1. Introduction
Nowadays, lane changing is a challenging task that necessitates precise maneuvers to ensure it is conducted safely, comfortably, and swiftly. Lane change include both mandatory and discretionary scenarios [
1]. Mandatory lane change refer to the motion planning of lane changing in situations where it is imperative to do so. Scenarios for mandatory lane change include merging from entrance ramps and changing lanes in the presence of obstacles ahead [
2]. Discretionary lane change are decisions made by a vehicle to change lanes when it is not demanded due to road conditions, but rather motivated by factors such as speed optimization, driving efficiency, or driver preference. Unlike mandatory lane change, which occur because of immediate necessities such as road obstructions, construction, or merging, discretionary lane change offer an additional layer of complexity to autonomous vehicle algorithms.
Current scholars have provided two research methodologies for decision making in autonomous vehicle lane change: (1) rule-based methods [
3,
4,
5,
6] and (2) learning-based methods [
7,
8].
Rule-based decision models use a set of predefined, hand-crafted rules to simulate the decision-making process of drivers. These rules may include adherence to traffic regulations, such as stopping at red lights and proceeding at green lights. The model is highly interpretable because the rules are clear and straightforward, making them easy to understand and maintain. However, rule-based models may lack flexibility when dealing with complex driving environments and unknown situations because hand-crafted rules may not easily adapt to such complexities and uncertainties [
3,
6].
Learning-based decision models rely on training models on large-scale driving data to autonomously learn and adapt to different driving conditions. These methods employ deep learning techniques that utilize neural networks and machine learning algorithms to address complex driving decision problems. Although this approach excels in adapting to varied driving scenarios, it has relatively poor interpretability, and there is little guarantee of safety.
Most current learning-based articles are dedicated to using deep reinforcement learning techniques for discretionary autonomous lane-change control of self-driving vehicles [
9,
10,
11,
12,
13,
14]. In [
9], the authors proposed a framework that integrates deep reinforcement learning with Q-masking to enhance the efficiency of autonomous lane change. In [
8], the authors enhanced the efficiency of the deep Q-learning algorithm and applied it to the autonomous lane-change scenario [
15]. In [
10], the authors introduced an automated lane-change method based on reinforcement learning, designing a Q-function approximator with a closed-form greedy policy capable of achieving smooth and efficient driving strategies in various and unpredictable scenarios. In [
11], the authors developed a deep reinforcement learning agent capable of robustly executing automated lane change in dynamic and uncertain highway environments, demonstrating superior performance over traditional heuristic-based methods. In [
12], the authors applied deep reinforcement learning to address the challenge of successful merging or lane changing for autonomous vehicles in high-density traffic, establishing a benchmark for driving in high-density traffic conditions.
The majority of the literature currently employs discrete reinforcement learning for implementing autonomous lane change [
8,
9,
10,
11,
12,
13,
14], where the high-level control outputs lane-change decisions using discrete reinforcement learning, and the low-level control uses car-following models such as the Intelligent Driver Model (IDM) [
16] to output vehicle acceleration. The decision-making and motion-planning modules, as two closely adjacent and important functional modules of autonomous vehicles, are highly interrelated in terms of functionality and ultimate performance. Therefore, the design of the decision-making process should take into account the feasibility of motion planning. Likewise, motion planning should be formulated based on the decision made [
17]. Therefore, in our work, we have adopted a hybrid action space to simultaneously address discrete lane-change decisions and continuous longitudinal acceleration control.
To apply deep reinforcement learning to the autonomous lane-change scenario, ensuring the safety of decision making is essential. There is a paucity of literature considering the safety aspects of autonomous lane change. Given the absence of research using safe reinforcement learning to ensure the safety of discretionary lane change, our paper uses the PID Lagrangian-based hybrid-action reinforcement learning approach [
18] to implement autonomous lane change. In [
19], the authors proposed a decision-making framework for autonomous vehicles in lane-change scenarios based on deep reinforcement learning with risk awareness. In [
20], the authors used a human-driving lane-change decision model combined with regret theory to improve the safety and efficiency of autonomous vehicles in mixed traffic. In [
21], the authors introduced a safe reinforcement learning algorithm into the field of autonomous driving, combining the Proximal Policy Optimization (PPO) algorithm with a PID Lagrangian approach to enhance the traffic compliance of motion planners for self-driving vehicles [
22].
