
A Review of Urdu Sentiment Analysis with Multilingual Perspective: A Case of Urdu and Roman Urdu Language


Abstract
:1. Introduction
1.1. Sentiment Analysis for Product Review
1.2. Research Inspiration
- The customers entered multilingual sentences (in Roman Urdu, pure Urdu, or a combination of both Roman Urdu and English) to express their opinions about any products.
- Countries, such as India and Pakistan, are a vast market for online business, and this business spreads day by day, hence motivating us to perform a study on people’s opinions using languages other than English about some online products.
- Advancement in multilingual sentiments compelled us to perform a comprehensive survey on Roman Urdu and Urdu sentences relating to the product reviews. This goal was achieved by searching the relevant studies, then identifying, summarizing, and evaluating.
1.3. Our Commitments and Contributions
- To discuss the importance of sentiment and multilingual sentiment analysis.
- To discuss various linguistic strategies used in multilingual sentiment analysis, especially in Urdu and Roman Urdu text.
- To evaluate presently available techniques related to multilingual sentiment analysis.
- To identify problems that occur in multilingual sentiments.
- To compare classification techniques used for multilingual sentiments.
- To suggest future work.
1.4. Relation to Previous Work
2. Methodology
2.1. Research Questions
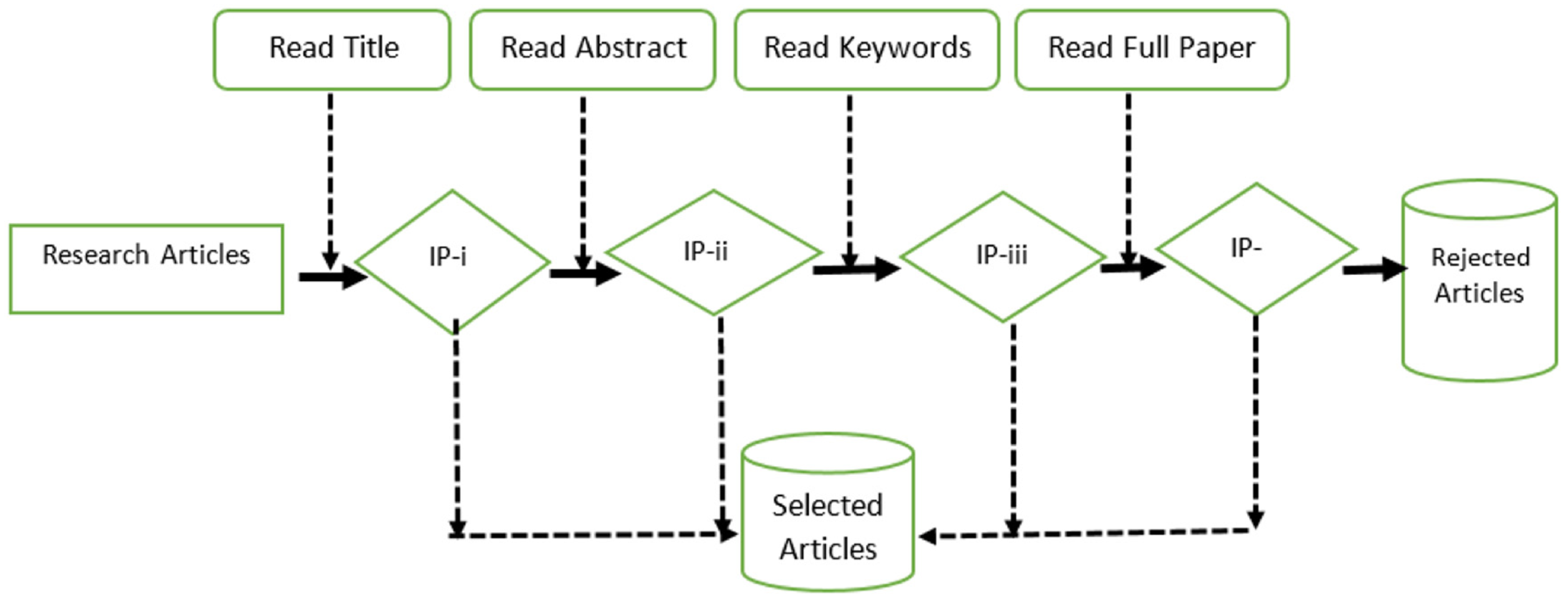
2.2. Technique and Criteria for Acceptance and Rejection
2.3. Study Quality Evaluation
2.4. Survey Execution
2.5. Survey Classification
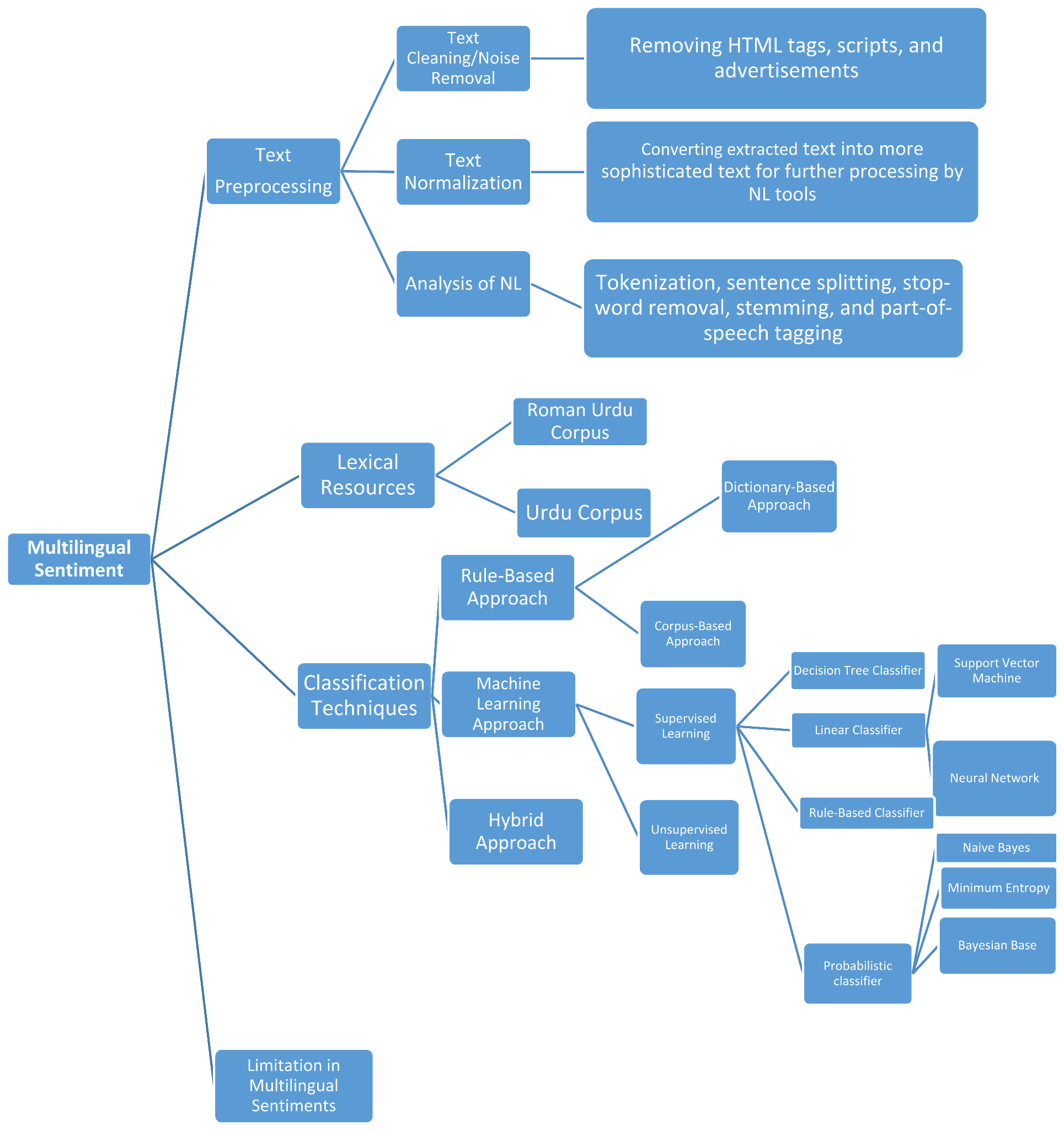
3. Research Question 1
- Text Cleaning/Noise Removal;
- Text Normalization;
- Tokenization and Part-of-Speech Tagging.
3.1. Text Cleaning/Noise Removal
3.2. Normalization
3.3. Analysis of Natural Language
3.3.1. Tokenization
3.3.2. Sentence Splitting
3.3.3. Stop Word Removal
3.3.4. Stemming
4. Research Question 2
4.1. Roman Urdu Corpus
- N-Gram: An n-gram is a contiguous sequence of words from a given text. When the value of n is 1, it refers to uni-grams; when the value of n is 2, it refers to bi-grams. For example, in the sentence, “I live in Pakistan”, the uni-grams are “I”, “live”, “in”, and “Pakistan”, and the bi-grams are “I live”, “live in”, and “in Pakistan”. TF-IDF: A statistical measure to determine the importance of words in a document.
