Enhancement of Low Contrast Images Based on Effective Space Combined with Pixel Learning

Abstract
:1. Introduction
2. Background
2.1. Retinex Model
2.2. Dehaze Model
3. Proposed Model
3.1. Enhance Model Based on Effective Space
3.2. Relationship with Retinex Model and Dehaze Model
4. Pixel Learning for Refinement
4.1. Pixel Learning
4.2. Mapping Model
4.3. Learning Label
5. Color Casts and Flowchart
5.1. White Balancing
5.2. Flowchart of the Proposed Methods
6. Experiment and Discussion
6.1. Parameter Configuration
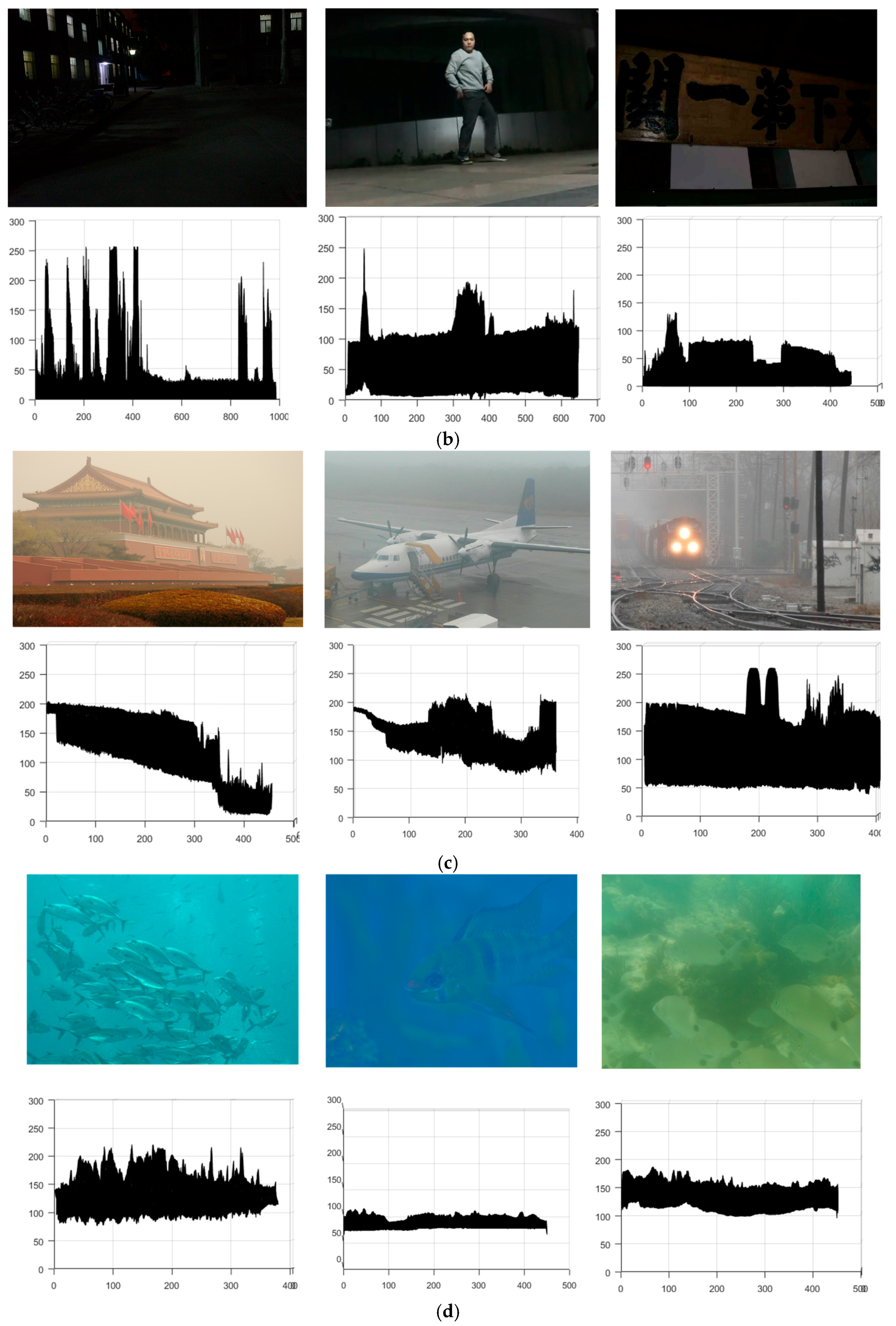
6.2. Scope of Application
6.3. Haze Removal
6.4. Lightning Compensation
6.5. Underwater Enhancement
6.6. Multidegraded Enhancement
6.7. Quantitative Comparison
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Land, E.H. Recent advances in Retinex theory and some implications for cortical computations: Color vision and the natural image. Proc. Natl. Acad. Sci. USA 1983, 80, 5163–5169. [Google Scholar] [CrossRef] [PubMed]
- Land, E.H. An alternative technique for the computation of the designator in the Retinex theory of color vision. Proc. Natl. Acad. Sci. USA 1986, 83, 3078–3080. [Google Scholar] [CrossRef] [PubMed]
- Land, E.H. Recent advances in Retinex theory. Vis. Res. 1986, 26, 7–21. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. Properties and performance of a center/surround Retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef] [PubMed]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. A multiscale Retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed]
- Kimmel, R.; Elad, M.; Shaked, D.; Keshet, R.; Sobel, I. A Variational Framework for Retinex. Int. J. Comput. Vis. 2003, 52, 7–23. [Google Scholar] [CrossRef]
- Ma, Z.; Wen, J. Single-scale Retinex sea fog removal algorithm fused the edge information. Jisuanji Fuzhu Sheji Yu Tuxingxue Xuebao J. Comput. Aided Des. Comput. Graph. 2015, 27, 217–225. [Google Scholar]
- Zhang, S.; Wang, T.; Dong, J.; Yu, H. Underwater Image Enhancement via Extended Multi-Scale Retinex. Neurocomputing 2017, 245, 1–9. [Google Scholar] [CrossRef]
- Si, L.; Wang, Z.; Xu, R.; Tan, C.; Liu, X.; Xu, J. Image Enhancement for Surveillance Video of Coal Mining Face Based on Single-Scale Retinex Algorithm Combined with Bilateral Filtering. Symmetry 2017, 9, 93. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Yin, C.; Dai, M. Biologically inspired image enhancement based on Retinex. Neurocomputing 2016, 177, 373–384. [Google Scholar] [CrossRef]
- Lin, H.; Shi, Z. Multi-scale retinex improvement for nighttime image enhancement. Opt. Int. J. Light Electron Opt. 2014, 125, 7143–7148. [Google Scholar] [CrossRef]
- Xie, S.J.; Lu, Y.; Yoon, S.; Yang, J.; Park, D.S. Intensity variation normalization for finger vein recognition using guided filter based singe scale Retinex. Sensors 2015, 15, 17089–17105. [Google Scholar] [CrossRef] [PubMed]
