1. Introduction
Pollution is related to the introduction into the environment of substances, from anthropogenic or natural origin, which are harmful or toxic to humans and ecosystems. Pollution usually alters the chemical, physical, biological, or radiological integrity of soil, water, and living species, resulting in alterations of the food chain, with effects on human health [
1,
2]. In particular, water pollution is mainly due to the increment in urban and industrial density. Growing population waste poses a threat to public health and jeopardizes the continuous use of water reserves [
3]. For example, contamination of watercourses is a consequence of wastewater discharge, from municipal, industrial, or farming runoffs [
4]. Typically, urban wastewater is a complex mixture containing water (usually over 99%) mixed with organic and inorganic compounds, both in suspension and dissolved with very small concentrations (mg/L) [
5]. Globally, two million tons of wastewater are discharged into the world waterways [
6]. Wastewater Treatment Plants (WWTPs) are used to combat water pollution of rivers in communities (municipalities) reducing suspended solids and the organic load to accelerate the natural process of water purification [
3,
7].
On the other hand, several properties and factors are usually considered in the water quality analysis and in the monitoring of pollution water sources in order to assess the impact of water pollution on flora, fauna, and humans. Water appearance, color or turbidity, temperature, taste, and smell often describe the physical properties of drinking water, whereas the water chemical characterization includes the analysis of organic and inorganic substance concentrations. Microbiological features are related to pathogenic agents (bacteria, viruses, and protozoa), which are relevant to public health and usually modify the water chemistry. In addition, radiological factors could be also considered in areas where water comes into contact with radioactive substances [
8]. Other specifications such as water hardness, pH, acidity, oils, and fats can also be taken into account in the water quality analysis.
Water quality monitoring focuses on programmed sampling, measurement, and recording of regulated water quality parameters. The water quality management in rivers can be more efficient when: (1) monitoring of rivers is continuous, hence its seasonal behavior can be characterized; (2) the sampling period is based on the spatio-temporal dynamics (trends or patterns) of the measured variables; (3) the choice of the sampling sites takes into account the basin irregularities; and (4) other factors at the study area are taken into consideration, such as population and industrial growth. Measurements are not usually taken uniformly at determined locations and times during the monitoring campaigns, and the pollutant concentrations in river waters do not follow linear variations. Therefore, the use of mathematical models with basic physics (that govern the transport process of pollution) and linear models can be complemented with data-driven models for modeling the river contaminants dynamics, in the sense of trends and spatio-temporal structures [
9].
For these reasons, several scientific works have scrutinized different spatio-temporal analysis of water quality from a statistical point of view, in order to understand their behavior and help to generate water decontamination designs in a more efficient way. Siyue et al. analyzed up to 41 sites at the Han River (China) during 2005 and 2006 in order to explore the spatio-temporal variations in the basin [
10]. Cluster methods and analysis of variance (ANOVA) grouped the 41 sampling sites into five statistically significant clusters. Results showed that dissolved inorganic nitrogen and nitrates had large spatial variability, while nitrogen had a relatively higher concentration in wet seasons compared with dry seasons, and phosphorous had the opposite trend. On the other hand, Serre et al. used the Bayesian maximum entropy to analyze spatio-temporal variability of water quality parameters in the case of phosphate estimation along the Raritan River basin (New Jersey, USA) between 1990 and 2002 [
11]. The database consisted of 1305 phosphate measurements at 55 monitoring stations. Their results showed that the spatio-temporal analysis improves the purely spatial analysis when the water samples are noisy and scarce. In addition, Duan et al. proposed a statistical multivariate analysis including cluster analysis, discriminant analysis and principal component analysis/factor analysis to distinguish spatio-temporal variation of water quality and contaminants [
12]. Fourteen parameters were studied in 28 sites of Eastern Poyang Lake Basin, Jiangxi Province of China from January 2012 to April 2015. This work also pointed out the spatio-temporal analysis as a tool to help in the optimization of the water quality monitoring programs. The impact of wastewater was also scrutinized in a detailed anthropogenic study of the Henares River (Spain) [
13]. The Henares River runs through residential, industrial, and farming areas. Thus, strategic points were chosen along the river, with five stations upstream of a WWTP, and five stations downstream. Six monitoring campaigns were carried out between April and June 2010, assembling 36 water samples altogether. Descriptive statistics, such as frequency or mean of pollutant concentration and uni-dimensional graphical representations were used to analyze their spatial and temporal evolution, showing the influence of the wastewater discharge and of the farm areas’ proximity. For example, high concentrations of polycyclic aromatic hydrocarbons, which are usually adsorbed on the river sediments, still continued along the Henares River regardless of season. Note that all these results point out the relevance of the observable dynamics of these pollutants with respect to time and space. This work pointed out the importance of the spatio-temporal analysis in order to visualize the trends of some compounds in the rivers, which could determine a possible relationship between river water contamination and wastewater effluent discharges.
However, and to the best of our knowledge, the variability of measurements jointly expressed in space and time has not been explored for analyzing the spatio-temporal distributions of water quality variables. In the present work, we propose scrutinizing the scope and limitations of state-of-the-art interpolation methods aiming to estimate the spatio-temporal dynamics (in terms of trends and structures) of relevant variables for water quality analysis usually taken in rivers. For visualization purposes, the absence of measurements at intermediate points in an irregular spatio-temporal sampling grid is fixed by using deterministic and stochastic interpolation methods, namely, Delaunay and k-Nearest Neighbors (kNN). For data-driven model diagnosis, a study on model residuals is performed, allowing for comparison of the model quality for both kinds of approaches.
