1. Introduction
Sign language, a structured sequence of hand motions, provides the most efficient means of communication for deaf people. Hard-of-hearing people have traditionally used sign language to interact with each other. The available approaches to the interpretation of sign language utilize vision techniques to translate signs autonomously. This primarily entails two tasks: isolated or word-based recognition and continuous or sentence-based recognition. The configuration of the fingers, the direction of the hand’s motion, and the placement of the hand in relation to the body serve as the fundamental components of arranged communications in sign language. Due to the prominence of autonomous devices like glove sensors and the rapid increase in people considered deaf, the detection of hand gestures has become more important. Using AI methods, it is possible to improve the capacity for decision making through the application of electronic technologies. The smart-glove wearable device is designed to help users convert sign language motions into spoken or written sentences, facilitating communication.
Progression learning entails training on both the various gesture activities exhibited during the movement of wearable glove devices and data subsets to gain knowledge gradually.
Progression learning is more about preserving and growing information as time passes than transferring understanding from one activity to another. The purpose of progression learning for network performance optimization is to identify the best neural architecture to use for the development of an individual image classification task, especially for sign language recognition.
Generally, the recognition of sign language is challenging owing to its learning intricacy [
1] and the variable techniques used to capture motion, direction, and hand positions. People frequently use hand gestures to express their thoughts and feelings; hence, research has focused on hand gestures in sign language prediction [
2]. Conversely, dynamic gestures address the issue of isolating hand-gesture identification in RGB films and can either be single words or continuous sentences. Traditional CNNs are ineffective in learning the representation of signs [
3]. The pertinent patterns are only present in the motion of the field of the signer’s hands, although there are many irrelevant patterns in the scene as a whole. Hence, it is necessary to focus on static and dynamic types by employing Python, OpenCV, and intelligent gloves [
4] that can recognize sign language. Markov properties [
5] can be seen in the problem of the dynamic recognition of gestures. This issue arises when the conditional likelihood of the density of this moment’s event, given all previous and present occurrences, depends solely on the recent event. This problem makes use of techniques like time-compressing templates. For individuals in these random populations of disabled people, communication hurdles arise from factors such as sign language variance [
6], sensor setup, classifying signs, study design, and the inability to comprehend or employ sign language. A continuous or dynamic sentence in sign language is broken into subwords via data segmentation [
7], a crucial preprocessing operation. This operation is performed by detecting the hand’s structure, orientation, and motion. These are then modeled further, and the associated component classifiers are taught. Since they can measure finger movements, sensory gloves [
8] are useful in a wide range of applications, particularly those required for real-time data collection. Vision and wearable glove devices are the most useful approaches for understanding sign language [
9]. Numerous academics have suggested systems for recognizing sign language based on these methods. The glove-based system employs electromechanical or optical indicators attached to the signer’s glove. It then transforms the movement of the fingers into electronic signals [
10] to determine the hand position for the recognition of messages being communicated. Each gesture is classified using a deep learning algorithm, based on CNNs [
11], that continuously learns and extracts the characteristics of each hand movement. The CNN model, employing the Kinect source of collected information, is used to extract depth motion trajectory information and perform spatiotemporal analysis of the joint features of the body [
12]. Then, a cutting-edge data glove with two forearm rings and a designed three-dimensional in-nature flex sensor [
13] is used to record the motion of the whole arm and all fingers in fine detail. Rather than using a word model, the Recurrent Neural Networks (RNNs) developed for subunits [
14], employing factorization concepts for sign language recognition, are preferred in the extraction of hand motion features, showing maximum accuracy. The ongoing improvement of AI is a long-standing development goal of learning, wherein agents learn from, keep, or store tasks performed in order to apply knowledge from earlier tasks to speed up convergence [
15]. Progression learning gradually raises the training workload for the translation of sign languages by expanding among its subnetworks according to a growth schedule, represented by a series of smaller networks like subwords, with increasing dimensions observed for all training epochs [
16]. It is specifically used to make sure the network is adequately optimized after each growth.
The current key contributions include the following:
Developing a sign language recognition system capable of accurately interpreting sentence-based sign language identification;
Promoting accessibility for hearing-disabled individuals by improving communication through AI-driven solutions;
Employing word error rate recognition and improving the accuracy of hand gestures using the progression learning capability of wearable glove sensors.
Section 2 of this paper focuses on the sign language prediction models used. In
Section 3, this article then describes the learning progress of the PLD-CNN model, including the memetic optimization technique for improving prediction accuracy. The results and evaluation metrics are investigated in
Section 4. Finally, a discussion and future directions are given in
Section 5.
2. Literature Review
Rastgoo et al. (2022) [
17] applied a combination of three deep convolutional neural networks (3DCNNs) to a hand sign language approach in order to estimate the specified angles of 3D key hand points between fingers, with Singular Value Decomposition (SVD) used for the feature extraction of key points from hand estimators in a real-time scenario. This was followed by the use of Long Short-Term Memory (LSTM) to identify the word sign from the fully convoluted layer, alongside the use of the Adam optimizer to enhance the network parameters. This overall technique had a recognition time of words of a minimum of 2 s and an accuracy of 99%. Since it uses a real-time scenario, the approach faces computational complexity due to the operations.
Al-Hammadi et al. (2020) [
18] proposed a dynamic recognition model to generate both signer-dependent and signer-independent methods using two modes of a 3D deep convolutional neural network (3DCNN + MLP + En) with a multi-layer perceptron and an encoder for feature fusion. This study was optimized using a mini-batch gradient descent approach in order to enhance the network parameters. The maximum recognition accuracy achieved was 98%, and the input clip restriction was the use of only 16 frames of gesture space.
Aly and Aly (2020) [
19] employed Hybridized Deep Learning models to generate a signer-independent Arabic Sign Language Prediction (HDL-ASLP) model. This model included the DeepLabV3+ for hand segmentation and a convolutional self-organizing map for feature extraction, making predictions using deep Bidirectional Long Short-Term Memory (Bi-LSTM). These approaches achieved 89.59% accuracy and a Mean Intersection of Union (MIoU) of 94.2 when applied to 23 words from three signers performing Arabic sign language gestures. This study was optimized with a stochastic gradient descent approach to enhance the network parameters. This was performed using the King Saud University Saudi-based Sign Language (KSUS2L) data source, and the only research gap identified was the limited availability of data samples for recognition.
In order to identify spatial and temporal patterns in human pose space, Li et al. (2020) [
20] implemented two types of deep learning models based on pose and appearance (pa) using Temporal Graph CN (pa-TGCN). The evaluation impacted the size of vocabulary and spatial features, and the Adam optimizer was used to train input sample parameters. Word-level American Sign Language (ASL) data sources with 2000 words from 100 signers were chosen, and an accuracy of up to 62.63% was obtained with few-shot learning methods.
DelPreto et al. (2022) [
21] developed a pre-trained LSTM model to detect static and dynamic gestures from an ASL data source of 12 words. The network was frequently responsive to slight positional changes, particularly when fingers were in contact, which resulted in significant resistance changes. Additionally, there was potential for some prediction delays to occur when the knit’s prior recorded response times were combined with the 2 s categorization window. The wearable device comprised an intelligent glove with an accelerometer fitted to track mobility and strain-sensitive resistances obtained to capture postural data. The Root-Mean-Square Error (RMSE) was 0.010, and there was an accuracy of 99% when calculations used the average means and standard deviations of the identified true gesture levels.
Rosero-Montalvo et al. (2018) [
22] presented an intelligent wearable glove device for the sign language translation of numbers using an evolutionary type of cross-generational elitist selection, heterogeneous recombination, and a cataclysmic mutation (CHC) algorithm with five kinds of flex sensors for data collection. This was balanced using the Kennard–Stone method, followed by the classification of signs using the K Nearest Neighbor (KNN) technique. The training set produced a classification accuracy of 87.8%, with a minimum of 64% of the information being stored using five colors labeled 1 to 5: black, red, green, blue, and cyan. The limitation of this procedure was its exclusive focus on translating numbers.
Zhang et al. (2019) [
23] suggested a multimodal CNN, using LSTM to model temporal dependencies using the MyoSign model, and then detached models from the inputs of many sensory channels. Then, Connectionist Temporal Classification (CTC) was used to overcome temporal gaps and perform continuous analysis throughout the entirety of sign language recognition from ASL at both word and sentence levels. The authors obtained an accuracy of 93.7% at the word level and 93.1% at the sentence level, evaluating the run time of both words and sentences and identifying the error sequences in the possible combinations. The fact that, when people are walking, the inertial signal pulses may be altered by body motions is a major drawback of this design.
Nandi et al. (2023) [
24] suggested using CNNs featuring multiple gradient optimization methods for sign language recognition, aiming to eliminate the deaf–dumb–normal barrier. A CNN was used to process 62,400 images from 26 participants, with data augmentation used to remove extraneous information and resize features. The use of batch processing and a dropout layer reduced image redundancy after refining the network parameters with a diffGrad optimizer. The sign language recognition system brought greater improvements than other approaches. The sign language recognition system was constructed using machine learning, computational image processing, and optimization methods. The study then investigated gestures in several directions in order to improve detection accuracy, focusing only on static signs from Indian sign language and failing to focus on dynamic gestures.
In 2022, Rwelli et al. [
25] recommended using wearable sensors to recognize Arabic sign language gestures based on a machine learning technique called a deep convolutional network (DCN). The purpose of doing so was to enable the extraction of features from sensor devices worn by hearing-impaired people. The study investigated 30 hand sign letters captured from gloves and recognized around 90% of the samples. The experimental procedure was used to acquire results for various training samples and detect sign language based on hand gestures. The limitations of this study included its size and exclusive focus on individual letters.
