
YOLO-GD: A Deep Learning-Based Object Detection Algorithm for Empty-Dish Recycling Robots


Abstract
:1. Introduction
- We design a lightweight dish detection model YOLO-GD for empty-dish recycling robots, which significantly reduces parameter numbers and improves the detection accuracy.
- We design a dish catch point method to effectively extract the catch points of different types of dishes. The catch points are used to recycle the dishes by controlling the robot arm.
- We have realized the quantification of the lightweight dish detection model YOLO-GD without losing accuracy and deploy it on the embedded mobile device, Jetson Nano.
- This paper also creates a dish dataset named Dish-20 (http://www.ihpc.se.ritsumei.ac.jp/obidataset.html; accessed on 28 March 2022), which contains 506 images in 20 classes. It not only provides training data for object detection in this paper but also helps in the field of empty-dish recycling automation.
2. Related Work
2.1. Research of Robotics
2.2. Object Detection
2.3. Quantification and Deployment
3. Object Detection System Embedded in Empty-Dish Recycling Robots
3.1. Overview of Empty-Dish Recycling Robot
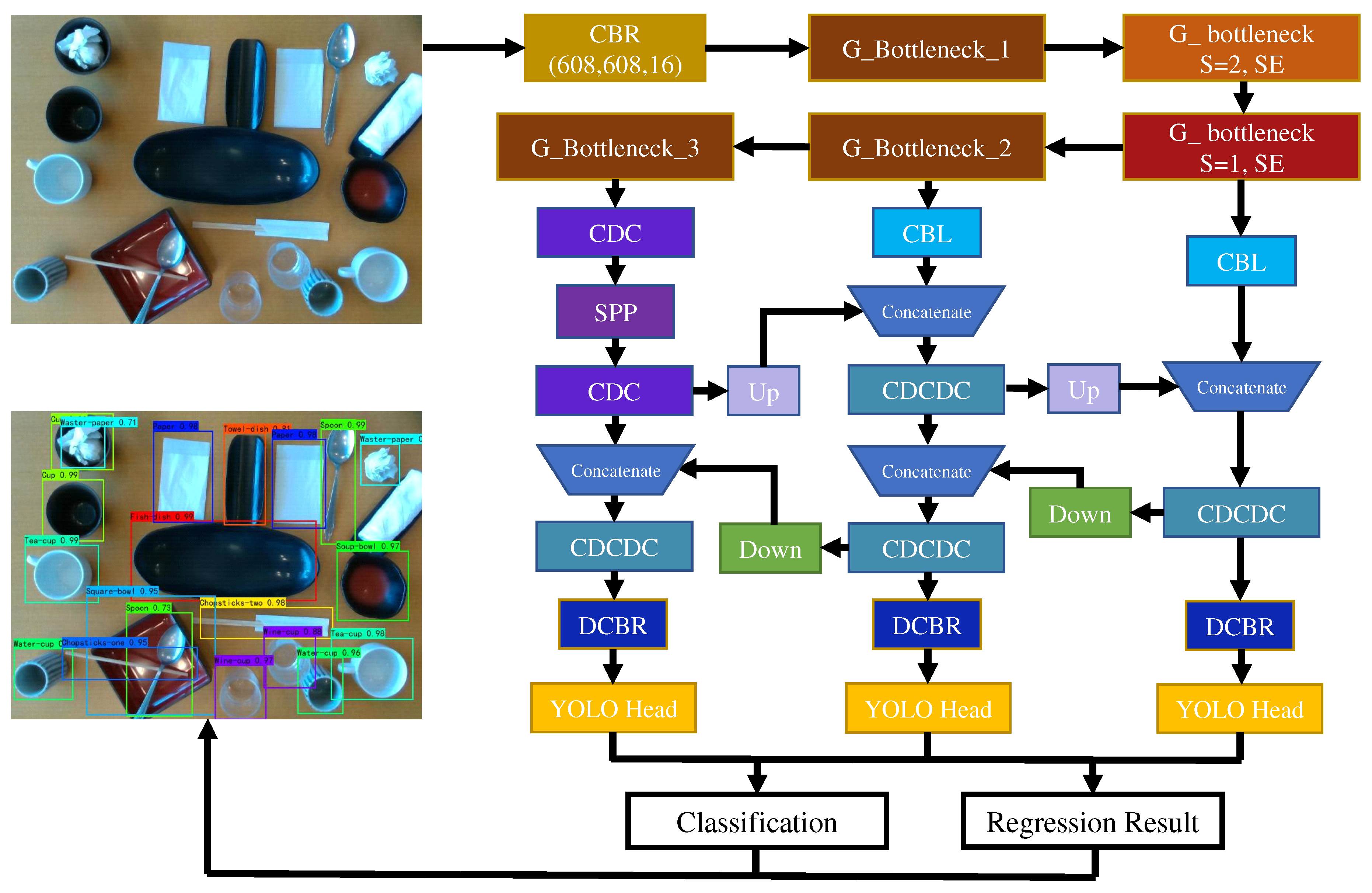
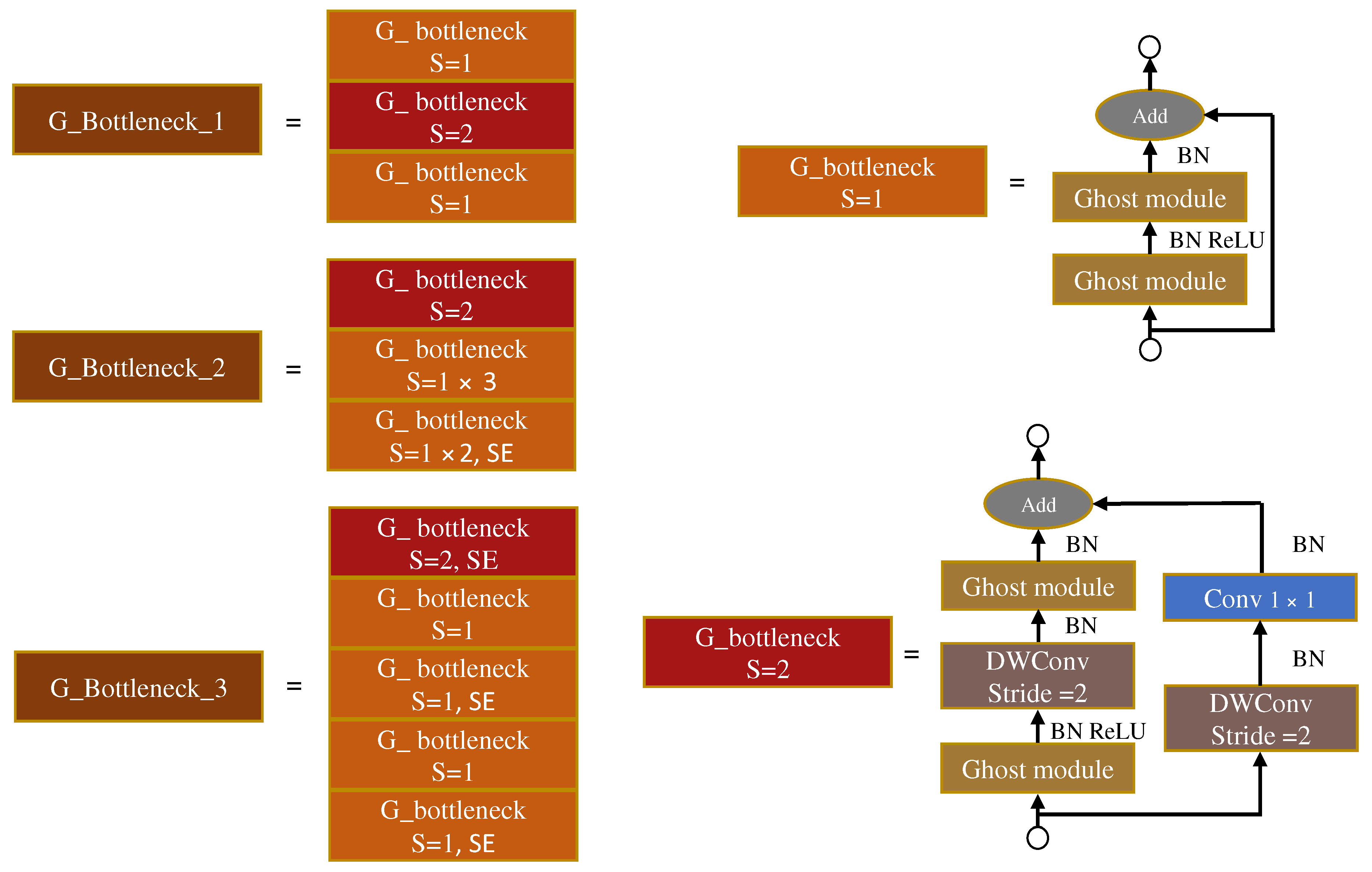
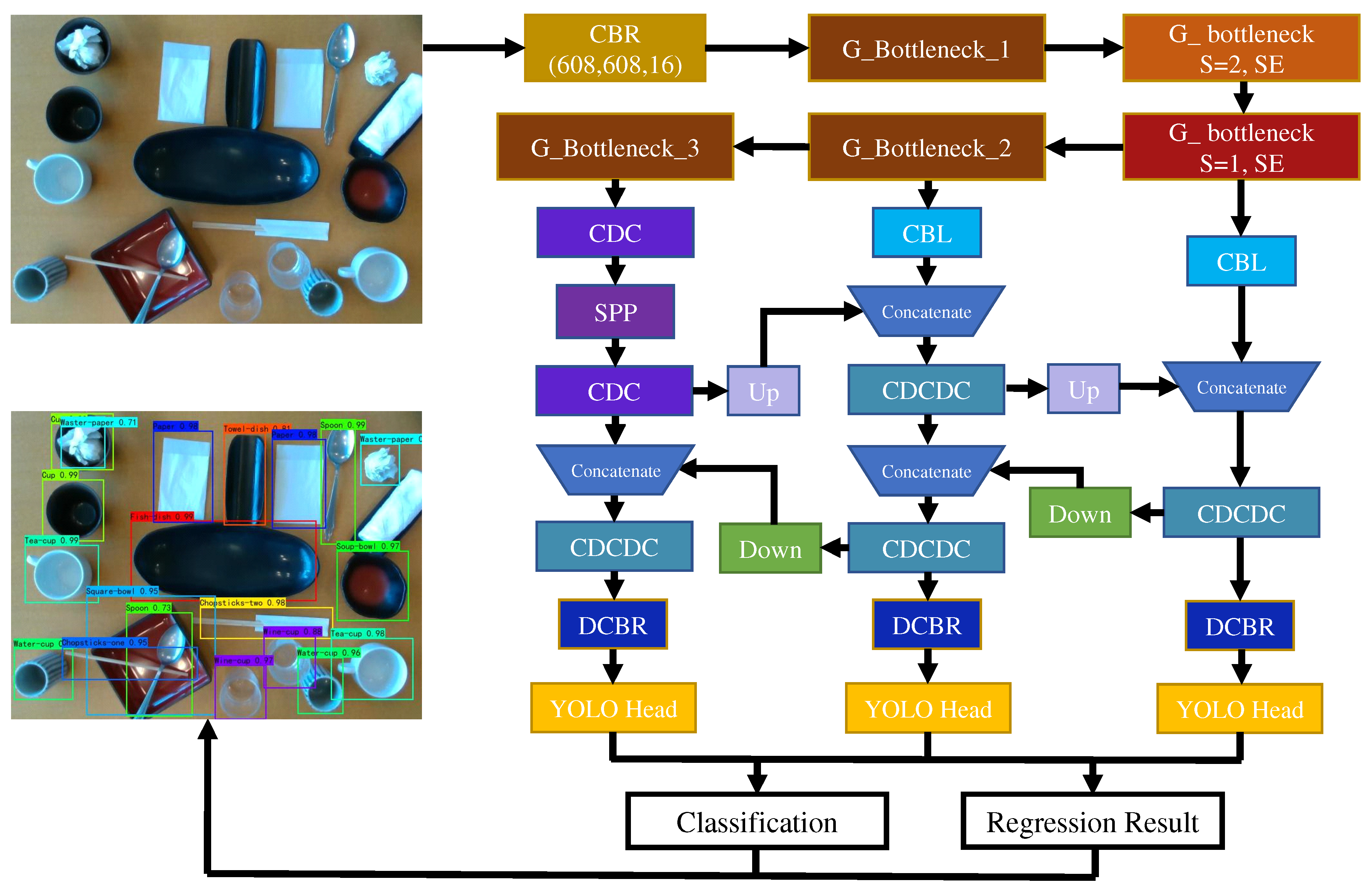
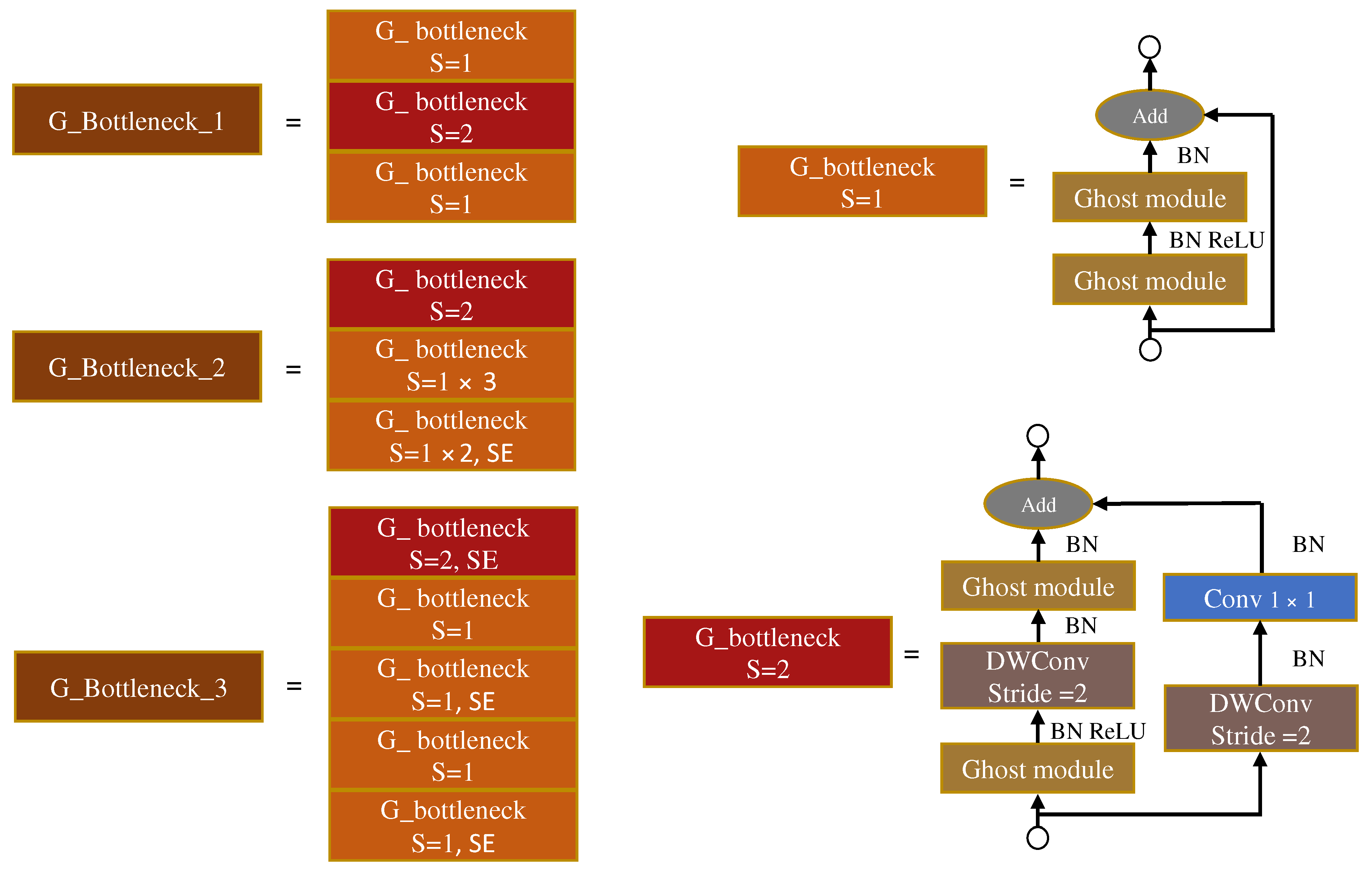
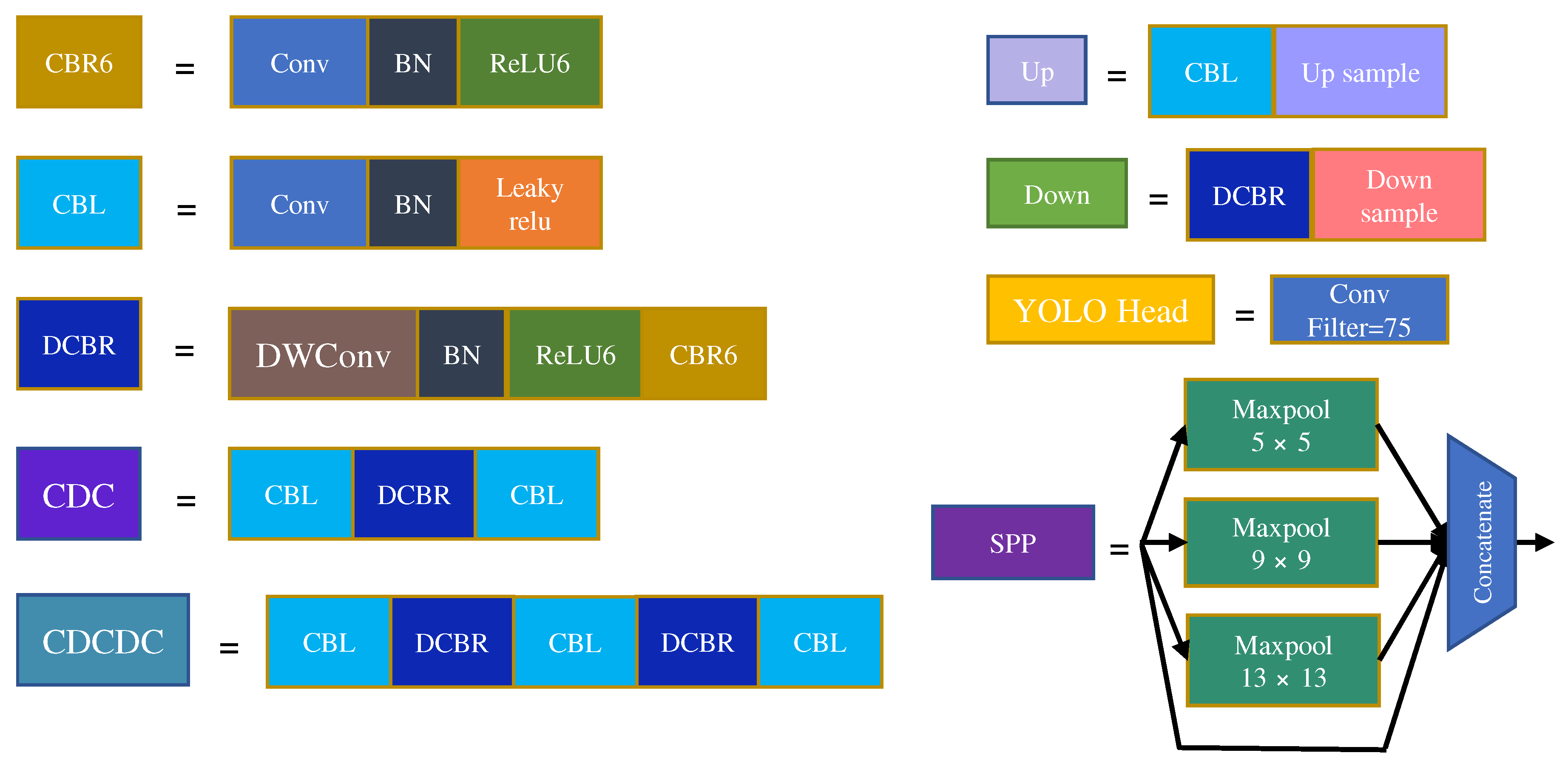
3.2. YOLO-GD Framework
3.3. Extraction of Catch Points
- Circle:Hough transform is used to detect the contours of the circle dish. The equation for a circle in Cartesian coordinates is shown in Equation (2).where (a, b) is the center of the circle and r is the radius, which can also be expressed as Equation (3).In the Cartesian coordinate system, all points on the same circle have the same equation for the circle. They map to the same