3.1. Mereological Completeness
Our initial attempt to construct a map of mereological completeness, or “wholeness”, based on WordNet [
13] holonym-meronym relations among words essentially failed: the quality of the sorted list was poor in the sense that the word order had little to do with the notion of completeness. For example, the terms artery, arm, and car appeared in the top 20 positions of the sorted list, whereas the terms vein, shoulder, and ship appeared in the bottom 20 positions. Examination of the “core” graph and of the very high proportion of map inconsistencies (more than a quarter:
Table 1) suggested that this negative result was ultimately due to word polysemy.
The quality of the completeness map improved dramatically when using holonymy/meronymy relations among senses, as suggested by a reduction of more than two orders of magnitude in the fraction of inconsistencies in the core (down to less than a quarter percent:
Table 1). In this case, the single word-tags of senses are meaningfully ordered in one dimension, as illustrated by the two ends of the corresponding sorted list (
Table 3).
Table 3.
Words sorted by completeness based on senses: two ends of the list.
Table 3.
Words sorted by completeness based on senses: two ends of the list.
| Top of the List | Bottom of the List |
|---|
| 4.56 | Angiospermae | −2.97 | paper_nautilus |
| 4.43 | Dicotyledones | −2.94 | Crayfish |
| 4.31 | Monocotyledones | −2.91 | whisk_fern |
| 4.23 | Spermatophyta | −2.89 | blue_crab |
| 4.17 | Rosidae | −2.88 | Platypus |
| 4.05 | World | −2.85 | Octopus |
| 3.99 | Reptilia | −2.82 | linolenic_acid |
| 3.97 | Dilleniidae | −2.82 | horseshoe_crab |
| 3.94 | Asteridae | −2.78 | Asian_horseshoe_crab |
| 3.88 | Eutheria | −2.71 | Mastoidale |
| 3.79 | Caryophyllidae | −2.71 | Bluepoint |
| 3.75 | Plantae | −2.69 | sea_lamprey |
| 3.74 | Vertebrata | −2.69 | Echidna |
| 3.70 | Commelinidae | −2.68 | passion_fruit |
| 3.67 | Rodentia | −2.68 | Echidna |
| 3.67 | Mammalia | −2.64 | palm_oil |
| 3.62 | Liliidae | −2.61 | Mescaline |
| 3.62 | Arecidae | −2.61 | Swordfish |
| 3.52 | Aves | −2.60 | guinea_hen |
| 3.52 | Magnoliidae | −2.57 | Scrubbird |
Interestingly, the histogram of the sense-based completeness values resembles a bimodal distribution suggesting the presence of two components (
Figure 3A). We thus analyzed separately the graphs of member meronymy or memberonymy (
Figure 3B) and part meronymy or partonymy (
Figure 3C).
Figure 3.
Sense-based mereological completeness map constructed from (A) the overall noun holonymy/meronymy relation; (B) noun member meronymy; and (C) noun partonymy.
Figure 3.
Sense-based mereological completeness map constructed from (A) the overall noun holonymy/meronymy relation; (B) noun member meronymy; and (C) noun partonymy.
The beginning and end of the member meronymy sorted lists were extremely similar to those of the overall completeness map (
Table 3). For example, one extreme included 6 out of 20 words in common as well as several others of the same kind (Squamata, Animalia, Insecta, Passeriformes, Crustacea, Chordata,
etc.). Similarly, the opposite extreme had paper_nautilus and horseshoe_crab in common and many other similar terms (grey_whale, opossum_shrimp, sea_hare, tropical_prawn, sand_cricket,
etc.). Such a stark correspondence is consistent with the intersections of the cores reported in
Table 2: more than 98.8% of the senses in the memberonymy core appear in the overall meronymy core against a mere 0.2% of the senses in the partonymy core. Together, these results suggest that memberonyms dominate the meronymy relation.
At the same time, and for the same reason, the sense-based completeness map obtained from noun partonymy is largely complementary to that obtained from member meronymy. Specifically, the overlap of the two cores is limited to only four senses (
Table 2). Therefore, based on these data, the two kinds of completeness cannot even be tested for statistical independence, because the two parts of the dictionary are essentially disjoint. Nevertheless, the partonymy-based map appears to be meaningful on its own, as illustrated by the term listed at the beginning and the end of the distribution (
Table 4). Note that the term “world” appeared at the top of the list in the completeness map built based on the overall meronymy relation.
