
A Haze Prediction Method Based on One-Dimensional Convolutional Neural Network





Abstract
:1. Introduction
2. Materials
3. Methodology
- (1)
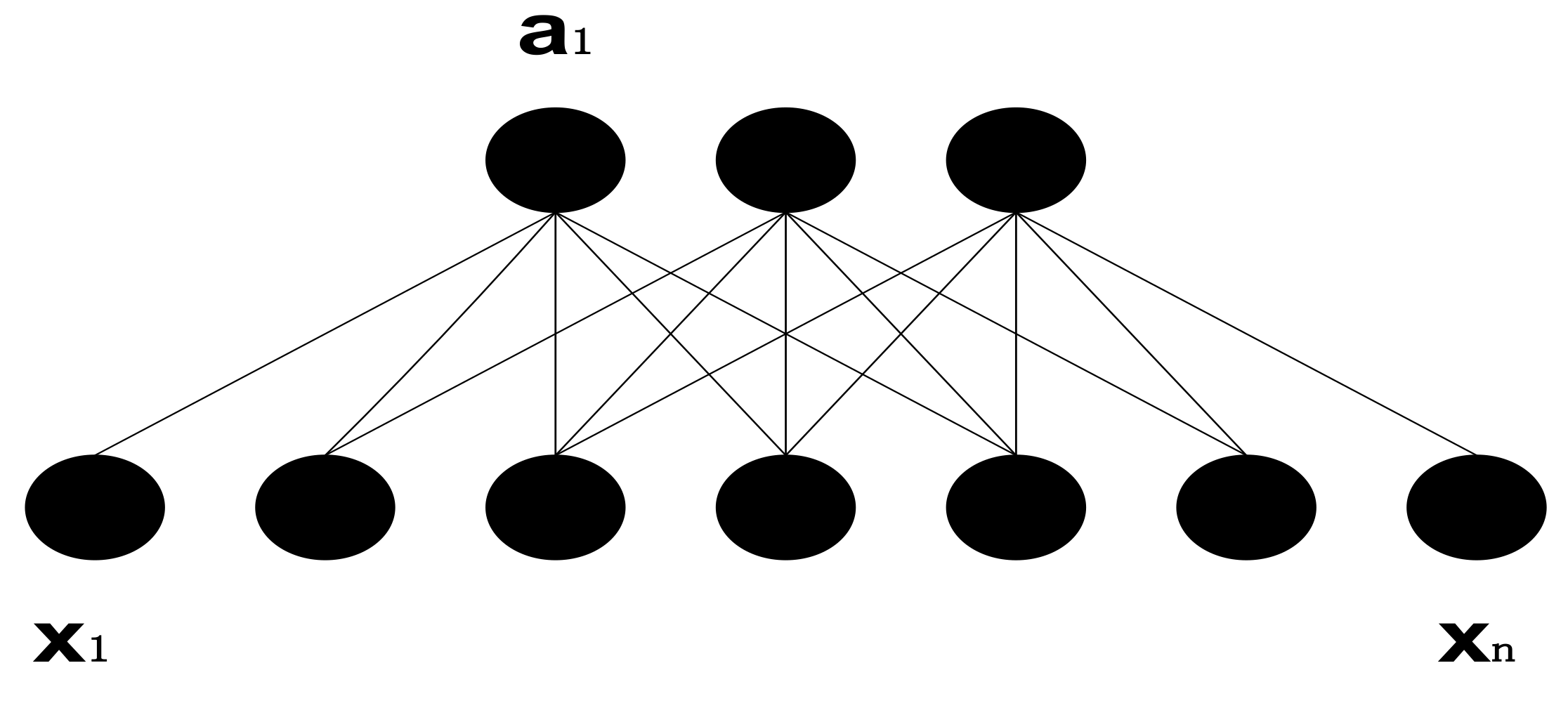
- Convolution process of one-dimensional convolution network: In a one-dimensional convolutional neural network, the convolution of the first layer can be regarded as an operational relationship between the weight vector and the input vector . The weight vector has a size of m, that is, the size of the convolution kernel is m. More specifically, is the haze period vector as output, and each of the elements is a haze concentration value at a time point. The convolution kernel of m size is used to convolve