A Prototype of Speech Interface Based on the Google Cloud Platform to Access a Semantic Website

 ,
,  ,
, 
Abstract
1. Introduction
2. Related Work
3. Current Problems
- The Semantic Web presents a dynamic growth of the knowledge, based on formal logic. However, it is difficult for common users to access this because they have problems with the construction of the simplest queries [3].
- Linked data initiative encompass structured databases in the RDF data model (Resource Description Framework) from the Semantic Web. Even for expert users, it is quite complex to explore such heterogeneous data [15].
- An increment quantity of RDF information is issued like Linked Data, so a perceptible way to access those data becomes more important, but the most expressive queries fail to be represented nor answered [10].
- Voice recognition software has become more popular, especially on smartphones, which implies that it is needed to operate on the interpretation of Natural Language queries into formal queries [16].
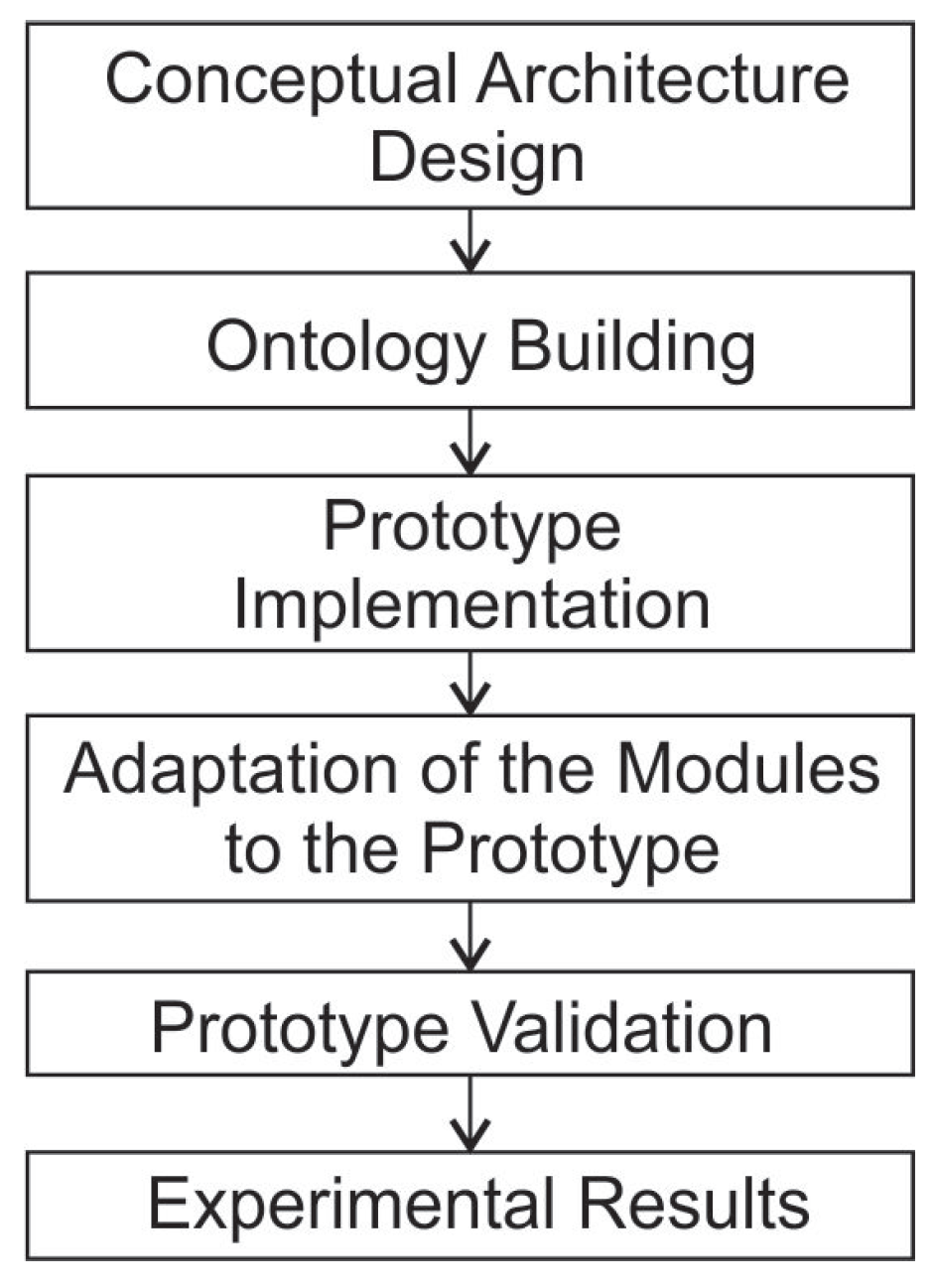
- Conceptual Architecture Design. In this stage, the main components of our prototype are defined, identifying the different modules to be used in the development of the prototype.