Table 4.
Two ends of the sorted list of partonyms.
Table 4.
Two ends of the sorted list of partonyms.
| Top of the List | Bottom of the List |
|---|
| 5.72 | northern_hemisphere | −3.69 | Papeete |
| 5.60 | western_hemisphere | −3.59 | Fingals_Cave |
| 5.37 | West | −3.49 | Grand_Canal |
| 5.17 | America | −3.15 | Saipan |
| 4.95 | eastern_hemisphere | −3.13 | Pago_Pago |
| 4.72 | southern_hemisphere | −3.04 | Apia |
| 4.51 | Latin_America | −3.04 | Vatican |
| 4.31 | Caucasia | −2.95 | Alhambra |
| 4.17 | North_America | −2.93 | Funafuti |
| 3.99 | Eurasia | −2.84 | Port_Louis |
| 3.79 | Laurasia | −2.76 | Ur |
| 3.73 | Strait_of_Gibraltar | −2.76 | Belmont_Park |
| 3.71 | South | −2.73 | Kaaba |
| 3.69 | United_States | −2.71 | Greater_Sunda_Islands |
| 3.57 | Corn_Belt | −2.69 | Lesser_Sunda_Islands |
| 3.53 | West | −2.66 | Malabo |
| 3.52 | South_America | −2.63 | Pearl_Harbor |
| 3.50 | Midwest | −2.61 | Kingstown |
| 3.44 | Middle_East | −2.61 | Tijuana |
| 3.44 | Austronesia | −2.57 | Valletta |
Strikingly, the sense-based completeness map has minimal if any overlap with the antonym/synonym word-based map of value, arousal, freedom, and richness constructed with either WordNet [
13] or Microsoft Word (Microsoft Office 2007 Professional for Windows, Microsoft Corporation, Redmond, WA, USA) (
Table 2). Words with holonyms or meronyms seemingly have no antonyms. Thus, the completeness dimension is by default independent of the antonym-based “sentiment” metrics (at any rate, the Pearson coefficients computed on the 63 common words with the MSE map indicated no statistically significant correlation after multiple-testing correction). In contrast, the completeness map overlaps substantially with the abstractness dimension, as discussed below.
3.2. Abstractness Based on Senses and Verb Troponymy
Switching from words to senses substantially improved the quality of semantic mapping for mereological completeness. The attempted map based on words yielded inconsistent values of the emergent coordinate, with similar words (e.g., vein and artery) found on opposite sides of the distribution. Adoption of senses eliminated the obstacle of polysemy and resulted in a coherent semantic map of completeness as well as a finer distinction between member meronymy and partonymy. At the same time, the requirement of a sizeable connected graph of relations as a starting point for this approach makes weak semantic mapping based on senses untenable in some cases, such as for synonym-antonym relations.
