A Fuzzy Synthetic Evaluation Approach to Assess Usefulness of Tourism Reviews by Considering Bias Identified in Sentiments and Articulacy

 , , , and
, , , and
Abstract
:1. Introduction
1.1. Sentiment Analysis
1.2. Reviews’ Usefulness and Reviewers’ Bias in Sentiment Analysis
2. Materials and Methods
2.1. Materials and Methodology
- Analyze reviews and investigate how lenient users of different nationalities are when expressing their sentiments in their reviews, by comparing and contrasting sentiment polarity and strength in review titles and full bodies.
- Examine how informative the users from different nationalities are, i.e., examine cultural differences in terms of reviews’ articulacy.
- Propose a fuzzy synthetic evaluation approach to calculate reviews’ usefulness by taking into consideration users’ cultural differences. Although this study considers the sentiment and articulacy determinants of reviews’ usefulness, the proposed approach allows users to specify their personalized perspective of usefulness by incorporating additional features that reflect their individual biases and preferences. Figure 1 illustrates the steps of the proposed methodology.
2.2. Methods
2.2.1. Fuzzy Relations
2.2.2. Fuzzy Synthetic Evaluation
- (i)
- Assume that is the set of criteria, and indicates criterion (i). This study assumes the criterion “usefulness”, thus, .
- (ii)
- Assume that is the set of indicators, where indicates indicator (j). It consists of the “title-sentiment (ts)”, “review-sentiment (rs)”, “title-articulacy (ta)”, and the “review-articulacy (ra)” indicators, thus, .
- (iii)
- Assume that is the set of assessment grades for criteria, indicators, and alternatives, with indicating assessment grades.
- , for , which in our case are
- (iv)
- Assume that is the set of the alternatives, where (z) is the number of reviews that are potentially considered by the users when seeking advice for a destination.
- (v)
- Establish the membership function matrix of fuzzy relation for each nationality ,
- (in our case ):
- (vi)
- (vii)
- Calculate the weights for each criterion . The weights are calculated using Equation (9):
- (viii)
- Establish the membership function matrix APF of the alternatives’ performance for each nationality as follows:
- (in our case ):
- (ix)
3. Results
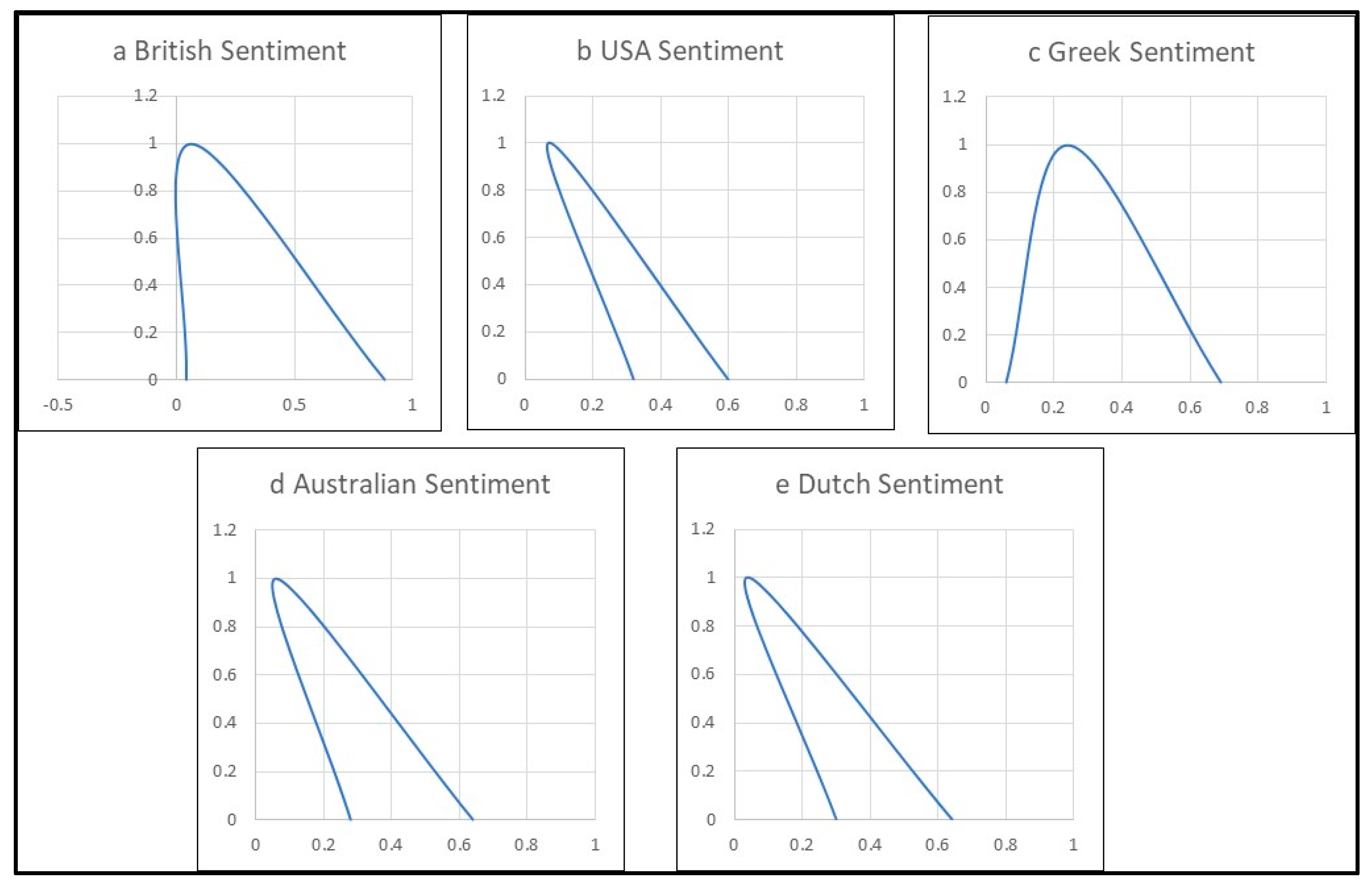
3.1. Reviews’ Sentiments Membership Functions
3.2. Reviews’ Articulacy Membership Functions
- indicates the normalized values of the number of words in the title for nationality and review , and
- represents the original number of words in the title for nationality and review.
3.3. Assessing Usefulness of Reviews by Incorporating Users’ Biases
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, B. Sentiment Analysis Essentials Sentiment Analysis: Mining Opinions, Sentiments, and Emotions; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Yu, L.; Wang, D.; Liu, D.; Liu, Y. Research on Intelligence Computing Models of Fine-Grained Opinion Mining in Online Reviews. IEEE Access 2019, 7, 116900–116910. [Google Scholar] [CrossRef]
- Oktaviani, V.; Warsito, B.; Yasin, H.; Santoso, R.; Suparti, S. Sentiment Analysis of e-Commerce Application in Traveloka Data Review on Google Play Site Using Naïve Bayes Classifier and Association Method 2020. J. Phys. Conf. Ser. 2021, 1943, 012147. [Google Scholar] [CrossRef]
