1. Introduction
The ocean occupies most of the Earth’s surface solution and is the habitat of tens of thousands of marine organisms. Additionally, they hold immense potential as a valuable reservoir of resources, including minerals, oil, natural gas, and a variety of other aquatic resources. Underwater image target detection research is gaining momentum due to the growing need for intelligent underwater detection in academic, industrial, and military applications [
1]. This includes various underwater tasks such as target localization, object search, aquatic life detection, seabed modeling, salvage and rescue, anti-mine, anti-submarine, etc. [
2]. Complex underwater environments can affect detection results. Factors such as insufficient light due to weather conditions and variations in underwater brightness due to water depth can increase the difficulty of detection. In addition, the process of acquiring and transmitting underwater images is costly, further increasing the complexity of this research problem [
3].
In the field of artificial intelligence and deep learning, symmetry plays an important role in helping to optimize model performance, simplify problems, and improve training efficiency. The concept of symmetry includes the property that the input data or model remains unchanged under certain transformations, such as spatial translation, rotation, scaling invariance, etc. Symmetry is utilized to reduce the model complexity, improve the generalization ability, and reduce the amount of data required.
In image processing, the symmetry of image translation, rotation, and other symmetries is used to design neural network structures with corresponding invariance, such as convolutional neural networks, to effectively capture image features and realize recognition and processing under symmetry transformation. In natural language processing, the symmetry of sentence structure is utilized to design models with positional coding or attention mechanisms to improve semantic understanding and task performance. In deep learning, the symmetry of the environment is utilized to reduce the training complexity and improve the learning efficiency of the intelligences, e.g., learning symmetric strategies in symmetric environments to reduce state space search. In summary, symmetry is of great significance in AI and deep learning. By using symmetry to design efficient models, we can improve generalization ability and training efficiency and promote technology development and application.
Target detection can be classified into two main categories: traditional techniques and deep learning-based techniques. Traditional techniques use established algorithms and analytical methods to detect targets, while deep learning-based techniques employ complex neural networks to learn and recognize targets from data. The process of finding the object of interest in an image involves two subtasks: target localization and target classification. Along with classifying the object, it is also necessary to determine its position. The traditional method for detection involves using the sliding window method, which requires more accurate traversal for higher accuracy detection. However, this method also results in greater time overhead required for detection. Additionally, there is an issue with the binary classification samples not being balanced due to the large number of background images compared to foreground images. There is a significant difference between the frames corresponding to the background and foreground in a single image. The problems with traditional detection methods can be summarized into two points: high accuracy, demanding a lot of time and complex operations, and a large number of samples needing to be generated manually [
4]. These advantages include the ability to effectively adapt to the complexity and variability of detection targets, reduced dependency on human intervention, and improved generalization capabilities. Currently, deep learning-based target detection algorithms are mainly classified into two categories: two-stage target recognition algorithms and single-stage target recognition algorithms. The R-CNN (area-CNN) [
5] family of algorithms, which combines convolutional neural networks (CNNs) and area suggestions to achieve a notable performance boost, represents the former class of methods. However, this algorithm’s poor computing performance makes it unsuitable for most real-world underwater target detection applications. Single-stage algorithms are currently the subject of extensive research in the field of target detection, and people have been working to improve their accuracy and performance. Numerous studies and experiments are being conducted to explore novel techniques and methodologies that can further improve the effectiveness of these algorithms. Researchers are actively looking for ways to optimize the existing single-stage algorithms by addressing various challenges and limitations associated with them. These endeavors aim to elevate the accuracy and overall performance of single-stage algorithms, making them a promising avenue for future advancements in target detection research. This is because single-stage algorithms may directly anticipate categorization and localization, which leads to faster detection speeds. The representative algorithms of this type are the SSD (Single Shot MultiBox Detector) [
6] algorithm and the YOLO (You Only Look Once) [
7] series algorithms (YOLO, YOLO9000 [
8], YOLOv3 [
9], YOLOv4 [
10], YOLOv5 [
11], YOLOv6 [
12], and YOLOv7 [
13]).