These methods are here applied to pollution measurements at the Machángara River and its tributaries in Quito, Ecuador. Whereas several previous studies of Machángara River pollution have been made since 1977 [
14], they have conducted statistical analysis on specific variables such as phosphates, pesticides, nitrates, and hydrocarbons, but a more detailed and complete view of the wastewater dynamics can still be addressed.
The rest of this paper is as follows. In
Section 2, the materials and methods are explained, including the mathematical description of the interpolation algorithms and details of the database used for this analysis. In
Section 3, results are presented for a number of measured variables, the algorithmic performance is benchmarked, a comparative analysis is made on the data-driven residuals of the models with both methods, and the analysis on several environmental variables and their spatio-temporal dynamics is described. In
Section 4, the results are discussed, and in
Section 5, the main conclusions are presented.
2. Materials and Methods
2.1. Study Area
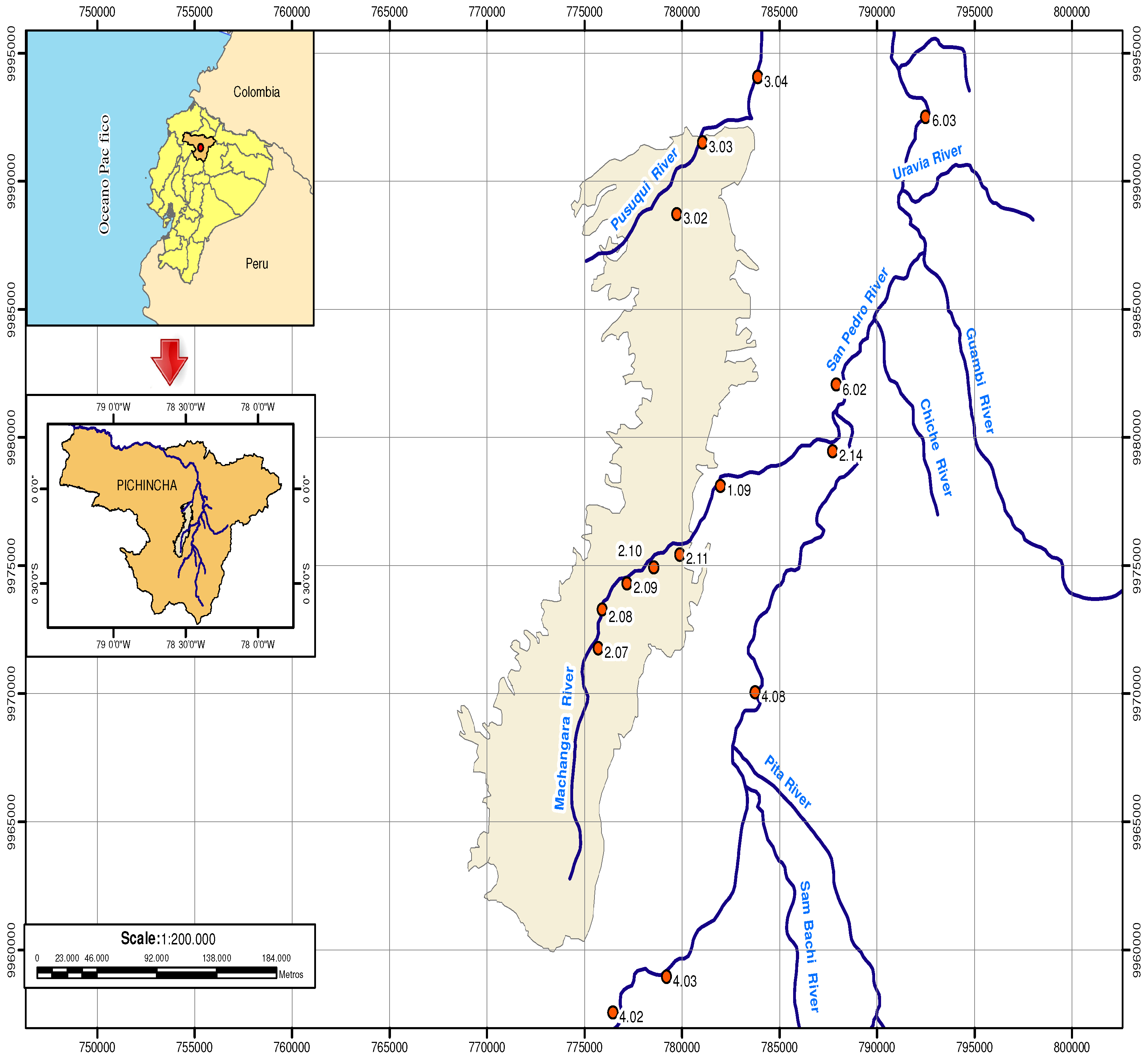
Quito, the capital of Ecuador, is located at approximately 2815 m above sea level, at UTMWGS84 coordinates with latitude 9973588.50 [00°13
47
S] and longitude 776529.41 [78°31
30
W], as depicted in
Figure 1, and it had an average temperature of 14 °C between 2002 and 2007. The Machángara River was chosen for this study because it is the main wastewater collector of Quito. This river runs through the city from south to north, collecting wastewater at a distance of approximately 22 km, and it receives about 75% of the city waste. Along the river pathway, 25 water quality monitoring stations are installed [
14,
15]. For our work, six stations were chosen in the upstream section of the River, within a reach of about 10 km, in order to monitor large amounts of wastewater. The identification of the monitoring stations is shown in
Table 1, and the water quality parameters to be analyzed are described in
Table 2.
