Non-Negative Tensor Factorization for Human Behavioral Pattern Mining in Online Games


Abstract
1. Introduction
Contributions
- Highlight the existence of an underlying structure in the data, that allows us to divide players into groups characterized by similar features and having correlated temporal behaviors;
- Provide an interpretation of the components extracted by the NTF;
- Validate the interpretation of the NTF results by analyzing the uncovered groups and their evolution over time;
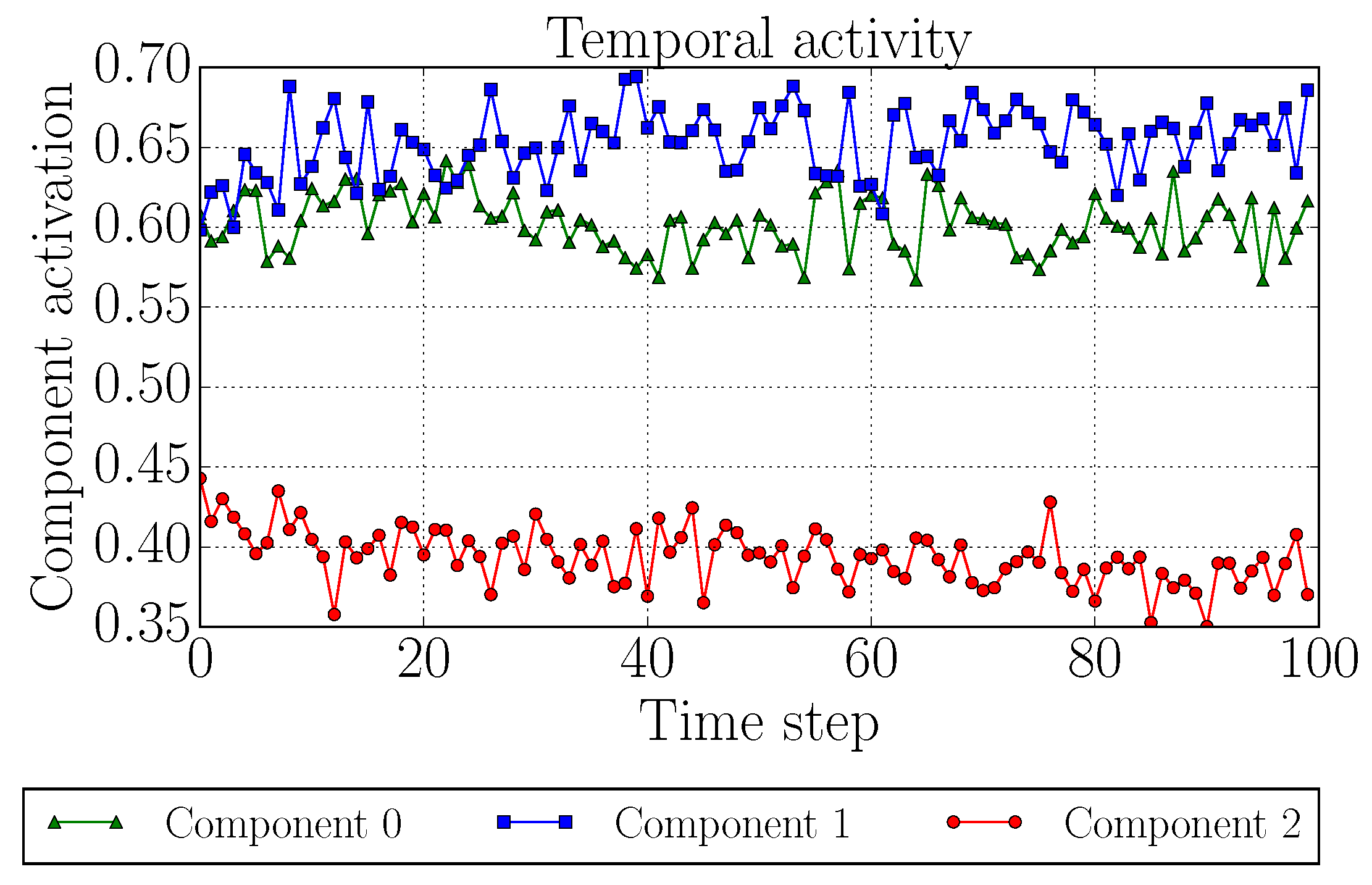
- Discover, by analyzing the temporal components, that players’ playing strategies are consistent over time;
- Provide and validate an explanation for players behavioral stability, namely that the design of the game strongly impacts team formation in each match, thus manipulating the team’s probability of victory.
