

Development of Circuits for Antilogarithmic Converters with Efficient Error–Area–Delay Product Using the Fractional-Bit Compensation Scheme for Digital Signal Processing Applications
Abstract
:1. Introduction
2. Antilogarithmic Conversion Methods
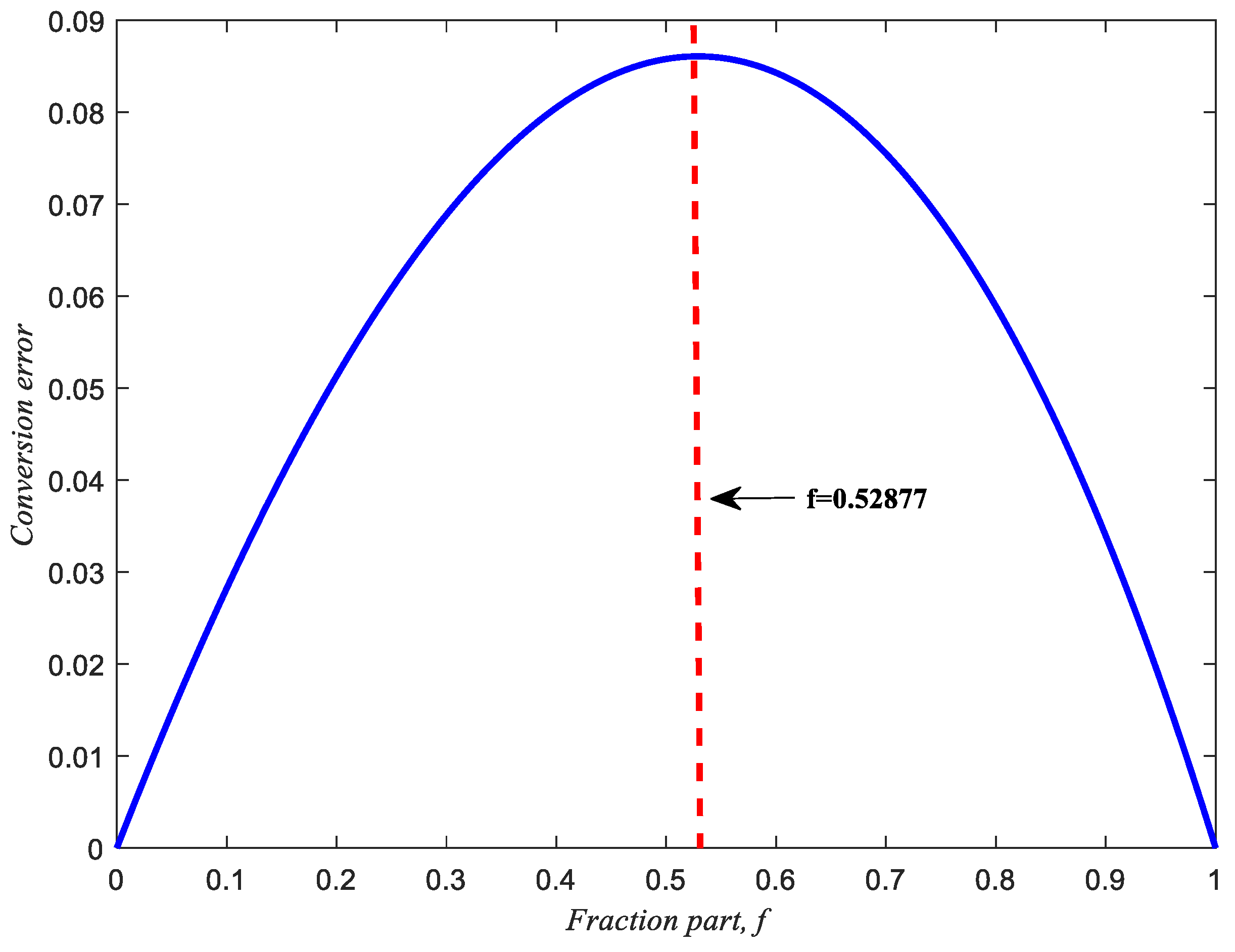
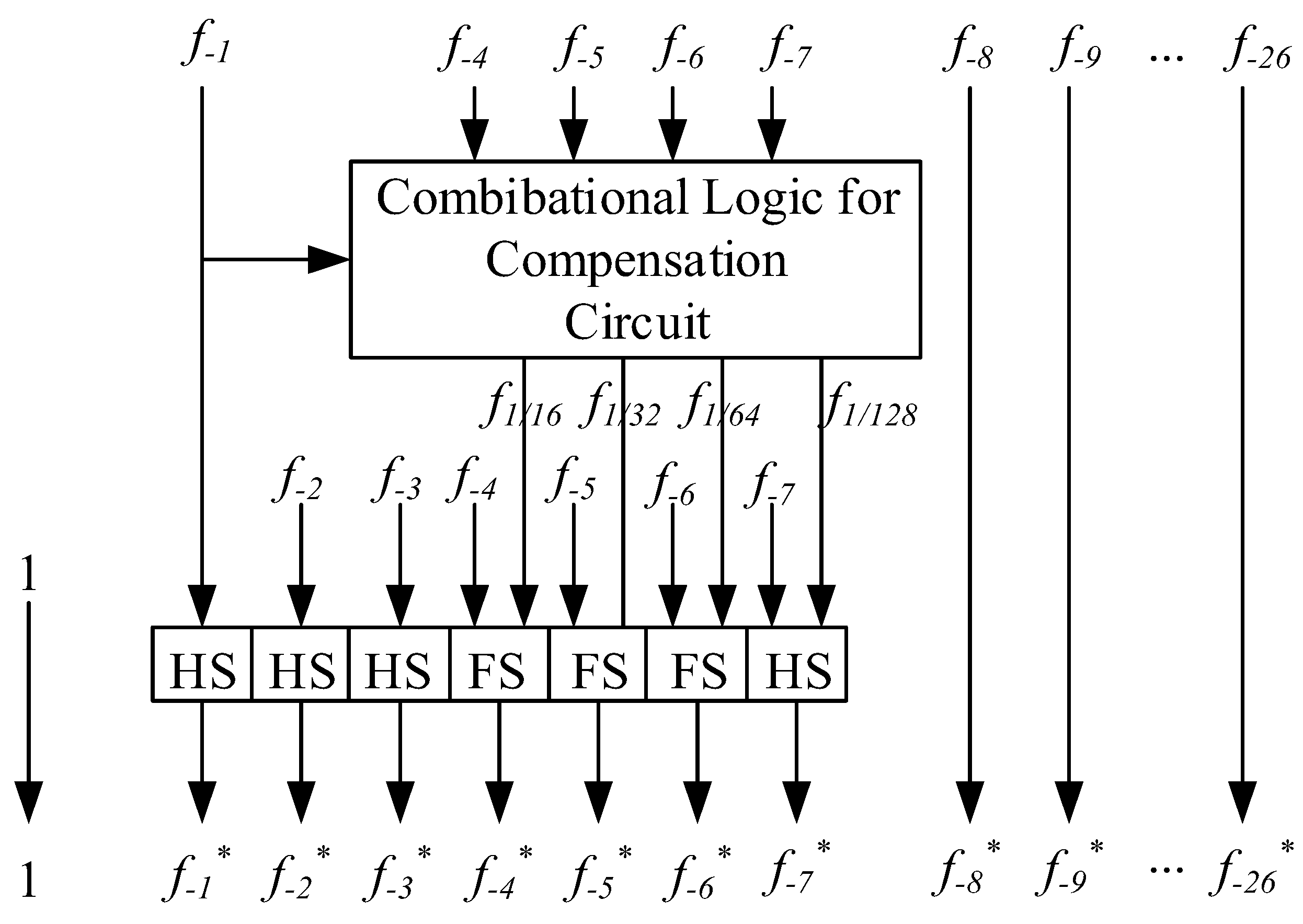
3. Proposed Algorithm for Fractional-Bit Compensation
4. Experimental Results and Hardware Implementation
5. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Walther, J.S. A Unified Algorithm for Elementary Functions. In Proceedings of the Spring Joint Computer Conference, Atlantic City, NJ, USA, 18–20 May 1971; pp. 379–385. [Google Scholar]
- Wong, W.F.; Goto, E. Fast Hardware-Based Algorithms for Elementary Function Computations Using Rectangular Multipliers. IEEE Trans. Comput. 1994, 43, 278–294. [Google Scholar] [CrossRef]
- Mitchell, J.N. Computer multiplication and division using binary logarithms. IRE Trans. Electron. Comput. 1962, EC-11, 512–517. [Google Scholar] [CrossRef]
- Stine, J.E.; Schulte, M.J. The symmetric table addition method for accurate function approximation. J. VLSI Sig. Proc. 1999, 21, 167–177. [Google Scholar] [CrossRef]
- Abed, K.H.; Siferd, R.E. VLSI implementation of a low-power antilogarithmic converter. IEEE Trans. Comput. 2003, 52, 1221–1228. [Google Scholar] [CrossRef]
- Juang, T.B.; Chen, S.H.; Cheng, H.J. A lower-error and ROM-free logarithmic converter for digital signal processing applications. IEEE Trans. Circuits Syst. II Express Briefs 2009, 56, 931–935. [Google Scholar]