point in the coordinate system. In the coordinate system, the number of points should have the total pixels of the circle. By judging the number of points at each intersection in the coordinate system, points greater than a threshold are considered a circle.For the segmented circular dish images, grayscale images, canny edge detection [48], and Gaussian filtering [49] are performed to extract the contours of the dish and reduce the interference. Through Hough transform circle detection, the center point coordinates, radius, and other information of the contour are extracted. The center point coordinates of the circle are moved up by a distance of the radius and set as the catch point [50].
- Ellipse:In the Cartesian coordinate system, the maximum distance from any point to the ellipse, the point with the smallest distance is the center of the ellipse, and the smallest maximum distance is the length of the long axis of the ellipse. As shown in Equation (4).where (p, q) is the center of the ellipse, a and b are the major and minor axes of the ellipse, respectively, and is the rotation angle.For the elliptical dish, grayscale conversion and canny edge detection are used to extract ellipse features. The disconnected contour lines are connected and their boundaries are smoothed by the closing operation in morphological processing [10]. The contour finding method is used to find the contour points of the ellipse, and the ellipse center, long axis, short axis, and rotation angle of the ellipse are extracted by ellipse fitting in OpenCV.In the segment elliptical dish image, the coordinates of the catch points are shown in Equation (5).
- Square:The straight-line equation is as follows:where is the distance of the straight line to the original point and is the angle between the straight line and the positive direction of the Cartesian coordinate x-axis.The different points on the straight line are transformed in the polar coordinate plane - into a set of sinusoids intersecting at one point. Determine the two-dimensional statistics on the polar coordinate plane and select the peak value. The peak value is the parameter of a straight line in the image space, thus realizing the straight line detection in the Cartesian coordinate.We consider the intersection of the two lines, and , in the Cartesian coordinate, with being defined by two distinct points, () and (), and being defined by two distinct points, () and ().where and are the vectors of and , respectively, and is the intersection angle between and .The intersection P of and can be defined using determinants,The determinants are written out as:The edge features of the square dish are highlighted by grayscale conversion and canny edge detection. The straight lines in the image are extracted using straight-line detection with Hough transform [51], and the straight lines with angles around 90° are selected by calculating the angle of all the straight lines. The intersection points are calculated for the retained straight lines, and the minimum circumscribed rectangle of all intersection points is calculated. The catch point is the midpoint of one side of the minimum circumscribed rectangle.
- Polygon:For the irregular dish, grayscale conversion, Gaussian filtering, and binarization conversion are performed to clarify the dish contours. The contour finding function in OpenCV is applied for finding all connected contours and taking the maximum value as the feature of the dish. All points in the contour are processed by the minimum circumscribed rectangle, and the center point is extracted as the catch point.
