
Risk Prediction Model for Chronic Kidney Disease in Thailand Using Artificial Intelligence and SHAP
 , , and
, , and
Abstract
:1. Introduction
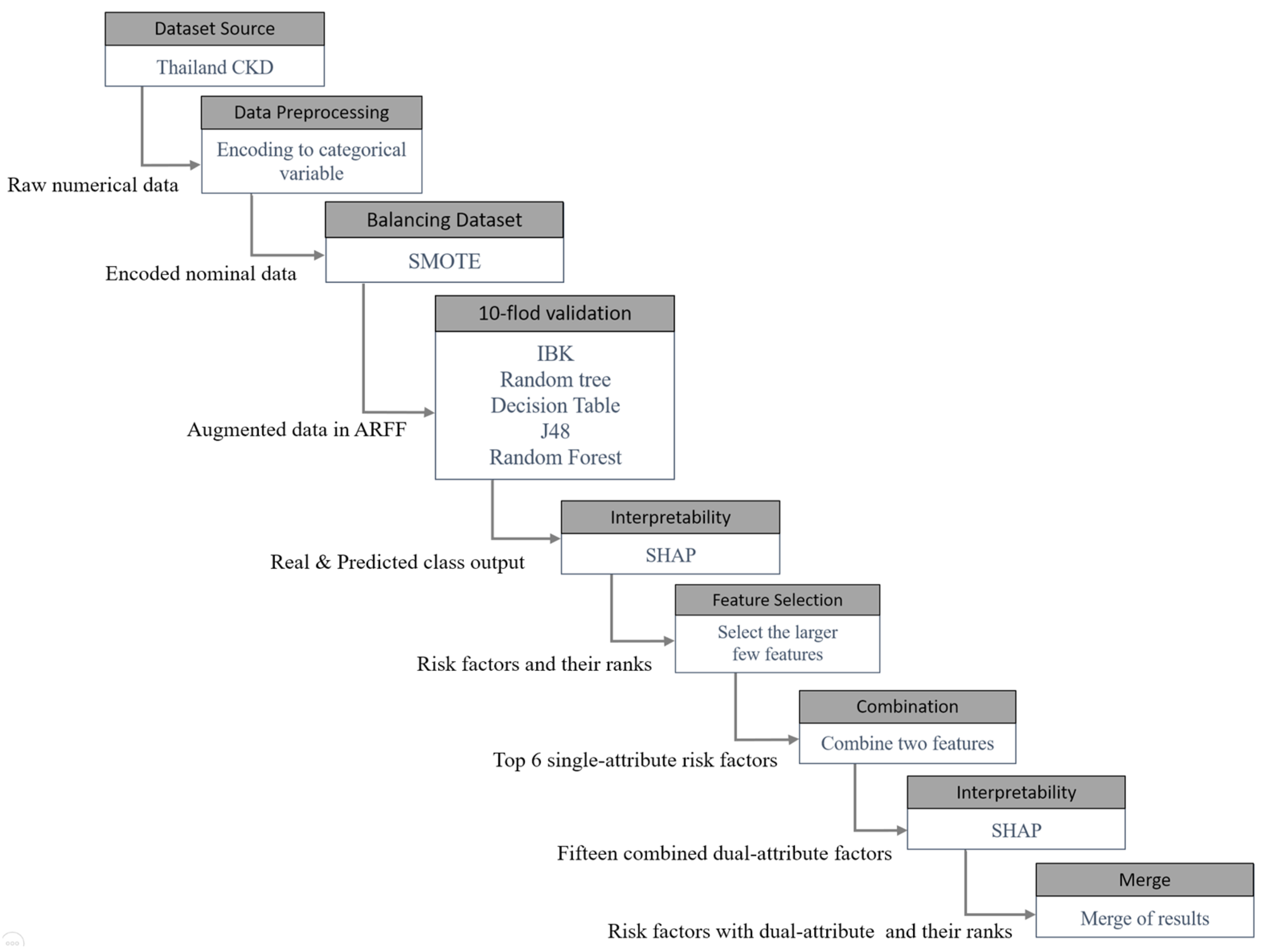
2. Materials and Methods
2.1. Data Preprocessing
2.1.1. Data Conversion
2.1.2. Dataset Balance
2.1.3. Model Validation
2.2. Artificial Intelligence with Various Machine Learning Algorithms
2.3. Interpretability
2.4. Performace Evaluation Indicators
3. Results
3.1. Performance Evaluation
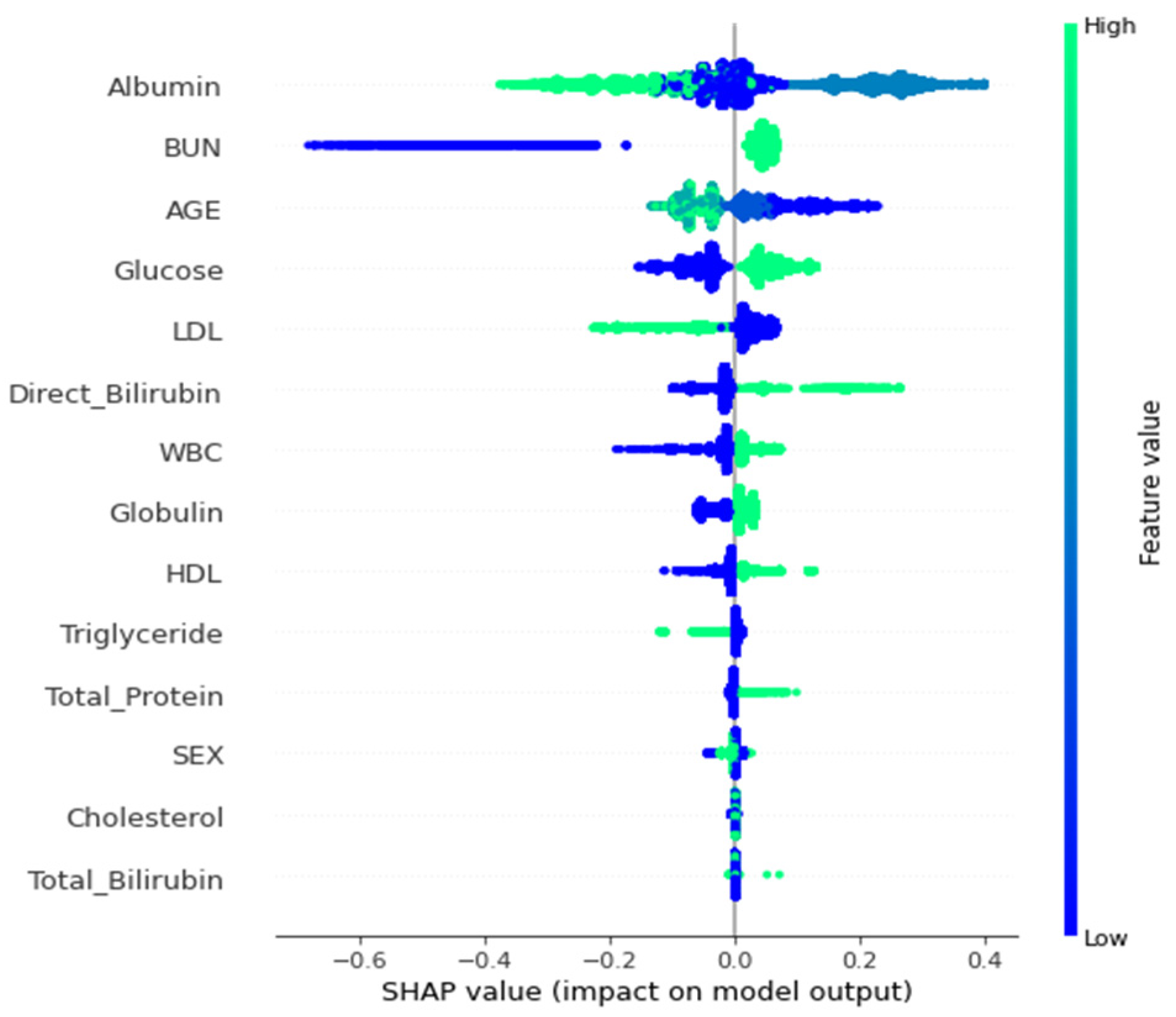
3.2. Interpretability
3.3. Extended Results for Dual-Attribute Factors
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chou, Y.H.; Chen, Y.M. Aging and renal disease: Old questions for new challenges. Aging Dis. 2021, 12, 515. [Google Scholar] [CrossRef] [PubMed]
- Tonelli, M.; Riella, M. Chronic kidney disease and the aging population. Braz. J. Nephrol. 2014, 36, 1–5. [Google Scholar] [CrossRef]
- Furuto, Y.; Kawamura, M.; Namikawa, A.; Takahashi, H.; Shibuya, Y. Health risk of travel for chronic kidney disease patients. J. Res. Med. Sci. Off. J. Isfahan Univ. Med. Sci. 2020, 25, 22. [Google Scholar] [CrossRef] [PubMed]
- Snively, C.S.; Gutierrez, C. Chronic kidney disease: Prevention and treatment of common complications. Am. Fam. Physician 2004, 70, 1921–1928. [Google Scholar] [PubMed]
- Tomic, D.; Shaw, J.E.; Magliano, D.J. The burden and risks of emerging complications of diabetes mellitus. Nat. Rev. Endocrinol. 2022, 18, 525–539. [Google Scholar] [CrossRef]
- Blonde, L.; Umpierrez, G.E.; Reddy, S.S.; McGill, J.B.; Berga, S.L.; Bush, M.; Chandrasekaran, S.; DeFronzo, R.A.; Einhorn, D.; Galindo, R.J.; et al. American Association of Clinical Endocrinology clinical practice guideline: Developing a diabetes mellitus comprehensive care plan—2022 update. Endocr. Pract. 2022, 28, 923–1049. [Google Scholar] [CrossRef] [PubMed]
- Rohm, T.V.; Meier, D.T.; Olefsky, J.M.; Donath, M.Y. Inflammation in obesity, diabetes, and related disorders. Immunity 2022, 55, 31–55. [Google Scholar] [CrossRef] [PubMed]
- Kanjanabuch, T.; Takkavatakarn, K. Global dialysis perspective: Thailand. Kidney360 2020, 1, 671. [Google Scholar] [CrossRef]
