1. Introduction
Social media play an important role in global crises, such as the COVID-19 pandemic. They serve as a key communication platform [
1] and are potentially a source of valuable information [
2]. During the last two decades, social media have amplified the spread of information, as well as misinformation and disinformation which may lead to an infodemic as a negative side effect [
3]. Thus, social media monitoring (infoveillance) is needed for better understanding of crisis communication.
In this light, natural language processing (NLP) offers a set of techniques and methods that contributes to the monitoring of crisis communication on social media. Namely, automatic keyword extraction, topic modelling, named entity recognition, text classification, sentiment analysis, fake news detection, etc., can be applied to different aspects of information monitoring. When dealing with a large amount of textual data, these techniques can perform more efficiently than humans [
4]. For example, when dealing with data gathered from social networks, sentiment analysis based on machine learning (ML) provides insights into public attitudes. In the context of the pandemic, this may contribute to the implementation of appropriate public health responses [
5]. Therefore, sentiment analysis (sometimes combined with topic modelling) is one of the most frequent NLP tasks implemented in COVID-19 information monitoring [
6,
7,
8,
9,
10,
11,
12].
Focusing on the similar tasks, in this research we describe the implementation of an NLP based framework for the analysis of tweets written in the Croatian language, integrating the sentiment analysis, the topis analysis and the analysis of message spreading (retweeting). There are fewer studies focused on other languages, such as sentiment analysis of Polish [
13] and Greek [
14] tweets or topic modelling for tweets in the Italian language [
15]. Studies limited to one language are important as a potential source of material for further comparative research of COVID-19-related communication in different languages. Thus, although the proposed framework covers only local aspects of online COVID-19 communication, limited to the Croatian language, it is a valuable contribution to the research in the context of monitoring the pandemic-related communication.
The goal of this research was to develop a framework that includes language resources for the Croatian language and then to apply it to the analysis and characterisation of COVID-19-related tweets. The main purpose of developing the framework was to answer the following research questions:
- RQ1:
What sentiment was present in COVID-19-related tweets posted during the first three pandemic waves and how did the amount of negative sentiment change over time?
- RQ2:
What is the number of tweets present in the different thematic clusters related to COVID-19 and how do these trends change over the three pandemic waves?