- Ontology Building. From the knowledge of the main concepts of the study case, the construction of the ontology begins, using some known building methodology that includes the whole ontology development cycle.
- Prototype Implementation. For the implementation of the interface, some open source development environment will be used with the respective updated libraries.
- Adaptation of the Modules to the Prototype. In this stage, the three modules to be used in our prototype are integrated.
- Prototype Validation. In this stage, the operation of the prototype is validated by prior training of the interface with simple queries.
- Experimental Results. We begin to obtain various experimental results with the designed prototype. The first two experiments were conducted by the working group and the last experiment was conducted with the help of several users (a survey was done), several indicators were obtained that are presented in our work.
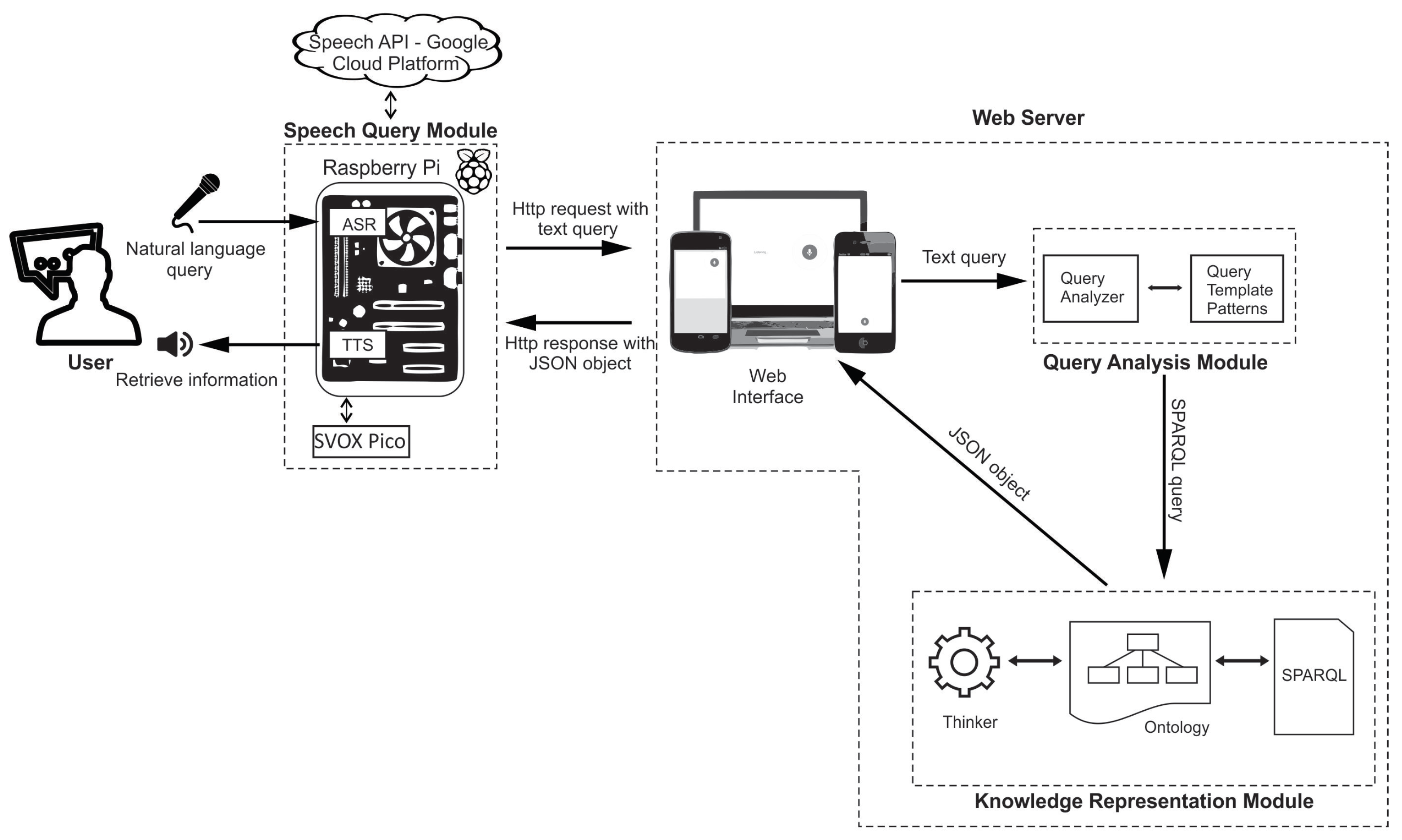
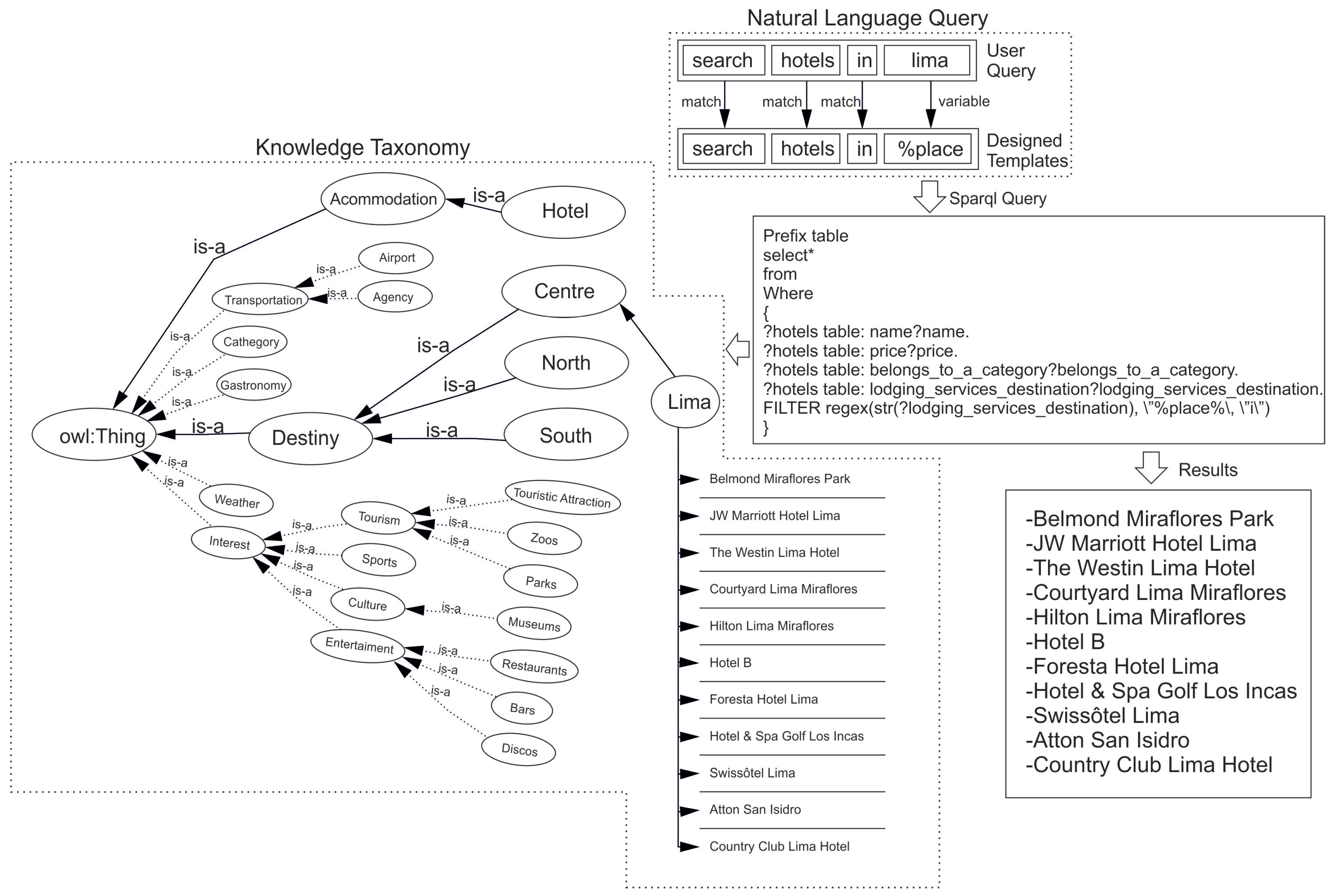
4. Implemented Architecture
4.1. Implementation of the Web Server Using the Semantic Web Tools
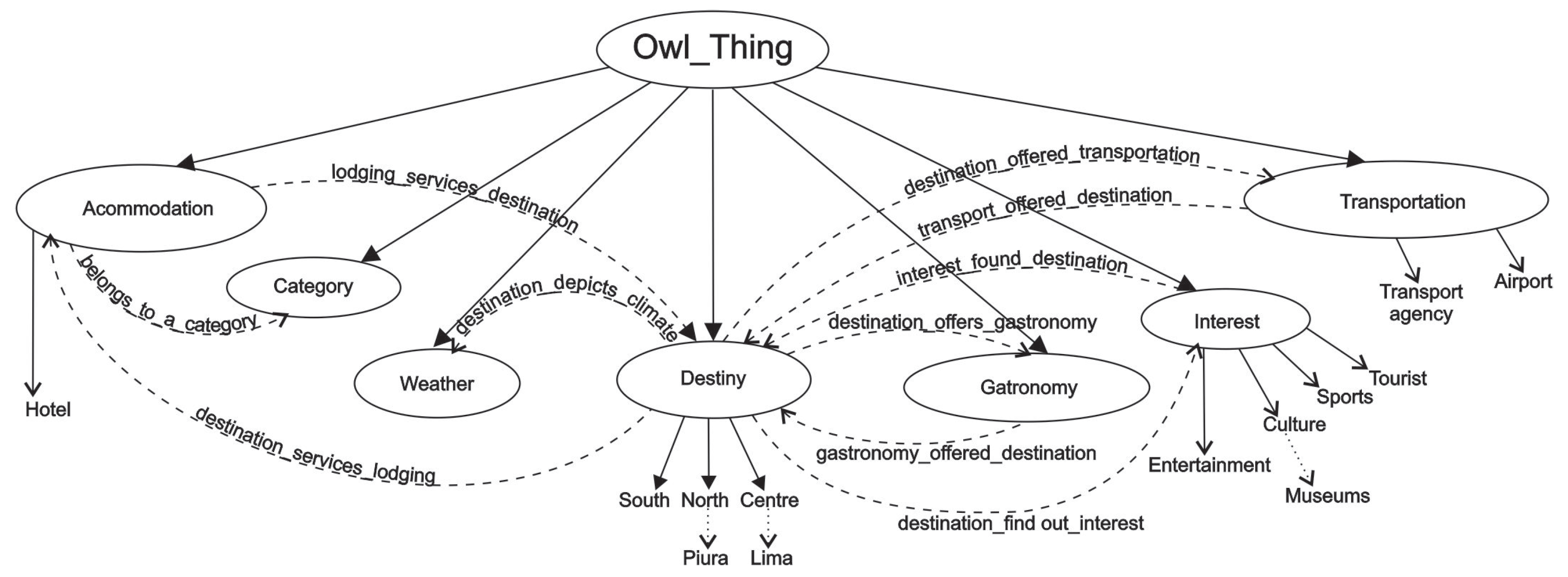
4.1.1. Knowledge Representation Module
