



Cognitive Classifier of Hand Gesture Images for Automated Sign Language Recognition: Soft Robot Assistance Based on Neutrosophic Markov Chain Paradigm


Abstract
1. Introduction
1.1. Motivation
1.2. Contribution and Novelty
2. State of the Art
The Need to Extend the Related Work
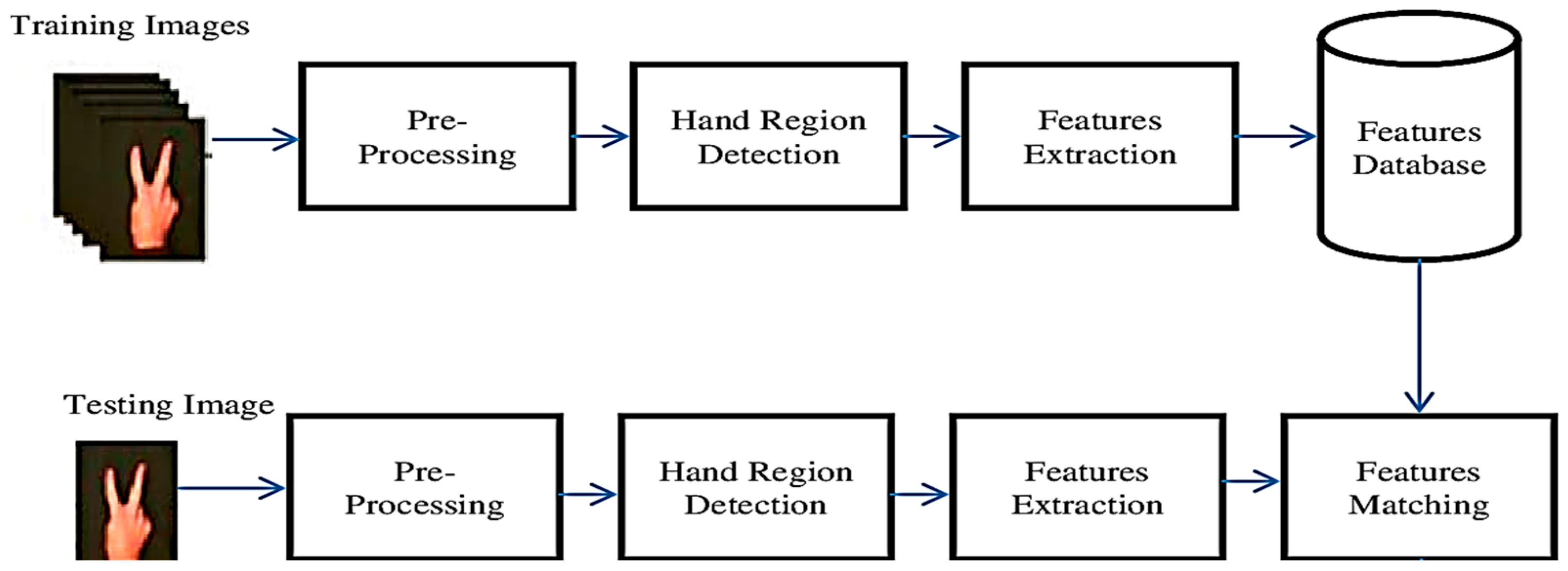
3. Methodology
3.1. Hand Detection
3.2. Feature Extraction
3.3. Neutrosophic Hidden Markov Model
- -
- Neutrosophic Representation of Gestures: Represent different possible gesture states using neutrosophic sets. Each state could have associated truth-membership, indeterminacy-membership, and false-membership values, capturing the uncertainty in recognizing a particular gesture. For observations, capture the uncertainty in detecting and interpreting individual features or components of gestures using neutrosophic sets. This accounts for variations in the observed data due to noise or imprecision.
- -
- Neutrosophic Transition Probabilities: Define the transition probabilities between neutrosophic gesture states. These transition probabilities should reflect the uncertainty in transitioning from one gesture state to another. For example, transitioning from a “hand raised” state to a “hand lowered” state may have some indeterminacy due to variations in the gesture execution.
- -
- Neutrosophic Emission Probabilities: Associate neutrosophic emission probabilities with each gesture state. These probabilities represent the likelihood of observing specific features or components given the current gesture state. Again, this accounts for uncertainty in the observed data.
- -
- Learning and Inference: Train the NHMM using a dataset of neutrosophic represented gestures. Learning involves estimating the neutrosophic parameters, such as transition and emission probabilities, from the training data. During inference, the NHMM can be used to recognize and classify new gestures. The model considers the uncertainty associated with each aspect of the gesture and provides a more nuanced understanding of the gesture recognition process.