- Sareminia, H.; Gharaei, F.M.; Mofrad, S.S.; Ghahramani, S. Identifying the Dimensions and Components of the Health-oriented Urban Form with An Emphasis on the Epidemic Disease: A systematic scoping review. Creat. City Des. 2023, 6, 27–38. [Google Scholar]
- Kumar, N.; Khatri, S. Implementing WEKA for medical data classification and early disease prediction. In Proceedings of the 2017 3rd International Conference on Computational Intelligence & Communication Technology (CICT), Ghaziabad, India, 9–10 February 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Kodati, S.; Vivekanandam, R.; Ravi, G. Comparative analysis of clustering algorithms with heart disease datasets using data mining WEKA tool. In Soft Computing and Signal Processing; Springer: Singapore, 2019; pp. 111–117. [Google Scholar]
- Lee, H.C.; Liu, J.H.; Ho, C.S. The Medical Outcomes Distribution and the Interpretation of Clinical Data Based on C4.5 Algorithm for the RCC Patients in Taiwan. Appl. Sci. 2021, 11, 2566. [Google Scholar] [CrossRef]
- Singh, P.; Haimovich, J.; Reeder, C.; Khurshid, S.; Lau, E.S.; Cunningham, J.W.; Philippakis, A.; Anderson, C.D.; Ho, J.E.; Lubitz, S.A.; et al. One clinician is all you need–cardiac magnetic resonance imaging measurement extraction: Deep learning algorithm development. JMIR Med. Inform. 2022, 10, e38178. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.-C.; Aqil, A.F. Combination of Transfer Learning Methods for Kidney Glomeruli Image Classification. Appl. Sci. 2022, 12, 1040. [Google Scholar] [CrossRef]
- Aldhyani, T.H.; Nair, R.; Alzain, E.; Alkahtani, H.; Koundal, D. Deep Learning Model for the Detection of Real Time Breast Cancer Images Using Improved Dilation-Based Method. Diagnostics 2022, 12, 2505. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Xu, C.; Li, J.; Liang, P.; Zeng, X.; Ren, H.; Cheng, W.; Wu, K. Explainable Pulmonary Disease Diagnosis with Prompt-Based Knowledge Extraction. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1816–1819. [Google Scholar]