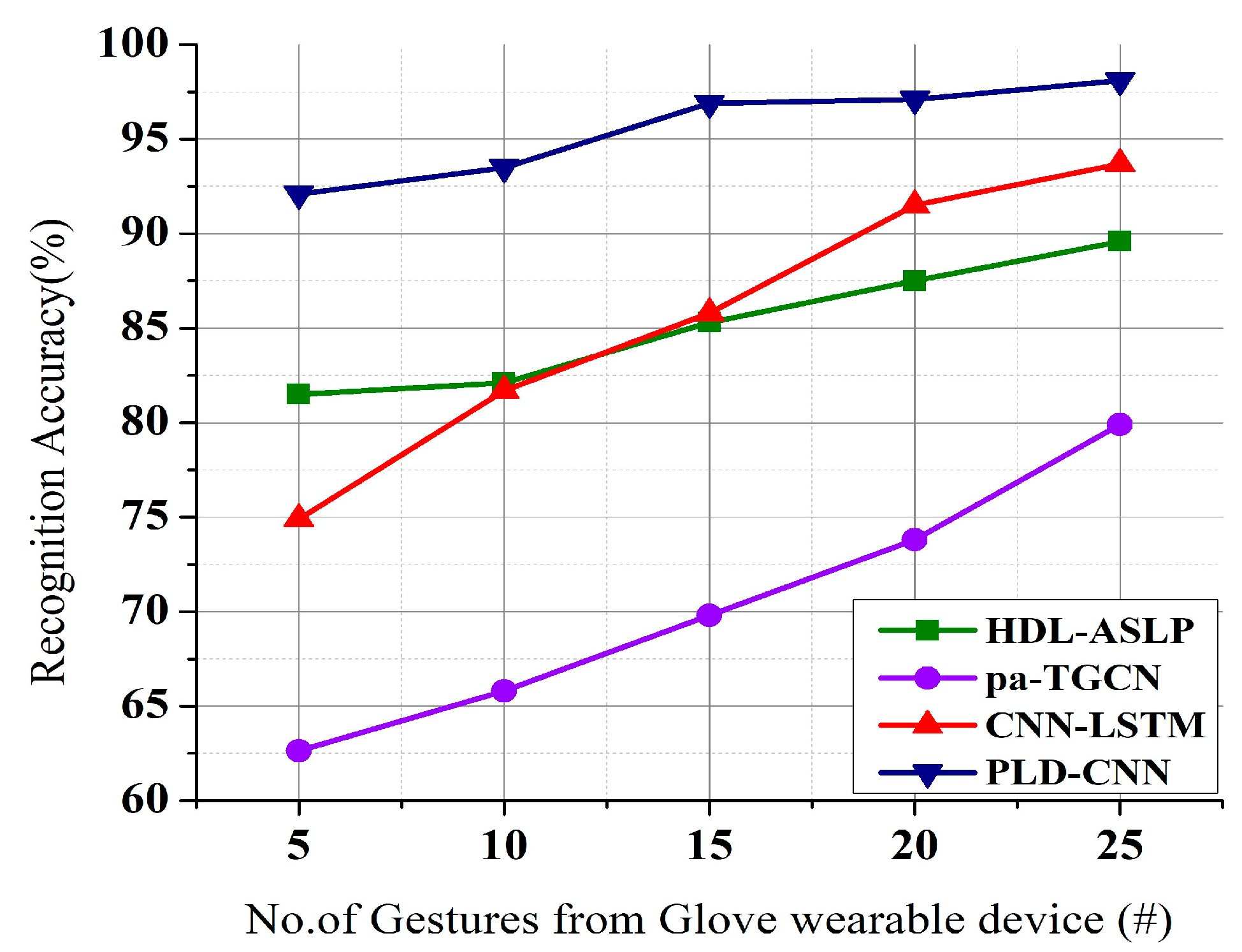
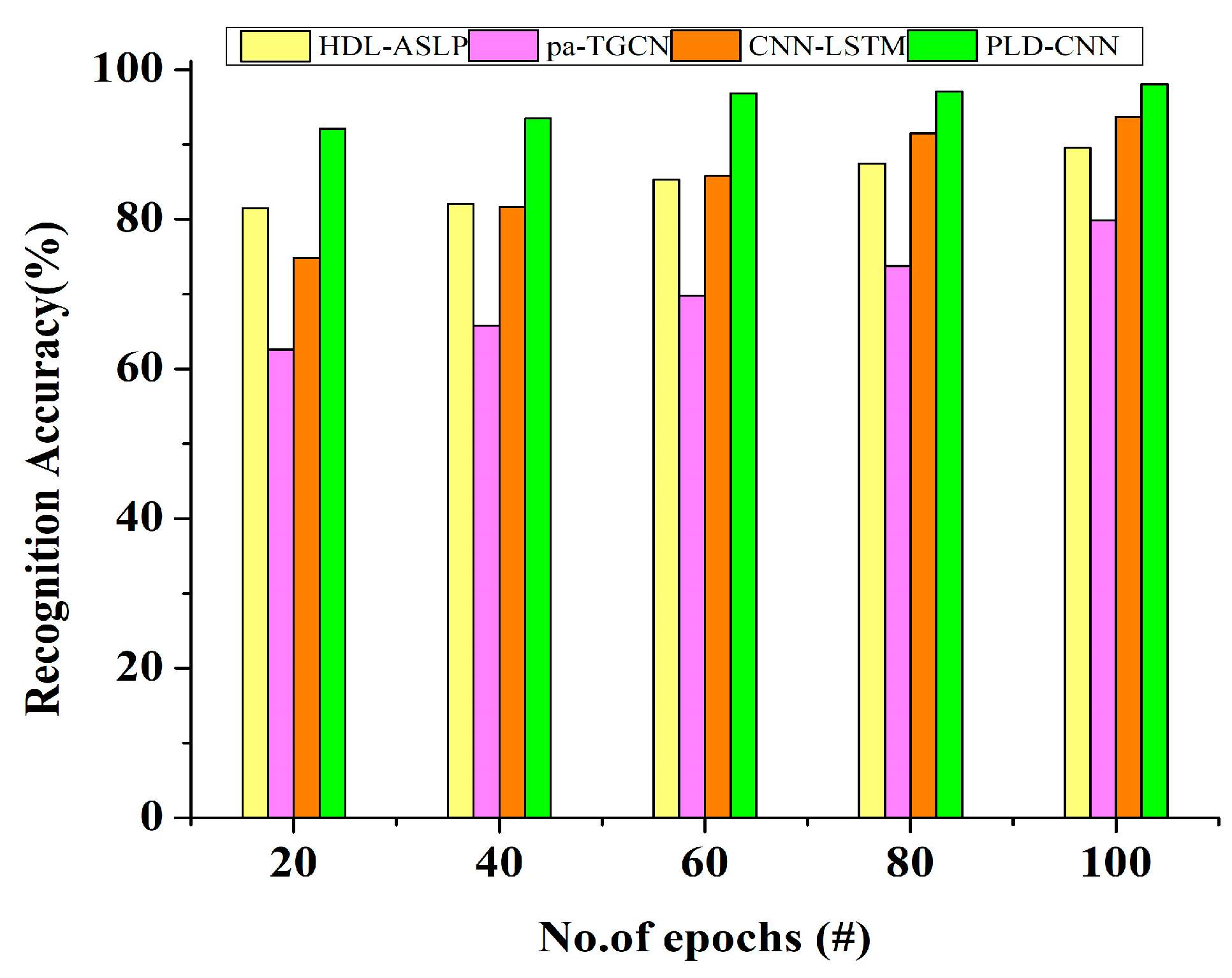
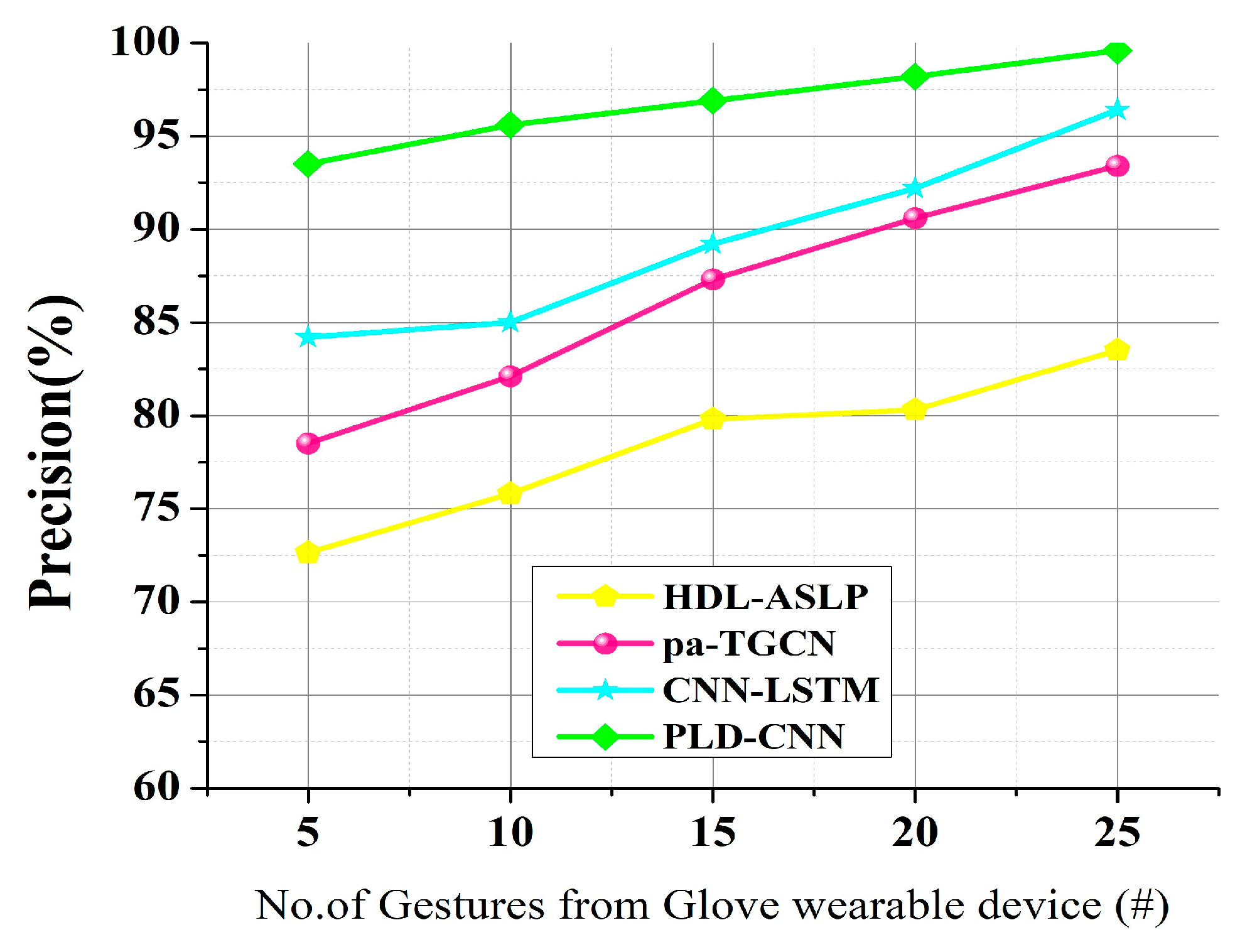
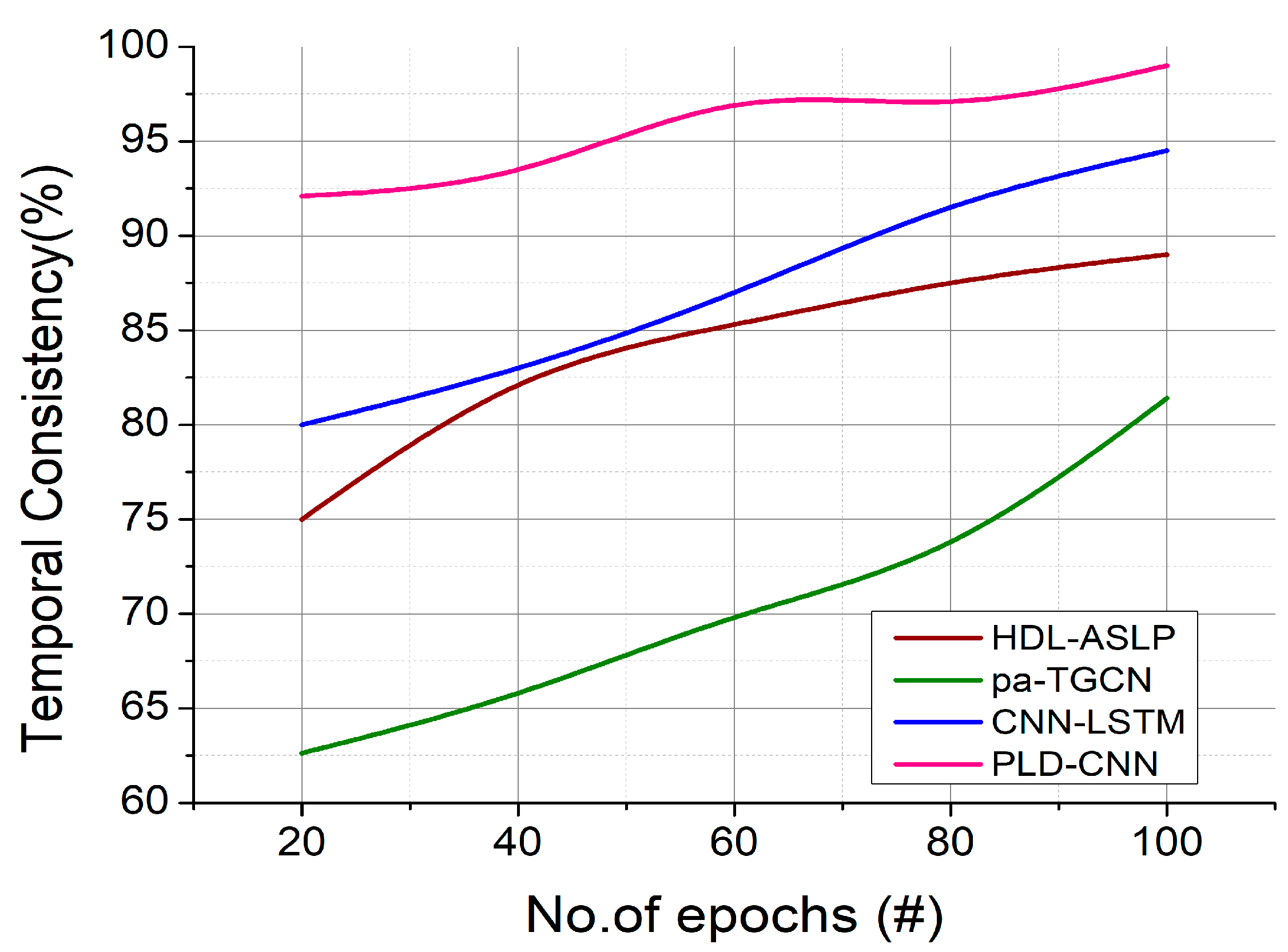
Table 1 summarizes the existing research by various scholars: Numerous studies using AI have been conducted to address various sign language recognition challenges for different languages. The existing limitations, like the shortage of studies into inertial signal pulses, need to be considered when designing the proposed algorithms to replace existing languages like HDL-ASLP [
19], pa-TGCN [
20], and CNN-LSTM [
23]. The findings of this literature review may assist in efforts to create reliable and signer-centered wearable glove-based sign language recognition systems. The three existing models chosen for comparison purposes involve input systems with data collected from video datasets and the use of wearable devices with inertial and electromyographic signals to capture signs.
