
Direct Uncertainty Minimization Framework for System Performance Improvement in Model Reference Adaptive Control

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Notation and Mathematical Preliminaries
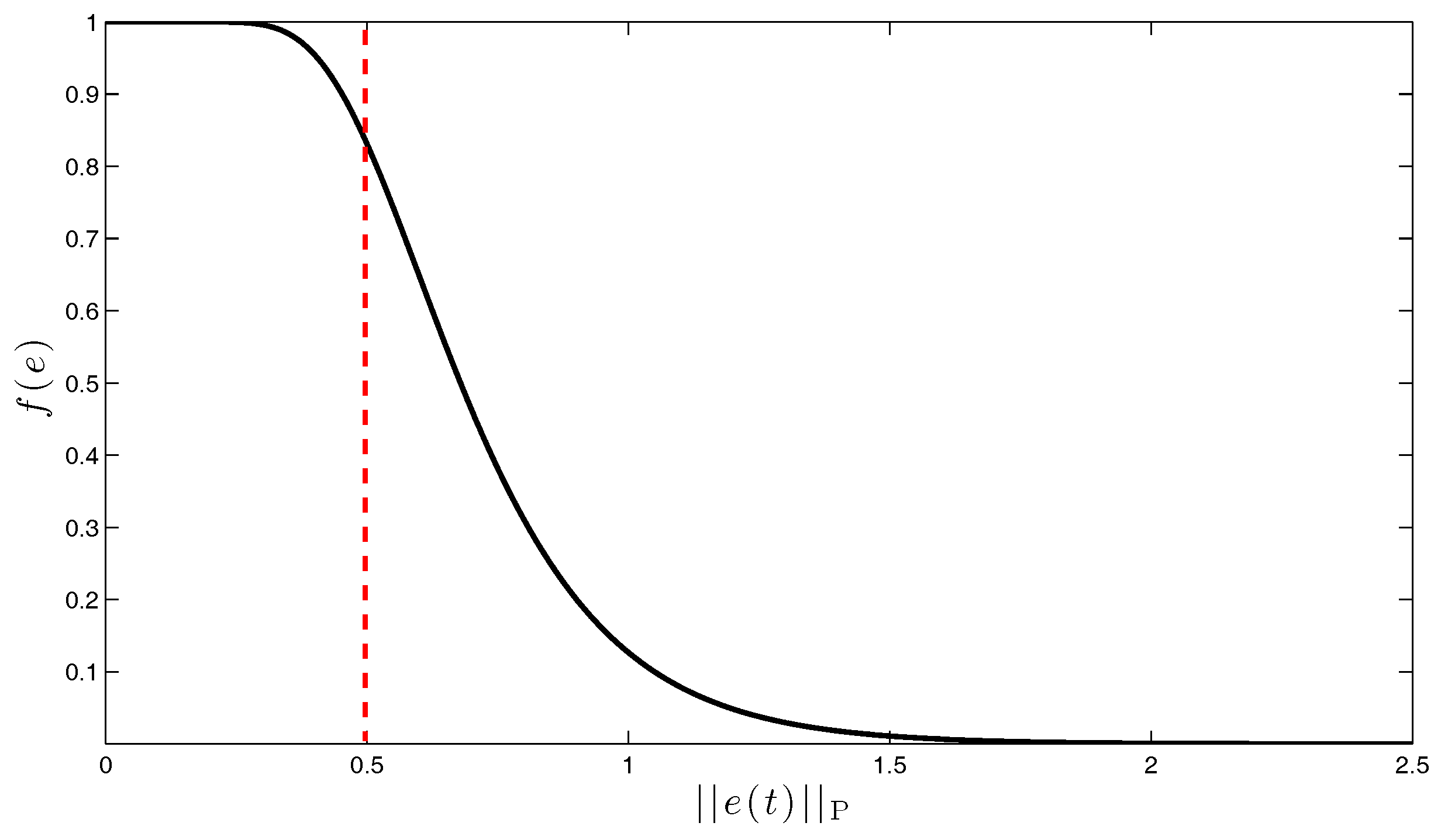
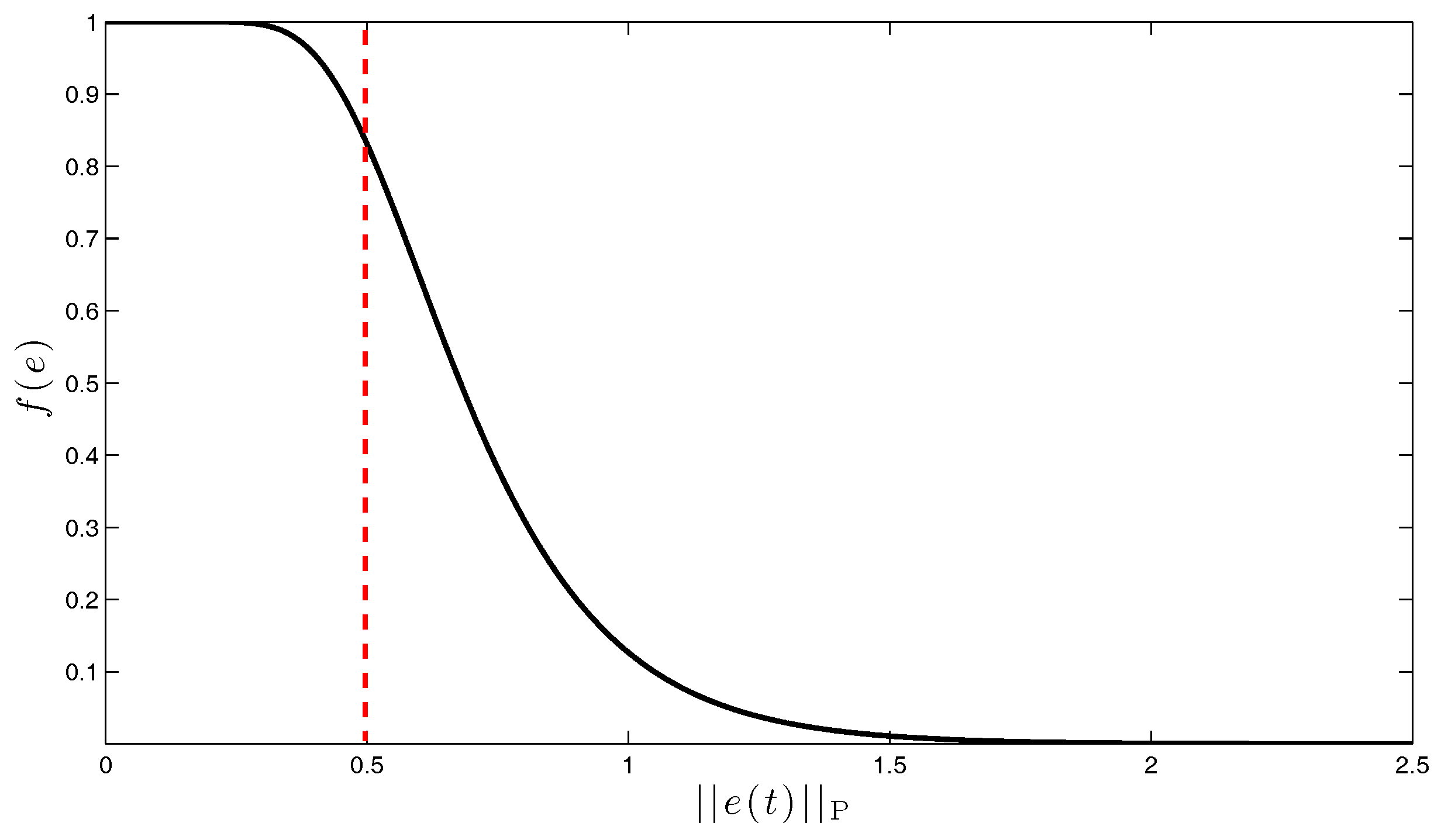
3. Direct Uncertainty Minimization for Adaptive System Performance Improvement: Linear Reference Model Case
4. Generalization to a Class of Nonlinear Reference Models
5. Illustrative Numerical Examples
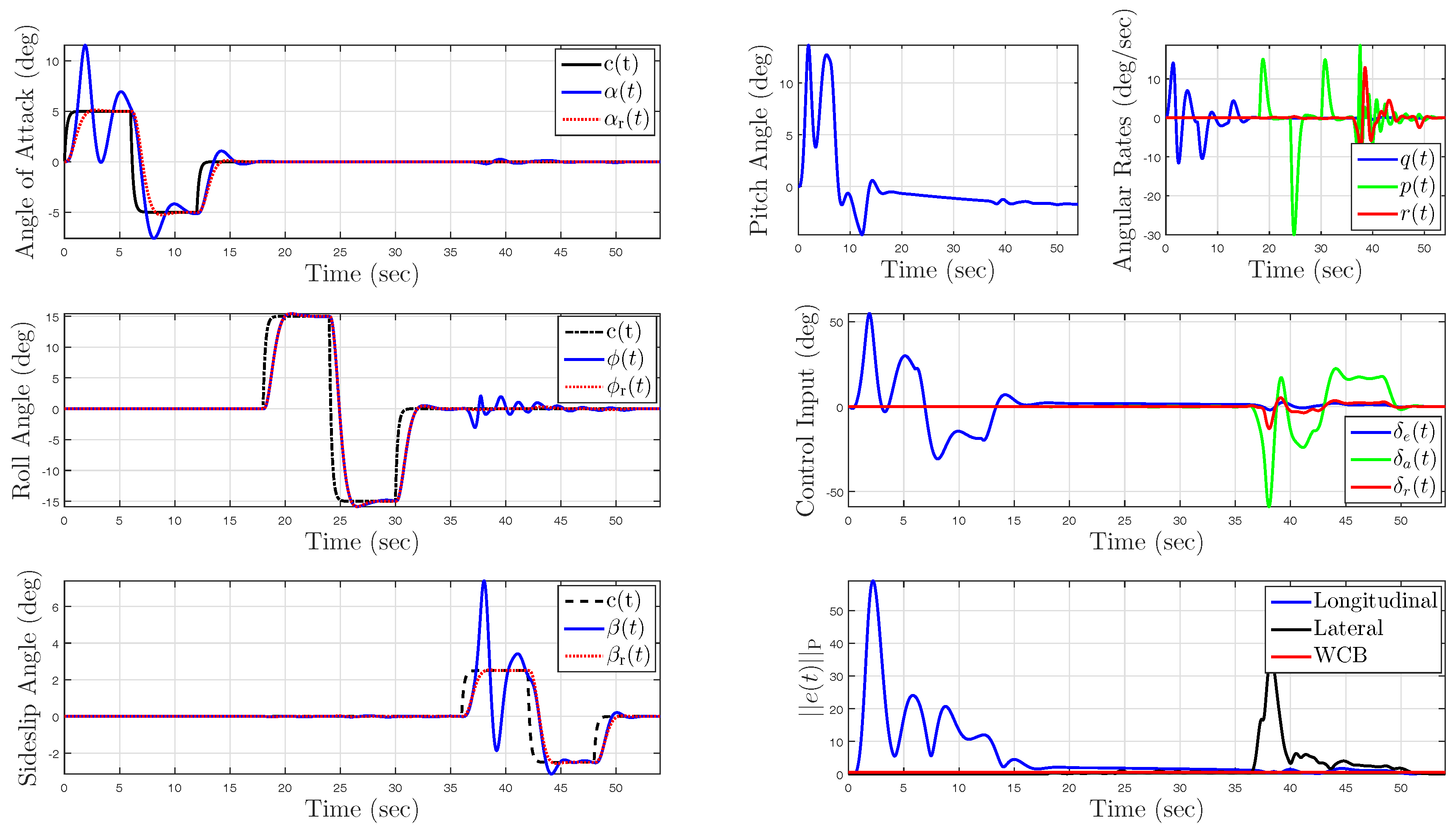
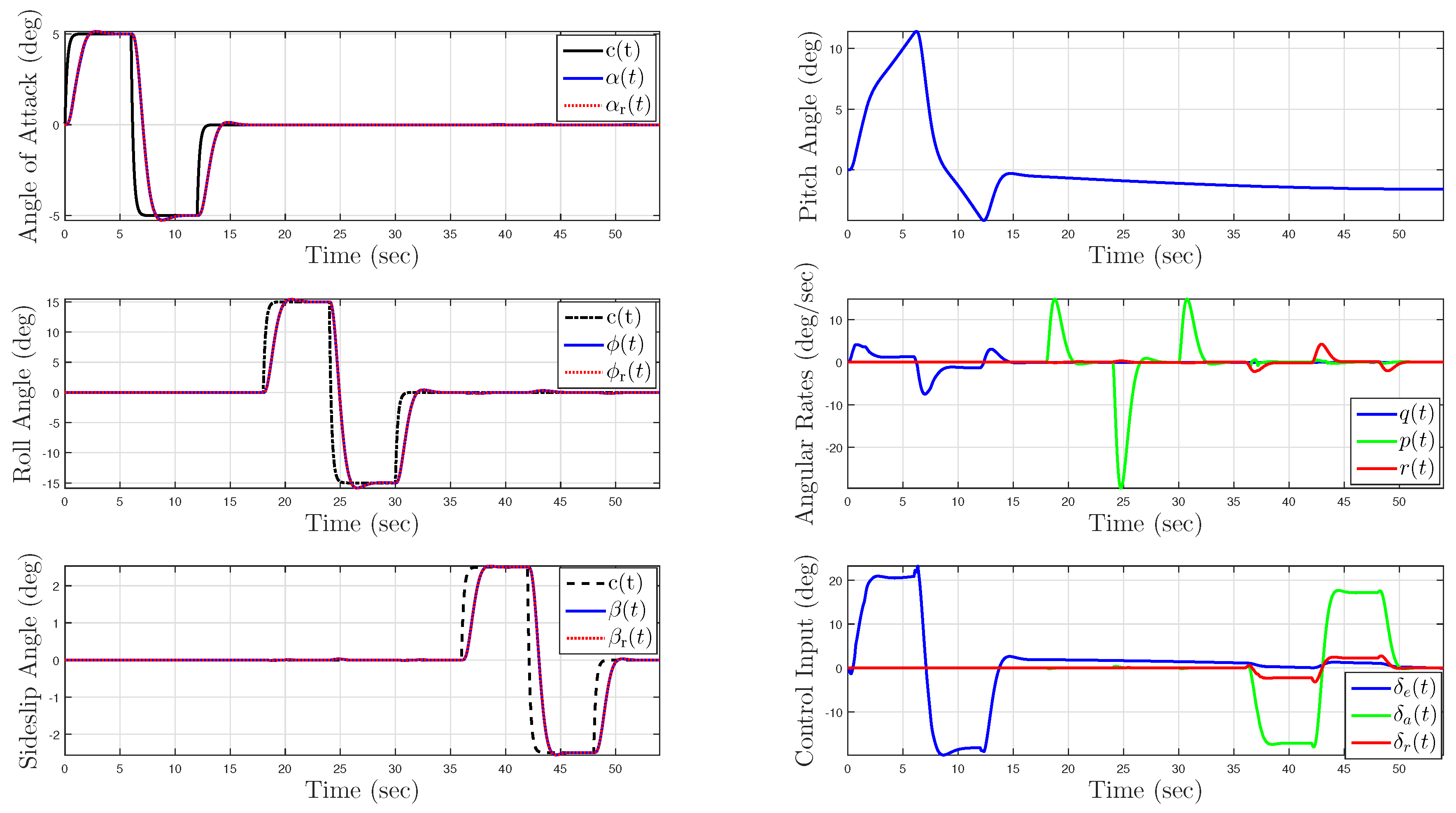
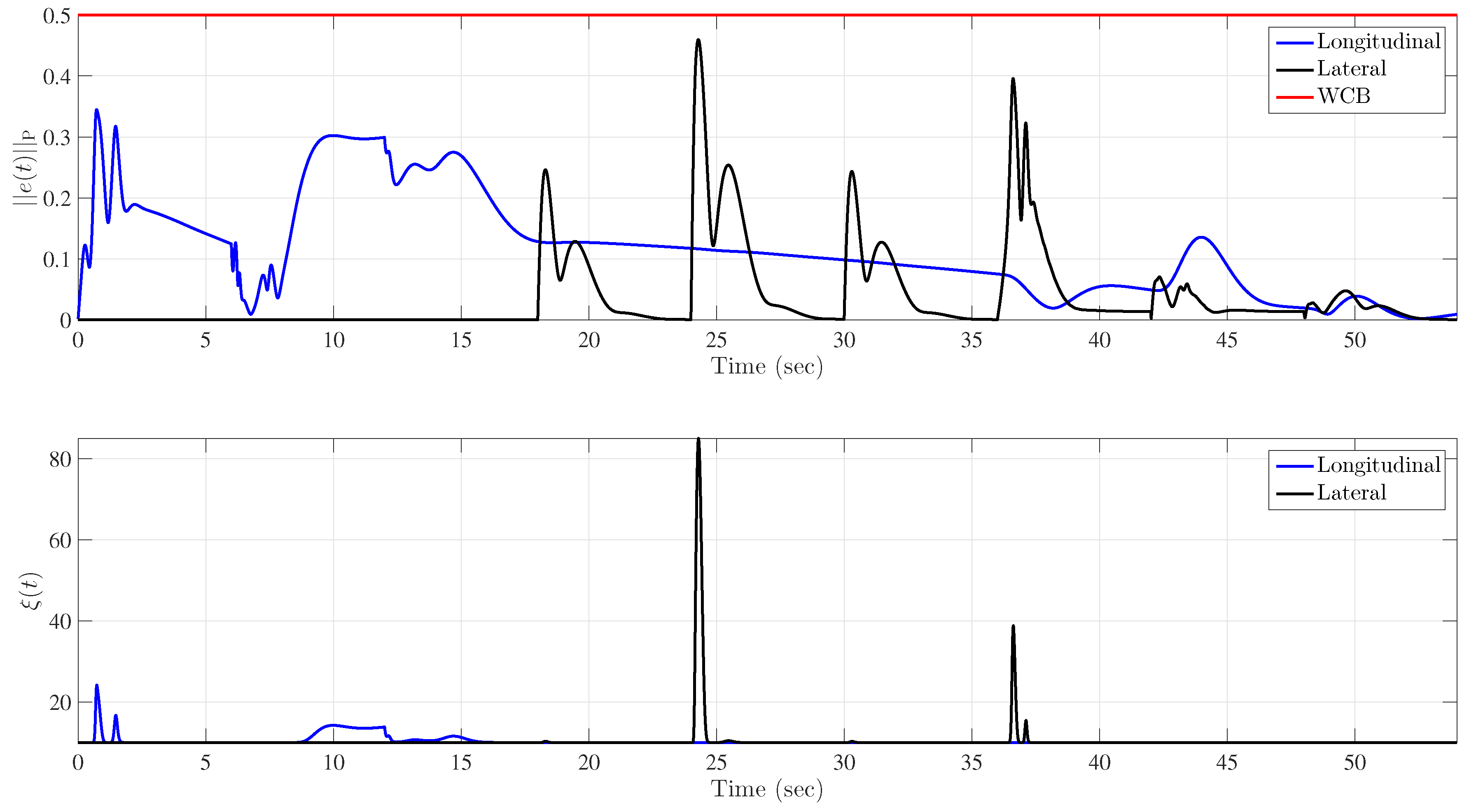
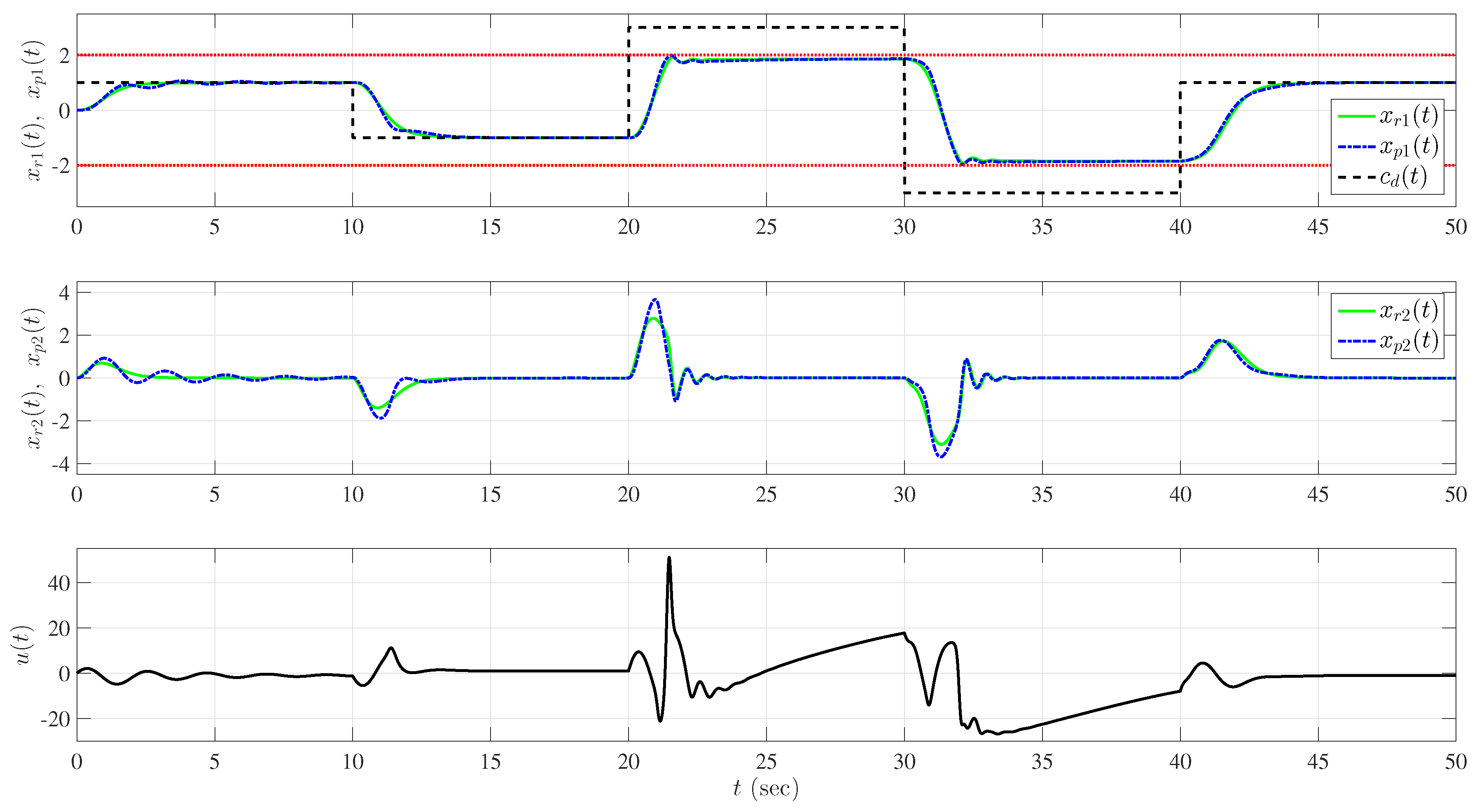
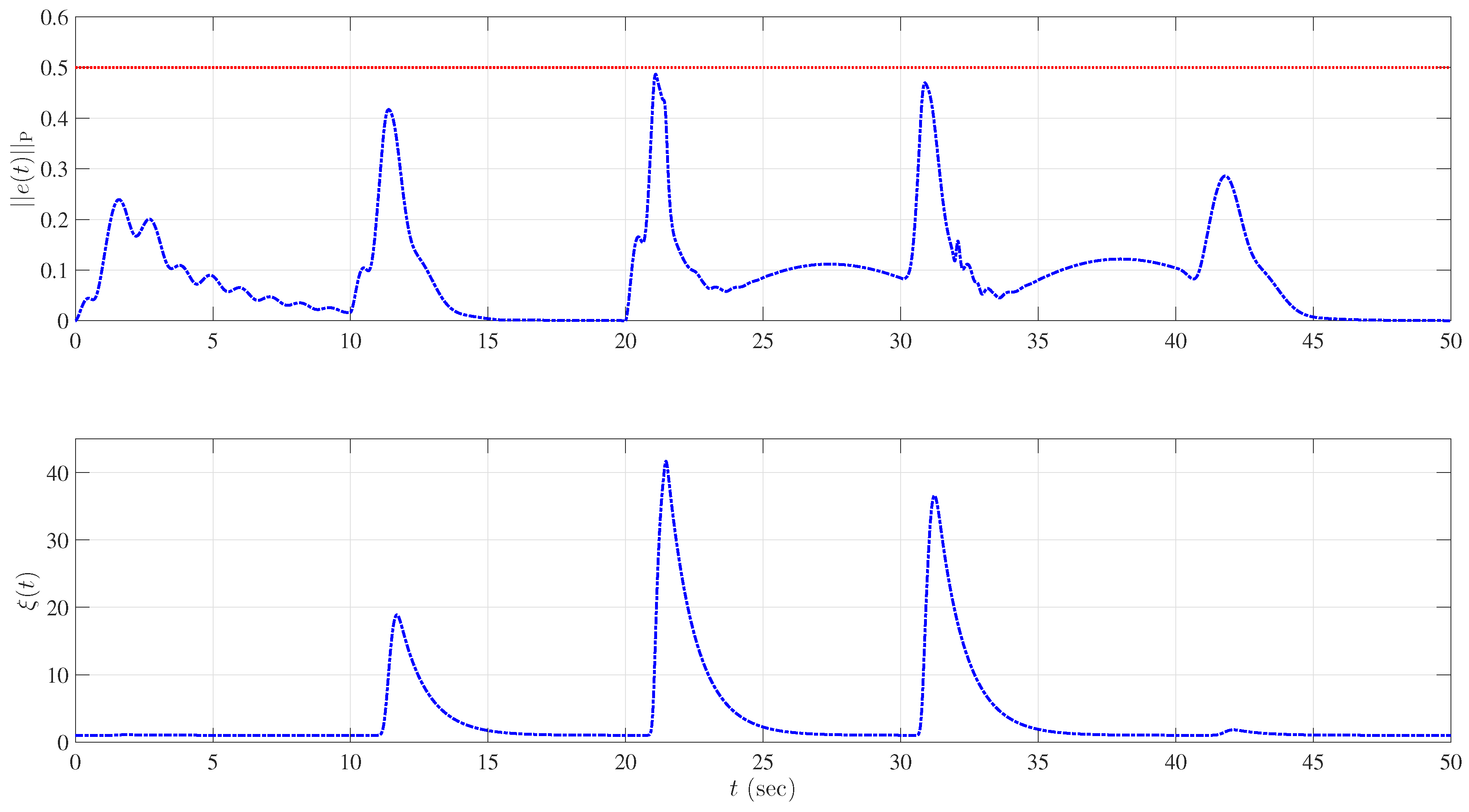
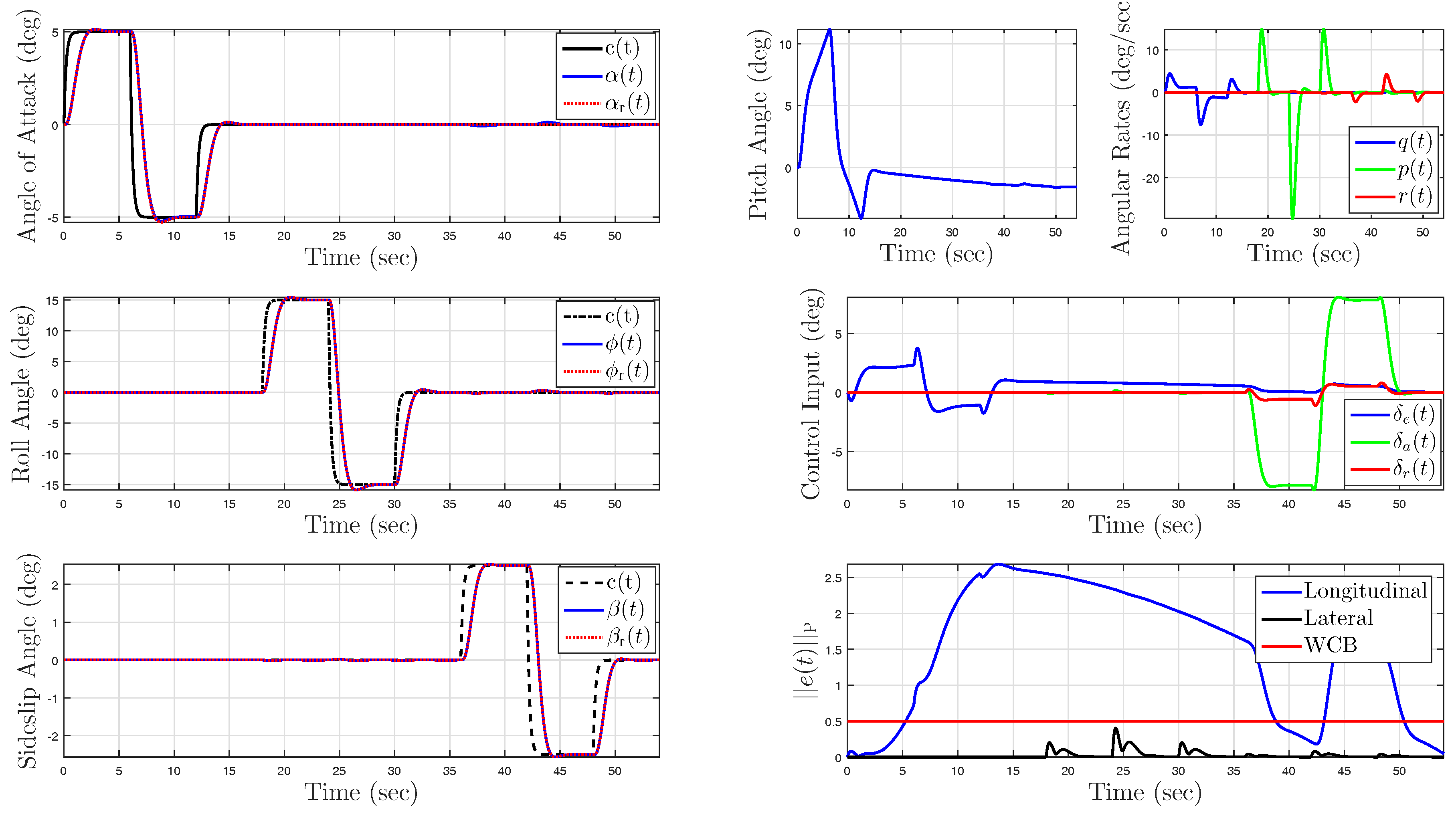
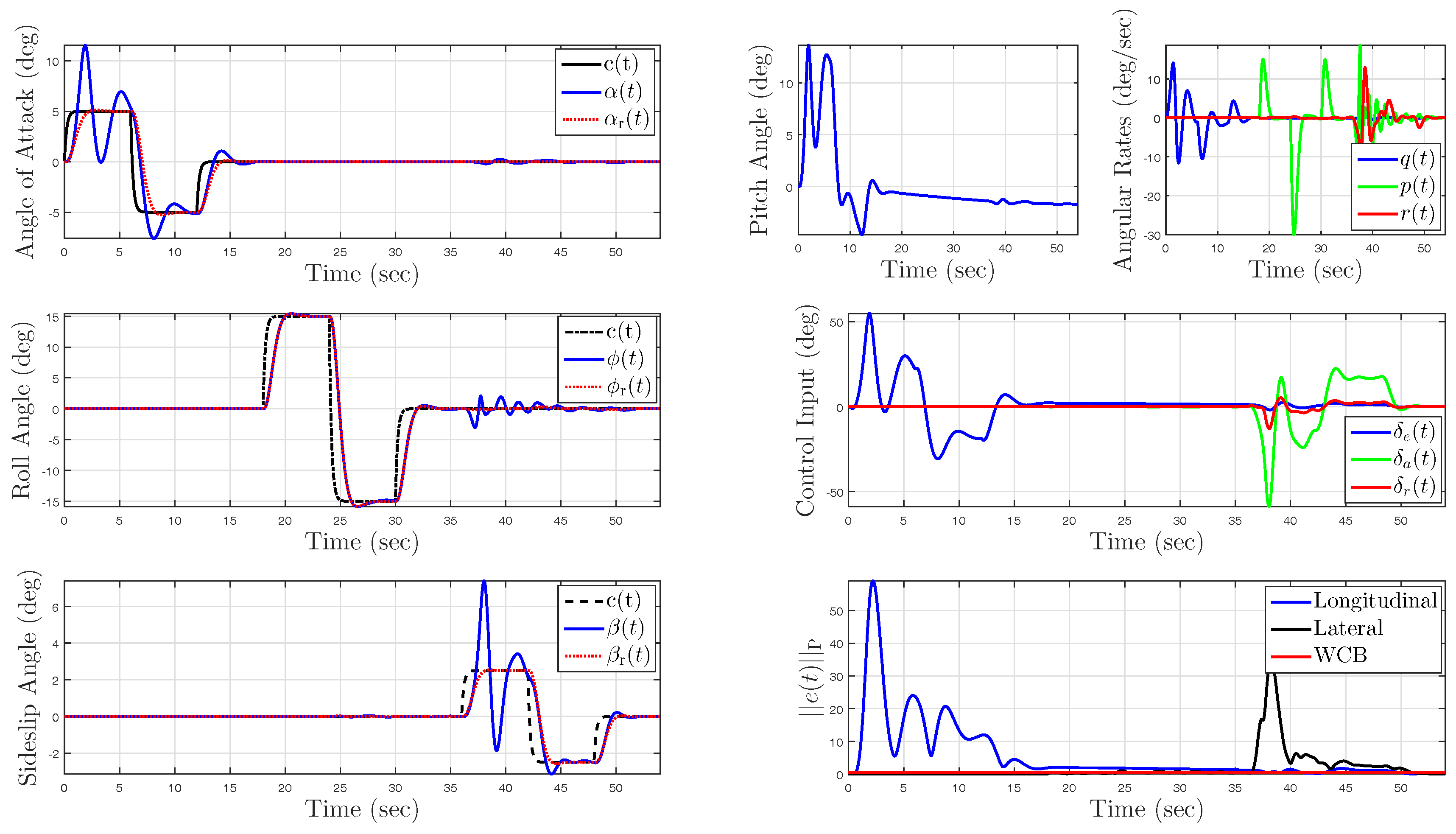
