A Filter Feature Selection Algorithm Based on Mutual Information for Intrusion Detection


Abstract
:1. Introduction
2. Related Technologies
3. Filter Feature Selection Algorithm
| Algorithm 1. The Proposed New Algorithm. The Redundant Penalty Between Features Mutual Information Algorithm (RPFMI) |
| Input: {initial set of all original features}, {empty set} |
| Output: |
| 01 for do |
| 02 calculate , , and |
| 03 end for |
| 04 select the feature that maximizes |
| 05 and |
| 06 for and do |
| 07 compute and |
| 08 end for |
| 09 while do |
| 10 select the feature using Equation (10) |
| 11 and |
| 12 if do |
| 13 for and do |
| 14 compute and |
| 15 end for |
| 16 end if |
| 17 end while |
4. Experiment and Results
4.1. Data Set
4.2. Performance Metrics
4.3. Experiment and Analysis
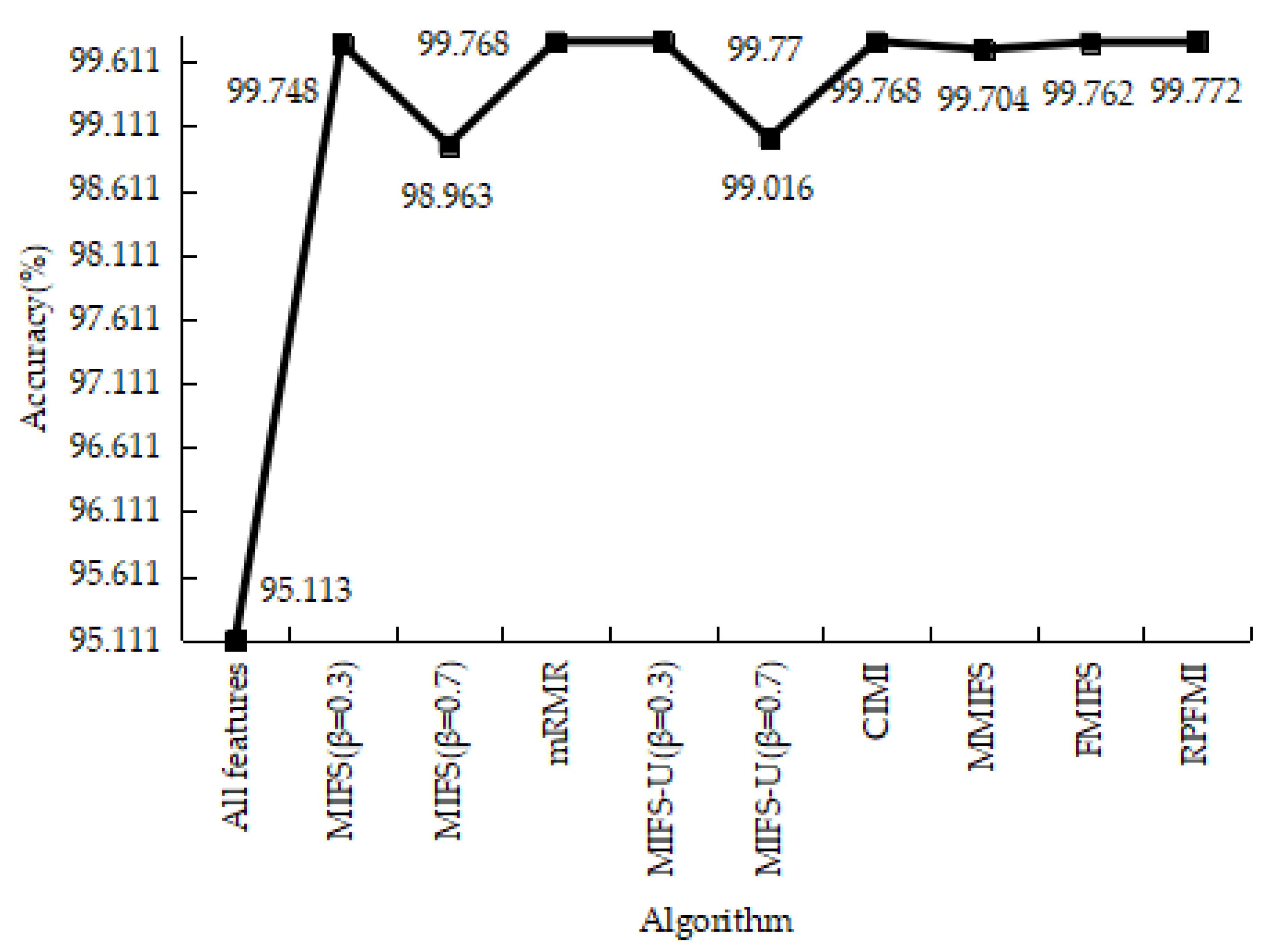
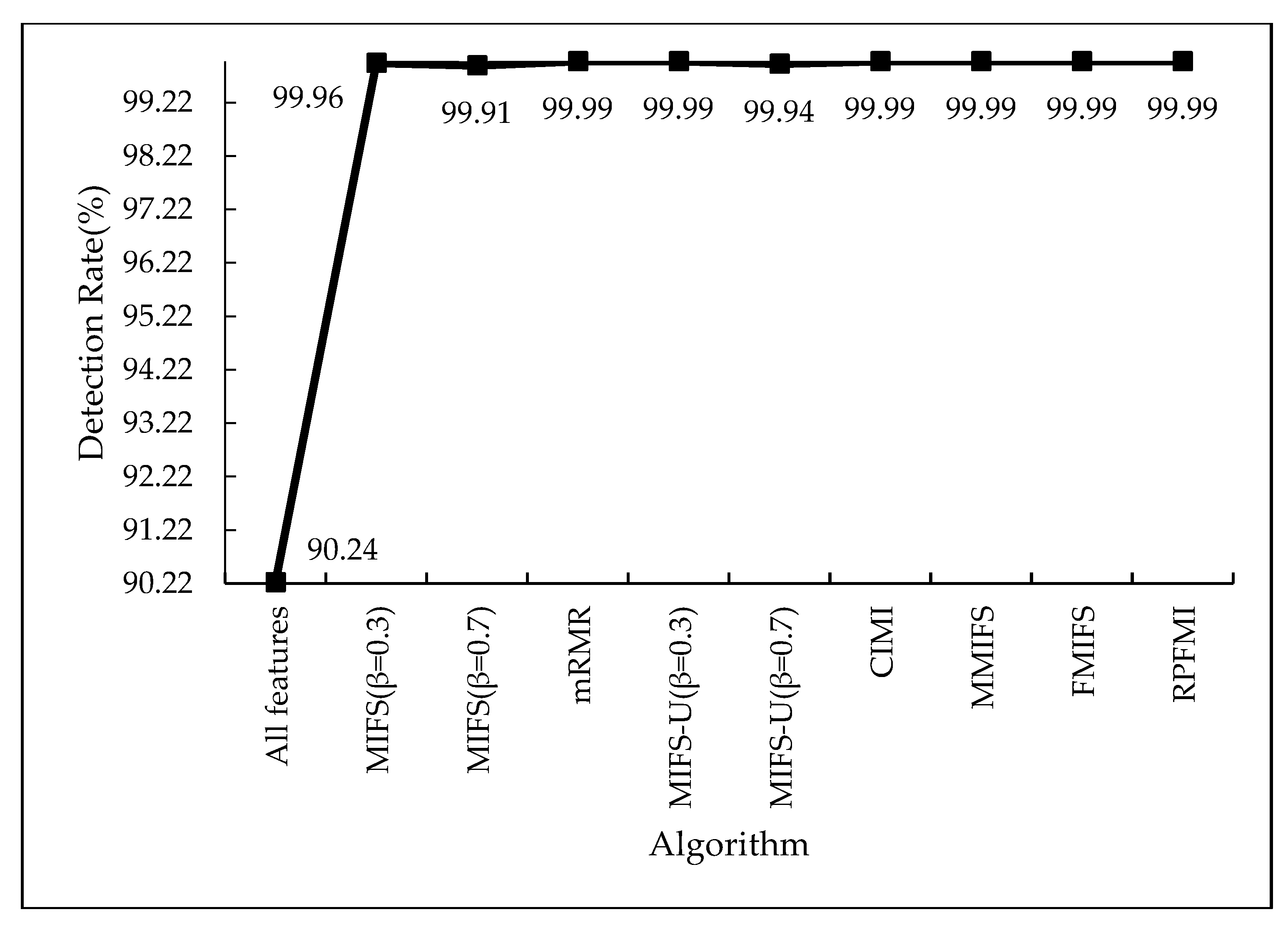
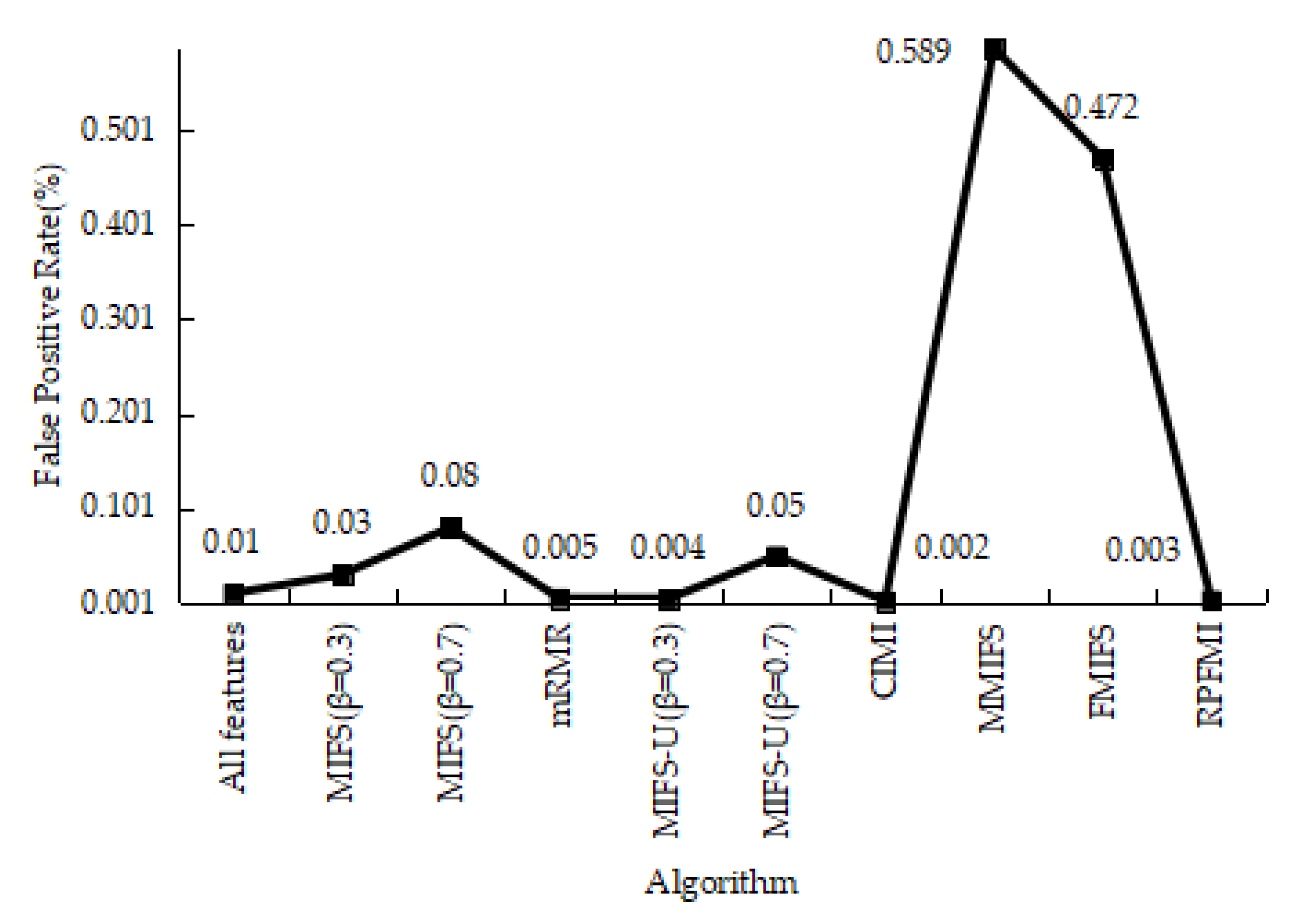
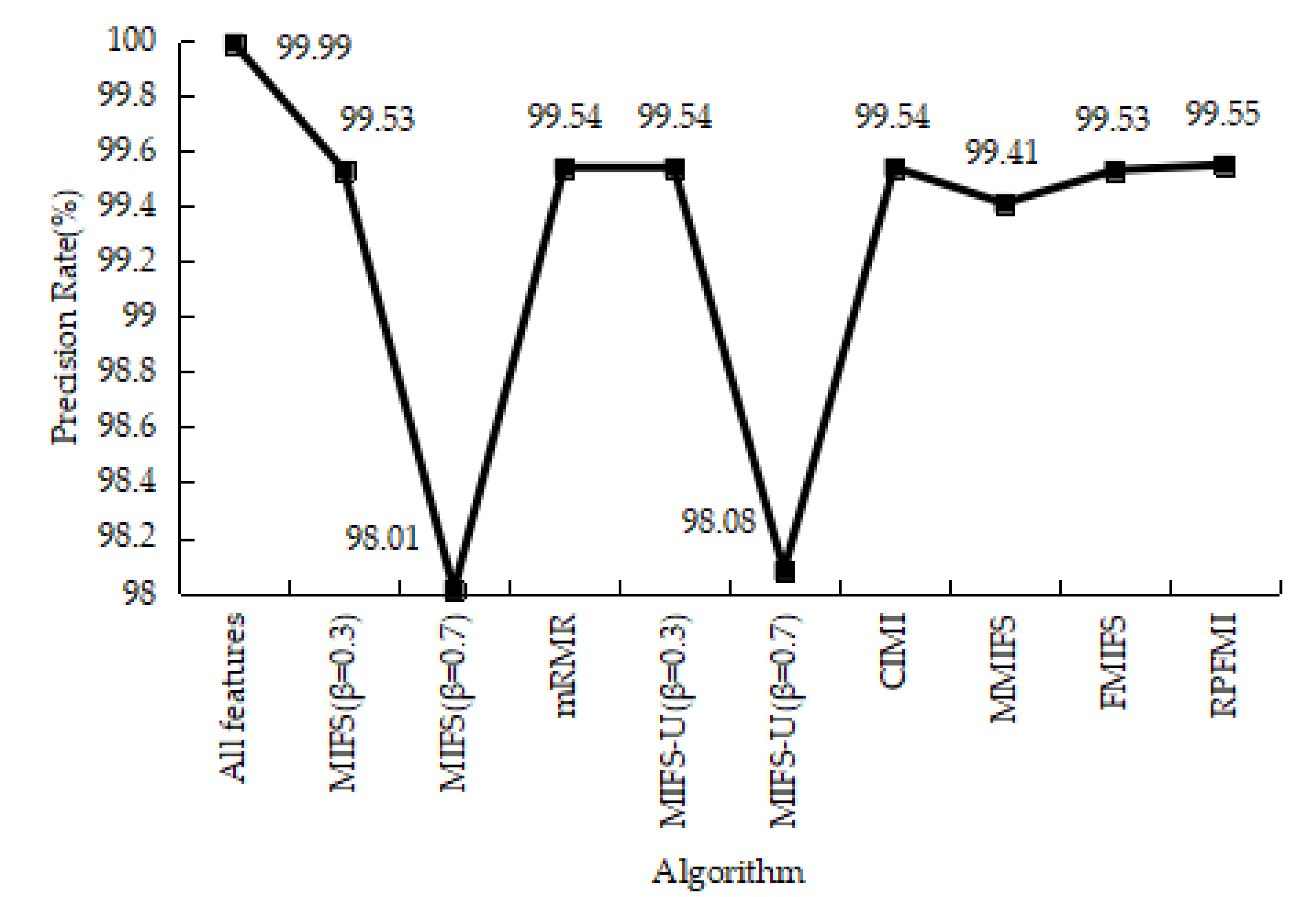
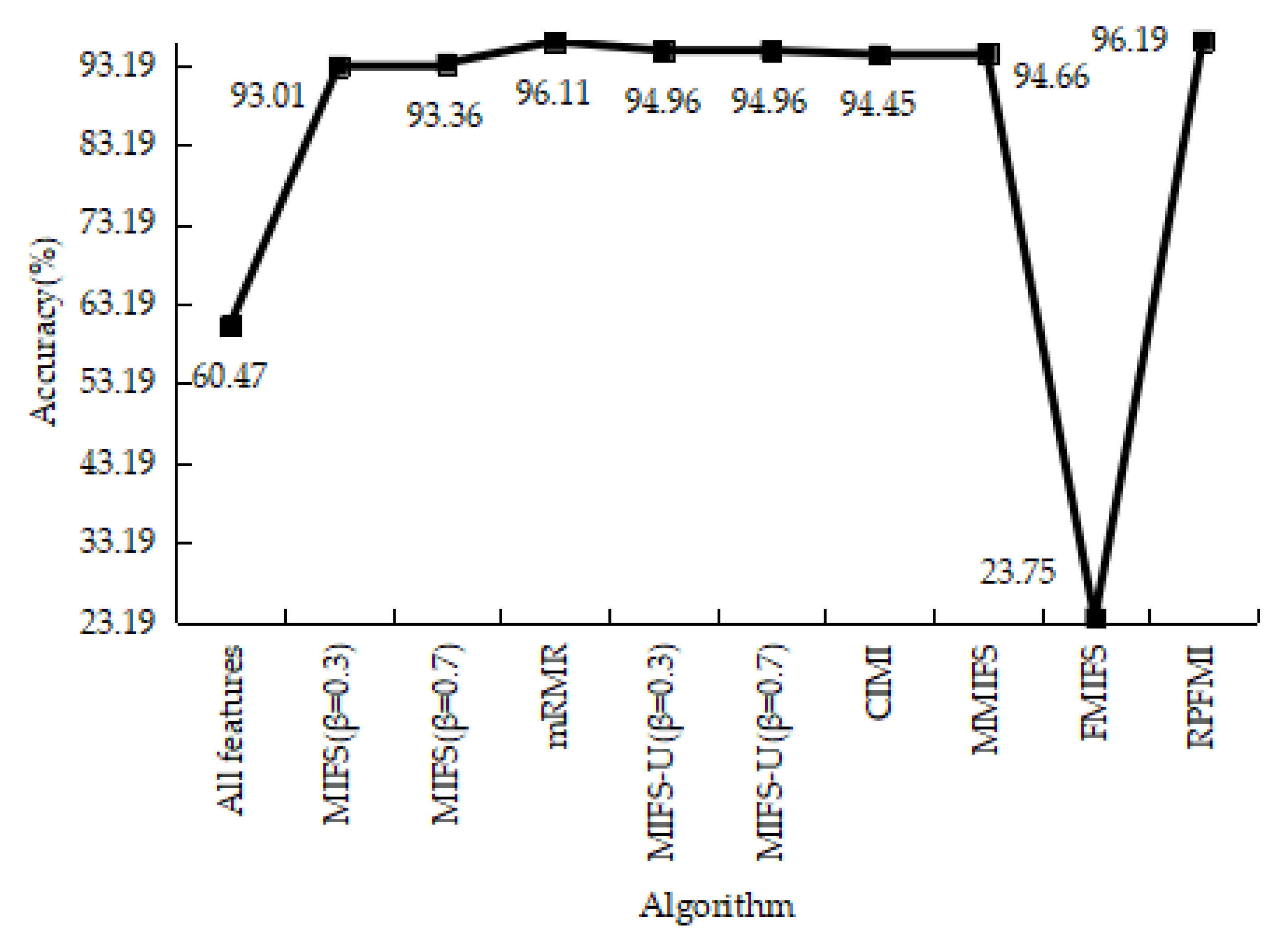
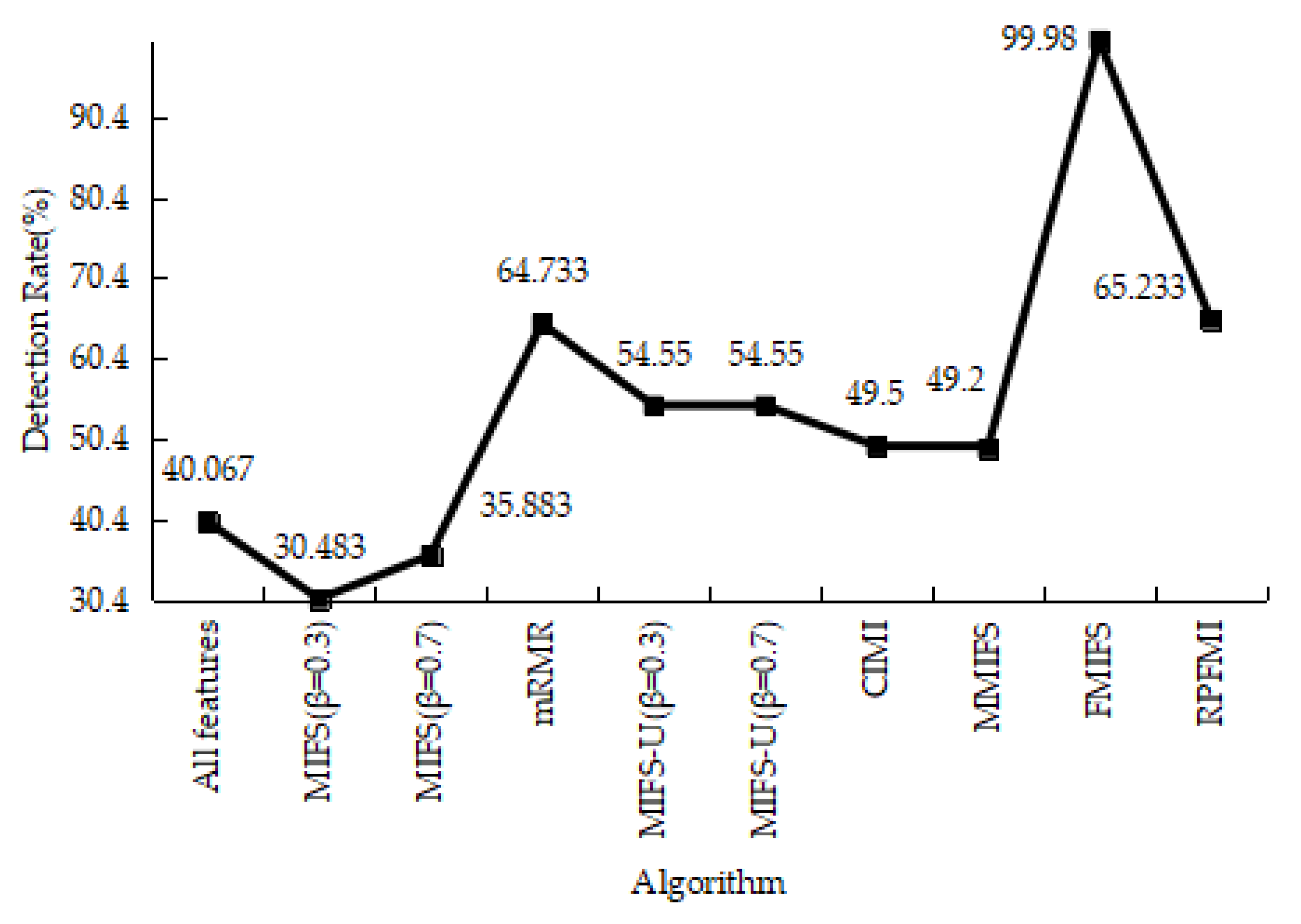
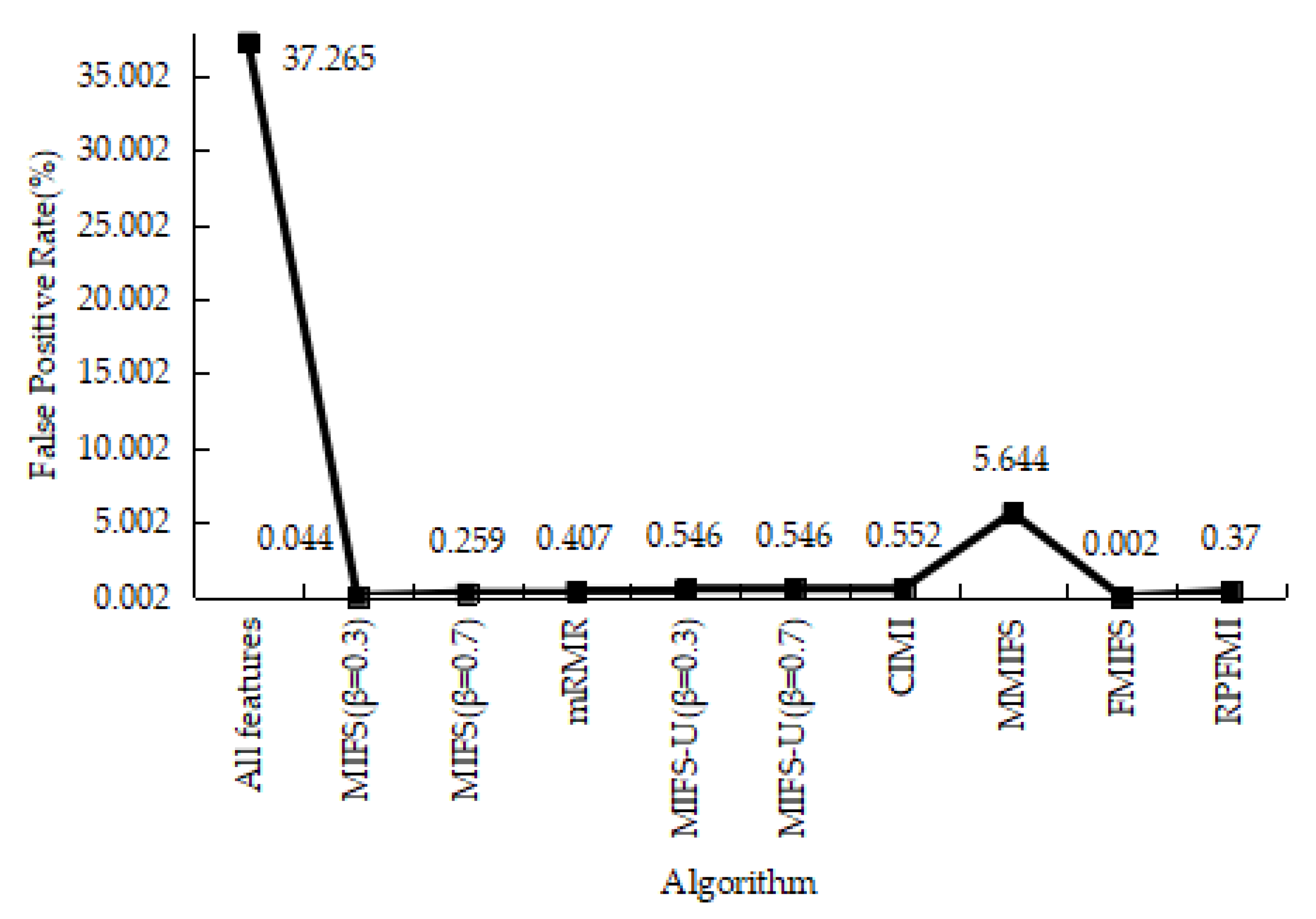
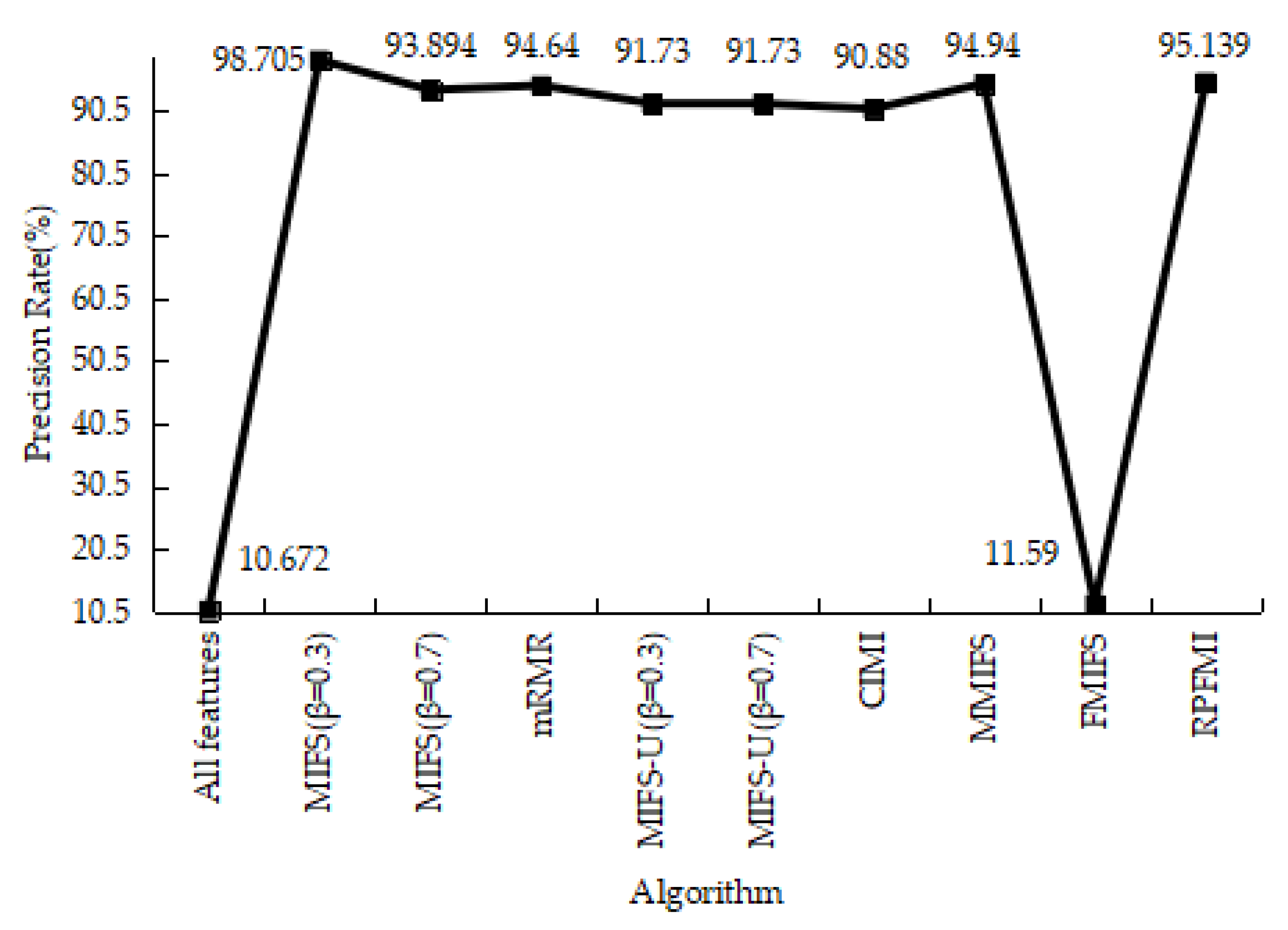
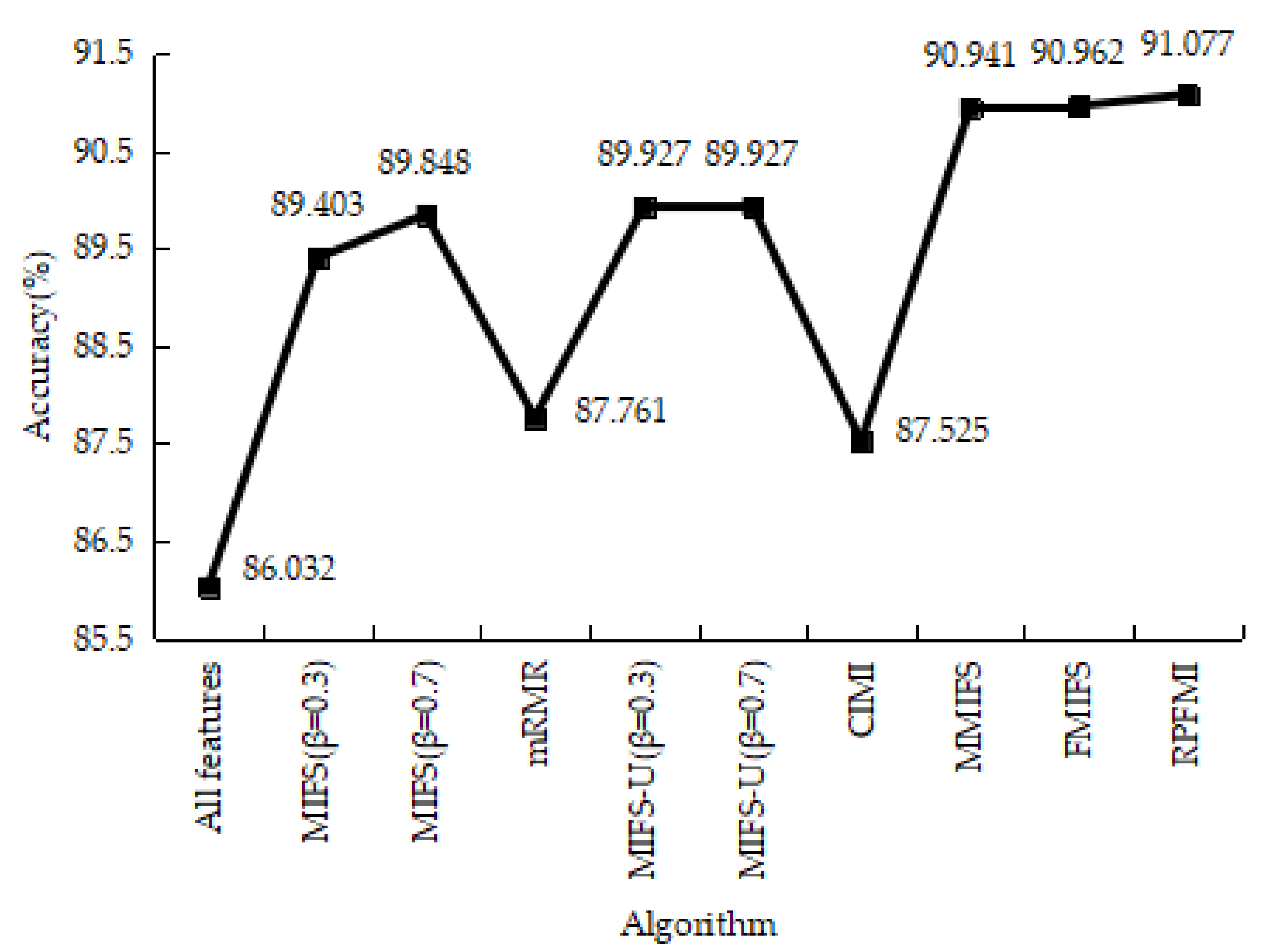
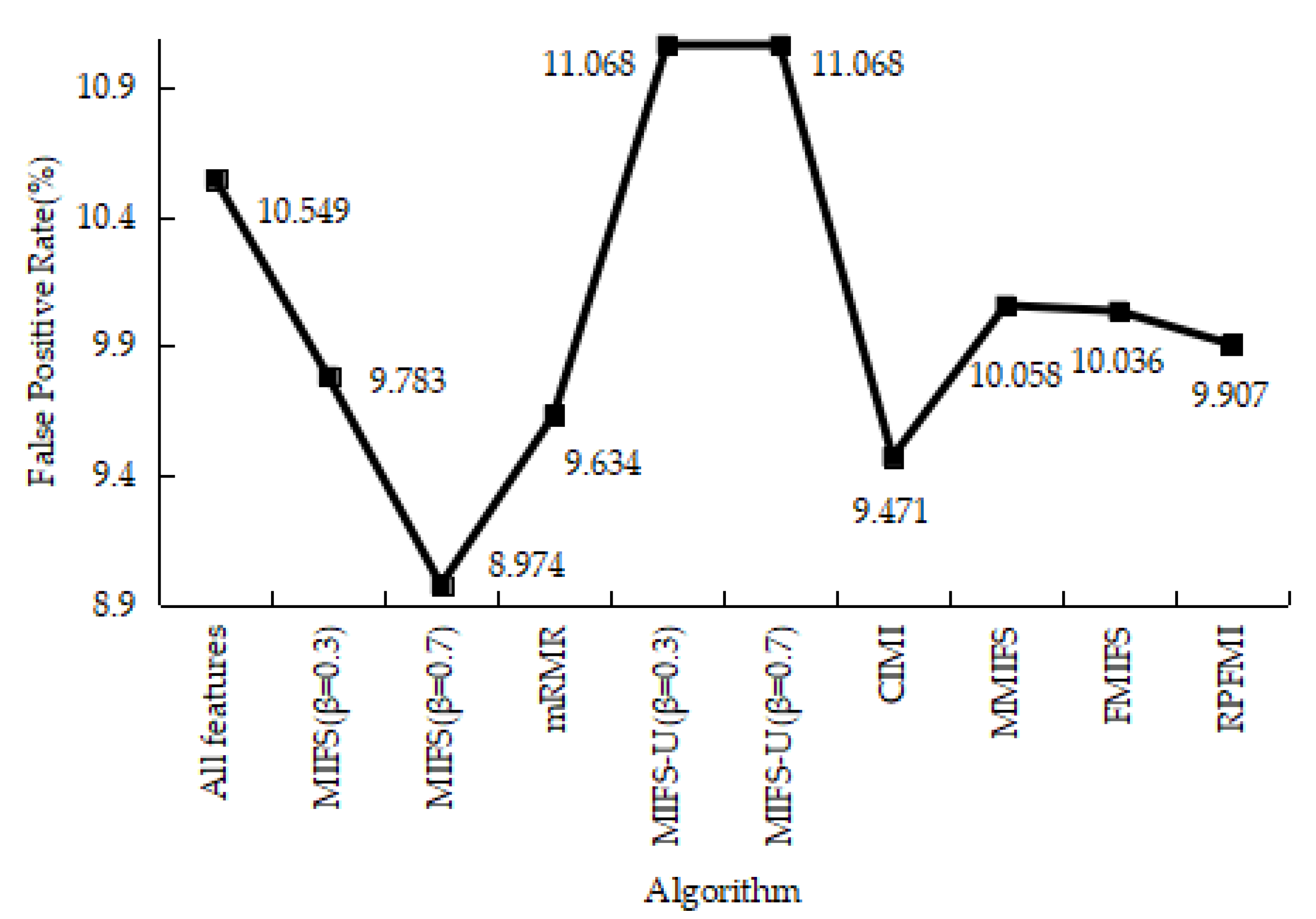
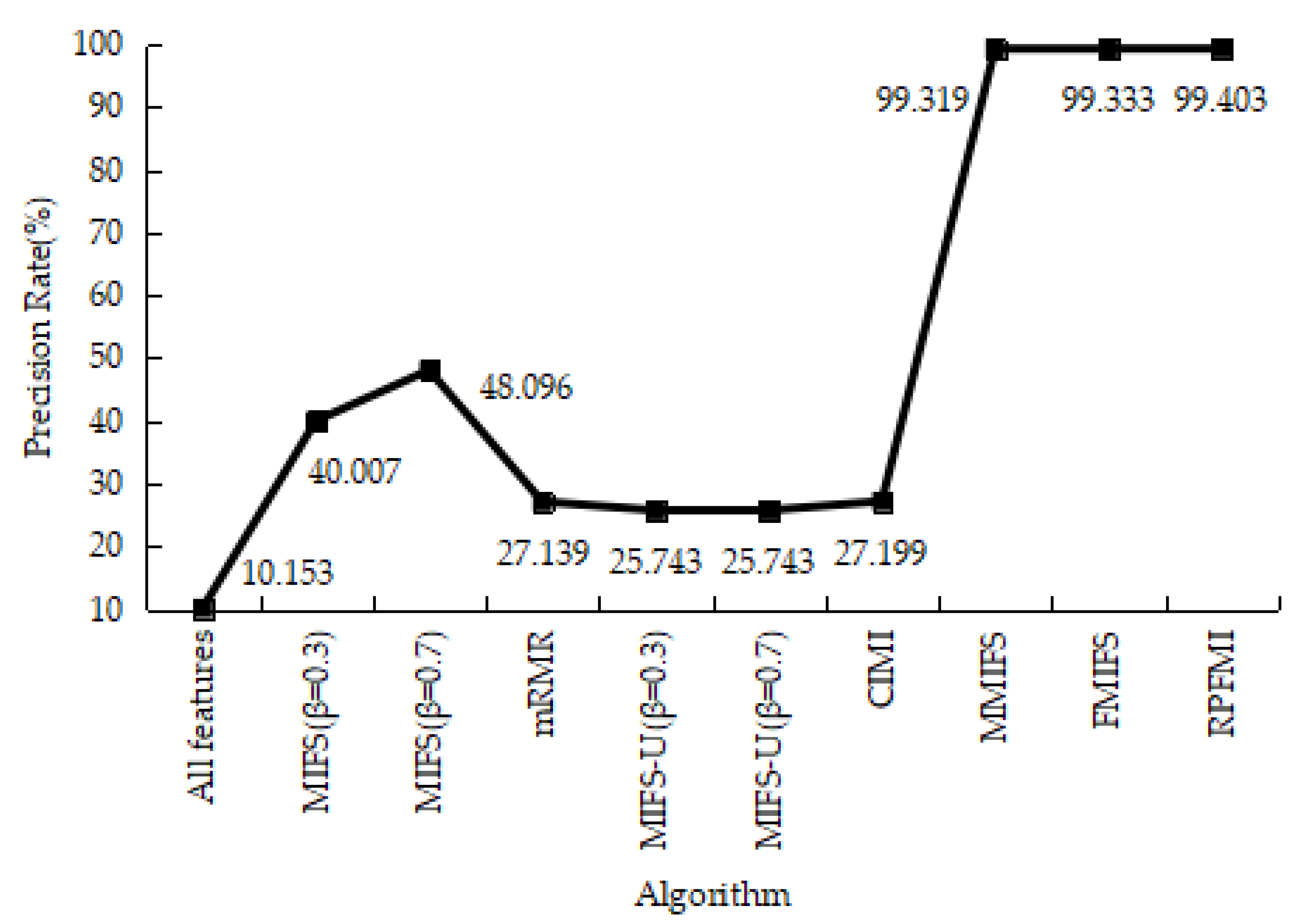
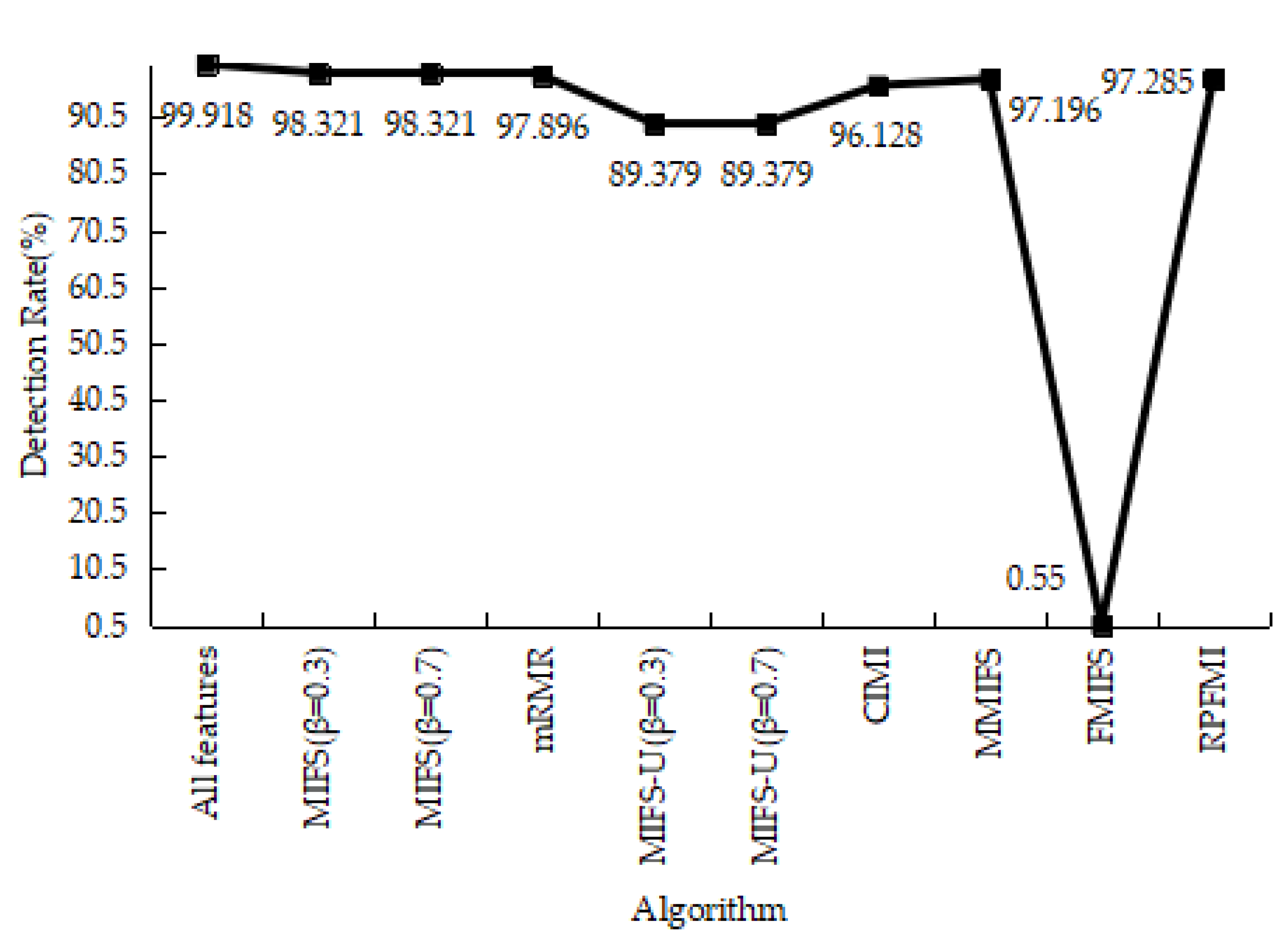
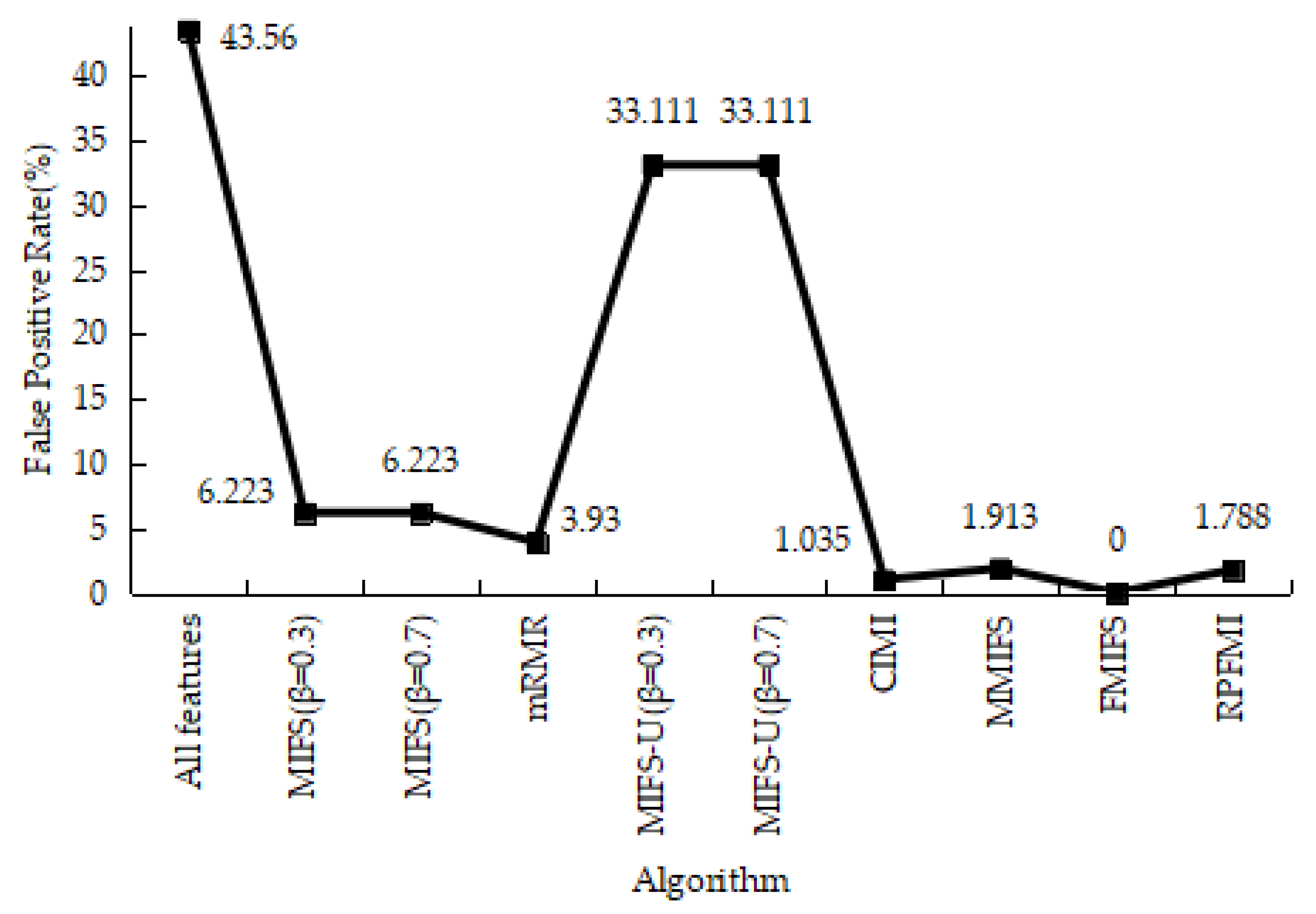
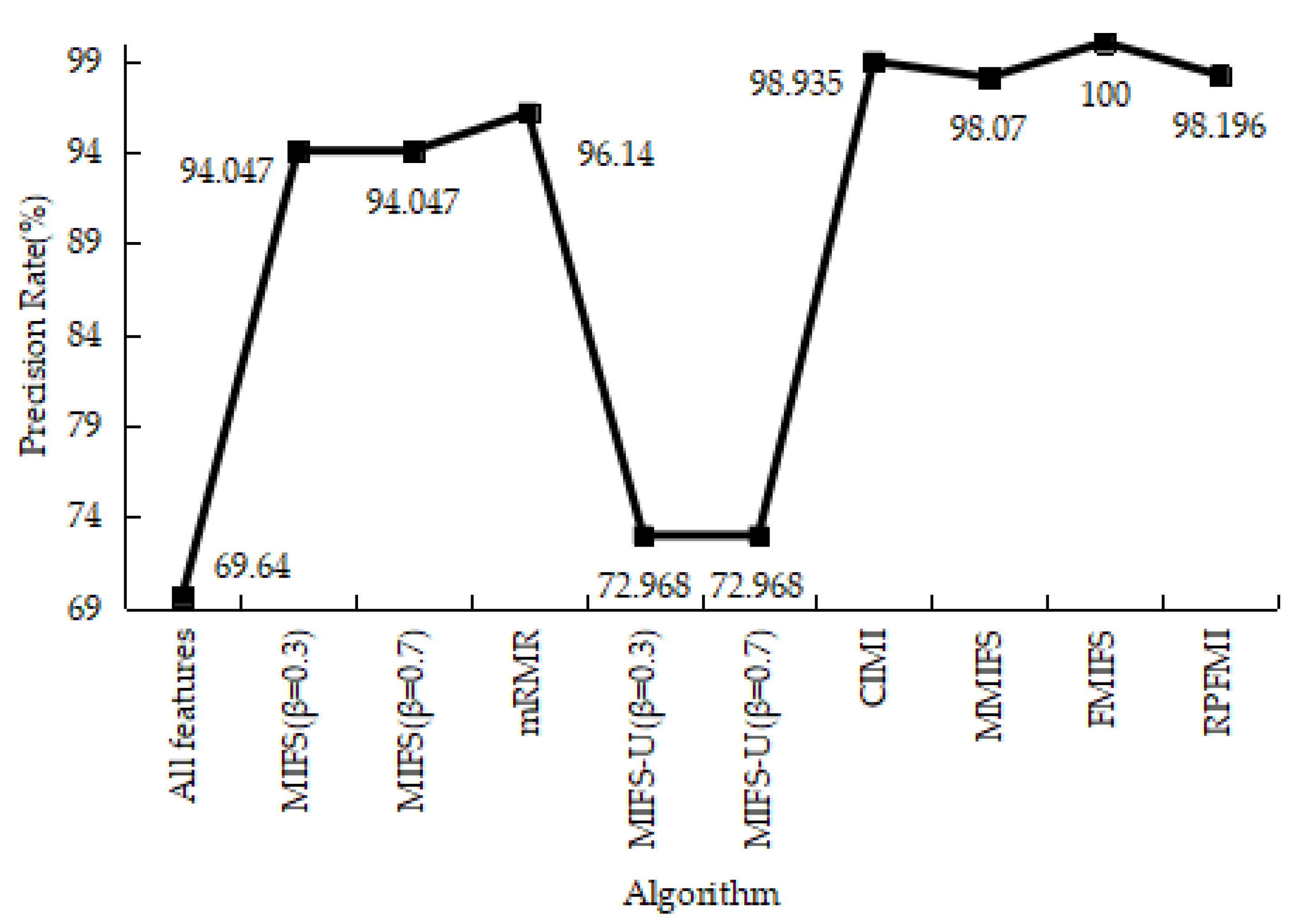
4.3.1. Denial-of-Service Test Experiment
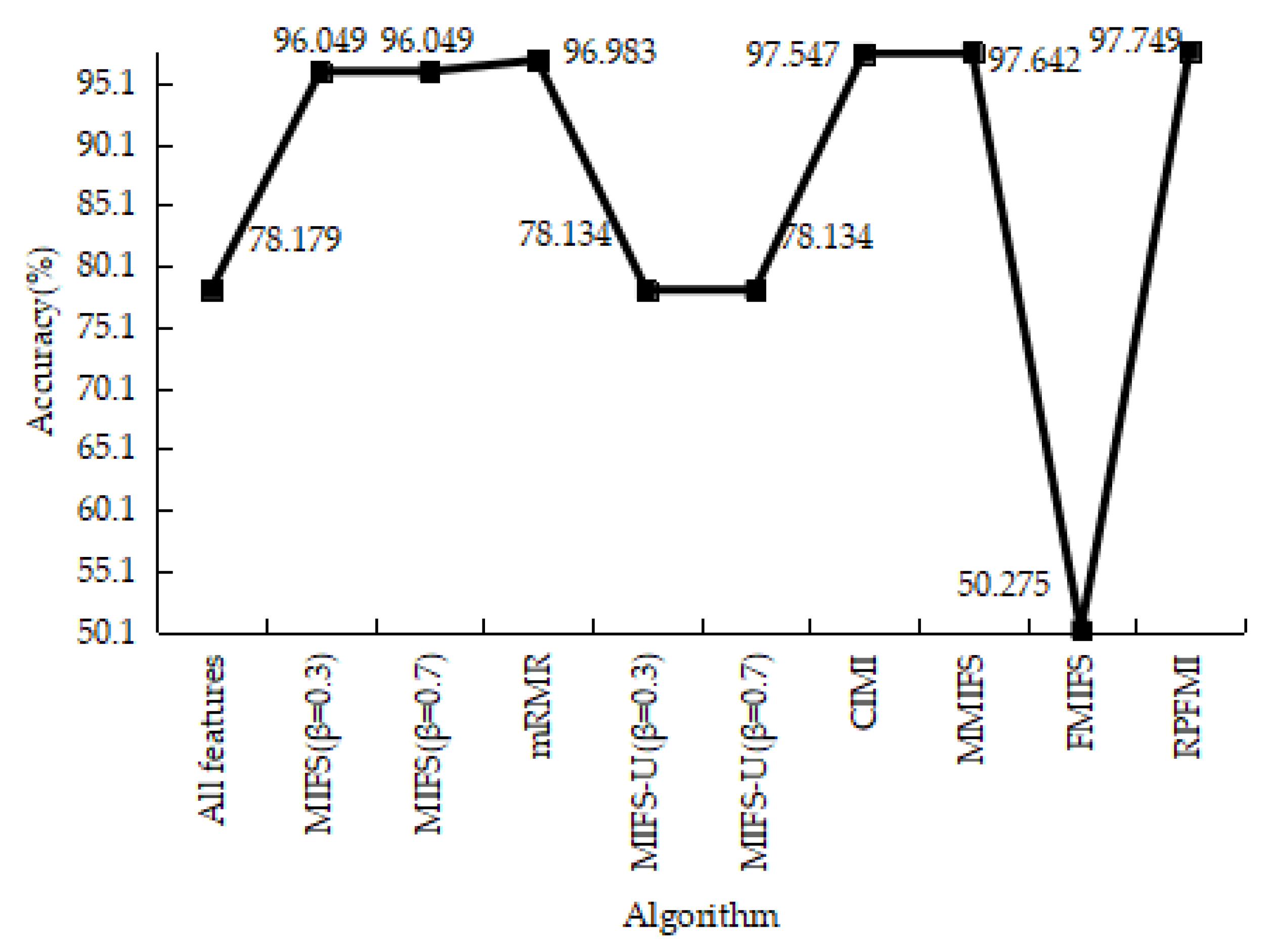
4.3.2. User-to-Root Test Experiment
4.3.3. Remote-to-Login Test Experiment
4.3.4. Kyoto 2006+ Test Experiment
4.3.5. Experiments Conclusion
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgements
Conflicts of Interest
References
- Singh, R.; Kumar, H.; Singla, R.K.; Ketti, R.R. Internet attacks and intrusion detection system: A review of the literature. Online Inf. Rev. 2017, 41, 171–184. [Google Scholar] [CrossRef]
- Xin, Y.; Kong, L.S.; Liu, Z.; Chen, Y.L.; Li, Y.; Zhu, H.; Gao, M.; Hou, H.; Wang, C. Machine Learning and Deep Learning Methods for Cybersecurity. IEEE Access 2018, 6, 35365–35381. [Google Scholar] [CrossRef]
- Wang, Z. Deep Learning-Based Intrusion Detection with Adversaries. IEEE Access 2018, 6, 38367–38384. [Google Scholar] [CrossRef]
