1. Introduction
In recent years, with the rapid integration of high-tech and advanced automotive technologies such as computers, the Internet, communications and navigation, automatic control, artificial intelligence, machine vision, precision sensors, high-precision maps and smart cars (or unmanned vehicles), smart driving has become one of the world’s automotive engineering research hotspots and a new impetus of the automotive industry’s growth. According to authoritative media at home and abroad, in the future of the automotive industry, more than 90% of scientific and technological innovation will focus on the field of automotive intelligence. Therefore, smart vehicles are safe, efficient, energy-efficient next-generation vehicles [
1,
2], and the study of smart cars has a very important significance, which has become the focus of the global automotive industry.
The driver intention is reflected by his/her own inner state in the driving process. It cannot be obtained directly during driving and is only predicted by the driver’s movements, vehicle status and traffic environment information. Driver’s intention classification and identification are identified as comprising the key technology for intelligent vehicles and are widely used in a variety of Advanced Driver Assistant Systems (ADAS) [
3,
4], such as the Adaptive Cruise Control System (ACC) [
5,
6], the Active Front Steering System (AFS) [
7,
8,
9,
10], the Parking Assistance Systems (PAS) [
11,
12], the steer-by-wire systems [
13] and Man-machine Co-driving Electric Power Steering (MCEPS) system [
14,
15]. The classification and identification of driver’s intention are based on the real-time acquisition of the driver’s operating signal and car state, or at the same time, by monitoring the driver’s head movement range and facial expressions, the driver’s behavior is distinguished and identified to obtain the driver’s driving intention [
16].
Many scholars are committed to study the classification and identification of driver’s intention. Liang Li et al. [
17] proposed a novel method based on an artificial error back-propagation neural network to identify the driver’s starting intention. Takano et al. [
18] proposed an intelligent cognitive method for driver’s intention identification based on the Hidden Markov Model (HMM). The method mainly includes data segmentation, time series data labeling and the identification and generation of the driving mode. Raksin et al. [
