
A Methodology for Estimating the Assembly Position of the Process Based on YOLO and Regression of Operator Hand Position and Time Information


Abstract
1. Introduction
2. Background
2.1. Assembly Process
2.2. Object-Detection Algorithm
2.3. Problem Statements
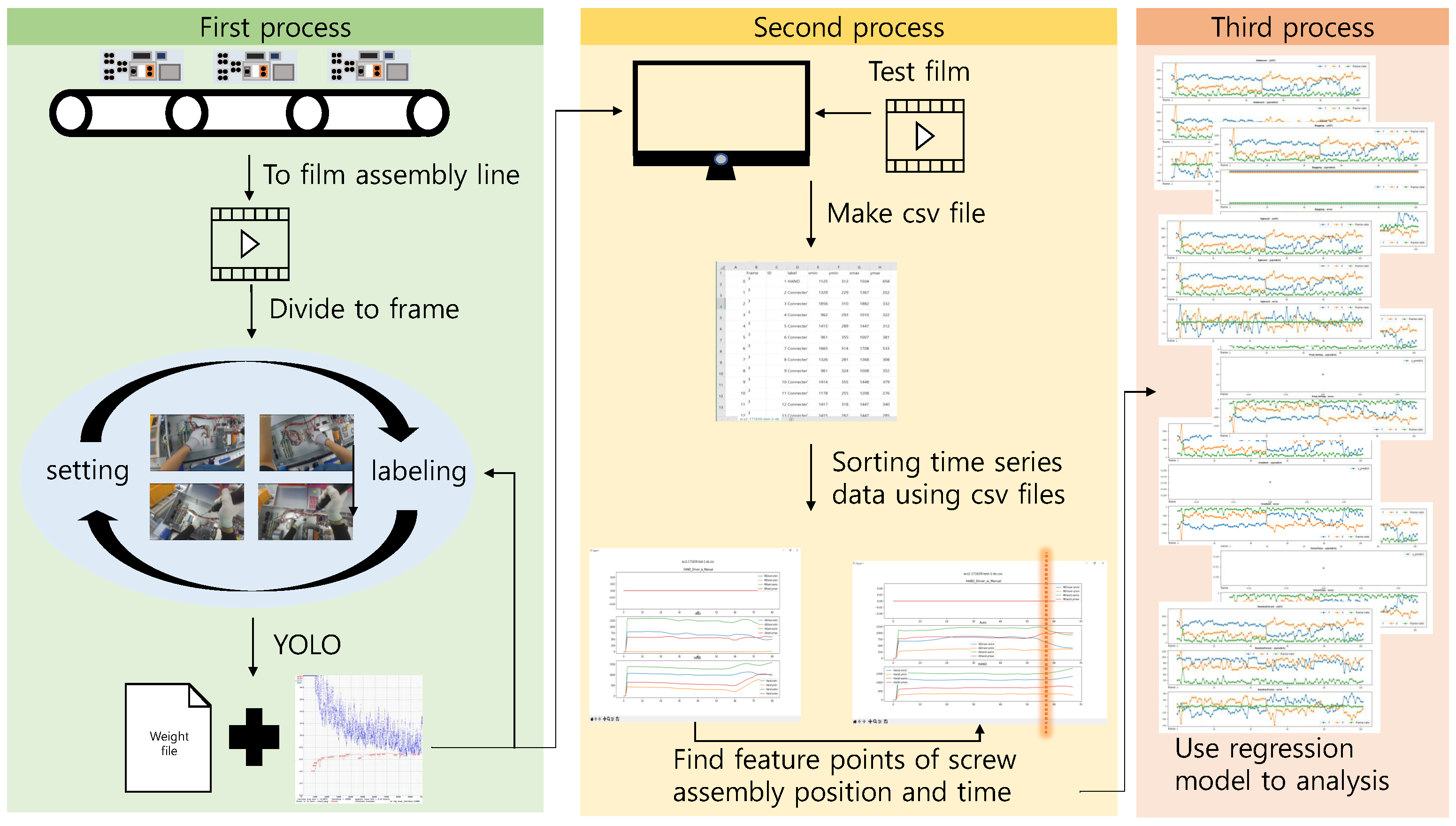
3. Proposed Methodology
3.1. Proposed Algorithm
3.2. Dataset for YOLO
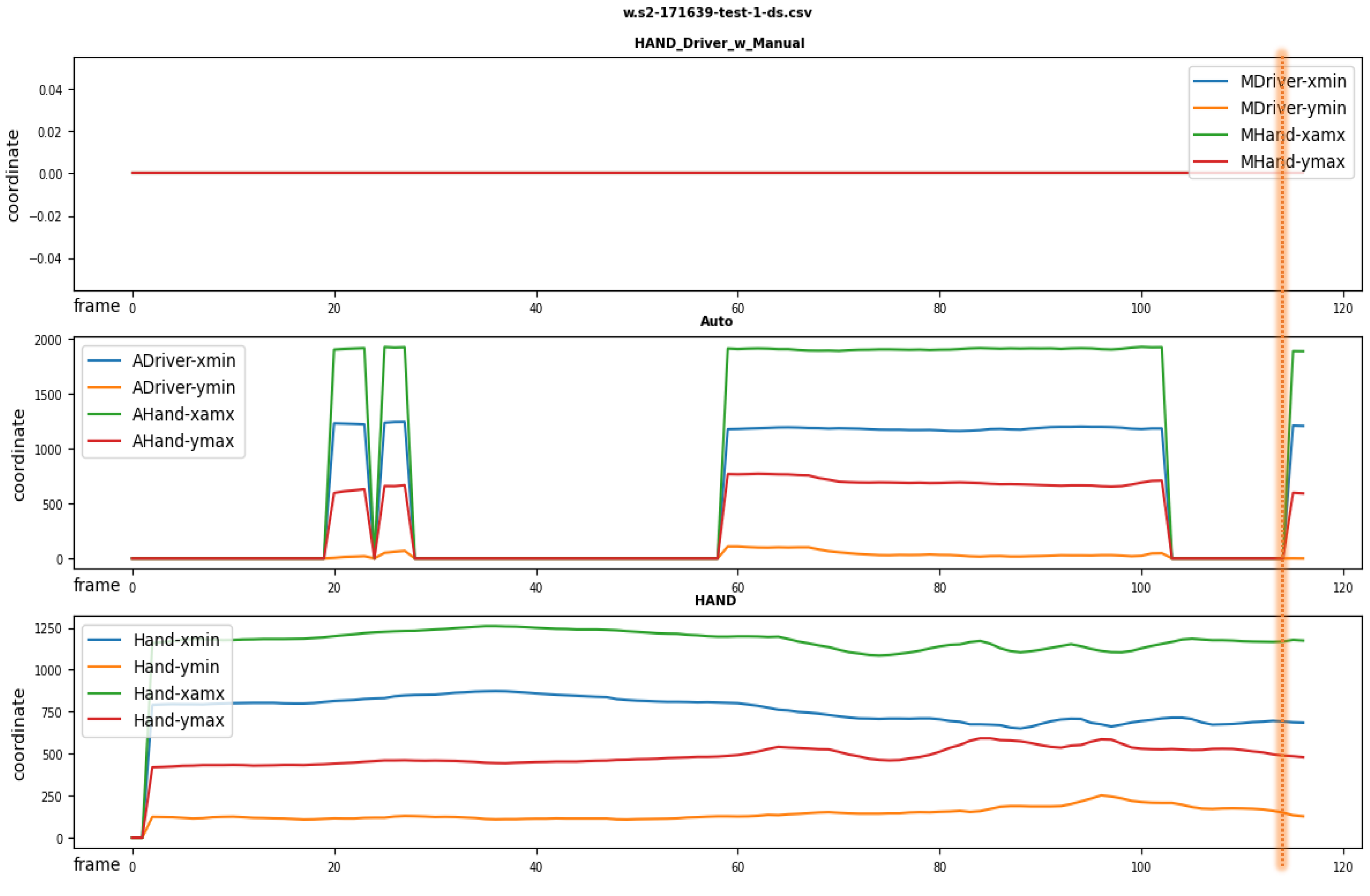
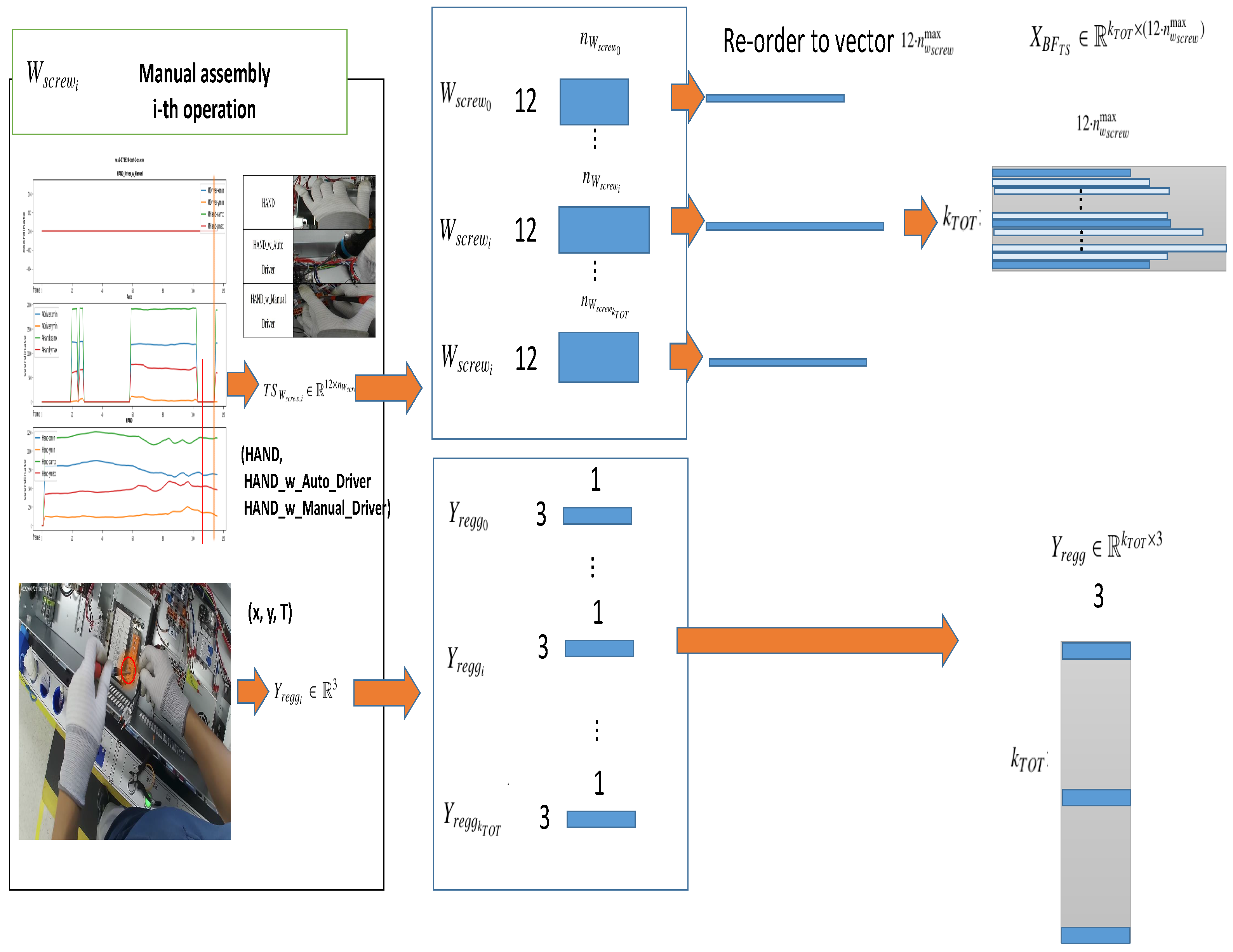
3.2.1. Pre-Processing for the Regression of the Assembly Timing and Position
3.2.2. Regression Algorithms
4. Method Validation Setup
System Configuration
5. Numerical Results and Discussion
5.1. YOLO Training and Reasoning Results
5.2. Regression Results
