1. Introduction
Natural biological phenomena are often explained using statistical methods by means of isolating the individual contexts of the phenomenon itself by establishing associations. For example, obesity, among other factors, maybe related to changes in nutrition or stress. Although these explanations fail to present a full account of the original observed phenomenon or capture the entirety of such complex dynamics, they aid in our understanding of the cause–effect relationships, especially when a plausible causal directionality can be established (e.g., increase in calorie consumption is plausibly causal to weight gain, and not the other way around). The next level of complexity is afforded by incorporating additional mechanisms arising from one or more other intermediate factors. In order to properly understand the mechanisms involved, we must understand the extent to which the exposure of interest (calorie intake) directly affects an outcome (weight gain) and the extent to which the exposure indirectly affects the outcome through intermediate factors (e.g., gut microbiome) [
1,
2,
3,
4]. Mediation analysis is at the heart of many human behavior studies and is quickly gaining traction in the biomedical research arena. With the explosion growth of the ‘omics, we see the development of new analysis and tools that provide access to the integration of new knowledge and their applications as mediators of treatment–effect relationships.
Microbiome research has advanced significantly in the last decade with the rise of computational power, next-generation sequencing, and data analytics [
5,
6]. Naturally arising have been translational investigations assessing the interplay of human–host microbial communities with various health and diseases states [
7,
8,
9], yet a notable challenge remains of understanding the extent to which and mechanisms by which such interactions take place. Three notable interactions comprise this dynamic relationship: first, the association between the environment and the host; second, the association between the microbiome and host health or disease; and third, the association between the environment and the microbiome. Because of this complexity, most available observational and experimental study designs are unable to properly assess direct causal roles of the microbiome, and, in many cases, alternative interpretations are plausible. We have seen a growing volume of evidence linking microbiome and human disease such as that of obesity, inflammatory bowel disease, and colorectal cancer [
10,
11]. Similarly, we have seen the relationship between environmental factors and the microbiome [
12]. Now, we believe it is important to assess how outside environmental factors or host genetic characteristics affect the microbiome and, together with changes of microbiome composition, influence human health and disease. Accordingly, there is an urgent need for statistical methods that establish and isolate the mediation role of microbes in these complex dynamics.
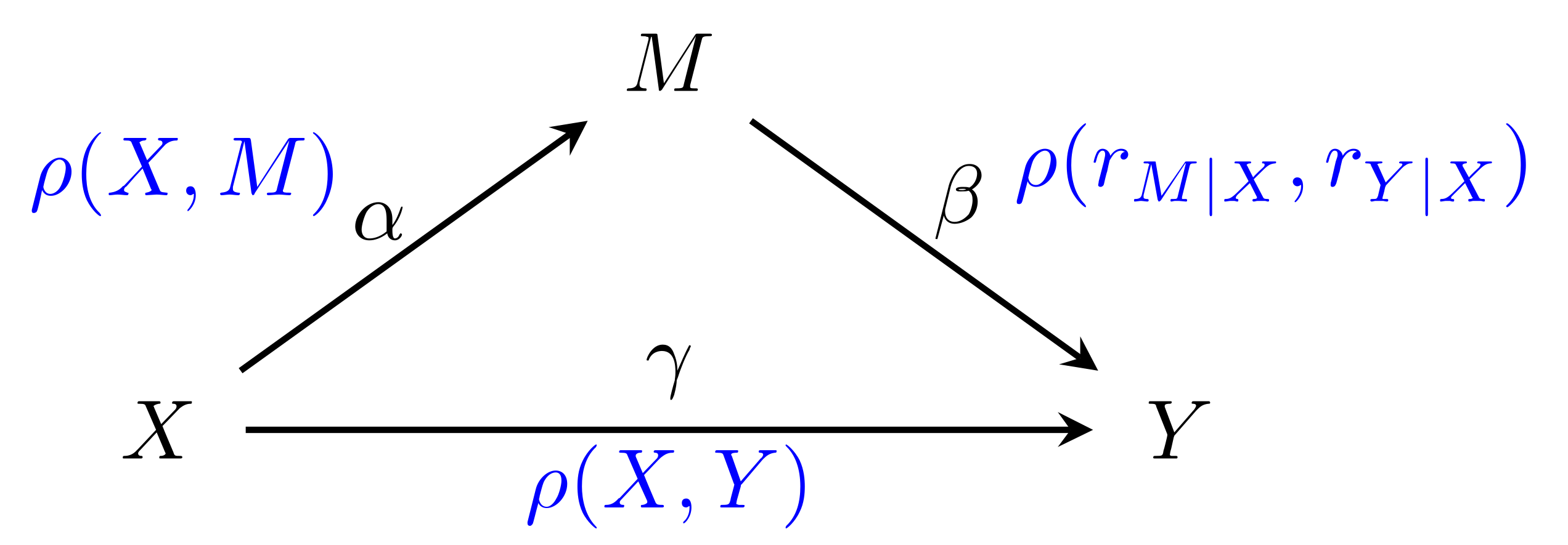
Formal approaches to the assessment of mediation effects are primarily based on the work by Baron and Kenny [
13] using the product of coefficients. The single mediator model (SMM) describes the relationship between exposure (X), response (Y), and a mediator (M), each of which are univariate random variables. SMM posits that the relationship between those can be described in terms of linear regressions, that capture the effect of the exposure on the response:
the effect of the exposure on the mediator:
and the effect of both on the response:
The downside of the conceptual simplicity of the linear regression-based framework is the lack of a convenient test that could allow for the evaluation of the hypotheses about the presence of mediation without the need to estimate the regression coefficients. To this end, Boca et al. [