- Nam, B.G.; Kim, H.J.; Yoo, H.J. Power and area-efficient unified computation of vector and elementary functions for handheld 3D graphics system. IEEE Trans. Comput. 2008, 57, 490–504. [Google Scholar] [CrossRef]
- Paul, S.; Jayakumar, N.; Khatri, S. A fast hardware approach for approximate, efficient logarithm and antilogarithm computations. IEEE Trans. VLSI Syst. 2009, 17, 269–277. [Google Scholar] [CrossRef]
- Liu, C.W.; Ou, S.H.; Chang, K.C.; Lin, T.C.; Chen, S.K. A low-error, cost-efficient design procedure for evaluating logarithms to be used in a logarithmic arithmetic processor. IEEE Trans. Comput. 2016, 65, 1158–1164. [Google Scholar] [CrossRef]
- Kuo, C.T. Design and realization of high performance logarithmic converters using non-uniform multi-regions constant adder correction schemes. Microsyst. Technol. 2018, 24, 4237–4245. [Google Scholar] [CrossRef]
- Loukrakpam, M.; Choudhury, M. Error-Aware Design Procedure to Implement Hardware-Efficient Antilogarithmic Converters. Circuit Syst. Signal Process. 2019, 38, 4266–4279. [Google Scholar] [CrossRef]
- Kuo, C.T. Design and Circuit Implementation of Area-Delay-Product-Efficient Logarithmic Converters Using Mantissa-Bit Compensation Scheme. Circuit Syst. Signal Process. 2022, 41, 4266–4279. [Google Scholar] [CrossRef]
- Juang, T.B.; Kuo, H.L.; Jan, K.S. Lower-error and area-efficient antilogarithmic converters with bit correction schemes. J. Chin. Inst. Eng. 2016, 39, 57–63. [Google Scholar] [CrossRef]
