Interpolation of Small Datasets in the Sandstone Hydrocarbon Reservoirs, Case Study of the Sava Depression, Croatia



Abstract
:1. Introduction
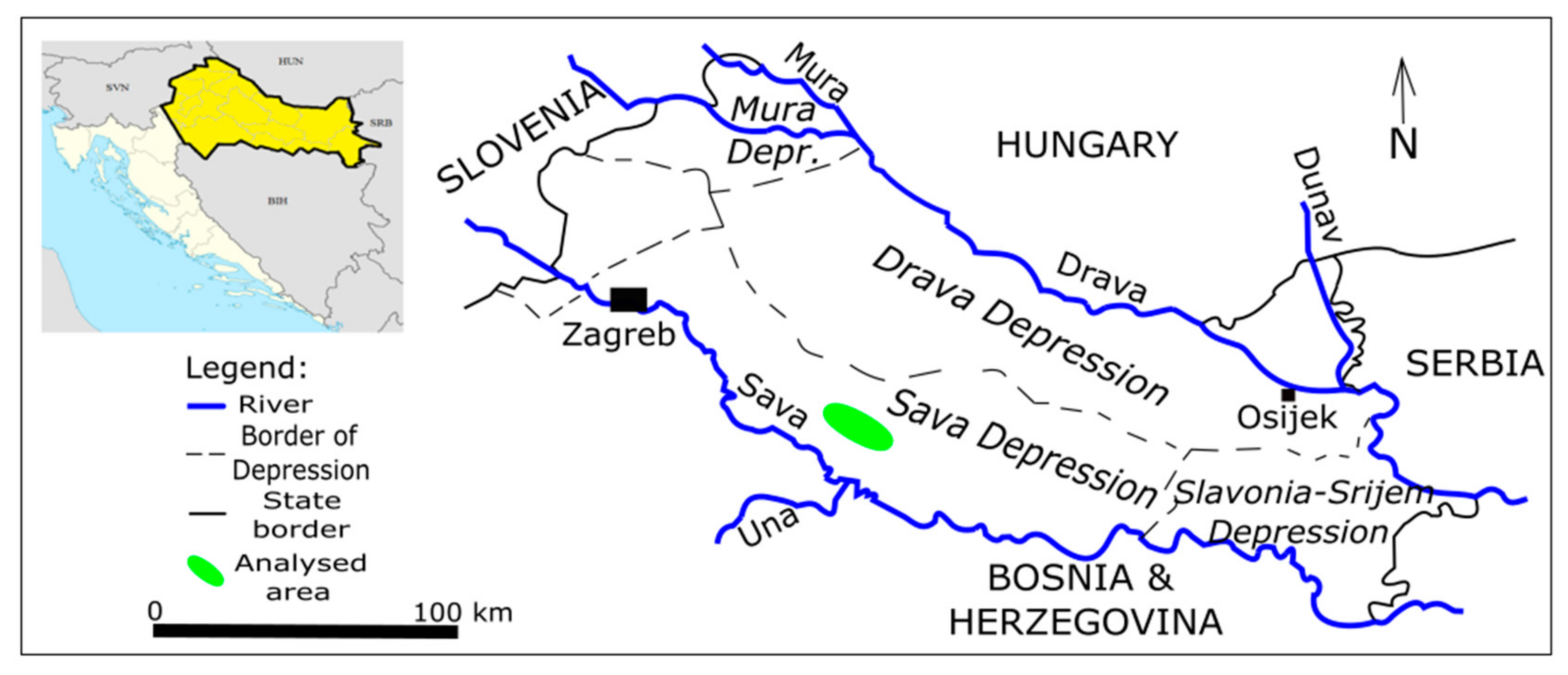
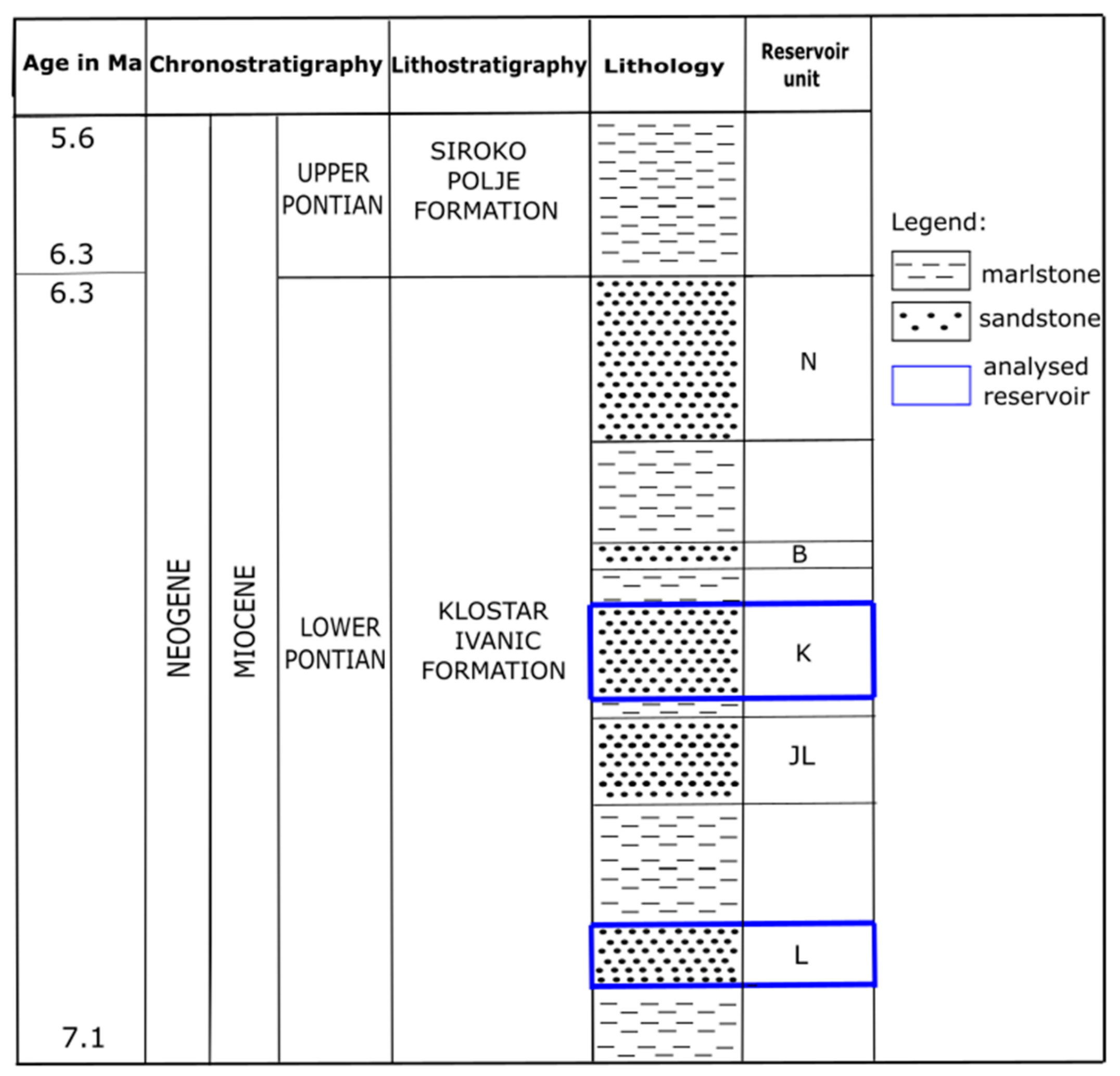
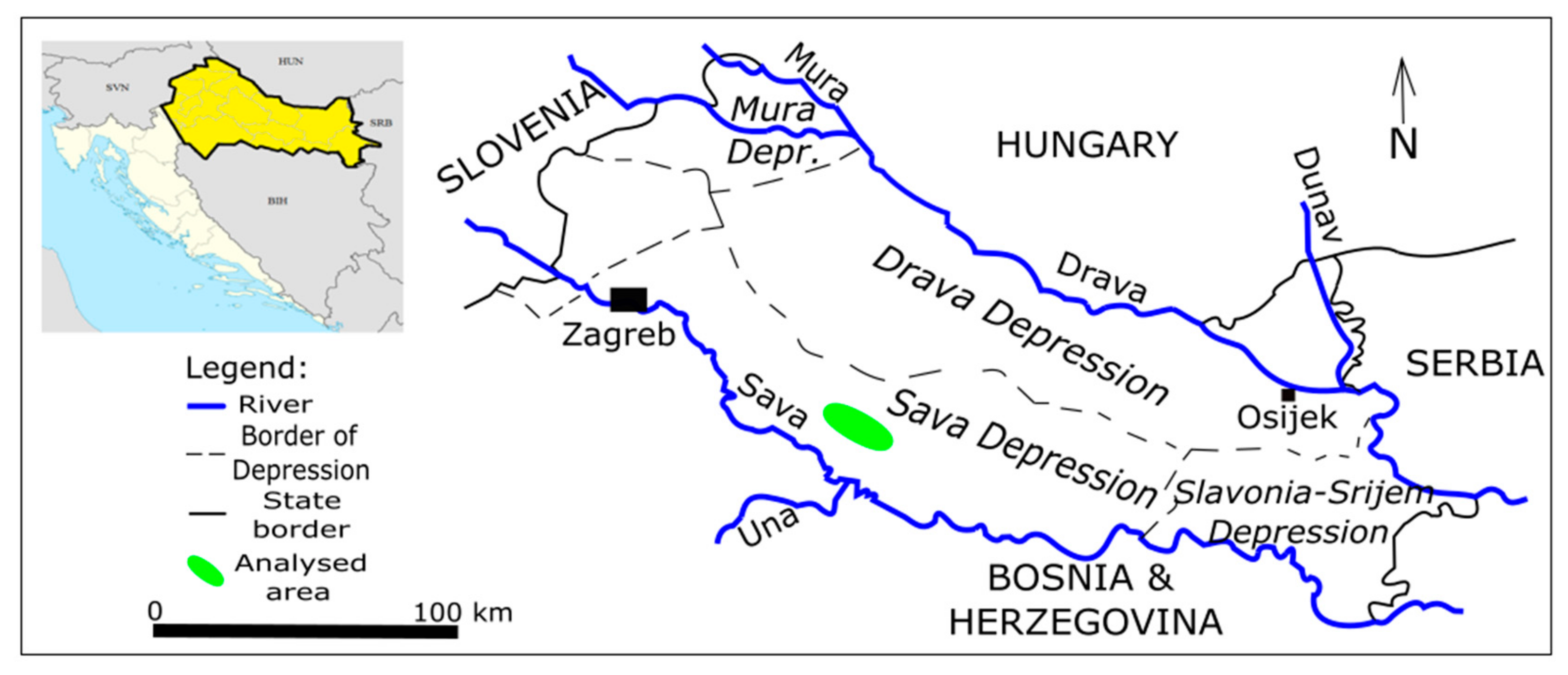
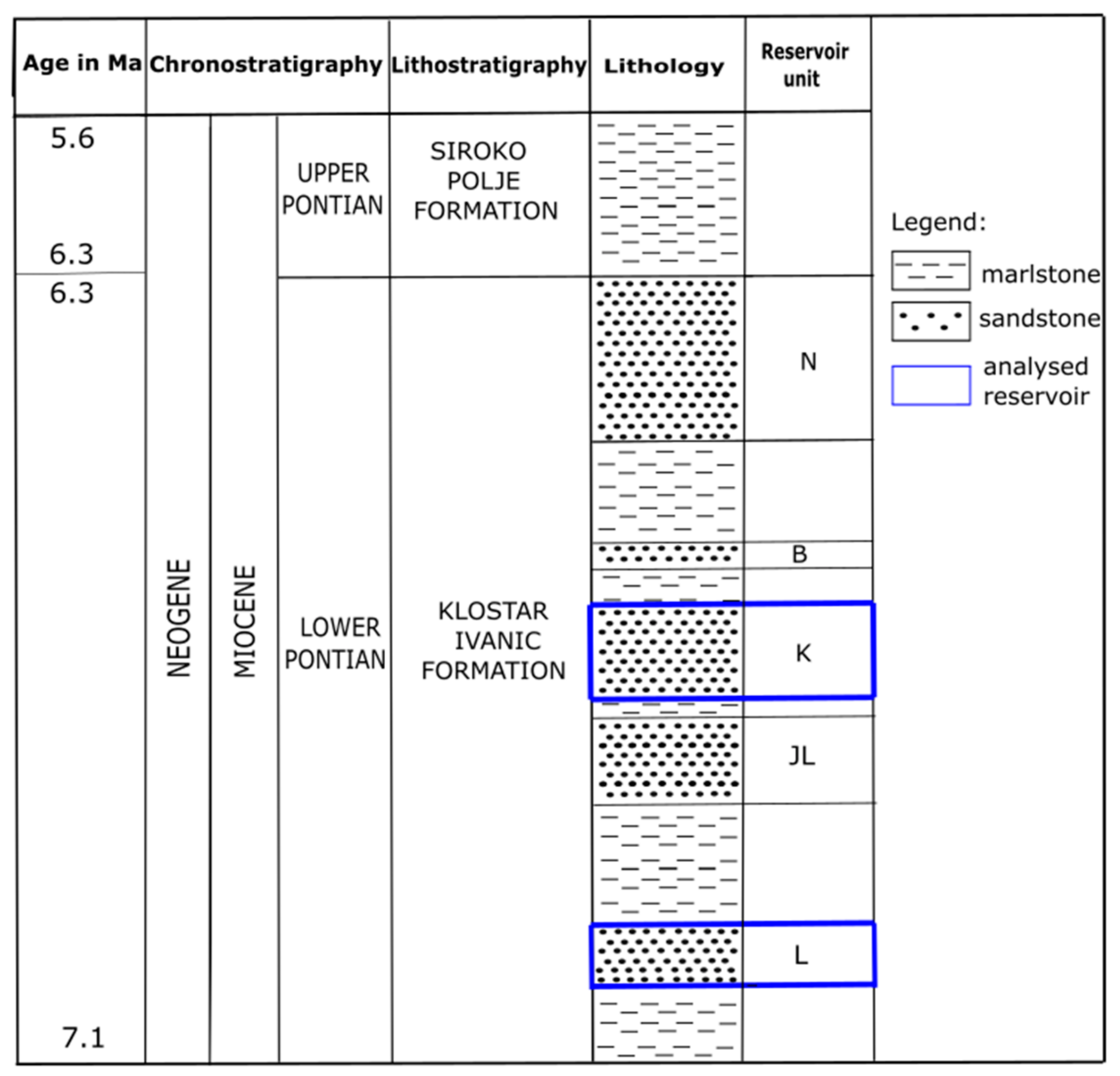
2. Geological Settings of the Sava Depression (Western Part)
- (a)
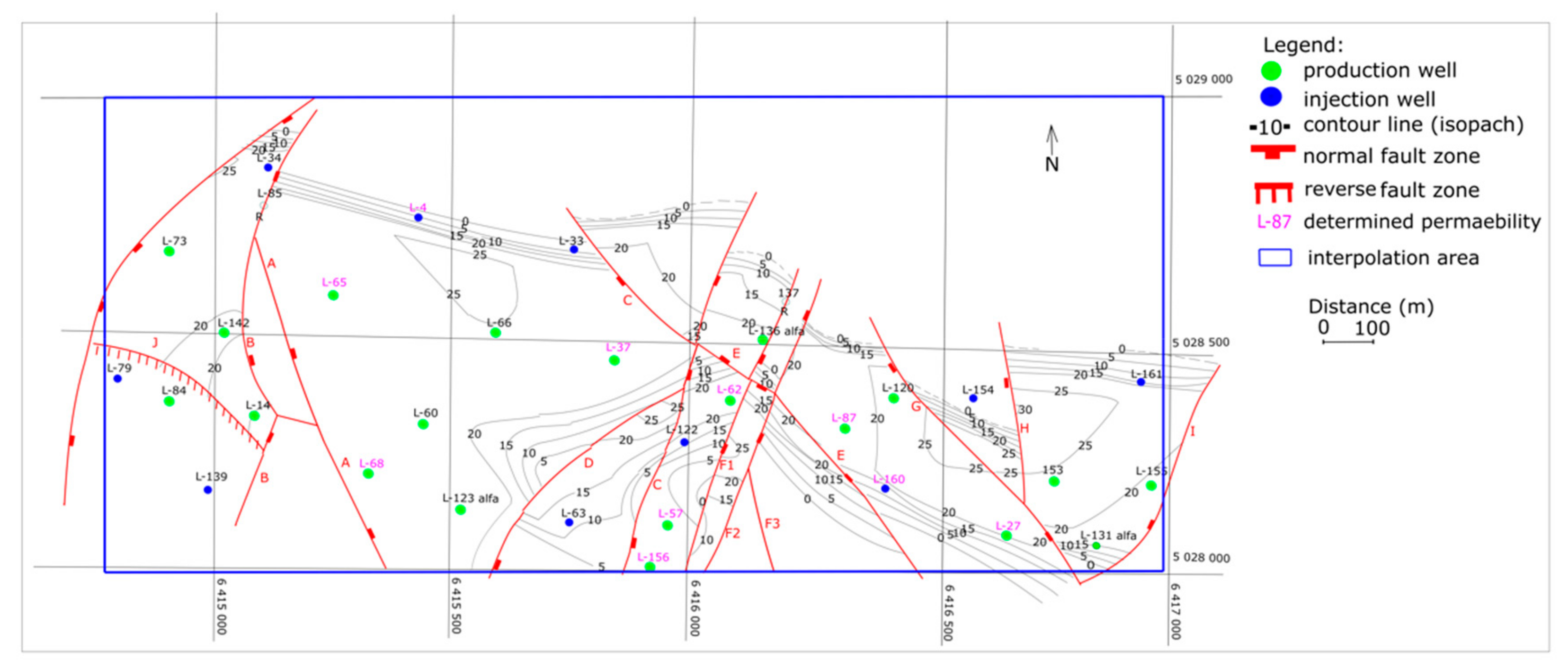
- “L” reservoir—porosity 19.7%, horiz. permeability 17.5 × 10−3 µm2 (17.5 mD), gross thickness 17.5 m;
- (b)
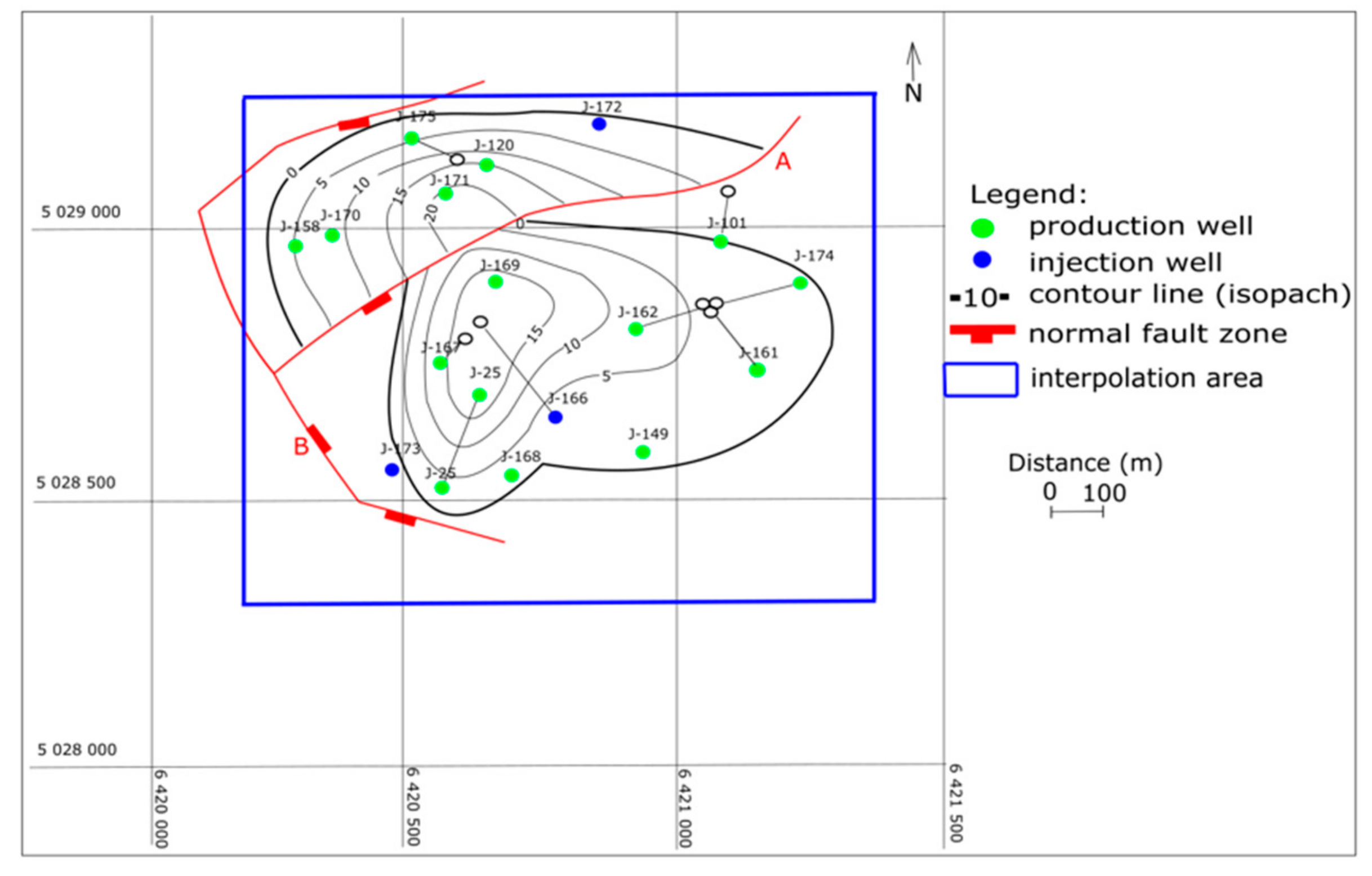
- “K” reservoir—porosity 22.7%, horiz. permeability 75.4 × 10−3 µm2 (75.4 mD), gross thickness 10 m.
3. Short Theory of Applied Interpolation Methods
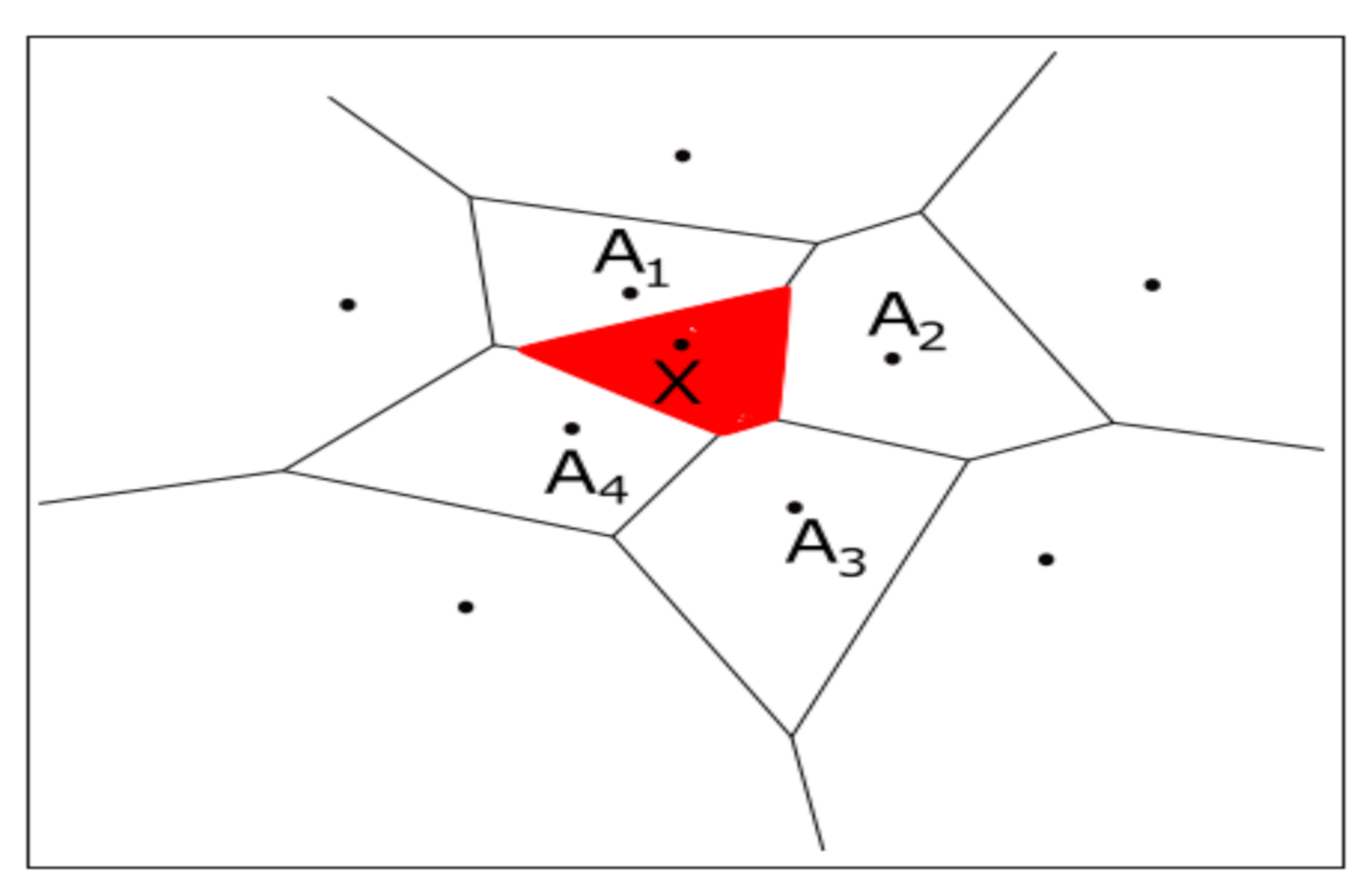
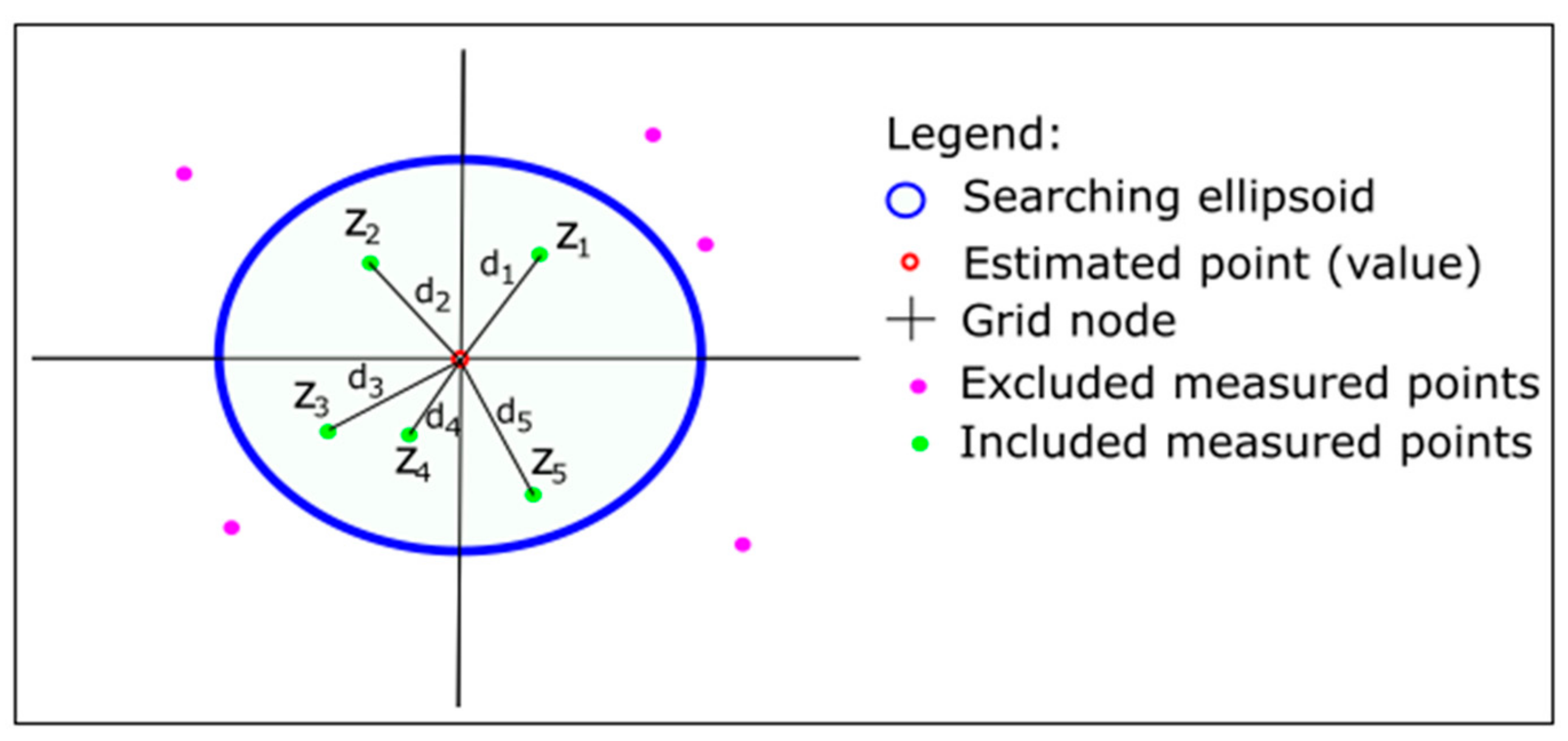
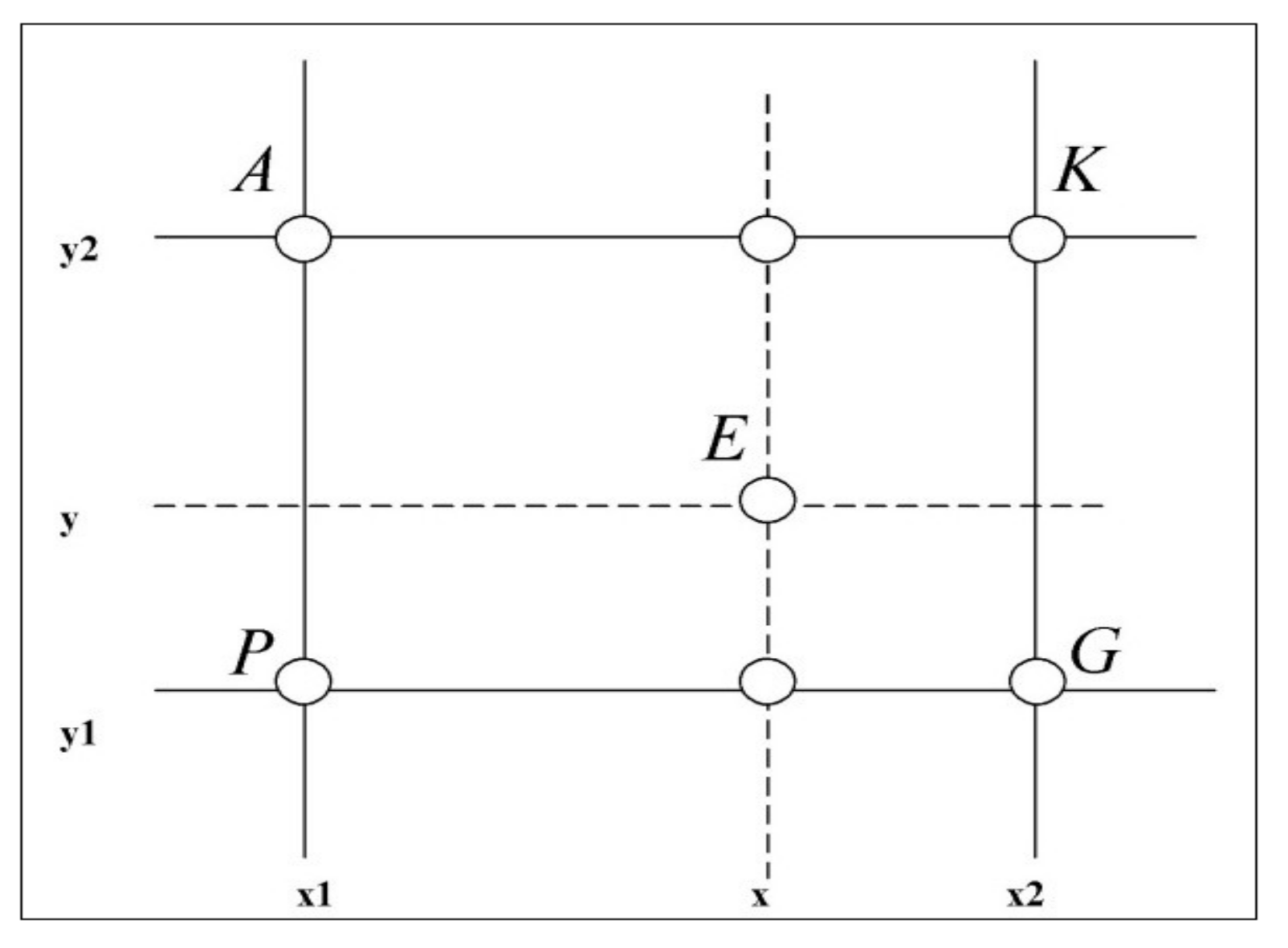
3.1. Inverse Distance Weighting Method
3.2. Nearest Neighbourhood Method
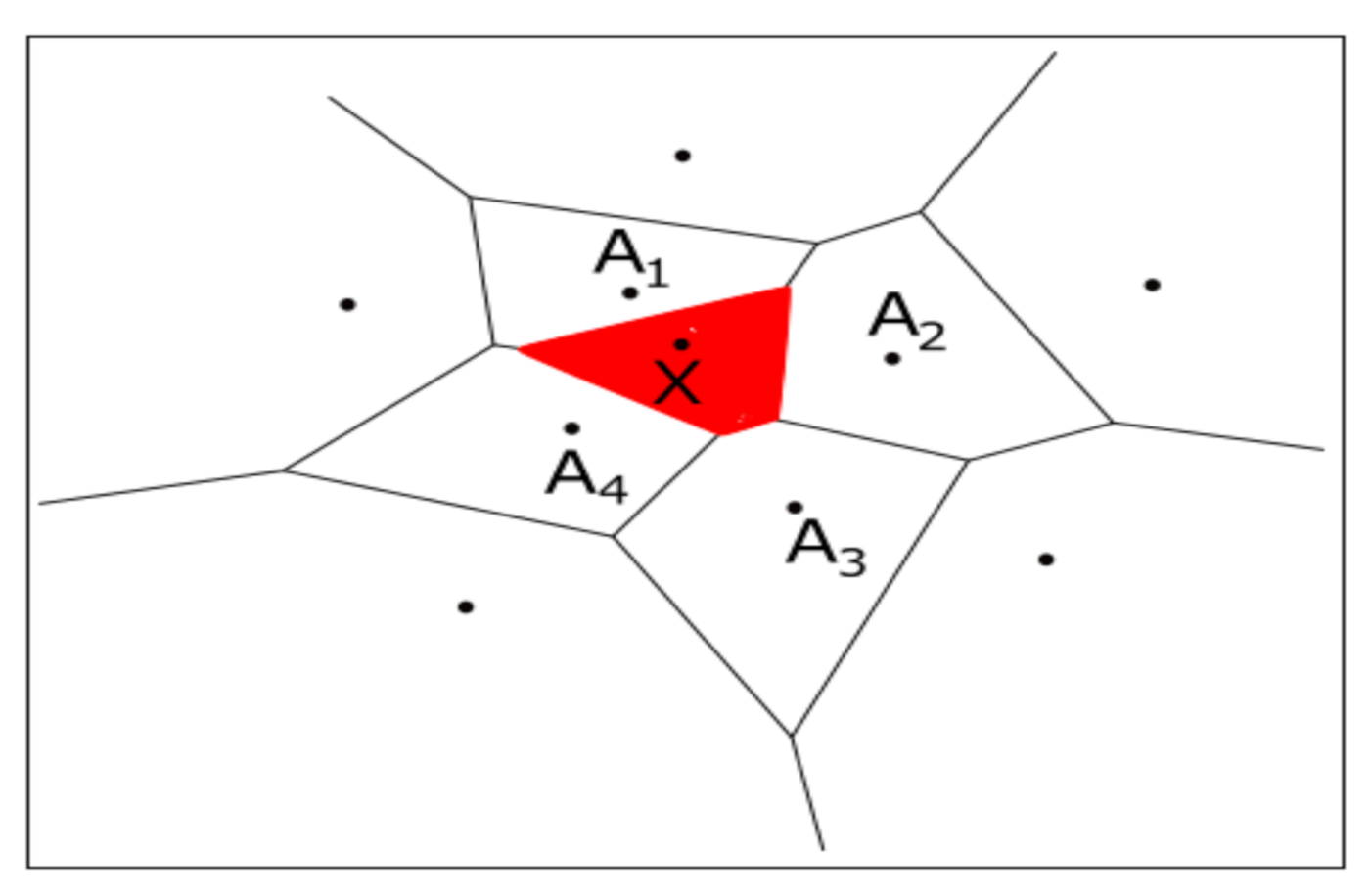
3.3. Natural Neighbour Method
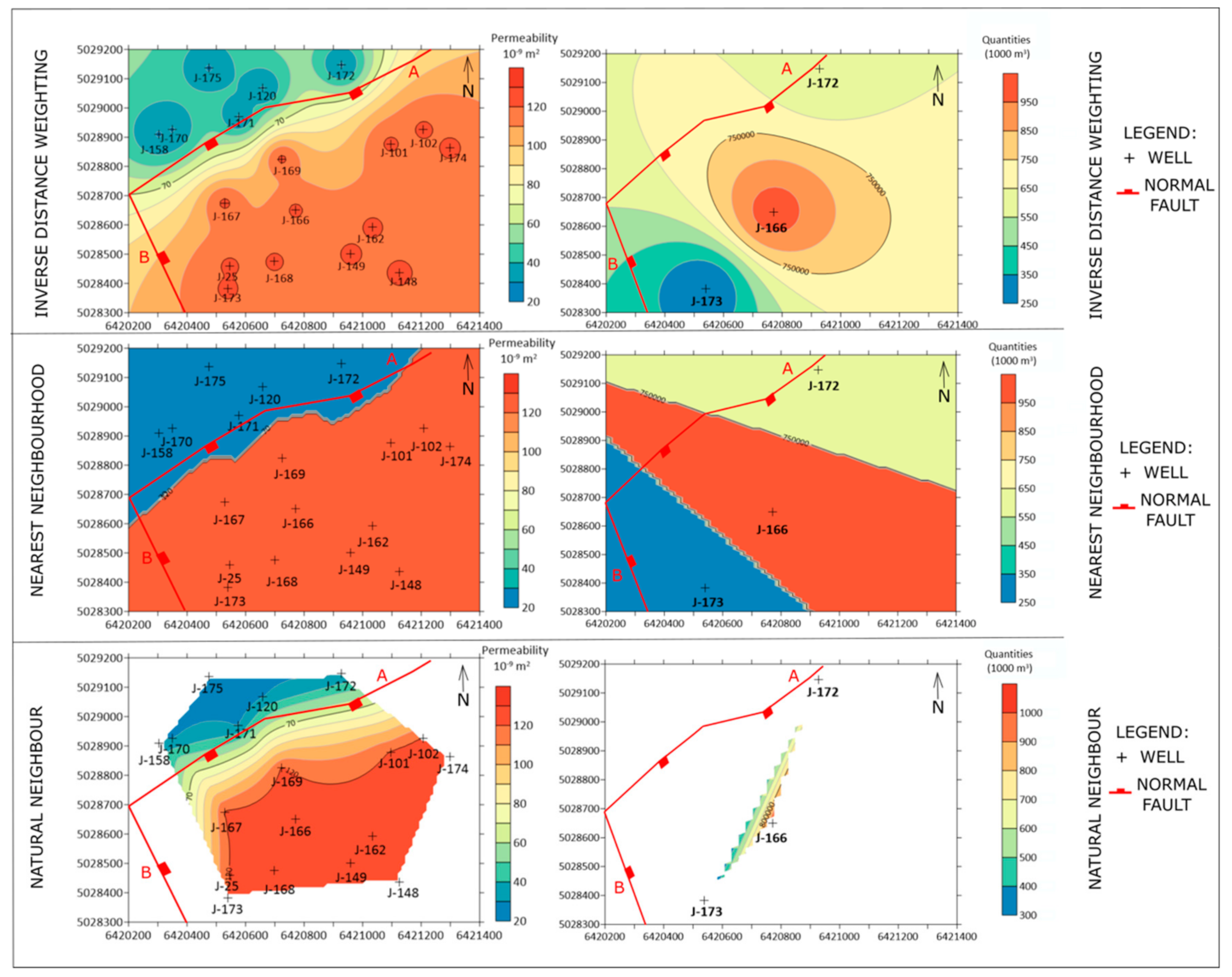
4. Interpolation in Reservoirs “L” and “K”—Injected Volumes and Permeabilities
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Malvić, T. History of geostatistical analyses performed in the Croatian part of the Pannonian Basin System. Nafta 2012, 63, 223–235. [Google Scholar]