- RQ3:
What is the distribution of sentiment polarity (in each thematic cluster and over time) and the distribution of retweets (across thematic clusters and sentiment)?
As mentioned above, an essential prerequisite for answering these questions is to develop a language model and datasets for the domain of COVID-19 texts in the Croatian language. We decided to use and train a BERT variant of the language model. BERT (Bidirectional Encoder Representations from Transformers) [
16] is a deep bidirectional Transformer that learns sentence representations. The BERT model was initially pre-trained on a large corpus of English texts, but the multilingual versions of BERT, mBERT [
17], trained on 104 languages and XLM-R, trained on 100 languages [
18] soon followed. Although mBERT and XLM-R achieve good results, it has been found that models trained on few languages (bilingual and trilingual models) or on one language (monolingual models) perform better than models trained on a large number of languages (multilingual models) [
19,
20,
21]. When it comes to less-resourced languages, such as Croatian, there is still a lack of available monolingual language models. Thus, for the purpose of this study, we used an existing trilingual CroSloEngualBERT language model [
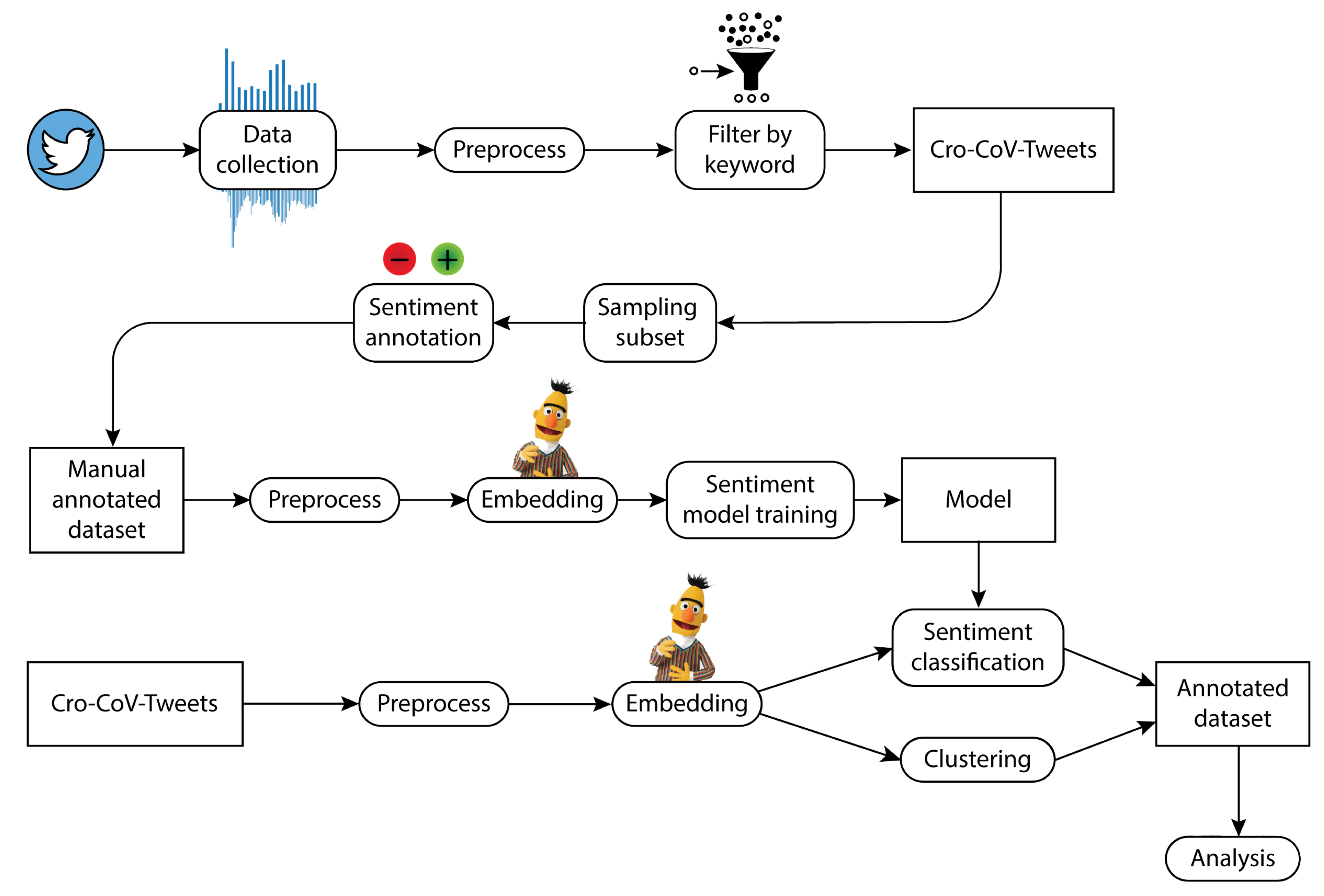
21] that was pre-trained using online news articles in Croatian, Slovene and English. However, the COVID-19 pandemic led to the emergence of new terminology that has not been covered within the CroSloEngualBERT. To fill this gap, we additionally trained the model on a dataset of COVID-19-related texts in the Croatian language (Cro-CoV-Texts). The result is a new version of the BERT language model, Cro-CoV-cseBERT, that can be used for any NLP task in the domain of COVID-19.
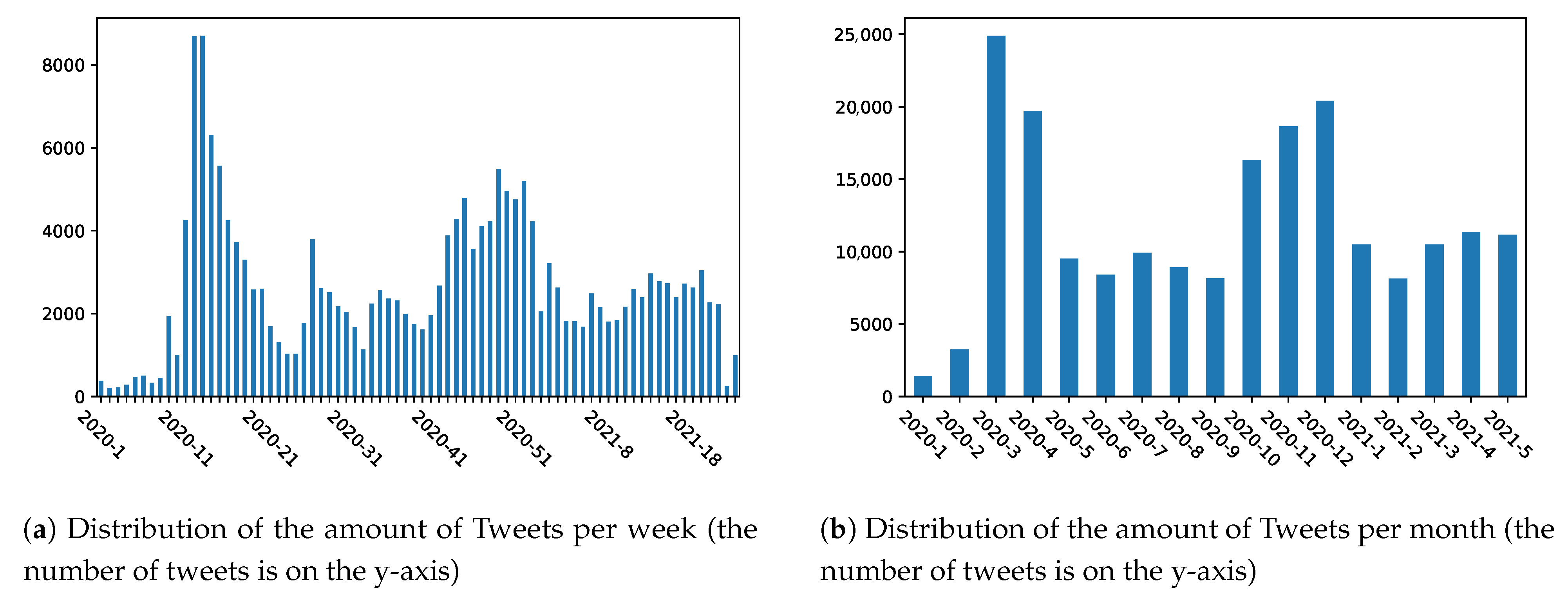
In the second step, we applied the Cro-CoV-cseBERT model for the representation of tweets. We collected data from Twitter and filtered 206,196 unique COVID-19-related tweets in the Croatian language posted between 1 January 2020 and 31 May 2021 and created a Cro-CoV-Tweets dataset. From this dataset, we chose a representative sample of 10,000 tweets, manually labelled each tweet with one of three possible labels (negative, neutral and positive) and constructed a Senti-Cro-CoV-Tweets dataset enabling supervised learning of sentiment. We represented each tweet as a Cro-CoV-cseBERT embedding and trained four different ML models (naïve Bayes, random forest, support vector machine, and multilayer perceptron) on the task of sentiment analysis. The performance of ML models has been assessed using standard evaluation measures. Multilayer perceptron proved to be the best performing model and, thus, we used it for the annotation of the rest of the Cro-CoV-Tweets dataset.