Safe reinforcement learning [
23] is a type of reinforcement learning that incorporates the concepts of safety or risk. Specifically, safe reinforcement learning emphasizes not only pursuing long-term maximum returns during the learning and implementation phases but also adhering to established safety constraints while ensuring reasonable system performance. Compared to Constrained Policy Optimization (CPO) algorithms [
24] and safe reinforcement learning algorithms based on Lyapunov functions [
25], the Lagrangian-based safe reinforcement learning algorithm performed equally well or even better in tests within the Safety Gym environment [
26]. The oscillations and overshooting observed during the learning process can lead to constraint violations by the agent when applied in practice. Therefore, the PID-based Lagrangian method was proposed [
18]. From a control perspective, traditional Lagrange multiplier updates behave as integral control, whereas the PID-based approach introduces proportional and differential controls to stabilize the learning process of the agent.
To the best of our knowledge, there are no existing studies that apply safe hybrid action space algorithms in the domain of discretionary lane change. Previous works have applied hybrid-action reinforcement learning to the discretionary lane-change scenario but have not considered safety [
27,
28,
29,
30]. In [
31], the authors adopted the safe proximal policy optimization algorithm to train the mandatory lane-change policy of an autonomous vehicle. Although the algorithm was designed with safety in mind, the lane-change strategy still exhibited a collision rate of 0.5% in the simulation tests.
The contribution of this paper includes the introduction of a novel safe hybrid-action reinforcement learning algorithm, PASAC-PIDLag, and its application to the discretionary lane-change scenario. We conducted a comprehensive and quantitative comparison between PASAC-PIDLag and its unsafe version PASAC, demonstrating that PASAC-PIDLag outperforms PASAC in terms of both safety and optimality.
Regarding the structure of the paper,
Section 2 presents the PASAC-PIDLag and PASAC algorithms,
Section 3 discusses the application of the algorithms to lane-change scenarios,
Section 4 presents the experiments and results, and
Section 5 presents the conclusions.
2. Reinforcement Learning Preliminaries
Reinforcement learning is a computational approach to learning from interaction. In this paradigm, an agent takes actions based on the current state of the environment at each time step. As a result, the environment transitions to another state in the next time step, and the agent receives a reward based on the action taken. Both the actions taken by the agent and the rewards provided by the environment are probabilistic. The goal of an RL algorithm is to maximize the expected discounted cumulative reward.
The framework used to model the environment and the agent’s interactions within it in RL is the Markov Decision Process (MDP). An MDP is defined as a tuple , where S is a finite set of states of the environment. A is a finite set of actions that the agent can choose from. P is the state-transition probability matrix. represents the probability of transitioning from state s to state after the agent takes action a. R is a reward function. represents the immediate reward the agent receives after taking action a in state s. is the discount factor, typically within the range , which determines the present value of future rewards.
The agent’s objective is to discover a policy
, which maps states to the probabilities of selecting each possible action, denoted as
, that maximizes the expected sum of discounted rewards. The optimal policy
can be formally defined as:
2.1. Soft Actor–Critic
The Soft Actor–Critic (SAC) algorithm [
32] is an off-policy, actor–critic reinforcement learning algorithm that incorporates the principles of entropy maximization to balance exploration and exploitation. SAC employs two types of neural networks: soft Q-networks that approximate the soft Q-functions, and policy networks that generate probability distribution over actions. The policy network is trained to maximize the expected reward and entropy. The SAC algorithm optimizes the following entropy-augmented objective function:
where
is the policy,
represents the parameters of the policy,
is the immediate reward for action
in state
,
is the distribution over states and actions under policy
,
is the policy entropy, and
is the entropy coefficient.
SAC uses two Q-networks,
and
, to evaluate the policy. The objective of the Q-network,
, is defined as the expected squared error between the current Q-function and the target:
where
is the action sampled from the current policy.
To stabilize learning, SAC employs soft target updates to slowly update the target network parameters
:
where
is a small number close to 0, indicating the rate at which the target network parameters are updated.