19] proposed an algorithm based on the driver’s intention to identify the direct yaw moment control, in which the driver steering intention identification is through the Hidden Markov Model (HMM). The use of the dynamic Bayesian network was combined with the past driving state and the current driving state to predict the driver’s intention of parking at the crossroads. Tesheng Hsiao [
20] used the maximum posterior probability assessment method to obtain the driver’s steering model parameters. He established a steering model that can effectively improve the recognition accuracy and that has the function of predicting the driver’s driving strategy. The previous research works mainly concentrated on a single traffic environment, such as the straight road or the crossroads intentions, and not on variety of typical steering conditions under the driving intention identification study.
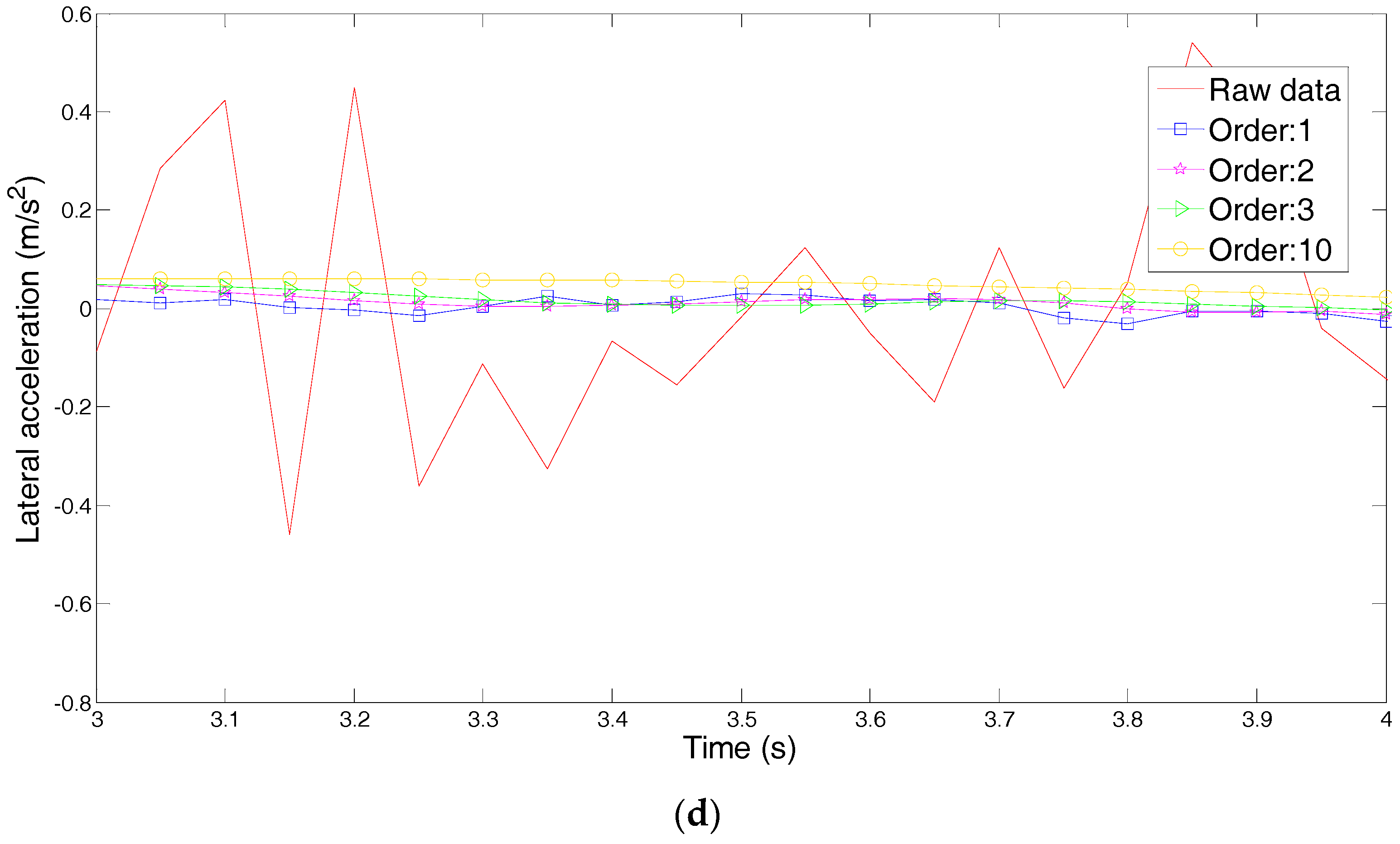
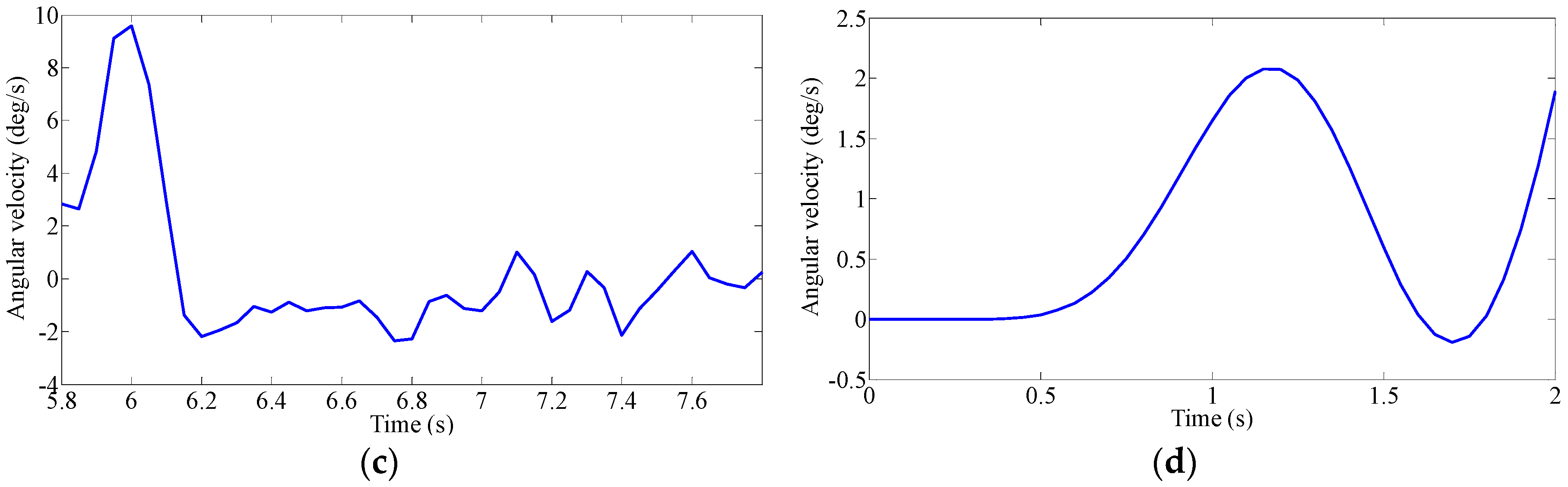
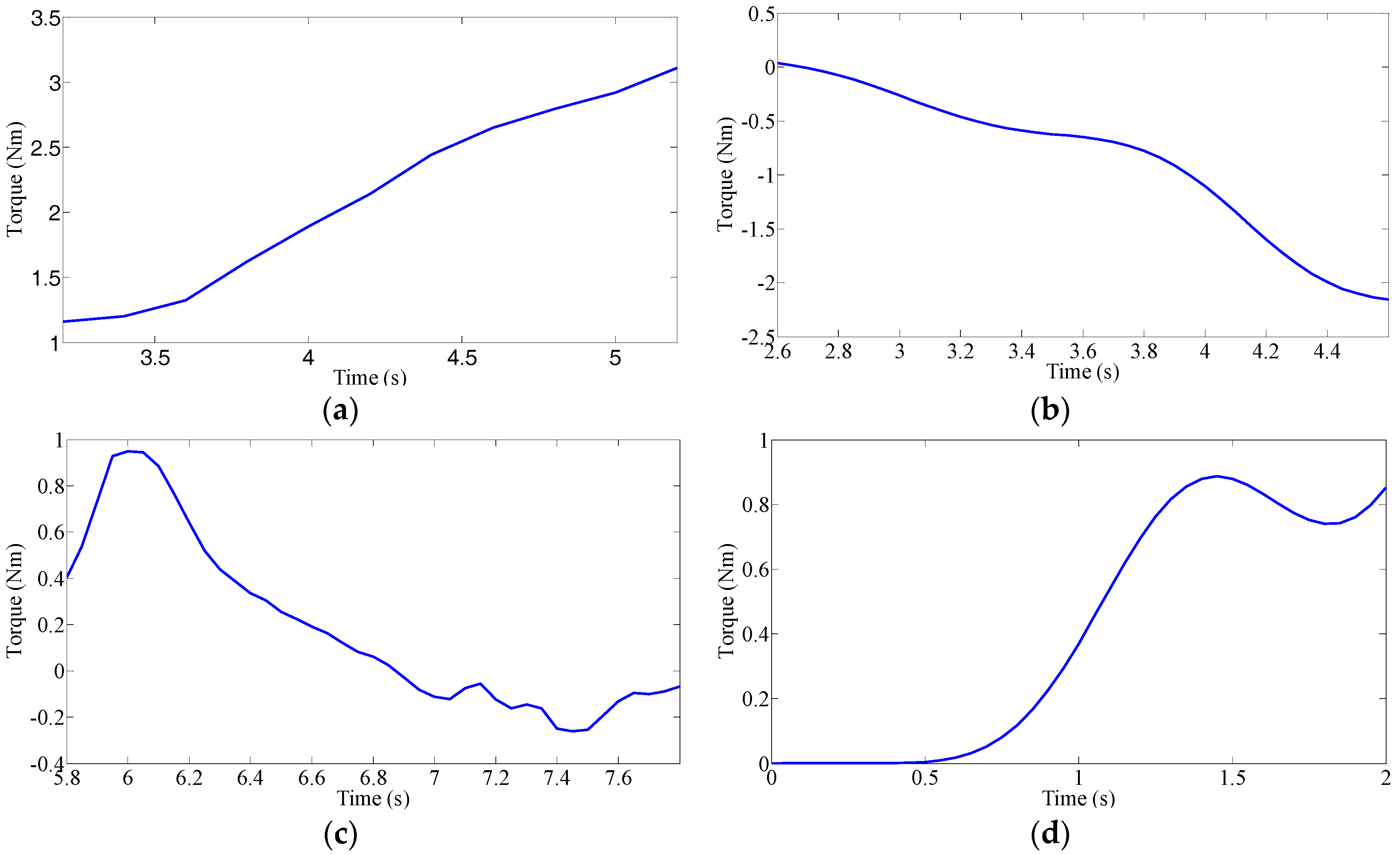
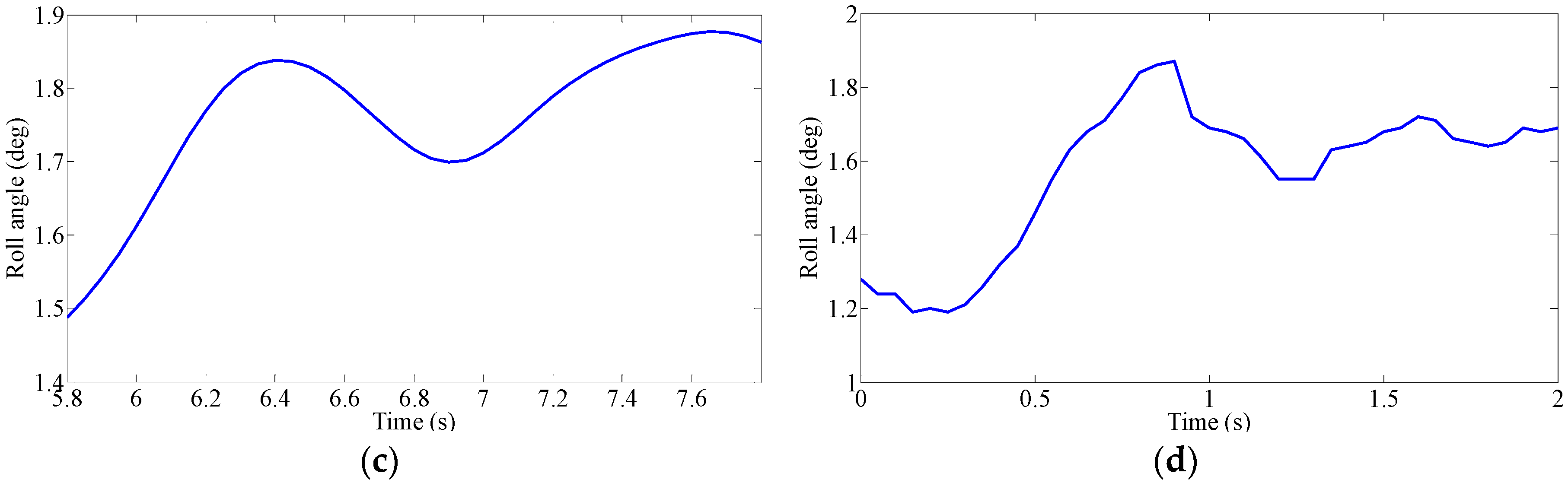
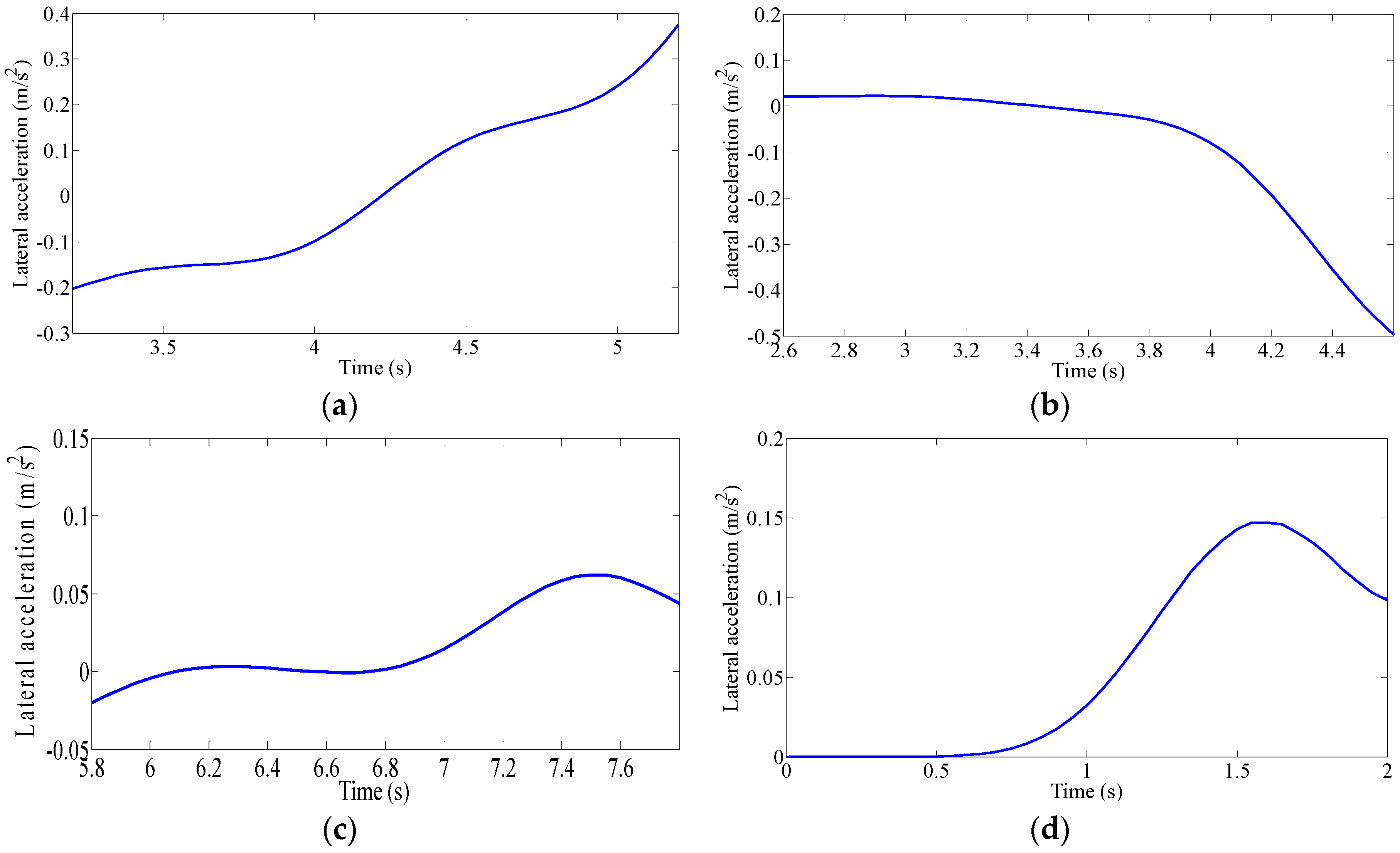
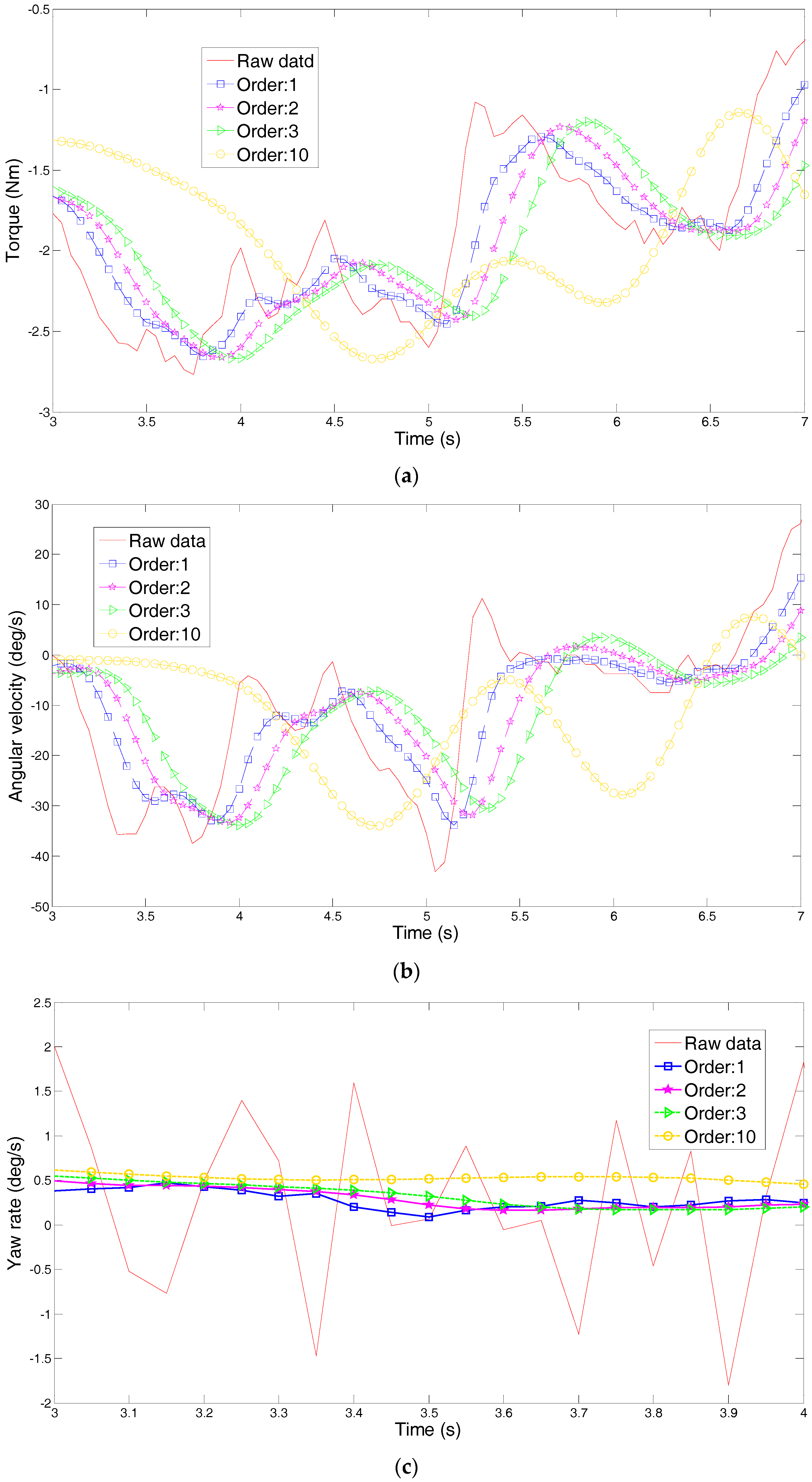
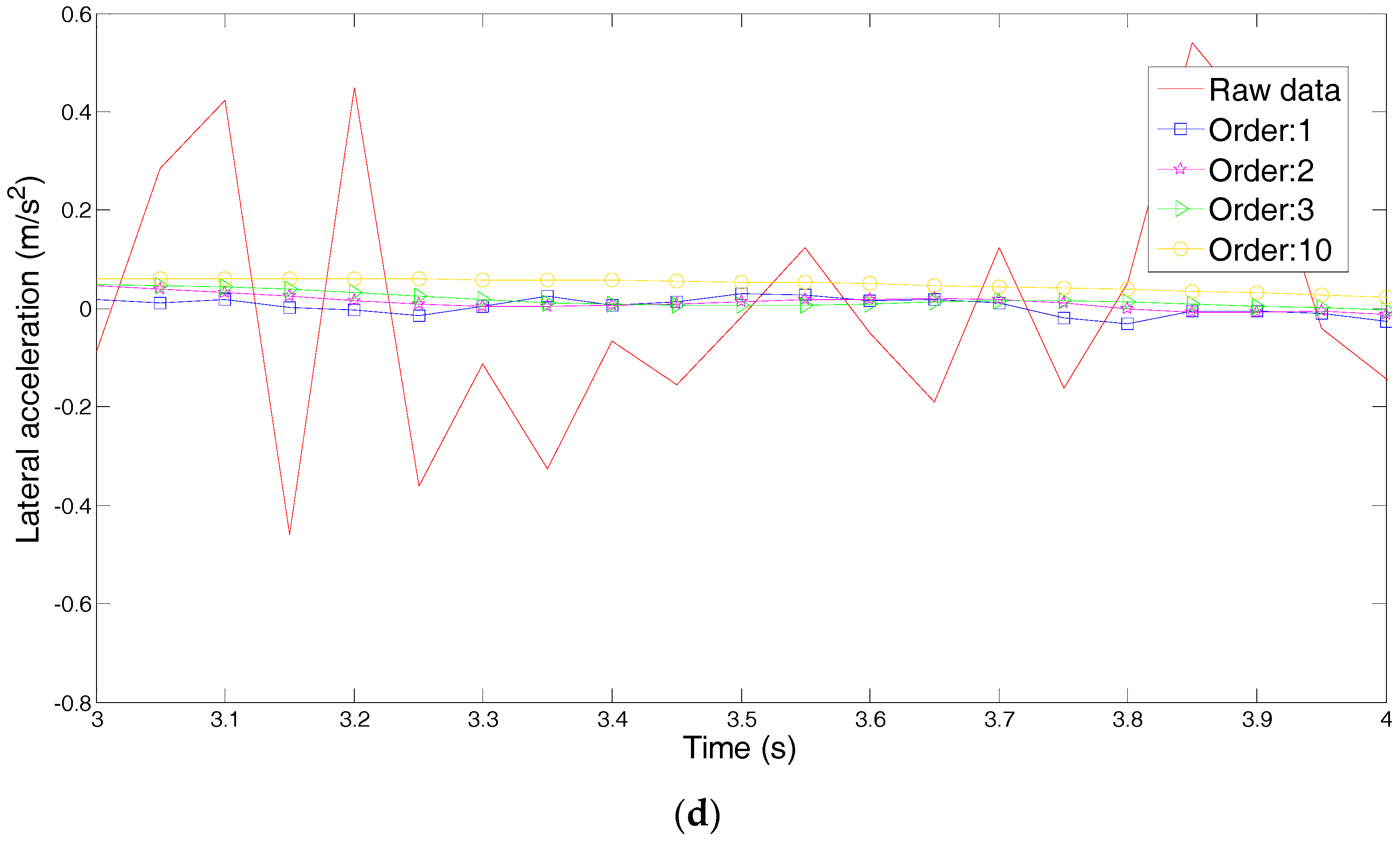
The driving intention under each condition requires multiple drivers’ characteristic steering parameters, such as driving parameters (steering angle, angular velocity and torque) and vehicle status parameters (roll angle, lateral acceleration and yaw rate). However, if all the characteristic parameters are used for classification and identification, the computational complexity is increased due to the large number of characteristic parameters. Additionally, analysis of the situation becomes much more difficult. Although each feature parameter provides some information, some of the characteristic parameters are correlated, and the characteristic parameters are not independent of each other. Therefore, the information provided by these characteristic parameters overlaps to some extent. Therefore, we need to use a kind of theoretical algorithm to reduce the dimension of the data and to decorrelate the input variables. Principal Component Analysis (PCA) is used to reduce the data dimension, which is used in various applications such as error recognition [
21], pedestrian identification [
