
Architectural Techniques for Improving the Power Consumption of NoC-Based CMPs: A Case Study of Cache and Network Layer


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Cache: Power Concept, Architecture, Power Saving Chips (Engineering Approach to Power Saving)
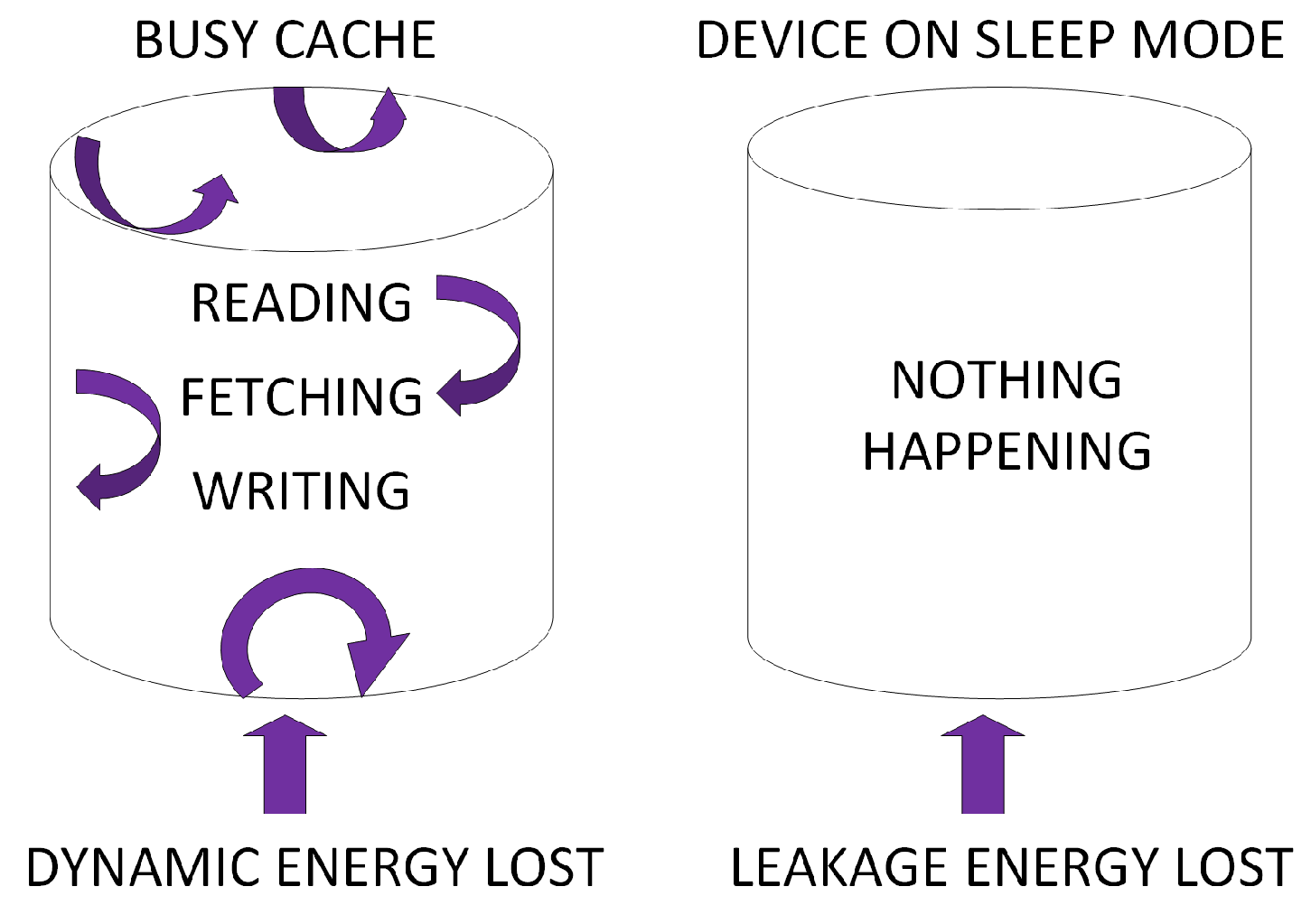
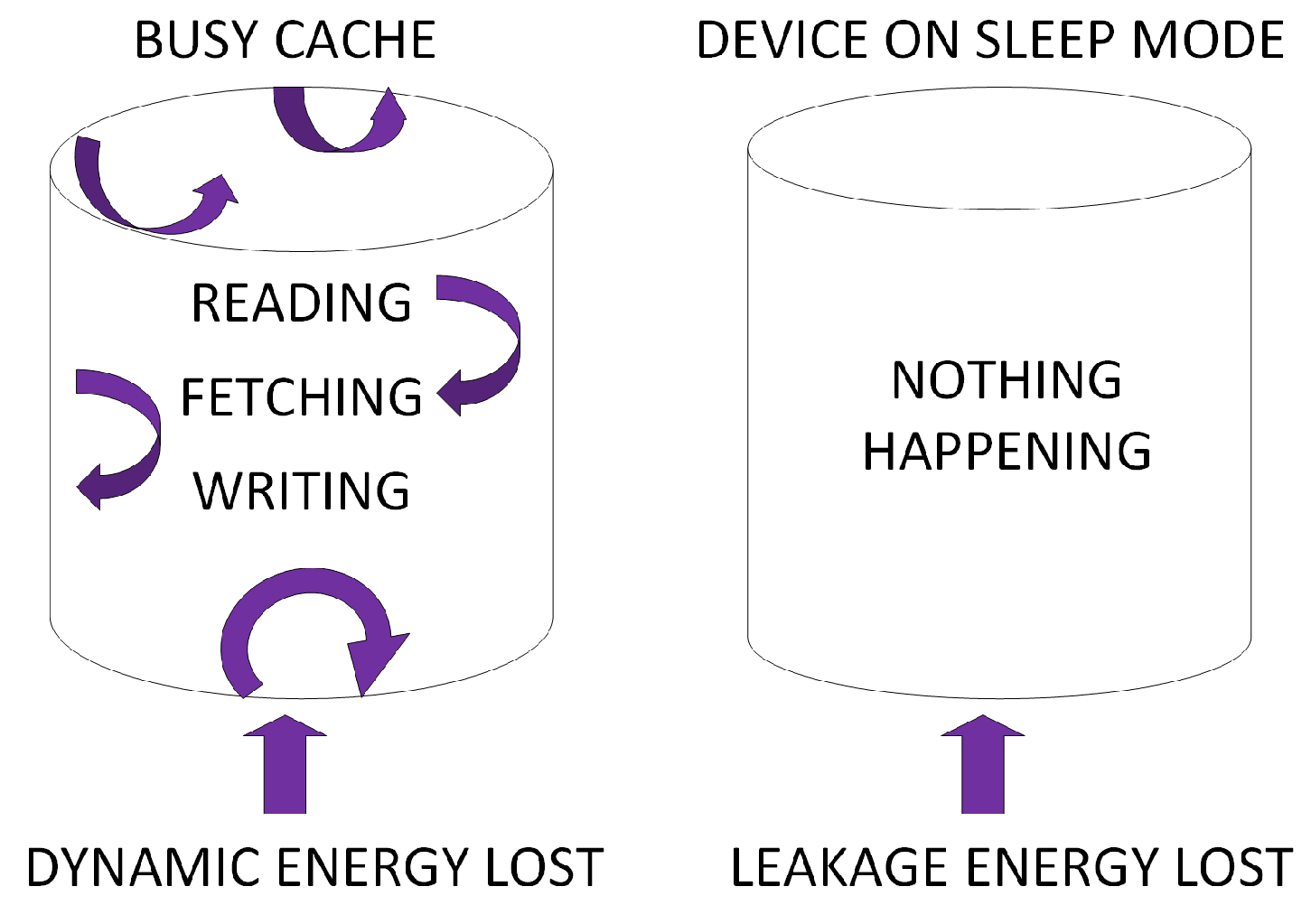
2.1. Cache Power Consumption
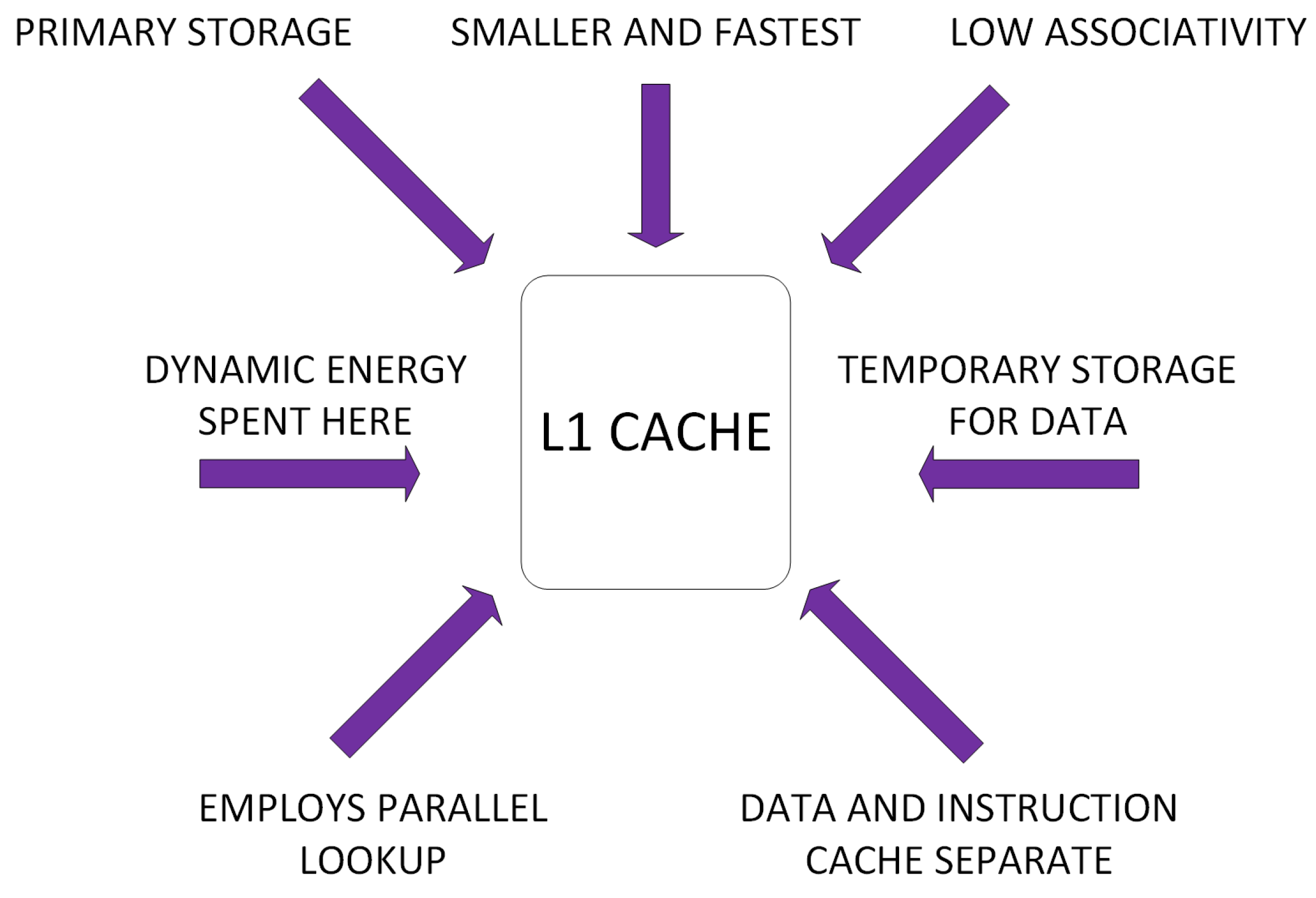
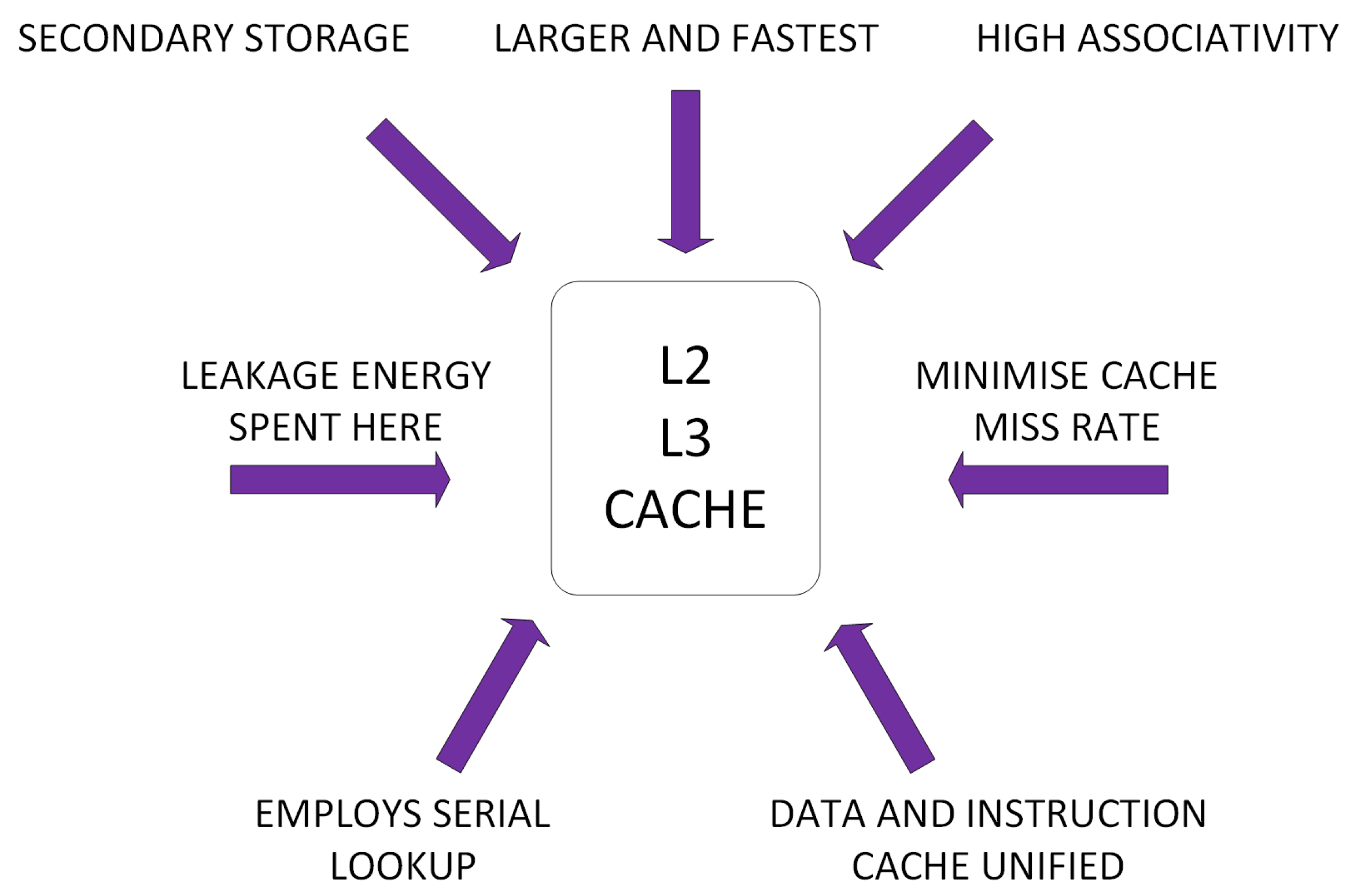
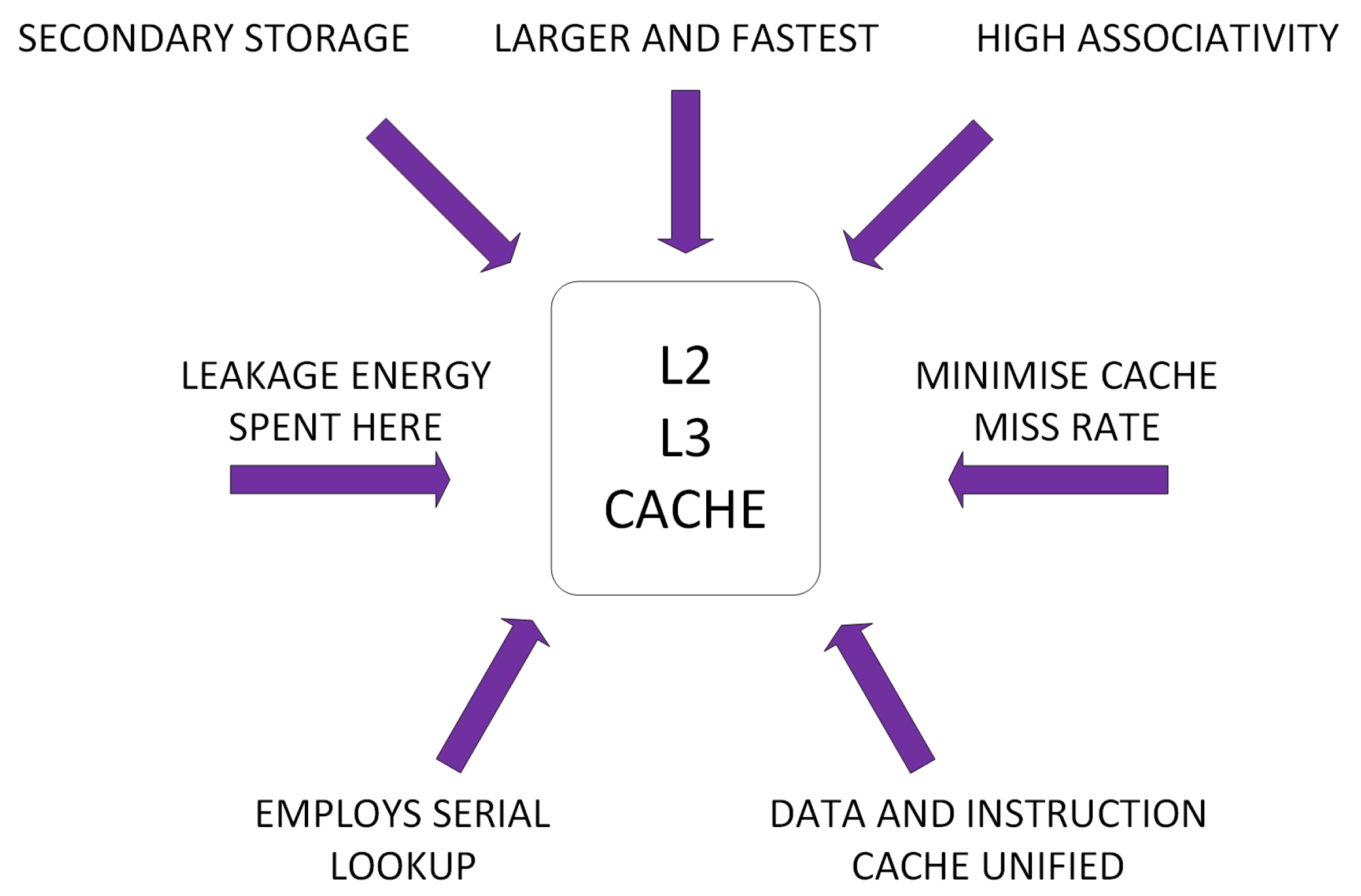
2.2. Cache Architecture
2.3. Power-Saving Chips
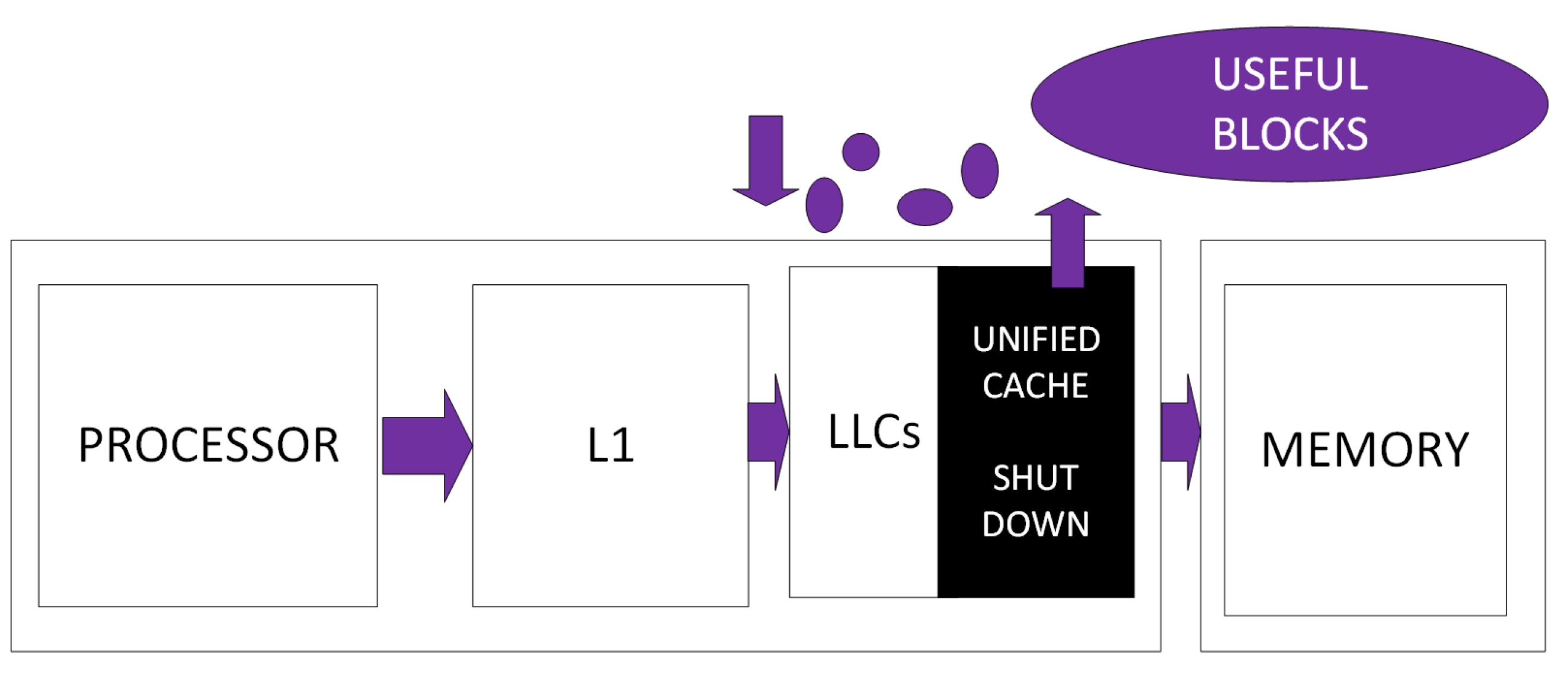
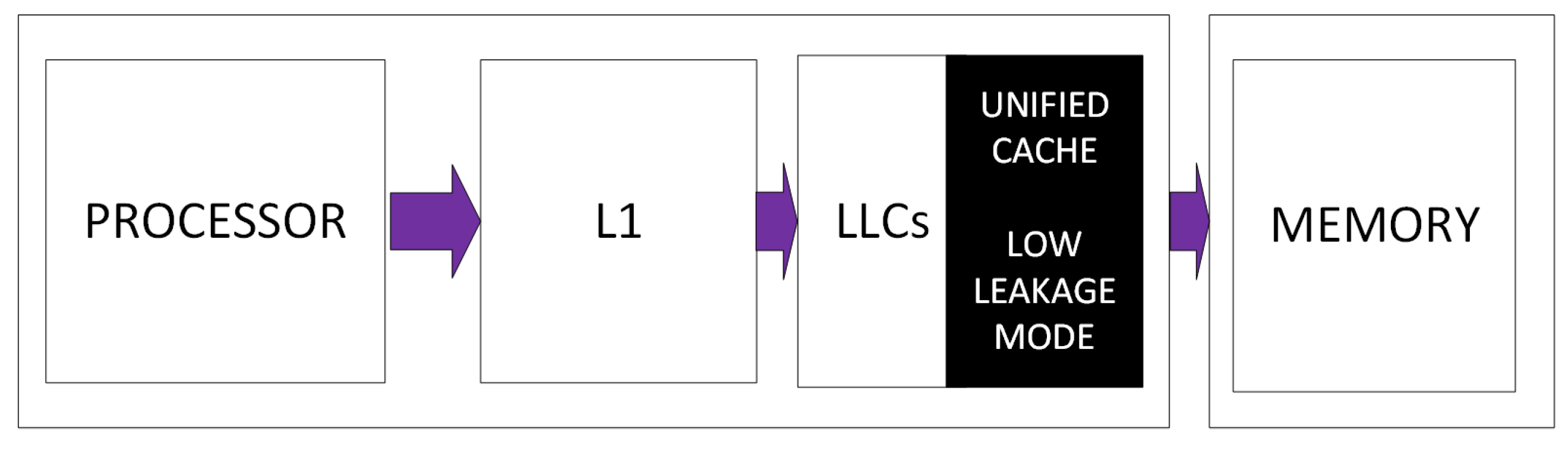
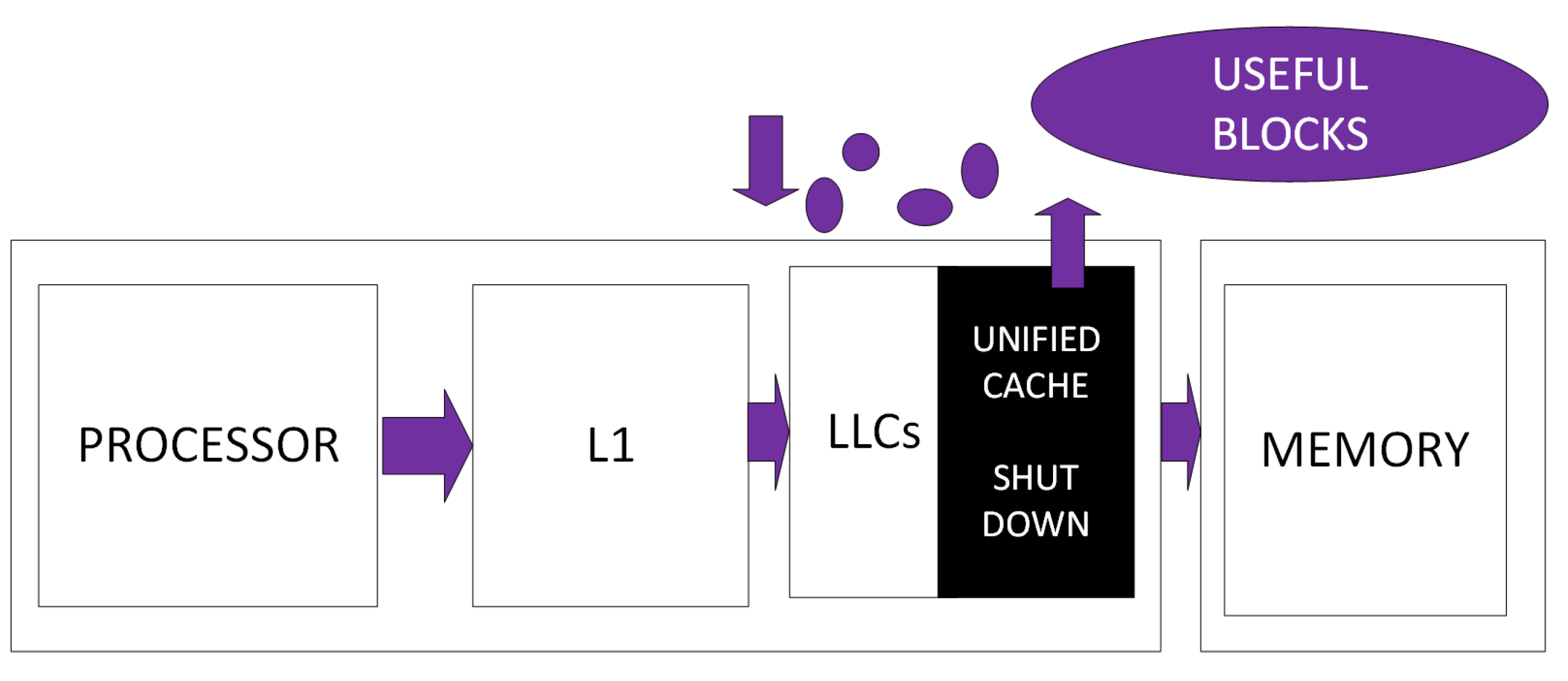
3. On the Leakage Power Saving Approaches in Cache Design
3.1. Concepts
3.2. Techniques
3.2.1. Offline Profiling
3.2.2. Online Profiling
4. On the Dynamic Power Saving Approaches in Cache Design
4.1. Concepts
4.2. Techniques
4.3. Dynamic and Leakage Power Saving Techniques
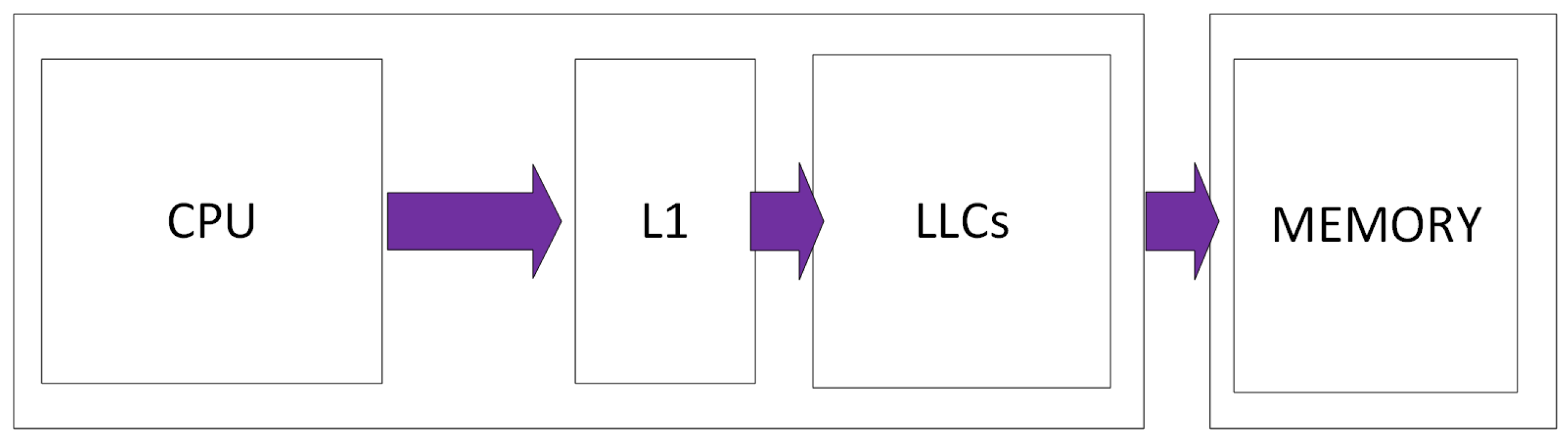
5. Reducing Power Consumption in the NoC Interconnect
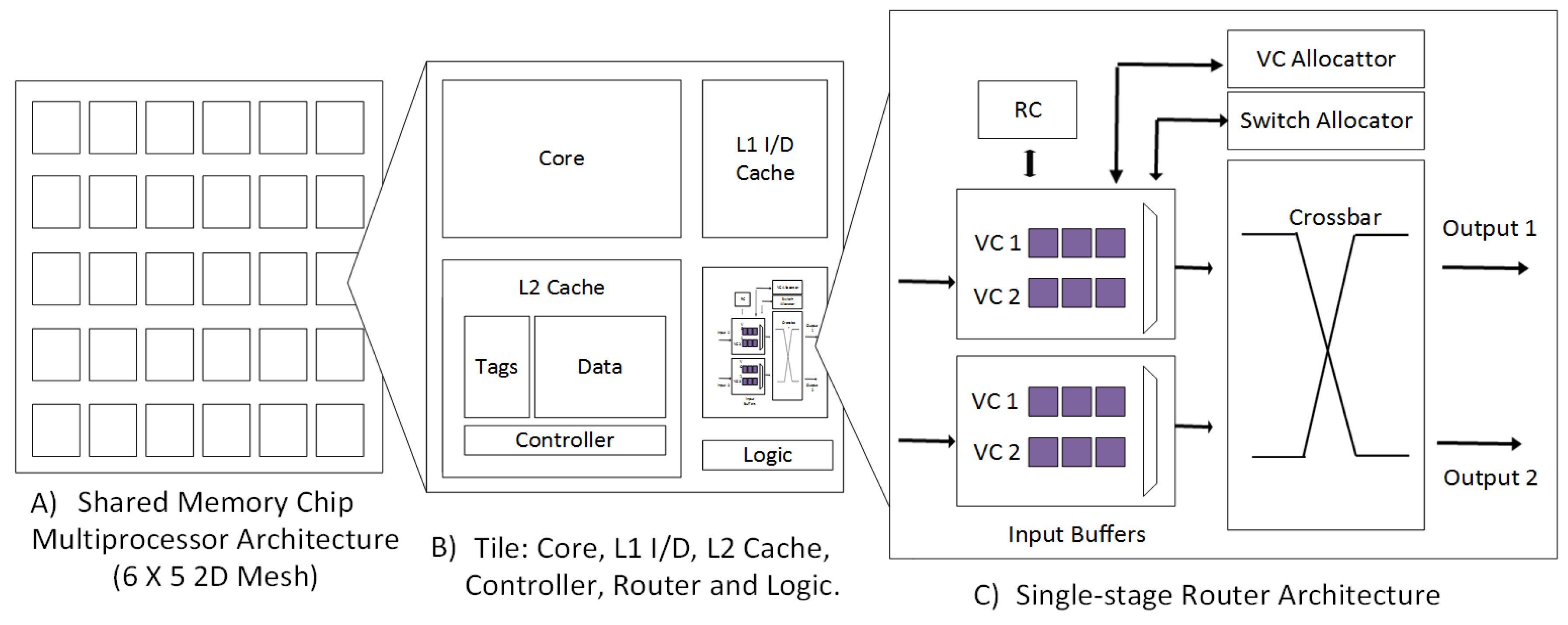
5.1. Router Architecture
5.2. Alternative Buffer Solutions
5.2.1. Input Buffer Alternatives
5.2.2. Pipeline Stages
5.2.3. Virtual Channel Low-Power Techniques
5.3. Low-Power Design Techniques for Crossbars
5.3.1. Reduction of the Crossbar Size
5.3.2. Low-Power Switching Algorithm Techniques
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Valero, A.; Sahuquillo, J.; Petit, S.; López, P.; Duato, J. Design of Hybrid Second-Level Caches. IEEE Trans. Comput. 2015, 64, 1884–1897. [Google Scholar] [CrossRef]
- Neishaburi, M.H.; Zilic, Z. A Fault Tolerant Hierarchical Network on Chip Router Architecture. In Proceedings of the IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems, Vancouver, BC, Canada, 3–5 October 2011; pp. 445–453. [Google Scholar]
- Jebaseeli, A.D.; Kiruba, M. Design of low power L2 cache architecture using partial way tag information. In Proceedings of the International Conference on Green Computing Communication and Electrical Engineering (ICGCCEE), Coimbatore, India, 6–8 March 2014; pp. 1–6. [Google Scholar]
- Chen, L.; Pinkston, T.M. NoRD: Node-Router Decoupling for Effective Power-gating of On-Chip Routers. In Proceedings of the 45th Annual IEEE/ACM International Symposium on Microarchitecture, Vancouver, BC, Canada, 1–5 December 2012; pp. 270–281. [Google Scholar]
- Sun, C.; Chen, C.H.O.; Kurian, G.; Wei, L.; Miller, J.; Agarwal, A.; Peh, L.S.; Stojanovic, V. DSENT—5A Tool Connecting Emerging Photonics with Electronics for Opto-Electronic Networks-on-Chip Modeling. In Proceedings of the 2012 Sixth IEEE/ACM International Symposium on Networks on Chip (NoCS), Lyngby, Denmark, 9–11 May 2012; pp. 201–210. [Google Scholar]
- Kudithipudi, D.; Petko, S.; John, E.B. Caches for Multimedia Workloads: Power and Energy Tradeoffs. IEEE Trans. Multimed. 2008, 10, 1013–1021. [Google Scholar] [CrossRef]
- Lin, I.C.; Chiou, J.N. High-Endurance Hybrid Cache Design in CMP Architecture With Cache Partitioning and Access-Aware Policies. IEEE Trans. Very Large Scale Integr. Syst. 2015, 23, 2149–2161. [Google Scholar] [CrossRef]
