A Scalable and Highly Configurable Cache-Aware Hybrid Flash Translation Layer

Abstract
:1. Introduction
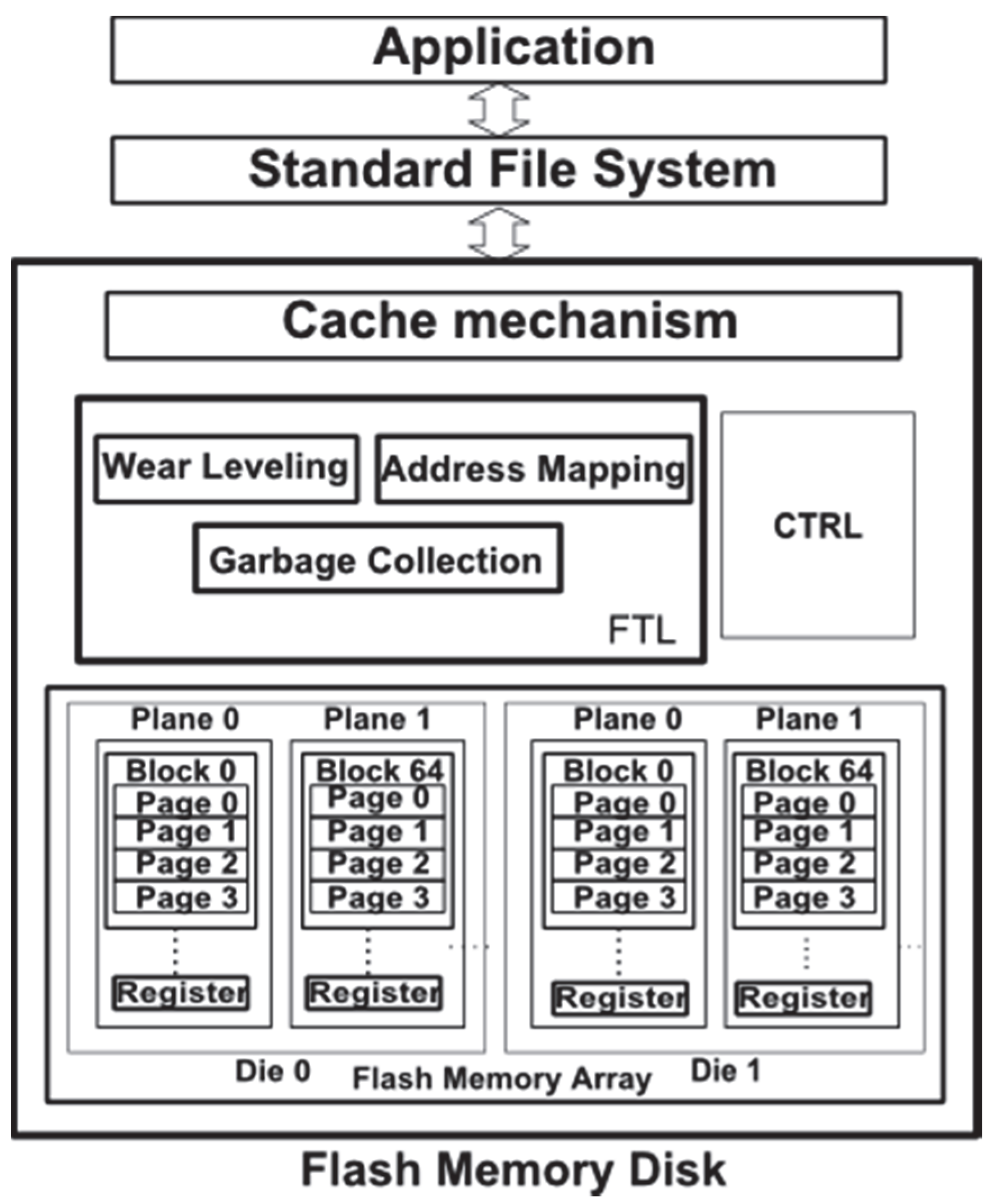
2. Overview on NAND Flash Memory

3. Related Work
3.1. FTL Schemes
3.2. Flash-Specific Cache Systems
3.3. Motivation
4. Cache-Aware Configurable Hybrid FTL Design

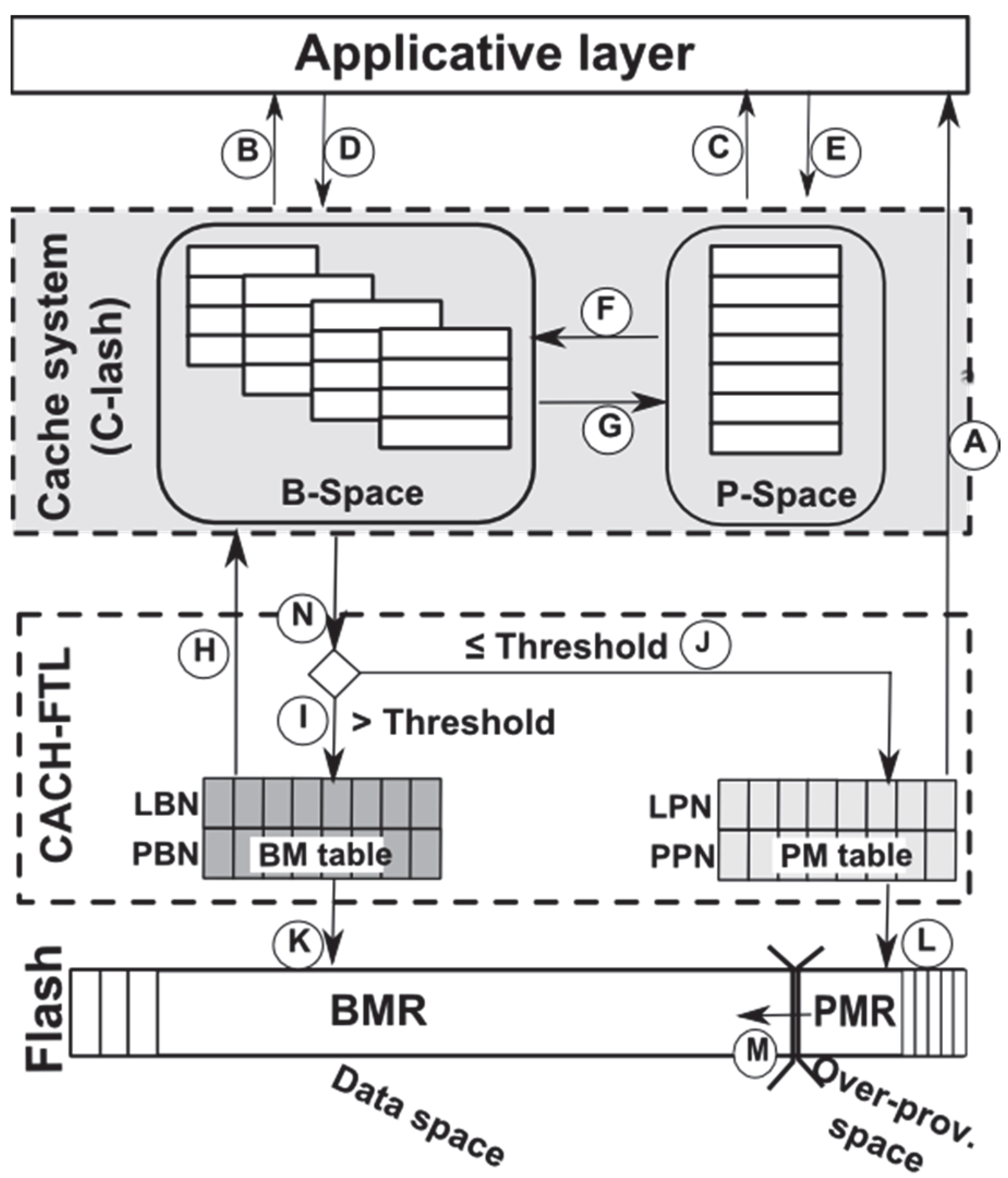