22] and image tracking [
23]. However, PCA is not used in the driving intention identification study under typical steering conditions.
In essence, the driver’s intention is a pattern recognition process. The cluster analysis is a typical method of pattern recognition. Compared with the traditional classification and identification of driver’s intention using the neural network and fuzzy mathematics, the clustering algorithm only needs a small amount of data, which eliminates the need to construct the nonlinear recognizer and ensures that the accuracy is stable. In order to classify and identify driver’s intention, three clustering analysis methods are studied: the Fuzzy C-Means algorithm (FCM), the Gustafson–Kessel algorithm (GK) and the Gath–Geva algorithm (GG). Due to its flexibility and robustness for ambiguity, the FCM algorithm is currently an active topic [
24] and has been widely applied in the areas of pattern recognition [
25], function approximation [
26], image processing [
27], machine learning [
28], and so on. The GK algorithm can generate a fuzzy partition that provides the degree of membership of each data point to a given cluster [
29]. The GG algorithm can make the parameters of the univariate membership functions be directly derived from the parameters of the clusters [
30].
Therefore, this paper selected five driving school coaches of different driving experiences and genders as real vehicle test driver, and four typical car steering conditions’ test data with four different vehicles were collected. Additionally, this paper used principal component analysis and clustering analysis to classify and identify the driver’s intention. The paper analyzed the advantages and disadvantages of the three different clustering methods (FCM, GK and GG) in the direction of driver’s steering intention.
The paper is organized as follows. In the second section, five driving school coaches of different ages and genders are selected as the test drivers for the real vehicle test. In the third section, driver’s characteristic steering parameters under different conditions are proposed. The fourth section uses principal component analysis and clustering analysis to classify and identify the driver’s intention. In the fifth section, the clustering results and analysis are presented. Finally, the conclusions are drawn in the last section.
