1. Introduction
Information asymmetry in business based on data management can be reduced by using machine learning (ML) techniques, allowing free competition between market agents. Information asymmetry in data management comes from two sources: (i) patterns of public information not observed by some actors in the negotiation and (ii) actions carried out by an economic actor that are difficult to read by the rest of the market. The concept of ML has contributed to the new industrial revolution (industry 4.0) in particular, with the massive use of big data (BD) and cloud techniques. Obtaining information through real-time data processing is a strategy that offers competitive advantages for decision-making, regardless of the size and commercial sector of the organization.
The machine learns by improving its calculation results without human intervention. The machine needs three fundamental elements for this learning: process data, communication with the cloud and BD, and calculation models. These three elements require technological advances in data science, ML, and artificial intelligence (AI).
At the beginning of the 19th century, mainly in the mail order industry, the practice of collecting, preserving, analyzing, and using data was initiated [
1]. The increasing use of email and the web, together with the recording of interactions (speech-text analyzer software and the flow of clickstreams from websites, among others), led to an explosion in data volumes.
For the purpose of this article, a definition adjusted of AI to our general line of thought is the one proposed by Haenlein and Kaplan [
2]. These authors defined AI as a system’s ability to interpret external data correctly, learn from said data, and use the knowledge to achieve specific goals and tasks through flexible adaptation [
3]. In recent years, the use of AI in the service industry has been rapidly gaining ground. According to Xu et al. [
4], AI in the context of customer service is defined as a technology-enabled system that evaluates service scenarios in real-time, using data collected from digital and/or physical sources to provide recommendations, alternatives, and personalized solutions to customer queries or problems. For example, AI technology can personalize services and product processing, processing past customer purchases and records. According to Dwivedi et al. [
5], AI includes different branches used to obtain data some examples are: expert systems, ML, pattern recognition (PR), fuzzy logic, evolutionary computing, deep learning (DL), probability theory, discriminant analysis, support systems, learning systems, decision trees, and DL with convolutional neural networks (CNN). These approaches have become very popular in recent years for being powerful visual models that automatically produce hierarchies of characteristics [
6], commonly trained by supervised learning. These types of networks are feedforward-type models [
7]. The difference between CNN and artificial neural networks (ANN) lies in the hidden layer. The hidden layer of a CNN model is generally made up of three layers, namely the convolutional layer, the subsampling layer (clustering layer), and the fully connected layer [
8]. CNN has made impressive achievements in many areas, including but not limited to computer vision and natural language processing (NLP) [
9].
Interest in AI has grown in different areas of engineering, achieving significant and hopeful methodological advances. Engineering has witnessed the growth of different AI methods in its various areas. One of these methods, and the focus of this review, is ML-supported AI methods for obtaining and managing data developed during the last five years. The scope of the review is to summarize the theoretical background of the methods, provide a critical analysis on their use, and summarize and discuss the latest research on the methodological approaches in the area.
The use of digitization to obtain and manage information was the subject of some previous studies. Stone et al. [
10] explained the evolution of ecosystems and the platforms used to obtain customer information and identify the management, research, and teaching implications of this evolution. The model considers the calculation of the customer’s functional life value. Zheng et al. [
11] surveyed AI-based intelligent visualization tools to extract information from BD. Lin et al. [
12] studied the satisfaction of the virtual customer-seller link in the context of conflicting recommendations. Likewise, Refs. [
13,
14] proposed the use of textual characteristics to analyze the information on the news for sensitive stock market prediction [
15].
Zhong et al. [
16] presented an AI-based BD analysis for RFID logistics data by defining different behaviors of smart manufacturing objects. Hollebeek et al. [
17] explored the use of robotic process automation (RPA), ML, and DL applications. Olshannikova et al. [
18] discussed how the capabilities of augmented reality and virtual reality could be applied to the field of BD visualization. Brill et al. [
19] conducted a qualitative empirical study to determine the level of satisfaction with digital assistants (Apple’s Siri, Amazon’s Alexa, Google’s Google Assistant). Based on RPA, ML, and DL, Sampson [
20] proposed a strategic framework to face the increasing effects of automation in highly skilled professional services jobs. Pantano and Pizzi [
21] investigated the technological advance of chatbots, indicating the real areas of development; providing a complete understanding of the actual progress. Xiao and Kumar [
22] carried out a conceptual framework that includes antecedents and consequences of the adoption and integration of robotics by companies in their customer service, technology marketing, and information technology operations.
Recently, Hoyer et al. [
23] proposed a new framework to understand the role of new technologies powered by AI (internet of things (IoT), augmented reality, virtual reality, mixed reality (MR), virtual assistants, chatbots, robots, blockchain, and 3D printing) in the customer/buyer process. In addition, Duan et al. [
24] and Liebowitz [
25] analyzed the advancement of AI technology and its capacity to process BD for decision-making. Duan et al. propose twelve research proposals in AI information systems. Kokina and Davenport [
26] discussed cognitive AI capabilities in auditing processes, with four large accounting firms launching numerous projects. While Singh et al. [
27] developed a conceptual framework of companies’ capabilities to operate with “one voice” to offer fluid, harmonious, and reliable interactions through various interfaces. Authors such as Kreutzer and Sirrenberg [
28] evaluated the capacity of AI systems for: prediction and profiling of potential customers, conversational commerce, sentiment analysis, and the creation and distribution of content. Furthermore, Heller et al. [
29] proposed an integrated framework to automate services based on augmented reality.
The articles of the debate highlight methodological advances aimed at developing AI applications mainly in the service industry (obtaining and managing data to aid decision-making). Methods, such as RPA, PR, and ML, have seen remarkable developments and increased use in database development and optimization in recent years. Recently, to address the limitations of RPA, authors, such as Berruti et al. [
30], have proposed intelligent process automation, which refers to the combination of AI, ML, and cognitive automation.
