
Technical, Musical, and Legal Aspects of an AI-Aided Algorithmic Music Production System

 , , ,
, , ,
Abstract
:1. Introduction
1.1. Contribution
1.2. Related Work
2. Materials and Methods
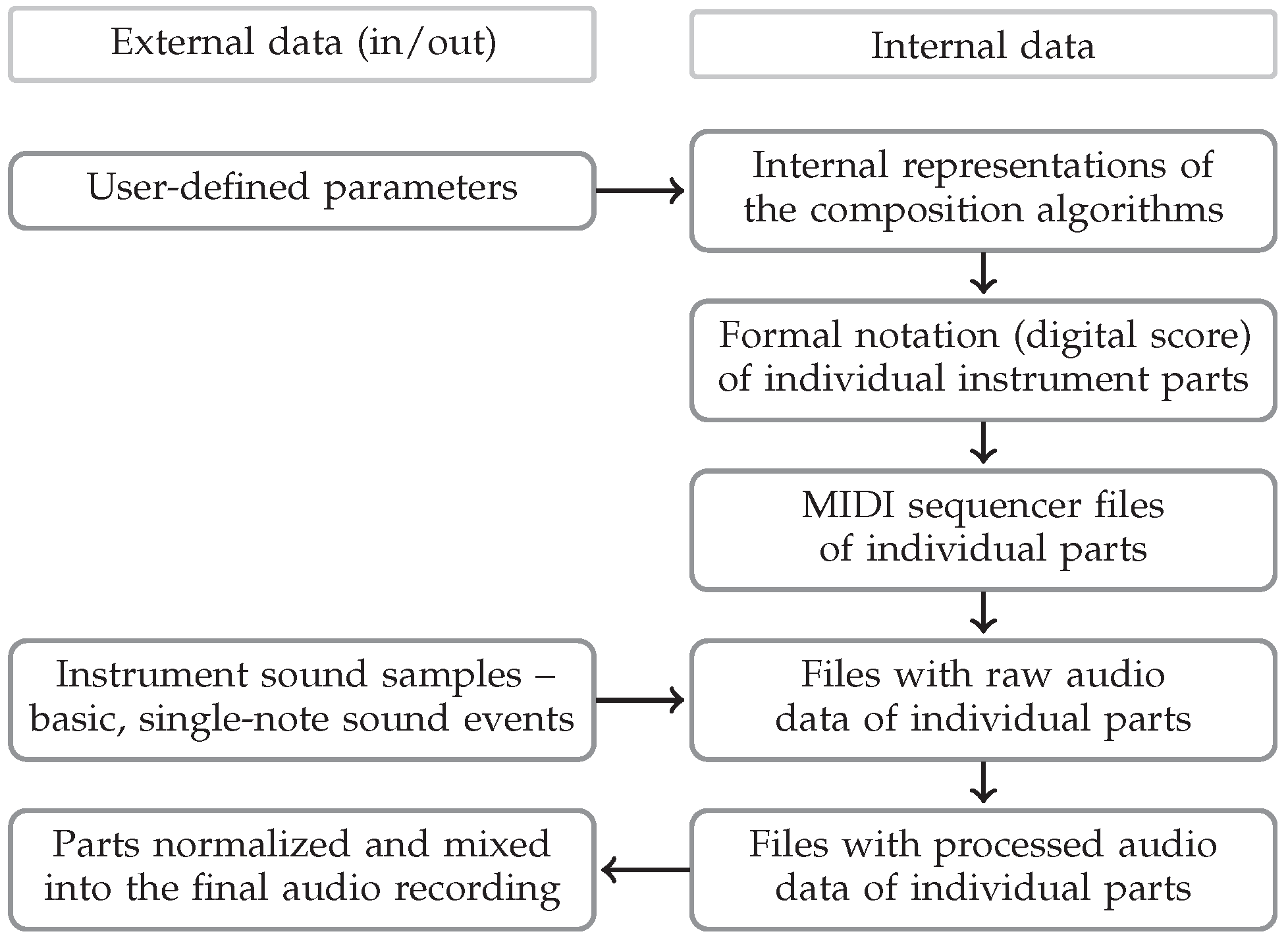
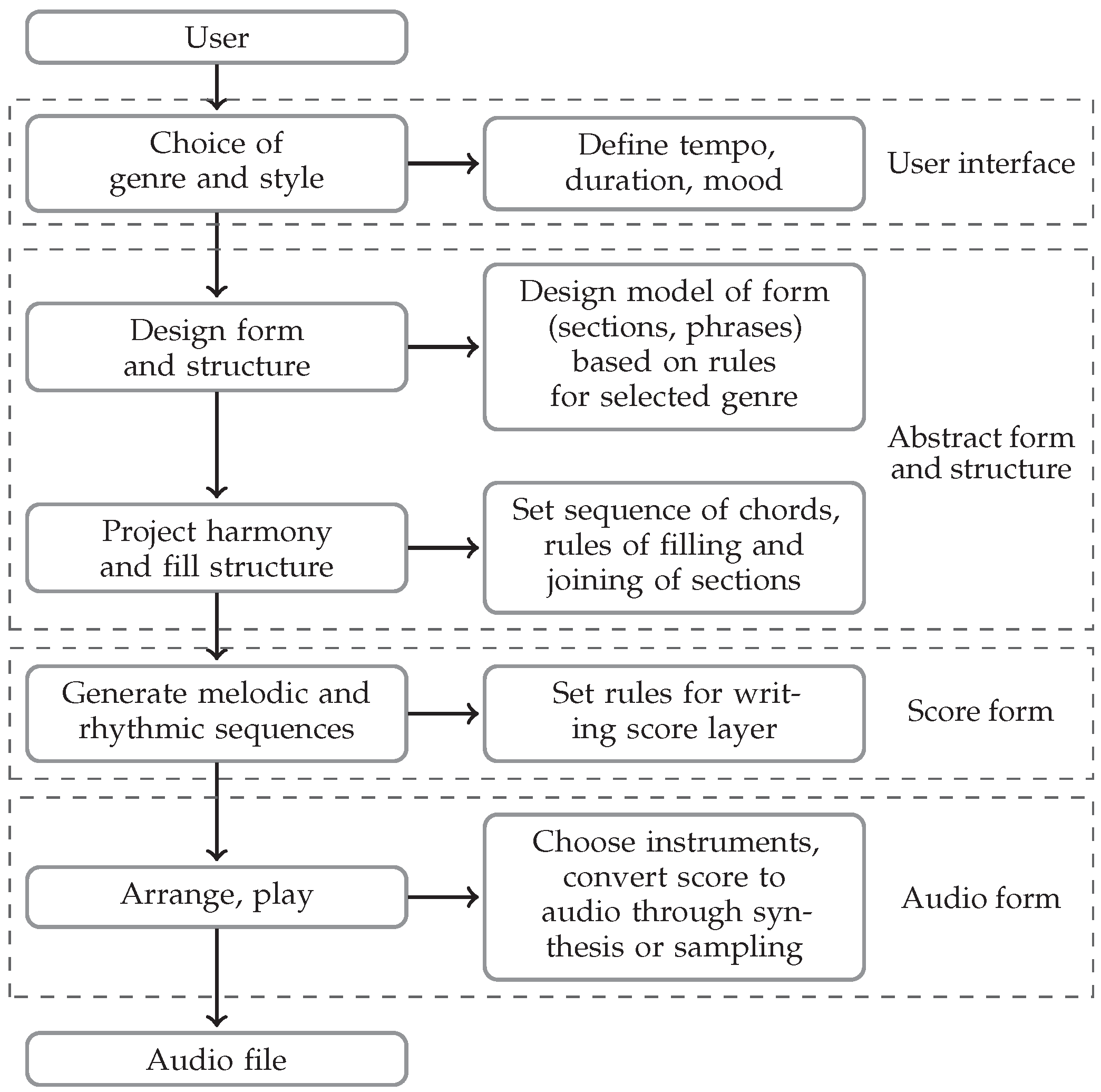
2.1. System Overview
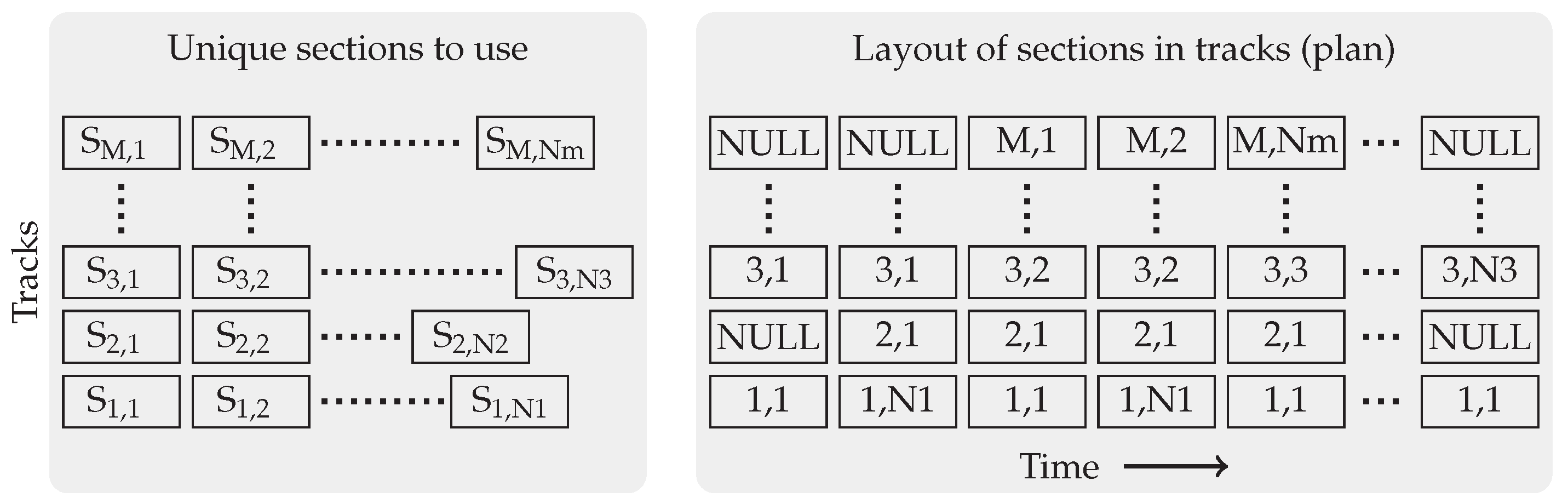
2.2. The Generator
2.3. The Critic
- creating, training, and testing sets,
- building, compiling, and training the neural network,
- evaluating the neural network on the test set.
- low level descriptors, e.g.,:
- –
- 13 first mel-frequency cepstral coefficients (MFCCs),
- –
- dissonance,
- –
- dynamic complexity,
- –
- pitch salience,
- –
- spectral complexity (Shannon entropy of a spectrum),
- –
- spectral energy band (high, low),
- rhythm descriptors, e.g.,:
- –
- beat count (number of detected beats),
- –
- beat loudness (spectral energy computed on beat segments),
- –
- BPM value,
- –
- danceability,
- –
- onset rate (number of detected onsets per second),
- tonal descriptors, e.g.,:
- –
- chord change rate,
- –
- key strength using diatonic profile.