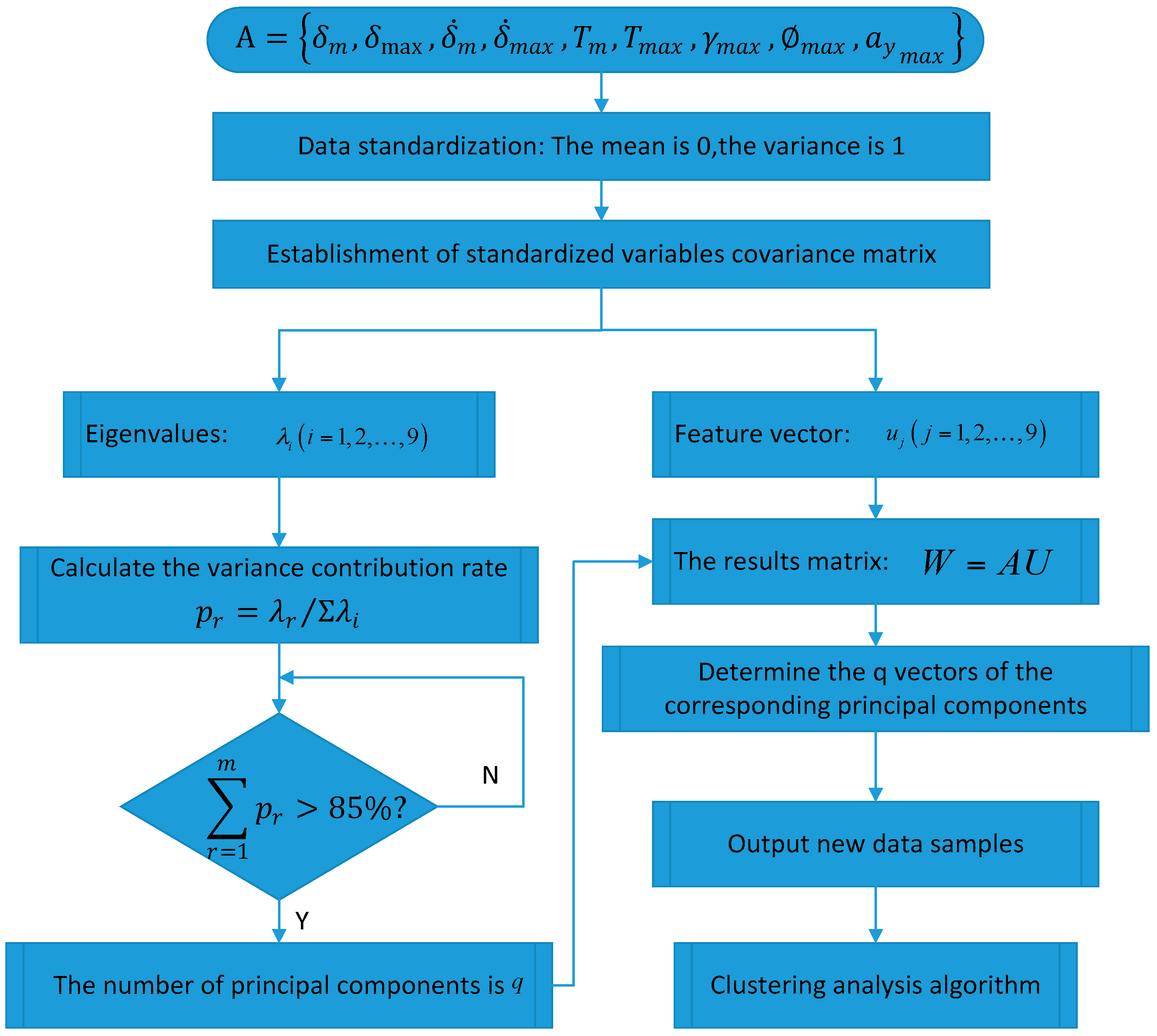
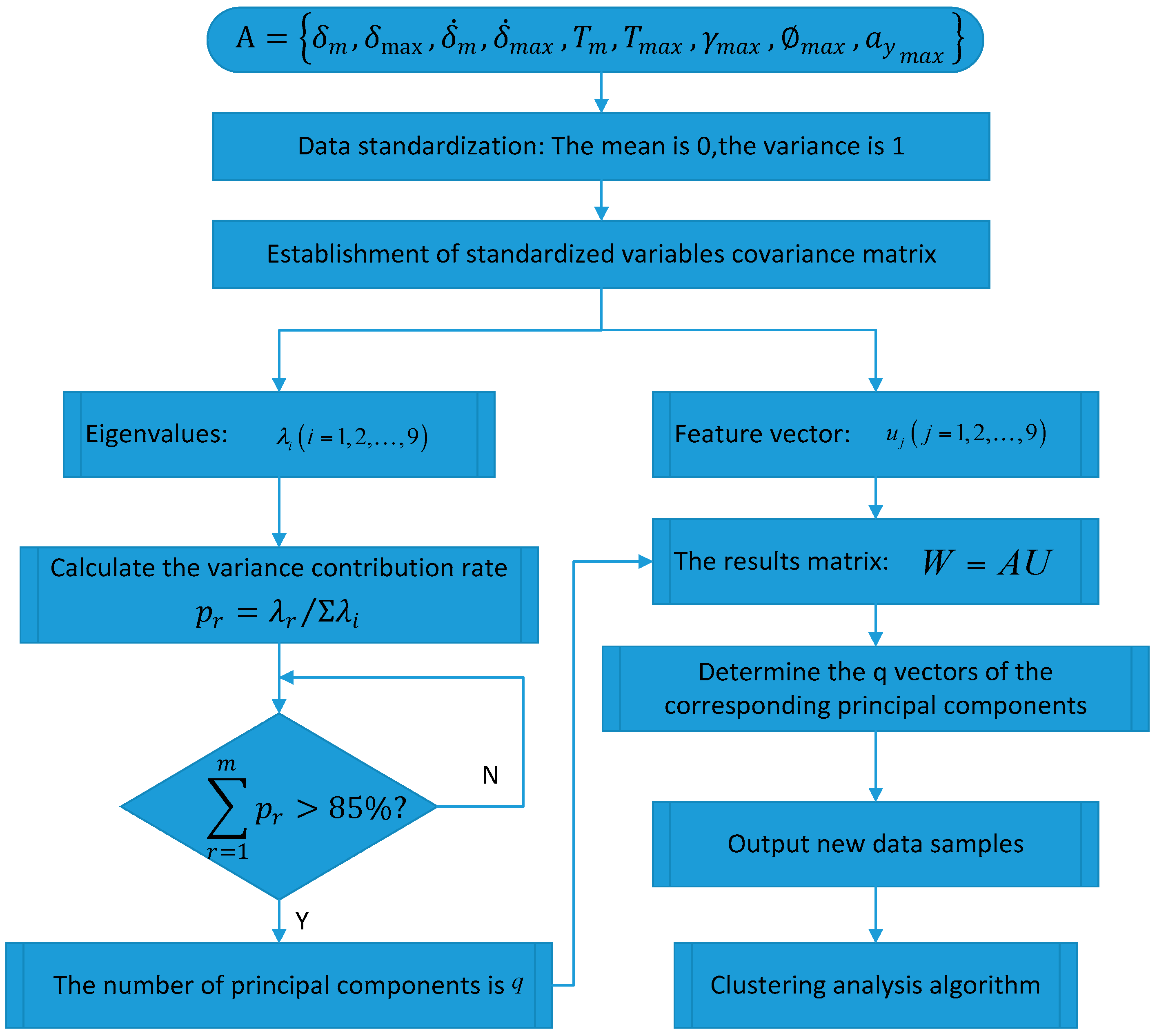
4. Principal Component Analysis of Steering Parameters
In solving practical problems and research, it is often possible to collect more information about the research object in order to have a comprehensive understanding of the problem. However, due to the theoretical development and application of technical constraints, having too many variables to be processed and too much information have become analysis obstacles. To solve this problem, Principal Component Analysis (PCA) should be used to analyze data. PCA is a statistical analysis method that simplifies multiple indicators into a small number of comprehensive indicators, with as few as possible to reflect the original variable information [
31], to ensure that the original loss of information and the number of variables is as small as possible. Let
be a
p-dimensional random vector, and its linear variation is as follows:
Using the new variable
PC1 to replace the original
p variables
X1,
X2, ...,
Xp,
PC1 should reflect as much as possible the original variable information. If the first principal component is not enough to represent the vast majority of the original variables’ information, two main components
PC2, and so on, will be used. The main purpose of principal component analysis is to simplify the data, so in practical applications, we will not take
p principal components and usually use
m (
m <
p) principal components. The number of principal components
m should be based on the cumulative contribution of the variance of each principal component to the final decision.
where
is the eigenvalue corresponding to each principal component,
k is the number of selected main components and
I is the total number of components.
The principal component analysis of 133 sets of experimental data is carried out by MATLAB software, and nine principal components (
Y1,
Y2, ...,
Y9) were obtained. The eigenvalue, contribution rate and cumulative contribution rate of each principal component are shown in
Table 4. According to the principal component analysis principle, the first four principal components are selected, and the correlation between the characteristic parameters and the principal components is analyzed. The representative average angular velocity, average steering angle, maximum yaw rate and maximum lateral acceleration, the four parameters of acceleration, are used for cluster analysis. The method of principal component analysis is shown in
Figure 10.
