
Efficient ROS-Compliant CPU-iGPU Communication on Embedded Platforms

 ,
,  ,
,  ,
,  , and
, and
Abstract
1. Introduction
2. Related Work
3. CPU-iGPU Communication and ROS Protocols
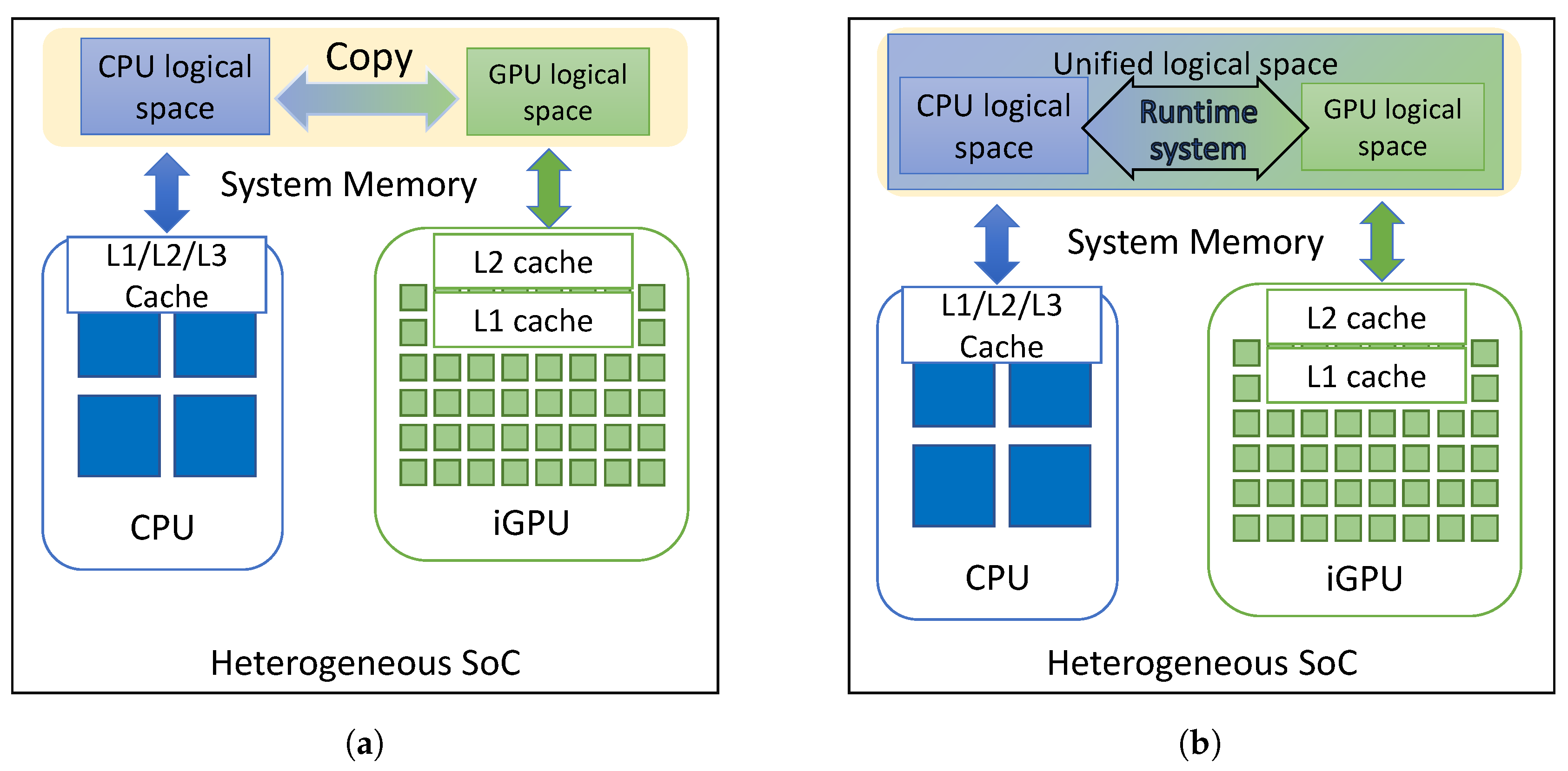
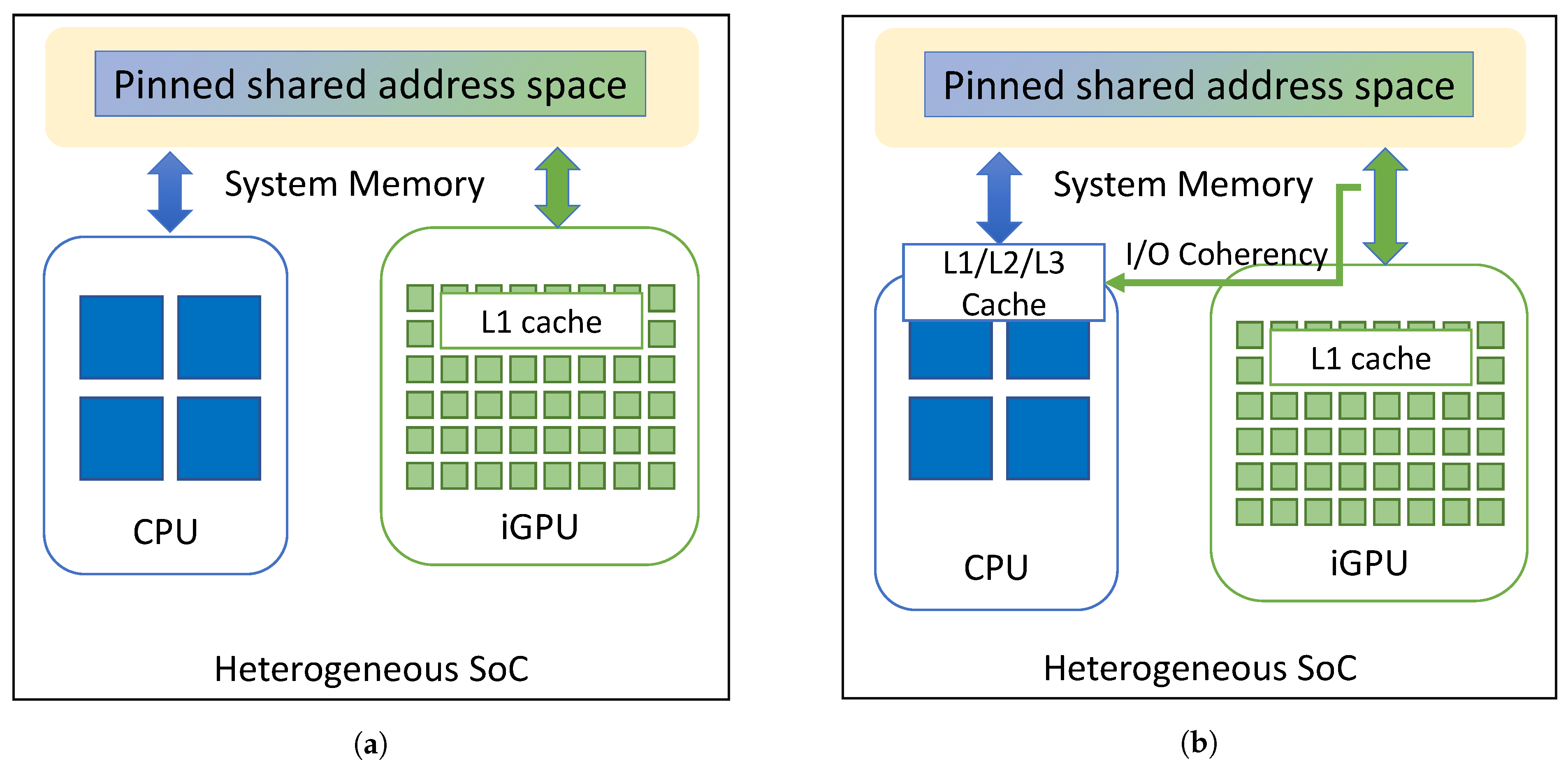
3.1. CPU–iGPU Communication in Shared-Memory Architectures
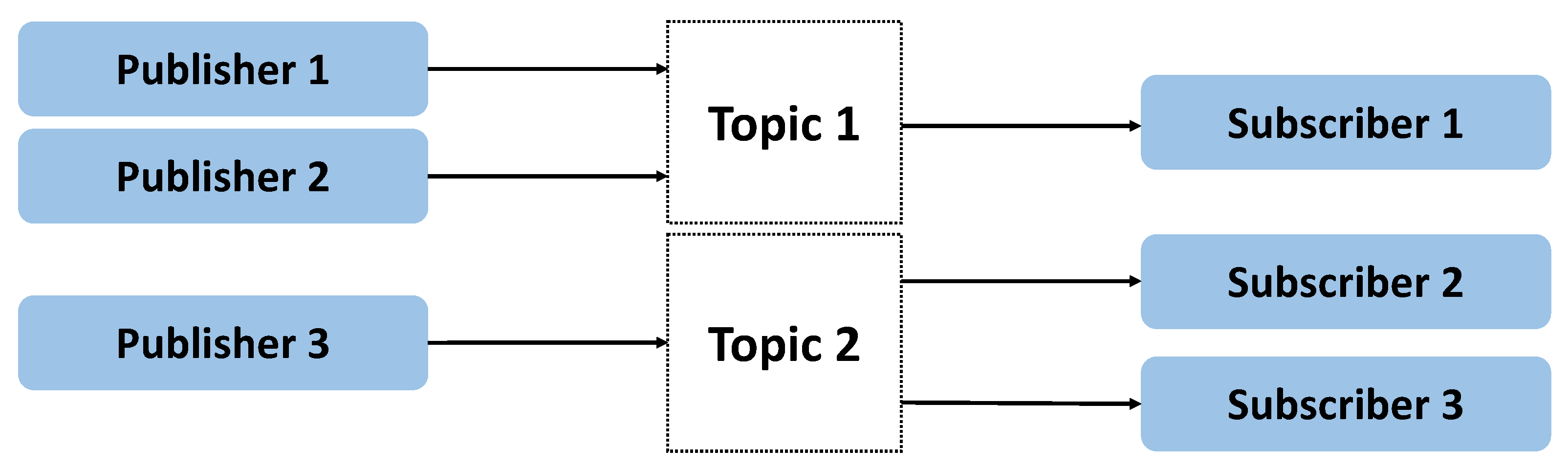
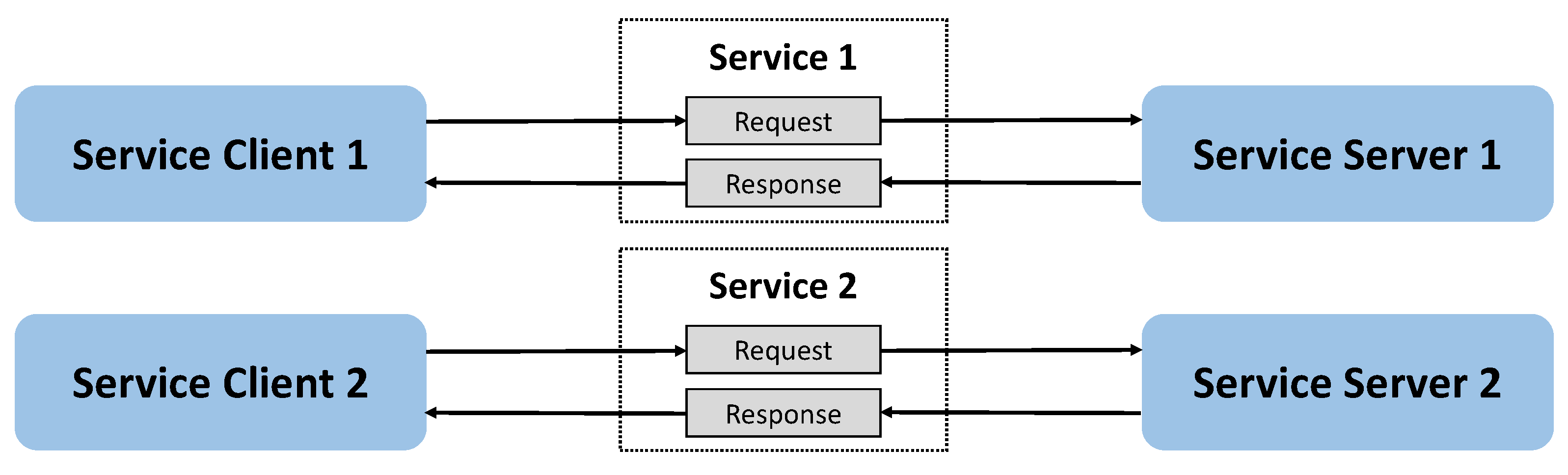
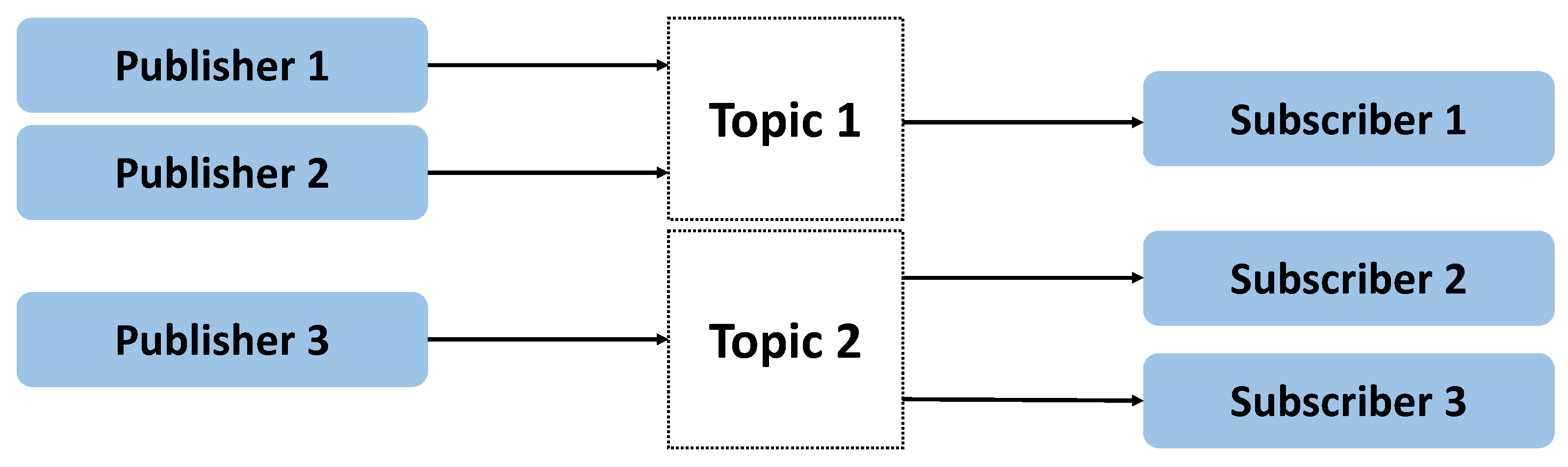
3.2. ROS-Based Communication between Nodes
