An Automated ECG Beat Classification System Using Deep Neural Networks with an Unsupervised Feature Extraction Technique

 ,
,  , ,
, , 
Abstract
:1. Introduction
2. Deep Learning
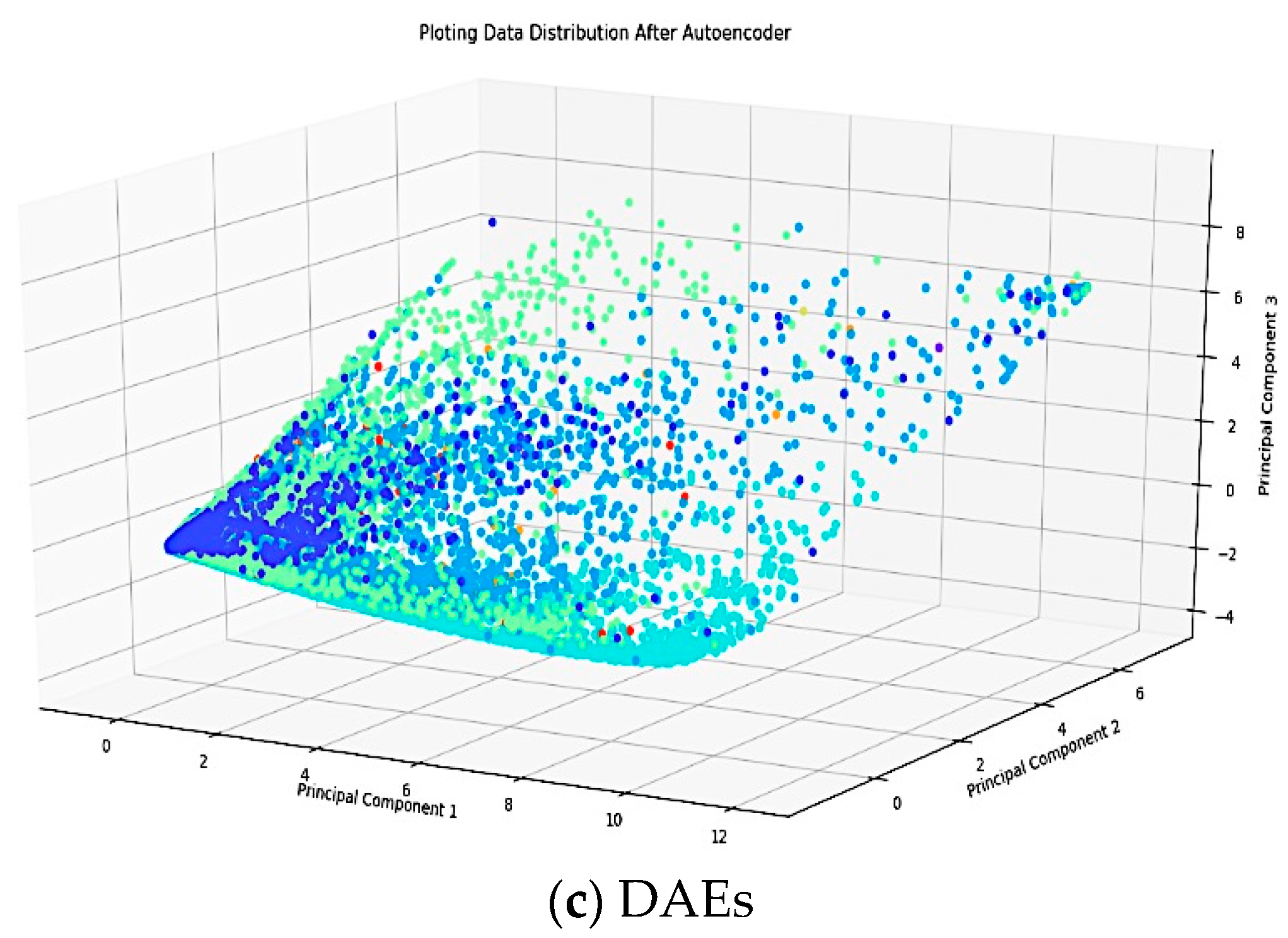
2.1. Deep Auto Encoder
2.2. Proposed Deep Learning Structure
3. Experimental Result
3.1. Data Preparation
3.2. Segmentation and Reconstruction
3.3. Classifier Structure
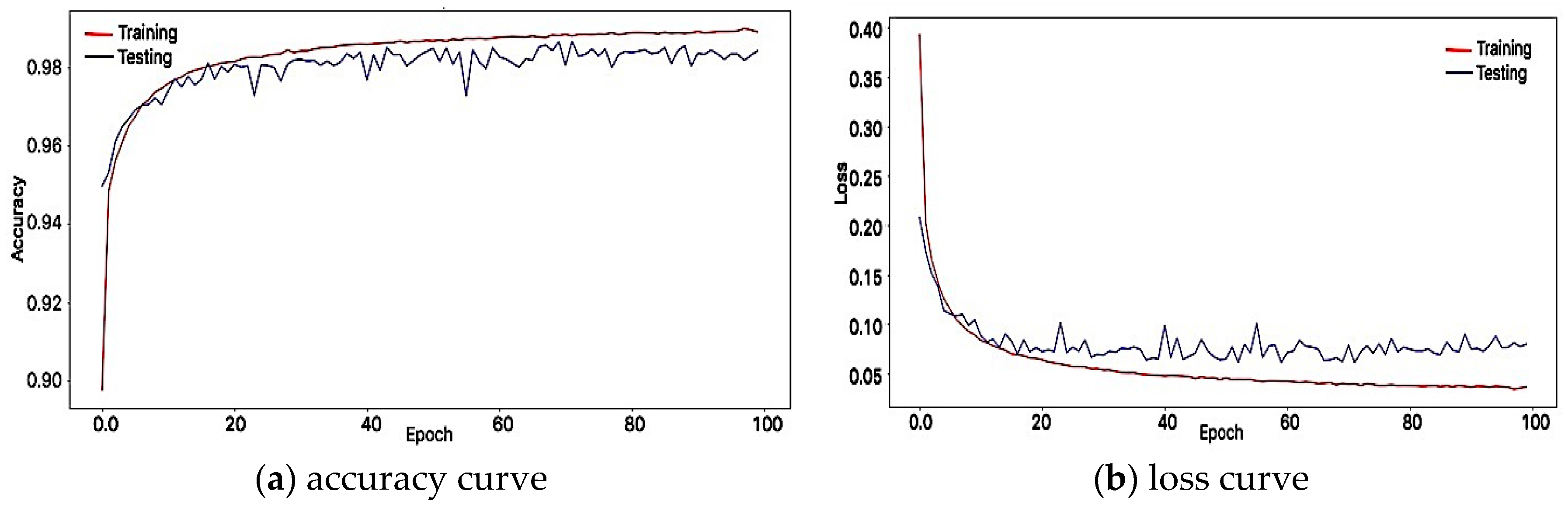
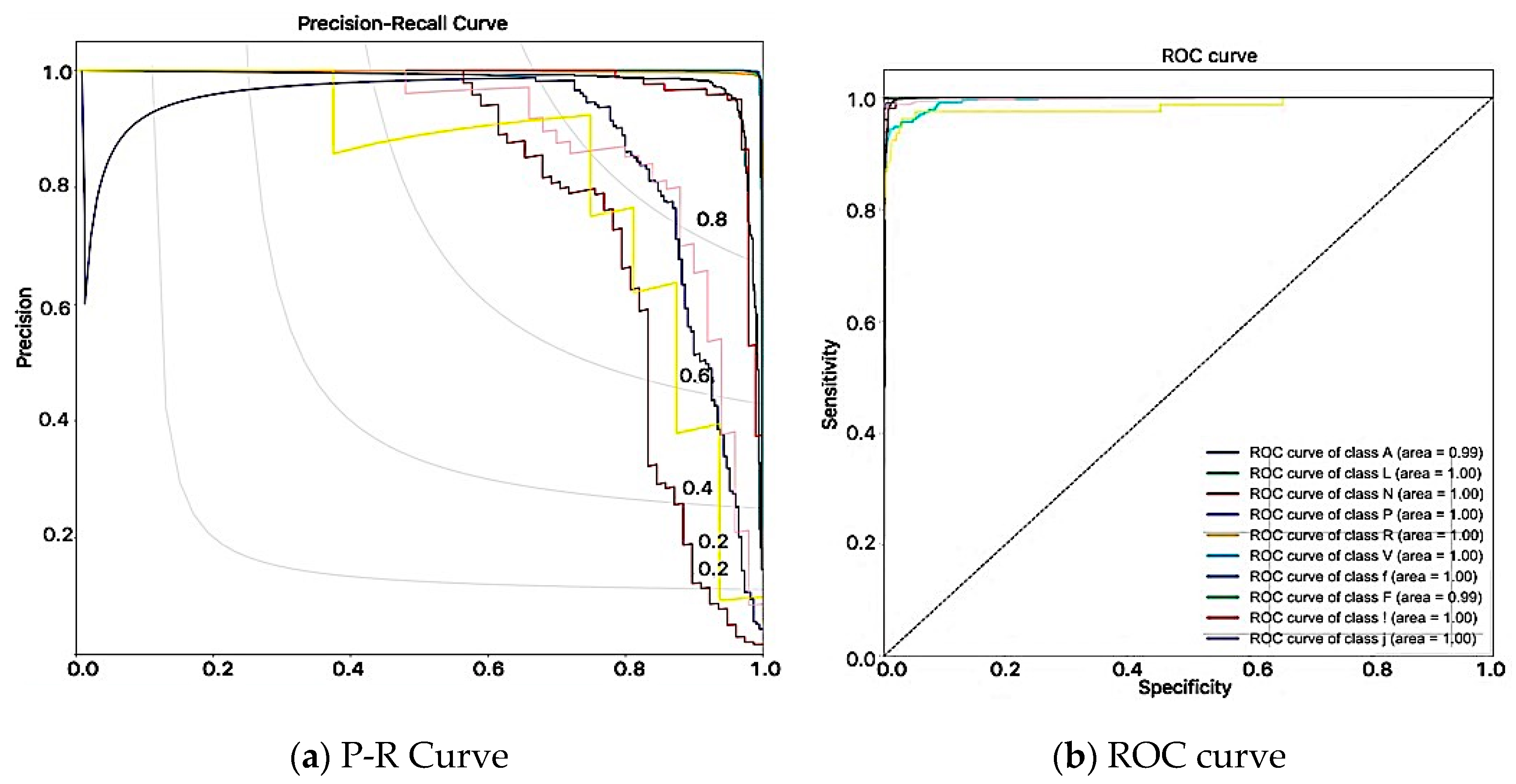
3.4. Results
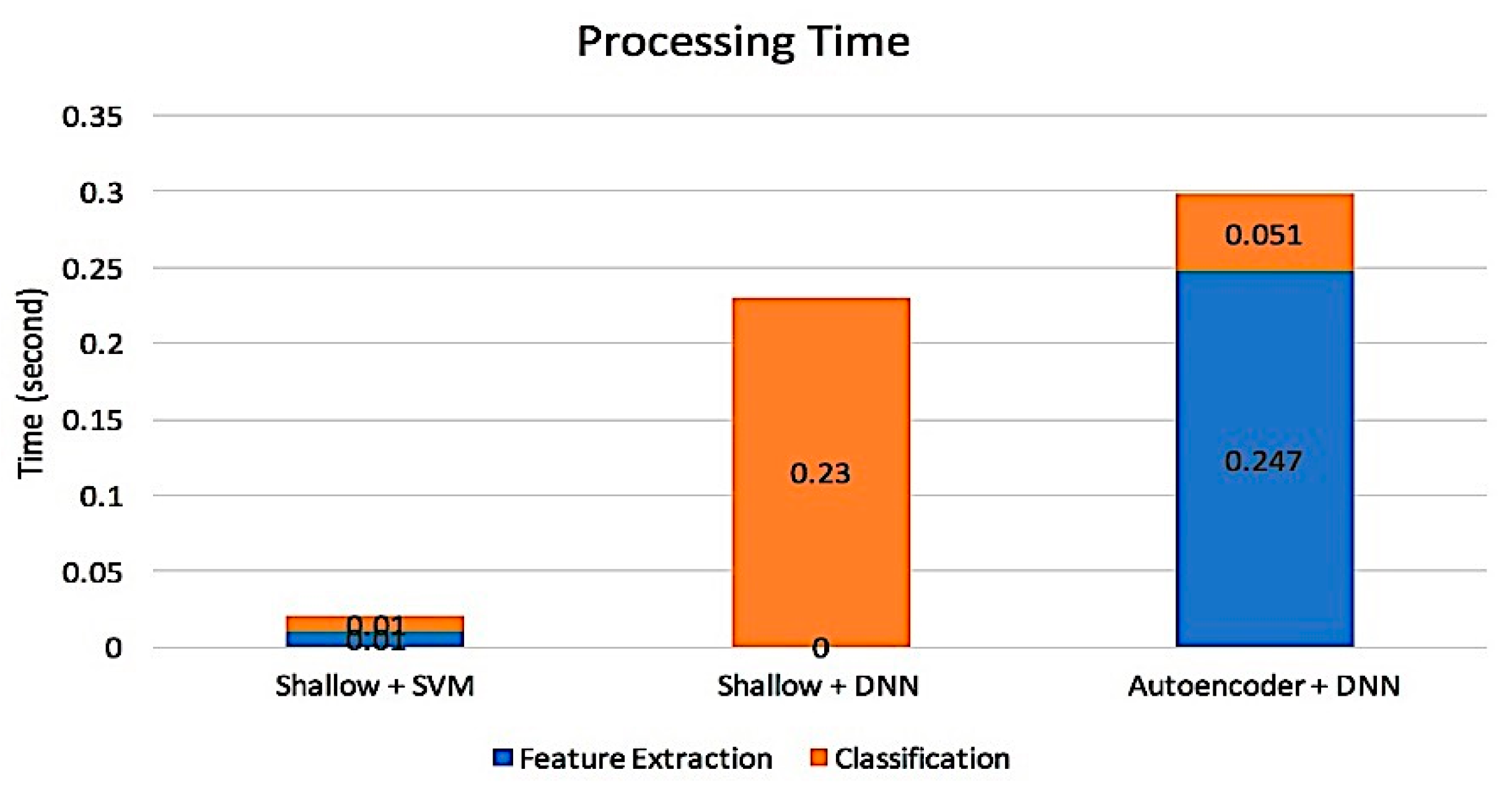
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Erickson, B.J.; Korfiatis, P.; Kline, T.L.; Akkus, Z.; Philbrick, K.; Weston, A.D. Deep learning in radiology: Does one size fit all? J. Am. Coll. Radiol. 2018, 15, 521–526. [Google Scholar] [CrossRef] [PubMed]
- Krittanawong, C.; Zhang, H.; Wang, Z.; Aydar, M.; Kitai, T. Artificial intelligence in precision cardiovascular medicine. J. Am. Coll. Cardiol. 2017, 69, 2657–2664. [Google Scholar] [CrossRef] [PubMed]
- Larrañaga, P.; Calvo, B.; Santana, R.; Bielza, C.; Galdiano, J.; Inza, I.; Lozano, J.A.; Armañanzas, R.; Santafé, G.; Pérez, A.; et al. Machine learning in bioinformatics. Brief. Bioinform. 2006, 7, 86–112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Darmawahyuni, A.; Nurmaini, S.; Sukemi; Caesarendra, W.; Bhayyu, V.; Rachmatullah, M.N.; Firdaus. Deep Learning with a Recurrent Network Structure in the Sequence Modeling of Imbalanced Data for ECG-Rhythm Classifier. Algorithms 2019, 12, 118. [Google Scholar] [CrossRef]
- Al Rahhal, M.M.; Bazi, Y.; AlHichri, H.; Alajlan, N.; Melgani, F.; Yager, R.R. Deep learning approach for active classification of electrocardiogram signals. Inf. Sci. 2016, 345, 340–354. [Google Scholar] [CrossRef]
- Cunningham, P.; Carney, J. Diversity versus quality in classification ensembles based on feature selection. In Proceedings of the European Conference on Machine Learning, Barcelona, Spain, 31 May–2 June 2000; pp. 109–116. [Google Scholar]