- Karim, I.; Vien, Q.T.; Le, T.A.; Mapp, G. A comparative experimental design and performance analysis of Snort-based intrusion detection system in practical computer networks. MDPI Comput. 2017, 6, 6. [Google Scholar] [CrossRef]
- Inayat, Z.; Gani, A.; Anuar, N.B.; Khan, M.K.; Anwar, S. Intrusion response systems: Foundations, design, and challenges. J. Netw. Comput. Appl. 2016, 62, 53–74. [Google Scholar] [CrossRef]
- Chen, J.L.; Qi, Y.S. Intrusion Detection method Based on Deep Learning. J. Jiangsu Univ. Sci. Technol. 2017, 6, 18. [Google Scholar]
- Chung, I.F.; Chen, Y.C.; Pal, N. Feature selection with controlled redundancy in a fuzzy rule based framework. IEEE Trans. Fuzzy Syst. 2017, 26, 734–748. [Google Scholar] [CrossRef]
- Tao, P.Y.; Sun, Z.; Sun, Z.X. An Improved Intrusion Detection Algorithm Based on GA and SVM. IEEE Access 2018, 6, 13624–13631. [Google Scholar] [CrossRef]
- Zhang, T.; Ren, P.; Ge, Y.; Zheng, Y.; Tang, Y.Y.; Chen, C.P. Learning Proximity Relations for Feature Selection. IEEE Trans. Knowl. Data Eng. 2016, 28, 1231–1244. [Google Scholar] [CrossRef]
- Yan, B.H.; Han, G.D. Effective feature extraction via stacked sparse autoencoder to improve intrusion detection system. IEEE Access 2018, 6, 41238–41248. [Google Scholar] [CrossRef]
- Peng, H.C.; Long, F.H.; Ding, C. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the 20th International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Mohamed, N.S.; Zainudin, S.; Othman, Z.A. Metaheuristic approach for an enhanced mRMR filter method for classification using drug response microarray data. Expert Syst. Appl. 2017, 90, 224–231. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Hui, K.H.; Ooi, C.S.; Lim, M.H.; Leong, M.S.; Al-Obaidi, S.M. An improved wrapper-based feature selection method for machinery fault diagnosis. PLoS ONE 2017, 12, e0189143. [Google Scholar] [CrossRef] [PubMed]
- Dash, M.; Liu, H. Feature Selection for Classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Wang, L.M.; Shao, Y.M. Crack Fault Classification for Planetary Gearbox Based on Feature Selection Technique and K-means Clustering Method. Chin. J. Mech. Eng. 2018, 31, 4. [Google Scholar] [CrossRef] [Green Version]
