Feature Adaptive and Cyclic Dynamic Learning Based on Infinite Term Memory Extreme Learning Machine

 ,
,
Abstract
:1. Introduction
2. Literature Review
3. Problem Formulation
- Use LT to transfer knowledge from to
- Use external memory to add knowledge of to .
- Perform transfer learning TL to move related knowledge to inputs 1 and 2 from to .
- Use external memory to move knowledge related to 3 from EM to .
4. Methodology
4.1. Generating Cyclic Dynamic Time Series Data
- denotes the original dataset;
- denotes the maximum code of the classes in D;
- the class that is extracted from D at moment t;
- denotes the class at the moment t and it is repeated for times in the time series; and
- the number of distinct samples in the time series.
| Algorithm 1. Pseudocode for converting a dataset into cyclic dynamic with a feature-adaptive time series. |
| Inputs D //dataset R //number of records per sample L //Length of time series C //Number of classes T //period of the time series Outputs Dt //time series data Start D = GenerateActiveFeatures(D); //to encode the non-active features for every class t = 1 for i = 1 until L y = sin(2*pi*t/T) yt = Quantize(y, C) //Quantize the value y according to the number of classes in D for j = 1 until R xt = Extract(yt, D) //extracts random samples from D with the label y Dt(t).x = xt Dt(t).y = yt t = t + 1 Endfor2 Endfor1 |
