


LUMDE: Light-Weight Unsupervised Monocular Depth Estimation via Knowledge Distillation


Abstract
1. Introduction
- —
- Explore knowledge distillation of dense depth estimation networks in the absence of depth ground truth.
- —
- Introduce the idea of a pose network into the student network to construct photometric loss, and Transformer as the discriminator of a GAN to capture holistic information.
- —
- Our model achieves SOTA performance for lightweight self-supervised depth estimation models on the publicly available NYUD-V2 dataset.
- —
- The model size and the computational complexity of the distilled depth module only account for 22.8% and 4.8% of those from the original depth module, respectively. The inference speed of the compact network has increased by 532%.
2. Related Works
2.1. Unsupervised Depth Estimation
2.2. Knowledge Distillation
2.3. GAN and Transformer
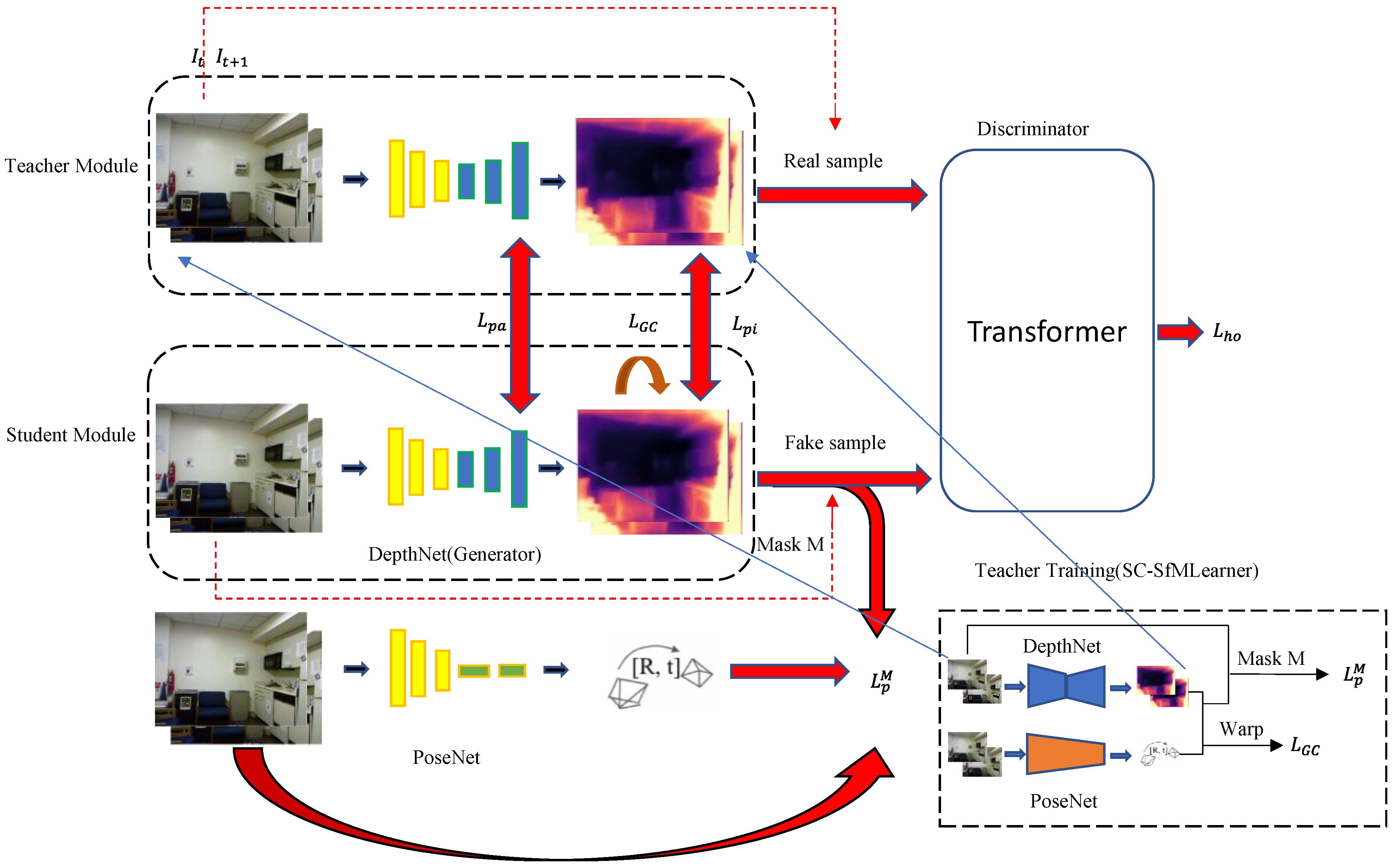
3. Method
3.1. Overview
3.2. Preliminaries
- 1.