- Monchiero, M.; Canal, R.; Gonzalez, A. Using Coherence Information and Decay Techniques to Optimize L2 Cache Leakage in CMPs. In Proceedings of the International Conference on Parallel Processing, Vienna, Austria, 22–25 September 2009; pp. 1–8. [Google Scholar]
- Fischer, K.; Chang, H.K.; Ingerly, D.; Jin, I.; Kilambi, H.; Longun, J.; Patel, R.; Pelto, C.; Petersburg, C.; Plekhanov, P.; et al. Performance enhancement for 14nm high volume manufacturing microprocessor and system on a chip processes. In Proceedings of the IEEE International Interconnect Technology Conference/Advanced Metallization Conference (IITC/AMC), San Jose, CA, USA, 23–26 May 2016; pp. 5–7. [Google Scholar]
- Mittal, S.; Vetter, J.S. A Survey Of Techniques for Architecting DRAM Caches. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1852–1863. [Google Scholar] [CrossRef]
- An Overview of Cache; Intel: Santa Clara, CA, USA, 2015; pp. 1–4. Available online: http://download.intel.com/design/intarch/papers/cache6.pdf (accessed on 1 January 2017).
- Mittal, S.; Cao, Y.; Zhang, Z. MASTER: A Multicore Cache Energy-Saving Technique Using Dynamic Cache Reconfiguration. IEEE Trans. Very Large Scale Integr. Syst. 2014, 22, 1653–1665. [Google Scholar] [CrossRef]
- Mittal, S. A Survey of Architectural Techniques for Improving Cache Power Efficiency. Sustain. Comput. Inf. Syst. 2013, 4, 43–48. [Google Scholar] [CrossRef]
- Warnock, J.; Chan, Y.; Harrer, H.; Carey, S.; Salem, G.; Malone, D.; Puri, R.; Zitz, J.A.; Jatkowski, A.; Strevig, G.; et al. Circuit and Physical Design of the zEnterprise™ EC12 Microprocessor Chips and Multi-Chip Module. IEEE J. Solid State Circuits 2014, 49, 9–18. [Google Scholar]
- Shum, C.K.; Busaba, F.; Jacobi, C. IBM zEC12: The Third-Generation High-Frequency Mainframe Microprocessor. IEEE Micro 2013, 33, 38–47. [Google Scholar] [CrossRef]
- Haupt, M.; Brunschwiller, T.; Keller, J.; Ozsun, O. Heat transfer modelling of a dual-side cooled microprocessor chip stack with embedded micro-channels. In Proceedings of the 21st International Workshop on Thermal Investigations of ICs and Systems (THERMINIC), Paris, France, 30 September–2 October 2015; pp. 1–4. [Google Scholar]
- Warnock, J.; Chan, Y.H.; Harrer, H.; Rude, D.; Puri, R.; Carey, S.; Salem, G.; Mayer, G.; Chan, Y.H.; Mayo, M.; et al. 5.5 GHz system z microprocessor and multi-chip module. In Proceedings of the IEEE International Solid-State Circuits Conference Digest of Technical Papers, San Francisco, CA, USA, 17–21 February 2013; pp. 46–47. [Google Scholar]
- Choi, M.; Jang, T.; Bang, S.; Shi, Y.; Blaauw, D.; Sylvester, D. A 110 nW Resistive Frequency Locked On-Chip Oscillator with 34.3 ppm/°C Temperature Stability for System-on-Chip Designs. IEEE J. Solid State Circuits 2016, 51, 2106–2118. [Google Scholar] [CrossRef]
- Yen, C.H.; Chen, C.H.; Chen, K.C. A memory-efficient NoC system for OpenCL many-core platform. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Lisbon, Portugal, 24–27 May 2015; pp. 1386–1389. [Google Scholar]
