Modeling Properties with Artificial Neural Networks and Multilinear Least-Squares Regression: Advantages and Drawbacks of the Two Methods †


Abstract
:1. Introduction
2. Materials and Methods
2.1. The Properties
2.2. Descriptors
2.3. Multilinear Least-Squares Regression
2.4. Multi-Layer Perceptron—Artificial Neural Networks
3. Results
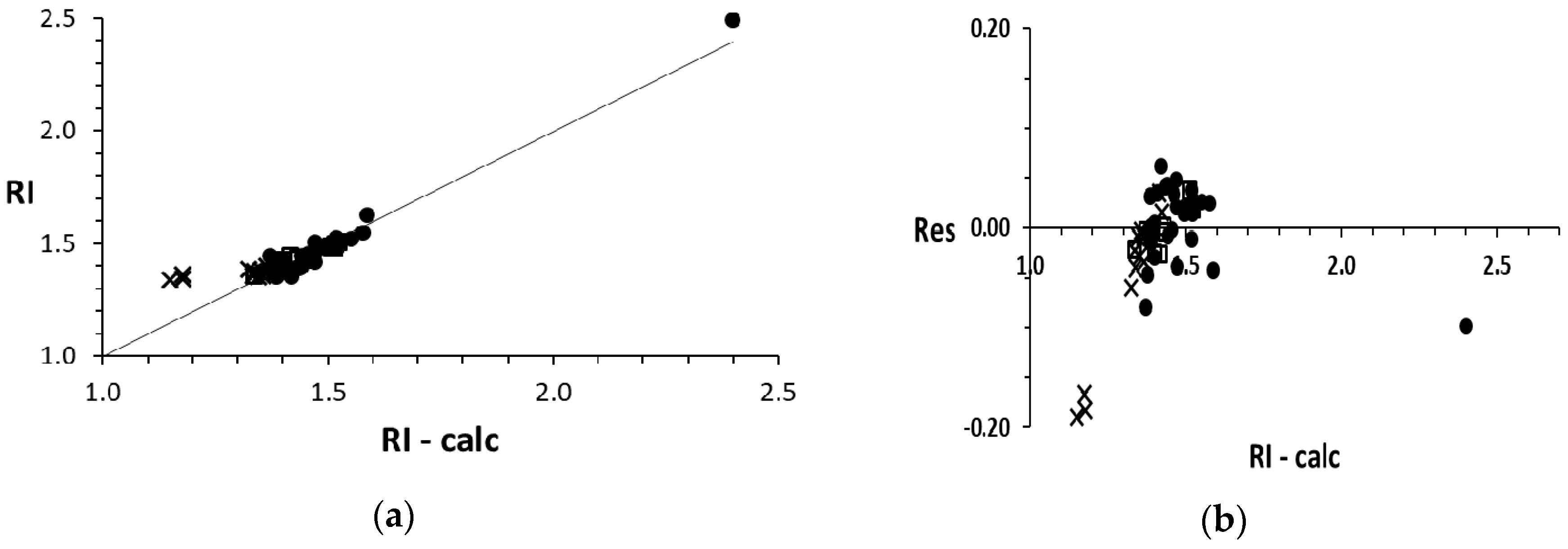
4. Plots
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. The Valence Delta
Appendix B. The Intrinsic-I-State and the Electrotopological S-State Indices
References
- Pogliani, L.; de Julián-Ortiz, J.V. Artificial neural networks and multilinear least squares to model physicochemical properties of organic solvents. Int. J. Chem. Mod. 2014, 6, 241–254. [Google Scholar]
- Randić, M. On characterization of molecular branching. J. Am. Chem. Soc. 1975, 97, 6609–6615. [Google Scholar] [CrossRef]
- Kier, L.B.; Hall, L.H. Molecular Connectivity in Structure-Activity Analysis; Wiley: New York, NY, USA, 1986. [Google Scholar]
- Kier, L.B.; Hall, L.H. The Electrotopological State. In Molecular Structure Description; Academic Press: New York, NY, USA, 1999. [Google Scholar]
- Todeschini, R.; Consonni, V. Molecular Descriptors for Chemoinformatics, 2nd ed.; Wiley-VCH: Weinheim, German, 2000. [Google Scholar]
- Pogliani, L. From molecular connectivity indices to semiempirical connectivity terms: Recent trends in graph theoretical descriptors. Chem. Rev. 2000, 100, 3827–3858. [Google Scholar] [CrossRef] [PubMed]
- García-Domenech, R.; Gálvez, J.; de Julián-Ortiz, J.V.; Pogliani, L. Some new trends in chemical graph theory. Chem. Rev. 2008, 108, 1127–1169. [Google Scholar] [CrossRef] [PubMed]
- Pogliani, L.; de Julián-Ortiz, J.V. Testing selected optimal descriptors with artificial neural networks. RSC Adv. 2013, 3, 14710–14721. [Google Scholar] [CrossRef]
- Pogliani, L.; de Julián-Ortiz, J.V. QSPR with descriptors based on averages of vertex invariants. An artificial neural network study. RSC Adv. 2014, 4, 44733–44740. [Google Scholar] [CrossRef]
- Topliss, J.G.; Costello, R.J. Chance correlations in structure-activity studies using multiple regression analysis. J. Med. Chem. 1972, 15, 1066–1069. [Google Scholar] [CrossRef] [PubMed]
- Zupan, J.; Gasteiger, J. Neural Networks in Chemistry and Drug Design: An Introduction, 2nd ed.; Wiley-VCH: Weinheim, German, 1999. [Google Scholar]
- Livingstone, D.J.; Manallack, D.T.; Tetko, I.V. Data modelling with neural networks: Advantages and limitations. J. Comput.-Aided Mol. Des. 1997, 11, 135–142. [Google Scholar] [CrossRef]
- Castillo, E.; Guijarro-Berdiñas, B.; Fontenla-Romero, O.; Alonso-Betanzos, A. A very fast learning method for neural networks based on sensitivity analysis. J. Mach. Learn. Res. 2006, 7, 1159–1182. [Google Scholar]
- Broyden–Fletcher–Goldfarb–Shanno Algorithm. Available online: http://en.wikipedia.org/wiki/Broyden%E2%80%93Fletcher%E2%80%93Goldfarb%E2%80%93Shanno_algorithm (accessed on 4 July 2018).