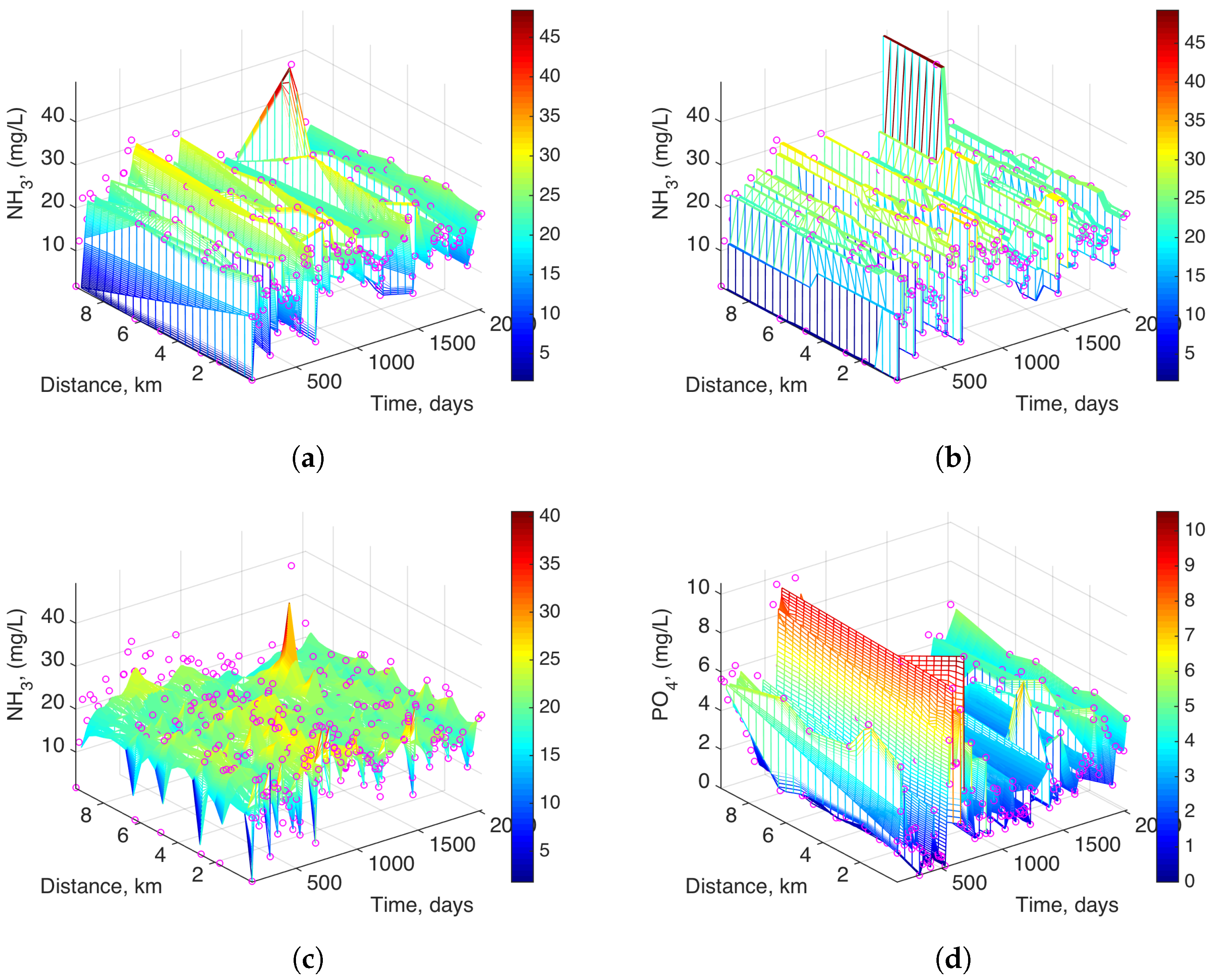
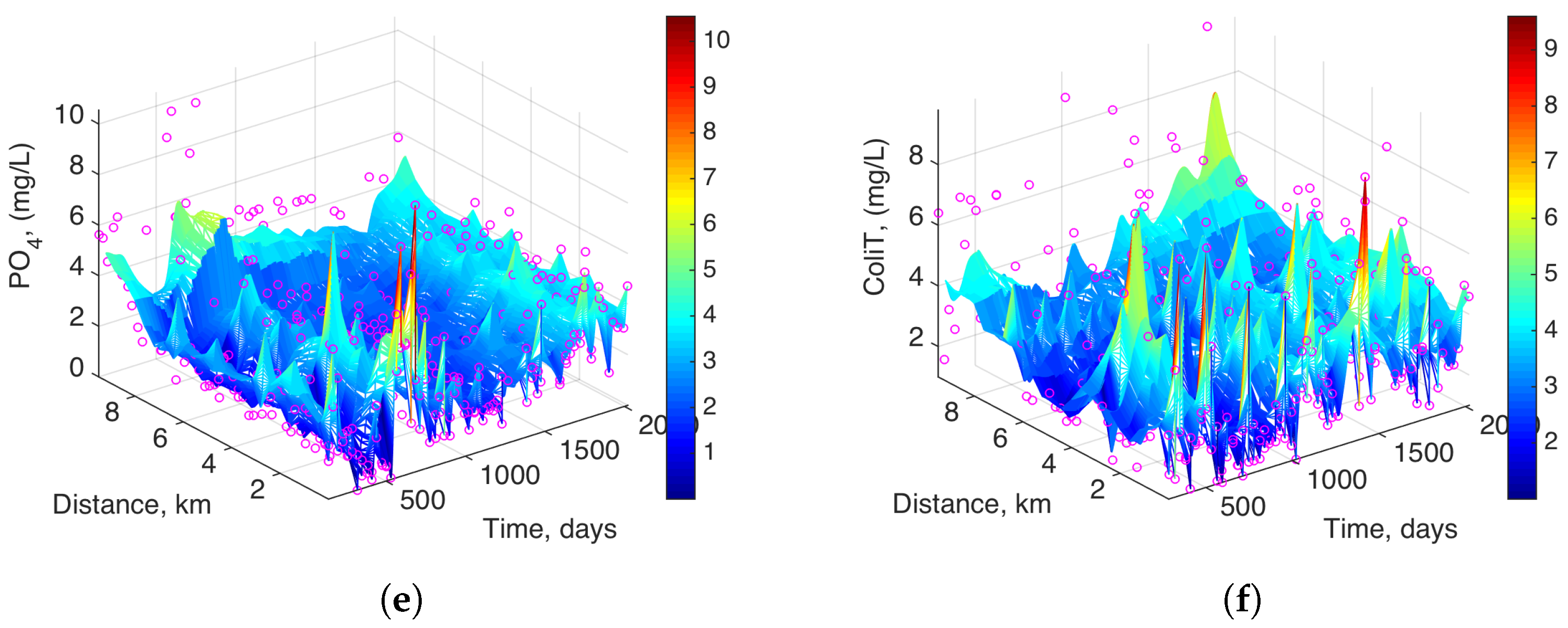
Sixty-four monitoring campaigns were carried out to measure 15 water quality parameters between 2002 and 2007. Note that a value of each parameter is usually collected in each campaign. However, some water quality parameters are sometimes not collected, and also more than one value can be registered in several campaigns. The number of water quality measurements available for each variable is shown in
Table 3. In the same time period, rainfall measurements were conducted at one weather station near the study area, and these measurements were assembled to compare rainfall with water quality variables at the Machángara River.
