Abstract
Proper identification of oriented knots and 2-component links requires a precise link nomenclature. Motivated by questions arising in DNA topology, this study aims to produce a nomenclature unambiguous with respect to link symmetries. For knots, this involves distinguishing a knot type from its mirror image. In the case of 2-component links, there are up to sixteen possible symmetry types for each link type. The study revisits the methods previously used to disambiguate chiral knots and extends them to oriented 2-component links with up to nine crossings. Monte Carlo simulations are used to report on writhe, a geometric indicator of chirality. There are ninety-two prime 2-component links with up to nine crossings. Guided by geometrical data, linking number, and the symmetry groups of 2-component links, canonical link diagrams for all but five link types (, , , , and ) are proposed. We include complete tables for prime knots with up to ten crossings and prime links with up to nine crossings. We also prove a result on the behavior of the writhe under local lattice moves.
Keywords:
writhe; chirality; nomenclature; link symmetries; link table; knot table; lattice polygons; DNA topology 1. Introduction
The unambiguous identification of links that are not topologically equivalent is of utmost relevance when studying links in a natural setting. Of special interest in the field of DNA topology is the action of enzymatic processes that produce DNA links. In this setting, one needs proper distinction between a link and its mirror image, or between two links related by reflection, orientation reversal, or component relabeling. For example, enzymes in the family of type II topoisomerases pass a segment of a DNA molecule through another thus introducing crossing changes (Figure 1b). Another class of enzymes, site-specific recombinases, bind to two DNA segments, cleave and reconnect the ends (Figure 1a). The local action of these enzymes on circular DNA molecules often results in global topological changes. Rigorous identification of the product links is used to study the topological mechanism of action of the enzymes. A mislabeling of the component orientation, or a mistaken chirality of the product can have severe implications on the mechanistic study. See more on this topic at the end of this section and in.
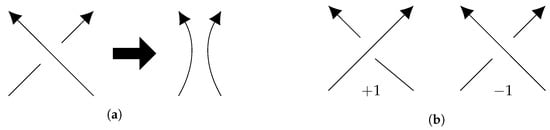
Figure 1.
(a) Example of a coherent band surgery use to model DNA recombination; (b) Contribution of each type of crossing to the projected writhe calculation.
One of the primary goals of knot theory is to distinguish between link types. Knot theory is the mathematical study of links, i.e., embeddings of one or more disjoint circles in three-dimensional space. Each circle is a component of the link. A knot is a link with one component. Two links are topologically equivalent if there is an ambient isotopy between them. Intuitively, two links are equivalent if one can be smoothly deformed into the other without allowing phantom crossings between the curves. Each equivalence class is called a link type, and throughout this paper we may refer to an equivalence class as an isotopy class.
Traditionally, links have been tabulated following the Alexander–Briggs notation [1] that organizes them by their minimal crossing number. The order of the links sharing the same crossing number is somewhat arbitrary. The link table in most common use is the Rolfsen table [2]. There, links are labeled using Conway’s notation [3] and an extension of the Alexander–Briggs notation [1]. In the Rolfsen table, each knot diagram represents the unoriented knot K and its mirror image . For a link of two or more components, in addition to L and , the link diagram represents the link type with any component relabeling. However, the link L and its mirror image may be in different isotopy classes (i.e., may not be topologically equivalent). Such links are known as chiral links. Similarly, one could orient the link or label the components in several different ways which may yield non-equivalent links. Links which differ only in these ways share many properties, and are represented by a single unoriented link diagram in the standard link tables. In sum, the Rolfsen table provides no way to refer to chirality, orientations or component labeling [2]. Hence, there has been a need to provide explicit diagrams in studies requiring any of this information. The objective here is to provide a link table that accounts for chirality, orientation, and component labeling.
One could of course compile yet another table with an arbitrary choice of mirroring, orientation, and component labeling motivated by an application at hand. Far from solving the problem, this would lead to further confusion. We instead propose to use geometric and topological properties of links to determine a standard diagram for each link. Our goal is to achieve a more clear relationship between isotopy classes of different link types. This is particularly useful when studying enzymatic actions and trying to establish relationships of link types before and after crossing changes or coherent band surgery (Figure 2). More specifically, we propose to use writhe and linking number (introduced in Section 2) to classify the different isotopy classes formed by mirroring, orientation reversal, and component relabeling.
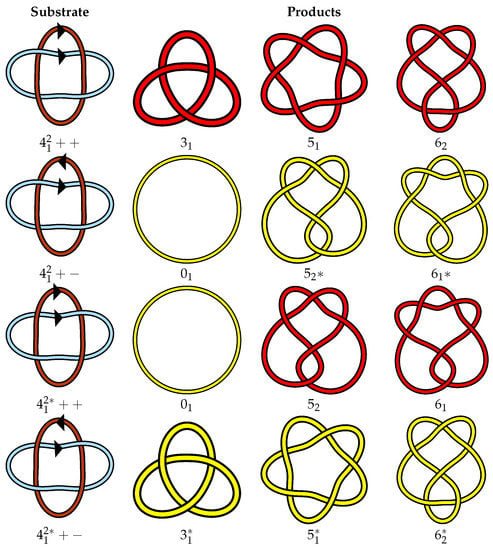
Figure 2.
Isotopy types of the link are pictured in the first column. Each row denotes a different isotopy type of the used as the starting point for a coherent band surgery (local reconnection). These can be interpreted as substrates of site-specific recombination at two dif sites, one on each component of the link. The right side shows all the potential products of said event, up to crossing number 6, depending on the isotopy type of the substrate. It is clear in this example that coherent band surgery on the different isotopy types of the link yields different knots. In particular, +− and ++ can be unknotted in one step, while ++ and +− cannot.
Here by “classify”, rather than any deeper topological classification, we mean to distinguish isotopy classes of links in such a way that they can be consistently referenced. In Section 3, we review previous efforts in this direction. In Section 4, we propose a classification based on linking number and total writhe (defined in Section 2) and define a canonical isotopy class for links. In Section 4 we define the BFACF algorithm. In Section 5, we use numerical data obtained from BFACF simulations to estimate the total writhe for all prime links with up to nine crossings. In Section 6 we describe the numerical methods. We use self-avoiding polygons in to represent knots and links with two components. For any given polygon length n, we estimate the mean writhe values of all length n representations of a given isotopy class. This extends previous work on knots [4,5] and our numerical methods may be applied to any other link type.