3. Results and Discussion
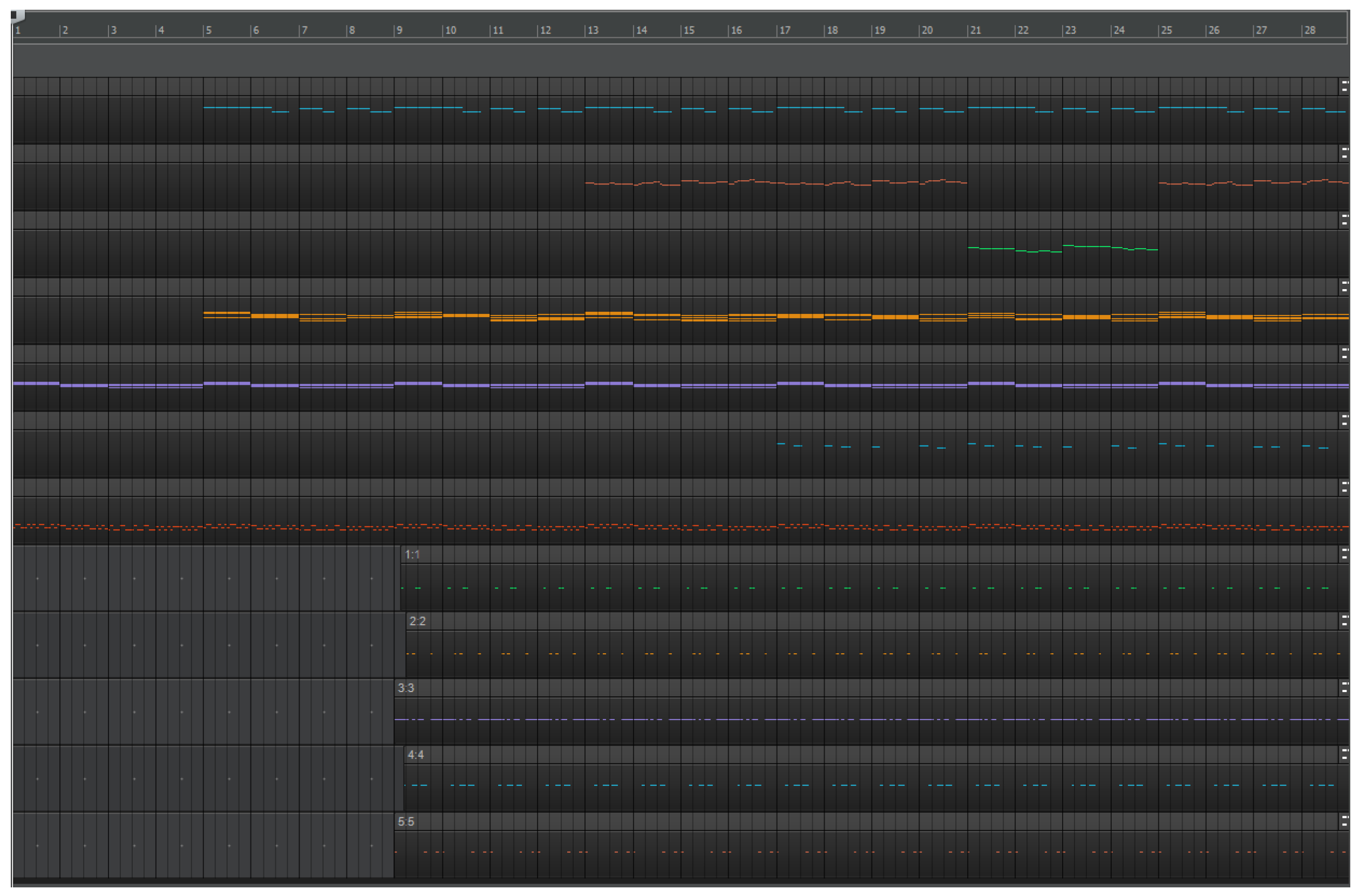
3.1. Results of the Generator–Critic System Operation
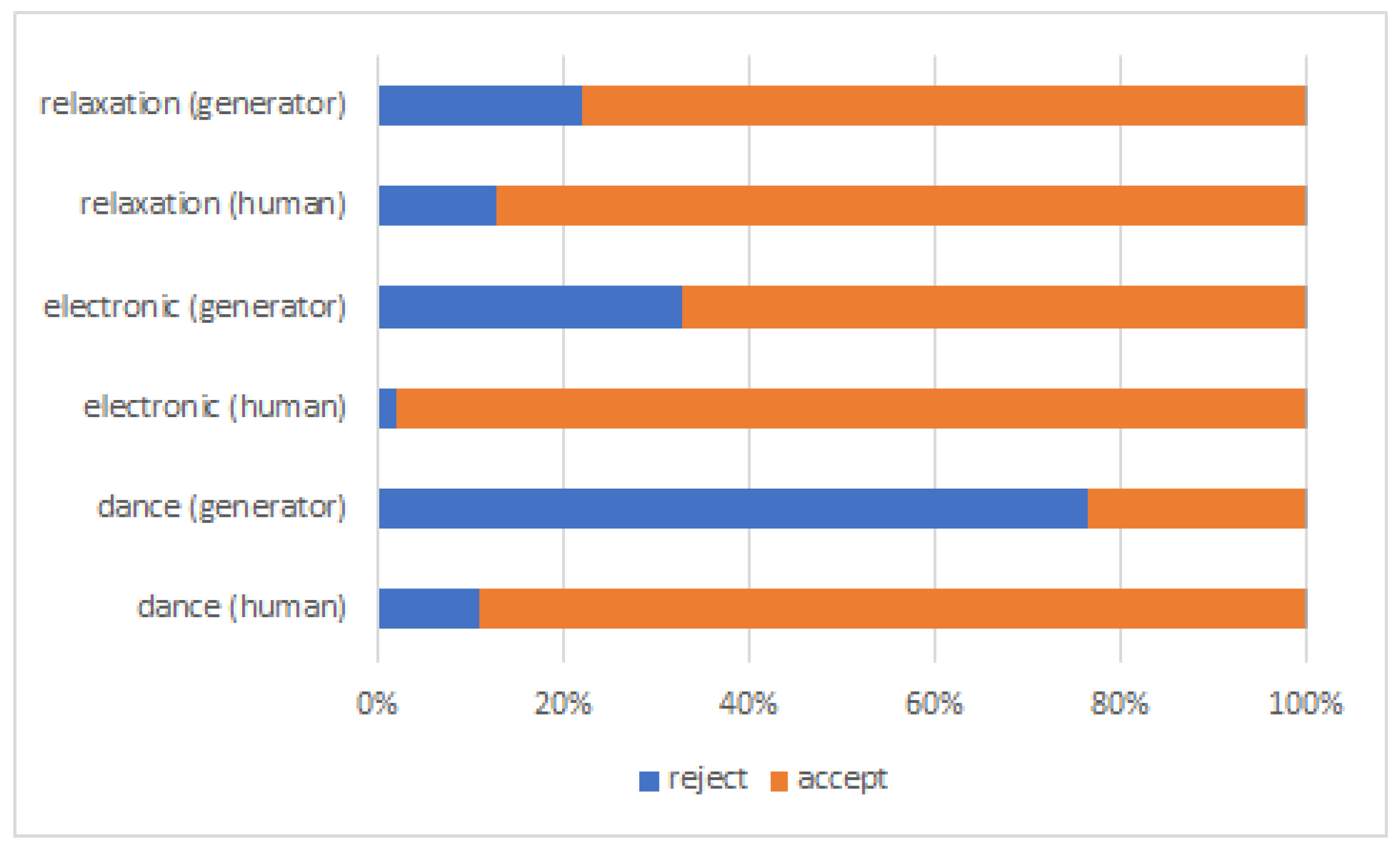
3.2. Auditory Evaluation
- accepted recordings, if human voted as fair, good, very good, or excellent,
- rejected recordings, if human voted as bad or poor.
3.3. Legal Aspects
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aggarwal, C.C. Data Classification: Algorithms and Applications, 1st ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2014. [Google Scholar]
- Kotsiantis, S.; Zaharakis, I.; Pintelas, P. Machine learning: A review of classification and combining techniques. Artif. Intell. Rev. 2006, 26, 159–190. [Google Scholar] [CrossRef]
- The European Broadcasting Union Document Tech 3286. Assessment Methods for the Subjective Evaluation of the Quality of Sound Programme Material—Music. 1997. Available online: https://tech.ebu.ch/publications/tech3286 (accessed on 3 October 2023).