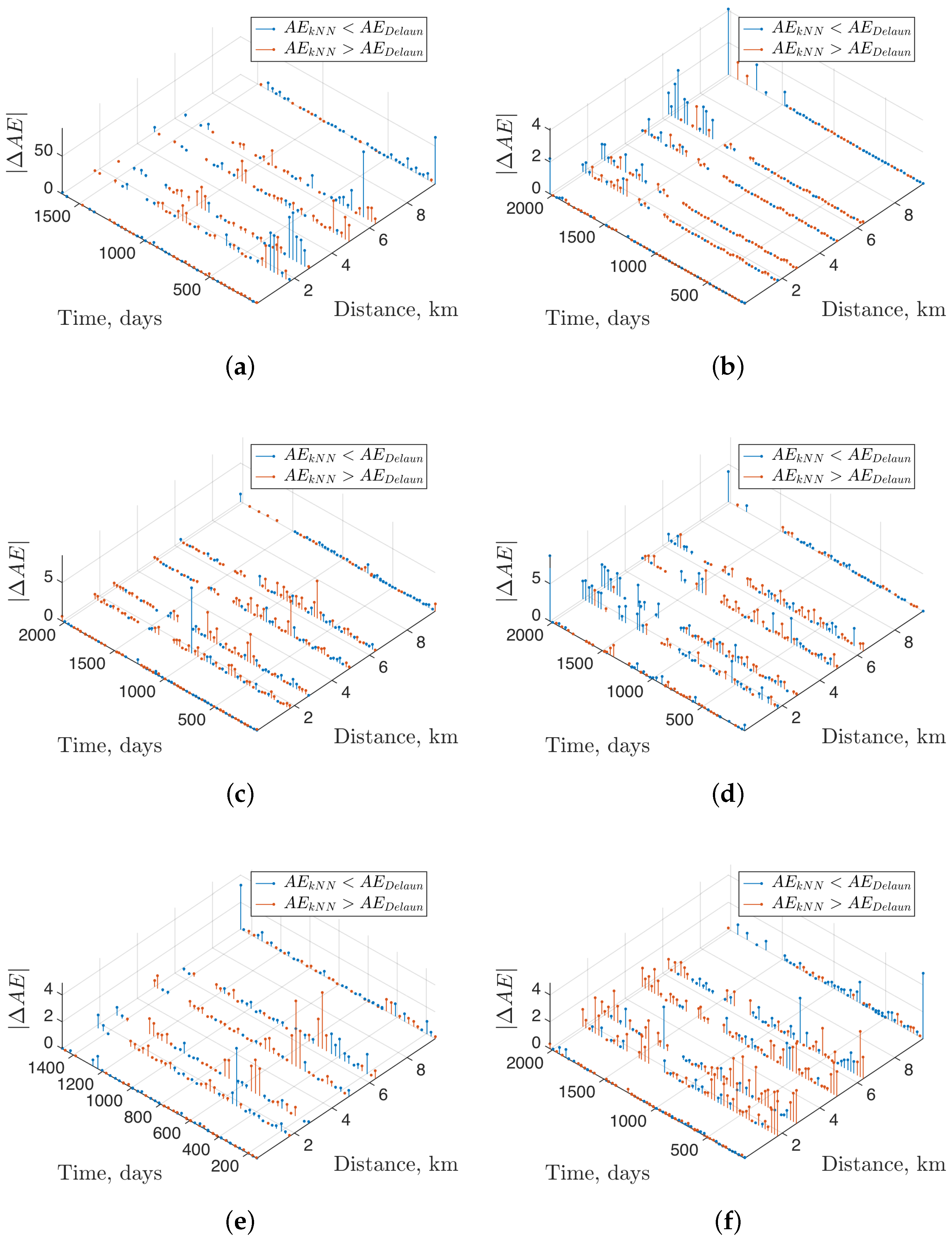
The preprocessing of the water quality database required the design of the following modules in Matlab™ (R2014b, TheMathWorks Inc., Natick, MA, USA): (1) station selection, which allowed the graphical selection of water quality monitoring stations from a map of Quito and those measurements; and (2) model estimation with smoothing interpolation methods and its representations, which allows us to work with the database of the selected monitoring stations in specific sections along the Machángara River. The latter module also helped to calculate the Mean Absolute Error (MAE) for the two studied interpolation algorithms, namely, Delaunay and kNN algorithms.