4. Efficient ROS-Compliant CPU–iGPU Communication
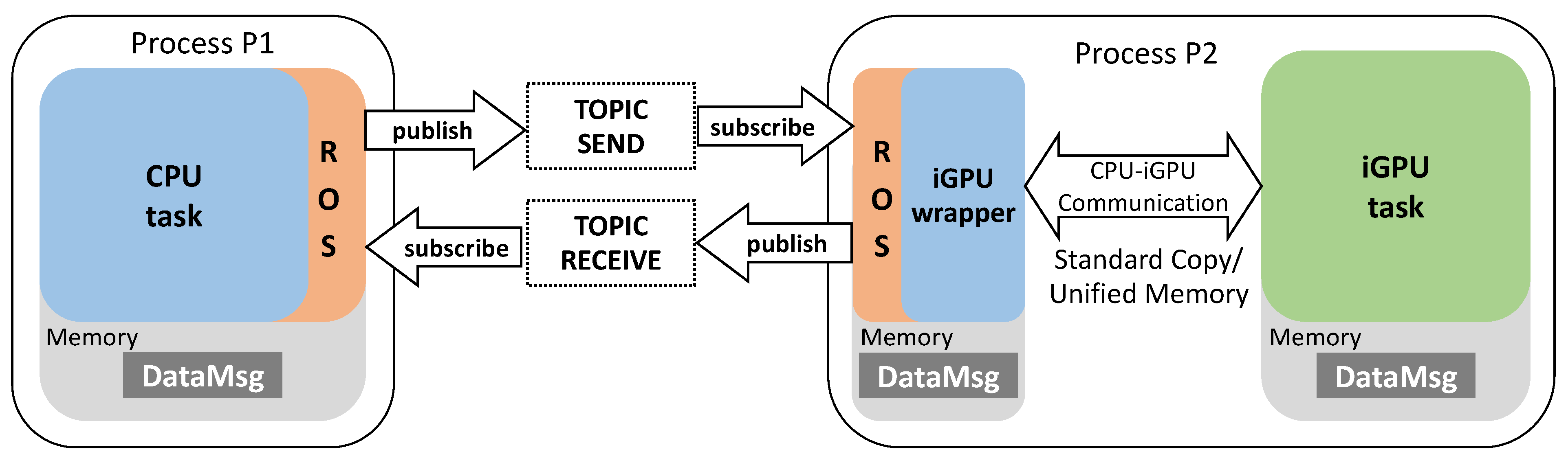
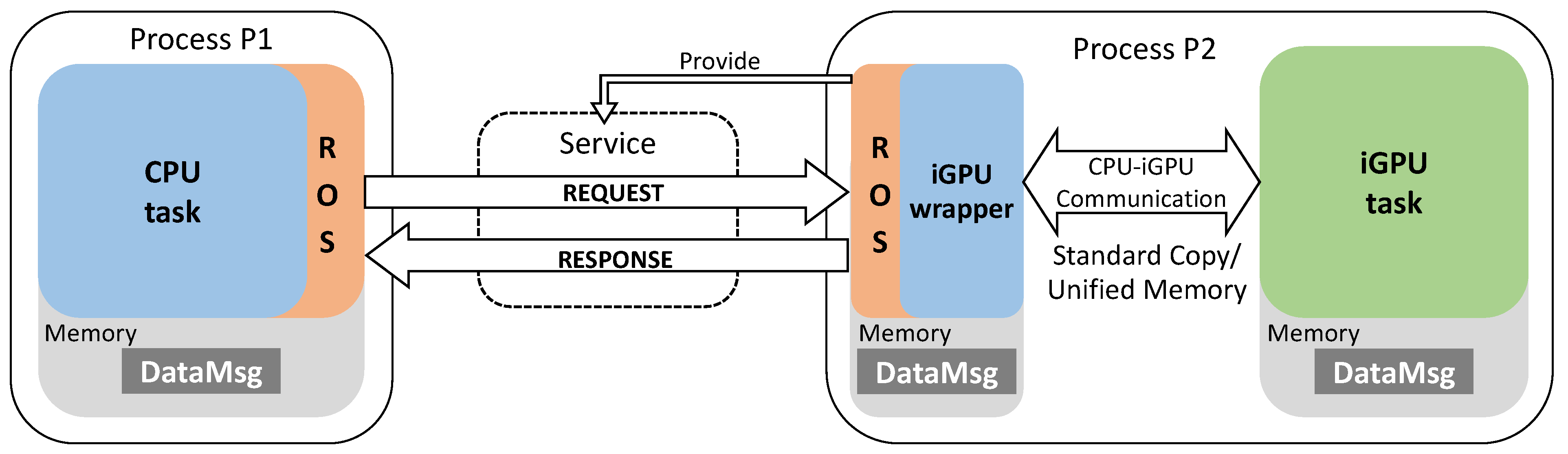
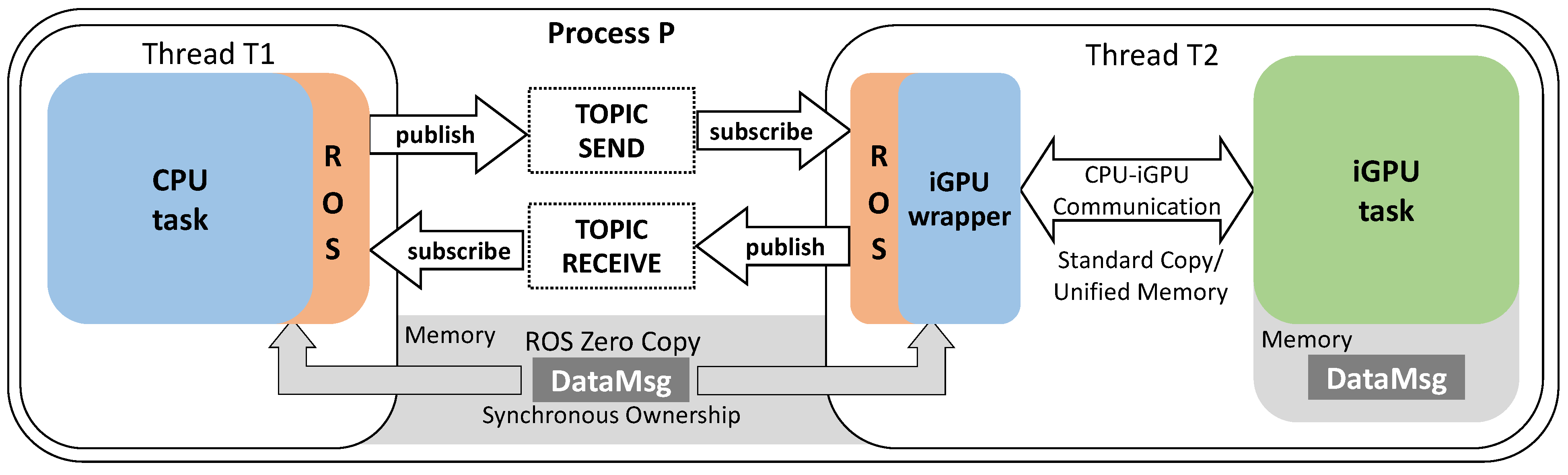
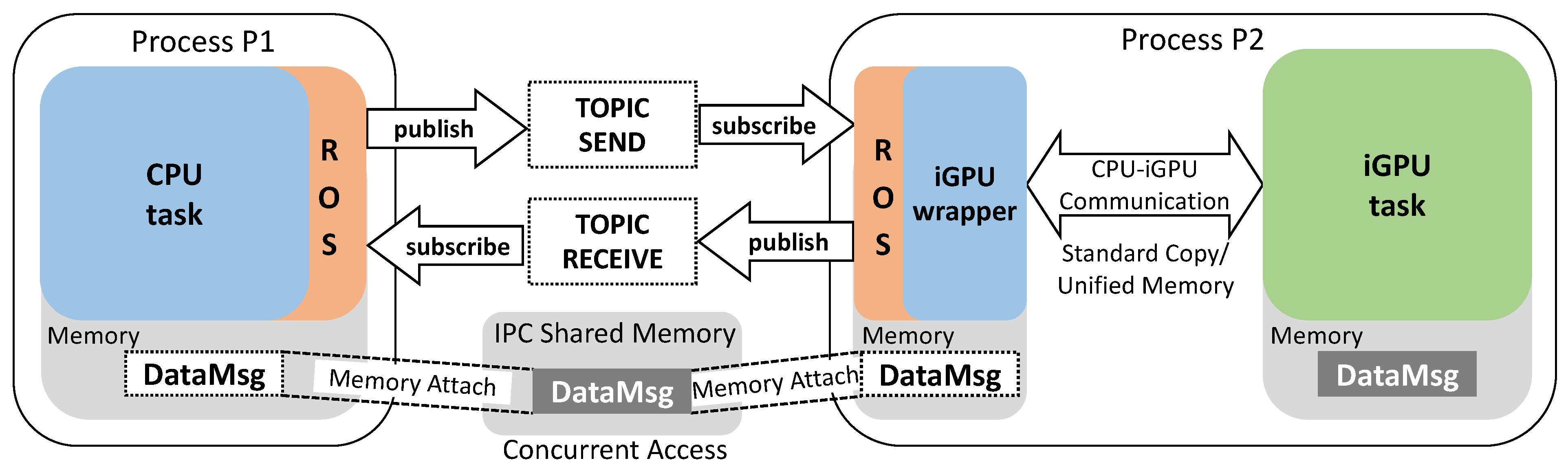
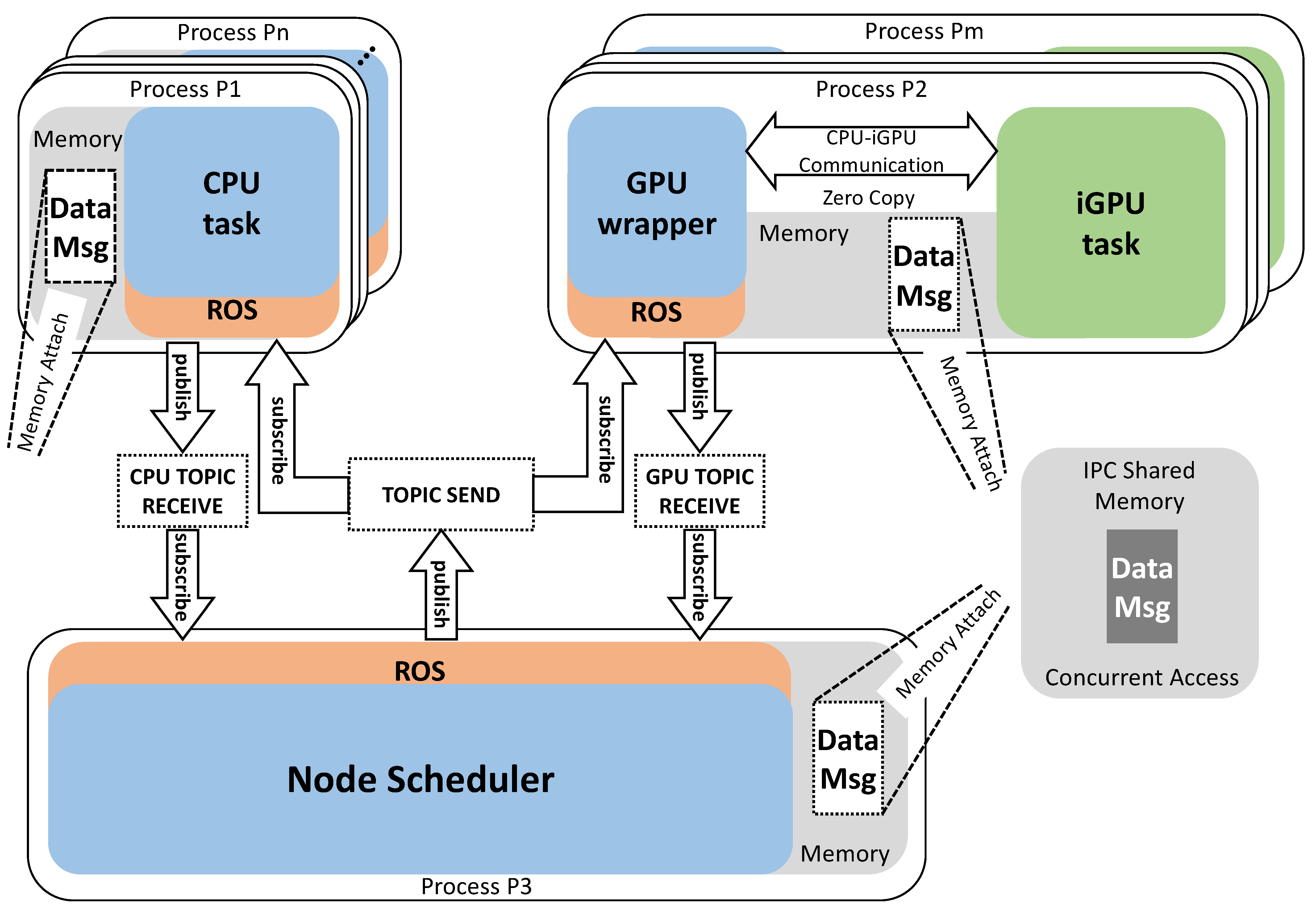
4.1. Making CPU–iGPU Communication Compliant to ROS
- ROS-ZC can be implemented only for communication between threads of the same process. When a zero-copy message is sent to a ROS node of a different process (i.e., inter-node communication), the communication mechanism automatically switches to the ROS standard copy;
- ROS-ZC does not allow for multiple nodes subscribed on the same data resource. If several nodes have to access a ROS-ZC message concurrently, ROS-ZC applies to only one of these nodes. The communication mechanism automatically switches to the ROS standard copy for the others. This condition holds for both intra-process and inter-process communication;
- ROS-ZC only allows for synchronous ownership of the memory address. A node that publishes a zero-copy message over a topic will not be allowed to access the message memory address. For this reason, CPU and iGPU operations cannot be performed in parallel, as the CPU node cannot execute operations after sending the message. Then the CPU node is forced to compute its operations either before or after the GPU operations (i.e., no overlapping computation is allowed over the shared memory address).