- Mihalic, Z.; Nikolic, S.; Trinajstic, N.J. Comparative study of molecular descriptors derived from the distance matrix. Chem. Inf. Comput. Sci. 1992, 32, 28–37. [Google Scholar] [CrossRef]
- Besalu, E.; de Julián-Ortiz, J.V.; Pogliani, L. Trends and plot methods in MLR studies. J. Chem. Inf. Model. 2007, 47, 751–760. [Google Scholar] [CrossRef] [PubMed]
- Besalú, E.; de Julián-Ortiz, J.V.; Pogliani, L. An overlooked property of plot methods. J. Math. Chem. 2006, 39, 475–484. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Solvents | M | Tb | ε | d | RI | FP | η | γ | UV | μ | MS | El |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (°) Acetone | 58.1 | 329 | 20.7 | 0.791 | 1.359 | 256 | 0.32 | 23.46 | 330 | 2.88 | 0.46 | 0.43 |
| (°) Acetonitrile | 41.05 | 355 | 37.5 | 0.786 | 1.344 | 278 | 0.37 | 28.66 | 190 | 3.92 | 0.534 | 0.50 |
| Benzene | 78.1 | 353 | 2.3 | 0.84 | 1.501 | 262 | 0.65 | 28.22 | 280 | 0 | 0.699 | 0.27 |
| Benzonitrile | 103.1 | 461 | 25.2 | 1.010 | 1.528 | 344 | 1.24 1 | 38.79 | ||||
| 1-Butanol | 74.1 | 391 | 17.1 | 0.810 | 1.399 | 308 | 2.95 | 24.93 | 215 | |||
| (°) 2-Butanone | 72.1 | 353 | 18.5 | 0.805 | 1.379 | 270 | 0.40 | 23.97 | 330 | 0.39 | ||
| Butyl Acetate | 116.2 | 398 | 5.0 | 0.882 | 1.394 | 295 | 0.73 | 24.88 | 254 | |||
| CS2 | 76.1 | 319 | 2.6 | 1.266 | 1.627 | 240 | 0.37 | 31.58 | 380 | 0 | 0.532 | |
| CCl4 | 153.8 | 350 | 2.2 | 1.594 | 1.460 | 0.97 | 26.43 | 263 | 0 | 0.691 | 0.14 | |
| Cl-Benzene | 112.6 | 405 | 5.6 | 1.107 | 1.524 | 296 | 0.80 | 32.99 | 287 | |||
| 1-Cl-Butane | 92.6 | 351 | 7.4 | 0.886 | 1.4024 | 267 | 0.35 | 23.18 | 225 | |||
| CHCl3 | 119.4 | 334 | 4.8 | 1.492 | 1.446 | 0.57 | 26.67 | 245 | 1.01 | 0.740 | 0.31 | |
| Cyclohexane | 84.2 | 354 | 2.0 | 0.779 | 1.426 | 255 | 1.00 | 24.65 | 200 | 0 | 0.627 | 0.03 |
| (°) Cyclopentane | 70.1 | 323 | 2.0 | 0.751 | 1.400 | 236 | 0.47 | 21.88 | 200 | 0.629 | ||
| 1,2-diCl-Benzene | 147.0 | 453 | 9.9 | 1.306 | 1.551 | 338 | 1.32 | 295 | 2.50 | 0.748 | ||
| 1,2-diCl-Ethane | 98.95 | 356 | 10.4 | 1.256 | 1.444 | 288 | 0.79 | 31.86 | 225 | 1.75 | ||
| diCl-Methane | 84.9 | 313 | 9.1 | 1.325 | 1.424 | 0.44 | 27.20 | 235 | 1.60 | 0.733 | 0.32 | |
| N,N-diMe-Acetamide | 87.1 | 438 | 37.8 | 0.937 | 1.438 | 343 | 268 | 3.8 | ||||
| N,N-diMeFormamide | 73.1 | 426 | 36.7 | 0.944 | 1.431 | 330 | 0.92 | 268 | 3.86 | |||
| 1,4-Dioxane | 88.1 | 374 | 2.2 | 1.034 | 1.422 | 285 | 1.54 | 32.75 | 215 | 0.45 | 0.606 | |
| Ether | 74.1 | 308 | 4.3 | 0.708 | 1.353 | 233 | 0.24 | 16.95 | 215 | 1.15 | 0.29 | |
| Ethyl acetate | 88.1 | 350 | 6.0 | 0.902 | 1.372 | 270 | 0.45 | 23.39 | 260 | 1.8 | 0.554 | 0.45 |
| (°) Ethyl alcohol | 46.1 | 351 | 24.3 | 0.785 | 1.360 | 281 | 1.20 | 21.97 | 210 | 1.69 | 0.575 | |
| Heptane | 100.2 | 371 | 1.9 | 0.684 | 1.387 | 272 | 19.65 | 200 | 0.00 | |||