2.2. Interpolation Algorithms
Our aim in the present work is to show that statistical interpolation can yield relevant information on the underlying dynamics of the analyzed variables, which can complement the current knowledge and analysis of measurements themselves. The proposed interpolation techniques not only improve data visualization, but they also allow the identification of trends and structures that are consistently supported by measurements being close in time or space. The result of such an interpolation process can provide an enhanced information view for assisting water analysts. Note that we are actually working here with two conventional and well-known approaches, namely, deterministic interpolation (given by Delaunay) and statistical interpolation (given by kNN). The first one does not provide more than just a grid visualization of time-spatial data, and the second one is well known in the machine learning literature for being able to provide us with the dynamics or trends in the underlying evolution of the measured variables. As a result, these trends are more easily and consistently observed in statistical interpolation approaches, especially when noise and perturbations are clearly present in the measurements. Note that, in this case, the interpolation process can be seen as a smoothing estimation process, which identifies the consistent trends and separates them from the system perturbations, as estimated by the model residuals.
In studies about multi-dimensional variables, it can be useful to search for dependencies among them; therefore, the construction of mathematical models should be able to describe those existing relationships. Regression models can explain the dependency relationship between a response variable and one or more independent or explanatory variables in such a way that these models can estimate new values from a new unobserved set of measurements from the explanatory variables.
The use of nonparametric regression is sometimes suitable when a response is difficult to obtain in terms of physical models or when the measuring methods are expensive. The main objective of the interpolation is to estimate one or more unknown independent variables from a given set of simultaneously measured samples from the independent variables and the response variable.
An intermediate goal in this work is to fill up the regular grid in the quantitative representation of water quality measurements at those times when no monitoring campaigns were conducted, and in those spaces of rivers where there are no monitoring stations. The interpolation methods used in this work were Delaunay Triangulation and kNN.
2.2.1. Interpolation with Delaunay Triangulation
The interpolation with Delaunay triangulation has been used in digital cartography for the generation of digital terrain models [
16]. The starting point of this method is a cloud of three-dimensional (3D) points, usually irregularly spatial distributed, which allows us to represent surfaces digitally. This triangulation approximates surfaces by irregular and planar triangles that connect the 3D points. In this work, we do not use the 3D spatial coordinates of the points as input space, but instead we pursue a representation for two-dimensional input spaces given by the time and location (in terms of the distance along the river path), where a measurement was taken.
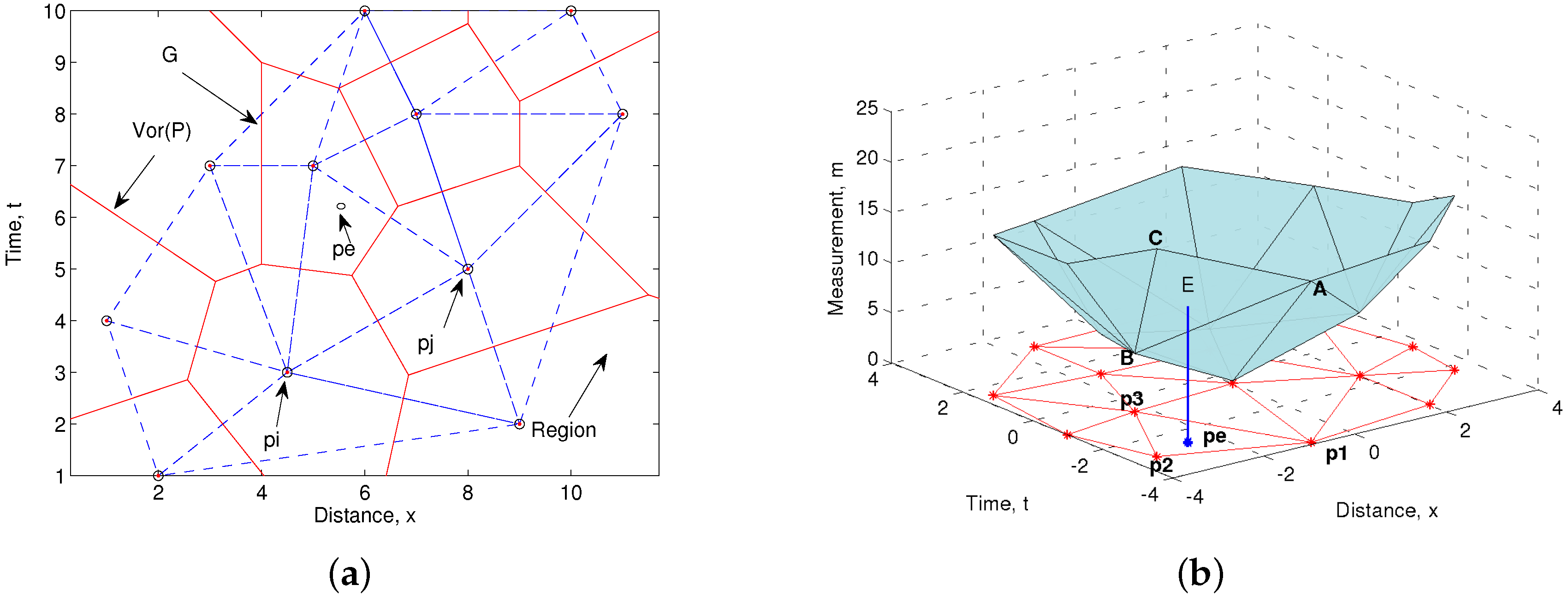
The Delaunay interpolation method is based on Voronoi diagrams and Delaunay triangulation, which uses the Euclidean distance as interpolation criterion [
17]. Given two points in the spatio-temporal plane
, denoted as
and
, the Euclidean distance among them is
Let
be a set of
n distinct points (or sites) in the spatio-temporal plane. The Voronoi diagram of
P is the subdivision of the plane in
n cells (
Figure 2a), one for each site in
P. The condition is that a point
lies in the cell corresponding to a site
if and only if
for each
with
. The Voronoi diagram of
P is denoted by
, and it indicates only the edges and vertices of the subdivision
[
17]. Graph
G has a node for every Voronoi cell equivalent for every site, and the union of external edges for each
G conforms a polygon
Pol.