4.1. Overview of the C-Lash System
4.2. CACH-FTL Scheme Management
4.2.1. Read Operation Management
4.2.2. Write Operation Management
| Algorithm 1. CACH-FTL write algorithms. |
|
4.2.3. BMR Block-Mapping Scheme
4.3. CACH-FTL Garbage Collection (GC) Mechanisms
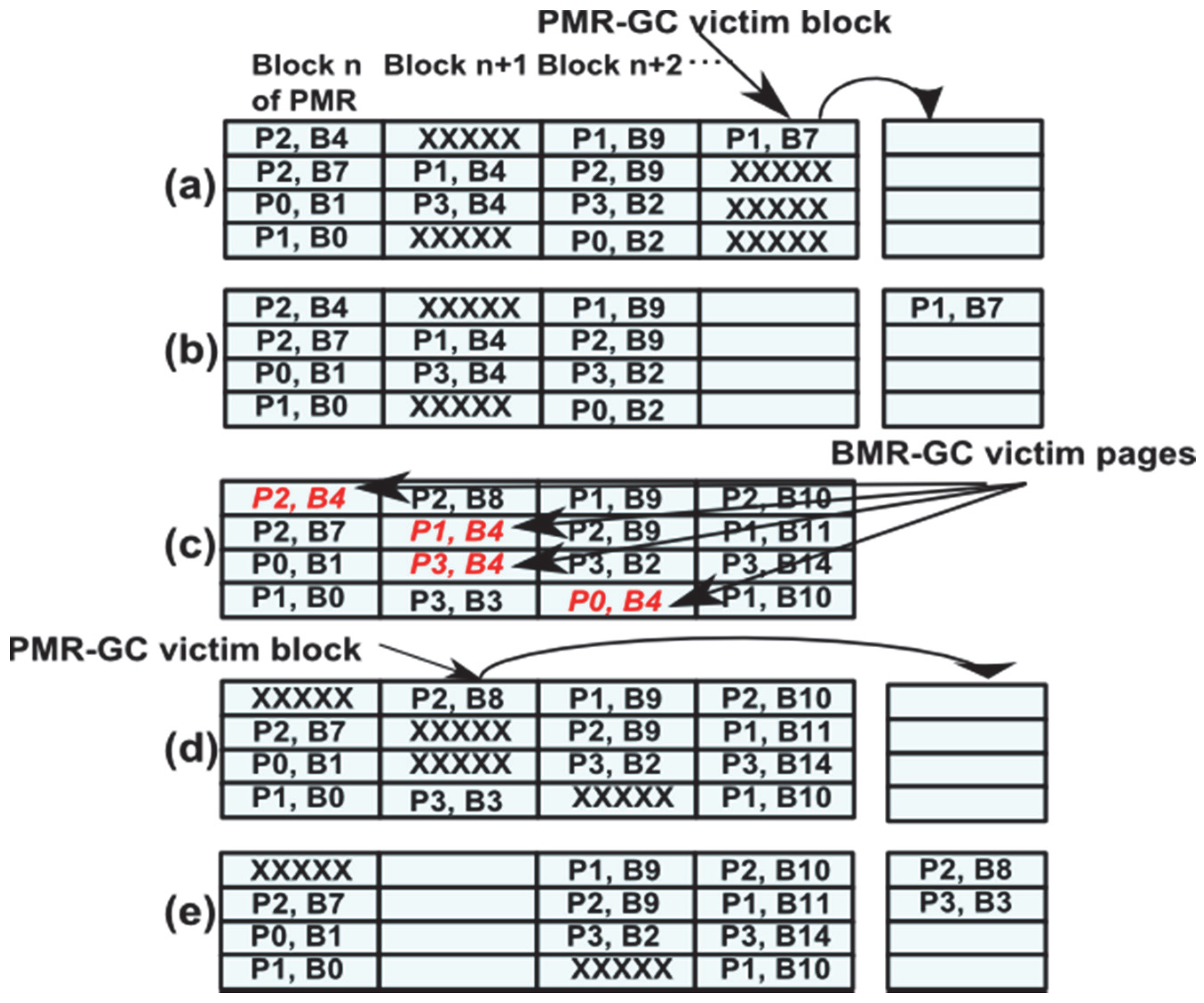
4.3.1. PMR Garbage Collector

4.3.2. BMR Garbage Collector
