Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey

Abstract
1. Introduction
2. Concept and Taxonomy of IDS
2.1. Classification by Detection Methods
2.2. Classification by Source of Data
3. Common Machine Learning Algorithms in IDS
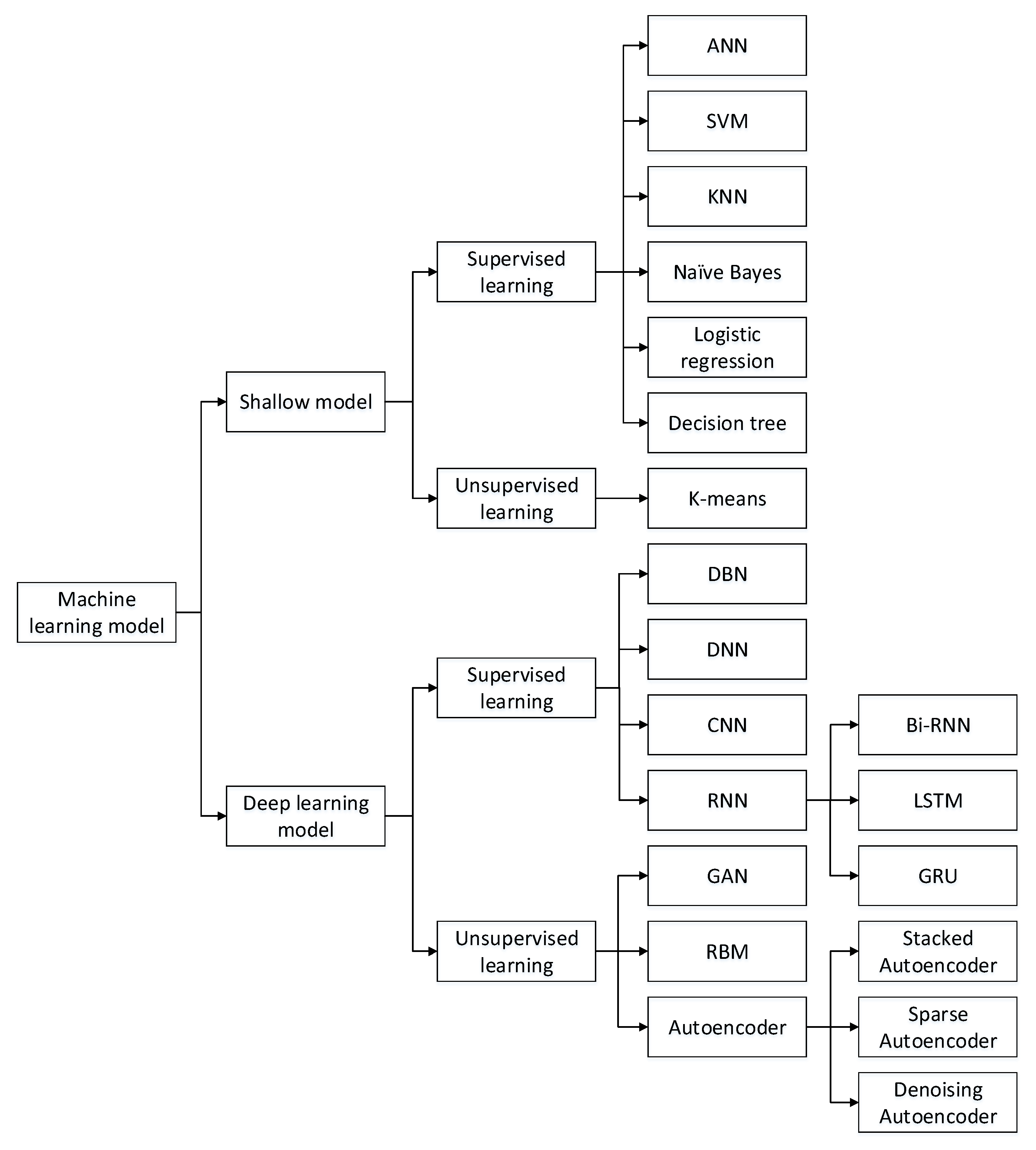
3.1. Machine Learning Models
3.1.1. Shallow Models
3.1.2. Deep Learning Models
3.1.3. Shallow Models Compared to Deep Models
3.2. Metrics
- Accuracy is defined as the ratio of correctly classified samples to total samples. Accuracy is a suitable metric when the dataset is balanced. In real network environments; however, normal samples are far more abundant than are abnormal samples; thus, accuracy may not be a suitable metric.
- Precision (P) is defined as the ratio of true positive samples to predicted positive samples; it represents the confidence of attack detection.
- Recall (R) is defined as the ratio of true positive samples to total positive samples and is also called the detection rate. The detection rate reflects the model’s ability to recognize attacks, which is an important metric in IDS.
- F-measure (F) is defined as the harmonic average of the precision and the recall.
- The false negative rate (FNR) is defined as the ratio of false negative samples to total positive samples. In attack detection, the FNR is also called the missed alarm rate.