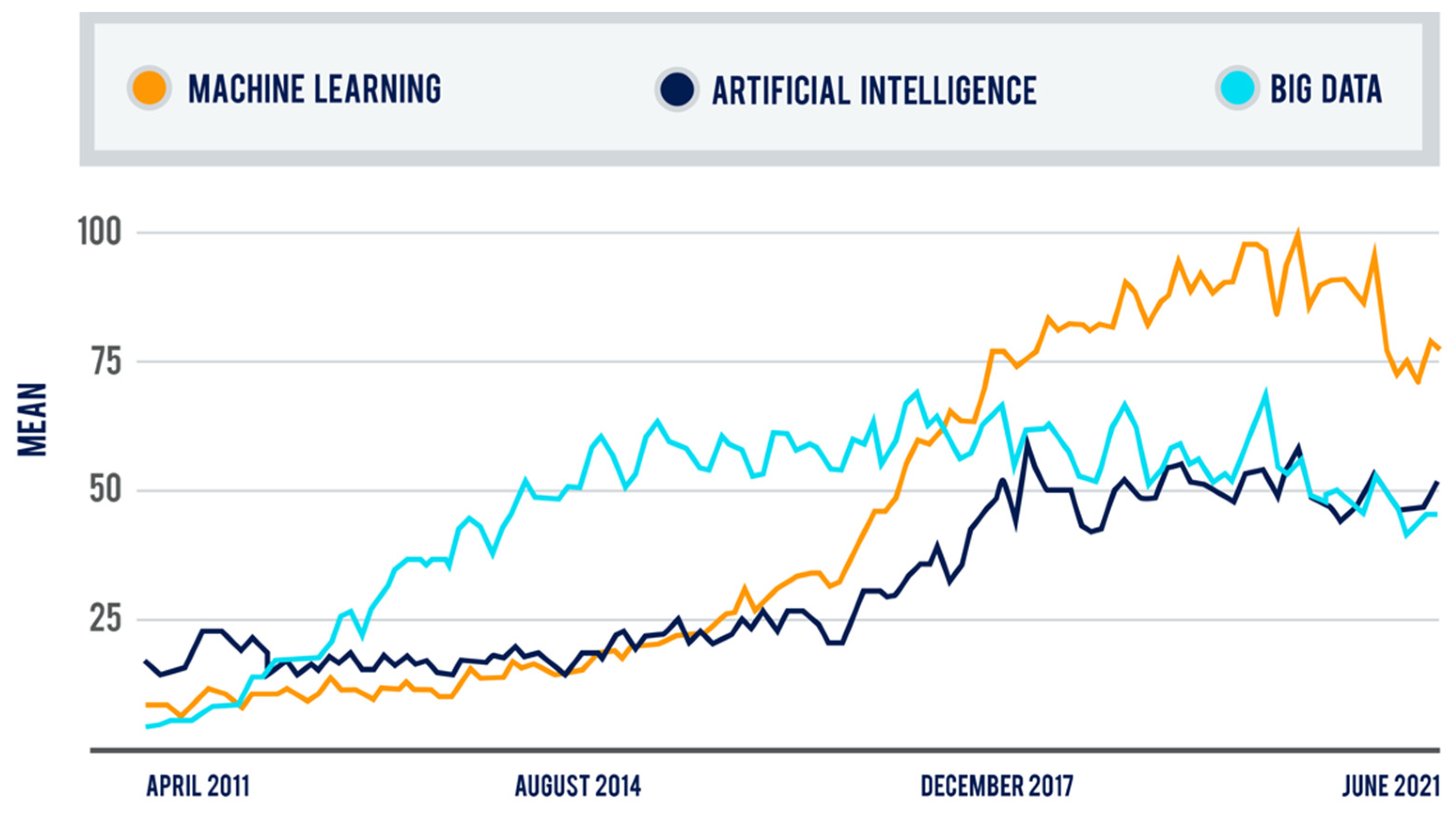
The popularity of ML is by and large due to the availability of powerful new computing tools and hardware and the increasing ease of generating and having access to large datasets, but adoption has been slow. Taking all web search categories into account, a google trends analysis [
31] (
Figure 1) on the popularity of ML, BD, and AI interestingly reveals an increase arithmetic mean in ML since 2016, reaching a peak between the years 2018 to 2020. Meanwhile, in AI, the behavior is stable without presenting high peaks from 2011 to 2016. However, the popularity of AI increased from 2016 to 2018, which corresponds to the positive result of the ML. Finally, the behavior of BD has remained stable from 2014 to 2021, presenting some popularity peaks every year. Together, this information highlights a positive correlation between ML, BD, and AI. All the above is evidenced in the growing behavior of the number of articles per year. In this study, the comparison of AI/ML/BD trends was only illustrative to show recent growth of AI and ML compared to BD.
The review article is structured as follows.
Section 1 presents a general introduction to the subject of AI and its importance for obtaining and managing data. Within the subject, we present the opinions of different authors, where some advances in AI applications are discussed. Next, we correlate the popularity of the ML domain, and the main limitations and contributions of the study are revealed.
Section 2 describes the methodology used.
Section 3 presents a conceptual framework for classifying studies and provides a literature review of the latest AI methodologies used in the ML domain, where the differences between these techniques are detailed. Additionally, a descriptive analysis of the studies is carried out.
Section 4 presents the discussions on the study thematic. Finally, the conclusions are provided in
Section 5.
Limitations and Contributions
This review article presents a broad perspective of research efforts on using emerging ML-supported AI methods for data collection and management. Research question: What are the main methodological proposals for data management that contribute to the development of the ML domain? This study is limited to the literature regarding AI/ML applications in relation to engineering disciplines. For each ML group, the review of each article focuses on the domain addressed by the study, the subgroup and type of research to which the study belongs, the research results, and the AI method used.
The contributions of this review article are: (1) studying and summarizing the AI categories used to obtain customer information; (2) defining and analyzing the main groups and subgroups that make up the ML theme; (3) identifying study types, future directions, and emerging approaches that use AI supported by ML methodologies for data management; (4) identifying the main AI methodological approaches used in the last five years to obtain and manage data; and (5) highlighting the main AI categories, areas of knowledge, research results, and current limitations/challenges of AI methods with ML.
The ML domain is constantly growing, and it is not possible to cover all of the algorithms in a single article. The multidisciplinary nature of ML was the most challenging difficulty to overcome in this review. However, the contributions of co-authors allowed the search to be limited to widely-used AI methodologies.
2. Methodology
This work corresponds to an extensive review of the literature published of the recent advances in methodological proposals that contribute to developing the AI concept supported by ML technology. The methodology used for this literature review was content analysis; a valid technique for the study of scientific documents [
32], used to: identify, classify, and analyze services in smart cities [
33], study advances in nanotechnology applied to innovative packaging [
34], propose a conceptual framework for strategic management [
35], and analyze reverse-logistics models aimed at solid waste management [
36,
37,
38].
This review identifies and analyzes research that proposes new AI methods emerging as reliable and efficient tools in data management. The development of the proposed methodology provides technical background on the indicated methods and knowledge on using these algorithms for data management problems. AI methodological developments for BD processing as a solution for data management were used by Allam and Dhunny [
39] to propose a framework that regulates and formulates BD processing policies through AI and ML aimed at the smart city concept.
Using the same methodology, Henrique et al. [
40] analyzed different ML methods and techniques to predict financial market values, resulting in a bibliographic review of the most critical studies on this topic. Likewise, van Klompenburg et al. [
41] used it to extract and synthesize ML algorithms used in predictive studies of agricultural crop yield.
This study is divided into categories, groups, and subgroups. The categories are represented by the 12 proposed emerging AI technologies. The groups constitute the four AI techniques represented in the ML domain. Each group contains the methodological contributions (subgroups) that illustrate some of the most outstanding algorithms used in the ML, identifying their degree of development through the investigations.
In this work, a systematic review of the scientific literature published between the years 2017 and 2021 has been carried out. For its preparation, the guidelines of the PRISMA statement [
42,
43] have been followed.
