Application of Cell-Free Protein Synthesis for Faster Biocatalyst Development


Chair for Bioprocess Engineering, Department of Biochemical and Chemical Engineering, TU Dortmund University, D-44227 Dortmund, Germany
*
Author to whom correspondence should be addressed.
†
These authors have contributed equally to this work.
Catalysts 2019, 9(2), 190; https://doi.org/10.3390/catal9020190
Submission received: 30 January 2019
/
Revised: 13 February 2019
/
Accepted: 15 February 2019
/
Published: 19 February 2019
(This article belongs to the Special Issue Biocatalysis for Industrial Applications)
Abstract
:Cell-free protein synthesis (CFPS) has become an established tool for rapid protein synthesis in order to accelerate the discovery of new enzymes and the development of proteins with improved characteristics. Over the past years, progress in CFPS system preparation has been made towards simplification, and many applications have been developed with regard to tailor-made solutions for specific purposes. In this review, various preparation methods of CFPS systems are compared and the significance of individual supplements is assessed. The recent applications of CFPS are summarized and the potential for biocatalyst development discussed. One of the central features is the high-throughput synthesis of protein variants, which enables sophisticated approaches for rapid prototyping of enzymes. These applications demonstrate the contribution of CFPS to enhance enzyme functionalities and the complementation to in vivo protein synthesis. However, there are different issues to be addressed, such as the low predictability of CFPS performance and transferability to in vivo protein synthesis. Nevertheless, the usage of CFPS for high-throughput enzyme screening has been proven to be an efficient method to discover novel biocatalysts and improved enzyme variants.
1. Introduction
Biocatalysis and biocatalytic processes affect many industries ranging from consumer products and food to the chemical and pharmaceutical industry. In many cases, biocatalysis can offer economically attractive and environmentally benign solutions. The potential of biocatalysis is, however, not yet fully exploited [1,2,3,4,5]. Some of the hurdles in implementing more processes are linked to the timelines and cost of developing a biocatalytic process, in particular when protein engineering is involved. Cell-free protein synthesis (CFPS) systems might contribute to accelerating the development process of new enzymes and enable rapid screening for suitable biocatalysts. The great advantage of CFPS is the ease of parallelization for efficient and quick synthesis of numerous protein variants. Furthermore, CFPS is easily adjustable to the translational requirements and simultaneously adaptable to the desired subsequent analytical setup.
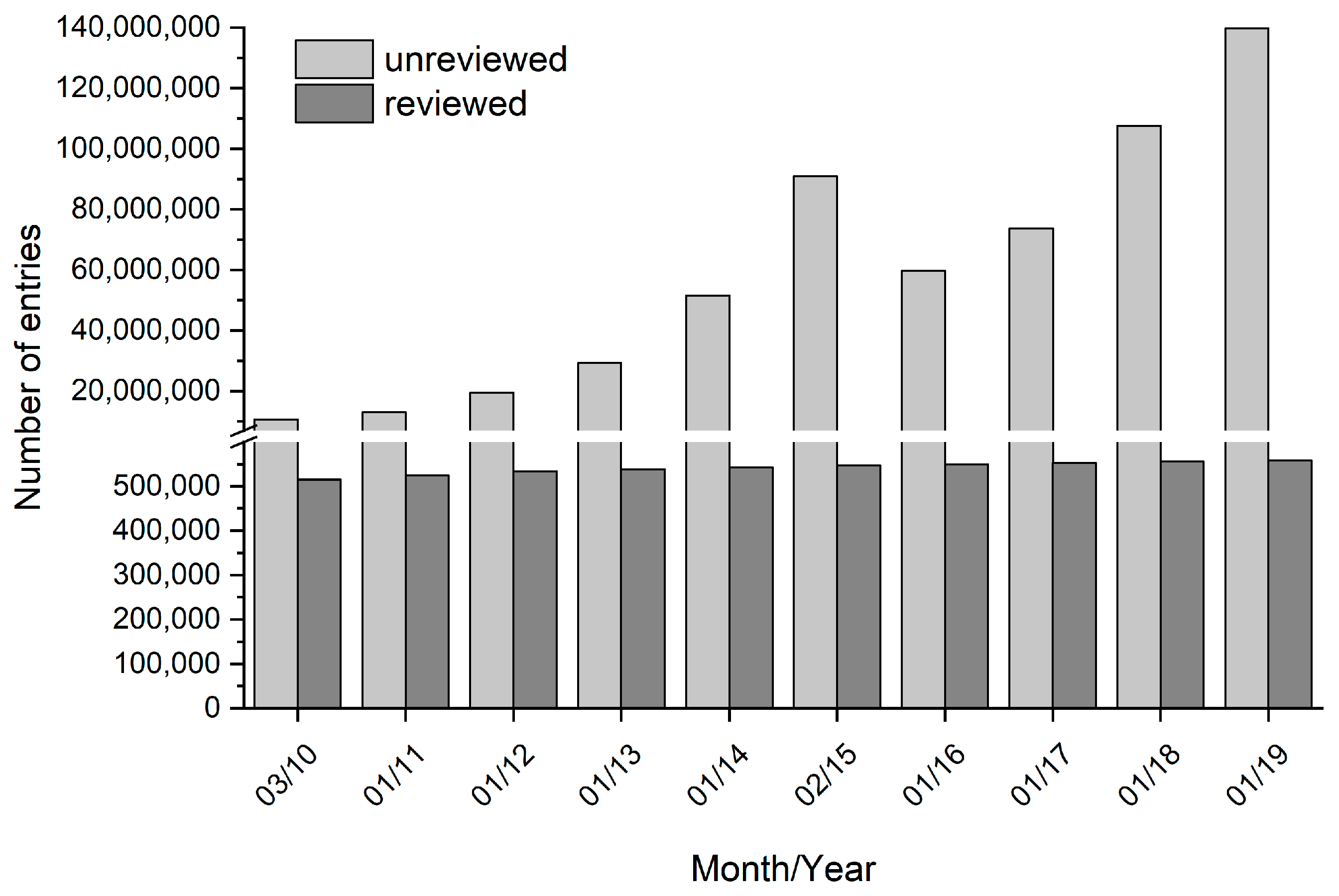
Nevertheless, in the recent decade, mainly technologies for reaction and process engineering [6,7,8], modelling tools [9,10], as well as automation, parallelization, and miniaturization [11,12] were improved in order to increase the efficiency of bioprocess development. However, the effort to genetically optimize biotransformation systems in industrial processes is often lagging behind and is not always integrated in the process development considerations. As recommended by Lima-Ramos et al., economic analysis should be carried out at an early development phase of the production process [13]. This means that the choice and also the biocatalyst improvement in order to tune the biocatalyst’s properties to the process requirements are required at an early stage [1]. The ability to modify proteins facilitates the development and implementation of biocatalyzed syntheses in industry [14]. However, screening of suitable biocatalysts is a complex task if mimicking the process conditions [15,16]. The availability of genes and genomes originating from metagenomes from natural pools or mutational creation is steadily increasing [17]. Furthermore, the generation of genetic libraries by gene-shuffling, error-prone PCR, or other methods is quite advanced and powerful [18]. Consequently, the gap between the number of known gene sequences and known genetic functions is continuously growing [19,20,21,22]. The comparison of reviewed and unreviewed gene sequences clearly illustrates this gap (Figure 1). The percentage of genes having any experimental proof for their annotation is relatively close to zero. In addition, biocatalytic processes often require knowledge about a function differing from the natural or physiological enzyme function, e.g., converting non-natural substrates in the presence of organic media. Data about these process relevant enzyme functions is even scarcer.
Closing the gap will advance medicine, chemistry, and industry. A strategy to predict and assign functions to unknown enzymes discovered in genome projects was suggested by the Enzyme Function Initiative [23,24]. This approach is mainly based on computational methods. However, these predictions are generally limited to new and unknown enzymes and are less suitable for genetic libraries of enzyme variants. Furthermore, assigning protein functions on the basis of sequences is challenging and not sufficiently consistent. While in silico predictions are useful in functional genomics and systems biology in order to describe dynamic processes, such as gene expression regulation, transcription, translation, and protein interactions, the final evidence about the enzyme’s function has to be performed with the enzyme itself. Screening of biocatalyst libraries in order to identify optimal variants can be performed with high-throughput methods, such as instrumental assays or assays based on fluorogenic or chromogenic substrates and reporters [25,26]. The rate limiting step in the generation of biocatalyst libraries is typically the heterologous expression and protein purification. A method is hence required for the large-scale or high-throughput production of enzyme libraries which can be tested on their functions. CFPS systems might be a solution to accelerate prototyping of new enzymes and to speed up screening for suitable or optimized biocatalysts [27]. A vast expansion in research activities on in vitro synthesized proteins in industry is justified by the need to achieve a more efficient development of bioprocesses. The application of CFPS combined with high-throughput analytics could close the gap and efficiently decrypt the enzyme-function-relation (Figure 2).
In the context of CFPS as tool for high-throughput protein synthesis, this review addresses the following topics. The compositions of CFPS systems are compared and the necessity of individual ingredients assessed. The applications and development status of CFPS are described focusing on screening in industrial applications of the past few years. Finally, remaining challenges and limitations of CFPS are discussed.
2. Cell-Free Protein Synthesis
Cell-free systems have been used for protein synthesis for decades, with a wide range of applications. The first cell-free protein synthesis system was established in 1961 by Nirenberg and Matthaei [29]. Since then, the usage of biological machinery without the use of living cells has undergone many improvements and became the method of choice for various applications [30]. There are several advantages of CFPS compared to heterologous expression. Proteins can be produced from DNA templates within a few hours with concentrations at a milligram per milliliter scale [31]. Moreover, difficult to synthesize proteins, like membrane anchored proteins [32], or proteins with a toxic effect on the metabolism of the host cells [33] can be easily produced with in vitro systems. While the hydrophobic properties of membrane proteins are often challenging for in vivo systems, the open environment of CFPS systems offers the possibility to support the synthesis of membrane proteins by supplementing membrane mimics, such as lipid-detergent-based systems, nanodiscs, or liposomes [34]. Furthermore, there are numerous other options for flexible adjustments of the reaction conditions. These include lowering the expression temperature [35], the addition of chaperones [36] or protein disulfide isomerase to facilitate protein folding [37], the incorporation of nonstandard amino acids [38], and the adjustment of codon usage to enhance translation [39].