the sequence of each m length in the input vector to obtain the output of the first layer. Where , this ensures that the haze concentration value at each moment in the input is included in the convolution operation. If the step size is 1, the convolution formula is as follows:
- (2)
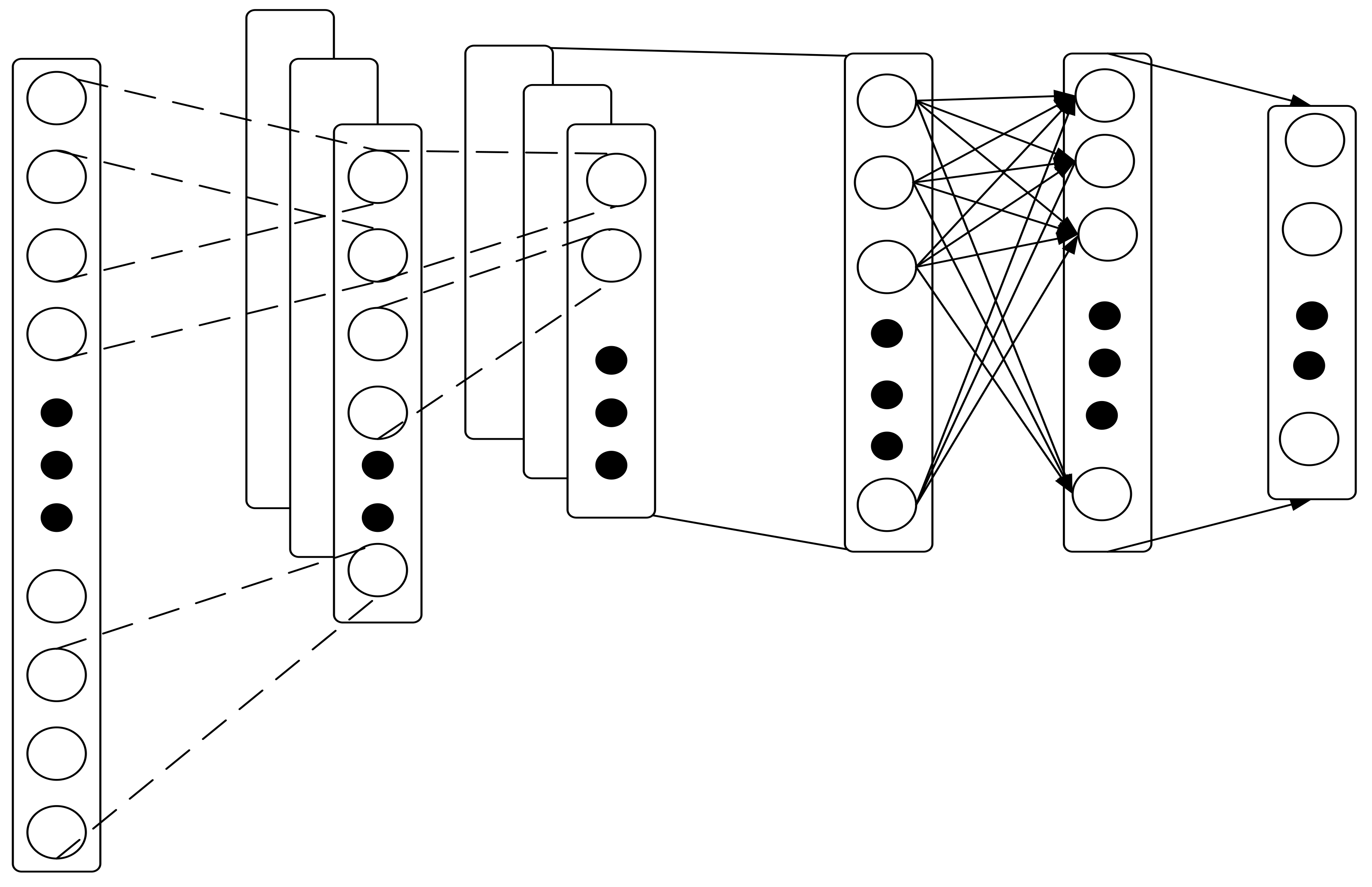
- One-dimensional convolution layer: Since the one-dimensional convolution input layer is a one-dimensional vector, its convolution kernel is also one-dimensional. To illustrate the convolution process more specifically, a one-dimensional convolution process with an input length of 7, a convolution kernel size of 5, and a convolution step of one is shown in Figure 2.