| Algorithm 2. CACH-FTL garbage collection algorithms. |
|
4.3.3. PMR-GC and BMR-GC Asynchronous Design
5. Performance Evaluation
5.1. Storage System and Performance Metrics
5.2. Simulated I/O Workloads

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequential Rate | Request Number | Inter-Arrival Times |
| 40%, default value | 250,000 default value | exponential (0, 200 ms) default value |
| (10% → 90%) | (10,000 → 5,000,000) | (50 → 500 ms) |
| Spatial Locality | Write Rate | Mean Request Size |
| 20% | 100% | 1 page (4 KB) |
| Number format: Mean, (Min, Max) | Financial 1 | Financial 2 | Cello99 |
|---|---|---|---|
| (24 Volumes) | (19 Volumes) | (5 Volumes) | |
| Write rate | 77%, | 18%, | 34%, |
| (4%, 100%) | (0%, 98%) | (19%, 53%) | |
| Sequentiality per request/per page | 23%/46% | 9%/38% | 9%/45% |
| (1%, 99%) | (3%, 96%) | (4%, 27%) | |
| Mean request. size (KB) | 5.6 | 5.3 | 4.5 |
| Trace time (h) | 12 | 12 | 168 |
6. Results and Discussion
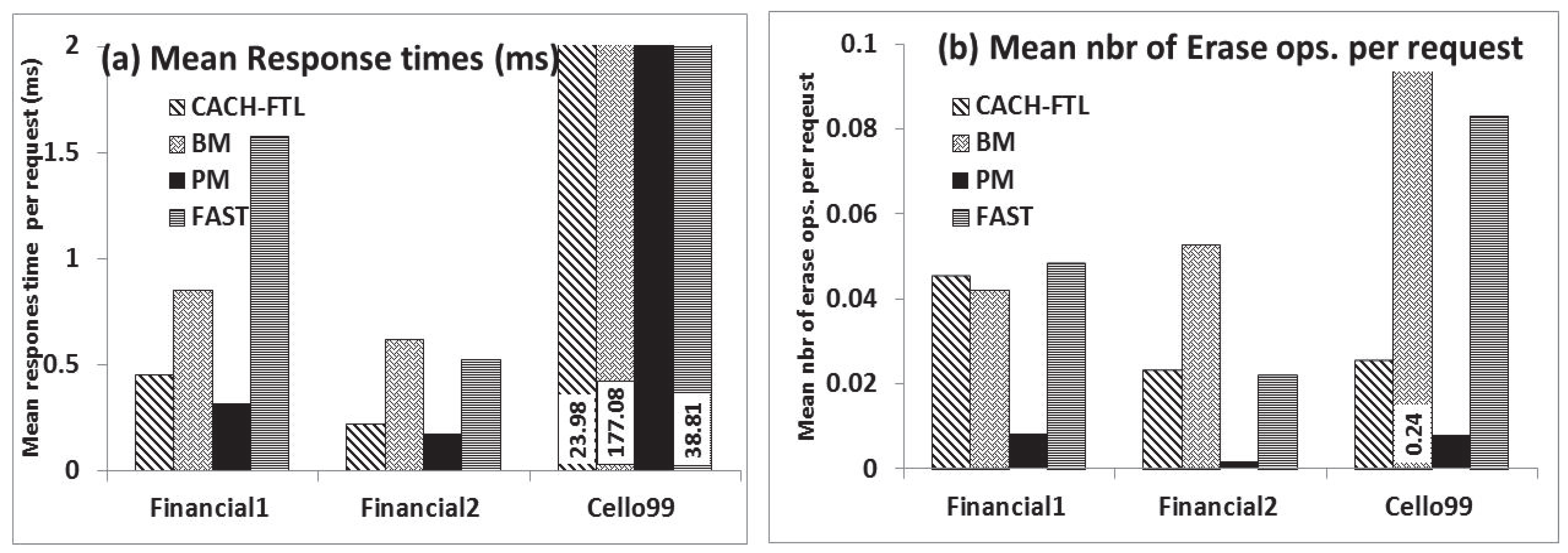
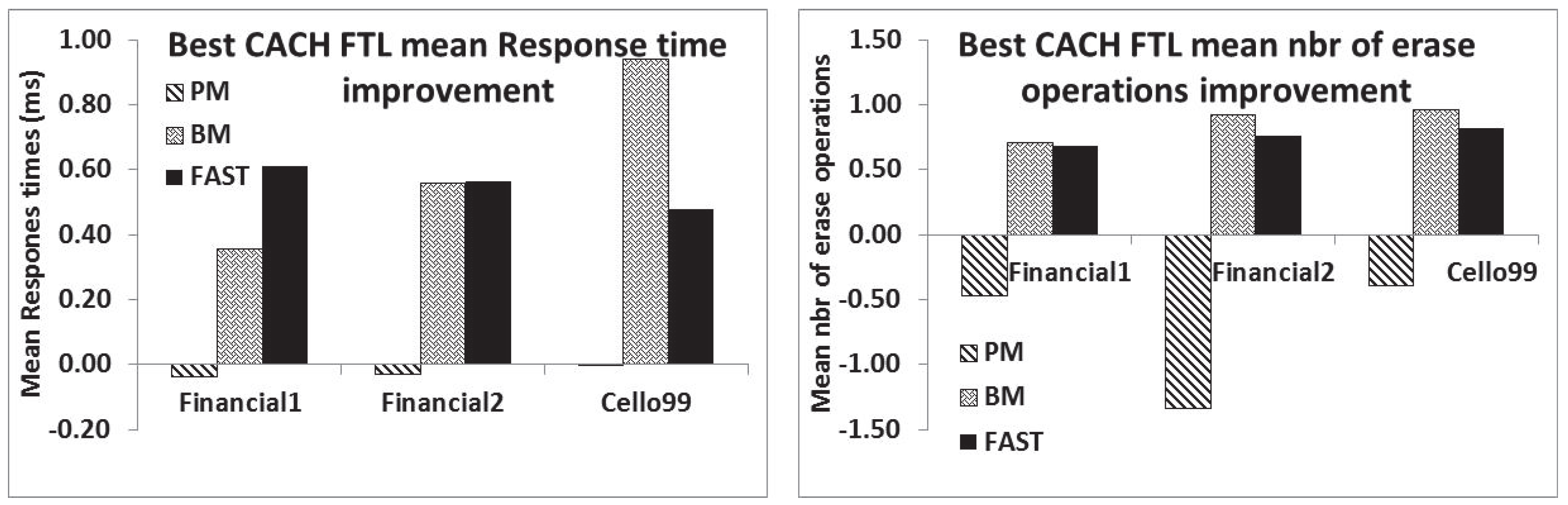
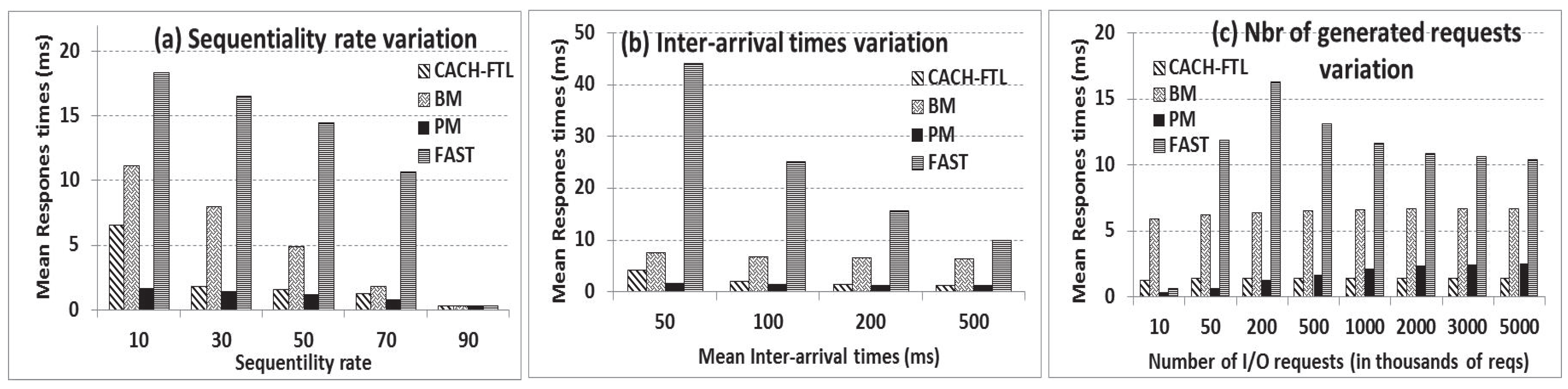
