
Estimation of Gumbel Distribution Based on Ordered Maximum Ranked Set Sampling with Unequal Samples

1
Department of Applied Statistics and Econometric, Faculty of Graduate Studies for Statistical Research, Cairo University, Cairo 12513, Egypt
2
Department of Basic Science, Faculty of Engineering, Modern Academy, Cairo 12513, Egypt
3
Department of Statistics, Faculty of Science, University of Tabuk, Tabuk 71491, Saudi Arabia
*
Author to whom correspondence should be addressed.
Axioms 2024, 13(4), 279; https://doi.org/10.3390/axioms13040279
Submission received: 2 February 2024
/
Revised: 21 March 2024
/
Accepted: 30 March 2024
/
Published: 22 April 2024
Abstract
:Sample selection is one of the most important factors in estimating the unknown parameters of distributions, as it saves time, saves effort, and gives the best results. One of the challenges is deciding on a suitable distribution estimate technique and adequate sample selection to provide the best results in comparison with earlier research. The method of moments (MOM) was decided on to estimate the unknown parameters of the Gumbel distribution, but with four changes in the sample selection, which were simple random sample (SRS), ranked set sampling (RSS), maximum ranked set sampling (MRSS), and ordered maximum ranked set sampling (OMRSS) techniques, due to small sample sizes. The MOM is a traditional method for estimation, but it is difficult to use when dealing with RSS modification. RSS modification techniques were used to improve the efficiency of the estimators based on a small sample size compared with the usual SRS estimator. A Monte Carlo simulation study was carried out to compare the estimates based on different sampling. Finally, two datasets were used to demonstrate the adaptability of the Gumbel distribution based on the different sampling techniques.
Keywords:
method of moments; general moments function; ranked set sampling; maximum ranked set sampling; ordered maximum ranked set samplingMSC:
62F10; 62D051. Introduction
McIntyre [1] initially offered the idea of using ranked set sampling (RSS) to estimate average pasture and forage yields, and subsequent discussions by Takahasi and Wakimoto [2] elaborated on this strategy. Recently, it has been used for issues in domains including environmental research, reliability engineering, and quality assurance when measuring the variable of interest might be prohibitively costly. When compared with simple random sampling (SRS), RSS may increase the efficiency and accuracy while decreasing costs. For instance, Lavine [3] investigated a comparison of RSS and SRS within a Bayesian framework. The literature has grown considerably in recent years, with most of it being summed up within a monograph by Chen et al. [4]. The RSS scheme can be described as follows: First, select an SRS of n sets of size n from the target population. Second, select the element of rank i from the ith set in a cycle for . The process can be repeated m times to obtain an RSS sample of size . Let be an SRS sample from a distribution with a cumulative distribution function (CDF) and the probability density function (PDF) . Let ; …, be independent random variables, where denotes the ith order statistic from the ith sample of size n, where , and the jth cycle of size m, where . Then, the PDF of is given by the following (see Esemen and Grler [5]):
McIntyre’s technique was first used by Halls and Dell [6]. Experimentally, they found that RSS is more effective than SRS. They also indicate the name of the classified sampling set currently in use. Al-Saleh and Al-Hadrami [7] used different set sizes for the RSS technique to estimate the mean of the normal and exponential distributions, and they found that this technique is more useful than SRS for estimating the mean of symmetric distributions. Khamnei and Mayan [8] estimated the parameters of the Gumbel distribution based on SRS and RSS when they compared the estimators of these two methods. Esemen and Gürler [5] estimated the parameters of the generalized Rayleigh distribution based on RSS and some of its modifications. Hassan et al. [9] estimated the parameters of the gamma/Gompertz distribution based on four types of RSS and SRS. It should be noted that do not necessarily follow a specific order. Balakrishnan and Li [10] discussed RSS by rearranging all in an ascending order, which is known as ordered ranked set sampling (ORSS). Stokes [11] proposed a variant of the ranked set sampling process called extreme ranked set sampling (ERSS), in which only the highest- or lowest-ranked evaluating unit is selected for measurement. As a variant of ERSS, Chacko [12] implemented an ordered extreme ranked set sampling (OERSS) by sorting the ERSS’s components by increasing magnitude. Using the MRSS with the unequal samples method, Eskandarzadeh et al. [13] investigated information metrics. After that, Basikhasteh et al. [14] discussed the OMRSS with unequal samples and some associated statistical properties. [15] estimated the mean of the exponential distribution using MRSS with unequal samples.