- Mesić Kiš, I.; Malvić, T. Zonal estimation and interpolation as simultaneous Approaches in the case of small input data set (Šandrovac Field, Northern Croatia). Min. Geol. Pet. Eng. Bull. 2014, 29, 9–16. [Google Scholar]
- Novak Zelenika, K.; Cvetković, M.; Malvić, T.; Velić, J.; Sremac, J. Sequential Indicator Simulations maps of porosity, depth and thickness of Miocene clastic sediments in the Kloštar field, Northern Croatia. J. Maps 2013, 9, 550–557. [Google Scholar] [CrossRef]
- Husanović, E.; Malvić, T. Review of deterministic geostatistical mapping methods in Croatian hydrocarbon reservoirs and advantages of such approach. Nafta 2014, 65, 57–63. [Google Scholar]
- Malvić, T.; Đureković, M. Application of methods: Inverse distance weighting, ordinary kriging and collocated cokriging in porosity evaluation, and comparison of results on the Beničanci and Stari Gradac fields in Croatia. Nafta 2003, 54, 331–340. [Google Scholar]
- Smoljanović, S.; Malvić, T. Improvements in reservoir characterization applying geostatistical modelling (estimation & stochastic simulations vs. standard interpolation methods), Case study from Croatia. Nafta 2005, 56, 57–63. [Google Scholar]