In recent work, we reported the construction of a semantic map of ontological generality (“abstractness”) based on words [
10]. Might the quality of such a map be improved by switching from words to senses in this case? The graph of noun hypernym/hyponyms relations among word senses is of sufficient size for semantic mapping (
Table 1), and the overlap between the two corpora is substantial enough (
Table 2) for allowing a direct comparison between the two approaches. We thus constructed a sense-based noun abstractness map (
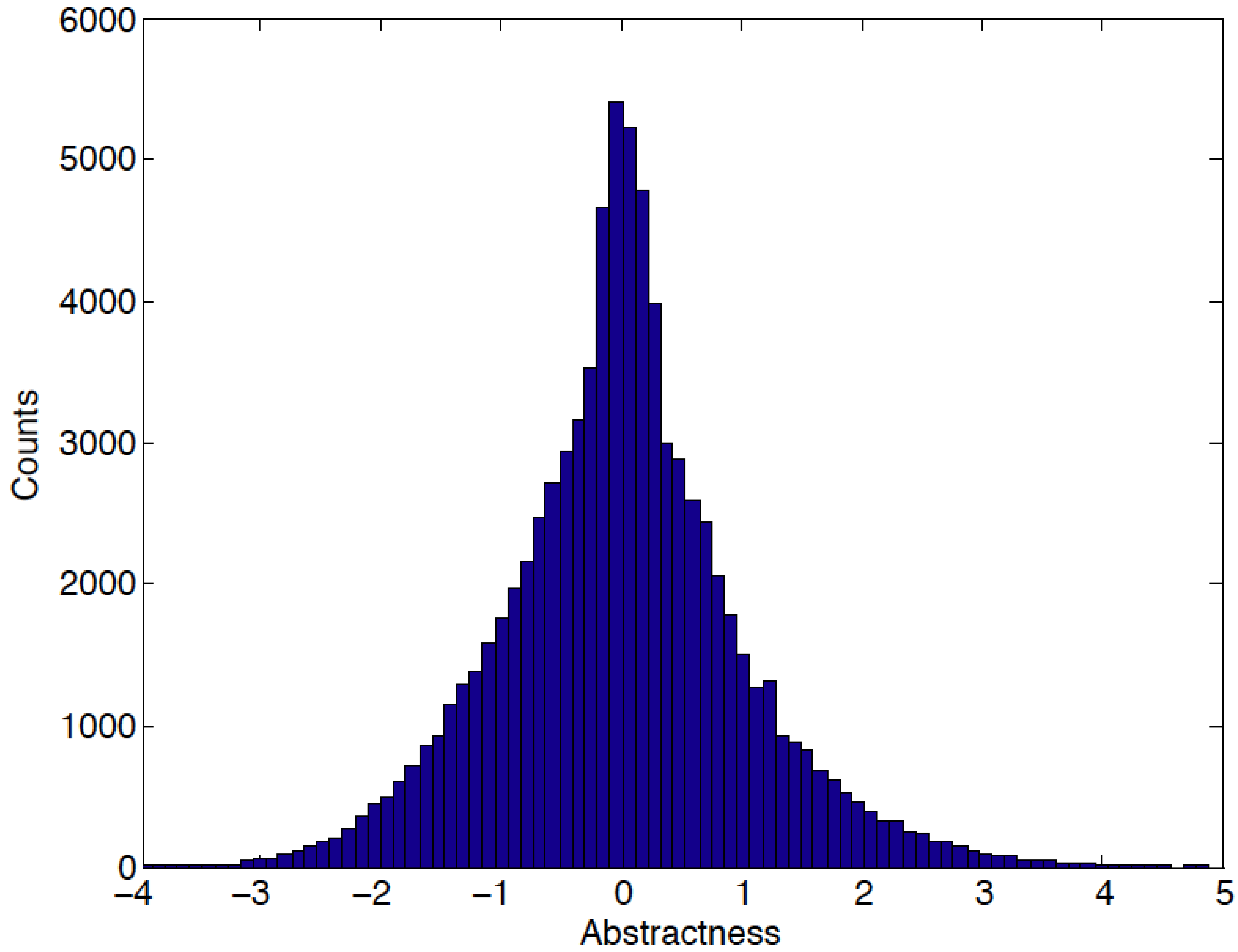
Figure 4).
Figure 4.
Histogram distribution of sense-based noun abstractness.
Figure 4.
Histogram distribution of sense-based noun abstractness.
Results of examination of the two ends of the sorted list of sense nouns are consistent with the expectation of high semantic quality of the map (
Table 5), similar to that reported for word-based abstractness. The word-based abstractness map had been previously shown to be practically orthogonal to the synonym/antonym-based dimensions [
10]. Similarly, the independence between sense-based abstractness and the four principal components of the MSE synonym/antonym map is supported by negligible values of Pearson correlation coefficients:
R = 0.031 with “valence”, 0.0069 with “arousal”, −0.0093 with “freedom”, and 0.0195 with “richness”.
Using word senses instead of words reduces the fraction of inconsistencies on the abstractness map 10-fold (
Table 1), suggesting that the switch to sense-based relationship may be advantageous in this case. At the same time, direct comparison between the word-based and sense-based abstractness maps reveals a more complex story. While the correlation between the two maps (
R = 0.61) is statistically very significant (
p < 10–99), the residual scatter indicates a considerable variance between the two coordinates (
Figure 5).