The reviewed studies were highly relevant to sign language recognition, with recent advancements in deep learning-related works including the release of wearable technology like 3DCNN [
17], 3DCNN + MLP + En [
18], pa-TGCN [
20], LSTM [
21], CNN-LSTM [
23], CNN-GO [
24], and DCN [
25].
3. Proposed System
Sign languages, each possessing distinctive linguistic patterns, are the principal means of communication for the deaf in society. Smart sensor innovations, integrated with AI and Machine Learning (ML), make wearable systems more powerful. The main goal of this research is to develop a wearable device-based sign language recognition system that uses deep convolutional neural networks to enable real-time interpretation and translation. The technical features of gesture recognition and sign-language-specific syntactic rules are highlighted using progression learning.
Glove-based systems can significantly influence numerous application fields because hand gestures are capable of conveying especially important data. Each gesture is classified using a deep learning algorithm, based on CNN, that continuously learns and extracts characteristics, employing a progression learning technique for this continuous learning process. A progression learning algorithm can be trained on this sign knowledge and correlate a certain hand gesture with its associated sign by gathering a moderate amount of information for every single word, divided and separated from the sentences, to provide an input. Progression networks are a step in the right direction since they resist forgetting and may use existing knowledge by making indirect links to previously learned elements, such as words and characters. Real-time hand gesture recognition is one of the most difficult study areas in human–computer interaction. Progression networks are an initial step towards developing a fully continuous learning agent because they have the components needed to learn several tasks sequentially while also facilitating transfer and being resistant to catastrophic forgetting.
The system should recognize sign language sentences when words are in a syntax-specific order. This means that the proposed PLD-CNN system analyzes signals, words, and the arrangement of sentences and language. The algorithm learns to recognize full phrases by interpreting sequential sign language patterns and structures through iterative improvement, improving hearing-impaired communication.
A MATLAB program was developed to prepare the inertial measurement unit (IMU) data. The IMU data are first preprocessed using a moving average filter, and then the smoothed IMU data are saved in separate CSV files. Sign languages differ by place, but they share fundamental gestures. This research develops a glove-input sign language recognition system for people in the deaf and hard-of-hearing communities. Training is performed on datasets containing several sign languages in order to address sign language variety. PLD-CNNs and HMMs help the system comprehend the rules of grammar and recognize certain gestures in order to establish a global sign language recognition system.
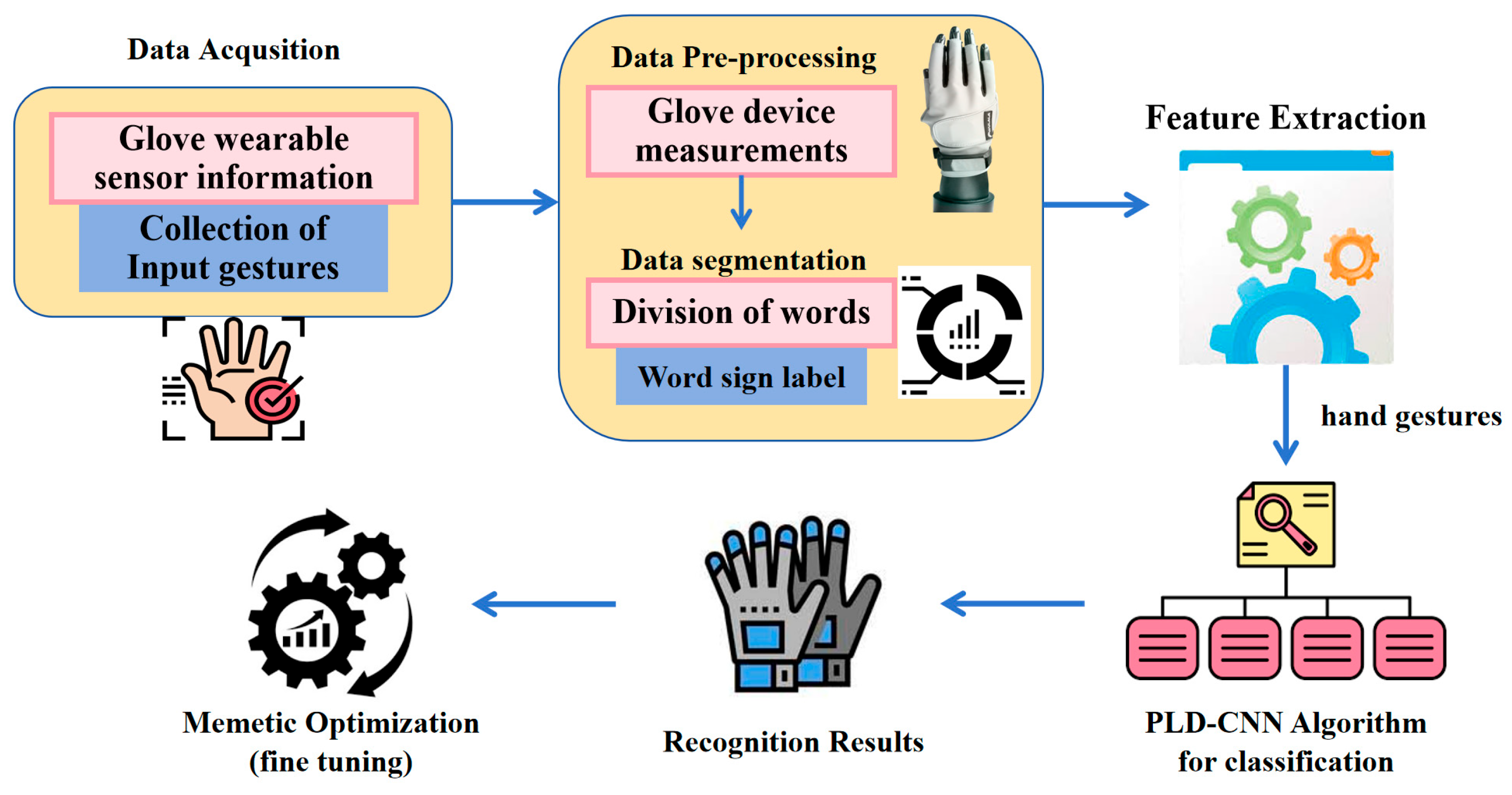
Figure 1 depicts the overall implementation procedure of the PLD-CNN algorithm for sign language prediction.
Figure 1 represents the structure of PLD-CNN-based sign language recognition. The system consists of several phases, such as data acquisition, preprocessing, feature extraction, sign language classification, and efficiency analysis. Initially, the data are collected from wearable glove sensors, which consist of several pieces of information. The gathered input gestures are preprocessed by examining the device measurements. Then, words are divided, and sign labels are segmented. The segmented details are fed into the feature extraction stage. The extracted features are processed using the PLD-CNN approach, which recognizes the gestures effectively.
3.1. Data Acquisition
Lightweight IMU sensors, capable of measuring accelerated and angular velocity, are selected for precise motion tracking. IMU sensors have Bluetooth communication options, allowing them to transfer information to a data collection device. An IMU sensor should be attached to each palm and every finger. It is necessary to ensure that the sensors are firmly fastened in order to reduce movement artifacts and guarantee a snug fit for the signer. Then, researchers should ensure that the sensors are positioned and aligned correctly on each finger and palm. Finally, it is necessary to calibrate the IMU sensors for the correction of any discrepancies or aberrations in their measurements.
Instead of vision-based systems, this research focused on using gloves to measure hand and finger positions or gestures. Sign language users may find this approach less natural, but it gives precision, control, adaptability to varied conditions, and accessibility. Despite potential downsides, these attributes certainly influenced our decision to use gloves for data collection.
The data are obtained from the glove sensors for use in capturing gestures from hand variations.