- Le, N.-Q.-K.; Ho, Q.-T.; Ou, Y.-Y. Incorporating deep learning with convolutional neural networks and position specific scoring matrices for identifying electron transport proteins. J. Comput. Chem. 2017, 38, 2000–2006. [Google Scholar] [CrossRef] [PubMed]
- Le, N.Q.K.; Huynh, T.-T.; Yapp, E.K.Y.; Yeh, H.-Y. Identification of clathrin proteins by incorporating hyperparameter optimization in deep learning and PSSM profiles. Comput. Methods Programs Biomed. 2019, 177, 81–88. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Nurmaini, A.G.S.; Partan, R.U.; Rachmatullah, M.N. Cardiac Arrhythmias Classification Using Deep Neural Networks and Principal Component Analysis Algorithm. Int. J. Adv. Soft Comput. Appl. 2018, 10, 14–32. [Google Scholar]
- Krumholz, H.M. Big data and new knowledge in medicine: The thinking, training, and tools needed for a learning health system. Health Aff. 2014, 33, 1163–1170. [Google Scholar] [CrossRef]
- Golden, J.A. Deep learning algorithms for detection of lymph node metastases from breast cancer: Helping artificial intelligence be seen. JAMA 2017, 318, 2184–2186. [Google Scholar] [CrossRef] [PubMed]
- Sengupta, P.P.; Huang, Y.M.; Bansal, M.; Ashrafi, A.; Fisher, M.; Shameer, K.; Gall, W.; Dudley, J.T. Cognitive machine-learning algorithm for cardiac imaging: A pilot study for differentiating constrictive pericarditis from restrictive cardiomyopathy. Circ. Cardiovasc. Imaging 2016, 9, e004330. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, L.; Rastegar-Mojarad, M.; Moon, S.; Shen, F.; Afzal, N.; Liu, S.; Zeng, Y.; Mehrabi, S.; Sohn, S.; et al. Clinical information extraction applications: A literature review. J. Biomed. Inform. 2018, 77, 34–49. [Google Scholar] [CrossRef] [PubMed]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adam, M.; Gertych, A.; Tan, R.S. A deep convolutional neural network model to classify heartbeats. Comput. Biol. Med. 2017, 89, 389–396. [Google Scholar] [CrossRef] [PubMed]