- Wang, C.; Zhu, X.; Yan, L. Sentiment Analysis for E-Commerce Reviews Based on Deep Learning Hybrid Model. In Proceedings of the 5th International Conference on Signal Processing and Machine Learning (SPML), Dalian, China, 4–6 August 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 38–46. [Google Scholar]
- Savci, P.; Das, B. Prediction of the Customers’ Interests Using Sentiment Analysis in e-Commerce Data for Comparison of Arabic, English, and Turkish Languages. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 227–237. [Google Scholar] [CrossRef]
- Hossain, M.J.; Das Joy, D.; Das, S.; Mustafa, R. Sentiment Analysis on Reviews of E-Commerce Sites Using Machine Learning Algorithms. In Proceedings of the International Conference on Innovations in Science, Engineering and Technology (ICISET), Chattogram, Bangladesh, 25–28 February 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022; pp. 522–527. [Google Scholar]
- Rajesh, P.; Suseendran, G. Prediction of N-Gram Language Models Using Sentiment Analysis on E-Learning Reviews. In Proceedings of the International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 17–19 June 2020; pp. 510–514. [Google Scholar]
- dos Santos Alencar, M.A.; de Magalhães Netto, J.F.; de Morais, F. A Sentiment Analysis Framework for Virtual Learning Environment. Appl. Artif. Intell. 2021, 35, 520–536. [Google Scholar] [CrossRef]
- Yan, X.; Jian, F.; Sun, B. SAKG-BERT: Enabling Language Representation with Knowledge Graphs for Chinese Sentiment Analysis. IEEE Access 2021, 9, 101695–101701. [Google Scholar] [CrossRef]
- Sayeedunnisa, S.F.; Hijab, M. Impact of e-Learning in Education Sector: A Sentiment Analysis View. In Proceedings of the IEEE Conference on Interdisciplinary Approaches in Technology and Management for Social Innovation (IATMSI), Gwalior, India, 21–23 December 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022; pp. 1–5. [Google Scholar]
- Singh, L.K.; Devi, R.R. Analysis of Student Sentiment Level Using Perceptual Neural Boltzmann Machine Learning Approach for E-learning Applications. In Proceedings of the 5th International Conference on Inventive Computation Technologies, ICICT 2022, Lalitpur, Nepal, 20–22 July 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022; pp. 1270–1276. [Google Scholar]
- Khanam, Z. Sentiment Analysis of User Reviews in an Online Learning Environment: Analyzing the Methods and Future Prospects. Eur. J. Educ. Pedagog. 2023, 4, 209–217. [Google Scholar] [CrossRef]
- Krouska, A.; Troussas, C.; Virvou, M. Deep Learning for Twitter Sentiment Analysis: The Effect of Pre-Trained Word Embedding. In Machine Learning Paradigms; Tsihrintzis, G., Jain, L., Eds.; Learning and Analytics in Intelligent Systems; Springer: Cham, Switzerland, 2020; pp. 111–124. [Google Scholar]
- Li, L.; Wu, Y.; Zhang, Y.; Zhao, T. Time+User Dual Attention Based Sentiment Prediction for Multiple Social Network Texts with Time Series. IEEE Access 2019, 7, 17644–17653. [Google Scholar] [CrossRef]
- Wang, T.; Lu, K.; Chow, K.P.; Zhu, Q. COVID-19 Sensing: Negative Sentiment Analysis on Social Media in China via BERT Model. IEEE Access 2020, 8, 138162–138169. [Google Scholar] [CrossRef] [PubMed]