- A.
- Training phase
- Initialization: initialize the parameters of the NHMM, including initial state neutrosophic measures π, transition neutrosophic measures A, and emission neutrosophic measures B.
- Forward Pass (Forward Algorithm): Compute the forward neutrosophic probabilities using the current model parameters. This involves propagating the neutrosophic measures through the states and time steps of the NHMM.
- Backward Pass (Backward Algorithm): Compute the backward neutrosophic probabilities, representing the probability of observing the remaining sequence given the current state of neutrosophic measures at a specific time.
- Expectation Step: Use the forward and backward neutrosophic probabilities to compute the expected number of transitions and emissions for each state. This step involves calculating the expected neutrosophic counts based on the current model parameters.
- Maximization Step: Update the model parameters (transition neutrosophic measures, emission neutrosophic measures) using the expected counts obtained in the expectation step. This step involves maximizing the likelihood of the neutrosophic observed data given the model.
- Iterative Refinement: Repeat steps 2–5 until convergence or until a specified number of iterations is reached. Convergence can be determined by monitoring the change in the neutrosophic log-likelihood between iterations.
- Final Model: The final model parameters obtained after convergence represent the trained neutrosophic HMM.
- B.
- Recognition phase
- Initialization: Initialize the Viterbi matrix to store the partial probabilities of the most likely sequence up to each state for each time step. Initialize the back pointer matrix to keep track of the path leading to the most likely sequence. Initialize the first column of the Viterbi matrix based on the neutrosophic emission probabilities and the initial probabilities of each neutrosophic state.
- Recursion: For each subsequent time step, calculate the partial probabilities in the Viterbi matrix based on the neutrosophic transition probabilities and the neutrosophic emission probabilities. Use the recursive formula that incorporates the truth, indeterminacy, and false memberships in the calculation.
- Backtracking: Update the back pointer matrix as the algorithm progresses, keeping track of the most likely path leading to each state.
- Termination: Once the entire sequence has been processed, find the final state with the highest probability in the last column of the Viterbi matrix. This state represents the most likely ending state of the sequence. Use the back pointer matrix to backtrack from the final state to the initial state, reconstructing the most likely sequence of neutrosophic states. The formal definition of the Viterbi recursion is as follows:
- -
- Initialization:
- -
- Recursion:
- -
- Termination:is the previous Viterbi path probability from the previous time step, is the transition probability from the previous state to the current state , and is the state observation likelihood of the observation symbol given the current state j [68,69]. The pseudocode of the suggested model is summarized in Algorithm 1.
| Algorithm 1: Neutrosophic HMM-based hand gesture recognition system | ||
| Step 1: Data Preprocessing # Extract features from hand gesture images Def extract_features (gesture images): # Implement feature extraction technique Features = [] For img in gesture_images: Feature = SVD_extract_feature_from_image (img) Features. Append (feature) Return features Step 2: Neutrosophic HMM Training Initialize: - Define the number of states (N) and observations (M). - Initialize neutrosophic parameters (truth, indeterminacy, falsity) for - Transition and emission probabilities. - Initialize initial state probabilities using neutrosophic parameters. Training (Baum–Welch Algorithm): { 1. Initialize transition and emission probability matrices with random neutrosophic parameters. 2. Repeat until convergence { | ||
| a. Forward pass: Compute the forward probabilities using neutrosophic arithmetic. | ||
| # Neutrosophic arithmetic would be employed for operations involving neutrosophic parameters, such as addition, multiplication, and comparison | ||
| b. Backward pass: Compute the backward probabilities using neutrosophic arithmetic. | ||
| c. Update transition and emission probabilities using neutrosophic arithmetic. | ||
| } Inference (Viterbi Algorithm): { 1. Given an observation sequence O (O = Features), initialize the Viterbi matrix and back pointer matrix. 2. For each observation in O { a. Update the Viterbi matrix using neutrosophic arithmetic. b. Update back pointer matrix. } 3. Terminate: Find the most likely sequence of states using backtracking. | ||
4. Results and Discussions
- -
- OpenCV is a popular Python library for computer vision tasks. It provides functionalities for image and video processing, including hand detection and tracking. OpenCV can be used for tasks such as contour detection, hand segmentation, and gesture recognition.
- -
- Scikit-learn: Scikit-learn is a widely used machine learning library in Python. It provides a high-level interface for various machine learning algorithms, including dimensionality reduction techniques such as Principal Component Analysis (PCA) and Truncated SVD (a variant of SVD). The Truncated SVD class in scikit-learn allows for an SVD-based feature extraction that is suitable for large datasets.