To statistically model extreme values, the two-parameter Gumbel distribution (GumD), also known as the type-I extreme value distribution, has been widely used in a variety of research fields, including life testing, water management, and hydrology (see Lambert and Duan [16]), and see Johnson et al. [17] to find more applications of this distribution. The PDF and CDF of the GumD distribution are defined as
and
where and are the shape and scale parameters, respectively. It is commonly applied to modeling a wide range of extreme data from the engineering, actuarial, and environmental sciences. Furthermore, the Gumbel distribution can be used in applications of hydrology and meteorological data. The generalized extreme value distribution’s limit distribution is known as the Gumbel distribution. In actuality, the Gumbel distribution is a limit form that transitions between the inverse Weibull and Fréchet distributions. Moreover, an inverse Weibull random variable’s logarithmic transformation may be used to create a Gumbel random variable. Due to having such statistical properties, the Gumbel di stribution has gained a lot of attention. For instance, one may refer to Simiu et al. [18], Kang et al. [19], Anderson and Daniewicz [20], and Dutta et al. [21].
In recent years, the estimation of parameters of different distributions based on RSS has gained a lot of attention. For instance, Hussian [22] discussed the estimation of parameters of the Kumaraswammy distribution based on RSS. Sadek et al. [23] considered the Bayesian estimation of the parameters for an exponential distribution under RSS. Joukar et al. [24] obtained an estimation of parameters for the exponential Poisson distribution based on RSS. Pedroso et al. [25] discussed parameter estimation for the Birnbaum–Saunders distribution based on RSS. Biradar [26] discussed the estimation of the parameters of the location scale family of distributions based on RSS with unequal sample sizes.
To the best of our knowledge, the estimation of parameters based on OMRSS with unequal samples has not been studied yet in the statistical literature. Motivated by the existing literature, parameter estimation for the GumD based on OMRSSU is proposed in this article. In this article, the performance of the MRSS method is compared with the other sampling techniques using MOM estimation with the SRS technique for the GumD parameters. The remaining parts of this article are structured as follows: Section 2 presents the sampling methods. MOM estimation is discussed in Section 3 for the sampling techniques. In Section 4, the Monte Carlo simulation results are presented to compare the efficiency of the SRS-based estimators with their counterparts RSS, MRSS, and OMRSS in terms of the mean squared error. In Section 5, results are given for two real datasets for illustrative purposes. Finally, Section 6 draws some concluding remarks.
2. Some Ranked Set Sampling Techniques
In this section, different sampling techniques for unit selection based on RSS, MRSS, and OMRSS and the associated PDF of a distribution are discussed.
2.1. Maximum Ranked Set Sampling
Eskandarzadeh et al. [13] modified RSS into maximum ranked set sampling (MRSS). This strategy was found to be effective and can generate a more effective estimator compared with traditional RSS by reducing the sample of traditional RSS by half. The MRSS procedure can be described as follows: First, identify n sets from SRS such that the size of the ith set is i for . Second, measure the maximum observation from each set by calculating the maximum statistical measure for units. Finally, obtain an MRSS of size by repeating the previous steps m times. The PDF of that gives the maximum observation by MRSS is given by
for changeable i, which takes the value of the set, where .
2.2. Ordered Maximum Ranked Set Sampling
Basikhasteh et al. [14] created a variant of MRSS known as OMRSS. This technique was demonstrated to be a more effective estimator compared with MRSS. The OMRSS technique can be described as follows. First, identify n sets from SRS such that the size of the ith set is i for . Second, measure the maximum observation from each set. Third, sort the maximum observation from the sets in ascending order of magnitude. Finally, obtain an OMRSS of size by repeating the previous steps m times.
The PDF of that is ranked by OMRSS for is given by
where denotes the summation over all permutations for , for which and ; denotes the summation over all permutations of , for which and ; denotes all permutations for ; and when u is between and n, d is between 0 and .