- Wongvorachan, T.; He, S.; Bulut, O. A comparison of undersampling, oversampling, and SMOTE methods for dealing with imbalanced classification in educational data mining. Information 2023, 14, 54. [Google Scholar] [CrossRef]
- Elreedy, D.; Atiya, A.F.; Kamalov, F. A theoretical distribution analysis of synthetic minority oversampling technique (SMOTE) for imbalanced learning. Mach. Learn. 2023, 1–21. [Google Scholar] [CrossRef]
- Gebreyesus, Y.; Dalton, D.; Nixon, S.; De Chiara, D.; Chinnici, M. Machine Learning for Data Center Optimizations: Feature Selection Using Shapley Additive exPlanation (SHAP). Future Internet 2023, 15, 88. [Google Scholar] [CrossRef]
- Arslan, Y.; Lebichot, B.; Allix, K.; Veiber, L.; Lefebvre, C.; Boytsov, A.; Goujon, A.; Bissyandé, T.F.; Klein, J. Towards refined classifications driven by shap explanations. In International Cross-Domain Conference for Machine Learning and Knowledge Extraction; Springer International Publishing: Cham, Switzerland, 2022; pp. 68–81. [Google Scholar]
- Mavrogiorgos, K.; Kiourtis, A.; Mavrogiorgou, A.; Kleftakis, S.; Kyriazis, D. A multi-layer approach for data cleaning in the healthcare domain. In Proceedings of the 8th International Conference on Computing and Data Engineering, Bangkok, Thailand, 11–13 January 2022. [Google Scholar]
- Van den Broeck, J.; Argeseanu Cunningham, S.; Eeckels, R.; Herbst, K. Data cleaning: Detecting, diagnosing, and editing data abnormalities. PLoS Med. 2005, 2, e267. [Google Scholar] [CrossRef]
- Swain, D.; Mehta, U.; Bhatt, A.; Patel, H.; Patel, K.; Mehta, D.; Acharya, B.; Gerogiannis, V.C.; Kanavos, A.; Manika, S. A Robust Chronic Kidney Disease Classifier Using Machine Learning. Electronics 2023, 12, 212. [Google Scholar] [CrossRef]
- Ventrella, P.; Delgrossi, G.; Ferrario, G.; Righetti, M.; Masseroli, M. Supervised machine learning for the assessment of chronic kidney disease advancement. Comput. Methods Programs Biomed. 2021, 209, 106329. [Google Scholar] [CrossRef]
- Akter, S.; Habib, A.; Islam, M.; Hossen, M.; Fahim, W.; Sarkar, P.R.; Ahmed, M. Comprehensive Performance Assessment of Deep Learning Models in Early Prediction and Risk Identification of Chronic Kidney Disease. IEEE Access 2021, 9, 165184–165206. [Google Scholar] [CrossRef]