Portillo et al. conjectured that given a chiral knot K, the mean writhe of all length n conformations in is bounded as n varies, and furthermore is either positive for all n or negative for all n [4]. The numerical data in [4] for knots with up to eight crossings supported this conjecture. Brasher et al. [5] extended the numerical work to knots with up to 10 crossings; their data remained consistent with the conjecture. Table S6 is the table of canonical knot diagrams extended from that presented by Brasher et al. [5]. We extend the conjecture to links as follows:
Conjecture 1.
Given a c-component link L, the mean of the self-writhe for each component is bounded as the total link length n varies. Moreover, if the link is chiral, then the sum of these mean self-writhes is either positive for every n or negative for every n.
Here, the total link length n is defined as the sum of the component lengths. Additionally, we could conjecture that if a link L with c components has a property that exchanging component i with component j yields a different link (i.e., L lacks exchange symmetry between components i and j), then for any total link length n, either the mean self-writhe of component i is smaller than the mean self-writhe of component j, or vice versa. We find, however, that, for smaller values of n, this ordering may not be consistent. Specifically, minimum length conformations of the link are provided as a counterexample (see Section 5).
Based on Conjecture 1 and the supporting numerical data presented in Section 5 and in the supplementary materials (online), we propose the following nomenclature. Let be the set consisting of an oriented link and all links obtained from it by mirroring, component reversal and relabeling. We choose the standard link diagram L representative of the set as the one corresponding to an isotopy class where the sum of self-writhes and linking number are most positive, with components labeled in order of decreasing self-writhe.
We argue that this is a natural approach to choose the standard link diagram since writhe and linking number are very closely related to chirality (see Section 3.4), and since we find that component self-writhe is related to exchange symmetries (i.e., component relabeling). Among the 2-component links with crossing number up to 9, only five are not fully disambiguated by our method. It is worth noting that previous approaches only partially disambiguate link isotopy classes (see Section 3.5 and Section 4.2 for more details). Additionally, the numerical methods used here to explore random conformations have been extensively used in studies of random knotting in the simple cubic lattice [6,7], and in applications to DNA studies. For example to explore whether or not biological processes, such as those performed by topoisomerases and recombinases, are truly random or have some order [8]. Relevance of proper link identification in DNA topology is discussed at the end of this section.
The structure of the paper is as follows. We start in Section 2 by defining writhe and linking number, which we will use to help distinguish the symmetry classes. Link symmetries and existing nomenclatures are reviewed and extended in Section 3. We describe a systematic way to define a canonical isotopy class for each link (Figure A1) in Section 4. In Section 5, we discuss the results of the numerical simulations used to distinguish between isotopy classes of links, and how they relate to Conjecture 1. Additional numerical results are included in the Supplementary Materials online. In Section 5, we also prove Theorem 2 that determines the difference in writhe between two polygons related by BFACF moves. This theorem deals with the boundedness of writhe for lattice links within the same isotopy class. The numerical methods used are described in Section 6. The key outcome of our work is Figure A1, the table of oriented link diagrams with labeled components based on our proposed nomenclature. For completeness, we have included Table S6, the writhe-based knot table extended to 10 crossings based on the work of Portillo et al. and Brasher et al. [4,5].
Importance of Link Symmetries in DNA Topology
Complete distinction between links related by reflection, orientation changes, and component relabeling is important in many problems in physics and biology. Our motivation for this study comes from the need to unambiguously identify knots and links arising from biological processes that change the topology of DNA. In its most common form, the B form, DNA forms a right-handed double helix consisting of two sugar phosphate backbones held together by hydrogen bonds. The backbones have an inherent antiparallel chemical orientation ( to ) and a circular molecule could be modeled as an orientable 2-component link where each backbone is represented by one link component.
More often, in DNA topology studies, the molecule is modeled as the curve drawn by the axis of the double helix. The axis can inherit the orientation of one of the backbones or be assigned an orientation based on its nucleotide sequence. In this way, one circular DNA molecule is modeled naturally as an oriented knot and two interlinked molecules are modeled as oriented 2-component links.
Different cellular processes can alter the topology of DNA. A notable example is that of replication of circular DNA. Replication is the process that makes two identical copies of a chromosome in preparation for cell division. If the chromosome is circular, as in the case of bacteria, replication gives rise to two interlinked chromosomes. If the original DNA circle is unknotted, then the newly replicated link is a right-handed torus link of type (Figure 2) [9]. The orientation given to the DNA circle before replication is naturally inherited by the components of the newly replicated link. Replication links are typically unlinked by enzymes in the family of type II topoisomerases which simplify the topology of their substrate DNA by a sequence of crossing changes. In [10], Grainge et al. showed that in Escherichia coli, in the absense of the topoisomerase Topo IV, replication links could be unlinked by site-specific recombination. Site-specific recombinases act by local reconnection, which can be modeled as a coherent band surgery on the substrate link (see Figure 1a). This process was studied in [8,11]. Importantly, the outcome of recombination can be dependent on the exact symmetry class of the link being acted on as illustrated in Figure 2.
Furthermore, links arising as products of enzymatic reactions on circular substrates may have distinguishable components if the nucleotide sequence differs from one component to the other. In addition, some enzymes in the group of topoisomerases and site-specific recombinases have been found to have a chirality bias when identifying their targets (topological selectivity) or to tie knots or links of particular topology and symmetry type (topological specificity).
2. Writhe and Linking Number
Linking number is a standard topological invariant of oriented links which may be calculated from a spatial conformation or a regular diagram. To calculate linking number of an oriented link L from a regular diagramof L, number the inter-component crossings from 1 to m, and assign characteristic to crossing i, where is either or according to the convention in Figure 1b. The linking number is lk. For a 2-component link embedded in space parametrized by curves , the linking number is calculated by the Gaussian integral
where are the vectors representing points along the curve [12].
Space writhe is a geometric invariant of a link conformation that measures entanglement complexity. The space writhe of a knot conformation parametrized by is found by taking the integral
where are the vectors representing points along the curve [12]. Note that space writhe is not a topological invariant.
For links with c components, each component has its own self-writhe calculated as above. We denote self-writhe of component i by where is the conformation of the ith component. The sum of self-writhes of a c-component link conformation is . We define the total writhe of a link conformation as . Note that, for a link L with conformation , we can write lk lk since linking number is an invariant. However, this substitution cannot be made for , as writhe is not a topological invariant.