- OneR Attribute: It uses simple association rules to find out only one main attribute involved in the principal prediction component: axes that give the data the maximum variation called principal component.
- Gain Ratio Attribute: It is the ratio of information gain to intrinsic information. The purpose of using this ratio is to reduce bias toward multivalued attributes. Khan and Malik [13] in their study collected sentiments comprised of 2000 automobile reviews in Roman Urdu having equal polarity of positive and negative reviews. One thousand six hundred reviews were used for training the machine, and the remaining 400 were used for testing the accuracy of the models trained via different classifiers.
4.2. Urdu Corpus
4.3. Sentiment Lexicon
4.4. Features for Sentiment Analysis
- (a)
- Word presence and frequency: Individual words or syllable n-grams, along with respective frequency counts, are analyzed in this sort of feature. Sometimes it employs term frequency ratings to highlight the relative importance of features or offers the terms binary weighting. The most commonly n-gram features include uni-gram, bi-gram, and tri gram.
- (b)
- Part of speech tags: These features are also known as language-dependent features. One of the approaches for creating a more particular feature in a document is part of speech (POS). The existence of a grammatical structure, such as adjective or negative, may be identified employing the POS-based feature in a document. The fundamental marker of feeling or opinion in a writing is the adjective and negation.
- (c)
- Words and phrases of opinion: These are terms that are widely used to convey views, such as “excellent” or “awful”, “like” or “dislike”. On the other hand, some sentences offer opinions simply employing opinion words.
- (d)
- Negative terms: The emergence of derogatory words may cause a shift in viewpoint attitude, such as “not good” is comparable to “awful”.
4.5. Feature Extraction Methods
- Lexicon-based approaches;
- Statistical approaches.
5. Research Question 3
- Rule-based/lexicon based approach;
- Dictionarybased approach;
- Corpus-based approach;
- Machine learning approach;
- Hybrid system.
5.1. Rule-Based/Lexicon-Based Approach
5.2. Dictionary-Based Approach
5.3. Corpus-Based Approach
5.4. Machine Learning Approach
- Supervised learning;
- Unsupervised learning.