- (3)
- One-dimensional convolution pooling layer: Due to the existence of the pooling layer, the one-dimensional convolutional neural network also fully exerts the neural network in theory due to the feature extraction, which can be equivalent in theory. The training speed of one-dimensional convolutional neural networks is inherently superior to other neural networks.
4. Experiments and Results
4.1. Comparison of 1D Convolutional Neural Network and GRU Circulatory Neural Network
- The input of the front layer and the input of this unit are weighted and then passed through an activation function to obtain an alternative value.
- Then, the input of the same front layer and the input of this unit are subjected to the same weighting, and the sigmoid activation function is mapped to 0, 1. This mapping value is the update gating parameter.
- Determine whether the parameter is updated by a gate control unit. By changing the relationship between the hidden layers of the cyclic neural network, the problem of weak correlation before and after the sequence input is solved.
- (1)
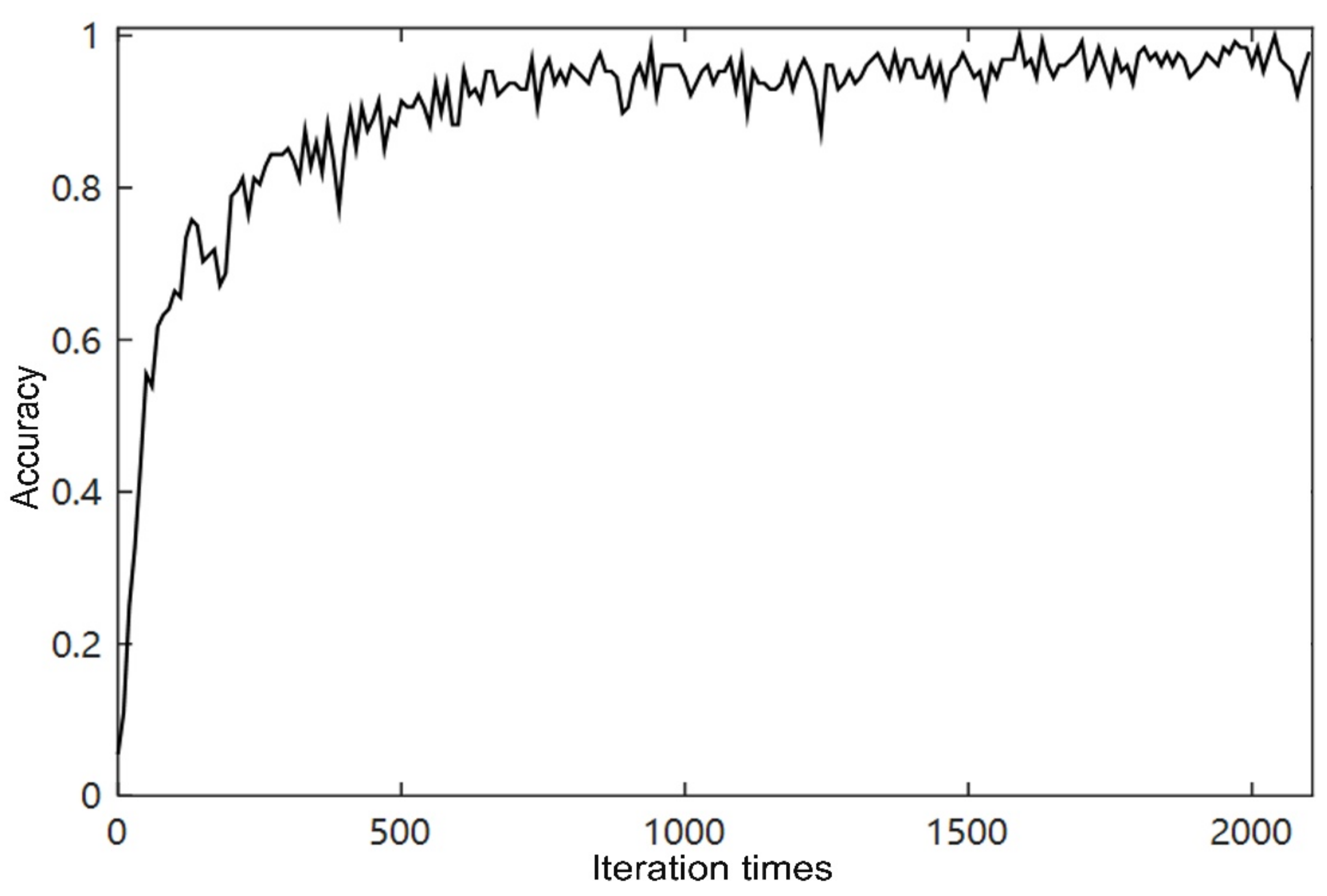
- Convolution: The number of iterations required for the neural network to achieve the best accuracy is less than that of the cyclic neural network. The convolutional neural network stops after 1600 iterations, and the cyclic neural network only achieves the optimal result as specified by us at the 2200th iteration.