3. Link Symmetries and Nomenclature
In this section, we define the different types of link symmetries and introduce the proposed link nomenclature.
3.1. Isotopy Classes
Two links are equivalent if there is an ambient isotopy that transforms one into the other. The set of all conformations which are isotopically equivalent form an isotopy class. When a link L is not equivalent to its mirror image L, then L and L form two distinct isotopy classes. However, when link diagrams are listed in a table of unoriented links, only one of these two isotopy classes is represented. It is easy to obtain the mirror image L from the diagram of L by changing all over-crossings to under-crossings and vice versa. The number of potential isotopy classes is increased by assigning orientations and labeling components. For an oriented c-component link with labeled components, there are up to distinct isotopy classes. This number comes from the 2 reflections, orientations, and labelings of the components.
In this paper, we consider links with or 2, but strive to develop methods which can be generalized to . When , there are two possible unoriented isotopy classes (the knot and its mirror image), and four possible oriented isotopy classes. For 2-component links, there are 16 possible isotopy classes for each oriented link with labeled components.
3.2. Doll and Hoste Notation
We use the notation of Doll and Hoste to differentiate isotopy classes of links [13]. Consider an oriented 2-component link of link type L with labeled components. We will refer to this initial link as L++. If we have a link in which the ith component is reversed from L++, then we replace the ith + with a −. If an oriented link is fully invertible (see below), the +’s and −’s may be omitted. The mirror image of L++ is denoted by L+. Likewise the mirror images of L+−, L−+, and L−− are L−, L+, and L−, respectively. This notation extends to c-component links by appending another + or − for each additional component. Note that this notation intrinsically assumes the components are labeled numerically from 1 to c.
We propose extending this notation by using an element of the permutation group to denote other possible labelings given L. Given , we use L to denote L with the ith component relabeled to for each i. If is the identity, then it may be omitted. Note that, for 2-component links, may only be the identity or the permutation exchanging 1 and 2. Applying this notation with reversals leaves an ambiguity for the order in which the relabeling and component reversals happen. For example, if L is a 2-component link and is the transposition of 1 and 2, then which is the reversed component in L+−? We take the convention that is applied to L after the orientations are determined. This means that the diagrams of L+− and L+− will look identical except for the names assigned to the components, which is to say that L+− and L+− have the same underlying unlabeled oriented link L+−. Figure 3 illustrates this notation in full for the link.

Figure 3.
Example of the link notation adopted and modified from the work of Doll and Hoste [13]. The lighter blue strand is component 1 and the darker red-orange strand is component 2. Here, is the nontrivial element of . Because has symmetry group , all links sharing a row in this figure are equivalent. The diagram labeled ++ here matches the diagram in Figure A1. All other diagrams are determined from ++.
3.3. Link Symmetries
The symmetries of a c-component link can be described by a subgroup of [14]. The generator from the first represents a reflection. The generator of the ith copy of in represents a reversal of the ith component. A permutation represents a relabeling where component i is relabeled as .
We adopt the notation for symmetry group names used in Cantarella et al. (Figure 1 of [15]). Specifically, each group is given a designation where k is the order of the group and j is an index (as determined by Cantarella et al. [15]). After cross-referencing with the work of Berglund et al. [14] and Henry and Weeks [16], we found that only 8 of the 27 subgroups occur for 2-component links with crossing number 9 or less. Find details of each of these subgroups in Table 1. The symmetry names used come from the work of Berglund et al. [14] and are defined for a 2-component link L as follows:

Table 1.
Symmetry groups for two-component links with up to nine crossings. Listed are names for the groups and their notation as a subgroup of [14,15]. Also listed are generators for the subgroup where is a reflection, and are reversals of components 1 and 2, respectively, and p is the exchange of the component labels. The final column indicates which of the 16 different possible isotopy classes are equivalent to L++. Here is the non-trivial element of .
- L is purely invertible if it is isotopic to the link found by simultaneously reversing both components (L++ = L−−).
- L is fully invertible if it is isotopic to L with every other choice of orientation.
- L has even operations symmetry if it is isotopic to links obtained by an even number of reflections and/or component reversals.
- L has pure exchange symmetry if it is isotopic to L with the component labels exchanged (L++ = L++).
- L has a non-pure exchange symmetry if it is isotopic to L with a combination of exchanged labels with a reflection and/or with component reversals, but L++ ≠ L++.
- L has no exchange symmetry, if it is not isotopic to L with the component labels exchanged regardless of any reversals or reflections.
- L has full symmetry if it is isotopic to every link obtained by component relabeling, component reversal, and reflection.
- L has no symmetry if it is not isotopic to any link obtained by component relabeling, component reversal, or reflection.
It is interesting to note that of the eight symmetry types observed for prime 2-component links with no more than nine crossings, only links with no symmetry lack any kind of inversion symmetry. More specifically, every prime 2-component link with at most nine crossings has L++ = L−− except for the , , and links which have no symmetry. In addition, the only links which have any kind of reflection symmetry are those with even operations symmetry or full symmetry. There are only four prime 2-component links with crossing number up to 9 that have even operations symmetry, and the only observed 2-component link with full symmetry is [15]. All other prime 2-component links lack reflection symmetry.
For the purposes of classification of isotopy types, the more interesting links are those which lack certain symmetries, as there will be more isotopy classes to disambiguate. As we will see in Section 3.4, writhe is connected to the isotopy class of links which lack pure exchange and/or reflection symmetries. Because of this, those links will be of particular interest to the results of our writhe experiments described in Section 6. Of the 92 prime 2-component links with crossing number 9 or less, 58 lack pure exchange symmetry and 87 lack reflection symmetry.
3.4. Symmetries, Writhe and Linking Number
Consider a 2-component link L++ with linking number lk(L++) . A link diagram for the mirror image L+ can be obtained by taking a diagram for L++ and switching all of the over/under-crossings. This changes the sign of each crossing’s contribution to the linking number, hence lk(L++) lk(L+). Thus, an oriented link with non-zero linking number cannot be equivalent to its mirror image as an oriented link. Note that it could, for example, have even operations symmetry, which would make it equivalent to its mirror as an unoriented link.
Similarly, reversing the orientation of one of the components will change the characteristic of each inter-component crossing, i.e.,
Thus, the linking number can help discern choices of orientation. Note that reversing the orientation of a link component does not change self-writhe of that component.