- Erickson, B.J.; Kitamura, F. Magician’s Corner: 9. Performance Metrics for Machine Learning Models. Radiol. Artif. Intell. 2021, 3, e200126. [Google Scholar] [CrossRef] [PubMed]
- Mavrogiorgou, A.; Kiourtis, A.; Kleftakis, S.; Mavrogiorgos, K.; Zafeiropoulos, N.; Kyriazis, D. A Catalogue of Machine Learning Algorithms for Healthcare Risk Predictions. Sensors 2022, 22, 8615. [Google Scholar] [CrossRef] [PubMed]
- Kao, H.Y.; Chang, C.C.; Chang, C.F.; Chen, Y.C.; Cheewakriangkrai, C.; Tu, Y.L. Associations between Sex and Risk Factors for Predicting Chronic Kidney Disease. Int. J. Environ. Res. Public Health 2022, 19, 1219. [Google Scholar] [CrossRef] [PubMed]
- Shih, C.C.; Chen, S.H.; Chen, G.D.; Chang, C.C.; Shih, Y.L. Development of a Longitudinal Diagnosis and Prognosis in Patients with Chronic Kidney Disease: Intelligent Clinical Decision-Making Scheme. Int. J. Environ. Res. Public Health 2021, 18, 12807. [Google Scholar] [CrossRef] [PubMed]
- Denic, A.; Glassock, R.J.; Rule, A.D. Structural and Functional Changes with the Aging Kidney. Adv. Chronic Kidney Dis. 2016, 23, 19–28. [Google Scholar] [CrossRef] [PubMed]
- Charleonnan, A.; Fufaung, T.; Niyomwong, T.; Chokchueypattanakit, W.; Suwannawach, S.; Ninchawee, N. Predictive analytics for chronic kidney disease using machine learning techniques. In Proceedings of the 2016 Management and Innovation Technology International Conference (MITicon), Bang-San, Thailand, 12–14 October 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Ferguson, T.; Ravani, P.; Sood, M.M.; Clarke, A.; Komenda, P.; Rigatto, C.; Tangri, N. Development and External Validation of a Machine Learning Model for Progression of CKD. Kidney Int. Rep. 2022, 7, 1772–1781. [Google Scholar] [CrossRef] [PubMed]
- Dritsas, E.; Trigka, M. Machine learning techniques for chronic kidney disease risk prediction. Big Data Cogn. Comput. 2022, 6, 98. [Google Scholar] [CrossRef]
- Wang, W.; Chakraborty, G.; Chakraborty, B. Predicting the risk of chronic kidney disease (CKD) using machine learning algorithm. Appl. Sci. 2020, 11, 202. [Google Scholar] [CrossRef]
