
Exponentiated Gradient Exploration for Active Learning

Abstract
:1. Introduction
2. Related Works
2.1. Active Learning
2.2. Random Exploration in Active Learning
2.3. Our Contributions
3. Active Learning with Random Exploration
3.1. ϵ-active
| Algorithm 1: ϵ-active |
| 1: Input: |
| 2: Output: |
| 3: |
| 4: if x was not queried in the past then Query O for label y of x |
| 5: Observe reward |
3.2. Computing the Optimal Random Exploration
| Algorithm 2: EG-active. |
| Input: candidate values for ϵ |
| β, τ and k: parameters for EG |
| N: number of iterations |
| and w, |
| for i=1 to N do |
| Sample d from discrete |
| Run the ϵ-active with |
| Receive the feedback |
| exp( ), |
| , |
| end for |
4. Experimental Evaluation
4.1. Corporate Data

4.2. Public Benchmarks

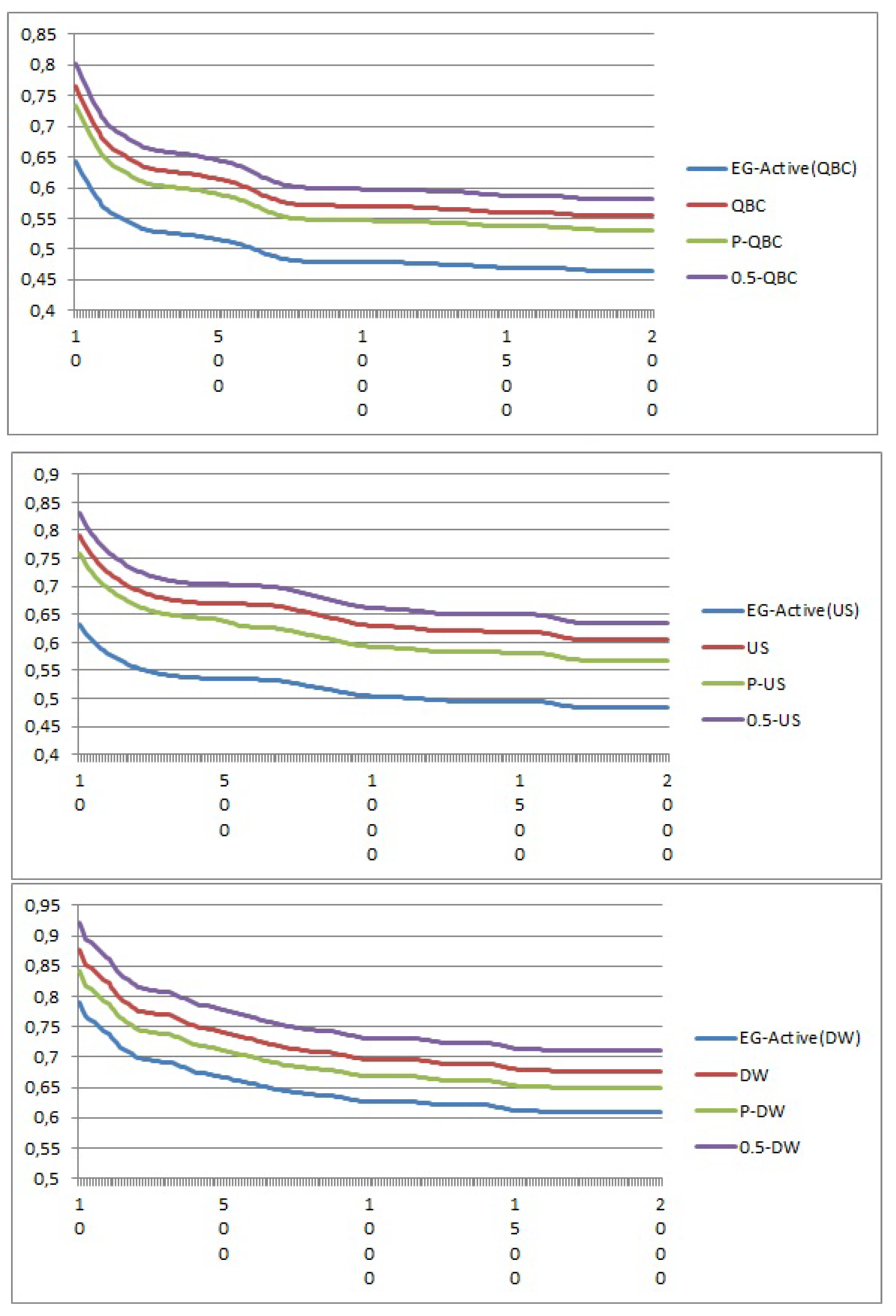{kind=link}
| UCI Datasets | Instances | Attributes | Classes |
|---|---|---|---|
| Abalone | 1484 | 7 | 3 |
| Breast | 699 | 9 | 2 |
| Ecoli | 336 | 7 | 8 |
| Glass | 214 | 9 | 7 |
| Haberman | 306 | 3 | 2 |
| Iris | 150 | 4 | 3 |
| Wine | 178 | 13 | 3 |
| Wdbc | 569 | 32 | 2 |
| Yeast | 1484 | 6 | 8 |
| UCI Datasets | QBC | 50-QBC | P-QBC | EG-active(QBC) |
|---|---|---|---|---|
| Abalone | ||||
| Breast | ||||
| Ecoli | ||||
| Glass | ||||
| Haberman | ||||
| Iris | ||||
| Wine | ||||
| Wdbc | ||||
| Yeast |
| UCI Datasets | US | 50-US | P-US | EG-active(US) |
|---|---|---|---|---|
| Abalone | ||||
| Breast | ||||
| Ecoli | ||||
| Glass | ||||
| Haberman | ||||
| Iris | ||||
| Wine | ||||
| Wdbc | ||||
| Yeast |
| UCI Datasets | DW | 50-DW | P-DW | EG-active(DW) |
|---|---|---|---|---|
| Abalone | ||||
| Breast | ||||
| Ecoli | ||||
| Glass | ||||
| Haberman | ||||
| Iris | ||||
| Wine | ||||
| Wdbc | ||||
| Yeast |
5. Conclusions
Conflicts of Interest
References
- Cohn, D.; Atlas, L.; Ladner, R. Improving Generalization with Active Learning. Mach. Learn. 1994, 15, 201–221. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey. In Computer Sciences Technical Report 1648; University of Wisconsin: Madison, WI, USA, 2010. [Google Scholar]
- Koronacki, J.; Ras, Z.W.; Wierzchon, S.T.; Kacprzyk, J. IAdvances in Machine Learning I. In Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2010; Volume 262, pp. 97–120. [Google Scholar]
- Osugi, T.; Kim, D.; Scott, S. Balancing exploration and exploitation: A new algorithm for active machine learning. In Proceedings of the Fifth IEEE International Conference on Data Mining, Houston, TX, USA, 27–30 November 2005; p. 8.
- Lewis, D.D.; Gale, W.A. A sequential algorithm for training text classifiers. In Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’94, Dublin, Ireland, 3–6 July 1994; Springer-Verlag: New York, NY, USA, 1994; pp. 3–12. [Google Scholar]
- Hamed, H.; MohammadReza, K. A variance based active learning approach for named entity recognition. In Intelligent Computing and Information Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 347–352. [Google Scholar]