In recent years, the field of underwater target identification has seen remarkable advancements driven by numerous professionals, academics, and researchers. Li et al. (2015) utilized Fast R-CNN [
14] to identify and detect fish species. To expedite the fish detection process, Faster R-CNN was subsequently employed. Zhou et al. [
15] introduced a Faster R-CNN network with feature mapping in 2017. To address the challenge of underwater image blurring on extremely noisy backgrounds, Long Chen et al. proposed a novel sample-weighted super network called Fast Processing in 2020 [
16]. In the same year, Qiao et al. [
17] presented a combination of LWAP and MLP neural networks. Lei et al. [
18] made significant improvements to the YOLO-v5s model through three key modifications: replacing the backbone network with a Swin Transformer.
However, the underwater environment poses numerous challenges, including severe color distortion and low visibility due to image capture in motion. These factors significantly impede the field of underwater target detection. As a more advanced algorithm within the YOLO family, YOLOv7 proves to be better suited for industrial applications. Based on the YOLOv7 model, this paper proposes an innovative approach for underwater imaging.
The innovative contributions of this paper are as follows:
Some of the MP and ELAN modules have been modified, and the SE attention module has been embedded in some of the modules to increase the model’s focus on regions of interest, and SE layers have been added at specific locations in the model to further enhance the model’s focus on regions of interest. As a result, the model can focus its computational power on regions of interest;
To enhance detection accuracy, a decoupling head with implicit knowledge is employed, replacing the original detection head. This decoupling head captures additional implicit information without requiring additional processing steps;
To assess the similarity of BBox, a new metric called the Normalized Wasserstein Distance (NWD) is introduced, replacing the traditional IoU metric. The NWD is more appropriate for assessing similarity between small targets because it measures distributional resemblance independent of target overlap.
The following sections of this paper are organized as follows:
Section 2 outlines the necessary knowledge for this paper. In
Section 3, the theoretical foundations of the proposed YOLOv7-SN model are introduced.