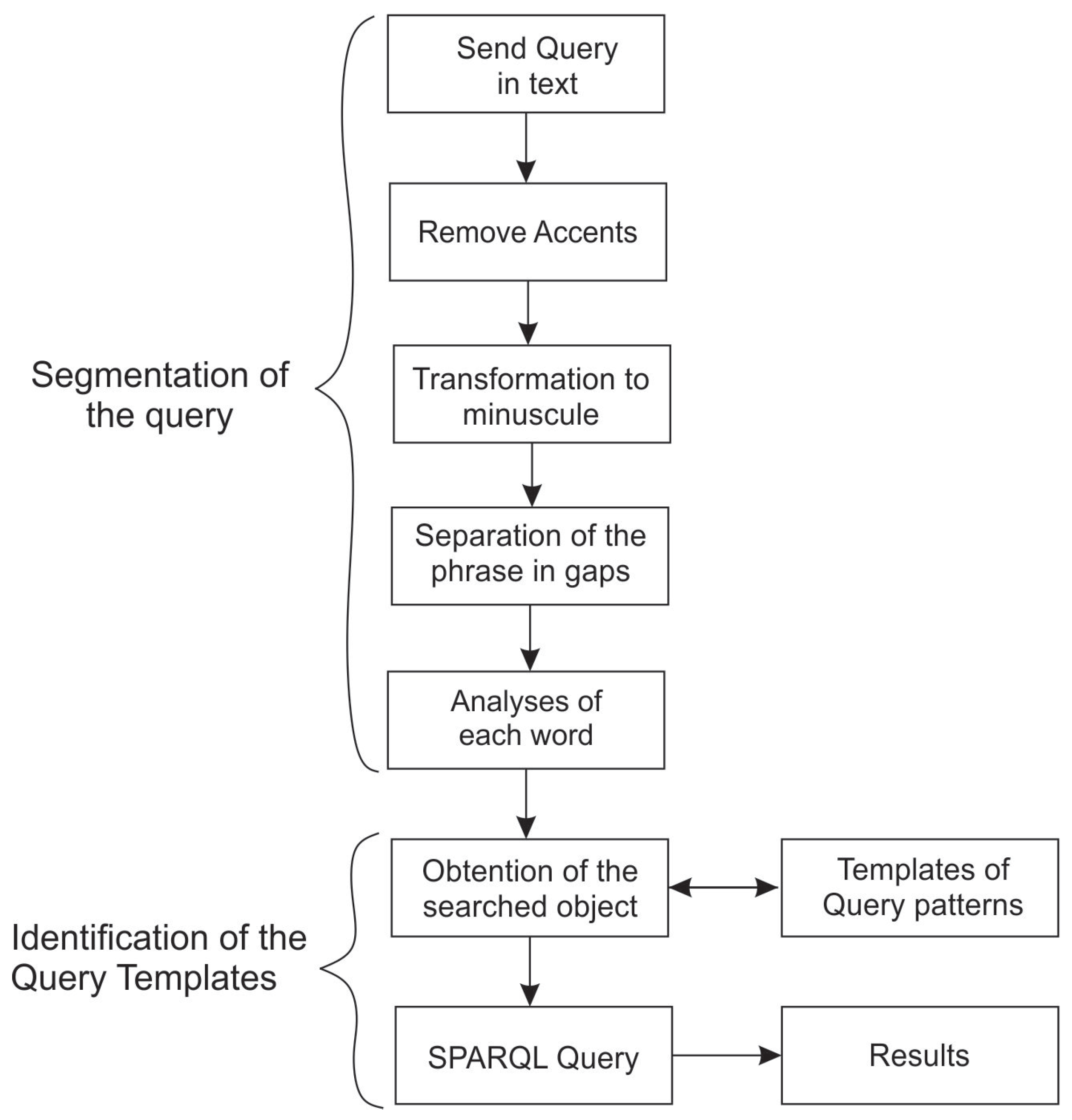
4.1.2. Query Analysis Module
- Comparison criteria
- SPARQL Query
PREFIX table: <http://www.owl-ontologies.com/Ontology1370130534.owl#>
SELECT*
WHERE {
?museums table:name?name.
?museums table:address?address.
?museums table:price?price.
?museums table:interest_found_destination?interest_found_destination
Filter(?interest_found_destination=:piura)
}
4.1.3. Web Interface
4.2. Implementation of the Speech—Query Module
4.2.1. Speech to Text Conversion (STT)
4.2.2. Text to Speech Conversion (TTS)
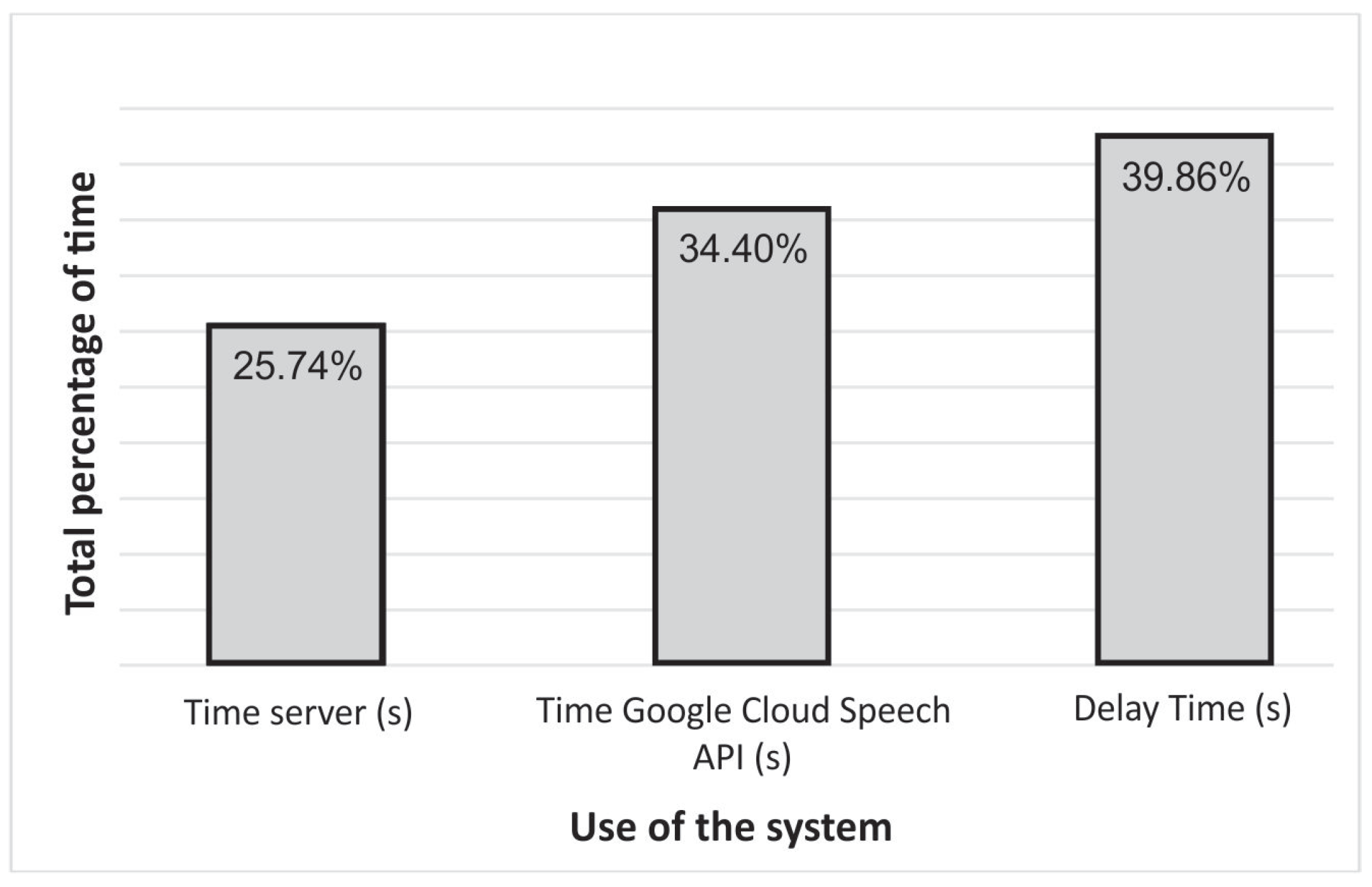
5. Experimental Results
- “The use of the interface was simple to learn”Agree|—|Neutral|—|Disagree,
- “Interact with the interface was a frustrating experience”Agree|—|Neutral|—|Disagree,
- “I think that the interface has all the potential I need”Agree|—|Neutral|—|Disagree,
- “I think that this interface is very pleasant to work”Agree|—|Neutral|—|Disagree.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Antoniou, G.; Van Harmelen, F. A Semantic Web Primer; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Bernstein, A.; Kaufmann, E.; Kaiser, C. Querying the semantic web with ginseng: A guided input natural language search engine. In Proceedings of the 15th Workshop on Information Technologies and Systems, Las Vegas, NV, USA, 9–10 December 2005; pp. 112–126. [Google Scholar]