- Jing, F.; Li, M.; Zhang, H.-J.; Zhang, B. Entropy-based active learning with support vector machines for content-based image retrieval. In Proceedings of the 2004 IEEE International Conference on Multimedia and Expo, ICME’04, Taipei, Taiwan, 27–30 June 2004; pp. 85–88.
- Seung, H.S.; Opper, M.; Sompolinsky, H. Query by committee. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, COLT ’92, New York, NY, USA, 27–29 July 1992; pp. 287–294.
- Zhu, X.; Lafferty, J.; Ghahramani, Z. Combining active learning and semi-supervised learning using gaussian fields and harmonic functions. In Proceedings of the ICML 2003 Workshop on The Continuum from Labeled to Unlabeled Data in Machine Learning and Data Mining, Washington, DC, USA, 21 August 2003; pp. 58–65.
- Zhang, T.; Oles, F.J. A probability analysis on the value of unlabeled data for classification problems. In Proceedings of the 17th International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000.
- Lughofer, E. Hybrid active learning for reducing the annotation effort of operators in classification systems. Pattern Recognit. 2012, 45, 884–896. [Google Scholar] [CrossRef]
- Saito, P.T.M.; de Rezende, P.J.; Falcao, A.X.; Suzuki, C.T.N.; Gomes, J.F. An active learning paradigm based on a priori data reduction and organization. Expert Syst. Appl. 2014, 41, 6086–6097. [Google Scholar] [CrossRef]
- Lughofer, E. Single-pass active learning with conflict and ignorance. Evol. Syst. 2012, 3, 251–271. [Google Scholar] [CrossRef]
- Bouneffouf, D. Freshness-Aware Thompson Sampling. In Processings of the 21st International Conference on Neural Information, ICONIP, Kuching, Malaysia, 3–6 November 2014; pp. 373–380.
- Bouneffouf, D. Context-Based Information Retrieval in Risky Environment. Aust. J. Intell. Inf. Proc. Syst. 2014, 14, 1–10. [Google Scholar]
- Kivinen, J.; Warmuth, M.K. Exponentiated gradient versus gradient descent for linear predictors. Inf. Comput. 1995, 132, 1–63. [Google Scholar] [CrossRef]
- Mitra, V.; Wang, C.-J.; Banerjee, S. Text classification: A least square support vector machine approach. Appl. Soft Comput. 2007, 7, 908–914. [Google Scholar] [CrossRef]
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bouneffouf, D. Exponentiated Gradient Exploration for Active Learning. Computers 2016, 5, 1. https://doi.org/10.3390/computers5010001
Bouneffouf D. Exponentiated Gradient Exploration for Active Learning. Computers. 2016; 5(1):1. https://doi.org/10.3390/computers5010001
Chicago/Turabian StyleBouneffouf, Djallel. 2016. "Exponentiated Gradient Exploration for Active Learning" Computers 5, no. 1: 1. https://doi.org/10.3390/computers5010001
APA StyleBouneffouf, D. (2016). Exponentiated Gradient Exploration for Active Learning. Computers, 5(1), 1. https://doi.org/10.3390/computers5010001