
The Impact of Symmetry: Explaining Contradictory Results Concerning Working Memory, Reasoning, and Complex Problem Solving

Abstract
:1. Introduction
1.1. Symmetry between Different Studies
1.2. Contradictory Results on the Relation between Working Memory, Reasoning, and Complex Problem Solving
1.3. The Relation between Working Memory and Reasoning
1.4. Complex Problem Solving
1.5. Hypotheses
2. Materials and Methods
2.1. Participants
2.2. Instruments and Procedure
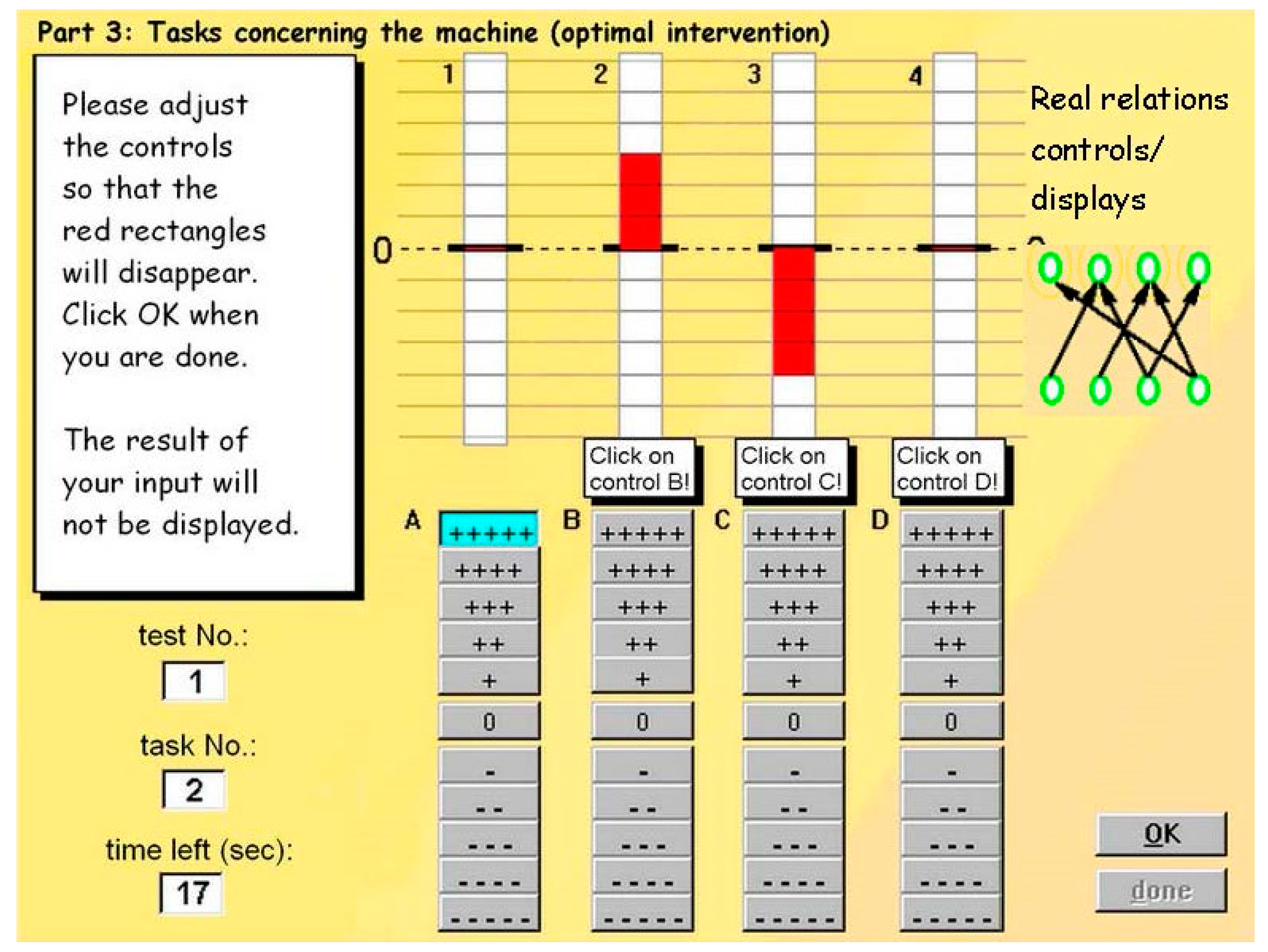
2.2.1. Multiflux
2.2.2. I-S-T 2000-R
2.2.3. Working Memory Tests
2.3. Statistical Analysis
2.3.1. Path Analysis
2.3.2. Models
3. Results
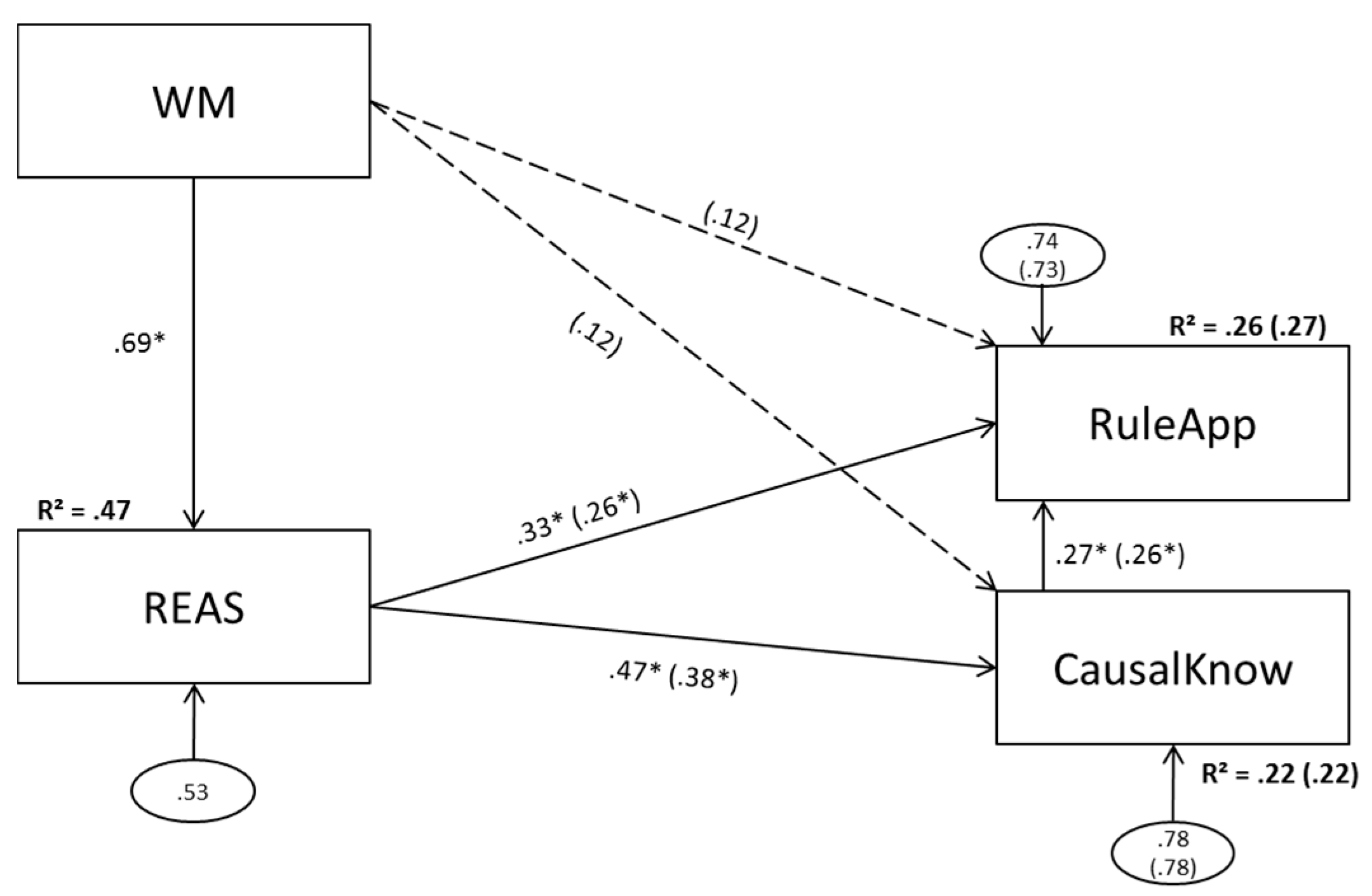
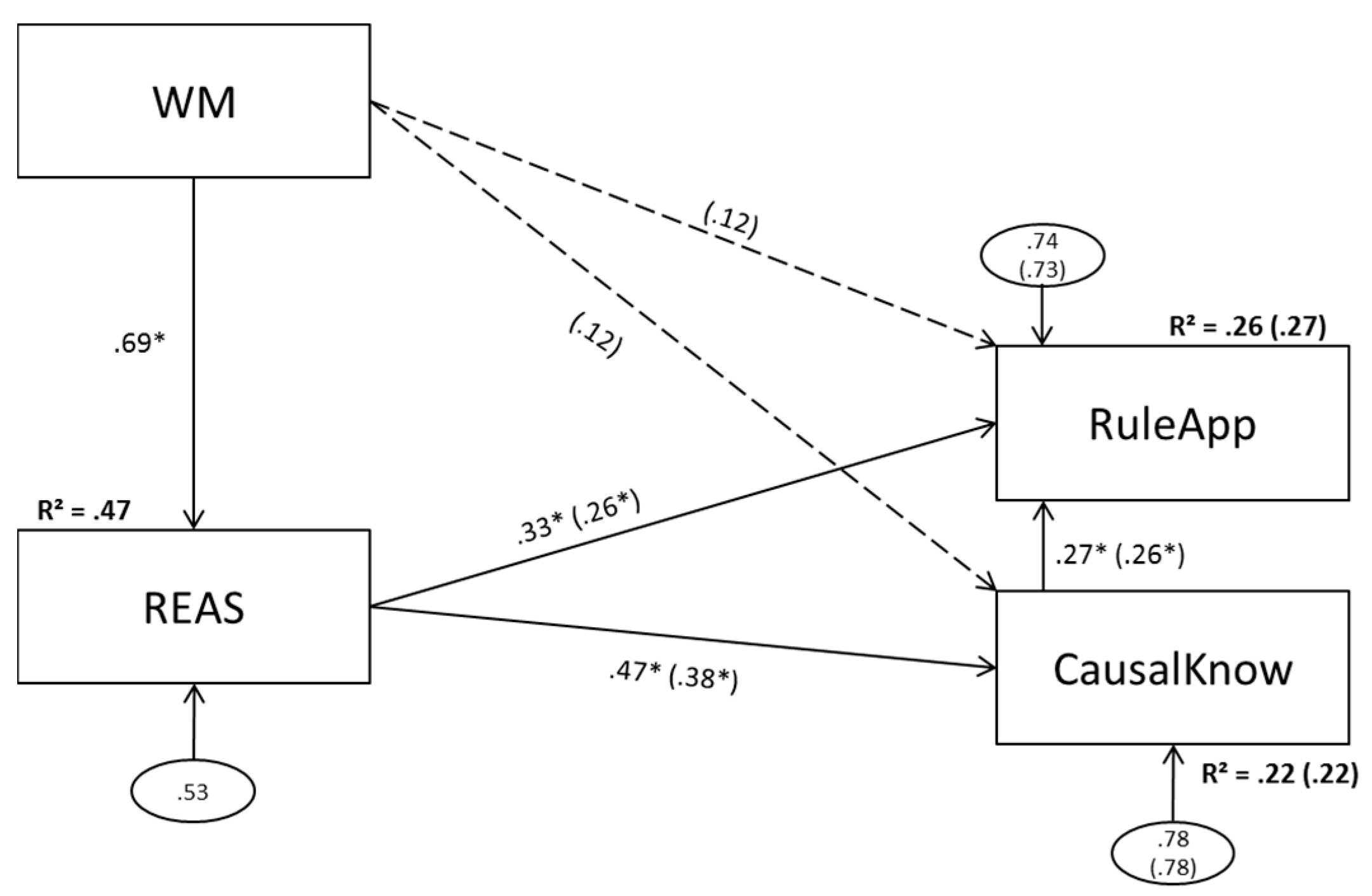
3.1. Model 1 (Aggregated Predictors)
3.1.1. Model 1a (No Direct Effect of Working Memory Scores on Complex Problem Solving)
3.1.2. Model 1b (Direct Effects of Working Memory Scores on Complex Problem Solving)
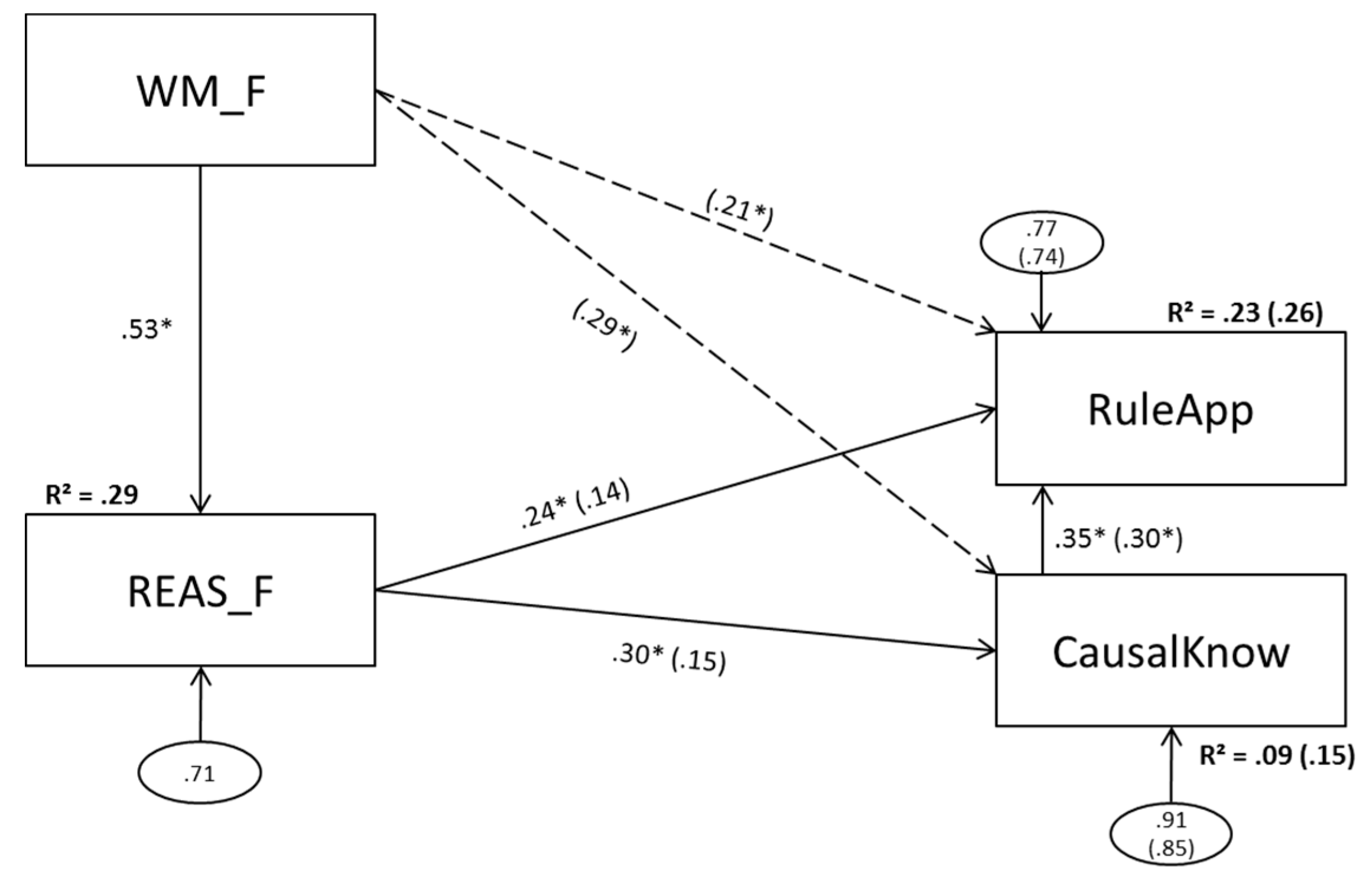
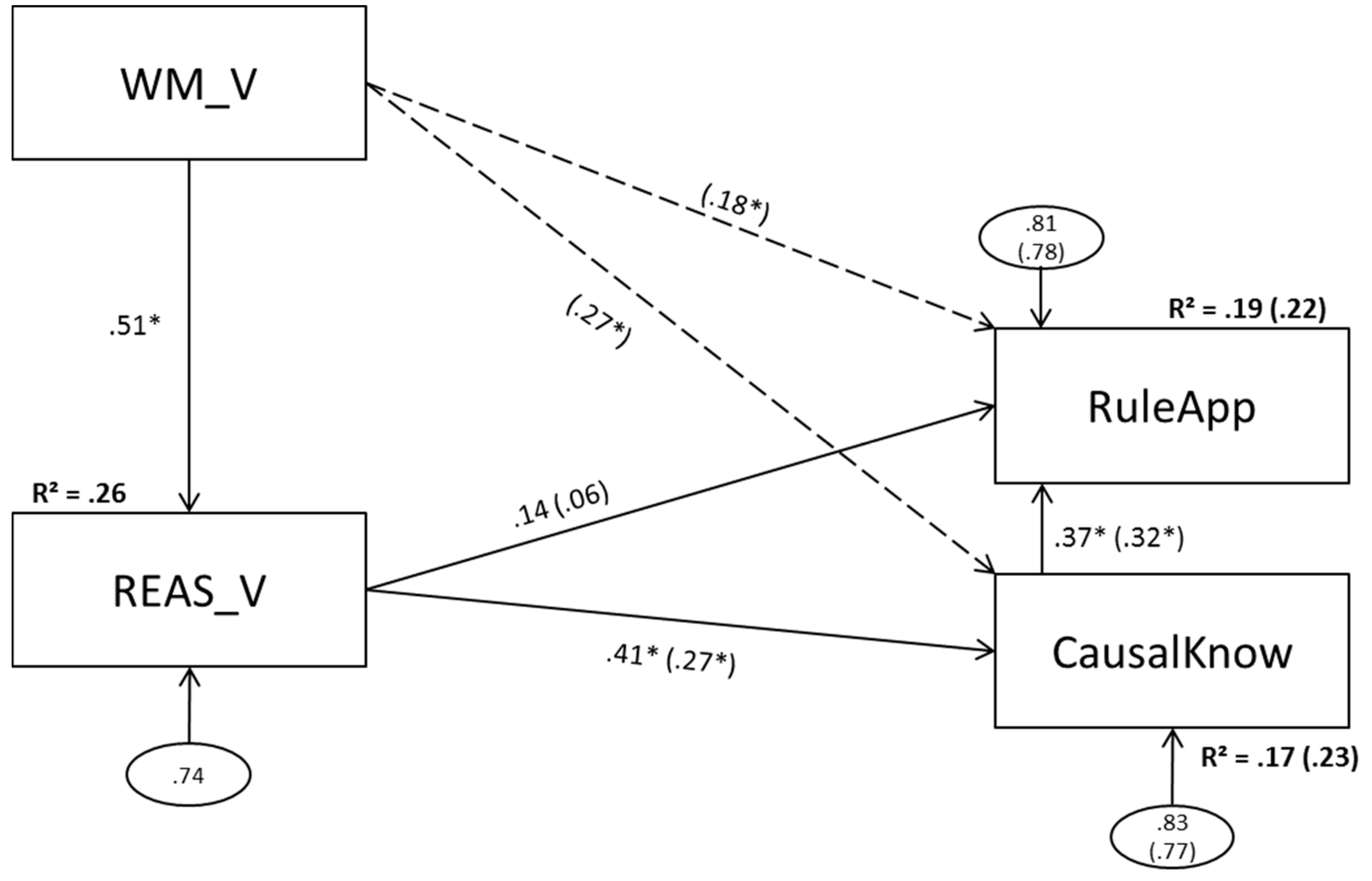
3.2. Model 2 (Figural Predictors)
3.2.1. Model 2a (No Direct Effect of Figural Working Memory Scores on Complex Problem Solving)
3.2.2. Model 2b (Direct Effects of Figural Working Memory Scores on Complex Problem Solving)
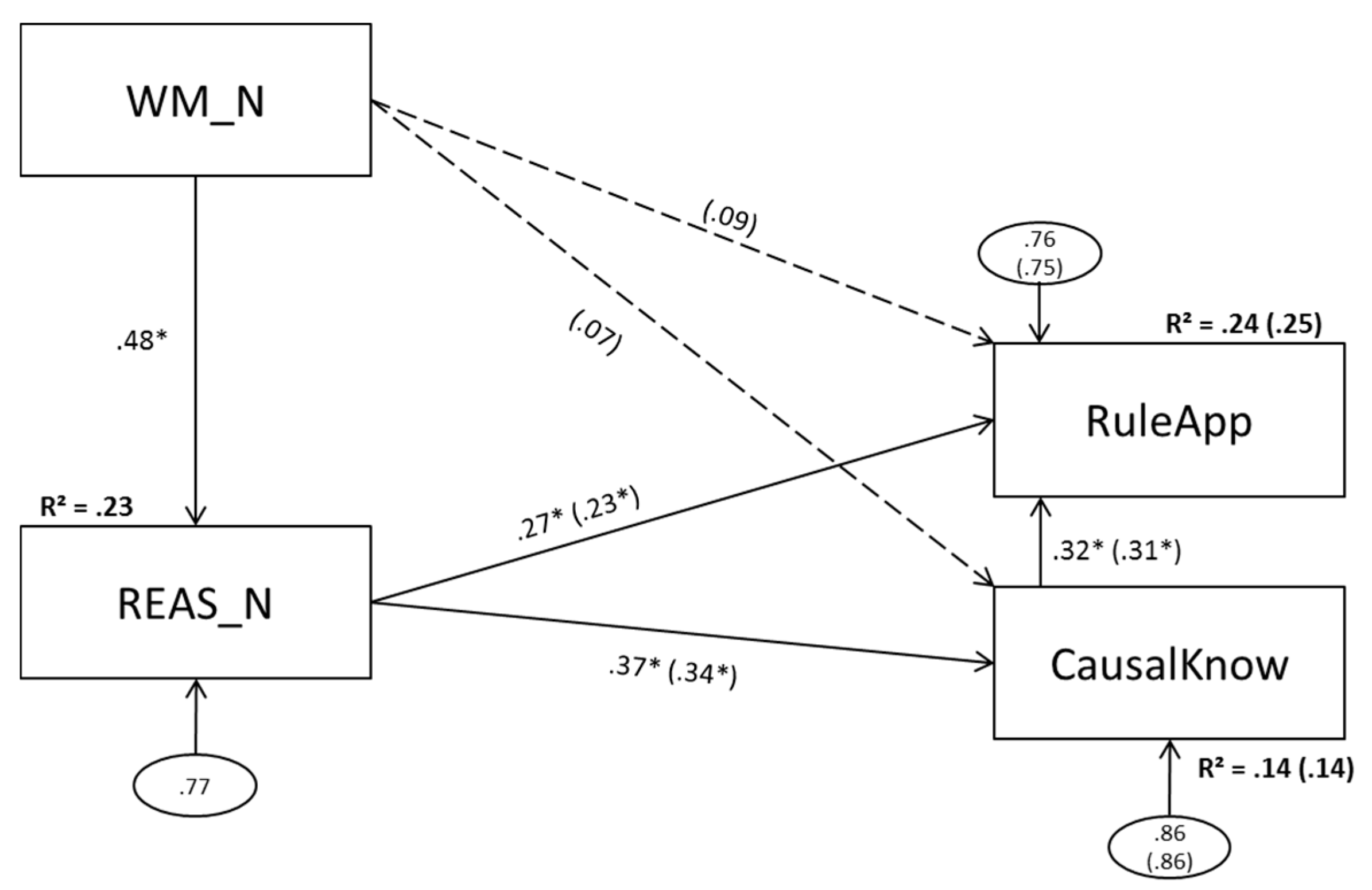
3.3. Model 3 (Numerical Predictors)
3.3.1. Model 2a (No Direct Effect of Numerical Working Memory Scores on Complex Problem Solving)
3.3.2. Model 3b (Direct Effects of Numerical Working Memory Scores on Complex Problem Solving)