Table 5.
Sorted lists of sense-based noun abstractness.
Table 5.
Sorted lists of sense-based noun abstractness.
| Top of the list | Bottom of the list |
|---|
| 4.56 | entity | −2.97 | cortina |
| 4.43 | abstraction | −2.94 | attic fan |
| 4.31 | psychological feature | −2.91 | riding mower |
| 4.23 | physical entity | −2.89 | venture capitalism |
| 4.17 | process | −2.88 | axle bar |
| 4.05 | communication | −2.85 | sneak preview |
| 3.99 | instrumentality | −2.82 | Loewi |
| 3.97 | cognition | −2.82 | glorification |
| 3.94 | attribute | −2.78 | secateurs |
| 3.88 | event | −2.71 | purification |
| 3.79 | artifact | −2.71 | shrift |
| 3.75 | act | −2.69 | Chabad |
| 3.74 | aquatic bird | −2.69 | index fund |
| 3.70 | whole | −2.68 | Amish |
| 3.67 | social event | −2.68 | iron cage |
| 3.67 | vertebrate | −2.64 | foresight |
| 3.62 | way | −2.61 | epanodos |
| 3.62 | relation | −2.61 | rehabilitation |
| 3.52 | placental | −2.60 | justification |
| 3.52 | basic cognitive process | −2.57 | flip-flop |
It is thus reasonable to ask which of the two coordinates (word-based or sense-based) provides a better quantification of the meaning of ontological generality when their values are mutually discordant. To answer this question, we sorted the points in the scatter plot of
Figure 5 by their distance from the linear fit (the red line). At least for these “outliers” with the most divergent values between the two maps (
Table 6), the notion of abstractness overall appears to better conform to the map constructed from words than to the map constructed from senses. Comparison of the node degrees of the outliers on the two maps suggests that the inconsistent assignments may be due to the corresponding graph being sparser. For example, the ontological generality of the concepts “theropod” and “think” appear to be more aligned with the values in
X (word-based) than in
Y (sense-based), and the corresponding graph degrees are also greater in
X than in
Y. The node degree in the graph of words is generally greater compared to the graph of senses, but the cases of low or similar degree in the graph of words compared to the degree in the graph of senses seem to correspond to a greater error in
X (abstractness coordinate on the map of words) than in
Y (abstractness coordinate on the map of senses). For instance, the abstractness of the concept “entity”, with the same degree in
X and
Y, is better captured by the value in the sense-based map than in the word-based map.
Figure 5.
Relation among the two maps of abstractness. The red line shows the linear fit (y = 0.61x – 0.052).
Figure 5.
Relation among the two maps of abstractness. The red line shows the linear fit (y = 0.61x – 0.052).
Table 6.
“Outliers”: words sorted by the difference of scaled coordinates in
Figure 5 (the distribution is “sliced” by lines parallel to the red line in
Figure 5). Two ends of the list are shown in the left and right columns.
X and
Y are map coordinates on the map constructed from words and from senses respectively; d
x and d
y are the corresponding degrees of graph nodes.
Table 6.
“Outliers”: words sorted by the difference of scaled coordinates in Figure 5 (the distribution is “sliced” by lines parallel to the red line in Figure 5). Two ends of the list are shown in the left and right columns. X and Y are map coordinates on the map constructed from words and from senses respectively; dx and dy are the corresponding degrees of graph nodes.