Supervised Learning
- Decision tree classification;
- Linear classification;
- Neural network-based classification;
- Probabilistic classification.
Decision Tree Classification
Linear Classification
- Support vector machine;
- Neural network.
Probabilistic Classification: Support Vector Machine
- Support vector method performs relatively well because there is a clear gap of separation between classes.
- It is more effective when used in high dimension space. Its performance becomes more effective in cases where several dimensions are more significant than the number of samples.
- Memory is managed more efficiently in this technique.
- SVM does not perform well when the data set is large.
- Noisy data can also affect the performance of SVM.
Neural Network
- Autoencoder;
- Perceptron;
- Multilayer perceptron (MLP);
- Feed forward perceptron;
- Restricted Boltzmann machine;
- Convolutional neural network;
- Recurrent neural network;
- Long short-term memory (LSTM);
- Gated recurrent neural network.
5.5. Hybrid Approach
6. Classification Techniques Used by Various Authors
7. Conclusions
8. Future Work
9. Human and Animal Rights
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Balahur, A.; Turchi, M. Multilingual sentiment analysis using machine translation. In Proceedings of the 3rd Workshop in Computational Approaches to Subjectivity and Sentiment Analysis, Jeju, Korea, 12 July 2012; pp. 52–60. [Google Scholar]
- Denecke, K. Using sentiwordnet for multilingual sentiment analysis. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering Workshop, Cancun, Mexico, 7–12 April 2008; pp. 507–512. [Google Scholar]
- Dashtipour, K.; Poria, S.; Hussain, A.; Cambria, E.; Hawalah, A.Y.; Gelbukh, A.; Zhou, Q. Multilingual sentiment analysis: State of the art and independent comparison of techniques. Cogn. Comput. 2016, 8, 757–771. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bilal, M.; Israr, H.; Shahid, M.; Khan, A. Sentiment classification of Roman-Urdu opinions using Naïve Bayesian, Decision Tree and KNN classification techniques. J. King Saud Univ. Comput. Inf. Sci. 2016, 28, 330–344. [Google Scholar] [CrossRef] [Green Version]
- Ghulam, H.; Zeng, F.; Li, W.; Xiao, Y. Deep learning-based sentiment analysis for roman urdu text. Procedia Comput. Sci. 2019, 147, 131–135. [Google Scholar] [CrossRef]
- Rafique, A.; Malik, M.K.; Nawaz, Z.; Bukhari, F.; Jalbani, A.H. Sentiment analysis for roman urdu. Mehran Univ. Res. J. Eng. Technol. 2019, 38, 463–470. [Google Scholar] [CrossRef]
- Akhtar, M.S.; Kumar, A.; Ekbal, A.; Bhattacharyya, P. A hybrid deep learning architecture for sentiment analysis. In Proceedings of the COLING 2016 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 482–493. [Google Scholar]
- Chhajro, M.; Khuhro, M.; Kumar, K.; Wagan, A.; Umrani, A.; Laghari, A. Multi-text classification of Urdu/Roman using machine learning and natural language preprocessing techniques. Indian J. Sci. Technol. 2020, 13, 1890–1900. [Google Scholar] [CrossRef]
- Nazir, S.; Nawaz, M.; Adnan, A.; Shahzad, S.; Asadi, S. Big data features, applications, and analytics in cardiology—A systematic literature review. IEEE Access. 2019, 7, 143742–143771. [Google Scholar] [CrossRef]
- Nazir, S.; Shahzad, S.; Mukhtar, N. Software birthmark design and estimation: A systematic literature review. Arab. J. Sci. Eng. 2019, 44, 3905–3927. [Google Scholar] [CrossRef]
- Keele, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Version 2.3, EBSE Technical Report, Keele University and Durham University Joint Report; EBSE: Keele, UK, 2007; pp. 1–57. [Google Scholar]
- Alam, M.; Hussain, S. Sequence to sequence networks for Roman-Urdu to Urdu transliteration. In Proceedings of the 2017 International Multi-Topic Conference (INMIC), Lahore, Pakistan, 24–26 November 2017; pp. 1–7. [Google Scholar]
- Khan, M.; Malik, K. Sentiment classification of customer’s reviews about automobiles in roman urdu. In Proceedings of the Future of Information and Communication Conference, Cham, Switzerland, 5–6 April 2018; Springer: Berlin/Heidelberg, Germany; pp. 630–640. [Google Scholar]
- Bose, R.; Aithal, P.; Roy, S. Sentiment Analysis on the Basis of Tweeter Comments of Application of Drugs by Customary Language Toolkit and TextBlob Opinions of Distinct Countries. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 8, 3684–3696. [Google Scholar]
- Khan, K.; Khan, W.; Rehman, A.; Khan, A.; Khan, A. Urdu sentiment analysis. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 646–651. [Google Scholar] [CrossRef]
- Sharf, Z.; Rahman, S.U. Lexical normalization of roman Urdu text. Int. J. Comput. Sci. 2017, 17, 213–221. [Google Scholar]
- Sharf, Z.; Mansoor, H.A. Opinion mining in roman urdu using baseline classifiers. Int. J. Comput. Sci. 2018, 18, 156–164. [Google Scholar]
- Posadas-Durán, J.-P.; Markov, I.; Gómez-Adorno, H.; Sidorov, G.; Batyrshin, I.; Gelbukh, A.; Pichardo-Lagunas, O. Syntactic n-grams as features for the author profiling task. In Proceedings of the CEUR Workshop, 2015 Working Notes Papers of the CLEF, Toulouse, France, 8–11 September 2015. [Google Scholar]
- Chikersal, P.; Poria, S.; Cambria, E. SeNTU: Sentiment analysis of tweets by combining a rule-based classifier with supervised learning. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 647–651. [Google Scholar]
- Rajagopal, D.; Cambria, E.; Olsher, D.; Kwok, K. A graph-based approach to commonsense concept extraction and semantic similarity detection. In Proceedings of the 22nd International Conference on World Wide Web Companion, Rio de Janeiro, Brazil, 13–17 May 2013; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2013; pp. 565–570. [Google Scholar]
