A Novel Optimization Algorithm Combing Gbest-Guided Artificial Bee Colony Algorithm with Variable Gradients


Abstract
:1. Introduction
2. Overview of Artificial Bee Colony Algorithm
- Every employed bee collects nectar at food sources according to Equation (2) [29];
- After food sources are selected in light of probability value (pi in Equation (3), which is in direct proportion to nectar amount of food source), every artificial onlooker collects nectar at new food sources, which are generated according to Equation (2) [30];
- Employing greedy selection, the “food sources” in each iteration are updated by employed bees and onlookers;
- If the nectar amount of a food source has not increased more than “limit” (a control parameter) times, it will be abandoned, and a scout will search for a new food source according to Equation (1).
3. The Gbest-Guided ABC Algorithm with Gradient Information
4. Experiments
4.1. Benchmark Functions and Parameter Settings
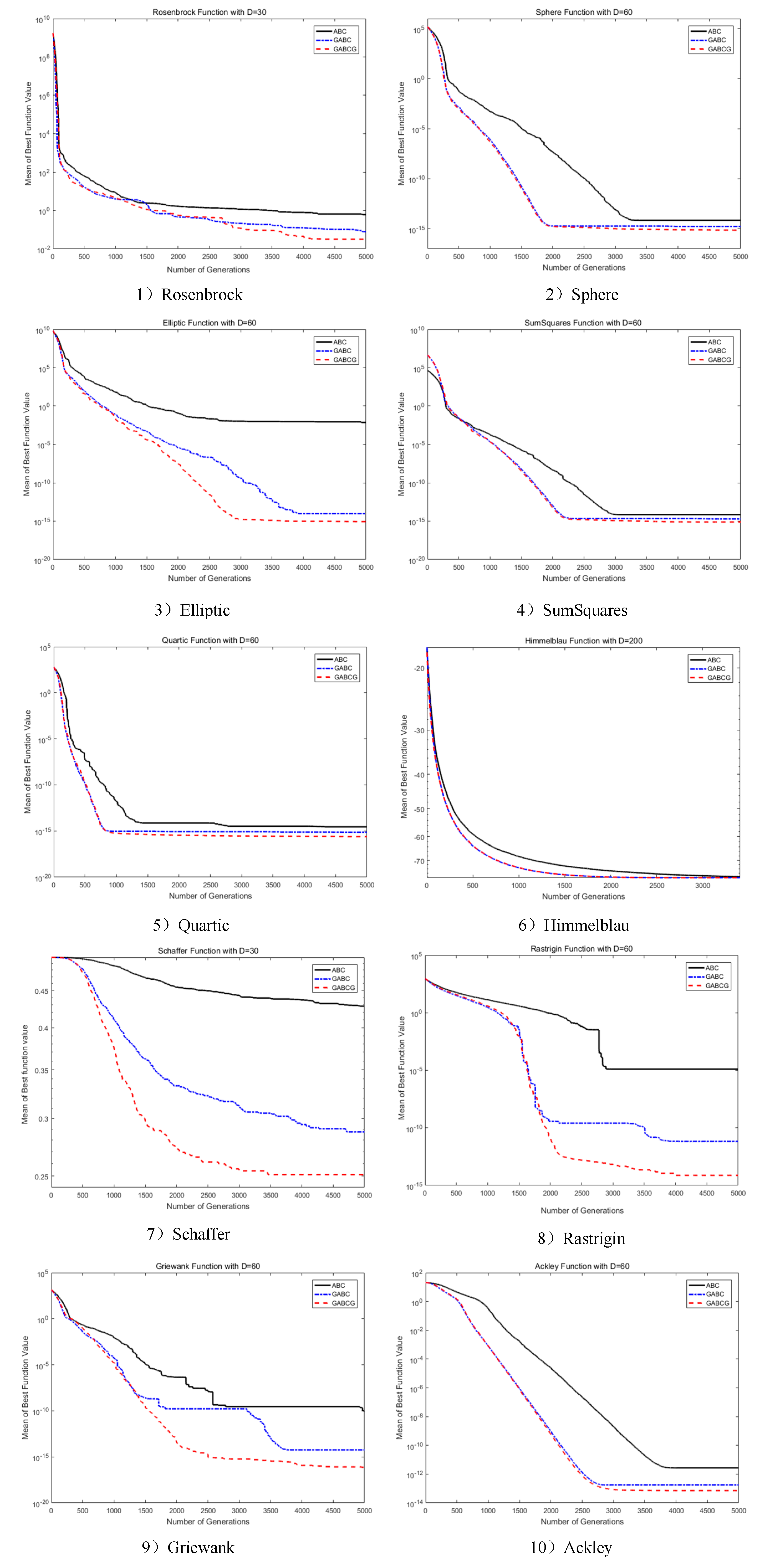
4.2. Performance Comparison between ABC, GABC, and GABCG
4.3. Effects of the Colony Size on the Performance of GABCG
4.4. Effects of Each Improvement Measure on the Performance of GABCG
4.5. The Gradient Effect on ABC/Best/1 and ABC/Best/2
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Maute, K.; Nikbay, M.; Farhat, C. Sensitivity analysis and design optimization of three-dimensional non-linear aeroelastic systems by the adjoint method. Int. J. Numer. Methods Eng. 2003, 56, 911–933. [Google Scholar] [CrossRef]
- Kuo, R.J.; Zulvia, F.E. The gradient evolution algorithm: A new metaheuristic. Inf. Sci. 2015, 316, 246–265. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Müller, L.; Verstraete, T. CAD Integrated Multipoint Adjoint-Based Optimization of a Turbocharger Radial Turbine. Int. J. Turbomachinery Propuls. Power 2017, 2, 14. [Google Scholar] [CrossRef] [Green Version]
- Xue, Y.; Jiang, J.; Zhao, B.; Ma, T. A self-adaptive artificial bee colony algorithm based on global best for global optimization. Soft Comput. 2017, 22, 2935–2952. [Google Scholar] [CrossRef]
- Karaboga, D. An Idea Based on Honey Bee Swarm for Numerical Optimization; Technical Report-TR06; Computer Engineering Department, Engineering Faculty, Erciyes University: Kayseri, Turkey, 2005. [Google Scholar]