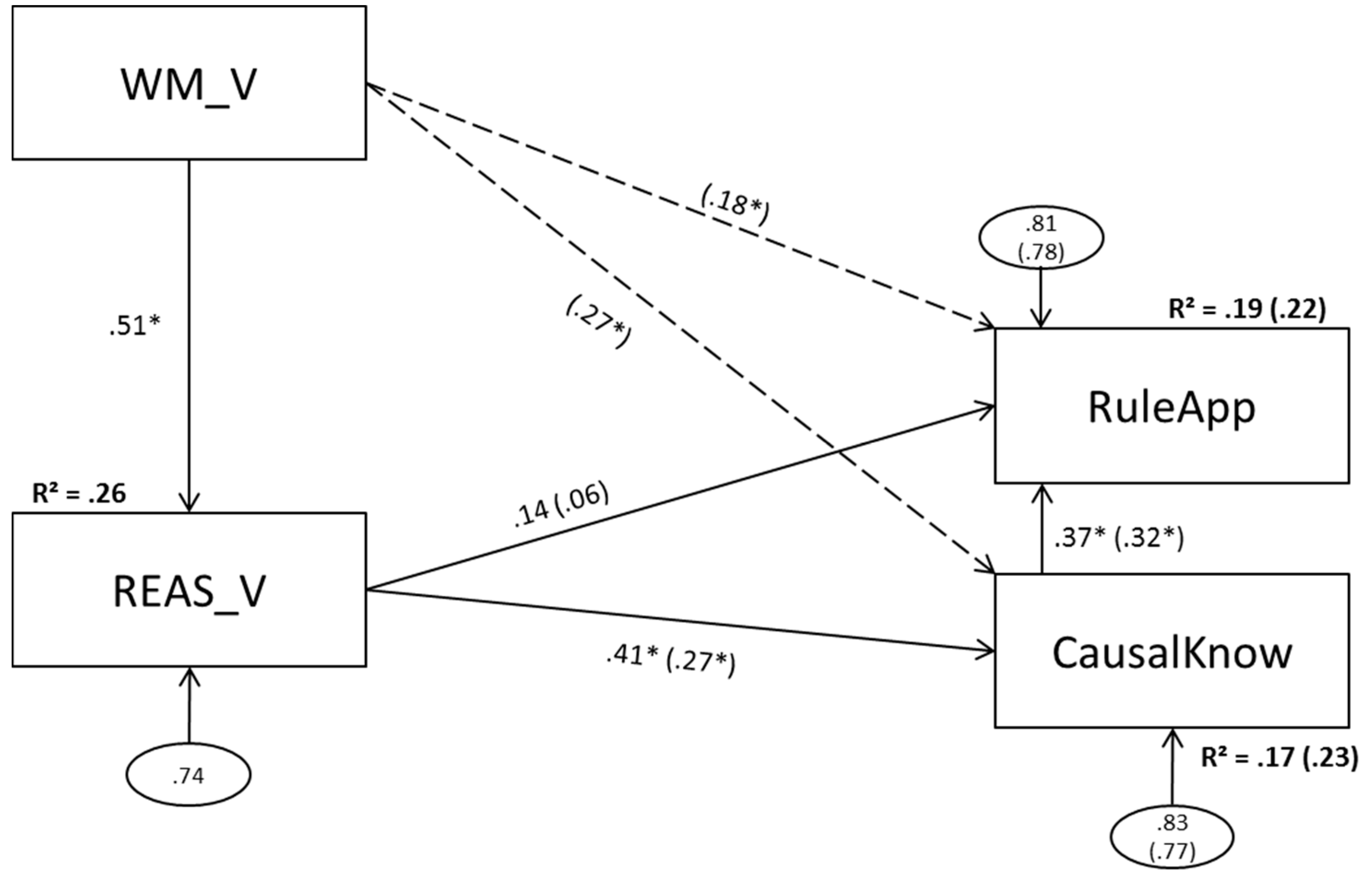
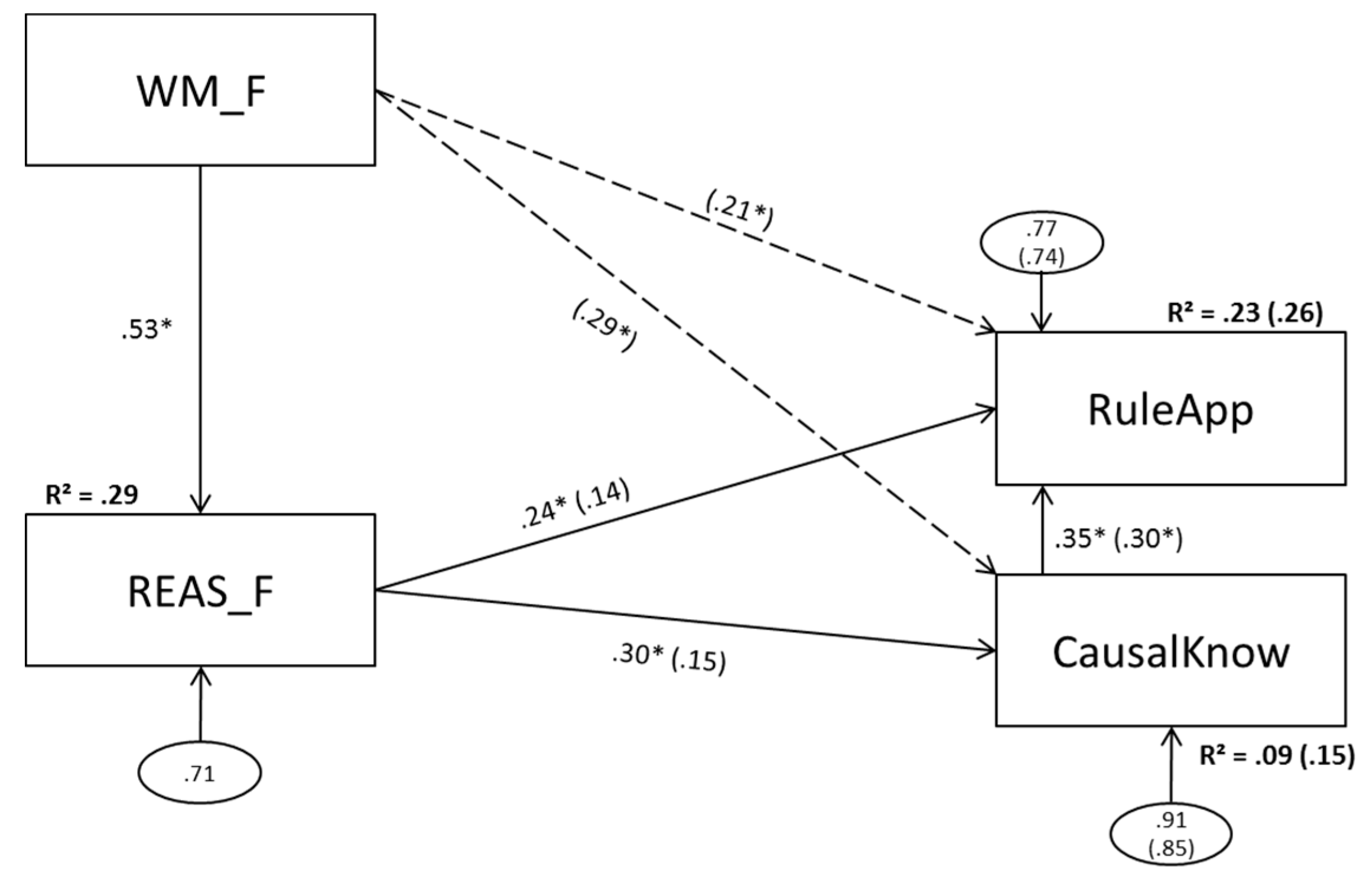
3.4. Model 4 (Verbal Predictors)
3.4.1. Model 4a (No Direct Effect of Verbal Working Memory Scores on Complex Problem Solving)
3.4.2. Model 4b (Direct Effects of Verbal Working Memory Scores on Complex Problem Solving)
4. Discussion
4.1. Main Results
4.2. Symmetry as a Central Factor for the Comparability of Different Studies
4.3. Implications for the Discriminant Validity of Reasoning and Working Memory
4.4. Limitations and Perspectives for Further Research
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wittmann, W.W.; Süß, H.-M. Investigating the paths between working memory, intelligence, knowledge, and complex problem solving performances via Brunswik symmetry. In Learning and Individual Differences: Process, Trait, and Content Determinants; Ackerman, P.L., Kyllonen, P.C., Roberts, R.D., Eds.; American Psychological Association: Washington, DC, USA, 1999; pp. 77–108. [Google Scholar]
- Brunswik, E. The conceptual framework of psychology. Psychol. Bull. 1952, 49, 654–656. [Google Scholar]
- Nesselroade, J.R.; McArdle, J.J. On the mismatching of levels of abstraction in mathematical-statistical model fitting. In Biological and Neuropsychological Mechanisms: Life-Span Developmental Psychology; Reese, H.W., Franzen, M.D., Eds.; Lawrence Erlbaum Associates, Inc.: Hillsdale, NJ, USA, 1997; pp. 23–49. [Google Scholar]