Taking the mirror image of a link will yield the opposite self-writhes, linking number, and total space writhe. That is, for a c-component link L in conformation with components ,
where is the reflection of conformation . We observe that writhe is in some way dependent on chirality, but not orientation, whereas linking number is dependent on both.
3.5. Previous Classification Schemes
There have been previous attempts to classify link isotopy classes. For chirality, Liang et al. [17] classified alternating links into chiral designations of either D or L based on a method called writhe profiles, which is related to projected writhes. While writhe profiles provide a useful way to classify many alternating knots and links, they do not classify non-alternating knots and links. Moreover, there is a discrepancy in the work of Liang et al. between how oriented and non-oriented links are classified.
For non-oriented links, in [17] the authors checked the sign of the projected writhe and assigned a D for a positive value and an L for a negative value. If the sum of self-writhes was zero, writhe profiles were calculated in order to specify a designation of D or L. For oriented links, the sign of the linking number was checked first and the link was assigned a D for a positive value and an L for a negative value. If the linking number was zero, the designation process for the non-oriented links was followed with minor changes to account for orientation.
A discrepancy arises when linking number is non-zero. Chirality is a property independent of orientation but linking number very much depends on orientation. Thus, linking number is not a good choice for a chiral designator. To see the issue more clearly, take the link as an example. The oriented link has four oriented symmetry classes which can be represented by ++, +−, ++, and +−(see Figure 3). The unoriented link only has two unoriented symmetry classes which could be represented by and . In the classification of Liang et al. [17], the link designated by ++ in Figure 3 would be given a D classification, while +− would get an L. However, as chirality is a property of the unoriented link and since ++ and +− both share the same underlying unoriented link representation, , then in a consistent classification scheme they should be given the same chiral designation.
Our classification method (Section 4) also uses writhe, but only to distinguish and classify link mirrors and component labelings, and we use linking number only to distinguish orientations.
4. Defining a Canonical Isotopy Class for Links
In order to classify link isotopy classes, we use Monte Carlo sampling of self-avoiding polygons of fixed link type in the simple cubic lattice , followed by a writhe calculation. Sampling is done via the BFACF algorithm as described in Section 4.1.
4.1. Cubic Lattice Links and the BFACF Algorithm
The numerical methods of this paper use links in . We refer to these as lattice links. A c-component lattice link is a disjoint union of c self-avoiding polygons. A self-avoiding polygon of length n is a sequence of points in such that for , , and for all . To obtain the polygon from these points, we include the edges , , where is the edge connecting and , with connecting and (Figure 4b). The length of a link in is the sum of the lengths of the components of the link. We denote the length of a lattice link by .
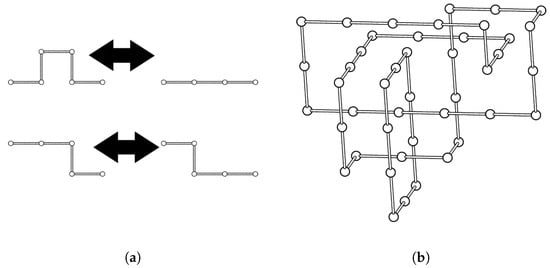
Figure 4.
(a) BFACF moves: ()-move, top; ()-move, bottom; (b) A minimum step cubic lattice representation of the link.
This representation is advantageous as it allows us to use the BFACF algorithm to sample a distribution of link conformations and analyze geometric trends such as writhe. The BFACF algorithm is a dynamic Markov chain Monte Carlo algorithm sampling from a state space of self-avoiding polygons in [18,19,20]. The state spaces are the lattice link isotopy classes. Transitions in the chain are deformations of the link as seen in Figure 4a. Janse van Rensburg and Whittington showed that the ergodicity class of a knot or link in BFACF is the set of all possible embeddings within that knot or link’s isotopy class in [6].
The transition probabilities of the BFACF algorithm depend on an adjustable parameter where [6]. The limiting distribution of the resulting Markov chain is
where
and is the total number of length n lattice links in the same isotopy class as L. This distribution has the property that all conformations of the same length have equal probability, dependent only on z and on the link type. Thus, the BFACF algorithm may be used to uniformly sample conformations of certain link isotopy class and length. The reader is directed to ([21], chapter 9) for a full treatment of the BFACF algorithm.
4.2. Canonical Isotopy Class
References to links in the literature most commonly use the name listed in the Rolfsen table [2]. This is effective for communicating general properties of links, but when working with oriented links or links with distinguished components, one must still explicitly draw a picture of the link for full clarity. Doll and Hoste provided a link table which included orientation and component labels in addition to providing a nomenclature for reversing components [13]. While the diagrams in the Doll and Hoste table were chosen in a systematic way (using Conway notation), there is inconsistency in which isotopy classes of each link are actually represented. For example, the two diagrams listed for are reflections of each other and are non-isotopic, since lacks reflection symmetry.
Our goal is to propose a systematic way to identify a representative isotopy class for each link type. We use writhe and linking number to aid in this. Let be the set of all length n lattice conformations of L. Let the average of the sum of self-writhes of the elements of be , i.e.,
Analogously, let be the self-avoiding polygon representing the ith component of , then we define the average of the self-writhes of component i of L as
Case 1, L is a knot ()
In the case of knots, we follow the writhe-guided nomenclature proposed in Portillo et al. and Brasher et al. [4,5]. This nomenclature specified the canonical knot K as the one where . In [4,5], the authors also provided numerical data in support of the conjecture that for each chiral knot K, was either consistently positive or consistently negative regardless of n, thus pointing to an unambiguous designation. Using the data from those papers and previously unpublished 10-crossing data, we constructed a table of knots through 10 crossings (Table S6). Note that these knots do not include orientation information, as the methods used do not discern orientations of knots.
Case 2, L is a 2-component link ()
The case of 2-component links is more complicated due to the extra link symmetries as detailed in Section 3 and Table 1. We appeal to Conjecture 1 and use self-writhes and linking number to define the canonical isotopy class of a link, and denote it by L++. In particular, we choose L++ so that (L++) , lk(L++) , and when possible. Once L++ is chosen, it can be used as a point of reference for obtaining all other isotopy classes of the link as described in Section 3.2, and illustrated in Figure 3.