- -
- Gesture Recognition Toolkit (GRT): GRT is a C++ library with Python bindings that provides tools for real-time gesture recognition. It offers algorithms for feature extraction, classification, and gesture spotting, making it suitable for building gesture recognition systems.
- -
- NumPy: This is a fundamental package for Python numerical computing. It provides support for multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays.
- -
- SciPy offers a wide range of numerical algorithms and mathematical functions that are not available in NumPy, including optimization, interpolation, integration, signal processing, and statistical functions. It provides high-level interfaces to optimize and integrate numerical algorithms efficiently, making it suitable for various scientific and engineering applications.
- -
- While specific Python libraries or packages dedicated to NHMMs may not be readily available, we can leverage general-purpose libraries for probabilistic modeling and machine learning (such as NumPy, SciPy, and scikit-learn) to implement the NHMMs functionalities.
- -
- Traditional classifiers aim to find deterministic decision boundaries that separate different classes in the feature space. This approach may not adequately capture uncertainty when there are overlapping regions between classes or the decision boundary is ambiguous due to variations in hand signs.
- -
- Traditional classifiers typically assign a single class label to each input instance based on its feature representation. This binary decision-making process does not provide information about the confidence or uncertainty associated with the assigned class label, making it challenging to assess the reliability of classification results.
- -
- Traditional classifiers often make simplifying assumptions about data distribution and may not explicitly model uncertainty in their classification process. This can lead to suboptimal performance, especially when dealing with ambiguous or uncertain hand signs.
- -
- Hand signs in sign language can be inherently ambiguous, with similar hand configurations or movements representing multiple meanings depending on context or subtle variations. Traditional classifiers may struggle to disambiguate between such signs and accurately assign class labels in uncertain scenarios.
4.1. Model’s Computational Complexity
- -
- The complexity of the preprocessing step in hand gesture recognition can be influenced by the specific combination of preprocessing techniques that is used and the size of the input images. In many cases, the preprocessing step has a linear or near-linear time complexity with respect to the number of pixels in the input image with complexity ), where is the number of pixels in the image.
- -
- The complexity of the feature extraction step based on SVD depends on the size of the input data and the desired number of features to be extracted. Consider an input matrix of size , where is the number of samples (e.g., gesture images) and is the number of features. The time complexity of computing the full SVD of a matrix of size is generally considered to be ). After computing the SVD, the next step might involve selecting a subset of the computed singular vectors/values as features. Common methods for selecting features include choosing the top-k singular vectors/values.
- -
- Training Complexity: Training an NHMM typically involves estimating parameters, which often involves the Baum–Welch algorithm. The time complexity of training an NHMM can be pretty high, and it is often polynomial in terms of the number of observations and the number of states with complexity ), where S is the number of states, is the number of observations, and I is the number of iterations required for convergence.
- -
- Inference Complexity: Inference in NHMMs involves computing the likelihood of the observed data given the model, which typically requires the Viterbi algorithm. The time complexity of inference in NHMMs is often polynomial in terms of the number of states and the number of observations with complexity ).
- -
- Prediction Complexity: If the prediction of future observations is required, it generally involves the use of complexities as the inference.
