
Evidential-Reasoning-Type Multi-Attribute Large Group Decision-Making Method Based on Public Satisfaction

1
School of Accounting, Hunan University of Finance and Economics, Changsha 410205, China
2
School of Mathematics and Statistics, Hunan First Normal University, Changsha 410205, China
3
Business School, Guangdong University of Foreign Studies, Guangzhou 510420, China
4
School of Business Administration, Hunan University of Finance and Economics, Changsha 410205, China
*
Author to whom correspondence should be addressed.
Axioms 2024, 13(4), 276; https://doi.org/10.3390/axioms13040276
Submission received: 17 February 2024
/
Revised: 25 March 2024
/
Accepted: 9 April 2024
/
Published: 20 April 2024
(This article belongs to the Special Issue Decision-Making Modeling and Optimization)
Abstract
:To address public participation-oriented, large group decision-making problems with uncertain attribute weights, we propose a multi-attribute decision-making method considering public satisfaction. Firstly, a large group is organized to provide their opinions in the form of linguistic variables. Public opinions can be categorized into two types based on their content: one reflects the effectiveness of an alternative implementation and the other reflects the public expectations. Secondly, the two types of public opinions are sorted separately by linguistic variables. The evaluation of alternatives and the evaluation of expectations in different attributes are determined, both of which are expressed in the form of linguistic distributions. These two evaluations are then compared to determine the public satisfaction of the attributes in different alternatives. Thirdly, based on the deviation of public satisfaction in different attributes, a weight optimization model is constructed to determine the attribute weights. Fourthly, leveraging the interval credibility of attribute satisfaction for various alternatives, an evidential reasoning non-linear optimization model is established to obtain the comprehensive utility evaluation value for each alternative, which is used for ranking. Finally, a numerical example is employed to validate the feasibility and effectiveness of the proposed approach. According to the results of the numerical example, it can be concluded that the proposed approach can be effectively applied to large group decision-making problems that consider public satisfaction. Based on the comparison of methods, the proposed approach has certain advantages in reflecting public opinions and setting reference points, which can ensure the reliability of the decision results.
MSC:
90B501. Introduction
In production and daily life, various decisions, such as the construction of livelihood projects, governance of the community environment, and the establishment of settlement policies, are related to public welfare. These decisions are widely influential and socially significant. The occurrence of a decision-making error can have critical consequences, potentially triggering a series of social issues [1,2]. The public is the primary stakeholder affected by these decisions. Therefore, the extent to which their expectations and demands are considered in the decision-making process, and their subsequent satisfaction with these decisions directly determine the success or failure of such decision-making activities. Some typical cases, such as the Flint water contamination crisis in the United States [3], the sewage treatment of Fukushima nuclear power plant in Japan [4], and the Manila bay reclamation project [5], have all encountered widespread opposition and scrutiny from the public before implementation. However, relevant departments failed to incorporate public opinions to revise and improve the established plan, resulting in severe damage to the ecological environment and the plan posing serious threats to public safety and living environments. Consequently, the government’s credibility has also been called into question. This highlights the need for extensively soliciting public opinions and making decisions based on public satisfaction, making it an indispensable task for this type of decision-making.
Public satisfaction primarily hinges on whether the public’s expectations and demands are met during the formulation or implementation of plans. To comprehensively gauge public opinions and assess satisfaction levels, a significant portion of the public is typically invited to participate in decision-making processes. The extensive involvement of the public has the characteristics of large group decision-making [6,7,8,9]. Conventionally, large groups engaged in decision-making activities range from 20 to 100 people. In contrast, for decisions related to livelihoods, the group size is in the thousands or tens of thousands. This stark contrast amplifies the complexity of the decision-making process compared to conventional large group decision-making scenarios. In addition to the abundance of information, strong subjectivity and a high degree of dispersion are typical characteristics of public opinion. To accommodate the subjective expression of the public’s needs, it is crucial to choose a reasonable method for expressing public opinions. According to the existing literature, linguistic evaluation possesses characteristics such as easy operation, strong flexibility, and the ability to reflect subjective opinions, making it a common choice for expressing public opinions [10,11]. The high dispersion of public opinion primarily stems from differences between individuals, including variations in knowledge background, level of attention, and degree of interest. Consequently, opinion information provided by different individuals tends to be noticeably diverse. To effectively measure public satisfaction, it is necessary to determine two types of evaluation based on public opinions: one is the alternative evaluation of implementation effects, and the other is the public expectation evaluation. Therefore, the key to achieving an effective identification of these two types of evaluation information lies in sorting and analyzing large-scale public opinions to understand their distribution.
The evaluation of alternatives primarily reflects the public’s genuine sentiments regarding the implementation effects of each alternative. Due to the complexity of livelihood decision-making problems, multiple attributes are usually set to describe the implementation effects of alternatives from various perspectives, which also causes this type of decision-making problem to be characterized by multi-attribute decision-making [12,13]. Introducing public satisfaction into multi-attribute decision-making activities is crucial because it serves as an important judgment basis and standard. Existing literature on public satisfaction primarily focuses on the mechanisms [14], assessment [15], identification of influencing factors [16] and enhancement strategies of public satisfaction [17], with relatively few studies on its application in multi-attribute decisions. In the study of multi-attribute decision-making methods, while current multi-attribute decision-making methods are relatively mature, such as the prospect theory [18], VlseKriterijumska Optimizacija I Kompromisno Resenje (VIKOR) method [19], Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) method [20], and Tomada de Decisão Interativa Multicritério (TODIM) method [21], few methods explicitly incorporate public satisfaction. Further exploration is needed to discuss how to integrate public satisfaction with multi-attribute decision-making methods to meet the actual needs of livelihood decision-making.