In principle, two methods can be distinguished according to the general composition of the CFPS solution. The first method is based on a purified cell extract as a complex solution with many undefined ingredients, whereas the second system uses a rational combination of individually purified components [40]. Both approaches contain all necessary constituents for the coupled transcription and translation machinery, such as ribosomes, aminoacyl-tRNA-synthetases, and translation factors for initiation, elongation, and product release (Figure 3). Various crude cell extracts obtained from prokaryotic, fungi, plant, and mammalian cells are described in literature [41,42]. In general, any organism can serve as the source for cell extract preparation. The choice of extract depends on the biochemical requirements and applications of the target protein. Commonly used extracts are derived from Escherichia coli, Saccharomyces cerevisiae [43], rabbit reticulocytes [44], wheat germs [45], insect cells [46], and Chinese hamster ovary (CHO) cells [47]. The most widely used source for crude cell lysates is E. coli, bearing some advantages over other CFPS systems. These advantages are the high rate of protein synthesis with high protein yields, simple and cost-effective cultivation and extract preparation, the possibility of genetic engineering with well-established tools, the use of low-cost energy sources, and the ability to fold complex proteins [48]. However, E. coli shares the common drawback of prokaryotic extracts and does not provide sufficient post-translational modifications, such as glycosylation. In applications where these modifications are required, other sources for the extract, such as CHO or yeast cells, should be considered [41].
Crude extracts are prepared by lysing the cells followed by removing cellular debris and large molecules, such as genomic DNA, via multiple rounds of washing and high-speed centrifugation. Depending on the used type of CFPS system, additional cofactors and supplements are needed. The E. coli extract CFPS system has experienced many improvements over the years and various compositions were described (Table 1). In the following, the purpose and necessity of the main components are described and discussed.
Ions are added in almost every published CFPS system as they are essential for the activity of many enzymes, as well as for the interaction between proteins and nucleic acids. Typical cations are magnesium (Mg2+) and potassium (K+), whose concentrations must be carefully elucidated for optimal protein synthesis. Acetate and glutamate, both major anions in the E. coli cytoplasm, can be used interchangeably [32].
Amino acids, adenosine triphosphate (ATP), guanosine triphosphate (GTP), cytidine triphosphate (CTP), and uridine triphosphate (UTP) are essential for protein synthesis and can hence be found in every system. The proteinogenic amino acids are the building blocks for proteins and can be expanded to non-natural amino acids for special applications. Whereas ATP is a universal energy source, GTP is a source of energy for protein synthesis. Together with UTP and CTP, they serve as the substrate for the transcription reaction mediated by RNA polymerase. Yang et al. alternatively used nucleoside monophosphates in order to reduce the reaction costs [55]. Although an additional conversion of the nucleoside monophosphates into the corresponding nucleoside triphosphates was required, the obtained protein yields were similar compared to systems with nucleoside triphosphates.
For successful and efficient protein synthesis, a competent energy regeneration system is crucial. ATP and GTP have to be regenerated for prolonged reactions and satisfying protein yields. This supply for protein synthesis is accomplished by using secondary energy sources containing a high-energy phosphate bond. Hence, different systems are described using creatine phosphate, phosphoenolpyruvate, or acetyl phosphate in combination with the enzymes creatine kinase, pyruvate kinase, and acetate kinase, respectively. To avoid the necessity of additional exogenous enzymes, systems were developed using endogenous enzymes present in the cell extract. Effective ATP regeneration from any glycolytic intermediate is enabled by adding β-nicotinamide adenine dinucleotide (NAD) and coenzyme A [57]. The conversion of pyruvate into phosphoenolpyruvate via endogenous phosphoenolpyruvate synthetase is coupled with the conversion of ATP to adenosine monophosphate (AMP). Hence, this reaction could significantly reduce the energy supply during protein synthesis by degrading both ATP and pyruvate. For further improvement of the CFPS performance, oxalate, a potent inhibitor of phosphoenolpyruvate synthetase, can be added to the reaction [50]. In general, the degradation of the secondary energy sources is a common limitation for the performance of CFPS systems. In addition, the resulting phosphate accumulation inhibits long-term protein synthesis by generating complexes with magnesium ions [58]. The recycling of inorganic phosphate can be achieved by phosphorylation of maltodextrin [59] or maltose [31]. The addition of these supplements enables one to overcome the limitation caused by phosphate inhibition.
Moreover, tRNA is a common supplement in CFPS systems. Although tRNA is present in the cell extract, increased concentrations of total tRNA improve the availability of amino acids for translation, and therefore the obtained overall protein synthesis yield. Furthermore, the specific addition of tRNA offers the opportunity to adjust the codon usage by adding rare codon tRNA [39]. For initiation of the translation reaction, formyl-methionine is obligatory. To ensure adequate supply, folinic acid is added to the CFPS reaction as a formyl donor substrate.
Most of the described systems contain the organic chemical buffering agent 4-(2-hydroxyethyl)-1-piperazineethanesulfonic acid (HEPES) for maintaining physiological pH. The complexity and difficulty of creating an efficient CFPS mixture is also illustrated by the addition of crowding agents. Polyethylene glycol (PEG) can be used to mimic the viscosity of the E. coli cytoplasm. PEG is also supposed to support the stability of mRNA and to induce macromolecular crowding effects. However, crowding agents inhibit translation, which might be caused by protein precipitation [60]. The usage of crowding agents and their impact on the transcription and translation machinery have to be critically considered. Another attempt describes the substitution of these unnatural components, as HEPES and PEG, with supplements naturally occurring in E. coli. The polycations spermidine and putrescine were incorporated to replace PEG and offer some advantages, such as stimulation of T7 RNA polymerase activity and stabilization of DNA, RNA, and tRNA [51]. Because of its stabilizing effect on T7 RNA polymerase, the reducing agent dithiothreitol (DTT) is often used in systems, which are based on the T7 regulation system [32]. Nevertheless, a major drawback is the reducing environment, which might prevent the formation of disulfide bonds. For oxidized target proteins, a compromise between T7 RNA polymerase stability and optimized synthesis environment should be considered.
The most widely used transcription regulation systems in cell-free expression systems are bacteriophage RNA polymerases, such as T7 or T3. These polymerases are known for strict promoter specificity and accept supercoiled, as well as linear DNA templates. Furthermore, these polymerases do not recognize chromosomal DNA, resulting in a strong decrease of background expression of unintended genes [61]. In general, there are two methods described for the application of these RNA polymerases. First, the addition of recombinantly produced and purified polymerase to the CFPS reaction [62]. Secondly, the usage of a T7 RNA polymerase producing strain for the preparation of the cell extracts [63]. This organism can be a natural producer of T7 RNA polymerase, such as E. coli BL21 (DE3), or a strain, harboring a plasmid for the overexpression of T7 RNA polymerase. Alternatively, endogenous E. coli RNA polymerases in combination with sigma factors are described, although the endogenous E. coli transcription machinery is much less efficient, as bacteriophage systems comparable protein yields can be obtained due to DNA template optimization [54].
This shows the great potential of optimization attempts for different DNA gene templates. In general, a template can be used either as a circular plasmid or in linear PCR fragment forms. Linear templates can be produced via PCR within hours and avoids the necessity of molecular cloning steps, while plasmid template preparation can take days [48]. For many high-throughput applications of CFPS, the usage of PCR products can circumvent the time-intensive template construction and cloning and yields a large number of different proteins within a few hours. The preparation of linear DNA gene templates can easily be done with gene-specific primers with additional overhanging sequences, consisting of regulatory features, such as a T7 promoter and a T7 terminator [64]. A noted disadvantage is the increased vulnerability of linear DNA to endogenous nucleases; hence a faster degradation can be observed [65]. To avoid this drawback in applications with E. coli extracts, three approaches are mentioned. Usage of strains, lacking the dominant nuclease RecB [66], addition of potent inhibitor of exonucleases, such as purified Gam protein of bacteriophage λ [52,67], or modification of the gene template with structures, which avoid the degradation of linear DNA [68]. These adjustments lead to comparable protein yields between linear and circular DNA gene templates [52,69].
In summary, several CFPS systems have been described, which enable production of protein yields from the lower microgram scale to the milligram scale in a single batch reaction. The slightly different compositions can significantly affect the efficiency and productivity of the CFPS reaction, as displayed by the addition of maltose or maltodextrin. Furthermore, it is shown that a CFPS system that omits several ingredients, which were considered as essential, is able to produce proteins in small quantities. Pedersen et al. have rationally improved their CFPS systems and tested five different proteins [70]. The final yields varied between 250 and 700 µg protein per mL of CFPS reaction mix. Consequently, it is not possible to compare the yields of distinct proteins. Moreover, the applied protocol for the cell-free extract preparation has a major effect on productivity.
3. Applications of Cell-Free Protein Synthesis
Cell-free protein synthesis serves as a platform for many biotechnology and synthetic biology projects. The growing interest for the CFPS technology is due to its applicability to synthesize “difficult” proteins, for example toxic or membrane proteins, proteins which incorporate non-natural amino acids, or proteins that require a tight control during synthesis in terms of reactant concentrations or timing of reactant addition, which is not guaranteed by heterologous expression [71]. These possibilities open the way to a novel understanding of enzymes and new applications, such as personalized medicines or new therapeutics and chemicals. Next to the aforementioned applications, CFPS is a promising approach for high-throughput synthesis to provide enzymes for functional analyses. In the following, we focus on CFPS in the context of compartmentalization, miniaturization in microfluidics and microarrays, rapid prototyping, and scale-up with regard to industrial application (Figure 4).
