Location Regularization-Based POI Recommendation in Location-Based Social Networks


1
Postdoctoral Research Station of Management Science and Engineering, Shandong Normal University, Jinan 250014, China
2
School of Management Science and Engineering, Shandong Normal University, Jinan 250014, China
3
Information Technology Bureau of Shandong Province, China Post Group, Jinan 250000, China
4
School of Information Science and Engineering, Shandong Normal University, Jinan 250014, China
*
Author to whom correspondence should be addressed.
Information 2018, 9(4), 85; https://doi.org/10.3390/info9040085
Submission received: 5 March 2018
/
Revised: 1 April 2018
/
Accepted: 7 April 2018
/
Published: 9 April 2018
Abstract
:POI (point-of-interest) recommendation as one of the efficient information filtering techniques has been widely utilized in helping people find places they are likely to visit, and many related methods have been proposed. Although the methods that exploit geographical information for POI recommendation have been studied, few of these studies have addressed the implicit feedback problem. In fact, in most location-based social networks, the user’s negative preferences are not explicitly observable. Consequently, it is inappropriate to treat POI recommendation as traditional recommendation problem. Moreover, previous studies mainly explore the geographical information from a user perspective and the methods that model them from a location perspective are not well explored. Hence, this work concentrates on exploiting the geographical characteristics from a location perspective for implicit feedback, where a neighborhood aware Bayesian personalized ranking method (NBPR) is proposed. To be specific, the weighted Bayesian framework that was proposed for personalized ranking is first introduced as our basic POI recommendation method. To exploit the geographical characteristics from a location perspective, we then constrain the ranking loss by using a regularization term derived from locations, and assume nearest neighboring POIs are more inclined to be visited by similar users. Finally, several experiments are conducted on two real-world social networks to evaluate the NBPR method, where we can find that our NBPR method has better performance than other related recommendation algorithms. This result also demonstrates the effectiveness of our method with neighborhood information and the importance of the geographical characteristics.
1. Introduction
Recently, the development of location positioning technology and smart mobile phones has boosted the appearance of LBSNs (location-based social networks), e.g., Yelp, Foursquare and Gowalla. User in LBSNs can express his/her preferences by checking in different POIs (e.g., hotels, restaurants and shopping mall), which resulting a huge amount of mobile data. These check-in data provides us the opportunities to analyze users’ mobile patterns and recommend possible visiting places to them. As an efficient way for people to discover new interesting unknown places, recently POI recommendation has become one of the hottest topics. According to the observations of the existing historical data, that is, users are inclined to visit neighboring places, the geographical influence has been investigated in different algorithms to further improve the POI recommendation [1,2,3,4]. For example, Ye et al. [1] utilized the power-law probabilistic method to model the geographical influence, and proposed a unified recommendation framework for POI recommendation, which fused geographical influence, social influence and user preferences together. Cheng et al. [2] first utilized a multi-center Gaussian method to model the influence of the geographical information, and further investigated it in a fused matrix factorization method.
Though the POI recommendation methods that exploit geographical influence have been studied, most of them mainly focused on feeding it into traditional explicit feedback-based frameworks. However, in fact, explicit observations that can reveal the users’ negative preferences for places are not feasible in most LBSNs. The interactions between users and locations are not explicit but implicit, which means only positive check-in behaviours are available. To cope with this challenge, implicit feedback-based recommendation methods are proposed recently. For example, Lian et al. [5] considered POI recommendation as the problem of one class collaborative filtering (OCCF) [6], and sought the weighted matrix factorization method to solve it. To incorporate the clustering phenomenon derived from the users’ mobile behaviours into the factorization model, the augmented users’ and POIs’ latent factors are proposed. Li et al. [7] considered the task of recommending POIs as the problem of pair-wise ranking, and learned the users’ preferences by an ordered weighted pair-wise classification (OWPC) method, where they introduced an extra factor matrix to exploit the geographical influence. Ying et al. [8] solved the pair-wise ranking problem by using the Bayesian personalized ranking (BPR) framework, and gave equal weight to different POI pairs. However, in reality, different POI pairs should contribute differently to the ranking function, since users usually favor different locations.
As we have mentioned above, most of these existing methods mainly exploit the geographical influence from the view of a user, and the method that considered it from the view of a location has not been fully studied. To further investigate the geographical influence, we analyze the users’ mobile data empirically and find that nearby places tend to be visited by common visitors. The shorter the distance between two locations is, the more common visitors they tend to share. This location-based feature is different from individual users and should be treated differently. Inspired by this observation, a pioneer work was proposed by Liu et al. [9], which exploited the geographical characteristics from a location perspective, and a method with two levels was proposed to model the geographical neighborhood location, that is, the region-level and instance-level. These characteristics are further incorporated into the weighted matrix factorization (WMF) framework to improve the recommendation accuracy. However, due to the limitation of WMF, their work optimized for a point-wise scoring function, and the ranking performance with geographical characteristics was unlearned.
Consequently, we put forward a new neighborhood aware ranking method for POI recommendation, which captures the geographical characteristics from a location perspective under the weighted BPR framework. Specifically, we consider check-ins as implicit feedback, and propose to utilize the weighted BPR method for this task by assuming that the more the difference of visit frequency between two POIs is, the more the importance of this POI pair should be. To model the geographical neighborhood of a location, we assume the nearest neighbors tend to have similar latent factors and accordingly utilize the location distance to regularize the ranking loss. To evaluate our proposed method, we conduct experiments on the datasets that from two real-world LBSNs, and the results indicate that our proposed method can outperform other related POI recommendation approaches, which also demonstrates the importance of the geographical characteristics and the effectiveness of our ranking-based method.
We arrange the remainder of this work as follows. Section 2 briefly reviews the related work to our study. Section 3 describes the POI recommendation problem that we intend to deal with and details our proposed neighborhood aware ranking method. Section 4 conducts experiments on two real-world LBSNs. Section 5 lists some conclusions of this work and gives some directions for future work.
2. Related Work
This section discusses some related work to our studies, which including implicit feedback-based recommendation, POI recommendation with geographical characteristics and other contexts.
2.1. Implicit Feedback-Based Recommendation
In many recommendation scenarios, the users’ feedback is implicit, where we can only infer the users’ preferences through observing various user behaviours, such as purchase, visit, click, et al., but never know the users’ tastes explicitly, which makes the recommendation problem more difficult. To tackle this challenge, many researchers have focused on processing implicit feedback [6,10,11]. E.g., Pan et al. [6] and Hu et al. [11] pointed out the missing values are mixed of negative samples and missing positive samples. Then they modeled the positive samples by using larger weights and missing samples by using smaller weights, and the weighted low rank approximation method was proposed. Although the weighted method can reduce the impact of negative samples, directly model all missing values as negative may not be reasonable. Rendle et al. [12] proposed a generic optimization method named BPR to directly optimize the model parameters for ranking, which was derived from the maximum posterior estimator and learned the user preferences based on pairs of items. However, in BPR, each item pair was treated equally and the difference of them cannot be distinguished.
2.2. POI Recommendation with Geographical Characteristics
With the advent of LBSNs [13,14] and the applications of locations (e.g., personalized location service [15,16]), researchers have started to design recommendation methods for POI recommendation in LBSNs. Motivated by the intuitions that nearby users are inclined to share more common locations, geographical influence between users has been exploited to improve POI recommendation. Many studies have been conducted to explore the mobile behaviours of users. Ye et al. [1] modeled the geographical influence among POIs by a power-law probabilistic method, and a unified framework for POI recommendation was finally derived. Cheng et al. [2] utilized the Multi-center Gaussian approach to explore the users’ check-in probability, and then fused it into a generalized matrix factorization framework. Instead of modeling the users’ behaviours in a universal way, Zhang et al. [17] proposed a personalized probabilistic approach to model the geographical influence individually. Lian et al. [5] viewed the users’ mobility records as implicit feedback, and investigated the geographical influence under the weighted matrix factorization framework. They proposed a augmented model to capture the spatial clustering phenomenon existed in users’ check-in behaviours. Li et al. [7] explored the geographical characteristics in a ranking-based factorization method, which learned the user preferences by ranking the POI pairs correctly. To incorporate the geographical influence, extra latent factor matrices were introduced. Guo et al. [18] introduced the BPR method for POI recommendation, and weighted each POI pair by the geographical distance between them.
2.3. Other Context Aware POI Recommendation
Except the geographical information, other types of contexts have also been explored [19,20,21,22], such as temporal influence, social influence, etc. For example, Li et al. [23] developed a two-step approach to explore the influence of friends to POI recommendation, which first learned a set of potential check-ins from users’ friends and then incorporated them into a matrix factorization model with different loss functions. Gao et al. [24] focused on modeling temporal effects for POI recommendation, and leveraged the temporal properties to generate a temporal aware recommendation framework. Gao et al. [21] further studied the relationship between content information and check-in actions, and then incorporated them into the content aware recommender system with regularization terms. These contexts and geographical characteristics are often fused together to improve the POI recommendation accuracy.
However, existing works mainly exploit geographical characteristics from a user perspective, and the work that exploits spatial information from a location perspective is not well studied. The geographical characteristics from a location perspective are independent of the characteristics from the individual users and should be treated as different recommendation factors. Liu et al. [9] exploited the geographical information from a location perspective based on the Weighted Matrix Factorization (WMF), but they optimized directly for a particular probability of a user to a location, and the recommendation performance in ranking-based method is unclear. In this work, we will consider the task of recommending POIs as a problem of pair-wise ranking, and introduce the algorithm of weighted BPR [18] as our basic recommendation framework. To learning from location perspective, we will model the geographical influence of neighborhood locations, and utilize the distance to regularize the ranking function to further improve recommendation accuracy.