- (2)
- Due to the characteristics of weight sharing and the local connection of the convolutional neural network, the training speed of the convolutional neural network is faster. The time for the convolutional neural network is about 120 s per 100 iterations, while the cyclic neural network is every 100 iterations. The time required is about 600 s.
- (3)
- Overall, although the initial accuracy of GRU increases slower than the one-dimensional convolutional neural network, optimization results continue to appear as the rounds increase. After more rounds of training, the GRU recurrent neural network can also obtain better results.
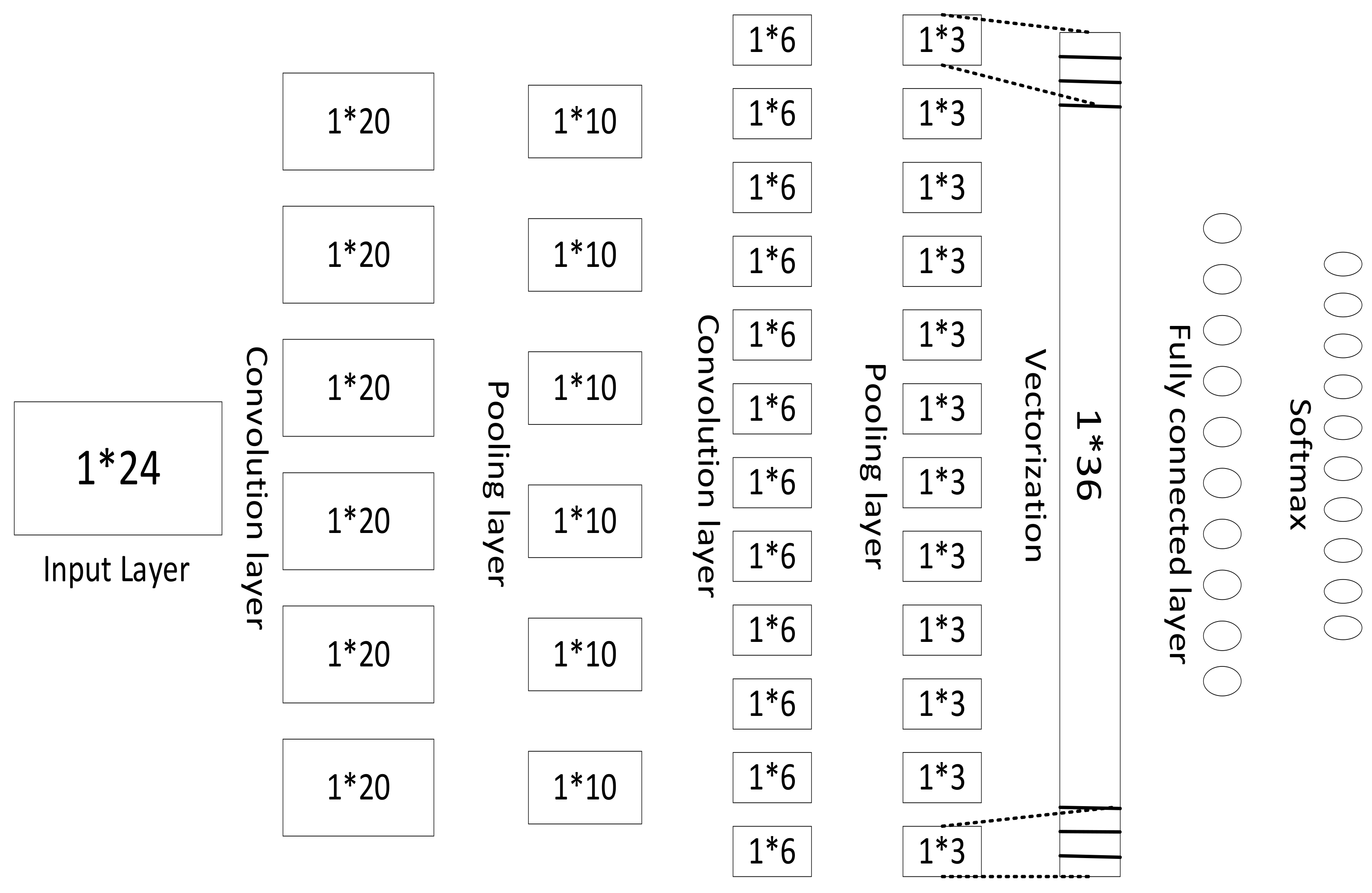
4.2. Experimental Process of One-Dimensional Convolutional Neural Network
5. Discussion
6. Conclusions
- The connection between layers in a convolutional neural network is sparsely connected and convoluted using a convolution kernel that is much smaller than the size of the input data, resulting in a smaller feature vector. This not only reduces the number of parameters but also reduces the storage size of the model, and the requirements for the amount of calculation are greatly reduced. Therefore, the efficiency of the one-dimensional convolutional neural network is significantly improved, and the time complexity is also greatly reduced.