As long as (L++) , then half of the isotopy classes will have (L++) . Then, if lk(L++) , half of those isotopy classes will have lk(L++) . Then, as long as , half of those isotopy classes will have . This narrows down the 16 isotopy classes to two potential candidates for L++. If L has pure exchange symmetry, then these candidates are equivalent and the canonical link L++ is chosen to be this isotopy class. There are three 2-component links with crossing number at most nine that lack pure exchange symmetry: , , and . In fact, these links have no symmetry.
The assumptions that (L++) , lk(L++) , and depend on the symmetry type of L. If there is reflection symmetry, then it is necessarily true that (L++) for all n. If (L++) and there is no reflection symmetry, then we cannot distinguish the link from its mirror image with our methods, but we did not observe this behavior. If there is pure exchange symmetry, then it is necessarily true that . If and there is no pure exchange symmetry, then we cannot distinguish the different component labelings with our methods, but we did not observe this behavior either. For links with full inversion symmetry, it is necessarily true that lk(L++) . If lk(L++) and L does not have full inversion symmetry, then we cannot distinguish orientations with our methods. This behavior is observed for only two links: and .
In Section 6, we describe the numerical methods used to estimate , , and for each 2-component link through nine crossings. Section 5 describes results of the numerical simulations, and analytical results on the effect of BFACF moves on the writhe of a lattice polygon. Partial data are presented in Table 2 and Figure 5. Complete data are included in supplementary Tables S2–S5.
Table 2.
Columns 2, 3, and 4 show confidence intervals for the average of the sum of self-writhes (++)), and self-writhes of components 1 and 2 (++ and ++) for length 200 links in . For each 2-component link indicated in column 1, the average is taken over an ensemble of statistically independent length 200 lattice links of type L as described in the numerical methods section. Combined with the linking number (column 7), these confidence intervals are used to determine which diagram appears as L++ in Figure A1. The Rolfsen ([2]) diagram’s designation under our notation is presented in column 5. Column 6 lists which isotopy class is represented by default KnotPlot. Note that the KnotPlot conformations are reflections of those in the Rolfsen table. Symmetry groups (column 8) are taken from the work of Henry and Weeks, Berglund et al., and from SnapPy [14,16,22].
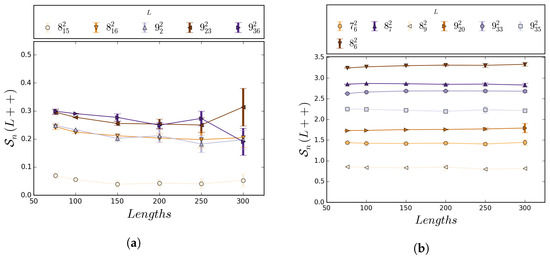
Figure 5.
Estimates with 95% confidence intervals for L++) for a selection of links for . Data were obtained from the simulations as described in Section 6. The expected value of was the lowest among links lacking reflection symmetry. Note that even though the expected value is relatively small for all lengths examined, the confidence intervals do not include 0. Limited variability of ++) was observed as length increased for all prime links with up to 9 crossings. This suggests a well-behaved nature of writhe for long lattice links. Confidence intervals for all sampled links can be found in Supplementary Table S2. Values shown are for some of the isotopy classes in Figure A1.
4.3. Proposed Link Table
The canonical isotopy class was chosen for each link as described in Section 4.2 using data obtained as described in Section 5 and Section 6. The , , , , and links were each narrowed down to two potential candidates by this process, differing by the simultaneous reversal of both components. For each of these links, some extra criterion is required to select a canonical link from the two candidates. We made an arbitrary choice between the two possible candidates for each of these five links, in order to provide a complete table and thus avoid the ambiguities of nomenclature that we set out to eliminate. The canonical or otherwise chosen link diagrams are represented in Figure A1.
4.4. Note on Minimum Lattice Links
In Portillo et al., an ideal lattice knot of type K was defined as a minimal step number (msn) lattice embedding of K [4]. The authors conjectured that the mean writhe of random polygons of given knot type and fixed length could be approximated by the mean writhe of the corresponding ideal msn conformation. They provided numerical evidence that there exists a constant such that the mean writhe of a random lattice polygon of type K and length n belongs to , independently of the value of n, where is the mean writhe of the ideal lattice conformations of K. We here inquire if this conjecture can be extended to links. Methods and results are presented in Section 5 and Section 6.
5. Results and Discussion
5.1. Numerical Results
Statistically independent ensembles of linked lattice polygons were obtained as described in Section 4.1 and Section 6. We calculated , , and for each sampled conformation . Using batch mean analysis to account for autocorrelation, these values were used to calculate 95% confidence intervals for , , with . For each link without reflection symmetry, each confidence interval for was found to be either entirely positive or entirely negative. Moreover, the signs of these confidence intervals are consistent across all sampled lengths for each link as predicted by Conjecture 1.
For links which lack pure exchange symmetry, confidence intervals for and are disjoint at each n. Moreover, we can choose a labeling of component 1 and component 2 for each link so that for . From this, we were able to choose canonical link isotopies for most links as described in Section 4. The data for , and for links with up to nine crossings are included in supplementary Tables S2–S4.
A regular diagram for each chosen isotopy class can be found in Figure A1. All data presented in this paper have been converted from sampled isotopy classes to L++ by relabeling components and negating writhe and linking number where appropriate. The confidence intervals of the mean writhes at for links up to crossing number 8 are presented in Table 2 while an extended table including 9-crossing information is included in supplementary materials (Table S5). These tables also list the link isotopy class from Rolfsen’s table and Knotplot using the notation from Section 3.2 based on our choice as L++ [2,15,23].
When the estimated values of and are compared for , they are found to only vary by a small amount. We estimated for each link, L, and pair of lengths, n and m. The largest difference for was found in the link, where is estimated to be about compared to for for a difference of about . Figure 5 illustrates this behavior of .
For individual component self-writhe, the largest difference was in , where was estimated at compared to for , giving a difference of about . For comparison, writhe in is always a multiple of , so no two links or link components can differ in writhe by less than [24]. In this way, and appear to be well-behaved.
We also analyzed minimum step links (described in Section 6.2, Table 3 and in the supplementary materials Table S1) and found that and also stayed reasonably close to the other values of and . We did, however, find ++ and ++, while for all other sampled lengths, which shows that component self-writhe of minimum step conformations may not be a sufficient indicator of self-writhe as n increases. We examined the minimum step conformations in our dataset and observed that component 1 was identical in all of them; it was planar rectangle which always has 0 writhe. One of the minimum step conformations for can be found in Figure 4b.