Compartmentalized microenvironments are used for CFPS to provide cell-like structures to enable functional protein analyses in preferably similar environments compared to the cell. Artificial microcompartments offer the great advantage of design and control structure and biochemical composition [75]. Liposomes or microgels are the simplest systems for modelling cells. These compartments provide micro reaction chambers to study membrane-associated protein processes or enzymatic reactions in the compartment [76,77]. Giant unilamellar vesicles (GUV) have a cell-like size and contain the same phospholipids that compose cell membranes [78,79]. Using GUVs, CFPS was efficiently applied for directed evolution of a membrane protein. Genes encoding for α-hemolysin pore protein in Staphylococcus aureus were subjected to mutagenesis for generating a randomly mutagenized gene library. The mutagenized genes were individually encapsulated in GUVs with a CFPS system and the HaloTag protein. HaloTag protein is a modified haloalkane dehalogenase and covalently binds to synthetic ligands [80]. The α-hemolysins were synthesized from the mutated genes and incorporated into the GUV membranes [72]. The GUVs were then exposed to a solution containing a fluorescent AF488 ligand. Dependent on the pore-forming activity of α-hemolysin, AF488 diffused more or less into the liposome and bound to HaloTag protein. The GUVs were sorted using fluorescence activated cell sorting (FACS) and active genes were recovered and amplified for transformation in S. aureus [72]. This approach allowed efficient evolution under functional screening conditions. In addition to the aforementioned examples, CPFS in compartmentalized microenvironments enabled the development of artificial minimal cells from the bottom up [81,82]. Such cell-like micro containers were optimized with regard to nutrient supply by co-expressing genes encoding α-hemolysin pore proteins, which enabled an continuous exchange of energy and material during expression [83]. These advancements resulted in a prolonged expression for up to 4 days compared to 2 h in bulk solution. Although we are far away from synthesizing viable and self-replicating artificial cells, mimicking cells is currently an active field of research for studying enzyme functionality in well-defined and controllable environments and also for screening of enzyme variants.
Miniaturization and automation using microchips has a tremendous potential for CFPS parallelization and high-throughput analysis of the synthesized proteins [48,84,85]. CFPS in microfluidic chips offers new opportunities, such as continuous protein production or compartmentalization with simultaneous protein detection and analysis [73]. The separation of reactants and the separation of transcription and translation machinery by, for example, inclusion in droplets or separation with dialysis membranes, result in significantly higher product yields and provide novel reactions modes [86,87,88]. Mazutis et al. succeeded to fulfill the individual biochemical requirements of protein synthesis and functional enzyme assay by separating multiple reaction steps in droplets and adding new reagents at defined times by droplet-fusion [89]. This microfluidic device was used to combine laccase production via CFPS with a laccase activity assay. The reaction conditions of CFPS and laccase assay reagents are generally incompatible. The application of the droplet-fusion technology enabled production of the enzyme in a droplet, which was subsequently fused to the assay reagent containing droplet. The combined synthesis and analysis were hence only possible by spatial and temporal separation. Another droplet-based microfluidic device has been used as an in vitro ultra-high-throughput screening platform [90]. Single genes were compartmentalized in droplets, amplified using PCR, fused to a CFPS containing droplet, and finally to the reagent containing droplet for a fluorogenic assay. Afterwards the droplets were analyzed and genes recovered from droplets which complied with the desired enzyme activity. In general, compared to screening systems using microtiter plates, costs, reagent consumption, production, and analysis time can be dramatically reduced.
Moreover, CFPS provides a powerful tool for the manufacturing of protein microarrays. These protein chips are solid-phase ligand binding assay systems for high-throughput testing of interactions and activities of proteins. Typical challenges in protein array technology are an efficient protein synthesis and availability, a functional protein immobilization and purification, and the long-term stability of immobilized proteins [74]. The parallel synthesis of several proteins directly onto an immobilizing surface can circumvent these drawbacks. Different methods are described, such as PISA (Protein In Situ Array), NAPPA (Nucleic Acid Programmable Protein Array), and DAPA (DNA to Protein Array) [91]. All approaches have in common that the transcription, translation, and immobilization take place simultaneously in situ (on-chip). They differ in the type of DNA template and of the protein capture entities. The protein arraying via PISA uses PCR DNA constructs, containing all necessary sequences for transcription and translation and additionally a tag-coding sequence for immobilization by means of a tag capture agent on the surface of the chip [92]. In contrast, the NAPPA method generates protein microarrays by printing DNA templates onto glass slides with a subsequent transcription and translation of the target proteins. Tags fused to the proteins enable the immobilization via antibodies and an easy purification. [93] A screening process for identification of new antibody responses to the Mycobacterium tuberculosis proteome with about 4,000 tested genes was performed with NAPPA generated microarrays and yielded 8 proteins with tuberculosis biomarker value [94]. The DAPA technology allows the production of replicate protein arrays [95]. A single DNA array template with covalently immobilized PCR DNA constructs can generate at least 20 copies of a protein array. The CFPS takes place in a permeable membrane carrying all components for the reaction, which is arranged between the DNA array slide and a second slide with a tag-capturing agent. Synthesized proteins can diffuse through the membrane and get immobilized onto the second slide. Further optimizations of DAPA led to an optimal combination of array supporting coatings and a 3D surface structure, which allows the synthesis of proteins in a comparable scale to classically spotted protein arrays [96].
The integration of advanced high-throughput technologies enables the application of CFPS for rapid prototyping in order to accelerate the screening process of enzymes with improved characteristics [97,98]. For example, 63 proteins of Pseudomonas aeruginosa in the size range of 18–59 kDa were produced and analyzed within 4 h by one person [99]. A mutant library consisting of 10,000 genes coding for sialyltransferase genes was screened to identify enzymes with improved activities within a few days [100]. Furthermore, a protocol named RAPPER (Rapid Parallel Protein EvaluatoR) was established for the fast preparation of functional enzyme variants from linear, mutagenic DNA templates [27]. The application of RAPPER facilitated an efficient evaluation of old yellow enzyme variants, which contained amino acid substitutions and deletions, with regard to conversion rates of various substrates [101]. CFPS is not only used to synthesize protein libraries but also for metabolic engineering purposes, e.g., to debug and optimize biosynthetic pathways. Cell-free prototyping of biosynthetic operons for the production of polyhydroxyalkanoates (PHAs) in combination with screening of relevant metabolite recycling enzymes revealed an operon, which produced higher levels of PHAs than the native operon [102]. The results of the prototyping were subsequently validated with in vivo assays. Cell-free metabolic engineering is thus a promising tool to identify the best combination of enzymes that work together [103,104]. Combining CFPS with cell-free metabolic engineering simplifies the manipulation of metabolic pathways and avoids the need for time-intensive engineering of organisms [105,106]. This was also recently demonstrated during an evaluation of bioengineering methods [107]. A group of scientists tried to synthesize 10 molecules in 90 days, which were unknown to them in advance. To achieve this goal, various enzymes were tested and optimized in order to construct functional biosynthesis routes. In the end, two of the molecules were produced with enzyme cascades synthesized via CFPS. CFPS is hence competitive to recombinant expression and complements in vivo protein synthesis approaches.
CFPS systems are widely used at a small scale for research and development purposes. However, after the enzyme is found with the desired functions, it is usually produced in large amounts using traditional protein synthesis approaches, such as overexpression or heterologous expression. Only some researchers publish the scale-up of CFPS systems for industrial application. Fujiwara et al. reported a scale-up with a volume of 9 L for the synthesis of GFP [108]. The achieved concentration of 0.5 mg mL−1 was comparable to other preparation methods and smaller scales. Although only a volume of about 9 L was tested, the authors expect scalability to hundreds of liters. Zawada et al. achieved a linear scalability using an optimized process with regard to extract preparation, gene sequence, and redox parameters [109]. The scalability was realized over a range of 250 µL to 100 L for the production of a multi-disulfide-bonded protein with a concentration of about 0.7 mg mL−1. This milestone production at a large scale might enable the commercial production of proteins that are inaccessible to cells in the future. Nevertheless, for most of the described applications in this review, namely high-throughput functional analyses, scale-up in terms of volume is not required.
4. Limitations and Challenges of CFPS
The applications discussed above demonstrate the importance and contribution of CFPS for efficiently synthesizing new enzymes for functional analyses. However, CFPS has technology-based limitations and impacts which have to be considered. Very recent research focuses on the effects imposed by the highly artificial environment in CFPS systems, which significantly differs from the natural protein synthesis in a viable cell.
One important aspect is certainly the influence of molecular interactions, for example the crowding phenomenon, viscosity, and related effects. The cytoplasmic space of cells exhibits a total protein concentration roughly 20-fold higher compared to CFPS extracts [110]. It is known that macromolecular crowding can have an influence on enzyme kinetics, increases transcription rates, and might enhance the robustness of gene expression [111,112,113]. Nevertheless, up to now, the impact of crowding on protein synthesis efficiency in CFPS systems is not reliably quantified and completely understood. Interestingly, the compartment volume, which is used for CFPS, seems to have an influence on protein synthesis rate and yield. Okano et al. showed that protein synthesis begins quicker in smaller volumes (56 fL), but maximally achieved protein concentrations are higher in bigger volumes (126 fL) [114]. The reasons for the dependency of protein synthesis on compartment size are manifold and can be attributed to dilution effects [114], but also to surface area to volume ratio [115]. In general, the artificiality of the protein synthesis environment, the overlapping influences of physical aspects, as well as the individual biochemical requirements of the transcription and translation machinery makes the predictability and transferability of CFPS difficult.
Another significant difference is the protein synthesis rate, which is usually slower for in vitro based protein synthesis compared to protein synthesis in vivo. The decreased efficiency is probably caused by the discrepancy of transcription and translation rate in CFPS systems, which are tightly synchronized in vivo. The translation in CFPS is hampered due to the limited availability of the elongation factor Tu and tRNA [116]. The accumulation of mRNA results in inactivation in the form of degradation or the formation of mRNA secondary structures and mRNA:DNA hybrids [117]. A solution might be the separation of transcription and translation machinery with an intermediate mRNA purification step [88]. However, this approach contradicts the demands of a time-efficient, easy, and universally applicable high-throughput protein synthesis strategy. The knowledge about CFPS extracts and their performance limits has to be improved to make this system more broadly applicable for industry.
CFPS extracts are complex reaction systems with predominantly unknown contents. Proteomics-based tools are able to decipher the composition of CFPS systems. By analyzing the proteome of CFPS extracts, more than 1000 proteins were identified [118]. This information contributes to improve extract preparation in order to increase the folding capacity, solubility, and activity of the target protein [119]. Furthermore, such proteomic analyses might contribute to describing and enhancing reproducibility of CFPS extract preparation. Next to proteomic-based analyses, modeling approaches for simulating the synthesis of target proteins enable one to reveal system limitations, and furthermore offer the possibility to estimate and optimize the CFPS performance in silico [120].