- Arima, E.; Noguchi, H.; Nakada, T.; Miwa, S.; Takeda, S.; Fujita, S.; Nakamura, H. Immediate sleep: Reducing energy impact of peripheral circuits in STT-MRAM caches. In Proceedings of the 33rd IEEE International Conference on Computer Design (ICCD), New York, NY, USA, 18–21 October 2015; pp. 149–156. [Google Scholar]
- Khaitan, S.K.; McCalley, J.D. A hardware-based approach for saving cache energy in multicore simulation of power systems. In Proceedings of the IEEE Power Energy Society General Meeting, Vancouver, BC, Canada, 21–25 July 2013; pp. 1–5. [Google Scholar]
- Wang, Y.; Roy, S.; Ranganathan, N. Run-time power-gating in caches of GPUs for leakage energy savings. In Proceedings of the Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 12–16 March 2012; pp. 300–303. [Google Scholar]
- Bengueddach, A.; Senouci, B.; Niar, S.; Beldjilali, B. Energy consumption in reconfigurable mpsoc architecture: Two-level caches optimization oriented approach. In Proceedings of the 8th IEEE Design and Test Symposium, Marrakesh, Morocco, 16–18 December 2013; pp. 1–6. [Google Scholar]
- Mittal, S.; Zhang, Z.; Vetter, J.S. FlexiWay: A cache energy saving technique using fine-grained cache reconfiguration. In Proceedings of the IEEE 31st International Conference on Computer Design (ICCD), Asheville, NC, USA, 6–9 October 2013; pp. 100–107. [Google Scholar]
- Mittal, S.; Zhang, Z.; Cao, Y. CASHIER: A Cache Energy Saving Technique for QoS Systems. In Proceedings of the 26th International Conference on VLSI Design and 2013 12th International Conference on Embedded Systems, Pune, India, 5–10 January 2013; pp. 43–48. [Google Scholar]
- Wang, W.; Mishra, P. System-Wide Leakage-Aware Energy Minimization Using Dynamic Voltage Scaling and Cache Reconfiguration in Multitasking Systems. IEEE Trans. Very Large Scale Integr. Syst. 2012, 20, 902–910. [Google Scholar] [CrossRef]
- Kadjo, D.; Kim, H.; Gratz, P.; Hu, J.; Ayoub, R. Power gating with block migration in chip-multiprocessor last-level caches. In Proceedings of the IEEE 31st International Conference on Computer Design (ICCD), Asheville, NC, USA, 6–9 October 2013; pp. 93–99. [Google Scholar]
- Cheng, W.K.; Cheng, P.C.; Li, X.L. Adaptive page allocation of DRAM/PCRAM hybrid memory architecture. In Proceedings of the 5th International Symposium on Next-Generation Electronics (ISNE), Hsinchu, Taiwan, 4–6 May 2016; pp. 1–2. [Google Scholar]
- De Abreu Silva, B.; Cuminato, L.A.; Bonato, V. Reducing the overall cache miss rate using different cache sizes for Heterogeneous Multi-core Processors. In Proceedings of the 2012 International Conference on Reconfigurable Computing and FPGAs, Cancun, Mexico, 5–7 December 2012; pp. 1–6. [Google Scholar]
- Bardine, A.; Comparetti, M.; Foglia, P.; Prete, C.A. Evaluation of Leakage Reduction Alternatives for Deep Submicron Dynamic Nonuniform Cache Architecture Caches. IEEE Trans. Very Large Scale Integr. Syst. 2014, 22, 185–190. [Google Scholar] [CrossRef]
- Zhu, H.; Kursun, V. Triple-threshold-voltage 9-transistor SRAM cell for data stability and energy-efficiency at ultra-low power supply voltages. In Proceedings of the 26th International Conference on Microelectronics (ICM), Seoul, Korea, 13–21 August 2014; pp. 176–179. [Google Scholar]