- Rajpurkar, P.; Hannun, A.Y.; Haghpanahi, M.; Bourn, C.; Ng, A.Y. Cardiologist-level arrhythmia detection with convolutional neural networks. arXiv 2017, arXiv:1707.01836. [Google Scholar]
- Zubair, M.; Kim, J.; Yoon, C. An automated ECG beat classification system using convolutional neural networks. In Proceedings of the 2016 6th international conference on IT convergence and security (ICITCS), Prague, Czech Republic, 26–29 September 2016; pp. 1–5. [Google Scholar]
- Sellami, A.; Hwang, H. A robust deep convolutional neural network with batch-weighted loss for heartbeat classification. Expert Syst. Appl. 2019, 122, 75–84. [Google Scholar] [CrossRef]
- Yıldırım, Ö.; Pławiak, P.; Tan, R.S.; Acharya, U.R. Arrhythmia detection using deep convolutional neural network with long duration ECG signals. Comput. Biol. Med. 2018, 102, 411–420. [Google Scholar] [CrossRef] [PubMed]
- Majumdar, A.; Ward, R. Robust greedy deep dictionary learning for ECG arrhythmia classification. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 4400–4407. [Google Scholar]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Proceedings of the 19th International Conference on Neural Information Processing Systems, NIPS’06, Vancouver, BC, Canada, 4–7 December 2006; pp. 153–160. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Nurmaini, S.; Partan, R.U.; Rachmatullah, M.N. Deep classifiers on the electrocardiogram interpretation system. Sriwijaya International Conference on Medical and Sciences. J. Phys Conf. Ser. 2019, 1246. [Google Scholar] [CrossRef]
- Martis, R.J.; Acharya, U.R.; Min, L.C. ECG beat classification using PCA, LDA, ICA and discrete wavelet transform. Biomed. Signal Process. Control 2013, 8, 437–448. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, H.; Zhao, S. Auto-encoder based dimensionality reduction. Neurocomputing 2016, 184, 232–242. [Google Scholar] [CrossRef]