Figure 2b shows the measurements (
m axe) of a variable which forms a polyhedron of irregular triangles where the measurements are the vertices. Note that bold uppercases are used to represent points (vertices of irregular triangles which form a polyhedron) defined in the coordinates
, while the projections of these vertices in the plane
are represented by bold lowercases. For example, samples represented by points
,
, and
form a triangle polyhedron, and when it is projected in the plane
, a new triangle with
,
, and
vertices is formed. The estimated value,
, at a new point
, is obtained two-fold: (1) a Delaunay triangle, which encloses the point
, is found; and (2)
is computed as the results of applying the values
and
in the plane equation defined by the points
,
and
in the linear interpolation, and as the
value of the nearest neighbor vertex in the nearest interpolation.
2.2.2. kNN Interpolation
The
kNN rule is among the simplest statistical learning tools in density estimation, classification, and regression. Trivial to train and easy to code, the nonparametric algorithm is surprisingly competitive and fairly robust to errors when using cross-validation procedures [
18]. The fitting is made by using only those measurements close to the target point
. A function of weights assigned to each
is based on the distance from
.
The usual calculation methods of known distances are Euclidean, Manhattan, Minkowski, weighted Euclidean, Mahalanobis, and Cosine, among others. The Mahalanobis distance between two points
and
is defined as
where ∑ is the covariance matrix. Mahalanobis distance has advantageous properties compared to the use of Euclidean distance, namely, it is invariant to changes in scale, and it does not depend on measurements units. By using matrix
, we consider correlations between variables and redundancy effect. The estimation function of
is represented by
, and it is estimated according to Distance Weighted Nearest Neighbor algorithm as
where
represents the samples near
, and
is the weights function that is defined in terms of Mahalanobis distance as
2.3. Performance Measures
The goal of any data-driven methodology is to estimate (learn) a useful model of the unknown system from available data. A criteria related to usefulness is the prediction accuracy (generalization), related to the capability of the model to provide accurate estimates for future data. In the learning problem, the goal is to estimate a function by using a finite number of training samples. The availability of a finite number of training samples implies that any estimate of an unknown function is often inaccurate. In regression learning problems, we can obtain a measurement of the performance in terms of the generalization capabilities of the model, with the goal of minimizing the empirical risk as described below [
19].
Given as the training set, the pairs are identified as inputs and as outputs, where x represents the distance, t is time, and m is any water quality measurement. The basic goal of supervised learning is to use the training set D to learn a function (in the hypothesis space H) that evaluates at a new pair and estimates its associated value .
In order to measure the quality of
function, we use a loss function denoted by
. The estimation for a given
is
, and the true value is
. One of the loss functions used in this paper is the absolute error loss, which can be written as
Given a function
, a loss function
l, and a probability distribution
g over
, the generalization error (also called
actual error) of
is defined as
which is also the expected loss on a new example which has been randomly drawn from the distribution.
In general, we do not know
g and cannot compute
. Therefore, we use the
empirical error (
or risk) of
as
and when the loss function is the absolute error loss, the empirical error is
which is the risk function used in this work, but from now on, we will use for it MAE, [
20,
21],
Therefore, predictive performance of regression models can be estimated by using standard metrics such as the regression MAE.
The loss function can be calculated using the validation data, which are sensitive to the choice of the validation set. This is a problem when the data set is small, and, in these cases, the cross validation technique allows more efficient use of available data [
22]. For statistical result evaluation, the
k-fold cross-validation method was used here, where data are partitioned into
k subsets or folds,
that are generally of the same size. A
partition serves for testing and the remaining ones for training. On the first iteration,
is used for the test and the remaining
for training. Therefore,
k iterations are carried out until
are tested, and the others are used for training. Each data set sample is used once for training and after that just for testing.
Leave-one-out is a special case of
k-fold cross-validation where
k is set to number of initial tuples. That is, only one sample is “left out” at a time for the test set. Therefore, in this work, we have used Leave-One-Out for the estimation of the MAE in the two interpolation algorithms used here, called Delaunay (either with linear or with nearest criterion) and
kNN (with Mahalanobis distance).
