
Codeword Structure Analysis for LDPC Convolutional Codes

Abstract
:1. Introduction
2. LDPC Convolutional Codes
3. Codewords Analysis
3.1. Structured Codewords

{kind=link}
| Submatrices | Permanent of the Submatrix |
|---|---|
3.2. Non-Structured Codewords
| Structured | Non-Structured | Structured |
| - | non-structured | |
| - | ||
| - | - | |
4. Eliminating the Low Weight Non-Structured Codewords
4.1. More Examples
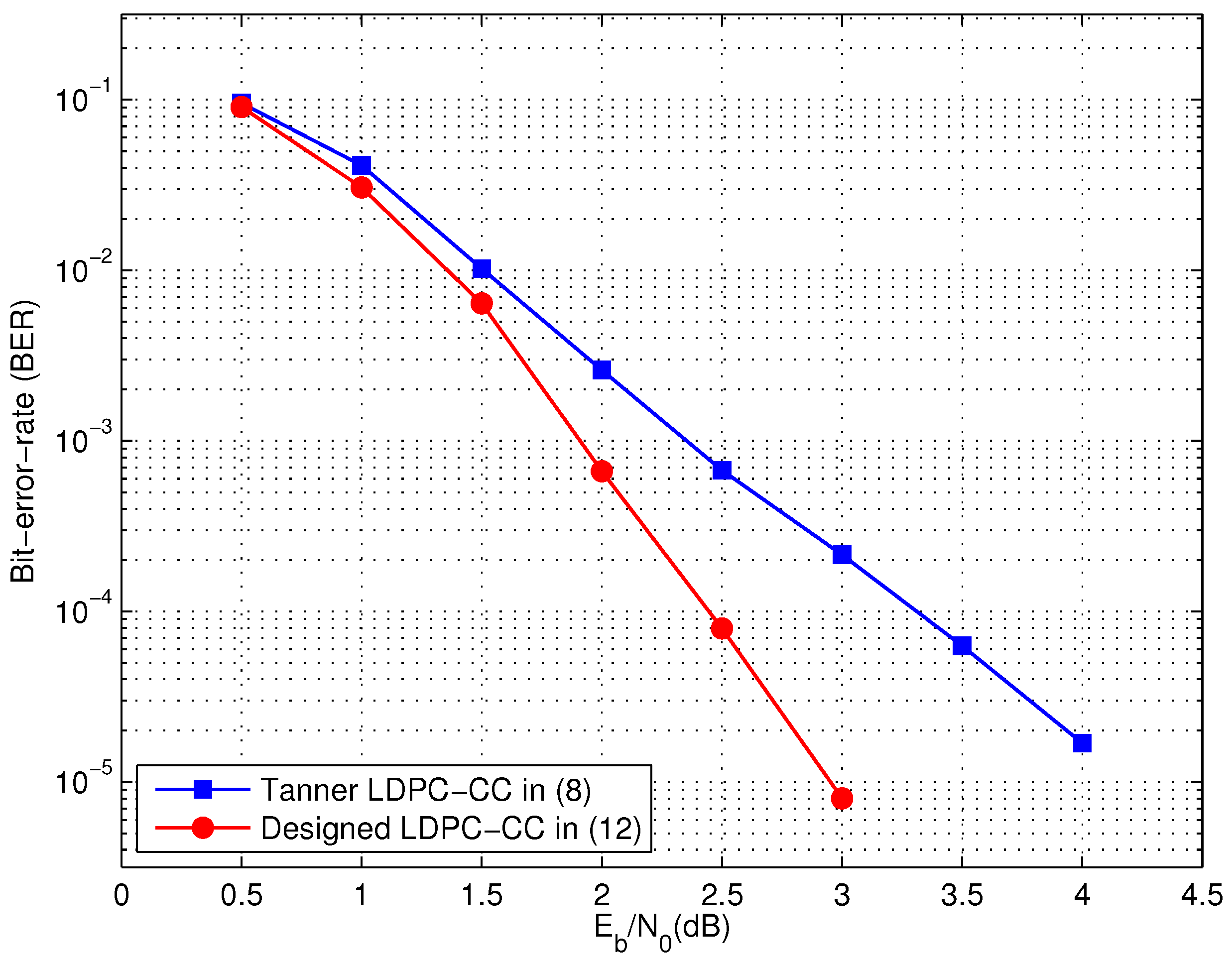
4.2. Improved Distance Spectrum

4.3. Rules for Designing Practical LDPC-CCs
- ensuring that each super code does not contain any codewords with weight smaller than the minimum weight of the structured codewords calculated using Lemma 1;
- eliminating the low weight non-structured codewords of the super codes as many as possible.