4.2. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sarhan, N.; Frintrop, S. Unraveling a Decade: A Comprehensive Survey on Isolated Sign Language Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 3210–3219. [Google Scholar]
- Wali, A.; Shariq, R.; Shoaib, S.; Amir, S.; Farhan, A. Recent progress in sign language recognition: A review. Mach. Vis. Appl. 2023, 34, 127–140. [Google Scholar] [CrossRef]
- Núñez-Marcos, A.; Perez-de-Viñaspre, O.; Labaka, G. A survey on Sign Language machine translation. Expert Syst. Appl. 2023, 213, 18993. [Google Scholar] [CrossRef]
- Minu, R. An Extensive Survey on Sign Language Recognition Methods. In Proceedings of the 7th International Conference on Computing Methodologies and Communication, Erode, India, 23–25 February 2023; pp. 613–619. [Google Scholar]
- Robert, E.; Duraisamy, H. A review on computational methods based automated sign language recognition system for hearing and speech impaired community. Concurr. Comput. Pract. Exp. 2023, 35, e7653. [Google Scholar] [CrossRef]
- Singh, S.; Chaturvedi, A. Applying Machine Learning for American Sign Language Recognition: A Brief Survey. In Proceedings of the International Conference on Communication and Intelligent Systems, Moscow, Russia, 14–16 December 2023; Springer Nature: Singapore, 2022; pp. 297–309. [Google Scholar]
- Liang, Z.; Li, H.; Chai, J. Sign Language Translation: A Survey of Approaches and Techniques. Electronics 2023, 12, 2678. [Google Scholar] [CrossRef]
- Rakesh, S.; Venu, M.; Jayaram, D.; Gupta, I.; Agarwal, K.; Nishanth, G. A Review on Sign Language Recognition Techniques. In Proceedings of the International Conference on Information and Management Engineering, Zhenjiang, China, 21–23 October 2022; Springer Nature: Singapore, 2022; pp. 301–309. [Google Scholar]
- Ingle, T.; Daware, S.; Kumbhar, N.; Raut, K.; Waghmare, P.; Dhawase, D. Sign Language Recognition. Scand. J. Inf. Syst. 2023, 35, 294–298. [Google Scholar]
- Kamble, N.; More, N.; Wargantiwar, O.; More, S. Deep Learning-Based Sign Language Recognition and Translation. In Proceedings of the International Conference on Soft Computing for Security Applications, Dhirajlal, Gandhi, India, 21–22 April 2023; Springer Nature: Singapore, 2023; pp. 49–63. [Google Scholar]
- Qahtan, S.; Alsattar, H.; Zaidan, A.; Deveci, M.; Pamucar, D.; Martinez, L. A comparative study of evaluating and benchmarking sign language recognition system-based wearable sensory devices using a single fuzzy set. Knowl. Based Syst. 2023, 269, 110519. [Google Scholar] [CrossRef]
- Kanavos, A.; Papadimitriou, O.; Mylonas, P.; Maragoudakis, M. Enhancing sign language recognition using deep convolutional neural networks. In Proceedings of the 14th International Conference on Information Intelligence, Systems and Applications, Volos, Greece, 10–12 July 2023; pp. 1–4. [Google Scholar]
- Kumar, R.; Goyal, V.; Goyal, L. State of the Art of Automation in Sign Language: A Systematic Review. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 1–80. [Google Scholar] [CrossRef]
- Kuppuswami, G.; Sujatha, R.; Nagarajan, D.; Kavikumar, J. Markov chain based on neutrosophic numbers in decision making. Kuwait J. Sci. 2021, 48, 1–16. [Google Scholar]
- Patil, A.; Kulkarni, A.; Yesane, H.; Sadani, M.; Satav, P. Literature survey: Sign language recognition using gesture recognition and natural language processing. Data Management, Analytics and Innovation. In Proceedings of the International Conference on Data Management, Analytics and Innovation, Pune, India, 19–21 January 2024; Springer: Berlin/Heidelberg, Germany, 2021; Volume 1, pp. 197–210. [Google Scholar]
- Sultan, A.; Makram, W.; Kayed, M.; Ali, A. Sign language identification and recognition: A comparative study. Open Comput. Sci. 2022, 12, 191–210. [Google Scholar] [CrossRef]
- Fadel, N.; Kareem, E. Computer Vision Techniques for Hand Gesture Recognition: Survey. In Proceedings of the International Conference on New Trends in Information and Communications Technology Applications, Baghdad, Iraq, 20–21 December 2023; Springer Nature: Cham, Switzerland, 2022; pp. 50–76. [Google Scholar]