- Ha, H.; Lee, S. Accurate hardware-efficient logarithm circuit. IEEE Trans. Circuits Syst.—II Express Briefs 2017, 64, 967–971. [Google Scholar] [CrossRef]
- Kim, H.; Nam, B.G.; Sohn, J.H.; Woo, J.H.; Yoo, H.J. A 231-MHz, 2.18Mw 32-bit logarithmic arithmetic unit for fixed-point 3-D graphics system. IEEE J Solid State Circuits. 2006, 41, 2373–2381. [Google Scholar] [CrossRef]
- Kuo, C.T.; Juang, T.B. Area-efficient and highly accurate antilogarithmic converters with multiple regions of constant compensation schemes. Microsyst. Technol. 2018, 24, 219–225. [Google Scholar] [CrossRef]
- Chaudhary, M.; Lee, P. Two-stage logarithmic converter with reduced memory requirements. IET Comput. Digit. Tech. 2014, 8, 23–29. [Google Scholar] [CrossRef]
- Chaudhary, M.; Lee, P. An improved two-step binary logarithmic converter for FPGAs. IEEE Trans. Circuits Syst. II Express Briefs 2015, 62, 476–480. [Google Scholar] [CrossRef]
- Pineiro, J.A.; Ercegovac, M.D.; Bruguera, J.D. Algorithm and architecture for logarithm, exponential, and powering computation. IEEE Trans. Comput. 2004, 53, 1085–1096. [Google Scholar] [CrossRef]
- Gutierrez, R.; Valls, J. Low cost hardware implementation of logarithm approximation. IEEE Trans. Very Large Scale Integr. Syst. 2011, 19, 2326–2330. [Google Scholar] [CrossRef]
- Juang, T.B.; Meher, P.K.; Jan, K.S. High-performance logarithmic converters using novel two-region bit-level manipulation schemes. In Proceedings of the 2011 International Symposium on VLSI Design, Automation and Test, Hsinchu, Taiwan, 25–28 April 2011. [Google Scholar]