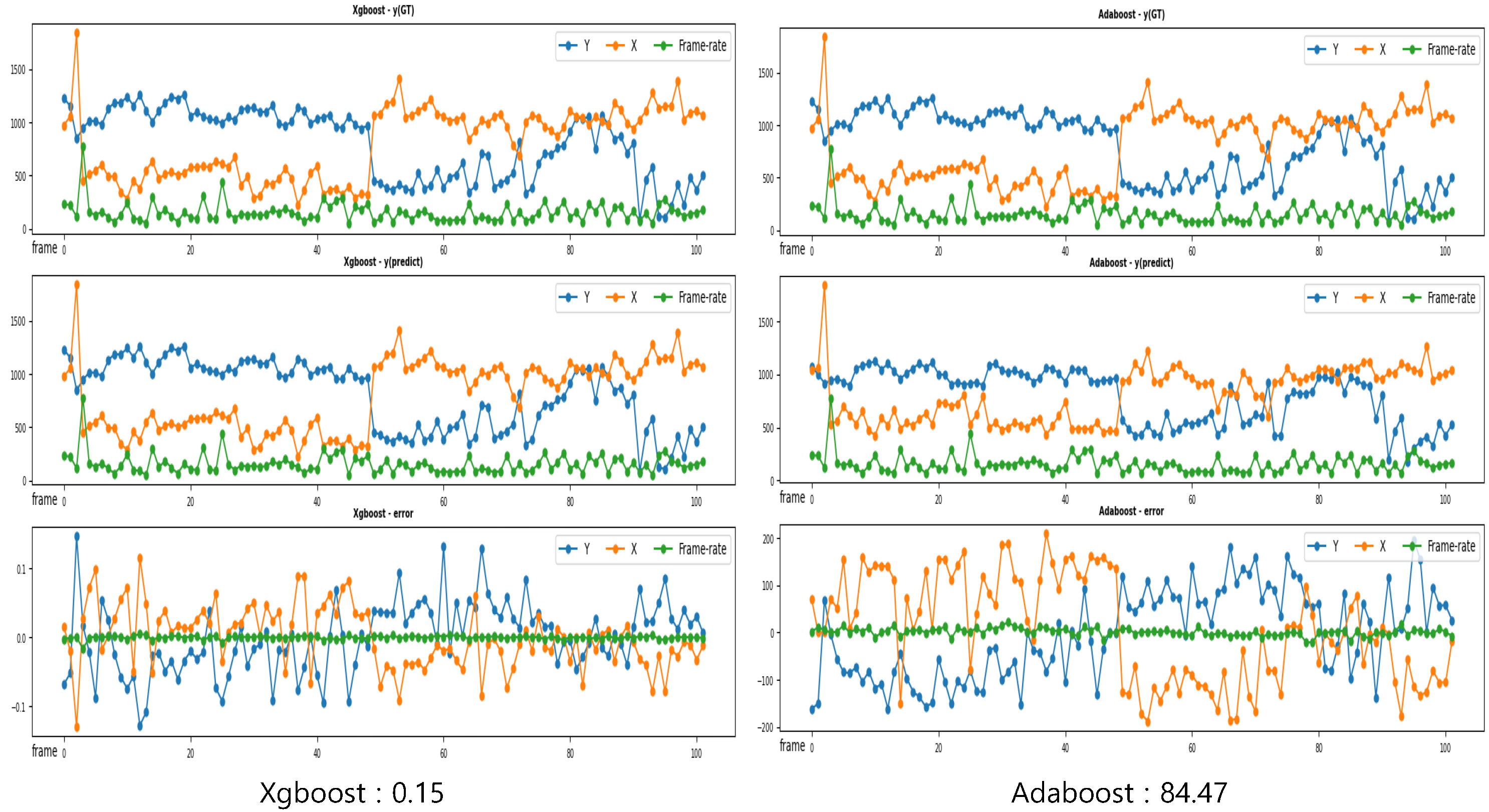
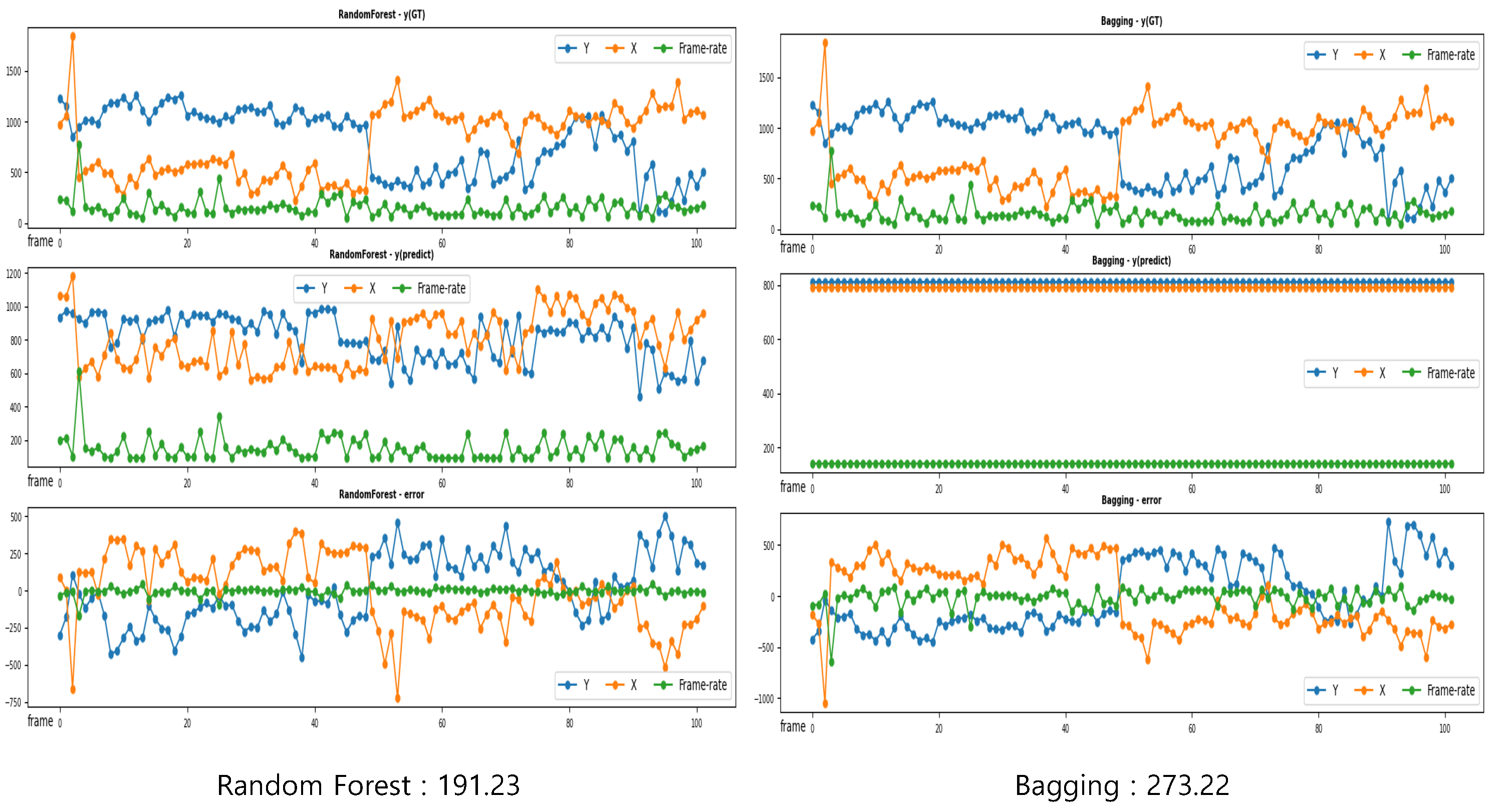
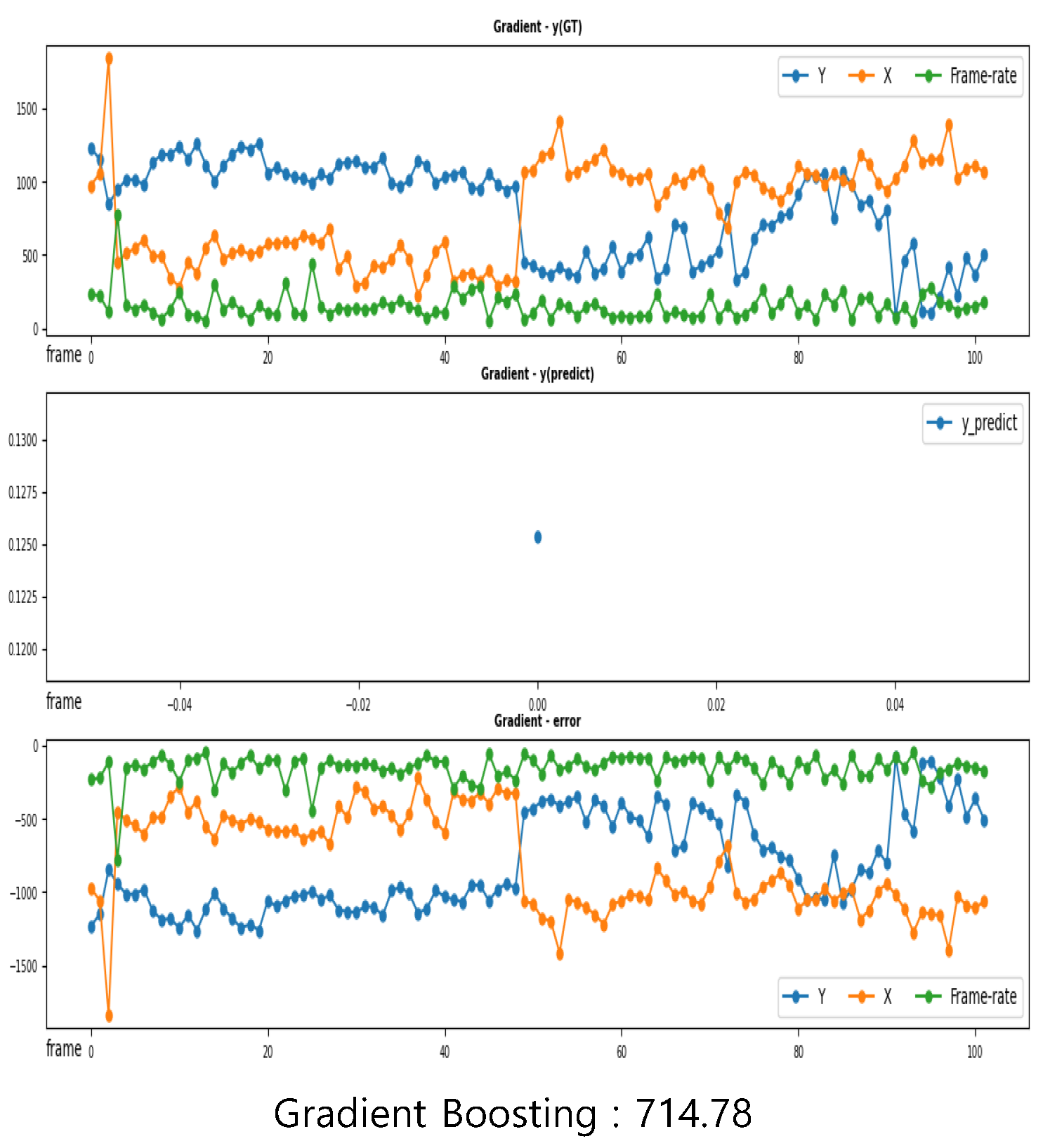
5.3. Visualization Results
5.3.1. Object-Detection Results of YOLO
5.3.2. Regression
5.4. Discussion and Future Works
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hozdić, E. Smart factory for industry 4.0: A review. Int. J. Mod. Manuf. Technol. 2015, 7, 28–35. [Google Scholar]
- Büchi, G.; Cugno, M.; Castagnoli, R. Smart factory performance and Industry 4.0. Technol. Forecast. Soc. Chang. 2020, 150, 119790. [Google Scholar] [CrossRef]
- Krüger, J.; Lien, T.K.; Verl, A. Cooperation of human and machines in assembly lines. CIRP Ann. 2009, 58, 628–646. [Google Scholar] [CrossRef]