3. Method of Moments
In this section, the moments of the GumD are found based on SRS, RSS, MRSS, and OMRSS using the general moments function . is a function that can be differentiated r times. When we want to integrate to find the usual moments using sampling techniques, the GumD requires a complicated mathematical process. This challenging situation is made simple and feasible by . The relationship between and the MOM is
3.1. Estimation Based on SRS
Mahdi and Cenac [27] obtained an estimation of the unknown parameters of the GumD using the MOM based on the SRS technique. Also, Choi [28] discussed the estimation of the parameters of the GumD using the SRS-based MOM based on . Let be used as an independent random sample of the GumD distribution using PDF, which is given in (2).
Lemma 1.
The rth moments using based on SRS are calculated using
Proof.
Using the for SRS:
Let , then when and . The will be
Hence,
□
After computation and simplification, in the particular cases of and , we obtain
and
where is called the Euler–Mascheroni constant and (see Mahdi and Cenac [27]) using the polygamma function = , where = .
Equations (6) and (7) for finding and were obtained from SRS. To obtain the MOM estimators and , we have to numerically solve the following:
3.2. Estimation Based on RSS
In this subsection, we substitute (2) and (3) into (1) to obtain MOM estimators for the GumD according to the RSS scheme. Let be independent random variables. It is said that represents the th-order statistic from the th sample of size n, where .
Lemma 2.
The rth moments using based on RSS are obtained using
Proof.
The for RSS is
where . By using the same substitution in SRS, i.e., , the will be . Using the binomial expansion for , we obtain . Here,
Hence,
□
3.3. Estimation Based on MRSS
To obtain MOM estimators for the GumD using the MRSS scheme, we substitute (2) and (3) into (4) in this subsection. Let be independent random variables of n sets from X for . In this case, is the for , and represents the sample from MRSS.
Lemma 3.
The rth moments using based on MaxRSS are displayed using
Proof.
The for MRSS is as follows:
By using the same substitution in SRS, i.e., , the is expressed as
Hence,
.
□
3.4. Estimation Based on OMRSS
In this subsection, MOM estimators for the GumD using the OMRSS scheme are obtained by substituting (2) and (3) into (5). For a sample of size n, the ordinal statistic is produced in ascending order: . If so, the sample from OMRSS is represented by , which is an ordinal statistic of for .
Lemma 4.
The rth moments using based on OMRSS for are obtained using
Proof.
The for OMRSS is given by
By taking the same substitution in SRS, i.e., , is
where . Hence,
□
4. Simulation Study
In this section, the comparability results of the sampling estimators based on MOM estimation are investigated based on simulations with different sample sizes n ranging from 4 to 7 for one cycle and different true parameter values of the shape parameter and the scale parameter , which were . The Monte Carlo simulation was performed using R software with l = 10,000 iterations for different sample sizes and different sampling techniques: SRS, RSS, MRSS, and OMRSS. The relative efficiency (RE) was obtained, including the average bias (AB) and mean square error (MSE).
- Absolute bias (AB): , where represents the parameters, whereas represents their estimates and N is the number of iterations. A lower value of AB suggests that the experimental data and prediction model are more accurately correlated.
- Mean squared error (MSE): . A greater performance of the estimations is indicated by a smaller value of MSE.
- Relative efficiency (RE): The relative efficiency represents the ratio of their efficiencies.
The simulation study was done using R 4.0.3 software. Some important R packages were used for this purpose, namely, Envstats, VGAM, Matrix, etc. Furthermore, the Optim package was used to solve the nonlinear equations to obtain the values of the estimates.