- Fix the student module parameters; minimize the to train the discriminator so that the module has enough capacity to recognize the fake and real samples.
- 2.
- Fix the discriminator parameters; use the along with other loss terms to train the compact network, thus generating high-quality depth maps.
3.3. Pose-Assisted Network
3.4. Transformer Adversarial Network
3.5. Pipeline of the Current Network
4. Experiments
- (1)
- Choosing the best student network backbone to balance prediction accuracy and computational cost. The backbone is selected from the most widely used lightweight networks;
- (2)
- An ablation study of our further improvements over the baseline model. We assume that the baseline performance is produced by the knowledge distillation strategy including pixel-wise, pair-wise, and holistic distillation;
- (3)
- The inference efficiency on medium- and low-speed computing equipment was evaluated.
4.1. Training Details
4.2. Selection of Teacher and Student Network
4.3. Ablation Study
4.4. Inference Efficiency
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Neural Info. Process. Syst. 2014, 27, 2366–2374. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Li, J.; Klein, R.; Yao, A. A two-streamed network for estimating fine-scaled depth maps from single rgb images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3372–3380. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, GA, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Yin, W.; Liu, Y.; Shen, C.; Yan, Y. Enforcing geometric constraints of virtual normal for depth prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5684–5693. [Google Scholar]
- Ummenhofer, B.; Zhou, H.; Uhrig, J.; Mayer, N.; Ilg, E.; Dosovitskiy, A.; Brox, T. Demon: Depth and motion network for learning monocular stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5038–5047. [Google Scholar]
- Teed, Z.; Deng, J. Deepv2d: Video to depth with differentiable structure from motion. arXiv 2018, arXiv:1812.04605. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Bian, J.; Li, Z.; Wang, N.; Zhan, H.; Shen, C.; Cheng, M.-M.; Reid, I. Unsupervised scale-consistent depth and ego-motion learning from monocular video. Neural Info. Process. Syst. 2019, 32, 35–45. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- LeCun, Y.; Denker, J.; Solla, S. Optimal brain damage. Neural Info. Process. Syst. 1989, 2, 598–605. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Kundu, J.N.; Lakkakula, N.; Babu, R.V. Um-adapt: Unsupervised multi-task adaptation using adversarial cross-task distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1436–1445. [Google Scholar]
- Liu, Y.; Shu, C.; Wang, J.; Shen, C. Structured knowledge distillation for dense prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 6, 78–93. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Neural Info. Process. Syst. 2017, 30, 214–228. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 842–857. [Google Scholar]
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised cnn for single view depth estimation: Geometry to the rescue. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 740–756. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, GA, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar]
- Ji, P.; Li, R.; Bhanu, B.; Xu, Y. Monoindoor: Towards good practice of self-supervised monocular depth estimation for indoor environments. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–18 October 2021; pp. 12787–12796. [Google Scholar]
- Zou, Y.; Luo, Z.; Huang, J.-B. Df-net: Unsupervised joint learning of depth and flow using cross-task consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 36–53. [Google Scholar]
- Ba, J.; Caruana, R. Do deep nets really need to be deep? Neural Info. Process. Syst. 2014, 27, 2654–2662. [Google Scholar]
- Urban, G.; Geras, K.; Kahou, S.; Aslan, O.; Wang, S.; Caruana, R.; Mohamed, A.; Philipose, M.; Richardson, M. Do Deep Convolutional Nets Really Need to be Deep (Or Even Convolutional)? arXiv 2016, arXiv:1603.05691. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Li, Q.; Jin, S.; Yan, J. Mimicking very efficient network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6356–6364. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Neural Info. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Shuai, B.; Hu, J.-F.; Lin, J.; Zheng, W.-S. Improving fast segmentation with teacher-student learning. arXiv 2018, arXiv:1810.08476. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Neural Info. Process. Syst. 2014, 27, 139–144. [Google Scholar]
- Wang, H.; Qin, Z.; Wan, T. Text generation based on generative adversarial nets with latent variables. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Melbourne, Australia, 3–6 June 2018; pp. 92–103. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Chen, Y.; Shen, C.; Wei, X.-S.; Liu, L.; Yang, J. Adversarial posenet: A structure-aware convolutional network for human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1212–1221. [Google Scholar]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic segmentation using adversarial networks. arXiv 2016, arXiv:1611.08408. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 12 June 2018).