Public expectation is the reference point for measuring public satisfaction. In the existing research, reference points of decision-making problems are selected based on the actual context of these problems and the expected goals of each alternative, for instance, selecting the dynamic decision reference points considering the evolution of public opinion [22,23], establishing multiple reference points for decisions [24,25], and setting reference points based on statistical methods [26]. When setting the reference points for decision-making based on public expectations, it is essential to consider both the actual situation of the decision-making problem and ensure that the reference points accurately reflect the public’s genuine expectations.
To ensure successful alternative implementation, maintaining public satisfaction with each attribute of the alternatives is crucial. Consequently, it is necessary to establish the public satisfaction eligibility standards for each attribute. This standardization makes each attribute present the characteristics of grade evaluation, necessitating consideration of grade evaluation requirements and characteristics when selecting decision-making methods. The evidential reasoning method, which is grounded in graded reliability, has been widely implemented in various complex multi-attribute decision-making problems [27,28]. This method ranks the alternatives by integrating the reliability of alternatives under different grades, so integrating the graded reliability of alternatives with public satisfaction is crucial to ensure its applicability in livelihood decision-making problems.
Based on the above analysis, combined with the actual characteristics of livelihood decision-making matters, this study introduces public satisfaction into decision-making activities and proposes an evidential-reasoning-type large group multi-attribute decision-making method based on public satisfaction. This study is structured as follows: Section 2 is the preliminaries, which mainly provides the description of the linguistic approach, Section 3 describes the principles of the proposed method, Section 4 validates the feasibility of the proposed method using a numerical example, Section 5 presents the sensitivity analysis and method comparison to verify the effectiveness of the proposed method, and Section 6 concludes the study.
2. Preliminaries
The linguistic approach is an estimation method that represents qualitative aspects as linguistic values by linguistic variables [29,30]. Suppose that is a finite and totally ordered discrete term set, where is the linguistic variable, is the linguistic level, and is the scaling coefficient such that [29,30].
For example, let , a set of seven terms could be
In these cases, the following conditions are usually required [31]:
- (1)
- The set is ordered: if ;
- (2)
- Max operator: if ;
- (3)
- Min operator: if .
3. Methodology
3.1. Problem Description
For a livelihood decision-making problem, suppose that the set of alternatives is , attribute set is , attribute weights are , where and attribute weights are partially known, is the weight of attribute , . Furthermore, assume public individuals are organized to evaluate the performance of attribute in alternative using linguistic variables, , public individuals are organized to provide their expectations for attribute in the form of linguistic variables, the set of linguistic variables used in performance evaluations and public expectations are . Experts are invited to provide the public satisfaction eligibility standard for attribute . The eligibility standard of public satisfaction provided by the expert for attribute is denoted as , whose value is expressed as a crisp number and . Public and expert opinions can be obtained through questionnaires, on-site interviews, or online voting, etc. We address the problem of obtaining the attribute satisfaction for various alternatives based on the above information. Consequently, we construct an evidential reasoning model based on public satisfaction to determine the optimal alternative.
3.2. Satisfaction Measurement Based on Public Opinions
- (1)
- We determine the linguistic distribution of attribute values for each alternative. We know that the number of the public participants in the performance evaluation of attribute over alternative is ; hence, linguistic variables form the set . The number of linguistic variable in is , , , where , and . Suppose the importance of performance evaluation performed by each public individual for various alternatives is equal. Thus, the public evaluation of is classified and quantified based on linguistic variables, and the linguistic distribution evaluation of attribute in alternative is obtained as follows:
- (2)
- We determine the linguistic distribution of public expectations. The number of public individuals providing expectations for attribute is ; hence, linguistic variables form the set . The number of linguistic variables in is , i.e., if the evaluation value of the attribute in alternative is not less than , then public individuals are satisfied with the performance of attribute in alternative . Contrastingly, public individuals are unsatisfied with the performance of attribute in alternative . Suppose that the importance of the expectations provided by each public individual is equal. Therefore, the public expectation in is classified and counted based on linguistic variables, and the linguistic distribution of the public expectation of attribute is obtained as follows:
- (3)
- We measure the attribute satisfaction of each alternative. According to the comparative relationship between the attribute evaluation of alternative and public expectation , the public satisfaction of attribute in alternative is determined as shown in Equation (3):
3.3. Determination of Attribute Weights
Suppose the attribute weights are partially known with the following specific representation [32]: (1) Weak ranking: ; (2) Strict ranking: , ; (3) Discrimination degree ranking: , ; (4) Multiple ranking: and ; (5) Interval form: and . The partially known attribute weights are used to formulate the constraint condition .
The attribute weights are determined based on the deviation of public satisfaction. Specifically, the satisfaction deviation of attribute in alternative is calculated as shown in Equation (4).
where, . For attribute , the larger the value of , the greater the satisfaction deviation degree of .
The deviation value of all alternatives with respect to attribute is calculated using Equation (5).
where, . For attribute , the larger the value of , the greater the satisfaction deviation degree over all alternatives.