- Parameter sharing: This makes the convolutional neural network robust to the translation of the input data. We can obtain the characteristics of these sequences by a one-dimensional convolution calculation. If we shift this feature event in the input, that is, delay it backward for a period of time, the convolution will still have exactly the same output value, but with the time delayed. This feature is beneficial for the extraction of time-dimensional features by one-dimensional convolutional neural networks and improves the accuracy of the network’s fitting of nonlinear mapping between input and output.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Ma, G.; Yu, F.; Cao, D. Health damage assessment due to PM2. 5 exposure during haze pollution events in Beijing-Tianjin-Hebei region in January 2013. Zhonghua Yi Xue Za Zhi 2013, 93, 2707–2710. [Google Scholar] [PubMed]
- Zheng, W.; Li, X.; Xie, J.; Yin, L.; Wang, Y. Impact of human activities on haze in Beijing based on grey relational analysis. Rend. Lincei 2015, 26, 187–192. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, X.; Yin, L. Sentence Representation Method Based on Multi-Layer Semantic Network. Appl. Sci. 2021, 11, 1316. [Google Scholar] [CrossRef]
- Ma, Z.; Zheng, W.; Chen, X.; Yin, L. Joint embedding VQA model based on dynamic word vector. PeerJ Comput. Sci. 2021, 7, e353. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.; Liu, X.; Ni, X.; Yin, L.; Yang, B. Improving Visual Reasoning Through Semantic Representation. IEEE Access 2021, 9, 91476–91486. [Google Scholar] [CrossRef]
- Zheng, W.; Yin, L.; Chen, X.; Ma, Z.; Liu, S.; Yang, B. Knowledge base graph embedding module design for Visual question answering model. Pattern Recognit. 2021, 120, 108153. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, X.; Yin, L. Research on image classification method based on improved multi-scale relational network. PeerJ Comput. Sci. 2021, 7, e613. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, W.; Liu, X.; Mou, Y.; Yin, L.; Yang, B. Research and improvement of feature detection algorithm based on FAST. Rend. Lincei. Sci. Fis. E Nat. 2021. [Google Scholar] [CrossRef]
- Li, X.; Yin, L.; Yao, L.; Yu, W.; She, X.; Wei, W. Seismic spatiotemporal characteristics in the Alpide Himalayan Seismic Belt. Earth Sci. Inform. 2020, 13, 883–892. [Google Scholar] [CrossRef]
- Tang, Y.; Liu, S.; Li, X.; Fan, Y.; Deng, Y.; Liu, Y.; Yin, L. Earthquakes spatio–temporal distribution and fractal analysis in the Eurasian seismic belt. Rend. Lincei Sci. Fis. E Nat. 2020, 31, 203–209. [Google Scholar] [CrossRef]
- Yin, L.; Li, X.; Zheng, W.; Yin, Z.; Song, L.; Ge, L.; Zeng, Q. Fractal dimension analysis for seismicity spatial and temporal distribution in the circum-Pacific seismic belt. J. Earth Syst. Sci. 2019, 128, 22. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.; Li, X.; Yin, L.; Yin, Z.; Yang, B.; Liu, S.; Song, L.; Zhou, Y.; Li, Y. Wavelet analysis of the temporal-spatial distribution in the Eurasia seismic belt. Int. J. Wavelets Multiresolut. Inf. Process. 2017, 15, 1750018. [Google Scholar] [CrossRef]