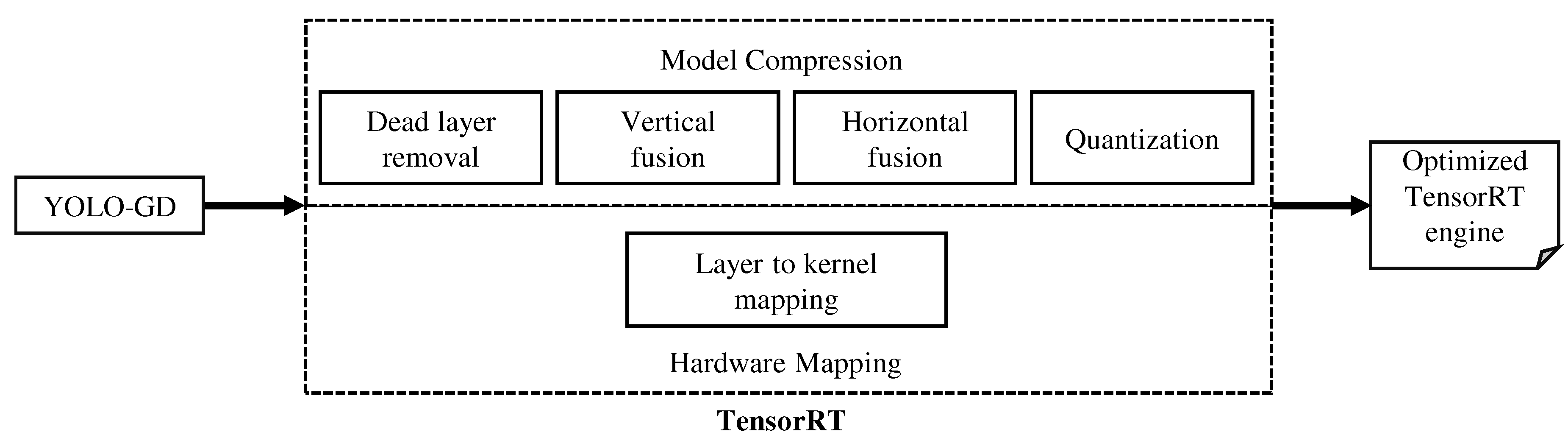
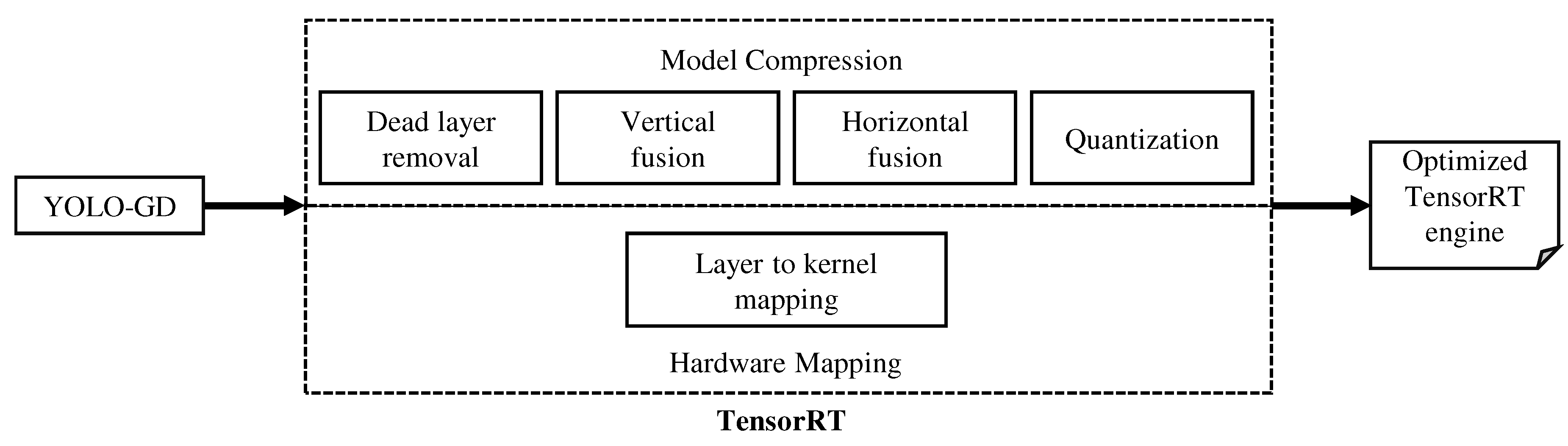
3.4. Model Quantification and Deployment
4. Evaluation
4.1. Dataset
4.2. Performance Indexes
4.3. Experimental Results
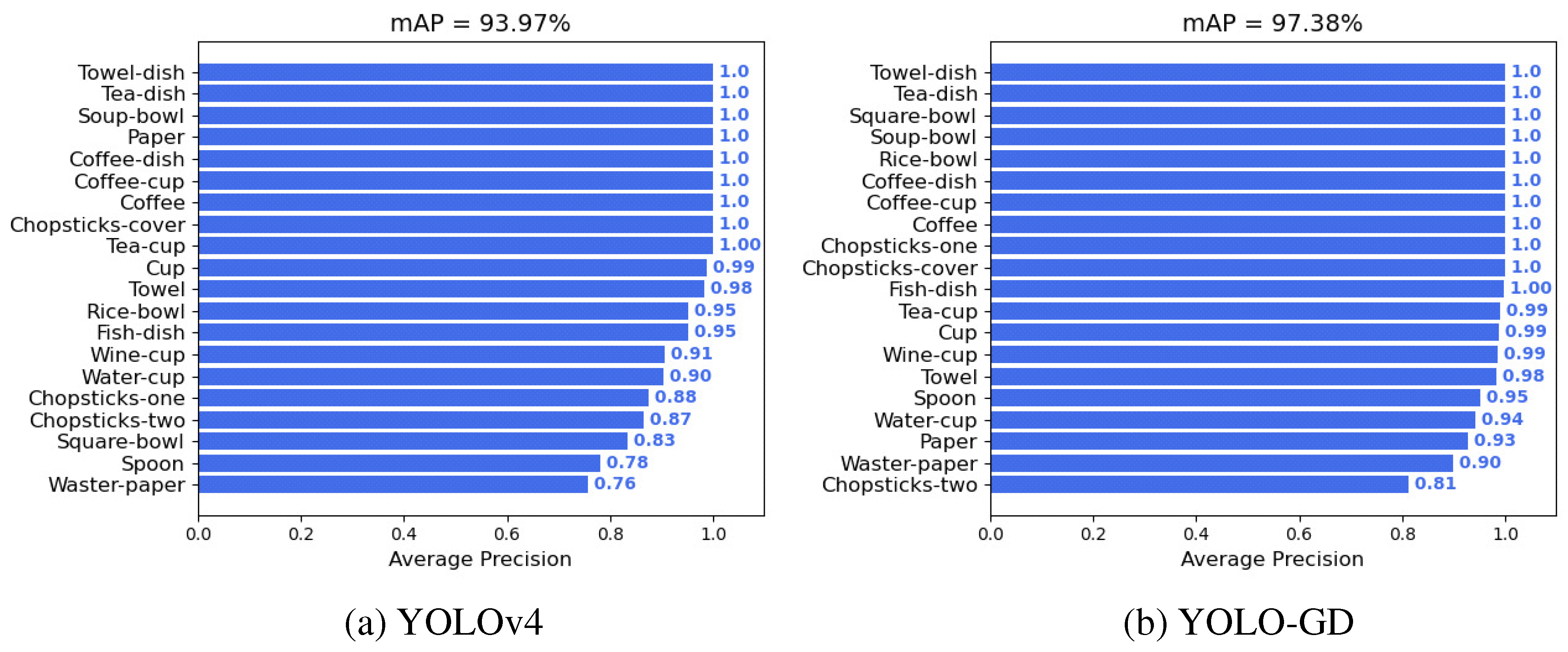
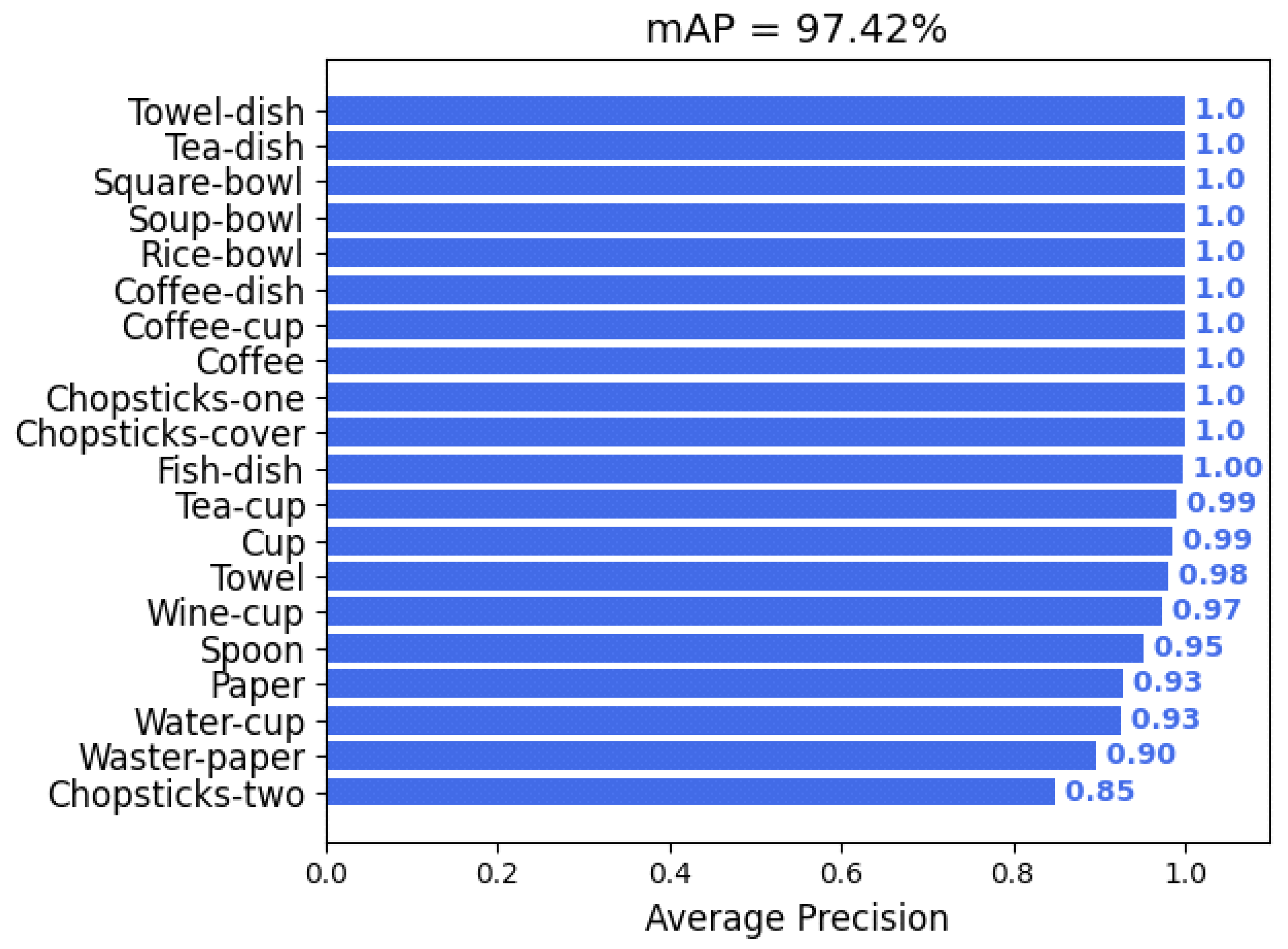
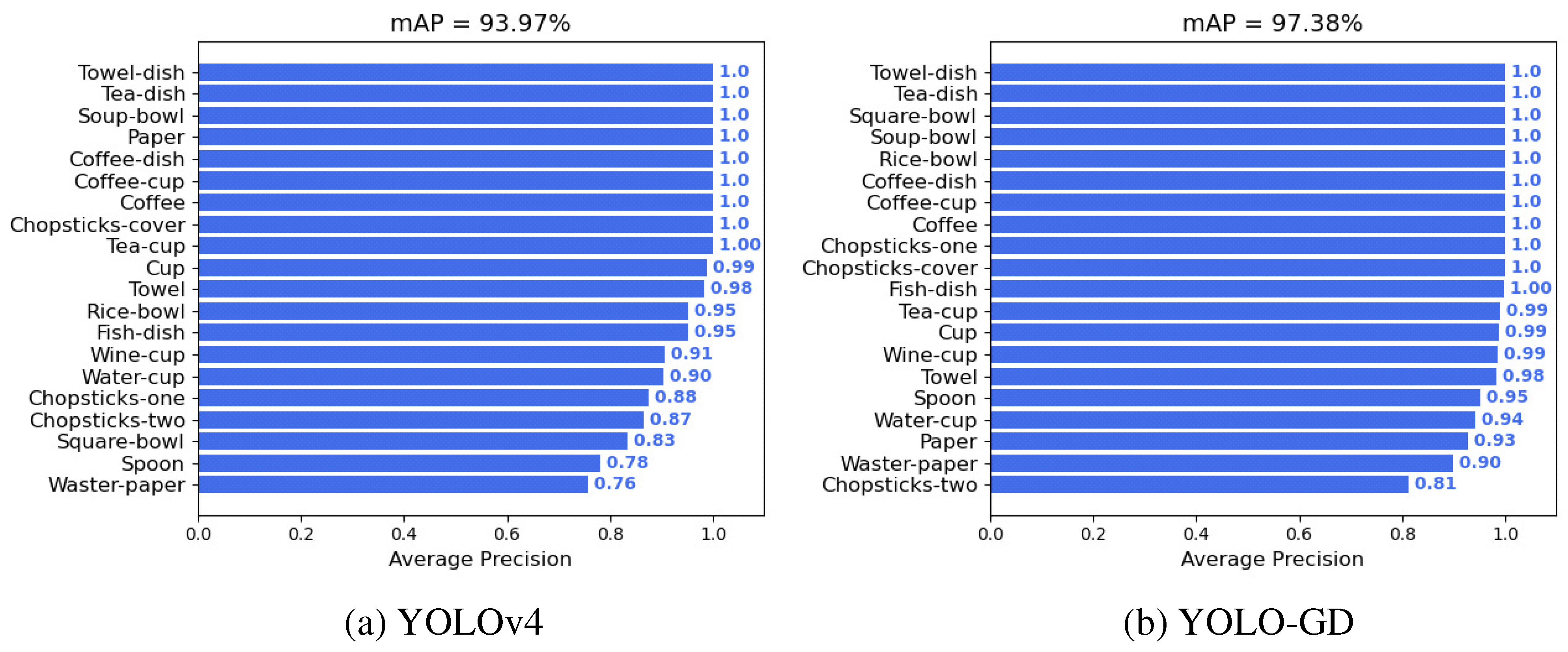
4.3.1. Performance Validation of the YOLO-GD Model
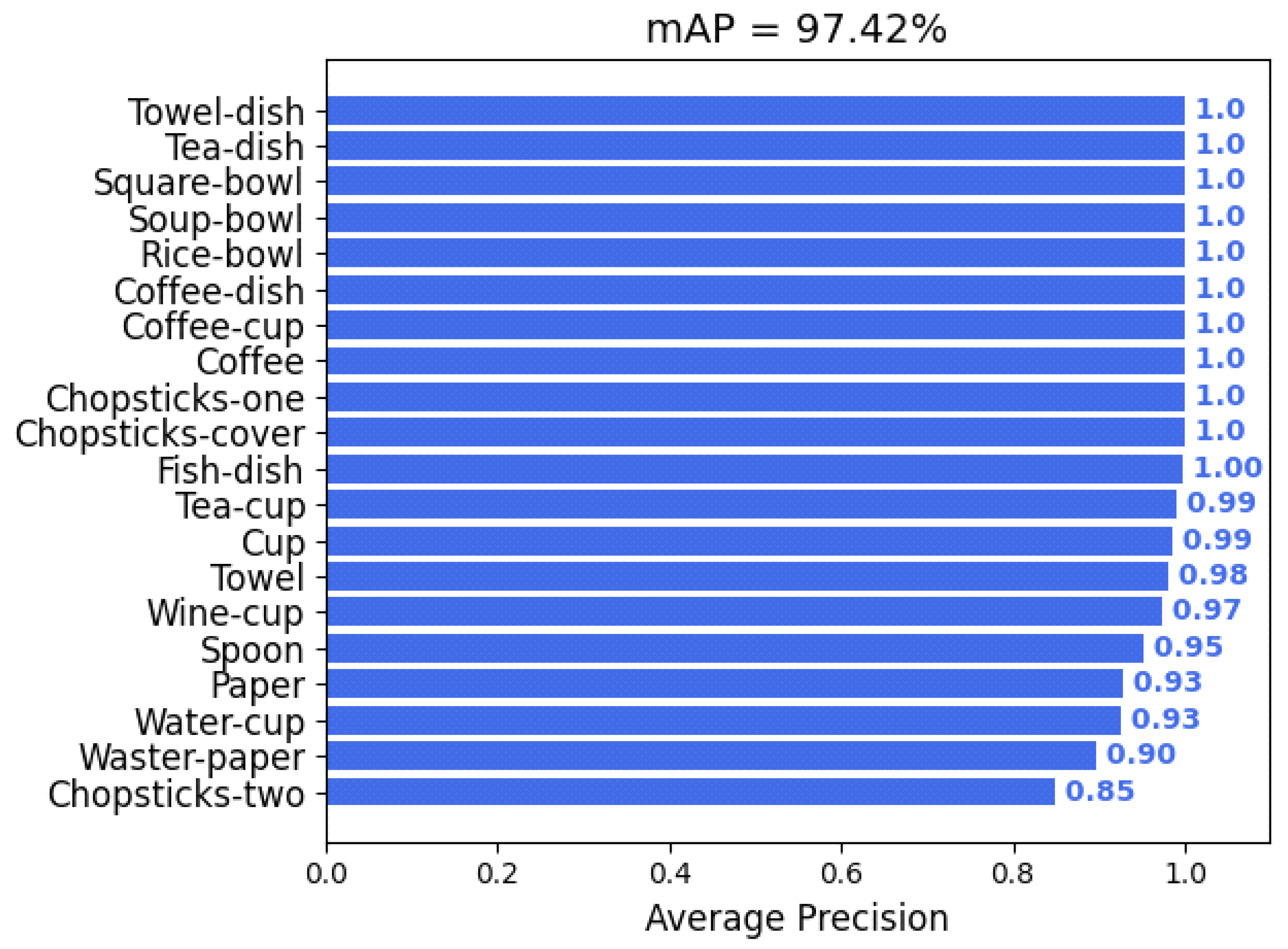
4.3.2. YOLO-GD Quantification, Deployment, and Result Analysis
4.4. Extraction Results of Catch Points
5. Discussion and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dotoli, M.; Fay, A.; Miśkowicz, M.; Seatzu, C. An overview of current technologies and emerging trends in factory automation. Int. J. Prod. Res. 2019, 57, 5047–5067. [Google Scholar] [CrossRef]
- Haase, C.B.; Bearman, M.; Brodersen, J.; Hoeyer, K.; Risor, T. ‘You should see a doctor’, said the robot: Reflections on a digital diagnostic device in a pandemic age. Scand. J. Public Health 2021, 49, 33–36. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Ji, X.; Tang, X.; Li, X. Intelligent search and rescue robot design based on KANO model and TRIZ theory. In Proceedings of the 2021 2nd International Conference on Intelligent Design (ICID), Xi’an, China, 19 October 2021; pp. 371–377. [Google Scholar] [CrossRef]
- Fukuzawa, Y.; Wang, Z.; Mori, Y.; Kawamura, S. A Robotic System Capable of Recognition, Grasping, and Suction for Dishwashing Automation. In Proceedings of the 2021 27th International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Shanghai, China, 26–28 November 2021; pp. 369–374. [Google Scholar] [CrossRef]
- Pereira, D.; Bozzato, A.; Dario, P.; Ciuti, G. Towards Foodservice Robotics: A Taxonomy of Actions of Foodservice Workers and a Critical Review of Supportive Technology. IEEE Trans. Autom. Sci. Eng. 2022, 1–39. [Google Scholar] [CrossRef]
- Yin, J.; Apuroop, K.G.S.; Tamilselvam, Y.K.; Mohan, R.E.; Ramalingam, B.; Le, A.V. Table Cleaning Task by Human Support Robot Using Deep Learning Technique. Sensors 2020, 20, 1698. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Candeias, A.; Rhodes, T.; Marques, M.; ao Costeira, J.P.; Veloso, M. Vision Augmented Robot Feeding. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, J.; Bai, T. SAANet: Spatial adaptive alignment network for object detection in automatic driving. Image Vis. Comput. 2020, 94, 103873. [Google Scholar] [CrossRef]
- Li, X.; Qin, Y.; Wang, F.; Guo, F.; Yeow, J.T.W. Pitaya detection in orchards using the MobileNet-YOLO model. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–30 July 2020; pp. 6274–6278. [Google Scholar] [CrossRef]
- Yue, X.; Lyu, B.; Li, H.; Fujikawa, Y.; Meng, L. Deep Learning and Image Processing Combined Organization of Shirakawa’s Hand-Notated Documents on OBI Research. In Proceedings of the 2021 IEEE International Conference on Networking, Sensing and Control (ICNSC), Xiamen, China, 3–5 December 2021; Volume 1, pp. 1–6. [Google Scholar] [CrossRef]
- Fujikawa, Y.; Li, H.; Yue, X.; Prabhu, G.A.; Meng, L. Recognition of Oracle Bone Inscriptions by using Two Deep Learning Models. Int. J. Digit. Humanit. 2022. [Google Scholar] [CrossRef]