- Wittmann, W.W. Multivariate reliability theory: Principles of symmetry and successful validation strategies. In Handbook of Multivariate Experimental Psychology, 2nd ed.; Perspectives on Individual Differences; Nesselroade, J.R., Cattell, R.B., Eds.; Plenum Press: New York, NY, USA, 1988; pp. 505–560. [Google Scholar]
- Bühner, M.; Krumm, S.; Ziegler, M.; Plücken, T. Cognitive Abilities and Their Interplay. J. Individ. Differ. 2006, 27, 57–72. [Google Scholar] [CrossRef]
- Bühner, M.; Kröner, S.; Ziegler, M. Working memory, visual-spatial-intelligence and their relationship to problem solving. Intelligence 2008, 36, 672–680. [Google Scholar] [CrossRef]
- Greiff, S.; Krkovic, K.; Hautamäki, J. The Prediction of Problem Solving Assessed via Microworlds: A Study on the Relative Relevance of Fluid Reasoning and Working Memory. Eur. J. Psychol. Assess. 2016, 32, 298–306. [Google Scholar] [CrossRef]
- Bakker, M.; van Dijk, A.; Wicherts, J.M. The rules of the game called psychological science. Perspect. Psychol. Sci. 2012, 7, 543–554. [Google Scholar] [CrossRef] [PubMed]
- Fanelli, D. Do pressures to publish increase scientists’ bias? An empirical support from US States Data. PLoS ONE 2010, 5, e10271. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, C.J.; Heene, M. A Vast Graveyard of Undead Theories: Publication Bias and Psychological Science’s Aversion to the Null. Perspect. Psychol. Sci. J. Assoc. Psychol. Sci. 2012, 7, 555–561. [Google Scholar] [CrossRef] [PubMed]
- Wittmann, W.W.; Hattrup, K. The relationship between performance in dynamic systems and intelligence. Syst. Res. Behav. Sci. 2004, 21, 393–409. [Google Scholar] [CrossRef]