- Alattar, F.; Shaalan, K. Using Artificial Intelligence to Understand What Causes Sentiment Changes on Social Media. IEEE Access 2021, 9, 61756–61767. [Google Scholar] [CrossRef]
- Silva, H.; Andrade, E.; Araújo, D.; Dantas, J. Sentiment Analysis of Tweets Related to SUS before and during COVID-19 Pandemic. IEEE Lat. Am. Trans. 2022, 20, 6–13. [Google Scholar] [CrossRef]
- Rodríguez-Ibánez, M.; Casánez-Ventura, A.; Castejón-Mateos, F.; Cuenca-Jiménez, P.M. A review on Sentiment Analysis from Social Media Platforms. Expert Syst. Appl. 2023, 223, 119862. [Google Scholar] [CrossRef]
- Krouska, A.; Troussas, C.; Virvou, M. Comparative Evaluation of Algorithms for Sentiment Analysis over Social Networking Services. J. Univers. Comput. Sci. (JUCS) 2017, 23, 755–768. [Google Scholar]
- Usher, J.; Morales, L.; Dondio, P. BREXIT: A Granger Causality of Twitter Political Polarisation on the FTSE 100 Index and the Pound. In Proceedings of the 2nd IEEE International Conference on Artificial Intelligence and Knowledge Engineering, AIKE 2019, Cagliari, Italy, 3–5 June 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 51–54. [Google Scholar]
- Shaghaghi, N.; Calle, A.M.; Manuel Zuluaga Fernandez, J.; Hussain, M.; Kamdar, Y.; Ghosh, S. Twitter Sentiment Analysis and Political Approval Ratings for Situational Awareness. In Proceedings of the IEEE Conference on Cognitive and Computational Aspects of Situation Management (CogSIMA), Tallinn, Estonia, 14–22 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 59–65. [Google Scholar]
- Schmale, A.; Mittendorf, V. Detecting Negative Campaigning on Twitter Against The Greens. In Proceedings of the Ninth IEEE International Conference on Social Networks Analysis, Management and Security (SNAMS), Milan, Italy, 29 November–1 December 2022; pp. 1–8. [Google Scholar]
- Orellana, S.; Bisgin, H. Using Natural Language Processing to Analyze Political Party Manifestos from New Zealand. Information 2023, 14, 152. [Google Scholar] [CrossRef]
- Ligthart, A.; Catal, C.; Tekinerdogan, B. Systematic Reviews in Sentiment Analysis: A Tertiary Study. Artif. Intell. Rev. 2021, 54, 4997–5053. [Google Scholar] [CrossRef]
- Thelwall, M.; Wilkinson, D.; Uppal, S. Data Mining Emotion in Social Network Communication: Gender Differences in MySpace. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 190–199. [Google Scholar] [CrossRef]
- Volkova, S.; Yoram, B. On Predicting Sociodemographic Traits and Emotions from Communications in Social Networks and their Implications to Online Self-Disclosure. Cyberpsychology Behav. Soc. Netw. 2015, 12, 726–736. [Google Scholar] [CrossRef] [PubMed]
- Babac, M.B.; Podobnik, V. A Sentiment Analysis of Who Participates, How and Why, at Social Media Sport Websites: How Differently Men and Women Write about Football. Online Inf. Rev. 2016, 40, 814–833. [Google Scholar] [CrossRef]
- Rangel, F.; Rosso, P. On the Impact of Emotions on Author Profiling. Inf. Process. Manag. 2016, 52, 73–92. [Google Scholar] [CrossRef]
- Thelwall, M. Gender Bias in Sentiment Analysis. Online Inf. Rev. 2018, 42, 45–57. [Google Scholar] [CrossRef]