The complexity and unspecific composition of CFPS extracts is also challenging for activity screenings. For example, side reactions or inhibition by extract components might influence the activity of the synthesized target enzyme. Possibilities for target enzyme isolation could be purification by removing all other components (as realized in [40]) or the immobilization of the target enzyme itself and subsequent washing steps. However, these purification steps require extra effort leading to reduced effectiveness of CFPS for rapid prototyping. Furthermore, the quantification of product molecules is difficult in such complex solutions. An example for integrated CFPS and activity screening was published by Gagoski et al. [121]. In this study, thermostable endo-1,4-β-glucanases and xylanases were characterized without purification using substrates labeled with a colorimetric dye. The release of the dye resulted in an absorption increase that correlates well with the enzyme activities. However, this method is limited to substrates and products which are optically quantifiable. Nevertheless, advanced chromatography or mass spectrometry systems combined with miniaturization and automation technologies for sample preparation enable rapid and parallel activity analyses of CFPS products.
In our opinion, different issues have to be addressed for CFPS to be widely accepted as protein synthesis platform in industrial applications: quality control methods are required for reproducible extract preparation; the CFPS preparation itself has to be generalizable and accessible for high-throughput; the transferability of in vitro expression is mandatory, when a subsequent in vivo expression at large scale is envisaged. Despite the discussed challenges of CFPS application, these systems provide new opportunities for getting deeper insights into cellular expression mechanisms and contribute to understanding the metabolic costs for protein production [122]. Furthermore, by using such an open system, bottlenecks of biomolecular editing tools can be identified and enhance our mechanistic understanding of genome-editing [123]. This knowledge enables improving the efficiency of protein synthesis, in vitro as well as in vivo.
5. Conclusions
In this review, we have shown that CFPS bears a high value for biocatalytic processes and has become an accepted alternative for in vivo expression systems. Different compositions of E. coli extract based CFPS systems were presented and the necessity and purpose of individual supplements, which significantly affect the efficiency and productivity of the CFPS reaction, were discussed. The rational improvement of supplemental components results in systems with protein yields in milligram per milliliter scale, which permits novel CFPS applications beyond pure research interests. The scale-up of CFPS is currently an almost negligible aspect due to the high costs for the reaction components and a reduced added value by shorter production times compared to cell-based expression. However, the integration of CFPS in platforms for high-throughput enzyme screening and analysis has been proven as a powerful and versatile tool for the fast discovery of new candidates or improved biocatalyst variants. In addition, the in vitro construction and study of synthetic pathways in combination with traditional strain development can become a valuable instrument for the engineering of biocatalytic processes. While CFPS permits a rapid and inexpensive identification of the best suitable enzyme candidates for application in a biocatalytic process, the traditional in vivo technologies enable a scale-up and subsequent high-level production. CFPS has become a technology which makes protein engineering and the prototyping of new enzymes accessible for many laboratories, as specialized equipment and considerable experience are not required. It is therefore ideally suited to help in the faster accumulation of functional data on enzymes.
Funding
This research received no external funding.
Acknowledgments
We acknowledge financial support by Deutsche Forschungsgemeinschaft and TU Dortmund University within the funding program Open Access Publishing.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Schmid, A.; Dordick, J.S.; Hauer, B.; Kiener, A.; Wubbolts, M.; Witholt, B. Industrial biocatalysis today and tomorrow. Nature 2001, 409, 258–268. [Google Scholar] [CrossRef] [PubMed]
- Chapman, J.; Ismail, A.E.; Dinu, C.Z. Industrial applications of enzymes: Recent advances, techniques, and outlooks. Catalysts 2018, 8, 238. [Google Scholar] [CrossRef]
- Pellis, A.; Cantone, S.; Ebert, C.; Gardossi, L. Evolving biocatalysis to meet bioeconomy challenges and opportunities. New Biotechnol. 2018, 40, 154–169. [Google Scholar] [CrossRef] [PubMed]
- Rosenthal, K.; Lütz, S. Recent developments and challenges of biocatalytic processes in the pharmaceutical industry. Curr. Opin. Green Sustain. Chem. 2018, 11, 58–64. [Google Scholar] [CrossRef]
- Bornscheuer, U.T. The fourth wave of biocatalysis is approaching. Philos. Trans. R. Soc. A 2018, 376. [Google Scholar] [CrossRef]
- Schmitz, L.M.; Rosenthal, K.; Lütz, S. Enzyme-based electrobiotechnological synthesis. In Bioelectrosynthesis. Advances in Biochemical Engineering/Biotechnology; Harnisch, F., Holtmann, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 87–134. [Google Scholar]
- Wang, X.D.; Saba, T.; Yiu, H.H.P.; Howe, R.F.; Anderson, J.A.; Shi, J.F. Cofactor NAD(P)H regeneration inspired by heterogeneous pathways. Chem-Us 2017, 2, 621–654. [Google Scholar] [CrossRef]
- Karande, R.; Schmid, A.; Buehler, K. Applications of multiphasic microreactors for biocatalytic reactions. Org. Process. Res. Dev. 2016, 20, 361–370. [Google Scholar] [CrossRef]
- Weissman, S.A.; Anderson, N.G. Design of experiments (DoE) and process optimization. A review of recent publications. Org. Process. Res. Dev. 2015, 19, 1605–1633. [Google Scholar] [CrossRef]
- Gernaey, K.V.; Lantz, A.E.; Tufvesson, P.; Woodley, J.M.; Sin, G. Application of mechanistic models to fermentation and biocatalysis for next-generation processes. Trends Biotechnol. 2010, 28, 346–354. [Google Scholar] [CrossRef]
- Fernandes, P. Miniaturization in biocatalysis. Int. J. Mol. Sci. 2010, 11, 858–879. [Google Scholar] [CrossRef] [PubMed]
- Wohlgemuth, R. Biocatalytic process design and reaction engineering. Chem. Biochem. Eng. Q. 2017, 31, 131–138. [Google Scholar] [CrossRef]
- Lima-Ramos, J.; Tufvesson, P.; Woodley, J.M. Application of environmental and economic metrics to guide the development of biocatalytic processes. Green Process. Synth. 2014, 3, 195–213. [Google Scholar] [CrossRef]
- Truppo, M.D. Biocatalysis in the pharmaceutical industry: The need for speed. ACS Med. Chem. Lett. 2017, 8, 476–480. [Google Scholar] [CrossRef] [PubMed]
- Fernandes, A.C.; Halder, J.M.; Nestl, B.M.; Hauer, B.; Gernaey, K.V.; Kruhne, U. Biocatalyst screening with a twist: Application of oxygen sensors integrated in microchannels for screening whole cell biocatalyst variants. Bioengineering 2018, 5, 30. [Google Scholar] [CrossRef] [PubMed]
- Lütz, S.; Giver, L.; Lalonde, J. Engineered enzymes for chemical production. Biotechnol. Bioeng. 2008, 101, 647–653. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tholey, A.; Heinzle, E. Methods for Biocatalyst Screening. In Tools and Applications of Biochemical Engineering Science; Schügerl, K., Zeng, A.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Wahler, D.; Reymond, J.L. Novel methods for biocatalyst screening. Curr. Opin. Chem. Biol. 2001, 5, 152–158. [Google Scholar] [CrossRef]
- Hammerich, O.; Speiser, B. Organic Electrochemistry, Revised and Expanded, 5th ed.; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Carbonell, P.; Currin, A.; Jervis, A.J.; Rattray, N.J.W.; Swainston, N.; Yan, C.Y.; Takano, E.; Breitling, R. Bioinformatics for the synthetic biology of natural products: Integrating across the Design-Build-Test cycle. Nat. Prod. Rep. 2016, 33, 925–932. [Google Scholar] [CrossRef]
- Ellens, K.W.; Christian, N.; Singh, C.; Satagopam, V.P.; May, P.; Linster, C.L. Confronting the catalytic dark matter encoded by sequenced genomes. Nucleic Acids Res. 2017, 45, 11495–11514. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Popovic, A.; Hai, T.; Tchigvintsev, A.; Hajighasemi, M.; Nocek, B.; Khusnutdinova, A.N.; Brown, G.; Glinos, J.; Flick, R.; Skarina, T.; et al. Activity screening of environmental metagenomic libraries reveals novel carboxylesterase families. Sci. Rep. 2017, 7, 44103. [Google Scholar] [CrossRef] [PubMed]