- Javadi, M.; Arani, S.A.A.A.; Sajedin, A.; Ebrahimpour, R. Classification of ECG arrhythmia by a modular neural network based on mixture of experts and negatively correlated learning. Biomed. Signal Process. Control 2013, 8, 289–296. [Google Scholar] [CrossRef]
- van der Maaten, L.; Postma, E.; den Herik, J. Dimensionality reduction: A comparative. J. Mach. Learn. Res. 2009, 10, 66–71. [Google Scholar]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed]
- Moody, G.B.; Mark, R.G. The impact of the MIT-BIH arrhythmia database. IEEE Eng. Med. Biol. Mag. 2001, 20, 45–50. [Google Scholar] [CrossRef] [PubMed]
- Darmawahyuni, A. Coronary Heart Disease Interpretation Based on Deep Neural Network. Comput. Eng. Appl. J. 2019, 8. [Google Scholar] [CrossRef]
- Yildirim, Ö. A novel wavelet sequence based on deep bidirectional LSTM network model for ECG signal classification. Comput. Biol. Med. 2018, 96, 189–202. [Google Scholar] [CrossRef] [PubMed]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef]
- Jiao, Y.; Du, P. Performance measures in evaluating machine learning based bioinformatics predictors for classifications. Quant. Biol. 2016, 4, 320–330. [Google Scholar] [CrossRef] [Green Version]
- Le, N.-Q.-K.; Ho, Q.-T.; Ou, Y.-Y. Classifying the molecular functions of Rab GTPases in membrane trafficking using deep convolutional neural networks. Anal. Biochem. 2018, 555, 33–41. [Google Scholar] [CrossRef]
- Le, N.-Q.-K.; Ou, Y.-Y. Prediction of FAD binding sites in electron transport proteins according to efficient radial basis function networks and significant amino acid pairs. BMC Bioinform. 2016, 17, 298. [Google Scholar] [CrossRef] [PubMed]
- Qin, Q.; Li, J.; Zhang, L.; Yue, Y.; Liu, C. Combining low-dimensional wavelet features and support vector machine for arrhythmia beat classification. Sci. Rep. 2017, 7, 6067. [Google Scholar] [CrossRef] [PubMed]
- Mathews, S.M.; Kambhamettu, C.; Barner, K.E. A novel application of deep learning for single-lead ECG classification. Comput. Biol. Med. 2018, 99, 53–62. [Google Scholar] [CrossRef] [PubMed]