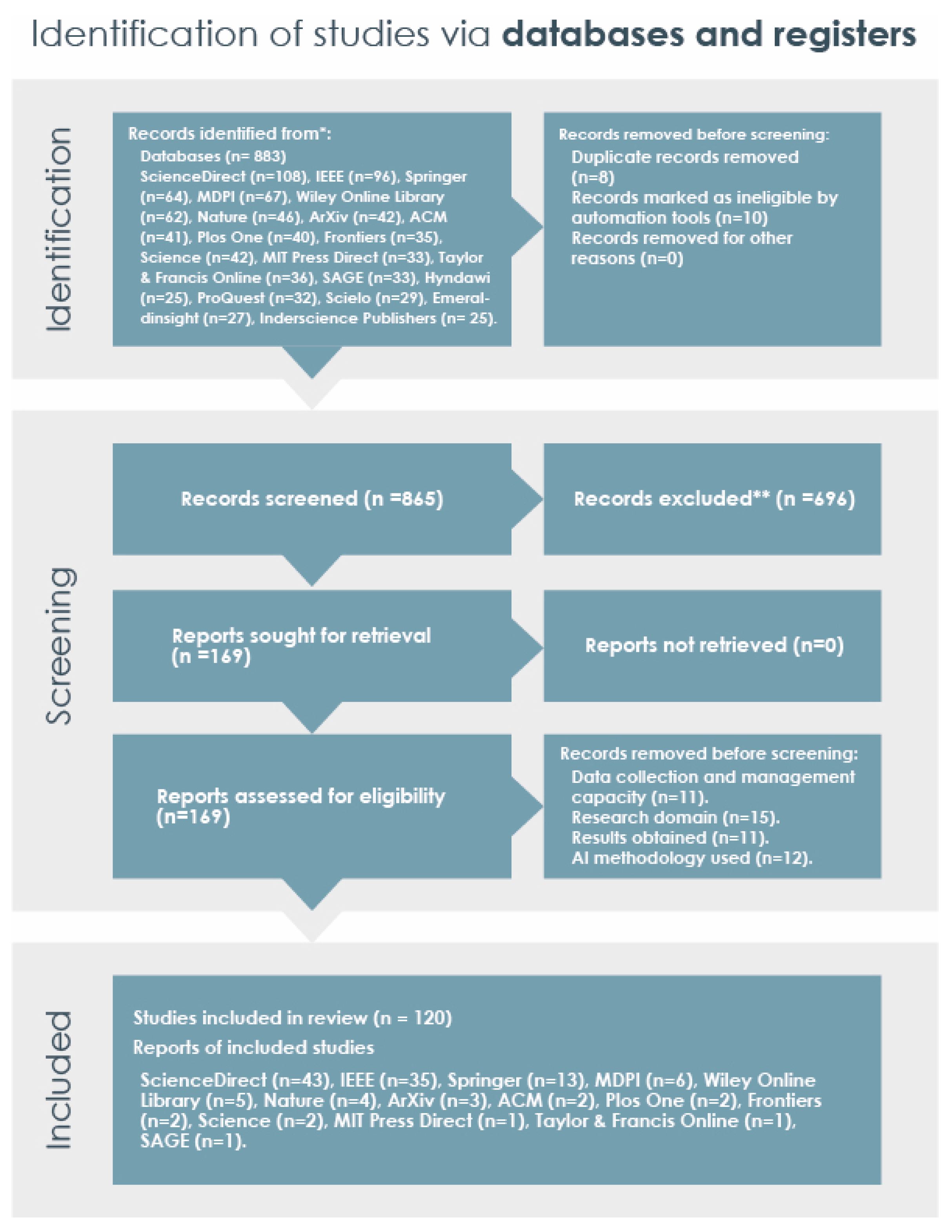
Figure 2 summarizes the proposed PRISMA methodology. The systematic search was carried out with the Google Scholar search engine using the WOS and Scopus digital platforms, mainly databases, such as Springer Link, EmeraldInsight, Science Direct, Wiley Online Library, Taylor & Francis Group, and IEEE Xplore Digital Library. The keywords used were machine learning, data management, BD, and artificial intelligence.
In addition, to choose an article, two types of quality measures were mainly considered: journal impact factor (JIF) and journal citation indicator (JCI), while not being excluding factors (
Table S1). Initially, we reviewed about 4000 publications in scientific journals, identifying 883 articles for the first step. For the second step, the studies were selected by reviewing the most relevant titles. Subsequently, in the third step, the summaries were read. After the final choice (reading the abstracts), in the fourth and last step, we read the complete publication. Then, the articles were reviewed in terms of the inclusion criteria: (1) scientific studies that are part of the WOS and SCOPUS digital platforms; (2) which propose methodological solutions for data collection and management; (3) that in the context of methodological advance, the conceptual bias is studied; (4) that develop comparisons between the solution methods and results obtained; and (5) that have been published between the years 2017 and 2021. The exclusion criteria were: (1) data collection and management capacity, (2) research domain, (3) results obtained, and (4) AI methodology used.
Categorical Classification of the Emerging AI Technologies, ML Groups and Subgroups
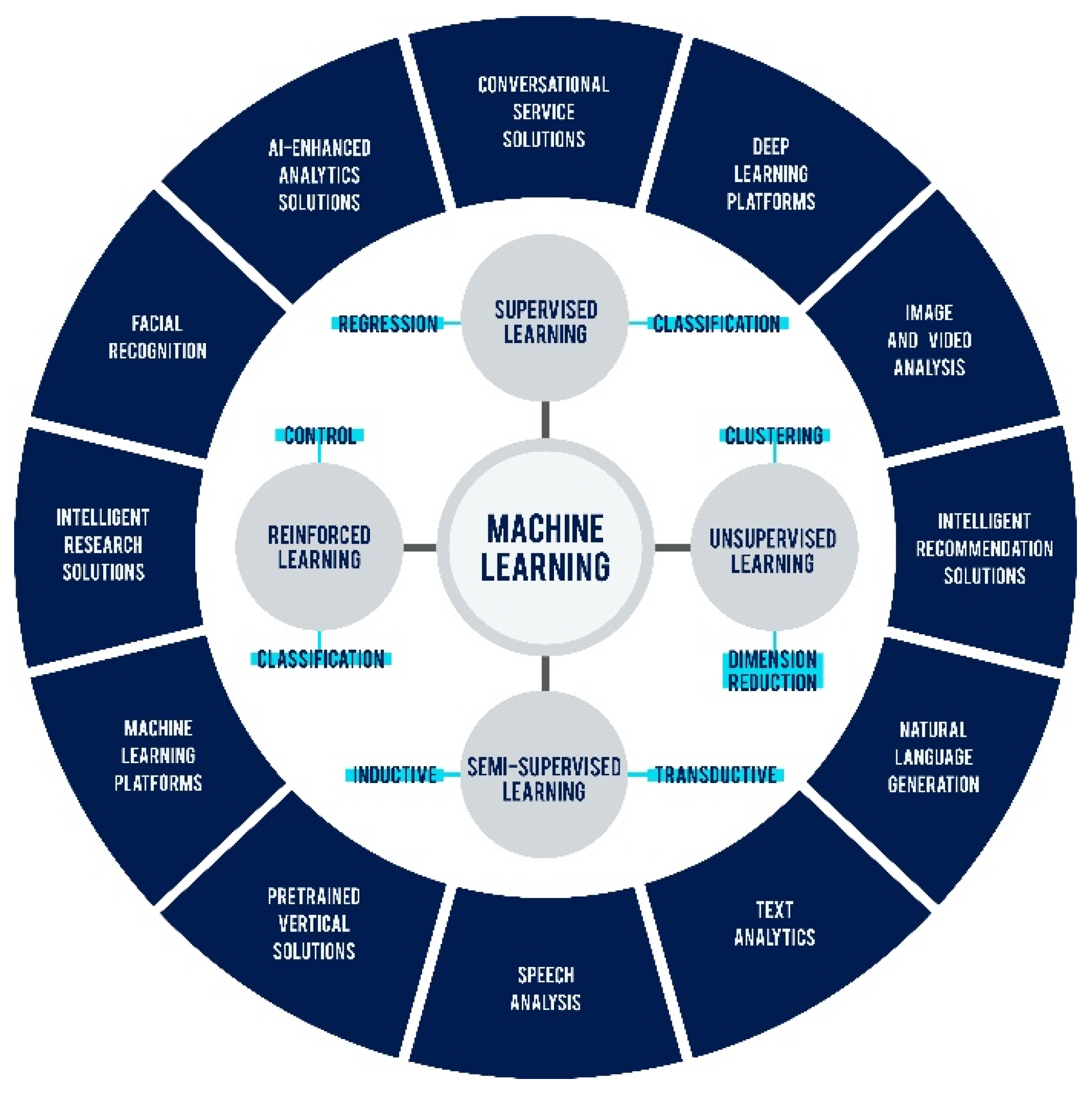
The 120 investigations classified in the literature review contribute to the development of the main AI technologies. To facilitate the analysis of the ML domain, based on the 12 technologies proposed by Purcell and Curram [
44], we sought to establish a conceptual framework, which is summarized in
Figure 3.