- Wallhoff, F.; Blume, J.; Bannat, A.; Rösel, W.; Lenz, C.; Knoll, A. A skill-based approach towards hybrid assembly. Adv. Eng. Inform. 2010, 24, 329–339. [Google Scholar] [CrossRef]
- Li, F.; Jiang, Q.; Zhang, S.; Wei, M.; Song, R. Robot skill acquisition in assembly process using deep reinforcement learning. Neurocomputing 2019, 345, 92–102. [Google Scholar] [CrossRef]
- Morioka, M.; Sakakibara, S. A new cell production assembly system with human–robot cooperation. CIRP Ann. 2010, 59, 9–12. [Google Scholar] [CrossRef]
- Kucukoglu, I.; Atici-Ulusu, H.; Gunduz, T.; Tokcalar, O. Application of the artificial neural network method to detect defective assembling processes by using a wearable technology. J. Manuf. Syst. 2018, 49, 163–171. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, J.; Joo, H.; Raj, M.S.; Ghaffari, R.; Kim, D. Wearable sensing systems with mechanically soft assemblies of nanoscale materials. Adv. Mater. Technol. 2017, 2, 1700053. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining Adaboost. In Empirical Inference: Festschrift in Honor of Vladimir N. Vapnik; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar] [CrossRef]
- Bauer, E.; Kohavi, R. An empirical comparison of voting classification algorithms: Bagging, boosting and variants. Mach. Learn. 1999, 36, 105–139. [Google Scholar] [CrossRef]