- Viegas, E.K.; Santin, A.O.; Oliveira, L.S. Toward a reliable anomaly-based intrusion detection in real-world environments. Comput. Netw. 2017, 127, 200–216. [Google Scholar] [CrossRef]
- Jain, A.K.; Duin, R.P.W.; Mao, J.C. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar] [CrossRef]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Kwak, N.; Choi, C.H. Input feature selection for classification problems. IEEE Tran. Neural Netw. 2002, 13, 143–159. [Google Scholar] [CrossRef] [PubMed]
- Novovičová, J.; Somol, P.; Haindl, M.; Pudil, P. Conditional Mutual Information Based Feature Selection for Classification Task; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Guo, C.; Ping, Y.; Liu, N.; Luo, S.S. A two-level hybrid approach for intrusion detection. Neurocomputing 2016, 214, 391–400. [Google Scholar] [CrossRef]
- Jia, B.; Ma, Y.; Huang, X.H.; Lin, Z.; Sun, Y. A Novel Real-Time DDoS Attack Detection Mechanism Based on MDRA Algorithm in Big Data. Math. Probl. Eng. 2016, 2016, 1–10. [Google Scholar] [CrossRef]
- Kdd Cup 99 Intrusion Detection Dataset Task Description. University of California Department of Information and Computer Science, 1999. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 20 December 2017).
- Wang, Y.W.; Feng, L.Z. Hybrid feature selection using component co-occurrence based feature relevance measurement. Expert Syst. Appl. 2018, 102, 83–99. [Google Scholar] [CrossRef]
- Boukhris, I.; Elouedi, Z.; Ajabi, M. Toward intrusion detection using belief decision trees for big data. Knowl. Inf. Syst. 2017, 53, 371–698. [Google Scholar] [CrossRef]
- Elshoush, H.T.; Osman, I.M. Alert correlation in collaborative intelligent intrusion detection systems-A survey. Appl. Soft Comput. 2011, 11, 4349–4365. [Google Scholar] [CrossRef]
- Tang, C.H.; Xiang, Y.; Wang, Y.; Qian, J.; Qiang, B. Detection and classification of anomaly intrusion using hierarchy clustering and SVM. Secur. Commun. Netw. 2016, 9, 3401–3411. [Google Scholar] [CrossRef]
- Chen, W.H.; Hsu, S.H.; Shen, H.P. Application of SVM and ANN for intrusion detection. Comput. Oper. Res. 2005, 32, 2617–2634. [Google Scholar] [CrossRef]