- Caro, D.D.; Petra, N.; Strollo, A.G.M. Efficient logarithmic converters for digital signal processing applications. IEEE Trans. Circuits Syst. II Express Briefs 2011, 58, 667–671. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Arithmetic Computation | Arithmetic Operation | LNS-Based Operation |
|---|---|---|
| Multiplication | out = a·b | A + B |
| Division | out = a/b | A − B |
| Square root | A >> 1 | |
| Squaring | out = a2 | A << 1 |
| Powering | out = ab | |
| Reciprocal | out = 1/a | −X |
| f−1–f−n | Uniform Partition Numbers | Key Uncompensated Region | Local Error | Local Percentage Error | Absolute Maximum Error | Absolute Maximum Percentage Error |
|---|---|---|---|---|---|---|
| n = 3 | 8 | First region | 0.0342 | 3.1427% | 0.0410 | 3.1427% |
| Last region | 0.0410 | 2.2351% | ||||
| n = 4 | 16 | First region | 0.0181 | 1.7327% | 0.0221 | 1.7327% |
| Last region | 0.0221 | 1.1551% | ||||
| n = 5 | 32 | First region | 0.0093 | 0.9083% | 0.0115 | 0.9083% |
| Last region | 0.0115 | 0.5883% | ||||
| n = 6 | 64 | First region | 0.0045 | 0.4502% | 0.0057 | 0.4502% |
| Last region | 0.0057 | 0.2873% | ||||
| n = 7 | 128 | First region | 0.0021 | 0.2126% | 0.0027 | 0.2126% |
| Last region | 0.0027 | 0.1347% | ||||
| n = 8 | 256 | First region | 0.0009 | 0.0916% | 0.0012 | 0.0578% |
| Last region | 0.0012 | 0.0578% |
| f−1–f−4 | Compensation Bit | f−1–f−4 | Compensation Bit | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 2−4 | 2−5 | 2−6 | 2−7 | 2−4 | 2−5 | 2−6 | 2−7 | ||