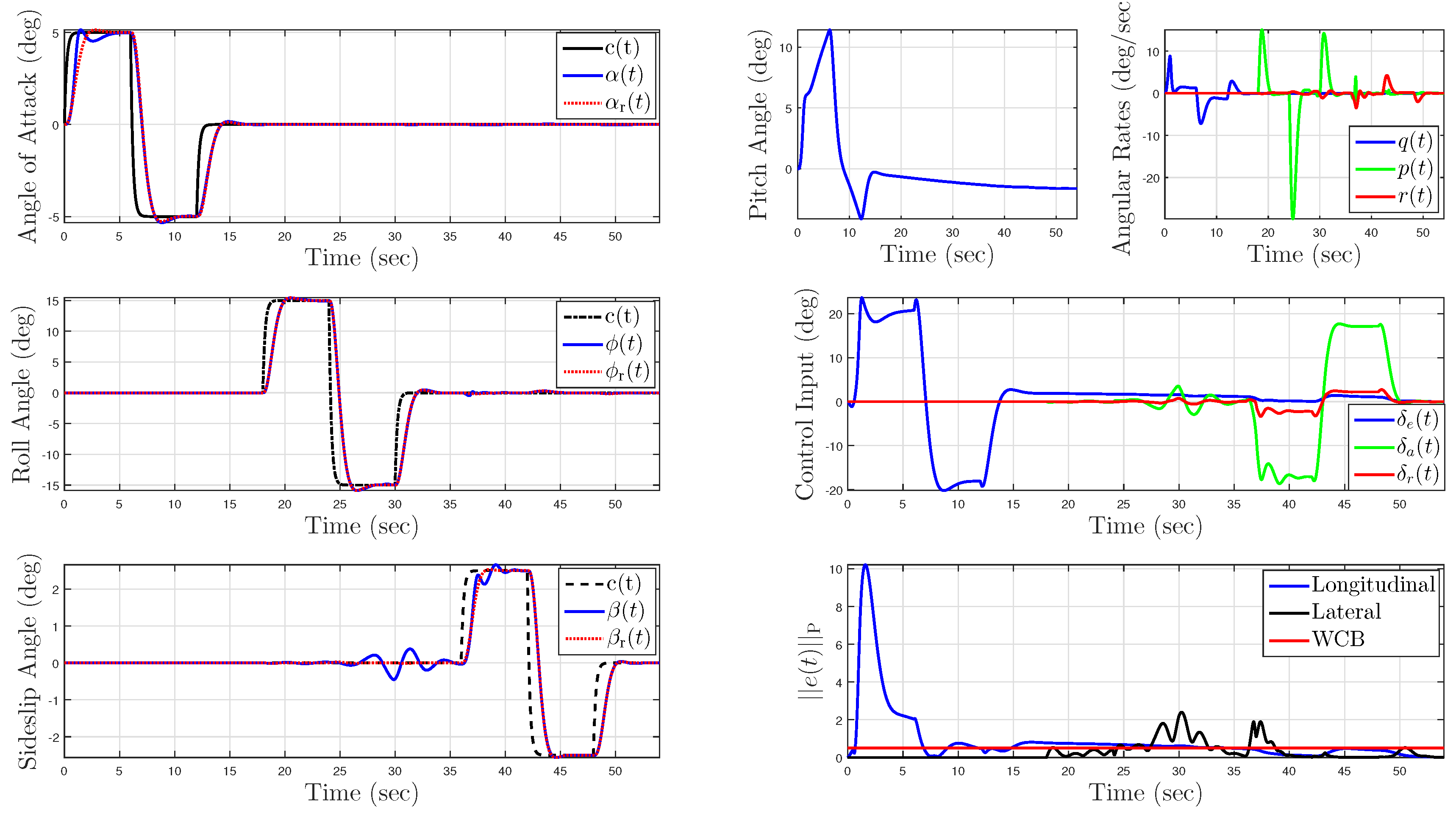
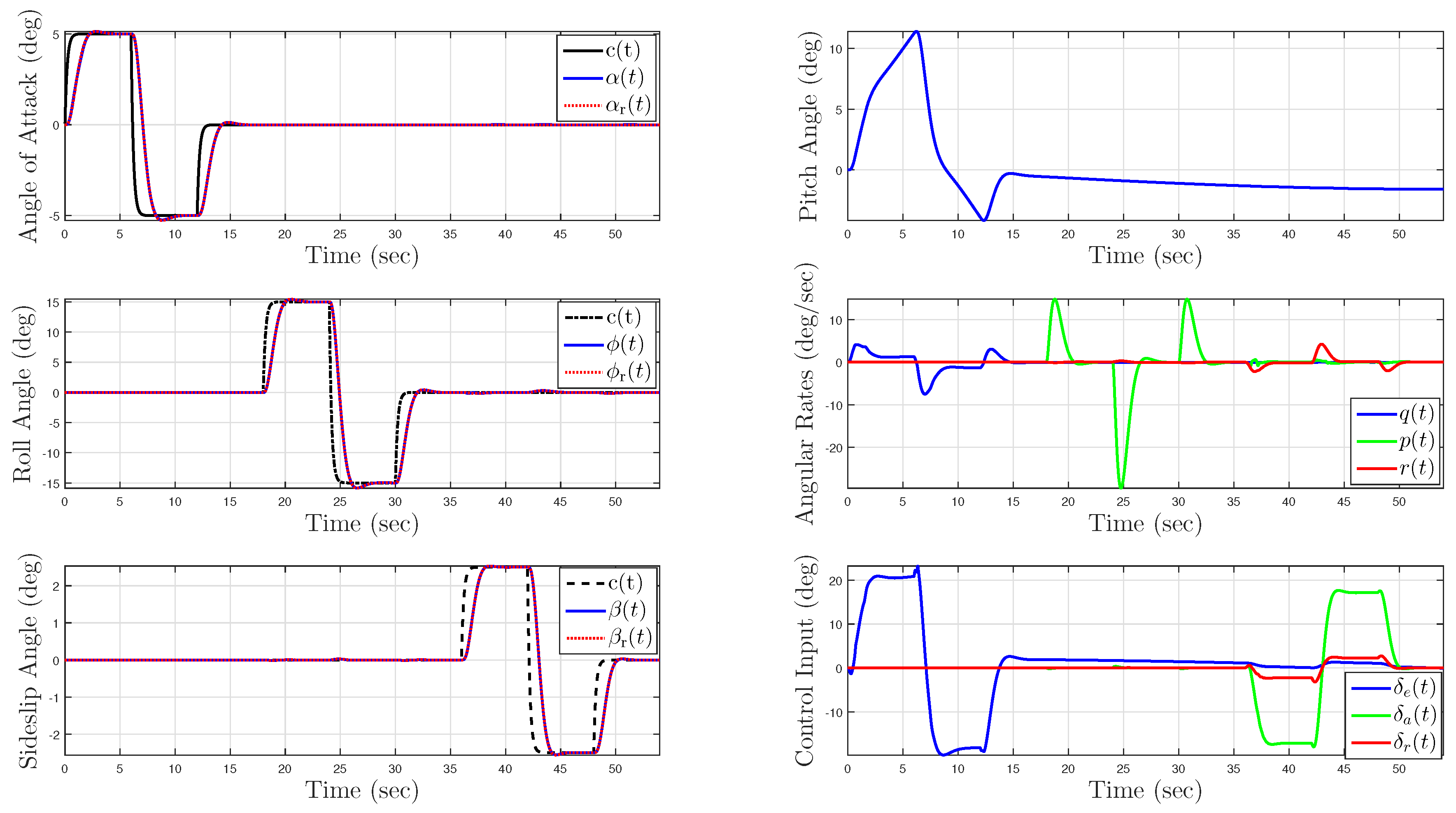
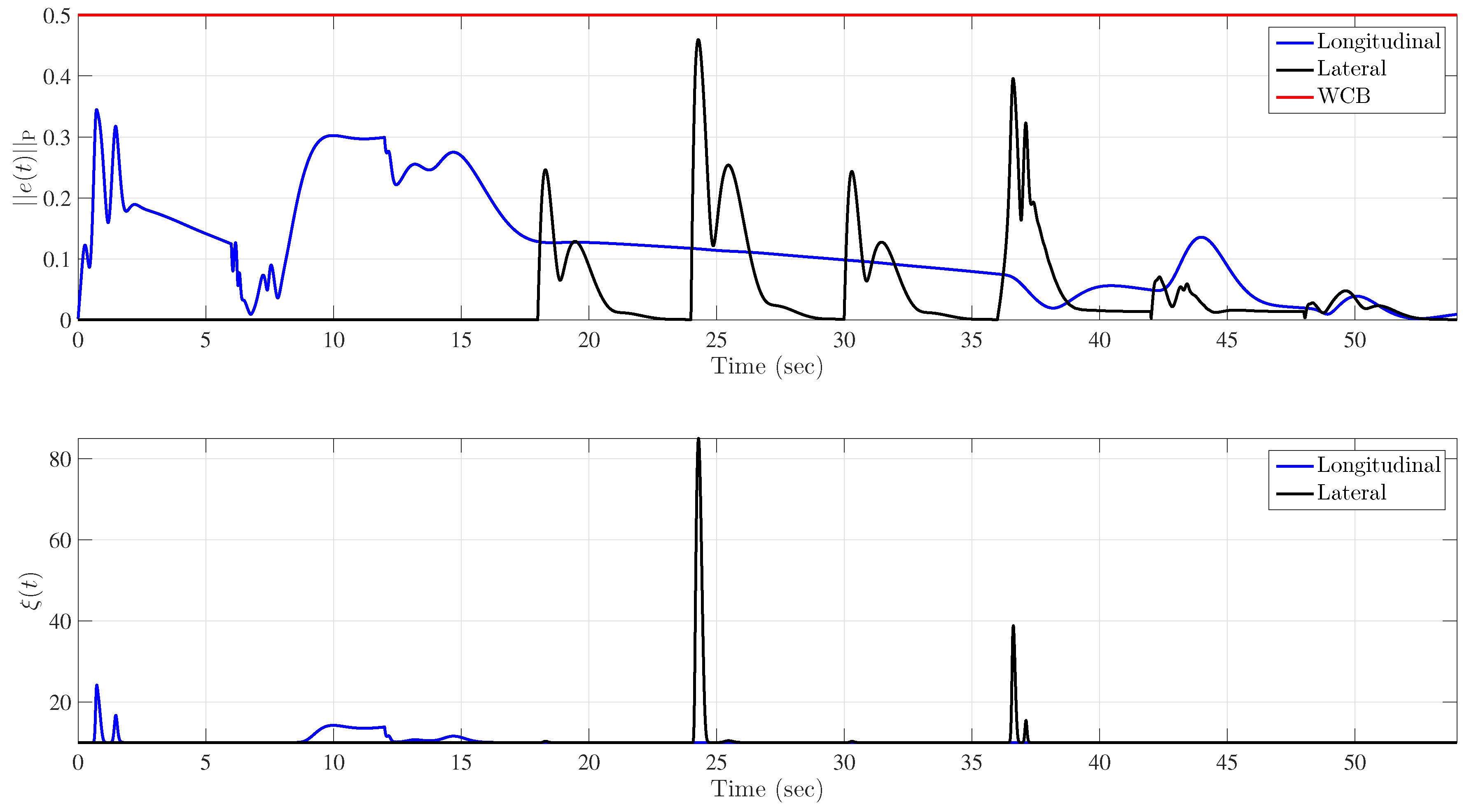
5.1. Example 1: Application to a Hypersonic Vehicle Model
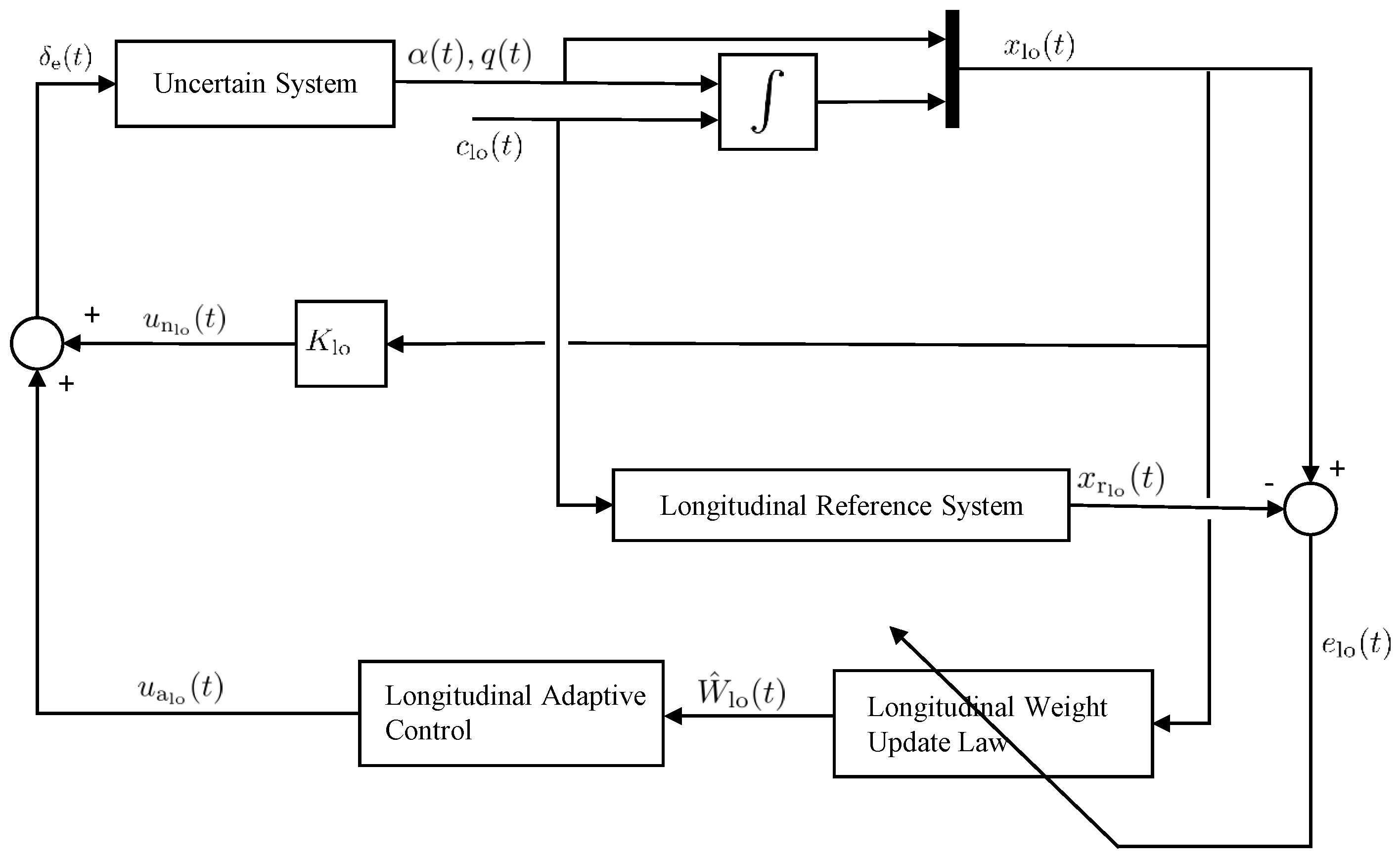
5.1.1. Longitudinal Control Design
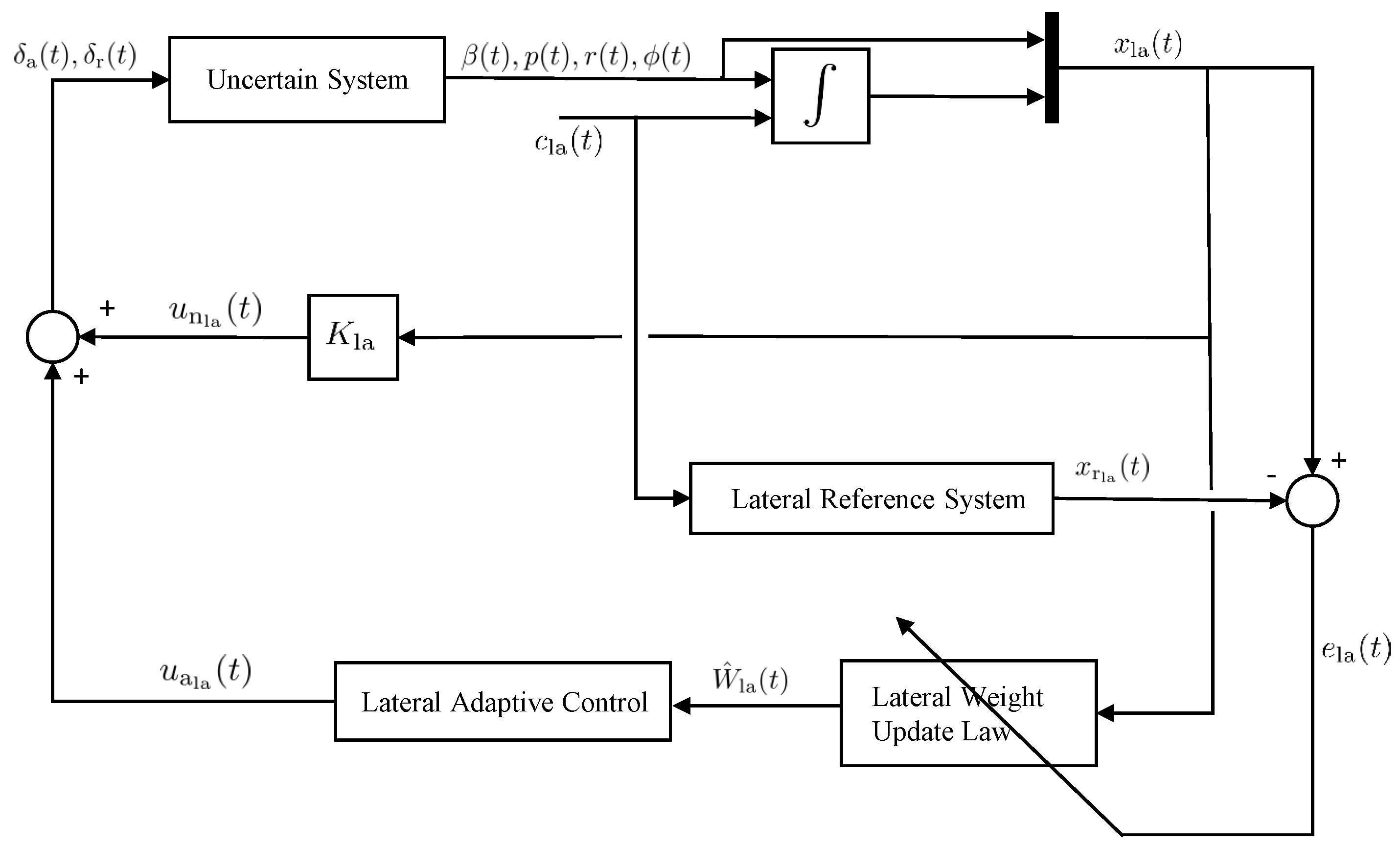
5.1.2. Lateral Control Design
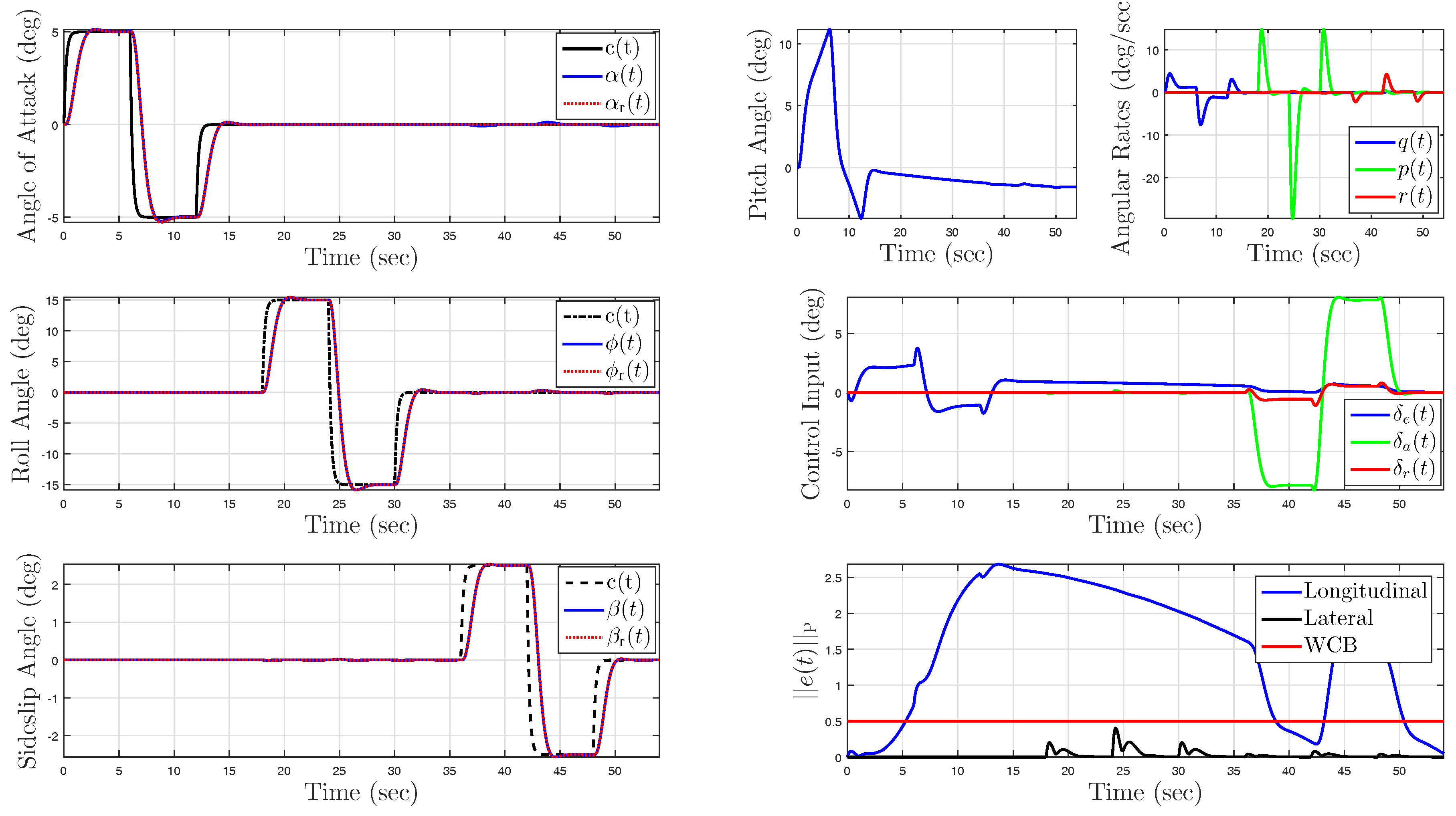
5.1.3. Nominal System without Uncertainty
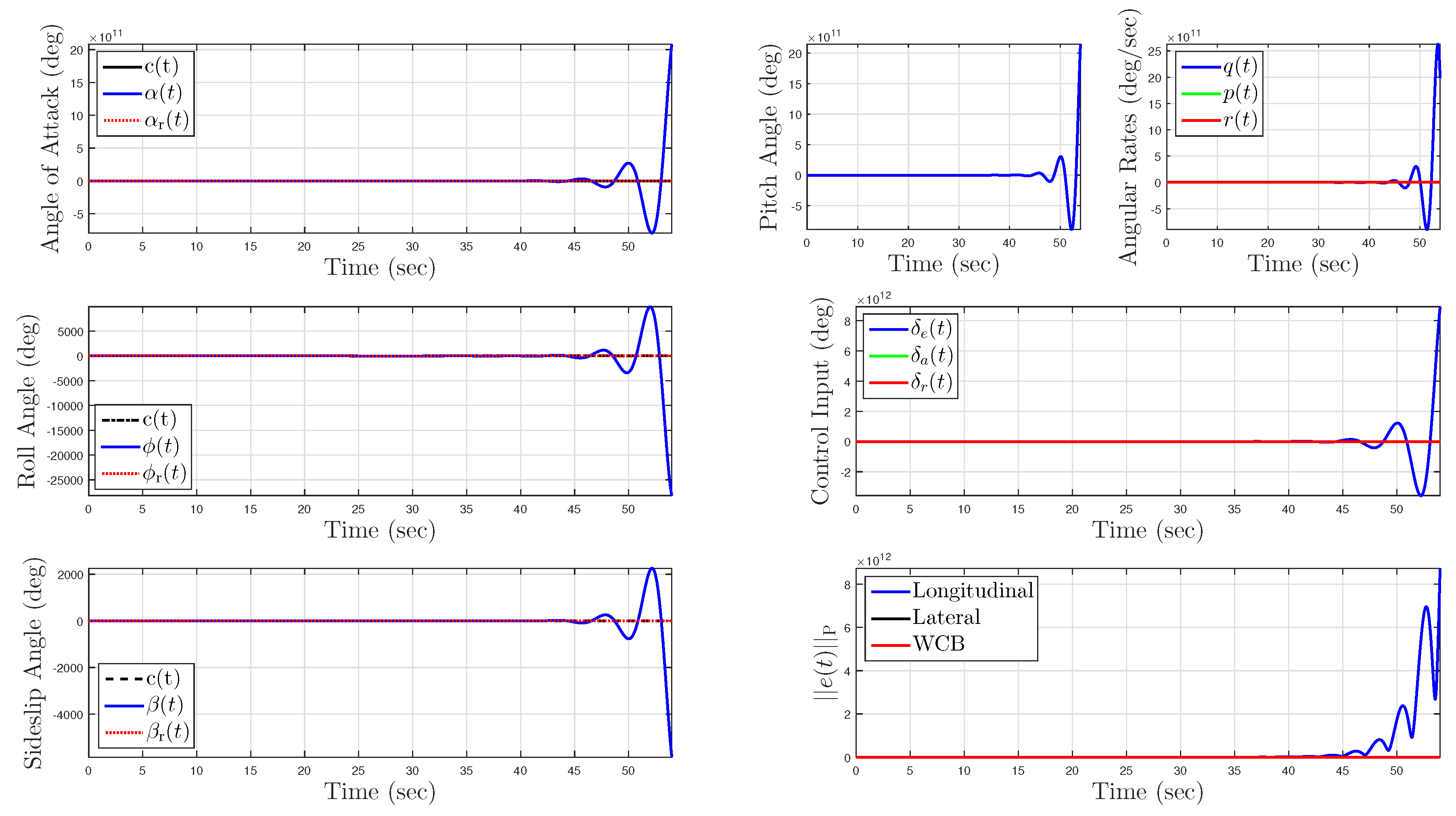
5.1.4. Uncertainty in Control Effectiveness and Stability Derivatives
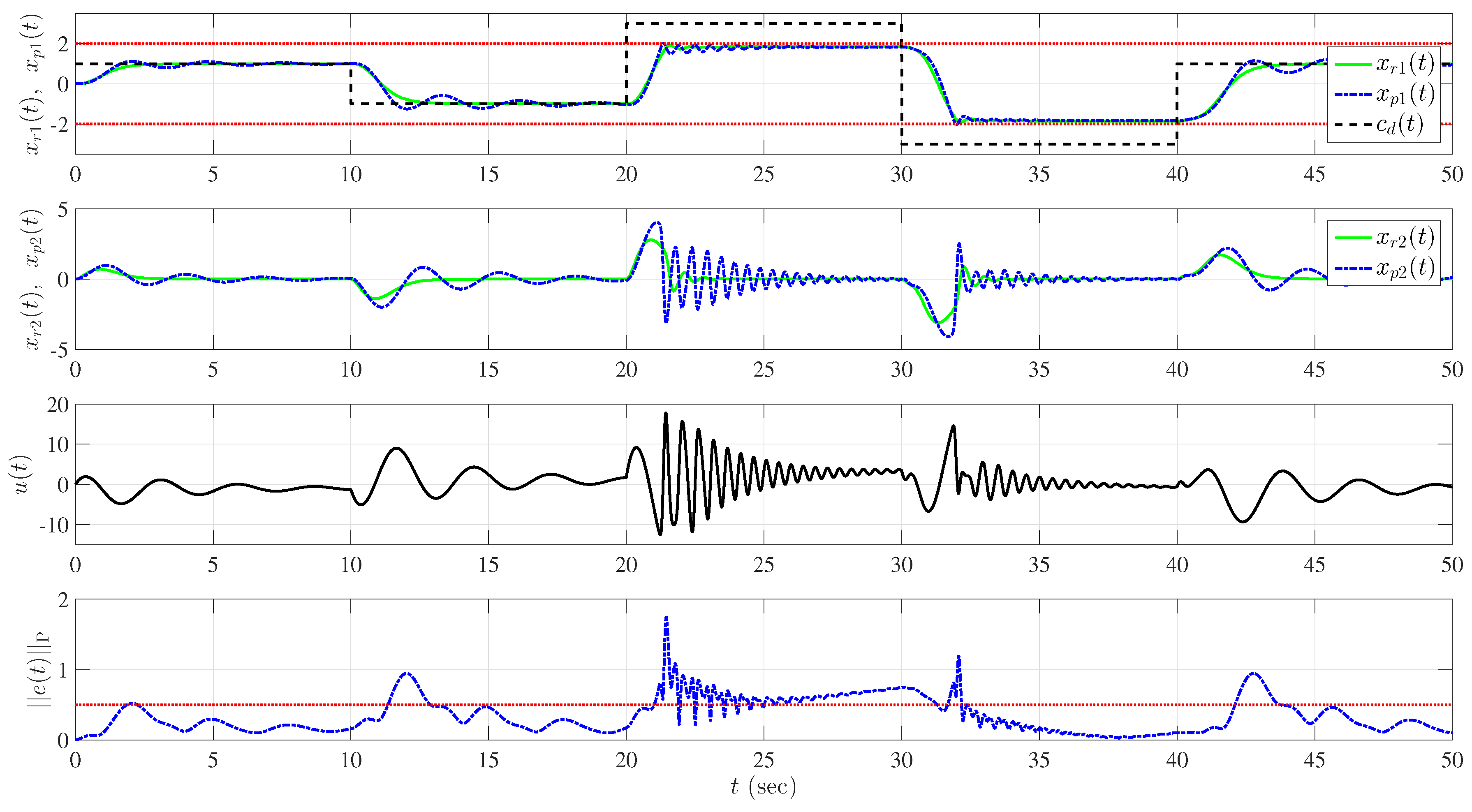
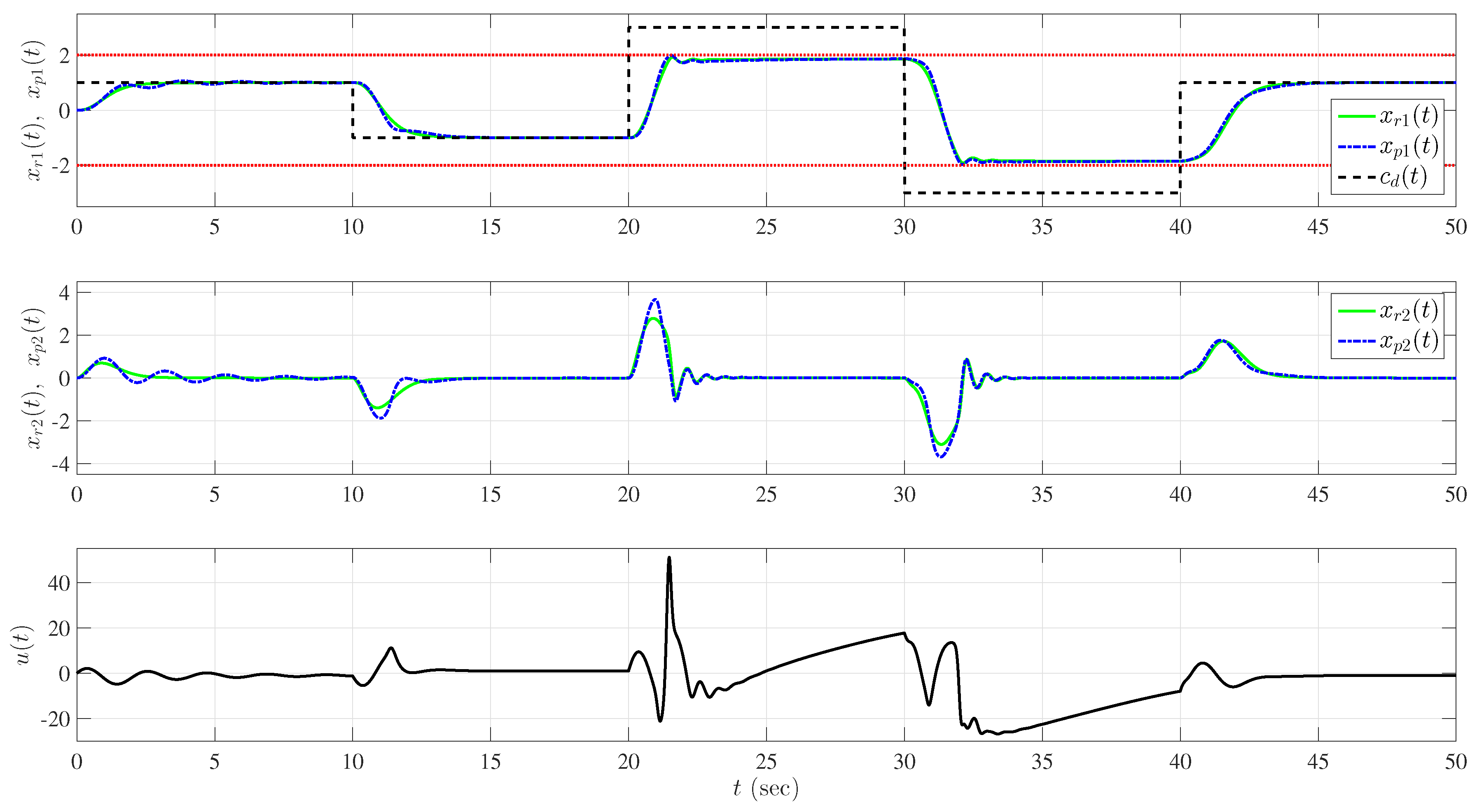
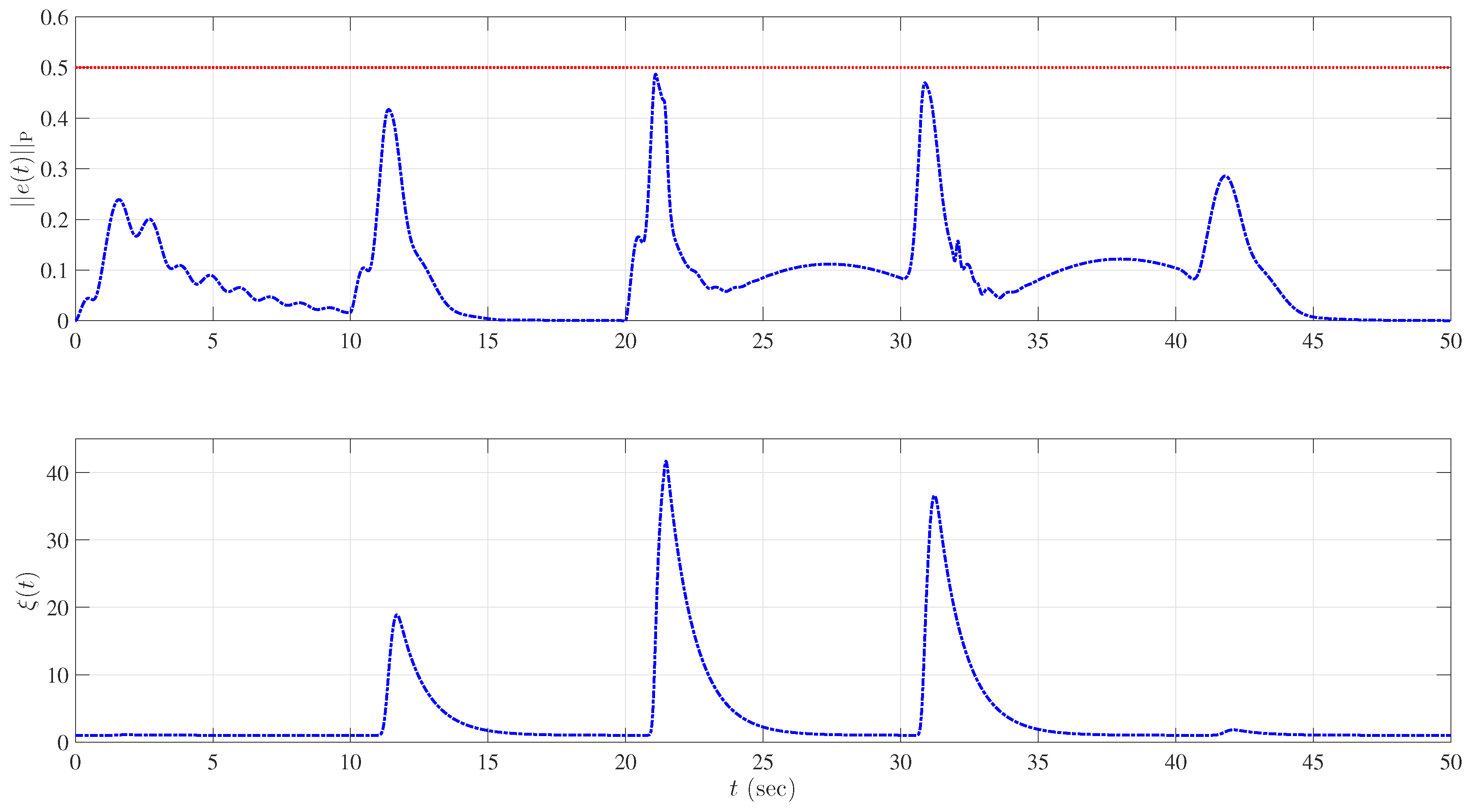
5.2. Example 2: Wing Rock Dynamics with Nonlinear Reference Model