The simulation results for the classical two-parameter GumD are presented in Table 1. The following are the results of the simulation. First, we concluded that the OMRSS-based estimators provided more accurate estimates, followed by the MRSS-based estimators, with very small biases. In almost all cases, the biases of the RSS, MRSS, and OMRSS techniques were very small compared with the biases of SRS, as illustrated in Table 1 in the different cases of true parameter values. From Table 1, it is noticed that for any fixed values of , the values of AB decreased with the increase in n. Next, we discovered that for all sample sizes, OMRSS estimators outperformed other sampling techniques, and that MRSS estimators also outperformed SRS and RSS estimators. For all sample sizes, RSS-based estimators outperformed SRS-based estimators with respect to . Table 2 provided an illustration of these results. Also, the MSEs of all estimators for based on RSS, MRSS, and OMRSS were almost always smaller than the MSEs of SRS estimators, and that the MSEs of the RSS estimators were always larger than the MSEs of the estimators based on OMRSS and MRSS. For different values of , the MSEs of the OMRSS-based estimators were always smaller than the MSEs of the other RSS-based estimators, as illustrated in Table 3 in the different cases of sample size. It should be noted that the performance of the MOM based on the SRS technique was investigated for the estimation of unknown GumD parameters in Mahdi and Cenac [27]. Here, we applied a different sampling technique for using them in the MOM estimation.
5. Empirical Study
Real datasets were used to establish the importance of applying the Gumble distribution to real life. This application saved time, saved effort, and achieved the desired result. It also showed the importance of the GumD in real life. Two actual datasets from Saudi Arabia and the United Kingdom were utilized to assess the GumD goodness-of-fit. The two real datasets were used to estimate the unknown parameters using the method of moments. The first dataset was used in Fayomi et al. [29] and represented a random sample of Saudi Arabia’s COVID-19 mortality rates over a 36-day period. The second dataset was used in Zayed et al. [30] and showed the total milk production from the first birth of 107 cows of the SINDI race. To ensure the reliability and suitability of this study, we used different sample sizes. The datasets were subjected to the Kolmogorov–Smirnov (KS), Anderson–Darling (AD), and Cramer–von Mises (CVM) statistical tests for goodness-of-fit, and the p-values in each test indicate that the distribution fits the data very well (see Table 4).
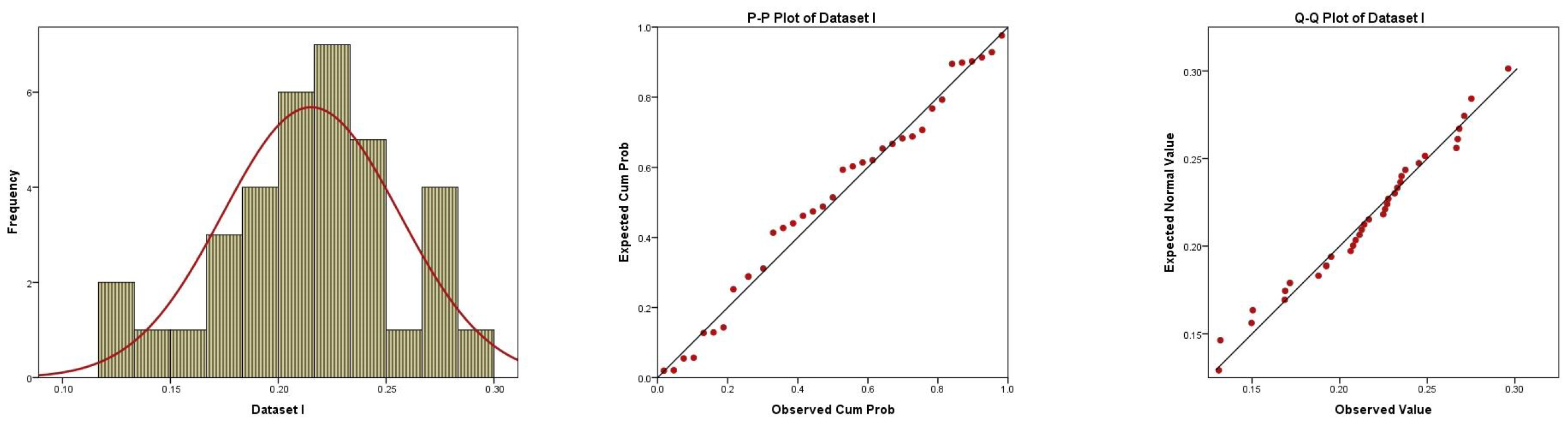
Figure 1 shows the histogram plot with the fitted PDF, P-P plot, and Q-Q plot of the Gumble distribution using dataset I. From this figure, we concluded that the GumD was appropriate for this dataset I. Figure 2 shows three plots of dataset I, where on the left is a boxplot with data explaining that the data had no outlier values, in the middle is an empirical CDF (ECDF) and a theoretical CDF plot with data explaining that the data were increasing, and on the right is a hazard estimated plot line indicating that the hazard was increasing. From Figure 1 and Figure 2, it can be observed that the given dataset I fit the GumD well.