| Top of the list | Bottom of the list |
|---|
| X | Y | dx | dy | | X | Y | dx | dy | |
|---|
| −3.41 | 1.68 | 18 | 11 | Theropod | 2.02 | −3.36 | 31 | 1 | Interrupt |
| 4.61 | 6.38 | 3 | 3 | Entity | 2.30 | −2.92 | 18 | 1 | Melody |
| −2.04 | 2.25 | 14 | 8 | Ornithischian | 2.39 | −2.69 | 37 | 1 | Sensation |
| −2.04 | 2.19 | 6 | 3 | Saurischian | 2.00 | −2.86 | 87 | 1 | Divide |
| −4.78 | 0.51 | 5 | 3 | Ornithomimid | 0.46 | −3.78 | 2 | 1 | Foresight |
| −4.78 | 0.50 | 10 | 7 | Maniraptor | 1.56 | −3.08 | 46 | 1 | Meal |
| −4.78 | 0.50 | 2 | 2 | Ankylosaur | 0.70 | −3.59 | 51 | 1 | Pile |
| −4.78 | 0.40 | 4 | 2 | Ceratosaur | 0.17 | −3.89 | 12 | 1 | Glorification |
| −3.41 | 1.07 | 8 | 5 | Hadrosaur | 0.48 | −3.69 | 2 | 1 | Floodgate |
| 2.66 | 4.69 | 55 | 20 | Attribute | 2.65 | −2.34 | 79 | 1 | Think |
| 0.89 | 3.57 | 1 | 1 | Otherworld | 0.90 | −3.38 | 1 | 1 | Countertransference |
| 2.07 | 4.27 | 13 | 6 | Diapsid | −0.51 | −4.23 | 2 | 1 | Cortina |
| −0.47 | 2.68 | 24 | 12 | Elapid | 1.43 | −3.02 | 13 | 1 | Doormat |
| 1.45 | 3.84 | 36 | 10 | Primate | 1.45 | −2.97 | 9 | 1 | Spirituality |
| 1.56 | 3.90 | 3 | 2 | Saurian | 1.24 | −3.08 | 7 | 1 | Insemination |
| −3.41 | 0.86 | 8 | 5 | Ceratopsian | 1.83 | −2.70 | 50 | 1 | Example |
| −0.67 | 2.53 | 14 | 8 | Dinosaur | 2.36 | −2.36 | 22 | 1 | Impedimenta |
| 0.44 | 3.18 | 25 | 3 | Monkey | 0.86 | −3.21 | 8 | 1 | Stooper |
| 1.83 | 4.02 | 3 | 3 | Waterfowl | 2.34 | −2.26 | 13 | 1 | Assignation |
| −2.17 | 1.54 | 9 | 3 | Dichromacy | −0.15 | −3.75 | 14 | 1 | Rehabilitation |
These results indicate some usefulness of polysemy for mapping abstractness. More precisely, these examples demonstrate a tradeoff between homonymy and graph connectivity. In fact, when both maps are combined, the quality improves further, at least judging by the tails of the lists sorted by the orthogonal to the red line slicing of
Figure 5: (Entity, Cognition, Vertebrate, Ability, Mammal, Concept, Trait, Artifact, Thinking, Message, Attribute, Happening, Equipment, Reptile, Assets, know-how, Non-accomplishment, Emotion, Food, Placental) from one end; and (Velociraptor, Oviraptorid, Utahraptor, Dromaeosaur, Coelophysis, Deinonychus, Struthiomimus, Deinocheirus, Regain, Apatosaur, Barosaur, Tritanopia, Tetartanopia, Plasmablast, Pachycephalosaur, Fructose, Gerund, Secateurs, Triceratops, Psittacosaur) from the opposite end. However, the pool of terms mapped in this case is limited to the subset that is common to both maps.
It should be remarked that, because senses represent unique meanings, their semantic relationships yield segregated maps for different parts of speech. In particular, the sense-based abstractness map analyzed above refers selectively to nouns. In contrast, the word-based abstractness map [
10] includes both nouns and verbs. We thus also constructed a sense-based verb abstractness map, from the verb “is-a” (troponymy) relationship (e.g., punching “is-a” kind of hitting). The total numbers of nodes and edges in the verb troponymy graph are respectively 13,563 and 13,256, resulting in 7621 verbs in the core. The two ends of the sorted list confirmed the expected ontological generality ranking for verbs (
Table 7).
The sense-based verb abstractness map was also uni-dimensional and its comparison with the word-based map (
Figure 6) paralleled the analysis reported above for sense-based noun abstractness.
Table 7.
Two ends of the sense list of sorted by troponymy.
Table 7.