- Gerlt, J.A.; Allen, K.N.; Almo, S.C.; Armstrong, R.N.; Babbitt, P.C.; Cronan, J.E.; Dunaway-Mariano, D.; Imker, H.J.; Jacobson, M.P.; Minor, W.; et al. The Enzyme Function Initiative. Biochemistry 2011, 50, 9950–9962. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gerlt, J.A.; Bouvier, J.T.; Davidson, D.B.; Imker, H.J.; Sadkhin, B.; Slater, D.R.; Whalen, K.L. Enzyme Function Initiative-Enzyme Similarity Tool (EFI-EST): A web tool for generating protein sequence similarity networks. Biochim. Biophys. Acta 2015, 1854, 1019–1037. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kempa, E.E.; Hollywood, K.A.; Smith, C.A.; Barran, P.E. High throughput screening of complex biological samples with mass spectrometry—From bulk measurements to single cell analysis. Analyst 2019, 144, 872–891. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.-L.; Wagner, J.M.; Alper, H.S. Enabling tools for high-throughput detection of metabolites: Metabolic engineering and directed evolution applications. Biotechnol. Adv. 2017, 35, 950–970. [Google Scholar] [CrossRef] [PubMed]
- Quertinmont, L.T.; Orru, R.; Lutz, S. RApid Parallel Protein EvaluatoR (RAPPER), from gene to enzyme function in one day. Chem. Commun. 2015, 51, 122–124. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Yang, X.; Yang, S.; Zhu, M.; Wang, X. Technology prospecting on enzymes: Application, marketing and engineering. Comput. Struct. Biotechnol. J. 2012, 2, e201209017. [Google Scholar] [CrossRef] [PubMed]
- Nirenberg, M.W.; Matthaei, J.H. The dependence of cell-free protein synthesis in E. coli upon naturally occurring or synthetic polyribonucleotides. Proc. Natl. Acad. Sci. USA 1961, 47, 1588–1602. [Google Scholar] [CrossRef] [PubMed]
- Jin, X.; Hong, S.H. Cell-free protein synthesis for producing ‘difficult-to-express’ proteins. Biochem. Eng. J. 2018, 138, 156–164. [Google Scholar] [CrossRef]
- Caschera, F.; Noireaux, V. Synthesis of 2.3 mg/mL of protein with an all Escherichia coli cell-free transcription-translation system. Biochimie 2014, 99, 162–168. [Google Scholar] [CrossRef]
- Schwarz, D.; Junge, F.; Durst, F.; Frolich, N.; Schneider, B.; Reckel, S.; Sobhanifar, S.; Dotsch, V.; Bernhard, F. Preparative scale expression of membrane proteins in Escherichia coli-based continuous exchange cell-free systems. Nat. Protoc. 2007, 2, 2945–2957. [Google Scholar] [CrossRef]
- Salehi, A.S.M.; Smith, M.T.; Bennett, A.M.; Williams, J.B.; Pitt, W.G.; Bundy, B.C. Cell-free protein synthesis of a cytotoxic cancer therapeutic: Onconase production and a just-add-water cell-free system. Biotechnol. J. 2016, 11, 274–281. [Google Scholar] [CrossRef]
- Sachse, R.; Dondapati, S.K.; Fenz, S.F.; Schmidt, T.; Kubick, S. Membrane protein synthesis in cell-free systems: From bio-mimetic systems to bio-membranes. FEBS Lett. 2014, 588, 2774–2781. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rosenblum, G.; Cooperman, B.S. Engine out of the chassis: Cell-free protein synthesis and its uses. FEBS Lett. 2014, 588, 261–268. [Google Scholar] [CrossRef] [PubMed]
- Niwa, T.; Kanamori, T.; Ueda, T.; Taguchi, H. Global analysis of chaperone effects using a reconstituted cell-free translation system. Proc. Natl. Acad. Sci. USA 2012, 109, 8937–8942. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sullivan, C.J.; Pendleton, E.D.; Sasmor, H.H.; Hicks, W.L.; Farnum, J.B.; Muto, M.; Amendt, E.M.; Schoborg, J.A.; Martin, R.W.; Clark, L.G.; et al. A cell-free expression and purification process for rapid production of protein biologics. Biotechnol. J. 2016, 11, 238–248. [Google Scholar] [CrossRef] [PubMed]
- Martin, R.W.; Des Soye, B.J.; Kwon, Y.-C.; Kay, J.; Davis, R.G.; Thomas, P.M.; Majewska, N.I.; Chen, C.X.; Marcum, R.D.; Weiss, M.G.; et al. Cell-free protein synthesis from genomically recoded bacteria enables multisite incorporation of noncanonical amino acids. Nat. Commun. 2018, 9, 1203. [Google Scholar] [CrossRef] [PubMed]
- Zhao, F.; Yu, C.-H.; Liu, Y. Codon usage regulates protein structure and function by affecting translation elongation speed in Drosophila cells. Nucleic Acids Res. 2017, 45, 8484–8492. [Google Scholar] [CrossRef] [PubMed]
- Ohashi, H.; Kanamori, T.; Shimizu, Y.; Ueda, T. A highly controllable reconstituted cell-free system-a breakthrough in protein synthesis research. Curr. Pharm. Biotechnol. 2010, 11, 267–271. [Google Scholar] [CrossRef]
- Zemella, A.; Thoring, L.; Hoffmeister, C.; Kubick, S. Cell-free protein synthesis: Pros and cons of prokaryotic and eukaryotic systems. ChemBioChem 2015, 16, 2420–2431. [Google Scholar] [CrossRef]
- Liu, W.-Q.; Zhang, L.; Chen, M.; Li, J. Cell-free protein synthesis: Recent advances in bacterial extract sources and expanded applications. Biochem. Eng. J. 2019, 141, 182–189. [Google Scholar] [CrossRef]
- Schoborg, J.A.; Hodgman, E.C.; Anderson, M.J.; Jewett, M.C. Substrate replenishment and byproduct removal improve yeast cell-free protein synthesis. Biotechnol. J. 2014, 9, 630–640. [Google Scholar] [CrossRef]
- Olliver, L.; Boyd, C.D. In vitro translation of mRNA in a rabbit reticulocyte lysate cell-free system. In The Nucleic Acid Protocols Handbook; Rapley, R., Ed.; Humana Press: Totowa, NJ, USA, 2000; pp. 885–890. [Google Scholar]
- Sawasaki, T.; Ogasawara, T.; Morishita, R.; Endo, Y. A cell-free protein synthesis system for high-throughput proteomics. Proc. Natl. Acad. Sci. USA 2002, 99, 14652–14657. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ezure, T.; Suzuki, T.; Ando, E. A cell-free protein synthesis system from insect cells. In Cell-Free Protein Synthesis: Methods and Protocols; Alexandrov, K., Johnston, W.A., Eds.; Humana Press: Totowa, NJ, USA, 2014; Volume 607, pp. 285–296. [Google Scholar]
- Brödel, A.K.; Sonnabend, A.; Kubick, S. Cell-free protein expression based on extracts from CHO cells. Biotechnol. Bioeng. 2014, 111, 25–36. [Google Scholar] [CrossRef]
- Carlson, E.D.; Gan, R.; Hodgman, C.E.; Jewett, M.C. Cell-free protein synthesis: Applications come of age. Biotechnol. Adv. 2012, 30, 1185–1194. [Google Scholar] [CrossRef] [Green Version]
- Pratt, J.M. Coupled transcription-translation in prokaryotic cell-free systems. In Transcription and Translation: A Practical Approach; Hames, B.D., Higgins, S.J., Eds.; IRL Press: Oxford, UK, 1984; pp. 179–209. [Google Scholar]
- Kim, D.-M.; Swartz, J.R. Oxalate improves protein synthesis by enhancing ATP supply in a cell-free system derived from Escherichia coli. Biotechnol. Lett. 2000, 22, 1537–1542. [Google Scholar] [CrossRef]
- Jewett, M.C.; Swartz, J.R. Mimicking the Escherichia coli cytoplasmic environment activates long-lived and efficient cell-free protein synthesis. Biotechnol. Bioeng. 2004, 86, 19–26. [Google Scholar] [CrossRef] [PubMed]
- Sitaraman, K.; Esposito, D.; Klarmann, G.; Le Grice, S.F.; Hartley, J.L.; Chatterjee, D.K. A novel cell-free protein synthesis system. J. Biotechnol. 2004, 110, 257–263. [Google Scholar] [CrossRef] [PubMed]
- Calhoun, K.A.; Swartz, J.R. An economical method for cell-free protein synthesis using glucose and nucleoside monophosphates. Biotechnol. Prog. 2005, 21, 1146–1153. [Google Scholar] [CrossRef]
- Shin, J.; Noireaux, V. Efficient cell-free expression with the endogenous E. coli RNA polymerase and sigma factor 70. J. Biol. Eng. 2010, 4, 8. [Google Scholar] [CrossRef]
- Yang, W.C.; Patel, K.G.; Wong, H.E.; Swartz, J.R. Simplifying and streamlining Escherichia coli-based cell-free protein synthesis. Biotechnol. Prog. 2012, 28, 413–420. [Google Scholar] [CrossRef] [PubMed]
- Krinsky, N.; Kaduri, M.; Shainsky-Roitman, J.; Goldfeder, M.; Ivanir, E.; Benhar, I.; Shoham, Y.; Schroeder, A. A simple and rapid method for preparing a cell-free bacterial lysate for protein synthesis. PLoS ONE 2016, 11, e0165137. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.-M.; Swartz, J.R. Regeneration of adenosine triphosphate from glycolytic intermediates for cell-free protein synthesis. Biotechnol. Bioeng. 2001, 74, 309–316. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.-M.; Swartz, J.R. Prolonging cell-free protein synthesis by selective reagent additions. Biotechnol. Prog. 2000, 16, 385–390. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhang, Y.H. Cell-free protein synthesis energized by slowly-metabolized maltodextrin. BMC Biotechnol. 2009, 9, 58. [Google Scholar] [CrossRef]