In the SAC algorithm, actions are selected according to a stochastic policy. This policy is typically parameterized as a Gaussian distribution, allowing the model to capture a range of possible actions. At each timestep
t, an action is sampled from this distribution, which is conditioned on the current state
:
where
and
are the mean and covariance of the policy’s Gaussian distribution, respectively, and are functions of the current state
parameterized by
. This stochastic policy approach facilitates exploration of the action space, which is an essential aspect of effective reinforcement learning.
2.2. Parameterized Soft Actor–Critic
Building upon the conventional SAC algorithm, we introduce the Parameterized Soft Actor–Critic (PASAC) algorithm, which is designed to operate within environments that have both discrete and continuous action spaces. In the PASAC algorithm, the policy’s output consists of continuous actions along with the probabilities of discrete actions. Let , where each discrete action is associated with a set of continuous parameters . Therefore, the action space is represented as , where represents continuous actions, and represents discrete actions.
2.3. Parameterized Soft Actor–Critic with PID Lagrangian
The Constrained Markov Decision Process (CMDP) [
33] extends the MDP framework by augmenting it with constraints restricting the set of feasible policies. The CMDP is characterized by the expanded tuple
, where
c is the cost function and
d is the corresponding cost limit.
The objective of the CMDP is to optimize policy
, yielding the highest expected sum of discounted rewards over trajectories while keeping the expected sum of discounted costs within the cost limit. Formally, in a CMDP formulation, the RL problem finds the optimal policy
that solves
where
represents the expected reward for the policy
and
denotes the cost associated with the policy
.
In this study, we address the constrained problem by employing the Lagrangian method, which allows us to convert a constrained problem into an unconstrained problem. Lagrangian techniques are a well-established approach for tackling optimization problems that include constraints. Given the CMDP, the unconstrained problem can be written as
where
L is the Lagrangian and
is the Lagrangian multiplier (a penalty coefficient).
In the traditional Lagrangian multiplier method, updates consider only integral control, which is related to the accumulation of constraint violations. Such updates can be conducted within the framework of the Lagrangian method by solving the dual problem, in which the multipliers are adjusted over time to satisfy the constraints.
The Lagrangian multiplier update formula can be represented as
where
is the learning rate of
.
In the PID method, the dual update rule is enhanced by adding proportional (P) and derivative (D) controls to the existing integral (I) term, with the goal of reducing oscillations in the system output and providing a quicker response to safety constraint violations. The new PID Lagrangian update rule is expressed as
where
is the constraint violation at time
t, with
d being the target value for the constraint.
,
, and
are the proportional, integral, and derivative gains, respectively. The proportional term
accounts for the current magnitude of the constraint violation, the integral term
considers the accumulated error over time, and the derivative term
takes into account the rate of change of the error. This combination helps to satisfy the constraints more quickly and smoothly during the learning process. The pseudocode of the PASAC-PIDLag algorithm is shown in Algorithm 1.
| Algorithm 1 Parameterized Soft Actor–Critic with PID Lagrangian |
- 1:
Algorithm: - 2:
Initialize ▹ Init parameters and replay buffer - 3:
Initialize PID gains , , , Lagrangian multiplier , target cost d - 4:
Initialize , ▹ Init cost and integral term - 5:
for each iteration do - 6:
for each environment step do - 7:
- 8:
- 9:
▹ Store transition - 10:
end for - 11:
for each gradient step do - 12:
▹Sample batch - 13:
for ▹ Update Q-function parameters - 14:
▹ Update policy parameters - 15:
for ▹ Update target network parameters - 16:
- 17:
- 18:
- 19:
▹ Update using PID controller - 20:
- 21:
end for - 22:
end for
|
3. Lane-Change Problem Formulation
3.1. Lane-Change Environment
The lane-change environment was created in the Simulation of Urban Mobility (SUMO) [
34] driving simulator. We used a two-lane road with a length of 1 km as our training road, and subsequently, testing was conducted on this road. In this paper, the perception range of the vehicles is represented by a circle with a radius of 200 m, and we assume that the ego vehicle can accurately perceive the status of all vehicles within this range. The surrounding vehicles on the road have an initial speed of 8.33 m/s and a maximum speed of 16.67 m/s, and they use the IDM [
16] model for longitudinal control and the SL2015 [
35] model for lateral control. In this study, we trained with a traffic flow density of 15 veh/km. As shown in
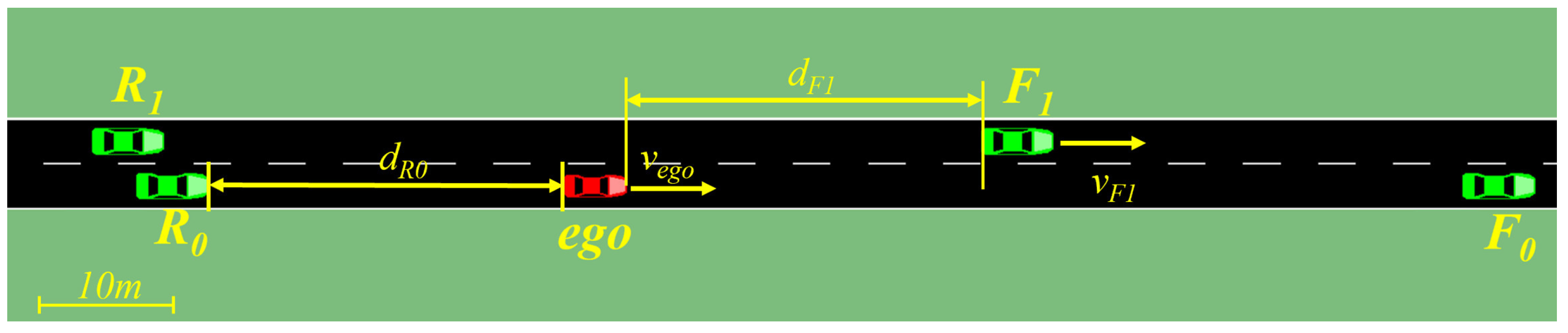
Figure 1, the red vehicle represents the ego vehicle, and the green vehicles represent other vehicles.
3.2. Environment State
In this paper, the state is characterized by ten variables: the distance
between the ego vehicle and the vehicle in front, the distance
between the ego vehicle and the vehicle behind, the distance
between the ego vehicle and the vehicle in front on the target lane, and the distance
between the ego vehicle and the vehicle behind on the target lane. Additionally, the speeds
,
,
, and
of these four vehicles, as well as the speed
and acceleration
of the ego vehicle, are considered.
3.3. Control Action
In this study, the continuous action of the control output is acceleration, and the discrete action is the lane-change decision. Vehicle dynamics and latency are not considered; hence, the vehicle instantaneously executes upon receiving an acceleration command or a lane-change decision. In training, the updates of the vehicle’s velocity, position, and lane-change decision occur at a time step of s, whereas in testing, the lane-change decision is output every 1 s. Moreover, accounting for the actual vehicle’s limits, the limit for continuous actions is defined as , where and represent the minimum and maximum accelerations, respectively.
The action space is defined as a tuple , where represents the continuous control of the vehicle’s acceleration, bounded by . is the discrete lane-change decision, where indicates changing to another lane, and signifies maintaining the current lane.
3.4. Reward
In the context of autonomous vehicle control, reward functions are designed to promote safe, efficient, and comfortable driving behavior. These functions are itemized as follows:
(1) This reward function aims to reduce meaningless lane change caused by the ego vehicle.
(2)
represents the safe following distance from the vehicle ahead in the same lane, which is set to 25 m in this study.
denotes the minimum speed limit for the lane when the distance to the vehicle ahead exceeds the safe distance.
(3) To facilitate the ego vehicle’s acquisition of car-following behavior and to mitigate the risk of collisions, we devised the following reward function predicated on the vehicle-to-vehicle distance metric:
where
represents the distance to the rear vehicle in the same lane and
denotes the distance to the forward vehicle in the same lane.
(4) To instruct the ego vehicle to autonomously navigate lane change while mitigating collision occurrences, a penalty of is incurred following each collision event.
(5) To reduce the jerk during the ego vehicle’s motion, we defined the following reward function:
where
represents the acceleration of the ego vehicle at the current time step and
represents the acceleration of the ego vehicle at the previous time step.
(6) For safe reinforcement learning, we employ the TTC as a cost metric. The TTC is expressed as
where
represents the velocity of the ego vehicle,
denotes the velocity of other vehicles, and
indicates the relative distance between the ego vehicle and other vehicles. When the TTC between the ego vehicle and either the leading or following vehicle is less than 2.7 s but greater than 0, the cost is incremented by 1; if the TTC is equal to or greater than 2.7 s or the TTC is not calculable (due to no vehicle being present), the cost remains at 0.