- Diosan, L.; Rogozan, A.; Pecuchet, J.P. Improving classification performance of support vector machine by genetically optimising kernel shape and hyper-parameters. Appl. Intell. 2012, 36, 280–294. [Google Scholar] [CrossRef]
- Amiri, F.; Yousefi, M.M.R.; Lucas, C.; Shakery, A.; Yazdani, N. Mutual information-based feature selection for intrusion detection systems. J. Netw. Comput. Appl. 2011, 34, 1184–1199. [Google Scholar] [CrossRef]
- Ambusaidi, M.A.; He, X.J.; Nanda, P.; Tan, Z. Building an intrusion detection system using a filter-based feature selection algorithm. IEEE Trans. Comput. 2016, 65, 2986–2998. [Google Scholar] [CrossRef]
- Brown, G.; Pocock, A.; Zhao, M.J.; Luján, M. Conditional Likelihood Maximisation: A Unifying Framework for Information Theoretic Feature Selection. J. Mach. Learn. Res. 2012, 13, 27–36. [Google Scholar]
- Brown, G. A New Perspective for Information Theoretic Feature Selection. In Proceedings of the International Conference on Artificial Intelligence & Statistics, Clearwater Beach, FL, USA, 16–18 April 2009; Volume 5. [Google Scholar]
- Kumar, S.; Sharma, A.; Tsunoda, T. An improved discriminative filter bank selection approach for motor imagery EEG signal classification using mutual information. In Proceedings of the 16th International Conference on Bioinformatics (InCoB)-Bioinformatics, Shenzhen, China, 20–22 September 2017. [Google Scholar]
- Bostani, H.; Sheikhan, M. Hybrid of binary gravitational search algorithm and mutual information for feature selection in intrusion detection systems. Soft Comput. 2017, 21, 2307–2324. [Google Scholar] [CrossRef]
- Aiello, M.; Mogelli, M.; Cambiaso, E.; Papaleo, G. Profiling DNS tunneling attacks with PCA and mutual information. Logic J. IGPL 2016, 24, 957–970. [Google Scholar] [CrossRef]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. A multi-step outlier-based anomaly detection approach to network-wide traffic. Inf. Sci. 2016, 348, 243–271. [Google Scholar] [CrossRef]
- Song, J.; Takakura, H.; Okabe, Y.; Eto, M.; Inoue, D.; Nakao, K. Statistical analysis of honeypot data and building of Kyoto 2006+ dataset for NIDS evaluation. In Proceedings of the First Workshop on Building Analysis Datasets and Gathering Experience Returns for Security, Salzburg, Austria, 10 April 2011. [Google Scholar]