- Malvić, T. Primjena Geostatistike u Analizi geoloških Podataka (Application of Geostatistics in Geological Data Analysis); INA-Industrija nafte d.d.: Zagreb, Croatia, 2008. [Google Scholar]
- Balić, D.; Velić, J.; Malvić, T. Selection of the most appropriate interpolation method for sandstone reservoirs in the Kloštar oil and gas field. Geol. Croat. 2008, 61, 27–35. [Google Scholar]
- Shahbeik, S.; Afzal, P.; Moarefvand, P.; Qumarsy, M. Comparison between ordinary kriging (OK) and inverse distance weighted (IDW) based on estimation error. Case study: Dardevey iron ore deposit, NE Iran. Arab. J. Geosci. 2014, 7, 3693–3704. [Google Scholar]
- Afzal, P. Comparing ordinary kriging and advanced inverse distance squared methods based on estimating coal deposits; case study: East-Parvadeh deposit, central Iran. J. Min. Environ. 2018, 9, 753–760. [Google Scholar]
- Bhunia, G.S.; Shit, P.K.; Maiti, R. Comparison of GIS-based interpolation methods for spatial distribution of soil organic carbon (SOC). J. Saudi Soc. Agric. Sci. 2016, 17, 114–126. [Google Scholar] [CrossRef]