Section 4 details the experimental evaluation and performance analysis conducted on the underwater image dataset. Finally,
Section 5 provides a summary of this work.
2. Related Work
2.1. YOLOv7
YOLOv7 is an algorithm for target detection that introduces model reparameterization [
19], a label assignment strategy [
20], an ELAN-efficient network architecture [
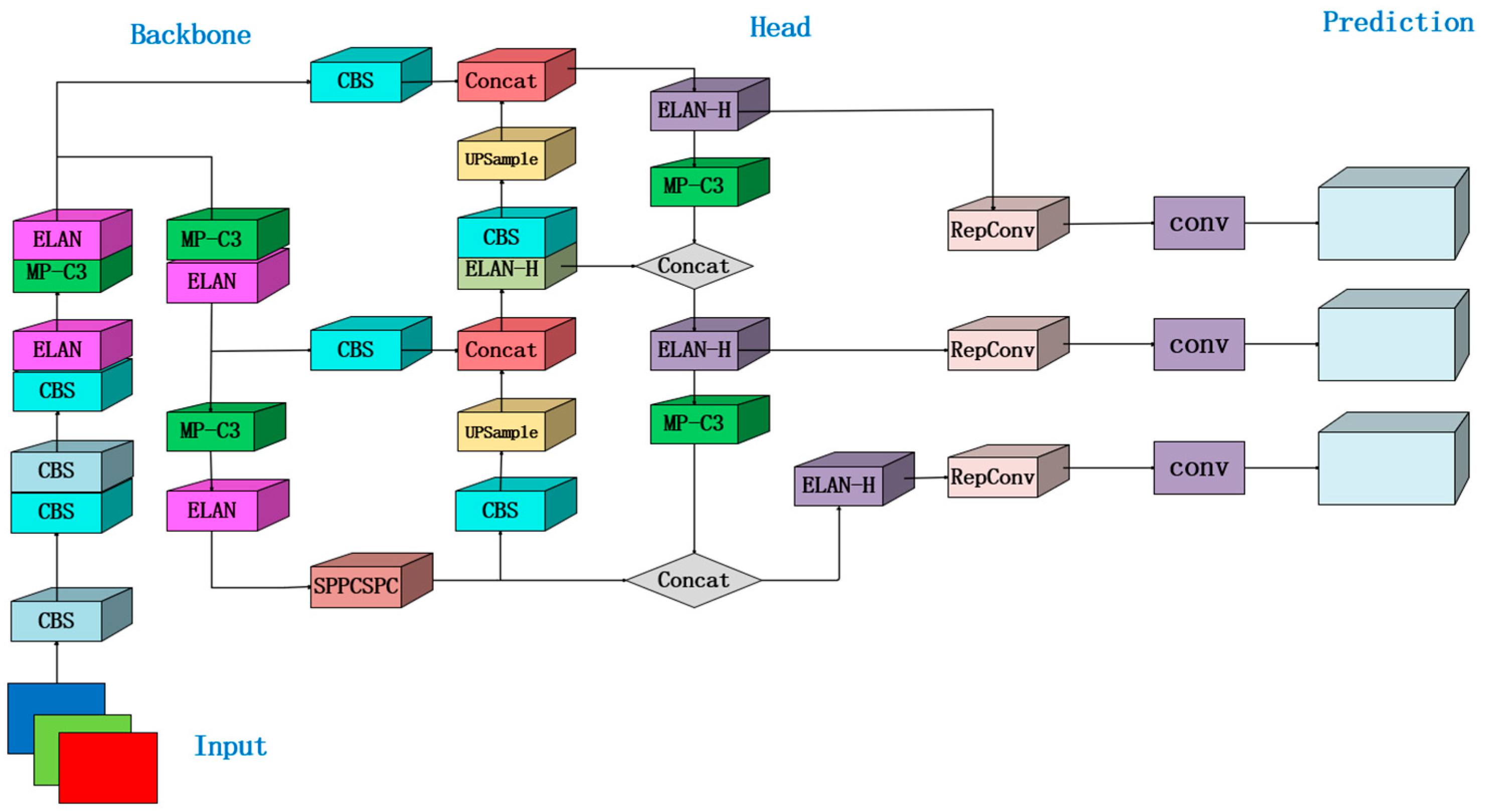
21], and a training method with auxiliary heads in the network architecture. YOLOv7 and YOLOv5 are similar in general, but with replacements and improvements in the internal components of the network structure, the auxiliary training head, and the label assignment idea. According to
Figure 1, the YOLOv7 network consists of three different parts.
The primary function of the input module in YOLOv7 is to perform essential processing tasks on the input image, such as data augmentation, adaptive image scaling, and anchor frame calculation. These tasks are crucial for pre-processing the input image and preparing it for further analysis and detection.
The main feature extraction module in the YOLOv7 network is called the backbone module. Its job is to acquire the input image and extract high-level semantic features that will be used in the target detection task. The backbone module in YOLOv7 employs several convolutional and other network layers to progressively decrease the resolution of the input image. Simultaneously, it extracts increasingly abstract and significant features.
The Head module in the YOLOv7 model is mainly responsible for the final regression prediction, which receives the multi-scale features from the Neck module and processes them through a series of operations to finally generate the output of target detection. The Head module usually includes convolutional layers, global average pooling layers, fully connected layers, etc., which convert the feature maps into the target’s location and category information. As an integral component of the Head module, the prediction module typically encompasses convolutional and fully connected layers.
To enhance the YOLOv7 model, the proposed YOLOv7-SN network preserves the overall structure of YOLOv7 while integrating a channel attention mechanism. This mechanism introduces a dilated convolution module, which effectively replaces the conventional detection head. The inclusion of a channel focus mechanism is intended to improve the detection performance of the model by enhancing the network’s ability to selectively focus on relevant features.