2.4. Behavior of Interpolation Errors
Given that the interpolation error depends on the analyzed variable, the number of measurements, and the interpolation method, it is advisable to use a relative error of the MAE value. Following [
23], in this work, we use
where MAE
is the relative error of MAE, and
u is the average value of each variable of water quality.
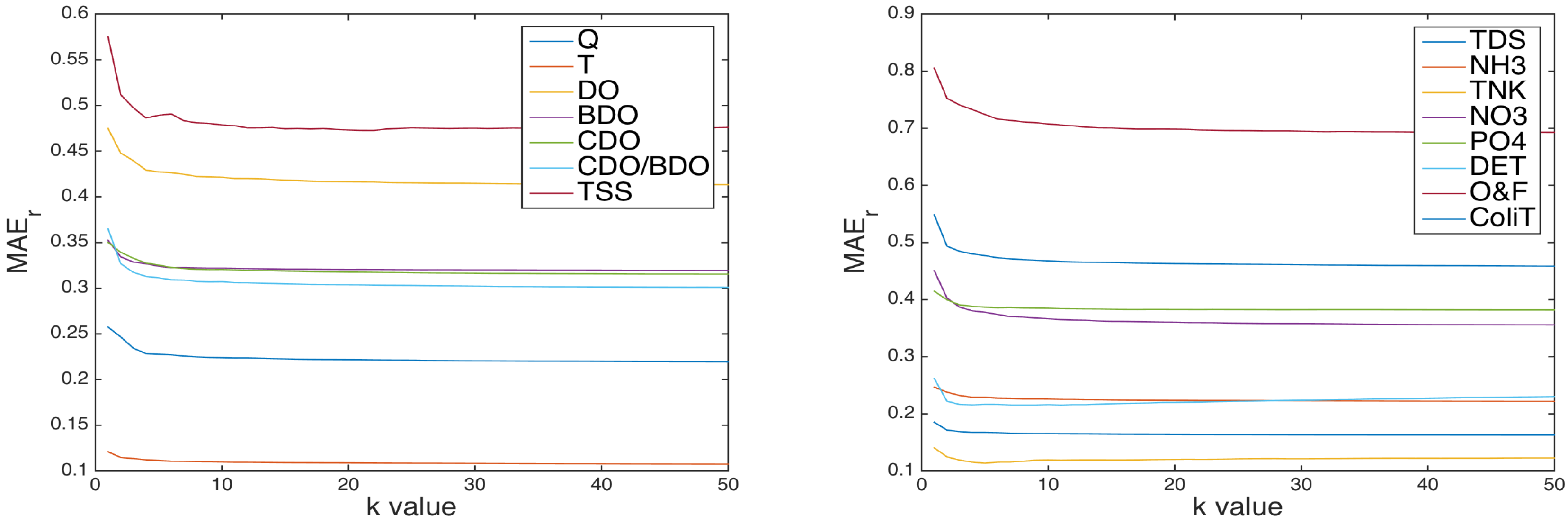
On the other hand, the MAE obtained by the kNN algorithm for different variables of water quality depends on the k parameter, which takes different values due to the nature of each variable.
4. Discussion
Since topography is stable with time, it can be treated with deterministic interpolation (such as the Delaunay algorithm). However, water dynamics can not be determined accurately by just deterministic interpolation, except for simple visualization purposes. Our work shows that statistical interpolation is capable of estimating the water dynamics with moderate model orders and distinguishing between dynamics, given by the spatio-temporal trends present in the model, and perturbations of a very different nature, given by the model residuals (including system perturbations, measurement errors, outliers and atypical values, and other uncertainty sources). Despite the main relevance of system knowledge to improve the water quality, our motivation for this work has been given by the idea that current system knowledge is partly guided by measurements. In addition, spatio-temporal statistical interpolation of measurements can enhance the information that can be extracted from the data for helping to improve the knowledge on the sources of pollution.
In many previous works, (i.e, [
10,
13]) databases built in no longer than two years were used. Alternatively, in this work, we used a five-year monitoring database, which allowed for a significant amount of records of water quality parameters similar to the work described in [
11,
28]. Our database consisted of 64 monitoring campaigns and 4867 water quality records. This allowed us to build interpolation grids with a spatial resolution of 400 m and a temporal resolution of one day. We obtained a simple to adjust
k value by using the
kNN algorithm where a stable and close to minimum MAE was achieved. This simplicity allowed us to construct a spatio-temporal grid with the measured water quality parameters and the data processed by nonuniform interpolation methods.