This study proposes to adapt and classify the AI technologies proposed by [
44] into 12 AI categories used to obtain and manage data (
Table 1); with four being the mature categories offering commercial value and impact on customer perception (AI-enhanced analytics solutions, DL platform, natural language generation (NLG), and speech analytics) [
45]. These technologies can be used at different levels to provide optimal solutions to specific problems.
Table 2 defines the ML groups and subgroups used for classifying the studies.
3. Literature Review
The literature review corresponds to the period 2017–2021. Different authors have provided models to the SL, UL, SSL, and RL groups during this period. These authors propose AI methodologies to solve ML problems in data collection and management. For each group, the maximum limit was 30 articles. A total of 120 studies were selected and are classified in
Table 3.
3.1. Supervised Learning Models for Data Collection and Management
Table 4 classified and listed the group 1 SL model (
Table 3) literature investigations into 12 AI categories (mentioned in
Table 1). SL can be used in regression problems and classification problems. In regression problems, the outputs are continuous, while in a classification problem, the outputs are categorical.
In SL, the correct input/output pairs are available, and the goal is to correctly map them from the input space to the output space.
Table 4 shows that 70% of studies correspond to the classification subgroup, 17% to the regression subgroup, and the remaining 13% to studies where both subgroups are addressed. This indicates a greater interest in the development of categorical methodologies for solving classification problems. In the literature review in
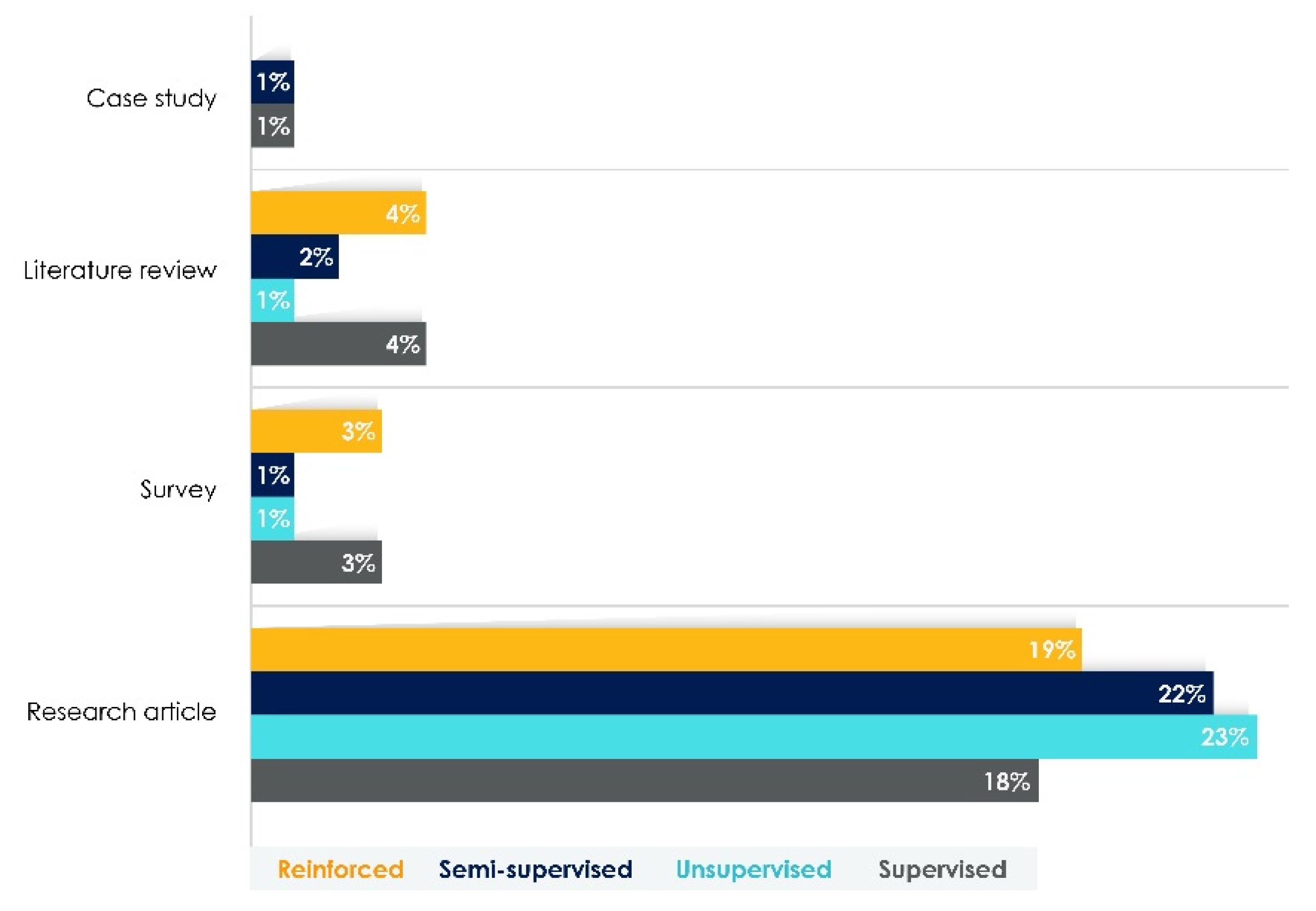
Table 4, 22 research articles, 4 literature review articles, 3 surveys and, one case study were found. Thus, the literature on SL presents a significant progress regarding the collection and organization of knowledge, reflected in the solid understanding of the approaches and algorithms developed.
Table 4 shows that the most popular AI methodology for SL is ANN (50% of publications). Subsequently, multidimensional AI methodologies were found, classified as SVM (10% of publications), followed by non-parametric-highly flexible methodologies, such as decision trees (7%). Another recursive partition method that involves predictions based on a collection of individual decision trees is random forests (7%).
The literature reviewed for each SL subgroup has expanded in volume and scope and now encompasses a broad algorithmic spectrum. The main AI methodologies used included comparisons with models of (1) regression: assembly methods, regression analysis, learning metrics, regression tree, non-linear regression, Bayesian model, among others; and (2) classification: K-nearest neighbor, Bayesian belief networks, principal component analysis, linear discriminant analysis, assembly methods, learning metrics, collaborative filtering, etc.
Three AI categories feature the most significant breakthroughs—image and video analytics, ML platforms, and pre-trained vertical solutions, all with five publications. However, we did not find studies for the categories AI-conversational service solutions and facial recognition.
3.2. Unsupervised Learning Models for Data Collection and Management
Table 5 detailed the methodological contributions found in the literature review of the group 2 UL model (
Table 3) into 12 AI categories (mentioned in
Table 1). UL is used to build clustering or dimension reduction models based on the input data without the corresponding output labels [
75].