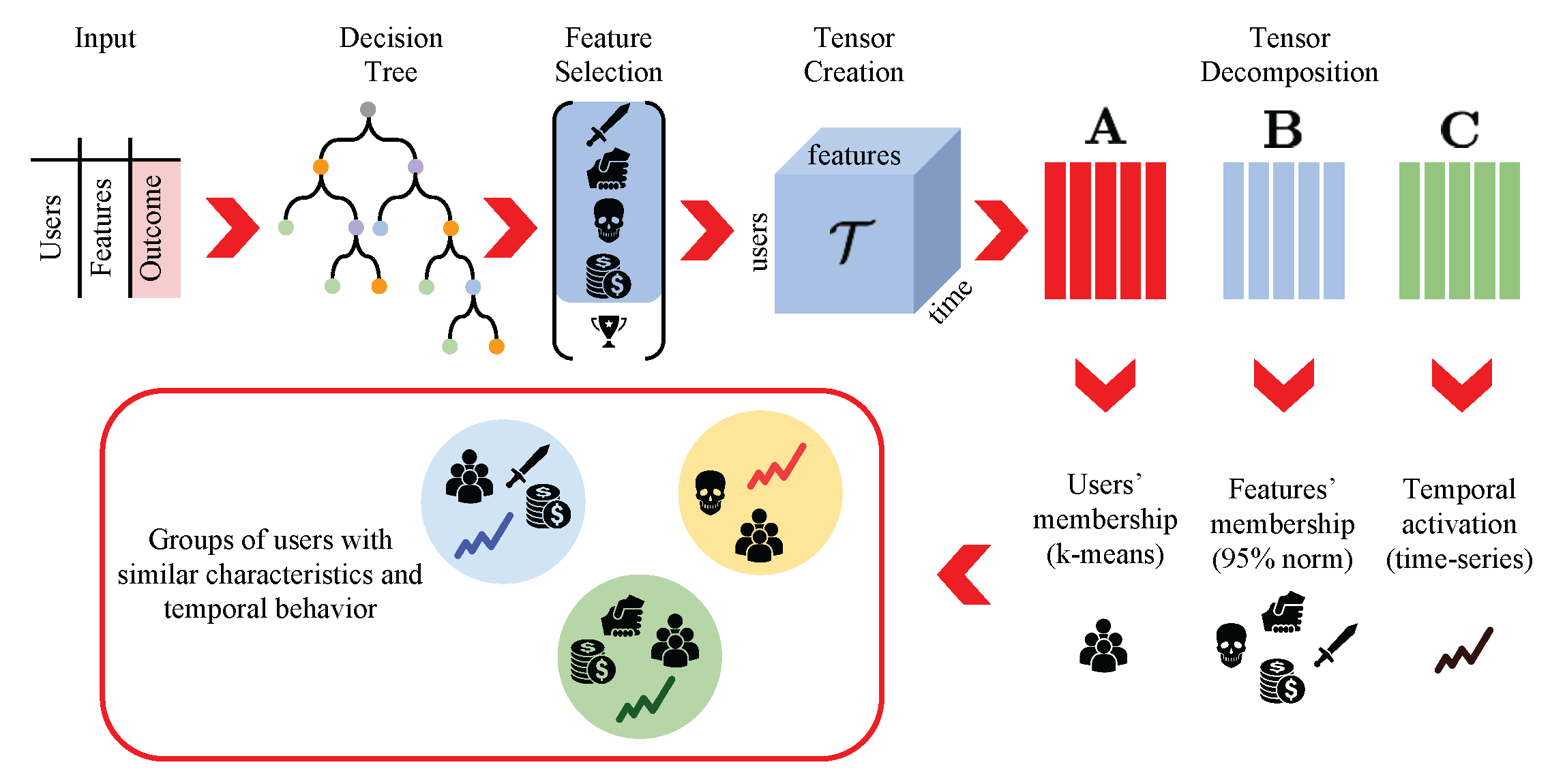
2. Materials and Methods
2.1. Feature Selection
2.2. Non-Negative Tensor Factorization
2.3. Rank Selection
3. Data and Feature Selection
3.1. League of Legends
3.2. The League of Legends Dataset
3.3. Feature Selection
4. Results and Discussion
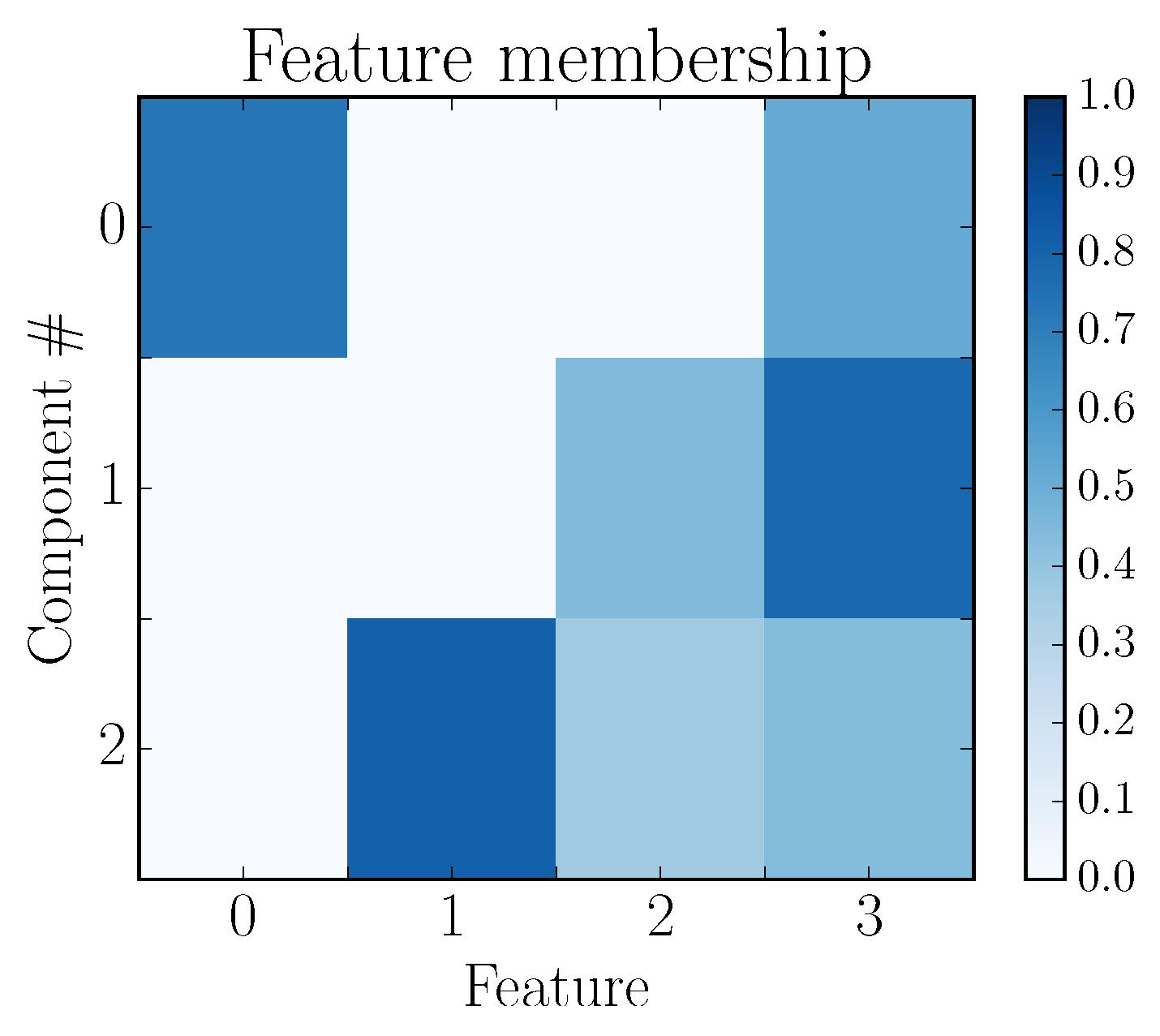
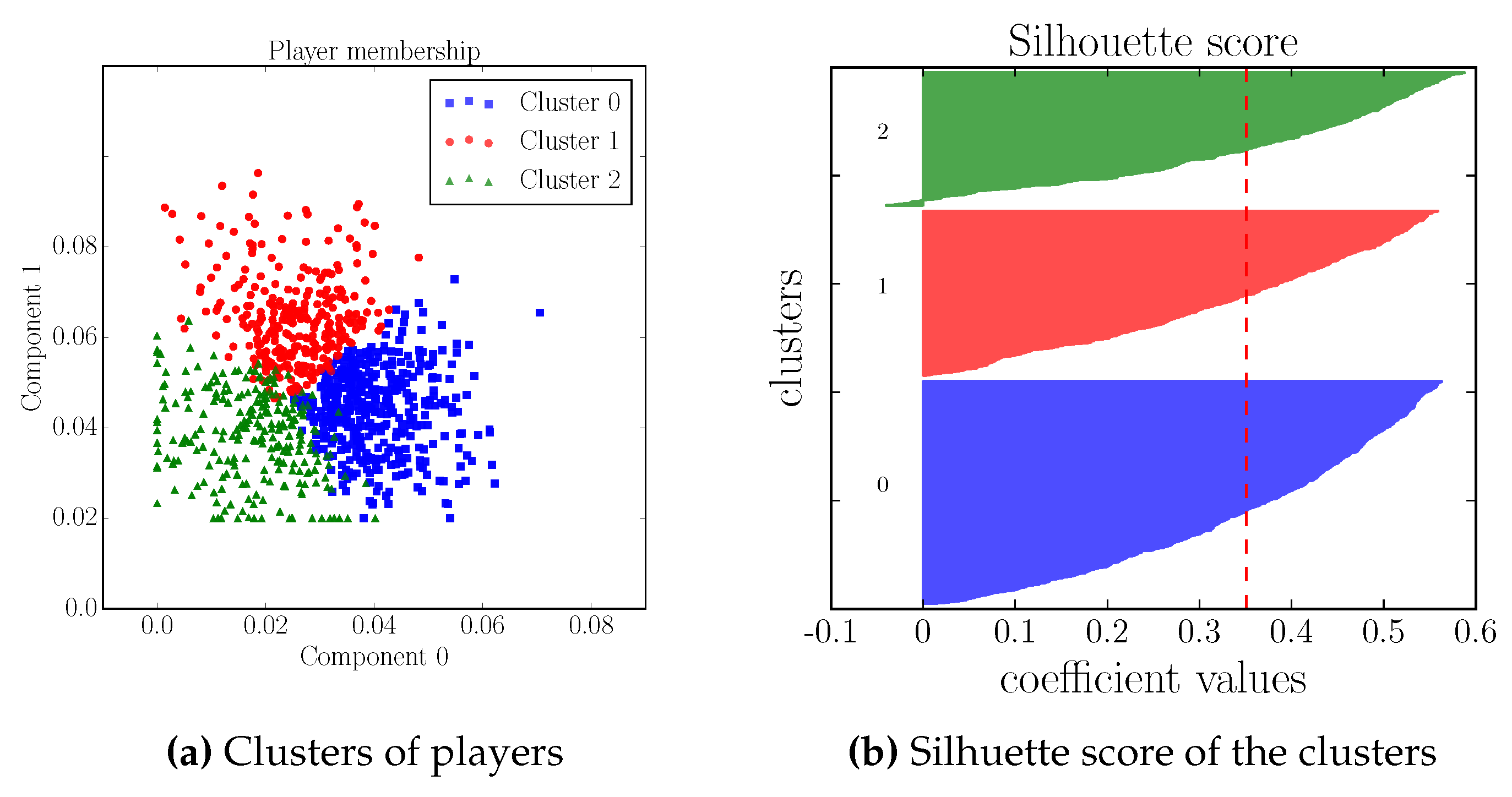
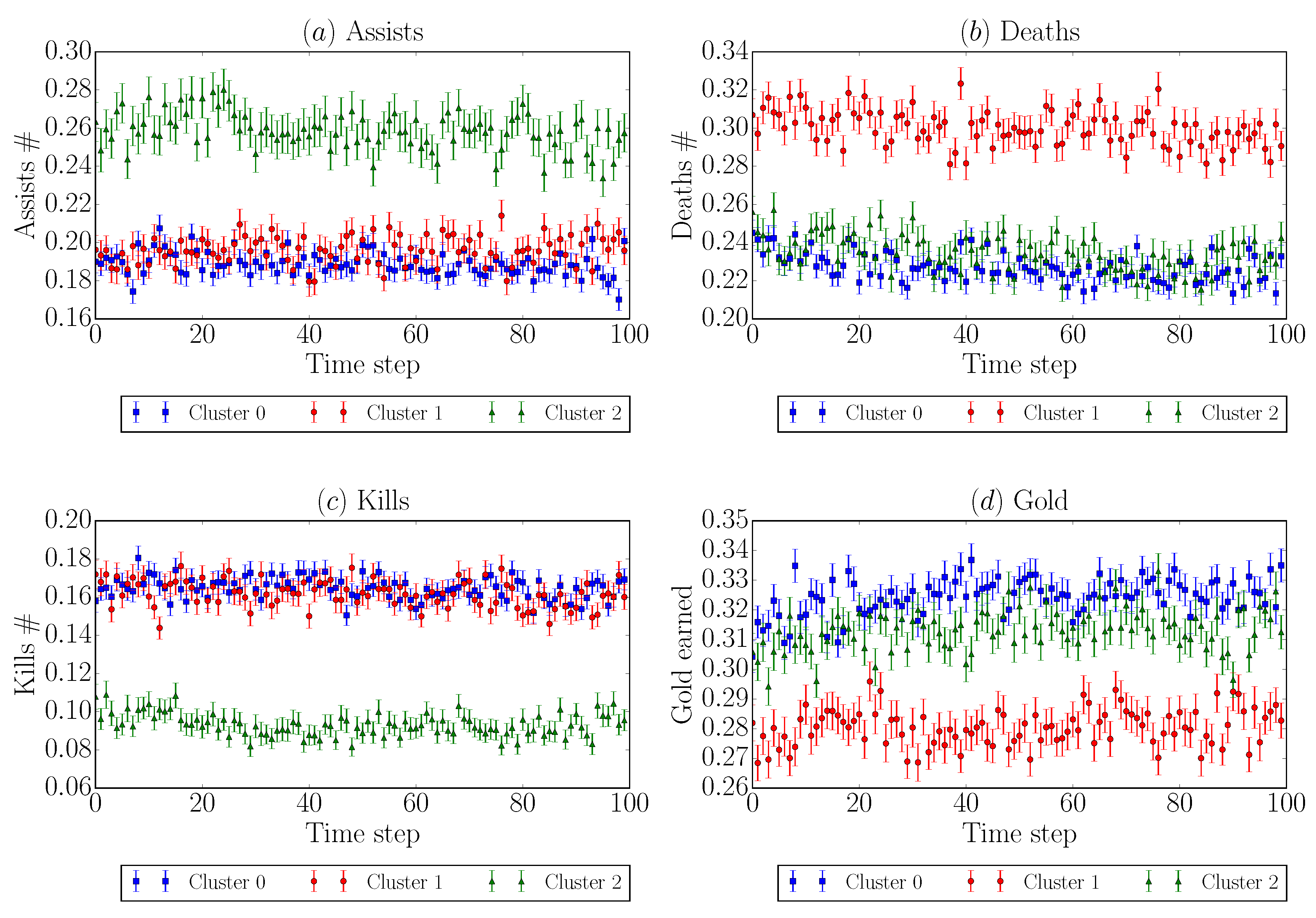
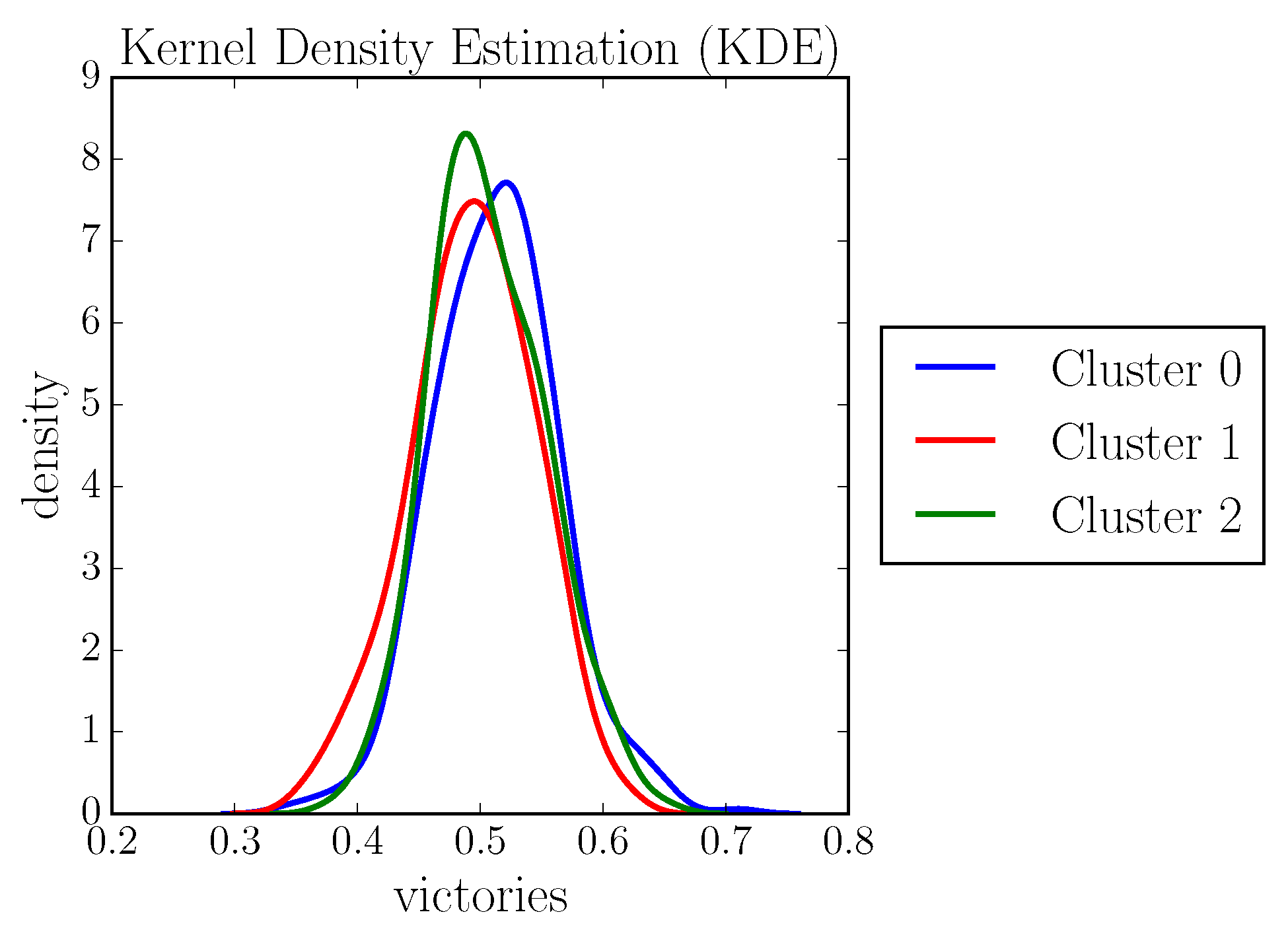
- Users belonging to Cluster 0 and thus to Component 1 are strongly characterized by the features kills and earned gold;
- Users in Cluster 1 and thus belonging to Component 2 are characterized by deaths, kills, and earned gold;
- Users belonging to Cluster 2 and Component 0 are strongly characterized by assists and earned gold.
4.1. Validation
4.2. Related Work
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix A.1. IDs
Appendix A.2. Temporal Information
Appendix A.3. Minions
Appendix A.4. Wards
Appendix A.5. Damages
Appendix A.6. Heals
Appendix A.7. Gold
Appendix A.8. Kills
Appendix A.9. Other Actions
Appendix A.10. Scores
Appendix A.11. Outcome
References
- Ferrari, S. From generative to conventional play: Moba and league of legends. In Proceedings of the 2013 DiGRA International Conference: DeFragging Game Studies, Atlanta, GA, USA, 26–29 August 2013; pp. 1–17. [Google Scholar]