- Chen, K.C.J.; Chao, C.H.; Wu, A.Y.A. Thermal-Aware 3D Network-On-Chip (3D NoC) Designs: Routing Algorithms and Thermal Managements. IEEE Circuits Syst. Mag. 2015, 15, 45–69. [Google Scholar] [CrossRef]
- Hameed, F.; Tahoori, M.B. Architecting STT Last-Level-Cache for performance and energy improvement. In Proceedings of the 17th International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 15–16 March 2016; pp. 319–324. [Google Scholar]
- Rossi, D.; Tenentes, V.; Khursheed, S.; Al-Hashimi, B.M. BTI and leakage aware dynamic voltage scaling for reliable low power cache memories. In Proceedings of the IEEE 21st International On-Line Testing Symposium (IOLTS), Halkidiki, Greece, 6–8 July 2015; pp. 194–199. [Google Scholar]
- Jing, N.; Jiang, L.; Zhang, T.; Li, C.; Fan, F.; Liang, X. Energy-Efficient eDRAM-Based On-Chip Storage Architecture for GPGPUs. IEEE Trans. Comput. 2016, 65, 122–135. [Google Scholar] [CrossRef]
- Chakraborty, S.; Das, S.; Kapoor, H.K. Performance Constrained Static Energy Reduction Using Way-Sharing Target-Banks. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium Workshop, Hyderabad, India, 25–29 May 2015; pp. 444–453. [Google Scholar]
- Sampaio, F.; Shafique, M.; Zatt, B.; Bampi, S.; Henkel, J. Approximation-aware Multi-Level Cells STT-RAM cache architecture. In Proceedings of the International Conference on Compilers, Architecture and Synthesis for Embedded Systems (CASES), Amsterdam, The Netherlands, 4–9 October 2015; pp. 79–88. [Google Scholar]
- Chien, T.K.; Chiou, L.Y.; Lee, C.C.; Chuang, Y.C.; Ke, S.H.; Sheu, S.S.; Li, H.Y.; Wang, P.H.; Ku, T.K.; Tsai, M.J.; et al. An energy-efficient nonvolatile microprocessor considering software-hardware interaction for energy harvesting applications. In Proceedings of the International Symposium on VLSI Design, Automation and Test (VLSI-DAT), Hsinchu, Taiwan, 25–27 April 2016; pp. 1–4. [Google Scholar]
- Saez, J.C.; Prieto, M.; Fedorova, A.; Blagodurov, S. A Comprehensive Scheduler for Asymmetric Multicore Systems. In Proceedings of the 5th European Conference on Computer Systems, Paris, France, 13–16 April 2010; pp. 139–152. [Google Scholar]
- Manoj, P.D.S.; Yu, H. Cyber-physical management for heterogeneously integrated 3D thousand-core on-chip microprocessor. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS2013), Beijing, China, 19–23 May 2013; pp. 533–536. [Google Scholar]
- Lou, M.; Wu, L.; Shi, S.; Lu, P. An energy-efficient two-level cache architecture for chip multiprocessors. In Proceedings of the Fifth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Hefei, China, 11–13 July 2014; pp. 1–5. [Google Scholar]
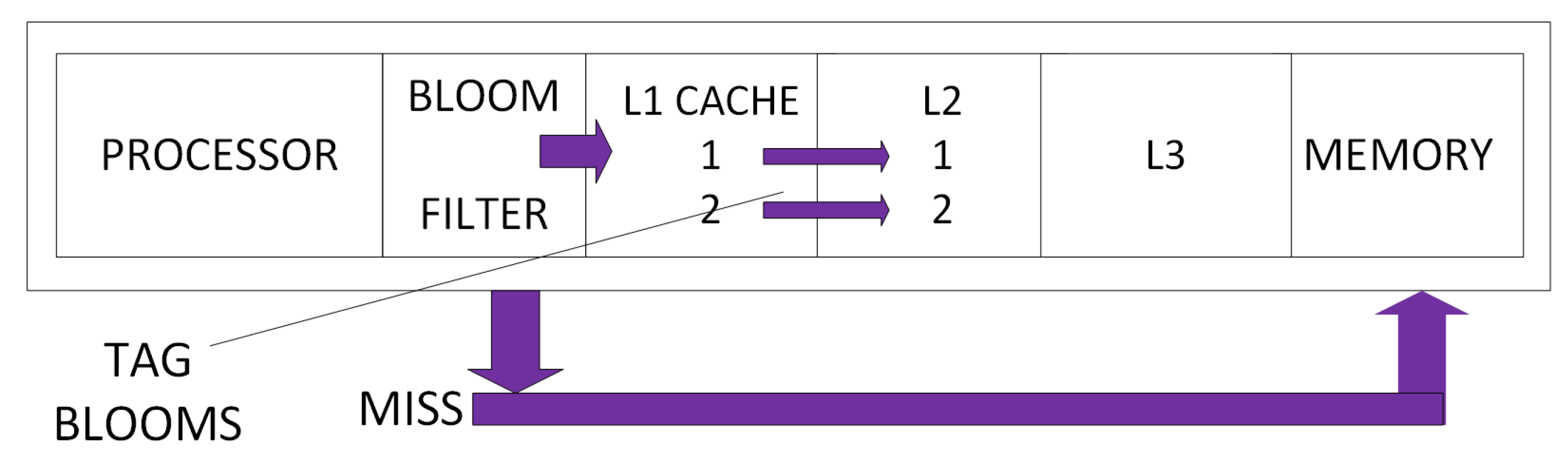
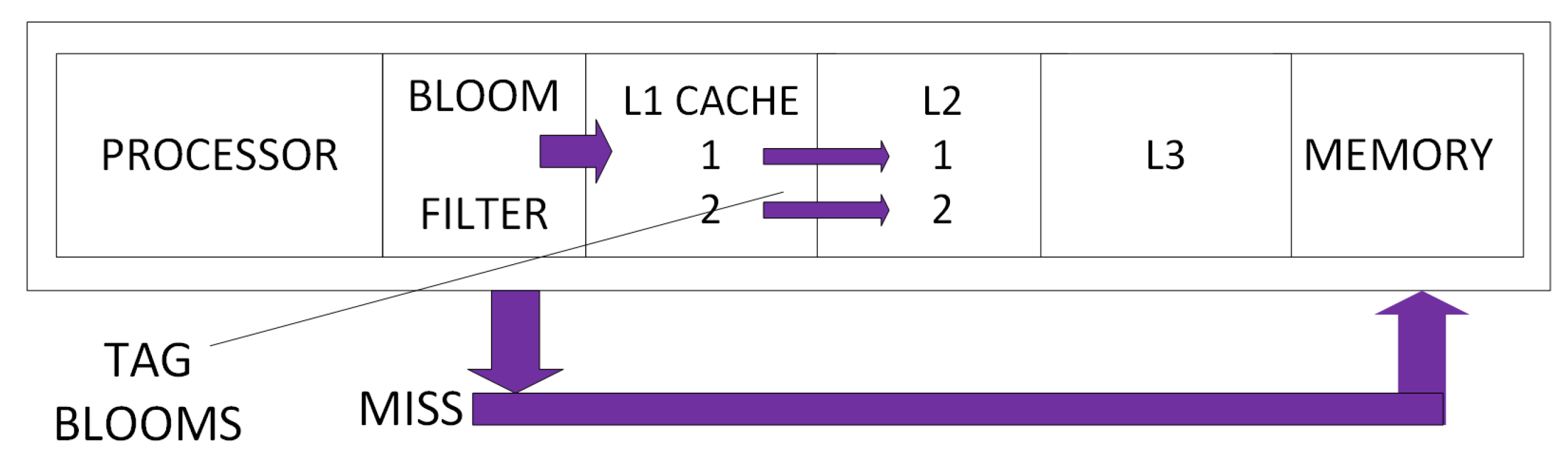
- Aneesh Kumar, A.G.; Janeera, D.A.; Ramesh, M. Power and performance efficient secondary cache using tag bloom architecture. In Proceedings of the International Conference on Electronics and Communication Systems (ICECS), Coimbatore, India, 13–14 Febuary 2014; pp. 1–5. [Google Scholar]
- Subha, S. A reconfigurable cache architecture. In Proceedings of the International Conference on High Performance Computing and Applications (ICHPCA), Bhubaneswar, India, 22–24 December 2014; pp. 1–5. [Google Scholar]