Next, we performed an extensive analysis of the Cro-CoV-Tweets dataset with the aim of answering the research questions. First, we observed trends of negativity in tweets posted during the pandemic. Furthermore, given the vectors of tweets, we performed clustering using a k-means algorithm and identified possible themes of tweets grouped into clusters. In the last step, we examined how sentiment in clusters changes over time and how COVID-19-related messages spread in social media in terms of retweeting.
To summarise, we identify three main contributions of this study.
We trained the Cro-CoV-cseBERT model for the representation of COVID-19 tweets in the Croatian language using a large dataset of COVID-19-related texts in the Croatian language;
We developed two datasets that could be further used in similar research: (i) Senti-Cro-CoV-Tweets—a dataset of 206,196 Croatian tweets related to COVID-19 posted during the first three waves of the pandemic and (ii) Senti-Cro-CoV-Tweets —a dataset of 10,000 Croatian COVID-19 tweets manually annotated for sentiment;
We provide an overview of sentiment, themes and retweeting of COVID-19 messages in the Croatian language, which should prove to be of help when it comes to monitoring the crisis communication.
This paper is structured as follows: in
Section 2, we review previous research focused on the analysis of the crisis communication related to COVID-19 in social media and applications of the BERT language model. In
Section 3, we describe the dataset collected from Twitter and the annotated dataset for the sentiment analysis. Next, in
Section 4, we describe the NLP methods that we used in this research. In
Section 5, we present and discuss the results. In
Section 6, we present the main findings, possible applications and limitations of this study. In the last section, we provide conclusions.
5. Results
5.1. Insights into the Negativity of Tweets Related to COVID-19
In this subsection, we aim to answer RQ1, i.e., what sentiment was present in COVID-19-related tweets posted during the first three pandemic waves and how did the amount of negative sentiment change over time? Initially, we trained the classification models for the three annotated categories: Negative, neutral, or positive and evaluated the performance of different models. After applying the best performing model (multilayer perceptron with Cro-CoV-cseBERT embeddings) to the Cro-CoV-Tweets dataset, the numbers of tweets per classes were as follows, neutral: 99,469; negative: 96,511 and positive: 10,216. As the percentage of positive tweets (5%) is low in comparison to the neutral (48.2%) and negative tweets (46.8%), we merged the neutral and positive tweets into one non-negative group enabling a better visualization on the relationship between the negative and non-negative tweets. This way, we obtained insights into the negativity of COVID-19-related tweets.