According to Equations (4) and (5), it can be seen that the higher the level of satisfaction deviation over attribute , the greater the differentiation of satisfaction over all alternatives in attribute , so a larger weight of the attribute should be given to improve the differentiation of the decision results. Based on the above analysis, combined with the attribute weight constraints, an optimization model is constructed to solve the attribute weights, as shown in the model (6).
3.4. Construction of the Evidential Reasoning Model Based on Public Satisfaction
- (1)
- Division of attribute evaluation grades
In order to ensure the effective implementation of alternatives, a public satisfaction eligibility standard must be established for each attribute. As different attributes correspond to different eligibility standards of satisfaction, to guarantee the effectiveness of the eligibility standard division for each attribute’s satisfaction, the experts are enlisted to provide evaluations for the public satisfaction eligibility standard. Based on the public satisfaction eligibility standard provided by experts for each attribute, the “Eligibility” grade over each attribute is determined and the attribute evaluation grade is divided into the following three levels combined with the upper and lower limits of public satisfaction: “Worst”, “Eligibility”, “Best”. The value range of public satisfaction for each attribute is [0, 1]; the “Worst” and “Best” grade nodes of each attribute are set to = 0 and = 1, respectively. The eligibility standard of public satisfaction provided by experts for attribute form the set which is statistically analyzed and their average and variance are expressed by Equations (7) and (8), respectively.
To ensure its validity and rationality, the attribute “Eligibility” grade node is expressed as an interval based on the statistical analysis results of the values in , and let this interval over attribute be . To satisfy the grade classification standard of attribute evaluation without overlapping with the other two grade nodes, the values of and must adhere to the constraint . The expansion coefficient of the attribute “Eligibility” grade node is denoted as , where . The values of and are selected by combining with those of and , respectively, as follows:
where and are positive numbers approximately equal to 0 and 1, respectively, and we set and in this paper.
- (2)
- Reliability measurement of the attribute evaluation grade interval
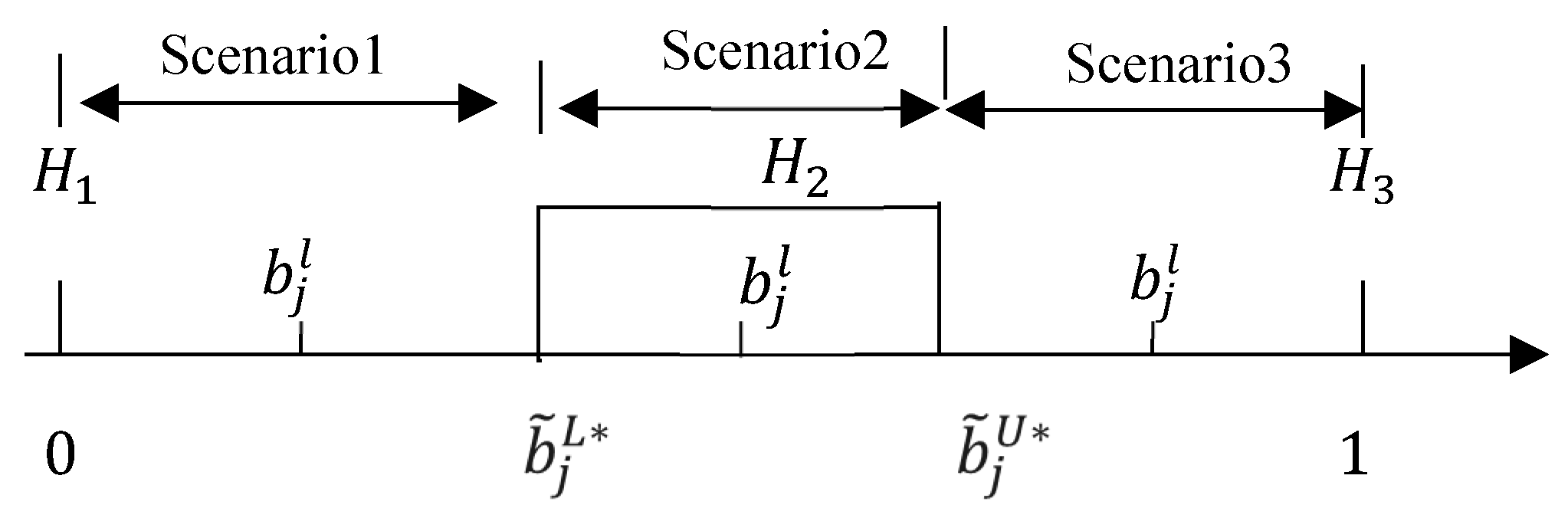
Figure 1 shows the scenarios of the relationship between public satisfaction and the three evaluation grades . The interval reliability of in each grade is set as , and the relationship between and each evaluation grade includes the following three scenarios:
Scenario 1: When lies between 0 and , the interval reliability conversion formulas for in each evaluation grade are as follows:
Scenario 2: When lies between and , the interval reliability conversion formulas for in each evaluation grade are as follows:
Scenario 3: When lies between and 1, the interval reliability conversion formulas for in each evaluation grade are as follows:
Due to the need of independent confidence structure, , and should satisfy the following normalization condition: [33].