- The false positive rate (FPR) is defined as the ratio of false positive samples to predicted positive samples. In attack detection, the FPR is also called the false alarm rate, and it is calculated as follows:
3.3. Benchmark Datasets in IDS
4. Research on Machine Learning-Based IDSs
4.1. Packet-Based Attack Detection
4.1.1. Packet Parsing-Based Detection
4.1.2. Payload Analysis-Based Detection
4.2. Flow-Based Attack Detection
4.2.1. Feature Engineering-Based Detection
4.2.2. Deep Learning-Based Detection
4.2.3. Traffic Grouping-Based Detection
4.3. Session-Based Attack Detection
4.3.1. Statistic-Based Feature Detection Methods
4.3.2. Sequence Feature-Based Detection
4.4. Log-Based Attack Detection
4.4.1. Rule and Machine Learning-Based Hybrid Methods
4.4.2. Log Feature Extraction-Based Detection
4.4.3. Text Analysis-Based Detection
5. Challenges and Future Directions
- The rule-based detection methods have low false alarm rates but high missed alarm rates include considerable expert knowledge. In contrast, the machine learning methods usually have high false alarm rates and low missed alarm rates. The advantages of both methods are complementary. Combining machine learning methods with rule-based systems, such as Snort [70,71,72,73], can result in IDSs with low false alarm rates and low missed alarm rates.
- Compared with shallow models, deep learning methods learn features directly from raw data, and their fitting ability is stronger. Deep learning models with deep structures can be used for classification, feature extraction, feature reduction, data denoising, and data augmentation tasks. Thus, deep learning methods can improve IDSs from many aspects.
- Unsupervised learning methods require no labeled data; thus they can be used even when a dataset shortage exists. The usual approach involves dividing data using an unsupervised learning model, manually labeling the clusters, and then training a classification model with supervised learning [89,90,91,92].
- In attack detection, the real-time requirement is essential. Thus, one research direction is to improve the efficiency of machine learning models. Reducing the time required for data collection and storage is also of concern.
- Interpretability is important for practical IDSs. Many machine learning models, especially deep learning models, are black boxes. These models report only the detection results and have no interpretable basis [93]. However, every cyber security decision should be made cautiously. An output result with no identifiable reason is not convincing. Thus, an IDS with high accuracy, high efficiency and interpretability is more practical.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Anderson, J.P. Computer Security Threat Monitoring and Surveillance; Technical Report; James P. Anderson Company: Philadelphia, PA, USA, 1980. [Google Scholar]
- Michie, D.; Spiegelhalter, D.J.; Taylor, C. Machine Learning, Neurall and Statistical Classification; Ellis Horwood Series in Artificial Intelligence: New York, NY, USA, 1994; Volume 13. [Google Scholar]
- Buczak, A.L.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun. Surv. Tutor. 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Xin, Y.; Kong, L.; Liu, Z.; Chen, Y.; Li, Y.; Zhu, H.; Gao, M.; Hou, H.; Wang, C. Machine learning and deep learning methods for cybersecurity. IEEE Access 2018, 6, 35365–35381. [Google Scholar] [CrossRef]
- Agrawal, S.; Agrawal, J. Survey on anomaly detection using data mining techniques. Procedia Comput. Sci. 2015, 60, 708–713. [Google Scholar] [CrossRef]
- Denning, D.E. An intrusion-detection model. IEEE Trans. Softw. Eng. 1987, 222–232. [Google Scholar] [CrossRef]