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Neural Info. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Jiang, Y.; Chang, S.; Wang, Z. Transgan: Two pure transformers can make one strong gan, and that can scale up. Neural Info. Process. Syst. 2021, 34, 14745–14758. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Bian, J.-W.; Zhan, H.; Wang, N.; Chin, T.-J.; Shen, C.; Reid, I. Unsupervised depth learning in challenging indoor video: Weak rectification to rescue. arXiv 2020, arXiv:2006.02708. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and PATTERN recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NEV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, GA, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Zhao, W.; Liu, S.; Shu, Y.; Liu, Y.-J. Towards better generalization: Joint depth-pose learning without posenet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, IL, USA, 16–20 June 2020; pp. 9151–9161. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Method | Pretrain | Error ↓ | Model Size (Depth) | Complexity | ||
|---|---|---|---|---|---|---|---|
| AbsRel | Log10 | RMS | |||||
| Teacher Network | Monodepth2 [9] | √ | 0.156 | 0.066 | 0.561 | 14.84M | 5.36GMac/10.7GFlops |
| × | 0.181 | 0.075 | 0.637 | ||||
| SC-SfMLearner [10] | √ | 0.148 | 0.062 | 0.545 | 14.84M | 5.36GMac/10.7GFlops | |
| × | 0.170 | 0.072 | 0.603 | ||||
| Student Network | MobileNet V1 [49] | × | No Convergence | None | |||
| MobileNet V2 [50] | √ | 0.169 | 0.071 | 0.589 | 3.62M | 688.7MMac/1.35GFlops | |
| × | 0.194 | 0.080 | 0.660 | ||||
| MobileNet V3(small) [51] | √ | 0.163 | 0.068 | 0.581 | 3.38M | 255.59MMac/507.26MFlops | |
| × | 0.186 | 0.077 | 0.639 | ||||
| MobileNet V3(large) [51] | √ | No Convergence | 6.33M | 620MMac/1.21GFlops | |||
| × | 0.183 | 0.076 | 0.634 | ||||
| ShuffleNet V2(0.5) [52] | √ | No Convergence | 4.03M | 790MMac/1.55GFlops | |||
| × | 0.193 | 0.080 | 0.663 | ||||
| ShuffleNet V2(1.0) [52] | √ | No Convergence | 5.79M | 1.15GMac/2.30GFlops | |||
| × | 0.186 | 0.078 | 0.642 | ||||
| Losses | Error ↓ | Accuracy ↑ | ||||
|---|---|---|---|---|---|---|
| AbsRel | Log10 | RMS | ||||
| L(pa) | 0.333 | 0.128 | 1.007 | 0.506 | 0.777 | 0.903 |
| L(pi) | 0.164 | 0.069 | 0.583 | 0.769 | 0.941 | 0.983 |
| L(ho) | 0.306 | 0.121 | 0.955 | 0.525 | 0.799 | 0.918 |
| L(pa) + L(pi) | 0.163 | 0.069 | 0.583 | 0.769 | 0.941 | 0.983 |
| L(pa) + L(ho) | 0.321 | 0.123 | 0.978 | 0.522 | 0.789 | 0.909 |
| L(pi) + L(ho) | 0.163 | 0.069 | 0.582 | 0.768 | 0.941 | 0.983 |
| L(pa) + L(pi) + L(ho) | 0.163 | 0.068 | 0.581 | 0.769 | 0.940 | 0.983 |
| Losses | Error ↓ | Accuracy ↑ | ||||