- Sannino, G.; de Pietro, G. A deep learning approach for ECG-based heartbeat classification for arrhythmia detection. Futur. Gener. Comput. Syst. 2018, 86, 446–455. [Google Scholar] [CrossRef]
- Singh, S.; Pandey, S.K.; Pawar, U.; Janghel, R.R. Classification of ECG Arrhythmia using Recurrent Neural Networks. Procedia Comput. Sci. 2018, 132, 1290–1297. [Google Scholar] [CrossRef]
- Swapna, G.; Soman, K.P.; Vinayakumar, R. Automated detection of cardiac arrhythmia using deep learning techniques. Procedia Comput. Sci. 2018, 132, 1192–1201. [Google Scholar]
- Yildirim, O.; Baloglu, U.B.; Tan, R.-S.; Ciaccio, E.J.; Acharya, U.R. A new approach for arrhythmia classification using deep coded features and LSTM networks. Comput. Methods Programs Biomed. 2019, 176, 121–133. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Description of Beats | Count | |
|---|---|---|---|
| Training | Testing | ||
| A | Atrial premature contraction | 2316 | 230 |
| L | Left bundle branch block | 7222 | 850 |
| N | Normal | 67545 | 7477 |
| P | Paced | 6315 | 710 |
| R | Right bundle branch block | 6528 | 727 |
| V | Premature ventricular contraction | 6411 | 718 |
| f | Fusion of paced and normal | 884 | 98 |
| F | Fusion of ventricular and normal | 724 | 78 |
| ! | Ventricular flutter wave | 422 | 50 |
| j | Nodal escape | 213 | 16 |
| Model | Feature Learning Structure | DAEs Training Time (s) | Classifier Structure | DNNs Training Time (s) | Proces-Sing Time (s) | DNNs Testing Time (s) |
| 1 | Auto-Encoder (252 - 32 - 252) | 991.07 | MLP (32 - 100 - 10) | 243.46 | 1234.53 | 0.08 |
| 2 | Auto-Encoder (252 - 32 - 252) | 991.07 | DNN 2 HLs (32 - 100 - 50 -10) | 280.94 | 1272.01 | 0.1 |
| 3 | Auto-Encoder (252 - 32 - 252) | 991.07 | DNN 3 HLs (32 - 100 - 50 - 100 - 10) | 313.33 | 1304.41 | 0.1 |
| 4 | Auto-Encoder (252 - 32 - 252) | 991.07 | DNN 4 HLs (32 - 100 - 50 - 100 - 50 - 10) | 327.84 | 1318.92 | 0.13 |