The output data is not available in UL, and the goal is to find patterns in the input data.
Table 5 shows that 80% of the studies correspond to the clustering subgroup, 13% to the reduction dimension subgroup, and the remaining 7% of studies addressed both subgroups. This indicates a greater interest in developing exploratory methodologies (structural description of data) for solving clustering problems. According to the analysis of the studies, 28 research articles were found, one literature review article, and one survey; no findings were presented for case studies. Thus, UL takes advantage of large amounts of unlabeled data. Currently, there are significant developments in mathematical modeling, reflected in the number of research articles.
According to
Table 5, the most widely used AI solution methodology is the ANN (43% of publications). AI methodologies, such as k-means (20% of publications), aimed to determine the number, quality, and cohesion of the groupings in a data set. Statistical methodologies, such as Markov’s (7% of publications), relate observable events and hidden events.
Different AI methodologies in each subgroup include comparisons with models of (1) clustering: partitional clustering, spectral clustering, single-link, bi-clustering, multinominal regression, leader clustering algorithm, gaussian mixture model, non-linear regression, clustering feature tree, literal fuzzy c-means, among others; and (2) dimension reduction: singular value decomposition, independent component analysis, locally linear embedded, spectral embedding, isomap embedding, factor analysis, multidimensional scaling, t-distributed stochastic neighbor embedding, non-negative matrix factorization etc.
The AI category that has made the greatest advancements is DL platforms, with five publications. We did not find studies for the category AI-facial recognition.
3.3. Semi-supervised Learning Models for Data Collection and Management
The SSL approach builds inductive or Transductive models based on the original tagged data and the untagged data with new tags [
105].
Table 6 presented an updated methodological description of the group 3 SSL model (
Table 3) into 12 AI categories (mentioned in
Table 1).
SSL takes advantage of large amounts of labeled and untagged data. Conceptually it is situated between SL and UL.
Table 6 shows that 67% of studies correspond to the inductive subgroup, 23% to the Transductive subgroup, and the remaining 10% to studies that address both subgroups. The preceding indicates more interest in developing methodologies that optimize predictive models for solving classification problems. In the literature review, we found 26 research articles, 2 literature review articles, one survey, and one case study. In recent years, research in this area has followed the general trends observed in machine learning, with much attention directed to models based on ANNs and generative learning.
According to
Table 6, the most widely used AI solution methodology was ANN (36% of publications). Next, was AI methodologies that analyze networks, known as graph theory (7% of publications). Probabilistic graphical methodologies provide simple ways to visualize the structure and properties of a probability model, such as Bayesian methods (7% of publications). Another method found commonly used for clustering data was the Gaussian mixture model (7%) and the k-nearest neighbor classification algorithm (7%).
The AI category with the greatest advancements was image and video analysis, with six publications. We found no publications of AI categories—AI-enhanced analytics solutions, conversational service solutions, speech analytics, and text analytics. We found only one recent survey that collects and organizes this knowledge, which may hamper the ability of researchers and engineers to use SSL. The literature on this subject has expanded in volume and scope and now encompasses a broad spectrum of theories, algorithms, and applications.
3.4. Reinforced Learning Models for Data Collection and Management
An RL algorithm aims to maximize cumulative rewards by learning strategies through interaction with the environment.
Table 7 classified and listed the group 4 RL model (
Table 3) literature investigations into 12 AI categories (mentioned in
Table 1).
RL is a framework for decision-making problems where the agent interacts through trial and error with its environment to discover optimal behavior.
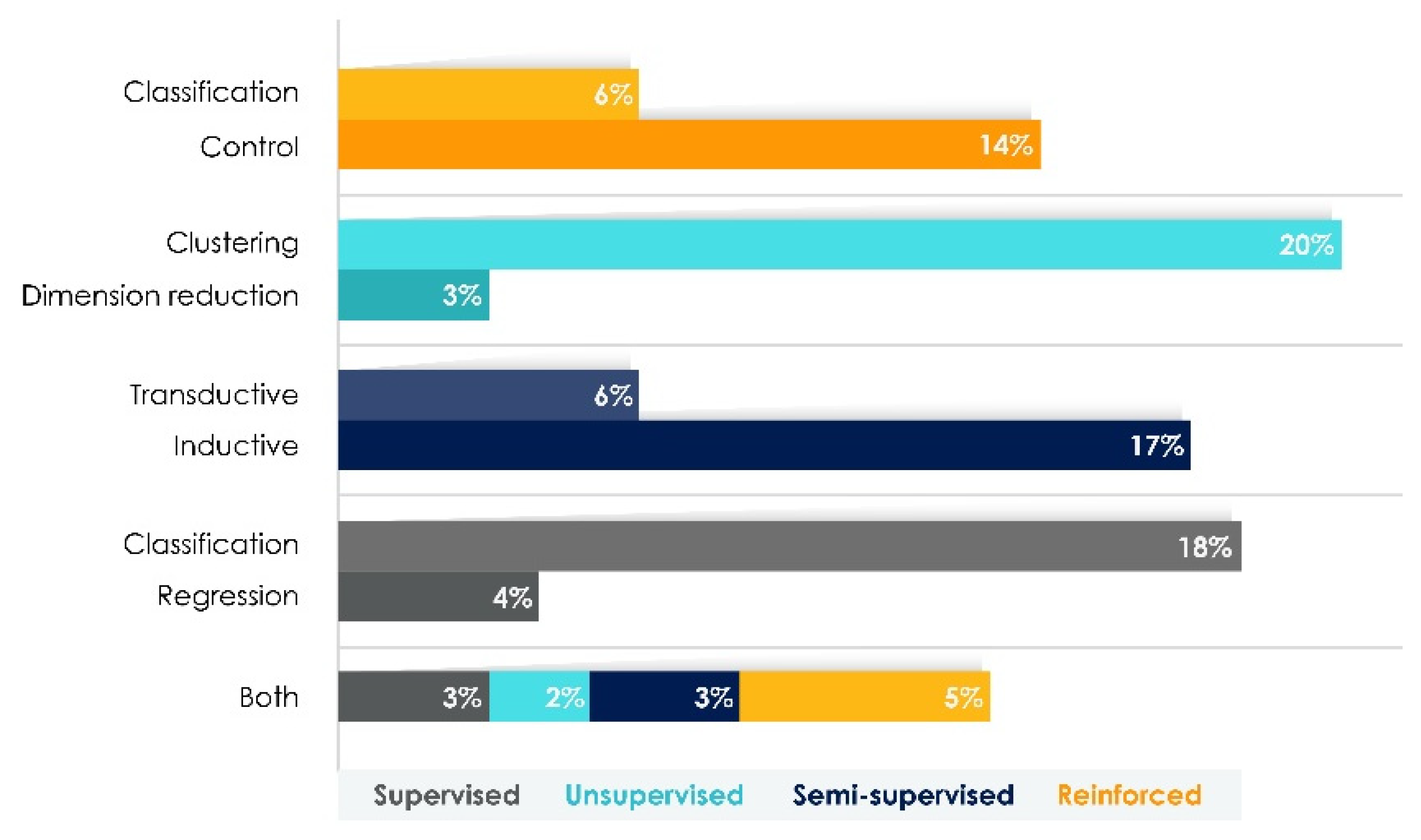
Table 7 shows that 57% of studies correspond to the control subgroup, 24% to the classification subgroup, and 18% to studies that address both subgroups. The above indicates a greater interest in methodological developments where computers make decisions on complex and stochastic systems to solve control problems. In the content analysis, we found 23 research articles, 4 literature review articles, and 3 surveys; no findings were presented for case studies. According to the literature, RL is the most popular technique for artificial agents to learn optimal strategy closely through experience. Such techniques are validated with the algorithmic developments found in the reviewed studies. Different studies analyzed models and solved RL problems using Markov’s decision process theory, Monte Carlo, and dynamic programming. RL is a potent engineering tool for modeling dynamic behaviors and achieving goals based on rewards and penalties.