- Heberlein, L.T.; Dias, G.V.; Levitt, K.N.; Mukherjee, B.; Wood, J.; Wolber, D. A network security monitor. In Proceedings of the 1990 IEEE Computer Society Symposium on Research in Security and Privacy, Oakland, CA, USA, 7–9 May 1990; pp. 296–304. [Google Scholar]
- Kuang, F.; Zhang, S.; Jin, Z.; Xu, W. A novel SVM by combining kernel principal component analysis and improved chaotic particle swarm optimization for intrusion detection. Soft Comput. 2015, 19, 1187–1199. [Google Scholar] [CrossRef]
- Syarif, A.R.; Gata, W. Intrusion detection system using hybrid binary PSO and K-nearest neighborhood algorithm. In Proceedings of the 2017 11th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 31 October 2017; pp. 181–186. [Google Scholar]
- Pajouh, H.H.; Dastghaibyfard, G.; Hashemi, S. Two-tier network anomaly detection model: A machine learning approach. J. Intell. Inf. Syst. 2017, 48, 61–74. [Google Scholar] [CrossRef]
- Mahmood, H.A. Network Intrusion Detection System (NIDS) in Cloud Environment based on Hidden Naïve Bayes Multiclass Classifier. Al-Mustansiriyah J. Sci. 2018, 28, 134–142. [Google Scholar] [CrossRef]
- Shah, R.; Qian, Y.; Kumar, D.; Ali, M.; Alvi, M. Network intrusion detection through discriminative feature selection by using sparse logistic regression. Future Internet 2017, 9, 81. [Google Scholar] [CrossRef]
- Peng, K.; Leung, V.C.; Huang, Q. Clustering approach based on mini batch kmeans for intrusion detection system over big data. IEEE Access 2018, 6, 11897–11906. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Deng, J.; Zhang, Z.; Marchi, E.; Schuller, B. Sparse autoencoder-based feature transfer learning for speech emotion recognition. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 511–516. [Google Scholar]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade; Springer: Berlin, Germany, 2012; pp. 599–619. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Boureau, Y.l.; Cun, Y.L.; Ranzato, M.A. Sparse feature learning for deep belief networks. In Proceedings of the 21st Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008; pp. 1185–1192. [Google Scholar]
- Zhao, G.; Zhang, C.; Zheng, L. Intrusion detection using deep belief network and probabilistic neural network. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; Volume 1, pp. 639–642. [Google Scholar]
- Alrawashdeh, K.; Purdy, C. Toward an online anomaly intrusion detection system based on deep learning. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 195–200. [Google Scholar]
- Yang, Y.; Zheng, K.; Wu, C.; Niu, X.; Yang, Y. Building an effective intrusion detection system using the modified density peak clustering algorithm and deep belief networks. Appl. Sci. 2019, 9, 238. [Google Scholar] [CrossRef]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 806–813. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar] [CrossRef]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Graves, A.; Jaitly, N. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1764–1772. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should i trust you?: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Li, J.; Monroe, W.; Jurafsky, D. Understanding neural networks through representation erasure. arXiv 2016, arXiv:1612.08220. [Google Scholar]
- Fong, R.C.; Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3429–3437. [Google Scholar]
- DARPA1998 Dataset. 1998. Available online: http://www.ll.mit.edu/r-d/datasets/1998-darpa-intrusion-detection-evaluation-dataset (accessed on 16 October 2019).
- KDD99 Dataset. 1999. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 16 October 2019).
- NSL-KDD99 Dataset. 2009. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 16 October 2019).
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications And Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Mayhew, M.; Atighetchi, M.; Adler, A.; Greenstadt, R. Use of machine learning in big data analytics for insider threat detection. In Proceedings of the MILCOM 2015—2015 IEEE Military Communications Conference, Canberra, Australia, 10–12 November 2015; pp. 915–922. [Google Scholar]