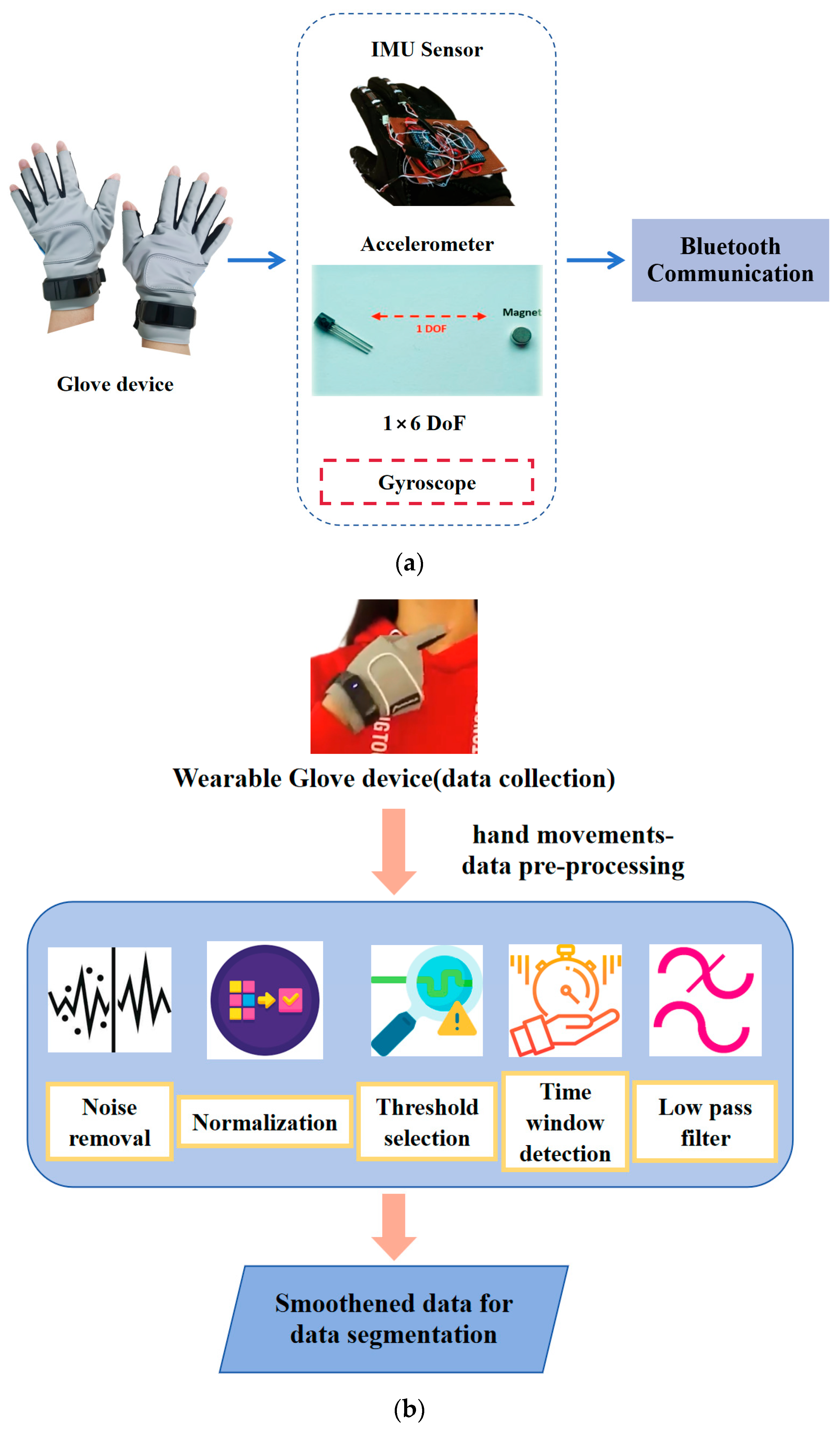
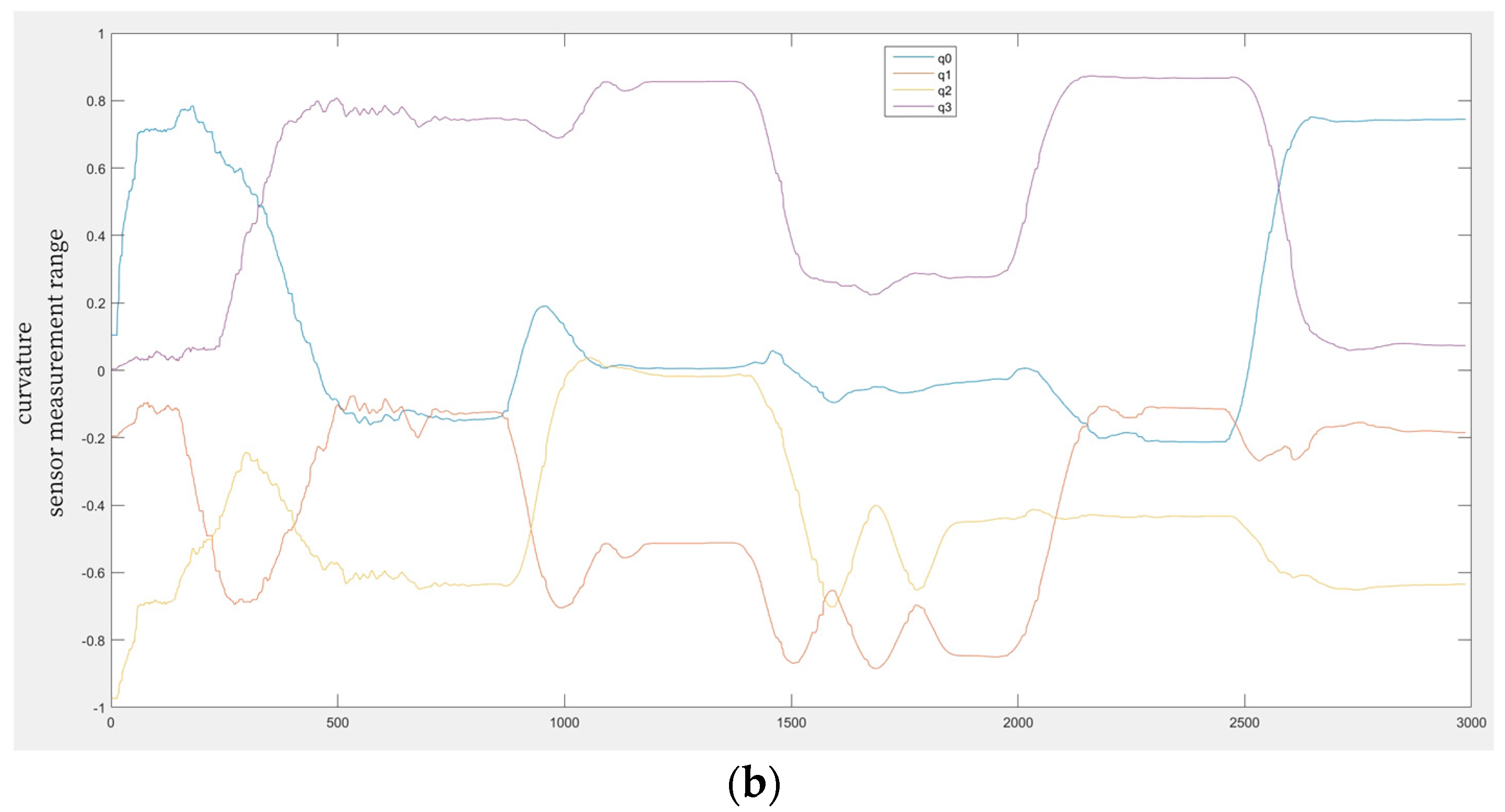
Figure 2a and specifications detail the glove-based wearable devices used to identify varying hand gestures, like hand movements and orientations. It is necessary to gather information as soon as the wearer makes the desired finger and hand movements.
The ethical considerations related to the use of wearable devices for sign language recognition emphasize user autonomy. Along these lines, it is necessary to provide clear information about data usage policies and allow participants to make informed decisions about their involvement. These measures aim to uphold ethical standards, safeguard user privacy, and respect the autonomy of individuals involved in the study.
3.2. Data Preprocessing
A wearable glove device collects data by using technology with specified hardware details when each finger is flexed while making various sign language gestures. The operation consists of storing large quantities of information, which is viewed as noise produced by the fingers shifting positions during each gestural movement. Before being input into the network, the measurements obtained from the gloves are preprocessed and converted into the features specified in this study. The features mentioned above were meticulously chosen to capture pertinent data regarding hand movements and gestures; the network subsequently employs this information for recognition.
Figure 2b illustrates the preprocessing techniques used for recognizing hand movements via wearable glove devices. It is necessary to reprocess the data collected from sensors in order to enhance its quality before segmentation. Common preprocessing procedures include noise removal and normalization to provide consistent and clean input. Optimal threshold levels that can assist in differentiating between hand gestures and prolonged resting conditions are selected. The threshold may differ depending on the particular sensors employed and may depend on sensor readings, including acceleration or location. By applying the chosen criteria to the sensor data, time windows are determined wherein hand movement is likely to occur. Various factors, such as external interference or inaccurate sensor readings, can cause noise in sensor data. By reducing noise and smoothing out the data, the low-pass filtering technique makes spotting important gestures simpler.
Using a low-pass filter in the preprocessing stage helps to remove high-frequency noise components, such as sensor noise and signals. This can improve the quality of input data and enhance the system’s robustness to noise.
The PLD-CNN model utilizes a technique known as progression learning to enable the system to learn and adjust to the latest information over long periods of time. By changing its representations based on evolving data and variances in hand gestures, this incremental procedure for learning helps the model become more robust and accomplished by updating its representations.
Low-pass filtering analyzes every temporal and spatial data point when used on sensor data. This method considers signal intensity values within a specific time window or region around each data point. The filter computes a weighted average of all values in the window, giving those nearer to the filtered data point greater weight. The data point’s new value in the filtered signal is the weighted average. The low-pass filter attenuates high-frequency noise, representing rapid alterations in the data. By averaging the noise over time, the filter reduces the high-frequency fluctuations in the signal. The filter maintains low-frequency components, representing the underpinning patterns or slower changes in the signal. The beginning of a possible gesture is indicated by the sensor data crossing the threshold, and the end of the potential gesture is designated by the sensor data falling below the same threshold. A low-pass filter smooths the signal, slows rapid changes, and retains the lower-frequency components while removing noise at higher frequencies from sensor data.