2.2. Attention Mechanisms
In the domain of computer vision, the human visual system tends to concentrate on salient objects, disregarding irrelevant parts of the visual field that do not contribute to object recognition [
22]. Similar to this mechanism, the attention mechanism [
23] in object detection models guides the model to focus on important objects and their respective locations within the acquired image [
24]. Previous research has successfully integrated attention mechanisms into deep neural networks with promising results in various tasks such as object classification [
25], image segmentation [
26], and target detection [
27].
Several attention modules have been proposed, including the SK module [
28], the CBAM module [
29], and the TA module [
30]. The CBAM module is an attention module designed specifically for feedforward convolutional neural networks. By incorporating both spatial and channel attention, the CBAM module enhances the model’s classification performance. Another commonly used channel attention module is the SK module, which was proposed in 2019. It leverages a convolutional kernel mechanism to assign varying levels of importance to different convolutional kernels concerning additional input images.
Momenta’s Squeeze–Excite (SE) [
31] network module, introduced in 2017, is another attention module that has achieved notable success in the ImageNet image recognition competition. The SE module models the interdependencies between feature channels and learns the significance of each channel by assigning weights to features. This process highlights key features while suppressing less-related ones. The SE module enhances the representativeness of the model and improves the detection of blurred images while maintaining a lightweight structure and minimal computational overhead.
2.3. Bounding Box Regression Loss Function
The Bounding Box Regression Loss Function [
32] is a loss function used to measure the difference between the predicted box and the real box in a target detection task. Its goal is to optimize the accuracy of the target detection model by minimizing the distance between the predicted box and the real box.
In recent years of research, the Bounding Box Regression Loss Function has undergone an evolutionary process and mainly includes the following forms [
33]:
SmoothL1 Loss: SmoothL1 Loss is a smooth L1 loss function that uses L2 loss when the difference between the predicted box and the real box is small and L1 loss when the difference is large to reduce the influence of outliers. IoU Loss: IoU Loss is a measure of the degree of overlap between the predicted and true frames by calculating the intersection and concurrency ratio (IoU) between them. GIoU Loss: GIoU Loss is an improved IoU Loss that takes into account information about the size and position of the bounding box between the predicted and true boxes. DIoU Loss: DIoU Loss is a further improved IoU Loss that takes into account the centroid distance between the predicted and real frames on top of GIoU Loss. CIoU Loss: CIoU Loss is a further improvement of DIoU Loss, which takes into account the difference in aspect ratio between the predicted frame and the real frame based on DIoU Loss.
2.4. Implicit Knowledge
Implicit knowledge refers to knowledge that is acquired and utilized subconsciously. However, there is currently no standard description or framework that comprehensively explains the mechanisms of implicit learning and the acquisition of implicit knowledge. In the context of neural networks, feature information acquired from shallow levels is often called explicit knowledge, while feature information learned from deeper levels is considered tacit knowledge. Implicit knowledge, on the other hand, is derived from deeper layers and encompasses the model’s latent knowledge that is not directly related to the observed data or specific comments. Explicit knowledge corresponds directly to observable data and observations.
A network with implicit learning is a single, cohesive network that integrates the encoding of implicit and explicit knowledge [
34], similar to how the human brain acquires knowledge through both conventional and subconscious learning. A unified network can produce a unified representation that fulfills multiple purposes at once. Kernel space alignment, multi-task learning convolutional neural networks, and prediction refinement are all possible.
3. Method
This section presents the methodology for underwater target identification utilizing the enhanced YOLOv7. The initial step involves dataset processing, encompassing both data labeling and augmentation. Following this, the enhanced YOLOv7 network is utilized to enhance the precision of the model’s detection. To be more specific, we substituted the original detection header with the Efficient Decoupled Head with Implicit Learning, integrated a module featuring null convolution into the backbone network, amalgamated the SE attention mechanism with multiple modules, and ultimately bolstered the confidence loss function.