| Hexane | 86.2 | 342 | 1.9 | 0.659 | 1.375 | 250 | 0.33 | 17.89 | 200 | 0.00 | ||
| 2-Methoxyethanol | 76.1 | 398 | 16.0 | 0.965 | 1.402 | 319 | 1.72 | 30.84 | 220 | |||
| (°) Methyl alcohol | 32.0 | 338 | 32.7 | 0.791 | 1.329 | 284 | 0.60 | 22.07 | 205 | 1.70 | 0.530 | 0.73 |
| 4-Me-2-Pentanone | 100.2 | 391 | 13.1 | 0.800 | 1.396 | 286 | 334 | |||||
| 2-Me-1-Propanol | 74.1 | 381 | 17.7 | 0.803 | 1.396 | 310 | ||||||
| 2-Me-2-Propanol | 74.1 | 356 | 10.9 | 0.786 | 1.387 | 277 | 19.96 | 1.66 | 0.534 | |||
| DMSO | 78.1 | 462 | 46.7 | 1.101 | 1.479 | 368 | 2.24 | 42.92 | 268 | 3.96 | ||
| (°) Nitromethane | 61.0 | 374 | 35.9 | 1.127 | 1.382 | 308 | 0.67 | 36.53 | 380 | 3.46 | 0.391 | |
| 1-Octanol | 130.2 | 469 | 10.3 | 0.827 | 1.429 | 354 | 10.6 2 | 27.10 | ||||
| (°) Pentane | 72.15 | 309 | 1.8 | 0.626 | 1.358 | 224 | 0.23 | 15.49 | 200 | 0.00 * | ||
| 3-Pentanone | 86.1 | 375 | 17.0 | 0.853 | 1.392 | 279 | 24.74 | |||||
| (°) 1-Propanol | 60.1 | 370 | 20.1 | 0.804 | 1.384 | 288 | 2.26 | 23.32 | 210 | |||
| (°) 2-Propanol | 60.1 | 356 | 18.3 | 0.785 | 1.377 | 295 | 2.30 | 20.93 | 210 | 0.63 | ||
| Pyridine | 79.1 | 388 | 12.3 | 0.978 | 1.510 | 293 | 0.94 | 36.56 | 305 | 2.2 | 0.611 | 0.55 |
| Tetra Cl-Ethylene | 165.8 | 394 | 2.3 | 1.623 | 1.506 | 0.90 | 0.802 | |||||
| (°) Tetra-Hydrofuran | 72.1 | 340 | 7.6 | 0.886 | 1.407 | 256 | 0.55 | 215 | 1.75 | 0.35 * | ||
| Toluene | 92.1 | 384 | 2.4 | 0.867 | 1.496 | 277 | 0.59 | 27.93 | 285 | 0.36 | 0.618 | 0.22 |
| 1,1,2-triCl,triF-Ethane | 187.4 | 321 | 2.4 | 1.575 | 1.358 | 0.69 | 230 | 0.02 | ||||
| 2,2,4-triMe-Pentane | 114.2 | 372 | 1.9 | 0.692 | 1.391 | 266 | 0.50 | 215 | 0.01 | |||
| o-Xylene | 106.2 | 417 | 2.6 | 0.870 | 1.505 | 305 | 0.81 | 29.76 | ||||
| p-Xylene | 106.2 | 411 | 2.3 | 0.866 | 1.495 | 300 | 0.65 | 28.01 | ||||
| (°) Acetic acid | 60.05 | 391 | 6.15 | 1.049 | 1.372 | 27.10 | 1.2 | 0.551 | ||||
| Decalin | 138.2 | 465 | 2.2 | 0.879 | 1.476 | 0.681 | ||||||
| diBr-Methane | 173.8 | 370 | 7.8 | 1.542 | 2.497 | 39.05 | 1.43 | 0.935 | ||||
| 1,2-diCl-Ethylen(Z) | 96.9 | 334 | 9.2 | 1.284 | 1.449 | 1.90 | 0.679 | |||||
| (°) 1,2-diCl-Ethylen(E) | 96.9 | 321 | 2.1 | 1.255 | 1.446 | 0 | 0.638 | |||||
| 1,1-diCl-Ethylen | 96.9 | 305 | 4.7 | 1.213 | 1.425 | 1.34 | 0.635 | |||||
| Dimethoxymethane | 76.1 | 315 | 2.7 | 0.866 | 1.356 | 0.611 | ||||||
| (°) Dimethylether | 46.1 | 249 | 5.0 | |||||||||
| Ethylen Carbonate | 88.1 | 511 | 89.6 | 1.321 | 1.425 | 4.91 | ||||||
| (°) Formamide | 45.0 | 484 | 109 | 1.133 | 1.448 | 57.03 | 3.73 | 0.551 | ||||
| (°) Methylchloride | 50.5 | 249 | 12.6 | 0.916 | 1.339 | 1.87 | ||||||
| Morpholine | 87.1 | 402 | 7.3 | 1.005 | 1.457 | 0.631 | ||||||
| Quinoline | 129.2 | 510 | 9.0 | 1.098 | 1.629 | 42.59 | 2.2 | 0.729 | ||||
| (°) SO2 | 64.1 | 263 | 17.6 | 1.434 | 1.6 | |||||||