3. POI Recommendation Criteria
This section will systematically explicate the method of modeling the geographical neighborhood characteristics from a location perspective. First, we describe the scenario of POI recommendation in location-based social networks. Second, the weighted BPR algorithm is introduced as our basic method for solving the POI recommendation problem, which exploits the effect of visit frequency by giving each POI pair different weights. Finally, we investigate the neighborhood aware POI ranking method by analyzing the problem from the view of Bayesian analysis, and derive a neighbor-based regularization term.
3.1. Problem Statement
Generally, there exist two main different aspects between POI recommendation and traditional recommender system: first, the check-in data is implicit, which only tells us the places that a user likes to visit, but the places that a user does not like to visit is unavailable. Second, as POI is actually a geographical location, the check-in behaviour has geographical characteristics, that is, nearby locations are inclined to be checked in by the same users. Based on the above two intuitions, the process of POI recommendation in LBSNs (as shown in Figure 1a) includes two core factors: the user preference and the geographical characteristics of POIs, which can be modeled by the visit frequency matrix and the geographical coordinates, separately (as presented in Figure 1a,b).
User-POI check-in frequency matrix denotes the spatial users’ favorites by recording their different visit frequency to different places. Each entry of this matrix reveals how often a specific user has visited a location, and unvisited places are denoted as “?”. Since the missing data is a mixture of negative and missing positive samples, simply treating them as negative observations cannot capture the real preferences of users. Hence, how to process implicit feedback has been one of the focuses of this work. The geographical information (denoted by the latitude and longitude) reveals the check-in activities in physical world, from which the users’ mobile patterns are learned, that is, users are more likely to visit nearby POIs, and neighboring POIs are inclined to be visited by similar users. These movement patterns are beneficial to model user behaviours. Therefore, how to effectively utilize geographically characteristics to enhance the recommendation performance is another problem to be solved in this work.
Note that, although the POI recommendation problem we studied is proposed for location-based social networks, it is quite general and can also be applied to the realistic spaces, such as the cultural cyber-physical spaces [25,26,27,28]. For example, POI recommendation method can be applied to recommend exhibits for users visiting museums, where the exhibits can be treated as POIs, and the users’ visiting behaviours to exhibits can be seen as check-in actions. In this scenario, the recommendation task is how to utilize the historical visiting behaviour and the deployed locations of these exhibits to enhance the quality of experience of museum touring, which can also be formalized as a personalized ranking problem as we have done in LBSNs.
3.2. Weighted BPR Criterion for POI Recommendation
BPR as the well-known pair-wise ranking-based recommendation method has been widely explored in recent studies. Contrary to directly optimizing for scoring single items, BPR learns the user and item preferences by correctly ranking the item pairs, which is more suitable to the scenarios that only positive samples can be observed. However, this method assumes that different item pairs should have the same contribution to the ranking function and treats them equally. However, in the real-world, users often express their favors to locations by checking in frequently. The higher the frequency is, the more the user prefers over this location, and the more the difference of these two POIs to this user is. Inspired by this, we first introduce the weighted BPR criterion [18] as our basic ranking method, and treat the POI pairs in a weighted way. The notations that are being used in our work are summarized in Table 1.
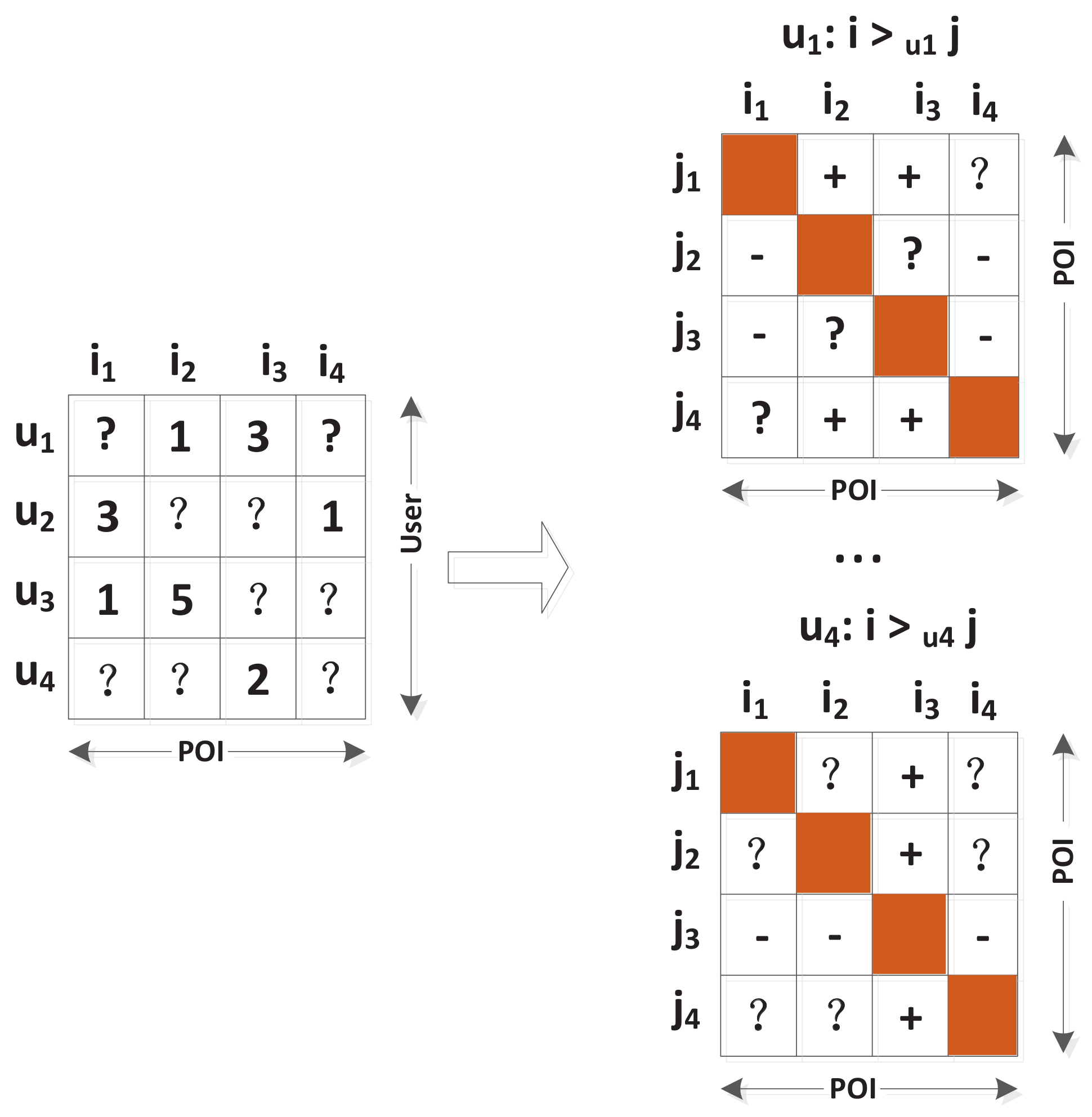
Let represent the user set, represent the POI set, and represent the visit matrix with different check-in frequencies (as Figure 2 has described). In this check-in matrix, each entry represents the check-in times of user u to POI i, and represents that the status of u to i is unknown, which means i is undiscovered or unattractive to u. In such an implicit feedback, the recommendation method needs to provide a personalized total ranking of all POIs to the user (In this work, we use symbol to denote a personalized total ranking of all POI pairs to user u, and utilize to denote the partial order relationship of two specific POIs, which means user u will more prefer i than j). To achieve this goal, we propose the pair-wise POI data by reconstructing the check-in matrix of users to POIs. In our data policy, we assume that compared with unvisited POIs users will prefer the POIs that he/she has visited. Figure 2 describes the examples of creating pair-wise preferences for specific users, where the sign “+” represents that a user likes i better than j, and the sign “−” represents that he/she likes j better than i. For example, user in Figure 2 has visited POI and unvisited POI , then we assume that this user will prefer POI over : . However, for the instances that POIs have both been visited by user u, we cannot deduce any preference for him/her (e.g., POI and for user ). The same is true for the cases that both POIs have been unvisited by the user (e.g., POI and for user ). The created training data : is formalized as:
where denotes the POI set that has been checked in by u, denotes the POI set that has been unvisited by u, and denotes user u prefers POI i over j. As the ranking with respect to u () is antisymmetric, the negative samples are regarded implicitly.
Then we maximize the following posterior probability [12] to learn the personalized POI ranking:
where is the parameter vector of any model class. denotes the likelihood function respected to user u. denotes the prior probability of parameter . By assuming the actions of all users are independent and the ordering of each POI pair with respect to a user is not related to the ordering of every other POI pair, we can derive as follows:
To get a personalized total order, the probability of user u prefers i over j (denoted by ) is defined as , where is the sigmoid function, and is an arbitrary real-valued function of the parameter vector that captures the special relationship between u, i and j. Note that, this framework is very general, and the value of can be estimated by an underlying model class like matrix factorization or adaptive KNN.