- Ravi, K.; Ravi, V. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl. Based Syst. 2015, 89, 14–46. [Google Scholar] [CrossRef]
- Mehmood, K.; Essam, D.; Shafi, K.; Malik, M.K. Sentiment analysis for a resource poor language—Roman Urdu. ACM Trans. Asian Low-Resour. Lang. Inf. Process (TALLIP) 2019, 19, 54. [Google Scholar] [CrossRef]
- Mehmood, K.; Essam, D.; Shafi, K.; Malik, M.K. Discriminative feature spamming technique for roman urdu sentiment analysis. IEEE Access. 2019, 7, 47991–48002. [Google Scholar] [CrossRef]
- Manzoor, M.A.; Mamoon, S.; Tao, S.K.; Zakir, A.; Adil, M.; Lu, J. Lexical Variation and Sentiment Analysis of Roman Urdu Sentences with Deep Neural Networks. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 719–726. [Google Scholar] [CrossRef]
- Mehmood, K.; Essam, D.; Shafi, K. Sentiment analysis system for Roman Urdu. In Science and Information Conference; Springer: Cham, Switzerland, 2018; pp. 29–42. [Google Scholar]
- Iqbal, F.; Ayoub, A.; Manzoor, J.; Basit, R.H. Bilingual Sentiment Analysis of Tweets Using Lexicon. In Proceedings of the 7th International Conference on Language and Technology, UET, Lahore, Pakistan, 15–16 February 2020; pp. 71–78. [Google Scholar]
- Sharjeel, M.; Nawab, R.M.A.; Rayson, P. COUNTER: Corpus of Urdu news text reuse. Lang. Resour. Eval. 2017, 51, 777–803. [Google Scholar] [CrossRef] [Green Version]
- Akhter, M.P.; Jiangbin, Z.; Naqvi, I.R.; Abdelmajeed, M.; Sadiq, M.T. Automatic detection of offensive language for urdu and roman urdu. IEEE Access. 2020, 8, 91213–91226. [Google Scholar] [CrossRef]
- Hashim, F.; Khan, M. Sentence level sentiment analysis using urdu nouns. In Proceedings of the 6th International Conference Conference on Language &Technology 2016; UET, Lahore, Paksitan, 17–18 November 2016; pp. 101–108. [Google Scholar]
- Dzakiyullah, N.R.; Hussin, B.; Saleh, C.; Handani, A.M. Comparison neural network and support vector machine for production quantity prediction. Adv. Sci. Lett. 2014, 20, 2129–2133. [Google Scholar] [CrossRef]
- Naz, F.; Anwar, W.; Bajwa, U.I.; Munir, E.U. Urdu part of speech tagging using transformation based error driven learning. World Appl. Sci. J. 2012, 16, 437–448. [Google Scholar]
- Qiu, G.; Liu, B.; Bu, J.; Chen, C. Opinion word expansion and target extraction through double propagation. Comput. Linguist. 2011, 37, 9–27. [Google Scholar] [CrossRef]
- Altınel, B.; Ganiz, M.C. Semantic text classification: A survey of past and recent advances. Inf. Process. Manag. 2018, 54, 1129–1153. [Google Scholar] [CrossRef]
- Sharma, H.; Kumar, S. A survey on decision tree algorithms of classification in data mining. Int. J. Sci. Res. 2016, 5, 2094–2097. [Google Scholar]
- Yang, H.; Fong, S. Optimized very fast decision tree with balanced classification accuracy and compact tree size. In Proceedings of the 3rd International Conference on Data Mining and Intelligent Information Technology Applications, Vienna, Austria, 29–31 August 2014; pp. 57–64. [Google Scholar]
- El-Masri, M.; Altrabsheh, N.; Mansour, H. Successes and challenges of Arabic sentiment analysis research: A literature review. Soc. Netw. Anal. Min. 2017, 7, 1–22. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Dorle, S.; Pise, N.N. Sentiment Analysis Methods and Approach: Survey. Int. J. Innov. Comput. Sci. Eng. 2017, 4, 7–11. [Google Scholar]
- Routray, P.; Swain, C.K.; Mishra, S.P. A survey on sentiment analysis. Int. J. Comput. Appl. 2013, 76, 1–8. [Google Scholar] [CrossRef]
- Hasan, M.; Ullah, S.; Khan, M.J.; Khurshid, K. Comparative Analysis of SVM, ANN and CNN For Classifying Vegetation Species Using Hyperspectral Thermal Infrared Data. Remote. Sens. Spat. Inf. Sci. 2019, XLII-2/W13, 1861–1868. [Google Scholar] [CrossRef] [Green Version]
- Syed, A.Z.; Aslam, M.; Martinez-Enriquez, A.M. Lexicon based sentiment analysis of Urdu text using SentiUnits. In Mexican International Conference on Artificial Intelligence, Pachuca, Mexico, 8–13 November 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 32–43. [Google Scholar]
- Naqvi, U.; Majid, A.; Abbas, S.A. UTSA: Urdu Text Sentiment Analysis Using Deep Learning Methods. IEEE Access 2021, 9, 114085–114094. [Google Scholar] [CrossRef]
- Suri, N.; Verma, T. Multilingual Sentimental Analysis on Twitter Dataset: A Review. Int. J. Adv. Comput. Sci. Appl. 2017, 10, 2789–2799. [Google Scholar]
- Raza, A.A.; Habib, A.; Ashraf, J.; Javed, M. A review on Urdu language parsing. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 93–97. [Google Scholar]
- Abbas, Q. Morphologically rich Urdu grammar parsing using Earley algorithm. Nat. Lang. Eng. 2016, 22, 775–810. [Google Scholar] [CrossRef] [Green Version]
- Shah, M.S. A research paper on product review based on geographic location using SVM approach in twitter. Int. Educ. Res. J. 2017, 3, 690–692. [Google Scholar]
- Daud, M.; Khan, R.; Daud, A. Roman Urdu opinion mining system (RUOMiS). arXiv 2015, arXiv:1501.01386. [Google Scholar] [CrossRef]
- Mehmood, F.; Ghani, M.U.; Ibrahim, M.A.; Shahzadi, R.; Mahmood, W.; Asim, M.N. A precisely xtreme-multi channel hybrid approach for roman urdu sentiment analysis. IEEE Access 2020, 8, 192740–192759. [Google Scholar] [CrossRef]
- Khattak, A.; Asghar, M.Z.; Saeed, A.; Hameed, I.A.; Hassan, S.A.; Ahmad, S. A survey on sentiment analysis in Urdu: A resource-poor language. Egypt. Inform. J. 2021, 22, 53–74. [Google Scholar] [CrossRef]