| 2,2-tetraCl-Ethane | 167.8 | 419 | 8.2 | 1.578 | 1.487 | 35.58 | 1.3 | 0.856 | ||||
| tetraMe-Urea | 116.2 | 450 | 23.1 | 0.969 | 1.449 | 3.47 | 0.634 | |||||
| triCl-Ethylen | 131.4 | 360 | 3.4 | 1.476 | 1.480 | 0.734 |
| MCI | Pseudo-MCI | Dual MCI + Δ + Σ | Dual Pseudo-MCI + TΣ/M |
|---|---|---|---|
| D = Σiδi | SψI = ΣiI | 0χd = (−0.5)nΠi(δi) | 0ψId = (−0.5)nΠi(Ii) |
| 0χ = Σ(δi)−0.5 | 0ψI = Σ(Ii)−0.5 | 1χd = (−0.5)(n+μ−1)Π(δi + δj) | 1ψId = (−0.5)(n+μ−1)Π(Ii + Ij) |
| 1χ = Σ(δiδj)−0.5 | 1ψI = Σ(IiIj)−0.5 | 1χs = Π(δi + δj)–0.5 | 1ψIs = Π(Ii + Ij)−0.5 |
| χt = (Πδi)−0.5 | TψI =(ΠIi)−0.5 | Δ = ΣEAnEA, Σ = ΣEA<SEA> | TΣ/M = Σ3/M1.7 |
| AM = Σi δi/n | GM = Σij(δiδj)1/2 | HM = 2Σij (δi−1 + δj−1)−1 |
| RM = Σij[(δi2 + δj2)/2]1/2 | SM = Σij (δi2 + δj2)/(δi + δj) | UM = Σij[δi − δj + (δi2 − 2δiδj + 5δj2)0.5]/2 |
| HoM = Σij(δip + δjp)1/p/2 | LM = Σij(δip + δjp)/(δip−1 + δjp−1) | StM = Σij[(δip − δjp)/(pδi + pδj)]1/(p−1) |
| δv-Type | Regression Equations |
|---|---|
| δvpo(1) |
Tb = 237.5 + 139.1 0χ + 24.69 Dv + 527.7 0ψI − 25.91 1ψI − 1500 0ψE + 41.53 TΣ/M
N(TR) = 45, r2 = 0.821, s = 22; N(+16EV) = 61, r2 = 0.792, s = 25 Excluded strong outliers: Formamide & SO2 ∈ {EV} |
| δvpo(50) |
ε = 2.804 − 12.05 χvt − 5.99∙10−5 1χvd + 132.7 1χvs + 0.021 1ψId − 421.2 1ψEs +38.12 TΣ/M
N(TR) = 43, r2 = 0.858, s = 4.2; N(+16EV) = 59, r2 = 0.896, s = 5.5 Excluded strong outliers: ethylencarbonate & quinoline ϵ {TR}, and MeOH & MeCl ∈ {EV}. |
| δvppo(−0.5) |
d = 0.733 + 0.024 Dv + 0.211 0χv + 1.463 1χvs − 0.022 SψE + 0.148 Δ
N(TR) = 45, r2 = 0.939, s = 0.07; N(+15EV) = 60, r2 = 0.914, s = 0.08 Excluded outliers: MeCl & MeOH ∈ {EV} |
| δvppo(1) |
RI = 1.573 − 0.156 HM + 0.617 RM + 0.067 RMv − 0.447 SM − 0.086 HoMv − 0.012 SME
N(TR) = 45, r2 = 0.957, s = 0.04; N(+14EV) = 59, r2 = 0.951, s = 0.03 Excluded outliers: MeCl & MeOH ∈ {EV} |
| δvpo(−0.5) |
γ = 8.683 + 0.386 Dv + 397.6 1χvs + 151.9 TψI − 502.4 1ψIs + 3.347 Δ
N(TR) = 29, r2 = 0.835, s = 3.1; N(+10EV) = 39, r2 = 0.792, s = 3.1 Excluded outlier: formamide, nitromethane ∈ {EV} |
| δvppo(0.5) |
FP = 387.1 + 26.99 HM − 94.38 HMI + 33.03 GME + 114.5 UMI − 83.10 HoME
N(TR) = 29, r2 = 0.829, s = 16; N(+11EV)= 40, r2 = 0.764, s = 17 Excluded outliers: Acetone ∈ {EV} |
| δvpo(−0.5) |
η = − 0.216 + 0.001 1χd + 0.486 1ψI + 2.20∙10−5 1ψId − 3.83∙10−6 0ψEd + 0.098 Σ
N(TR) = 28, r2 = 0.969, s = 0.4; N(+10EV) = 38, r2 = 0.939, s = 0.4 Excluded outlier: MeOH ∈ {EV} |
| δvpo(5) φ = 0, 1 |
μ = 0.038 + 0.002 1χd − 0.189 Dv + 0.078 0χvd + 0.077 SψE + 4.039 TΣ/M
N(TR) = 24, r2 = 0.919, s = 0.4; N(+9EV) = 33, r2 = 0.768, s = 0.7 Excluded outlier: formamide & MeOH ∈ {EV} |
| δvpo(50) |
UV = 299.1 + 50.54 SMv − 37.34 LMv − 9.048 HoME + 1.310 StME
N(TR) = 25, r2 = 0.893, s = 15; N(+8EV) = 33, r2 = 0.826, s = 21 Excluded outlier: 4-Me-2-pentanone ϵ {TR}; 2-butanone, MeOH, acetonitrile ϵ {EV} |