By decomposing the estimator as , and delegating the task of predicting to the popular matrix factorization (MF) model (in this case, the model parameter refers to the user and item latent factors U and V in MF), and utilize to compute the predicted preference value of u to v (just like they did in MF), the likelihood function of the frequency-based weighted ranking method (WBPR-F) can be found:
To complete the Bayesian inference, like in MF the zero-mean spherical Gaussian priors are introduced:
where denotes the Gaussian distribution with variance and mean zero.
Then, the maximum posterior estimator of WBPR-F can be formulated as [18]:
where and represent the latent factors of POIs and users, respectively. and denote parameters for regularization. weights the prediction according to the difference of two visit frequencies , which denotes how much attention we should pay to this POI pair. As the objective function of WBPR-F is differentiable, gradient decent-based methods are chosen for calculating the corresponding latent factors U and V (more details can be found in [12,18]).
In WBPR-F, the introduction of the weight factor provides an efficient way to treat POI pairs not identically but differently. For instance, suppose user u has checked in at POI i and j; if u has similar check-in frequency to them, we cannot distinguish the user’s preference to these two POIs confidently (a small value of the weight factor is achieved), and then less attention should be paid to this POI pair. On the other hand, if a great difference existing in the visit frequencies of these two POIs, we can derive the user’s preference from them confidently (a high value of the weight factor is achieved). And we will pay more attention to this POI pair, as they will contribute more to the ranking function.
3.3. Our Neighborhood Aware Ranking Criteria
3.3.1. Empirical Data Analysis
To better understand the LBSN data, we investigate the users’ check-in activities that are gathered from Gowalla and Brightkite (more details can be seen in Section 4.1). More specifically, we investigate the influence of POI neighborhood characteristic and answer the question in the following: Do POIs with neighboring relationships tend to be checked in by same users? To answer this question, firstly, we measure the similarity of POIs by counting the common users that have visited them.
We use to denote the user set that has visited i in the past, and represents the size of the user set . Then, the POI similarity between i and j is computed as:
In this similarity function, for two POIs, the more common users they share, the more similarity they have. However, this similarity measure ignores the impact of active users. However, in fact, most of the POIs have both been visited by active users, and the active users cannot be utilized to distinguish between two POIs. Intuitively, the more common inactive users two POIs share, the more similar these two POIs are. Based on this observation, the adjusted similarity measure was proposed [29]:
In this equation, we punish the popular users by incorporating the term , where denotes the POI set that has been checked in by u.
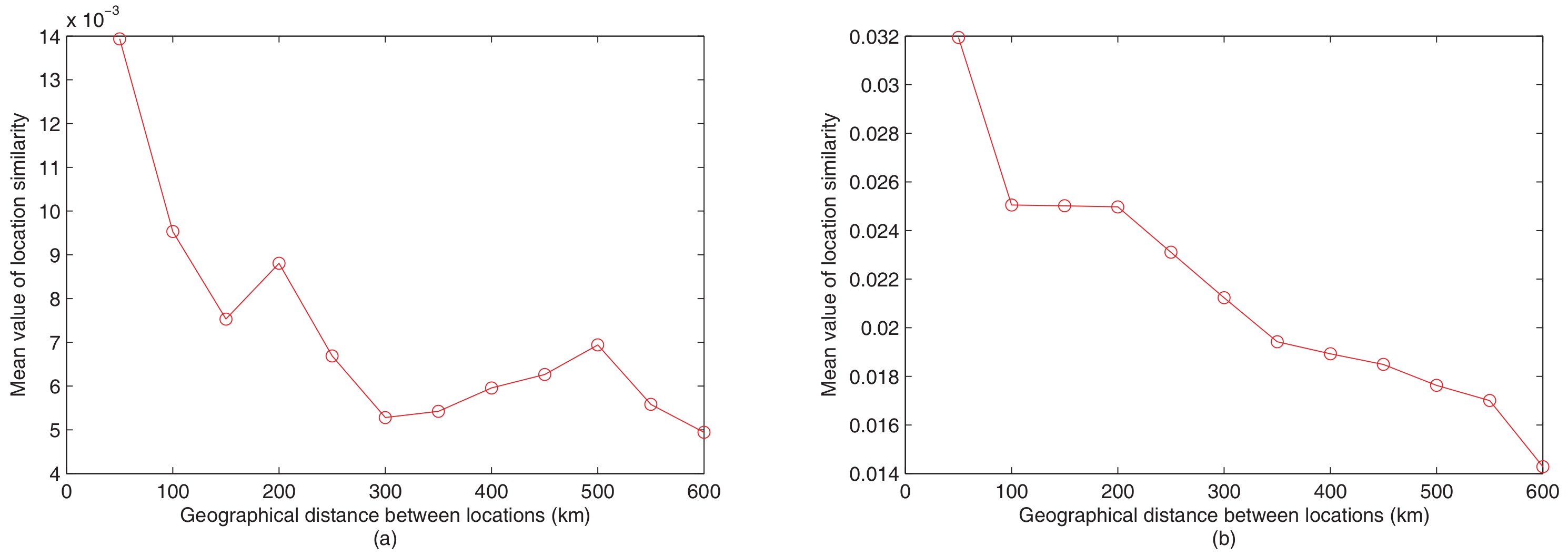
Based on the above similarity function, we first randomly choose POI pairs from these two datasets separately, and then investigate the relationship between the similarities of these POIs and the geographical distance of them. Figure 3 shows how the similarity of these randomly chosen POI pairs varies with the increase of geographical distance (Here, we use the Haversine formula to compute the location distance), where we can find that with the decrease of the distance, the mean value of the POI similarity increases in both Gowalla and Brightkite dataset. As the similarity function between two POIs measures how many common users they share, the increase of the similarity represents they tend to be checked in by more common users. This result demonstrates the positive relationship between the POI similarity and geographical distance, and provides a positive answer for us: POIs with neighboring relationships are inclined to be visited by the same users.
3.3.2. Exploitation of Neighborhood Characteristics
Based on the empirical observation that nearby locations are inclined to be checked in by common users, the geographical characteristics are considered for location recommendation task. However, prior work mainly explores this characteristic from a user perspective, and the method that models the geographical information from a location perspective has not been well studied.
Let denote the POI neighborhood relation graph, denote the POI set, and denote the geographical neighborhood relation set (edge set). represents the matrix of geographical relationship, with each entry denotes the geographical distance between POI v and t. Due to the fact that users always share similar preferences on nearest neighboring POIs, nearby places are inclined to be visited by similar users. In other words, the feature vector of a POI v is related to the feature vectors of its neighboring POIs. We formulate this geographical neighborhood characteristic as follows [30]:
where denotes the set of K nearest POIs of v according to the geographical distance. In experiments, we set K as 4 (In this study, we conduct several experiments to investigate the influence of different settings of K, and from the results we can observe that the ranking performance is not very sensitive to the size of nearest neighbors). is the estimated latent factor of v given the feature vectors of its direct geographical neighbors. is the form of the row normalization of the geographical neighborhood relationship matrix , so that .
Now, two factors are existed in the latent POI feature vector V: the conditional distribution of V given the latent feature vector of its geographical neighbors and the zero-mean spherical Gaussian prior. Therefore,
3.3.3. Bayesian Inference
The posterior probability of the feature vectors of users and POIs are derived as:
Note that the neighborhood relation graph does not impact the conditional distribution of the observed POI pairs, which only influences the POI latent feature vector. The conditional probability of given U and V is arrived as follows:
where indicates the pair-wise preference of user u over POI i and POI j in a weighted way. For convenience, the arguments of is skipped in the remaining of this work.
Similar to the work in [12], we also introduce the zero-mean spherical Gaussian as the user feature vector U prior to complete the Bayesian inference of the personalized ranking task:
Then, the posterior probability of the latent feature vectors U and V can be further written as:
The log-posterior probability of U and V is derived as:
Keeping the parameters fixed, maximizing the log-posterior over latent feature vectors of users and POIs is equivalent to minimize the following objective function, that is, the neighborhood aware Bayesian personalized ranking method (),
where is the regularization parameter that determines how much our method should depend on the neighboring POIs. and are the regularization parameters of latent factors U and V, respectively.
As the ranking criterion is differentiable (denoted by Equation (10)), we use the gradient descent-based strategy proposed in BPR [12] for minimization. To reduce the cost of updating the latent feature vectors and the data skewness caused by popular POIs, not all POI pairs () but only the bootstrap sampling-based training triples are used. With this method, the mainly cost of our method is linear with respect to the number of sampled triples, which can lead our method to complete the training process in a very short time. We update the following gradients to learn the latent factors of U and V:
Algorithm 1 presents the learning procedure of the latent feature vectors U and V.
| Algorithm 1: The learning process of U and V for NBPR | |
| 1 | Input: |
| 2 | The visit frequency matrix R, neighborhood regularization parameter , |
| learning rate , weight factor w, regularization parameters and | |
| 3 | Output: |
| 4 | U, V |
| 5 | conduct initialization to U and V |
| 6 | do |
| 7 | Extract the sample from |
| 8 | |
| 9 | Using Equation (11) to update ; |
| 10 | Using Equation (12) to update ; |
| 11 | Using Equation (13) to update ; |
| 12 | Calculate L(t) (the value of L in t step) according to Equation (10); |
| 13 | while L(t)−L() > tolerate error (not convergence); |
| 14 | U and V; |
3.4. Computational Complexity
Minimizing the ranking loss of NBPR is mainly cost by computing the objective function (denoted by Equation (10)) and the corresponding gradients of , and . By assuming the number of nearest neighbors per POI is K and the dimensionality of the feature vectors is l, the computational complexity of Equation (10) is arrived, that is, . Since in our experiments, K and l are set as relatively very small values, the complexity of computing the ranking loss is mainly determined by the number of training triples , which does not increase much (compared with the BPRMF method). The complexities of computing the gradients , are and , respectively (N is the number of sampled triples). Then, the total complexity of computing the gradients is , which is linear with respect to the number of sampled triples.