- Al-Farid, F.; Hashim, N.; Abdullah, J.; Bhuiyan, M.; Shahida Mohd, W.; Uddin, J.; Haque, M.; Husen, M. A structured and methodological review on vision-based hand gesture recognition system. J. Imaging 2022, 8, 153. [Google Scholar] [CrossRef]
- Bhiri, N.; Ameur, S.; Alouani, I.; Mahjoub, M.; Khalifa, A. Hand gesture recognition with focus on leap motion: An overview, real world challenges and future directions. Expert Syst. Appl. 2023, 225, 120125. [Google Scholar] [CrossRef]
- Wu, S.; Li, Z.; Li, S.; Liu, Q.; Wu, W. An overview of gesture recognition. In Proceedings of the International Conference on Computer Application and Information Security, Dubai, United Arab Emirates, 24–25 January 2023; Volume 12609, pp. 600–606. [Google Scholar]
- Franslin, N.; Ng, G. Vision-based dynamic hand gesture recognition techniques and applications: A review. In Proceedings of the 8th International Conference on Computational Science and Technology, Labuan, Malaysia, 28–29 August 2021; Springer: Singapore, 2022; pp. 125–138. [Google Scholar]
- Parihar, S.; Shrotriya, N.; Thakore, P. Hand Gesture Recognition: A Review. In Proceedings of the International Conference on Mathematical Modeling and Computational Science, Bangkok, Thailand, 10–11 January 2025; Springer Nature: Singapore, 2023; pp. 471–483. [Google Scholar]
- Parcheta, Z.; Martínez-Hinarejos, C. Sign language gesture recognition using HMM. In Proceedings of the 8th Iberian Conference in Pattern Recognition and Image Analysis, Faro, Portugal, 20–23 June 2017; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 419–426. [Google Scholar]
- Buttar, A.; Ahmad, U.; Gumaei, A.; Assiri, A.; Akbar, M.; Alkhamees, B. Deep Learning in Sign Language Recognition: A Hybrid Approach for the Recognition of Static and Dynamic Signs. Mathematics 2023, 11, 3729. [Google Scholar] [CrossRef]
- Tu, G.; Li, Q.; Jiang, D. Dynamic Gesture Recognition Based on HMM-DTW Model Using Leap Motion. In Proceedings of the International Symposium of Artificial Intelligence Algorithms and Applications, Vienna, Austria, 16–17 March 2024; Springer: Singapore, 2020; pp. 788–798. [Google Scholar]
- Sagayam, K.; Hemanth, D.; Vasanth, X.; Henesy, L.; Ho, C. Optimization of a HMM-based hand gesture recognition system using a hybrid cuckoo search algorithm. In Hybrid Metaheuristics Image Analysis; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 87–114. [Google Scholar]
- Sawicki, A.; Daunoravičienė, K.; Griškevičius, J. Recognition of human-computer interaction gestures acquired by internal motion sensors with the use of hidden Markov models. Adv. Comput. Sci. Research. 2021, 15, 1–14. [Google Scholar]
- Elmezain, M.; Alwateer, M.; El-Agamy, R.; Atlam, E.; Ibrahim, H. Forward hand gesture spotting and prediction using HMM-DNN model. Informatics 2022, 10, 1. [Google Scholar] [CrossRef]
- Miah, A.; Hasan, M.; Shin, J.; Okuyama, Y.; Tomioka, Y. Multistage spatial attention-based neural network for hand gesture recognition. Computers 2023, 12, 13. [Google Scholar] [CrossRef]
- Mohammed, A.; Lv, J.; Islam, M.; Sang, Y. Multi-model ensemble gesture recognition network for high-accuracy dynamic hand gesture recognition. J. Ambient Intell. Humaniz. Comput. 2023, 14, 6829–6842. [Google Scholar] [CrossRef]
- Dubey, A. Enhanced hand-gesture recognition by improved beetle swarm optimized probabilistic neural network for human–computer interaction. J. Ambient Intell. Humaniz. Comput. 2023, 14, 12035–12048. [Google Scholar] [CrossRef]
- Miah, A.; Hasan, M.; Shin, J. Dynamic Hand Gesture Recognition using Multi-Branch Attention Based Graph and General Deep Learning Model. IEEE Access 2023, 11, 4703–4716. [Google Scholar] [CrossRef]
- Alabdullah, B.; Ansar, H.; Mudawi, N.; Alazeb, A.; Alshahrani, A.; Alotaibi, S.S.; Jalal, A. Smart Home Automation-Based Hand Gesture Recognition Using Feature Fusion and Recurrent Neural Network. Sensors 2023, 23, 7523. [Google Scholar] [CrossRef]
- Damaneh, M.; Mohanna, F.; Jafari, P. Static hand gesture recognition in sign language based on convolutional neural network with feature extraction method using ORB descriptor and Gabor filter. Expert Syst. Appl. 2023, 211, 118559. [Google Scholar] [CrossRef]