- Kamińska, A.; Grzywna, A. Comparison of deteministic interpolation methods for the estimation of groundwater level. J. Ecol. Eng. 2014, 15, 55–60. [Google Scholar]
- Hofstra, N.; Haylock, M.; New, M.; Jones, P.; Frei, C. Comparison of six methods for the interpolation of daily European climate data. J. Geophys. Res. 2008, 113, 1–19. [Google Scholar] [CrossRef]
- Babak, O.; Clayton, V.D. Statistical approach to inverse distance interpolation. Stoch. Environ. Res. Risk Assess. 2008, 23, 543–553. [Google Scholar] [CrossRef]
- Malvić, T. Review of Miocene shallow marine and lacustrine depositional environments in Northern Croatia. Geol. Q. 2012, 56, 493–504. [Google Scholar] [CrossRef]
- Critelli, S. Provenenace of Mesozoic to Cenozoic circum-Mediterranean sandstones in relation to tectonic setting. Earth Sci. Rev. 2018, 185, 624–648. [Google Scholar] [CrossRef]
- Critelli, S.; Muto, F.; Perri, F.; Tripodi, V. Interpreting Provenance Relations from Sandstone Detrital Modes, Southern Italy Foreland Region: Stratigraphic record of the Miocene tectonic evolution. Mar. Pet. Geol. 2017, 87, 47–59. [Google Scholar] [CrossRef]
- Popov, S.V.; Rogl, F.; Rozanov, A.Y.; Steininger, F.F.; Shcherba, I.G.; Kovac, M. Lithological-Paleogeographic maps of Paratethys 10 maps Late Eocene to Pliocene. Cour. Forsch. Senckenberg 2004, 250, 1–46. [Google Scholar]