- McGrew, K.S. CHC Theory and the Human Cognitive Abilities Project: Standing on the Shoulders of the Giants of Psychometric Intelligence Research; Elsevier: San Diego, CA, USA, 2009. [Google Scholar]
- Kröner, S.; Plass, J.L.; Leutner, D. Intelligence assessment with computer simulations. Intelligence 2005, 33, 347–368. [Google Scholar] [CrossRef]
- Fung, W.; Swanson, H.L. Working memory components that predict word problem solving: Is it merely a function of reading, calculation, and fluid intelligence? Mem. Cogniti. 2017. [Google Scholar] [CrossRef] [PubMed]
- Meissner, A.; Greiff, S.; Frischkorn, G.T.; Steinmayr, R. Predicting Complex Problem Solving and school grades with working memory and ability self-concept. Learn. Individ. Differ. 2016, 49, 323–331. [Google Scholar] [CrossRef]
- Kretzschmar, A.; Neubert, J.C.; Wüstenberg, S.; Greiff, S. Construct validity of complex problem solving: A comprehensive view on different facets of intelligence and school grades. Intelligence 2016, 54, 55–69. [Google Scholar] [CrossRef]
- Bühner, M.; Krumm, S.; Pick, M. Reasoning = working memory ≠ attention. Intelligence 2005, 33, 251–272. [Google Scholar] [CrossRef]
- Kyllonen, P.C. g: Knowledge, speed, strategies, or working-memory capacity? A systems perspective. In The General Factor of Intelligence: How General Is It; Lawrence Erlbaum Associates Publishers: Mahwah, NJ, USA, 2002; pp. 415–445. [Google Scholar]