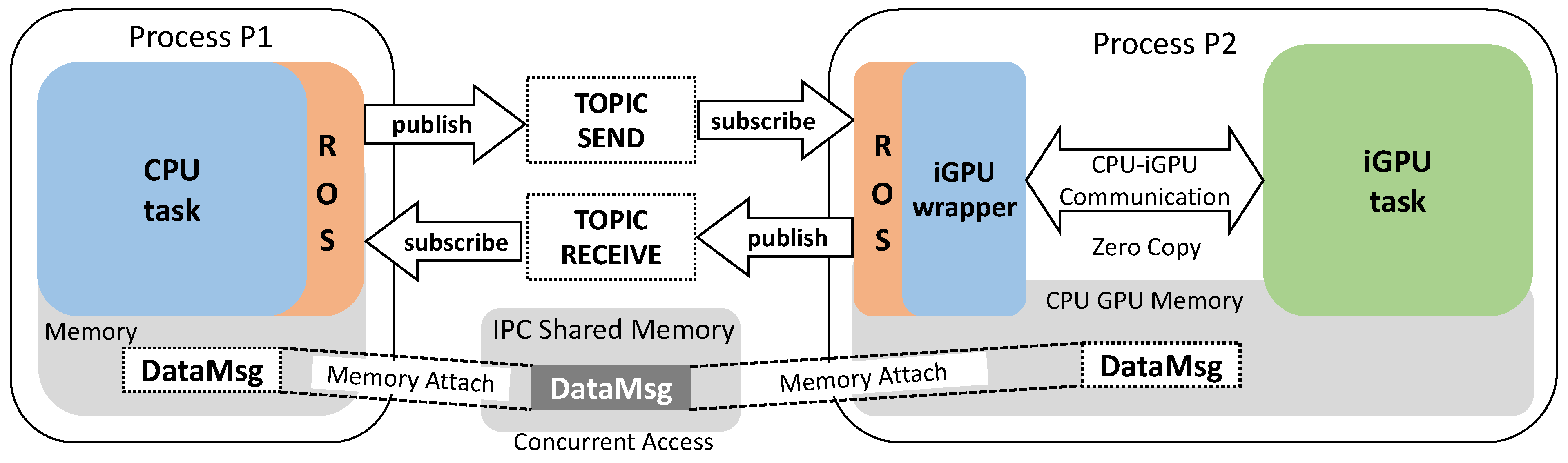
- Not only intra-process: This solution also applies to inter-process communication by means of a IPC shared memory managed by the operating system;
- Unique data allocation: the only memory allocated for data exchange is the shared memory;
- Efficient CUDA-ZC: The reference to the shared memory does not change during the whole communication process between ROS nodes. As a consequence, it also applies to the CUDA-ZC communication between the wrapper and the iGPU task. (see Figure 10);
- Easy concurrency: The shared memory can be accessed concurrently by different nodes allowing parallel execution between nodes over the same memory space when the application is safe from race condition.
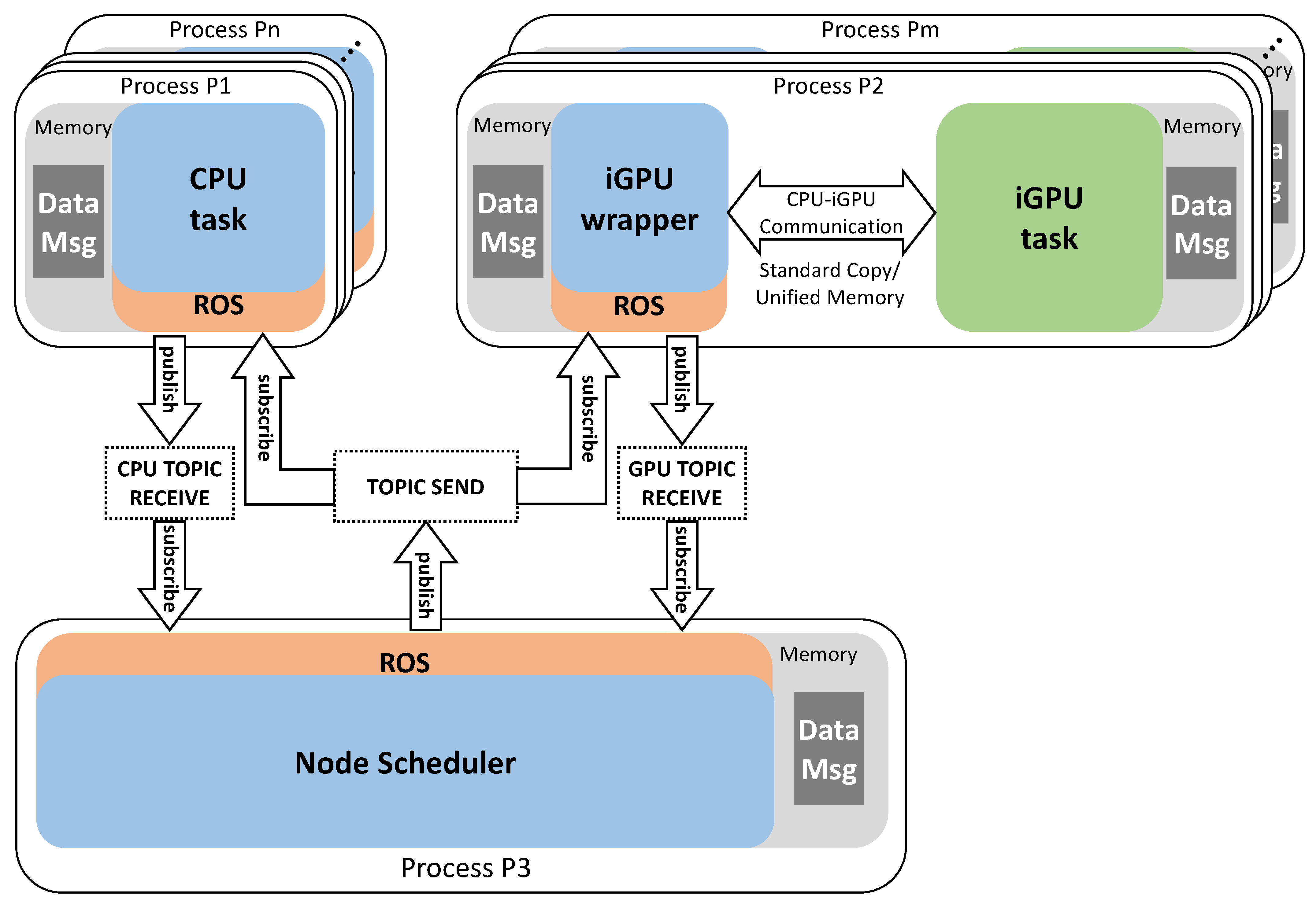
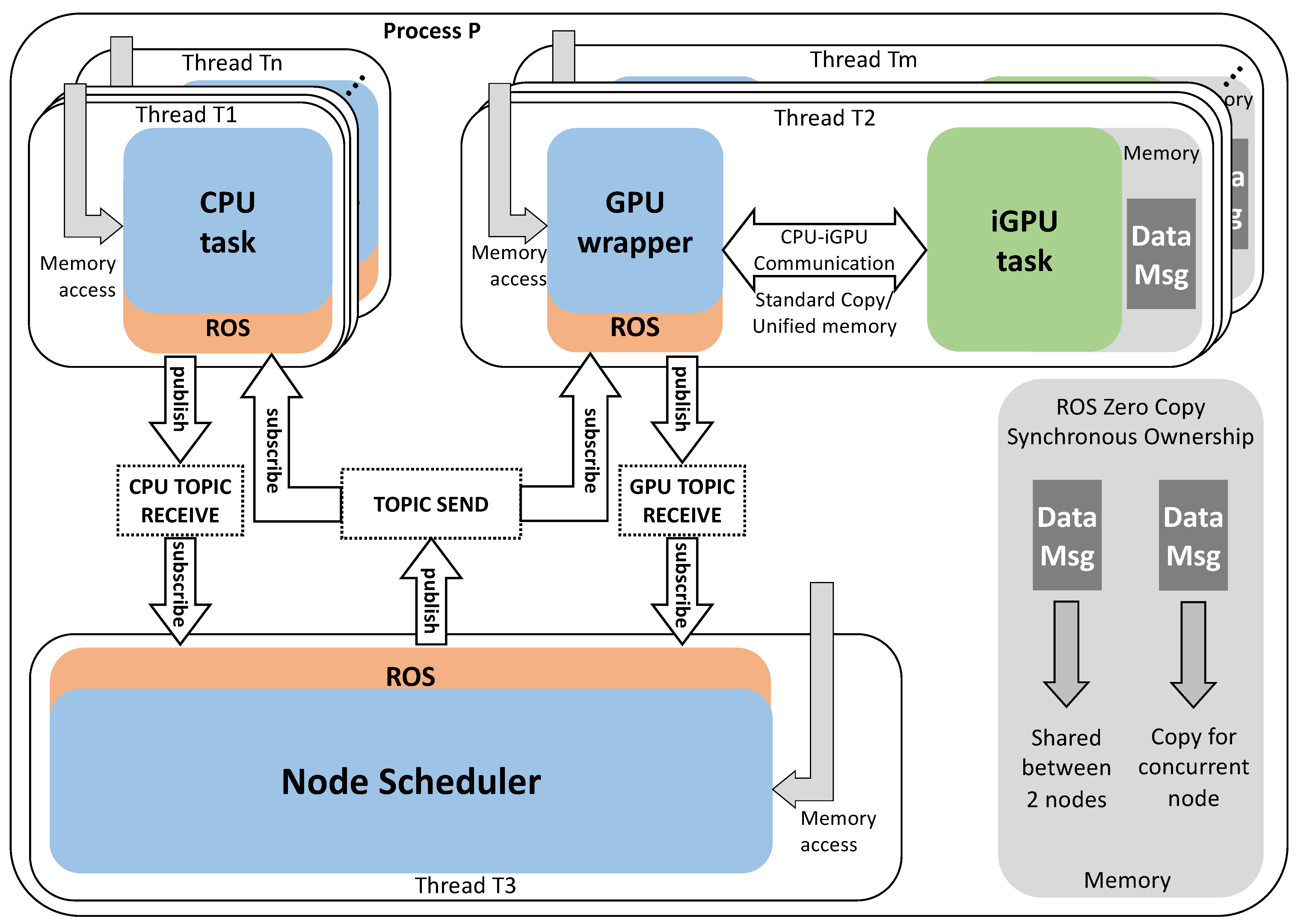
4.2. Making Multi-Node CPU–iGPU Communication Compliant to ROS
5. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mittal, S. A Survey of Techniques for Managing and Leveraging Caches in GPUs. J. Circuits Syst. Comput. 2014, 23, 1430002. [Google Scholar] [CrossRef]