- Şencan, A.; Kılıç, B.; Kılıç, U.; Kiliç, B. Design and economic optimization of shell and tube heat exchangers using Artificial Bee Colony (ABC) algorithm. Energy Convers. Manag. 2011, 52, 3356–3362. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Karaboga, D.; Akay, B. A comparative study of Artificial Bee Colony algorithm. Appl. Math. Comput. 2009, 214, 108–132. [Google Scholar] [CrossRef]
- Derakhshan, S.; Pourmahdavi, M.; Abdolahnejad, E.; Reihani, A.; Ojaghi, A. Numerical shape optimization of a centrifugal pump impeller using artificial bee colony algorithm. Comput. Fluids 2013, 81, 145–151. [Google Scholar] [CrossRef]
- Liouane, N. A Hybrid Method Based on Conjugate Gradient Trained Neural Network and Differential Evolution for Non Linear Systems Identification. In Proceedings of the 2013 International Conference on Electrical Engineering and Software Applications (ICEESA), Hammamet, Tunisia, 21–23 March 2013; pp. 1–5. [Google Scholar]
- Said, S.M.; Nakamura, M. Parallel Enhanced Hybrid Evolutionary Algorithm for Continuous Function Optimization. In Proceedings of the 2012 Seventh International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, Victoria, BC, Canada, 12–14 November 2012; pp. 125–131. [Google Scholar]
- Shahidi, N.; Esmaeilzadeh, H.; Abdollahi, M.; Ebrahimi, E.; Lucas, C. Self-adaptive memetic algorithm: An adaptive conjugate gradient approach. In Proceedings of the IEEE Conference on Cybernetics and Intelligent Systems 2004 ICCIS-04, Singapore, 1–3 December 2005; pp. 6–11. [Google Scholar] [CrossRef]
- Du, T.; Fei, P.; Shen, Y. A Modified Niche Genetic Algorithm Based on Evolution Gradient and Its Simulation Analysis. In Proceedings of the Third International Conference on Natural Computation (ICNC 2007), Haikou, China, 24–27 August 2007; Volume 4, pp. 35–39. [Google Scholar]
- Eslami, M.; Shareef, H.; Mohamed, A.; Khajehzadeh, M.; Eslami, M.; Mohamed, A. Gradient-based artificial bee colony for damping controllers design. In Proceedings of the 2013 IEEE 7th International Power Engineering and Optimization Conference (PEOCO), Langkawi, Malaysia, 3–4 June 2013; pp. 293–297. [Google Scholar]
- Xie, J.; Su, S.; Wang, J. Search Strategy of Artificial Bee Colony Algorithm Guided by Approximate Gradient. J. Front. Comput. Sci. Technol. 2016, 31, 2037–2044. [Google Scholar]
- Gao, W.; Liu, S.-Y. A modified artificial bee colony algorithm. Comput. Oper. Res. 2012, 39, 687–697. [Google Scholar] [CrossRef]
- Gao, W.; Liu, S.-Y.; Huang, L.-L. Enhancing artificial bee colony algorithm using more information-based search equations. Inf. Sci. 2014, 270, 112–133. [Google Scholar] [CrossRef]