- Foo, C.Y.; Koivisto, E.M. Defining grief play in MMORPGs: Player and developer perceptions. In Proceedings of the 2004 ACM SIGCHI International Conference on Advances in Computer Entertainment Technology, Singapore, 3–5 June 2005; ACM: New York, NY, USA, 2004; pp. 245–250. [Google Scholar]
- Kou, Y.; Gui, X. Playing with strangers: Understanding temporary teams in League of Legends. In Proceedings of the First ACM SIGCHI Annual Symposium on Computer-Human Interaction in Play, Toronto, ON, Canada, 19–21 October 2014; ACM: New York, NY, USA, 2014; pp. 161–169. [Google Scholar]
- Brown, B.; Bell, M. CSCW at play: ‘there’ as a collaborative virtual environment. In Proceedings of the 2004 ACM conference on Computer Supported Cooperative Work, Chicago, IL, USA, 6–10 November 2004; ACM: New York, NY, USA, 2004; pp. 350–359. [Google Scholar]
- Nuangjumnong, T. The effects of gameplay on leadership behaviors: An empirical study on leadership behaviors and roles in multiplayer online battle arena games. In Proceedings of the 2014 IEEE International Conference on Cyberworlds (CW), Santander, Spain, 6–8 October 2014; pp. 300–307. [Google Scholar]