- Chittora, P.; Chaurasia, S.; Chakrabarti, P.; Kumawat, G.; Chakrabarti, T.; Leonowicz, Z.; Jasiński, M.; Jasiński, Ł.; Gono, R.; Jasińska, E.; et al. Prediction of chronic kidney disease—A machine learning perspective. IEEE Access 2021, 9, 17312–17334. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Learning Algorithms | Parameter Settings |
|---|---|
| IBK | KNN: 1, batchSize: 100, crossValidate: False, debug: False, distanceWeighting: No, doNotCheckCapabilities: False, meanSquared: False, nearestNeighbourSearchAlgorithm: LinearNNSearch, numDecimalPlaces: 2, windowsSize: 0 |
| Random Tree | KValue: 0, allowUnclassifiedInstances: False, batchSize: 100, breakTiesRandomly: False, debug: False, doNotCheckCapabilities: False, maxDepth: 0, minNum: 1.0, minVarianceProp: 0.001, numDecimalPlaces: 2, numFolds: 0, seed: 1 |
| Decision Table | batchSize: 100, crossVal: 1, debug: False, displayRules: False, evaluationMeasure: accuracy/RMSE, numDecimalPlaces: 2, search: BestFirst-D1-N5, useIBK: False |
| J48 | batchSize: 100, binarySplits:F alse, collapseTree: True, confidenceFactor: 0.25, debug: False, doNotCheckCapabilities: False, doNotMakeSplitPoitActualValue: False, minNumObj: 2, numDecimalPlaces: 2, numFolds: 3, reuceErrorPruning: False, saveinstanceData: False, seed: 1, subtreeRaising: True, unpruned:False, useLplace: False, useMDLcorrection: True |
| Random Forest | bagSizePercent: 100, batSize: 100, reakTiesRandomly: False, calcOutOfBag: False, computeAttributeImportance: False, debug: False, maxDepth: 0, numDecimalPlaces: 2, numExecutionSlots: 1, numFeatures: 0, numIterations: 100, outputOutOfBagComplexityStatistics: False, printClassifiers: False, seed: 1, storeOutOfBagPredictions: False |
| Algorithm | TP Rate (Recall, Sensitivity) | FP rate (1-Specificity) | Precision | F1 Score | ROC Area | PRC Area | Accuracy (%) | Category |
|---|---|---|---|---|---|---|---|---|
| IBK | 0.825 | 0.041 | 0.952 | 0.884 | 0.955 | 0.949 | 89.1546 | Normal |
| 0.959 | 0.175 | 0.845 | 0.898 | 0.955 | 0.953 | Abnormal | ||
| Random Tree | 0.883 | 0.064 | 0.933 | 0.907 | 0.918 | 0.902 | 90.9839 | Normal |
| 0.936 | 0.117 | 0.889 | 0.912 | 0.918 | 0.877 | Abnormal | ||