14] have provided a mediation testing framework that casts the regression equations in terms of correlations and partial correlations. They further propose a multiple testing framework for the evaluation of the hypotheses related to the presence of multiple mediators. However, the omnibus mediation hypothesis still lacks an acceptable simple solution. Furthermore, no current approach allows for multivariate exposures and responses.
Microbiome analytics must take into account the multivariate nature of such data, and thus often use distance-based approaches. In these cases, power and type I error characteristics are often directly related to the chosen distance metric. Some proposed methods such as the work of Zhao et al. [
15] utilize multiple distance and dissimilarity metrics in a regression-based association testing framework. As another example, Tang et al. [
6] assessed true association by using multiple distances simultaneously and by allowing the flexible adjustment of confounders through computing residuals by regression of the covariates on confounders. As we have seen in published reviews, limitations exist to proposed methods upon the application to ‘omics data [
16]. One such case is microbiome data, which are high-dimensional, under-sampled, compositional, and over-dispersed; nonetheless, we would like to be able to explain their role as a mediator just like a univariate mediator would. Within this article, we present a framework for multivariate distance mediation analysis that is suitable to such data.
In this article, we present a framework for testing multivariate distance mediation to allow for multivariate exposures, responses, and mediators. We build our test on the mediation approach published by Boca et al. [
14] and extend it to high-dimensional data via distance-based methodologies. We present simulation results on the robustness and sensitivity of the proposed methods and further make comparisons with other proposed approaches, such as permutation-based testing by Boca et al. [
14] and sample-wise distance matrices by Zhang et al. [
17]. Lastly, we analyze two real datasets to demonstrate the power of the proposed methods and their application to high-dimensional microbiome data.
3. Results
3.1. Empirical Evaluation of MODIMA
The simulation results comprise the sample size-dependent type I error rates and power as a fraction of rejected null hypotheses at a significance threshold of 0.05 for each test (
Figure 3 and
Figure 4). In the case of the single mediator, when the null hypothesis is true (
Figure 3A), the association of the exposure with the mediator (
) or the effect of the mediator on the response (
) are absent. A test properly controlling type I error rate is expected to have a fraction of rejections equal to the nominal error rate (0.05, in this case). In the cases of
, as α and γ are increased, we observe inflation of this type I error rate for MODIMA; however, Sampson [
14] and Chen [
17] methods often display overly conservative type I error rates. This effect has been previously described [
20] and is related to the fact that zero partial distance correlation does not correspond to conditional independence. We review this point further in the Discussion section. Our proposed method is able to demonstrate equal or better power (
Figure 3B), often increasing power with the increase of mediating effect. Within a few selected parameters, all three methods performed equally. Notably, the MedTest method often shows the least power and does not perform well when the association of the mediator with the exposure is much higher than the association of the mediator with the response (
Figure 3B,
column). In fact, that appears to be the most challenging condition for all approaches to make the necessary rejections. Our approach maintains the best performance in that instance.