3.5. Construction of Nonlinear Optimization Model Based on Evidence Reasoning
Based on the attribute weights and interval reliability of public satisfaction, the interval mass function is obtained as follows:
According to its value principle, the reliability structure is complete and yields [33].
The interval mass functions of attribute in alternative are fused with the evidence reasoning nonlinear optimization model (20), and the comprehensive interval reliability of each alternative is obtained at different grades. Here, and are the objective function values of the optimization model and the interval formed by them represents the possible degree of alternative at grade as follows: .
In summary, the specific steps of the proposed method are as follows:
Step 1: Equation (1) determines the attribute evaluations for different alternatives, which are expressed as linguistic distributions.
Step 2: Equation (2) determines the public expectations for different attributes, which are also expressed as linguistic distributions.
Step 3: Equation (3) determines the public satisfaction of the attribute for various alternatives.
Step 4: The model (6) is used to determine attribute weights.
Step 5: Equations (7)–(9) determines the “Eligibility” grade interval of each attribute, thereby classifying the attribute evaluation grades.
Step 6: Equations (10)–(18) determines the interval reliability of at different evaluation grades.
Step 7: The model (20) determines the overall interval reliability of each alternative at different grades.
Step 8: The utility values of the three grades are selected as follows: ; ; . Equation (21) yields the comprehensive utility values of various alternatives and determines their sorting results [33].
In Equation (21), and represent the maximum and minimum values of comprehensive utility values of alternative , respectively, as shown in Equations (22) and (23):
To determine the values of and , Equations (22) and (23) are taken into model (20) as the unique objective functions, and the two optimization models are solved, respectively, with the objectives of maximization and minimization, the value of and are obtained. According to the study presented in [33], the obtained alternative interval reliability is complete, therefore, .
4. Analysis of Numerical Example
A specific numerical example is introduced to validate the reliability of the proposed method. The background of the numerical example is as follows: A large-scale shed renovation project is commencing in an old town, and the relocation households are approximately 10,000. Based on the available local land resources and future urban development plans, four alternatives of resettlement are formed:
- Alternative 1 (): The resettlement community will be constructed 10 km north of the original address.
- Alternative 2 (): The resettlement community will be constructed 12 km south of the original address.
- Alternative 3 (): The resettlement community will be constructed 8 km east of the original address.
- Alternative 4 (): The resettlement community will be constructed 9 km west of the original address.
To comprehensively describe the effect of implementation for each alternative, the alternatives are evaluated based on the following four attributes: completeness of the supporting facilities (), degree of travel convenience (), quality of the living environment (), and satisfaction of the school district ().
Based on the various attributes, the public evaluates the performance of the alternative as linguistic variables. Depending on the complexity of the decision object and the characteristics of the decision scenario, the linguistic scale coefficient is set to 7. The correspondence between linguistic variables and natural language is described in Section 2. Five-thousand public individuals participate in attribute evaluation for each alternative, as shown in Table 1 (partial data are omitted owing to length constraints).
In order to obtain the expected values for each attribute, four-thousand people are invited to provide their expectations for the four attributes, and the public expectations are also represented as linguistic variables. In order to be consistent with the linguistic scale of performance evaluation above, the linguistic scale coefficient of public expectations is also set to 7, and the public expectation is shown in Table 2 (partial data are omitted owing to length constraints).
In order to obtain the eligibility standard for different attributes, one-hundred experts are invited to provide the eligibility standard of public satisfaction for each attribute, the evaluation value given by the expert is the crisp number in the interval [0, 1], and the evaluation value of experts is shown in Table 3 (partial data are omitted owing to length constraints).
The specific decision-making steps are as follows:
Step 1: Based on the data in Table 1, the linguistically distributed attribute evaluation value of various alternatives is determined by Equation (1), as shown in Table 4.
Step 2: Based on the data in Table 2, the linguistic distribution of public expectation for each attribute is determined by Equation (2), as shown in Table 5.
Step 3: Using the data in Table 4 and Table 5, the public satisfaction of attributes in different alternatives are determined by Equation (3), as shown in Table 6.
Step 4: The partially known attribute weights are as follows: ; ; ; ; . The model (6) is subjected to the attribute weight constrains to yield the following attribute weights: ; ; ; .
Step 5: Equations (7) and (8) determine the mean and variance of the eligibility standard for various attributes, as shown in Table 7.
The expansion coefficient of the “Eligibility” grade node is set as . Using the mean and variance in Table 7, Equation (9) determines the “Eligibility” grade node interval value of each attribute as follows: .
Step 6: Equations (10)–(18) determine the interval reliability of various grades for different alternatives, as shown in Table 8.
Step 7: Using the data in Table 8 for modeling, the model (20) determines the overall interval reliability of alternatives at different grades, as shown in Table 9.
Step 8: The final sorting result is based on the comprehensive utility value of each alternative obtained using Equations (21)–(23). The sorting result indicates that the third alternative is optimal.
5. Sensitivity Analysis and Method Comparison
5.1. Sensitivity Analysis
To investigate the influence of the “Eligibility” grade on the ranking results, the expansion coefficients of its grade node are selected as 0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0. Table 10 shows the corresponding “Eligibility” grade scale interval of each attribute and sorting results for various “Eligibility” grade scales.