- Schweizer, K.; Moosbrugger, H. Attention and working memory as predictors of intelligence. Intelligence 2004, 32, 329–347. [Google Scholar] [CrossRef]
- Süß, H.-M.; Oberauer, K.; Wittmann, W.W.; Wilhelm, O.; Schulze, R. Working-memory capacity explains reasoning ability—And a little bit more. Intelligence 2002, 30, 261–288. [Google Scholar] [CrossRef]
- Ackerman, P.L.; Beier, M.E.; Boyle, M.O. Working Memory and Intelligence: The Same or Different Constructs? Psychol. Bull. 2005, 131, 30–60. [Google Scholar] [CrossRef] [PubMed]
- Engle, R.W.; Tuholski, S.W.; Laughlin, J.E.; Conway, A.R.A. Working memory, short-term memory, and general fluid intelligence: A latent-variable approach. J. Exp. Psychol. Gen. 1999, 128, 309–331. [Google Scholar] [CrossRef] [PubMed]
- Schweizer, K. Investigating the relationship of working memory tasks and fluid intelligence tests by means of the fixed-links model in considering the impurity problem. Intelligence 2007, 35, 591–604. [Google Scholar] [CrossRef]
- Colom, R.; Rebollo, I.; Palacios, A.; Juan-Espinosa, M.; Kyllonen, P.C. Working memory is (almost) perfectly predicted by g. Intelligence 2004, 32, 277–296. [Google Scholar] [CrossRef]
- Kyllonen, P.C. Is working memory capacity Spearman’s g. In Human Abilities: Their Nature and Measurement; Lawrence Erlbaum Associates, Inc.: Hillsdale, NJ, USA, 1996; pp. 49–75. [Google Scholar]
- Kyllonen, P.C.; Christal, R.E. Reasoning ability is (little more than) working-memory capacity? Intelligence 1990, 14, 389–433. [Google Scholar] [CrossRef]