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Duarte, M.A.; Narendra, K.S. Combined direct and indirect approach to adaptive control. IEEE Trans. Autom. Control 1989, 34, 1071–1075. [Google Scholar] [CrossRef]
- Slotine, J.J.E.; Li, W. Composite adaptive control of robot manipulators. Automatica 1989, 25, 509–519. [Google Scholar] [CrossRef]
- Lavretsky, E. Combined/composite model reference adaptive control. IEEE Trans. Autom. Control 2009, 54, 2692. [Google Scholar] [CrossRef]
- Volyanskyy, K.Y.; Calise, A.J.; Yang, B.J. A novel Q-modification term for adaptive control. In Proceedings of the American Control Conference, Minneapolis, MN, USA, 14–16 June 2006.
- Volyanskyy, K.Y.; Calise, A.J.; Yang, B.J.; Lavretsky, E. An error minimization method in adaptive control. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, Keystone, CO, USA, 21–24 August 2006.
- Volyanskyy, K.Y.; Haddad, M.; Calise, A.J. A new neuroadaptive control architecture for nonlinear uncertain dynamical systems: Beyond-and-modifications. IEEE Trans. Neural Netw. 2009, 20, 1707–1723. [Google Scholar] [CrossRef] [PubMed]
- Chowdhary, G.; Johnson, E.N. Theory and flight-test validation of a concurrent-learning adaptive controller. J. Guid. Control Dyn. 2011, 34, 592–607. [Google Scholar] [CrossRef]
- Chowdhary, G.; Yucelen, T.; Mühlegg, M.; Johnson, E.N. Concurrent learning adaptive control of linear systems with exponentially convergent bounds. Int. J. Adapt. Control Signal Process. 2013, 27, 280–301. [Google Scholar] [CrossRef]