4.2. Learning Model Transfer
- One ‘1’ is assigned to each line; the remaining are all ‘0’;
- One ‘1’ is assigned to each column at most; the remaining are all ‘0’;
- implies that original feature vector’s ith dimension will become the jth dimension defining the new feature vector post that the feature dimension has changed.
- Lower feature dimensions imply that can be applied for an all-zero vector. Thus, the new adding features do not need any additional corresponding input weight.
- In cases when an increase emerges in the feature dimension, should the ith item of represent the new feature, then a random generation must be applied for the ith item of , which is based on the distribution.
4.3. External Memory Model for ITM-OSELM
4.4. ITM-OSELM Algorithm
| Algorithm 2. Pseudocode for the ITM-OSELM algorithm used to calculate accuracy. |
| Inputs Dt = {D0, D1, ....} //sequence of labeled data N //total number of features L //number of hidden neurons g //type of activation function Outputs yp //predicted classes Ac //prediction accuracy Starts activeFeatures = checkActive(D(0)) currentClassifier = initiateClassifier(activeFeatures, L) currentEM = initiate(N, L) yp = predict(currentClassifer,D(0).x,g) Ac(0) = calculateAccuracy(yp,D(0).y) currentClassifier = OSELM(currentClassifier,D(0).x,D(0).y,g) for each chunck D(i) of data [Change,activeFeatures,newActive,oldActive] = checkActive(D(i),D(i-1)) if(Change) nextEM = EMUpdateEM(currentEM,oldActive) nextClassifier = transferLearning(currentClassifier,activeFeatures) nextClassifier = updateNewActive(nextEM,newActive) currentClassifer = nextClassifier currentEM = nextEM end yp = predict(currentClassifier,D(i).x,g) Ac(i) = calculateAccuracy(yp,D(i).y) currentClassifier = OSELM(currentClassifier,D(i).x,D(i).y,g) endfor1 |
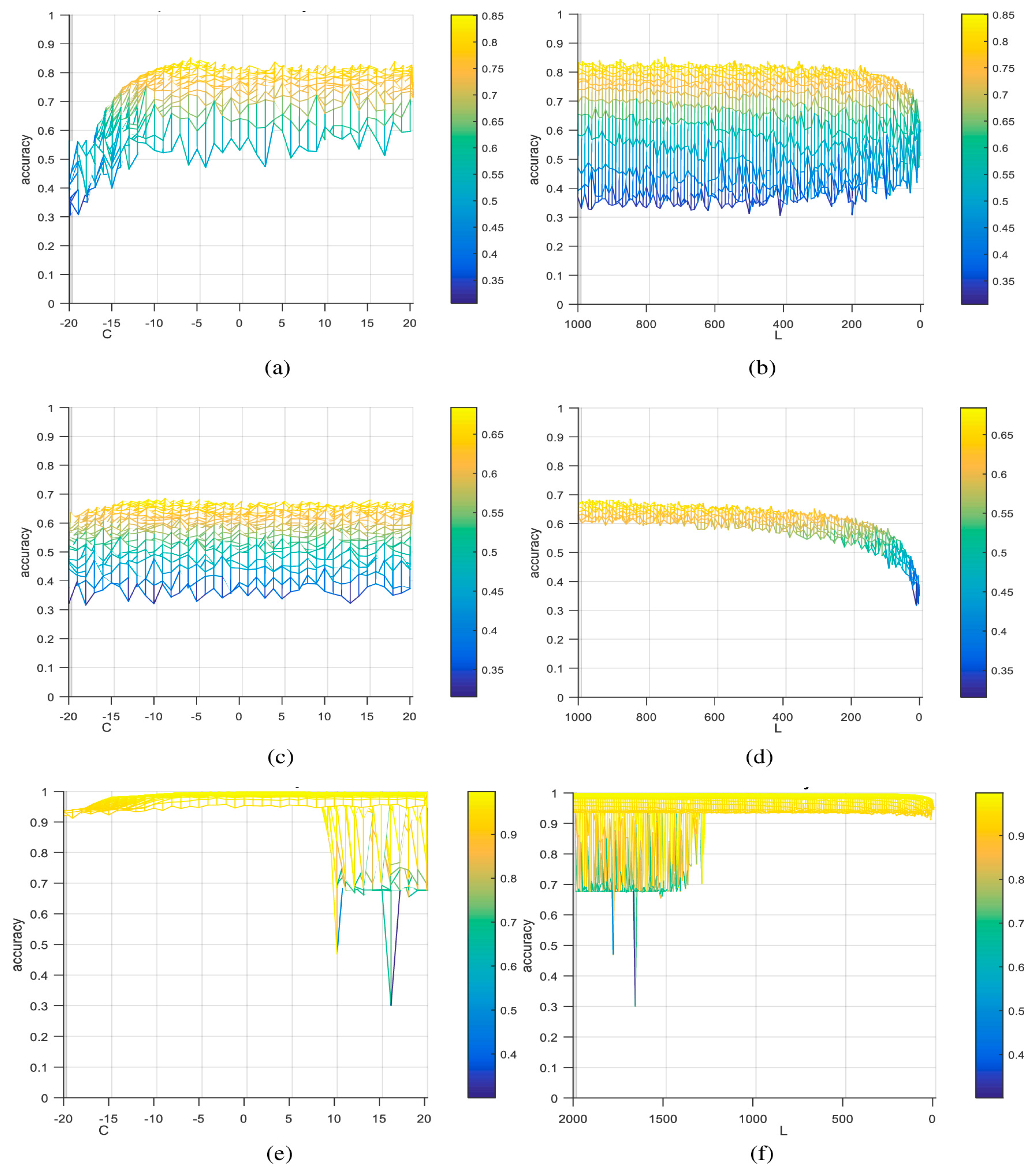
4.5. Evaluation Analysis of ITM-OSELM
5. Experimental Work and Results
5.1. Datasets Description
5.2. Characterization
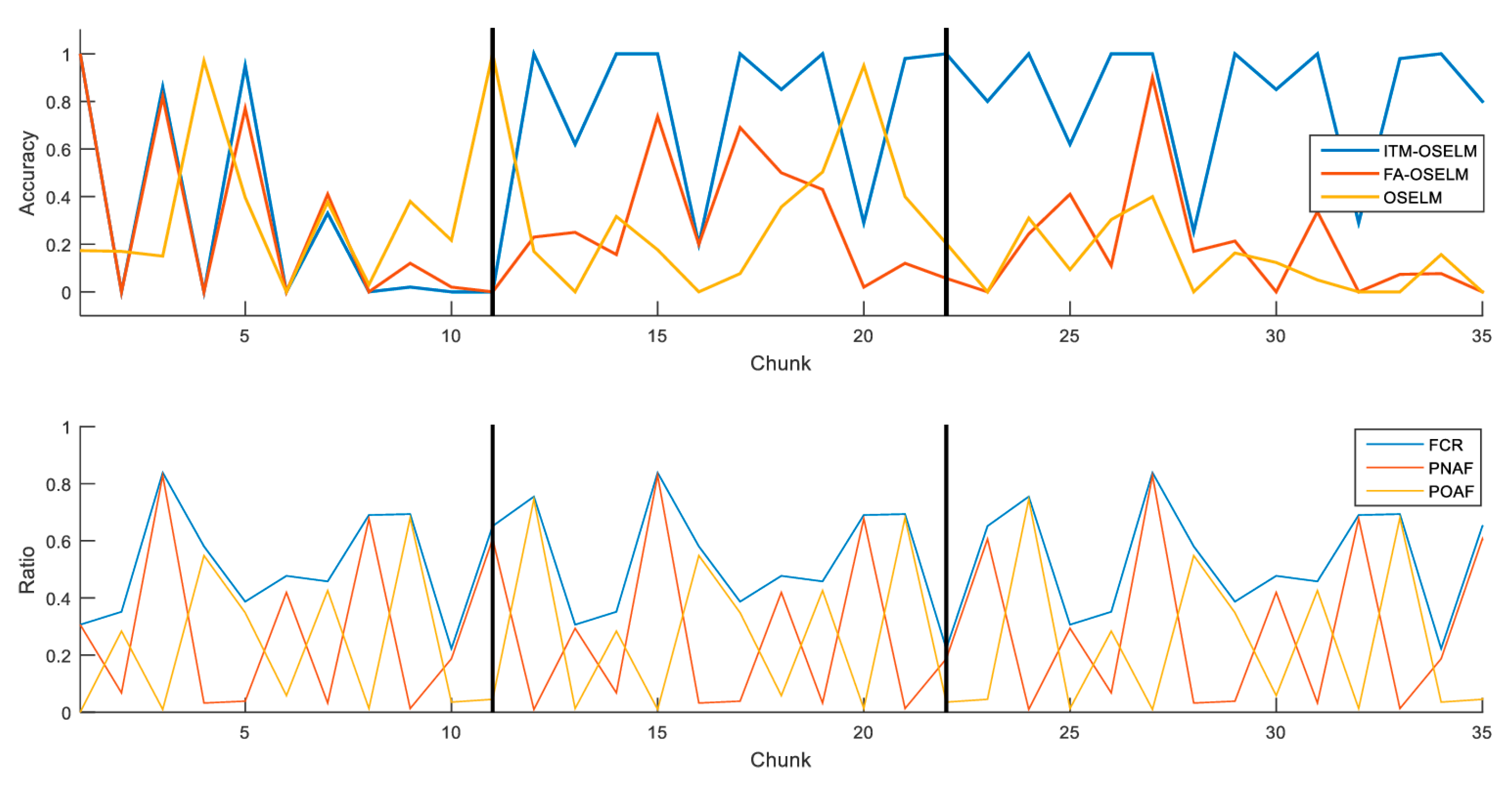
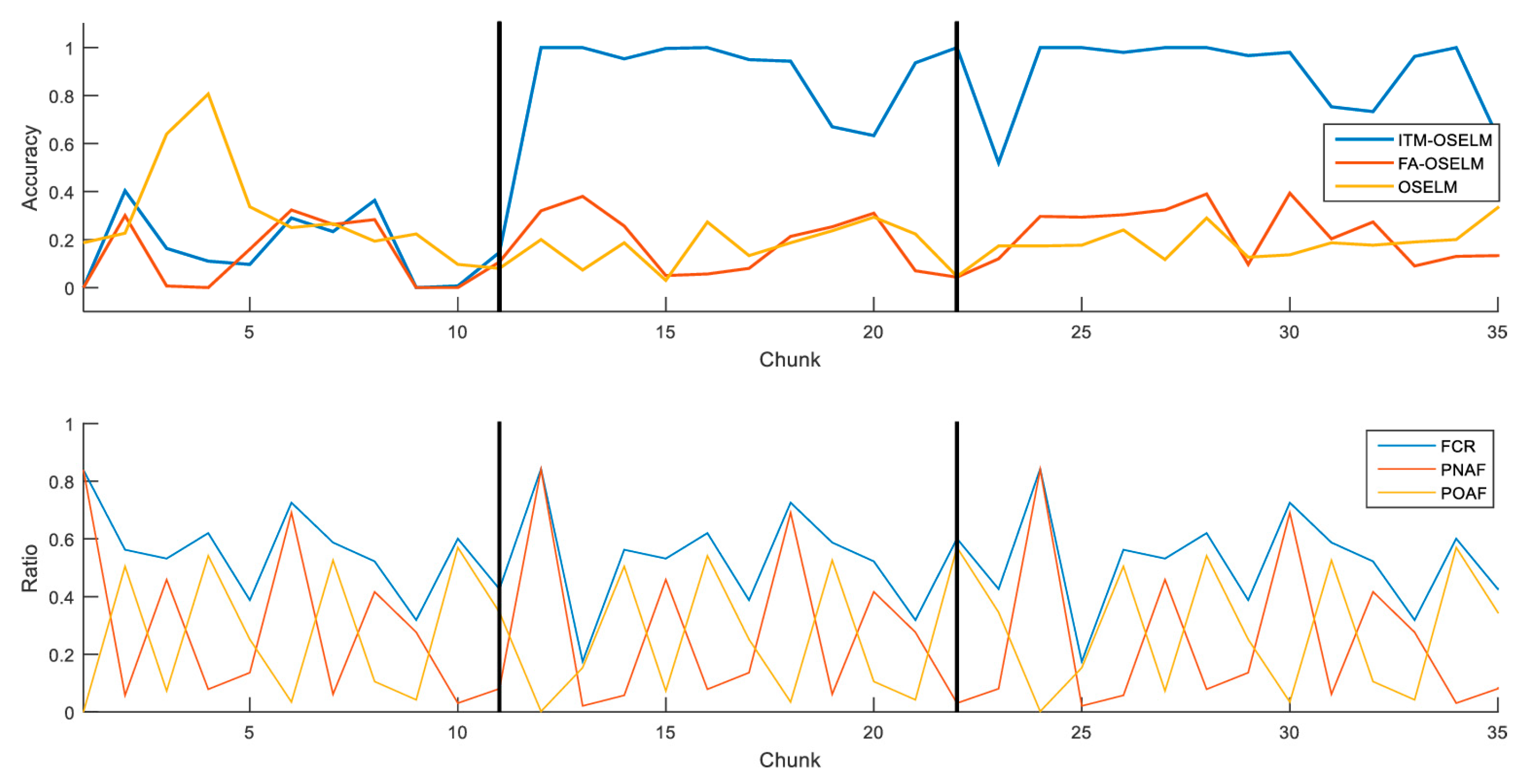
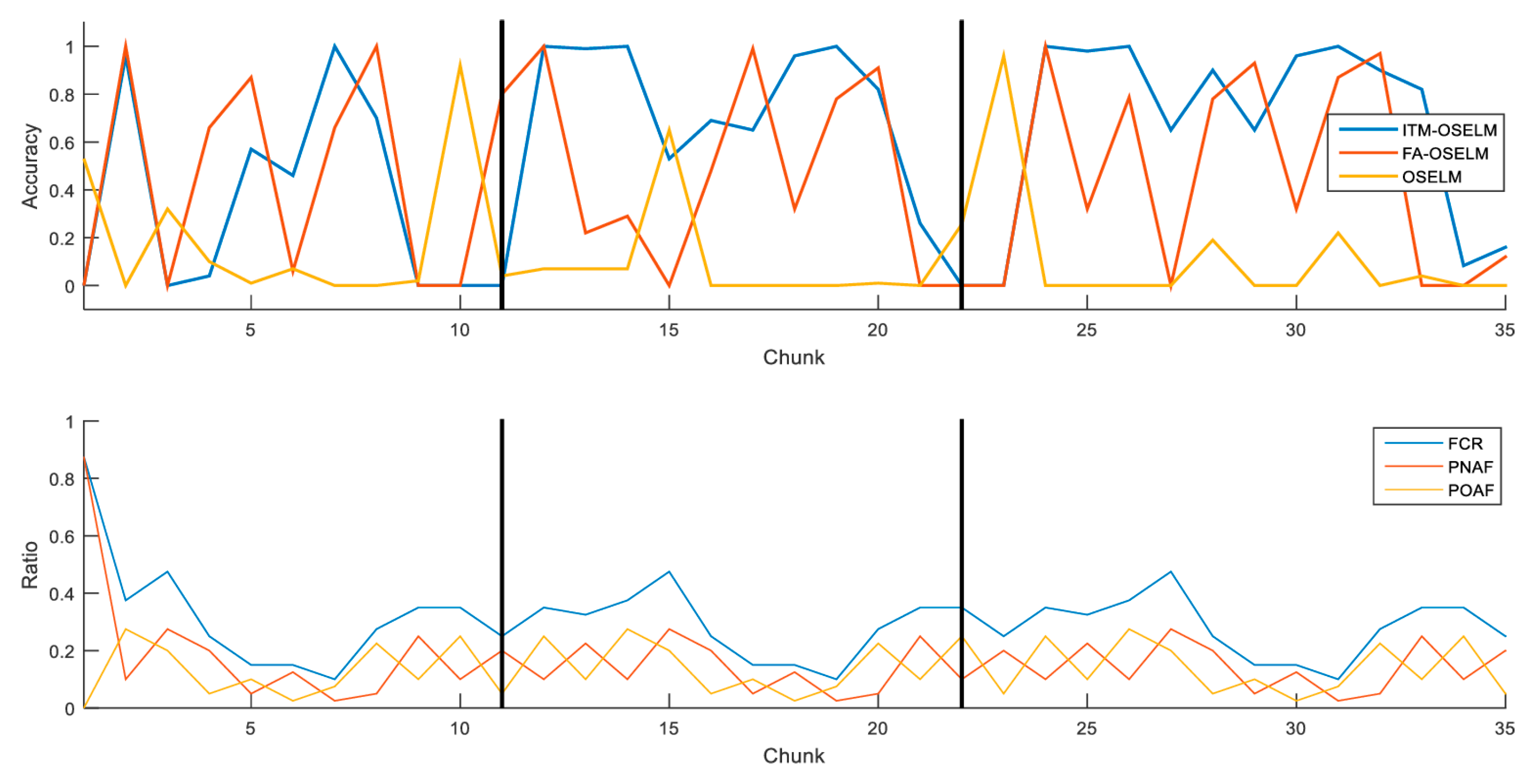
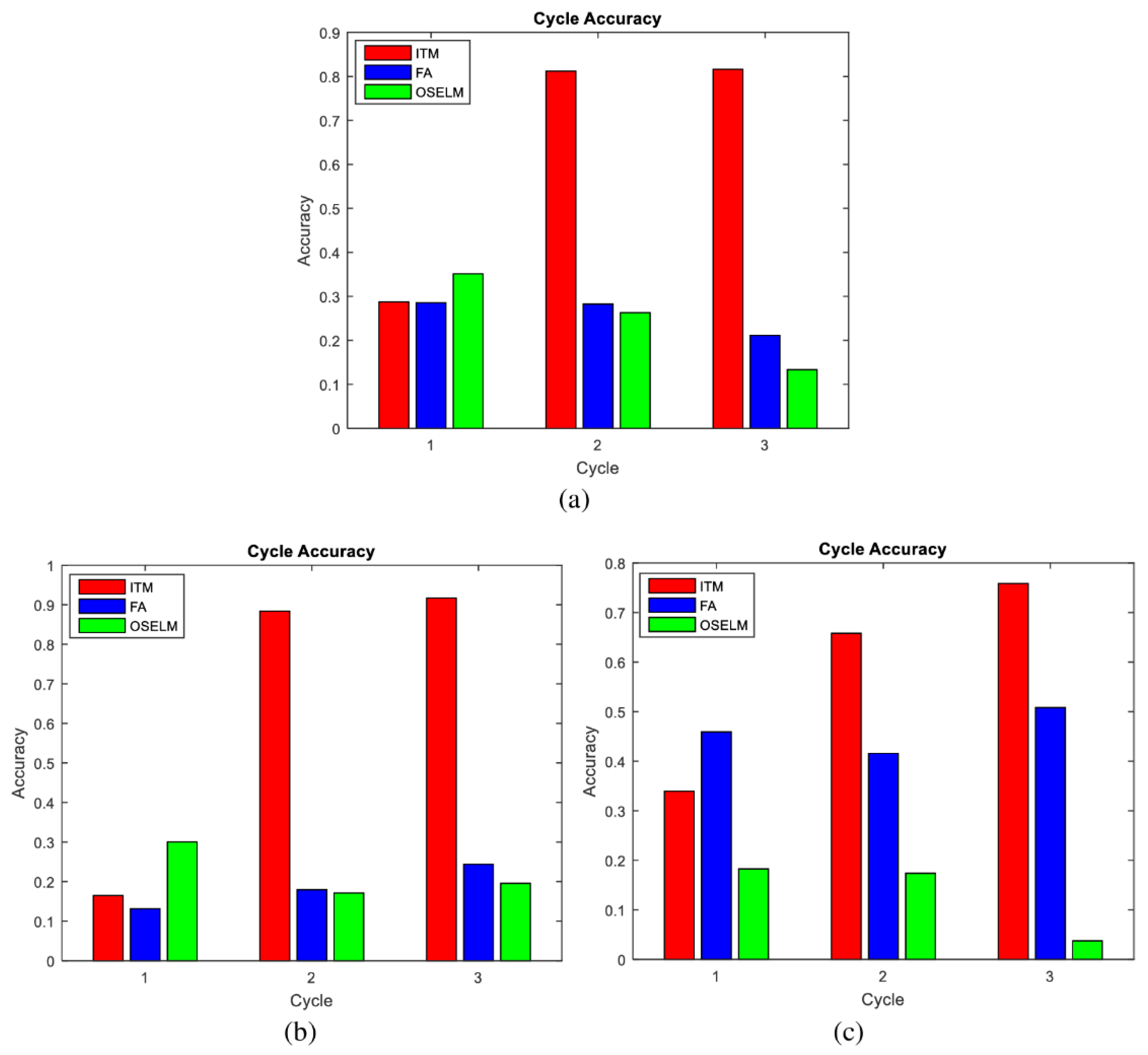
5.3. Accuracy Results
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, J.; Liao, Y.; Wang, S.; Han, J. Study on Driving Decision-Making Mechanism of Autonomous Vehicle Based on an Optimized Support Vector Machine Regression. Appl. Sci. 2018, 8, 13. [Google Scholar] [CrossRef]