- Hu, L.; Li, T.; Xie, N.; Hu, J. False positive elimination in intrusion detection based on clustering. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 519–523. [Google Scholar]
- Liu, H.; Lang, B.; Liu, M.; Yan, H. CNN and RNN based payload classification methods for attack detection. Knowl.-Based Syst. 2019, 163, 332–341. [Google Scholar] [CrossRef]
- Min, E.; Long, J.; Liu, Q.; Cui, J.; Chen, W. TR-IDS: Anomaly-based intrusion detection through text-convolutional neural network and random forest. Secur. Commun. Netw. 2018, 2018, 4943509. [Google Scholar] [CrossRef]
- Zeng, Y.; Gu, H.; Wei, W.; Guo, Y. Deep-Full-Range: A Deep Learning Based Network Encrypted Traffic Classification and Intrusion Detection Framework. IEEE Access 2019, 7, 45182–45190. [Google Scholar] [CrossRef]
- Yu, Y.; Long, J.; Cai, Z. Network intrusion detection through stacking dilated convolutional autoencoders. Secur. Commun. Netw. 2017, 2017, 4184196. [Google Scholar] [CrossRef]
- Rigaki, M.; Garcia, S. Bringing a gan to a knife-fight: Adapting malware communication to avoid detection. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 70–75. [Google Scholar]
- Goeschel, K. Reducing false positives in intrusion detection systems using data-mining techniques utilizing support vector machines, decision trees, and naive Bayes for off-line analysis. In Proceedings of the SoutheastCon 2016, Norfolk, VA, USA, 30 March–3 April 2016; pp. 1–6. [Google Scholar]
- Kuttranont, P.; Boonprakob, K.; Phaudphut, C.; Permpol, S.; Aimtongkhamand, P.; KoKaew, U.; Waikham, B.; So-In, C. Parallel KNN and Neighborhood Classification Implementations on GPU for Network Intrusion Detection. J. Telecommun. Electron. Comput. Eng. 2017, 9, 29–33. [Google Scholar]
- Potluri, S.; Ahmed, S.; Diedrich, C. Convolutional Neural Networks for Multi-class Intrusion Detection System. In Mining Intelligence and Knowledge Exploration; Springer: Cham, Switzerland, 2018; pp. 225–238. [Google Scholar]
- Zhang, B.; Yu, Y.; Li, J. Network Intrusion Detection Based on Stacked Sparse Autoencoder and Binary Tree Ensemble Method. In Proceedings of the 2018 IEEE International Conference on Communications Workshops (ICC Workshops), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Zhang, H.; Yu, X.; Ren, P.; Luo, C.; Min, G. Deep Adversarial Learning in Intrusion Detection: A Data Augmentation Enhanced Framework. arXiv 2019, arXiv:1901.07949. [Google Scholar]
- Teng, S.; Wu, N.; Zhu, H.; Teng, L.; Zhang, W. SVM-DT-based adaptive and collaborative intrusion detection. IEEE/CAA J. Autom. Sin. 2017, 5, 108–118. [Google Scholar] [CrossRef]
- Ma, T.; Wang, F.; Cheng, J.; Yu, Y.; Chen, X. A hybrid spectral clustering and deep neural network ensemble algorithm for intrusion detection in sensor networks. Sensors 2016, 16, 1701. [Google Scholar] [CrossRef]
- Ahmim, A.; Maglaras, L.; Ferrag, M.A.; Derdour, M.; Janicke, H. A novel hierarchical intrusion detection system based on decision tree and rules-based models. In Proceedings of the 2019 15th International Conference on Distributed Computing in Sensor Systems (DCOSS), Santorini Island, Greece, 29–31 May 2019; pp. 228–233. [Google Scholar]
- Alseiari, F.A.A.; Aung, Z. Real-time anomaly-based distributed intrusion detection systems for advanced Metering Infrastructure utilizing stream data mining. In Proceedings of the 2015 International Conference on Smart Grid and Clean Energy Technologies (ICSGCE), Offenburg, Germany, 20–23 October 2015; pp. 148–153. [Google Scholar]