3.1. The Proposed YOLOv7-SN Model
The proposed YOLOv7-SN model incorporates the new ELAN-S and MP-S modules, replacing the original ELAN and MP-C3 modules. The SE attention mechanism is introduced to enhance the channel characteristics of the input feature maps and thus improve the accuracy and performance of the model. Following this, the RFE module [
35], comprising three distinct dilated convolutions with varying dilated rates, is integrated after the SPPCSPC module. This addition serves to capture additional multi-scale information, expand the sensory area, and reduce the number of parameters, thus reducing the chance of overfitting. Furthermore, the accuracy of model detection is heightened through the replacement of the initial detection head with an efficient decoupling head utilizing implicit learning. The location of these attention modules concerning the RFE module and the structure of the modified YOLOv7-SN is illustrated in
Figure 2.
In terms of spectral feature extraction, the proposed YOLOv7-SN model is better suited for complex underwater environments. First, the image to be detected is input into the model. Through a series of improved convolutional and pooling layers, the model can extract the feature information of the image. These features can include edges, textures, etc. Then, after the convolutional layers, the model uses a fully connected layer to further process the feature information. The fully connected layer can map the features of the image to the target category. After the fully connected layer, the YOLO model uses a softmax function to make probabilistic predictions for each target category. Finally, in addition to the prediction of target categories, the model predicts bounding boxes for each target. These bounding boxes are used to locate the position of the target in the image.
3.1.1. Improvements Based on the Attention Mechanism
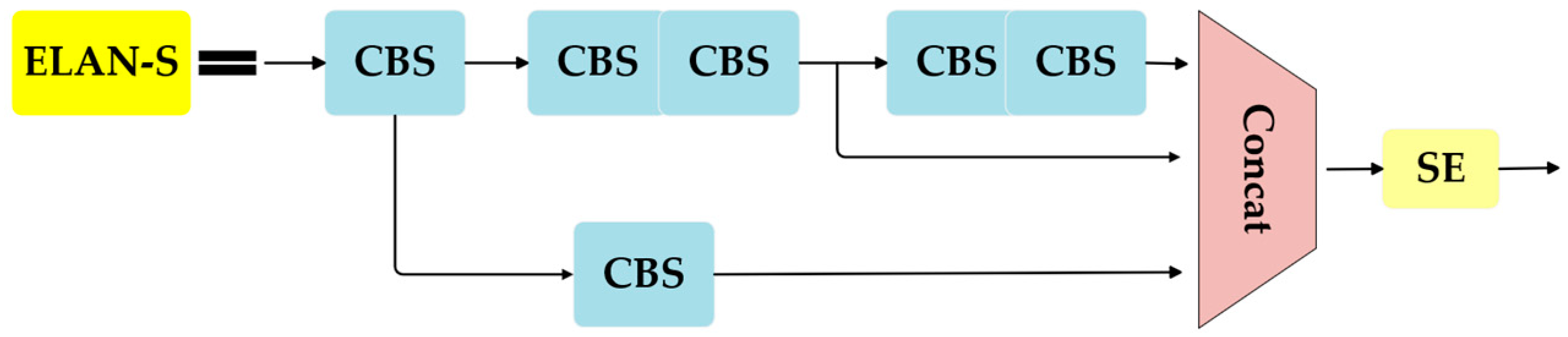
The model can extract higher-level characteristics and more information thanks to the enhanced backbone network’s introduction of the ELAN-S structure, which substitutes the SE attention module for the CBS convolution module in the ELAN structure following the contact module. This will be more beneficial in navigating the intricate and crowded underwater landscape. The specific ELAN-S modules are shown in
Figure 3.
Furthermore, we use two enhanced MP-S modules to replace the original MP-C3 module. The MP-S module enables the network to adaptively adjust the channel weights, while the header network can learn and capture contextual information more effectively. The specific MP-S modules are shown in
Figure 4.
The structural details of the SE Attention module are depicted in
Figure 5. The module starts with a global pooling layer and passes through a series of fully connected layers that linearly transform the features using a weight matrix to achieve a nonlinear combination. The ReLU activation function is used to solve the vanishing gradient problem and increase the sparsity of the model. Another activation function, Sigmoid, transforms the input into a probability distribution. The “Scale” operation then normalizes the information to ensure that the elements are appropriately weighted. By adaptively recalibrating the feature response, the attention module can effectively catch and emphasize important features.