6.1. CACH-FTL versus PM, BM and FAST



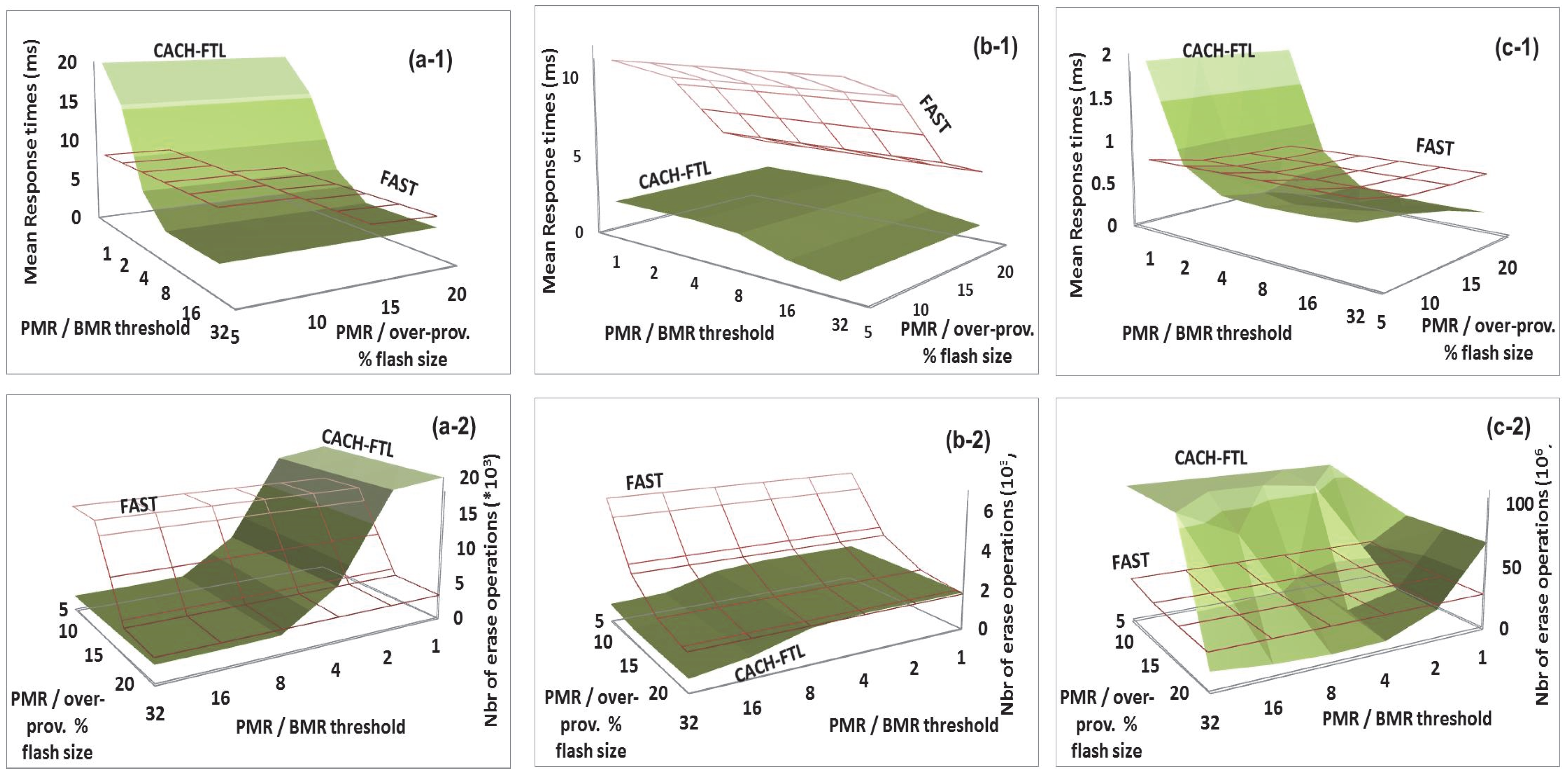
6.2. CACH-FTL Adaptability: Redirection Threshold and Over-Provisioning Space Configuration

7. Conclusion and Future Work
Conflicts of Interest
References
- Market Research. Available online: http://www.marketresearch.com/corporate/aboutus/press.asp?view=3&article=2223 (accessed on 19 March 2014).