- Popov, S.V.; Shcherba, I.G.; Ilyina, L.B.; Nevesskaya, L.A.; Paramonova, N.P.; Khondkarian, S.O.; Magyar, I. Late Miocene to Pliocene palaeogeography of the Paratethys and its relation to the Mediterranean. Palaeogeogr. Palaeoclimatol. Palaeoecol. 2006, 238, 91–106. [Google Scholar] [CrossRef]
- Piller, W.E.; Harzhauser, M.; Mandic, O. Miocene Central Paratethys stratigraphy– current status and future directions. Stratigraphy 2007, 4, 151–168. [Google Scholar]
- Pavelić, D.; Kovačić, M. Sedimentology and stratigraphy of the Neogene rift-type North Croatian Basin (Pannonian Basin System, Croatia): A review. Mar. Pet. Geol. 2018, 91, 455–469. [Google Scholar] [CrossRef]
- Malvić, T. Kriging, cokriging or stochastical simulations, and the choice between deterministic or sequential approaches. Geol. Croat. 2008, 61, 37–47. [Google Scholar]
- Ivšinović, J. Deep mapping of hydrocarbon reservoirs in the case of a small number of data on the example of the Lower Pontian reservoirs of the western part of Sava Depression. In Proceedings of the 2nd Croatian congress on geomathematics and geological terminology, Zagreb, Croatia, 6 October 2018. [Google Scholar]