- Nvidia Inc. Nvidia Tootlkit Documentation, Unified Memory. Available online: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#um-unified-memory-programming-hd (accessed on 27 March 2021).
- Fickenscher, J.; Reinhart, S.; Hannig, F.; Teich, J.; Bouzouraa, M. Convoy tracking for ADAS on embedded GPUs. In Proceedings of the IEEE Intelligent Vehicles Symposium, Los Angeles, CA, USA, 11–14 June 2017; pp. 959–965. [Google Scholar]
- Wang, X.; Huang, K.; Knoll, A. Performance Optimisation of Parallelized ADAS Applications in FPGA-GPU Heterogeneous Systems: A Case Study with Lane Detection. IEEE Trans. Intell. Veh. 2019, 4, 519–531. [Google Scholar] [CrossRef]
- Otterness, N.; Yang, M.; Rust, S.; Park, E.; Anderson, J.; Smith, F.; Berg, A.; Wang, S. An evaluation of the NVIDIA TX1 for supporting real-time computer-vision workloads. In Proceedings of the IEEE Real-Time and Embedded Technology and Applications Symposium, RTAS, Pittsburgh, PA, USA, 18–21 April 2017; pp. 353–363. [Google Scholar]
- Nvidia Inc. Jetson AGX Xavier and the New Era of Autonomous Machines. Available online: https://info.nvidia.com/emea-jetson-xavier-and-the-new-era-of-autonomous-machines-reg-page.html (accessed on 27 March 2021).