- Rajshakhar, P.; Bosu, A.; Kazi, S.Z. Expressions of Sentiments during Code Reviews: Male vs. Female. In Proceedings of the 26th IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Hangzhou, China, 24–27 February 2019; IEEE: Piscataway, NJ, USA; pp. 26–37. [Google Scholar]
- Sun, T.; Gaut, A.; Tang, S.; Huang, Y.; ElSherief, M.; Zhao, J.; Mirza, D.; Belding, E.; Chang, K.; Wang, W.Y. Mitigating Gender Bias in Natural Language Processing: Literature Review. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1630–1640. [Google Scholar]
- Ordenes, V.F.; Silipo, R. Machine Learning for Marketing on the KNIME Hub: The Development of a Live Repository for Marketing Applications. J. Bus. Res. 2021, 137, 393–410. [Google Scholar] [CrossRef]
- López, M.; Valdivia, A.; Martínez-Cámara, E.; Luzón, M.V.; Herrera, F. E2SAM: Evolutionary Ensemble of Sentiment Analysis Methods for Domain Adaptation. Inf. Sci. 2019, 480, 273–286. [Google Scholar] [CrossRef]
- Davis, S.R.; Worsnop, C.J.; Hand, E.M. Gender Bias Recognition in Political News Articles. Mach. Learn. Appl. 2022, 8, 100304. [Google Scholar] [CrossRef]
- Kim, J.M.; Jun, M.; Kim, C.K. The Effects of Culture on Consumers’ Consumption and Generation of Online Reviews. J. Interact. Mark. 2018, 43, 134–150. [Google Scholar] [CrossRef]
- Litvin, S.W. Hofstede, Cultural Differences, and TripAdvisor hotel Reviews. Int. J. Tour. Res. 2019, 21, 712–717. [Google Scholar] [CrossRef]
- Ngai, E.W.T.; Heung, V.C.S.; Wong, Y.H.; Chan, F.K.Y. Consumer Complaint Behaviour of Asians and Non-Asians about Hotel Services: An Empirical Analysis. Eur. J. Mark. 2007, 41, 1375–1391. [Google Scholar] [CrossRef]
- Choi, H.S.; Leon, S. An Empirical Investigation of Online Review Helpfulness: A Big Data Perspective. Decis. Support Syst. 2020, 139, 113403. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, X.; Liang, S.; Yang, Y.; Law, R. Infusing New Insights: How Do Review Novelty and Inconsistency Shape the Usefulness of Online Travel Reviews. Tour. Manag. 2023, 96, 104703. [Google Scholar] [CrossRef]
- Park, D.H.; Lee, J. eWOM Overload and its Effect on Consumer Behavioral Intention Depending on Consumer Involvement. Electron. Commer. Res. Appl. 2008, 7, 386–398. [Google Scholar] [CrossRef]
- Siering, M.; Muntermann, J.; Rajagopalan, B. Explaining and Predicting Online Review Helpfulness: The Role of Content and Reviewer-Related signals. Decis. Support Syst. 2018, 108, 1–12. [Google Scholar] [CrossRef]
- Hong, H.; Xu, D.; Wang, G.A.; Fan, W. Understanding the Determinants of Online Review Helpfulness: A Meta-Analytic Investigation. Decis. Support Syst. 2017, 102, 1–11. [Google Scholar] [CrossRef]
- Lee, S.; Choeh, J.Y. The Interactive Impact of Online Word-Of-Mouth and Review Helpfulness on Box Office Revenue. Manag. Decis. 2018, 56, 849–866. [Google Scholar] [CrossRef]
- Cao, Q.; Duan, W.; Gan, Q. Exploring Determinants of Voting for the “Helpfulness” of Online User Reviews: A Text Mining Approach. Decis. Support Syst. 2011, 50, 511–521. [Google Scholar] [CrossRef]
- Baek, H.; Ahn, J.; Choi, Y. Helpfulness of Online Consumer Reviews: Readers’ Objectives and Review Cues. Int. J. Electron. Commer. 2012, 17, 99–126. [Google Scholar] [CrossRef]