- Gao, W.; Liu, S.; Huang, L. A global best artificial bee colony algorithm for global optimization. J. Comput. Appl. Math. 2012, 236, 2741–2753. [Google Scholar] [CrossRef] [Green Version]
- Gao, W.; Liu, S.-Y.; Huang, L.-L. A Novel Artificial Bee Colony Algorithm Based on Modified Search Equation and Orthogonal Learning. IEEE Trans. Cybern. 2013, 43, 1011–1024. [Google Scholar] [CrossRef]
- Zhu, G.; Kwong, S. Gbest-guided artificial bee colony algorithm for numerical function optimization. Appl. Math. Comput. 2010, 217, 3166–3173. [Google Scholar] [CrossRef]
- Guo, P.; Cheng, W.; Liang, J. Global artificial bee colony search algorithm for numerical function optimization. In Proceedings of the 2011 Seventh International Conference on Natural Computation, Shanghai, China, 26–28 July 2011; Volume 3, pp. 1280–1283. [Google Scholar]
- Jadhav, H.; Roy, R. Gbest guided artificial bee colony algorithm for environmental/economic dispatch considering wind power. Expert Syst. Appl. 2013, 40, 6385–6399. [Google Scholar] [CrossRef]
- Huo, Y.; Zhuang, Y.; Gu, J.; Ni, S.; Xue, Y. Discrete gbest-guided artificial bee colony algorithm for cloud service composition. Appl. Intell. 2014, 42, 661–678. [Google Scholar] [CrossRef]
- Roy, R.; Jadhav, H. Optimal power flow solution of power system incorporating stochastic wind power using Gbest guided artificial bee colony algorithm. Int. J. Electr. Power Energy Syst. 2015, 64, 562–578. [Google Scholar] [CrossRef]
- Cui, L.; Zhang, K.; Li, G.; Fu, X.; Wen, Z.; Lu, N.; Lu, J. Modified Gbest-guided artificial bee colony algorithm with new probability model. Soft Comput. 2017, 22, 2217–2243. [Google Scholar] [CrossRef]
- Zhang, Y.; Zeng, P.; Wang, Y.; Zhu, B.; Kuang, F. Linear Weighted Gbest-Guided Artificial Bee Colony Algorithm. In Proceedings of the 2012 Fifth International Symposium on Computational Intelligence and Design, Hangzhou, China, 28–29 October 2012; pp. 155–159. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. Artificial Bee Colony (ABC) Optimization Algorithm for Solving Constrained Optimization Problems. Comput. Vis. 2007, 4529, 789–798. [Google Scholar] [CrossRef]
- Karaboga, D.; Gorkemli, B.; Ozturk, C.; Karaboga, N. A comprehensive survey: Artificial bee colony (ABC) algorithm and applications. Artif. Intell. Rev. 2012, 42, 21–57. [Google Scholar] [CrossRef]