4. Experiments
In this session, we first evaluate our method with other related POI recommendation algorithms in two location-based social networks, and then several experiments are conducted to investigate the impact of the parameters to our method.
4.1. Datasets
In our experiments, two real-world location-based social networks—Brightkite and Gowalla [31] are exploited to measure our recommendation performance. The first one is Brightkite, which is created in 2007 for purpose of enabling users to check in at the places that they have gone by posting a message or using the mobile applications. Brightkite is also a social network service that allows people to make friends with the one who is nearby and who has been there before. The Brightkite dataset we used was collected from April 2008 to October 2010 by using its public API, which contains 4.5 million check-in activities produced by 58,228 users. The second typical location-based social network is Gowalla, which is launched in 2007 and closed in 2012. Compared with Brightkite, Gowalla provides similar location and social services that enable users to check in at places and make friends based on where they have visited. The Gowalla dataset we used was crawled by its API from February 2009 to October 2010, which contains 6.4 million check-in activities produced by 196,591 users. In order to simplify the recommendation problem, only check-in data is considered in our data. In order to further reduce the data sparseness, only users that have visited more than 3 places and the POIs that have been visited more than 20 times are kept, which results in the dataset with 100,069 check-in behaviours. For the Gowalla data, only users that have visited more than 5 locations and the POIs that have been visited more than 30 times are kept, which results in the dataset with 575,323 check-in behaviours. More details of our datasets are shown in Table 2.
4.2. Evaluation Metrics
We use two popular measures Precision@k and Recall@k [24] as the metric of POI recommendation performance. Precision@k reveals the fraction of relevant POIs (previously labeled as positive samples) among the total recommended instances. Recall@k denotes the fraction of relevant instances among the total relevant POIs in the dataset. The definition of Recall@k and Precision@k can be formalized as:
where M is the user number, and denotes the POI set visited by user u in the testing data. represents the POI set of the top-k recommendation list recommended for user u, where k is the list size. In our experiments, we set k as 5, and the corresponding metrics Precision@5 and Recall@5 are used.
4.3. Performance Comparison
To prove the effectiveness of our proposed method, we conduct several experiments on the following methods:
MostPopular. This is the second basic recommendation method, which ranks the POIs according to how often they have been checked in. Although this popularity-based method is very simple, it should have reasonable performance, since most users prefer to visit popular places.
WRMF. This is the weighted matrix factorization method [6,11] proposed for the one class collaborative filtering problem, which fits the negative samples with small weights and positive samples with large weights.
GeoMF. This is the state-of-the-art POI recommendation method [5], which utilizes the augmented matrix factorization method to model the geographical influence and the user interest.
BPRMF. This is the pair-wise item ranking method [12] proposed for implicit feedback. It models the user and item factors by analyzing the problem from the view of the Bayesian, and optimizes the ranking criteria directly.
IRenMF. This is another state-of-the-art POI recommendation method [9], which exploits two levels of geographical characteristics, that is, instance level and region level for recommendations.
WBPR-F. This is the weighted BPR method [18], which extends the BPR method for POI recommendation by giving different POI pairs different weights.
NBPR. This is our neighborhood aware ranking method proposed in Section 3.3, which extends the WBPR-F method and proposes to model the geographical characteristics from a location perspective.
In experiments, for each user, the randomly selected 80% user-POI pairs (actions) are utilized for training, and the remaining 20% are used for testing. To ensure the validity of our proposed method, we first conduct the 5-fold cross-validation on the training data with a grid search (The search space is over ). Then, we check the recommendation performance 5 times independently on the remaining test data which is not used in the model selection step. The parameters of our method are set as follows: for the Brightkite data, we set the neighbor regularization parameter as 0.004, and for the Gowalla data, we set as 0.002. For these two datasets, we set the regularization parameters of latent factors both as , , and set the dimension l of the latent factors as 10.
The experimental results evaluated by Precision and Recall on Brightkite and Gowalla have been shown in Table 3, from which we can find though the MostPopular method is simple, it can reach reasonable results, since most users tend to check in at popular places. The WRMF method that is proposed for the OCCF problem by giving unvisited POIs smaller weights performs better than the MostPopular method, but dose worse than GeoMF. GeoMF improves WRMF by incorporating the geographical clustering phenomenon into the recommendation framework and achieves a substantial improvement over WRMF. IRenMF as the state-of-the-art POI recommendation method that also extends WRMF performs better than GeoMF in Gowalla data, and achieves similar results with GeoMF in Brightkite data. BPRMF as the state-of-the-art ranking-based recommendation method proposed for the data with only implicit feedback performs better than WRMF in these two datasets, which demonstrates that it is more reasonable to learn the user latent factors from the pair-wise rank criteria than to optimize for a particular probability. WBPR-F further improves BPRMF by treating each POI pairs differently other than treating them equally, and achieves a higher recommendation performance. This result denotes treating each POI pair differently is more suitable for POI recommendation.
To explore the effectiveness of the neighborhood characteristics, we include comparisons between the NBPR, GeoMF, IRenMF and WBPR-F method. We find that the NBPR method performs better than WBPR-F, GeoMF and IRenMF in both Gowalla and Brightkite datasets, which demonstrates the importance of the neighborhood characteristics, and also indicates that our method can utilize these factors more effectively. We notice that MF-based methods BPRMF, WRMF, GeoMF, IRenMF, WBPR-F and NBPR can achieve a reasonable performance with the low dimensions of latent feature vectors, and can be well applied to very large datasets. In our experiment settings, the dimension of the latent factors is set as 10.
4.4. Impact of Parameter
In NBPR, the neighborhood regularization parameter balances the information from check-in matrix and the features from their neighboring POIs. It leverages how much our method should depend on their neighbors. If , we will only utilize the check-in matrix for recommendation. If , we will only utilize the information of their neighbors to derive the latent feature vectors of the POIs. In other cases, we learn the POI feature vectors from check-in matrix as well as the factors of their neighboring locations.
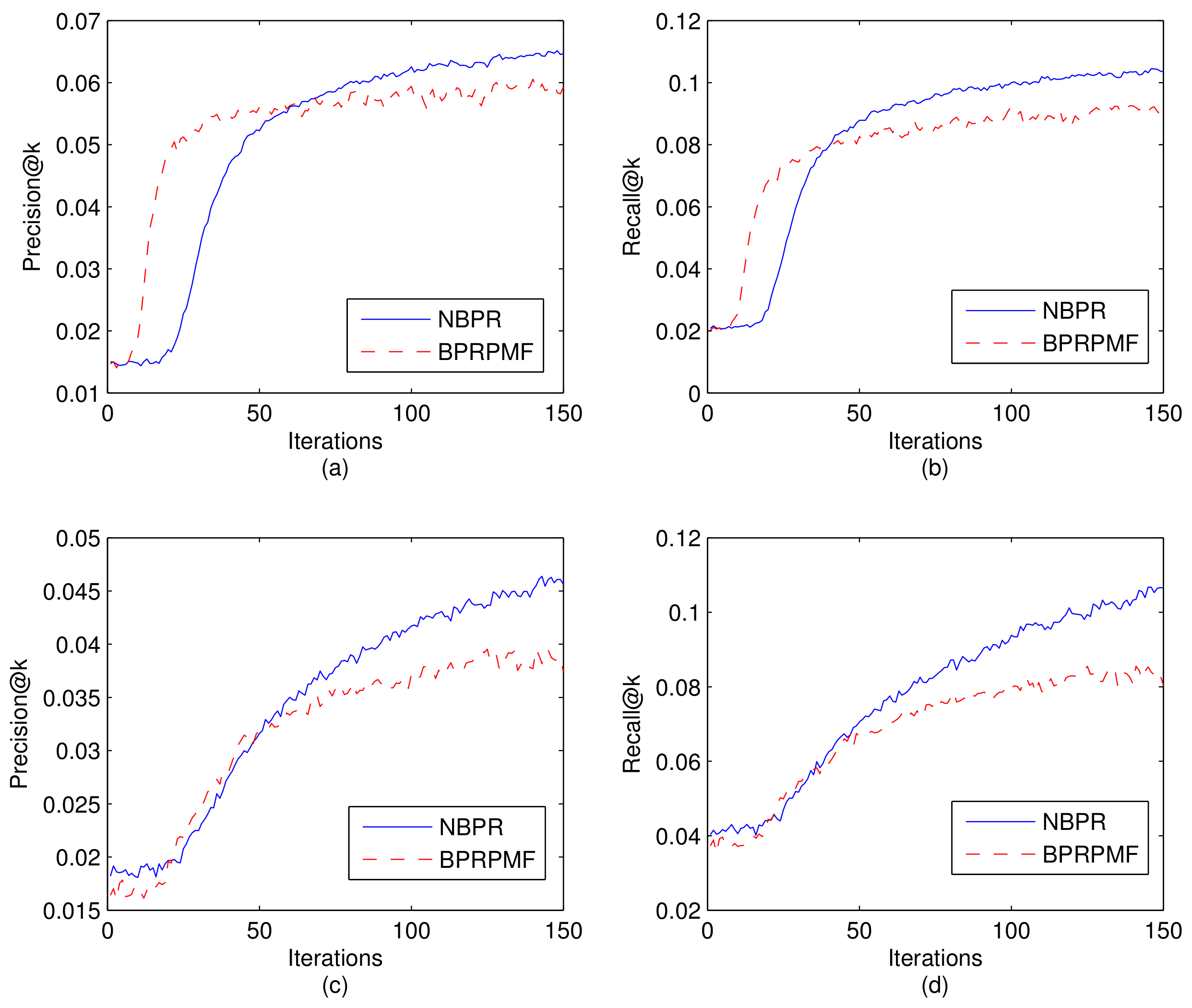
The recommendation results (Precision and Recall) with the changes of parameter are presented in Figure 4, from which we can observe that the recommendation results is significantly affected by the parameter , which denotes that incorporating the latent factors of neighboring POIs considerably improves the recommendation accuracy. In both Gowalla and Brightkite datasets, with the increase of , the recommendation performance (values of Precision and Recall) increases at first, but when surpasses a certain value, the recommendation performance decreases with further increases the value. This result demonstrates that purely utilizing check-in matrix or the feature factors of neighboring POIs for recommendation cannot performs better than merging these two information together. In experiments, the 5-fold cross-validation method with a grid search (the search space can be seen in Section 4.3) in the training data is used to obtain a suitable value of , and the value that can reach the best cross validation score is adopted. We set as 0.004 and 0.002 for Brightkite and Gowalla, separately.