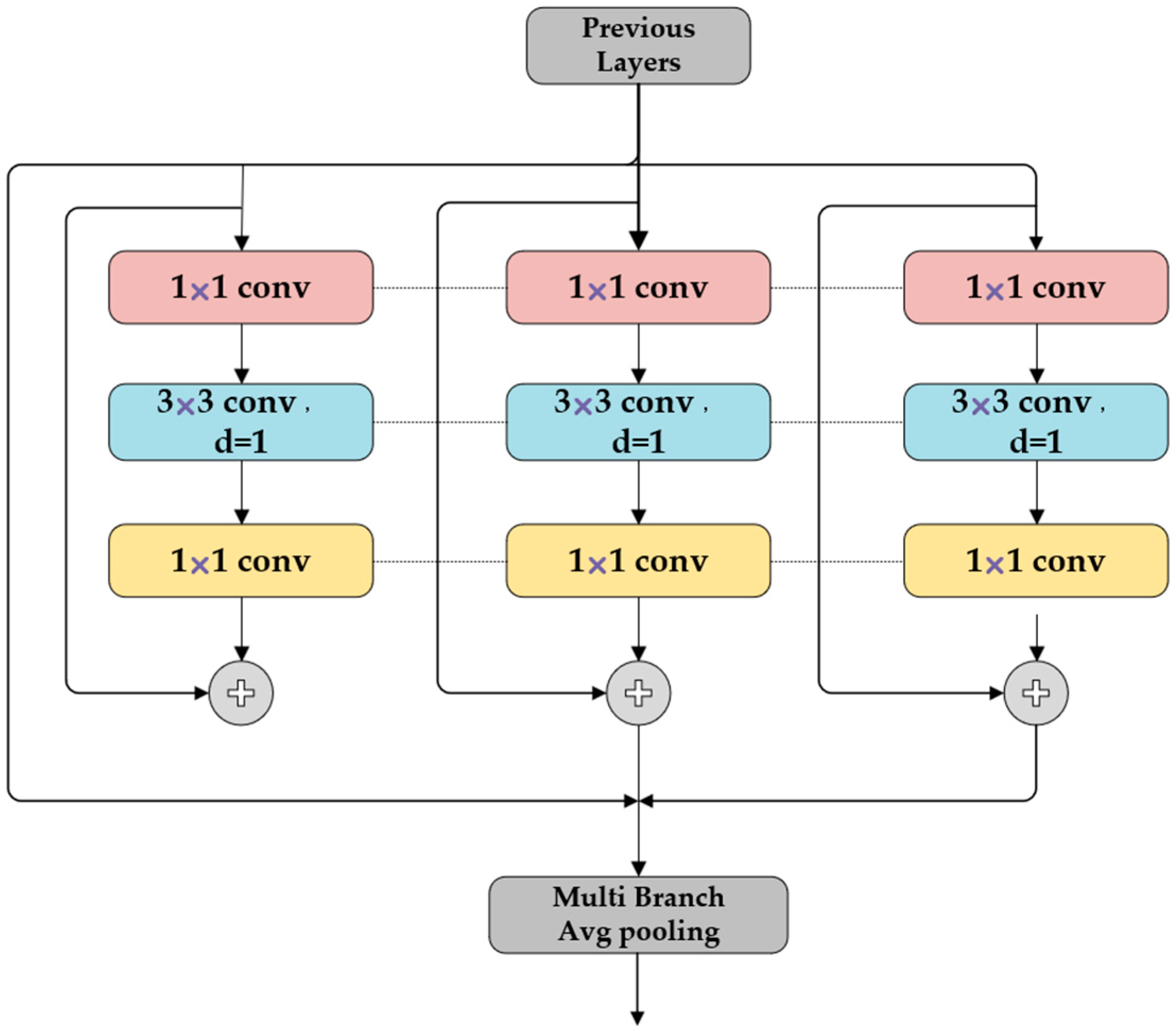
3.1.2. RFE
After the SPPCSPC module, the upgraded head network adds an RFE module made up of a dilated convolution [
36] module. The RFE module (Receptive Field Enhancement Module) makes full use of the different widths of the receptive fields of the feature maps to obtain multi-scale information through dilated convolution. As seen in
Figure 6, the structure comprises two parts: an aggregated weighted layer based on dilated convolution and a multi-branch. In the first part of the structure, features are extracted using three different dilated convolutions with different dilated rates (1, 2, and 3). A fixed convolution kernel of 3 × 3 size is used to extract multi-scale information, and residual concatenation is used to avoid the gradient explosion problem. The output feature layer is finally obtained by adding the characteristics of the four branches.