In the case of the many mediators, we generated mixtures of microbiome data to be used as mediators. We computed distance metrics of Bray, Jensen–Shannon divergence (JSD), and UniFrac and present the latter here in
Figure 4. The former two can be found as part of our supplementary data. When the null hypothesis is true (
Figure 4A), both MODIMA and MedTest are able to maintain rejection rates. The behavior of MODIMA to inflate the rejection rates under
observed in the single mediator case is no longer present in the multiple mediator simulation case. Power curves (
Figure 4B) show MODIMA excelling under certain scenarios, whereas MedTest displays better power in others. Overall, MODIMA excels under scenarios where the
- relationship noted by
is smaller or, in other words, relatively small to no direct relationship between the exposure and outcome. Under the smaller sample sizes, we often see MODIMA performing slightly better.
We next demonstrate the application of MODIMA in two empirical examples.
3.2. Application Example 1: Microbiome-Mediated Responses to Subtherapeutic Antibiotic Treatment Influencing Body Fat
Antibiotics have undoubtedly provided remarkable public health benefits in the last century. During that same time span, we see a marked increase in antibiotics use across many populations [
33]. Furthermore, we see the largest use of antibacterial agents within the animal farming industry, often exclusively used in low doses to stimulate weight gain in farm animals [
34]. There is growing concern about the effects from the long-term use of antibiotics and antibacterial agents [
35,
36]. Here, we build on the evidence on phenotypic and microbial responses to early-life subtherapeutic antibiotic treatment using murine models expanding on findings presented by Cho et al. [
37].
In each experiment, each study group (control or antibiotic(s)) was composed of ten mice. The mice were allowed ad libitum access to food and water and fed standard laboratory chow. Beginning on day 28 of life, mice were given water or water containing one of the following antibiotic regimens: penicillin VK, vancomycin, penicillin VK plus vancomycin, and chlortetracycline, each at doses equivalent to 1 μg antibiotic per g body weight. On a weekly basis, mice were weighed three times, food intake measured, and fecal pellets collected. Dual energy X-ray absorptiometry (DEXA) and a 7 Tesla MRI system were used to collect animal fat composition, lean body mass, percent body fat, and bone mineral density. The IDEAL Dixon method based on chemical shift properties was used to separate MRI images into fat and lean tissue [
38]. Weight values were calculated from MRI-determined fat percent to validate scale weight. The microbiome composition was established by sequencing of the v3 region of the 16S rRNA gene using 454-FLX Titanium chemistry (Roche, Bradford, CT, USA). Preprocessing was performed using QIIME pipeline [
39] at a 97% similarity threshold.
A total of 96 samples (50 cecal and 46 fecal) across 50 animals were used for all downstream analysis, resulting in 6547 unique taxa. Four antibiotic regimens of penicillin n = 10, vancomycin n = 10, penicillin plus vancomycin n = 10, and chlortetracycline n = 10 were used for comparison with controls n = 10. For each subject, cecal and fecal microbiome data were available.
Jensen–Shannon divergence (JSD) distances were computed for microbiota (mediator) and Euclidean distances for antibiotic use (exposure) as well as percent fat (outcome). The mediating relationship of the combined cecal and fecal microbial composition between antibiotic intake and percent fat resulted in a MODIMA statistic of 0.002 (p = 0.99). Assessing the relationship of antibiotic use and percent fat, we see a bias-corrected distance correlation (bcdCor) estimate of 0.173. Likewise, we see dCor estimates of microbiota (cecal and fecal combined) to antibiotic use and percent fat to be 0.113 and 0.000. Partial distance correlation (pdCor) between the relationship of antibiotic use, percent fat, and microbiota (cecal and fecal JSD) is calculated to be 0.021 (p = 0.46).
Further antibiotic-specific comparisons are made between individual antibiotic therapies and control. Most notable changes are seen when cecal and fecal are assessed individually with a specific antibiotic treatment. An assessment of cecal and fecal microbiome mediation of the penicillin versus control exposure results in MODIMA statistics of 0.019 (p = 0.28) and 0.034 (p = 0.09), respectively. Partial distance correlations are observed to be 0.023 and 0.110 for cecal and fecal. For fecal specifically, although mild correlation is present, and when assessed for mediation using MODIMA, effects are not detectable. Comparison of chlortetracycline and control using samples from fecal microbiome revealed the largest and only statistically significant mediation, with MODIMA statistic of 0.141 (p = 0.016).