- Yuan, X.; Li, C.; Li, X. DeepDefense: identifying DDoS attack via deep learning. In Proceedings of the 2017 IEEE International Conference on Smart Computing (SMARTCOMP), Hong Kong, China, 29–31 May 2017; pp. 1–8. [Google Scholar]
- Radford, B.J.; Apolonio, L.M.; Trias, A.J.; Simpson, J.A. Network traffic anomaly detection using recurrent neural networks. arXiv 2018, arXiv:1803.10769. [Google Scholar]
- Wang, W.; Sheng, Y.; Wang, J.; Zeng, X.; Ye, X.; Huang, Y.; Zhu, M. HAST-IDS: Learning hierarchical spatial-temporal features using deep neural networks to improve intrusion detection. IEEE Access 2017, 6, 1792–1806. [Google Scholar] [CrossRef]
- Meng, W.; Li, W.; Kwok, L.F. Design of intelligent KNN-based alarm filter using knowledge-based alert verification in intrusion detection. Secur. Commun. Netw. 2015, 8, 3883–3895. [Google Scholar] [CrossRef]
- McElwee, S.; Heaton, J.; Fraley, J.; Cannady, J. Deep learning for prioritizing and responding to intrusion detection alerts. In Proceedings of the MILCOM 2017—2017 IEEE Military Communications Conference (MILCOM), Baltimore, MD, USA, 23–25 October 2017; pp. 1–5. [Google Scholar]
- Tran, N.N.; Sarker, R.; Hu, J. An Approach for Host-Based Intrusion Detection System Design Using Convolutional Neural Network. In Proceedings of the International Conference on Mobile Networks and Management, Chiba, Japan, 23–25 September 2017; Springer: Berlin, Germany, 2017; pp. 116–126. [Google Scholar]
- Tuor, A.; Kaplan, S.; Hutchinson, B.; Nichols, N.; Robinson, S. Deep learning for unsupervised insider threat detection in structured cybersecurity data streams. In Proceedings of the Workshops at the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Bohara, A.; Thakore, U.; Sanders, W.H. Intrusion detection in enterprise systems by combining and clustering diverse monitor data. In Proceedings of the Symposium and Bootcamp on the Science of Security, Pittsburgh, PA, USA, 19–21 April 2016; pp. 7–16. [Google Scholar]
- Uwagbole, S.O.; Buchanan, W.J.; Fan, L. Applied machine learning predictive analytics to SQL injection attack detection and prevention. In Proceedings of the 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 1087–1090. [Google Scholar]
- Vartouni, A.M.; Kashi, S.S.; Teshnehlab, M. An anomaly detection method to detect web attacks using Stacked Auto-Encoder. In Proceedings of the 2018 6th Iranian Joint Congress on Fuzzy and Intelligent Systems (CFIS), Kerman, Iran, 28 February–2 March 2018; pp. 131–134. [Google Scholar]
- Potluri, S.; Diedrich, C. Accelerated deep neural networks for enhanced Intrusion Detection System. In Proceedings of the 2016 IEEE 21st International Conference on Emerging Technologies and Factory Automation (ETFA), Berlin, Germany, 6–9 September 2016; pp. 1–8. [Google Scholar]
- Pektaş, A.; Acarman, T. Deep learning to detect botnet via network flow summaries. Neural Comput. Appl. 2018, 1–13. [Google Scholar] [CrossRef]
- Kim, J.; Shin, N.; Jo, S.Y.; Kim, S.H. Method of intrusion detection using deep neural network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Korea, 13–16 February 2017; pp. 313–316. [Google Scholar]
- Shone, N.; Ngoc, T.N.; Phai, V.D.; Shi, Q. A deep learning approach to network intrusion detection. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 41–50. [Google Scholar] [CrossRef]
- Ammar, A. A decision tree classifier for intrusion detection priority tagging. J. Comput. Commun. 2015, 3, 52. [Google Scholar] [CrossRef][Green Version]
- Patel, J.; Panchal, K. Effective intrusion detection system using data mining technique. J. Emerg. Technol. Innov. Res. 2015, 2, 1869–1878. [Google Scholar]
- Khamphakdee, N.; Benjamas, N.; Saiyod, S. Improving intrusion detection system based on snort rules for network probe attacks detection with association rules technique of data mining. J. ICT Res. Appl. 2015, 8, 234–250. [Google Scholar] [CrossRef][Green Version]