- Cheong, Y.G.; Park, K.; Kim, H.; Kim, J.; Hyun, S. Machine Learning Based Intrusion Detection Systems for Class Imbalanced Datasets. J. Korea Inst. Inf. Secur. Cryptol. 2017, 27, 1385–1395. [Google Scholar]
- Belhadj-Aissa, N.; Guerroumi, M. A New Classification Process for Network Anomaly Detection Based on Negative Selection Mechanism. In Proceedings of the 9th International Conference on Security, Privacy, and Anonymity in Computation, Communication and Storage (SpaCCS), Zhangjiajie, China, 16–18 November 2016. [Google Scholar]
- Kevric, J.; Jukic, S.; Subasi, A. An effective combining classifier approach using tree algorithms for network intrusion detection. Neural Comput. Appl. 2017, 28, 1051–1058. [Google Scholar] [CrossRef]
- Meena, G.; Choudhary, R.R. A review paper on IDS classification using KDD 99 and NSL KDD dataset in WEKA. In Proceedings of the International Conference on Computer, Communications and Electronics (Comptelix), Jaipur, India, 1–2 July 2017. [Google Scholar]
- Wan, M.; Shang, W.L.; Zeng, P. Double Behavior Characteristics for One-Class Classification Anomaly Detection in Networked Control Systems. IEEE Trans. Inf. Forensics Secur. 2017, 12, 3011–3023. [Google Scholar] [CrossRef] [Green Version]
- Kushwaha, P.; Buckchash, H.; Raman, B. Anomaly based intrusion detection using filter based feature selection on KDD-CUP 99. In Proceedings of the IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017. [Google Scholar]
- Duan, S.; Levitt, K.; Meling, H.; Peisert, S.; Zhang, H. ByzID: Byzantine Fault Tolerance from Intrusion Detection. In Proceedings of the IEEE International Symposium on Reliable Distributed Systems, Nara, Japan, 6–9 October 2014. [Google Scholar]
- Rosas, F.; Chen, K.C. Social learning against data falsification in sensor networks. In Proceedings of the International Conference on Complex Networks and their Applications, Lyon, France, 29 November–1 December 2017. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Number of Records | Percentage |
|---|---|---|
| Normal | 97,278 | 19.69 |
| DOS | 391,458 | 79.24 |
| U2R | 52 | 0.01 |
| Probe | 4107 | 0.83 |
| R2L | 1126 | 0.23 |
| Total | 494,021 | 100 |