3.3. Application Example 2: Microbiome-Mediated Responses to Dietary Fiber Intake Influencing Body Mass Index (BMI)
A growing body of evidence suggests that diet influences the compositional diversity of gut bacteria [
8]. We also see an association between changes in gut bacteria diversity and human health, such as obesity [
41]. Through a study of diet and 16S ribosomal DNA (rDNA) fecal samples, Wu et al. (2011) reported that long-term diet was strongly associated with enterotype clustering [
42]; here, we briefly describe their methods. Healthy human subjects (
n = 98) were enrolled in a cross-sectional study where long-term diet information was collected using self-reported questionnaires assessing usual dietary composition over the preceding year. Diet information was subsequently converted to a list of 214 nutrient categories and their corresponding intake amounts. Stool samples were collected, frozen immediately (−80 °C), processed using MoBio PowerSoil kits, amplified V1–V2 region primers targeting bacterial 16S genes, and sequenced using 454/Roche. Sequences were denoised using QIIME pipeline [
39] following default settings. Other demographic information including body mass index (BMI) was collected upon enrollment. Weighted and unweighted UniFrac distances for microbial communities were calculated and used for downstream analyses.
Wu et al. [
42] previously reported a strong inverse association between body fat intake and microbial taxa (Spearman
These same microbial taxa were observed to be associated with BMI (PERMANOVA, unweighted
p = 0.001, weighted
p = 0.145). Here, we assessed the influence of dietary fiber intake on BMI mediated by microbiota. The correlation of percent fiber intake (exposure) and BMI (response) is small yet significant (
Figure 6A), and fiber intake and microbiota (mediator) is small and approaching statistical significance (
Figure 6B). Mediator–response relationships (total effects) are modeled in
Figure 6C,D using first and second principal coordinates and residuals of exposure–response. Zhang et al. [
17] applied their omnibus mediation method MedTest using multiple distance metrics to assess this mediation and showed a permutation-based
p-value of 0.0309. Furthermore, mediation by individual taxa at different ranks was assessed. Zhang et al. [
17] observed three ranks to be significant: family Lachnospiraceae (
p = 0.0129), genus
Lachnospira of the family Lachnospiraceae (
p = 0.0430), and family Ruminococcaceae (
p = 0.0468). We applied our proposed distance mediation analysis methods to this dataset and present our findings.
Distance metrics of Jensen–Shannon divergence (JSD), Bray–Curtis, Jaccard, and UniFrac (unweighted, weighted, and generalized) were computed using distance function in R package phyloseq (version 1.26.1) [
31], vegdist function in R package vegan (version 2.5.4) [
32], and GUniFrac function in R package GUniFrac (version 1.1) [
43], respectively, following similar methodologies as presented by Zhang et al. [
17]. Distance correlation (dCor) estimates between pairs of exposure, mediator, and response showed no evidence of correlation using any of the distance metrics (data not presented here but are available as Additional Files 2 at
https://github.com/Alekseyenko/MODIMA). In a likewise fashion, the partial distance correlation estimate between fiber intake, microbiome, and BMI was not indicative of any correlation (estimate using JSD applied to mediator = 0.029,
p = 0.04). MODIMA was applied using various distance metrics.
Table 1 summarizes the results for MODIMA
p-values for each distance metric as well as Bonferroni-adjusted test. As shown, we see that only the Jaccard metric shows a significant
p-value at α of 0.05, with Bray–Curtis and unweighted UniFrac distances approaching the significance threshold. We further observe MODIMA resulting in lower
p-values than MedTest in single-distance mediation tests with the exception of Jaccard.
To further assess potentially mediating taxa within this dataset, we sliced the released phylogenetic rooted tree using library phytools (version 0.6.60) [
44], beginning at root (slice 0.01) to the height of 1 at 0.01 increments. Each of these slices resulted in subtree clades that were used for comparison testing. Each arbitrary slice resulted in clades that held taxa unique to them. We saw that, aside from a handful of the clades within certain slices, no mediation was observed with MedTest. This suggests that, if present, the mediation effect of the microbiota on the fiber intake and BMI relationship is likely small enough to be undetectable within the given sample size.
4. Discussion
In this article, we developed a framework for multivariate omnibus distance mediation analysis (MODIMA). Although the proposed methods have wide applications to various data types, we specifically showed their robustness in high-dimensional settings by applying them to novel and previously published microbiome data. In simulations, we showed that our method to detect mediation under various scenarios is more powerful than previously published work. Simulations showed that MODIMA holds empirical type I error rates at the desired nominal significance level under the multiple mediator case.