| δvpo(50) |
−χ·106 = 0.617 + 0.044 0χd + 2.208 1χvs − 2.212 1ψIs + 0.070 Δ − 0.016 Σ
N(TR) = 23, r2 = 0.876, s = 0.04; N(+7EV) = 30, r2 = 0.875, s = 0.04 Excluded outlier: nitromethane & MeOH ∈ {EV} |
| δvppo(1) |
El = 0.018 + 0.181 × 10−3 1χd − 0.675∙10−6 1χvd + 0.003 0ψId + 140.8 TΣ/M
N(TR) = 15, r2 = 0.934, s = 0.06; N(+3EV) = 18, r2 = 0.931, s = 0.06 |
| δv-Type | ANN-MLP | (Variables) → Property |
|---|---|---|
| δvpo(1) Ntr = 105 | 6-1-1 (e, l) * 41 0.005/0.003 |
(0χ, Dv, 0ψI, 1ψI, 0ψE, TΣ/M) → Tb
N(36TR + 9TE) = 45, r2 = 0.850, s = 21; N(+16EV) = 61 r2 = 0.820, s = 23 Excluded outlier: dMe-Ether & SO2 ∈ {EV} |
| δvpo(50) Ntr = 103 | 6-1-1 (e, s) 8 0.004/0.002 |
(χtv, 1χvd, 1χvs, 1ψId, 1ψEs, TΣ/M) → ε
N(34TR + 9TE) = 43, r2 = 0.871, s =3.8; N(+16EV) = 59, r2 = 0.793, s = 5.1 Excl.out.: ethylencarbonate & quinoline ϵ {TR}, formamide & acetone ∈ {EV}. |
| δvppo(−0.5) Ntr = 103 | 5-1-1 (t, t) 33 0.002/0.0006 |
(Dv, 0χv, 1χvs, SψE, Δ) → d
N(36TR + 9TE) = 45, r2 = 0.956, s = 0.1; N(+15EV) = 60, r2 = 0.930, s = 0.1 Excluded outliers: MeCl & MeOH ∈ {EV} |
| δvppo(1) Ntr = 103 | 6-1-1 (i, i) 20 0.001/0.0001 |
(0χ, Dv, 0χv, 0ψE, Δ, TΣ/M) → RI
N(35TR + 10TE) = 45, r2 = 0.959, s = 0.03; N(+14EV) = 59, r2 = 0.943, s = 0.04 Excluded outliers: formamide & MeOH ∈ {EV} |
| δvpo(−0.5) Ntr = 105 | 5-1-1 (e, t) 27 0.005/0.006 |
(Dv, 1χvs, TψI, 1ψIs, Δ) → γ
N(22TR + 7TE) = 29, r2 = 0.841, s = 2.8; N(+10EV) = 39, r2 = 0.705, s = 3.7 Excluded outlier: nitromethane & formamide ∈ {EV} |
| δvppo(0.5) Ntr = 103 | 5-1-1 (e, e) 39 0.009/0.009 |
(HM, HMI, GME, UMI, HoME) → FP
N(22TR + 7TE) = 29, r2 = 0.801, s = 16; N(+11EV) = 40, r2 = 0.769, s = 16 Excluded outliers: 2Me-Butane ∈ {EV} |
| δvpo(−0.5) Ntr = 103 | 5-1-1 (e, l) 17 0.001/0.0004 |
(1χd, 1ψI, 1ψId, 0ψEd, Σ) → η
N(22TR + 6TE) = 28, r2 = 0.972, s = 0.3; N(+10EV) = 38, r2 = 0.942, s = 0.4 Excluded outlier: MeOH ∈ {EV} |
| δvpo(5) [φ = 0, 1] Ntr = 103 | 5-1-1 (e, s) 18 0.002/0.003 |
(1χd, Dv, 0χvd, SψE, TΣ/M) → μ
N(19TR + 5TE) = 24, r2 = 0.926, s = 0.4; N(+9EV) = 33, r2 = 0.768, s = 0.7 Excluded outliers: formamide & MeOH ∈ {EV} |
| δvpo(50) Ntr = 103 | 4-1-1 (s, i) 16 0.003/0.002 |
(SMv, LMv, HoME, StME) → UV
N(20TR + 5TE) = 25, r2 = 0.892, s = 14; N(+8EV) = 33, r2 = 0.794, s = 22 Excl. outl.: 4M2-pentanone ϵ {TR}; 2-butanone, MeOH, Acetonitrile, ∈ {EV} |
| δvpo(50) Ntr = 103 | 5-1-1 (s, s) 15 0.008/0.001 |
(0χd, 1χvs, 1ψIs, Δ, Σ) → −χ·106 (=MS)
N(19TR + 4TE) = 23, r2 = 0.809, s = 0.04; N(+7EV) = 30, r2 = 0.810, s = 0.05 Excluded outliers: nitromethane & MeOH ∈ {EV} |
| δvppo(1) Ntr = 103 | 4-1-1 (i, i) 20 0.002/0.0003 |
(AMv, HME, GME, StMI) → El
N(12TR + 3TE) = 15, r2 = 0.966, s = 0.04; N(+3EV) = 18, r2 = 0.955, s = 0.04 pentane and THF ϵ {TR}; excl. Out.: MeOH & 2-propanol ∈ {EV} |
| δv-Type | ANN-MLP | (Variables) → Property |