6. Clustering Results and Analysis
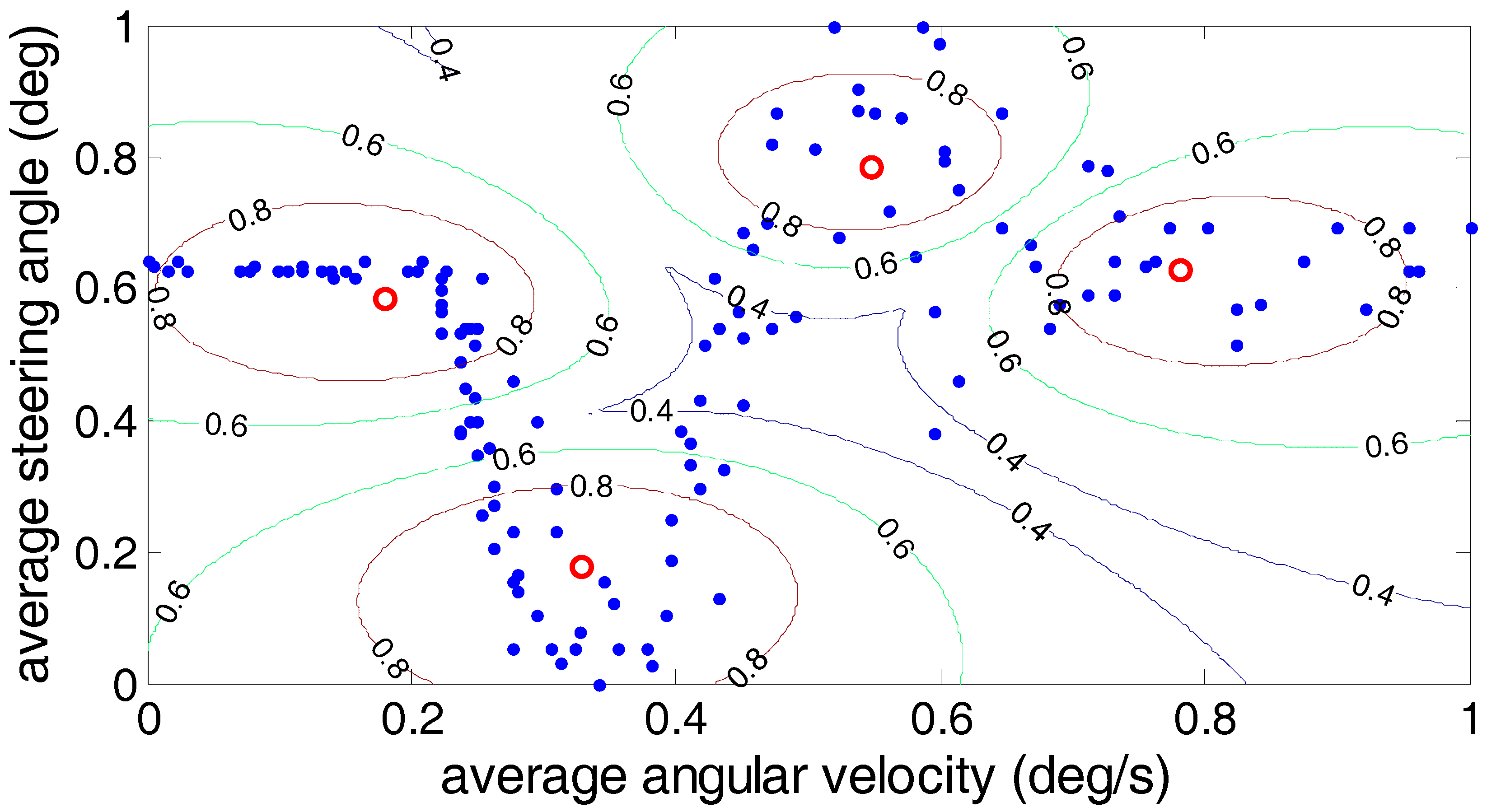
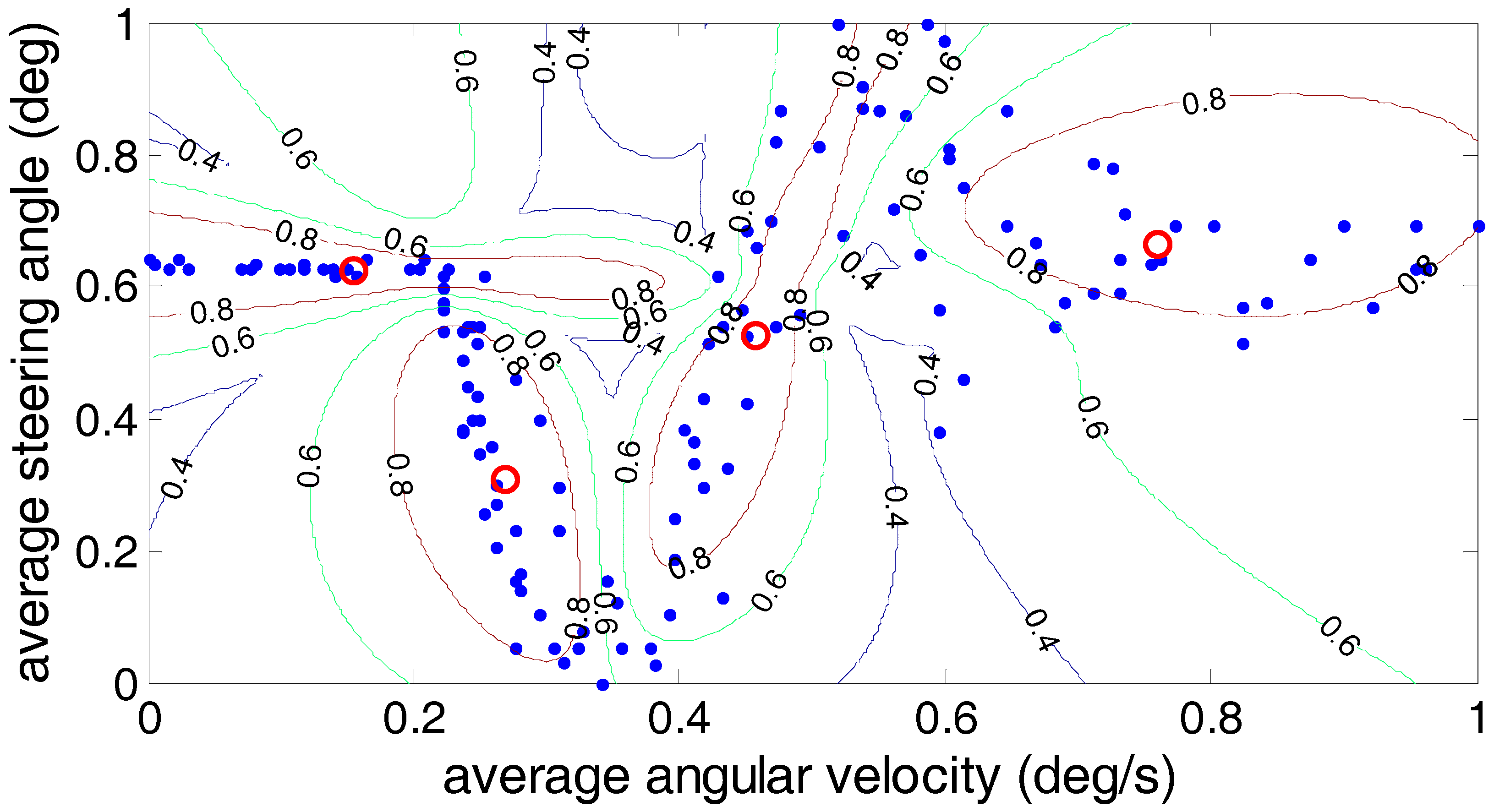
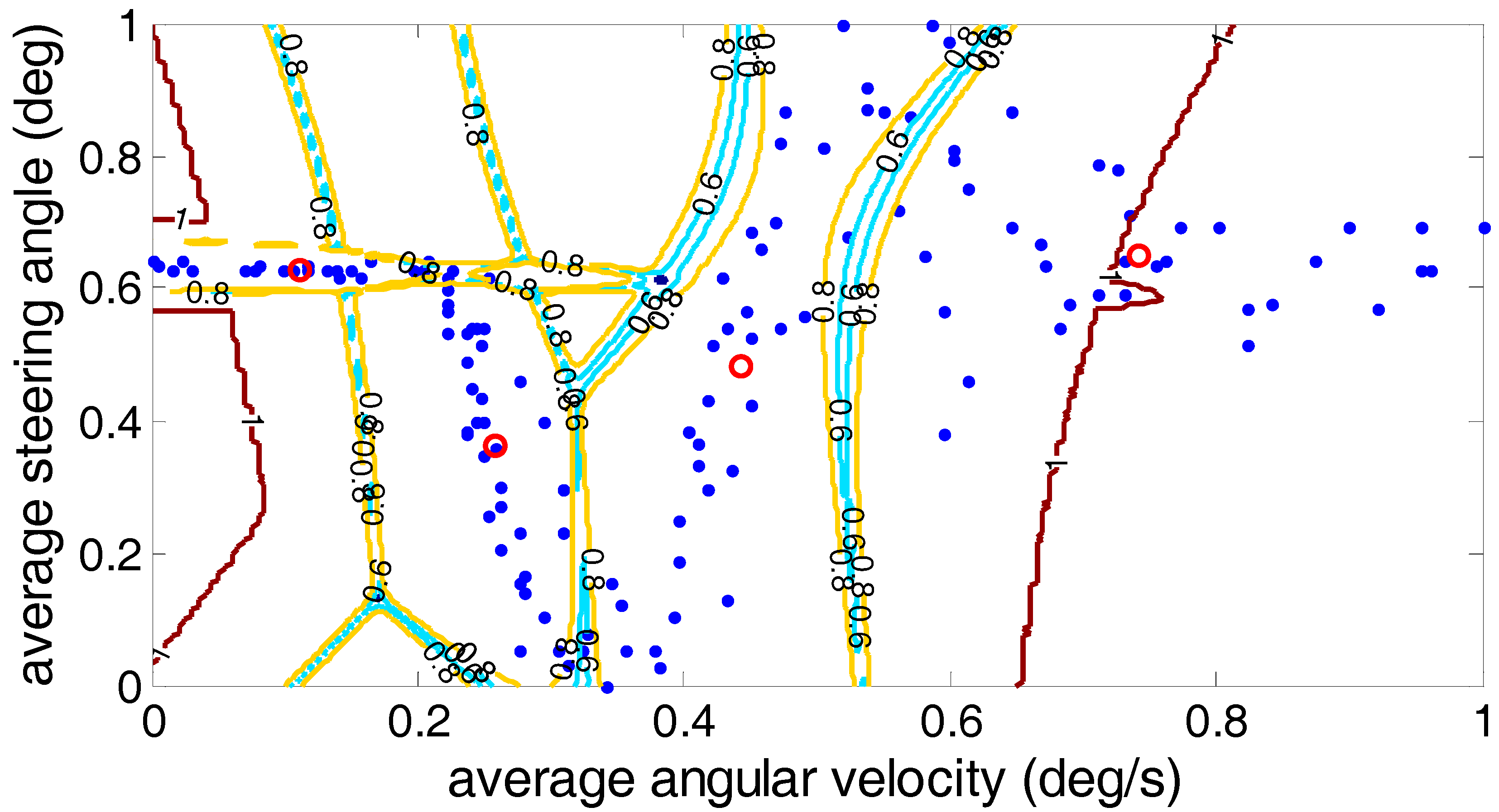
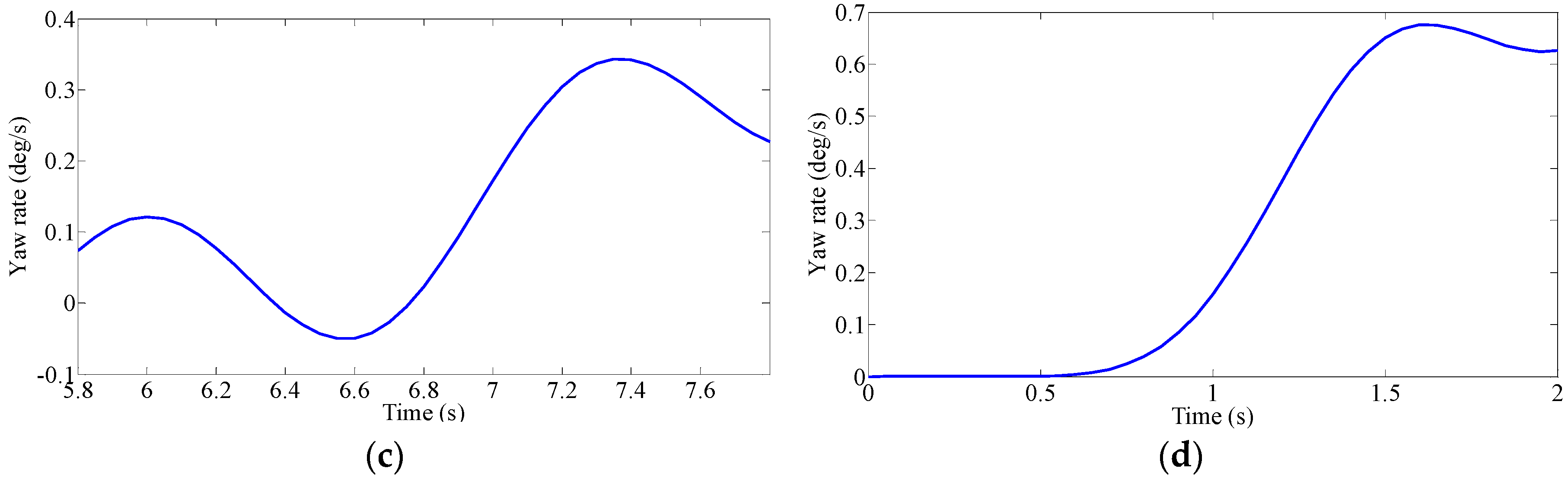
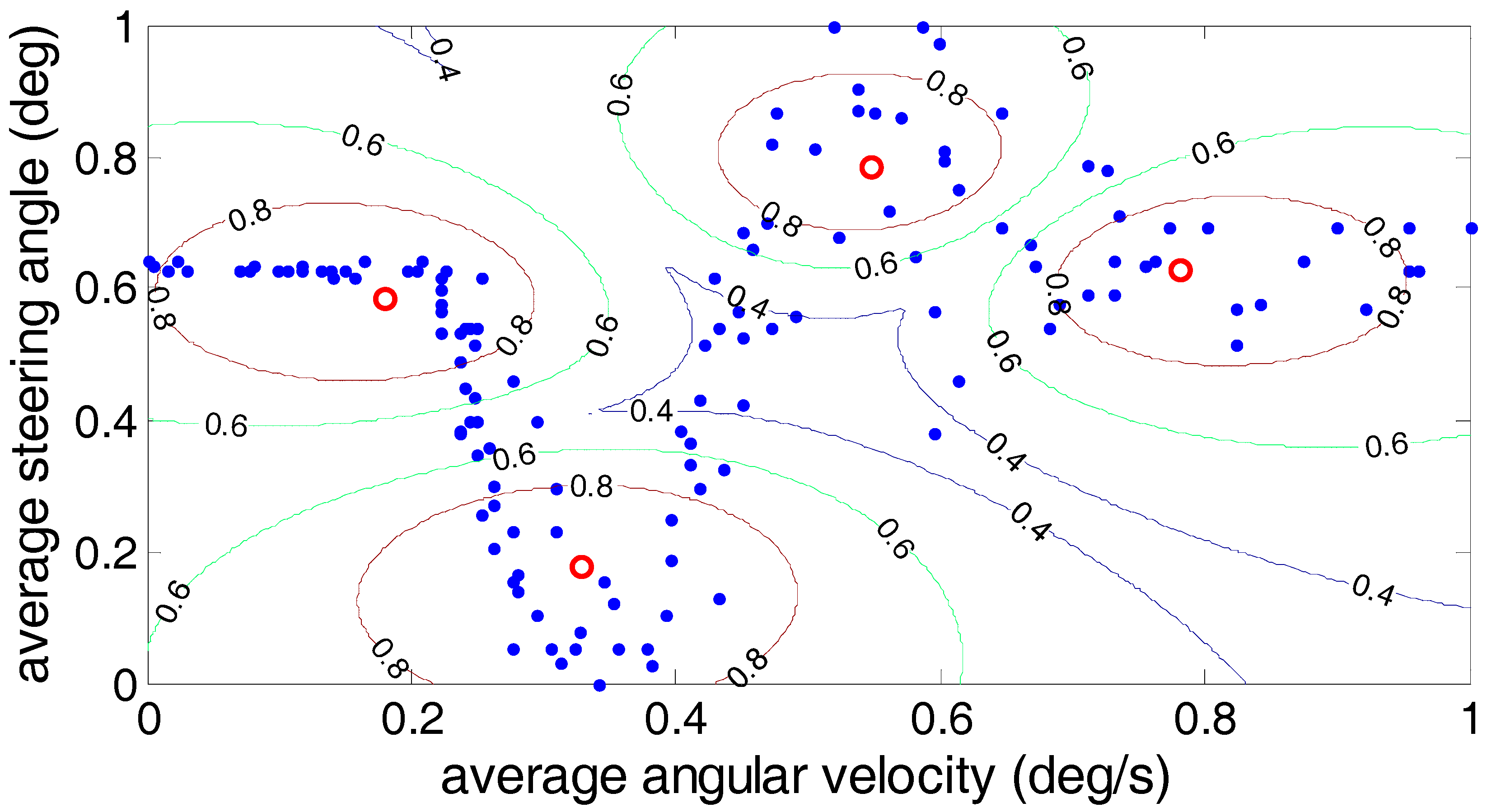
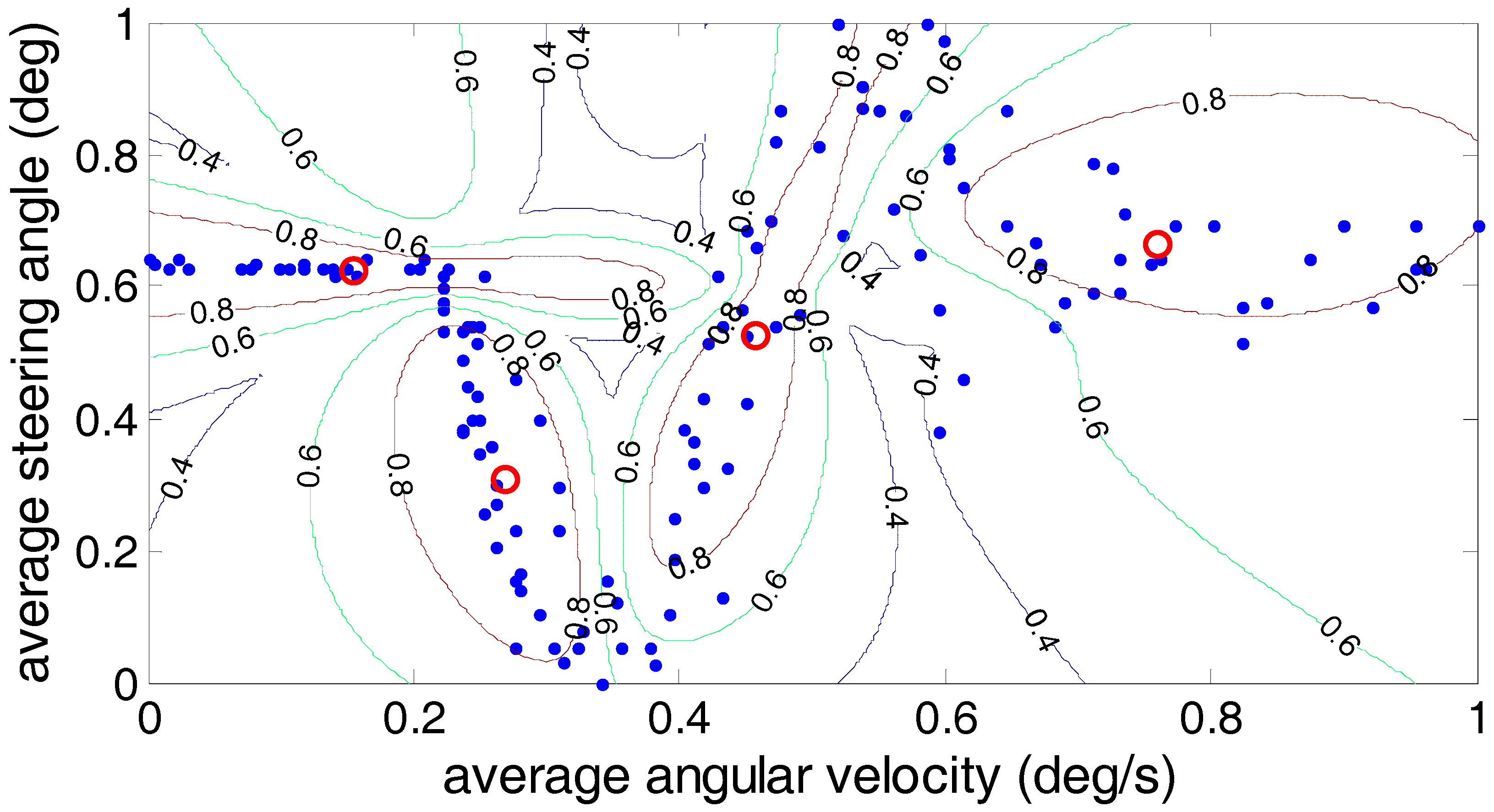
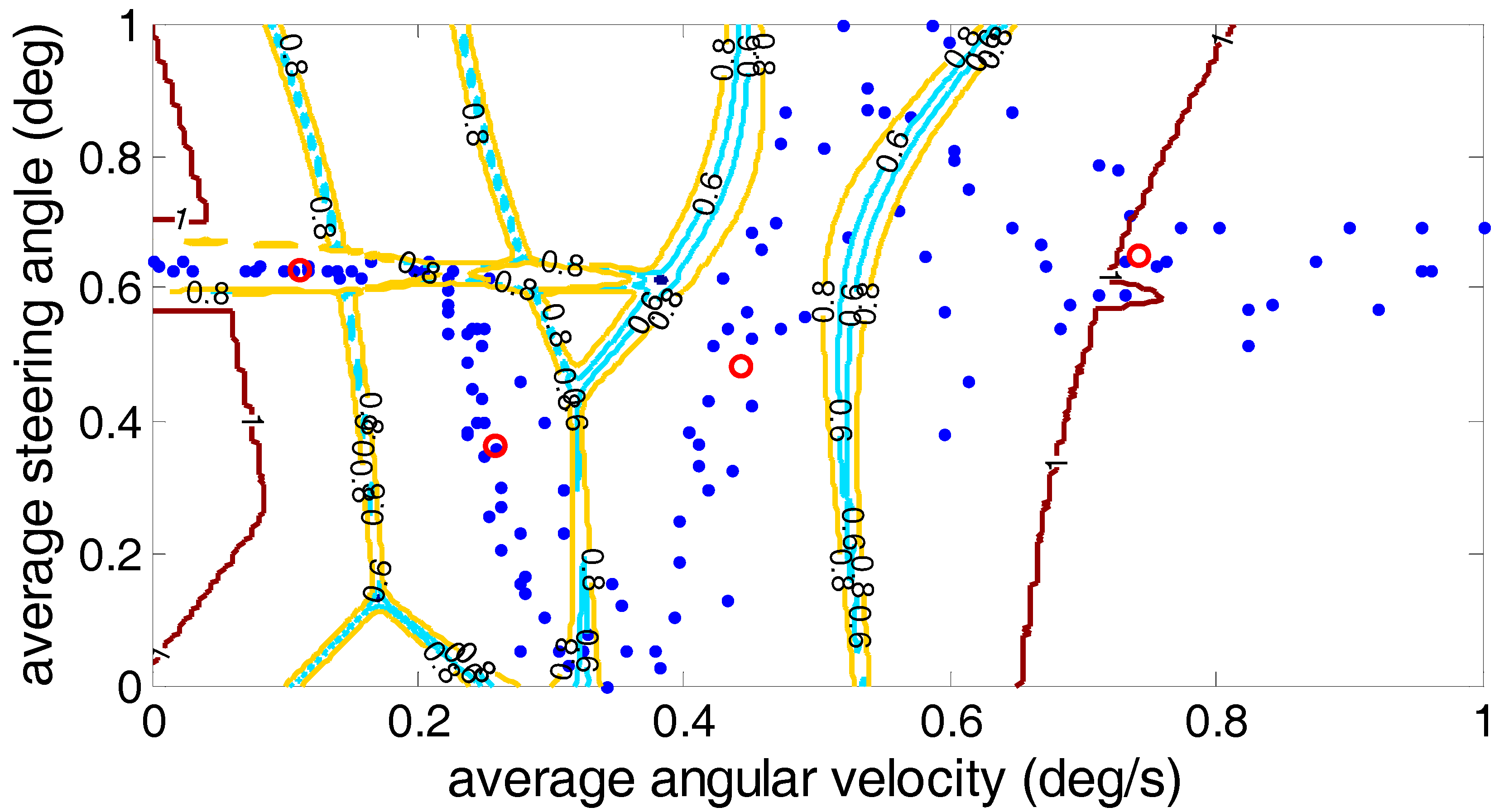
In order to further analyze the driver’s steering characteristics under the steering conditions after clustering, the results are shown by the average angular velocity and the average steering angle. As shown in
Figure 11,
Figure 12 and
Figure 13, the fuzzy C-means algorithm, the Gustafson–Kessel algorithm and the Gath–Geva algorithm were used to divide the driver’s steering test results into four classes, and in each algorithm, the cluster center for each class is marked. (0.18, 0.59), (0.33, 0.18), (0.55, 0.785) and (0.785, 0.625) are the four clustering centers given by the fuzzy C-means algorithm; the Gustafson–Kessel algorithm gives four clustering centers: (0.155, 0.62), (0.27, 0.305), (0.46, 0.53) and (0.76, 0.67). The four cluster centers (0.115, 0.63), (0.255, 0.365), (0.44, 0.48) and (0.742, 0.649) are given by the Gath–Geva algorithm. According to the fourth cluster center, we can see that the average angular velocity and the average steering angle of the drivers’ steering are larger. This reflects the driver’s steering intention