- Olivier, R.; Hanqiang, C. Nearest Neighbor Value Interpolation. Int. J. Adv. Comput. Sci. Appl. 2012, 3, 18–24. [Google Scholar] [CrossRef]
- Boissonnat, J.-D.; Cazals, F. Natural neighbor coordinates of points on a surface. Comput. Geom. 2001, 19, 155–173. [Google Scholar] [CrossRef]
- Tsidaev, A. Parallel Algorithm for Natural Neighbor Interpolation. In Proceedings of the 2nd Ural Workshop on Parallel, Distributed, and Cloud Computing for Young Scientists, Yekaterinburg, Russia, 6 October 2016. [Google Scholar]
- Traversoni, L. Natural neighbour finite elements. Trans. Ecol. Environ. 1994, 8, 291–297. [Google Scholar]
- Malvić, T.; Ivšinović, J.; Velić, J.; Rajić, R. Kriging with a Small Number of Data Points Supported by Jack-Knifing, a Case Study in the Sava Depression (Northern Croatia). Geosciences 2019, 9, 36. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wells in Reservoir “L” (Average Value Belong to Each of These Wells) | Permeability (10−3 µm2) (Horiz. Averaged) | ||
| L-27, L-87, L-160 | 24.2 | ||
| L-57, L-62, L-156 | 27.0 | ||
| L-4, L-37, L-65, L-68 | 23.2 | ||