- Sapienza, A.; Peng, H.; Ferrara, E. Performance Dynamics and Success in Online Games. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 902–909. [Google Scholar]
- Kou, Y.; Nardi, B. Regulating anti-social behavior on the Internet: The example of League of Legends. In Proceedings of the iConference 2013, Fort Worth, TX, USA, 12–15 February 2013; pp. 616–622. [Google Scholar]
- Ducheneaut, N.; Moore, R.J. The social side of gaming: A study of interaction patterns in a massively multiplayer online game. In Proceedings of the 2004 ACM Conference on Computer Supported Cooperative Work, Chicago, IL, USA, 6–10 November 2004; ACM: New York, NY, USA, 2004; pp. 360–369. [Google Scholar]
- Shores, K.B.; He, Y.; Swanenburg, K.L.; Kraut, R.; Riedl, J. The identification of deviance and its impact on retention in a multiplayer game. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, MD, USA, 15–19 February 2014; ACM: New York, NY, USA, 2014; pp. 1356–1365. [Google Scholar]
- Dabbish, L.; Kraut, R.; Patton, J. Communication and commitment in an online game team. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; ACM: New York, NY, USA, 2012; pp. 879–888. [Google Scholar]
- Ratan, R.A.; Taylor, N.; Hogan, J.; Kennedy, T.; Williams, D. Stand by your man: An examination of gender disparity in League of Legends. Games Cult. 2015, 10, 438–462. [Google Scholar] [CrossRef]