- John, V.; Liu, Z.; Guo, C.; Mita, S.; Kidono, K. Real-time lane estimation using deep features and extra trees regression. In Lecture Notes in Computer Science, Proceedings of the Image and Video Technology: 7th Pacific-Rim Symposium, PSIVT 2015, Auckland, New Zealand, 25–27 November 2015; Revised Selected Papers 7; Springer: Cham, Switzerland, 2016; pp. 721–733. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of Gradient Boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Biau, G.; Scornet, E. A Random Forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]
- Phyo, P.; Byun, Y.; Park, N. Short-term energy forecasting using machine-learning-based ensemble voting regression. Symmetry 2022, 14, 160. [Google Scholar] [CrossRef]
- Fabian, P. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2011. [Google Scholar]
- Bisong, E. Introduction to Scikit-learn. In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: Berkeley, CA, USA, 2019; pp. 215–229. [Google Scholar] [CrossRef]
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for autonomous landing spot detection in faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Chen, C.; Wang, T.; Li, D.; Hong, J. Repetitive assembly action recognition based on object detection and pose estimation. J. Manuf. Syst. 2020, 55, 325–333. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, P.; Gao, R.X. Hybrid machine learning for human action recognition and prediction in assembly. Robot. Comput.-Integr. Manuf. 2021, 72, 102184. [Google Scholar] [CrossRef]
- Andrianakos, G.; Dimitropoulos, N.; Michalos, G.; Makris, S. An approach for monitoring the execution of human based assembly operations using machine learning. Procedia Cirp. 2019, 86, 198–203. [Google Scholar] [CrossRef]
- Ralyté, J.; Rolland, C. An Assembly Process Model for Method Engineering. In Lecture Notes in Computer Science, Proceedings of the Advanced Information Systems Engineering: 13th International Conference, CAiSE 2001, Interlaken, Switzerland, 4–8 June 2001; Proceedings 13; Springer: Berlin/Heidelberg, Germany, 2001; pp. 267–283. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. Available online: https://ieeexplore.ieee.org/document/8296962 (accessed on 1 April 2024).