- Kaufmann, E.; Bernstein, A. Evaluating the usability of natural language query languages and interfaces to Semantic Web knowledge bases. Web Semant. Sci. Serv. Agents World Wide Web 2010, 8, 377–393. [Google Scholar] [CrossRef]
- Valencia-García, R.; García-Sánchez, F.; Castellanos-Nieves, D. OWLPath: An OWL ontology-guided query editor. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2011, 41, 121–136. [Google Scholar] [CrossRef]
- Zheng, Z. Question answering using web news as knowledge base. In Proceedings of the Tenth Conference on European Chapter of the Association for Computational Linguistics-Volume 2, Budapest, Hungary, 12–17 April 2003; pp. 251–254. [Google Scholar]
- Wang, C.; Xiong, M.; Zhou, Q.; Yu, Y. Panto: A portable natural language interface to ontologies. In European Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2007; pp. 473–487. [Google Scholar]
- Tejedor, J.; García, R.; Fernández, M.; López-Colino, F.J.; Perdrix, F.; Macías, J.A.; Gil, R.M.; Oliva, M.; Moya, D.; Colás, J.; et al. Ontology-based retrieval of human speech. In Proceedings of the 18th International Workshop on Database and Expert Systems Applications, DEXA’07, Regensburg, Germany, 3–7 September 2007; pp. 485–489. [Google Scholar]
- Damljanovic, D.; Agatonovic, M.; Cunningham, H. FREyA: An Interactive Way of Querying Linked Data Using Natural Language. In ESWC Workshops; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7117, pp. 125–138. [Google Scholar]
- Unger, C.; Bühmann, L.; Lehmann, J.; Ngonga Ngomo, A.C.; Gerber, D.; Cimiano, P. Template-based question answering over RDF data. In Proceedings of the 21st ACM International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 639–648. [Google Scholar]
- Chang, Y.S.; Hung, S.H.; Wang, N.J.; Lin, B.S. CSR: A Cloud-assisted speech recognition service for personal mobile device. In Proceedings of the 2011 IEEE International Conference on Parallel Processing (ICPP), Taipei, Taiwan, 13–16 September 2011; pp. 305–314. [Google Scholar]
- Mell, P.; Grance, T. The NIST Definition of Cloud Computing (Draft); NIST Special Publication: Gaithersburg, MD, USA, 2011; Volume 800, p. 7. [Google Scholar]