- Véron, M.; Marin, O.; Monnet, S. Matchmaking in multi-player on-line games: Studying user traces to improve the user experience. In Proceedings of the Network and Operating System Support on Digital Audio and Video Workshop, Singapore, 19–21 March 2014; ACM: New York, NY, USA, 2014; pp. 7–12. [Google Scholar]
- Cichocki, A.; Zdunek, R.; Phan, A.H.; Amari, S.I. Nonnegative Matrix and Tensor Factorizations: Applications to Exploratory Multi-Way Data Analysis and Blind Source Separation; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Lim, L.H.; Comon, P. Nonnegative approximations of nonnegative tensors. J. Chemom. 2009, 23, 432–441. [Google Scholar] [CrossRef]
- Liavas, A.P.; Kostoulas, G.; Lourakis, G.; Huang, K.; Sidiropoulos, N.D. Nesterov-based Alternating Optimization for Nonnegative Tensor Factorization: Algorithm and Parallel Implementation. IEEE Trans. Signal Process. 2017, 66, 944–953. [Google Scholar] [CrossRef]
- Rajapakse, M.; Tan, J.; Rajapakse, J. Color channel encoding with NMF for face recognition. In Proceedings of the 2004 IEEE International Conference on Image Processing, Singapore, 24–27 October 2004; pp. 2007–2010. [Google Scholar]