under the U-turn condition. Analysis of the first and second cluster centers revealed that these two types of conditions exist; the lower average angular velocity and larger average steering angle. It can be judged at this time that the first cluster reflects the drivers’ steering intention under the lane change condition, and the second cluster centers reflects drivers’ steering intention under the lane keeping condition. The remaining third cluster center between the fourth and first two cluster centers usually belongs to the ordinary driver’s intentions for the turn right/left steering conditions.
Three kinds of clustering analysis methods can be used to separate the experimental data under different steering conditions into four different types. However, by comparing the three clustering methods, we can find that for the third cluster center, the average steering angle is greater than the average steering angle of the center of the fourth cluster using the fuzzy C-means algorithm, which is contrary to the fact that the average steering angle under the normal right/left turn is less than the average steering angle of the U-turn. Therefore, the accuracy of the Gustafson–Kessel algorithm and the Gath–Geva algorithm is superior to the fuzzy C-means algorithm.
In order to analyze the clustering effect more scientifically, in the clustering method, the most representative criteria for evaluating the clustering effect are the Partition Coefficient (PC) and the Classification Entropy (CE), which are defined as follows:
The Partition Coefficient (
PC) measures the amount of “overlapping” between clusters. It is defined by Bezdek as follows:
The Classification Entropy (
CE) measures the fuzziness of the cluster partition only, which is similar to the partition coefficient.
In this paper,
C is the number of clusters and
N is the total number of experiments. When the two validity evaluation functions reach the optimal value, that is
PC (
c) reaches the maximum value and
CE (
c) reaches the minimum value, the clustering analysis effect is better. The comparisons of
PC (
c) and
CE (
c) and the required time among different clustering algorithms under different working conditions are shown in
Table 5.
By analyzing
Table 6, we can see that the Gath–Geva algorithm achieves the maximum value for the Partition Coefficient (
PC). At the same time, the Gath–Geva algorithm achieves the minimum value for the Classification Entropy (
CE). Due to the complexity of the Gath–Geva algorithm, the time consumed area is somewhat more than the fuzzy C-means, but it is also within acceptable limits. To sum up, the Gath–Geva algorithm is better than the other two methods for the classification and identification of driver’s intention.