| Class | Number of Records | Number of Novel Attacks |
|---|---|---|
| Normal | 60,593 | — |
| DOS | 229,853 | 6555 |
| U2R | 228 | 189 |
| Probe | 4166 | 1789 |
| R2L | 16,189 | 10,196 |
| Total | 311,029 | 18,729 |
| Feature Name | Type Setting 1 | Type Setting 2 |
|---|---|---|
| protocol type = tcp | tcp = 1 | others = 0 |
| protocol type = udp | udp = 1 | others = 0 |
| protocol type = icmp | icmp = 1 | others = 0 |
| flag | SF = 1 | others = 0 |
| Class | Predicted Negative Class | Predicted Positive Class |
|---|---|---|
| Actual negative class | True Negative (TN) | False Positive (FP) |
| Actual positive class | False Negative (FN) | True Positive (TP) |
| Model | Number of Features | Selected Features |
|---|---|---|
| ) [19] | 28 | 7, 2, 4, 19, 15, 16, 18, 17, 31, 14, 28, 23, 20, 26, 11, 27, 40, 3, 29, 1, 42, 13, 32, 38, 30, 39, 5, 41 |
| ) [19] | 31 | 7, 2, 19, 15, 16, 18, 17, 14, 23, 20, 31, 26, 28, 11, 27, 40, 29, 3, 1, 42, 39, 30, 4, 5, 32, 13, 41, 36, 38, 35, 34 |
| mRMR [20] | 11 | 7, 19, 2, 4, 28, 13, 3, 38, 31, 32, 40 |
| ) [21] | 23 | 7, 2, 13, 3, 32, 28, 19, 15, 18, 23, 31, 26, 16, 27, 20, 29, 14, 4, 11, 17, 40, 42, 38 |
| ) [21] | 31 | 7, 2, 31, 19, 15, 18, 23, 27, 28, 3, 16, 26, 20, 32, 14, 29, 11, 17, 40, 4, 30, 42, 39, 13, 5, 38, 41, 1, 36, 35, 37 |
| CIMI [22] | 17 | 7, 2, 13, 3, 32, 28, 19, 15, 18, 23, 31, 26, 16, 27, 20, 29, 14 |
| MMIFS [32] | 6 | 7, 2, 4, 13, 38, 3 |
| FMIFS [33] | 12 | 19, 15, 13, 31, 18, 20, 17, 38, 7, 4, 2, 16 |
| RPFMI | 23 | 7, 2, 13, 4, 19, 15, 16, 17, 18, 14, 28, 20, 23, 31, 29, 11, 26, 27, 40, 42, 3, 38, 1 |
| Model | FP | FN | TN | TP |
|---|---|---|---|---|
| All features | 0.26 | 195.21 | 1999.74 | 1804.79 |
| MIFS ) [19] | 9.44 | 0.66 | 1990.56 | 1999.34 |
| MIFS ) [19] | 39.84 | 1.64 | 1960.16 | 1998.36 |
| mRMR [20] | 9.2 | 0.1 | 1990.8 | 1999.9 |
| MIFS-U ) [21] | 9.11 | 0.09 | 1990.89 | 1999.91 |
| MIFS-U ) [21] | 38.3667 | 0.9833 | 1961.633 | 1999.017 |
| CIMI [22] | 9.2667 | 0.0333 | 1990.733 | 1999.967 |
| MMIFS [32] | 11.78 | 0.07 | 1988.22 | 1999.93 |
| FMIFS [33] | 9.44 | 0.07 | 1990.56 | 1999.93 |
| RPFMI | 9.08 | 0.06 | 1990.92 | 1999.94 |
| Algorithm | Number of Features | Selected Features |
|---|---|---|