- Step 1: Compute the enumerator for the structured codewords that the super code contains. In this paper, the structured codewords are calculated based on the formation of the unavoidable cycles [21]. For example, the weight matrix of the super code formed by the second and the third columns of Equation (12) is an all-one matrix of size . According to the result in [21], this weight matrix contains = 10 unavoidable cycles of length 12. If an all-one weight matrix contains only two columns or two rows, the structure of an unavoidable cycle of length n in the weight matrix forms a structured codeword of weight . Hence, we have for the super code formed by arbitrary two columns of Equation (12).
- Step 2: For each entry in the polynomial syndrome former matrix of the super code, we randomly choose a monomial with power smaller than the syndrome former memory and calculate the number of the codewords that the associated super code has. If it is larger than , this monomial is replaced by another one until a valid one is found. If all of the monomials with power smaller than have been tested, we simply increase the value of and repeat the process in Step 2.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix
A. Proof of Lemma 1
References
- IEEE 802.16e Task Group. IEEE Standard for Local and Metropolitan Area Networks Part 16: Air Interface for Fixed and Mobile Broadband Wireless Access Systems Amendment 2: Physical and Medium Access Control Layers for Combined Fixed and Mobile Operation in Licensed Bands and Corrigendum 1; IEEE Std. 802.16e; IEEE: Piscataway, NJ, USA, 2006. [Google Scholar]
- European Telecommunications Standards Institute (ETSI). DVB-T2 Implementation Guidelines for a Second Generation Digital Terrestrial Television Broadcasting System (DVB-T2); DVB Blue Book A133 or ETSI TR 102831; ETSI: Sophia Antipolis, France, 2012. [Google Scholar]
- IEEE 802.11n Task Group. IEEE Draft Standard for Information Technology: Telecommunications and information Exchange Between Systems: Local and Metropolitan Area Networks: Specific Requirements Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications Amendment 4: Enhancements for Higher Throughput; IEEE Std. 802.11n/D2.00; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar]
- Felström, A.J.; Zigangirov, K.S. Time-varying periodic convolutional codes with low-density parity-check matrices. IEEE Trans. Inf. Theory 1999, 45, 2181–2191. [Google Scholar] [CrossRef]
- Lentmaier, M.; Sridharan, A.; Costello, D.J., Jr.; Zigangirov, K.S. Iterative decoding threshold analysis for LDPC convolutional codes. IEEE Trans. Inf. Theory 2010, 56, 5274–5289. [Google Scholar] [CrossRef]
- Bazzi, L.; Ghazi, B.; Urbanke, R.L. Linear Programming Decoding of Spatially Coupled Codes. IEEE Trans. Inf. Theory 2014, 60, 4677–4698. [Google Scholar] [CrossRef]
- Schwandter, S.; Graell i Amat, A.; Matz, G. Spatially-coupled LDPC codes for decode-and-forward relaying of two correlated sources over the BEC. IEEE Trans. Commun. 2014, 62, 1324–1337. [Google Scholar] [CrossRef]
- Abu-Surra, S.; Divsalar, D.; Ryan, W.E. Enumerators for Protograph-Based Ensembles of LDPC and Generalized LDPC Codes. IEEE Trans. Inf. Theory 2011, 57, 858–886. [Google Scholar] [CrossRef]
- Kasai, K.; Declercq, D.; Poulliat, C.; Sakaniwa, K. Multiplicatively Repeated Nonbinary LDPC Codes. IEEE Trans. Inf. Theory 2011, 57, 6788–6795. [Google Scholar] [CrossRef]
- Xia, S.; Fu, F. On the minimum pseudocodewords of LDPC codes. IEEE Commun. Lett. 2006, 10, 363–365. [Google Scholar]
- Chertkov, M.; Stepanov, M. Searching for low weight pseudo-codewords. In Proceedings of the Information Theory and Application Workshop, La Jolla, CA, USA, 29 January–2 February 2007.