- Ranganathan, P. From microprocessors to nanostores: Rethinking data-centric systems. Computer 2011, 44, 39–48. [Google Scholar] [CrossRef]
- Ban, A. Flash File System. US Patent No 5,404,485, 4 April 1995. [Google Scholar]
- Jo, H.; Kang, J.; Park, S.; Kim, J.; Lee, J. FAB: Flash-aware buffer management policy for portable media players. IEEE Trans. Consum. Electron. 2006, 52, 485–493. [Google Scholar] [CrossRef]
- Kang, S.; Park, S.; Jung, H.; Shim, H.; Cha, J. Performance trade-offs in using NVRAM write buffer for flash memory-based storage devices. IEEE Trans. Comput. 2009, 58, 744–758. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, S. BPLRU: A Buffer Management Scheme for Improving Random Writes in Flash Storage. In Proceedings of the 6th USENIX Conference on File and Storage Technologies (FAST), San Jose, CA, USA, 26–29 February 2008.
- Wu, G.; Eckart, B.; He, X. BPAC: An Adaptive Write Buffer Management Scheme for Flash-Based Solid State Drives. In Proceedings of the 26th IEEE Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010.
- Debnath, B.; Subramanya, S.; Du, D.; Lilja, D.J. Large Block CLOCK (LB-CLOCK): A Write Caching Algorithm for Solid State Disks. In Proceedings of the IEEE International Symposium on Modeling, Analysis & Simulation of Computer and Telecommunication Systems (MASCOTS), London, UK, 21–23 September 2009.
- Hu, J.; Jiang, H.; Tian, T.; Xu, L. PUD-LRU: An Erase-Efficient Write Buffer Management Algorithm for Flash Memory SSD. In Proceedings of the IEEE International Symposium on of Modeling, Analysis & Simulation of Computer and Telecommunication Systems (MASCOTS), Miami Beach, FL, USA, 17–19 August 2010.
- Seo, D.; Shin, D. Recently-evicted-first buffer replacement policy for flash storage devices. IEEE Trans. Consum. Electron. 2008, 54, 1228–1235. [Google Scholar] [CrossRef]
- Boukhobza, J.; Olivier, P.; Rubini, R. A Cache Management Strategy to Replace Wear Leveling Techniques for Embedded Flash Memory. In Proceedings the of International Symposium on Performance Evaluation of Computer & Telecommunication Systems (SPECTS), The Hague, The Netherlands, 27–30 June 2011.
- Boukhobza, J.; Olivier, P.; Rubini, S. CACH-FTL: A Cache-Aware Configurable Hybrid Flash Translation Layer. In Proceedings of Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), 27 February–1 March 2013.
- Brewer, J.E.; Gill, M. Nonvolatile Memory Technologies with Emphasis on Flash; IEEE Press Series, Wiley Inter-Science: Piscataway, NJ, USA, 2008; pp. 22–24. [Google Scholar]
- Ban, A. Flash File System Optimized for Page-Mode Flash Technologies. US Patent No 5,937,425, 10 August 1999. [Google Scholar]
- Wu, C.; Kuo, T. An Adaptive Two-Level Management for the Flash Translation Layer in Embedded Systems. In Proceedings of the IEEE/ACM international conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 5–9 November 2006.
- Hsieh, J.; Tsai, Y.; Kuo, T.; Lee, T. Configurable flash-memory management: Performance versus overheads. IEEE Trans. Comput. 2008, 57, 1571–1583. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.M.; Noh, S.H.; Min, S.L.; Cho, Y. A space-efficient flash translation layer for compactflash systems. IEEE Trans. Consum. Electron. 2002, 48, 366–375. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, D.; Wang, M.; Qin, Z.; Guan, Y. RNFTL: A Reuse-Aware NAND Flash Translation Layer for Flash Memory. In Proceedings of the ACM SIGPLAN/SIGBED Conference on Languages, Compilers, and Tools for Embedded Systems (LCTES), Stockholm, Sweden, 13–15 April 2010.