Based on Table 10, the ranking results remain unchanged using different expansion coefficients of the “Eligibility” grade; hence, the decision results are real and reliable. The range of the “Eligibility” grade interval increases with the increasing expansion coefficient, whereas the differentiation degree of the comprehensive utility value gradually decreases. Therefore, to ensure the effectiveness of the alternative ranking, a suitable “Eligibility” grade interval expansion coefficient should be selected to divide the attribute grades.
5.2. Comparison of Methods
The prospect theory approach [34] and TOPSIS method [35] have been widely applied in various decision-making activities, both methods involve setting reference points to make decisions, which is similar to the method proposed in this paper. To further verify the effectiveness of the proposed method, we compare it with the prospect theory approach and TOPSIS method in the same numerical example.
Based on the example data, decision activities are performed in the following two decision-making situations: (i) decisions based on public evaluations that are expressed as linguistic distributions; (ii) decisions based on public satisfaction with the alternative expressed as crisp numbers. In (i), the prospect value of each alternative is estimated using the attribute expectation in the form of a linguistic distribution as the reference point. Furthermore, the TOPSIS value of each alternative is calculated using the upper and lower limits of the linguistic scale as the positive and negative ideal solutions of the attribute, respectively. In (ii), the prospect value of each alternative is calculated using the eligibility standard average of public satisfaction over each attribute provided by experts as the reference point. The TOPSIS value of each alternative is calculated using the upper and lower limits of public satisfaction as the positive and negative ideal solutions of attributes, respectively. Table 11 shows the decision results obtained using the aforementioned methods in two decision-making situations.
Table 11 indicates that the decision results obtained by the prospect theory and TOPSIS method in various situations are not completely consistent with those obtained using the proposed method. This is because the proposed method makes decisions based on public satisfaction, whereas the first situation is based on the evaluation value of the alternative. Decision-making situations, along with the decision-making outcomes, are different. Although the decision-making basis in the second situation is consistent with that in the proposed method, the reference point settings are different for different methods. The prospect theory considers the average value of the public satisfaction eligibility standard provided by experts as the attribute reference point, which is represented as a crisp number. TOPSIS considers the upper and lower limits of the public satisfaction for each attribute as the reference point, and these limits are also represented as crisp numbers. In the proposed method, based on the statistical analysis results, the eligibility grade node of public satisfaction over each attribute is determined as interval numbers. Because the reference points of the three methods differ in setting or expression, the decision-making results are also different.
Compared to the above two methods, the proposed method has the following advantages: (1) It obtains public satisfaction, which is considered as the decision-making basis, by comparing the alternative evaluation and public expectation in different attributes. These decision-making results can better reflect the public opinion. The public satisfaction of each attribute over the alternative is expressed as a crisp number. Compared to the evaluation value of the alternative expressed as linguistic distribution, the degree of information uncertainty is low, thereby reducing the complexity of subsequent decision-making activities. (2) When setting the reference point, the proposed method considers the eligibility standard of satisfaction as variability in different attributes. Simultaneously, the “Eligibility” grade nodes are set as interval numbers based on the distribution of the possible values of the eligibility standard of each attribute, ensuring scientific and effective grade division. In the decision-making situation based on public satisfaction, the reference point of the prospect theory is the average of the eligibility standards of each attribute provided by experts without considering the possible interval range of “ Eligibility “ grades. The reference point of the TOPSIS method is selected using the upper and lower limits of the public satisfaction value of each attribute without considering the eligibility standards and specific requirements of public satisfaction in different attributes. (3) Based on the classification of attribute evaluation grades, the proposed method combines public satisfaction with the evidential reasoning model and makes decisions based on the interval reliability of alternatives under different grades, thereby enhancing the reliability of the decision results.
6. Conclusions
This study investigated the decision-making activities of people concerning their livelihoods and proposed an evidential-reasoning-type large group decision-making method considering public satisfaction. The main contributions of this paper are as follows: (1) Enabling the public to express their opinions as linguistic variables satisfies the need for subjective expression. The alternative evaluation and expectation values in different attributes are determined based on public opinions and are organized into the form of a linguistic distribution. Compared to linguistic variables, the use of linguistic distribution provides a clearer and more intuitive representation, which reduces the impact of the size and discreteness of information on decision-making processes, facilitating the measurement of public satisfaction with attribute in different alternatives. (2) The public satisfactions with attributes in alternative are obtained by comparing the alternative evaluation value and expected value in each attribute. This satisfaction measurement method can effectively reduce the uncertainty in the degree of decision-making information, laying the groundwork for subsequent decision-making activities. (3) Based on the specific requirements of different attributes for the eligibility standard of public satisfaction in combination with the data characteristics of the eligibility standard provided by experts, the “Eligibility” grade is expressed as an interval number, ensuring scientific attribute evaluation level division. (4) An evidential reasoning model considering public satisfaction is constructed to determine the comprehensive utility evaluation value of each alternative. This process is based on the interval reliability of various grades for different alternatives to ensure accurate decision-making results. Practically, the decision-making environment of livelihood matters is not static. To ensure effective decision-making, multi-stage decisions should be made in accordance with the dynamic variations of the decision-making environment to determine the final outcomes. The proposed method, which is primarily aimed at single-stage decision-making issues concerning livelihoods, can be further extended and applied to such issues with dynamic multi-stage characteristics.