- Li, H.; Wang, Z.; Yue, X.; Wang, W.; Tomiyama, H.; Meng, L.A. Comprehensive Analysis of Low-Impact Computations in Deep Learning Workloads. In Proceedings of the 2021 on Great Lakes Symposium on VLSI; Association for Computing Machinery: New York, NY, USA, 2021; pp. 385–390. [Google Scholar]
- Li, H.; Yue, X.; Wang, Z.; Wang, W.; Chai, Z.; Tomiyama, H.; Meng, L. Optimizing the deep neural networks by layer-wise refined pruning and the acceleration on FPGA. In Computational Intelligence and Neuroscience; Hindawi: London, UK, 2022. [Google Scholar]
- Li, G.; Wang, J.; Shen, H.W.; Chen, K.; Shan, G.; Lu, Z. CNNPruner: Pruning Convolutional Neural Networks with Visual Analytics. IEEE Trans. Vis. Comput. Graph. 2021, 27, 1364–1373. [Google Scholar] [CrossRef]
- Wang, X.; Yue, X.; Li, H.; Meng, L. A high-efficiency dirty-egg detection system based on YOLOv4 and TensorRT. In Proceedings of the 2021 International Conference on Advanced Mechatronic Systems (ICAMechS), Tokyo, Japan, 9–12 December 2021; pp. 75–80. [Google Scholar] [CrossRef]
- Wang, L.; Yoon, K.J. Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 July 2018. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 13–19 June 2020. [Google Scholar]
- Zhu, D.; Seki, H.; Tsuji, T.; Hiramitsu, T. Mechanism and Design of Tableware Tidying-up Robot for Self-Service Restaurant. In Proceedings of the 2021 IEEE International Conference on Mechatronics and Automation (ICMA), Takamatsu, Japan, 8–11 August 2021; pp. 825–830. [Google Scholar] [CrossRef]
- Kawamura, S.; Sudani, M.; Deng, M.; Noge, Y.; Wakimoto, S. Modeling and System Integration for a Thin Pneumatic Rubber 3-DOF Actuator. Actuators 2019, 8, 32. [Google Scholar] [CrossRef] [Green Version]
- Kinugawa, J.; Suzuki, H.; Terayama, J.; Kosuge, K. Underactuated robotic hand for a fully automatic dishwasher based on grasp stability analysis. Adv. Robot. 2022, 36, 167–181. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Girshick, R.B. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, Y.; Li, S.; Du, H.; Chen, L.; Zhang, D.; Li, Y. YOLO-ACN: Focusing on Small Target and Occluded Object Detection. IEEE Access 2020, 8, 227288–227303. [Google Scholar] [CrossRef]
- Cao, Z.; Liao, T.; Song, W.; Chen, Z.; Li, C. Detecting the shuttlecock for a badminton robot: A YOLO based approach. Expert Syst. Appl. 2021, 164, 113833. [Google Scholar] [CrossRef]
- Zhang, Y.; Lee, C.; Hsieh, J.; Fan, K. CSL-YOLO: A New Lightweight Object Detection System for Edge Computing. arXiv 2021, arXiv:2107.04829. [Google Scholar]
- Wang, G.; Ding, H.; Yang, Z.; Li, B.; Wang, Y.; Bao, L. TRC-YOLO: A real-time detection method for lightweight targets based on mobile devices. IET Comput. Vis. 2022, 16, 126–142. [Google Scholar] [CrossRef]
- Guan, L.; Jia, L.; Xie, Z.; Yin, C. A Lightweight Framework for Obstacle Detection in the Railway Image based on Fast Region Proposal and Improved YOLO-tiny Network. IEEE Trans. Instrum. Meas. 2022. [Google Scholar] [CrossRef]
- Hirose, S.; Wada, N.; Katto, J.; Sun, H. Research and examination on implementation of super-resolution models using deep learning with INT8 precision. In Proceedings of the 2022 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Korea, 21–24 February 2022; pp. 133–137. [Google Scholar] [CrossRef]