| Wells in Reservoir “K” (Average Value Belongs to Each of These Wells) | Permeability (10−3 µm2) (Horiz. Averaged) | ||
| J-25, J-101, J-102, J-148, J-149, J-162, J-166, J-167, J-168, J-169, J-173, J-174 | 121.2 | ||
| J-120, J-158, J-170, J-171, J-172, J-175 | 29.6 | ||
| Reservoir “K” | Reservoir “L” | ||
| Well | Injected Volumes (m3) | Well | Injected Volumes (m3) |
| J-166 | 992,045 | L-4 | 132,116 |
| J-172 | 593,591 | L-33 | 420,251 |
| J-173 | 273,788 | L-34 | 167,108 |
| L-63 | 440,031 | ||
| L-79 | 132,352 | ||
| L-122 | 535,171 | ||
| L-139 | 241,085 | ||
| L-154 | 565,872 | ||
| L-160 | 467,987 | ||
| L-161 | 376,438 | ||
| Variable | Number of Data | Values of Cross-Validation | ||
|---|---|---|---|---|
| Inverse Distance Weighting | Nearest Neighbourhood | Natural Neighbour | ||
| Injected volumes | 10 | 1.21 × 1010 | 2.64 × 1010 | 2.36 × 1010 |
| Permeability | 10 | 1.41 | 2.22 | 3.48 |
| Variable | Number of Data | Value of Cross-Validation | ||
|---|---|---|---|---|
| Inverse Distance Weighting | Nearest Neighbourhood | Natural Neighbour | ||
| Injected volumes | 3 | 2.86 × 1011 | 3.96 × 1011 | - |
| Permeability | 18 | 480.8 | 1397.4 | 1044.7 |
| Number of Data | Applicability of Interpolation Method | ||
|---|---|---|---|