Author Contributions
Methodology, C.C., Y.W. and P.W.; Software, H.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (No. 11901186, No. 72101076), the Social Science Foundation of Hunan Province (No. 19YBQ113, No. 21YBQ107), the Scientific Research Foundation of Hunan Education Department (No. 23A0679, No. 22B0630) and the Natural Science Foundation of Hunan Province (No. 2021JJ41088, No. 2023JJ30109).
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wei, Q.; Zhou, C. A multi-criteria decision-making framework for electric vehicle supplier selection of government agencies and public bodies in China. Environ. Sci. Pollut. Res. 2023, 30, 10540–10559. [Google Scholar] [CrossRef] [PubMed]
- Yao, X.; He, J.; Bao, C. Public participation modes in China’s environmental impact assessment process: An analytical framework based on participation extent and conflict level. Environ. Impact Assess. Rev. 2020, 84, 106400. [Google Scholar] [CrossRef]
- Pieper, K.J.; Martin, R.; Tang, M.; Walters, L.; Parks, J.; Roy, S.; Devine, C.L.; Edwards, M.A. Evaluating water lead levels during the Flint water crisis. Environ. Sci. Technol. 2018, 52, 8124–8132. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Liu, Y.; Wu, X.; Chen, J. Assessment of the impact of Fukushima nuclear wastewater discharge on the global economy based on GTAP. Ocean. Coast. Manag. 2022, 228, 106296. [Google Scholar] [CrossRef]
- Rodolfo, K.S. On the geological hazards that threaten existing and proposed reclamations of Manila Bay. Philipp. Sci. Lett. 2014, 7, 228–240. [Google Scholar]
- Gai, T.; Cao, M.; Chiclana, F.; Zhang, Z.; Dong, Y.; Herrera-Viedma, E.; Wu, J. Consensus-trust driven bidirectional feedback mechanism for improving consensus in social network large-group decision making. Group Decis. Negot. 2023, 32, 45–74. [Google Scholar] [CrossRef]
- Du, Z.; Yu, S.; Cai, C. Constrained Community Detection and Multistage Multicost Consensus in Social Network Large-Scale Decision-Making. IEEE Trans. Comput. Soc. Syst. 2023, 16, 997–1012. [Google Scholar] [CrossRef]
- Du, Z.; Luo, H.; Lin, X.; Yu, S. A trust-similarity analysis-based clustering method for large-scale group decision-making under a social network. Inf. Fusion 2020, 63, 13–29. [Google Scholar] [CrossRef]
- Du, Z.; Yu, S.; Wang, J.; Luo, H.; Lin, X. A comprehensive loss analysis-based decision support method for e-democratic multi-agent cooperative decision-making. Expert Syst. Appl. 2024, 238, 122040. [Google Scholar] [CrossRef]
- Zhu, G.; Cai, C.; Pan, B.; Wang, P. A multi-agent linguistic-style large group decision-making method considering public expectations. Int. J. Comput. Intell. Syst. 2021, 14, 188. [Google Scholar] [CrossRef]
- Liu, Y.; Wei, G.; Liu, H.; Xu, L. Group decision making for internet public opinion emergency based upon linguistic intuitionistic fuzzy information. Int. J. Mach. Learn. Cybern. 2022, 13, 579–594. [Google Scholar] [CrossRef]
- Lin, S.H.; Huang, X.; Fu, G.; Chen, J.T.; Zhao, X.; Li, J.H.; Tzeng, G.H. Evaluating the sustainability of urban renewal projects based on a model of hybrid multiple-attribute decision-making. Land Use Policy 2021, 108, 105570. [Google Scholar] [CrossRef]
- Yamagishi, K.D.; Abellana, D.P.M.; Tanaid, R.A.B.; Tiu, A.M.C.; Selerio, E.F., Jr.; Medalla, M.E.F.; Ocampo, L.A. Destination planning of small islands with integrated multi-attribute decision-making (MADM) method. Tour. Plan. Dev. 2023, 20, 1019–1053. [Google Scholar] [CrossRef]
- Li, H.; Lv, L.; Zuo, J.; Bartsch, K.; Wang, L.; Xia, Q. Determinants of public satisfaction with an urban water environment treatment PPP project in Xuchang, China. Sustain. Cities Soc. 2020, 60, 102244. [Google Scholar] [CrossRef]
- Inturri, G.; Giuffrida, N.; Le Pira, M.; Ignaccolo, M. Linking public transport user satisfaction with service accessibility for sustainable mobility planning. ISPRS Int. J. Geo-Inf. 2021, 10, 235. [Google Scholar] [CrossRef]
- Chen, W.; Shi, Y.; Fan, L.; Huang, L.; Gao, J. Influencing factors of public satisfaction with COVID-19 prevention services based on structural equation modeling (Sem): A study of Nanjing, China. Int. J. Environ. Res. Public Health 2021, 18, 13281. [Google Scholar] [CrossRef] [PubMed]
- Vishkaei, B.M.; Fathi, M.; Khakifirooz, M.; De Giovanni, P. Bi-objective optimization for customers’ satisfaction improvement in a Public Bicycle Sharing System. Comput. Ind. Eng. 2021, 161, 107587. [Google Scholar] [CrossRef]