- Jeong, E.; Kim, J.; Tan, S.; Lee, J.; Ha, S. Deep Learning Inference Parallelization on Heterogeneous Processors With TensorRT. IEEE Embed. Syst. Lett. 2022, 14, 15–18. [Google Scholar] [CrossRef]
- Jeong, E.; Kim, J.; Ha, S. TensorRT-Based Framework and Optimization Methodology for Deep Learning Inference on Jetson Boards. ACM Trans. Embed. Comput. Syst. 2022. [Google Scholar] [CrossRef]
- Stäcker, L.; Fei, J.; Heidenreich, P.; Bonarens, F.; Rambach, J.; Stricker, D.; Stiller, C. Deployment of Deep Neural Networks for Object Detection on Edge AI Devices With Runtime Optimization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Virtual, 11–17 October 2021; pp. 1015–1022. [Google Scholar]
- Wang, Y.; Yu, P. A Fast Intrusion Detection Method for High-Speed Railway Clearance Based on Low-Cost Embedded GPUs. Sensors 2021, 21, 7279. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Cao, Q.; Jiang, H.; Zhang, W.; Li, J.; Yao, J. A Fast Filtering Mechanism to Improve Efficiency of Large-Scale Video Analytics. IEEE Trans. Comput. 2020, 69, 914–928. [Google Scholar] [CrossRef]
- Shao, Z.; Wang, L.; Wang, Z.; Du, W.; Wu, W. Saliency-Aware Convolution Neural Network for Ship Detection in Surveillance Video. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 781–794. [Google Scholar] [CrossRef]
- Yue, X.; Li, H.; Shimizu, M.; Kawamura, S.; Meng, L. Deep Learning-based Real-time Object Detection for Empty-Dish Recycling Robot. In Proceedings of the 13th Asian Control Conference (ASCC 2022), Jeju Island, Korea, 4–7 May 2022. [Google Scholar]
- Liu, J.; Cong, W.; Li, H. Vehicle Detection Method Based on GhostNet-SSD. In Proceedings of the 2020 International Conference on Virtual Reality and Intelligent Systems (ICVRIS), Zhangjiajie, China, 18–19 July 2020; pp. 200–203. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. arXiv 2014, arXiv:1406.4729. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. arXiv 2018, arXiv:1803.01534. [Google Scholar]
- Ding, L.; Goshtasby, A. On the Canny edge detector. Pattern Recognit. 2001, 34, 721–725. [Google Scholar] [CrossRef]
- Fu, Y.; Zeng, H.; Ma, L.; Ni, Z.; Zhu, J.; Ma, K.K. Screen Content Image Quality Assessment Using Multi-Scale Difference of Gaussian. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2428–2432. [Google Scholar] [CrossRef]
- Yue, X.; Lyu, B.; Li, H.; Meng, L.; Furumoto, K. Real-time medicine packet recognition system in dispensing medicines for the elderly. Meas. Sens. 2021, 18, 100072. [Google Scholar] [CrossRef]
- Meng, L. Recognition of Oracle Bone Inscriptions by Extracting Line Features on Image Processing. In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods—Volume 1: ICPRAM,. INSTICC, SciTePress, Porto, Portugal, 24–26 February 2017; pp. 606–611. [Google Scholar] [CrossRef]
- Shafi, O.; Rai, C.; Sen, R.; Ananthanarayanan, G. Demystifying TensorRT: Characterizing Neural Network Inference Engine on Nvidia Edge Devices. In 2021 IEEE International Symposium on Workload Characterization (IISWC); IEEE Computer Society: Los Alamitos, CA, USA, 2021; pp. 226–237. [Google Scholar] [CrossRef]