For the PASAC algorithm, the total reward at each timestep is given by
For the PASAC-PIDLag algorithm, the total reward and cost at each timestep are given by
We do not include collisions in the cost calculation because the safety policy derived from safe RL may sometimes approach the collision constraint too closely, potentially resulting in collisions.
4. Experiments and Results
In this section, we present the training results under a traffic density of 15 veh/km. The PASAC-PIDLag algorithm outperforms the PASAC-Lag in terms of rewards and costs. The PASAC-Lag method is the traditional Lagrangian method that focuses solely on integral control. Therefore, we did not conduct tests on it. We analyzed both PASAC-PIDLag and PASAC algorithms under a traffic density of 15 veh/km. Additionally, we conducted a generalization analysis of these two algorithms under traffic densities of 10 veh/km and 18 veh/km.
4.1. Training
Our training setup consisted of an NVIDIA RTX 3060 GPU and an Intel i7-12700F CPU, with each training session running for approximately 5 h and covering 400,000 timesteps. The timestep interval was set at 0.1 s to better reflect real-world scenarios. Additionally, we initialized vehicles on the main road within a 50 m buffer zone at the start of each episode. The initial speed of the ego vehicle was set to 8.33 m/s. At the beginning of each episode, the lane for ego vehicle departure was randomly chosen from the two-lane road. During the training process, we evaluated ten episodes for each training episode, and we selected the best-performing policy as the model for subsequent testing.
The hyperparameter configurations for the PASAC-PIDLag, PASAC-Lag, and PASAC algorithms are listed in
Table 1.
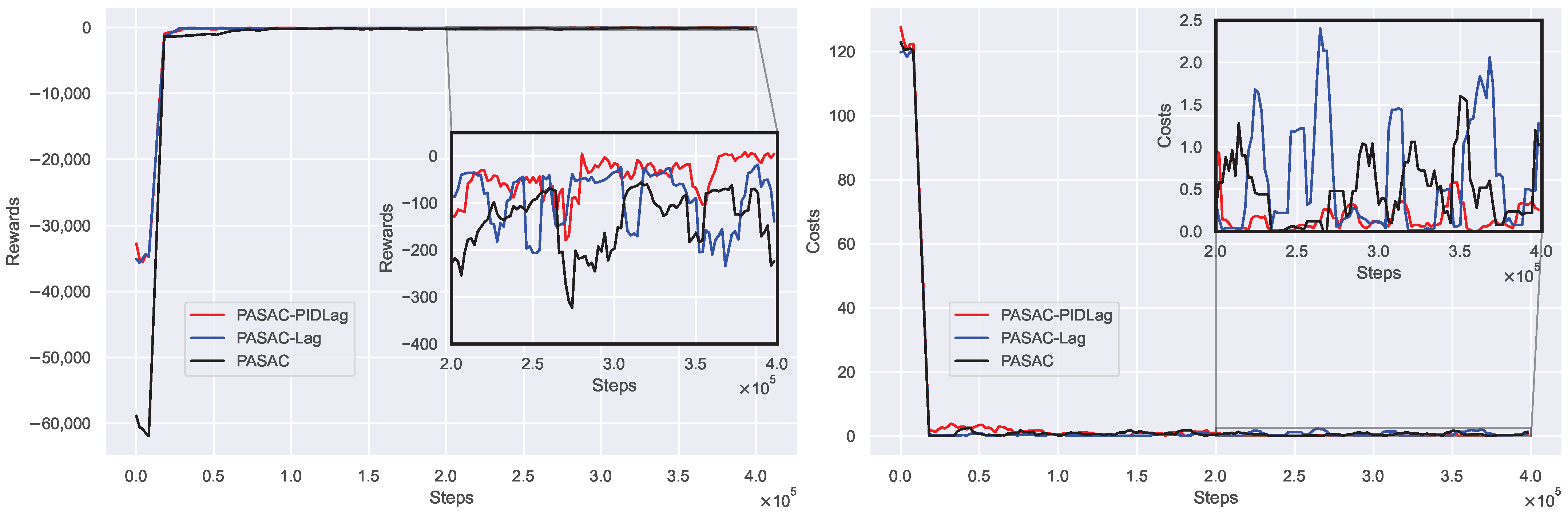
Figure 2 illustrates the training curves for these algorithms. From the training curves, it is evident that the PASAC-PIDLag algorithm demonstrates superior performance compared to both the PASAC-Lag and PASAC algorithms. The training curve of the PASAC-PIDLag algorithm outperforms that of the PASAC-Lag, as the incorporation of PID control in PASAC-PIDLag has successfully reduced the oscillation amplitudes of the cost, leading to more stable performance. Consequently, the PASAC-Lag algorithm was not considered for further testing.