- Ge, X.; Luo, D.; Xu, J. Cell-free protein expression under macromolecular crowding conditions. PLoS ONE 2011, 6, e28707. [Google Scholar] [CrossRef] [PubMed]
- Nevin, D.E.; Pratt, J.M. A coupled in vitro transcription-translation system for the exclusive synthesis of polypeptides expressed from the T7 promoter. FEBS Lett. 1991, 291, 259–263. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, E.; Wang, Y. A modified procedure for fast purification of T7 RNA polymerase. Protein Expr. Purif. 1999, 16, 355–358. [Google Scholar] [CrossRef] [PubMed]
- Kim, T.W.; Kim, D.M.; Choi, C.Y. Rapid production of milligram quantities of proteins in a batch cell-free protein synthesis system. J. Biotechnol. 2006, 124, 373–380. [Google Scholar] [CrossRef]
- Woodrow, K.A.; Airen, I.O.; Swartz, J.R. Rapid expression of functional genomic libraries. J. Proteome Res. 2006, 5, 3288–3300. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.L.; Ivashkiv, L.; Chen, H.Z.; Zubay, G.; Cashel, M. Cell-free coupled transcription-translation system for investigation of linear DNA segments. Proc. Natl. Acad. Sci. USA 1980, 77, 7029–7033. [Google Scholar] [CrossRef]
- Michel-Reydellet, N.; Woodrow, K.; Swartz, J. Increasing PCR fragment stability and protein yields in a cell-free system with genetically modified Escherichia coli extracts. J. Mol. Microbiol. Biotechnol. 2005, 9, 26–34. [Google Scholar] [CrossRef]
- Garamella, J.; Marshall, R.; Rustad, M.; Noireaux, V. The all E. coli TX-TL toolbox 2.0: A platform for cell-free synthetic biology. ACS Synth. Biol. 2016, 5, 344–355. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.Z.; Hayes, C.A.; Shin, J.; Caschera, F.; Murray, R.M.; Noireaux, V. Protocols for implementing an Escherichia coli based TX-TL cell-free expression system for synthetic biology. JoVE 2013, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.Z.; Yeung, E.; Hayes, C.A.; Noireaux, V.; Murray, R.M. Linear DNA for rapid prototyping of synthetic biological circuits in an Escherichia coli based TX-TL cell-free system. ACS Synth. Biol. 2014, 3, 387–397. [Google Scholar] [CrossRef] [PubMed]
- Pedersen, A.; Hellberg, K.; Enberg, J.; Karlsson, B.G. Rational improvement of cell-free protein synthesis. New Biotechnol. 2011, 28, 218–224. [Google Scholar] [CrossRef] [PubMed]
- Jaroentomeechai, T.; Stark, J.C.; Natarajan, A.; Glasscock, C.J.; Yates, L.E.; Hsu, K.J.; Mrksich, M.; Jewett, M.C.; DeLisa, M.P. Single-pot glycoprotein biosynthesis using a cell-free transcription-translation system enriched with glycosylation machinery. Nat. Commun. 2018, 9, 2686. [Google Scholar] [CrossRef] [PubMed]
- Fujii, S.; Matsuura, T.; Sunami, T.; Kazuta, Y.; Yomo, T. In vitro evolution of alpha-hemolysin using a liposome display. Proc. Natl. Acad. Sci. USA 2013, 110, 16796–16801. [Google Scholar] [CrossRef] [PubMed]
- Damiati, S.; Kompella, U.B.; Damiati, S.A.; Kodzius, R. Microfluidic devices for drug delivery systems and drug screening. Genes 2018, 9, 103. [Google Scholar] [CrossRef]
- He, M.; Stoevesandt, O.; Taussig, M.J. In situ synthesis of protein arrays. Curr. OpiN Biotechnol. 2008, 19, 4–9. [Google Scholar] [CrossRef]
- Beppu, K.; Izri, Z.; Maeda, Y.T.; Sakamoto, R. Geometric effect for biological reactors and biological fluids. Bioengineering 2018, 5, 110. [Google Scholar] [CrossRef]
- Caschera, F.; Noireaux, V. Integration of biological parts toward the synthesis of a minimal cell. Curr. Opin. Chem. Biol. 2014, 22, 85–91. [Google Scholar] [CrossRef]
- Jiao, Y.; Liu, Y.; Luo, D.; Huck, W.T.S.; Yang, D. Microfluidic-assisted fabrication of clay microgels for cell-free protein synthesis. ACS Appl. Mater. Interfaces 2018, 10, 29308–29313. [Google Scholar] [CrossRef] [PubMed]
- Breton, M.; Amirkavei, M.; Mir, L.M. Optimization of the electroformation of giant unilamellar vesicles (GUVs) with unsaturated phospholipids. J. Membr. Biol. 2015, 248, 827–835. [Google Scholar] [CrossRef] [PubMed]
- Elani, Y.; Law, R.V.; Ces, O. Protein synthesis in artificial cells: Using compartmentalisation for spatial organisation in vesicle bioreactors. Phys. Chem. Chem. Phys. 2015, 17, 15534–15537. [Google Scholar] [CrossRef] [PubMed]
- Los, G.V.; Encell, L.P.; McDougall, M.G.; Hartzell, D.D.; Karassina, N.; Zimprich, C.; Wood, M.G.; Learish, R.; Ohana, R.F.; Urh, M.; et al. HaloTag: A novel protein labeling technology for cell imaging and protein analysis. ACS Chem. Biol. 2008, 3, 373–382. [Google Scholar] [CrossRef] [PubMed]
- Jia, H.; Heymann, M.; Bernhard, F.; Schwille, P.; Kai, L. Cell-free protein synthesis in micro compartments: Building a minimal cell from biobricks. New Biotechnol. 2017, 39, 199–205. [Google Scholar] [CrossRef] [PubMed]
- Fenz, S.F.; Sachse, R.; Schmidt, T.; Kubick, S. Cell-free synthesis of membrane proteins: Tailored cell models out of microsomes. Biochim. Biophys. Acta 2014, 1838, 1382–1388. [Google Scholar] [CrossRef] [Green Version]
- Noireaux, V.; Libchaber, A. A vesicle bioreactor as a step toward an artificial cell assembly. Proc. Natl. Acad. Sci. USA 2004, 101, 17669–17674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, K.H.; Kim, D.M. Applications of cell-free protein synthesis in synthetic biology: Interfacing bio-machinery with synthetic environments. Biotechnol. J. 2013, 8, 1292–1300. [Google Scholar] [CrossRef] [PubMed]
- Damiati, S.; Mhanna, R.; Kodzius, R.; Ehmoser, E.K. Cell-free approaches in synthetic biology utilizing microfluidics. Genes 2018, 9, 144. [Google Scholar] [CrossRef]
- Mei, Q.; Fredrickson, C.K.; Simon, A.; Khnouf, R.; Fan, Z.H. Cell-free protein synthesis in microfluidic array devices. Biotechnol. Prog. 2007, 23, 1305–1311. [Google Scholar] [CrossRef]
- Timm, A.C.; Shankles, P.G.; Foster, C.M.; Doktycz, M.J.; Retterer, S.T. Toward microfluidic reactors for cell-free protein synthesis at the point-of-care. Small 2016, 12, 810–817. [Google Scholar] [CrossRef] [PubMed]
- Georgi, V.; Georgi, L.; Blechert, M.; Bergmeister, M.; Zwanzig, M.; Wustenhagen, D.A.; Bier, F.F.; Jung, E.; Kubick, S. On-chip automation of cell-free protein synthesis: New opportunities due to a novel reaction mode. Lab Chip 2016, 16, 269–281. [Google Scholar] [CrossRef] [PubMed]
- Mazutis, L.; Baret, J.C.; Treacy, P.; Skhiri, Y.; Araghi, A.F.; Ryckelynck, M.; Taly, V.; Griffiths, A.D. Multi-step microfluidic droplet processing: Kinetic analysis of an in vitro translated enzyme. Lab Chip 2009, 9, 2902–2908. [Google Scholar] [CrossRef] [PubMed]
- Fallah-Araghi, A.; Baret, J.C.; Ryckelynck, M.; Griffiths, A.D. A completely in vitro ultrahigh-throughput droplet-based microfluidic screening system for protein engineering and directed evolution. Lab Chip 2012, 12, 882–891. [Google Scholar] [CrossRef]
- Contreras-Llano, L.E.; Tan, C. High-throughput screening of biomolecules using cell-free gene expression systems. Synth. Biol. 2018, 3. [Google Scholar] [CrossRef]
- He, M.; Taussig, M.J. Single step generation of protein arrays from DNA by cell-free expression and in situ immobilisation (PISA method). Nucleic Acids Res. 2001, 29, e73. [Google Scholar] [CrossRef] [PubMed]
- Ramachandran, N.; Hainsworth, E.; Bhullar, B.; Eisenstein, S.; Rosen, B.; Lau, A.Y.; Walter, J.C.; LaBaer, J. Self-assembling protein microarrays. Science 2004, 305, 86–90. [Google Scholar] [CrossRef]
- Song, L.; Wallstrom, G.; Yu, X.; Hopper, M.; Van Duine, J.; Steel, J.; Park, J.; Wiktor, P.; Kahn, P.; Brunner, A.; et al. Identification of antibody targets for tuberculosis serology using high-density nucleic acid programmable protein arrays. Mol. Cell. Proteom. 2017, 16, 277–289. [Google Scholar] [CrossRef]
- He, M.; Stoevesandt, O.; Palmer, E.A.; Khan, F.; Ericsson, O.; Taussig, M.J. Printing protein arrays from DNA arrays. Nat. Methods 2008, 5, 175. [Google Scholar] [CrossRef]
- Schmidt, R.; Cook, E.A.; Kastelic, D.; Taussig, M.J.; Stoevesandt, O. Optimised ‘on demand’ protein arraying from DNA by cell free expression with the ‘DNA to Protein Array’ (DAPA) technology. J. Proteom. 2013, 88, 141–148. [Google Scholar] [CrossRef]
- Catherine, C.; Lee, K.H.; Oh, S.J.; Kim, D.M. Cell-free platforms for flexible expression and screening of enzymes. Biotechnol. Adv. 2013, 31, 797–803. [Google Scholar] [CrossRef] [PubMed]