| ) [19] | 15 | 8, 9, 16, 21, 22, 23, 4, 27, 10, 12, 20, 19, 26, 39, 15 |
| ) [19] | 19 | 8, 9, 16, 21, 22, 23, 10, 4, 27, 12, 20, 19, 26, 17, 15, 5, 39, 14, 18 |
| mRMR [20] | 16 | 8, 9, 16, 21, 22, 23, 4, 27, 10, 39, 15, 12, 11, 18, 14, 19 |
| ) [21] | 3 | 8, 1, 2 |
| ) [21] | 3 | 8, 1, 2 |
| CIMI [22] | 2 | 8, 1 |
| MMIFS [32] | 14 | 8, 9, 16, 21, 22, 23, 4, 27, 39, 10, 15, 11, 18, 14 |
| FMIFS [33] | 9 | 8, 9, 16, 21, 22, 23, 27, 4, 10 |
| RPFMI | 16 | 8, 9, 16, 21, 22, 23, 10, 4, 27, 39, 15, 11, 14, 18, 12, 19 |
| Model | FP | FN | TN | TP |
|---|---|---|---|---|
| All features | 670.7667 | 119.8667 | 1129.233 | 80.1333 |
| ) [19] | 0.8 | 139.0333 | 1799.2 | 60.9667 |
| ) [19] | 4.6667 | 128.2333 | 1795.333 | 71.7667 |
| mRMR [20] | 7.3333 | 70.5333 | 1792.667 | 129.4667 |
| ) [21] | 9.8333 | 90.9 | 1790.167 | 109.1 |
| ) [21] | 9.8333 | 90.9 | 1790.167 | 109.1 |
| CIMI [22] | 9.9333 | 101 | 1790.067 | 99 |
| MMIFS [32] | 5.2400 | 101.6 | 1794.76 | 98.4 |
| FMIFS [33] | 1525 | 0.0273 | 275 | 199.9727 |
| RPFMI | 6.6667 | 69.5333 | 1793.333 | 130.4667 |
| Algorithm | Number of Features | Selected Features |
|---|---|---|
| ) [19] | 14 | 8, 9, 10, 14, 15, 16, 19, 21, 22, 20, 4, 17, 12, 18 |
| ) [19] | 20 | 8, 9, 10, 14, 15, 16, 19, 21, 22, 20, 12, 18, 4, 17, 26, 27, 23, 31, 30, 11 |
| mRMR [20] | 12 | 8, 9, 10, 14, 15, 16, 19, 21, 22, 20, 4, 17 |
| ) [21] | 30 | 8, 1, 2, 3, 4, 5, 6, 7, 11, 12, 13, 17, 18, 20, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38 |
| ) [21] | 30 | 8, 1, 2, 3, 4, 5, 6, 7, 11, 12, 13, 17, 18, 20, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38 |
| CIMI [22] | 27 | 8, 1, 9, 10, 14, 15, 16, 19, 21, 22, 32, 3, 4, 17, 20, 12, 23, 6, 34, 38, 18, 26, 27, 11, 24, 37, 31 |
| MMIFS [32] | 10 | 8, 9, 10, 12, 15, 16, 21, 22, 14, 19 |
| FMIFS [33] | 8 | 8, 9, 10, 12, 15, 16, 21, 14 |
| RPFMI | 5 | 8, 9, 10, 12, 15 |
| Model | FP | FN | TN | TP |
|---|---|---|---|---|
| All features | 89.47 | 189.89 | 1710.53 | 10.11 |
| MIFS () [19] | 35.84 | 176.1 | 1764.16 | 23.9 |
| MIFS () [19] | 41.51 | 161.535 | 1758.49 | 38.465 |
| mRMR [20] | 71.36 | 173.42 | 1728.64 | 26.58 |
| MIFS-U () [21] | 2.25 | 199.22 | 1797.75 | 0.78 |
| MIFS-U () [21] | 2.25 | 199.22 | 1797.75 | 0.78 |