Clearly, any analysis based on distances should not blindly and thoughtlessly pick the metric to be used. Ideally, the structure of the data and the analyst’s intuition about the problem should guide the selection of an appropriate measure. A universally best distance measure may not exist for all problems and different data may result in different best performing distances, in terms of sensitivity and specificity. For example, although very popular and used in many studies, weighted UniFrac distance failed to result in a rejection in application example 2. This does not imply that this distance is universally bad. Its performance in combination with that of unweighted UniFrac is possibly telling us that beyond the phylogenetic signal the relative abundances are not informative of the mediation that may or may not exist in the data. A limitation of our method relative to MedTest is that MODIMA works on a specific distance metric rather than pooling analyses from multiple metrics. A future improvement to the method should incorporate the ability to use multiple distances. In the interim, a test-and-adjust approach can be used with MODIMA with multiple distances.
With regard to empirical power as the exposure–mediator and mediator–outcome effects are increased, MODIMA displayed increasing empirical power characteristics relative to other methods. We further see that there was increased power as sample size increased from 20 to 200, a typical expectation. It should be noted that most ‘omics investigations operate on the lower end of that sample size spectrum; therefore, the ability to correctly detect differences under small sample scenarios is important.
In both of our empirical examples, although the mediating effect of the microbiota was plausible, we failed to detect the mediation. This is unsurprising for datasets of such small size and relatively small total effect of the exposure on the response (e.g., dCor = 14–17% for antibiotics–percent body fat and dCor = 9% for fiber–BMI). The microbiome in dietary fiber effect on the body mass index example demonstrates a discrepancy observed between our method and an alternative approach. Through additional analyses, we demonstrate that either the effect is again too small to be detected in a dataset of this size, or that it may be absent altogether.
Our application of the distance correlation and partial distance correlation metrics to the problem of modeling distance mediation illustrates somewhat unintuitive notions relating dependence and correlation in the context of causal analyses. First, the absence of partial correlation does not automatically imply the absence of partial dependence. The equivalence of partial correlation and conditional dependence is only true for a multivariate normal family of distributions. Furthermore, distance correlation methods demonstrate non-zero partial correlation (even asymptotically) in certain scenarios with conditionally independent univariate normal variables [
20]. Specifically, as is relevant to the mediation analysis, consider X is a standard normal random variable and M and Y are each an independent linear combination of X and another standard normal variate. In that case, pdCor(M, Y | X) > 0, indicating the presence of partial distance correlation. This suggests that the notion of conditional dependence captured by partial distance correlation is different from that intuitively expected. Székely and Rizzo [
20] suggest that partial distance correlation implies that there exists a pair of U-equivalent random variables that are in fact conditionally independent. The extent to which a lack of correspondence between conditional independence and zero partial distance correlation is a problem with multivariate data is unknown at the moment. However, it is easy to see via simulation that adding additional mediators uncorrelated to the exposure will decrease the population values of pdCor, which in finite sample size results in fewer rejections and thus less inflated type I errors. This is demonstrated in our multiple mediator simulations, where adding a moderate number of mediators results in better type I error control in simulation under the null hypothesis (
Figure 4A).
Another potential pitfall of multivariate mediation analysis pertains to the interpretations of significant mediation results. Consider, for example, a scenario where X is a true cause for both Y and M1, while independent of M2, which is a true cause of Y. Although no univariate mediation relationships exist under this scenario, multivariately M = (M1, M2) is not conditionally independent of Y, given X and multivariate (distance) mediation does exist. This suggests that, whenever multivariate distance mediation is established, further interpretations of this relationship must be treated with caution in order not to attribute this relationship to any individual univariate marginals of the X, M, Y triple, but to treat this relationship as existing in the joint distribution.
Omnibus mediation analysis with ’omics-sized mediators is the first step towards enabling top-down approaches in genomic data. As opposed to the more widely used methods that integrate the univariate signals of individual measurements of microbes, gene expression, or genetic variants, the top-down approach starts with the collective effect of those and prunes the individual measurements down to a small set of most important ones. The significance of this approach is that top-down thinking allows for capturing effects, such as epistasis and otherwise complexly intertwined relationships. We envision that future versions of the omnibus mediation approach of this paper and of alternative approaches will allow to assign importance to components in addition to assessing the overall effect of the entire collection.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}