- Li, X.; Zheng, W.; Wang, D.; Yin, L.; Wang, Y. Predicting seismicity trend in southwest of China based on wavelet analysis. Int. J. Wavelets Multiresolut. Inf. Process. 2015, 13, 1550011. [Google Scholar] [CrossRef]
- Li, X.; Zheng, W.; Lam, N.; Wang, D.; Yin, L.; Yin, Z. Impact of land use on urban water-logging disaster: A case study of Beijing and New York cities. Environ. Eng. Manag. J. 2017, 16, 1211–1216. [Google Scholar]
- Holben, B.N.; Eck, T.F.; Slutsker, I.A.; Tanre, D.; Buis, J.; Setzer, A.; Vermote, E.; Reagan, J.A.; Kaufman, Y.; Nakajima, T. AERONET—A federated instrument network and data archive for aerosol characterization. Remote Sens. Environ. 1998, 66, 1–16. [Google Scholar] [CrossRef]
- Pérez, P.; Trier, A.; Reyes, J. Prediction of PM2.5 concentrations several hours in advance using neural networks in Santiago, Chile. Atmos. Environ. 2000, 34, 1189–1196. [Google Scholar] [CrossRef]
- Grivas, G.; Chaloulakou, A. Artificial neural network models for prediction of PM10 hourly concentrations, in the Greater Area of Athens, Greece. Atmos. Environ. 2006, 40, 1216–1229. [Google Scholar] [CrossRef]
- Marzano, F.S.; Rivolta, G.; Coppola, E.; Tomassetti, B.; Verdecchia, M. Rainfall nowcasting from multisatellite passive-sensor images using a recurrent neural network. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3800–3812. [Google Scholar] [CrossRef]
- Slini, T.; Kaprara, A.; Karatzas, K.; Moussiopoulos, N. PM10 forecasting for Thessaloniki, Greece. Environ. Model. Softw. 2006, 21, 559–565. [Google Scholar] [CrossRef]
- Zheng, W.; Li, X.; Yin, L.; Wang, Y. The retrieved urban LST in Beijing based on TM, HJ-1B and MODIS. Arab. J. Sci. Eng. 2016, 41, 2325–2332. [Google Scholar] [CrossRef]
- Chen, X.; Yin, L.; Fan, Y.; Song, L.; Ji, T.; Liu, Y.; Tian, J.; Zheng, W. Temporal evolution characteristics of PM2.5 concentration based on continuous wavelet transform. Sci. Total Environ. 2020, 699, 134244. [Google Scholar] [CrossRef]
- Li, X.; Zheng, W.; Yin, L.; Yin, Z.; Song, L.; Tian, X. Influence of social-economic activities on air pollutants in Beijing, China. Open Geosci. 2017, 9, 314–321. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.; Li, X.; Yin, L.; Wang, Y. Spatiotemporal heterogeneity of urban air pollution in China based on spatial analysis. Rend. Lincei 2016, 27, 351–356. [Google Scholar] [CrossRef]
- Sun, Y.; Zhuang, G.; Tang, A.; Wang, Y.; An, Z. Chemical characteristics of PM2.5 and PM10 in haze−fog episodes in Beijing. Environ. Sci. Technol. 2006, 40, 3148–3155. [Google Scholar] [CrossRef]
- Yin, Z.; Wang, H. Seasonal prediction of winter haze days in the north central North China Plain. Atmos. Chem. Phys. 2016, 16, 14843–14852. [Google Scholar] [CrossRef] [Green Version]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM network: A Machine Learning Approach for Precipitation Nowcasting. Available online: https://papers.nips.cc/paper/2015/hash/07563a3fe3bbe7e3ba84431ad9d055af-Abstract.html (accessed on 1 September 2021).