Target detection tasks require a large practical receptive domain, which can be further increased using dilated convolution with several convolution kernels. The demand for shape information in the target identification task necessitates a greater number of convolutional kernels to extract more shape features. Therefore, models equipped with multiple kernel convolutions are more suitable for intense downstream detection tasks.
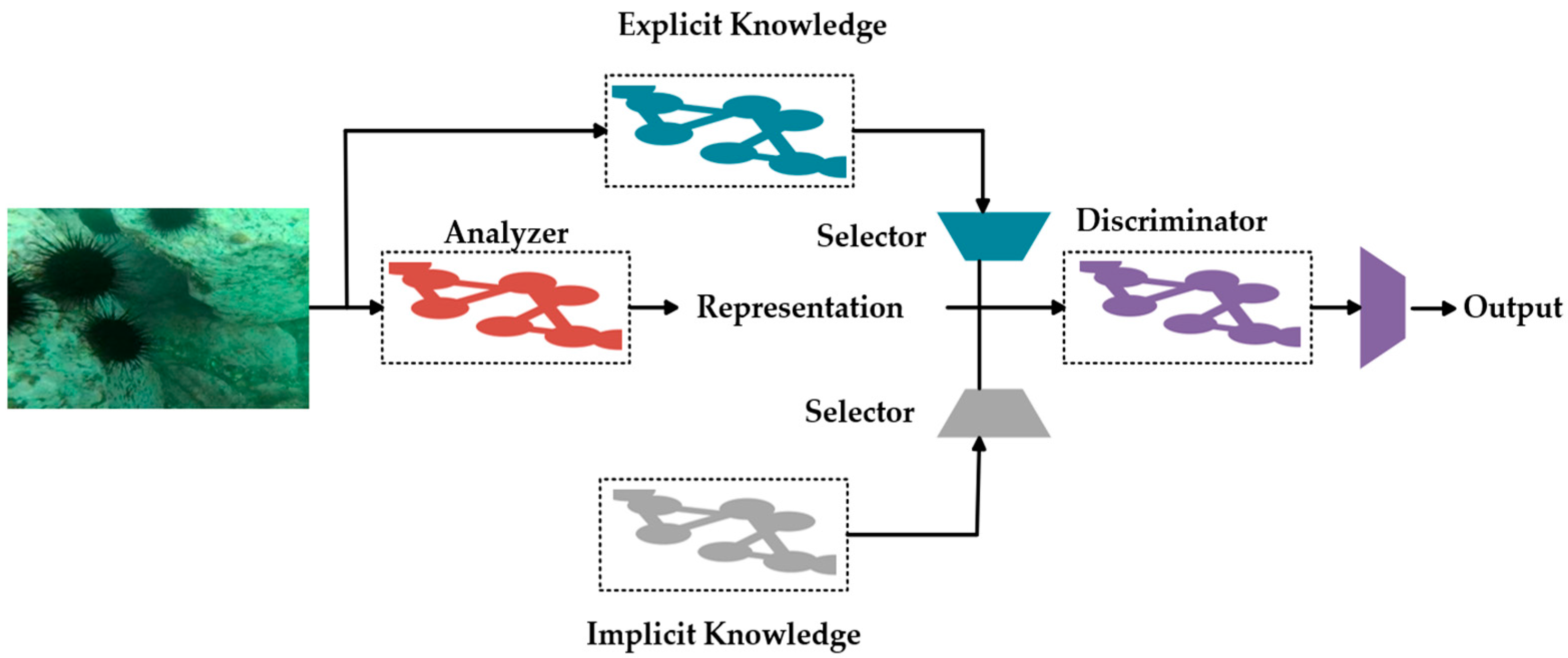
3.1.3. Implicit Leaning-Based Detection Head
In terms of detection head improvement, we replace the original detection head with an efficient decoupled head with implicit learning, applying implicit learning to multi-task deep learning. Implicit learning, as the name suggests, refers to learning outside of normal learning (which we call epiphenomenal knowledge), just like the subconscious learning of the brain, where the subconsciously learned experiences will be encoded and stored in the brain. Utilizing this wealth of experience as a huge database, humans can efficiently process data, even if it is not seen beforehand. In this paper, we encode implicit and explicit knowledge together through a unified network to generate a unified representation that serves both underwater detection tasks.
The technique adds relatively little extra cost (less than 10,000 parameters and calculations) while improving the performance of the model. The combination of implicit and display learning is used to complete various tasks, as seen in
Figure 7.
In traditional network training, we can use the objective function of (1) to represent:
where
x is observation,
θ is the set of parameters of a neural network,
represents the operation of the neural network,
is the error term, and
y is the target of a given task.
We use the joint network, which is based on the traditional network described above. Together, we use explicit and implicit knowledge to model the error term and then use it to guide the training process of the multipurpose network. The corresponding training Formula (2) is as follows:
where
and
are the arithmetic operations that model the explicit and implicit errors of the observation
x and latent code
z, respectively. n is a mission-specific operation for selectively integrating information from explicit and tacit knowledge. There are now some ways to incorporate explicit knowledge, so we can further write (2) into (3).
where ⨂ represents some possible operators that can combine
and