- Shakeel Ahmad, Y.D.A.-O. Applying IoT for Sentiment Classification and Tone Analysis of Urdu Tweets. Int. J. Comput. Sci. Netw. Secur. 2019, 19, 166–173. [Google Scholar]
- Khan, W.; Daud, A.; Khan, K.; Nasir, J.A.; Basheri, M.; Aljohani, N.; Alotaibi, F.S. Part of speech tagging in urdu: Comparison of machine and deep learning approaches. IEEE Access 2019, 7, 38918–38936. [Google Scholar] [CrossRef]
- Latiffi, M.I.A.; Yaakub, M.R. Sentiment analysis: An enhancement of ontological-based using hybrid machine learning techniques. Asian J. Inf. Technol. 2018, 7, 61–69. [Google Scholar] [CrossRef]
- Mukhtar, N.; Khan, M.A. Effective lexicon-based approach for Urdu sentiment analysis. Artif. Intell. Rev. 2020, 53, 2521–2548. [Google Scholar] [CrossRef]
- Soni, V.; Patel, M.R. Unsupervised opinion mining from text reviews using SentiWordNet. Int. J. Comput. Trends Technol. 2014, 11, 234–238. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quality Assessment Criteria | Research Questions | Sample Studies | Remarks | |||||
|---|---|---|---|---|---|---|---|---|
| S1 Chhajro et al. [8] | S2 Dashtipour et al. [3] | S3 Bilal et al. [4] | S4 Ghulam et al. [5] | S5 Rafique et al. [6] | S6 Akhtar et al. [7] | |||
| QA1 | The article provided details about preprocessing technique(s) used for multilingual (Urdu and Roman Urdu) sentiments. | 1 | 1 | 1 | 0 | 0.5 | 1 | S4 explained no preprocessing techniques in their research. S5 partially defined it. |
| QA2 | The article provided details of feature extraction techniques used for multilingual sentiment analysis. | 1 | 1 | 0.5 | 0.5 | 0.5 | 1 | S3, S4, and S5 partially discussed feature extraction techniques in their research articles. |
| QA3 | The article provided a classification technique for multilingual sentiments especially for Roman Urdu and Urdu using some classifiers. | 1 | 1 | 1 | 1 | 1 | 1 | All researchers used one or more classification techniques along with proper plate form. |
| QA4 | The article gave enough relevant data to evaluate multilingual sentiments. | 0.5 | 0 | 0.5 | 0.5 | 0.5 | 1 | S2 did not have its own data set; similarly, S1, S3, S4, and S5 consisted of limited data sets. Only S6 contained enough data. |
| Summation (out of 4) Normalized score (0–1) | 3.5 | 3 | 3 | 2.5 | 2.5 | 4.0 | ||
| 0.88 | 0.75 | 0.75 | 0.63 | 0.63 | 1.0 | |||
| Study No | Study | Objective(s) | Techniques Utilized | Data Set/Source | Results | Future Work and Limitations |
|---|---|---|---|---|---|---|
| 1 | Syed et al. [41] | Text preprocessing subjectivity classification Sentiment classification on Urdu text | Space insertion and space deletion Document-level classification Lexicon-based subjectivity analysis | 450 user reviews of the movies | Average of 69% F-measure on all corpus | Extension of annotated lexicon Noun phrases consideration No mechanism for handling implicit negation |
| 2 | Bilal et al. [4] | Text preprocessing Subjectivity classification Sentiment classification Comparison of three different classifiers on Roman Urdu | Sentiment classification of Roman Urdu opinions Compression of naïve Bayesian, decision tree, and KNN classification techniques | 300 sentiments, out of which 150 were positive and 150 were negative | 97.33% accuracy shown by naïve Bayesian over other classifiers | Classifier checked on limited data sets Require checking on more processed and normalized large data sets |
| 3 | Ghulam et al. [5] | Application of long short-term memory model on selected Roman Urdu text | Deep learning technique LSTM for checking Roman Urdu sentences for polarity | 300 sentences of Roman Urdu | 95.18% accuracy with 97% precision Recall 92% and F1 score 94%, as compared to machine learning techniques, such as NB, RF, and SVM | Preprocessing techniques not mentioned Significantly less information regarding collection of data Methodology was not transparent in terms of data applied |
| 4 | Alam and ul Hussain [12] | Develop a deep learning classifier for Roman Urdu sentences using LSTM technique | Complete data were randomly shuffled and divided into a train (75%) and test set (25%) For seq2seq architecture, three-layer LSTMs were chosen, and maximum sequence length was set to 15 | 0.113 million Roman Urdu sentences | 50.68 and 48.6% on evaluation metric BLEU | In future, more data sets to be collected for checking their accuracy in Roman Urdu |
| 5 | Rafique et al. [6] | Develop a classifier for Roman Urdu sentiments using different features using machine learning algorithms | Collection of Roman Urdu sentiments from various online sources Preprocessing Comparison of different classifiers over Roman Urdu text Construction of eight features, such as uni-gram, TF, IDF, bi-gram, etc. Application of three multilingual classifiers over eight features | 806 different Roman Urdu sentiments were collected from other websites, out of which 406 were negative and 400 were positive | SVM gives the best results on the features uni-gram + bi-gram + TFID Accuracy = 87.22% | Data set was limited No proper arrangement of data set Use of deep learning for Roman Urdu included in their future plan |