Two ends of the sense list of sorted by troponymy.
| X | Top of the list | X | Bottom of the list |
|---|
| 4.01 | Transfer | −3.71 | talk_shop |
| 3.89 | Take | −3.64 | Refocus |
| 3.40 | Touch | −3.62 | Embargo |
| 3.30 | Connect | −3.60 | Gore |
| 3.29 | Make | −3.39 | Rat |
| 3.20 | Interact | −3.36 | Ligate |
| 3.18 | Communicate | −3.28 | Descant |
| 3.14 | Cause | −3.21 | Ferret |
| 3.12 | Move | −3.17 | Tug |
| 3.11 | Give | −3.05 | Din |
| 3.07 | Tell | −3.04 | Distend |
| 3.07 | change_shape | −3.04 | Rise |
| 3.07 | Inform | −3.01 | Evangelize |
| 3.05 | create_by_mental_act | −3.00 | Caponize |
| 2.99 | Get | −2.96 | Tampon |
| 2.99 | Change | −2.93 | trouble_oneself |
| 2.98 | Pass | −2.91 | Slant |
| 2.96 | create_from_raw_material | −2.90 | slam-dunk |
| 2.85 | change_magnitude | −2.90 | Pooch |
| 2.81 | Travel | −2.89 | Streamline |
Figure 6.
(
A) Verb troponymy map constructed from word senses based on WordNet 3.1 [
13], represented by a histogram; (
B) Troponymy of verb senses
vs. abstractness of words. Red line shows linear fits (
y = 0.37
x + 0.8).
Figure 6.
(
A) Verb troponymy map constructed from word senses based on WordNet 3.1 [
13], represented by a histogram; (
B) Troponymy of verb senses
vs. abstractness of words. Red line shows linear fits (
y = 0.37
x + 0.8).
Completeness and abstractness turn out to be essentially independent semantic coordinates. Examples of words that discriminate the two dimensions, partially borrowed from the sorted lists, include: Northern hemisphere (whole, concrete), world (whole, abstract), part (part, abstract), whisker (part, concrete). The size of the overlap of two cores (10,903 words) allows quantification of the linear independence of abstractness and completeness with good statistical significance (
Figure 7A;
R2 < 0.013). The same appear to apply to the relationship between abstractness and the two distinct kinds of completeness corresponding to member meronymy and partonymy, respectively (
Figure 7B,C). However, it appears that memberonymy is more similar to abstractness, compared to partonymy (
Table 3,
Table 4 and
Table 5, respectively).
Figure 7.
(A) Abstractness and completeness dimensions are linearly independent semantic dimensions, with the Pearson correlation R = 0.113; (B,C) Memberonymy and partonymy separated.
Figure 7.
(A) Abstractness and completeness dimensions are linearly independent semantic dimensions, with the Pearson correlation R = 0.113; (B,C) Memberonymy and partonymy separated.
3.3. Analysis of Text Corpora
Lastly, we utilized the map data to compute the mean values of abstractness, completeness, valence, and arousal of two categories of recent articles from the Journal of Neuroscience: mini-reviews and brief communications (
Figure 8). On average, relative to brief communications, mini-reviews tend to be more exciting, more positive, at a more general level, and more comprehensive. Interestingly, the strongest effect size was observed in the new “completeness” dimension (note the equal scales in all three panels of
Figure 8). This suggests that newly identified semantic dimensions may be directly reducible to practical applications.
Figure 8.
Semantic measures of documents from the Journal of Neuroscience. Filled ovals show the means with standard errors. Blue: Brief communications; Red: Mini-reviews. The numbers of words for the two types of documents for each measure are, respectively: Valence, 33,971 and 35,787; Arousal, 33,971 and 35,787; Freedom, 33,971 and 35,787; Richness, 33,971 and 35,787; Abstractness, 40,255 and 38,156; Completeness, 1453 and 1717. The largest differences between the two kinds of documents are in Completeness, Abstractness, and Valence.
Figure 8.
Semantic measures of documents from the Journal of Neuroscience. Filled ovals show the means with standard errors. Blue: Brief communications; Red: Mini-reviews. The numbers of words for the two types of documents for each measure are, respectively: Valence, 33,971 and 35,787; Arousal, 33,971 and 35,787; Freedom, 33,971 and 35,787; Richness, 33,971 and 35,787; Abstractness, 40,255 and 38,156; Completeness, 1453 and 1717. The largest differences between the two kinds of documents are in Completeness, Abstractness, and Valence.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