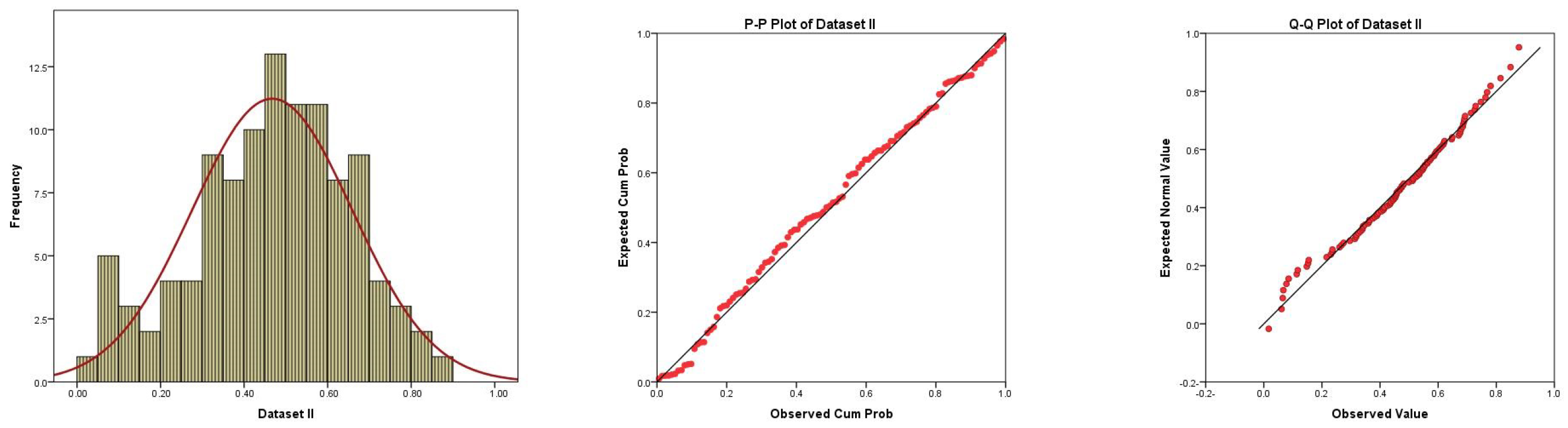
Figure 3 illustrates the histogram graph with the fitted PDF, P-P plot, and Q-Q plot of the GumD based on dataset II. Based on this figure, we concluded that the GumD fit dataset II. Figure 4 displays three graphs of dataset II. The graph on the left shows a boxplot showing the data had no outlier values. The middle graph depicts an empirical CDF and theoretical CDF plot with data indicating that the data were increasing. The right graph depicts a hazard estimated plot line, indicating that the hazard was increasing. From Figure 3 and Figure 4, it was observed that the given dataset II fit the GumD well.
We used the MOM to estimate the unknown parameters of the GumD. During the estimation period, some measurements of error were used, such as , mean absolute error (), mean bias error (), and standard error () values, which were calculated using
where is the value from a dataset and is the value of x that came from the simulation after estimating the unknown parameters. In Table 5, the values of MSE, MAE, MBE, and SE are shown for dataset I with sample size and dataset II with sample size with cycle size . Compare the GumD with the SRS, RSS, MRSS, and OMRSS techniques based on the MOM in this table. Based on the results of these measures, we may be able to select the best sample technique for estimating the GumD based on the smaller values of measurements of error. Based on the numerical results of the real datasets, the conclusions can be summarized as follows: First, in general, all measures of error based on the RSS, MRSS, and OMRSS methods were lower than those measures based on the SRS technique. Second, the OMRSS technique was superior to all other sampling techniques. It had the lowest values for the measures of error. Third, it can also be seen that the SRS was inferior to other sampling techniques. It had the highest values measures of error for various estimation techniques. Fourth, the SE had a largest values compared with the other measures of error based on the sampling techniques, while MSE had the lowest values of the measures of error. Finally, the MSE was the same as the MBE for all estimation methods and sampling techniques. It was also the smallest compared with the other measures.