- Mamdouh, N.; Khattab, A. YOLO-Based Deep Learning Framework for Olive Fruit Fly Detection and Counting. IEEE Access 2021, 9, 84252–84262. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Xu, Q.; Lin, R.; Yue, H.; Huang, H.; Yang, Y.; Yao, Z. Research on Small Target Detection in Driving Scenarios Based on Improved Yolo Network. IEEE Access 2020, 8, 27574–27583. [Google Scholar] [CrossRef]
- Kumar, P.; Batchu, S.; Swamy, S.N.; Kota, S.R. Real-Time Concrete Damage Detection Using Deep Learning for High Rise Structures. IEEE Access 2021, 9, 112312–112331. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Rio de Janeiro, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | F | Recall | Precision | AP |
|---|---|---|---|---|
| Chopsticks-cover | 1.00 | 100.00% | 100.00% | 100.00% |
| Chopsticks-one | 0.93 | 87.50% | 100.00% | 87.50% |
| Chopsticks-two | 0.91 | 87.04% | 95.92% | 86.57% |
| Coffee | 1.00 | 100.00% | 100.00% | 100.00% |
| Coffee-cup | 1.00 | 100.00% | 100.00% | 100.00% |
| Coffee-dish | 1.00 | 100.00% | 100.00% | 100.00% |
| Cup | 0.99 | 98.78% | 98.78% | 98.72% |
| Fish-dish | 0.96 | 96.30% | 96.30% | 95.06% |
| Paper | 1.00 | 100.00% | 100.00% | 100.00% |
| Rice-bowl | 0.98 | 95.24% | 100.00% | 95.24% |
| Soup-bowl | 1.00 | 100.00% | 100.00% | 100.00% |
| Spoon | 0.84 | 78.57% | 89.19% | 78.06% |
| Square-bowl | 0.91 | 83.33% | 100.00% | 83.33% |
| Tea-cup | 1.00 | 100.00% | 99.05% | 99.99% |
| Tea-dish | 1.00 | 100.00% | 100.00% | 100.00% |
| Towel | 0.99 | 98.18% | 100.00% | 98.18% |
| Towel-dish | 1.00 | 100.00% | 100.00% | 100.00% |
| Waster-paper | 0.78 | 78.38% | 78.38% | 75.65% |
| Water-cup | 0.95 | 91.18% | 98.41% | 90.45% |
| Wine-cup | 0.95 | 90.54% | 100.00% | 90.54% |
| Category | F | Recall | Precision | AP |
|---|---|---|---|---|
| Chopsticks-cover | 1.00 | 100.00% | 100.00% | 100.00% |
| Chopsticks-one | 1.00 | 100.00% | 100.00% | 100.00% |
| Chopsticks-two | 0.89 | 81.48% | 97.78% | 81.28% |
| Coffee | 1.00 | 100.00% | 100.00% | 100.00% |
| Coffee-cup | 1.00 | 100.00% | 100.00% | 100.00% |
| Coffee-dish | 1.00 | 100.00% | 100.00% | 100.00% |
| Cup | 0.99 | 98.78% | 98.78% | 98.69% |
| Fish-dish | 0.98 | 100.00% | 96.43% | 99.74% |
| Paper | 0.96 | 92.86% | 100.00% | 92.86% |
| Rice-bowl | 1.00 | 100.00% | 100.00% | 100.00% |
| Soup-bowl | 1.00 | 100.00% | 100.00% | 100.00% |
| Spoon | 0.98 | 95.24% | 100.00% | 95.24% |
| Square-bowl | 0.96 | 100.00% | 92.31% | 100.00% |
| Tea-cup | 0.99 | 99.04% | 99.04% | 99.04% |
| Tea-dish | 1.00 | 100.00% | 100.00% | 100.00% |
| Towel | 0.99 | 98.18% | 100.00% | 98.18% |
| Towel-dish | 1.00 | 100.00% | 100.00% | 100.00% |
| Waster-paper | 0.94 | 91.89% | 97.14% | 89.88% |
| Water-cup | 0.97 | 94.12% | 100.00% | 94.12% |
| Wine-cup | 0.99 | 98.65% | 100.00% | 98.65% |
| IoU | Area | maxDets | AP | AR |
|---|---|---|---|---|
| 0.50:0.95 | All | 20 | 0.726 | - |
| 0.50 | All | 20 | 0.936 | - |
| 0.75 | All | 20 | 0.884 | - |
| 0.50:0.95 | Small | 20 | −1.000 | - |
| 0.50:0.95 | Medium | 20 | 0.706 | - |
| 0.50:0.95 | Large | 20 | 0.753 | - |
| 0.50:0.95 | All | 1 | - | 0.566 |
| 0.50:0.95 | All | 10 | - | 0.762 |
| 0.50:0.95 | All | 20 | - | 0.762 |
| 0.50:0.95 | Small | 20 | - | −1.000 |
| 0.50:0.95 | Medium | 20 | - | 0.732 |
| 0.50:0.95 | Large | 20 | - | 0.787 |
| IoU | Area | maxDets | AP | AR |
|---|---|---|---|---|