| 5 | Auto-Encoder (252 - 32 - 252) | 991.07 | DNN 5 HLs (32 - 100 - 50 - 100 - 50 - 100 - 10) | 354.68 | 1345.75 | 0.42 |
| 6 | Deep Auto-Encoder (252 - 128 - 64 - 32 - 64 - 128 - 252) | 1866.67 | MLP (32 - 100 - 10) | 241.24 | 2107.91 | 0.08 |
| 7 | Deep Auto-Encoder (252 - 128 - 64 - 32 - 64 - 128 - 252) | 1866.67 | MLP 2 HLs (32 - 100 - 50 - 10) | 273.55 | 2140.22 | 0.09 |
| 8 | Deep Auto-Encoder (252 - 128 - 64 - 32 - 64 - 128 - 252) | 1866.67 | DNN 3 HLs (32 - 100 - 50 - 100 - 10) | 315.34 | 2182.01 | 0.10 |
| 9 | Deep Auto-Encoder (252 - 128 - 64 - 32 - 64 - 128 - 252) | 1866.67 | DNN 4 HLs (32 - 100 - 50 - 100 - 50 - 10) | 353.26 | 2219.93 | 0.12 |
| 10 | Deep Auto-Encoder (252 - 128 - 64 - 32 - 64 - 128 - 252) | 1866.67 | DNN 5 HLs (32 - 100 - 50 - 100 - 50 - 100 - 10) | 381.51 | 2248.18 | 0.14 |
| Method | Input Layer | Output Layer | Hidden Layer Neuron | Activation Function Hidden | Activation Function Output | Learning Rate | Loss Function | Batch Size |
|---|---|---|---|---|---|---|---|---|
| DAEs Pre-Training | 252 | 252 | 128-64-32-64-128 | ReLU | Sigmoid | 0.0001 | MSE | 8 |
| DNNs Fine-Tuning | 32 | 10 | 100-50-50-50-100 | ReLU | Softmax | 0.001 | Cross-Entropy | 32 |
| Training | Model Validation (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Accuracy | 99.23 | 99.63 | 99.83 | 99.83 | 99.78 | 99.74 | 99.80 | 99.90 | 99.64 | 99.55 |
| Sensitivity | 70.73 | 84.69 | 92.80 | 89.57 | 93.79 | 90.55 | 92.31 | 94.10 | 83.41 | 80.70 |
| Specificity | 99.07 | 99.61 | 99.83 | 99.80 | 99.82 | 99.77 | 99.80 | 99.90 | 99.60 | 99.50 |
| Precision | 81.85 | 94.77 | 95.79 | 96.97 | 93.39 | 94.98 | 94.49 | 97.43 | 93.55 | 91.80 |
| F1-Score | 75.26 | 88.38 | 94.10 | 91.98 | 93.54 | 92.27 | 93.26 | 95.70 | 84.48 | 84.00 |
| Testing | Model Validation (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Accuracy | 99.22 | 99.55 | 99.71 | 99.74 | 99.64 | 99.62 | 99.68 | 99.73 | 99.58 | 99.52 |