|---|---|---|
| δvpo(1) Ntr = 103 | 6-2-1 (t, t) 73 0.004/0.002 |
(0χ, Dv, 0ψI, 1ψI, 0ψE, TΣ/M) → Tb
N(36TR + 9TE) = 45, r2 = 0.891, s = 17; N(+16EV) = 61 r2 = 0.871, s = 20 Excluded outlier: SO2 & MeOH ∈ {EV} |
| δvpo(50) Ntr = 105 | 6-3-1 (t, e) 55 0.002/0.001 |
(χtv, 1χvd, 1χvs, 1ψId, 1ψEs, TΣ/M) → ε
N(34TR + 9TE) = 43, r2 = 0.942, s =2.5; N(+16EV) = 59, r2 = 0.830, s = 4.5 Excl. Out.: ethylencarbonate & quinoline ∈ {TR}, formamide & nitromethane ∈ {EV} |
| δvppo(−0.5) Ntr = 103 | 5-4-1 (t, l) 58 0.0004/0.0001 |
(Dv, 0χv, 1χvs, SψE, Δ) → d
N(36TR + 9TE) = 45, r2 = 0.990, s = 0.04; N(+15EV) = 60, r2 = 0.966, s = 0.1 Excluded outliers: formamide & MeCl ∈ {EV}. |
| δvppo(1) Ntr = 103 | 6-2-1 (t, s) 20 0.0001/0.0004 |
(0χ, Dv, 0χv, 0ψE, Δ, TΣ/M) → RI
N(35TR + 10TE) = 45, r2 = 0.995, s = 0.03; N(+14EV) = 59, r2 = 0.987, s = 0.05 Excluded outliers: formamide & MeOH ∈ {EV} |
| δvpo(−0.5) Ntr = 105 | 5-4-1 (t, e) 36 0.004/0.002 |
(Dv, 1χvs, T ψI, 1ψIs, Δ) → γ
N(22TR + 7TE) = 29, r2 = 0.908, s = 2.1; N(+10EV) = 39, r2 = 0.871, s = 2.4 Excluded outlier: nitromethane & formamide ∈ {EV} |
| δvpo(1) Ntr = 105 | 5-5-1 (t, l) 35 0.003/0.009 |
(D, 1ψIs, 0ψEd, Δ, TΣ/M) → FP
N(22TR + 7TE) = 29, r2 = 0.919, s = 10; N(+11EV) = 40, r2 = 0.860, s = 13 Excluded outliers: nitromethane ∈ {EV} |
| δvpo(−0.5) Ntr = 105 | 5-3-1 (e, l) 35 0.0003/0.0003 |
(1χd, 1ψI, 1ψId, 0ψEd, Σ) → η
N(22TR + 6TE) = 28, r2 = 0.982, s = 0.3; N(+10EV) = 38, r2 = 0.975, s = 0.3 Excluded outlier: 2-butanone ∈ {EV} |
| δvpo(5) [φ = 0, 1] Ntr = 105 | 5-2-1 (t, t) 77 0.001/0.001 |
(1χd, Dv, 0χvd, SψE, TΣ/M) → μ
N(19TR + 5TE) = 24, r2 = 0.970, s = 0.2; N(+9EV) = 33, r2 = 0.874, s = 0.5 Excluded outliers: HAc, and MeOH ∈ {EV} |
| δvpo(0.5) Ntr = 105 | 4-5-1 (t, e) 142 0.002/0.0006 |
(Dv, 0χv, 0ψE, Δ) → UV
N(20TR + 5TE) = 25, r2 = 0.970, s = 7.5; N(+8EV) = 33, r2 = 0.895, s = 13, Excl. Out.: 4M2-pentanone ϵ {TR}; nitromethane, MeOH, acetone ∈ {EV} |
| δvpo(50) Ntr = 103 | 5-3-1 (e, s) 18 0.003/0.0008 |
(0χd, 1χvs,1ψIs, Δ, Σ) → −χ·106 (=MS)
N(19TR + 4TE) = 23, r2 = 0.907, s = 0.03; N(+7EV) = 29, r2 = 0.871, s = 0.04 Excluded outliers: nitromethane, MeOH ∈ {EV} |
| δvppo(1) Ntr = 103 | 4-2-1 (t, s) 22 0.001/0.003 |
(AMv, HME, GME, StMI) → El
N(12TR + 3TE) = 15, r2 = 0.973, s = 0.03; N(+3EV) = 18, r2 = 0.975, s = 0.03 pentane and THF ϵ {TR}; excluded outliers: acetonitrile & 2-propanol ∈ {EV} |
| δv-Type | ANN-MLP | (Variables) → Property |
|---|---|---|
| δvpo(1) Ntr = 103 | 6-11-1 (t, t) 39 0.005/0.005 |
(0χ, Dv, 0ψI, 1ψI, 0ψE, TΣ/M) → Tb
N(36TR + 9TE) = 45, r2 = 0.846, s = 21; N(+16EV) = 61 r2 = 0.826, s = 24 Excluded utlier: MeOH & SO2 ∈ {EV} |
| δvpo(50) Ntr = 105 | 6-3-1 (t, e) 66 0.002/0.001 |
(χtv, 1χvd, 1χvs, 1ψId, 1ψEs, TΣ/M) → ε
N(34TR + 9TE) = 43, r2 = 0.942, s =2.5; N(+16EV) = 59, r2 = 0.742, s = 5.7 Excl. Out.: ethylencarbonate & quinoline ϵ {TR}, formamide & acetone ∈ {EV} |