| 0.50:0.95 | All | 20 | 0.753 | - |
| 0.50 | All | 20 | 0.970 | - |
| 0.75 | All | 20 | 0.907 | - |
| 0.50:0.95 | Small | 20 | −1.000 | - |
| 0.50:0.95 | Medium | 20 | 0.709 | - |
| 0.50:0.95 | Large | 20 | 0.766 | - |
| 0.50:0.95 | All | 1 | - | 0.588 |
| 0.50:0.95 | All | 10 | - | 0.788 |
| 0.50:0.95 | All | 20 | - | 0.788 |
| 0.50:0.95 | Small | 20 | - | −1.000 |
| 0.50:0.95 | Medium | 20 | - | 0.734 |
| 0.50:0.95 | Large | 20 | - | 0.795 |
| Model | Weights | Parameters | FLOPs |
|---|---|---|---|
| YOLOv4 | 256.20 MB | 63.84 M | 58.43 G |
| YOLO-GD | 45.80 MB | 11.17 M | 6.61 G |
| Model | FPS | Inference Time per Image |
|---|---|---|
| Unquantized model | 4.81 | 207.92 ms |
| Quantified model | 30.53 | 32.75 ms |
| Category | F | Recall | Precision | AP |
|---|---|---|---|---|
| Chopsticks-cover | 1.00 | 100.00% | 100.00% | 100.00% |
| Chopsticks-one | 0.97 | 100.00% | 94.12% | 100.00% |
| Chopsticks-two | 0.91 | 85.19% | 97.87% | 84.99% |
| Coffee | 1.00 | 100.00% | 100.00% | 100.00% |
| Coffee-cup | 1.00 | 100.00% | 100.00% | 100.00% |
| Coffee-dish | 1.00 | 100.00% | 100.00% | 100.00% |
| Cup | 0.99 | 98.78% | 98.78% | 98.68% |
| Fish-dish | 0.98 | 100.00% | 96.43% | 99.74% |
| Paper | 0.96 | 92.86% | 100.00% | 92.86% |
| Rice-bowl | 1.00 | 100.00% | 100.00% | 100.00% |
| Soup-bowl | 1.00 | 100.00% | 100.00% | 100.00% |
| Spoon | 0.98 | 95.24% | 100.00% | 95.24% |
| Square-bowl | 0.96 | 100.00% | 92.31% | 100.00% |
| Tea-cup | 0.99 | 99.04% | 99.04% | 99.04% |
| Tea-dish | 1.00 | 100.00% | 100.00% | 100.00% |
| Towel | 0.99 | 98.18% | 100.00% | 98.18% |
| Towel-dish | 1.00 | 100.00% | 100.00% | 100.00% |
| Waster-paper | 0.94 | 91.89% | 97.14% | 89.81% |
| Water-cup | 0.96 | 92.65% | 100.00% | 92.65% |
| Wine-cup | 0.99 | 97.30% | 100.00% | 97.30% |
| IoU | Area | maxDets | AP | AR |
|---|---|---|---|---|
| 0.50:0.95 | All | 20 | 0.747 | - |
| 0.50 | All | 20 | 0.970 | - |
| 0.75 | All | 20 | 0.903 | - |
| 0.50:0.95 | Small | 20 | −1.000 | - |
| 0.50:0.95 | Medium | 20 | 0.709 | - |
| 0.50:0.95 | Large | 20 | 0.759 | - |
| 0.50:0.95 | All | 1 | - | 0.581 |
| 0.50:0.95 | All | 10 | - | 0.780 |
| 0.50:0.95 | All | 20 | - | 0.780 |
| 0.50:0.95 | Small | 20 | - | −1.000 |
| 0.50:0.95 | Medium | 20 | - | 0.735 |
| 0.50:0.95 | Large | 20 | - | 0.787 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, X.; Li, H.; Shimizu, M.; Kawamura, S.; Meng, L. YOLO-GD: A Deep Learning-Based Object Detection Algorithm for Empty-Dish Recycling Robots. Machines 2022, 10, 294. https://doi.org/10.3390/machines10050294
Yue X, Li H, Shimizu M, Kawamura S, Meng L. YOLO-GD: A Deep Learning-Based Object Detection Algorithm for Empty-Dish Recycling Robots. Machines. 2022; 10(5):294. https://doi.org/10.3390/machines10050294
Chicago/Turabian StyleYue, Xuebin, Hengyi Li, Masao Shimizu, Sadao Kawamura, and Lin Meng. 2022. "YOLO-GD: A Deep Learning-Based Object Detection Algorithm for Empty-Dish Recycling Robots" Machines 10, no. 5: 294. https://doi.org/10.3390/machines10050294
APA StyleYue, X., Li, H., Shimizu, M., Kawamura, S., & Meng, L. (2022). YOLO-GD: A Deep Learning-Based Object Detection Algorithm for Empty-Dish Recycling Robots. Machines, 10(5), 294. https://doi.org/10.3390/machines10050294