- Racherla, P.; Friske, W. Perceived “Usefulness” of Online Consumer Reviews: An Exploratory Investigation Across Three Services Categories. Electron. Commer. Res. Appl. 2012, 11, 548–559. [Google Scholar] [CrossRef]
- Liu, Z.; Park, S. What Makes a Useful Online Review? Implication for Travel Product Websites. Tour. Manag. 2015, 47, 140–151. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, Z. Predicting the Helpfulness of Online Product Reviews: A Multilingual Approach. Electron. Commer. Res. Appl. 2018, 27, 1–10. [Google Scholar] [CrossRef]
- Chatterjee, S. Drivers of Helpfulness of Online Hotel Reviews: A Sentiment and Emotion Mining Approach. Int. J. Hosp. Manag. 2020, 85, 102356. [Google Scholar] [CrossRef]
- Bigne, E.; Ruiz, C.; Cuenca, A.; Perez, C.; Garcia, A. What Drives the Helpfulness of Online Reviews? A Deep Learning Study of Sentiment Analysis, Pictorial Content and Reviewer Expertise for Mature Destinations. J. Destin. Mark. Manag. 2021, 20, 100570. [Google Scholar] [CrossRef]
- Zhu, L.; Yin, G.; He, W. Is this Opinion Leader’s Review Useful? Peripheral Cues for Online Review Helpfulness. J. Electron. Commer. Res. 2014, 15, 2014. [Google Scholar]
- Mudambi, S.M.; Schuff, D. What Makes a Helpful Online Review? A Study of Customer Reviews on Amazon.com. MIS Q. 2010, 34, 185–200. [Google Scholar] [CrossRef]
- Chua, A.Y.K.; Banerjee, S. Understanding Review Helpfulness as a Function of Reviewer Reputation, Review Rating, and Review Depth. J. Assoc. Inf. Sci. Technol. 2015, 66, 354–362. [Google Scholar] [CrossRef]
- Onikoyi, B.; Nnamoko, N.; Korkontzelos, I. Gender Prediction with descriptive Textual Data Using a Machine Learning Approach. Nat. Lang. Process. J. 2023, 4, 100018. [Google Scholar] [CrossRef]
- Rita, P.; Ramos, R.; Borges-Tiago, M.T.; Rodrigues, D. Impact of the Rating System on Sentiment and Tone of Voice: A Booking.com and TripAdvisor Comparison Study. Int. J. Hosp. Manag. 2022, 104, 103245. [Google Scholar] [CrossRef]
- Gitto, S.; Mancuso, P. Improving Airport Services Using Sentiment Analysis of the Websites. Tour. Manag. Perspect. 2017, 22, 132–136. [Google Scholar] [CrossRef]
- Wojarnik, G. Sentiment Analysis as a Factor Included in the Forecasts of Price Changes in the Stock Exchange. Procedia Comput. Sci. 2021, 3176–3183. [Google Scholar] [CrossRef]
- Jiang, M.; Chen, T.Y.; Wang, S. On the Effectiveness of Testing Sentiment Analysis Systems with Metamorphic Testing. Inf. Softw. Technol. 2022, 150, 106966. [Google Scholar] [CrossRef]
- Dhakate, N.; Joshi, R. Classification of Reviews of E-Healthcare Services to Improve Patient Satisfaction: Insights from an Emerging Economy. J. Bus. Res. 2023, 164, 114–115. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.Y.; Hsu, P.Y.; Sheen, G.J. A Fuzzy-Based Decision-Making Procedure for Data Warehouse System Selection. Expert Syst. Appl. 2007, 32, 939–953. [Google Scholar] [CrossRef]
- Ross, T.J. Fuzzy Logic with Engineering Applications, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Luukka, P. Similarity Classifier Using Similarities Based on Modified Probabilistic Equivalence Relations. Knowl. Based Syst. 2009, 22, 57–62. [Google Scholar] [CrossRef]