- Lan, X.; Zuo, Z.; Shen, H.; Zhang, L.; Hu, J. Framelet-based sparse regularization for uneven intensity correction of remote sensing images in a Retinex variational framework. Opt. Int. J. Light Electron Opt. 2016, 127, 1184–1189. [Google Scholar] [CrossRef]
- Wang, G.; Dong, Q.; Pan, Z.; Zhang, W.; Duan, J.; Bai, L.; Zhanng, J. Retinex theory based active contour model for segmentation of inhomogeneous images. Digit. Signal Process. 2016, 50, 43–50. [Google Scholar] [CrossRef]
- Jiang, B.; Woodell, G.A.; Jobson, D.J. Novel Multi-Scale Retinex with Color Restoration on Graphics Processing Unit; Springer: New York, NY, USA, 2015. [Google Scholar]
- Shi, Z.; Zhu, M.; Guo, B.; Zhao, M. A photographic negative imaging inspired method for low illumination night-time image enhancement. Multimedia Tools Appl. 2017, 76, 1–22. [Google Scholar] [CrossRef]
- Wang, Y.; Zhuo, S.; Tao, D.; Bu, J.; Li, N. Automatic local exposure correction using bright channel prior for under-exposed images. Signal Process. 2013, 93, 3227–3238. [Google Scholar] [CrossRef]
- Shwartz, S.; Namer, E.; Schechner, Y.Y. Blind Haze Separation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1984–1991. [Google Scholar]
- Shen, X.; Li, Q.; Tian, Y.; Shen, L. An Uneven Illumination Correction Algorithm for Optical Remote Sensing Images Covered with Thin Clouds. Remote Sens. 2015, 7, 11848–11862. [Google Scholar] [CrossRef]
- Kopf, J.; Neubert, B.; Chen, B.; Cohen, M.; Cohen, D.; Deussen, O.; Uyttendaele, M.; Lischinski, D. Deep photo: Model-based photograph enhancement and viewing. ACM Trans. Graph. 2008, 27, 1–10. [Google Scholar] [CrossRef]
- Fattal, R. Single image dehazing. ACM Trans. Graph. 2008, 27, 1–9. [Google Scholar] [CrossRef]
- Tan, R.T. Visibility in bad weather from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2008, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [PubMed]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Meng, G.; Wang, Y.; Duan, J.; Xiang, S.; Pan, C. Efficient Image Dehazing with Boundary Constraint and Contextual Regularization. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 617–624. [Google Scholar]
- Jo, S.Y.; Ha, J.; Jeong, H. Single Image Haze Removal Using Single Pixel Approach Based on Dark Channel Prior with Fast Filtering. In Computer Vision and Graphics; Springer: Cham, Switzerland, 2016; pp. 151–162. [Google Scholar]
- Ju, M.; Zhang, D.; Wang, X. Single image dehazing via an improved atmospheric scattering model. Vis. Comput. 2017, 33, 1613–1625. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, J. Single Image Dehazing Using Fixed Points and Nearest-Neighbor Regularization. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Switzerland, 2016; pp. 18–33. [Google Scholar]
- Kim, J.-H.; Jang, W.-D.; Sim, J.-Y.; Kim, C.-S. Optimized contrast enhancement for real-time image and video dehazing. J. Vis. Commun. Image Represent. 2013, 24, 410–425. [Google Scholar] [CrossRef]