- Ahn, J.; Yoo, S.; Choi, K. Prediction Hybrid Cache: An Energy-Efficient STT-RAM Cache Architecture. IEEE Trans. Comput. 2016, 65, 940–951. [Google Scholar] [CrossRef]
- Lee, J.; Kim, S. Filter Data Cache: An Energy-Efficient Small L0 Data Cache Architecture Driven byMiss Cost Reduction. IEEE Trans. Comput. 2015, 64, 1927–1939. [Google Scholar] [CrossRef]
- Mallya, N.B.; Patil, G.; Raveendran, B. Way Halted Prediction Cache: An Energy Efficient Cache Architecture for Embedded Processors. In Proceedings of the 2015 28th International Conference on VLSI Design, Bangalore, India, 3–7 January 2015; pp. 65–70. [Google Scholar]
- Cilku, B.; Prokesch, D.; Puschner, P. A Time-Predictable Instruction-Cache Architecture that Uses Prefetching and Cache Locking. In Proceedings of the IEEE International Symposium on Object/Component/Service-Oriented Real-Time Distributed Computing Workshops, Auckland, New Zealand, 13–17 April 2015; pp. 74–79. [Google Scholar]
- Kalla, P.; Hu, X.S.; Henkel, J. Distance-based recent use (DRU): An enhancement to instruction cache replacement policies for transition energy reduction. IEEE Trans. Very Large Scale Integr. Syst. 2006, 14, 69–80. [Google Scholar] [CrossRef]
- Mohammadi, M.; Han, S.; Aamodt, T.M.; Dally, W.J. On-Demand Dynamic Branch Prediction. IEEE Comput. Arch. Lett. 2015, 14, 50–53. [Google Scholar] [CrossRef]
- Nadgir, A.; Kandemir, M.; Chen, G.; Chen, G. An access pattern based energy management strategy for instruction caches. In Proceedings of the IEEE International [Systems-on-Chip] SOC Conference, Portland, OR, USA, 17–20 September 2003; pp. 175–178. [Google Scholar]
- Ray, A.; Choudhry, A. Time optimization of instruction execution in FPGA using embedded systems. In Proceedings of the International Conference on Futuristic Trends on Computational Analysis and Knowledge Management (ABLAZE), New Delhi, India, 25–27 February 2015; pp. 566–572. [Google Scholar]
- Li, T.; John, L.K. OS-aware tuning: Improving instruction cache energy efficiency on system workloads. In Proceedings of the IEEE International Performance Computing and Communications Conference, Phoenix, AZ, USA, 10–12 April 2006. [Google Scholar]
- Zhang, C.; Zhang, X.; Yan, Y. Multi-column implementations for cache associativity. In Proceedings of the International Conference on Computer Design VLSI in Computers and Processors, Austin, TX, USA, 12–15 October 1997; pp. 504–509. [Google Scholar]
- Kim, H.; Gratz, P. Leveraging Unused Cache Block Words to Reduce Power in CMP Interconnect. IEEE Comput. Arch. Lett. 2010, 9, 33–36. [Google Scholar]
- Datta, A.K.; Patel, R. CPU Scheduling for Power/Energy Management on Multicore Processors Using Cache Miss and Context Switch Data. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1190–1199. [Google Scholar] [CrossRef]
- Kim, N.; Ahn, J.; Seo, W.; Choi, K. Energy-efficient exclusive last-level hybrid caches consisting of SRAM and STT-RAM. In Proceedings of the IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), Daejeon, Korea, 5–7 October 2015; pp. 183–188. [Google Scholar]