- Buciu, I.; Pitas, I. Application of non-negative and local non negative matrix factorization to facial expression recognition. In Proceedings of the IEEE 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; pp. 288–291. [Google Scholar]
- Zhang, T.; Fang, B.; Tang, Y.Y.; He, G.; Wen, J. Topology preserving non-negative matrix factorization for face recognition. IEEE Trans. Image Process. 2008, 17, 574–584. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Fu, M.; Lu, X. Substance dependence constrained sparse NMF for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2975–2986. [Google Scholar] [CrossRef]
- Tsinos, C.G.; Rontogiannis, A.A.; Berberidis, K. Distributed blind hyperspectral unmixing via joint sparsity and low-rank constrained non-negative matrix factorization. IEEE Trans. Comput. Imaging 2017, 3, 160–174. [Google Scholar] [CrossRef]
- Yang, J.; Leskovec, J. Overlapping community detection at scale: A nonnegative matrix factorization approach. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; ACM: New York, NY, USA, 2013; pp. 587–596. [Google Scholar]
- Psorakis, I.; Roberts, S.; Ebden, M.; Sheldon, B. Overlapping community detection using bayesian non-negative matrix factorization. Phys. Rev. E 2011, 83, 066114. [Google Scholar] [CrossRef] [PubMed]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42. [Google Scholar] [CrossRef]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; ACM: New York, NY, USA, 2008; pp. 931–940. [Google Scholar]