- Wang, L.; Von Laszewski, G.; Younge, A.; He, X.; Kunze, M.; Tao, J.; Fu, C. Cloud computing: A perspective study. New Gener. Comput. 2010, 28, 137–146. [Google Scholar] [CrossRef]
- Bukhari, A.C.; Kim, Y.G. Ontology-assisted automatic precise information extractor for visually impaired inhabitants. Artif. Intell. Rev. 2012, 38, 9–24. [Google Scholar] [CrossRef]
- Yahya, M.; Berberich, K.; Elbassiousni, S.; Ramanath, M.; Tresp, V.; Weikum, G. Natural Language Questions for the Web of Data. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Stroudsburg, PA, USA, 12–14 July 2012; pp. 379–390. [Google Scholar]
- Pradel, C.; Haemmerlé, O.; Hernandez, N. Natural language query interpretation into SPARQL using patterns. In Proceedings of the Fourth International Conference on Consuming Linked Data-Volume 1034, CEUR-WS, Sydney, Australia, 22 October 2013; pp. 13–24. [Google Scholar]
- Androutsopoulos, I.; Lampouras, G.; Galanis, D. Generating natural language descriptions from OWL ontologies: The NaturalOWL system. J. Artif. Intell. Res. 2013, 48, 671–715. [Google Scholar]
- Bansal, R.; Chawla, S. Design and development of semantic web-based system for computer science domain-specific information retrieval. Perspect. Sci. 2016, 8, 330–333. [Google Scholar] [CrossRef]