- Bhaumik, G.; Verma, M.; Govil, M.; Vipparthi, S. Hyfinet: Hybrid feature attention network for hand gesture recognition. Multimed. Tools Appl. 2023, 82, 4863–4882. [Google Scholar] [CrossRef]
- Ibrahim, I. Hand Gesture Recognition System Utilizing Hidden Markov Model for Computer Visions Applications. Int. J. Adv. Acad. Res. 2023, 9, 36–44. [Google Scholar]
- John, J.; Deshpande, S. A Comparative Study on Challenges and Solutions on Hand Gesture Recognition. In Computational Intelligence for Engineering and Management Applications; Springer Nature: Singapore, 2023; pp. 229–240. [Google Scholar]
- Saboo, S.; Singha, J. Dynamic hand gesture tracking and recognition: Survey of different phases. Int. J. Syst. Innov. 2023, 7, 47–70. [Google Scholar]
- John, J.; Deshpande, S. Hand Gesture Identification Using Deep Learning and Artificial Neural Networks: A Review. In Computational Intelligence for Engineering and Management Application; Springer: Berlin/Heidelberg, Germany, 2023; pp. 389–400. [Google Scholar]
- Yalçın, S.; Kaya, I. Analyzing of process capability indices based on neutrosophic sets. Comput. Appl. Math. 2022, 41, 287. [Google Scholar] [CrossRef]
- Nanni, L.; Loreggia, A.; Lumini, A.; Dorizza, A. A Standardized Approach for Skin Detection: Analysis of the Literature and Case Studies. J. Imaging 2023, 9, 35. [Google Scholar] [CrossRef] [PubMed]
- ArulMurugan, S.; Somaiswariy, S. Virtual mouse using hand gestures by skin recognition. J. Popul. Ther. Clin. Pharmacol. 2023, 30, 251–258. [Google Scholar]
- Abujayyab, S.; Almajalid, R.; Wazirali, R.; Ahmad, R.; Taşoğlu, E.; Karas, I.; Hijazi, I. Integrating object-based and pixel-based segmentation for building footprint extraction from satellite images. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 101802. [Google Scholar] [CrossRef]
- Sengupta, S.; Mittal, N.; Modi, M. Morphological Transformation in Color Space-Based Edge Detection of Skin Lesion Images. In Proceedings of the International Conference in Innovations in Cyber Physical Systems, Delhi, India, 22–23 October 2021; Springer: Singapore, 2021; pp. 265–273. [Google Scholar]
- Khanam, R.; Johri, P.; Diván, M. Human Skin Color Detection Technique Using Different Color Models. In Trends and Advancements of Image Processing and Its Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 261–279. [Google Scholar]
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand gesture recognition based on computer vision: A review of techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Dong, Z.; Wang, J.; Xia, L. Parallel temporal feature selection based on improved attention mechanism for dynamic gesture recognition. Complex Intell. Syst. 2023, 9, 1377–1390. [Google Scholar] [CrossRef]
- Kowdiki, M.; Khaparde, A. Automatic hand gesture recognition using hybrid meta-heuristic-based feature selection and classification with dynamic time warping. Comput. Sci. Rev. 2021, 39, 100320. [Google Scholar] [CrossRef]
- Nogales, R.; Benalcázar, M. Hand Gesture Recognition Using Automatic Feature Extraction and Deep Learning Algorithms with Memory. Big Data Cogn. Comput. 2023, 7, 102. [Google Scholar] [CrossRef]
- Yadukrishnan, V.; Anilkumar, A.; Arun, K.; Madhu, M.; Hareesh, V. Robust Feature Extraction Technique for Hand Gesture Recognition System. In Proceedings of the International Conference on Intelligent Computing & Optimization, Hua Hin, Thailand, 27–28 April 2023; Springer Nature: Cham, Switzerland, 2023; pp. 250–259. [Google Scholar]
- Jiang, J.; Yang, W.; Ren, H. Seismic wavefield information extraction method based on adaptive local singular value decomposition. J. Appl. Geophys. 2023, 210, 104965. [Google Scholar] [CrossRef]
- Zhu, H.; Wu, C.; Zhou, Y.; Xie, Y.; Zhou, T. Electric shock feature extraction method based on adaptive variational mode decomposition and singular value decomposition. IET Sci. Meas. Technol. 2023, 17, 361–372. [Google Scholar] [CrossRef]
- Shahsavani, F.; Nasiripour, R.; Shakeri, R.; Gholamrezaee, A. Arrhythmia detection based on the reduced features with K-SVD sparse coding algorithm. Multimed. Tools Appl. 2023, 82, 12337–12350. [Google Scholar] [CrossRef]