4.5. The Influence of the Recommendation Number
In POI recommender system, users usually give the returned POI numbers to avoid being overwhelmed by a large number of irrelevant POIs. Appropriate recommendation list size is the key factor in improving the user experience. Hence, we investigate the recommendation performance of our method with varying the number of relevant POIs that should be recommended, and set the POI number k from 1 to 10.
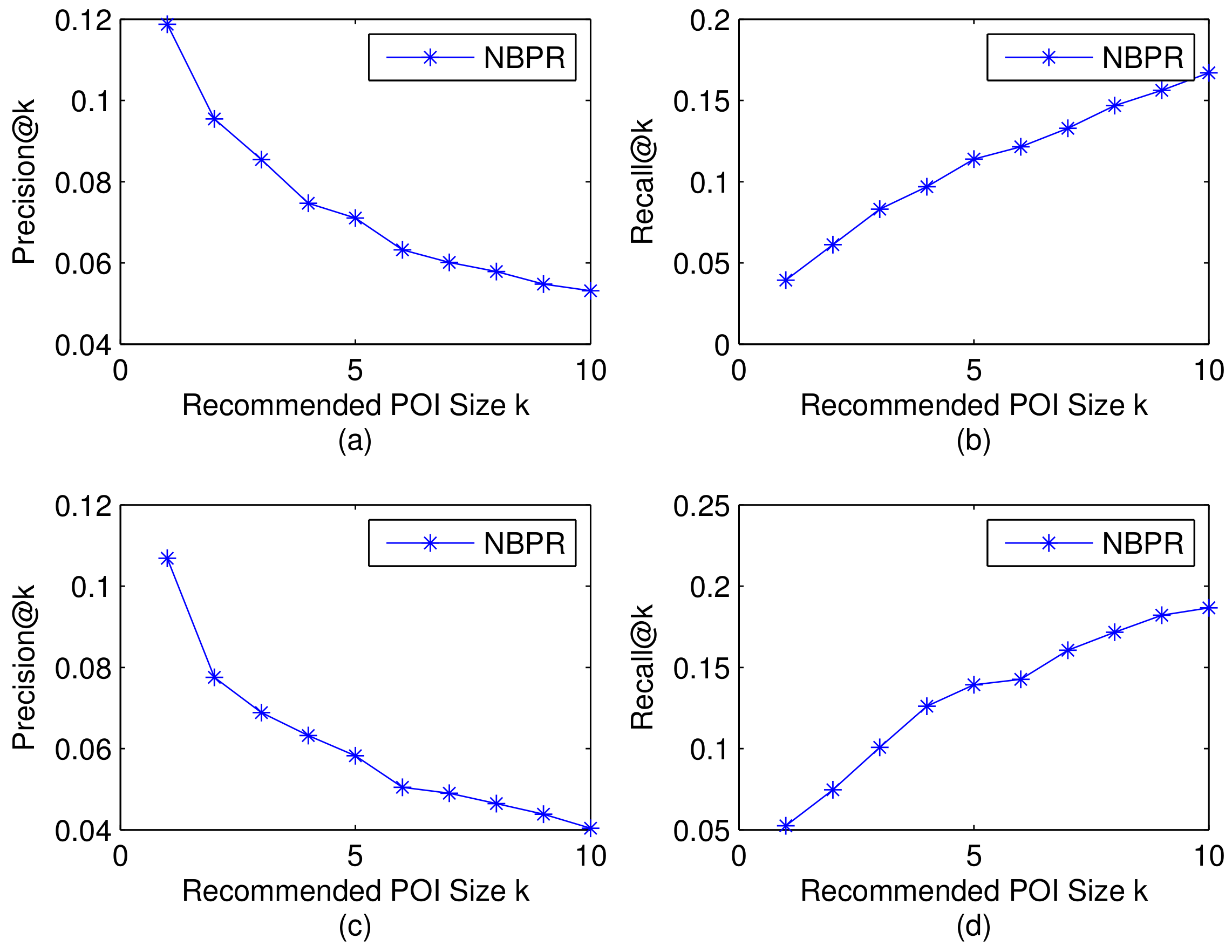
By considering the top-k most relevant POIs returned by the system, the top-k recommendation result can be arrived. The recommendation performance of our method with the impact of parameter k is shown in Figure 5. From this result, we can observe that increase of the recommendation list results in the increase of the hits of the relevant POIs, and accordingly leads to the decrease of Precision@k and the increase of Recall@k. The increase of Recall indicates that the recommended POIs can hit more relevant POIs in history, which denotes the capability of our method to retrieve relevant POIs is increasing. The decrease of Precision means the recommended POIs can cover less relevant POIs, which represents the capability of our method to retrieve correct POIs is decreasing.
4.6. Convergence Analysis
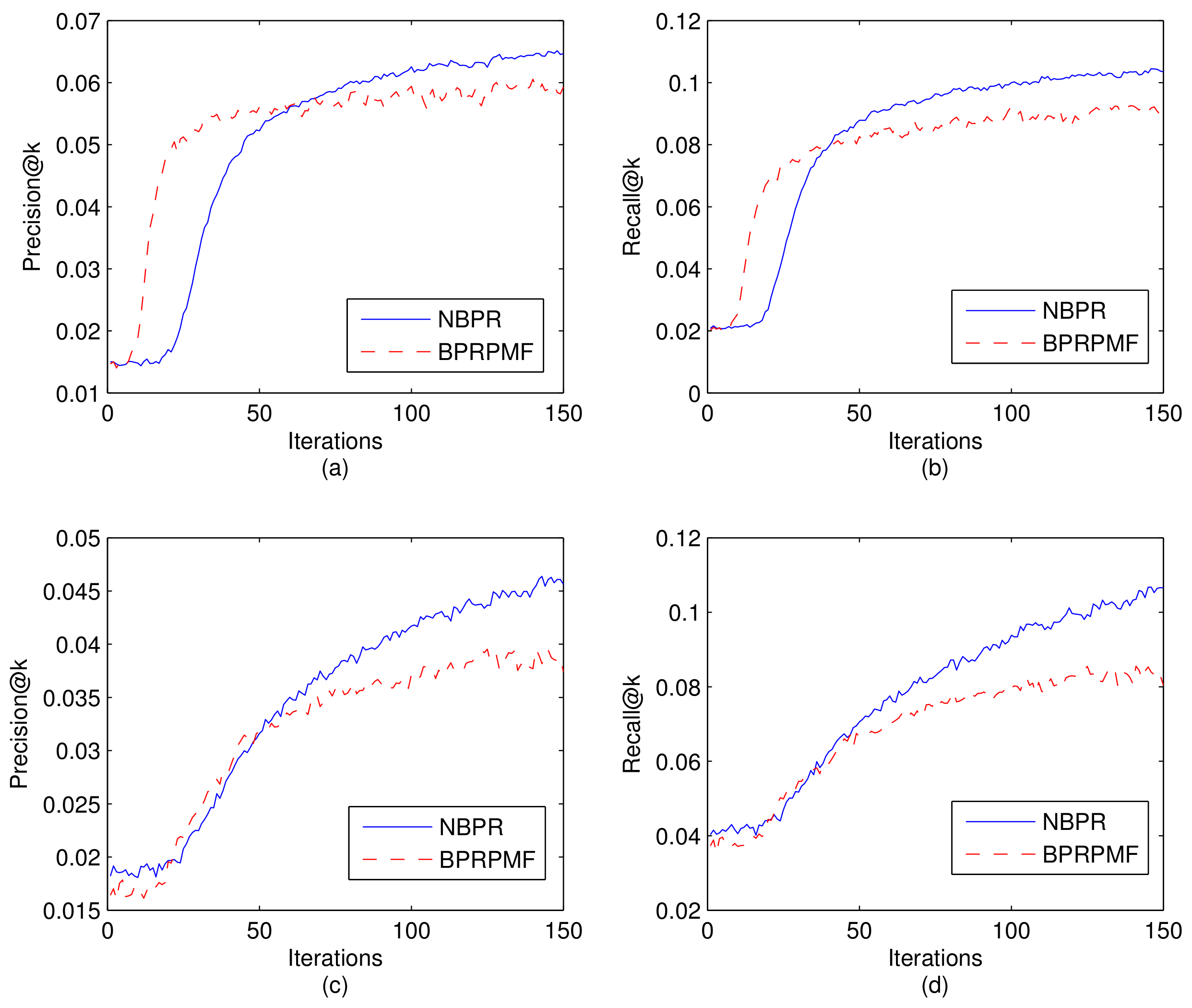
To explore the efficiency of our neighborhood aware recommendation method, we conduct experiments to compare the convergence of our NBPR method with the BPRMF method. To make them comparable, we select the same sample number for training, and set the learning rate both as 0.05. Figure 6 shows the comparison results. From this result, we can observe that both NBPR and BPRMF method converge very fast in these two datasets. For Brightkite data, the convergence is within 80 iterations. For Gowalla data, the convergence is within 50 iterations. From this result, we can also observe that the convergence rate of NBPR is not slowed down by incorporating the neighborhood relationship, on the contrary NBPR can reach a better performance than BPRMF.