- Kane, M.J.; Hambrick, D.Z.; Conway, A.R.A. Working memory capacity and fluid intelligence are strongly related constructs: Comment on Ackerman, Beier, and Boyle (2005). Psychol. Bull. 2005, 131, 66–71. [Google Scholar] [CrossRef] [PubMed]
- Oberauer, K.; Schulze, R.; Wilhelm, O.; Süß, H.-M. Working memory and intelligence—Their correlation and their relation: Comment on Ackerman, Beier, and Boyle (2005). Psychol. Bull. 2005, 131, 61–65. [Google Scholar] [CrossRef] [PubMed]
- Funke, J. Complex problem solving. In Encyclopedia of the Sciences of Learning; Seel, N.M., Ed.; Springer Science Business Media: Berlin, Germany, 2011. [Google Scholar]
- Wüstenberg, S.; Greiff, S.; Funke, J. Complex problem solving: More than reasoning? Intelligence 2012, 40, 1–14. [Google Scholar] [CrossRef]
- Dörner, D.; Bick, T. Lohhausen: Vom Umgang mit Unbestimmtheit und Komplexität. [Lohhausen: On dealing with Uncertainty and Complexity]; Verlag Hans Huber: Bern, Switzerland, 1983. [Google Scholar]
- Funke, J. Einige Bemerkungen zu Problemen der Problemlöseforschung oder: Ist Testintelligenz doch ein Prädiktor? Diagnostica 1983, 29, 283–302. [Google Scholar]
- Kröner, S. Intelligenzdiagnostik per Computersimulation [Intelligence Assessment with Computer Simulations]; Waxmann Verlag: Münster, Germany, 2001. [Google Scholar]
- Süß, H.-M. Intelligenz, Wissen und Problemlösen: Kognitive Voraussetzungen für Erfolgreiches Handeln bei Computersimulierten Problemen; Hogrefe: Göttingen, Germany, 1996. [Google Scholar]