- Klein, B.; Wolf, L.; Afek, Y. A dynamic convolutional layer for short range weather prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4840–4848. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Xu, C.; Yang, B.; Guo, F.; Zheng, W.; Poignet, P. Sparse-view CBCT reconstruction via weighted Schatten p-norm minimization. Optics Express 2020, 28, 35469–35482. [Google Scholar] [CrossRef]
- Liu, S.; Wang, L.; Liu, H.; Su, H.; Li, X.; Zheng, W. Deriving bathymetry from optical images with a localized neural network algorithm. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5334–5342. [Google Scholar] [CrossRef]
- Ding, Y.; Tian, X.; Yin, L.; Chen, X.; Liu, S.; Yang, B.; Zheng, W. Multi-Scale Relation Network for Few-Shot Learning Based on Meta-Learning; Springer: Cham, Switzerland, 2019; pp. 343–352. [Google Scholar]
- Ni, X.; Yin, L.; Chen, X.; Liu, S.; Yang, B.; Zheng, W. Semantic representation for visual reasoning. In Proceedings of the MATEC Web of Conferences, Les Ulis, France, 2 June 2019. [Google Scholar]
- Tang, Y.; Liu, S.; Deng, Y.; Zhang, Y.; Yin, L.; Zheng, W. An improved method for soft tissue modeling. Biomed. Signal Process. Control. 2021, 65, 102367. [Google Scholar] [CrossRef]
- Tang, Y.; Liu, S.; Deng, Y.; Zhang, Y.; Yin, L.; Zheng, W. Construction of force haptic reappearance system based on Geomagic Touch haptic device. Comput. Methods Programs Biomed. 2020, 190, 105344. [Google Scholar] [CrossRef]
- Yang, B.; Liu, C.; Huang, K.; Zheng, W. A triangular radial cubic spline deformation model for efficient 3D beating heart tracking. Signal Image Video Process. 2017, 11, 1329–1336. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhang, J.; Min, X.; Zhu, Y.; Zhai, G.; Zhou, J.; Yang, X.; Zhang, W. HazDesNet: An End-to-End Network for Haze Density Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 1–16. [Google Scholar] [CrossRef]
- Tran, T.N.; Phuc, D.T. Grid search of multilayer perceptron based on the walk-forward validation methodology. Int. J. Electr. Comput. Eng. 2021, 11, 1742. [Google Scholar]
- Żbikowski, K. Using volume weighted support vector machines with walk forward testing and feature selection for the purpose of creating stock trading strategy. Expert Syst. Appl. 2015, 42, 1797–1805. [Google Scholar] [CrossRef]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]
- Bahari, R.; Abbaspour, R.A.; Pahlavani, P. Prediction of PM2.5 concentrations using temperature inversion effects based on an artificial neural network. In Proceedings of the ISPRS International Conference of Geospatial Information Research, Tehran, Iran, 15–17 November 2014; p. 17. [Google Scholar]
- Mogireddy, K.; Devabhaktuni, V.; Kumar, A.; Aggarwal, P.; Bhattacharya, P. A new approach to simulate characterization of particulate matter employing support vector machines. J. Hazard. Mater. 2011, 186, 1254–1262. [Google Scholar] [CrossRef]
- Hooyberghs, J.; Mensink, C.; Dumont, G.; Fierens, F.; Brasseur, O. A neural network forecast for daily average PM10 concentrations in Belgium. Atmos. Environ. 2005, 39, 3279–3289. [Google Scholar] [CrossRef]
- Voukantsis, D.; Karatzas, K.; Kukkonen, J.; Räsänen, T.; Karppinen, A.; Kolehmainen, M. Intercomparison of air quality data using principal component analysis, and forecasting of PM10 and PM2.5 concentrations using artificial neural networks, in Thessaloniki and Helsinki. Sci. Total Environ. 2011, 409, 1266–1276. [Google Scholar] [CrossRef] [PubMed]
- Yeh, C.-H.; Huang, C.-H.; Kang, L.-W. Multi-scale deep residual learning-based single image haze removal via image decomposition. IEEE Trans. Image Process. 2019, 29, 3153–3167. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Concentration | 35 | 70 | 105 | 140 | 175 | 210 | 245 | 280 | 315 | 500 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Tian, J.; Huang, W.; Yin, L.; Zheng, W.; Liu, S. A Haze Prediction Method Based on One-Dimensional Convolutional Neural Network. Atmosphere 2021, 12, 1327. https://doi.org/10.3390/atmos12101327
Zhang Z, Tian J, Huang W, Yin L, Zheng W, Liu S. A Haze Prediction Method Based on One-Dimensional Convolutional Neural Network. Atmosphere. 2021; 12(10):1327. https://doi.org/10.3390/atmos12101327
Chicago/Turabian StyleZhang, Ziyan, Jiawei Tian, Weizheng Huang, Lirong Yin, Wenfeng Zheng, and Shan Liu. 2021. "A Haze Prediction Method Based on One-Dimensional Convolutional Neural Network" Atmosphere 12, no. 10: 1327. https://doi.org/10.3390/atmos12101327