Table 3.
Mean self-writhes of minimum step prime 2-component links with 8 or fewer crossings. Numbers based on all conformations found in the preprint by Freund et al. [25].
5.2. Boundedness of Writhe under BFACF Moves
BFACF moves not only define our sampling method, but also function as Reidemeister moves for lattice links in the sense that any lattice link conformation can be transformed into any other lattice conformation of the same link by a finite sequence of BFACF moves [6]. It is of interest, then, how BFACF moves may affect space writhe. We find that not only do BFACF moves affect space writhe in a bounded way, but writhe changes in a way entirely predicted by the local geometry of the edges within two steps of the BFACF move. To prove this, we will appeal to a special formulation of space writhe for lattice links proven by Lacher and Sumners [26].
To perform the lattice link writhe calculation, we first define the push-off of a lattice link for . We obtain by translating along the vector .
Theorem 1.
The total writhe of a lattice link may be calculated as follows:
where is the linking number of [26].
Since we can calculate the total writhe of a link from the self-writhes of the individual components, Equation (9) is sufficient to find writhe for links with any number of components. This yields the following interesting corollary:
Corollary 1.
If σ is a simple cubic lattice representation of a link, then for some [26].
A BFACF move is performed by taking an edge of a self-avoiding polygon in and pushing it one unit in one of the four directions perpendicular to the direction of the edge. We will refer to the edge being pushed as the BFACF edge. If an endpoint of the BFACF edge traces an existing edge of the polygon during that push, then the traced edge is deleted. On the other hand, if an endpoint of the BFACF edge does not trace another edge of the polygon, then an edge is added in the traced space. With this in mind, we prove the following theorem:
Theorem 2.
If and are related by a single BFACF move, then . More specifically, .
Proof.
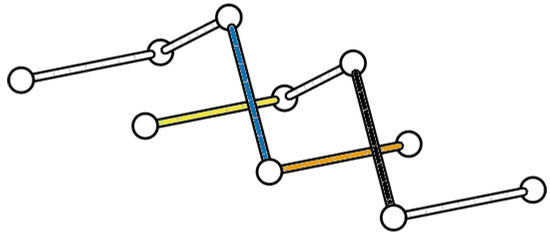
We will consider the BFACF move which transforms into . Without loss of generality, we may assume that
- the BFACF edge runs from to ), and
- the result of the BFACF move will push the BFACF edge to an edge from to .
We may rotate and translate the conformation to make these assumptions true, which will not affect the writhe of the conformations.
Now consider the BFACF move. This move may pass the lattice through one of the push-offs from Theorem 1, changing the linking number of the polygon with that push-off. One such strand passage will change the linking number by , in turn changing the space writhe by . If the move passes the polygon through a push-off edge, then the push-off edge must have endpoints and (e.g., the black BFACF edge and orange push-off edge in Figure 6). Checking where this edge must come from in the original polygon by reversing the push-off, we see it is necessary that this edge either has an endpoint at or at . In the former case, this means that the edge before to the BFACF edge runs in the x-direction, and there are two such possible edges. In the latter case, the edge before the BFACF edge must run from to and the edge before that must run in the x-direction, and there are two such possible edges. If there is no edge from to , then this second case will result in a self-intersection of the link and is not a valid BFACF move. We can see that the four possible edges to result in this change are all mutually exclusive, so from all of these cases, only one can contribute the change in writhe.
Figure 6.
If a BFACF move is performed on the black edge in the direction of the orange (medium gray in grayscale) edge of the push-off beneath it, then the linking number with the push-off will change by which will change the writhe by . This same BFACF move will also push the blue (dark gray) edge of the push-off through the yellow (light gray) edge of the link, which will cause the linking number to change by another , hence this will contribute a change to the writhe. Thus, a BFACF move pushing the black edge into the page will result in a lattice link with a writhe less than the current link’s writhe.
Now suppose that one of the push-offs of the BFACF edge passes through an edge of the original link when the BFACF move is performed (e.g., the blue push-off edge being pushed through the yellow edge in Figure 6). The four push-offs of the BFACF edge run from to , to , to , and to . We note that in each of these cases the edge which the crossing change is occuring with must be running in the x-direction and have an endpoint at either or . Similar to the previous cases, each of these possible edges are mutually exclusive and must either be the edge after the BFACF edge or the edge after that. Again, since they are mutually exclusive cases, the change in writhe from these cases can only be .
Thus, at most two of the above cases may be true at any given time, each contributing to a change in writhe of . Thus, the total change in writhe from any BFACF move is in the set . ☐
6. Numerical Methods
6.1. BFACF Simulations
We use methods adopted from Portillo et al. and Brasher et al. to procure estimates of , , and for 2-component links [4,5]. in particular, BFACF was run to sample conformations of the 91 prime non-split 2-component links with crossing number less than or equal to 9. Only one isotopy class was sampled for each link, as the writhe values for other isotopy classes will be either identical or of opposite sign (as described in Section 3.4). Choices of z values were chosen based on prior systematic runs used to estimate the expected length of the conformations. These same runs were also used to estimate the required number of steps between samples for statistical independence of samples. Statistical independence for these prior runs was determined by calculating integrated auto-correlation.
Samples were taken for links of length 76, 100, 150, 200, 250, and 300. Up to independent samples were taken for most lengths of each link, with up to and independent samples for lengths 100 and 150, respectively. Initial sampling was done for lengths 100 and 150, but in many cases runs were terminated before all samples were taken to free up computational resources, as analysis showed the number samples already taken provided sufficiently narrow confidence intervals. For the other lengths, 20,000 was selected as a sufficiently large number for the level of confidence desired. Samples were discarded and not counted if their length did not match the target length for the run.
Once the samples were obtained, the component self-writhes and the sums of self-writhes were calculated. This resulted in three lines of data for each component: the sum of self-writhes; component 1 self-writhe; and component 2 self-writhe. Batch mean analysis was then used to ensure statistical independence of these data and to calculate 95% confidence intervals for the mean of each of these values [27]. Batch mean analysis is a method, which puts sequential data into blocks, if necessary, to reduce auto-correlation and uses the average of each block as a data point.