| 0000 | 0 | 0 | 0 | 0 | 1000 | 1 | 0 | 0 | 0 |
| 0001 | 0 | 0 | 1 | 0 | 1001 | 1 | 0 | 0 | 0 |
| 0010 | 0 | 1 | 0 | 0 | 1010 | 1 | 0 | 0 | 0 |
| 0011 | 0 | 1 | 1 | 0 | 1011 | 1 | 0 | 0 | 0 |
| 0100 | 0 | 1 | 1 | 0 | 1100 | 0 | 1 | 0 | 1 |
| 0101 | 1 | 0 | 0 | 0 | 1101 | 0 | 1 | 0 | 1 |
| 0110 | 1 | 0 | 0 | 0 | 1110 | 0 | 0 | 1 | 0 |
| 0111 | 1 | 0 | 0 | 0 | 1111 | 0 | 0 | 0 | 0 |
| Partition Items | Partition Region | Compensation Value | Partition Items | Partition Region | Compensation Value |
|---|---|---|---|---|---|
| 1 | [0, 1/16) | 0 | 5 | [5/16, 12/16) | −8/128 |
| 2 | [1/16, 2/16) | −2/128 | 6 | [12/16, 14/16) | −5/128 |
| 3 | [2/16, 3/16) | −4/128 | 7 | [14/16, 15/16) | −2/128 |
| 4 | [3/16, 5/16) | −6/128 | 8 | [15/16, 1) | 0 |
| f−1–f−4 | Compensation Bit | f−1–f−4 | Compensation Bit | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 2−4 | 2−5 | 2−6 | 2−7 | 2−4 | 2−5 | 2−6 | 2−7 | ||
| 0000 | 0 | 0 | 0 | 0 | 1000 | 1 | 0 | 0 | 0 |
| 0001 | 0 | 0 | 1 | 0 | 1001 | 1 | 0 | 0 | 0 |
| 0010 | 0 | 1 | 0 | 0 | 1010 | 1 | 0 | 0 | 0 |
| 0011 | 0 | 1 | 1 | 0 | 1011 | 1 | 0 | 0 | 0 |
| 0100 | 0 | 1 | 1 | 1 | 1100 | 0 | 1 | 0 | 1 |
| 0101 | 1 | 0 | 0 | 0 | 1101 | 0 | 1 | 0 | 1 |
| 0110 | 1 | 0 | 0 | 0 | 1110 | 0 | 0 | 1 | 0 |
| 0111 | 1 | 0 | 0 | 0 | 1111 | 0 | 0 | 0 | 0 |
| Partition Items | Partition Region | Compensation Value | Partition Items | Partition Region | Compensation Value |
|---|---|---|---|---|---|