- Papalexakis, E.E.; Faloutsos, C.; Sidiropoulos, N.D. Tensors for data mining and data fusion: Models, applications, and scalable algorithms. ACM Trans. Intell. Syst. Technol. (TIST) 2017, 8, 16. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Gauvin, L.; Panisson, A.; Cattuto, C. Detecting the community structure and activity patterns of temporal networks: A Non-negative Tensor Factorization approach. PLoS ONE 2014, 9, e86028. [Google Scholar] [CrossRef] [PubMed]
- Sapienza, A.; Panisson, A.; Wu, J.; Gauvin, L.; Cattuto, C. Detecting Anomalies in Time-varying Networks using Tensor Decomposition. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 516–523. [Google Scholar]
- Panisson, A.; Gauvin, L.; Quaggiotto, M.; Cattuto, C. Mining concurrent topical activity in microblog streams. arXiv, 2014; arXiv:1403.1403. [Google Scholar]
- Royer, J.P.; Thirion-Moreau, N.; Comon, P. Computing the polyadic decomposition of nonnegative third order tensors. Signal Process. 2011, 91, 2159–2171. [Google Scholar] [CrossRef]
- Kolda, T.G. Multilinear Operators for Higher-Order Decompositions; Technical Report; Sandia National Laboratories: Albuquerque, NM, USA, 2006.