- El-Ansari, A.; Beni-Hssane, A.; Saadi, M. A Multiple Ontologies Based System for Answering Natural Language Questions. In Europe and MENA Cooperation Advances in Information and Communication Technologies; Springer: Basel, Switzerland, 2017; pp. 177–186. [Google Scholar]
- Euzenat, J. Research challenges and perspectives of the Semantic Web. IEEE Intell. Syst. 2002, 17, 86–88. [Google Scholar] [CrossRef]
- Yu, L. Introduction to the Semantic Web and Semantic Web Services; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Bechhofer, S.; Van Harmelen, F.; Hendler, J.; Horrocks, I.; McGuinness, D.; Patel-Sch neider, P.; Stein, L. Owl Web Ontology Language Reference. 2004. Available online: https://www.w3.org/TR/owl-ref/ (accessed on 7 July 2018).
- Del Castillo, J.M.M. Hacia la Biblioteca Digital Semantica, 3rd ed.; Pol. Industrial de Somonte: Asturias, Spain, 2011. [Google Scholar]
- Fernández-López, M.; Gómez-Pérez, A.; Juristo, N. Methontology: From ontological art towards ontological engineering. In Proceedings of the Ontological Engineering AAAI-97 Spring Symposium Series, Palo Alto, CA, USA, 24–25 March 1997; Available online: www.aaai.org (accessed on 7 July 2018).