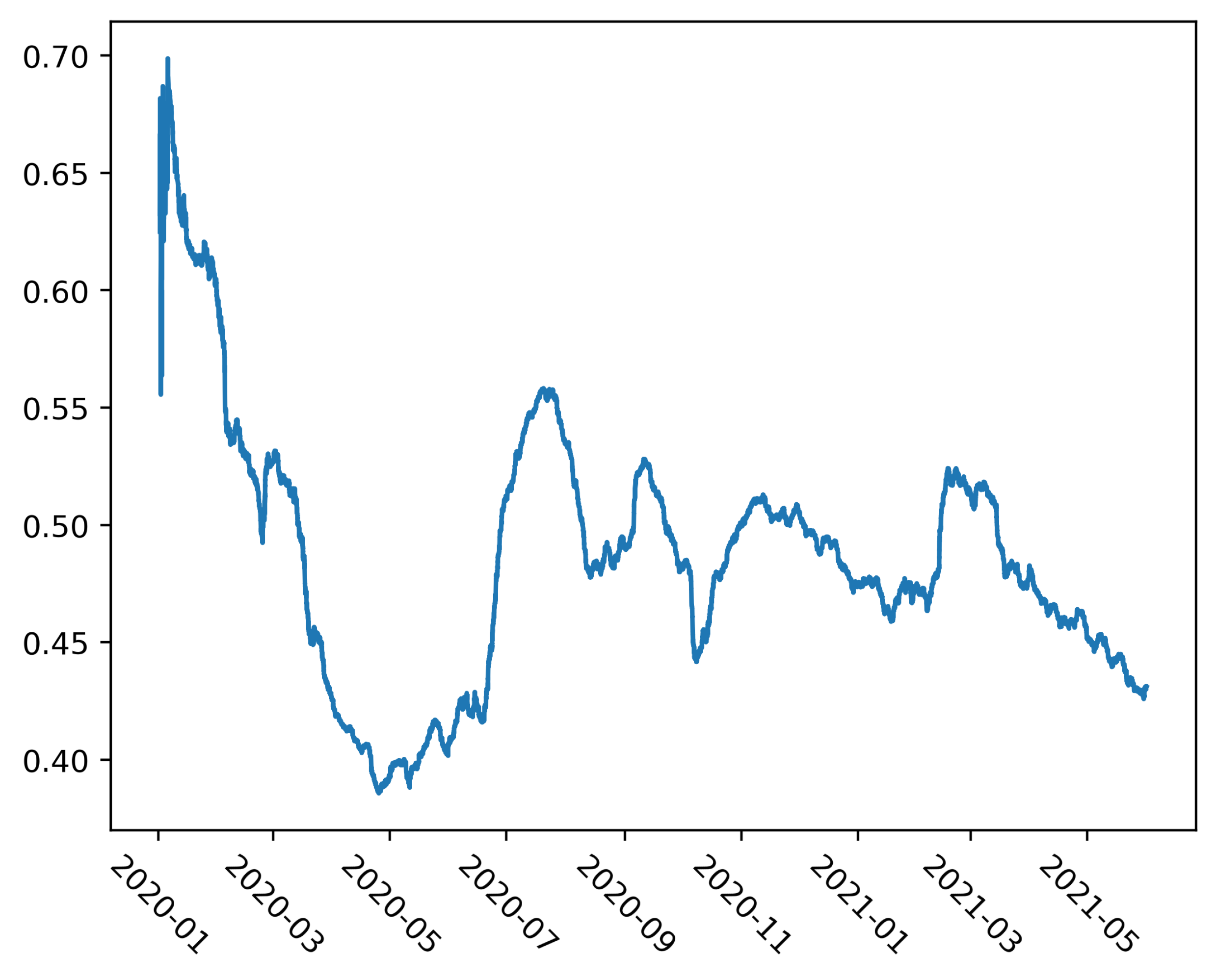
In
Figure 3, the sentiment is visualized through time by averaging sentiment over a 30-day sliding window. To calculate the average sentiment, the negative sentiment is treated as 1 and non-negative (neutral and positive) as 0. The higher the value of the sentiment, the more negative it is, hence, we reference it as negativity. In May 2020, the negativity was at its lowest, which coincides with the time when there were almost no new COVID-19 cases and strict lockdown measures were starting to relax. In May 2021, the negativity decreased again as the summer was getting closer and the number of COVID-19 cases was getting lower.
5.2. Analysis and Description of Clusters Related to COVID-19
To answer the second research question (RQ2: What is the number of tweets present in the different thematic clusters related to COVID-19 and how do these trends change over the three pandemic waves?), we clustered the tweets into 10 clusters. Next, we explored the content of clusters by extracting tweets with representations closest to the center of the cluster in the learned representation space. We use the Euclidean distance for the quantification of the distance between representations. Tweets that are grouped together are semantically similar, describing a theme captured in a cluster, as listed in
Table 3.
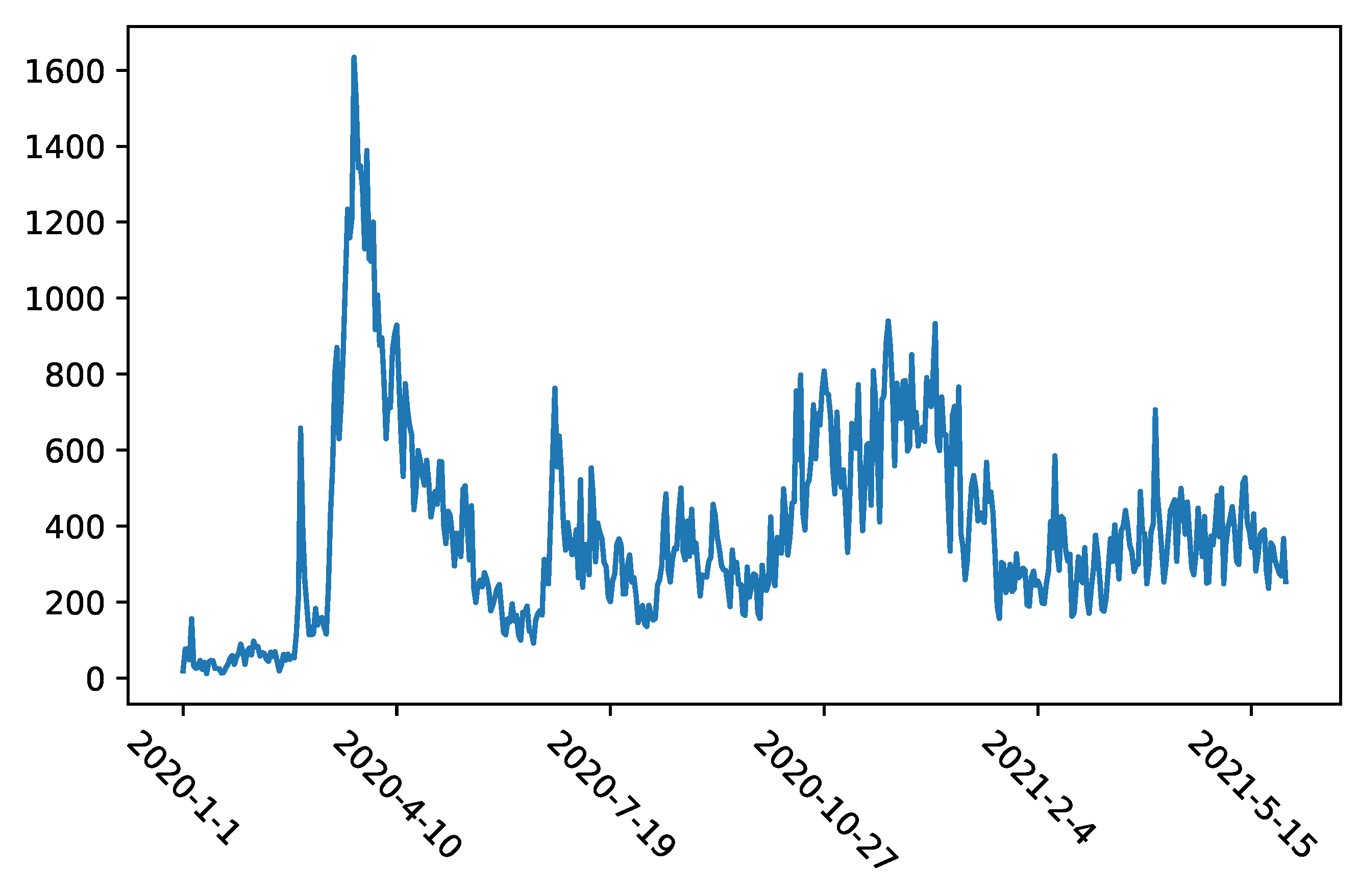
Then, we explored the distribution of tweets across thematic clusters and how these trends were changing during the whole observed period. The results are shown in
Figure 4.
According to the results, the highest number of tweets belong to the cluster #4 related to the “Public discussion regarding anti-pandemic policies and vaccines” with 29.63% of tweets in total (cluster #4). It is followed by the clusters with themes related to “Coping with the pandemic” (cluster #2 with 18.37% of tweets in total) and “Public comments on statements of the politicians and scientists” (cluster #6 with 15.10% of tweets in total). The remaining 37% of tweets are distributed across the other 7 identified themes in such a way that there is no cluster with more than 7% of tweets.
When we analyse the trends across the three waves, it seems that the number of tweets belonging to each cluster/theme is relatively constant during all three pandemic waves. The biggest change is present in cluster #2 (“Coping with the pandemic”) which contains 26% of the tweets in the first pandemic wave, while in the next two waves, the percentage is smaller (16.12% in the second wave and 13.41% in the third wave). This can be explained by the fact