- Li, Y.; Tan, R.T.; Brown, M.S. Nighttime Haze Removal with Glow and Multiple Light Colors. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 226–234. [Google Scholar]
- Ji, T.; Wang, G. An approach to underwater image enhancement based on image structural decomposition. J. Ocean Univ. China 2015, 14, 255–260. [Google Scholar] [CrossRef]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Ma, C.; Ao, J. Red Preserving Algorithm for Underwater Imaging. In Geo-Spatial Knowledge and Intelligence; Springer: Singapore, 2017; pp. 110–116. [Google Scholar]
- Ebner, M. Color constancy based on local space average color. Mach. Vis. Appl. 2009, 20, 283–301. [Google Scholar] [CrossRef]
- Van Herk, M. A fast algorithm for local minimum and maximum filters on rectangular and octagonal kernels. Pattern Recognit. Lett. 1992, 13, 517–521. [Google Scholar] [CrossRef]
- Le, P.Q.; Iliyasu, A.M.; Sanchez, J.A.G.; Hirota, K. Representing Visual Complexity of Images Using a 3D Feature Space Based on Structure, Noise, and Diversity. Lect. Notes Bus. Inf. Process. 2012, 219, 138–151. [Google Scholar] [CrossRef]
- Gu, K.; Zhai, G.; Lin, W.; Liu, M. The Analysis of Image Contrast: From Quality Assessment to Automatic Enhancement. IEEE Trans. Cybernet. 2017, 46, 284–297. [Google Scholar] [CrossRef] [PubMed]
- Hou, W.; Gao, X.; Tao, D.; Li, X. Blind image quality assessment via deep learning. IEEE Trans. Neural Netw. Learn. Syst. 2017, 26, 1275–1286. [Google Scholar]
- Gu, K.; Li, L.; Lu, H.; Lin, W. A Fast Computational Metric for Perceptual Image Quality Assessment. IEEE Trans. Ind. Electron. 2017. [Google Scholar] [CrossRef]
- Wu, Q.; Li, H.; Meng, F.; Ngan, K.N.; Luo, B.; Huang, C.; Zeng, B. Blind Image Quality Assessment Based on Multichannel Feature Fusion and Label Transfer. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 425–440. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values | Equations |
|---|---|---|
| Radius of max/min filter | 20 | Equation (13) |
| Radius of mean filter | 40 | Equation (13) |
| thred1 | 20 | Equation (12) |
| thred2 | 20 | Equations (14) and (15) |
| tD | 150 | Equation (18) |
| tU | 70 | Equation (18) |
| thredWB | 50 | Equation (19) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Li, G.; Han, G. Enhancement of Low Contrast Images Based on Effective Space Combined with Pixel Learning. Information 2017, 8, 135. https://doi.org/10.3390/info8040135
Li G, Li G, Han G. Enhancement of Low Contrast Images Based on Effective Space Combined with Pixel Learning. Information. 2017; 8(4):135. https://doi.org/10.3390/info8040135
Chicago/Turabian StyleLi, Gengfei, Guiju Li, and Guangliang Han. 2017. "Enhancement of Low Contrast Images Based on Effective Space Combined with Pixel Learning" Information 8, no. 4: 135. https://doi.org/10.3390/info8040135
APA StyleLi, G., Li, G., & Han, G. (2017). Enhancement of Low Contrast Images Based on Effective Space Combined with Pixel Learning. Information, 8(4), 135. https://doi.org/10.3390/info8040135