- Yucelen, T.; Johnson, E.N. Artificial basis functions in adaptive control for transient performance improvement. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, Boston, MA, USA, 19–22 August 2013.
- Gruenwald, B.; Yucelen, T.; Fravolini, M. Performance oriented adaptive architectures with guaranteed bounds. In Proceedings of the AIAA Infotech@Aerospace Conference, Kissimmee, FL, USA, 5–9 January 2015.
- Gruenwald, B.; Yucelen, T. On transient performance improvement of adaptive control architectures. Int. J. Control 2015, 88, 2305–2315. [Google Scholar] [CrossRef]
- Yucelen, T.; Gruenwald, B.; Muse, J.; De La Torre, G. Adaptive control with nonlinear reference systems. In Proceedings of the American Control Conference, Chicago, IL, USA, 1–3 July 2015.
- Arabi, E.; Gruenwald, B.C.; Yucelen, T.; Nguyen, N.T. A set-theoretic model reference adaptive control architecture for disturbance rejection and uncertainty suppression with strict performance guarantees. Int. J. Control 2017, in press. [Google Scholar]
- Narendra, K.S.; Annaswamy, A.M. Stable Adaptive Systems; Courier Corporation: Mineola, NY, USA, 2012. [Google Scholar]
- Lavretsky, E.; Wise, K.A. Robust Adaptive Control; Springer: New York, NY, USA, 2013. [Google Scholar]
- Ioannou, P.A.; Sun, J. Robust Adaptive Control; Courier Corporation: Mineola, NY, USA, 2012. [Google Scholar]
- Khalil, H.K. Nonlinear Systems; Prentice Hall: Upper Saddle River, NJ, USA, 1996. [Google Scholar]