- Ruggeri, K.; Alí, S.; Berge, M.L.; Bertoldo, G.; Bjørndal, L.D.; Cortijos-Bernabeu, A.; Davison, C.; Demić, E.; Esteban-Serna, C.; Friedemann, M.; et al. Replicating patterns of prospect theory for decision under risk. Nat. Hum. Behav. 2020, 4, 622–633. [Google Scholar] [CrossRef]
- Gul, M.; Ak, M.F.; Guneri, A.F. Pythagorean fuzzy VIKOR-based approach for safety risk assessment in mine industry. J. Saf. Res. 2019, 69, 135–153. [Google Scholar] [CrossRef]
- Solangi, Y.A.; Longsheng, C.; Shah, S.A.A. Assessing and overcoming the renewable energy barriers for sustainable development in Pakistan: An integrated AHP and fuzzy TOPSIS approach. Renew. Energy 2021, 173, 209–222. [Google Scholar] [CrossRef]
- Liu, P.; Teng, F. Probabilistic linguistic TODIM method for selecting products through online product reviews. Inf. Sci. 2019, 485, 441–455. [Google Scholar] [CrossRef]
- Cheng, F.; Zhang, Q.; Tian, Y.; Zhang, X. Maximizing receiver operating characteristics convex hull via dynamic reference point-based multi-objective evolutionary algorithm. Appl. Soft Comput. 2020, 86, 105896. [Google Scholar] [CrossRef]
- Gao, J.; Xu, Z.S.; Liao, H.C. A dynamic reference point method for emergency response under hesitant probabilistic fuzzy environment. Int. J. Fuzzy Syst. 2017, 19, 1261–1278. [Google Scholar] [CrossRef]
- Nguyen, B.H.; Xue, B.; Andreae, P.; Ishibuchi, H.; Zhang, M. Multiple reference points-based decomposition for multi objective feature selection in classification: Static and dynamic mechanisms. IEEE Trans. Evol. Comput. 2019, 24, 170–184. [Google Scholar] [CrossRef]
- Zhu, J.J.; Ma, Z.Z.; Wang, H.H.; Chen, Y. Risk decision-making method using interval numbers and its application based on the prospect value with multiple reference points. Inf. Sci. 2017, 12, 385–386. [Google Scholar] [CrossRef]
- Rabbani, M.; Foroozesh, N.; Mousavi, S.M.; Farrokhi-Asl, H. Sustainable supplier selection by a new decision model based on interval-valued fuzzy sets and possibilistic statistical reference point systems under uncertainty. Int. J. Syst. Sci. Oper. Logist. 2019, 6, 162–178. [Google Scholar] [CrossRef]
- Fu, C.; Yang, J.B.; Yang, S.L. A group evidential reasoning approach based on expert reliability. Eur. J. Oper. Res. 2015, 246, 886–893. [Google Scholar] [CrossRef]
- Liu, Z.G.; Pan, Q.; Dezert, J.; Martin, A. Combination of classifiers with optimal weight based on evidential reasoning. IEEE Trans. Fuzzy Syst. 2017, 26, 1217–1230. [Google Scholar] [CrossRef]
- Xu, Z.S. Uncertain linguistic aggregation operators based approach to multiple attribute group decision making under uncertain linguistic environment. Inf. Sci. 2004, 168, 171–184. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E.; Verdegay, J.L. A sequential selection process in group decision making with a linguistic assessment approach. Inf. Sci. 1995, 85, 223–239. [Google Scholar] [CrossRef]
- Park, K.S. Mathematical programming models for characterizing dominance and potential optimality when multicriteria alternative values and weights are simultaneously incomplete. IEEE Trans. Syst. Man Cybern.-Part A Syst. Hum. 2004, 34, 601–614. [Google Scholar] [CrossRef]
- Wang, Y.M.; Yang, J.B.; Xu, D.L.; Chin, K.-S. The evidential reasoning approach for multiple attribute decision analysis using interval belief degrees. Eur. J. Oper. Res. 2006, 175, 35–66. [Google Scholar] [CrossRef]
- Gao, K.; Sun, L.; Yang, Y.; Meng, F.; Qu, X. Cumulative prospect theory coupled with multi-attribute decision making for modeling travel behavior. Transp. Res. Part A Policy Pract. 2021, 148, 1–21. [Google Scholar] [CrossRef]
- Rafiei-Sardooi, E.; Azareh, A.; Choubin, B.; Mosavi, A.H.; Clague, J.J. Evaluating urban flood risk using hybrid method of TOPSIS and machine learning. Int. J. Disaster Risk Reduct. 2021, 66, 102614. [Google Scholar] [CrossRef]
Figure 1.
Relationship between public satisfaction and various evaluation grades.


{kind=link}
Table 1.
Public attribute evaluation of various alternatives.
| No. | No. | ||||||||||
| 1 | 1 | 2 | 1 | ||||||||
| 2 | 2 | ||||||||||
| … | … | … | … | … | … | … | … | … | … | ||
| 4999 | 4999 | ||||||||||
| 5000 | 5000 | ||||||||||
| No. | No. | ||||||||||
| 3 | 1 | 4 | 1 | ||||||||
| 2 | 2 | ||||||||||
| … | … | … | … | … | … | … | … | … | … | ||
| 4999 | 4999 | ||||||||||
| 5000 | 5000 |
Table 2.
Public expectations for different attributes.
| No. | ||||
|---|---|---|---|---|
| 1 | ||||
| 2 | ||||
| … | … | … | … | … |
| 3999 | ||||
| 4000 |
Table 3.