6. Conclusions
In this study, the unknown parameters of Gumbel distribution were estimated using the method of moments based on the SRS, RSS, MRSS, and OMaxRSS techniques. The conclusions can be divided into three parts: First, theoretical results were obtained using the method of moments with sampling techniques. The first and second moments of sampling techniques were obtained and solved numerically to obtain the estimators. Second, based on the comparative study’s simulation results, numerical comparisons between SRS and different RSS techniques revealed that, in general, estimates based on the RSS, MRSS, and OMRSS techniques were more efficient than the SRS estimators. Furthermore, RSS was shown to be less efficient than the MRSS and OMRSS techniques with large MSEs. The OMRSS was more efficient than other SRS-based RSS techniques for different sample sizes. Finally, based on the results of two real datasets used in a comparative study, a numerical comparison between SRS and RSS techniques shows that all measures of error based on the RSS, MRSS, and OMRSS techniques had lower values than those based on the SRS technique. For the sampling techniques, the MSE was the same as the MBE. In comparison with the other measures, the MSE was also the smallest. The RSS had the largest value in the measures compared with the other MRSS and OMRSS techniques. The OMRSS technique was superior to all other sampling techniques; it had the lowest values for the measures of error.
Author Contributions
Conceptualization: N.M.H. and O.A.A.; methodology: N.M.H.; software: N.M.H.; validation: N.M.H. and O.A.A.; formal analysis: N.M.H. and O.A.A.; investigation: N.M.H. and O.A.A.; resources: O.A.A.; data curation: N.M.H.; writing—original draft preparation: N.M.H.; writing—review and editing: O.A.A.; visualization: N.M.H.; supervision: O.A.A.; project administration: O.A.A.; funding acquisition: O.A.A. All authors read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used in this article are already available in the public domain.
Acknowledgments
The authors express their gratitude to the editor, the associate editor, and the anonymous reviewers for their constructive suggestions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- McIntyre, G.A. A method for unbiased selective sampling, using ranked sets. Aust. J. Agric. Res. 1952, 3, 385–390. [Google Scholar] [CrossRef]
- Takahasi, K.; Wakimoto, K. On unbiased estimates of the population mean based on the sample stratified by means of ordering. Ann. Inst. Stat. Math. 1968, 20, 1–31. [Google Scholar] [CrossRef]
- Lavin, M. The ‘Bayesics’ of ranked set sampling. Environ. Ecol. Stat. 1999, 6, 47–57. [Google Scholar] [CrossRef]
- Chen, Z.; Bai, Z.; Sinha, B.K. Ranked Set Sampling: Theory and Applications; Springer: New York, NY, USA, 2004; Volume 176. [Google Scholar]
- Esemen, M.; Gürler, S. Parameter estimation of generalized Rayleigh distribution based on ranked set sample. J. Stat. Comput. Simul. 2018, 88, 615–628. [Google Scholar] [CrossRef]
- Halls, L.K.; Dell, T.R. Trial of ranked-set sampling for forage yields. For. Sci. 1966, 12, 22–26. [Google Scholar]
- Al-Saleh, M.F.; Al-Hadhrami, S.A. Estimation of the mean of the exponential distribution using moving extremes ranked set sampling. Stat. Pap. 2003, 44, 367–382. [Google Scholar] [CrossRef]
- Khamnei, H.J.; Mayan, S.R. Comparison of parameter estimation in the exponentiated Gumbel distribution based on ranked set sampling and simple random sampling. J. Math. Stat. Sci. 2016, 2016, 490–497. [Google Scholar]
- Hassan, N.M.; Rady, E.H.A.; Rashwan, N.I. Estimate the Parameters of the Gamma/Gompertz Distribution based on Different Sampling Schemes of Ordered Sets. J. Stat. Appl. Probab. 2022, 11, 899–914. [Google Scholar]