3.3. Data Segmentation
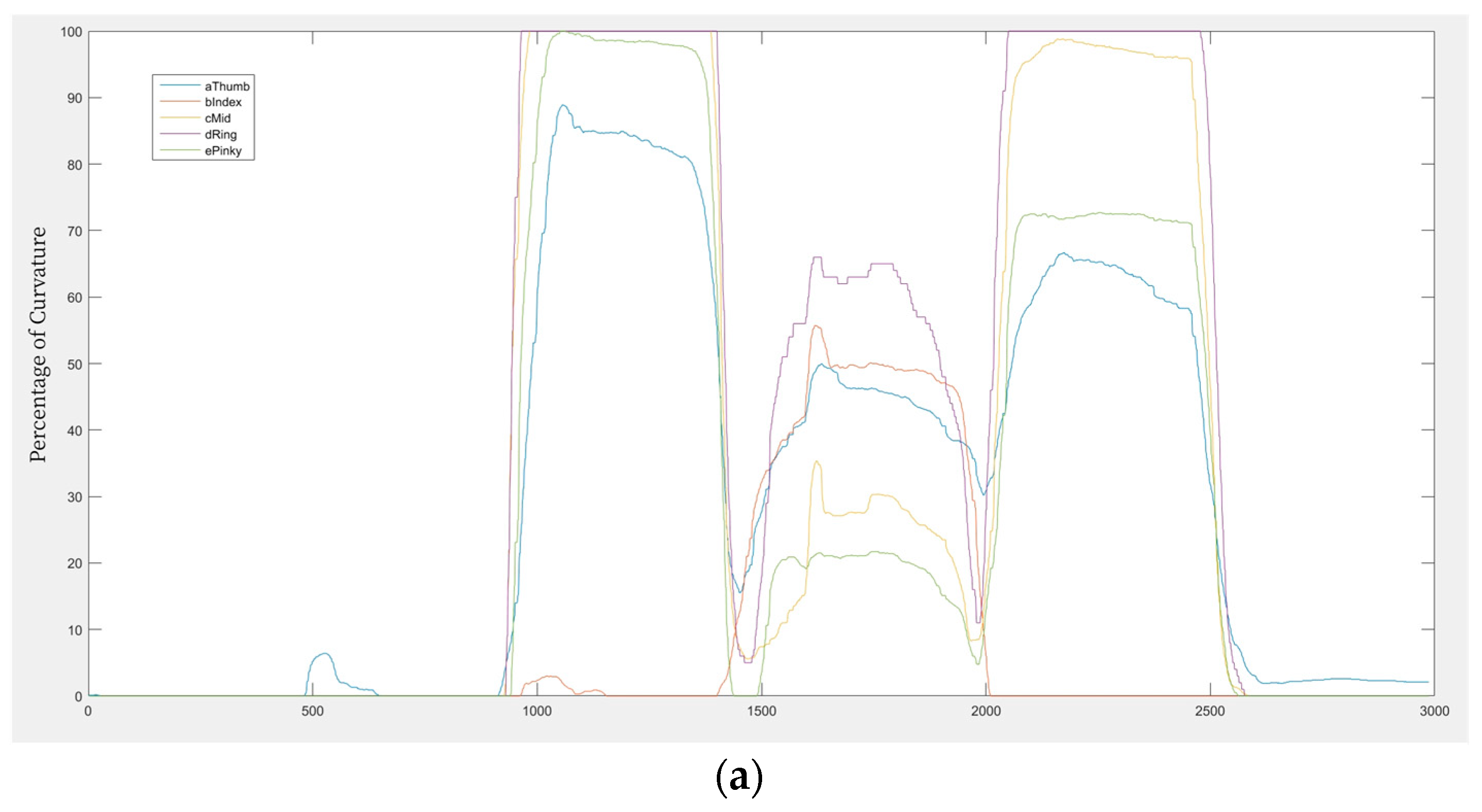
The information is divided into discrete gestures. These are divided into subwords, representing the basic units of sentences in sign language. During the division of words from a continuous sentence, the performance of the signer in maintaining the contraction of their muscles according to the sentences used for communication is assessed. The IMU palm sensor, with its 1×6 DoF specifications, captures finger variations, including thumb, index, middle, ring, and pinky (little finger) movements, along with finger stretching, hand movements, and overall hand posture during the learning phase of gesture translation between continuous subwords. Each subword fragment is subjected to feature extraction in order to produce sets of features representing continuous sign components, which are then used as input for the appropriate PLD-CNN algorithm at the element level. The next phase of subword-level identification integrates these elements after each has been analyzed individually. For additional processing, the segmented motions might be used as input for recognition models such as deep convolutional neural networks after performing feature extraction. Every sentence consists of numerous words, and each signal is signified accordingly. The goal of this step is to segment each indication individually. There will be n corresponding segments in each sentence due to segmentation.
High-dimensional models (HMMs) are frequently used in sequential data modeling and can be used to identify patterns in time-series data. This system most likely uses HMMs to simulate the sequential nature of sentences that have been communicated through sign language. In HMMs, every movement or gesture can be categorized as a state, and transitioning between states is equivalent to transitions between gestures. HMMs can assist in segmenting the input data into meaningful units, such as individual signs or words, and in finding the sequence of these units that is most likely to produce a complete sentence.
A collection of states in the hidden Markov model for a segmentation task that represents various data segments or patterns for a gesture sign language with one gesture to another gesture state as is represented in HMM as . Each condition may be associated with a specific type of region. The features of the gesture within each segment are represented by the observations connected to each state. The emission probability represents the probability of emitting an observation of finger variation when in state . The forward method calculates the likelihood of witnessing a succession of gestures, given the models used. It employs recursive equations to obtain forward probabilities . Using these observations, the Viterbi algorithm determines the most probable series of hidden states, with the recognition of subwords set to and These probabilities determine how likely it is for one segment to transfer to another, that is, for a signer to transition from one gesture to another for identifying the continuity of words to make a sentence. Hidden Markov models (HMMs) represent individual phrases or gestures, collecting statistically significant trends and associated transitions. By predicting the probabilities of word sequences, these models, when paired with linguistic models, assist in the recognition of cohesive and grammatically accurate sentences in sign language. To efficiently model permissible sequences of words (sentences) in sign language, this research uses a combination of linguistic models and HMMs for individual gestures.
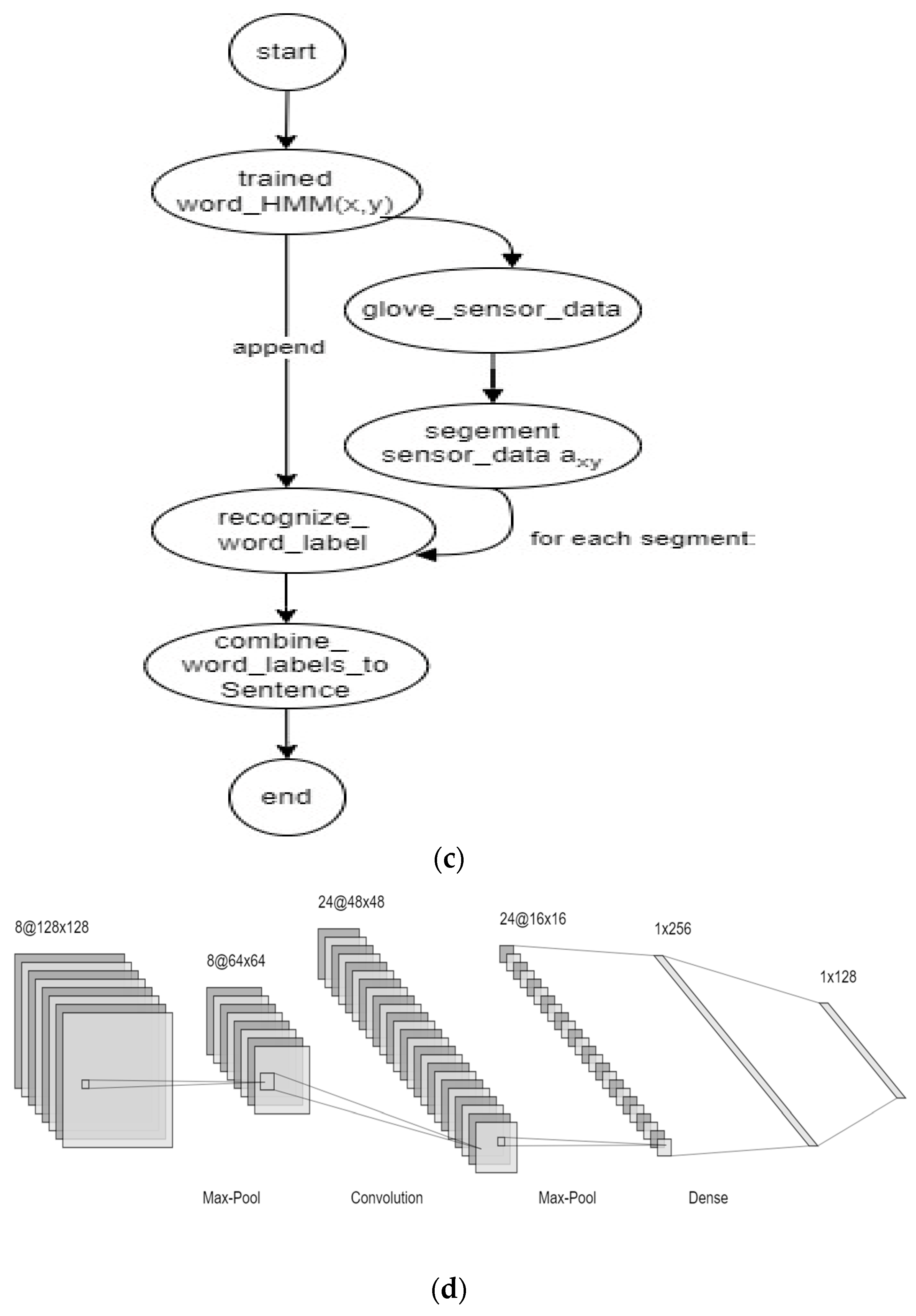
Pseudocode: Recognizing word sign label using HMM
Word_HMM = load _trained word_HMM(x,y)
sensor_data = capture_glove_sensor_data()#input
segments = segment_glove_sensor_data(sensor_data for )#segment
recognized_labels = []
for each segment in segments:
recognized_label = recognize_word_label × (segment, word_HMM)
recognized_label.append(previous recognized_label)
sentence_label = combine_wordlabels_toSentence(recognized_wordlabels)
recognized_Sentencelabel()
This pseudocode illustrates the key phases utilized in the process of using glove-sensor data and HMM to recognize sign movements and create a sentence sign label.
The explanation of pseudocode represents the recognition of word sign labels by using HMM with glove sensors to record each phrase as a sequence of sign language gestures. Learning patterns and characteristics extracted from input gesture sequences are used to train the PLD-CNN model in order to recognize these words. Using extracted features to identify word boundaries in the input sentence, the model generates recognized words. Subword extraction breaks down each word gesture towards subwords, which may be sign language letters or phonetics. The PLD-CNN model processes each word-containing gesture to extract subword-related unit information. The model outputs recognize subwords in order to capture gestural characteristics, including finger movements, hand forms, and trajectories. The model recognizes each subword unit to obtain a finer gestural word analysis and a better understanding of the area overall.
In sign language recognition, the applied control graph representation in
Figure 2c provides an overview of the procedure used to recognize word sign labels by utilizing HMMs. The steps in this process involve loading a pre-trained HMM model, gathering sensor data from a glove device, segmenting the data, and detecting word labels for each segment using the HMM model. After that, the detected labels are joined to generate a sentence label, which makes it easier to understand the meaning of sign language utterances. This algorithmic approach uses convolutional neural networks (HMMs) to describe temporal relationships in gestures and improve the accuracy of sign language recognition systems.
Once all time steps have been completed, it is necessary to revisit the and values to identify the most likely order of concealed states. The path that maximizes the combined likelihood of the observed gestural information and the state sequence corresponds to this. The word sign label is the classification given to a particular sign or gesture that denotes a word in sign language. These labels make the recognition and classification of particular indications within a sentence easier. The transition probabilities used in segmentation are often created to reflect the possibility of switching between segments. The possibility of observing particular finger points and characteristics in a given state is defined by probabilities. These estimations capture the features of each segment via segmentation tasks. Continuous glove–sensor data and gestural information are divided into subword indication portions. The next step is to label the segmented information accordingly, and the word sign labels are recognized via sign language recognition using glove sensors and the HMM segmentation technique. Continuous sensor input is segmented into different sign gestures, and each segment is then associated with a particular word sign label depending on the trained HMMs. The system can identify and categorize signs in the glove device data because the HMMs represent the variations at the time of each sign. The annotators should be fluent in sign language to appropriately label every sign in context. It is also necessary to train a unique HMM for the sign labeling of each subword using the annotated data. The HMM simulates the time-varying patterns of each sign based on the retrieved features.
The sign language recognition method presented in this research, in which sequence modeling often uses probabilistic HMMs, relies on HMMs. These models can describe gesture-related temporal dynamics in sign language recognition in order to capture sign language’s sequential character. Typical HMM model preparation and training software includes a Python module called “hmmlearn”, which implements HMMs.