that this theme was the most interesting in the early stage of the pandemic, while at a later point, the people had already learned how to cope with the pandemic. On the contrary, cluster #6 (“Public comments on statements of the politicians and scientists”) has a higher number of tweets in the second and third wave than in the first wave. It seems that people needed to comment on politicians and scientists more intensely after the first wave.
5.3. Statistics across the Clusters
In the last part of the analysis, we analysed sentiment and retweeting across clusters aiming to answer the third research question (RQ3: What is the distribution of sentiment polarity (in each thematic cluster and over time) and the distribution of retweets (across thematic clusters and sentiment)?).
Sentiment is calculated as the average sentiment in each cluster (i.e., negative sentiment is represented as 1, and the rest is represented as 0, as defined in
Section 5.2).
Figure 5 shows cluster statistics sorted by the presence of negativity. We report the total number of tweets in each cluster, the average number of retweets of a tweet for each cluster, the percentage of retweets for each cluster, and the negativity across clusters.
According to these results, we determined that the three most negative clusters refer to tweets related to the “Revolt against the COVID-19 policies and behaviour of citizens” (cluster #3 with 0.89 negativity score), “Public discussion regarding anti-pandemic policies and vaccines”, (cluster #4 with 0.804 negativity score) and “Ironic comments of COVID-19” (cluster #8 with 0.673 negativity score). If we take into account the topics, the high amount of negativity is not surprising for clusters #3 and #8. However, it is not the case with cluster #4 which is dedicated to the discussion of anti-pandemic policies and vaccines. In some previous studies of COVID-19 tweets in English related to the vaccination [
33,
34], the attitudes were far more positive or neutral than negative.
The most non-negative cluster of tweets is “Information about new daily COVID-19 cases” (cluster #7 with negativity score 0.055). The reason is that this cluster contains only tweets about new cases with no subjective messages and these tweets are always classified as neutral. The clusters related to the “Informative facts” (cluster #0 with negativity score 0.113), “Education and implementation of the COVID-19 policies” (cluster #1 with negativity score 0.122) and “Coping with the pandemic” (cluster #2 with negativity score 0.67) are also detected as highly non-negative. This may indicate that there is a degree of optimistic attitudes in tweets related to education, implementation of COVID-19 policies and coping with the pandemic in general.