4.2. Testing
In our experiments, we evaluated the performance of the trained policy over 400 episodes under a traffic density of 15 veh/km, encompassing approximately 300,000 timesteps. At the onset of each episode, the initial velocity of the ego vehicle was set to 8.33 m/s (equivalent to 30 km/h). Moreover, to assess the generalizability of our approach, we also conducted tests on the aforementioned strategy at traffic densities of 10 veh/km and 18 veh/km.
4.3. Comparison and Analysis
Based on the results obtained from the dataset of 400 test episodes, as shown in
Table 2, it is evident that the PASAC-PIDLag algorithm outperformed the PASAC algorithm on multiple evaluation metrics. The PASAC-PIDLag algorithm exhibited a notably lower collision rate, indicating a safer driving policy adept at mitigating the risk of accidents more effectively. In addition, this algorithm necessitated fewer lane-change maneuvers, suggesting more stable and efficient driving behavior with the potential to diminish disruptive actions within the traffic flow. In terms of velocity, the PASAC-PIDLag algorithm achieved a higher average speed, a pivotal factor in enhancing the rate of transport. Moreover, the jerk metric was significantly reduced for the PASAC-PIDLag algorithm. Upon comprehensive consideration of these performance indicators, the PASAC-PIDLag algorithm surpassed the PASAC algorithm in terms of both optimality and safety.
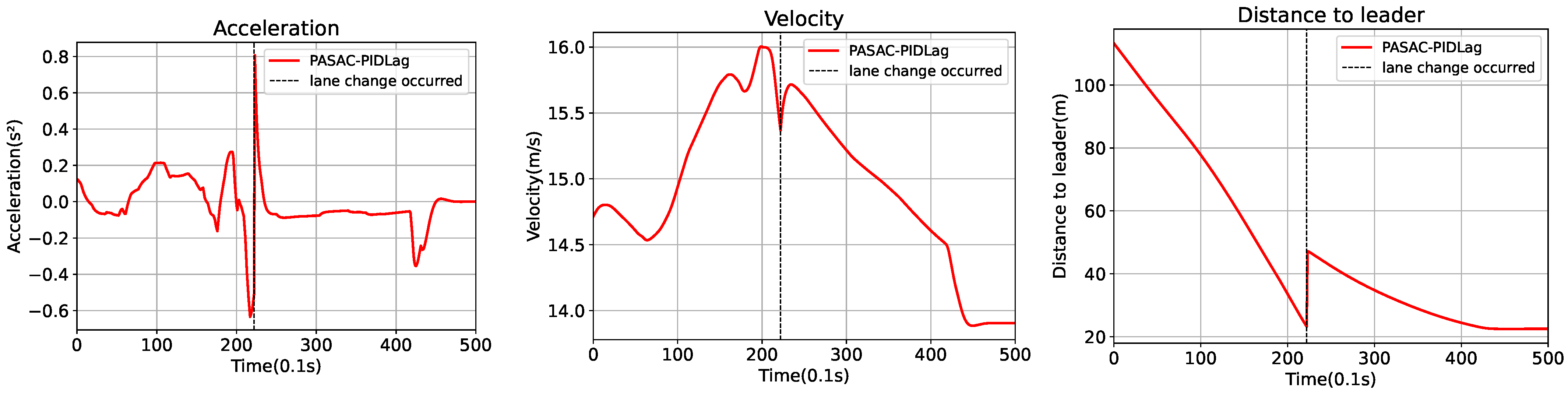
Figure 3 depicts an analysis of a lane-changing episode under the PASAC-PIDLag algorithm. Subsequent to this lane-change event, there was an immediate and discernible change in the distance to the preceding vehicle, indicative of the completion of the lane change. The graph detailing relative distance demonstrates that the vehicle initiated the lane-change maneuver when it was at a safe following distance of approximately 25 m. Moreover, the velocity graph depicts a modest escalation in the ego vehicle’s speed following the lane change, which was shortly followed by a decrease.