- Grani, P.; Proietti, R.; Cheung, S.; Yoo, S.J.B. Flat-Topology High-Throughput Compute Node with AWGR-Based Optical-Interconnects. J. Lightwave Technol. 2016, 34, 2959–2968. [Google Scholar] [CrossRef]
- Farmahini-Farahani, A.; Ahn, J.H.; Morrow, K.; Kim, N.S. DRAMA: An Architecture for Accelerated Processing Near Memory. IEEE Comput. Arch. Lett. 2015, 14, 26–29. [Google Scholar] [CrossRef]
- Goudarzi, M.; Ishihara, T.; Yasuura, H. A Software Technique to Improve Yield of Processor Chips in Presence of Ultra-Leaky SRAM Cells Caused by Process Variation. In Proceedings of the Asia and South Pacific Design Automation Conference, Yokohama, Japan, 23–26 January 2007; pp. 878–883. [Google Scholar]
- Samavatian, M.H.; Abbasitabar, H.; Arjomand, M.; Sarbazi-Azad, H. An efficient STT-RAM last level cache architecture for GPUs. In Proceedings of the 51st ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 1–5 June 2014; pp. 1–6. [Google Scholar]
- Lee, D.; Choi, K. Energy-efficient partitioning of hybrid caches in multi-core architecture. In Proceedings of the 22nd International Conference on Very Large Scale Integration (VLSI-SoC), Playa del Carmen, Mexico, 6–8 October 2014; pp. 1–6. [Google Scholar]
- Dai, J.; Wang, L. An Energy-Efficient L2 Cache Architecture Using Way Tag Information Under Write-Through Policy. IEEE Trans. Very Large Scale Integr. Syst. 2013, 21, 102–112. [Google Scholar] [CrossRef]
- Lee, J.; Woo, D.H.; Kim, H.; Azimi, M. GREEN Cache: Exploiting the Disciplined Memory Model of OpenCL on GPUs. IEEE Trans. Comput. 2015, 64, 3167–3180. [Google Scholar] [CrossRef]
- Tu, C.Y.; Chang, Y.Y.; King, C.T.; Chen, C.T.; Wang, T.Y. Traffic-aware frequency scaling for balanced on-chip networks on GPGPUs. In Proceedings of the 20th IEEE International Conference on Parallel and Distributed Systems (ICPADS), Hsinchu, Taiwan, 16–19 December 2014; pp. 87–94. [Google Scholar]
- Agyeman, M.O.; Ahmadinia, A.; Shahrabi, A. Low power heterogeneous 3D Networks-on-Chip architectures. In Proceedings of the 2011 International Conference on High Performance Computing Simulation, Istanbul, Turkey, 4–8 July 2011. [Google Scholar]
- Hoskote, Y.; Vangal, S.; Singh, A.; Borkar, N.; Borkar, S. A 5-GHz Mesh Interconnect for a Teraflops Processor. IEEE Micro 2007, 27, 51–61. [Google Scholar] [CrossRef]
- Taylor, M.B.; Psota, J.; Saraf, A.; Shnidman, N.; Strumpen, V.; Frank, M.; Amarasinghe, S.; Agarwal, A.; Lee, W.; Miller, J.; et al. Evaluation of the Raw microprocessor: An exposed-wire-delay architecture for ILP and streams. In Proceedings of the 31st Annual International Symposium on Computer Architecture, München, Germany, 19–23 June 2004; pp. 2–13. [Google Scholar]
- DiTomaso, D.; Kodi, A.K.; Louri, A.; Bunescu, R. Resilient and Power-Efficient Multi-Function Channel Buffers in Network-on-Chip Architectures. IEEE Trans. Comput. 2015, 64, 3555–3568. [Google Scholar] [CrossRef]
- Kundu, P. On-Die Interconnects for Next Generation CMPs. In Proceedings of the Workshop on On- and Off-Chip Interconnection Networks for Multicore Systems, Stanford, CA, USA, 6–7 December 2006. [Google Scholar]