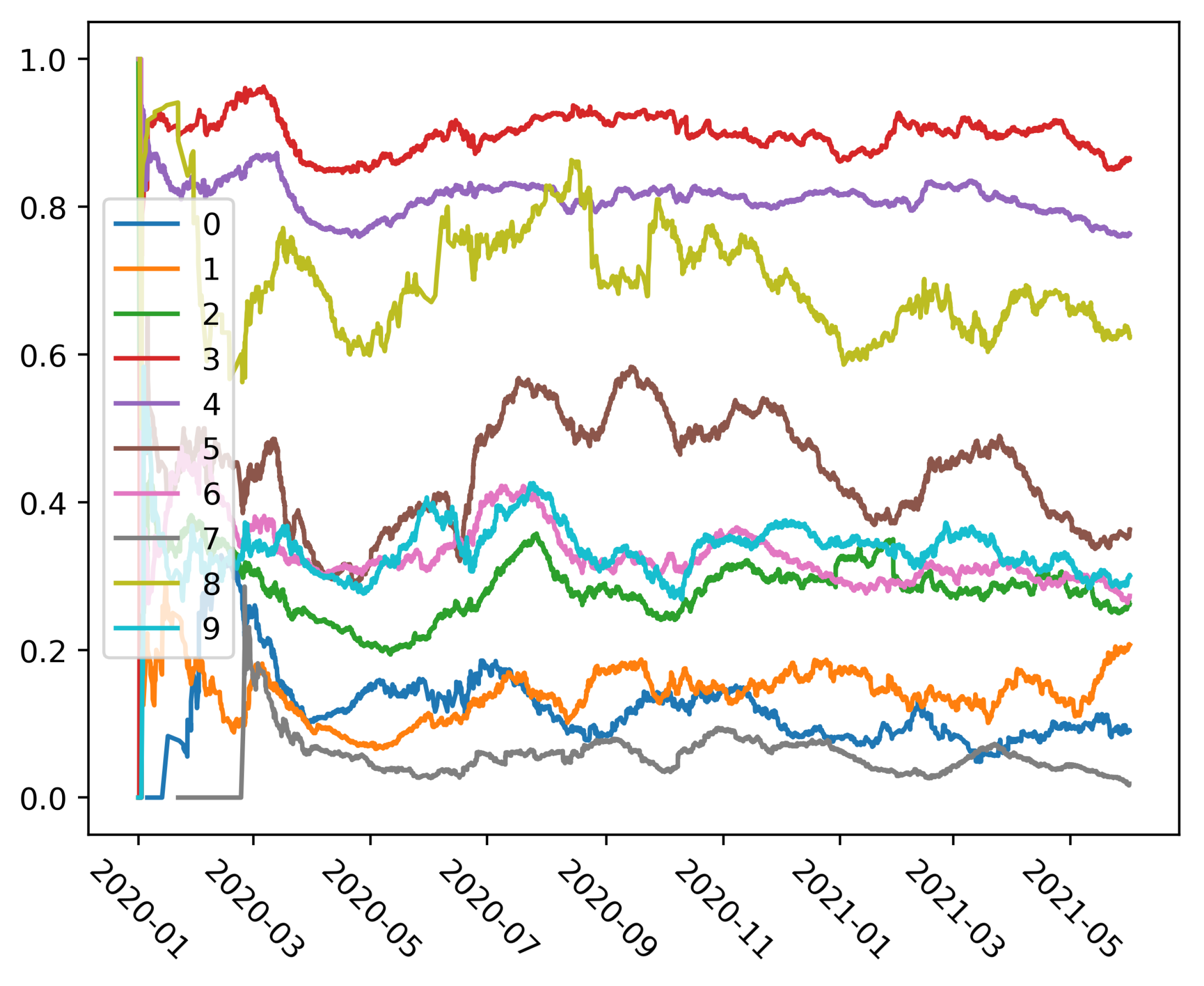
The graph visualised in
Figure 6 shows how sentiment of each cluster changes over the observed period. From the graph, it can be seen that the sentiment is uniformly distributed for most of the clusters throughout all three waves. The most negative sentiment is consistently present in clusters #3, #4, while in cluster #8, the negative sentiment is not uniformly distributed. The fluctuations in cluster #8 may be caused by the small number of tweets, since it is the cluster with the smallest number of entries The clusters identified as non-negative (#7, #0 and #1) also show uniform distribution during the three pandemic waves. Sentiment in cluster #5 focused on the “Impact of COVID-19 policies on economy and education” varied over the time, similar as in the cluster #8. Sentiment in this cluster was less negative in the end of the first wave (in May and July of 2020) and, then, it has suddenly increased to negative at the beginning of the second wave (in August of 2020). Later, at the end of the second wave, the negativity is lower again. It seems that the topics related to economy and education are the most prone to changes in accordance to the pandemic waves.