The PLD-CNN model used in this study recovers words and subwords from glove–sensor sign language motions. For example, a sequence of sign language gestures captured using glove sensors represents the sentence: “I have a headache and cough.”
Word: “I”, “have”, “a”, “headache”, “and”, “cough”.
Subwords: {“I”}, {“h”, “a”, “v”, “e”}, {“a”}, {“h”, “e”, “a”, “d”, “a”, “c”, “h”. “e”}, {“a”, “n”, “d”}, {“c”, “o”, “u”, “g”, “h”}.
Deep convolutional neural networks evaluate movements in order to identify word boundaries and break them down into letters or phonetic components. Deaf and hard-of-hearing people can better communicate by recognizing and interpreting sign language sentences.
HMMs are commonly utilized in sign language recognition systems to capture the temporal correlations and sequential patterns inherent in gestures. The recognition process can account for sign language temporal elements like gesture order and transitions using HMMs, which complement deep neural networks.
3.4. Feature Extraction
One of the primary goals of utilizing conventional machine learning algorithms is feature engineering. As the inputs for the specific machine learning model features, the standard statistical features utilized in the study of data from wearable glove-sensor devices for sign language recognition, including gestural information collected by peripheral glove sensors for the recognition of sign languages, encompass Mean Absolute Value (MAV), variance, and standard deviation. These features are frequently utilized as input features for training ML algorithms or for additional analysis since they might reveal important details about the nature of the sensor data.
Deep convolutional neural networks can extract hand gesture features from sign language inputs. Let us denote an input image depicting
a hand shape made during a sign language gesture, as
. This image is typically represented as a matrix of pixel values, where each pixel encodes the intensity or color information at a specific spatial location. Deep CNNs start with convolutional layers that learn to recognize and extract low-level characteristics like angles, boundaries, and texture patterns from the input gesture images. Convolutional operations build feature maps by sliding a tiny filter, called the kernel or feature detector, through the input image and by performing element-wise multiplications and summing. This operation is mathematically expressed in Equation (1) and Equation (2):
where
is the value of the feature map at the position
,
represents the pixel value of the input image at the position
, and
denotes the value of the filter at the position
. Deep CNNs extract discriminative features that capture the visual characteristics that differentiate one sign or gesture from another.
This allows the network to distinguish hand shapes and movements, enabling sign language gesture recognition. The same applies to the motion trajectory of a particular keypoint in frame , where is the total number of points in the trajectory. Deep CNNs’ output features are abstract representations of input motion patterns and can be used for gesture detection.
Mean Absolute Value (MAV):
In a segment of sensor data, the MAV determines the overall relative magnitude of each data point obtained from the fingers and each palm movement obtained from the gloves. This method is a measurement of the average intensity or frequency of the signal. MAV can assist in capturing the total power or force of hand motions during a gesture using Equation (3):
where
n represents the total number of gestures in the segment and
represents the individual data points of identified gesture samples.
Variance ():
Variance measures how evenly or unevenly data points are distributed within a segment. This parameter gauges how widely apart data points are from the mean and sheds light on how widely spaced-out sensor measurements might vary. It can assist in differentiating between motions that vary in their degree of reliability or predictability.
represents the mean of the gesture sample data in Equation (4).
Standard deviation:
The square root of
yields the standard deviation, and the average departure of points of data from the mean is measured. The standard deviation indicates the range of the data and is closely associated with variance.
Equation (5) demonstrates that sign language, which utilizes the properties of finger motions, can be learned from data produced using glove sensors, which are utilized as feature inputs for ML-based predictive models.
3.5. Progression Learning for Enhancing Recognition Accuracy over Time
Sentences in sign language are first processed by being broken down into words. This progression method of learning continuously improves the system by producing a training set. As the system progresses through the phases, progression learning takes place, with each level expanding on the knowledge acquired in the one before it. The learning makes it possible to accurately recognize the entire sentence word by word using information from the glove sensor.
The PLD-CNN model uses progression learning implements with minimum latency values of <5 ms. A low-energy-efficient communication protocol like Bluetooth minimizes data overhead and transmission latency to conserve computational resources for the wearable devices utilized, along with employing feature extraction, memetic optimization, and efficiency analysis to improve computing efficiency. These solutions maximize system efficacy by balancing accuracy and computational efficiency to recognize sign language and manage the computational demands of wearable devices with GPUs.
The AI model better understands sentences in sign language because of the dataset in question. The progression learning network method accesses previously learned features for deep combination through the lateral connections of gestures identified, and it is appropriate for any progression learning environment, such as in the continuous observation of gesture signs during a sentence. The extracted dataset used for implementation purposes is divided into data for training (75%), and random testing data (25%). Incremental training drastically reduces the training time by allowing us to train the network solely for a new set of gestures obtained from the glove device and optimize the most recent fully linked layer without training the network again. The progression learning deep model, introduced here, is gradually trained on new inputs from wearable glove sensors using the suggested PLD-CNN technique, enabling the learning of recently obtained gestures without needing access to previous training information. Because progression learning enables the recognition system to gradually acquire context and increase accuracy as more motion is recorded, it can offer sentence-based classifications in sign language from wearable glove devices. Staged model training uses learning progressions with deep CNNs. With each stage, emphasis is placed on understanding gestures more precisely. The recognition algorithm improves in recognizing gestures at each level of progression learning. As stated, model training progressively utilizes PLD-CNN, emphasizing gesture understanding.
In order to record dynamic movements, sensors track joint angles, finger trajectories, and palm orientations at high sampling rates. Gloves use inertial measurement units (IMUs) and flexible sensors on each finger to capture tiny signing gestures and positions. IMU data track hand motions in 9-DOF, allowing the model to learn rotational motions and quick sign switches. Orientation heuristics enable the interpretation of hand directions as sign meanings based on the identified words in a gesture. These words are brought together to make a complete sentence for effective communication. A progression learning approach is ideal for sign language recognition because it can incrementally learn to distinguish between subunits and model longer sign sequences. Fluent transitions are learned through progression training. Large natural sign language video datasets with 100 sentences of sign language gestures are preprocessed to extract annotated gesture sequences. Fluent signing with authentic co-articulations and transitions serves a crucial role in training the progression learning models in real-world languages.