- Omkar, S.; Senthilnath, J.; Khandelwal, R.; Naik, G.N.; Gopalakrishnan, S. Artificial Bee Colony (ABC) for multi-objective design optimization of composite structures. Appl. Soft Comput. 2011, 11, 489–499. [Google Scholar] [CrossRef]
- Qiu, J.; Xu, M.; Liu, M.; Xu, W.; Wang, J.; Su, S. A novel search strategy based on gradient and distribution information for artificial bee colony algorithm. J. Comput. Methods Sci. Eng. 2017, 17, 377–395. [Google Scholar] [CrossRef]
- Eslami, M. Gradient based Artificial Bee Colony algorithm. In Proceedings of the Academics World 8th International Conference, Dubai, UAE, 13 November 2015; pp. 50–54. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| //Control Parameters: CS: The colony size MC: Maximum cycle number in order to terminate the algorithm Limit: The control Parameter in order to abandoned the food source Bas: The counter for counting the number of being exploited Fit: The fitness of a food source Sen: The gradient of a variable element NormFit: The fitness probability of a food source NormSen: The gradient probability of a variable element for g from 1 to MC: //Employed Bees Phase for i from 1 to CS/2: if GlobalMin = = Fit(i): Randomly seletct a variable element j if rand < NormSen(j): Produce a new candidate solution by Equation (5) else: Reselect a variable element end else: Produce a new candidate solution by Equation (5) end end //Onlookers Phase for i from 1 to CS/2: if rand < NorFit(i): if GlobalMin = = Fit(i): Randomly seletct a variable element j if rand < NormSen(j): Produce a new candidate solution by Equation (5) else: Reselect a variable element end else: Produce a new candidate solution by Equation (5) end else: Reselect a food source end end Employ greed selection to food sources //Scout Phase ind = max(Bas) if Bas(ind) > Limit && all(abs(Sen(ind)) < 10*max(Sen(GlobalMin)): Update the original solution using Equation (1) randomly end Remember the best solution obtained so far end |
| f | Function | C | Initial Range | f(x*) |
|---|---|---|---|---|
| Rosenbrock | UN | [−50,50] | ||
| Sphere | US | [−100,100] | ||
| Elliptic | UN | [−100,100] | ||
| SumSquares | US | [−10,10] | ||
| Quartic | US | [−1.28,1.28] | ||
| Himmelblau | MS | [−5,5] | ||
| Schaffer | MN | [−100,100] | ||
| Rastrigin | MS | [−5.12,5.12] | ||
| Griewank | MN | [−600,600] | ||
| Ackley | MN | [−32.768,32.768] |
| Function | D | ABC | GABC | GABCG | |||
|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | ||