- Li, C.; Min, X.; Sun, S.; Lin, W.; Tang, Z. DeepGait: A Learning Deep Convolutional Representation for View-Invariant Gait Recognition Using Joint Bayesian. Appl. Sci. 2017, 7, 210. [Google Scholar] [CrossRef]
- Lu, J.; Huang, J.; Lu, F. Time Series Prediction Based on Adaptive Weight Online Sequential Extreme Learning Machine. Appl. Sci. 2017, 7, 217. [Google Scholar] [CrossRef]
- Sun, Y.; Xiong, W.; Yao, Z.; Moniz, K.; Zahir, A. Network Defense Strategy Selection with Reinforcement Learning and Pareto Optimization. Appl. Sci. 2017, 7, 1138. [Google Scholar] [CrossRef]
- Wang, S.; Lu, S.; Dong, Z.; Yang, J.; Yang, M.; Zhang, Y. Dual-Tree Complex Wavelet Transform and Twin Support Vector Machine for Pathological Brain Detection. Appl. Sci. 2016, 6, 169. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the Backpropagation Neural Network. In Neural Networks for Perception; Harcourt Brace & Co.: Orlando, FL, USA, 1992; pp. 65–93. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No.04CH37541), Budapest, Hungary, 25–29 July 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 2, pp. 985–990. [Google Scholar] [CrossRef]
- Huang, G.-B.; Liang, N.-Y.; Rong, H.-J.; Saratchandran, P.; Sundararajan, N. On-Line Sequential Extreme Learning Machine. In Proceedings of the IASTED International Conference on Computational Intelligence, Calgary, AB, Canada, 4–6 July 2005; p. 6. [Google Scholar]