- Gungormusler, A.; Paterson-Paulberg, N.; Haahr, M. barelyMusician: An Adaptive Music Engine for Video Games. In Proceedings of the Audio Engineering Society Conference: 56th International Conference: Audio for Games, London, UK, 11–13 February 2015. [Google Scholar]
- Williams, D.; Kirke, A.; Eaton, J.; Miranda, E.; Daly, I.; Hallowell, J.; Roesch, E.; Hwang, F.; Nasuto, S.J. Dynamic Game Soundtrack Generation in Response to a Continuously Varying Emotional Trajectory. In Proceedings of the Audio Engineering Society Conference: 56th International Conference: Audio for Games, London, UK, 11–13 February 2015. [Google Scholar]
- Williams, D.; Hodge, V.; Gega, L.; Murphy, D.; Cowling, P.; Drachen, A. AI and Automatic Music Generation for Mindfulness. In Proceedings of the Audio Engineering Society Conference: 2019 AES International Conference on Immersive and Interactive Audio, York, UK, 27–29 March 2019. [Google Scholar]
- Komosinski, M.; Szachewicz, P. Automatic species counterpoint composition by means of the dominance relation. J. Math. Music 2015, 9, 75–94. [Google Scholar] [CrossRef]
- De Prisco, R.; Zaccagnino, G.; Zaccagnino, R. A Genetic Algorithm for Dodecaphonic Compositions. In Proceedings of the European Conference on the Applications of Evolutionary Computation, Aberystwyth, UK, 3–5 March 2011; pp. 244–253. [Google Scholar] [CrossRef]
- Hiller, L.A., Jr.; Isaacson, L.M. Musical Composition with a High-Speed Digital Computer. J. Audio Eng. Soc. 1958, 6, 154–160. [Google Scholar]
- Carnovalini, F.; Rodà, A. Computational Creativity and Music Generation Systems: An Introduction to the State of the Art. Front. Artif. Intell. 2020, 3, 14. [Google Scholar] [CrossRef]
- Fernandez, J.; Vico, F. AI Methods in Algorithmic Composition: A Comprehensive Survey. J. Artif. Intell. Res. 2013, 48, 513–582. [Google Scholar] [CrossRef]
- Donnelly, P.; Sheppard, J. Evolving Four-Part Harmony Using Genetic Algorithms. In Proceedings of the European Conference on the Applications of Evolutionary Computation, Aberystwyth, UK, 3–5 March 2011; pp. 273–282. [Google Scholar] [CrossRef]
- Mycka, J.; Żychowski, A.; Mańdziuk, J. Toward human-level tonal and modal melody harmonizations. J. Comput. Sci. 2023, 67, 101963. [Google Scholar] [CrossRef]
- Briot, J.P.; Hadjeres, G.; Pachet, F.D. Deep Learning Techniques for Music Generation—A Survey. arXiv 2019, arXiv:1709.01620. [Google Scholar]
- Biswas, A.; Wennekes, E.; Wieczorkowska, A.; Laskar, R.H. (Eds.) Advances in Speech and Music Technology. Computational Aspects and Applications; Signals and Communication Technology; Springer: Cham, Switzerland, 2023. [Google Scholar] [CrossRef]
- Ycart, A.; Benetos, E. Learning and Evaluation Methodologies for Polyphonic Music Sequence Prediction with LSTMs. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1328–1341. [Google Scholar] [CrossRef]
- Chen, J.; Pan, F.; Zhong, P.; He, T.; Qi, L.; Lu, J.; He, P.; Zheng, Y. An Automatic Method to Develop Music with Music Segment and Long Short Term Memory for Tinnitus Music Therapy. IEEE Access 2020, 8, 1. [Google Scholar] [CrossRef]
- Huang, C.Z.A.; Vaswani, A.; Uszkoreit, J.; Shazeer, N.; Simon, I.; Hawthorne, C.; Dai, A.M.; Hoffman, M.D.; Dinculescu, M.; Eck, D. Music Transformer. arXiv 2018, arXiv:1809.04281. [Google Scholar]
- Min, J.; Liu, Z.; Wang, L.; Li, D.; Zhang, M.; Huang, Y. Music Generation System for Adversarial Training Based on Deep Learning. Processes 2022, 10, 2515. [Google Scholar] [CrossRef]
- Neves, P.; Fornari, J.; Florindo, J. Generating music with sentiment using Transformer-GANs. arXiv 2022, arXiv:2212.11134. [Google Scholar]
- Jin, C.; Wang, T.; Liu, S.; Tie, Y.; Li, J.; Li, X.; Lui, S. A transformer-based model for multi-track music generation. Int. J. Multimed. Data Eng. Manag. 2020, 11, 36–54. [Google Scholar] [CrossRef]