| 6 | Sharf and Rahman [16] | Development of lexical normalization techniques for Roman Urdu Comparison of different lexical normalization techniques used for different languages | Developed an algorithm for Romanizing Urdu Lexicon-based approach Rule-based approach Machine learning and phonetic algorithms | Approximately 300,000 tweets of Roman Urdu collected from various websites | Lexical normalization results depended on the number of the tweet’s success rate of the phonetic algorithm Biography shows 91% success rate | The initial stage work focused on the normalization of the Roman Urdu text Data collected only from some specific categories The central part of the data consisted of a paragraph Moving towards deep learning is a future plan |
| 7 | Sharf and Mansoor [17] | Roman Urdu discourse development Parsing and tagging Roman Urdu data sets | Calculation of precision, recall, and F1 scores over several sentences with discourse Calculation of success rate of false negative and false positive | 15,000 sentences of Roman Urdu from Twitter, Reddit, Urdu poetry, and social worker biographies | The high value of the F1 score was obtained from the majority of data sets with discourse | Roman Urdu data collection is a challenging task The majority of sentences collected related to biographies but not general In the future, they plan to use neural network for the Roman Urdu data set to get more accuracy |
| 8 | Naqvi et al. [42] | Roman Urdu data collection Comparing nine popular classification methods over Roman Urdu sentiments Development of unique algorithms with the combination of the above classifiers | Calculation of precision, recall, and F score and accuracy of multipoint NB, SGD classifiers, and linear SVC for supervised learning, and k-nearest neighbor for unsupervised learning | 22,000 sentiments of Roman Urdu collected, out of which 4500 were labeled positive, 4900 negative, and 13,000 sets as neutral | The best result was obtained from SVM with F1 score accuracy of up to 81% Worst result computed from a decision tree with F1 value of 38% | The combination of nine classifiers made ambiguity in the system More accurate results may be obtained using deep learning techniques with Roman Urdu |
| 9 | Sharjeel et al. [27] | Roman Urdu corpus-based study Development of corpus of Urdu news text reuse Linguistic analysis of corpus | Corpus of Urdu News text reuse (counter) using three annotators: wholly derived, partially derived, and non-derived | 1200 documents collected from various news sites | Naïve Bayes on classification reported F1 results on COUNTER corpus for the binary and ternary classification using word grams to overlap others | Planning to use character n-grams Corpus will be evaluated on another state-of-the-art semantics for the Urdu language |
| 10 | Khan and Malik [13] | Collect customer reviews about automobiles in Roman Urdu Preprocessing Assign subjectivity | WEKA classifier on data sets Multinomial naïve Bayes performed best among other classifiers in terms of precision, recall, F-measure, and accuracy | 2000 automobile reviews in Roman Urdu, out of which 1000 were positive and 1000 were negative | 89.75% accuracy on multinomial naïve Bayes | Enhance the study on a specific area of the Internet, for example, the engine of an automobile Multicase sentiment classification required to count neutral sentiment |
| 11 | Dzakiyullah et al. [30] | Explore the unique features in Urdu text Collection of data Preprocessing Polarity identification | Compared the various algorithms based on already given values | Not mentioned | Only provided the review of previous work done on Urdu sentiments | Introductory level paper related to pure Urdu text Missing classifier Data set missing |
| 12 | Bose et al. [14] | Preprocessing Classification of unstructured data Customer product reviews of the six most popular products on Amazon | AFINN, ANEW, EMDEX, Lab Mat, and SentiWordNet with lexical classifier | 568,454 number of sentiments related to fine food from Amazon web server collected from October 1999 to October 2012 | Not mentioned | Data showed some graphs, but their style was confusing There was no proper table that showed the results |
| 13 | Naz et al. [31] | Part-of-speech tagging Urdu part-of-speech tagging Different approaches for part-of-speech tagging | Brill’s transformation-based learning (TBL) | 4323 Urdu sentences having 123,775 tokens from CRULP | Brill transformation approach outperforms uni-gram and bi-gram with a backoff method with 90% training fraction and keeping corpus size of 32,133 number of tokens 100% precision, 95% recall, and 94.435% F-measure obtained | Results depended on corpus fraction and also on the size of the corpus |
| 14 | Suri et al. [43] | Comparison of various approaches for multilingual sentiment analysis for Twitter database Apache Hadoop MapReduce | Comparison of various classifiers over Hadoop MapReduce | Twitter data set, 1000 Facebook posts, Amazon customer reviews on products | Results showed that Twitter is beneficial in the prediction of items, product sales, and quality of services, etc. | Each classifier showed some limitations concerning the data set available Preprocessing played a vital role in data accuracy |
| 15 | Raza et al. [44] | Urdu parsing Top-down and bottom-up parsing techniques Preprocessing Normalization | Phrase structure Parsing on Urdu text | 2850 sentences | 74.48% | Lack of using their own data sets Survey type paper No clear suggestion for improving the process of parsing |
| 16 | Abbas [45] | Urdu parser development Obtain the morphological rich, context-free grammar | URDU.KON-TB tree-bank, tree-bank parser | 1400 annotated sentences | 87% F-score, which outperformed exiting parsing work of Urdu on tree-banking approach | Very impressive working regarding generating Urdu parser using URDU.KON-TB tree-bank |