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Regression Algorithm | Description |
|---|---|
| Xgboost | Xgboost is an algorithm that utilizes decision trees and hyper parameters Γ and Δ to prevent overfitting, which can occur in Gradient Tree Boosting. Its structure reduces the loss function by weighting learning in the ensemble process and supports parallel processing, resulting in faster speeds. |
| Adaboost | Adaboost is a similar algorithm to Random Forest, which uses stumps (single-condition decision trees) for classification. In Adaboost, the result value for each stump influences the weight and classification of subsequent stumps, a process known as boosting. |
| Bagging | Bagging is an algorithm that uses bootstrapping, which is a method of randomly sampling and extracting a certain amount of data from a given dataset with replacement. The learning process is then repeated n times to obtain an average and the final prediction result is derived through higher prediction values or majority voting. These characteristics have the advantage of being able to offset errors in the classifier. |
| Extra-Trees | Extra-Trees is an algorithm with a structure similar to Random Forest, but it differs from Random Forest in that it selects the data with the highest score during the process of extracting random data. This prevents overfitting and enables node segmentation to be performed quickly, resulting in high accuracy and speed. |
| Gradient Boosting | Gradient Boosting is a structure similar to Adaboost, consisting of a stump. In Gradient Boosting, new learning is conducted by assigning high weights to data that were incorrectly predicted from the results of previous learning. The algorithm repeats this process to learn in the direction of minimizing the loss function. However, a disadvantage of Gradient Boosting is its long learning time. |
| Random Forest | Random Forest is an algorithm that consists of several decision trees. The decision tree is used as a solution to overfitting, which occurs when the learning data are insufficient or the number of features is large and shows the same results as the learning data. |
| Prediction Voting Regressor for Unfitted Estimators | The Prediction Voting Regressor for Unfitted Estimators is an algorithm that uses multiple estimators to predict the entire dataset and calculates their average to make the final prediction. This approach increases the reliability of the prediction due to the use of multiple estimators. However, there is a risk of overfitting during the random parameter specification process. |
| Specification Item | Details |
|---|---|
| Video Format | MP4 (H.264), 1080P@30FPS |
| Lens Type | 140 wide angle |
| Input | Type-c usb, TRRS port |
| Bluetooth | Build-in, remote control compatible |
| Size (L × W × H) | 47 mm × 92 mm × 35 mm |
| Photo model | 4, 8, 12 Mega pixels |
| Battery | 3000 mAh rechargeable |
| memory | Micro sd, SDHC, SDXC, up to 256 gb |
| Waterproof | IP × 7 waterproof |
| Weight | 97 g |
| Sensor type | SONY 12MP |
| Microphone | Build-in |
| Wi-Fi | 2.4/5.8 G |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, B.; Jeong, S.; Yoo, Y. A Methodology for Estimating the Assembly Position of the Process Based on YOLO and Regression of Operator Hand Position and Time Information. Appl. Sci. 2024, 14, 3611. https://doi.org/10.3390/app14093611
Lim B, Jeong S, Yoo Y. A Methodology for Estimating the Assembly Position of the Process Based on YOLO and Regression of Operator Hand Position and Time Information. Applied Sciences. 2024; 14(9):3611. https://doi.org/10.3390/app14093611
Chicago/Turabian StyleLim, Byeongju, Seyun Jeong, and Youngjun Yoo. 2024. "A Methodology for Estimating the Assembly Position of the Process Based on YOLO and Regression of Operator Hand Position and Time Information" Applied Sciences 14, no. 9: 3611. https://doi.org/10.3390/app14093611
APA StyleLim, B., Jeong, S., & Yoo, Y. (2024). A Methodology for Estimating the Assembly Position of the Process Based on YOLO and Regression of Operator Hand Position and Time Information. Applied Sciences, 14(9), 3611. https://doi.org/10.3390/app14093611