5. Conclusions and Future Work
The development of the location-based social network makes the POI recommendation as an important application of locations. In this work, we focus on how to utilize the geographical characteristics and visit frequency to improve POI recommendation, and propose a neighborhood aware recommendation method from a location perspective named NBPR. We derive the ranking loss of NBPR by analyzing the problem for the view of Bayesian, and model the geographical distance as the location regularization to regularize the pair-wise ranking function. Experimental results on two location-based social networks indicate the importance of the geographical characteristics and the availability of our neighborhood aware recommendation algorithm.
Our current and future research plans include how to further improve our performance of the POI recommendation by exploring more influential factors, and its applicability under realistic scenarios. Specifically, in future work, we plan to extend this work in the following two aspects: first, more factors (such as social relation and visiting sequence of users) that can reflect the user interests will be investigated. The feature factor of users will incorporate both the features from collaborative filtering and other influential contexts. Fused regularization terms will be added to the objective function. Second, the method that can reduce the computational complexity of the training process will be studied. We will develop more efficient sampling strategies and parallel methods to speed up the optimization process.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (Nos. 61602282, 61772321, 71301086), the China Postdoctoral Science Foundation (No. 2016M602181), the Innovation Foundation of Science and Technology Development Center of Ministry of Education and New H3C Group (No. 2017A15047), and the Shandong Provincial Natural Science Fund Project (No. ZR2016FP07).
Author Contributions
Lei Guo conceived and designed the algorithm and the experiments, and wrote the manuscript; Haoran Jiang performed the experiments and analyzed the experiments; Xinhua Wang provided the instructions during design the algorithm. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ye, M.; Yin, P.; Lee, W.C.; Lee, D.L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the 34th international ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 325–334. [Google Scholar]
- Cheng, C.; Yang, H.; King, I.; Lyu, M.R. Fused Matrix Factorization with Geographical and Social Influence in Location-Based Social Networks. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; Volume 12, pp. 17–23. [Google Scholar]
- Zhang, J.D.; Chow, C.Y. iGSLR: personalized geo-social location recommendation: A kernel density estimation approach. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 334–343. [Google Scholar]
- Liu, B.; Fu, Y.; Yao, Z.; Xiong, H. Learning geographical preferences for point-of-interest recommendation. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1043–1051. [Google Scholar]
- Lian, D.; Zhao, C.; Xie, X.; Sun, G.; Chen, E.; Rui, Y. GeoMF: Joint geographical modeling and matrix factorization for point-of-interest recommendation. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 831–840. [Google Scholar]
- Pan, R.; Zhou, Y.; Cao, B.; Liu, N.N.; Lukose, R.; Scholz, M.; Yang, Q. One-class collaborative filtering. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 502–511. [Google Scholar]
- Li, X.; Cong, G.; Li, X.L.; Pham, T.A.N.; Krishnaswamy, S. Rank-GeoFM: A ranking based geographical factorization method for point of interest recommendation. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 433–442. [Google Scholar]
- Ying, H.; Chen, L.; Xiong, Y.; Wu, J. PGRank: Personalized Geographical Ranking for Point-of-Interest Recommendation. In Proceedings of the 25th International Conference Companion on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; pp. 137–138. [Google Scholar]
- Liu, Y.; Wei, W.; Sun, A.; Miao, C. Exploiting geographical neighborhood characteristics for location recommendation. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 739–748. [Google Scholar]
- Guo, L.; Ma, J.; Jiang, H.R.; Chen, Z.M.; Xing, C.M. Social Trust Aware Item Recommendation for Implicit Feedback. J. Comput. Sci. Technol. 2015, 30, 1039–1053. [Google Scholar] [CrossRef]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Yin, H.; Cui, B.; Chen, L.; Hu, Z.; Zhang, C. Modeling location-based user rating profiles for personalized recommendation. ACM Trans. Knowl. Discov. Data (TKDD) 2015, 9, 19. [Google Scholar] [CrossRef]
- Gao, H.; Tang, J.; Liu, H. Personalized location recommendation on location-based social networks. In Proceedings of the 8th ACM Conference on Recommender Systems, Foster City, Silicon Valley, CA, USA, 6–10 October 2014; pp. 399–400. [Google Scholar]
- Zheng, V.W.; Zheng, Y.; Xie, X.; Yang, Q. Towards mobile intelligence: Learning from GPS history data for collaborative recommendation. Artif. Intell. 2012, 184, 17–37. [Google Scholar] [CrossRef]
- Cho, S.B. Exploiting machine learning techniques for location recognition and prediction with smartphone logs. Neurocomputing 2016, 176, 98–106. [Google Scholar] [CrossRef]
- Zhang, J.D.; Chow, C.Y.; Li, Y. iGeoRec: A personalized and efficient geographical location recommendation framework. IEEE Trans. Serv. Comput. 2015, 8, 701–714. [Google Scholar] [CrossRef]
- Guo, L.; Jiang, H.; Wang, X.; Liu, F. Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs. Information 2017, 8, 20. [Google Scholar] [CrossRef]
- Liu, Y.; Pham, T.A.N.; Cong, G.; Yuan, Q. An experimental evaluation of point-of-interest recommendation in location-based social networks. Proc. VLDB Endow. 2017, 10, 1010–1021. [Google Scholar] [CrossRef]
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Thalmann, N.M. Time-aware point-of-interest recommendation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 363–372. [Google Scholar]
- Gao, H.; Tang, J.; Hu, X.; Liu, H. Content-Aware Point of Interest Recommendation on Location-Based Social Networks. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 1721–1727. [Google Scholar]
- Griesner, J.B.; Abdessalem, T.; Naacke, H. POI Recommendation: Towards Fused Matrix Factorization with Geographical and Temporal Influences. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 301–304. [Google Scholar]
- Li, H.; Ge, Y.; Hong, R.; Zhu, H. Point-of-Interest Recommendations: Learning Potential Check-ins from Friends. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 975–984. [Google Scholar]
- Gao, H.; Tang, J.; Hu, X.; Liu, H. Exploring temporal effects for location recommendation on location-based social networks. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 93–100. [Google Scholar]
- Tsiropoulou, E.E.; Thanou, A.; Paruchuri, S.T.; Papavassiliou, S. Self-organizing museum visitor communities: A participatory action research based approach. In Proceedings of the 2017 12th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Bratislava, Slovakia, 9–10 July 2017; pp. 101–105. [Google Scholar]
- Tsiropoulou, E.E.; Thanou, A.; Papavassiliou, S. Modelling museum visitors’ Quality of Experience. In Proceedings of the 2016 11th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Thessaloniki, Greece, 20–21 October 2016; pp. 77–82. [Google Scholar]
- Tsiropoulou, E.E.; Thanou, A.; Papavassiliou, S. Quality of Experience-based museum touring: A human in the loop approach. Soc. Netw. Anal. Min. 2017, 7, 33. [Google Scholar] [CrossRef]
- De Rojas, C.; Camarero, C. Visitors’ experience, mood and satisfaction in a heritage context: Evidence from an interpretation center. Tour. Manag. 2008, 29, 525–537. [Google Scholar] [CrossRef]
- Breese, J.S.; Heckerman, D.; Kadie, C. Empirical analysis of predictive algorithms for collaborative filtering. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; pp. 43–52. [Google Scholar]
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the 4th ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 135–142. [Google Scholar]
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and mobility: User movement in location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1082–1090. [Google Scholar]
Figure 1.
Point-of-interest (POI) recommendation scenario in location-based social networks (LBSNs). (a) One typical case of LBSNs. (b) The check-in frequency matrix of users to POIs.
Figure 1.
Point-of-interest (POI) recommendation scenario in location-based social networks (LBSNs). (a) One typical case of LBSNs. (b) The check-in frequency matrix of users to POIs.

Figure 2.
The reconstruct data policy from user-POI visit frequency matrix to pair-wise POI pairs.