- Shah, S.A.R.; Issac, B. Performance comparison of intrusion detection systems and application of machine learning to Snort system. Future Gener. Comput. Syst. 2018, 80, 157–170. [Google Scholar] [CrossRef]
- Fouladi, R.F.; Kayatas, C.E.; Anarim, E. Frequency based DDoS attack detection approach using naive Bayes classification. In Proceedings of the 2016 39th International Conference on Telecommunications and Signal Processing (TSP), Vienna, Austria, 27–29 June 2016; pp. 104–107. [Google Scholar]
- Alkasassbeh, M.; Al-Naymat, G.; Hassanat, A.; Almseidin, M. Detecting distributed denial of service attacks using data mining techniques. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 436–445. [Google Scholar] [CrossRef]
- Niyaz, Q.; Sun, W.; Javaid, A.Y. A deep learning based DDoS detection system in software-defined networking (SDN). arXiv 2016, arXiv:1611.07400. [Google Scholar] [CrossRef]
- Yadav, S.; Subramanian, S. Detection of Application Layer DDoS attack by feature learning using Stacked AutoEncoder. In Proceedings of the 2016 International Conference on Computational Techniques in Information and Communication Technologies (ICCTICT), New Delhi, India, 11–13 March 2016; pp. 361–366. [Google Scholar]
- Nguyen, S.N.; Nguyen, V.Q.; Choi, J.; Kim, K. Design and implementation of intrusion detection system using convolutional neural network for dos detection. In Proceedings of the 2nd International Conference on Machine Learning and Soft Computing, Phu Quoc Island, Vietnam, 2–4 February 2018; pp. 34–38. [Google Scholar]
- Bontemps, L.; McDermott, J.; Le-Khac, N.A. Collective anomaly detection based on long short-term memory recurrent neural networks. In Proceedings of the International Conference on Future Data and Security Engineering, Tho City, Vietnam, 23–25 November 2016; Springer: Cham, Switzerland, 2016; pp. 141–152. [Google Scholar]
- Bapat, R.; Mandya, A.; Liu, X.; Abraham, B.; Brown, D.E.; Kang, H.; Veeraraghavan, M. Identifying malicious botnet traffic using logistic regression. In Proceedings of the 2018 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27 April 2018; pp. 266–271. [Google Scholar]
- Abdelhamid, N.; Thabtah, F.; Abdel-jaber, H. Phishing detection: A recent intelligent machine learning comparison based on models content and features. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 72–77. [Google Scholar]
- Peng, K.; Leung, V.; Zheng, L.; Wang, S.; Huang, C.; Lin, T. Intrusion detection system based on decision tree over big data in fog environment. Wirel. Commun. Mob. Comput. 2018, 2018, 4680867. [Google Scholar] [CrossRef]
- He, Z.; Zhang, T.; Lee, R.B. Machine learning based DDoS attack detection from source side in cloud. In Proceedings of the 2017 IEEE 4th International Conference on Cyber Security and Cloud Computing (CSCloud), New York, NY, USA, 26–28 June 2017; pp. 114–120. [Google Scholar]
- Doshi, R.; Apthorpe, N.; Feamster, N. Machine learning ddos detection for consumer internet of things devices. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 29–35. [Google Scholar]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Shabtai, A.; Breitenbacher, D.; Elovici, Y. N-BaIoT— Network-based detection of IoT botnet attacks using deep autoencoders. IEEE Pervasive Comput. 2018, 17, 12–22. [Google Scholar] [CrossRef]
- Diro, A.; Chilamkurti, N. Leveraging LSTM networks for attack detection in fog-to-things communications. IEEE Commun. Mag. 2018, 56, 124–130. [Google Scholar] [CrossRef]
- Foroutan, S.A.; Salmasi, F.R. Detection of false data injection attacks against state estimation in smart grids based on a mixture Gaussian distribution learning method. IET Cyber-Phys. Syst. Theory Appl. 2017, 2, 161–171. [Google Scholar] [CrossRef]