| Rosenbrock | 10 | 4.25 × 10−1 | 2.19 × 10−1 | 3.40 × 10−2 | 1.73 × 10−2 | 1.47 × 10−2 | 1.46 × 10−2 |
| 30 | 6.15 × 10−1 | 3.28 × 10−1 | 5.45 × 10−2 | 3.65 × 10−2 | 3.16 × 10−2 | 3.71 × 10−2 | |
| Sphere | 30 | 7.62 × 10−16 | 1.47 × 10−16 | 4.33 × 10−16 | 6.79 × 10−16 | 2.39 × 10−18 | 3.36 × 10−17 |
| 60 | 7.14 × 10−15 | 3.84 × 10−15 | 1.62 × 10−15 | 2.10 × 10−16 | 7.76 × 10−15 | 2.88 × 10−14 | |
| Elliptic | 30 | 4.23 × 10−7 | 1.70 × 10−6 | 4.80 × 10−16 | 7.03 × 10−17 | 2.75 × 10−16 | 6.66 × 10−17 |
| 60 | 7.22 × 10−3 | 7.63 × 10−3 | 9.89 × 10−15 | 1.57 × 10−14 | 1.21 × 10−15 | 7.63 × 10−16 | |
| SumSquares | 30 | 7.43 × 10−15 | 1.06 × 10−16 | 4.37 × 10−16 | 4.87 × 10−17 | 2.17 × 10−16 | 3.62 × 10−17 |
| 60 | 7.10 × 10−15 | 5.03 × 10−15 | 1.95 × 10−15 | 3.51 × 10−16 | 7.72 × 10−16 | 1.03 × 10−16 | |
| Quartic | 30 | 2.78 × 10−16 | 6.52 × 10−17 | 1.07 × 10−16 | 3.37 × 10−17 | 5.55 × 10−17 | 1.71 × 10−17 |
| 60 | 2.72 × 10−15 | 2.12 × 10−15 | 7.21 × 10−16 | 1.22 × 10−16 | 2.37 × 10−16 | 3.27 × 10−17 | |
| Himmelblau | 100 | −78.3323 | 1.28 × 10−11 | −78.3323 | 1.04 × 10−13 | −78.3323 | 6.01 × 10−14 |
| 200 | −78.3273 | 2.06 × 10−2 | −78.3323 | 1.06 × 10−11 | −78.3323 | 6.80 × 10−12 | |
| Schaffer | 10 | 2.54 × 10−2 | 1.37 × 10−2 | 2.27 × 10−2 | 1.39 × 10−2 | 9.72 × 10−3 | 3.52 × 10−8 |
| 30 | 4.24 × 10−1 | 2.59 × 10−2 | 2.87 × 10−1 | 4.19 × 10−2 | 2.51 × 10−1 | 3.61 × 10−2 | |
| Rastrigin | 30 | 1.07 × 10−11 | 1.61 × 10−11 | 7.96 × 10−14 | 3.20 × 10−14 | 0 | 0 |
| 60 | 1.27 × 10−5 | 4.53 × 10−5 | 6.68 × 10−12 | 1.04 × 10−11 | 1.14 × 10−14 | 3.47 × 10−14 | |
| Griewank | 30 | 4.84 × 10−14 | 9.12 × 10−14 | 3.07 × 10−16 | 2.45 × 10−16 | 3.70 × 10−18 | 2.03 × 10−17 |
| 60 | 8.62 × 10−11 | 4.55 × 10−10 | 2.20 × 10−14 | 5.17 × 10−14 | 6.66 × 10−17 | 1.29 × 10−16 | |
| Ackley | 30 | 1.24 × 10−13 | 4.10 × 10−14 | 4.02 × 10−14 | 4.27 × 10−15 | 3.08 × 10−14 | 3.05 × 10−15 |
| 60 | 2.72 × 10−12 | 1.50 × 10−12 | 1.79 × 10−13 | 3.22 × 10−14 | 7.15 × 10−14 | 5.34 × 10−15 | |
| Function | CZ | ABC | GABC | GABCG | |||
|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | ||
| Rosenbrock | 80 | 6.15 × 10−1 | 3.28 × 10−1 | 5.45 × 10−2 | 3.65 × 10−2 | 3.16 × 10−2 | 3.71 × 10−2 |
| 160 | 2.33 × 10−1 | 9.72 × 10−2 | 4.98 × 10−2 | 3.29 × 10−2 | 2.20 × 10−2 | 2.56 × 10−2 | |
| 240 | 1.65 × 10−1 | 1.80 × 10−1 | 2.94 × 10−2 | 1.78 × 10−2 | 1.12 × 10−2 | 1.50 × 10−2 | |