Eligibility standard for attribute satisfaction given by experts.
| Eligibility Standard for Attribute Satisfaction | |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 |
Table 4.
Linguistically distributed attribute evaluation values of various alternatives.
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 |
Table 5.
Linguistic distribution of public expectations for different attributes.
Table 6.
Public satisfaction of attributes in different alternatives.
| 1 | 0.7652 | 0.8608 | 0.6207 | 0.7198 |
| 2 | 0.4919 | 0.9701 | 0.5144 | 0.8659 |
| 3 | 0.5203 | 0.9654 | 0.9184 | 0.8632 |
| 4 | 0.5161 | 0.6271 | 0.9204 | 0.6908 |
Table 7.
Statistical analysis of the eligibility standard for attribute satisfaction.
| Mean | Variance | |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 |
Table 8.
Interval reliability of various grades for different alternatives.
| H1 | H2 | H3 | H1 | H2 | H3 | |
| 1 | [0.0000, 0.0000] | [0.5904, 0.7582] | [0.2418, 0.4096] | [0.0000, 0.0000] | [0.3453, 0.4411] | [0.5589, 0.6547] |
| 2 | [0.1833, 0.2874] | [0.7126, 0.8167] | [0.0000, 0.0000] | [0.0000, 0.0000] | [0.0742, 0.0947] | [0.9053, 0.9258] |
| 3 | [0.1361, 0.2463] | [0.7537, 0.8639] | [0.0000, 0.0000] | [0.0000, 0.0000] | [0.0858, 0.1096] | [0.8904, 0.9142] |
| 4 | [0.1431, 0.2524] | [0.7476, 0.8569] | [0.0000, 0.0000] | [0.0000, 0.0837] | [0.9163, 1.0000] | [0.0000, 0.0749] |
| H1 | H2 | H3 | H1 | H2 | H3 | |
| 1 | [0.0000, 0.1007] | [0.8993, 1.0000] | [0.0000, 0.0412] | [0.0000, 0.0000] | [0.7108, 0.8890] | [0.1110, 0.2892] |
| 2 | [0.1489, 0.2547] | [0.7453, 0.8511] | [0.0000, 0.0000] | [0.0000, 0.0000] | [0.3402, 0.4254] | [0.5746, 0.6598] |
| 3 | [0.0000, 0.0000] | [0.2063, 0.2634] | [0.7366, 0.7937] | [0.0000, 0.0000] | [0.3470, 0.4340] | [0.5660, 0.6530] |
| 4 | [0.0000, 0.0000] | [0.2012, 0.2569] | [0.7431, 0.7988] | [0.0000, 0.0000] | [0.7844, 0.9810] | [0.0190, 0.2156] |
Table 9.
Sorting results of the alternatives.
| Grade | Comprehensive Utility Value | Alternative Sort | |||
|---|---|---|---|---|---|
| H1 | H2 | H3 | |||
| 1 | [0.0000, 0.0196] | [0.6802, 0.8263] | [0.1737, 0.3083] | 0.6160 | 3 |
| 2 | [0.0609, 0.1039] | [0.4634, 0.5515] | [0.3877, 0.4327] | 0.6640 | 2 |
| 3 | [0.0202, 0.0372] | [0.2992, 0.3755] | [0.6041, 0.6640] | 0.8028 | 1 |
| 4 | [0.0200, 0.0550] | [0.7141, 0.8360] | [0.1441, 0.2468] | 0.5793 | 4 |
Table 10.
Ranking results for various “Eligibility” grades.
| Expansion Coefficient | Interval Scale of “Eligibility” Grade | Composite Utility Value | Sorting Results |
|---|---|---|---|
| 0 | |||
| 0.5 | |||
| 1.0 | |||
| 1.5 | |||
| 2.0 | |||
| 2.5 | |||
| 3.0 |
Table 11.
Result comparison of different methods.
| Decision Situations | Decision Methods | Evaluation Value of Alternative | Sorting Results | |||
|---|---|---|---|---|---|---|
| Decision based on the public evaluation | prospect theory | 0.3951 | 0.2729 | 0.8956 | 0.3032 | |
| TOPSIS | 0.6566 | 0.6917 | 0.7695 | 0.6622 | ||
| Decision based on the alternative public satisfaction | prospect theory | 0.1041 | −0.0088 | 0.1780 | 0.0119 | |
| TOPSIS | 0.7394 | 0.7293 | 0.8340 | 0.6973 | ||
| The method proposed in this paper | 0.6160 | 0.6640 | 0.8028 | 0.5793 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cai, C.; Wang, Y.; Wang, P.; Zou, H. Evidential-Reasoning-Type Multi-Attribute Large Group Decision-Making Method Based on Public Satisfaction. Axioms 2024, 13, 276. https://doi.org/10.3390/axioms13040276
AMA Style
Cai C, Wang Y, Wang P, Zou H. Evidential-Reasoning-Type Multi-Attribute Large Group Decision-Making Method Based on Public Satisfaction. Axioms. 2024; 13(4):276. https://doi.org/10.3390/axioms13040276
Chicago/Turabian StyleCai, Chenguang, Yuejiao Wang, Pei Wang, and Hao Zou. 2024. "Evidential-Reasoning-Type Multi-Attribute Large Group Decision-Making Method Based on Public Satisfaction" Axioms 13, no. 4: 276. https://doi.org/10.3390/axioms13040276
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.