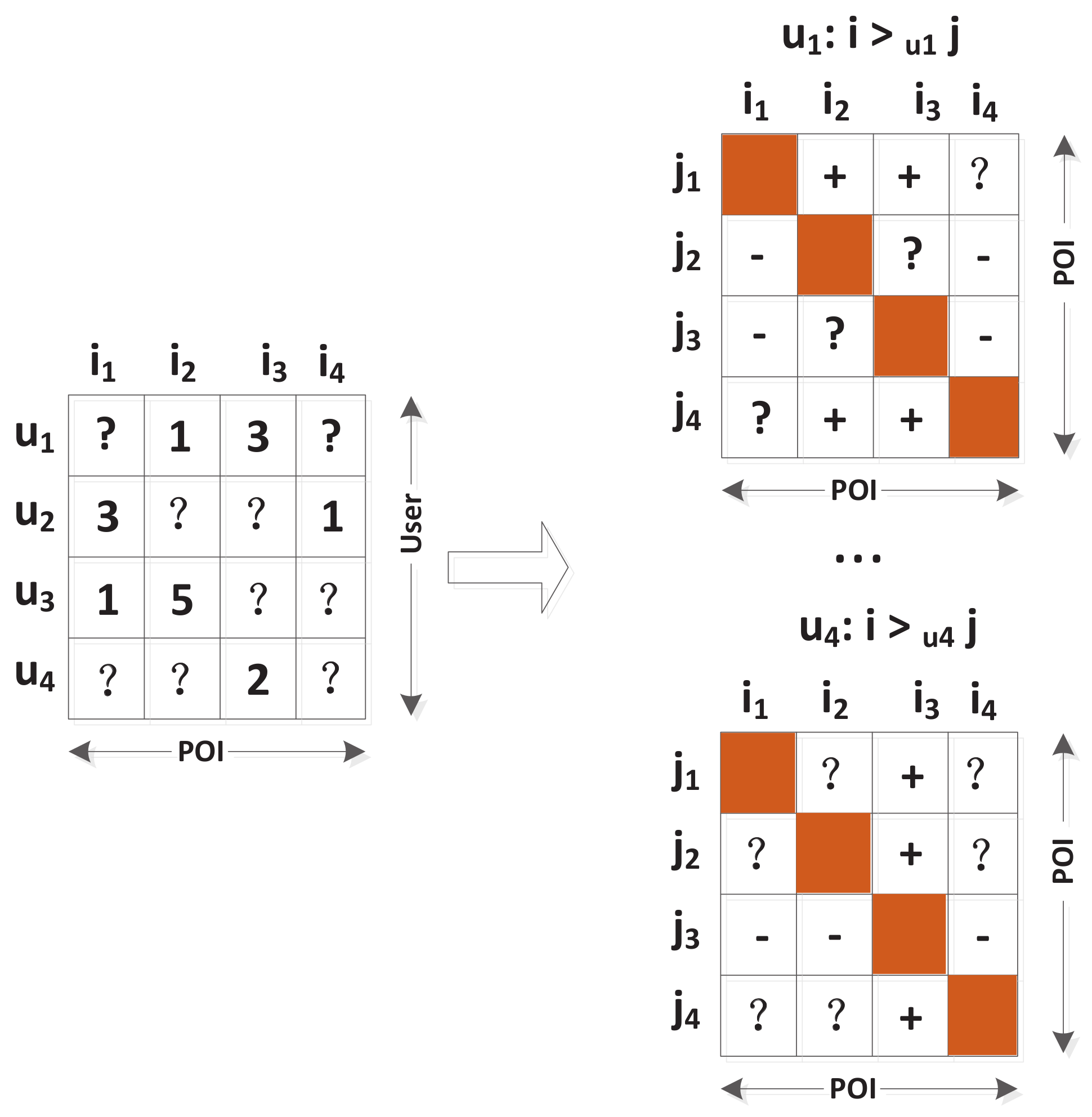
Figure 3.
The variation trend of POI similarity with the increase of the geographical distance in two datasets: (a) Gowalla and (b) Brightkite.
Figure 3.
The variation trend of POI similarity with the increase of the geographical distance in two datasets: (a) Gowalla and (b) Brightkite.
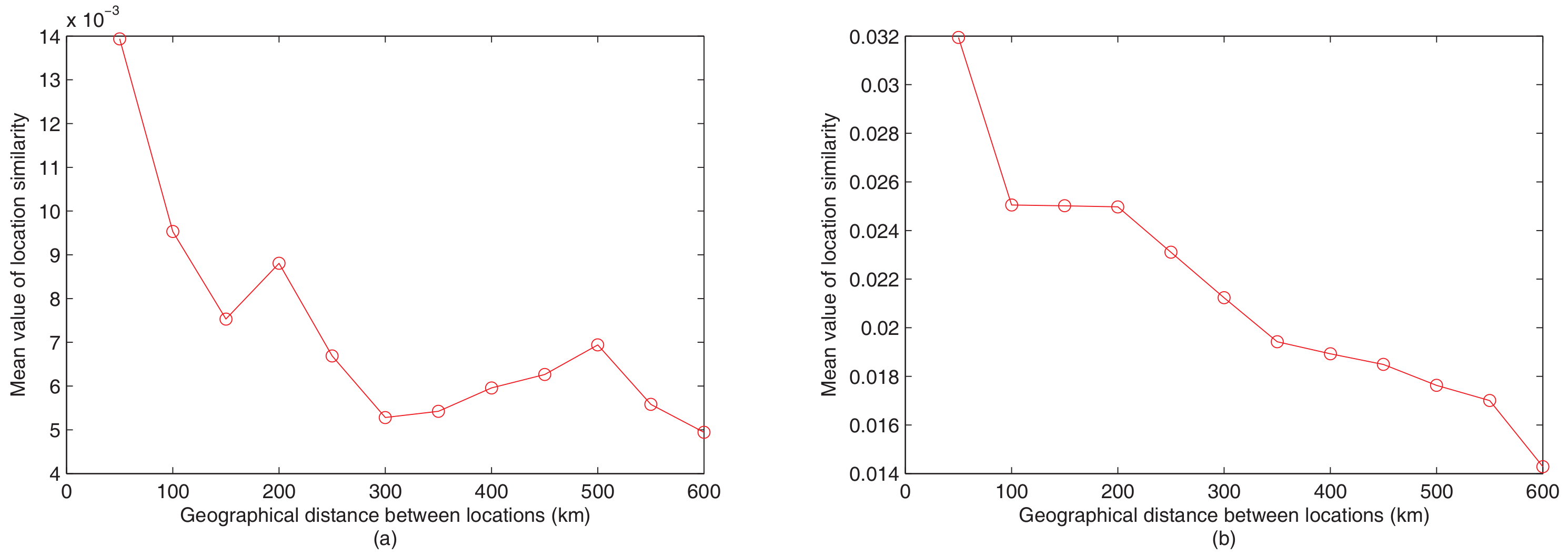
Figure 4.
The recommendation performance of our method with the changes of parameter in two LBSNs. (a) Precision@k in the Gowalla data; (b) Recall@k in the Gowalla data; (c) Precision@k in the Brightkite data; (d) Recall@k in the Brightkite data.
Figure 4.
The recommendation performance of our method with the changes of parameter in two LBSNs. (a) Precision@k in the Gowalla data; (b) Recall@k in the Gowalla data; (c) Precision@k in the Brightkite data; (d) Recall@k in the Brightkite data.
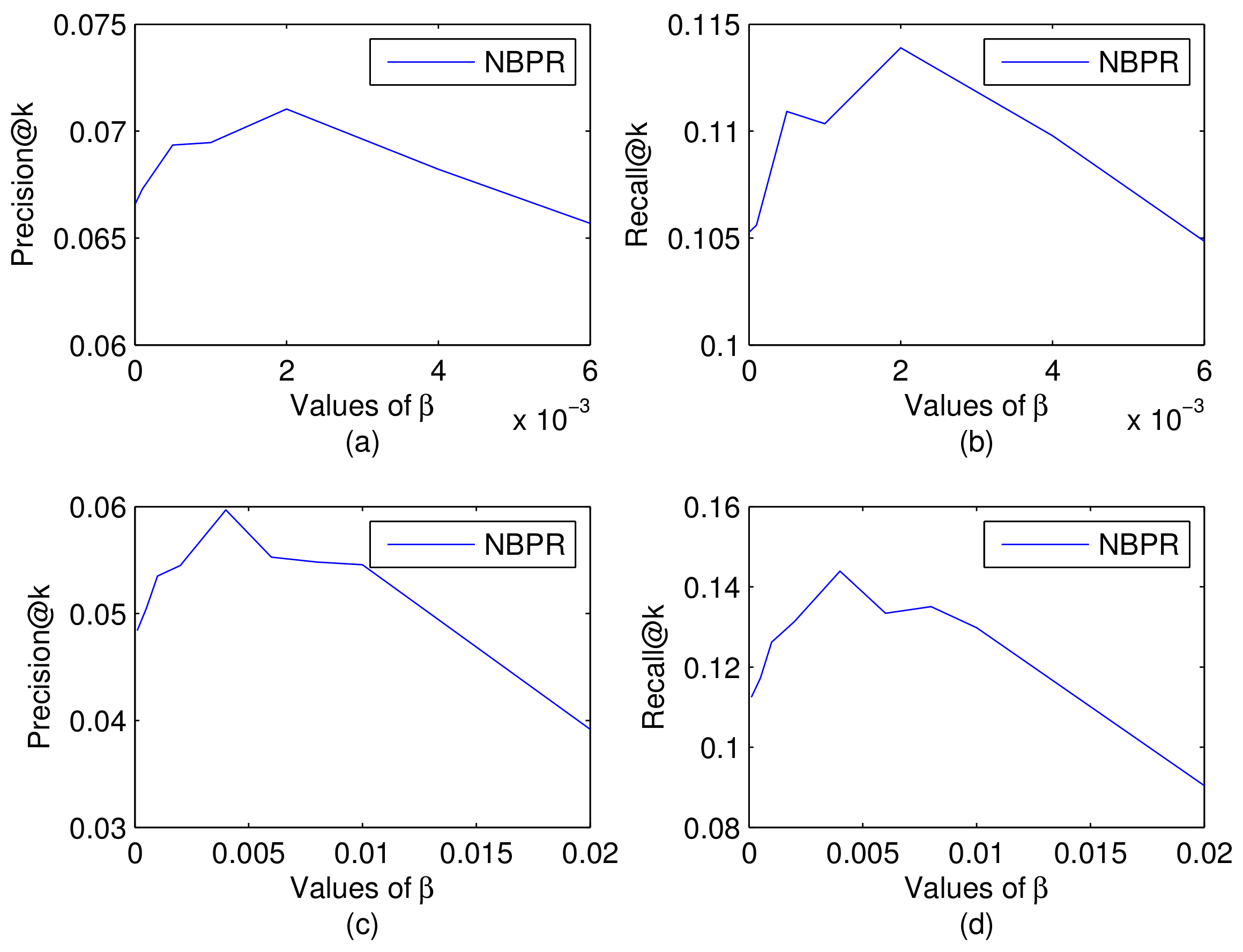
Figure 5.