- Smarandache, R.; Pusane, A.E.; Vontobel, P.O.; Costello, D.J., Jr. Pseudocodeword performance analysis for LDPC convolutional codes. IEEE Trans. Inf. Theory 2009, 55, 2577–2598. [Google Scholar] [CrossRef]
- Bahl, L.R.; Cullum, C.D.; Frazer, W.D.; Jelinek, F. An efficient algorithm for computing free distance. IEEE Trans. Inf. Theory 1972, 18, 437–439. [Google Scholar] [CrossRef]
- Cedervall, M.; Johannesson, R. A fast algorithm for computing distance spectrum of convolutional codes. IEEE Trans. Inf. Theory 1989, 35, 1146–1159. [Google Scholar] [CrossRef]
- Rouanne, M.; Costello, D.J., Jr. An algorithm for computing the distance spectrum of trellis codes. IEEE J. Sel. Areas Commun. 1989, 7, 929–940. [Google Scholar] [CrossRef]
- Bocharova, I.E.; Handlery, M.; Johannesson, R. A BEAST for Prowling in Trees. IEEE Trans. Inf. Theory 2004, 50, 1295–1302. [Google Scholar] [CrossRef]
- Zhou, H.; Mitchell, D.G.M.; Goertz, N.; Costello, D.J., Jr. Distance spectrum estimation of LDPC convolutional codes. In Proceedings of the 2012 IEEE International Symposium on Information Theory Proceedings (ISIT), Cambridge, MA, USA, 1–6 July 2012.
- Smarandache, R.; Vontobel, P.O. Quasi-Cyclic LDPC Codes: Influence of proto- and Tanner-graph structure on minimum Hamming distance upper bounds. IEEE Trans. Inf. Theory 2012, 58, 585–607. [Google Scholar] [CrossRef]
- Tanner, R.M.; Sridhara, D.; Sridharan, A.; Fuja, T.E.; Costello, D.J., Jr. LDPC block and convolutional codes based on circulant matrices. IEEE Trans. Inf. Theory 2004, 50, 2966–2984. [Google Scholar] [CrossRef]
- Pusane, A.E.; Lentmaier, M.; Zigangirov, K.S.; Costello, D.J., Jr. Reduced complexity decoding strategies for LDPC convolutional codes. In Proceedings of the International Symposium on Information Theory, Chicago, IL, USA, 27 June–2 July 2004.
- Zhou, H.; Goertz, N. Unavoidable cycles in polynomial-based time-invariant LDPC convolutional codes. In Proceedings of the 11th European Wireless Conference on Sustainable Wireless Technologies, Vienna, Austria, 27–29 April 2011.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, H.; Feng, J.; Li, P.; Xia, J. Codeword Structure Analysis for LDPC Convolutional Codes. Information 2015, 6, 866-879. https://doi.org/10.3390/info6040866
Zhou H, Feng J, Li P, Xia J. Codeword Structure Analysis for LDPC Convolutional Codes. Information. 2015; 6(4):866-879. https://doi.org/10.3390/info6040866
Chicago/Turabian StyleZhou, Hua, Jiao Feng, Peng Li, and Jingming Xia. 2015. "Codeword Structure Analysis for LDPC Convolutional Codes" Information 6, no. 4: 866-879. https://doi.org/10.3390/info6040866