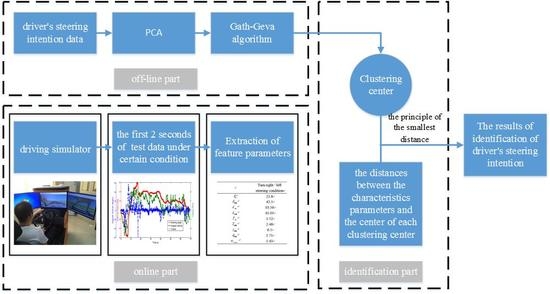
7. The Results of the Identification of Driver’s Steering Intention
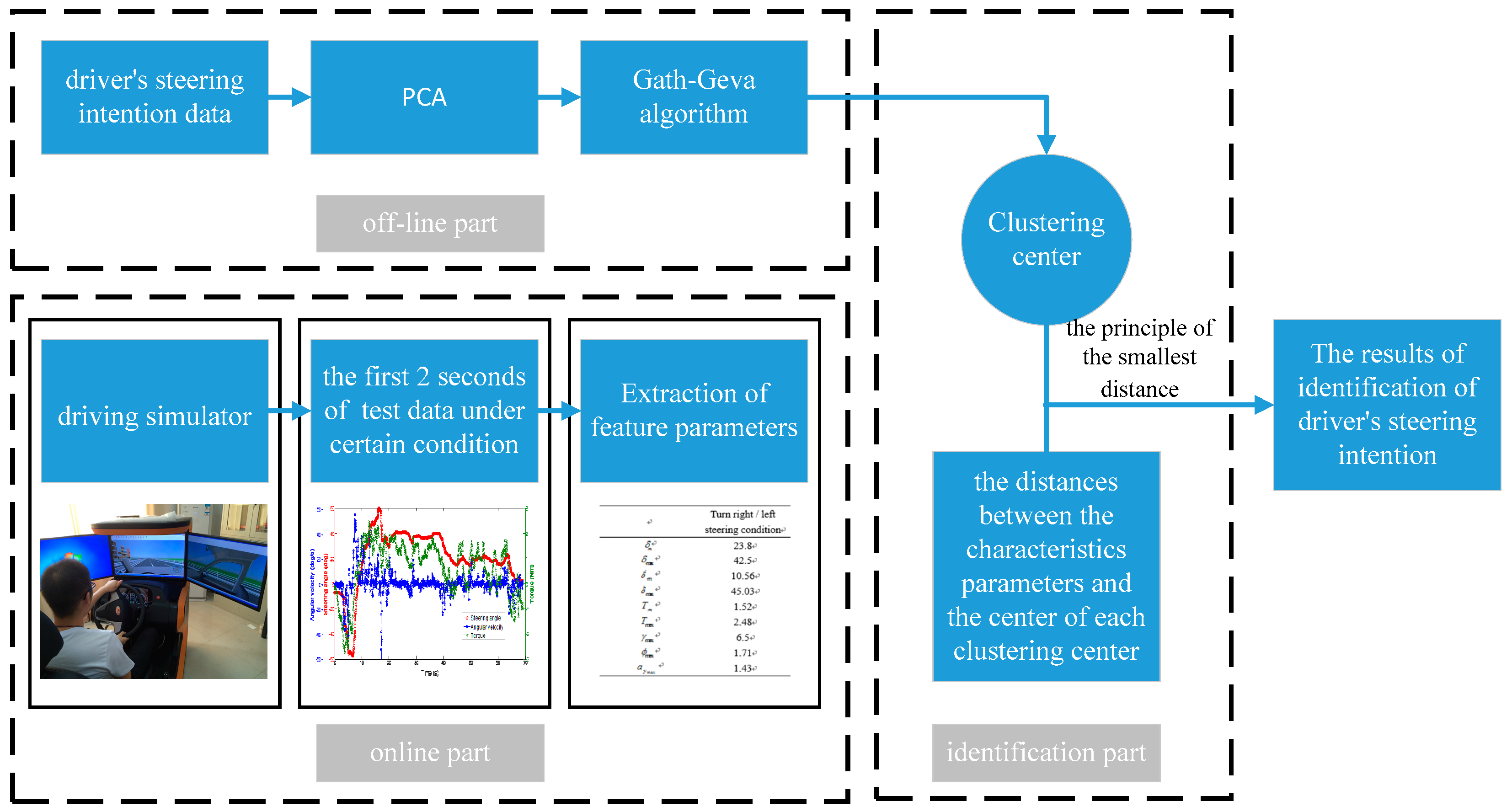
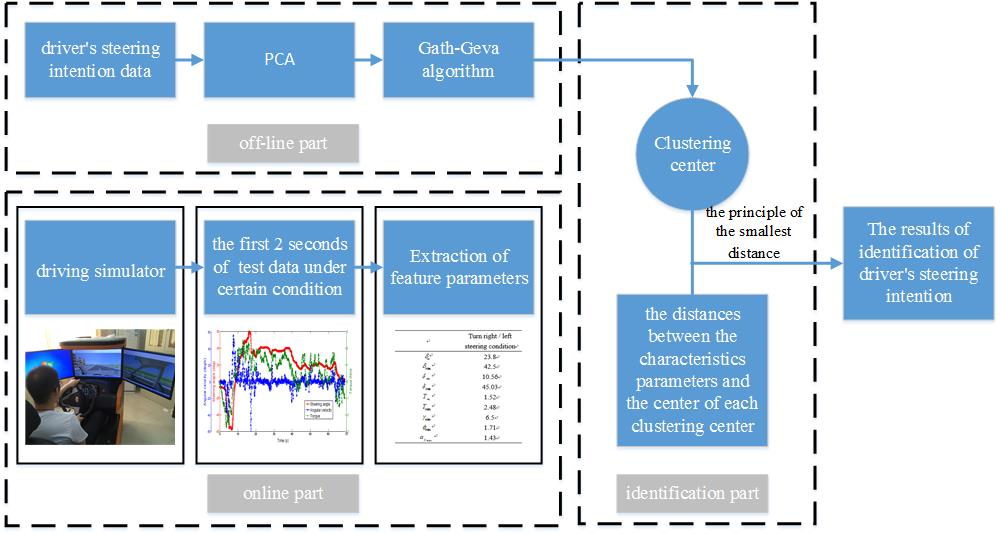
The identification process of the driver’s steering intention is shown in
Figure 14 by the method of principal component analysis and the Gath–Geva algorithm, including the offline part, online part and identification. The offline part is to analyze the driver’s steering intention data under different steering conditions through the principal component analysis and Gath–Geva algorithm analysis and get the clustering center. The online and identification parts are the processes of the real-time identification of the driver’s steering intention. Firstly, the first 2 s of the test data are obtained under a certain condition in the driving simulator. Secondly, the characteristics of the data parameters are extracted, and then, the distances between the characteristic parameters and the center of each clustering center are calculated. Finally, according to the principle of the smallest distance, the driver’s steering intention is determined. The distance calculation formula is:
where
x represents the characteristic parameters of one condition,
;
represents the clustering center parameters for clustering,
.
In order to verify the validity of the identification method designed by this article, five different drivers were selected. Five tests were carried out on the driving simulator, namely turning right, turning left, lane changing, lane keeping and U-turn condition. (0.45, 0.65), (0.44, 0.48) and (0.742, 0.649) are given by the Gath–Geva algorithm according to the above, respectively representing lane changing, lane keeping, turning right and U-turn condition. As shown in
Table 6, in Conditions 1–5, the distances between the characteristic parameters and the center of each clustering center were calculated. It is shown that the results of each identification are exactly the same as the actual driver’s intention. Therefore, the effectiveness of the identification method designed by this article is verified.






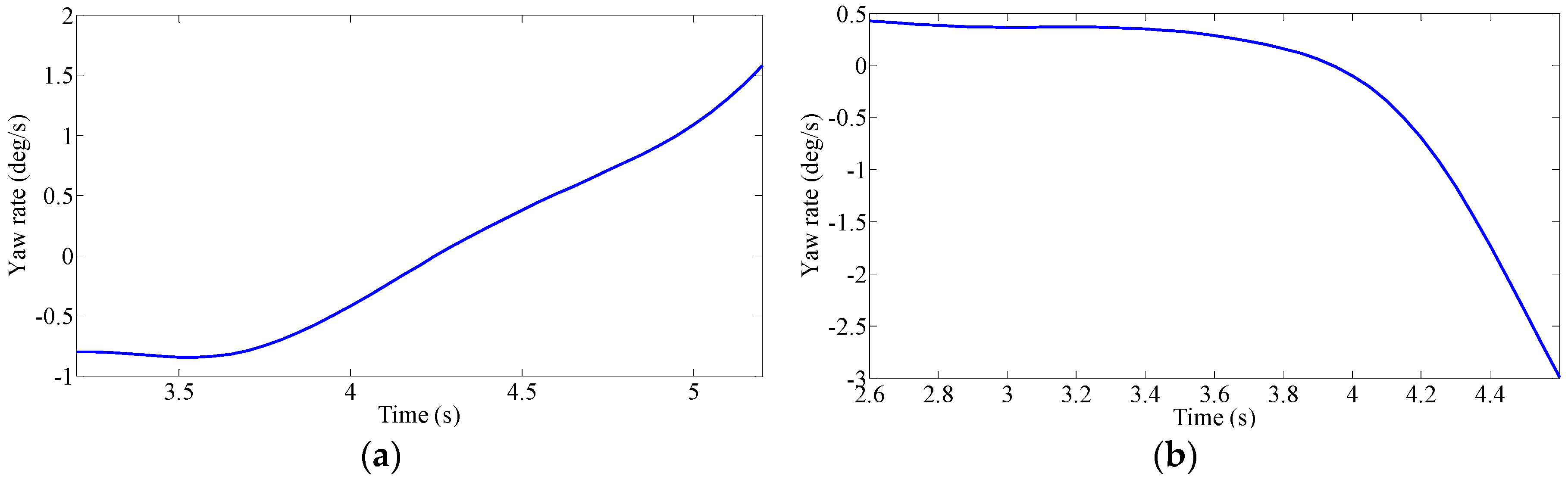

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}