- Kim, H.; Park, H.; Eldén, L. Non-negative Tensor Factorization based on alternating large-scale non-negativity-constrained least squares. In Proceedings of the 2007 IEEE 7th International Symposium on BioInformatics and BioEngineering, Boston, MA, USA, 14–17 October 2007; pp. 1147–1151, NTF algorithm based on ANLS + regularization. [Google Scholar]
- Kim, J.; Park, H. Fast nonnegative tensor factorization with an active-set-like method. In High-Performance Scientific Computing; Springer: Berlin/Heidelberg, Germany, 2012; pp. 311–326. [Google Scholar]
- Bro, R.; Kiers, H.A. A new efficient method for determining the number of components in PARAFAC models. J. Chemom. 2003, 17, 274–286. [Google Scholar] [CrossRef]
- Mørup, M.; Hansen, L.K. Automatic relevance determination for multi-way models. J. Chemom. 2009, 23, 352–363. [Google Scholar] [CrossRef]
- Kou, Y.; Nardi, B.A. Governance in League of Legends: A hybrid system. In Proceedings of the Foundation of Digital Games, Fort Lauderdale, FL, USA, 3–7 April 2014. [Google Scholar]
- Donaldson, S. Mechanics and metagame: Exploring binary expertise in League of Legends. Games Cult. 2017, 12, 426–444. [Google Scholar] [CrossRef]
- Ong, H.Y.; Deolalikar, S.; Peng, M. Player Behavior and Optimal Team Composition for Online Multiplayer Games. arXiv, 2015; arXiv:1503.02230. [Google Scholar]
- Lee, C.S.; Ramler, I. Investigating the impact of game features and content on champion usage in league of legends. In Proceedings of the Foundation of Digital Games, Pacific Grove, CA, USA, 22–25 June 2015. [Google Scholar]
- Kim, J.; Keegan, B.C.; Park, S.; Oh, A. The Proficiency-Congruency Dilemma: Virtual Team Design and Performance in Multiplayer Online Games. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; ACM: New York, NY, USA, 2016; pp. 4351–4365. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| X | constant |
| x | scalar |
| vector | |
| matrix | |
| matrix entry | |
| tensor | |
| entry of a three-dimensional tensor | |
| ○ | outer product |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sapienza, A.; Bessi, A.; Ferrara, E. Non-Negative Tensor Factorization for Human Behavioral Pattern Mining in Online Games. Information 2018, 9, 66. https://doi.org/10.3390/info9030066
Sapienza A, Bessi A, Ferrara E. Non-Negative Tensor Factorization for Human Behavioral Pattern Mining in Online Games. Information. 2018; 9(3):66. https://doi.org/10.3390/info9030066
Chicago/Turabian StyleSapienza, Anna, Alessandro Bessi, and Emilio Ferrara. 2018. "Non-Negative Tensor Factorization for Human Behavioral Pattern Mining in Online Games" Information 9, no. 3: 66. https://doi.org/10.3390/info9030066
APA StyleSapienza, A., Bessi, A., & Ferrara, E. (2018). Non-Negative Tensor Factorization for Human Behavioral Pattern Mining in Online Games. Information, 9(3), 66. https://doi.org/10.3390/info9030066