| 1 2 3 4 5 | [0, 1/16) [1/16, 2/16) [2/16, 3/16) [3/16, 4/16) [4/16, 5/16) | 0 −2/128 −4/128 −6/128 −7/128 | 6 7 8 9 | [5/16, 12/16) [12/16, 14/16) [14/16, 15/16) [15/16, 1) | −8/128 −5/128 −2/128 0 |
| f−1–f−5 | Compensation Bit | f−1–f−5 | Compensation Bit | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 2−4 | 2−5 | 2−6 | 2−7 | 2−4 | 2−5 | 2−6 | 2−7 | ||
| 00000 | 0 | 0 | 0 | 0 | 10000 | 1 | 0 | 0 | 1 |
| 00001 | 0 | 0 | 0 | 1 | 10001 | 1 | 0 | 0 | 1 |
| 00010 | 0 | 0 | 1 | 0 | 10010 | 1 | 0 | 0 | 1 |
| 00011 | 0 | 0 | 1 | 1 | 10011 | 1 | 0 | 0 | 1 |
| 00100 | 0 | 1 | 0 | 0 | 10100 | 1 | 0 | 0 | 1 |
| 00101 | 0 | 1 | 0 | 1 | 10101 | 1 | 0 | 0 | 1 |
| 00110 | 0 | 1 | 1 | 0 | 10110 | 1 | 0 | 0 | 1 |
| 00111 | 0 | 1 | 1 | 1 | 10111 | 0 | 1 | 1 | 1 |
| 01000 | 0 | 1 | 1 | 1 | 11000 | 0 | 1 | 1 | 1 |
| 01001 | 1 | 0 | 0 | 0 | 11001 | 0 | 1 | 1 | 1 |
| 01010 | 1 | 0 | 0 | 1 | 11010 | 0 | 1 | 0 | 1 |
| 01011 | 1 | 0 | 0 | 1 | 11011 | 0 | 1 | 0 | 1 |
| 01100 | 1 | 0 | 0 | 1 | 11100 | 0 | 0 | 1 | 1 |
| 01101 | 1 | 0 | 0 | 1 | 11101 | 0 | 0 | 1 | 1 |
| 01110 | 1 | 0 | 0 | 1 | 11110 | 0 | 0 | 0 | 0 |
| 01111 | 1 | 0 | 0 | 1 | 11111 | 0 | 0 | 0 | 0 |
| Partition Items | Partition Region | Compensation Value | Partition Items | Partition Region | Compensation Value |
|---|---|---|---|---|---|
| 1 | [0, 1/32) | 0 | 8 | [7/32, 9/32) | −7/128 |
| 2 | [1/32, 2/32) | −1/128 | 9 | [9/32, 10/32) | −8/128 |
| 3 | [2/32, 3/32) | −2/128 | 10 | [10/32, 23/32) | −9/128 |
| 4 | [3/32, 4/32) | −3/128 | 11 | [23/32, 26/32) | −7/128 |
| 5 | [4/32, 5/32) | −4/128 | 12 | [26/32, 28/32) | −5/128 |