- Jiang, L.; Zhao, J.; Lian, J.; Xu, Z. Cell-free protein synthesis enabled rapid prototyping for metabolic engineering and synthetic biology. Synth. Syst. Biotechnol. 2018, 3, 90–96. [Google Scholar] [CrossRef] [PubMed]
- Murthy, T.V.; Wu, W.; Qiu, Q.Q.; Shi, Z.; LaBaer, J.; Brizuela, L. Bacterial cell-free system for high-throughput protein expression and a comparative analysis of Escherichia coli cell-free and whole cell expression systems. Protein Expr. Purif. 2004, 36, 217–225. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.C.; Kim, K.S.; Kang, T.J.; Choi, J.H.; Song, J.J.; Choi, Y.H.; Kim, B.G.; Kim, D.M. Implementing bacterial acid resistance into cell-free protein synthesis for buffer-free expression and screening of enzymes. Biotechnol. Bioeng. 2015, 112, 2630–2635. [Google Scholar] [CrossRef]
- Quertinmont, L.T.; Lutz, S. Cell-free protein engineering of Old Yellow Enzyme 1 from Saccharomyces pastorianus. Tetrahedron 2016, 72, 7282–7287. [Google Scholar] [CrossRef]
- Kelwick, R.; Ricci, L.; Webb, A.J.; Freemont, P.S.; Bell, D.; Chee, S.M. Cell-free prototyping strategies for enhancing the sustainable production of polyhydroxyalkanoates bioplastics. Synth. Biol. 2018, 3, 1–44. [Google Scholar] [CrossRef]
- Dudley, Q.M.; Karim, A.S.; Jewett, M.C. Cell-free metabolic engineering: Biomanufacturing beyond the cell. Biotechnol. J. 2015, 10, 69–82. [Google Scholar] [CrossRef]
- Morgado, G.; Gerngross, D.; Roberts, T.M.; Panke, S. Synthetic biology for cell-free biosynthesis: Fundamentals of designing novel in vitro multi-enzyme reaction networks. In Synthetic Biology—Metabolic Engineering; Zhao, H., Zeng, A.-P., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 117–146. [Google Scholar]
- Dudley, Q.M.; Anderson, K.C.; Jewett, M.C. Cell-free mixing of Escherichia coli crude extracts to prototype and rationally engineer high-titer mevalonate synthesis. ACS Synth. Biol. 2016, 5, 1578–1588. [Google Scholar] [CrossRef]
- Karim, A.S.; Jewett, M.C. A cell-free framework for rapid biosynthetic pathway prototyping and enzyme discovery. Metab. Eng. 2016, 36, 116–126. [Google Scholar] [CrossRef] [Green Version]
- Casini, A.; Chang, F.Y.; Eluere, R.; King, A.M.; Young, E.M.; Dudley, Q.M.; Karim, A.; Pratt, K.; Bristol, C.; Forget, A.; et al. A pressure test to make 10 molecules in 90 days: External evaluation of methods to engineer biology. J. Am. Chem. Soc. 2018, 140, 4302–4316. [Google Scholar] [CrossRef]
- Fujiwara, K.; Doi, N. Biochemical preparation of cell extract for cell-free protein synthesis without physical disruption. PLoS ONE 2016, 11, e0154614. [Google Scholar] [CrossRef] [PubMed]
- Zawada, J.F.; Yin, G.; Steiner, A.R.; Yang, J.; Naresh, A.; Roy, S.M.; Gold, D.S.; Heinsohn, H.G.; Murray, C.J. Microscale to manufacturing scale-up of cell-free cytokine production—A new approach for shortening protein production development timelines. Biotechnol. Bioeng. 2011, 108, 1570–1578. [Google Scholar] [CrossRef] [PubMed]
- Swartz, J.R. Expanding biological applications using cell-free metabolic engineering: An overview. Metab. Eng. 2018. [Google Scholar] [CrossRef] [PubMed]
- Tan, C.; Saurabh, S.; Bruchez, M.P.; Schwartz, R.; Leduc, P. Molecular crowding shapes gene expression in synthetic cellular nanosystems. Nat. Nanotechnol. 2013, 8, 602–608. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fritz, B.R.; Jamil, O.K.; Jewett, M.C. Implications of macromolecular crowding and reducing conditions for in vitro ribosome construction. Nucleic Acids Res. 2015, 43, 4774–4784. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, N.-N.; Vibhute, M.A.; Zheng, L.; Zhao, H.; Yelleswarapu, M.; Huck, W.T.S. Macromolecularly crowded protocells from reversibly shrinking monodisperse liposomes. J. Am. Chem. Soc. 2018, 140, 7399–7402. [Google Scholar] [CrossRef]
- Okano, T.; Matsuura, T.; Suzuki, H.; Yomo, T. Cell-free protein synthesis in a microchamber revealed the presence of an optimum compartment volume for high-order reactions. ACS Synth. Biol. 2014, 3, 347–352. [Google Scholar] [CrossRef]
- Sakamoto, R.; Noireaux, V.; Maeda, Y.T. Anomalous scaling of gene expression in confined cell-free reactions. Sci. Rep. 2018, 8, 7364. [Google Scholar] [CrossRef]
- Niess, A.; Failmezger, J.; Kuschel, M.; Siemann-Herzberg, M.; Takors, R. Experimentally validated model enables debottlenecking of in vitro protein synthesis and identifies a control shift under in vivo conditions. ACS Synth. Biol. 2017, 6, 1913–1921. [Google Scholar] [CrossRef]
- Hansen, M.M.; Ventosa Rosquelles, M.; Yelleswarapu, M.; Maas, R.J.; van Vugt-Jonker, A.J.; Heus, H.A.; Huck, W.T. Protein synthesis in coupled and uncoupled cell-free prokaryotic gene expression systems. ACS Synth. Biol. 2016, 5, 1433–1440. [Google Scholar] [CrossRef]
- Hurst, G.B.; Asano, K.G.; Doktycz, C.J.; Consoli, E.J.; Doktycz, W.L.; Foster, C.M.; Morrell-Falvey, J.L.; Standaert, R.F.; Doktycz, M.J. Proteomics-based tools for evaluation of cell-free protein synthesis. Anal. Chem. 2017, 89, 11443–11451. [Google Scholar] [CrossRef] [PubMed]
- Foshag, D.; Henrich, E.; Hiller, E.; Schafer, M.; Kerger, C.; Burger-Kentischer, A.; Diaz-Moreno, I.; Garcia-Maurino, S.M.; Dotsch, V.; Rupp, S.; et al. The E. coli S30 lysate proteome: A prototype for cell-free protein production. New Biotechnol. 2018, 40, 245–260. [Google Scholar] [CrossRef] [PubMed]
- Vilkhovoy, M.; Horvath, N.; Shih, C.H.; Wayman, J.A.; Calhoun, K.; Swartz, J.; Varner, J.D. Sequence specific modeling of E. coli cell-free protein synthesis. ACS Synth. Biol. 2018, 7, 1844–1857. [Google Scholar] [CrossRef] [PubMed]
- Gagoski, D.; Shi, Z.; Nielsen, L.K.; Vickers, C.E.; Mahler, S.; Speight, R.; Johnston, W.A.; Alexandrov, K. Cell-free pipeline for discovery of thermotolerant xylanases and endo-1,4-β-glucanases. J. Biotechnol. 2017, 259, 191–198. [Google Scholar] [CrossRef] [PubMed]
- Borkowski, O.; Bricio, C.; Murgiano, M.; Rothschild-Mancinelli, B.; Stan, G.B.; Ellis, T. Cell-free prediction of protein expression costs for growing cells. Nat. Commun. 2018, 9, 1457. [Google Scholar] [CrossRef] [PubMed]
- Marshall, R.; Maxwell, C.S.; Collins, S.P.; Jacobsen, T.; Luo, M.L.; Begemann, M.B.; Gray, B.N.; January, E.; Singer, A.; He, Y.H.; et al. Rapid and scalable characterization of CRISPR technologies using an E. coli cell-free transcription-translation system. Mol. Cell 2018, 69, 146–157. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Number of sequences in UniProt databases during the last decade. The dark grey bars show the number of reviewed entries, which represent manually annotated sequences with information extracted from literature. The light grey bars show the number of unreviewed entries, which represent the computationally analyzed sequences that are not manually annotated.
Figure 1.
Number of sequences in UniProt databases during the last decade. The dark grey bars show the number of reviewed entries, which represent manually annotated sequences with information extracted from literature. The light grey bars show the number of unreviewed entries, which represent the computationally analyzed sequences that are not manually annotated.

Figure 2.
Overview of the currently existing amount of available nucleotide sequences (NCBI), described enzymes (BRENDA), and applied enzymes [28] in context with the high-throughput-discovery of gene-enzyme-function relation. The available potential of genetic diversity (natural ressources and synthesized sequences) can be accessed via rapid prototyping of proteins using CFPS and high-throughput analyses, in order to increase knowledge about enzyme functionality and finally, make the discovery and development of enzyme-based industrial applications more efficient.
Figure 2.
Overview of the currently existing amount of available nucleotide sequences (NCBI), described enzymes (BRENDA), and applied enzymes [28] in context with the high-throughput-discovery of gene-enzyme-function relation. The available potential of genetic diversity (natural ressources and synthesized sequences) can be accessed via rapid prototyping of proteins using CFPS and high-throughput analyses, in order to increase knowledge about enzyme functionality and finally, make the discovery and development of enzyme-based industrial applications more efficient.

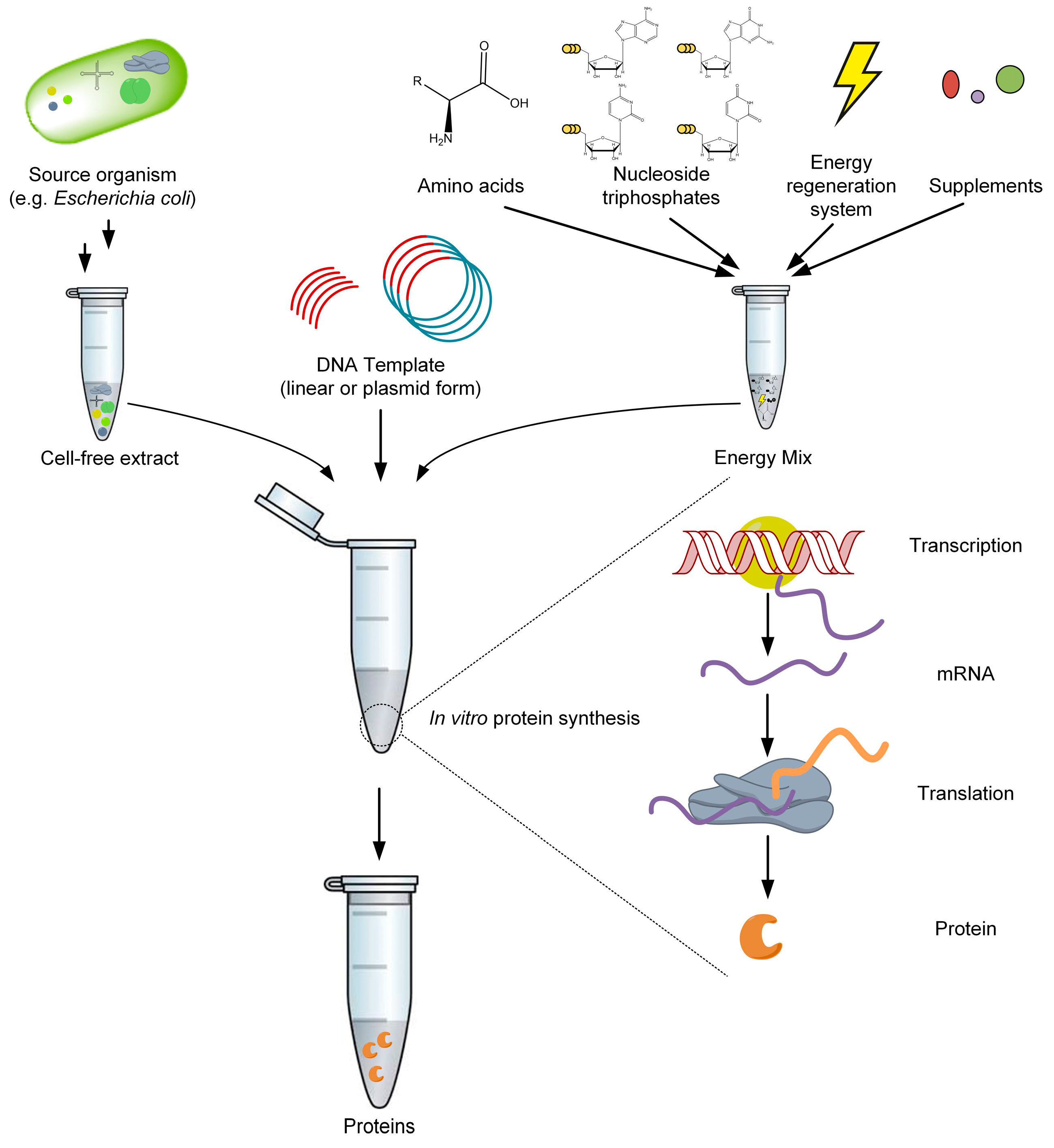
Figure 3.