| Elliptic | 80 | 7.22 × 10−3 | 7.63 × 10−3 | 9.89 × 10−15 | 1.57 × 10−14 | 1.21 × 10−15 | 7.63 × 10−16 |
| 160 | 1.04 × 10−4 | 6.44 × 10−5 | 1.83 × 10−15 | 3.44 × 10−16 | 6.50 × 10−16 | 8.46 × 10−17 | |
| 240 | 2.47 × 10−5 | 1.93 × 10−5 | 1.74 × 10−15 | 2.75 × 10−16 | 5.27 × 10−16 | 6.98 × 10−17 | |
| Schaffer | 80 | 4.24 × 10−1 | 2.59 × 10−2 | 2.87 × 10−1 | 4.19 × 10−2 | 2.51 × 10−1 | 3.61 × 10−2 |
| 160 | 3.95 × 10−1 | 1.81 × 10−2 | 2.41 × 10−1 | 3.12 × 10−2 | 2.30 × 10−1 | 5.60 × 10−2 | |
| 240 | 3.36 × 10−1 | 3.51 × 10−2 | 1.88 × 10−1 | 3.96 × 10−2 | 1.73 × 10−1 | 4.41 × 10−2 | |
| Rastrigin | 80 | 1.27 × 10−5 | 4.53 × 10−5 | 6.68 × 10−12 | 1.04 × 10−11 | 1.14 × 10−14 | 3.47 × 10−14 |
| 160 | 5.29 × 10−7 | 2.86 × 10−6 | 1.87 × 10−12 | 2.09 × 10−12 | 7.58 × 10−15 | 3.60 × 10−14 | |
| 240 | 2.92 × 10−9 | 7.81 × 10−9 | 7.39 × 10−13 | 2.53 × 10−13 | 3.79 × 10−15 | 2.08 × 10−14 | |
| Griewank | 80 | 8.62 × 10−11 | 4.55 × 10−10 | 2.20 × 10−14 | 5.17 × 10−14 | 6.66 × 10−17 | 1.29 × 10−16 |
| 160 | 1.83 × 10−14 | 2.15 × 10−14 | 1.11 × 10−15 | 5.56 × 10−16 | 5.55 × 10−17 | 5.85 × 10−17 | |
| 240 | 1.22 × 10−14 | 9.87 × 10−15 | 6.66 × 10−16 | 2.09 × 10−16 | 4.44 × 10−17 | 5.73 × 10−17 | |
| Function | D | ABC/best/1 | ABC/best/1G | ABC/best/2 | ABC/best/2G | ||||
|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | ||
| Rosenbrock | 10 | 7.77 × 10−3 | 9.40 × 10−3 | 2.24 × 10−3 | 1.20 × 10−3 | 7.77 × 10−1 | 1.54 | 1.84 × 10−1 | 1.23 × 10−1 |
| 30 | 7.42 | 2.20 × 10−1 | 7.39 × 10−2 | 8.24 × 10−2 | 3.95 × 10−1 | 3.21 × 10−1 | 2.62 × 10−1 | 4.80 | |
| Sphere | 30 | 3.85 × 10−16 | 6.49 × 10−17 | 3.72 × 10−16 | 5.58 × 10−18 | 5.08 × 10−16 | 8.52 × 10−17 | 4.86 × 10−16 | 4.34 × 10−17 |
| 60 | 1.40 × 10−15 | 2.14 × 10−16 | 1.37 × 10−15 | 5.23 × 10−17 | 2.12 × 10−15 | 2.68 × 10−16 | 2.14 × 10−15 | 2.18 × 10−14 | |
| Schaffer | 10 | 9.72 × 10−3 | 2.35 × 10−9 | 9.71 × 10−3 | 3.15 × 10−10 | 1.18 × 10−2 | 7.04 × 10−3 | 1.18 × 10−2 | 3.60 × 10−3 |
| 30 | 2.50 × 10−1 | 2.92 × 10−2 | 2.26 × 10−1 | 4.73 × 10−2 | 3.72 × 10−1 | 2.88 × 10−2 | 3.79 × 10−1 | 2.92 × 10−2 | |
| Rastrigin | 30 | 4.17 × 10−14 | 2.56 × 10−14 | 3.79 × 10−14 | 3.28 × 10−14 | 7.58 × 10−14 | 3.45 × 10−14 | 9.47 × 10−14 | 3.28 × 10−14 |
| 60 | 6.56 × 10−13 | 2.44 × 10−13 | 6.44 × 10−13 | 3.28 × 10−13 | 1.84 × 10−12 | 8.21 × 10−13 | 1.48 × 10−12 | 6.92 × 10−14 | |
| Griewank | 30 | 1.29 × 10−15 | 4.72 × 10−15 | 3.70 × 10−17 | 6.41 × 10−17 | 1.05 × 10−9 | 2.71 × 10−9 | 2.50 × 10−11 | 2.58 × 10−11 |