| 6 | [5/32, 6/32) | −5/128 | 13 | [28/32, 30/32) | −3/128 |
| 7 | [6/32, 7/32) | −6/128 | 14 | [30/32, 1) | 0 |
| Compared Items | Juang et al. [13] | Proposed Case 1 |
|---|---|---|
| Compensation scheme | Bit | Fractional bits |
| Segment number | 2 | 2 |
| Significant fractional bit | none | none |
| Max. positive percentage error | 1.72% | 1.9089% |
| Min. negative percentage error | −0.6% | 0 |
| Total percentage conversion error | 2.32% | 1.9089% |
| Area (µm2) | 1729.62 | 1772.97 |
| Delay (ns) | 0.7 | 0.7 |
| ADP | 1210.734 | 1241.079 |
| ADP saving | 0 | −2.51% |
| eADP | 28.0890 | 23.6910 |
| eADP saving | 0 | 15.66% |
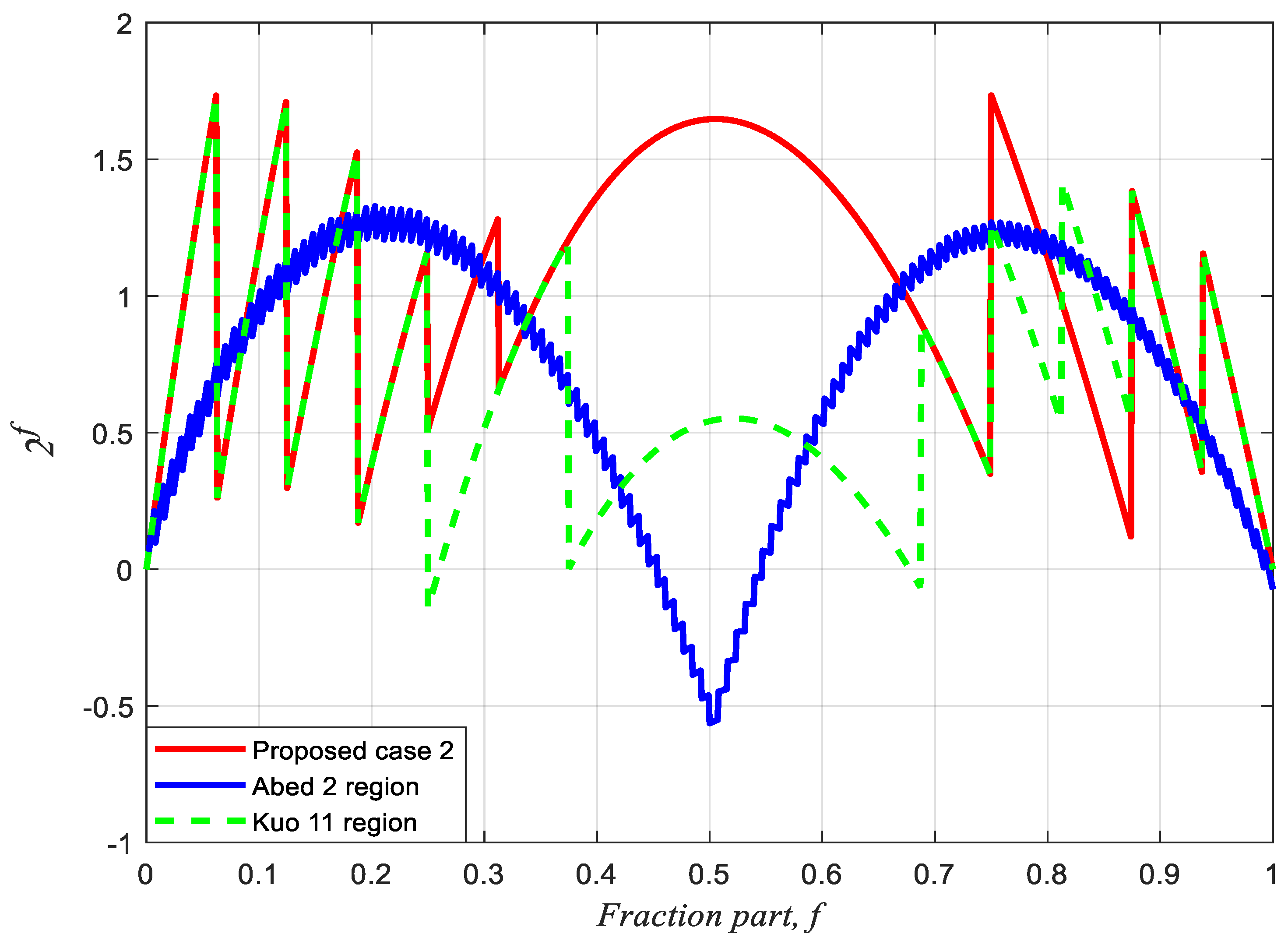
| Compared Items | Abed & Siferd [5,16] | Kuo & Juang [16] | Proposed Case 2 |
|---|---|---|---|
| Compensation scheme | Shift-and-Add | Constant | Fractional bits |
| Segment number | 2 | 11 | 2 |
| Significant fractional bit | 7 | none | none |
| Max. positive percentage error | 1.3310% | 1.7327% | 1.7330% |
| Min. negative percentage error | −0.5631% | −0.0992% | 0 |
| Total percentage conversion error | 1.8941% | 1.8319% | 1.7330% |
| Area (µm2) | 3562.57 | 2807.48 | 1869.44 |
| Delay (ns) | 2 | 1.4 | 0.8 |
| ADP | 7125.14 | 3930.47 | 1495.55 |
| ADP saving | 0 | 44.84% | 79.01% |
| eADP | 134.9573 | 71.2594 | 25.9179 |
| eADP saving | 0 | 47.20% | 80.80% |
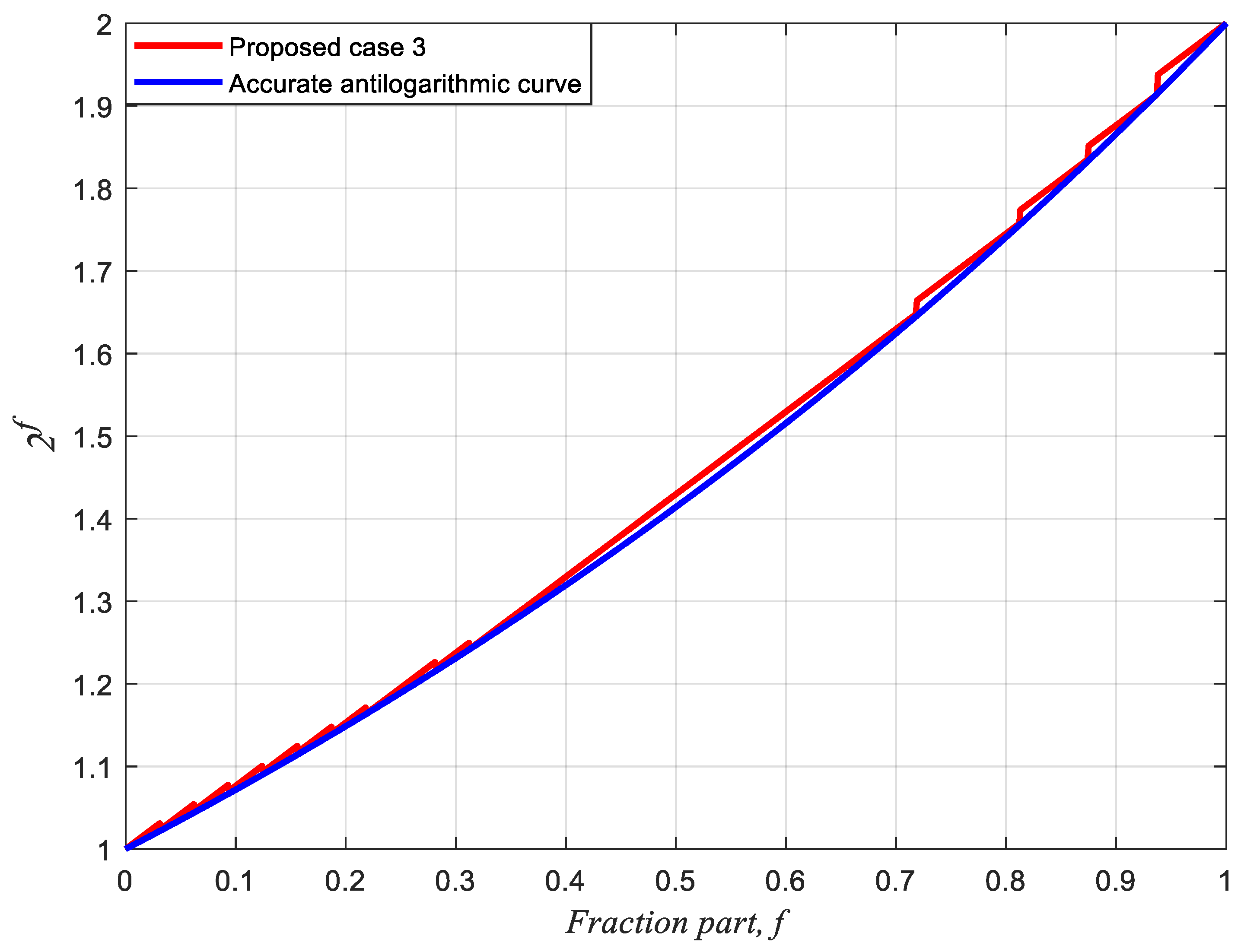
| Compared Items | Abed & Siferd [5,16] | Kuo & Juang [16] | Loukrakpam [11] | Proposed Case 3 |
|---|---|---|---|---|