. When ⨂ represents a multiplication operator, if the subsequent layer is a convolutional layer, then use (4) for the integration. When ⨂ represents an addition operation, if the preceding layer is a convolutional layer and there is no activation function. In this case, use (5) for the integral operation.
3.2. NWD-Based Loss Function Improvement
The original YOLOv7 model employs the CIoU (Compatible Intersection on Union) bounding box loss function [
37], which aims to address the potential instability associated with typical IoU loss functions for bounding box regression by combining IoU with a distance factor. Despite its good performance in many target detection applications, CIoU loss still has certain shortcomings in tiny target recognition.
Due to the small size and few pixels of underwater targets, the distance and angle differences between their bounding boxes are relatively small, and a slight localization error can have a significant impact on the IoU, and the CIoU loss function may not be able to effectively distinguish the differences between their components. Therefore, the performance of CIoU in underwater target detection will be slightly insufficient.
To mitigate these issues, a Normalized Gaussian Wasserstein distance (NWD) [
38] is used instead of a loss function. The NWD is defined by the Wasserstein distance between two normal distributions, as shown in Equation (6) below. This equation serves as the mathematical definition of the NWD loss function.
where
Na,
Nb is the number of true frames in the neighborhood of each prediction frame, and the coefficient
is calculated as follows:
Furthermore, the relative significance of actual and predicted frame loss is determined by representing the height, width, and centroid coordinates of the two frames.
In terms of small object recognition, the NWD loss function is superior to the CIoU in the following ways:
Stability: The model is more stable since the NWD loss function explicitly accounts for the distribution variations, making it more resistant to modest item localization mistakes;
Feature sensitivity: By better capturing the distinctive characteristics of small items, the NWD loss function raises the model’s accuracy in identifying small objects;
Global Consideration: The model can better comprehend the relationship between small things and other objects in the image because the NWD loss function considers the global information of every object in the picture.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}