| Inverse Distance Weighting | Nearest Neighbourhood | Natural Neighbour | |
| 1–5 | Yes | Yes | No |
| 6–10 | Yes | Yes | Yes |
| 11–19 | Yes | Yes | Yes |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malvić, T.; Ivšinović, J.; Velić, J.; Rajić, R. Interpolation of Small Datasets in the Sandstone Hydrocarbon Reservoirs, Case Study of the Sava Depression, Croatia. Geosciences 2019, 9, 201. https://doi.org/10.3390/geosciences9050201
Malvić T, Ivšinović J, Velić J, Rajić R. Interpolation of Small Datasets in the Sandstone Hydrocarbon Reservoirs, Case Study of the Sava Depression, Croatia. Geosciences. 2019; 9(5):201. https://doi.org/10.3390/geosciences9050201
Chicago/Turabian StyleMalvić, Tomislav, Josip Ivšinović, Josipa Velić, and Rajna Rajić. 2019. "Interpolation of Small Datasets in the Sandstone Hydrocarbon Reservoirs, Case Study of the Sava Depression, Croatia" Geosciences 9, no. 5: 201. https://doi.org/10.3390/geosciences9050201
APA StyleMalvić, T., Ivšinović, J., Velić, J., & Rajić, R. (2019). Interpolation of Small Datasets in the Sandstone Hydrocarbon Reservoirs, Case Study of the Sava Depression, Croatia. Geosciences, 9(5), 201. https://doi.org/10.3390/geosciences9050201