| Decision Table | 0.867 | 0.103 | 0.893 | 0.880 | 0.929 | 0.921 | 88.1909 | Normal |
| 0.897 | 0.133 | 0.871 | 0.884 | 0.929 | 0.925 | Abnormal | ||
| J48 | 0.885 | 0.074 | 0.923 | 0.904 | 0.926 | 0.906 | 90.5593 | Normal |
| 0.926 | 0.115 | 0.890 | 0.907 | 0.926 | 0.896 | Abnormal | ||
| Random Forest | 0.907 | 0.065 | 0.934 | 0.920 | 0.968 | 0.960 | 92.1305 | Normal |
| 0.935 | 0.093 | 0.910 | 0.922 | 0.968 | 0.965 | Abnormal |
| Folds | TP Rate (Recall, Sensitivity) | FP Rate (1-Specificity) | Precision | ROC Area | Prc Area | Accuracy (%) | Class | |
|---|---|---|---|---|---|---|---|---|
| 5 | 0.901 | 0.063 | 0.935 | 0.968 | 0.960 | 91.9154 | Normal | |
| 0.937 | 0.099 | 0.905 | 0.968 | 0.966 | Abnormal | |||
| Weighted Avg. | 0.919 | 0.081 | 0.920 | 0.968 | 0.963 | |||
| 10 | 0.907 | 0.065 | 0.934 | 0.968 | 0.960 | 92.1305 | Normal | |
| 0.935 | 0.093 | 0.910 | 0.968 | 0.965 | Abnormal | |||
| Weighted Avg. | 0.921 | 0.079 | 0.922 | 0.968 | 0.963 | |||
| 15 | 0.905 | 0.064 | 0.934 | 0.968 | 0.960 | 92.0394 | Normal | |
| 0.936 | 0.095 | 0.908 | 0.968 | 0.966 | Abnormal | |||
| Weighted Avg. | 0.920 | 0.080 | 0.921 | 0.968 | 0.963 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, M.-C.; Lojanapiwat, B.; Chang, C.-C.; Noppakun, K.; Khumrin, P.; Li, S.-H.; Lee, C.-Y.; Lee, H.-C.; Khwanngern, K. Risk Prediction Model for Chronic Kidney Disease in Thailand Using Artificial Intelligence and SHAP. Diagnostics 2023, 13, 3548. https://doi.org/10.3390/diagnostics13233548
Tsai M-C, Lojanapiwat B, Chang C-C, Noppakun K, Khumrin P, Li S-H, Lee C-Y, Lee H-C, Khwanngern K. Risk Prediction Model for Chronic Kidney Disease in Thailand Using Artificial Intelligence and SHAP. Diagnostics. 2023; 13(23):3548. https://doi.org/10.3390/diagnostics13233548
Chicago/Turabian StyleTsai, Ming-Che, Bannakij Lojanapiwat, Chi-Chang Chang, Kajohnsak Noppakun, Piyapong Khumrin, Ssu-Hui Li, Chih-Ying Lee, Hsi-Chieh Lee, and Krit Khwanngern. 2023. "Risk Prediction Model for Chronic Kidney Disease in Thailand Using Artificial Intelligence and SHAP" Diagnostics 13, no. 23: 3548. https://doi.org/10.3390/diagnostics13233548