The recommendation performance of our method with the changes of the recommendation number in two LBSNs. (a) Precision@k in the Gowalla data; (b) Recall@k in the Gowalla data; (c) Precision@k in the Brightkite data; (d) Recall@k in the Brightkite data.
Figure 5.
The recommendation performance of our method with the changes of the recommendation number in two LBSNs. (a) Precision@k in the Gowalla data; (b) Recall@k in the Gowalla data; (c) Precision@k in the Brightkite data; (d) Recall@k in the Brightkite data.
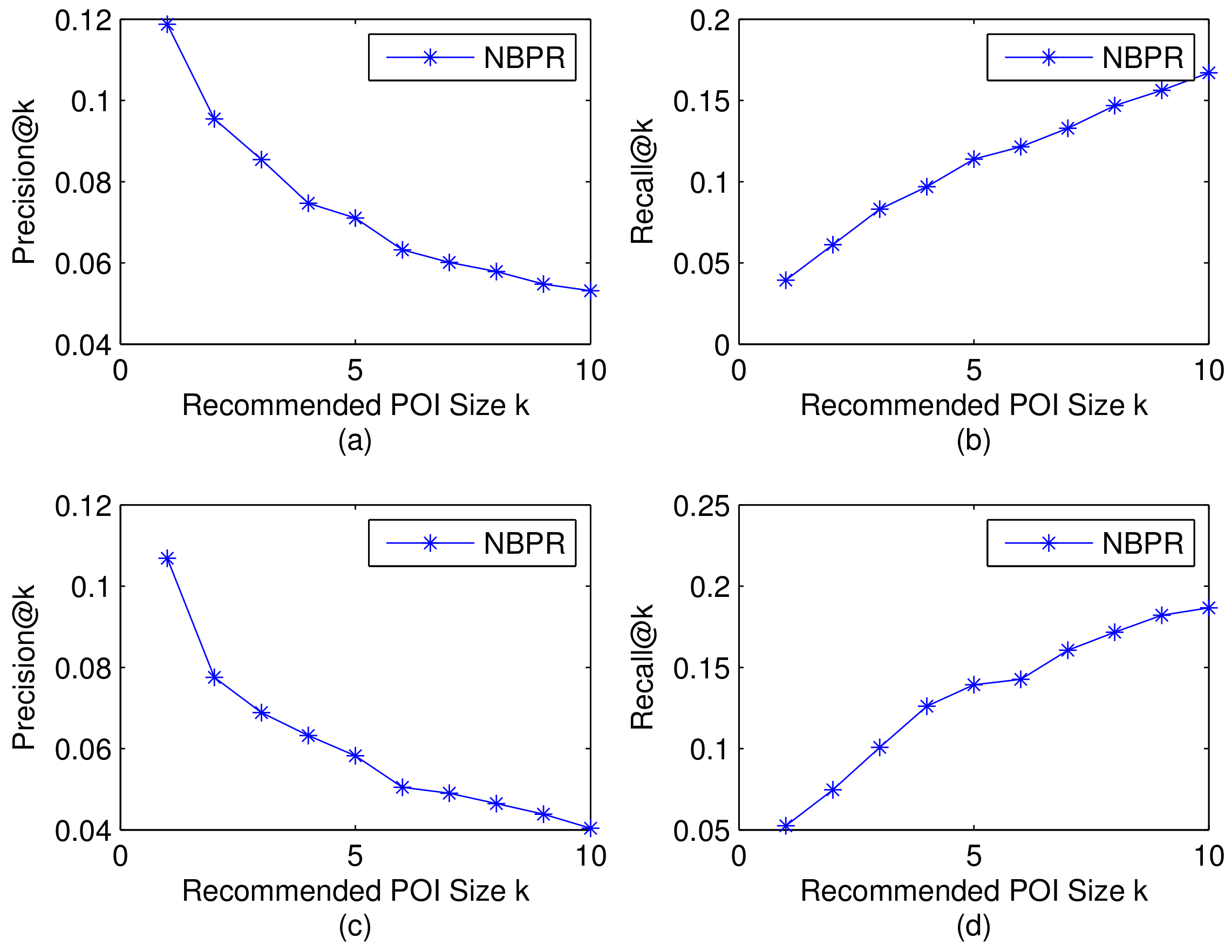
Figure 6.
The convergence comparison results on two LBSNs. (a) Precision@k in the Gowalla data; (b) Recall@k in the Gowalla data; (c) Precision@k in the Brightkite data; (d) Recall@k in the Brightkite data.
Figure 6.
The convergence comparison results on two LBSNs. (a) Precision@k in the Gowalla data; (b) Recall@k in the Gowalla data; (c) Precision@k in the Brightkite data; (d) Recall@k in the Brightkite data.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Table of notations of this work.
| Notations | Meaning |
|---|---|
| the check-in matrix and the reconstructed check-in data, respectively | |
| the check-in frequency of user u over POI i | |
| the relationship between user u, POI i and POI j | |
| a personalized total ranking of all POI pairs to user u | |
| the user and POI set, respectively | |
| a personalized total ranking of all POI pairs to user u | |
| user u prefers POI i than j | |
| the parameter of any model class | |
| the latent feature factors of users and POIs, respectively | |
| the column vector of U and V, respectively | |
| the estimated feature vector of POI v | |
| the weight factor of the relationship between and j | |
| the regularization parameters of , respectively | |
| the regularization parameter of relationship between V and its neighbors | |
| the regularization parameter that equals | |
| the user set that has visited POI i in the past | |
| the POI neighborhood relation graph | |
| the geographical neighborhood relation | |
| S | the adjacency matrix of graph |
| the geographical distance between POI v and t | |
| the row normalization form of matrix S | |
| the set of K nearest POIs of POI v, where K is an integer | |
| the POI set visited by user u in the test data | |
| the top-k POI set that recommended to user u, where k is the size of the recommendation list |
Table 2.
Statistics of the Brightkite and Gowalla datasets.
| Statistics | Gowalla | Brightkite |
|---|---|---|
| Check-in sparsity | 99.838 | 99.833 |
| # of users | 32,134 | 11,142 |
| # of POIs | 8867 | 4369 |
| # of check-ins | 575,323 | 100,069 |
| Min. # of check-ins per POI | 1 | 1 |
| Min. # of POIs per user | 5 | 3 |
Table 3.
Comparison results of our method with other related recommendation methods under the evaluation of Recall and Precision (, training , confidence level = 95%).
Table 3.
Comparison results of our method with other related recommendation methods under the evaluation of Recall and Precision (, training , confidence level = 95%).
| Metric | Dataset | MostPopular | WRMF | GeoMF | BPRMF | IRenMF | WBPR-F | NBPR |
|---|---|---|---|---|---|---|---|---|
| Gowalla | ||||||||
| Brightkite | ||||||||
| Gowalla | ||||||||
| Brightkite |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Guo, L.; Jiang, H.; Wang, X. Location Regularization-Based POI Recommendation in Location-Based Social Networks. Information 2018, 9, 85. https://doi.org/10.3390/info9040085
AMA Style
Guo L, Jiang H, Wang X. Location Regularization-Based POI Recommendation in Location-Based Social Networks. Information. 2018; 9(4):85. https://doi.org/10.3390/info9040085
Chicago/Turabian StyleGuo, Lei, Haoran Jiang, and Xinhua Wang. 2018. "Location Regularization-Based POI Recommendation in Location-Based Social Networks" Information 9, no. 4: 85. https://doi.org/10.3390/info9040085
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.