| CIMI [22] | 79.04 | 170.47 | 1720.96 | 29.53 |
| MMIFS [32] | 0.13 | 181.05 | 1799.87 | 18.95 |
| FMIFS [33] | 0.13 | 180.64 | 1799.87 | 19.36 |
| RPFMI | 0.13 | 178.33 | 1799.87 | 21.67 |
| Algorithm | Number of Features | Selected Features |
|---|---|---|
| MIFS () [19] | 14 | 16, 4, 17, 14, 20, 15, 12, 7, 13, 8, 2, 11, 6, 19 |
| MIFS () [19] | 14 | 16, 4, 17, 14, 20, 15, 12, 7, 13, 8, 2, 11, 6, 19 |
| mRMR [20] | 7 | 16, 17, 4, 14, 20, 19, 2 |
| MIFS-U () [21] | 14 | 16, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 |
| MIFS-U () [21] | 14 | 16, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 |
| CIMI [22] | 4 | 16, 1, 19, 17 |
| MMIFS [32] | 7 | 16, 17, 4, 19, 14, 2, 3 |
| FMIFS [33] | 3 | 16, 17, 4 |
| RPFMI | 6 | 16, 17, 4, 14, 19, 2 |
| Model | FP | FN | TN | TP |
|---|---|---|---|---|
| All features | 871.2 | 1.64 | 1128.8 | 1998.36 |
| ) [19] | 124.46 | 33.58 | 1875.54 | 1966.42 |
| ) [19] | 124.46 | 33.58 | 1875.54 | 1966.42 |
| mRMR [20] | 78.6 | 42.09 | 1921.4 | 1957.91 |
| ) [21] | 662.22 | 212.42 | 1337.78 | 1758.58 |
| ) [21] | 662.22 | 212.42 | 1337.78 | 1758.58 |
| CIMI [22] | 20.69 | 77.45 | 1979.31 | 1922.55 |
| MMIFS [32] | 38.25 | 56.09 | 1961.75 | 1943.91 |
| FMIFS [33] | 0 | 1989 | 2000 | 11 |
| RPFMI | 35.75 | 54.31 | 1964.25 | 1945.69 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, F.; Zhao, J.; Niu, X.; Luo, S.; Xin, Y. A Filter Feature Selection Algorithm Based on Mutual Information for Intrusion Detection. Appl. Sci. 2018, 8, 1535. https://doi.org/10.3390/app8091535
Zhao F, Zhao J, Niu X, Luo S, Xin Y. A Filter Feature Selection Algorithm Based on Mutual Information for Intrusion Detection. Applied Sciences. 2018; 8(9):1535. https://doi.org/10.3390/app8091535
Chicago/Turabian StyleZhao, Fei, Jiyong Zhao, Xinxin Niu, Shoushan Luo, and Yang Xin. 2018. "A Filter Feature Selection Algorithm Based on Mutual Information for Intrusion Detection" Applied Sciences 8, no. 9: 1535. https://doi.org/10.3390/app8091535
APA StyleZhao, F., Zhao, J., Niu, X., Luo, S., & Xin, Y. (2018). A Filter Feature Selection Algorithm Based on Mutual Information for Intrusion Detection. Applied Sciences, 8(9), 1535. https://doi.org/10.3390/app8091535