- Jiang, X.; Liu, J.; Chen, Y.; Liu, D.; Gu, Y.; Chen, Z. Feature Adaptive Online Sequential Extreme Learning Machine for lifelong indoor localization. Neural Comput. Appl. 2016, 27, 215–225. [Google Scholar] [CrossRef]
- Cristianini, N.; Schölkopf, B. Support Vector Machines and Kernel Methods: The New Generation of Learning Machines. AI Mag. 2002, 23, 12. [Google Scholar] [CrossRef]
- Camastra, F.; Spinetti, M.; Vinciarelli, A. Offline Cursive Character Challenge: A New Benchmark for Machine Learning and Pattern Recognition Algorithms. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 913–916. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Jain, V.; Learned-Miller, E. Online domain adaptation of a pre-trained cascade of classifiers. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 577–584. [Google Scholar] [CrossRef] [Green Version]
- Al-Khaleefa, A.S.; Ahmad, M.R.; Md Isa, A.A.; Mohd Esa, M.R.; Al-Saffar, A.; Aljeroudi, Y. Infinite-Term Memory Classifier for Wi-Fi Localization Based on Dynamic Wi-Fi Simulator. IEEE Access 2018, 6, 54769–54785. [Google Scholar] [CrossRef]
- Özgür, A.; Erdem, H. A review of KDD99 dataset usage in intrusion detection and machine learning between 2010 and 2015. PeerJ Prepr. 2016, 4, e1954v1. [Google Scholar] [CrossRef]
- Lee, W.; Stolfo, S.J. A framework for constructing features and models for intrusion detection systems. ACM Trans. Inf. Syst. Secur. 2000, 3, 227–261. [Google Scholar] [CrossRef] [Green Version]
- Pfahringer, B. Winning the KDD99 classification cup: Bagged boosting. ACM Sigkdd Explor. Newsl. 2000, 1, 65–66. [Google Scholar] [CrossRef]
- Sabhnani, M.; Serpen, G. Why Machine Learning Algorithms Fail in Misuse Detection on KDD Intrusion Detection Data Set. Intell. Data Anal. 2004, 8, 403–415. [Google Scholar] [CrossRef]
- Torres-Sospedra, J.; Montoliu, R.; Martinez-Uso, A.; Avariento, J.P.; Arnau, T.J.; Benedito-Bordonau, M.; Huerta, J. UJIIndoorLoc: A new multi-building and multi-floor database for WLAN fingerprint-based indoor localization problems. In Proceedings of the 2014 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Busan, Korea, 27–30 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 261–270. [Google Scholar] [CrossRef]
- Lohan, E.S.; Torres-Sospedra, J.; Richter, P.; Leppäkoski, H.; Huerta, J.; Cramariuc, A. Crowdsourced WiFi-fingerprinting database and benchmark software for indoor positioning. Zenodo Repos. 2017. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | C | L | Accuracy |