- He, Y.; Mendis, G.J.; Wei, J. Real-time detection of false data injection attacks in smart grid: A deep learning-based intelligent mechanism. IEEE Trans. Smart Grid 2017, 8, 2505–2516. [Google Scholar] [CrossRef]
- Jing, X.; Bi, Y.; Deng, H. An Innovative Two-Stage Fuzzy kNN-DST Classifier for Unknown Intrusion Detection. Int. Arab. J. Inf. Technol. 2016, 13, 359–366. [Google Scholar]
- Farnaaz, N.; Jabbar, M. Random forest modeling for network intrusion detection system. Procedia Comput. Sci. 2016, 89, 213–217. [Google Scholar] [CrossRef]
- Ravale, U.; Marathe, N.; Padiya, P. Feature selection based hybrid anomaly intrusion detection system using K means and RBF kernel function. Procedia Comput. Sci. 2015, 45, 428–435. [Google Scholar] [CrossRef]
- Jabbar, M.; Aluvalu, R.; Reddy, S. Cluster based ensemble classification for intrusion detection system. In Proceedings of the 9th International Conference on Machine Learning and Computing, Singapore, 24–26 February 2017; pp. 253–257. [Google Scholar]
- Guo, W.; Mu, D.; Xu, J.; Su, P.; Wang, G.; Xing, X. Lemna: Explaining deep learning based security applications. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15 October 2018; pp. 364–379. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Misuse Detection | Anomaly Detection | |
|---|---|---|
| Detection performance | Low false alarm rate; High missed alarm rate | Low missed alarm rate; High false alarm rate |
| Detection efficiency | High, decrease with scale of signature database | Dependent on model complexity |
| Dependence on domain knowledge | Almost all detections depend on domain knowledge | Low, only the feature design depends on domain knowledge |
| Interpretation | Design based on domain knowledge, strong interpretative ability | Outputs only detection results, weak interpretative ability |
| Unknown attack detection | Only detects known attacks | Detects known and unknown attacks |
| Host-Based IDS | Network-Based IDS | |
|---|---|---|
| Source of data | Logs of operating system or application programs | Network traffic |
| Deployment | Every host; Dependent on operating systems; Difficult to deploy | Key network nodes; Easy to deploy |
| Detection efficiency | Low, must process numerous logs | High, can detect attacks in real time |
| Intrusion traceability | Trace the process of intrusion according to system call paths | Trace position and time of intrusion according to IP addresses and timestamps |
| Limitation | Cannot analyze network behaviors | Monitor only the traffic passing through a specific network segment |
| Algorithms | Advantages | Disadvantages | Improvement Measures |
|---|---|---|---|
| ANN | Able to deal with nonlinear data; Strong fitting ability | Apt to overfitting; Prone to become stuck in a local optimum; Model training is time consuming | Adopted improved optimizers, activation functions, and loss functions |
| SVM | Learn useful information from small train set; Strong generation capability | Do not perform well on big data or multiple classification tasks; Sensitive to kernel function parameters | Optimized parameters by particle swarm optimization (PSO) [8] |
| KNN | Apply to massive data; Suitable to nonlinear data; Train quickly; Robust to noise | Low accuracy on the minority class; Long test times; Sensitive to the parameter K | Reduced comparison times by trigonometric inequality; Optimized parameters by particle swarm optimization (PSO) [9]; Balanced datasets using the synthetic minority oversampling technique (SMOTE) [10] |
| Naïve Bayes | Robust to noise; Able to learn incrementally | Do not perform well on attribute-related data | Imported latent variables to relax the independent assumption [11] |
| LR | Simple, can be trained rapidly; Automatically scale features | Do not perform well on nonlinear data; Apt to overfitting | Imported regularization to avoid overfitting [12] |