Figure 4 presents the SUMO scene of the successful lane-change maneuver executed by the PASAC-PIDLag algorithm.
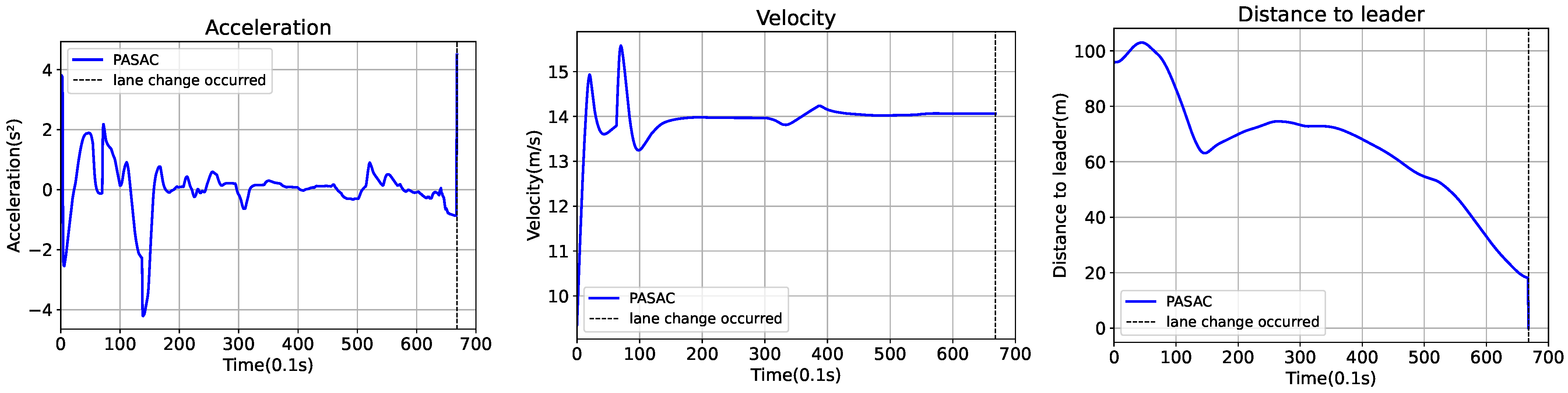
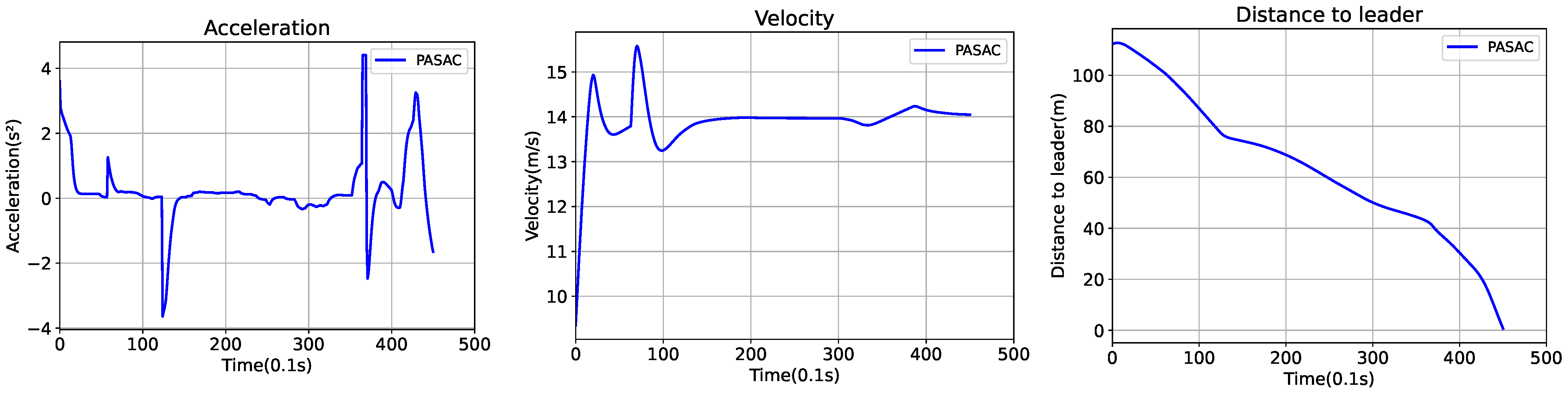
Figure 5 depicts an episode of collision occurrence within the PASAC algorithm framework, in which the ego vehicle collided after executing a lane change. The data presented in the figure reveal that the ego vehicle was steadily closing in on the vehicle ahead until the following distance diminished to 19 m, which triggered a decision to change lanes. At this juncture, the presence of another vehicle in the target lane led to a collision.