- Hu, G.; Liu, H.; Chen, C.; He, P.; Li, J.; Hou, H. Selection of Green Remediation Alternatives for Chemical Industrial Sites: An Integrated Life Cycle Assessment and Fuzzy Synthetic Evaluation Approach. Sci. Total Environ. 2022, 845, 157211. [Google Scholar] [CrossRef]
- Xu, Y.; Yeung, J.F.Y.; Chan, A.P.C.; Chan, D.W.M.; Wang, S.Q.; Ke, Y. Developing a Risk Assessment Model for PPP projects in China—A Fuzzy Synthetic Evaluation Approach. Autom. Constr. 2010, 19, 929–943. [Google Scholar] [CrossRef]
- Akter, M.; Jahan, M.; RuKabir, R.; Karim, D.S.; Haque, A.; Munsur, M.; Salehin, M. Risk Assessment Based on Fuzzy Synthetic Evaluation Method. Sci. Total Environ. 2019, 658, 818–829. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Hwang, B.G.; Gao, Y. A Fuzzy Synthetic Evaluation Approach for Risk Assessment: A Case of Singapore’s Green Projects. J. Clean. Prod. 2016, 115, 203–213. [Google Scholar] [CrossRef]
- Yager, R.R. On Ordered Weighted Averaging Aggregation Operators in Multicriteria Decision Making. IEEE Trans. Syst. Man. Cybern. 1988, 18, 183–190. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Sentiment | ||||||
|---|---|---|---|---|---|---|
| Title | Review | Title | Review | Title | Review | |
| Negative | Neutral | Positive | ||||
| British | 4.08 | 4.68 | 6.83 | 6.65 | 89.08 | 88.67 |
| American | 4.73 | 32.21 | 5.89 | 7.10 | 89.37 | 60.67 |
| Australian | 2.60 | 28.74 | 6.46 | 6.40 | 90.94 | 64.86 |
| Greek | 3.55 | 6.26 | 6.68 | 24.13 | 89.77 | 69.61 |
| Dutch | 3.86 | 30.68 | 6.69 | 4.56 | 89.45 | 64.76 |
| Nationality | Title Sentiment Fuzzy Set | Reviews’ Sentiment Fuzzy Set |
|---|---|---|
| British | ||
| American | ||
| Australian | ||
| Greek | ||
| Dutch |
| Articulacy | ||||
|---|---|---|---|---|
| Title | Review | |||
| Average Number | Standard Deviation | Average Number | Standard Deviation | |
| British | 4.28 | 2.64 | 97.07 | 41.38 |
| American | 4.59 | 2.62 | 98.60 | 39.90 |
| Australian | 4.37 | 2.57 | 97.23 | 39.46 |
| Greek | 4.34 | 2.79 | 79.76 | 39.60 |
| Dutch | 4.57 | 2.64 | 40.78 | 40.78 |
| Linguistic Scale | Triangular Fuzzy Scale | ||
|---|---|---|---|
| Negative/Low | 0.00 | 0.00 | 0.25 |
| Neutral/Medium | 0.25 | 0.50 | 0.75 |
| Positive/High | 0.50 | 0.75 | 1.00 |
| Nationality | Title Articulacy Fuzzy Set | Reviews’ Articulacy Fuzzy Set |
|---|---|---|
| British | ||
| American | ||
| Greek | ||
| Australian | ||
| Dutch |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kardaras, D.K.; Troussas, C.; Barbounaki, S.G.; Tselenti, P.; Armyras, K. A Fuzzy Synthetic Evaluation Approach to Assess Usefulness of Tourism Reviews by Considering Bias Identified in Sentiments and Articulacy. Information 2024, 15, 236. https://doi.org/10.3390/info15040236
Kardaras DK, Troussas C, Barbounaki SG, Tselenti P, Armyras K. A Fuzzy Synthetic Evaluation Approach to Assess Usefulness of Tourism Reviews by Considering Bias Identified in Sentiments and Articulacy. Information. 2024; 15(4):236. https://doi.org/10.3390/info15040236
Chicago/Turabian StyleKardaras, Dimitrios K., Christos Troussas, Stavroula G. Barbounaki, Panagiota Tselenti, and Konstantinos Armyras. 2024. "A Fuzzy Synthetic Evaluation Approach to Assess Usefulness of Tourism Reviews by Considering Bias Identified in Sentiments and Articulacy" Information 15, no. 4: 236. https://doi.org/10.3390/info15040236