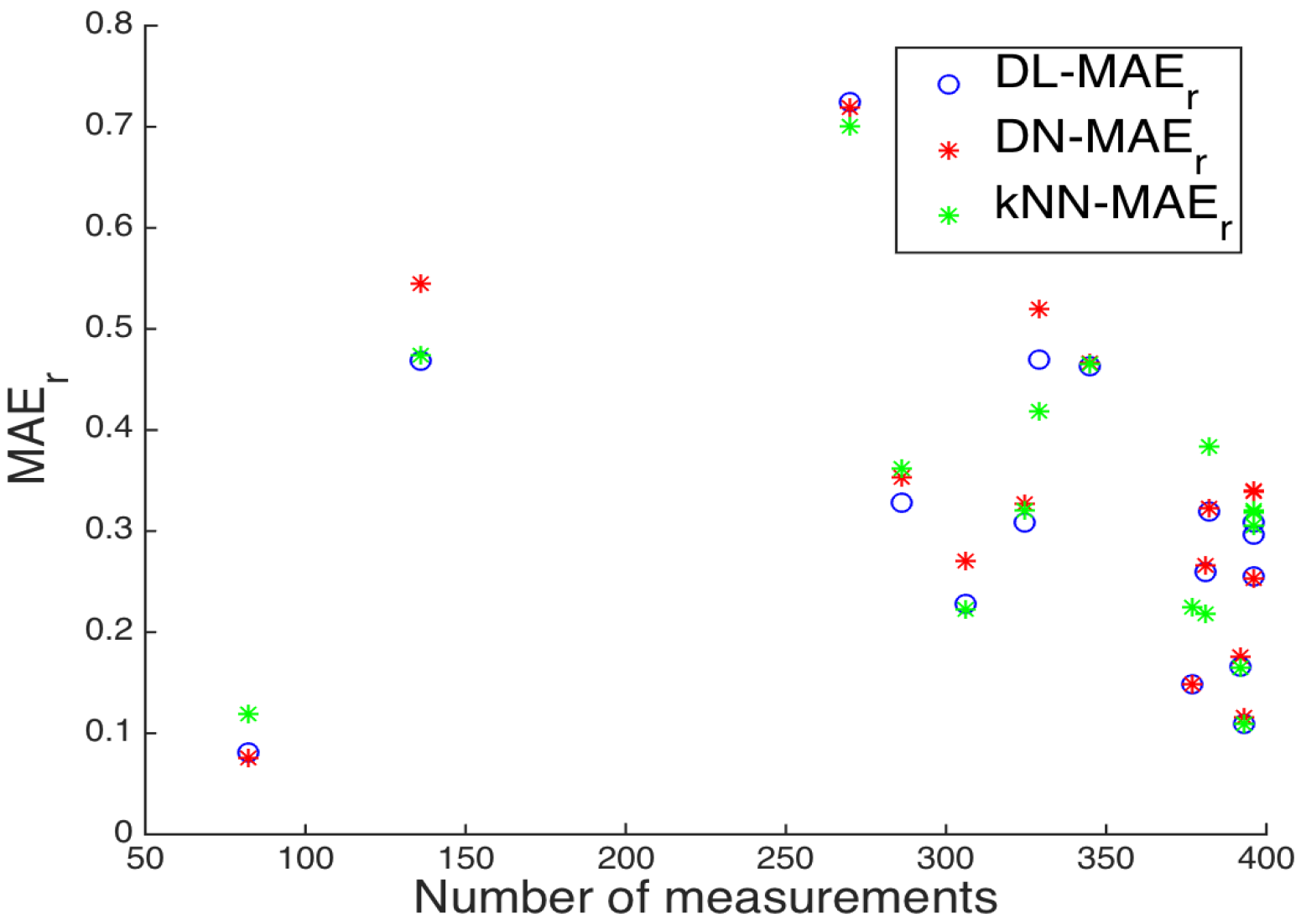
When analyzing the model residuals for comparison between kNN and Delaunay interpolation, we found that kNN estimation provides acceptable estimation of the variable dynamics in the presence of atypical samples, and in slow-dynamics variables, whereas it can present some over-smoothing effects on fast-changing variables. This suggests that, whereas conventional interpolation algorithms can provide acceptable estimation capabilities, further interpolation algorithms should be designed for overcoming their current limitations.
The MAE obtained for phosphates in [
11] was 0.466 by using Bayesian methods, while, in this work, it is 1.08 when using
kNN. This difference could be due to different water quality datasets, and, therefore, it does not stand for a straight comparison. However, we consider this previous work as comparable to ours in terms of estimation techniques. While [
29] presents only the nitrate dynamics of the Turia River (Valencia Spain), in this paper we show nitrogen and other variables with good spatio-temporal resolution.
5. Conclusions
The proposed spatio-temporal analysis of water quality measurements using interpolation algorithms for measurements from campaigns can provide useful and relevant information on their dynamics, in the sense of trends and structure. This can complement the current knowledge from the experience and from physical models and help extend it. New methods of interpolation are encouraged to overcome the limitations of conventional interpolation methods in this scenario. While a secondary target, visualization of these trends provides a way of visually inspecting the data models, and residual visualization can provide data quality measurement of the estimation model under use and its uncertainty.
Water quality values resulting from the application of the smoothing interpolation algorithms, especially for those places that are difficult to reach and for irregular time periods, can also provide relevant information for designers of wastewater treatment plants. For example, it can be used for other sections of the Machángara River and make studies about inter-dependence between water quality variables, (e.g., nitrates and phosphates).
The database used in this work corresponds to a period between 2002 and 2007, a time period when few hydrology monitoring stations existed for capturing the rainfall in the city or near the study zone. Even today, there are no more water quality monitoring stations than those ones constructed in 2002–2007. The major contributors of wastewater in the Machángara River are domestic and industrial discharge, and furthermore, in our city, there were no separate pipes for rainfall and wastewater (and still today there are not yet any). For these reasons, in our study, we especially missed having denser spatial sampling rates (stations), as well as the always desirable increase in time sampling rates (measurement campaigns).
A limitation of this study is the lack of time records (the hour of the day) in which the water samples were collected and analyzed. Variables such as water temperature, concentrations of detergents, phosphates, oils and fats are not constant during the 24 h, since they depend on discharge of domestic and industrial wastewater and meteorological conditions. Therefore, conducting an extended study considering smaller time periods between samples for 24 h each day could provide us with useful information for studies on the uses of water than could be characterized by time and population type.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}