Hand movements are the only thing that the current glove-based technology takes into consideration; it does not consider facial expressions.
IMU sensors and wearables are given as inputs into Algorithm 1, where noise is eliminated, adjusted, and low-pass-filtered to improve data quality. Trained HMM word sign labels segment preprocessed inputs into gestures. Extracting key gestural properties allows for continuous sign–gesture representation. A progression learning system trains a deep CNN model using these attributes. The model learns linguistic and gestural information to improve recognition. Network parameters are optimized for accuracy using memetic optimization. The recognition system is assessed using different criteria to ensure its efficacy. This iterative approach enhances the performance of sign language gesture recognition.
| Algorithm 1: Progression Learning Procedure for Sign Language Gesture Recognition |
Step 1: Input layer performs data acquisition
Collect input from IMU sensors and wearable devices.
Step 2: Data preprocessing
Preprocess the sensor data to enhance quality using noise removal, normalization, and low-pass filtering.
Divide phases into groups of 75% for training and 25% for randomly tested data.
Step 3: Data segmentation
Segment the preprocessed sensor data into discrete gestures.
Associate each segment of finger variations with a specific word sign label based on the trained using HMMs.
Step 4: Feature extraction
Extract features from each gesture/subword in order to represent continuous sign gestures, varying based on hand variations and
Use dense convolutional layers to learn hierarchical representations of input gesture features.
Step 5: Progression learning
Train a model using the features extracted with the deep convolutional neural network learning procedure.
The model learns and adapts to the complexities of sign language gestures over time.
Step 6: Orientation learning towards gestural identification
Learn the network parameters and update them with information from new sentences and gestures
Word and subword recognition using from learned sequences enhances recognition accuracy and robustness.
Step 7: Memetic optimization algorithm
Finetune network parameters and improve accuracy in recognizing sign language gestures.
Step 8: Evaluation
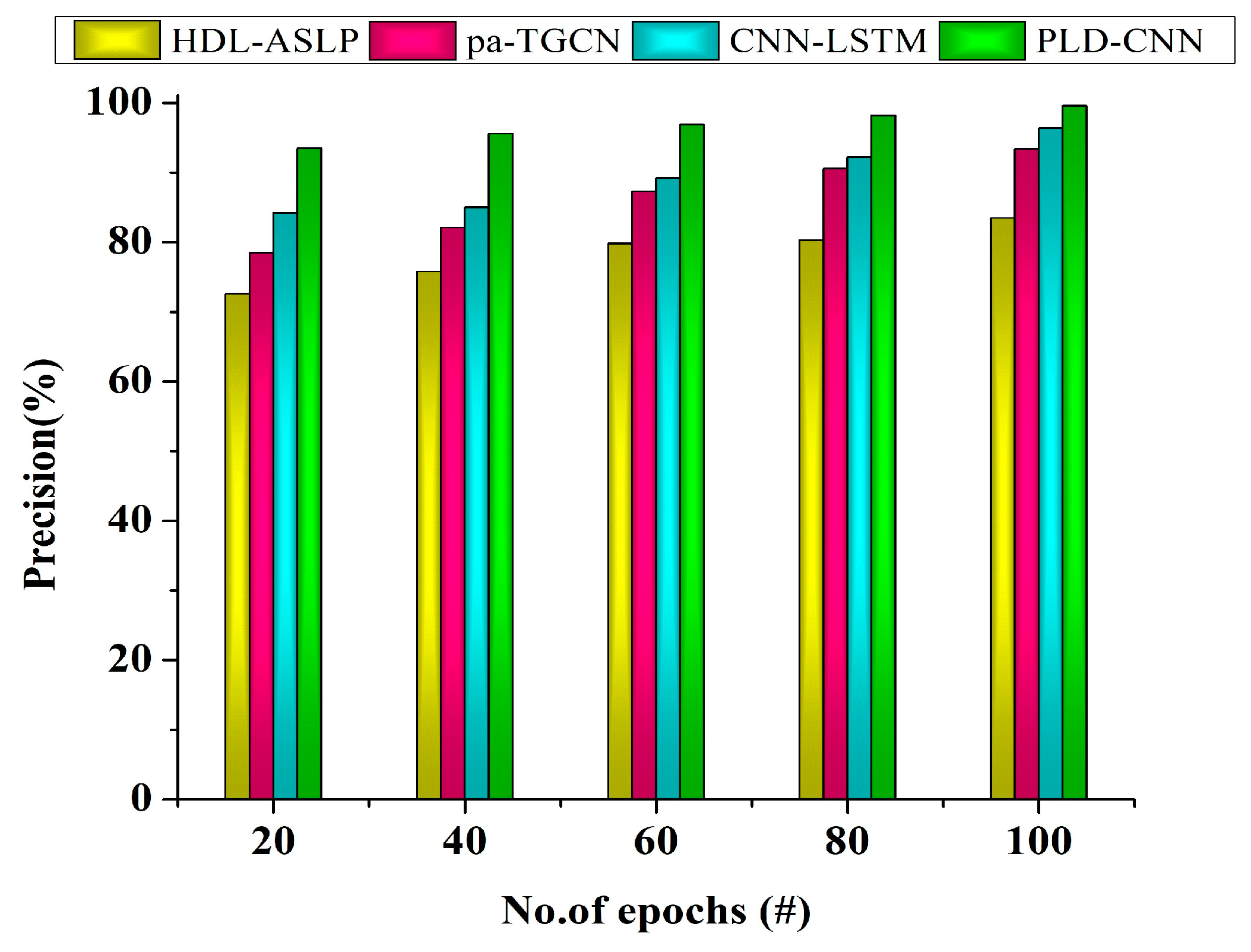
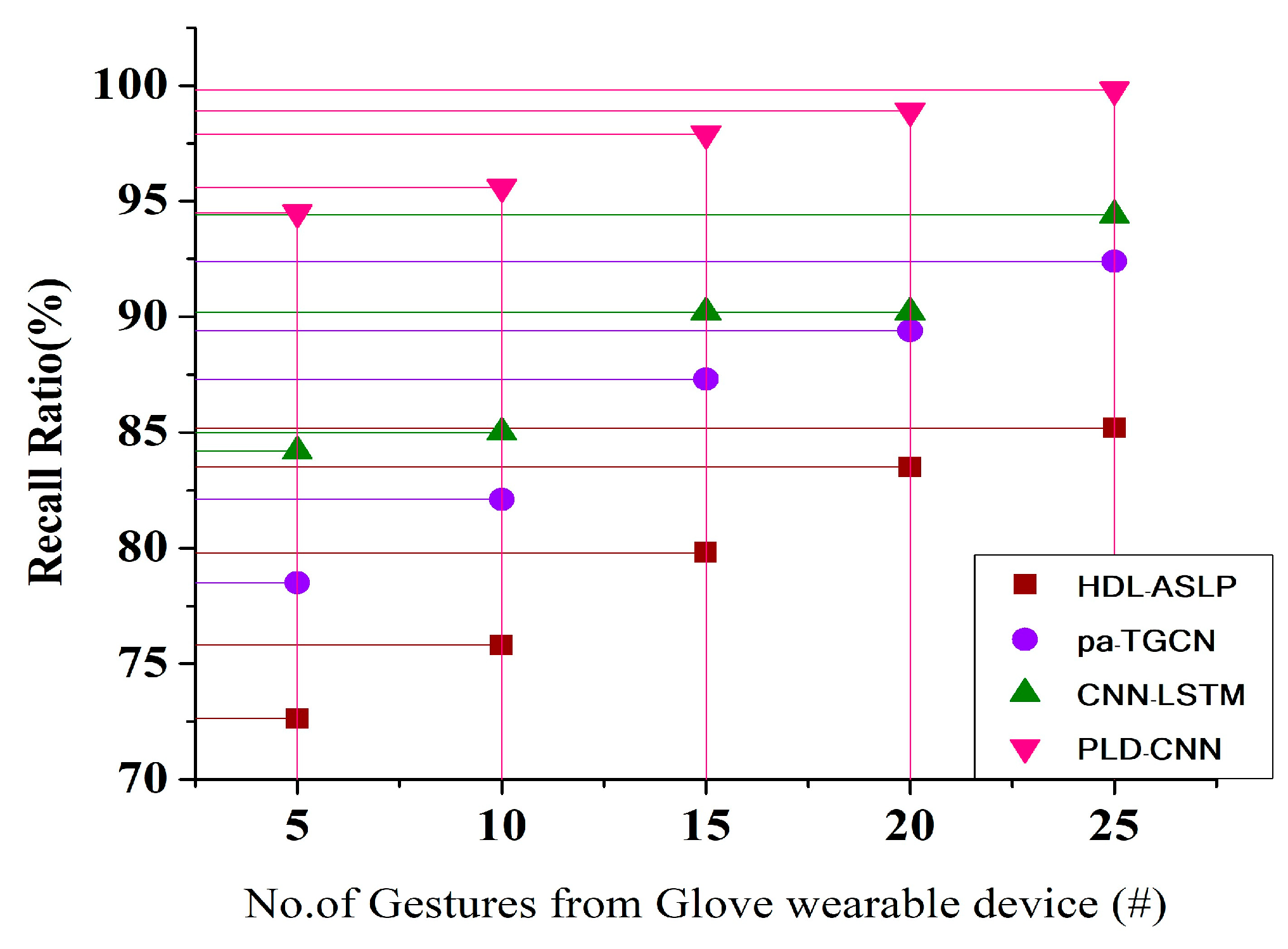
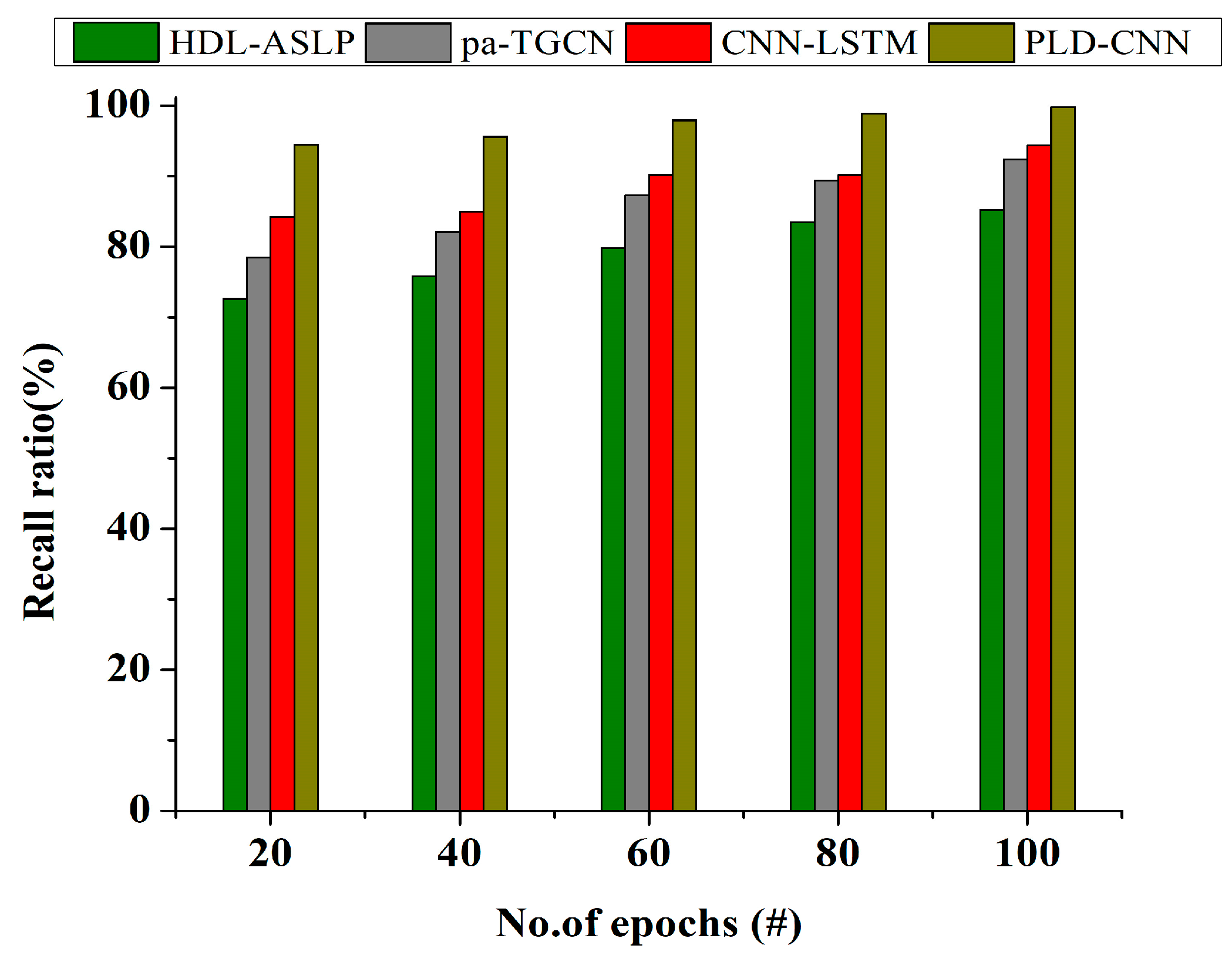
Conduct performance validation using accuracy, precision, recall, and F1 score metrics, WER, and temporal consistency. |
3.6. Orientation Learning for Tracking Glove Devices and Finger Signs
Orientation describes the direction that the glove device is facing, the fingers of the hand, or the IMU palm are facing. The goal of orientation learning is to precisely track how the glove device and the fingers on the hand are oriented. The investigation of orientation learning will allow for the proper detection of sign language motions and signs. A variety of hand and finger movements are used in sign language. Since the direction of the hand can vary for various signs, the glove device’s orientation aids in identifying the precise gestures being made. It adjusts the degree of yaw caused by fluctuations in the finger by applying magnetic sensor data collected from the glove device. This adjustment ensures that the system recognizes the right term and interprets the movements correctly. Typically, the orientation can be estimated using the angle of an accelerometer, as part of the IMU glove device, and the weight components along its axes. A portion of subwords is used, with their orientation shifting over incremental time due to the wide range of progression sign gestures, and the initial and final orientations of a complete subword fragment are of the utmost significance in sentence-level communication related to sign meanings produced by the signer. Calculations that utilize the inertial measurements along finger and palm reading lines are commonly used to estimate orientation from accelerometer data. It is typical to estimate orientation by computing the roll, pitch, and yaw degrees. These angles describe the orientation of the device in three dimensions. Based on accelerometer readings, the following formulae can be used to determine the roll, pitch, and yaw angles using the equations below (6 to 8):
where
represents the finger movements along the
x-axis and
represents the finger movements along the
y-axis. This is followed by the pitch angle analysis of the rotation of glove devices to identify gestures around the
x-axis. The yaw degree represents the finger rotations around the
z-axis.
where
represents the magnetic sensor readings of a wearable glove used to correct the yaw degree related to all five finger variations, ranging from a to e, in order to identify the correct word through learning progression.
Individual gestural identification:
The recognition approach is initially taught to recognize particular sign language motions. For instance, the paradigm in column 1 identifies these movements individually but ignores the context in which they occur. Progression networks that inhibit catastrophic recollection by developing an entirely new neural network, which acts as a segment associated with every gesture being identified and enables transmission through the creation of extensions to the characteristics of sections learned earlier, incorporate these requirements. Let
be the set of sign language gestures, where each gesture is represented as
,
i ∈ [
1, 2, …, n] and where n represents the number of sentence gestures. Let
represent the recognition result for the gesture
that can be obtained from the previously trained deep CNNs. Then, the structure of CNN is illustrated in
Figure 2d.
The recognition of a sentence
consisting of
gestures can be represented, as given in Equation (9):
Deep CNN parameters must be initialized, and a recognition method must be used to determine the next task based on sensor duties, which are focused on finger and palm gestures, for use in continuous learning. We must develop a mechanism with which to effectively increase the recognition model’s capacity to adapt when learning new tasks. Likewise, there is a pressing need for a technique to collect, maintain, and use knowledge in order to learn subsequent tasks without significantly degrading the previously learned information. Similarly, the identified result for sentence
is given in Equation (10):
where
reflects how well each gesture in the statement is recognized.
represents the operation that concatenates or combines the recognition findings of different gestures to create the classification outcome for the complete sentence. The network starts with a single column, representing deep CNNs with multiple layers
and a hidden activation
where
represents the number of gesture units identified at layer
and the corresponding trained parameter setting for translation convergence. When moving to the second layer of gesture recognition related to finger orientation, the previously learned gestures for words are frozen
for further learning, and the new column with the next set of gestures selected for the second phase of sentence communication is randomly instantiated, and the current layer learns inputs from
, where
represents the previously identified subwords. The model is enabled by progression learning to excel at identifying signs within words while considering context and communication flow. As previously learned finger traits are used in several activities, learning in order to transfer becomes more effective. This method ensures that prior task knowledge is preserved and is impervious to catastrophic forgetting.