|---|---|---|---|
| TampereU | 2−6 | 750 | 0.8501 |
| UJIndoorLoc | 2−9 | 850 | 0.6841 |
| KDD99 | 2−14 | 600 | 0.9977 |
| Dataset | Algorithm | Cycle 1 | Cycle 2 | Cycle 3 |
|---|---|---|---|---|
| TampereU dataset | ITM-OSELM | 28.73% | 81.17% | 81.61% |
| FA-OSELM | 28.55% | 28.25% | 21.11% | |
| OSELM | 35.12% | 26.28% | 13.33% | |
| UJIndoorLoc dataset | ITM-OSELM | 16.48% | 88.36% | 91.69% |
| FA-OSELM | 13.12% | 17.94% | 24.39% | |
| OSELM | 30.06% | 17.14% | 19.56% | |
| KDD99 dataset | ITM-OSELM | 33.91% | 65.83% | 75.86% |
| FA-OSELM | 45.91% | 41.58% | 50.81% | |
| OSELM | 18.27% | 17.39% | 3.75% |
| Dataset | Algorithms | Cycle 2 vs. Cycle 1 | Cycle 3 vs. Cycle 2 |
|---|---|---|---|
| TampereU dataset | ITM-OSELM | 182.52% | 0.54% |
| FA-OSELM | −1.05% | −25.27% | |
| OSELM | −25.17% | −49.27% | |
| UJIndoorLoc dataset | ITM-OSELM | 436.16% | 3.76% |
| FA-OSELM | 36.73% | 35.95% | |
| OSELM | −42.98% | 14.11% | |
| KDD99 dataset | ITM-OSELM | 94.13% | 15.23% |
| FA-OSELM | −9.431% | 22.19% | |
| OSELM | −4.81% | −78.43% |
| Dataset | Algorithms 1 vs. Algorithm 2 | Cycle 1 | Cycle 2 | Cycle 3 |
|---|---|---|---|---|