- Liu, B.; Pejó, B.; Tang, Q. Privacy-Preserving Federated Singular Value Decomposition. Appl. Sci. 2023, 13, 7373. [Google Scholar] [CrossRef]
- Mifsud, M.; Camilleri, T.; Camilleri, K. HMM-based gesture recognition for eye-swipe typing. Biomed. Signal Process. Control 2023, 86, 105161. [Google Scholar] [CrossRef]
- Manouchehri, N.; Bouguila, N. Human Activity Recognition with an HMM-Based Generative Model. Sensors 2023, 23, 1390. [Google Scholar] [CrossRef]
- Hassan, M.; Ali, S.; Kim, J.; Saadia, A.; Sanaullah, M.; Alquhayz, H.; Safdar, K. Developing a Novel Methodology by Integrating Deep Learning and HMM for Segmentation of Retinal Blood Vessels in Fundus Images. Interdiscip. Sci. Comput. Life Sci. 2023, 15, 273–292. [Google Scholar] [CrossRef]
- Nagarajan, D.; Kavikumar, J. Single-Valued and Interval-Valued Neutrosophic Hidden Markov Model. Math. Probl. Eng. 2022, 2022, 5323530. [Google Scholar] [CrossRef]
- Nagarajan, D.; Kavikumar, J.; Tom, M.; Mahmud, M.; Broumi, S. Modelling the progression of Alzheimer’s disease using Neutrosophic hidden Markov models. Neutrosophic Sets Syst. 2023, 56, 31–40. [Google Scholar]
- Li, J.; Pedrycz, W.; Wang, X.; Liu, P. A Hidden Markov Model-based fuzzy modeling of multivariate time series. Soft Comput. 2023, 27, 837–854. [Google Scholar] [CrossRef]
- Mahdi, A.; Nazaruddin, Y.; Mandasari, M. Driver Behavior Prediction Based on Environmental Observation Using Fuzzy Hidden Markov Model. Int. J. Sustain. Transp. 2023, 6, 22–27. [Google Scholar] [CrossRef]
- Ren, X.; He, D.; Gao, X.; Zhou, Z.; Ho, C. An Improved Hidden Markov Model for Indoor Positioning. In Proceedings of the International Conference on Communications and Networking, Guilin, China, 21–24 August 2022; Springer Nature: Cham, Switzerland, 2022; pp. 403–420. [Google Scholar]
- Nwanga, M.; Okafor, K.; Achumba, I.; Chukwudebe, G. Predictive Forensic Based—Characterization of Hidden Elements in Criminal Networks Using Baum-Welch Optimization Technique. In Proceedings of the International Conference in Illumination of Artificial Intelligence in Cybersecurity and Forensics, New York, NY, USA, 30 November–1 December 2023; Springer International Publishing: Cham, Switzerland, 2022; pp. 231–254. [Google Scholar]
- Zhang, S.; Yang, L.; Zhang, Y.; Lu, Z.; Yu, J.; Cui, Z. Tensor-Based Baum–Welch Algorithms in Coupled Hidden Markov Model for Responsible Activity Prediction. IEEE Trans. Comput. Soc. Syst. 2023, 10, 2924–2937. [Google Scholar] [CrossRef]
- Sleem, A.; Abdel-Baset, M.; El-henawy, I. PyIVNS: A python based tool for Interval-valued neutrosophic operations and normalization. SoftwareX 2020, 12, 100632. [Google Scholar] [CrossRef]
- Qi, J.; Ma, L.; Cui, Z.; Yu, Y. Computer vision-based hand gesture recognition for human-robot interaction: A review. Complex Intell. Syst. 2023, 9, 1581–1606. [Google Scholar] [CrossRef]
- Gupta, R.; Singh, A. Hand Gesture Recognition using OpenCV. In Proceedings of the 2023 10th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 15 March 2023; pp. 145–148. [Google Scholar]
- Padgal, G.; Oza, S. An efficient Viterbi algorithm for communication system. Res. J. Eng. Technol. 2022, 13, 10–16. [Google Scholar] [CrossRef]
- Huang, Q.; Wei, S.; Zhang, L. Radar Interferometric Phase Ambiguity Resolution Using Viterbi Algorithm for High-Precision Space Target Positioning. IEEE Signal Process. Lett. 2023, 30, 1242–1246. [Google Scholar] [CrossRef]
- Huang, K.; Xu, M.; Qi, X. NGMMs: Neutrosophic Gaussian mixture models for breast ultrasound image classification. In Proceedings of the 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society, Guadalajara, Mexico, 1–5 November 2021; pp. 3943–3947. [Google Scholar]
- Liu, X.; Wang, S.; Lu, S.; Yin, Z.; Li, X.; Yin, L.; Tian, J.; Zheng, W. Adapting feature selection algorithms for the classification of Chinese texts. Systems 2023, 11, 483. [Google Scholar] [CrossRef]
- Balaha, M.; El-Kady, S.; Balaha, H.; Salama, M.; Emad, E.; Hassan, M.; Saafan, M.A. vision-based deep learning approach for independent-users Arabic sign language interpretation. Multimed. Tools Appl. 2023, 82, 6807–6826. [Google Scholar] [CrossRef]