- Balakrishnan, N.; Li, T. Ordered ranked set samples and applications to inference. J. Stat. Plan. Inference 2008, 138, 3512–3524. [Google Scholar] [CrossRef]
- Stokes, S.L. Inferences on the correlation coefficient in bivariate normal populations from ranked set samples. J. Am. Stat. Assoc. 1980, 75, 989–995. [Google Scholar] [CrossRef]
- Chacko, M. Ordered extreme ranked set sampling and its application in parametric estimation. J. Stat. Theory Appl. 2016, 15, 248–258. [Google Scholar] [CrossRef]
- Eskandarzadeh, M.; Crescenzo, A.D.; Tahmasebi, S. Measures of information for maximum ranked set sampling with unequal samples. Commun. Stat.-Theory Methods 2018, 47, 4692–4709. [Google Scholar] [CrossRef]
- Basikhasteh, M.; Lak, F.; Tahmasebi, S. Ordered maximum ranked set sampling with unequal sample. Statistics 2020, 54, 856–870. [Google Scholar] [CrossRef]
- Biradar, B.S.; Santosha, C.D. Estimation of the mean of the exponential distribution using maximum ranked set sampling with unequal samples. Open J. Stat. 2014, 4, 641. [Google Scholar] [CrossRef]
- Lambert, J.H.; Li, D. Evaluating risk of extreme events for univariate-loss functions. J. Water Resour. Plan. Manag. 1994, 120, 382–399. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions; John Wiley & Sons: Hoboken, NJ, USA, 1995; Volume 2. [Google Scholar]
- Simiu, E.; Heckert, N.A.; Filliben, J.J.; Johnson, S.K. Extreme wind load estimates based on the Gumbel distribution of dynamic pressures: An assessment. Struct. Saf. 2001, 23, 221–229. [Google Scholar] [CrossRef]
- Kang, D.; Ko, K.; Huh, J. Determination of extreme wind values using the Gumbel distribution. Energy 2015, 86, 51–58. [Google Scholar] [CrossRef]
- Anderson, K.V.; Daniewicz, S.R. Statistical analysis of the influence of defects on fatigue life using a Gumbel distribution. Int. J. Fatigue 2018, 112, 78–83. [Google Scholar] [CrossRef]
- Dutta, S.; Sultana, F.; Kayal, S. Statistical inference for Gumbel type-II distribution under simple step-stress life test using type-II censoring. Iran. J. Sci. 2023, 47, 155–173. [Google Scholar] [CrossRef]
- Hussian, M.A. Bayesian and maximum likelihood estimation for Kumaraswamy distribution based on ranked set sampling. Am. J. Math. Stat. 2014, 4, 30–37. [Google Scholar]
- Sadek, A.; Sultan, K.S.; Balakrishnan, N. Bayesian estimation based on ranked set sampling using asymmetric loss function. Bull. Malays. Math. Sci. Soc. 2015, 38, 707–718. [Google Scholar] [CrossRef]
- Joukar, A.; Ramezani, M.; MirMostafaee, S.M.T.K. Parameter estimation for the exponential-Poisson distribution based on ranked set samples. Commun. Stat. Theory Methods 2021, 50, 560–581. [Google Scholar] [CrossRef]
- Pedroso, V.C.; Taconeli, C.A.; Giolo, S.R. Estimation based on ranked set sampling for the two-parameter Birnbaum–Saunders distribution. J. Stat. Comput. Simul. 2021, 91, 316–333. [Google Scholar] [CrossRef]
- Biradar, B.S. Parametric estimation of location and scale parameters based on ranked set sampling with unequal set sizes. Commun. Stat. Simul. Comput. 2022, 1–16. [Google Scholar] [CrossRef]
- Mahdi, S.; Cenac, M. Estimating Parameters of Gumbel Distribution using the Methods of Moments, probability weighted Moments and maximum likelihood. Rev. Matemática Teoría Apl. 2005, 12, 151–156. [Google Scholar] [CrossRef]
- Choi, B.J. Estimation for scale parameter of type-I extreme value distribution. J. Korean Data Inf. Sci. Soc. 2015, 26, 535–545. [Google Scholar] [CrossRef]
- Fayomi, A.; Hassan, A.S.; Baaqeel, H.; Almetwally, E.M. Bayesian Inference and Data Analysis of the Unit–Power Burr X Distribution. Axioms 2023, 12, 297. [Google Scholar] [CrossRef]
- Zayed, M.A.; Hassan, A.S.; Almetwally, E.M.; Aboalkhair, A.M.; Al-Nefaie, A.H.; Almongy, H.M. A Compound Class of Unit Burr XII Model: Theory, Estimation, Fuzzy, and Application. Sci. Program. 2023, 2023, 4509889. [Google Scholar] [CrossRef]
Figure 1.