The analysis of sharing these tweets in terms of retweeting shows that the percentage of retweeting is generally low. There is only one cluster with a high average number of retweets. This is the cluster #1 (“Education and implementation of the COVID-19 policies”) which is identified as a highly non-negative cluster with a small amount of tweets (6.31%). The average number of retweets in this cluster is around 20 which is relatively high since there is a low number of retweets in the whole dataset. Except this cluster, the only other clusters with more than 5 retweets on average are the two most negative clusters #3 (“Revolt to the COVID-19 policies and behaviour of citizens”) and #4 (“Public discussion regarding anti-pandemic policies and vaccines”).
In the last step, we analysed and compared the amount of retweeting across clusters. The highest percentage of retweets (more than 34%) is present in cluster #4. This makes sense because this cluster contains the highest number of tweets. Next, clusters #1 and #2 have around 20% of retweets, while tweets in the rest of the clusters contain less than 10% of retweets. Cluster #2 is the one with the highest number of average retweets per one tweet and, thus, it contains a large proportion of retweets as well.
According to the results related to retweeting, it seems that the cluster with the most non-negative sentiment and two clusters with the most negative sentiment have a higher percentage of retweets than the other clusters. Thus, we cannot conclude that retweeting of COVID-19 tweets in the Croatian language goes in favour of negative or non-negative sentiment. Rather, we can only notice that both sentiments are retweeted equally.
6. Discussion
6.1. Principal Results
Principal results of this research can be divided into two parts: (i) the Cro-CoV-cseBERT-based framework developed for the COVID-19 tweets analysis described in
Section 3 and
Section 4, and (ii) the results of the application of the framework on the dataset of COVID-19 tweets in the Croatian language described in
Section 5. The Cro-CoV-cseBERT-based framework is a prerequisite for an extensive analysis of COVID-19 tweets that enables answering the three research questions.
The Cro-CoV-cseBERT-based framework was developed for the task of analysis of COVID-19-related communication on Twitter in Croatia. For that purpose, we developed language resources for the Croatian language intended for the representation and analysis of COVID-19 tweets. Within the proposed framework, we used the existing NLP methods for the task of sentiment analysis and clustering. That is in line with some other similar studies that use similar approaches for other languages [
6,
7,
8,
9,
10,
11]. However, in order to deal with the texts in the Croatian language related to the domain of COVID-19, we have to develop adequate language resources. Thus, in response to other similar studies, this research contributes in terms of (i) Cro-CoV-cseBERT language model, (ii) a dataset of 206,196 unique COVID-19 tweets in the Croatian language posted between 1 January 2020 and 31 May 2021—Cro-CoV-Tweets dataset, and (iii) a dataset of 10,000 tweets annotated manually with one of the three labels describing the sentiment (positive, negative, neutral)—Senti-Cro-CoV-Tweets dataset.
In the second part of the research, we performed an extensive analysis of COVID-19-related tweets in the Croatian language. Specifically, we addressed the three open research questions and our main findings are summarized below.
Regarding the first research question related to sentiment, we found that negative sentiment is present in 46.8% of the COVID-19-related tweets. The negativity of tweets varies substantially over the three pandemic waves. The amount of negative sentiment in tweets is highest during the first wave, during the lockdown period. Later, the higher number of negative tweets is exhibited during August 2020, probably due to the sudden and early end of the tourist season (note that tourism is one of the main economic sectors in Croatia). Again, one negative peak appeared in April 2021 caused by the uncertainty brought about by the third epidemic wave. Less negative tweets are present in May/June 2020 and May 2021 due to the decrease in the number of confirmed COVID-19 cases. These results confirm our previous findings in [
29], where we have presented similar results for tweets in Croatian and Polish posted during the first wave of the pandemic. Our findings are also in line with similar studies for other languages which have already revealed that negative attitudes and emotions are dominant in tweets posted during the COVID-19 pandemic, such as [
6,
7,
8,
9,
11,
28].
The second research question is related to the main themes present in the COVID-19 tweets and how these trends change over time. The cluster with the highest number of tweets (29.63%) is associated with the theme “Public discussion regarding anti-pandemic policies and vaccines”. It is followed by the clusters with themes related to “Coping with the pandemic” (18.37%) and “Public comments on statements of the politicians and scientists” (15.10%). The number of tweets in clusters is more consistent over time than sentiment is. Greatest changes are present in the cluster of tweets related to the “Messages on how to cope with the pandemic” that had more tweets in the first than in the second and the third waves. This makes sense because this topic was the focal point when it came to providing important information when the pandemic first started. The cluster related to the theme “Public comments on statements of the politicians and scientists” has a higher number of tweets in the second and third waves than in the first wave. It would seem that people become more and more dissatisfied with the politicians and scientists as the pandemic progresses, which makes sense.
A more detailed analysis of thematic clusters is performed in relation to the third research question which aimed to explore the distribution of negative sentiment and retweets across clusters. The most negative sentiment is present in clusters related to themes “Revolt against the COVID-19 policies and behaviour of citizens” and “Public discussion regarding anti-pandemic policies and vaccines”. These results differ from two related studies that explored sentiment of COVID-19 tweets related to vaccines [
33,
34] which have revealed that sentiment in the case of vaccination tends to be positive (both in England and USA). Less negative sentiment is present in thematic clusters that tend to be strictly informative, such as the cluster with the theme “Information about new daily COVID-19 cases”. Other two clusters that are positioned as highly non-negative clusters are related to themes “Education and implementation of the COVID-19 policies” and “Coping with the pandemic”. This indicates that possibly optimistic attitudes are present in tweets related to education, implementation of COVID-19 policies and coping with the pandemic in general. The analysis of retweeting conducted in the last step revealed that the highest number of retweets is present in the cluster with the theme “Education and implementation of the COVID-19 policies”. It should be added that retweeting is not a frequent action on Croatian Twitter. Still, in general, we found that negative and non-negative tweets have a similar number of retweets on average.