- Badia, A. Question answering and database querying: Bridging the gap with generalized quantification. J. Appl. Logic 2007, 5, 3–19. [Google Scholar] [CrossRef]
- Yu, L. A Developer’s Guide to the Semantic Web; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Partner, K. Ultimate Guide to Raspberry Pi; Dennis Publishing Limited: London, UK, 2014. [Google Scholar]
- Mika, P.; Tummarello, G. Web semantics in the clouds. IEEE Intell. Syst. 2008, 23, 82–87. [Google Scholar] [CrossRef]
- Duarte, T.; Prikladnicki, R.; Calefato, F.; Lanubile, F. Speech recognition for voice-based machine translation. IEEE Softw. 2014, 31, 26–31. [Google Scholar] [CrossRef]
- Stefanovic, M.; Četic, N.; Kovacevic, M.; Kovacevic, J.; Janković, M. Voice control system with advanced recognition. In Proceedings of the 2012 20th IEEE Telecommunications Forum (TELFOR), Belgrade, Serbia, 20–22 November 2012; pp. 1601–1604. [Google Scholar]
- Naeem, A.; Qadar, A.; Safdar, W. Voice Controlled Intelligent Wheelchair using Raspberry Pi. Int. J. Technol. Res. 2014, 2, 65. [Google Scholar]
- Berenson, M.; Levine, D.; Krehbiel, T.C. Estadistica para administración; Pearson Education: Naucalpan de Juárez, Mexico, 2001. [Google Scholar]
- Gallego, C.F. Cálculo del tamaño de la muestra. Matronas Profesión 2004, 5, 5–13. [Google Scholar]
- Standard, I. Ergonomic Requirements for Office Work with Visual Display Terminals (Vdts)—Part 11: Guidance on Usability. ISO Standard 9241-11: 1998; International Organization for Standardization: Geneva, Switzerland, 1998. [Google Scholar]
- Nielsen, J. Usability Engineering; Elsevier: San Diego, CA, USA, 1994. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Queries | Number of Hits | Number of Failures | Percentage of Hits |
|---|---|---|---|
| 30 | 25 | 5 | 83.3 |
| Queries | Server Time (s) | Google Cloud Speech API (s) | Delay Time (s) | Total Time (s) |
|---|---|---|---|---|
| Find hotels in Lima | 2.380 | 1.660 | 2.475 | 6.515 |
| Find hotels in Piura | 2.343 | 1.986 | 2.451 | 6.780 |
| Find hotels in Ica | 1.974 | 1.796 | 2.107 | 5.877 |
| Find museums in Lima | 0.217 | 2.126 | 2.405 | 4.748 |
| Find museums in Piura | 0.179 | 1.570 | 2.368 | 4.117 |
| Find museums in Ica | 0.278 | 2.127 | 2.466 | 4.871 |
| Find hotels of 4 and 5 stars in Lima | 1.498 | 2.381 | 1.707 | 5.586 |
| Find hotels of 4 and 5 stars in Piura | 2.374 | 2.490 | 2.496 | 7.360 |
| Find hotels of 4 and 5 stars in Ica | 2.273 | 1.924 | 2.449 | 6.646 |
| Agree | Neutral | Disagree | Percentage of Agreements |
|---|---|---|---|
| 25 | 3 | 2 | 83.33 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosales-Huamaní, J.A.; Castillo-Sequera, J.L.; Montalvan-Figueroa, J.; Andrade-Choque, J. A Prototype of Speech Interface Based on the Google Cloud Platform to Access a Semantic Website. Symmetry 2018, 10, 268. https://doi.org/10.3390/sym10070268
Rosales-Huamaní JA, Castillo-Sequera JL, Montalvan-Figueroa J, Andrade-Choque J. A Prototype of Speech Interface Based on the Google Cloud Platform to Access a Semantic Website. Symmetry. 2018; 10(7):268. https://doi.org/10.3390/sym10070268
Chicago/Turabian StyleRosales-Huamaní, Jimmy Aurelio, José Luis Castillo-Sequera, Juan Carlos Montalvan-Figueroa, and Joseps Andrade-Choque. 2018. "A Prototype of Speech Interface Based on the Google Cloud Platform to Access a Semantic Website" Symmetry 10, no. 7: 268. https://doi.org/10.3390/sym10070268
APA StyleRosales-Huamaní, J. A., Castillo-Sequera, J. L., Montalvan-Figueroa, J., & Andrade-Choque, J. (2018). A Prototype of Speech Interface Based on the Google Cloud Platform to Access a Semantic Website. Symmetry, 10(7), 268. https://doi.org/10.3390/sym10070268