Histogram, P-P plot, and Q-Q plot for the fit of GumD based on dataset I.

Figure 2.
Boxplot, ECDF, and hazard plot for the fit of GumD based on dataset I.

Figure 3.
Histogram, P-P plot, and Q-Q plot for the fit of GumD based on dataset II.

Figure 4.
Boxplot, ECDF, and hazard plot for the fit of GumD based on dataset II.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Average estimates and ABs for different sampling techniques.
| n | ||||||
|---|---|---|---|---|---|---|
| 0.7 | ||||||
| 0.5 | 1 | |||||
| 2 | ||||||
| 0.7 | ||||||
| 1 | 1 | |||||
| 2 |
Table 2.
REs of the RSS-based estimators for the different true parameter values.
| n | |||||
|---|---|---|---|---|---|
| 0.7 | |||||
| 0.5 | 1 | ||||
| 2 | |||||
| 0.7 | |||||
| 1 | 1 | ||||
| 2 |
Table 3.
MSEs of the different sampling techniques.
| n | ||||||
|---|---|---|---|---|---|---|
| 0.7 | ||||||
| 0.5 | 1 | |||||
| 2 | ||||||
| 0.7 | ||||||
| 1 | 1 | |||||
| 2 |
Table 4.
The KSs, ADs, and Ws, and the associated p-values of these tests on the dataset.
| KSs | p-Value | ADs | p-Value | Ws | p-Value | |
|---|---|---|---|---|---|---|
| Dataset I | 0.52462 | 0.9343 | 0.2779 | 0.6311 | 0.0421 | 0.6322 |
| Dataset II | 0.38101 | 0.4818 | 0.4542 | 0.2649 | 0.0561 | 0.4230 |
Table 5.
The estimators and selected measures for datasets using sampling techniques.
| n | Measures | |||||
|---|---|---|---|---|---|---|
| Dataset I | ( ) | (0.7832, 0.4542) | (0.3848, 0.4559) | (0.3874, 0.3972) | (0.4560, 0.2137) | |
| 1.1499 | 0.5270 | 0.4154 | 0.2356 | |||
| 0.9304 | 0.5832 | 0.4805 | 0.4367 | |||
| 1.1499 | 0.5270 | 0.4154 | 0.2356 | |||
| 1.0724 | 0.7260 | 0.6445 | 0.4854 | |||
| Dataset II | ( ) | (0.5002, 0.3973) | (0.2899, 0.3361) | (0.3091, 0.1852) | (0.6168, 0.2513) | |
| 0.2852 | 0.1644 | 0.1301 | 0.1074 | |||
| 0.3836 | 0.3029 | 0.2896 | 0.2796 | |||
| 0.2852 | 0.1644 | 0.1301 | 0.1074 | |||
| 0.5340 | 0.4055 | 0.3608 | 0.3277 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hassan, N.M.; Alamri, O.A. Estimation of Gumbel Distribution Based on Ordered Maximum Ranked Set Sampling with Unequal Samples. Axioms 2024, 13, 279. https://doi.org/10.3390/axioms13040279
AMA Style
Hassan NM, Alamri OA. Estimation of Gumbel Distribution Based on Ordered Maximum Ranked Set Sampling with Unequal Samples. Axioms. 2024; 13(4):279. https://doi.org/10.3390/axioms13040279
Chicago/Turabian StyleHassan, Nuran Medhat, and Osama Abdulaziz Alamri. 2024. "Estimation of Gumbel Distribution Based on Ordered Maximum Ranked Set Sampling with Unequal Samples" Axioms 13, no. 4: 279. https://doi.org/10.3390/axioms13040279
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.