison in the fourth and fifth groups, respectively. Then, we set up a sixth set of experiments, still keeping the same total sample size (2412 sets) as the first five sets of experiments but randomly selecting 80% of the total sample size to train the network on the traditional ELM structure. This was conducted to compare the results with the second and third sets of experiments on prediction with the proposed PKNN structure to verify the prediction ability of the proposed model after the dependence on the reliability training samples is reduced. Finally, we supplemented a seventh set of experiments by taking about 60% (1458 sets) of the total sample size of the first six sets, with the training set share remaining the same as that of the sixth set. Then, we compared it with the prediction results of the ELM structure in the sixth set of experiments to further compare and illustrate the prediction ability of the proposed PKNN model with the reduction in the total reliability sample size. In addition, after keeping the same total sample size and fixing the training set share for the third and sixth sets of experiments, the test sets they used for validation also naturally formed a set of control groups with a share of 50% and 20%, respectively. The results of the comparison between these two sets of experiments can be used to further illustrate how well the generalization ability of both the traditional ELM structure and the proposed PKNN structure is. In
Table 3, we give the mean relative errors of the prediction of the degradation of each component of the
S-parameters in the seven sets of experimental test sets, and their error equations are shown below.
where
ymea and
ypre represent the measured output and the predicted output of the neural network, respectively.
N is the number of data.
From the comparison of the prediction results between the first and third sets of experiments, the overall prediction accuracy of the PKNN model for the degradation of each component of the S-parameter is better than that of the ELM structure. The improvement is at least 51.6% for each component and a reduction of 74.3% in the overall error for the same sample size and training configuration. For the fourth and fifth groups of BP and RBF algorithm networks, the overall prediction accuracy of PKNN is about three times higher than theirs. From the comparison of the prediction results between the third and sixth sets of experiments, compared with the aging prediction of the ELM structure without knowledge injection, the PKNN-based aging model can meet or even exceed its prediction accuracy for all the components of the S-parameters with at least a 37.5% reduction in the amount of training data. Furthermore, for the second set of experiments with only 50% knowledge injection, although the accuracy of the PKNN model decreased compared to the third set, the total prediction accuracy still improved by 11.4% compared to the sixth set. Moreover, the size of the test samples to be validated for the PKNN model in the third set of experiments (1206 sets) is about 2.5 times larger than that of the ELM model in the sixth set of experiments (482 sets), while its overall error has been reduced by 57.2%, which is evident in the significant improvement of its generalization ability. From the comparison of the prediction results between the sixth and seventh sets of experiments, the proposed PKNN model reduces its overall error by 63.2%, with the total reliability sample size reduced by at least 39.6% while controlling the same occupancy of the training set, further demonstrating the superiority of the proposed model in terms of reliability sample dependency while guaranteeing accuracy.
In addition, we have further compared the third and sixth sets of experiments, which have been verified to have improved prediction accuracy and generalization ability in terms of the efficiency and convergence of the network training optimization. In this paper, for each set of training samples, the input layer of NETWORK1, which describes the S-parameters of the fresh state of the device, has three input neurons, and the input layers of NETWORK2 and NETWORK2’, which describe the amount of degradation of the S-parameters of the device, have five and thirteen input neurons, respectively. The D-ELM structure is a single hidden layer structure with 120 hidden neurons. Therefore, the number of individuals to be optimized in the AGA optimization process is 480 for the population of NETWORK1 and 720 and 1680 for the population of NETWORK2 and NETWORK2’, respectively. The stopping criterion is set to a maximum of 1000 generations. The fitness evolution curve of NETWORK1 during the training iterations is shown in
Figure 10a. The total optimization time is 1956, and its fitness value is optimized by 17.2%. For NETWORK2 using the ELM structure and NETWORK2’ using the PKNN structure, their fitness evolution curves are shown in
Figure 10b,c. The optimized convergence duration is 4939s and 2173s, respectively, and the convergence speed is accelerated by about 56.0%, and their fitness values are optimized by 34.6% and 30.8%, respectively. The results of the above networks in terms of efficiency and convergence of training and optimization are summarized in
Table 4, from which it can also be seen that the overall fitness range of the PKNN aging model for its population during optimization iterations is about three times higher than that of the traditional ELM network. The high superiority of individuals throughout the optimization period further illustrates the advantages of the proposed model in terms of simulation accuracy.
Using the prior knowledge-based AGA-D-ELM network developed above, we predict the
S-parameters of InP DHBT devices in the fresh state and the degradation of the
S-parameters under different stress magnitudes and stress times. A comparison of the simulations of NETWORK1 and the conventional MLP network for the fresh
S-parameters is given in
Figure 11, which further illustrates the accuracy of the predictions of the D-ELM structure. As shown in
Figure 12a and
Figure 13a, we observed the performance of different batches of 0.7 × 13 μm
2 InP DHBT devices under the bias of (
VCE = 1.6 V,
Ib = 200 μA) and subjected to two stress conditions: (
VCB,stress = 3.4 V,
tstress = 250 min) and (
VCB,stress = 4.3 V,
tstress = 310 min). The model predictions of the degradation of the real and imaginary parts of each component of
S-parameters are compared with the corresponding test results using the NETWORK2’ and NETWORK2 trained in the second and third sets of experiments, respectively. In addition, to further complement the predictive effectiveness of the proposed model, we present the simulation results of the model in
Figure 12b and
Figure 13b for the magnitude and phase of the degradation of each
S-parameter component in the Advanced Design System (ADS). The simulation accuracy of NETWORK2’ on the degradation of S-parameters is still able to reach or even be better than that of NETWORK2 after the dependence on reliability training samples is reduced. It can be seen that the proposed PKNN network structure is able to predict the degradation trend of the
S-parameters of the HBT devices after the accelerated aging well, which provides guidance for the establishment of a highly efficient and accurate aging model for microwave devices in practical applications.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}