- Lumpp, F.; Patel, H.; Bombieri, N. A Framework for OptimizingCPU-iGPU Communication on Embedded Platforms. In Proceedings of the ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 11–15 July 2021. [Google Scholar]
- Lee, E.; Seshia, S. Introduction to Embedded Systems—A Cyber-Physical Systems Approach; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Adam, K.; Butting, A.; Heim, R.; Kautz, O.; Rumpe, B.; Wortmann, A. Model-driven separation of concerns for service robotics. In DSM 2016, Proceedings of the International Workshop on Domain-Specific Modeling, Amsterdam, The Netherlands, 30 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 22–27. [Google Scholar]
- Hammoudeh Garcia, N.; Deval, L.; Lüdtke, M.; Santos, A.; Kahl, B.; Bordignon, M. Bootstrapping MDE Development from ROS Manual Code—Part 2: Model Generation. In Proceedings of the 2019 ACM/IEEE 22nd International Conference on Model Driven Engineering Languages and Systems (MODELS 2019), Munich, Germany, 15–20 September 2019; pp. 95–105. [Google Scholar]
- Bardaro, G.; Semprebon, A.; Matteucci, M. A use case in model-based robot development using AADL and ROS. In Proceedings of the 1st International Workshop on Robotics Software Engineering, Gothenburg, Sweden, 27 May–3 June 2018; pp. 9–16. [Google Scholar]
- Wenger, M.; Eisenmenger, W.; Neugschwandtner, G.; Schneider, B.; Zoitl, A. A model based engineering tool for ROS component compositioning, configuration and generation of deployment information. In Proceedings of the IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Berlin, Germany, 6–9 September 2016. [Google Scholar]
- Neis, P.; Wehrmeister, M.; Mendes, M. Model Driven Software Engineering of Power Systems Applications: Literature Review and Trends. IEEE Access 2019, 7, 177761–177773. [Google Scholar] [CrossRef]
- Estévez, E.; Sánchez-García, A.; Gámez-García, J.; Gómez-Ortega, J.; Satorres-Martínez, S. A novel model-driven approach to support development cycle of robotic systems. Int. J. Adv. Manuf. Technol. 2016, 82, 737–751. [Google Scholar] [CrossRef]
- Open Source Robotics Foundation. Robot Operating System. Available online: http://www.ros.org/ (accessed on 27 March 2021).
- Yang, J.; Thomas, A.G.; Singh, S.; Baldi, S.; Wang, X. A Semi-Physical Platform for Guidance and Formations of Fixed-Wing Unmanned Aerial Vehicles. Sensors 2020, 20, 1136. [Google Scholar] [CrossRef] [PubMed]
- Martin, J.; Casquero, O.; Fortes, B.; Marcos, M. A Generic Multi-Layer Architecture Based on ROS-JADE Integration for Autonomous Transport Vehicles. Sensors 2019, 19, 69. [Google Scholar] [CrossRef]
- Kato, S.; Tokunaga, S.; Maruyama, Y.; Maeda, S.; Hirabayashi, M.; Kitsukawa, Y.; Monrroy, A.; Ando, T.; Fujii, Y.; Azumi, T. Autoware on Board: Enabling Autonomous Vehicles with Embedded Systems. In Proceedings of the 2018 ACM/IEEE 9th International Conference on Cyber-Physical Systems (ICCPS), Porto, Portugal, 11–13 April 2018; pp. 287–296. [Google Scholar] [CrossRef]
- Open Source Robotics Foundation. ROS 2 Documentation. Available online: https://docs.ros.org/en/dashing/index.html (accessed on 27 March 2021).
- Open Source Robotics Foundation. ROS Wiki. Available online: http://wiki.ros.org/ (accessed on 27 March 2021).
- Open Source Robotics Foundation. Efficient Intra-Process Communication. Available online: https://docs.ros.org/en/foxy/Tutorials/Intra-Process-Communication.html (accessed on 27 March 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NVIDIA Device | Benchmark | GPU Copy | Time (ms) | SD (ms) | |
|---|---|---|---|---|---|
| Jetson TX2 | Cache | CUDA-SC | 833.0 | ± | 3.8 |
| Jetson TX2 | Cache | CUDA-ZC | 8509.1 | ± | 131.7 |
| Jetson TX2 | Concurrent | CUDA-SC | 1053.0 | ± | 8.2 |
| Jetson TX2 | Concurrent | CUDA-ZC | 1316.1 | ± | 33.9 |
| Jetson Xavier | Cache | CUDA-SC | 207.7 | ± | 9.8 |
| Jetson Xavier | Cache | CUDA-ZC | 244.7 | ± | 11.0 |
| Jetson Xavier | Concurrent | CUDA-SC | 381.2 | ± | 8.3 |
| Jetson Xavier | Concurrent | CUDA-ZC | 256.9 | ± | 6.1 |
| Arch. | GPU Copy | ROS Type | ROS Copy | Time (ms) | SD (ms) | Overhead | |
|---|---|---|---|---|---|---|---|
| 2 nodes (Figure 6) | CUDA-SC | Topic | ROS-SC | 22,825.2 | ± | 5763.5 | 2640% |
| 2 nodes (Figure 7) | CUDA-SC | Service | ROS-SC | 22,715.0 | ± | 3929.8 | 2627% |
| 2 nodes (Figure 8) | CUDA-SC | Topic | ROS-ZC | 1056.0 | ± | 32.2 | 27% |
| 2 nodes (Figure 8) | CUDA-ZC | Topic | ROS-ZC | 10,254.2 | ± | 189.0 | 21% |
| 2 nodes (Figure 9) | CUDA-SC | Topic | ROS-SHM-ZC | 852.6 | ± | 7.7 | 2% |
| 2 nodes (Figure 10) | CUDA-ZC | Topic | ROS-SHM-ZC | 9474.0 | ± | 226.3 | 11% |
| 3 nodes (Figure 11) | CUDA-SC | Topic | ROS-SC | 6334.2 | ± | 3562.1 | 660% |
| 3 nodes (Figure 11) | CUDA-SC | Service | ROS-SC | 6755.5 | ± | 4589.0 | 711% |
| 3 nodes (Figure 12) | CUDA-SC | Topic | ROS-ZC | 1087.6 | ± | 39.4 | 31% |
| 3 nodes (Figure 13) | CUDA-SC | Topic | ROS-SHM-ZC | 862.7 | ± | 9.7 | 4% |
| 3 nodes (Figure 13) | CUDA-ZC | Topic | ROS-SHM-ZC | 9408.1 | ± | 213.0 | 11% |