Table 7 shows that the most popular AI methodology for SL is ANN (50% of publications). Next was control methodologies that assign probabilities, such as the direct search for policies (10%). Followed by methodologies to obtain optimal policies, such as Markov’s decision processes (7%).
The two AI categories with the biggest breakthroughs are smart research solutions (8 publications) and DL platforms (7 publications). We found no studies for the categories AI-conversational service solutions, NLG, speech analytics, and text analysis.
3.5. Descriptive Analysis of the Studies
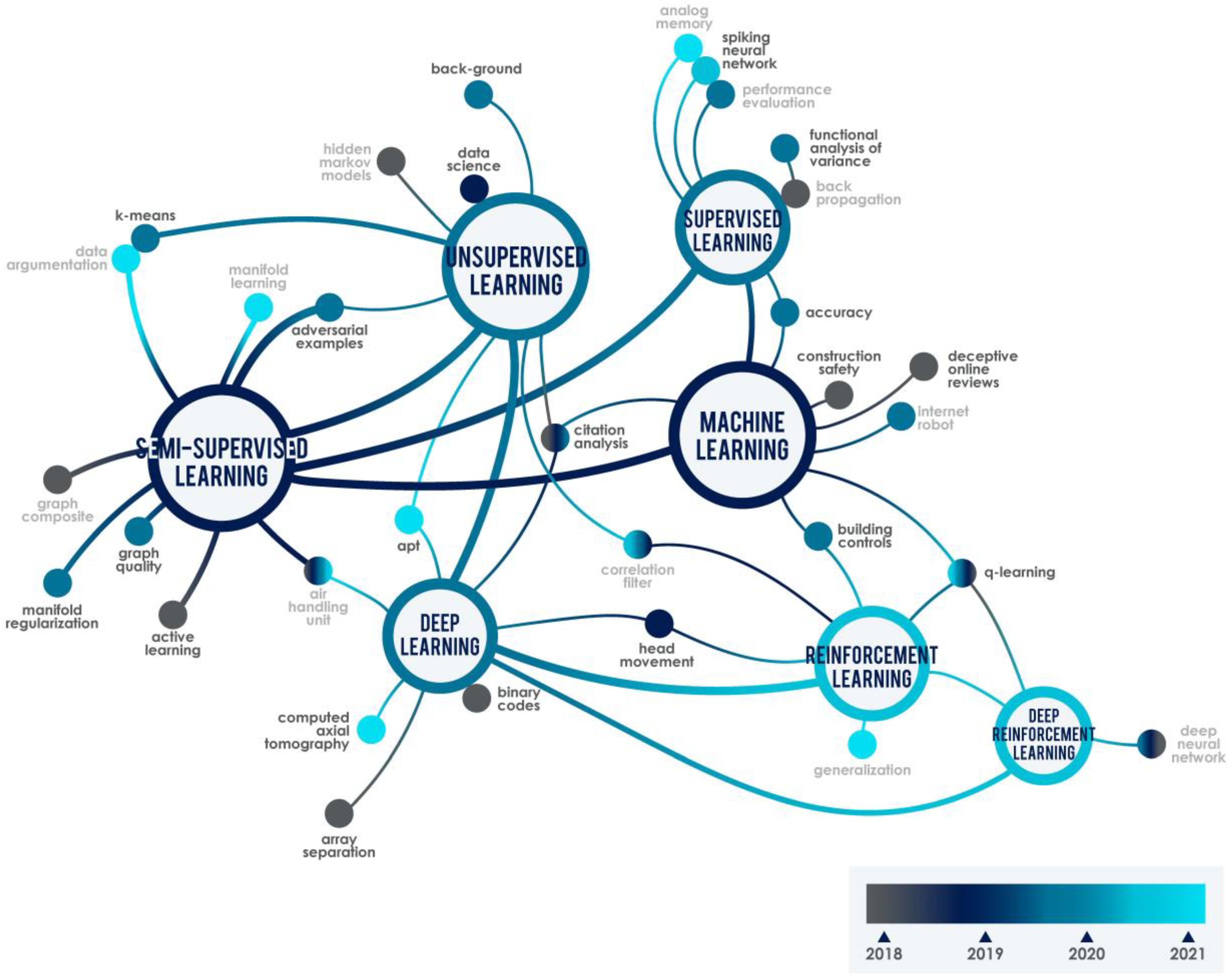
Figure 4, using the VOS viewer software, summarizes the main keywords found in the literature review.
According to
Figure 4, the number of papers for each main keyword per year is the following: 2017—machine learning (23 publications); 2018—supervised learning (10 publications); unsupervised learning (20 publications); 2019—semi-supervised learning (21 publications), deep learning (14 publications); 2020—reinforcement learning (13 publications); and 2021—deep reinforcement learning (9 publications).
The distribution of publications by study type: the type of study most evoked were research articles (with 99 investigations), followed by literature reviews (with 11), surveys (with 8), and case studies (with 2) (
Figure 5).
The number of publications per subgroup: eight subgroups with 120 articles were used in the literature review. The classification subgroup made the most significant contribution, adding the groups SL and RL would be 28 publications, followed by the clustering (24 publications), the inductive subgroup (20 publications), the control subgroup (17 publications), transductive (7 publications), regression (5 publications), and dimension reduction (4 publications) (
Figure 6).