- Lotz, C.; Sparfeldt, J.R.; Greiff, S. Complex problem solving in educational contexts—Still something beyond a “good g”? Intelligence 2016, 59, 127–138. [Google Scholar] [CrossRef]
- Funke, J. Human Problem Solving in 2012. J. Probl. Solving 2013, 6, 3. [Google Scholar] [CrossRef]
- Amthauer, R.; Brocke, B.; Liepmann, D.; Beauducel, A. IST 2000R; Hogrefe: Göttingen, Germany, 2001. [Google Scholar]
- Oberauer, K.; Süß, H.-M.; Wilhelm, O.; Wittman, W.W. The multiple faces of working memory: Storage, processing, supervision, and coordination. Intelligence 2003, 31, 167–193. [Google Scholar] [CrossRef]
- Greiff, S.; Funke, J. Systematische Erforschung komplexer Problemlösefähigkeit anhand minimal komplexer Systeme. Projekt Dynamisches Problemlösen. Z. Pädagogik 2010, 56, 216–227. [Google Scholar]
- Greiff, S.; Wüstenberg, S.; Holt, D.V.; Goldhammer, F.; Funke, J. Computer-based assessment of Complex Problem Solving: Concept, implementation, and application. Educ. Technol. Res. Dev. 2013, 61, 407–421. [Google Scholar] [CrossRef]
- Hu, L.; Bentler, P.M. Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Struct. Equ. Model. Multidiscip. J. 1999, 6, 1–55. [Google Scholar] [CrossRef]
- MacCallum, R.C.; Browne, M.W.; Sugawara, H.M. Power analysis and determination of sample size for covariance structure modeling. Psychol. Methods 1996, 1, 130–149. [Google Scholar] [CrossRef]
- Required Sample Size and Power for SEM|Timo Gnambs. Available online: http://timo.gnambs.at/en/scripts/powerforsem (accessed on 10 March 2017).