Before fully analyzing the results, we double-checked the robustness of the sampling methods by comparing certain results to known facts. First, every link with reflection symmetry must have a mean sum of self-writhes which is exactly zero. Hence, the confidence interval for must contain zero for these links. This was true of each link with symmetry group and that we sampled, and can be seen in Figure 7a.
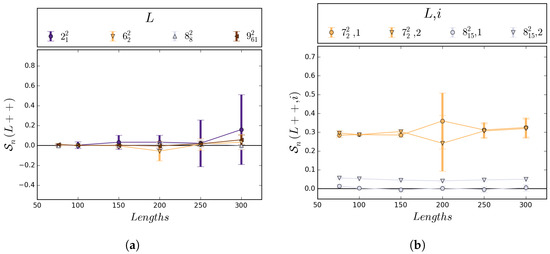
Figure 7.
(a) This graph shows 95% confidence intervals for L++) of the four links with reflection symmetry and crossing number up to 9, for lengths 76, 100, 150, 200, 250, and 300; (b) This graph illustrates the expected behavior of for a link with pure exchange symmetry () and a link without pure exchange symmetry (), where i denotes the component number. The large error bars are due to a smaller sample size for at length 200; however, even for low sample sizes, the error bars overlap as expected.
In addition, for each link with the pure exchange symmetry, the mean self-writhes of each component must be exactly equal, i.e., . To check for this, we made sure the confidence intervals for and had non-empty intersection for links with symmetry group , , or (see Figure 7b). The samples taken for links with these symmetries matched our expectations as well. Thus, the methods appear to have sampled satisfactorily.
We did, however, require extra samples for the link at lengths 200, 250, and 300. Since lacks pure exchange symmetry, it is expected that . The data showed this for lengths 76, 100, and 150. However, as length of a link increases, the variance of writhe also increases, which means more samples are required to maintain the same width of confidence intervals as for smaller lengths. For the link, the self-writhes of the components are both relatively small and close together, which means they must have particularly tight confidence intervals to ensure they are disjoint. For lengths 200, 250, and 300, the confidence intervals for the self-writhe of each component were not disjoint in the original sampling of , which meant uncertainty as to whether they were distinct or if one was larger than the other. Extra samples were taken for these lengths, and with about 45,000 total samples at each length, the intervals were found to be disjoint for lengths 200 and above, matching the data for lower lengths.
The Hopf link, provided another issue, in that it is difficult to sample efficiently. Analysis of the autocorrelation of writhe and length of the Hopf link under BFACF moves shows that many more steps may be required between samples. In addition, a high variance of length appears to cause many samples to be rejected. Because of this, the data for is somewhat sparse. However, has even operations symmetry with pure exchange, which means there are only 2 isotopy classes. Since the linking numbers of these classes are 1 and , we choose ++ such that lk++. It is also worth noting that, due to the symmetry of , it is necessary that . Therefore sampling here serves only to test the robustness of our methods as described above.
The unlink, , was not sampled, as BFACF fails to converge for split links without extra restrictions such as confinement. The unlink has full symmetry, however, so there is only one choice for isotopy class and every unlink is the canonical unlink. The complete set of confidence intervals for , , and for all 2-component links with nine or less crossings can be found in supplementary Tables S2–S4.
6.2. Minimum Length Links
In addition to these BFACF simulations, results were obtained for minimum length lattice links from preliminary data produced by Freund et al. [25]. The data obtained were the set of all known minimum length conformations of each 2-component link with crossing number up to 9. We took the assumption that these sets of conformations were complete, and calculated the mean self-writhes of the minimum lengths directly. We use the notation , , and to refer to the mean self-writhes of the minimum length lattice links and their components. We took only the set of conformations representing L++, as determined here, for each link. The results through eight crossings are presented in Table 3, and the results through nine crossings can be found in the supplementary materials in Table S1.
7. Conclusions
Using the BFACF algorithm, we here provide numerical support for Conjecture 1 for each of the ninety-two prime 2-component links with up to 9 crossings. Our results show that, on average, the values of component self-writhes maintain an ordering for sufficiently long lattice links. Using the linking number and the gathered writhe data we are able to unambiguously designate a canonical isotopy class for each prime 2-component link with crossing number up to 9, except for , , , , and . These five exceptional links are not fully disambiguated by our method; in each case we chose one out of two possible isotopy classes for inclusion in our link table. Figure A1 includes all regular minimal diagrams corresponding to the canonical isotopy classes of 2-component links with 9 or fewer crossings. This table can be used in conjunction with the provided nomenclature to clearly communicate precise link isotopy classes in future research. In addition, we prove a theorem about the boundedness of changes in writhe under the BFACF moves. This result can be useful in proving or finding a counterexample to conjecture 1.
Supplementary Materials
The following are available online at http://www.mdpi.com/2073-8994/10/11/604/s1, Table S1: table of mean self-writhes for minimum length lattice links extended from Table 3, Table S2: table of ++) for all sampled n, Table S3: table of ++ for all sampled n, Table S4: table of ++ for all sampled n, Table S5: summary of link information extended from Table 2, Table S6: table of canonical knot diagrams extended from the table presented by Brasher et al. [5].
Author Contributions
Conceptualization, S.W. and M.V.; Methodology, S.W., M.F. and M.V.; Software, S.W. and M.F.; Validation, S.W., M.F. and M.V.; Formal Analysis, S.W., M.F. and M.V.; Investigation, S.W. and M.F.; Resources, M.V.; Data Curation, M.F. and S.W.; Writing—Original Draft Preparation, S.W., M.F. and M.V.; Writing—Review and Editing, S.W., M.F. and M.V.; Visualization, S.W., M.F. and M.V.; Supervision, M.V.; Project Administration, M.V.; Funding Acquisition, M.V.
Funding
This research was supported by the National Science Foundation CAREER Grant DMS1519375, DMS1716987, and DMS1817156 (M.F., M.V., S.W.).
Acknowledgments
The authors are grateful to the following individuals: Robert Scharein for providing assistance with Knotplot; Robert Stolz for assistance with batch mean analysis; Reuben Brasher for assistance with BFACF and preliminary work on the knot table (Table S6); Priya Kshirsagar for preliminary work. We are indebted to Chris Soteros, Koya Shimokawa, and to Javier Arsuaga and other members of the Arsuaga–Vazquez lab for valuable feedback.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Link Table





Figure A1.