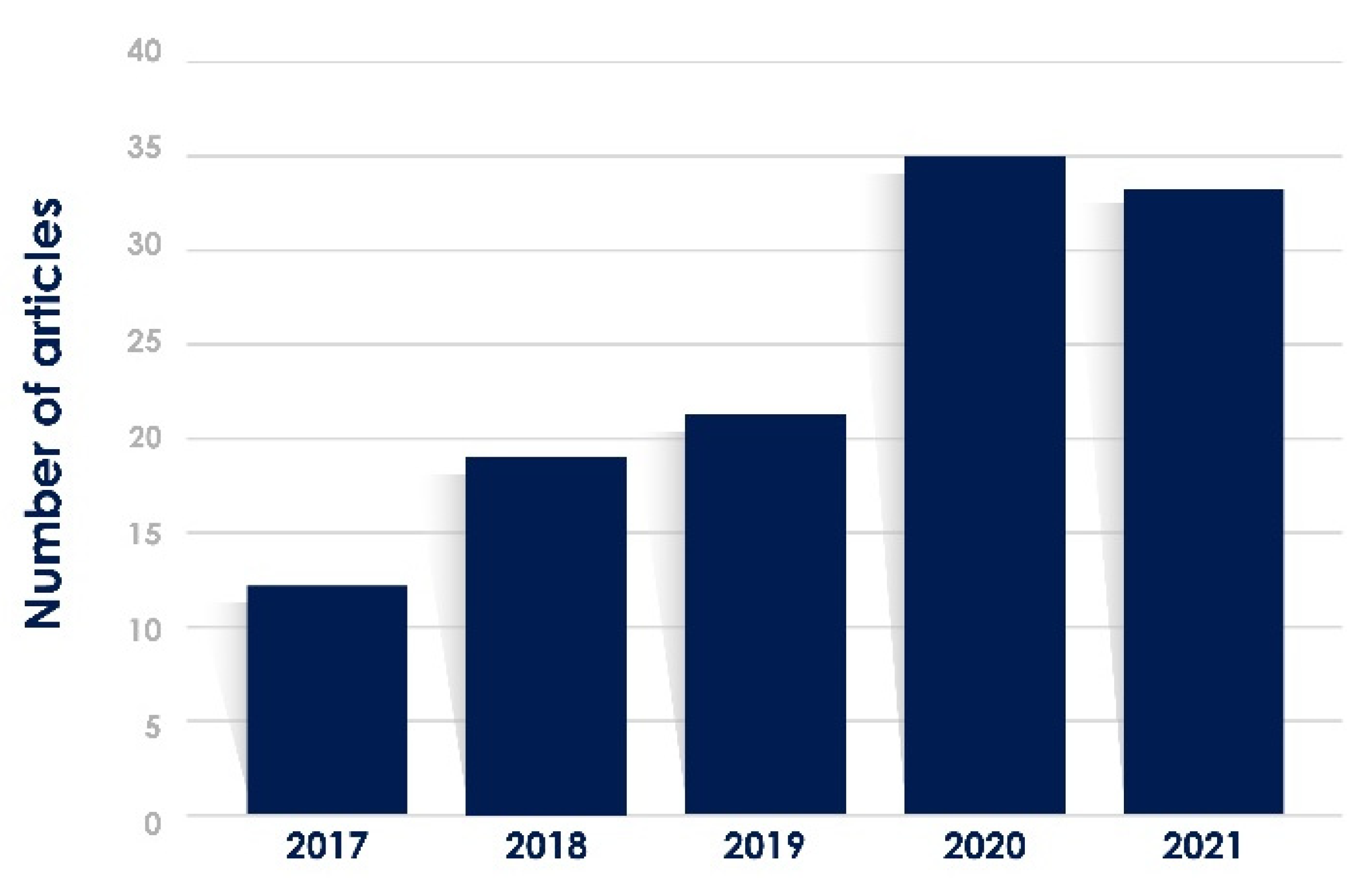
The number of articles per year: according to the analysis in
Figure 1, the growing popularity of ML, AI, and BD is evident. This confirms the increasing interest that researchers have been giving to ML in the last five years. In this research, 35 articles belonging to the literature review were published in 2020 (
Figure 7).
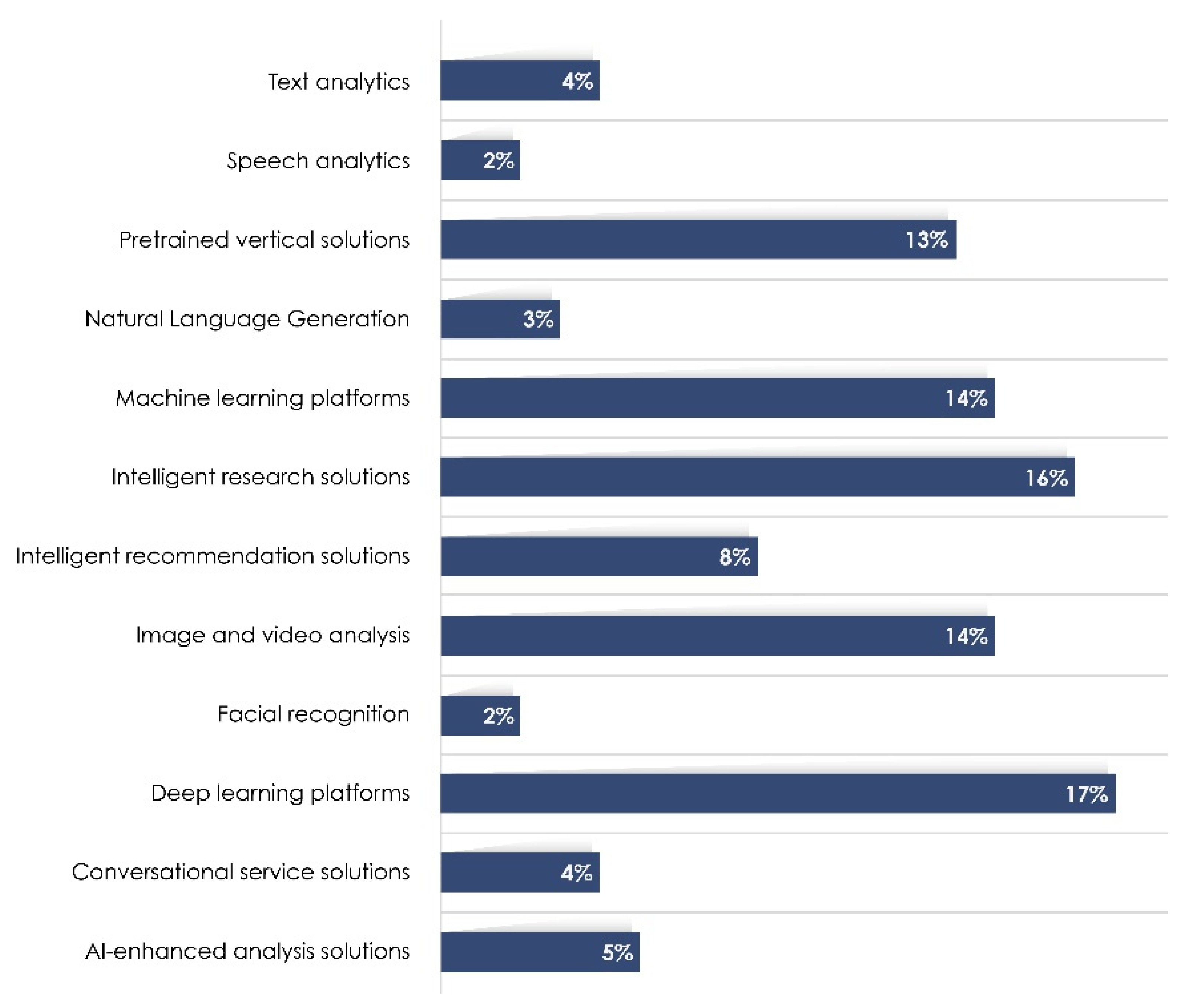
Distribution of AI categories: according to the literature review, five AI categories make the most significant methodological contributions. As shown in
Figure 8, the most important is the DL platform (with 21 studies), followed by intelligent research solutions (with 20), image and video analytics—ML platforms (with 17), and pre-trained vertical solutions (with 16).
Distribution of the areas of knowledge: the analysis of the 120 studies that make up this literature review shows that the area of computer engineering and systems presents the most widely used methodological developments (with 62 investigations). This is followed by telecommunications (with 14), infrastructure (with 12), transportation (with 10), health (with 10), the financial area (with 6), marketing and news (with 4), and agriculture (with 2).