| Sensitivity | 69.25 | 82.00 | 88.29 | 86.06 | 90.18 | 86.36 | 89.97 | 91.20 | 80.72 | 80.41 |
| Specificity | 99.08 | 99.54 | 99.72 | 99.71 | 99.69 | 99.67 | 99.68 | 99.80 | 99.55 | 99.46 |
| Precision | 80.46 | 91.37 | 90.32 | 94.12 | 88.88 | 89.26 | 89.26 | 93.60 | 94.97 | 93.35 |
| F1-Score | 73.78 | 85.75 | 89.26 | 88.59 | 89.45 | 87.63 | 89.78 | 91.80 | 80.93 | 85.38 |
| Class | A | L | N | P | R | V | F | F | ! | j |
|---|---|---|---|---|---|---|---|---|---|---|
| A | 2086 | 3 | 210 | 0 | 14 | 0 | 0 | 0 | 0 | 3 |
| L | 0 | 7222 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| N | 39 | 10 | 67412 | 0 | 10 | 44 | 2 | 6 | 0 | 22 |
| P | 0 | 0 | 1 | 6303 | 0 | 1 | 10 | 0 | 0 | 0 |
| R | 11 | 0 | 4 | 0 | 6511 | 2 | 0 | 0 | 0 | 0 |
| V | 2 | 5 | 29 | 0 | 0 | 6354 | 0 | 20 | 1 | 0 |
| f | 1 | 2 | 38 | 6 | 0 | 3 | 832 | 0 | 0 | 2 |
| F | 2 | 1 | 73 | 0 | 0 | 35 | 0 | 613 | 0 | 0 |
| ! | 0 | 0 | 4 | 1 | 0 | 4 | 0 | 1 | 412 | 0 |
| j | 1 | 0 | 47 | 0 | 4 | 0 | 0 | 0 | 0 | 161 |
| Class | A | L | N | P | R | V | f | F | ! | j |
|---|---|---|---|---|---|---|---|---|---|---|
| A | 190 | 0 | 37 | 0 | 0 | 1 | 0 | 0 | 0 | 2 |
| L | 0 | 847 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| N | 7 | 1 | 7449 | 0 | 2 | 13 | 1 | 0 | 0 | 4 |
| P | 0 | 0 | 0 | 707 | 0 | 0 | 3 | 0 | 0 | 0 |
| R | 4 | 0 | 2 | 0 | 720 | 1 | 0 | 0 | 0 | 0 |
| V | 0 | 5 | 10 | 1 | 0 | 693 | 0 | 4 | 5 | 0 |
| f | 1 | 1 | 7 | 1 | 0 | 0 | 87 | 1 | 0 | 0 |
| F | 0 | 1 | 15 | 0 | 0 | 7 | 0 | 54 | 1 | 0 |
| ! | 0 | 1 | 0 | 0 | 0 | 2 | 0 | 0 | 47 | 0 |
| j | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 13 |
| Classifier | Accuracy (%) | Precision (%) | Sensitivity (%) | Specificity (%) | F1-Score (%) |
|---|---|---|---|---|---|
| Random Forest + PCA | 98.85 | 87.21 | 60.00 | 98.30 | 66.89 |
| SVM + PCA + DWT | 99.76 | 98.30 | 97.22 | 99.69 | 97.94 |
| DL with SAE | 99.52 | 90.70 | 86.68 | 99.45 | 81.70 |
| DNNs + PCA + DWT | 99.76 | 98.20 | 91.80 | 99.78 | 97.80 |