6.2. Possible Applications of the Results
There are several possible applications of this research.
Outputs of the first phase of the research can be of further use as resources in the domain of NLP tasks focused on the Croatian language. Thus, Cro-CoV-cseBERT can be used in any NLP application with the task of analysis of COVID-19-related texts. The dataset Cro-CoV-Tweets of publicly available tweets can serve as a resource for other similar studies. Next, the dataset Senti-Cro-CoV-Tweets of 10,000 tweets labeled with sentiment is a valuable resource for training and/or evaluation of other supervised models in the task of sentiment analysis.
Furthermore, the analysis and characterisation of tweets during the pandemic provides interesting information about COVID-19 communication on social media. It reveals public opinions and attitudes related to COVID-19 themes, allowing the authorities to address crisis communication problems, such as, for instance, perception of COVID-19 policies, public attitudes towards vaccines or opinions regarding problems related to the economy, etc. All these results will be available through an interactive web application that allows queries over different time periods and provides data visualizations of sentiment, topics, and retweets. This will enable scientists to exploit our results in other scientific fields such as psychology or sociology.
As a study of COVID-19-related communication on Twitter limited to the Croatian language and Croatia, this study may serve as a resource for further comparative research of COVID-19-related communication in different languages. Additionally, the proposed framework can be extended and used for further analysis of tweets posted during the pandemic and post-pandemic periods. In addition to this, similar approaches could be applied to other languages using appropriate language resources.
6.3. Limitations
This research has a few limitations. First, we characterised the social media content related to the COVID-19 pandemic by only taking into account Twitter. However, a large amount of information is present in media which were not covered by this study. For example, Facebook is not included because its policies do not allow data scraping and analysis. Additionally, individuals are also exposed to COVID-19-related information through online news portals and traditional sources. Therefore, to obtain a more realistic picture of media content related to the pandemic, it would be advisable to extend the analysis to all the available sources. Hence, in future work, we plan to extend this study by integrating heterogeneous data sources, such as other social media platforms, online news portals and all the other sources of textual data in social media such as user comments on online news media. The second limitation arises from the fact that automatic classifiers never have one hundred percent accuracy. In the case of sentiment classifier that we have trained, the accuracy is 0.79. That means that around 20% of tweets are not correctly annotated. This is a common drawback of all studies in the domain of NLP. However, the achieved accuracy is sufficient to give an overview of public opinions and attitudes. The third limitation is that this study analysed only texts in the Croatian language and, thus, the results are interesting to a smaller community. As mentioned in previous sections, these results can be of interest for further comparison of COVID-19-related communication on Twitter in different countries. In addition, a similar approach could be applied to any other language and/or country since the entire methodology is portable and only dependent on the available data sources and the maturity of the NLP methods per selected language.
7. Conclusions
In this study, we describe an NLP-based framework for the task of analysis of COVID-19-related communication on the Twitter in Croatia. For that purpose we developed language resources for the Croatian language intended for the representation and analysis of COVID-19 tweets. We applied the proposed framework on a dataset of 206,196 COVID-19 tweets in the Croatian language posted between 1 January 2020 and 31 May 2021 (Cro-CoV-Tweets).
Overall results can be summarized as follows. Negative sentiment is present in 46.8% of the COVID-19-related tweets. The negativity of tweets varies over the three pandemic waves, while the number of tweets across the 10 identified thematic clusters does not substantially vary across the three pandemic waves. The cluster with the highest number of tweets (almost 30%) is “Public discussion regarding anti-pandemic policies and vaccines”, which is also ranked as the second most negative cluster. The most negative cluster is related to the theme “Revolt against the COVID-19 policies and behaviour of citizens”. The highest number of retweets is present in the cluster with the theme “Education and implementation of the COVID-19 policies”, which is ranked as the third most non-negative cluster. In terms of retweeting, we can notice that both sentiments are retweeted to an equal extent.
This research demonstrates the possibilities afforded by the convenience and usefulness of NLP methods which can process a large amount of textual data and provide insights into the sentiment and topics of the observed texts. In this way, natural language processing can complement the achievements of traditional approaches used in research in the domains of humanities and social sciences when it comes to the task of analysing the public opinion and attitudes toward various COVID-19-related themes.
Possible future extensions of this work include further development of the Cro-CoV-cseBERT model in terms of fine-tuning for the supervised task of sentiment analysis (Cro-CoV-cseBERT) and some other experiments in which we plan to combine embeddings from heterogeneous sources (text, metadata and network properties) for tweet representation. Moreover, we plan to use other NLP techniques such as topic modelling and named entity recognition for crisis communication monitoring.
We believe our work contributes to the pursuit of the expanding social media research when it comes to the task of monitoring online communication regarding the COVID-19 pandemic.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