Regular oriented diagrams representing the link isotopy classes for L++ chosen as described in Section 4. Next to each link name is its symmetry group, which may be cross-referenced with Table 1. For links lacking pure exchange symmetry, the lighter blue strand is labeled as component 1 and the darker red-orange strand is component 2.
References
- Briggs, G. On types of knotted curves. Ann. Math. 1927, 28, 562–586. [Google Scholar]
- Rolfsen, D. Knots and Links; AMS/Chelsea Publication Series; AMS Chelsea Pub.: Providence, RI, USA, 1976. [Google Scholar]
- Conway, J.H. An enumeration of knots and links, and some of their algebraic properties. In Computational Problems in Abstract Algebra; Elsevier: Amsterdam, The Netherlands, 1970; pp. 329–358. [Google Scholar]
- Portillo, J.; Diao, Y.; Scharein, R.; Arsuaga, J.; Vazquez, M. On the mean and variance of the writhe of random polygons. J. Phys. A Math. Theor. 2011, 44, 275004. [Google Scholar] [CrossRef] [PubMed]
- Brasher, R.; Scharein, R.G.; Vazquez, M. New biologically motivated knot table. Biochem. Soc. Trans. 2013, 41, 606–611. [Google Scholar] [CrossRef] [PubMed]
- Janse Van Rensburg, E.; Whittington, S. The BFACF algorithm and knotted polygons. J. Phys. A Math. Gen. 1991, 24, 5553. [Google Scholar] [CrossRef]
- Janse Van Rensburg, E.J.; Orlandini, E.; Sumners, D.W.; Tesi, M.C.; Whittington, S.G. The Writhe of Knots in the Cubic Lattice. J. Knot Theory Its Ramif. 1997, 6, 31–44. [Google Scholar] [CrossRef]
- Stolz, R.; Yoshida, M.; Brasher, R.; Flanner, M.; Ishihara, K.; Sherratt, D.J.; Shimokawa, K.; Vazquez, M. Pathways of DNA unlinking: A story of stepwise simplification. Sci. Rep. 2017, 7, 12420. [Google Scholar] [CrossRef] [PubMed]
- Adams, D.E.; Shekhtman, E.M.; Zechiedrich, E.L.; Schmid, M.B.; Cozzarelli, N.R. The role of topoisomerase IV in partitioning bacterial replicons and the structure of catenated intermediates in DNA replication. Cell 1992, 71, 277–288. [Google Scholar] [CrossRef]
- Grainge, I.; Bregu, M.; Vazquez, M.; Sivanathan, V.; Ip, S.C.; Sherratt, D.J. Unlinking chromosome catenanes in vivo by site-specific recombination. EMBO J. 2007, 26, 4228–4238. [Google Scholar] [CrossRef] [PubMed]
- Shimokawa, K.; Ishihara, K.; Grainge, I.; Sherratt, D.J.; Vazquez, M. FtsK-dependent XerCD-dif recombination unlinks replication catenanes in a stepwise manner. Proc. Natl. Acad. Sci. USA 2013, 110, 20906–20911. [Google Scholar] [CrossRef] [PubMed]
- Klenin, K.; Langowski, J. Computation of writhe in modeling of supercoiled DNA. Biopolymers 2000, 54, 307–317. [Google Scholar] [CrossRef]
- Doll, H.; Hoste, J. A tabulation of oriented links. Math. Comp. 1991, 57, 747–761. [Google Scholar] [CrossRef]
- Berglund, M.; Cantarella, J.; Casey, M.P.; Dannenberg, E.; George, W.; Johnson, A.; Kelley, A.; LaPointe, A.; Mastin, M.; Parsley, J.; et al. Intrinsic Symmetry Groups of Links with 8 and Fewer Crossings. Symmetry 2012, 4, 143–207. [Google Scholar] [CrossRef]
- Cantarella, J.; Cornish, J.; Mastin, M.; Parsley, J. The 27 Possible Intrinsic Symmetry Groups of Two-Component Links. Symmetry 2012, 4, 129–142. [Google Scholar] [CrossRef]
- Henry, S.R.; Weeks, J.R. Symmetry Groups of Hyperbolic Knots and Links. J. Knot Theory Its Ramif. 1992, 1, 185–201. [Google Scholar] [CrossRef]
- Liang, C.; Cerf, C.; Mislow, K. Specification of chirality for links and knots. J. Math. Chem. 1996, 19, 241–263. [Google Scholar] [CrossRef]
- Berg, B.; Foerster, D. Random paths and random surfaces on a digital computer. Phys. Lett. B 1981, 106, 323–326. [Google Scholar] [CrossRef]
- De Carvalho, C.A.; Caracciolo, S. A new Monte-Carlo approach to the critical properties of self-avoiding random walks. J. Phys. 1983, 44, 323–331. [Google Scholar] [CrossRef]
- De Carvalho, C.A.; Caracciolo, S.; Fröhlich, J. Polymers and g| φ| 4 theory in four dimensions. Nucl. Phys. B 1983, 215, 209–248. [Google Scholar] [CrossRef]
- Madras, N.; Slade, G. The Self-Avoiding Walk; Probability and Its Applications; Birkhäuser: Basel, Switzerland, 1993. [Google Scholar]
- Culler, M.; Dunfield, N.M.; Goerner, M.; Weeks, J.R. SnapPy, a Computer Program for Studying the Geometry and Topology of 3-Manifolds. Available online: http://snappy.computop.org (accessed on 3 March 2017).
- Hypnagogic Software. KnotPlot. Available online: http://www.knotplot.com/ (accessed on 24 October 2014).
- Laing, C.; Sumners, D.W. Computing the writhe on lattices. J. Phys. A 2006, 39, 3535–3543. [Google Scholar] [CrossRef]
- Freund, G.; Witte, S.; Vazquez, M. Bounds for the Minimum Step Number for 2-Component Links in the Simple Cubic Lattice. 2018. in progress. [Google Scholar]
- Lacher, R.; Sumners, D. Data Structures and Algorithms for Computation of Topological Invariants of Entanglements: Link, Twist and Writhe; Prentice-Hall: New York, NY, USA, 1991. [Google Scholar]
- Fishman, G. Monte Carlo: Concepts, Algorithms, and Applications; Springer Series in Operations Research and Financial Engineering; Springer: New York, NY, USA, 2013. [Google Scholar]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).