- Lewis, F.L.; Liu, K.; Yesildirek, A. Neural net robot controller with guaranteed tracking performance. IEEE Trans. Neural Netw. 1995, 6, 703–715. [Google Scholar] [CrossRef] [PubMed]
- Lewis, F.L.; Yesildirek, A.; Liu, K. Multilayer neural-net robot controller with guaranteed tracking performance. IEEE Trans. Neural Netw. 1996, 7, 388–399. [Google Scholar] [CrossRef] [PubMed]
- Pomet, J.B.; Praly, L. Adaptive nonlinear regulation: Estimation from the Lyapunov equation. IEEE Trans. Autom. Control 1992, 37, 729–740. [Google Scholar] [CrossRef]
- Krstic, M.; Kanellakopoulos, I.; Kokotovic, P.V. Nonlinear and Adaptive Control Design; Wiley: New York, NY, USA, 1995. [Google Scholar]
- Haddad, W.M.; Chellaboina, V. Nonlinear Dynamical Systems and Control: A Lyapunov-Based Approach; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]



© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gruenwald, B.C.; Yucelen, T.; Muse, J.A. Direct Uncertainty Minimization Framework for System Performance Improvement in Model Reference Adaptive Control. Machines 2017, 5, 9. https://doi.org/10.3390/machines5010009
Gruenwald BC, Yucelen T, Muse JA. Direct Uncertainty Minimization Framework for System Performance Improvement in Model Reference Adaptive Control. Machines. 2017; 5(1):9. https://doi.org/10.3390/machines5010009
Chicago/Turabian StyleGruenwald, Benjamin C., Tansel Yucelen, and Jonathan A. Muse. 2017. "Direct Uncertainty Minimization Framework for System Performance Improvement in Model Reference Adaptive Control" Machines 5, no. 1: 9. https://doi.org/10.3390/machines5010009