|---|---|---|---|---|---|---|
| AbsRel | Log10 | RMS | ||||
| L(P) | 0.158 | 0.073 | 0.569 | 0.778 | 0.940 | 0.983 |
| L(PM) | 0.155 | 0.071 | 0.562 | 0.791 | 0.943 | 0.983 |
| L(GC) | 0.319 | 0.118 | 0.938 | 0.539 | 0.808 | 0.919 |
| L(P) + L(GC) | 0.155 | 0.065 | 0.559 | 0.796 | 0.943 | 0.982 |
| L(PM) + L(GC) | 0.148 | 0.062 | 0.545 | 0.803 | 0.948 | 0.985 |
| Method | Error ↓ | Accuracy ↑ | ||||
|---|---|---|---|---|---|---|
| AbsRel | Log10 | RMS | ||||
| Teacher Network | 0.148 | 0.062 | 0.545 | 0.803 | 0.948 | 0.985 |
| Student Network (Baseline) | 0.163 | 0.068 | 0.581 | 0.769 | 0.940 | 0.983 |
| Performance | ↑ 10.1% | ↑ 9.7% | ↑ 6.6% | ↓ 4.2% | ↓ 0.8% | ↓ 0.2% |
| Baseline + PoseNet | 0.160 | 0.067 | 0.575 | 0.775 | 0.942 | 0.984 |
| Baseline + Transformer | 0.161 | 0.068 | 0.577 | 0.773 | 0.942 | 0.984 |
| Baseline + PoseNet + Transformer (LUMDE) | 0.158 | 0.067 | 0.565 | 0.782 | 0.943 | 0.984 |
| Performance | ↑ 6.7% | ↑ 8.1% | ↑ 3.7% | ↓ 2.6% | ↓ 0.5% | ↓ 0.1% |
| Method | Error ↓ | ||
|---|---|---|---|
| AbsRel | Log10 | RMS | |
| Teacher Network | 0.148 | 0.062 | 0.545 |
| LUMDE | 0.158 | 0.067 | 0.565 |
| Student Network w/o KD | 0.185 | 0.076 | 0.635 |
| Type | Method | Error ↓ | Accuracy ↑ | Model Size (Depth) | ||||
|---|---|---|---|---|---|---|---|---|
| AbsRel | Log10 | RMS | ||||||
| w/o KD | Zhao et al. [54] | 0.189 | 0.079 | 0.686 | 0.701 | 0.912 | 0.978 | - |
| Godard et al. [9] | 0.160 | - | 0.601 | 0.767 | 0.949 | 0.988 | 14.84M | |
| Bian et al. [46] | 0.147 | 0.062 | 0.536 | 0.804 | 0.950 | 0.986 | 14.84M | |
| Pan Ji et al. [22] | 0.134 | - | 0.526 | 0.823 | 0.958 | 0.989 | - | |
| w/KD | Kundu et al. [14] | 0.175 | 0.065 | 0.673 | 0.783 | 0.920 | 0.984 | - |
| LUMDE | 0.158 | 0.067 | 0.565 | 0.782 | 0.943 | 0.984 | 3.38M | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, W.; Dong, X.; Liu, N.; Chen, Y. LUMDE: Light-Weight Unsupervised Monocular Depth Estimation via Knowledge Distillation. Appl. Sci. 2022, 12, 12593. https://doi.org/10.3390/app122412593
Hu W, Dong X, Liu N, Chen Y. LUMDE: Light-Weight Unsupervised Monocular Depth Estimation via Knowledge Distillation. Applied Sciences. 2022; 12(24):12593. https://doi.org/10.3390/app122412593
Chicago/Turabian StyleHu, Wenze, Xue Dong, Ning Liu, and Yuanfeng Chen. 2022. "LUMDE: Light-Weight Unsupervised Monocular Depth Estimation via Knowledge Distillation" Applied Sciences 12, no. 24: 12593. https://doi.org/10.3390/app122412593
APA StyleHu, W., Dong, X., Liu, N., & Chen, Y. (2022). LUMDE: Light-Weight Unsupervised Monocular Depth Estimation via Knowledge Distillation. Applied Sciences, 12(24), 12593. https://doi.org/10.3390/app122412593