- Civit, M.; Civit-Masot, J.; Cuadrado, F.; Escalona, M. A systematic review of artificial intelligence-based music generation: Scope, applications, and future trends. Expert Syst. Appl. 2022, 209, 118190. [Google Scholar] [CrossRef]
- Tzanetakis, G.; Cook, P. Musical Genre Classification of Audio Signals. IEEE Trans. Speech Audio Process. 2002, 10, 293–302. [Google Scholar] [CrossRef]
- Lidy, T.; Rauber, A.; Pertusa, A.; Quereda, J.M.I. Improving Genre Classification by Combination of Audio and Symbolic Descriptors Using a Transcription Systems. In Proceedings of the ISMIR, Vienna, Austria, 23–27 September 2007; pp. 61–66. [Google Scholar]
- Gan, J. Music Feature Classification Based on Recurrent Neural Networks with Channel Attention Mechanism. Mob. Inf. Syst. 2021, 2021, 1–10. [Google Scholar] [CrossRef]
- Zhang, K. Music Style Classification Algorithm Based on Music Feature Extraction and Deep Neural Network. Wirel. Commun. Mob. Comput. 2021, 2021, 1–7. [Google Scholar] [CrossRef]
- Ashraf, M.; Abid, F.; Din, I.U.; Rasheed, J.; Yesiltepe, M.; Yeo, S.F.; Ersoy, M.T. A Hybrid CNN and RNN Variant Model for Music Classification. Appl. Sci. 2023, 13, 1476. [Google Scholar] [CrossRef]
- Nasrullah, Z.; Zhao, Y. Music Artist Classification with Convolutional Recurrent Neural Networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Laurier, C.; Grivolla, J.; Herrera, P. Multimodal Music Mood Classification Using Audio and Lyrics. In Proceedings of the 2008 Seventh International Conference on Machine Learning and Applications, San Diego, CA, USA, 11–13 December 2008; pp. 688–693. [Google Scholar] [CrossRef]
- Seo, Y.S.; Huh, J.H. Automatic Emotion-Based Music Classification for Supporting Intelligent IoT Applications. Electronics 2019, 8, 164. [Google Scholar] [CrossRef]
- Ferreira, P.; Limongi, R.; Favero, L.P. Generating Music with Data: Application of Deep Learning Models for Symbolic Music Composition. Appl. Sci. 2023, 13, 4543. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Zhou, T.; Xu, L.; Zhang, Q. An automatic music generation and evaluation method based on transfer learning. PLoS ONE 2023, 18, e0283103. [Google Scholar] [CrossRef]
- Gallagher, M. The Music Tech Dictionary: A Glossary of Audio-Related Terms and Technologies; Course Technology; Muska/Lipman: St. Clairsville, OH, USA, 2009. [Google Scholar]
- Mido Webpage. Available online: https://mido.readthedocs.io/en/stable/ (accessed on 21 March 2024).
- Pyo Webpage. Available online: https://pypi.org/project/pyo/ (accessed on 21 March 2024).
- LilyPond Webpage. Available online: https://lilypond.org/ (accessed on 21 March 2024).
- FluidSynth Webpage. Available online: https://www.fluidsynth.org/ (accessed on 21 March 2024).
- SoundFont Technical Specification. Available online: http://www.synthfont.com/sfspec24.pdf (accessed on 21 March 2024).
- SoX Webpage. Available online: https://sourceforge.net/projects/sox/ (accessed on 21 March 2024).
- Engelbrecht, A.P. Computational Intelligence: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar] [CrossRef]
- Schedl, M.; Hauger, D.; Urbano, J. Harvesting microblogs for contextual music similarity estimation: A co-occurrence-based framework. Multimed. Syst. 2014, 20, 693–705. [Google Scholar] [CrossRef]
- Bogdanov, D.; Haro, M.; Fuhrmann, F.; Gómez, E.; Herrera, P. Content-based music recommendation based on user preference examples. In Proceedings of the ACM Conference on Recommender Systems. Workshop on Music Recommendation and Discovery (Womrad 2010), Barcelona, Spain, 26 September 2010; Volume 633. [Google Scholar]
- Act of 4 February 1994 on Copyright and Related Rights (in Polish). Available online: http://www.prawoautorskie.gov.pl/media/download_gallery/D19940083Lj_19.07.pdf (accessed on 3 October 2023).