| 17 | Shah [46] | Collection of tweets Preprocessing Feature extraction Product review extraction | Support vector machine with KNN | 2477 words and phrases from Twitter using search AI | Accuracy rate 93.33% | Other classifiers were required to check the data |
| 18 | Daud et al. [47] | Roman Urdu opinion mining system (ruomis) | Ruomis system consists of crawling of site, translating Roman Urdu reviews into English language, identifying the opinion polarity, and giving rating in graphical form | 1620 comments Roman Urdu on three different mobile phones were collected and labeled as positive, negative, or neutral | Precision 27.1%, recall 100%, and F1 score 42.7% | Although results were not very satisfactory, their efforts for translating Roman Urdu text into English format were appreciable More work required in preprocessing and authors are interested in creating semantic dictionary in future |
| 19 | Mehmood et al. [48] | A precisely extreme multichannel hybrid approach for Roman Urdu sentiment analysis | Hybrid approach by combining machine learning (SVM, LR, and NB) along with deep learning approaches (CNN and RNN) | Data set consisted of 3241 mobile-related Roman Urdu sentences collected through website WhatMobile.com | 84% accuracy, 81.68% precision, 82.84% recall 82.21% F1 | In future, their focus is to apply generated neural word embedding for other natural language processing tasks, such as cyberbullying detection and machine translation |
| 20 | Hasan et al. [40] | Opinion within opinion: Segmentation approach for Urdu sentiment analysis | SEGMODEL (segmentation model) | Two data sets: D1 = 443 product reviews of cars and cosmetic products D2 = 401 product reviews of an electronic device | 75% accuracy obtained from an average of both D1 and D2 | |
| 21 | Akhter et al. [28] | To explore the offensive language in Urdu and Roman Urdu script Data set preparation Feature selection in classification models | Uni-gram, bi-gram, and tri-gram Combination of Urdu and Roman Urdu sentences Machine learning models of Bayes, tree, rule-based, KNN | 2171 Urdu sentences and 10,000 Roman Urdu sentences | Comparison of 17 models from seven machine learning techniques to process and detect offensive language | |
| 22 | Khattak et al. [49] | Finding all the related work for resource-poor Urdu language in text processing, corpus, and sentiment lexicon Comparison and evaluation of different preprocessing techniques used for Urdu language | Qualitative and quantitative evaluation approach to compare the various articles in Urdu language | Researcher data sets used in various research papers | LSTM technique of deep learning outperformed the other approaches to get the best accuracy for Urdu sentiment analysis | Urdu idioms and proverbs need to be addressed correctly A comprehensive Urdu dictionary is required for obtaining the best results |
| 23 | Iqbal et al. [26] | Data collection of Roman Urdu tweets Data preprocessing Translation and labeling of Urdu tweets Normalization and tokenization of tweets | Lexicon-based approach on sentence-level classification | A total of 2673 positive, 1923 negative, and 426 neutral tweets were collected | In the approach presented here, the accuracy of 98% for positive class, 94% for negative class, and 96% for a neutral class was achieved with a data set containing 4177 tweets | Authors aim to build their own lexicon, making it more generic and applying the proposed approach to a larger data set for further validation |
| 24 | Shakeel Ahmad [50] | Develop the Internet of Things-based classification model used for Urdu sentiment analysis Presented Urdu tweet crawling framework used for crawling Urdu tweets from Twitter in real time | Acquiring Urdu tweets in real-time using Twython Cleaning Urdu tweets using tweet preprocessor API Sentiment classification of Urdu text using IBM Watson’s IoT-based natural language understanding toolkit | 10126 number of Urdu tweets using Twython (https://twython.readthedocs.io/en/lates/, accessed on 15 August 2021) | Proposed Urdu tone analysis system IoT-based showed up to 92%, which outperformed all other techniques, such as SVM, KNN, RF, and naïve Bayesian classifiers | In future, emojis and slang terms will be included, which may enhance the system’s overall performance |
| 25 | Mehmood et al. [22] | Developing a large Roman Urdu corpus Identifying (a) word-level features, (b) character-level features, and (c) feature union (word + character level). Applying classification algorithms | Proposed a confidence-based voting technique for Roman Urdu sentiment analysis called Word Voting or wVoting, a machine learning algorithm | 11,000 reviews in Roman Urdu collected from six different domains | wVoting outperformed all other techniques, such as LR, NB, and ANN, and wVoting had an accuracy rate of 82.16% | Roman Urdu sentiment analysis is a challenging task because of the variety of writing styles Research should be continued to obtain more fruitful results using more normalized words |
| 26 | Mehmood et al. [25] | Collection of Roma Urdu corpus Preprocessing Feature selection Appling novel type technique for analysis of Roman Urdu Comparison of various results with various features | wVoting, which used discriminative feature spamming (DSFT) for Roman Urdu sentiment | 11,000 reviews in Roman Urdu collected from six different domains | wVoting with discriminative feature spamming (DSFT) outperformed all other techniques, such as LR, NB, and ANN, and wVoting had accuracy rate of 83.95% | |