The principle of cell-free protein synthesis. The cell-free extract contains the machinery for the coupled transcription and translation reaction; the DNA template consists of regulatory sequences and encodes the target protein; the energy mix contains building blocks for mRNA and protein synthesis, as well as components for energy regeneration and supplemental substances.
Figure 3.
The principle of cell-free protein synthesis. The cell-free extract contains the machinery for the coupled transcription and translation reaction; the DNA template consists of regulatory sequences and encodes the target protein; the energy mix contains building blocks for mRNA and protein synthesis, as well as components for energy regeneration and supplemental substances.

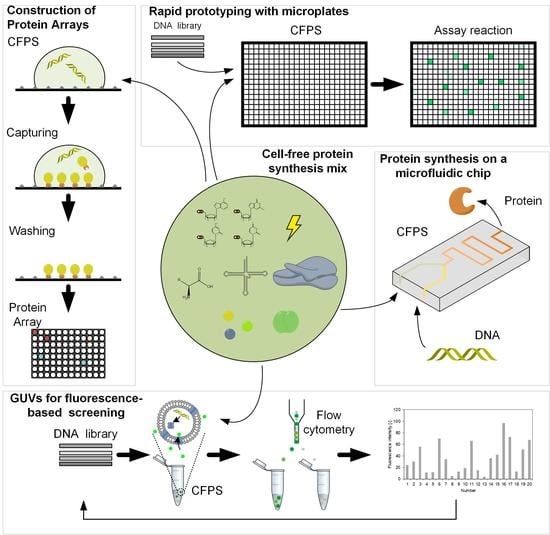
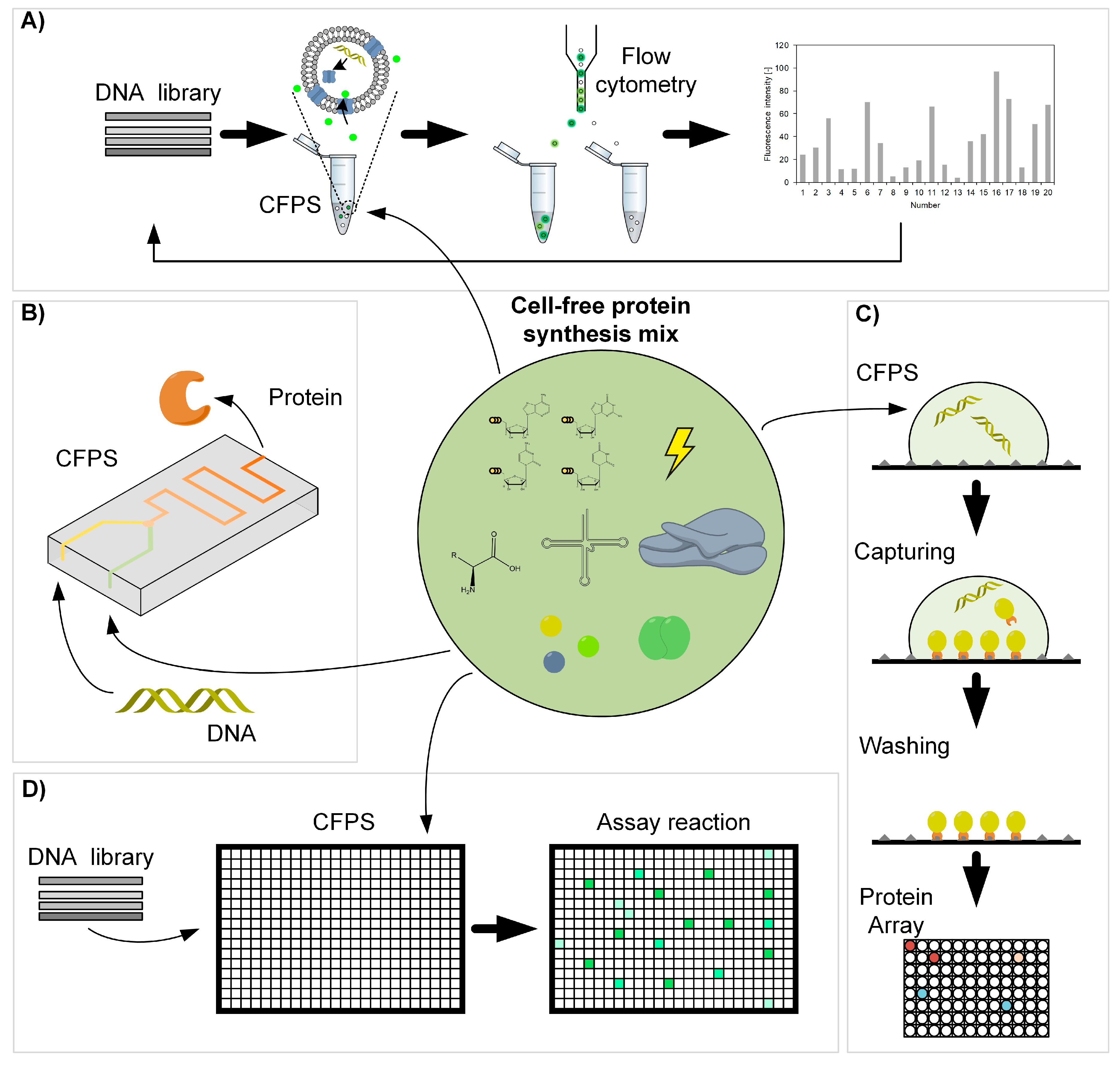
Figure 4.
Applications of cell-free protein synthesis. (A) Giant unilamellar vesicles (GUV) for fluorescence-based screening, adapted from [72]. (B) Protein synthesis on a microfluidic chip, adapted from [73]. (C) Construction of Protein Arrays, adapted from [74]. (D) Rapid prototyping with microplates.
Figure 4.
Applications of cell-free protein synthesis. (A) Giant unilamellar vesicles (GUV) for fluorescence-based screening, adapted from [72]. (B) Protein synthesis on a microfluidic chip, adapted from [73]. (C) Construction of Protein Arrays, adapted from [74]. (D) Rapid prototyping with microplates.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Selection of E. coli-based cell-free protein synthesis systems. (X) means the component is included, (-) means the component is not included in the CFPS system.
Table 1.
Selection of E. coli-based cell-free protein synthesis systems. (X) means the component is included, (-) means the component is not included in the CFPS system.
| Protein | CAT | CAT | CAT | eGFP | CAT | deGFP | sfGFP | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Yield [µg mL−1] | - | 194 | 700 | - | 800 | - | 639 | 700 | 2300 | 150 | |
| Purpose | Component | Pratt, 1984 [49] | Kim, 2000 [50] | Jewett, 2004 [51] | Sitaraman, 2004 [52] | Calhoun, 2005 [53] | Ohashi, 2010 [40] | Shin, 2010 [54] | Yang, 2012 [55] | Caschera, 2014 [31] | Krinsky, 2016 [56] |
| Substrates for protein synthesis | Amino acids | X | X | X | X | X | X | X | X | X | X |
| Energy source; substrate | ATP | X | X | X | X | - | X | X | X | X | X |
| Substrates for transcription | GTP, CTP, UTP | X | X | X | X | - | X | X | - | X | X |
| Reduction of reaction costs | Nucleoside monophosphates | - | - | - | - | X | - | - | X | - | - |
| Supply of amino acids | tRNA | X | X | X | X | X | X | X | X | X | - |
| Buffer | HEPES | - | X | - | X | X | X | X | - | X | X |
| Stabilizes polymerases | DTT | X | X | - | X | - | X | X | - | X | - |
| Increased yields | cAMP | X | X | - | X | - | X | X | - | X | - |
| Formation of initiator formyl-methionine | Folinic acid | X | X | X | X | X | X | X | X | X | - |
| Viscosity; stability of mRNA; crowding effects | Polyethylene glycol | X | X | - | X | - | - | X | X | X | X |
| Energy regeneration; phosphorylation of nucleoside monophosphates | Creatine phosphate | - | - | - | - | - | X | - | - | - | - |
| Phosphoenolpyruvate | X | X | - | - | X | - | - | X | - | - | |
| Pyruvate | - | - | X | - | - | - | - | - | - | - | |
| 3-Phosphoglyceric acid | - | - | - | X | - | - | X | - | X | X | |
| Recycling of inorganic phosphate | Maltose | - | - | - | - | - | - | - | - | X | - |
| Regeneration of ATP from pyruvate | NAD | - | X | X | - | X | - | X | X | X | - |
| Coenzyme A | - | X | X | - | X | - | X | X | X | - | |
| Stabilization of nucleic acids; stimulate polymerase activity | Spermidine | - | - | X | - | X | X | X | X | X | - |
| Putrescine | - | - | X | - | X | - | - | X | - | - | |
| Inhibitor of PEP synthetase | Oxalate | - | X | X | - | X | - | - | - | - | - |
| Kations and anions | Mg2+, K+, NH4+, acetate, glutamate | X | X | X | X | X | X | X | X | X | X |
CAT: chloramphenicol acetyl transferase, eGFP: enhanced green fluorescent protein, deGFP/sfGFP: variants of eGFP, DTT: dithiothreitol, PEP: phosphoenolpyruvate.
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Rolf, J.; Rosenthal, K.; Lütz, S. Application of Cell-Free Protein Synthesis for Faster Biocatalyst Development. Catalysts 2019, 9, 190. https://doi.org/10.3390/catal9020190
AMA Style
Rolf J, Rosenthal K, Lütz S. Application of Cell-Free Protein Synthesis for Faster Biocatalyst Development. Catalysts. 2019; 9(2):190. https://doi.org/10.3390/catal9020190
Chicago/Turabian StyleRolf, Jascha, Katrin Rosenthal, and Stephan Lütz. 2019. "Application of Cell-Free Protein Synthesis for Faster Biocatalyst Development" Catalysts 9, no. 2: 190. https://doi.org/10.3390/catal9020190
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.