Subword recognition:
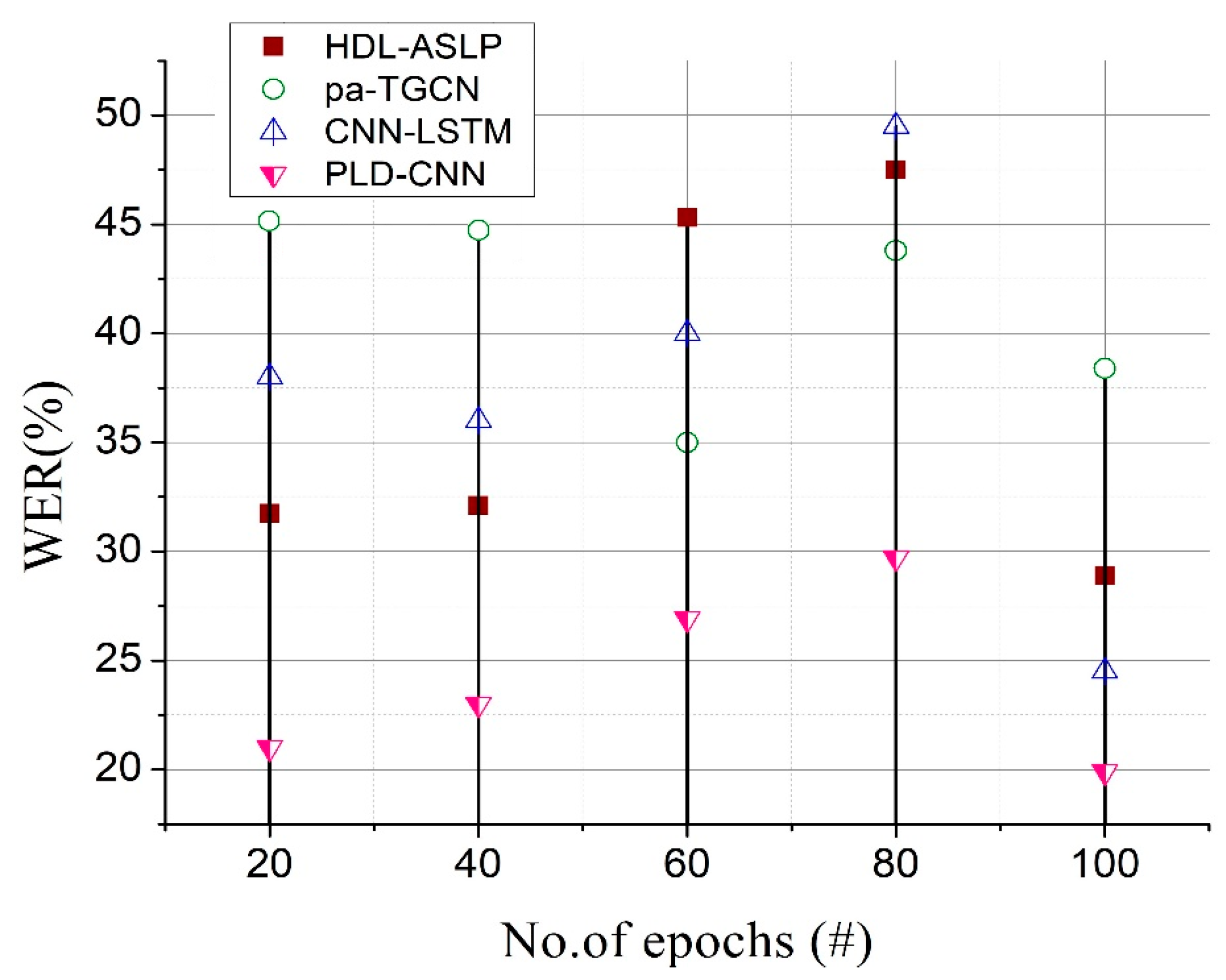
The model concentrates on identifying subwords from whole sentences or transitioning between motions in the second stage, which aids in capturing more intricate linkages between movements. The recognition system generates a series of recognized words or signals based on the input glove–sensor data. The word error rate (
WER) is useful when evaluating the recognized sequence’s general efficacy while also accounting for insertions, deletions, and substitutions. As it considers the location and kind of inaccuracies committed in the recognized sequences compared to the reference sequence, it offers a more thorough evaluation than the use of correctness alone:
where
represents the number of insertions of accurate words into the sequence,
is deletions like missing words or signs in the recognized sequence, and
is the substitution of mismatched or identified words.
refers to the total number of signs in the references. The recognition performance increases as the
WER decreases (refer to Equation (11)). A larger
WER implies greater recognition of errors, while a
WER of 0% indicates flawless recognition (no errors).
WER is useful when measuring the recognized sequence’s overall quality while also accounting for insertions, deletions, and substitutions. As it considers both the location and type of inaccuracies committed in the recognized sequence compared to the source sequence, it offers a more thorough evaluation than correctness alone.
Sentence analysis:
This method understands that gesture combinations can indicate several words and that order matters by aggregating the previously analyzed phases. Then, more phrases are subsequently added to the process, with each building on what was learned at the prior level. These techniques should become more adept at identifying minute features in sign language gestures.
This stage analyzes the sign language sentence’s entire context order by aggregating subwords. Considering the setting and similarities discovered at each level of progression learning, the ultimate recognized result is a logical interpretation of the communication in a given sentence. With progression learning, the recognition system can gradually increase its comprehension of sentences in sign language, enhancing its accuracy and contextual awareness as it advances through stages. It is necessary to utilize validation data and suitable measures, including accuracy, precision, recall, and the F1 score, to assess each model’s performance. These metrics guarantee that recognition accuracy improves at each level.
3.7. Memetic Optimization Algorithm for Improving the Precision of the Recognition System
The parameters of the recognition network model can be adjusted, and its accuracy can be increased using memetic optimization methods. Memetic optimization improves the detection of sign language motions, improving success in correctly identifying and converting signs into text by iteratively improving the model’s performance using local search approaches.
The memetic optimization approach improves sign language recognition systems by optimizing neural network model parameters. This optimization method iteratively improves model performance using evolutionary algorithms and local searches. The method adjusts network parameters based on training and validation data to enhance recognition accuracy and reduce sign language translation problems.
Impact on precision enhancement:
Setting up parameters:
The memetic optimization algorithm adjusts neural network parameters to better capture the complicated patterns and nuances of sign language movements, improving recognition accuracy.
Iterative refinement:
The algorithm updates and optimizes the model’s configuration, utilizing fresh data and user input to improve performance.
Local search approaches:
The algorithm refines the model’s ability to make decisions by using local search approaches, resulting in more accurate sign language gesture and sentence recognition.
Reducing translation difficulties:
The optimization process improves the system’s ability to identify and interpret sign language gestures, facilitating the communication abilities of hearing-impaired people.
In this optimization phase of training, the objective functions need to be designed to boost training and validation accuracy and improve the translational computation cost of the proposed progression learning.
In progression learning for sign language recognition, the optimization problem induces the iterative enhancement of a neural network model’s performance by adjusting its parameters via memetic optimization techniques. The primary objective of doing so is to optimize the system’s precision in identifying and transcribing sign language gestures, facilitating more effective communication among users who are hard of hearing.
As an example, let us consider a sign language recognition system that encounters initial difficulties in accurately interpreting intricate gestures due to a lack of training information. By employing progression learning and memetic optimization techniques, the system progressively enhances the performance of its neural network model by adjusting its parameters in response to feedback received from validation data. As the system advances through distinct phases, it acquires greater proficiency in discerning hidden characteristics within sign language gestures, culminating in an upward trend in accuracy. The system learns from fresh data and improves the accuracy of its sign language identification performance at each level. The model is updated, and new information is added to improve sign language phrase interpretation and translation, improving communication for deaf and hard-of-hearing people.
The memetic optimization technique is employed to train the proposed neural network model using the parameter settings outlined below.
Initialization and fitness function:
The challenge in understanding hand motions in sign language recognition is turning them into meaningful signals or words. A sample of potential solutions—recognition models or algorithms—is developed to solve this issue. For applications that recognize sign language, recognition accuracy must be maximized. The technique operates well in comprehending and interpreting sign motions detected by glove sensors, as evidenced by a greater level of recognition accuracy . The solution space may be thoroughly explored thanks to the genetic algorithm element of the memetic optimization technique. It considers a wide range of options and investigates various strategies and setups for sign language recognition. The equation shows the number of correctly recognized gestures in relation to the total number of gestures.
Selection of local search methods:
Sign language recognition may need to be fine-tuned in order to capture the subtleties of hand gestures and movements effectively. The memetic algorithm incorporates local search approaches in order to enhance population-level individual answers for the words identified as having the best accuracy. These methods are intended to improve the recognition models’ performance when dealing with certain gestures and variations. The fitness rating measures how successfully a proposed PLD-CNN recognition system or algorithm interprets hand gestures and converts them into words and meaningful sentences. More physically active individuals have a better probability of being chosen as parents, and it is necessary to create new candidate solutions using genetic operators such as crossover (recombination) and mutation. Genetic information extracted from two source solutions is combined during crossover to produce offspring. Individuals undergo minor random alterations as a result of mutation.
Iterative refinement: The memetic optimization approach iteratively improves the population’s recognition models. It determines the most effective settings for various sign language movements, increasing recognition accuracy. Achieving a desired fitness level, running for a predetermined amount of time, or attaining a gesture generations are instances of common termination criteria.
High-quality solutions: The algorithm converges to high-quality recognition models through global discovery and local exploitation. The sign language system used for recognition is improved and becomes more dependable thanks to these models, which are skilled at accurately distinguishing and interpreting sign language motions. If necessary, researchers should repeat the memetic optimization procedure repeatedly to significantly enhance the system’s performance in light of fresh information or shifting demands.
In summary, the proposed methodology met the objective of reducing the translation challenges faced while performing sentence-based sign language communication among disabled people, achieving a very robust performance. Additionally, the PLD-CNN demonstrated that the progression technique is robust to all types of gestures, which are taken as learning features, in conflicting operations during sign language recognition with intelligent glove devices. Further, this model can efficiently perform translation for appropriate source and target regions. The accuracy of sign language recognition is improved over time via progression learning. This entails breaking down phrases into words, assembling a training dataset using a CNN, and incrementally enhancing the system’s knowledge through learning over time. The method uses subword recognition, orientation tracking, incremental training, and staged model training to improve sign language recognition accuracy gradually. Memetic optimization eventually produces high-quality recognition models, which lessen translation difficulties and boost sign language communication precision, particularly for sentence-based communication for deaf and hard-of-hearing people.
Through the use of a progression learning approach, the model’s capacity can be effectively increased by progressively adding more learning modules as needed. This enables upscaling to manage large and varied datasets. Identifying the best architectures and hyperparameters to fit expanding datasets is made easier by the supported memetic optimization. For use in the real world, the glove-sensor devices offer a reliable and useful way to record sign language inputs. The adaptable progression learning method allows for the sustainable addition of more recent linguistic data units by various components.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}