- Sewell, K.; Dreslinski, R.G.; Manville, T.; Satpathy, S.; Pinckney, N.; Blake, G.; Cieslak, M.; Das, R.; Wenisch, T.F.; Sylvester, D.; et al. Swizzle-Switch Networks for Many-Core Systems. IEEE J. Emerg. Sel. Top. Circuits Syst. 2012, 2, 278–294. [Google Scholar] [CrossRef]
- Vangal, S.R.; Howard, J.; Ruhl, G.; Dighe, S.; Wilson, H.; Tschanz, J.; Finan, D.; Singh, A.; Jacob, T.; Jain, S.; et al. An 80-Tile Sub-100-W TeraFLOPS Processor in 65-nm CMOS. IEEE J. Solid State Circuits 2008, 43, 29–41. [Google Scholar] [CrossRef]
- Taylor, M.B.; Kim, J.; Miller, J.; Wentzlaff, D.; Ghodrat, F.; Greenwald, B.; Hoffman, H.; Johnson, P.; Lee, J.W.; Lee, W.; et al. The Raw microprocessor: A computational fabric for software circuits and general-purpose programs. IEEE Micro 2002, 22, 25–35. [Google Scholar] [CrossRef]
- Palma, J.C.S.; Indrusiak, L.S.; Moraes, F.G.; Reis, R.; Glesner, M. Reducing the Power Consumption in Networks-on-Chip through Data Coding Schemes. In Proceedings of the 2007 14th IEEE International Conference on Electronics, Circuits and Systems, Marrakech, Morocco, 11–14 December 2007; pp. 1007–1010. [Google Scholar]
- Feng, C.; Liao, Z.; Lu, Z.; Jantsch, A.; Zhao, Z. Performance analysis of on-chip bufferless router with multi-ejection ports. In Proceedings of the IEEE 11th International Conference on ASIC (ASICON), Chengdu, China, 3–6 November 2015; pp. 1–4. [Google Scholar]
- Fallin, C.; Craik, C.; Mutlu, O. CHIPPER: A low-complexity bufferless deflection router. In Proceedings of the IEEE 17th International Symposium on High Performance Computer Architecture, San Antonio, TX, USA, 12–16 February 2011; pp. 144–155. [Google Scholar]
- Daya, B.K.; Peh, L.S.; Chandrakasan, A.P. Towards High-Performance Bufferless NoCs with SCEPTER. IEEE Comput. Arch. Lett. 2016, 15, 62–65. [Google Scholar] [CrossRef]
- Xiang, X.Y.; Tzeng, N.F. Deflection Containment for Bufferless Network-on-Chips. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium (IPDPS), Chicago, IL, USA, 23–27 May 2016; pp. 113–122. [Google Scholar]
- Kodi, A.K.; Sarathy, A.; Louri, A.; Wang, J. Adaptive inter-router links for low-power, area-efficient and reliable Network-on-Chip (NoC) architectures. In Proceedings of the Asia and South Pacific Design Automation Conference, Yokohama, Japan, 19–22 January 2009; pp. 1–6. [Google Scholar]
- Li, C.; Ampadu, P. A compact low-power eDRAM-based NoC buffer. In Proceedings of the IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Rome, Italy, 22–24 July 2015; pp. 116–121. [Google Scholar]
- Postman, J.; Krishna, T.; Edmonds, C.; Peh, L.S.; Chiang, P. SWIFT: A Low-Power Network-On-Chip Implementing the Token Flow Control Router Architecture With Swing-Reduced Interconnects. IEEE Trans. Very Large Scale Integr. Syst. 2013, 1432–1446. [Google Scholar] [CrossRef]
- Shenbagavalli, S.; Karthikeyan, S. An efficient low power NoC router architecture design. In Proceedings of the Online International Conference on Green Engineering and Technologies (IC-GET), Coimbatore, India, 27 November 2015; pp. 1–8. [Google Scholar]