| 5 nodes (Figure 11) | CUDA-SC | Topic | ROS-SC | 12,234.2 | ± | 3487.9 | 1369% |
| 5 nodes (Figure 13) | CUDA-SC | Topic | ROS-SHM-ZC | 1737.1 | ± | 9.1 | 109% |
| 5 nodes (Figure 13) | CUDA-ZC | Topic | ROS-SHM-ZC | 11,381.6 | ± | 65.6 | 34% |
| Arch. | GPU Copy | ROS Type | ROS Copy | Time (ms) | SD (ms) | Overhead | |
|---|---|---|---|---|---|---|---|
| 2 nodes (Figure 6) | CUDA-SC | Topic | ROS-SC | 4666.0 | ± | 68.9 | 343% |
| 2 nodes (Figure 7) | CUDA-SC | Service | ROS-SC | 4930.0 | ± | 73.3 | 368% |
| 2 nodes (Figure 8) | CUDA-SC | Topic | ROS-ZC | 1584.6 | ± | 46.3 | 50% |
| 2 nodes (Figure 8) | CUDA-ZC | Topic | ROS-ZC | 1910.6 | ± | 73.1 | 45% |
| 2 nodes (Figure 9) | CUDA-SC | Topic | ROS-SHM-ZC | 1046.1 | ± | 82.3 | −1% |
| 2 nodes (Figure 10) | CUDA-ZC | Topic | ROS-SHM-ZC | 1203.2 | ± | 47.2 | −9% |
| 3 nodes (Figure 11) | CUDA-SC | Topic | ROS-SC | 8244.6 | ± | 2938.4 | 683% |
| 3 nodes (Figure 11) | CUDA-SC | Service | ROS-SC | 8505.7 | ± | 767.6 | 708% |
| 3 nodes (Figure 12) | CUDA-SC | Topic | ROS-ZC | 2261.7 | ± | 47.1 | 115% |
| 3 nodes (Figure 13) | CUDA-SC | Topic | ROS-SHM-ZC | 997.9 | ± | 75.6 | −5% |
| 3 nodes (Figure 13) | CUDA-ZC | Topic | ROS-SHM-ZC | 1172.5 | ± | 41.5 | −11% |
| 5 nodes (Figure 11) | CUDA-SC | Topic | ROS-SC | 41,773.4 | ± | 12,118.6 | 3867% |
| 5 nodes (Figure 13) | CUDA-SC | Topic | ROS-SHM-ZC | 1923. | ± | 89.7 | 131% |
| 5 nodes (Figure 13) | CUDA-ZC | Topic | ROS-SHM-ZC | 1978.3 | ± | 131.9 | 50% |
| Arch. | GPU Copy | ROS Type | ROS Copy | Time (ms) | SD (ms) | Overhead | |
|---|---|---|---|---|---|---|---|
| 2 nodes (Figure 6) | CUDA-SC | Topic | ROS-SC | 8371.3 | ± | 3210.8 | 3930% |
| 2 nodes (Figure 7) | CUDA-SC | Service | ROS-SC | 10,385.2 | ± | 3423.4 | 4900% |
| 2 nodes (Figure 8) | CUDA-SC | Topic | ROS-ZC | 338.1 | ± | 48.8 | 63% |
| 2 nodes (Figure 8) | CUDA-ZC | Topic | ROS-ZC | 653.6 | ± | 35.4 | 167% |
| 2 nodes (Figure 9) | CUDA-SC | Topic | ROS-SHM-ZC | 230.0 | ± | 15.5 | 11% |
| 2 nodes (Figure 10) | CUDA-ZC | Topic | ROS-SHM-ZC | 251.9 | ± | 25.3 | 3% |
| 3 nodes (Figure 11) | CUDA-SC | Topic | ROS-SC | 5139.1 | ± | 3484.6 | 2374% |
| 3 nodes (Figure 11) | CUDA-SC | Service | ROS-SC | 6744.4 | ± | 4367.4 | 3147% |
| 3 nodes (Figure 12) | CUDA-SC | Topic | ROS-ZC | 333.9 | ± | 30.5 | 61% |
| 3 nodes (Figure 13) | CUDA-SC | Topic | ROS-SHM-ZC | 236.9 | ± | 13.1 | 14% |
| 3 nodes (Figure 13) | CUDA-ZC | Topic | ROS-SHM-ZC | 400.9 | ± | 20.8 | 64% |
| 5 nodes (Figure 11) | CUDA-SC | Topic | ROS-SC | 7466.4 | ± | 5225.2 | 3495% |
| 5 nodes (Figure 13) | CUDA-SC | Topic | ROS-SHM-ZC | 492.5 | ± | 15.6 | 137% |
| 5 nodes (Figure 13) | CUDA-ZC | Topic | ROS-SHM-ZC | 847.6 | ± | 36.4 | 246% |
| Arch. | GPU Copy | ROS Type | ROS Copy | Time (ms) | SD (ms) | Overhead | |
|---|---|---|---|---|---|---|---|
| 2 nodes (Figure 6) | CUDA-SC | Topic | ROS-SC | 3501.0 | ± | 3052.9 | 818% |
| 2 nodes (Figure 7) | CUDA-SC | Service | ROS-SC | 5307.0 | ± | 5841.7 | 1292% |
| 2 nodes (Figure 8) | CUDA-SC | Topic | ROS-ZC | 658.5 | ± | 41.7 | 73% |
| 2 nodes (Figure 8) | CUDA-ZC | Topic | ROS-ZC | 672.4 | ± | 34.9 | 162% |
| 2 nodes (Figure 9) | CUDA-SC | Topic | ROS-SHM-ZC | 403.3 | ± | 43.0 | 6% |
| 2 nodes (Figure 10) | CUDA-ZC | Topic | ROS-SHM-ZC | 266.7 | ± | 23.4 | 4% |
| 3 nodes (Figure 11) | CUDA-SC | Topic | ROS-SC | 17,054.5 | ± | 5763.9 | 4374% |
| 3 nodes (Figure 11) | CUDA-SC | Service | ROS-SC | 25,033.2 | ± | 14,269.0 | 6467% |
| 3 nodes (Figure 12) | CUDA-SC | Topic | ROS-ZC | 655.7 | ± | 42.1 | 72% |
| 3 nodes (Figure 13) | CUDA-SC | Topic | ROS-SHM-ZC | 408.0 | ± | 56.9 | 7% |
| 3 nodes (Figure 13) | CUDA-ZC | Topic | ROS-SHM-ZC | 451.3 | ± | 62.6 | 76% |
| 5 nodes (Figure 11) | CUDA-SC | Topic | ROS-SC | 43,808.4 | ± | 8735.0 | 11,392% |
| 5 nodes (Figure 13) | CUDA-SC | Topic | ROS-SHM-ZC | 761.9 | ± | 86.5 | 100% |
| 5 nodes (Figure 13) | CUDA-ZC | Topic | ROS-SHM-ZC | 859.0 | ± | 66.5 | 234% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Marchi, M.; Lumpp, F.; Martini, E.; Boldo, M.; Aldegheri, S.; Bombieri, N. Efficient ROS-Compliant CPU-iGPU Communication on Embedded Platforms. J. Low Power Electron. Appl. 2021, 11, 24. https://doi.org/10.3390/jlpea11020024
De Marchi M, Lumpp F, Martini E, Boldo M, Aldegheri S, Bombieri N. Efficient ROS-Compliant CPU-iGPU Communication on Embedded Platforms. Journal of Low Power Electronics and Applications. 2021; 11(2):24. https://doi.org/10.3390/jlpea11020024
Chicago/Turabian StyleDe Marchi, Mirco, Francesco Lumpp, Enrico Martini, Michele Boldo, Stefano Aldegheri, and Nicola Bombieri. 2021. "Efficient ROS-Compliant CPU-iGPU Communication on Embedded Platforms" Journal of Low Power Electronics and Applications 11, no. 2: 24. https://doi.org/10.3390/jlpea11020024
APA StyleDe Marchi, M., Lumpp, F., Martini, E., Boldo, M., Aldegheri, S., & Bombieri, N. (2021). Efficient ROS-Compliant CPU-iGPU Communication on Embedded Platforms. Journal of Low Power Electronics and Applications, 11(2), 24. https://doi.org/10.3390/jlpea11020024