The journals with the most publications are Neurocomputing, IEEE Access, IEEE Transactions on Pattern Analysis and Machine Intelligence, and IEEE Transactions on Neural Networks and Learning Systems (
Table S1). Regarding the origin of the research by country, China proposes the greatest ML methodological developments (39), followed by the USA (32) (
Figure S1). We reviewed 883 publications under the ML, SL, UL, SSL, and RL criteria and/or obtaining and managing information. Finally, 120 publications were selected in the fourth step; the largest number of contributions were made by Science Direct databases, IEEE, and Springer (
Figure S2). In total, 113 articles and 7 conference articles made the most important contributions.
4. Discussion
The most widely used ML technique corresponds to SL; even so, today’s BD requires UL and RL learning paradigms. However, the accuracy of UL and RL techniques is accompanied by high computational costs.
The literature review suggests using different metrics to evaluate the performance and efficiency of ML models. We found different metrics to evaluate the performance and efficiency of AI methodologies; area under the curve (AUC), Nash–Sutcliffe coefficient radius (NS), relative percentage difference (RPD), precision, accuracy, median absolute error (MedAE), recall, normalized mean squared error (NMSE), root mean square prediction error (RMSEP), mean squared prediction error (MSPE), correlation coefficient (R), and specificity. The accuracy metric was the most used by the classification subgroup, followed by mean absolute percentage error (MAPE), mean squared error (MSE), mean absolute error (MAE), root mean squared error (RMSE), F-score, and normalized root mean square deviation or error (NRMSE) for the regression subgroup. Future works are necessary to obtain precision levels close to 100%.
The analysis of the data partition formats suggests that the most typical partition ratio is (80:20) training/testing. Additionally, other studies adopted the training/validation/test data partition (80:10:10). We found no studies that stated a general rule for adopting data partitioning. The literature suggests that partition formats (80/20) following the Pareto rule provide optimal divisions for AI and ML data analysis.
Based on this study, we observed possible research avenues to improve ML predictions (1) integration of two or more AI methodologies; (2) integration of new AI methodologies with soft computing or other conventional methods; (3) use of data decomposition techniques to improve data set quality; (4) use of a set of methods to generalize models and reduce uncertainty; and (5) use of complementary algorithms to improve the quality of new AI methodological proposals.
The deep RL-DL/RL combination promises to revolutionize the future of AI in areas such as automatic driving, NLP, robots, among others. The findings of the review mainly suggest the use of two types of RL models: when the environment and state are known, they use model-based RL solutions (e.g., AlphaZero); when the environment and the state are partially known, they use the model-free RL, whose algorithms are mainly Q-learning (value-based) and gradient policy algorithms (probability-based).
The ML architecture through the IoT concept analyses and interprets complex and large volumes of data, particularly CNN. The ANN analysis of learning rates found that most studies use fixed rates. However, some studies suggest the use of adjustable rates using special algorithms. Regarding the activation function, it was observed that the linear function was the most used. Additionally, within the findings in ANN, some information processing architectures were found for signals supported on graphs, known as graph neural networks (GNN). Most of these methodological proposals are supported in deep learning and mainly propose GNN architectures based on CNN, recurrent ANN, and deep autoencoders.
The next great challenge lies in the superposition of the four ML groups: the ability to select the most appropriate AI method. This involves anticipating various scenarios (selection of parameters) and dealing with different levels of uncertainty (missing or incomplete data, computational capacity, classification precision, among others).
Despite multiple advancements of the 12 AI categories used for data collection and management, there are still multiple problems, challenges, methodologies, and future trends that AI/ML must overcome. While some UL techniques remove unnecessary data, there is still a need for massive processing power capable of analyzing all scenarios. NLG processing is a long way from being a natural and accurate translation. Jargon, accents, and understanding the language remain big challenges for ML because although image classification is a settled issue, the machine does not really understand the meaning of the image. For now, we continue to classify everything without defining intermediate states, despite the constant developments in fuzzy or soft systems.
The lack of video training is a sensitive topic for ML. Video data sets are much richer in content than still images; therefore, ML needs deeper systems capable of learning and responding efficiently with little input data. This challenge requires solving storage capacity (memory capacity to store past events) through technologies such as a collective memory network between all artificial thinking entities and differentiable neural computers, added to a modular system that integrates different algorithms. The ML reasoning ability is associated with the future development of a model of ideas; this model should serve as an interface, helping to interpret ML’s own language.
Currently, changes in the importance and frequency of participating in online activities before and during COVID-19 created new challenges for ML. According to Mouratidis and Papagiannakis [
165], during the pandemic, there were substantial increases in the importance of teleworking (31% increase), teleconferencing (34% increase), e-learning (34% increase), and telehealth (21% increase), among others. To reduce the effect of the pandemic on the education sector, most educational institutions were forced to teach online classes. As an academic tool (Zoom Microsoft Teams, Moodle, Google Classroom, virtual reality applications, etc.), the web provides a global open platform for storing data and presenting it in text, graphic, audio, and video formats, and in communication tools for synchronous and asynchronous communication [
166]. AI-supported e-learning (AIeL) refers to the use of AI techniques in e-learning (the use of computer and network technologies for learning or training) [
167]. Through web platforms, AIeL proposes ML approaches to: identify the learning style and personalize learning experiences [
168,
169], personalized hybrid recommender for the adjustment or association of content to students [
170,
171], DL algorithms for monitoring student emotions in real-time [
172,
173], a multi-agent system to improve the Moodle platform in intelligent tutoring systems [
174], a cyber threat detection model in e-learning systems [
175], and fuzzy ANN for learning English [
176]. Finally, different authors have evaluated the impact of AIeL during the COVID 19 pandemic [
177,
178,
179,
180,
181].
5. Conclusions
This review article presents the importance of continuous AI methodological developments for ML applications during 2017–2021. A total of 181 studies were used, of which 120 are part of the literary analysis. The literature indicated that, among the numerous methods, ML has been increasingly adopted and used to develop emerging AI technologies. In general, ML areas are closely related, as they fundamentally overlap in scope.
The most used tools to evaluate the performance of AI methods were accuracy, RMSE, R, specificity, MAPE, MPAE, followed by MSE, in addition to generalizability, robustness, calculation cost, and speed. The most commonly used ML algorithm was ANN, followed by SVM, k-means, and Bayesian methods. Some studies adopted hybrid methodologies to harness the power of different techniques to compensate for the weakness of specific techniques. The knowledge areas evaluated make software and systems engineering the next generation approaches to perform data collection and management, with fault diagnosis being the application area with the greatest solution proposals, followed by robotics, autonomous computing, and driving. This review showed that classification tasks are the most frequently used methods by so-called intelligent systems, either by statistical algorithms or AI. The literature also suggests that the AI-based DL platforms require less information, which improves complicated decision problems, making it the alternative solution with the greatest AI methodological proposals.
Based on the methodology proposed in this study, mature AI technologies, such as speech analytics, facial recognition, NLG, and conversational service solutions, had slower methodological developments, showing researchers are interested in less developed AI categories.
Future work should amplify the discussions in the proposed study areas. For example, one of the concepts that needs to be expanded is the emerging PR AI method; the objective of this study would be to know the impact that PR advances generate in different areas of engineering, from a perspective framed in generative models versus discriminative models.
It is essential to broaden the literature review, also focusing on the emerging DL AI method, for example, to analyze the advances that CNN applications have had in different areas of engineering. Likewise, analyzing the methodological advances of DL architectures, recurrent neural networks, automatic encoders, deep belief networks, among others, is important. Finally, the design of an adequate methodology that integrates multiple emerging AI technologies to facilitate data collection and management is envisaged.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}