| TampereU dataset | ITM-OSELM vs. OSELM | 0.73103 | 2.78 × 10−3 | 3.21 × 10−6 |
| ITM-OSELM vs. FA-OSELM | 0.934221 | 2.96 × 10−4 | 2.01 × 10−4 | |
| UJIndoorLoc dataset | ITM-OSELM vs. OSELM | 0.126012 | 2.13 × 10−7 | 5.5 × 10−10 |
| ITM-OSELM vs. FA-OSELM | 0.141881 | 5.13 × 10−7 | 5.5 × 10−10 | |
| KDD99 dataset | ITM-OSELM vs. OSELM | 0.422419 | 1.086 × 10−3 | 2.24 × 10−6 |
| ITM-OSELM vs. FA-OSELM | 0.299556 | 3.532 × 10−2 | 3.28 × 10−2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
AL-Khaleefa, A.S.; Ahmad, M.R.; Isa, A.A.M.; Esa, M.R.M.; AL-Saffar, A.; Hassan, M.H. Feature Adaptive and Cyclic Dynamic Learning Based on Infinite Term Memory Extreme Learning Machine. Appl. Sci. 2019, 9, 895. https://doi.org/10.3390/app9050895
AL-Khaleefa AS, Ahmad MR, Isa AAM, Esa MRM, AL-Saffar A, Hassan MH. Feature Adaptive and Cyclic Dynamic Learning Based on Infinite Term Memory Extreme Learning Machine. Applied Sciences. 2019; 9(5):895. https://doi.org/10.3390/app9050895
Chicago/Turabian StyleAL-Khaleefa, Ahmed Salih, Mohd Riduan Ahmad, Azmi Awang Md Isa, Mona Riza Mohd Esa, Ahmed AL-Saffar, and Mustafa Hamid Hassan. 2019. "Feature Adaptive and Cyclic Dynamic Learning Based on Infinite Term Memory Extreme Learning Machine" Applied Sciences 9, no. 5: 895. https://doi.org/10.3390/app9050895