- Galván-Ruiz, J.; Travieso-González, C.M.; Pinan-Roescher, A.; Alonso Hernández, J.B. Robust Identification System for Spanish Sign Language Based on Three-Dimensional Frame Information. Sensors 2023, 23, 481. [Google Scholar] [CrossRef]
- Kashlak, A.; Loliencar, P.; Heo, G. Topological Hidden Markov Models. J. Mach. Learn. Res. 2023, 24, 1–49. [Google Scholar]



{kind=link}
{kind=link}
| Model | Recognition Rate % | |||
|---|---|---|---|---|
| GMM | FGMM | IT2FGMM | NGMM | |
| 6 states/10 mixtures | 77.2 | 88.6 | 95.8 | 97.1 |
| 6 states/6 mixtures | 74.5 | 77.2 | 88.3 | 95.4 |
| 6 states/4 mixtures | 70.3 | 75.7 | 86.9 | 94.6 |
| 6 states/3 mixtures | 67.8 | 73.5 | 85.3 | 93.1 |
| 4 states/2 mixtures | 60.7 | 70.2 | 82.9 | 92.8 |
| Overall Average | 70.10 | 77.04 | 87.84 | 94.60 |
| Proposed Model | No. of Features (SVD Coefficients) | ||
|---|---|---|---|
| 25 Features | 30 Features | 50 Features | |
| Recognition Rate | 92.7 | 94.6 | 97.1 |
| Instruments Used | Feature Vector Length | Average Recognition Rate | |
|---|---|---|---|
| Proposed System (SVD coefficients + NHMM classifier) | None: Free Hands | 30 SVD coefficients | 94.6 |
| Vision-based deep learning approach [72] | Determined according to the CNN parameters | 91.2 |
| Database | No. of Samples | Classifiers | Accuracy | Comments |
|---|---|---|---|---|
| 28 ArSL | 10 samples/letter | KNN | 97.1% | Traditional kNN relies on instance-based classification and does not explicitly model uncertainty |
| HMM | 97.7% | They assume that observations are generated from a finite set of hidden states with known transition probabilities and emission probabilities, but they do not provide a formal mechanism for quantifying uncertainty | ||
| Naïve Bayes | 98.3% | They assume independence between features and rely on the strong conditional independence assumption, which may not accurately capture the complex dependencies present in hand gesture data. | ||
| MLP | 99.1% | They learn deterministic mappings from input features to output labels and do not provide a formal mechanism for quantifying uncertainty. | ||
| SVM | 90.7% | Traditional SVM relies on margin-based classification and does not explicitly model uncertainty. | ||
| Proposed Model | 97.1% | NHMMs explicitly model uncertainty using neutrosophic logic, allowing for the representation of indeterminacy, uncertainty, and contradiction in hand gesture data. |
| Proposed Model | No. of Features (SVD Coefficients) | ||
|---|---|---|---|
| Ergodic | LR | LRB | |
| Average Recognition Rate | 73.56 | 89.34 | 95.76 |
| Input Samples | A | B | C | Five | Point | V | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| A | 10 | 0 | 0 | 0 | 0 | 0 | 100 |
| B | 0 | 8 | 2 | 0 | 0 | 0 | 80 |
| C | 0 | 2 | 8 | 0 | 0 | 0 | 80 |
| Five | 0 | 0 | 0 | 10 | 0 | 0 | 100 |
| Point | 0 | 0 | 0 | 0 | 10 | 0 | 100 |
| V | 0 | 0 | 0 | 0 | 0 | 10 | 100 |
| Accuracy (%) | 100 | 80 | 80 | 100 | 100 | 100 | 93.33% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Saidi, M.; Ballagi, Á.; Hassen, O.A.; Saad, S.M. Cognitive Classifier of Hand Gesture Images for Automated Sign Language Recognition: Soft Robot Assistance Based on Neutrosophic Markov Chain Paradigm. Computers 2024, 13, 106. https://doi.org/10.3390/computers13040106
Al-Saidi M, Ballagi Á, Hassen OA, Saad SM. Cognitive Classifier of Hand Gesture Images for Automated Sign Language Recognition: Soft Robot Assistance Based on Neutrosophic Markov Chain Paradigm. Computers. 2024; 13(4):106. https://doi.org/10.3390/computers13040106
Chicago/Turabian StyleAl-Saidi, Muslem, Áron Ballagi, Oday Ali Hassen, and Saad M. Saad. 2024. "Cognitive Classifier of Hand Gesture Images for Automated Sign Language Recognition: Soft Robot Assistance Based on Neutrosophic Markov Chain Paradigm" Computers 13, no. 4: 106. https://doi.org/10.3390/computers13040106
APA StyleAl-Saidi, M., Ballagi, Á., Hassen, O. A., & Saad, S. M. (2024). Cognitive Classifier of Hand Gesture Images for Automated Sign Language Recognition: Soft Robot Assistance Based on Neutrosophic Markov Chain Paradigm. Computers, 13(4), 106. https://doi.org/10.3390/computers13040106