Figure 6 displays the instance of a lane-change maneuver resulting in a collision in SUMO, as directed by the PASAC algorithm.
Figure 7 illustrates another scenario in which a collision occurred under the PASAC algorithm, where the ego vehicle collided during the car-following process. The data and the figure show that due to the presence of a vehicle in the adjacent lane, the ego vehicle was unable to change lanes, resulting in a collision during car following.
Figure 8 presents an example of a collision involving an ego vehicle trained using the PASAC algorithm in a car-following scenario in SUMO.
A comparison of lane-changing decisions between the PASAC and PASAC-PIDLag algorithms demonstrated that the strategy derived from the PASAC algorithm was sometimes incapable of effectively balancing the decision related to lane changing and car following under certain conditions.
4.4. Generalization Analysis
To evaluate the generalizability of the proposed algorithm, we first conducted tests under a traffic density of 10 veh/km, and the results are presented in
Table 3. The data presented in
Table 3 reveal that at such a reduced traffic density, both algorithms demonstrated the ability to maintain a collision rate of zero. Notwithstanding this equivalence in safety, the PASAC-PIDLag algorithm surpassed its counterpart, PASAC, by securing a greater average reward, attaining a higher mean velocity, and exhibiting a lower average jerk. These findings imply that the PASAC-PIDLag algorithm not only meets safety benchmarks but also excels in performance, offering an enhanced level of optimality over the PASAC algorithm.
Our final series of tests were conducted at a traffic flow density of 18 veh/km. The results outlined in
Table 4 reveal that at this higher traffic density, the collision rate of the PASAC-PIDLag algorithm remained lower than that of the PASAC algorithm. Furthermore, the PASAC-PIDLag algorithm demonstrated its superiority across all measured metrics, including average reward, average speed, and average jerk.
5. Conclusions
In this paper, we introduced PASAC-PIDLag, a safe hybrid-action reinforcement learning algorithm specifically applied to the scenario of autonomous lane change. This method represents a novel approach that aims to enhance both safety and optimality in the application of reinforcement learning in the autonomous driving domain. We compared it with its unsafe version, PASAC. Both algorithms were trained and tested under a traffic flow density of 0.15 veh/km and underwent generalization tests at densities of 0.10 veh/km and 0.18 veh/km. The results indicated that at a traffic density of 15 veh/km, the strategy trained by the PASAC-PIDLag algorithm managed to maintain zero collisions, while the collision rate for the PASAC algorithm was observed to be 1%. The PASAC algorithm was observed to encounter two types of collisions at a density of 15 veh/km. The reward structure in this study involves both lane changing and car following, which may lead to collisions arising from unsuccessful lane-changing or car-following maneuvers.
Both algorithms achieved zero collisions at a lower traffic density of 10 veh/km. At a higher traffic density of 18 veh/km, the collision rate of the PASAC-PIDLag algorithm was lower than that of the PASAC algorithm. Across the three traffic densities, the PASAC-PIDLag algorithm consistently achieved higher average speeds, lower average jerks, and greater average rewards. Overall, the PASAC-PIDLag algorithm showed superior performance with respect to safety and optimality.
In future work, we aim to further the application of safe reinforcement learning-based control in actual vehicles. Applying reinforcement learning to real vehicles presents numerous challenges, particularly regarding varying road conditions. In subsequent efforts, we plan to utilize driving simulation software to create road scenarios with obstacles such as construction zones, potholes, and lane congestion. Training within these simulated environments will address the challenge of adapting to diverse road conditions. Additionally, we will employ meta-reinforcement learning to rapidly adapt to different road conditions.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}