| 60 | 1.14 × 10−15 | 9.17 × 10−16 | 8.51 × 10−16 | 7.22 × 10−16 | 2.26 × 10−10 | 4.76 × 10−10 | 2.61 × 10−9 | 3.48 × 10−9 | |
| Ackley | 30 | 3.26 × 10−14 | 3.36 × 10−15 | 3.20 × 10−14 | 2.59 × 10−15 | 4.38 × 10−14 | 5.59 × 10−15 | 4.83 × 10−14 | 8.20 × 10−15 |
| 60 | 1.16 × 10−13 | 1.38 × 10−14 | 1.13 × 10−13 | 2.05 × 10−15 | 1.86 × 10−13 | 2.72 × 10−14 | 2.14 × 10−13 | 2.82 × 10−14 | |
| Elliptic | 30 | 3.65 × 10−16 | 6.84 × 10−17 | 3.47 × 10−16 | 6.53 × 10−17 | 8.88 × 10−1 | 8.41 × 10−1 | 8.03 × 10−2 | 2.64 × 10−1 |
| 60 | 2.24 × 10−15 | 7.33 × 10−16 | 2.22 × 10−15 | 6.04 × 10−16 | 1.31 × 10−2 | 9.21 × 10−1 | 6.58 × 10−1 | 4.51 × 10−1 | |
| SumSquares | 30 | 3.47 × 10−16 | 5.72 × 10−17 | 3.36 × 10−16 | 5.52 × 10−17 | 5.02 × 10−16 | 8.31 × 10−17 | 4.85 × 10−16 | 6.90 × 10−17 |
| 60 | 1.40 × 10−15 | 1.18 × 10−16 | 1.37 × 10−15 | 1.71 × 10−16 | 2.01 × 10−15 | 2.07 × 10−16 | 2.02 × 10−15 | 2.75 × 10−16 | |
| Quartic | 30 | 6.89 × 10−17 | 2.10 × 10−17 | 6.72 × 10−17 | 1.17 × 10−17 | 2.02 × 10−16 | 5.59 × 10−17 | 1.94 × 10−16 | 4.63 × 10−17 |
| 60 | 5.47 × 10−16 | 1.00 × 10−16 | 5.35 × 10−16 | 9.67 × 10−17 | 7.63 × 10−16 | 1.53 × 10−16 | 8.01 × 10−16 | 1.39 × 10−16 | |
| Himmelblau | 100 | −78.3323 | 3.22 × 10−14 | −78.3323 | 3.11 × 10−14 | −78.3323 | 6.39 × 10−14 | −78.3323 | 3.38 × 10−14 |
| 200 | −78.3323 | 3.93 × 10−13 | −78.3323 | 4.52 × 10−13 | −78.3323 | 4.12 × 10−12 | −78.3323 | 4.14 × 10−12 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruan, X.; Wang, J.; Zhang, X.; Liu, W.; Fu, X. A Novel Optimization Algorithm Combing Gbest-Guided Artificial Bee Colony Algorithm with Variable Gradients. Appl. Sci. 2020, 10, 3352. https://doi.org/10.3390/app10103352
Ruan X, Wang J, Zhang X, Liu W, Fu X. A Novel Optimization Algorithm Combing Gbest-Guided Artificial Bee Colony Algorithm with Variable Gradients. Applied Sciences. 2020; 10(10):3352. https://doi.org/10.3390/app10103352
Chicago/Turabian StyleRuan, Xiaodong, Jiaming Wang, Xu Zhang, Weiting Liu, and Xin Fu. 2020. "A Novel Optimization Algorithm Combing Gbest-Guided Artificial Bee Colony Algorithm with Variable Gradients" Applied Sciences 10, no. 10: 3352. https://doi.org/10.3390/app10103352
APA StyleRuan, X., Wang, J., Zhang, X., Liu, W., & Fu, X. (2020). A Novel Optimization Algorithm Combing Gbest-Guided Artificial Bee Colony Algorithm with Variable Gradients. Applied Sciences, 10(10), 3352. https://doi.org/10.3390/app10103352