- Lee, S.; Park, D.; Chung, T.; Lee, D.; Park, S.; Song, H. A log buffer based flash translation layer using fully associative sector translation. ACM Trans. Embed. Comput. Syst. 2007, 6, 1–27. [Google Scholar] [CrossRef]
- Cho, H.; Shin, D.; Eom, Y.I. KAST: K-Associative Sector Translation for NAND Flash Memory in Real-Time Systems. In Proceedings of Design, Automation and Test in Europe (DATE), Nice, France, 20–24 April 2009.
- Lee, S.; Shin, D.; Kim, Y.; Kim, J. LAST: Locality aware sector translation for NAND flash memory based storage systems. ACM SIGOPS Oper. Syst. Rev. 2008, 42, 36–42. [Google Scholar]
- Lee, H.; Yun, H.; Lee, D. HFTL: Hybrid flash translation layer based on hot data identification for flash memory. IEEE Trans. Consum. Electron. 2009, 55, 2005–2011. [Google Scholar] [CrossRef]
- Guan, Y.; Wang, G.; Wang, Y.; Chen, R.; Shao, Z. Block-Level Log-Block Management for NAND Flash Memory Storage Systems. In Proceedings of the ACM SIGPLAN/SIGBED Conference on Languages, Compilers and Tools for Embedded Systems (LCTES), Seattle, WA, USA, 20–21 June 2013.
- Wei, Q.; Gong, B.; Pathak, S.; Veeravalli, B.; Zeng, L.; Okada, K. WAFTL: A Workload Adaptive Flash Translation Layer with Data Partition. In Proceedings of the 27th IEEE Symposium on Mass Storage Systems and Technologies (MSST), Denver, CO, USA, 23–27 May 2011.
- Park, D.; Debnath, B.; Du, D. A Workload-Aware Adaptive Hybrid Flash Translation Layer with an Efficient Caching Strategy. In Proceedings of the IEEE International Symposium on of Modeling, Analysis & Simulation of Computer and Telecommunication Systems (MASCOTS), 25–27 July 2011.
- Liao, X.; Hu, S. Bridging the information gap between buffer and flash translation layer for flash memory. IEEE Trans. Consum. Electron. 2011, 57, 1765–1773. [Google Scholar] [CrossRef]
- Kim, Y.; Taurus, B.; Gupta, A.; Urgaonkar, B. FlashSim: A Simulator for NAND Flash-Based Solid-State Drives. In Proceedings of the 1st International Conference on Advances in System Simulation (SIMUL), Porto, Portugal, 20–25 September 2009.
- Ganger, G.R.; Worthington, B.; Patt, Y.N. The Disksim Simulation Environment Version 3.0 Reference Manual; Tech. Report CMU-CS-03-102; Carnegie Melon University: Pittsburgh, PA, USA, 2003. [Google Scholar]
- Agrawal, N.; Prabhakaran, V.; Wobber, T.; Davis, J.D.; Manasse, M.; Panigrahy, R. Design Tradeoffs for SSD Performance. In Proceedings of the USENIX Annual Technical Conference (ATC), Oslo, Norway, 23–25 June 2008.
- Storage Performance Council Website. Available online: http://www.storageperformance.org/home/ (accessed on 22 January 2014).
- OLTP Traces—UMass Trace Repository. Available online: http://traces.cs.umass.edu/index.php/Storage/Storage/ (accessed on 22 January 2014).
- Cello99 Traces, HP Labs. Available online: http://tesla.hpl.hp.com/opensource/cello99 (accessed on 22 January 2014).
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Boukhobza, J.; Olivier, P.; Rubini, S. A Scalable and Highly Configurable Cache-Aware Hybrid Flash Translation Layer. Computers 2014, 3, 36-57. https://doi.org/10.3390/computers3010036
Boukhobza J, Olivier P, Rubini S. A Scalable and Highly Configurable Cache-Aware Hybrid Flash Translation Layer. Computers. 2014; 3(1):36-57. https://doi.org/10.3390/computers3010036
Chicago/Turabian StyleBoukhobza, Jalil, Pierre Olivier, and Stéphane Rubini. 2014. "A Scalable and Highly Configurable Cache-Aware Hybrid Flash Translation Layer" Computers 3, no. 1: 36-57. https://doi.org/10.3390/computers3010036