| 27 | Mehmood et al. [23] | Data Preprocessing Uni-gram and bi-gram feature selection application of five algorithms for feature reduction Computing of accuracy by applying the five algorithms | Naïve Bayes, logistic regression, support vector machine (SVM), k-nearest neighbors (KNN), decision tree (DT) | Data set consisted of 779 reviews, out of which 412 were positive and 367 were negative | Results showed high accuracy of naïve Bayesian classifier with average of 67.58% In second linear regression, showed average accuracy of 66.17% | |
| 28 | Manzoor et al. [24] | Preprocessing Normalization Creation of lexical variation of Roman Urdu table for normalization of Roman Urdu words | Self-attention biLSTM deep learning technique | Collected 20,000 sentences, out of which 10,000 Roman Urdu sentences (negative and positive reviews) were processed, and more than 3000 sentences were normalized | Accuracy on preprocessed data was obtained = 68.4% Accuracy on normalized data was obtained = 69.3% | They tried to enhance the efficiency of SA biLSTM and bring it to use for language inference and generation tasks and vocabulary |
| 29 | Hashim and Khan [29] | Sentence-level sentiment analysis using Urdu nouns Sentence boundary identification Urdu corpus creation and data cleaning Part-of-speech tagging | Sentence-level lexicon-based classifications | 1000 Urdu opinions were collected from various online sources related to politics, current affairs, sport, health, and entertainment | 86.8% accuracy was counted from the given Urdu text using sentence-level, lexicon-based classifier | This research focused only on subjective nouns of news articles In the future, their focus is to analyze products and movie reviews |
| 30 | Akhtar et al. [7] | Develop a hybrid approach to use for resource-poor languages, such as Roman Urdu, Hindi, and Urdu | Hybrid that combined both the features of machine learning and deep learning (SVM + CNN) | More than 13,000 views collected from various online sites and Twitter Hindi | Results showed accuracy up to 74% in some cases when used with proposed approach | It worked only for aspect-based sentiment classification In future, they will work on aspect term extraction |
| 31 | Chhajro et al. [8] | Classification of Roman Urdu and Urdu news text using natural language processing and machine learning classification model | KNN, linear SVM logistic regression, naïve Bayes classifier, and random forest classifier | Collection of 10,500 new texts in Urdu and Roman Urdu language | Linear SVM outperformed other classifiers with accuracy of 96.1% | In future, they will extend their work to other categories of Roman Urdu and Urdu news data |
| 32 | Khan et al. [51] | Comparison made on machine learning and deep learning approaches for part-of-speech tagging in Urdu using language-independent features set | CRF (conditional random field) model, SVM (support vector machine), DRNN (deep recurrent neural network), HMM (hidden Markov model) DRNN model also included LSTM-RNN and LSTM-RNN with CRF output | CLE (Centre of Language Engineering) data set and Bushra Jawaid data set | In CLE data set CRF model gave more accurate result than other models and the accuracy of this model was 83.52. In Bushra Jawaid Data set LSTM-RNN has more accurate result and its accuracy was 88.7 | Their planning is to propose such a sophisticated deep learning based Urdu POS tagging system which will base on semi-supervised learning |
| 33 | Latiffi et al. [52] | Enhance the ontology-based approach Combination of ontology based on formal concept analysis (FCA) | Combination of ontology based on formal concept analysis (FCA), a process of obtaining a formal ontology or a concept hierarchy from a group of objects with their properties and k-nearest neighbor (KNN) to classify the reviews | Technique applied on English language data sets; however, it can also be used for other languages | Authors believe that this technique is the most suitable for all type of sentiment analysis | They expect to refine and investigate for implied sentiment classification |
| 34 | Mukhtar et al. [53] | Developed a lexicon-based model for analysis of Urdu sentiments using adjectives, nouns, and negations, as well as verbs, intensifiers, and context-dependent words | Made new Urdu lexicon and applied this approach to find accuracy, F-measure, precision, and recall | A total of 6025 sentences were collected from 151 various Urdu blogs | 89.03% accuracy with 86% precision, 90% recall, and 88% F-measure obtained from the model | They will extend the lexicon by adding more words and also considering adverbs |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, I.U.; Khan, A.; Khan, W.; Su’ud, M.M.; Alam, M.M.; Subhan, F.; Asghar, M.Z. A Review of Urdu Sentiment Analysis with Multilingual Perspective: A Case of Urdu and Roman Urdu Language. Computers 2022, 11, 3. https://doi.org/10.3390/computers11010003
Khan IU, Khan A, Khan W, Su’ud MM, Alam MM, Subhan F, Asghar MZ. A Review of Urdu Sentiment Analysis with Multilingual Perspective: A Case of Urdu and Roman Urdu Language. Computers. 2022; 11(1):3. https://doi.org/10.3390/computers11010003
Chicago/Turabian StyleKhan, Ihsan Ullah, Aurangzeb Khan, Wahab Khan, Mazliham Mohd Su’ud, Muhammad Mansoor Alam, Fazli Subhan, and Muhammad Zubair Asghar. 2022. "A Review of Urdu Sentiment Analysis with Multilingual Perspective: A Case of Urdu and Roman Urdu Language" Computers 11, no. 1: 3. https://doi.org/10.3390/computers11010003