| δvppo(−0.5) Ntr = 105 | 5-8-1 (t, l) 18 0.001/0.001 |
(Dv, 0χv, 1χvs, SψE, Δ) → d
N(36TR + 9TE) = 45, r2 = 0.970, s = 0.05; N(+15EV) = 60, r2 = 0.938, s = 0.07 Excluded outliers: MeCl & MeOH ∈ {EV} |
| δvppo(1) Ntr = 105 | 6-4-1 (e, i) 66 0.0001/0.0004 |
(0χ, Dv, 0χv, 0ψE, Δ, TΣ/M) → RI
N(35TR + 10TE) = 45, r2 = 0.990, s = 0.02; N(+14EV) = 59, r2 = 0.984, s = 0.02 Excluded outliers: MeCl & MeOH ∈ {EV} |
| δvpo(−0.5) Ntr = 103 | 5-10-1 (l, s) 42 0.004/0.002 |
(Dv, 1χvs, TψI, 1ψIs, Δ) → γ
N(22TR + 7TE) = 29, r2 = 0.890, s = 2.3; N(+10EV) = 39, r2 = 0.851, s = 2.6 Excluded outlier: nitromethane & formamide ∈ {EV} |
| δvpo(1) Ntr = 105 | 5-4-1 (l, l) 81 0.003/0.01 |
(D, 1ψIs, 0ψEd, Δ, TΣ/M) → FP
N(22TR + 7TE) = 29, r2 = 0.899, s = 11; N(+11EV) = 40, r2 = 0.840, s = 14 Excluded outliers: 2Me-Butane ∈ {EV} |
| δvpo(−0.5) Ntr = 103 | 5-3-1 (e, l) 26 0.0003/0.0003 |
(1χd, 1ψI, 1ψId, 0ψEd, Σ) → η
N(22TR + 6TE) = 28, r2 = 0.981, s = 0.3; N(+10EV) = 38, r2 = 0.974, s = 0.3 Excluded outlier: 2-butanone ∈ {EV} |
| δvpo(5) [φ = 0, 1] Ntr = 105 | 5-4-1 (t, t) 49 0.001/0.0005 |
(1χd, Dv, 0χvd, SψE, TΣ/M) → μ
N(19TR + 5TE) = 24, r2 = 0.977, s = 0.2; N(+9EV) = 33, r2 = 0.835, s = 0.6 Excluded outliers: HAc, and MeOH ∈ {EV} |
| δvpo(0.5) Ntr = 105 | 4-5-1 (t, e) 108 0.001/0.0003 |
(Dv, 0χv, 0ψE, Δ) → UV
N(20TR + 5TE) = 25, r2 = 0.970, s = 7.3; N(+8EV) = 33, r2 = 0.941, s = 10 Excl. Out.: 4M2-pentanone ϵ {TR}; nitromethane, 2-butanone, acetone ∈ {EV} |
| δvpo(50) Ntr = 105 | 5-4-1 (t, i) 78 0.0004/0.0001 |
(0χd, 1χvs,1ψIs, Δ, Σ) → −χ·106 (=MS)
N(19TR + 4TE) = 23, r2 = 0.989, s = 0.01; N(+7EV) = 29, r2 = 0.852, s = 0.04 Excluded outliers: nitromethane & MeOH ∈ {EV} |
| δvppo(1) Ntr = 105 | 4-5-1 (t, t) 49 0.002/0.001 |
(AMv, HME, GME, StMI) → El
N(12TR + 3TE) = 15, r2 = 0.973, s = 0.03; N(+3EV) = 18, r2 = 0.973, s = 0.03 pentane and THF ϵ {TR} and excluded MeOH & 2-propanol ∈ {EV} |
| δv-Type | ANN-MLP | (Variables) → Property |
|---|---|---|
| δvpo(1) Ntr = 105 | 4-1-1 (e, e) 25 0.008/0.008 |
(0χ, Dv, 0ψI, 0ψE) → Tb
N(36TR + 9TE) = 45, r2 = 0.758, s = 26; N(+16EV) = 61 r2 = 0.714, s = 29 Excluded outlier: dMe-Ether & SO2 ∈ {EV} |
| δvpo(50) Ntr = 103 | 4-1-1 (i, s) 8 0.006/0.01 |
(χtv, 1χvs, 1ψEs, TΣ/M) → ε
N(34TR + 9TE) = 43, r2 = 0.761, s =5.2; N(+16EV) = 59, r2 = 0.903, s = 5.2 Excl.out.: ethylencarbonate & quinoline ϵ {TR}, nitromethane & HAc ∈ {EV} |
| δvppo(−0.5) Ntr = 103 | 4-1-1 (l, t) 17 0.004/0.002 |
(Dv, 0χv, SψE, Δ) → d
N(36TR + 9TE) = 45, r2 = 0.917, s = 0.1; N(+15EV) = 60, r2 = 0.895, s = 0.1 Excluded outliers: SO2 & Formamide ∈ {EV} |
| δvppo(1) Ntr = 103 | 4-1-1 (i, e) 14 0.0008/0.0008 |
(0χ, Dv, 0χv, 0ψE) → RI
N(35TR + 10TE) = 45, r2 = 0.926, s = 0.05; N(+14EV) = 59, r2 = 0.914, s = 0.05 Excluded outliers: THF & MeCl ∈ {EV} |