| Compensation scheme | Shift-and-Add | Constant | Shift-and-Add | Fractional bits |
| Segment number | 6 | 14 | 2 | 2 |
| Significant fractional bit | 7 | none | 7 | none |
| Max. positive percentage error | 0.9572% | 1.2% | 1.5054% | 1.1551% |
| Min. negative percentage error | −0.5786% | −0.1436% | −0.0488% | −0.0512% |
| Total percentage conversion error | 1.5358% | −0.1436% | 1.5542% | 1.2063% |
| Area (µm2) | 6439.91 | 3319.75 | 5425.36 | 2122.24 |
| Delay (ns) | 6439.91 | 1.5 | 1.8 | 1.1 |
| ADP | 11,913.83 | 4979.63 | 9765.65 | 2334.46 |
| ADP saving | 0 | 58.20% | 18.31% | 80.41% |
| eADP | 182.9726 | 66.9063 | 151.78 | 28.1606 |
| eADP saving | 0 | 63.43% | 17.05% | 84.61% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuo, C.-T. Development of Circuits for Antilogarithmic Converters with Efficient Error–Area–Delay Product Using the Fractional-Bit Compensation Scheme for Digital Signal Processing Applications. Appl. Sci. 2024, 14, 1487. https://doi.org/10.3390/app14041487
Kuo C-T. Development of Circuits for Antilogarithmic Converters with Efficient Error–Area–Delay Product Using the Fractional-Bit Compensation Scheme for Digital Signal Processing Applications. Applied Sciences. 2024; 14(4):1487. https://doi.org/10.3390/app14041487
Chicago/Turabian StyleKuo, Chao-Tsung. 2024. "Development of Circuits for Antilogarithmic Converters with Efficient Error–Area–Delay Product Using the Fractional-Bit Compensation Scheme for Digital Signal Processing Applications" Applied Sciences 14, no. 4: 1487. https://doi.org/10.3390/app14041487