- Article 94, Section 1 of the Act of 4 February 1994 on Copyright and Related Rights (in Polish). Available online: http://www.prawoautorskie.gov.pl/media/download_gallery/D19940083Lj_19.07.pdf (accessed on 3 October 2023).
- Wojtczak, S.; Księżak, P. Copyright Law towards Artificial Intelligence (An Attempt at An Alternative View). State Law (PańStwo Prawo) 2021, 2, 21. (In Polish) [Google Scholar]
- Guadamuz, A. The monkey selfie: Copyright lessons for originality in photographs and internet jurisdiction. Internet Policy Rev. 2016, 5, 1. [Google Scholar] [CrossRef]
- Szpyt, K. The Use of Artificial Intelligence in Post-mortem Creativity and the Copyright of the Deceased Creator (in Polish). In The Law of Artificial Intelligence (Polish: Prawo Sztucznej Inteligencji); Lai, L., Świerczyński, M., Eds.; C.H. Beck: Warsaw, Poland, 2020; pp. 160–161. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Type | Comment |
|---|---|---|
| Genre | Enumeration | Single choice from a list |
| Duration | Integer | [s] |
| Tempo | Integer | [BPM] |
| Mood | Floating point | Range from sad to happy |
| Oddity | Floating point | Range from normal to odd |
| Tuning | Floating point | Fundamental frequency of A4 [Hz] |
| Task | FL | GA | RBS |
|---|---|---|---|
| Form design | + | ||
| Harmonic progression generation | + | ||
| Lead motifs generation | + | + | |
| Lead phrases design | + | + | |
| Drum patterns design | + | + | |
| Bass lines generation | + | ||
| Accompanying tracks design | + | + | |
| Applying effects and mixing | + |
| Label | Rhythm | Intervals |
|---|---|---|
| mot1 | 8, 16, 16, 8 | 1, 2, 1 |
| mot2 | 4, 8, 8, 4, 8 | 5, 1, 1, −2 |
| mot3 | 8, 8, 2, 8 | 1, −1, −2 |
| Genre | Correct (Class 1) | Incorrect (Class 2) |
|---|---|---|
| Relaxation | 940 | 1060 |
| Dance | 659 | 1341 |
| Electronic | 311 | 1689 |
| Genre | Actual | Predicted Negative | Predicted Positive |
|---|---|---|---|
| Relaxation | Negative | TN = 765 | FP = 400 |
| Positive | FN = 295 | TP = 540 | |
| Dance | Negative | TN = 1199 | FP = 347 |
| Positive | FN = 142 | TP = 312 | |
| Electronic | Negative | TN = 1674 | FP = 280 |
| Positive | FN = 15 | TP = 31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwiecień, J.; Skrzyński, P.; Chmiel, W.; Dąbrowski, A.; Szadkowski, B.; Pluta, M. Technical, Musical, and Legal Aspects of an AI-Aided Algorithmic Music Production System. Appl. Sci. 2024, 14, 3541. https://doi.org/10.3390/app14093541
Kwiecień J, Skrzyński P, Chmiel W, Dąbrowski A, Szadkowski B, Pluta M. Technical, Musical, and Legal Aspects of an AI-Aided Algorithmic Music Production System. Applied Sciences. 2024; 14(9):3541. https://doi.org/10.3390/app14093541
Chicago/Turabian StyleKwiecień, Joanna, Paweł Skrzyński, Wojciech Chmiel, Andrzej Dąbrowski, Bartłomiej Szadkowski, and Marek Pluta. 2024. "Technical, Musical, and Legal Aspects of an AI-Aided Algorithmic Music Production System" Applied Sciences 14, no. 9: 3541. https://doi.org/10.3390/app14093541