- Zinbarg, R.E.; Yovel, I.; Revelle, W.; McDonald, R.P. Estimating generalizability to a latent variable common to all of a scale’s indicators: A comparison of estimators for ωh. Appl. Psychol. Meas. 2006, 30, 121–144. [Google Scholar] [CrossRef]
- Yuan, K.-H.; Marshall, L.L.; Bentler, P.M. Assessing the effect of model misspecifications on parameter estimates in structural equation models. Sociol. Methodol. 2003, 33, 241–265. [Google Scholar] [CrossRef]
- Hilbert, S.; Nakagawa, T.T.; Puci, P.; Zech, A.; Bühner, M. The Digit Span Backwards Task: Verbal and Visual Cognitive Strategies in Working Memory Assessment. Eur. J. Psychol. Assess. 2015, 1, 1–7. [Google Scholar] [CrossRef]
- Vickers, D.; Mayo, T.; Heitmann, M.; Lee, M.D.; Hughes, P. Intelligence and individual differences in performance on three types of visually presented optimisation problems. Person. Individ. Differ. 2004, 36, 1059–1071. [Google Scholar] [CrossRef]
- Wittmann, W.W.; Matt, G.E. Aggregation und Symmetrie. Grundlagen einer multivariaten Reliabilitäts-und Validitätstheorie, dargestellt am Beispiel der differentiellen Validität des Berliner Intelligenzstrukturmodells. Diagnostica 1986, 32, 309–329. [Google Scholar]
- Oberauer, K.; Süß, H.-M.; Schulze, R.; Wittman, W.W. Working memory capacity: Facets of a cognitive ability construct. Person. Individ. Differ. 2000, 29, 1045. [Google Scholar] [CrossRef]
- Jäger, A.O. Mehrmodale Klassifikation von Intelligenzleistungen: Experimentell kontrollierte Weiterentwicklung eines deskriptiven Intelligenzstrukturmodells. Diagnostica 1982, 28, 195–225. [Google Scholar]
- Hilbert, S.; Schwaighofer, M.; Zech, A.; Sarubin, N.; Arendasy, M.; Bühner, M. Working memory tasks train working memory but not reasoning: A material-and operation-specific investigation of transfer from working memory practice. Intelligence 2017, 61, 102–114. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tests Scores | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| Problem Solving | |||||||||
| (1) Causal Knowledge | |||||||||
| (2) Rule Application | .42 | ||||||||
| Working Memory | |||||||||
| (3) Working Memory | .39 | .39 | |||||||
| (4) Working Memory (Figural) | .37 | .40 | .90 | ||||||
| (5) Working Memory (Numerical) | .23 | .28 | .76 | .56 | |||||
| (6) Working Memory (Verbal) | .41 | .35 | .83 | .61 | .53 | ||||
| Reasoning | |||||||||
| (7) Reasoning | .47 | .46 | .69 | .66 | .48 | .58 | |||
| (8) Figural Reasoning | .30 | .35 | .51 | .53 | .38 | .33 | .79 | ||
| (9) Numerical Reasoning | .37 | .39 | .62 | .59 | .48 | .50 | .86 | .52 | |
| (10) Verbal Reasoning | .41 | .29 | .41 | .35 | .18 | .52 | .58 | .21 | .32 |
| Tests Scores | M (Range) | SD | n | rtt |
|---|---|---|---|---|
| Problem Solving | ||||
| Causal Knowledge | 53.16 (26–64) | 9.17 | 124 | ω = .80 b |
| Rule Application | 5.86 (0–16) | 4.37 | 124 | ω = .72 b |
| Working memory | ||||
| Working Memory | 1.14 (0.23–1.75) | 0.27 | 124 | ω = .81 b |
| Working Memory (Figural) | 0.59 (−0.53–1.19) | 0.32 | 124 | ω = .83 b |
| Working Memory (Numerical) | 2.17 (1.38–2.82) | 0.28 | 124 | ω = .31 b |
| Working Memory (Verbal) | 1.54 (−0.11–2.30) | 0.37 | 124 | ω = .45 b |
| Reasoning | ||||
| Reasoning | 114.47 * (73–154) | 18.58 | 124 | ω = .93 a |
| Reasoning (Figural) | 33.75 * (14–55) | 8.48 | 124 | α = .88 a |
| Reasoning (Numerical) | 40.08 * (21–58) | 9.77 | 124 | α = .94 a |
| Reasoning (Verbal) | 40.64 * (11–52) | 5.92 | 124 | α = .74 a |
| Tests Scores | χ2 [df] | p | RMSEA [CI90] | Achieved Power RMSEA a | CFI | SRMR |
|---|---|---|---|---|---|---|
| Model 1a (aggregated) | 2.30 [2] | .317 | .035 [.000; .187] | .09 | .998 | .031 |
| Model 2a (figural) | 13.10 [2] | .001 | .213 [.114; .330] | .09 | .879 | .094 |
| Model 3a (numerical) | 1.62 [2] | .443 | .000 [.000; .169] | .09 | .999 | .033 |
| Model 4a (verbal) | 11.88 [2] | .003 | .201 [.102; .318] | .09 | .893 | .089 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zech, A.; Bühner, M.; Kröner, S.; Heene, M.; Hilbert, S. The Impact of Symmetry: Explaining Contradictory Results Concerning Working Memory, Reasoning, and Complex Problem Solving. J. Intell. 2017, 5, 22. https://doi.org/10.3390/jintelligence5020022
Zech A, Bühner M, Kröner S, Heene M, Hilbert S. The Impact of Symmetry: Explaining Contradictory Results Concerning Working Memory, Reasoning, and Complex Problem Solving. Journal of Intelligence. 2017; 5(2):22. https://doi.org/10.3390/jintelligence5020022
Chicago/Turabian StyleZech, Alexandra, Markus Bühner, Stephan Kröner, Moritz Heene, and Sven Hilbert. 2017. "The Impact of Symmetry: Explaining Contradictory Results Concerning Working Memory, Reasoning, and Complex Problem Solving" Journal of Intelligence 5, no. 2: 22. https://doi.org/10.3390/jintelligence5020022
APA StyleZech, A., Bühner, M., Kröner, S., Heene, M., & Hilbert, S. (2017). The Impact of Symmetry: Explaining Contradictory Results Concerning Working Memory, Reasoning, and Complex Problem Solving. Journal of Intelligence, 5(2), 22. https://doi.org/10.3390/jintelligence5020022