| δvppo(0.5) Ntr = 105 | 4-1-1 (i, l) 26 0.01/0.02 |
(HMI, GME, UMI, HoME) → FP
N(22TR + 7TE) = 29, r2 = 0.719, s = 19; N(+11EV) = 40, r2 = 0.702, s = 18 Excluded outliers: 2Me-Butane ∈ {EV} |
| δvpo(−0.5) Ntr = 103 | 3-1-1 (t, i) 67 0.0007/0.0003 |
(1χd, 0ψEd, Σ) → η
N(22TR + 6TE) = 28, r2 = 0.965, s = 0.4; N(+10EV) = 38, r2 = 0.917, s = 0.5 Excluded outlier: MeOH ∈ {EV} |
| δvpo(5) [φ = 0, 1] Ntr = 105 | 4-1-1 (t, e) 22 0.009/0.005 |
(Dv, 0χvd, SψE, TΣ/M) → μ
N(19TR + 5TE) = 24, r2 = 0.795, s = 0.6; N(+9EV) = 33, r2 = 0.746, s = 0.7 Excluded outliers: HAc & MeOH ∈ {EV} |
| P | MLS (Table 4) | ANN 1HN (Table 5) | ANN enHN (Table 6) | ANN snHN (Table 7) |
|---|---|---|---|---|
| Tb | 45/0.82/22 61/ 0.79/25 | 45/0.85/21 61/0.82/23 | 45/0.89/17 2/61/0.87/20 | 45/0.85/21 11/61/0.83/24 |
| ε | 43/0.86/4.2 59/0.90/5.5 | 43/0.87/3.8 59/0.79/5.1 | 43/0.94/2.5 3/59/0.83/4.5 | 43/0.94/2.5 5/59/0.83/5.7 |
| d | 45/ 0.94/0.07 60/0.91/0.08 | 45/0.96/0.1 60/ 0.93/0.1 | 45/0.99/0.04 4/60/0.97/0.1 | 45/0.97/0.05 8/60/0.94/0.1 |
| RI | 45/ 0.96/0.04 59/0.95/0.03 | 45/0.96/0.03 59/0.94/0.04 | 45/0.995/0.03 2/59/0.99/0.05 | 45/0.99/0.02 4/59/0.98/0.02 |
| γ | 29/0.84/3.1 39/0.79/3.1 | 29/0.84/2.8 39/0.71/3.7 | 29/0.91/2.1 4/39/0.87/2.4 | 29/0.89/2.3 10/39/0.85/2.6 |
| FP | M/29/0.83/16 40/0.76/17 | M/29/0.80/16 40/0.77/16 | 29/0.92/10 5/40/0.86/13 | 29/0.90/11 4/40/0.84/14 |
| η | 28/0.97/0.4 38/0.94/0.4 | 28/0.97/0.3 38/0.94/0.4 | 28/0.98/0.3 3/38/0.98/0.3 | 28/0.98/0.3 3/38/0.97/0.3 |
| μ | 24/0.92/0.4 33/0.77/0.7 | 24/0.93/0.4 33/0.77/0.7 | 24/0.97/0.2 2/33/0.87/0.5 | 24/0.98/0.2 4/33/0.84/0.6 |
| UV | M/25/0.89/15 33/0.83/21 | M/25/0.89/14 33/0.79/22 | 25/0.97/7.5 5/33/0.90/13 | 25/0.97/7.3 5/33/0.94/10 |
| −χ·106 | 23/0.88/0.04 30/0.88/0.04 | 23/0.81/0.04 30/0.81/0.05 | 23/0.91/0.03 3/29/0.87/0.04 | 23/0.99/0.01 4/29/0.85/0.04 |
| El | 15/0.93/0.06 18/0.93/0.06 | M/15/0.97/0.04 18/0.96/0.04 | M/15/0.97/0.03 2/18/0.98/0.03 | M/15/0.97/0.03 5/18/0.97/0.03 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Julián-Ortiz, J.V.; Pogliani, L.; Besalú, E. Modeling Properties with Artificial Neural Networks and Multilinear Least-Squares Regression: Advantages and Drawbacks of the Two Methods. Appl. Sci. 2018, 8, 1094. https://doi.org/10.3390/app8071094
De Julián-Ortiz JV, Pogliani L, Besalú E. Modeling Properties with Artificial Neural Networks and Multilinear Least-Squares Regression: Advantages and Drawbacks of the Two Methods. Applied Sciences. 2018; 8(7):1094. https://doi.org/10.3390/app8071094
Chicago/Turabian StyleDe Julián-Ortiz, Jesus Vicente, Lionello Pogliani, and Emili Besalú. 2018. "Modeling Properties with Artificial Neural Networks and Multilinear Least-Squares Regression: Advantages and Drawbacks of the Two Methods" Applied Sciences 8, no. 7: 1094. https://doi.org/10.3390/app8071094