| DL (proposed method) | 99.73 | 93.60 | 91.20 | 99.80 | 91.80 |
| No | Classifier | Accuracy (%) | Sensitivity (%) | Specificity (%) | Precision (%) | F1 –Score (%) |
|---|---|---|---|---|---|---|
| 1 | CNN [17] | 92.70 | - | - | - | - |
| 2 | DBN [36] | 98.60 | 88.00 | 99.25 | - | - |
| 3 | DBN and SAE [20] | 90.20 | 51.03 | 82.76 | - | - |
| 4 | CNN [16] | - | 78.4 | - | 80.00 | 77.60 |
| 5 | CNN [15] | 89.05 | 95.90 | 88.37 | - | - |
| 6 | CNN [19] | 99.39 | - | - | - | - |
| 7 | RNN [31] | 91.33 | - | - | - | - |
| 8 | RBM and DBN [37] | 94.60 | - | - | - | - |
| 9 | DNN [38] | 99.68 | 99.48 | 99.83 | - | - |
| 10 | RNN [39] | 88.10 | 92.40 | 83.35 | - | - |
| 11 | CNN and RNN [40] | 83.40 | - | - | - | - |
| 12 | CNN [18] | 93.91 | 93.93 | 94.19 | - | - |
| 13 | DEEP CODED FEATURES and LSTM [41] | 99.23 | - | - | - | - |
| 14 | Our DL Model | 99.73 | 91.20 | 99.80 | 93.60 | 91.80 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nurmaini, S.; Umi Partan, R.; Caesarendra, W.; Dewi, T.; Naufal Rahmatullah, M.; Darmawahyuni, A.; Bhayyu, V.; Firdaus, F. An Automated ECG Beat Classification System Using Deep Neural Networks with an Unsupervised Feature Extraction Technique. Appl. Sci. 2019, 9, 2921. https://doi.org/10.3390/app9142921
Nurmaini S, Umi Partan R, Caesarendra W, Dewi T, Naufal Rahmatullah M, Darmawahyuni A, Bhayyu V, Firdaus F. An Automated ECG Beat Classification System Using Deep Neural Networks with an Unsupervised Feature Extraction Technique. Applied Sciences. 2019; 9(14):2921. https://doi.org/10.3390/app9142921
Chicago/Turabian StyleNurmaini, Siti, Radiyati Umi Partan, Wahyu Caesarendra, Tresna Dewi, Muhammad Naufal Rahmatullah, Annisa Darmawahyuni, Vicko Bhayyu, and Firdaus Firdaus. 2019. "An Automated ECG Beat Classification System Using Deep Neural Networks with an Unsupervised Feature Extraction Technique" Applied Sciences 9, no. 14: 2921. https://doi.org/10.3390/app9142921