| Decision tree | Automatically select features; Strong interpretation | Classification result trends to majority class; Ignore the correlation of data | Balanced datasets with SMOTE; Introduced latent variables |
| K-means | Simple, can be trained rapidly; Strong scalability; Can fit to big data | Do not perform well on nonconvex data; Sensitive to initialization; Sensitive to the parameter K | Improved initialization method [13] |
| Algorithms | Suitable Data Types | Supervised or Unsupervised | Functions |
|---|---|---|---|
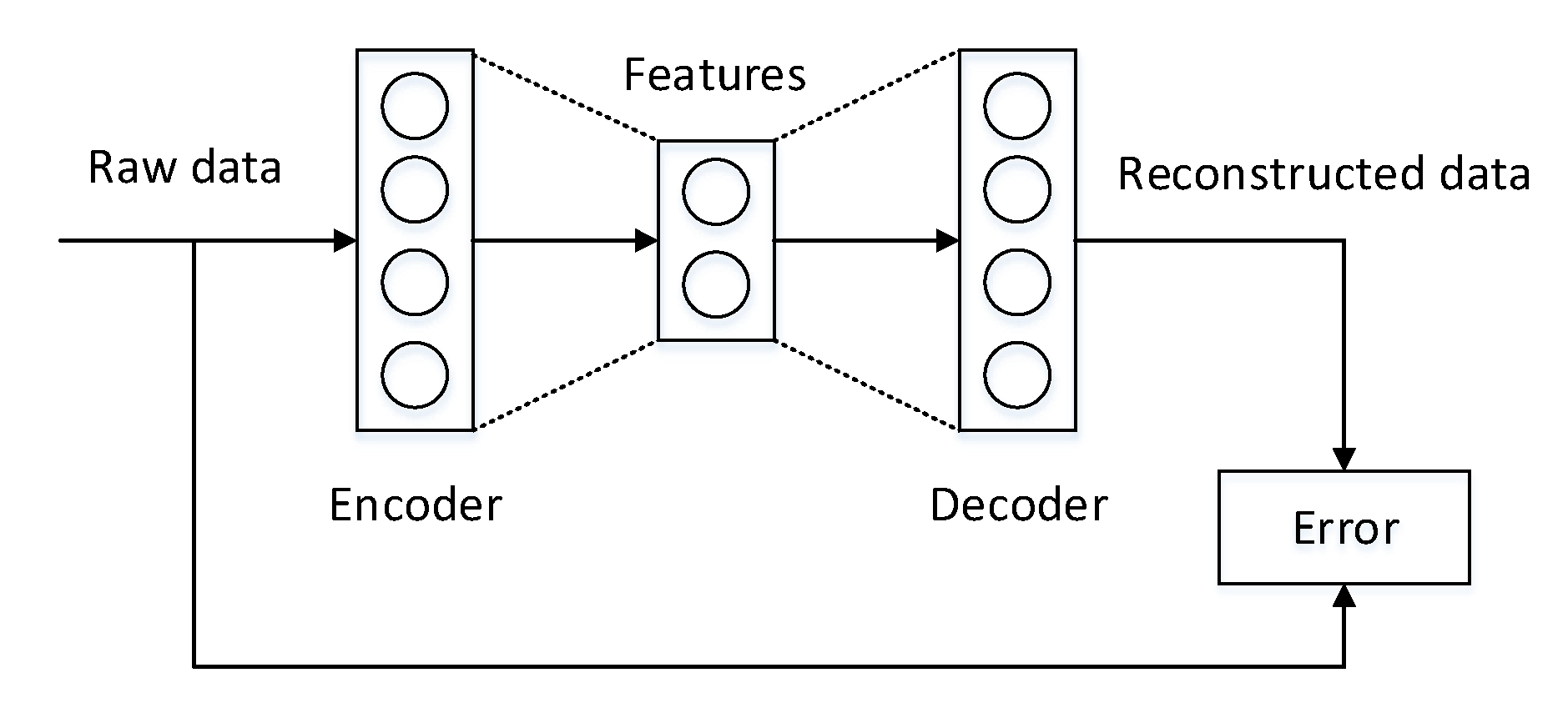
| Autoencoder | Raw data; Feature vectors | Unsupervised | Feature extraction; Feature reduction; Denoising |
| RBM | Feature vectors | Unsupervised | Feature extraction; Feature reduction; Denoising |
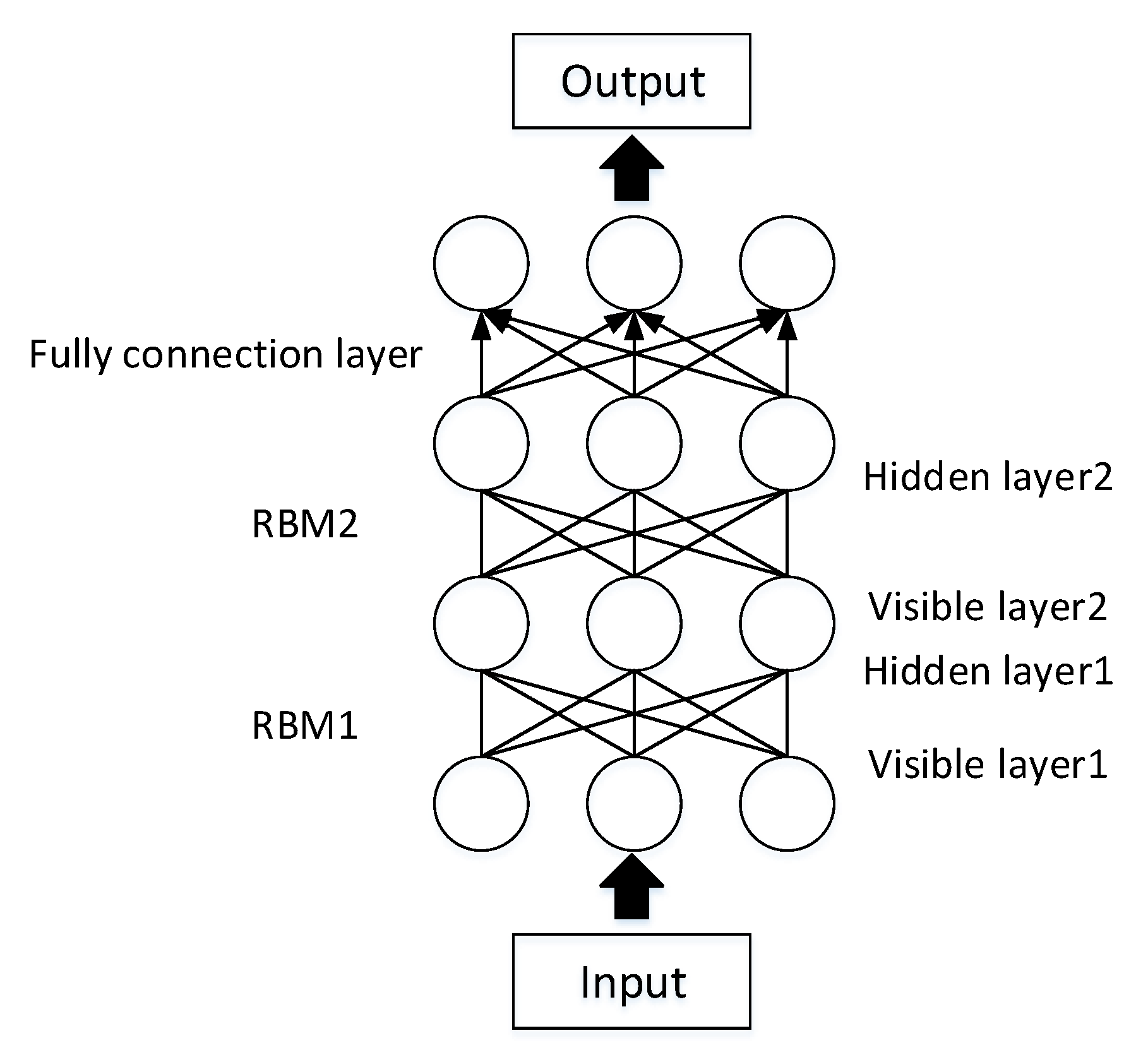
| DBN | Feature vectors | Supervised | Feature extraction; Classification |
| DNN | Feature vectors | Supervised | Feature extraction; Classification |
| CNN | Raw data; Feature vectors; Matrices | Supervised | Feature extraction; Classification |
| RNN | Raw data; Feature vectors; Sequence data | Supervised | Feature extraction; Classification |
| GAN | Raw data; Feature vectors | Unsupervised | Data augmentation; Adversarial training |
| Methods | Papers | Data Sources | Machine Learning Algorithms | Datasets |
|---|---|---|---|---|
| Packet parsing | Mayhew et al. [40] | Packet | SVM and K-means | Private dataset |
| Hu et al. [41] | Packet | Fuzzy C-means | DARPA 2000 | |
| Payload analysis | Min et al. [43] | Packet | CNN | ISCX 2012 |
| Zeng et al. [44] | Packet | CNN, LSTM, and autoencoder | ISCX 2012 | |
| Yu et al. [45] | Packet | Autoencoder | CTU-UNB | |
| Rigak et al. [46] | Packet | GAN | Private dataset | |
| Statistic feature for flow | Goeschel et al. [47] | Flow | SVM, decision tree, and Naïve Bayes | KDD99 |
| Kuttranont et al. [48] | Flow | KNN | KDD99 | |
| Peng et al. [13] | Flow | K-means | KDD99 | |
| Deep learning for flow | Potluri et al. [49] | Flow | CNN | NSL-KDD and UNSW-NB15 |
| Zhang et al. [50] | Flow | Autoencoder and XGBoost | NSL-KDD | |
| Zhang et al. [51] | Flow | GAN | KDD99 | |
| Traffic grouping | Teng et al. [52] | Flow | SVM | KDD99 |
| Ma et al. [53] | Flow | DNN | KDD99 and NSL-KDD | |
| Statistic feature for session | Ahmim et al. [54] | Session | Decision tree | CICIDS 2017 |
| Alseiari et al. [55] | Session | K-means | Private dataset | |
| Sequence feature for session | Yuan et al. [56] | Session | CNN and LSTM | ISCX 2012 |
| Radford et al. [57] | Session | LSTM | ISCX IDS | |
| Wang et al. [58] | Session | CNN | DARPA 1998 and ISCX 2012 | |
| Rule-based | Meng et al. [59] | Log | KNN | Private dataset |
| McElwee et al. [60] | Log | DNN | Private dataset | |
| Log feature extraction with sliding window | Tran et al. [61] | Log | CNN | NGIDS-DS and ADFA-LD |
| Tuor et al. [62] | Log | DNN and RNN | CERT Insider Threat | |
| Bohara et al. [63] | Log | K-means and DBSCAN | VAST 2011 Mini Challenge 2 | |
| Text analysis | Uwagbole et al. [64] | Log | SVM | Private dataset |
| Vartouni et al. [65] | Log | Isolate forest | CSIC 2010 dataset |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Lang, B. Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Appl. Sci. 2019, 9, 4396. https://doi.org/10.3390/app9204396
Liu H, Lang B. Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Applied Sciences. 2019; 9(20):4396. https://doi.org/10.3390/app9204396
Chicago/Turabian StyleLiu, Hongyu, and Bo Lang. 2019. "Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey" Applied Sciences 9, no. 20: 4396. https://doi.org/10.3390/app9204396
APA StyleLiu, H., & Lang, B. (2019). Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Applied Sciences, 9(20), 4396. https://doi.org/10.3390/app9204396