- Sharma, P.K.; Bairathi, R. Study and analysis of the behavior of a generic mesh architecture of NoC routers. In Proceedings of the International MultiConference of Engineers and Computer Scientists, Hong Kong, China, 17–19 March 2010; pp. 17–19. [Google Scholar]
- Nadi, M.; Ghadiry, M.H.; Dermany, M.K. The Effect of Number of Virtual Channels on NoC EDP. J. Appl. Math. Informat. 2010, 3, 539–551. [Google Scholar]
- Muhammad, S.T.; El-Moursy, M.A.; El-Moursy, A.A.; Refaat, A.M. Optimization for traffic-based virtual channel activation low-power NoC. In Proceedings of the International Conference on Energy Aware Computing Systems Applications (ICEAC), Toledo, Spain, 22–28 July 2015; pp. 1–4. [Google Scholar]
- Zhan, J.; Ouyang, J.; Ge, F.; Zhao, J.; Xie, Y. Hybrid Drowsy SRAM and STT-RAM Buffer Designs for Dark-Silicon-Aware NoC. IEEE Trans. Very Large Scale Integr. Syst. 2016, 24, 3041–3054. [Google Scholar] [CrossRef]
- Nasirian, N.; Bayoumi, M. Low-latency power-efficient adaptive router design for network-on-chip. In Proceedings of the 28th IEEE International System-on-Chip Conference (SOCC), Kohala Coast, HI, USA, 27–29 August 2015; pp. 287–291. [Google Scholar]
- Phan, H.P.; Tran, X.T. Fuzzy-logic based low power solution for Network-on-Chip architectures. In Proceedings of the 2016 International Conference on Advanced Technologies for Communications (ATC), Hanoi City, Vietnam, 12–14 October 2016; pp. 334–338. [Google Scholar]
- Agyeman, M.O.; Ahmadinia, A.; Shahrabi, A. Efficient routing techniques in heterogeneous 3D Networks-on-Chip. Parallel Comput. 2013, 39, 389–407. [Google Scholar] [CrossRef]
- Agyeman, M.O.; Ahmadinia, A.; Shahrabi, A. Heterogeneous 3D Network-on-Chip Architectures: Area and Power Aware Design Techniques. J. Circuits Syst. Comput. 2013, 22, 1350016. [Google Scholar] [CrossRef]
- Xia, Y.; Hamdi, M.; Chao, H.J. A Practical Large-Capacity Three-Stage Buffered Clos-Network Switch Architecture. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 317–328. [Google Scholar] [CrossRef]
- Yang, S.; Xin, S.; Zhao, Z.; Wu, B. Minimizing Packet Delay via Load Balancing in Clos Switching Networks for Datacenters. In Proceedings of the International Conference on Networking and Network Applications (NaNA), Hokkaido, Japan, 23–25 July 2016; pp. 23–28. [Google Scholar]
- Zhang, J.; Gu, H. A partially adaptive routing algorithm for Benes network on chip. In Proceedings of the 2nd IEEE International Conference on Computer Science and Information Technology, Beijing, China, 8–11 August 2009; pp. 614–618. [Google Scholar]
- Jiang, Y.; Yang, M. On circuit design of on-chip non-blocking interconnection networks. In Proceedings of the 27th IEEE International System-on-Chip Conference (SOCC), Seattle, WA, USA, 3–5 November 2014; pp. 192–197. [Google Scholar]
- Naik, A.; Ramesh, T.K. Efficient Network on Chip (NoC) using heterogeneous circuit switched routers. In Proceedings of the International Conference on VLSI Systems, Architectures, Technology and Applications (VLSI-SATA), Tamil Nadu, India, 10–12 January 2016; pp. 1–6. [Google Scholar]
- Kim, J.; Nicopoulos, C.; Park, D. A Gracefully Degrading and Energy-Efficient Modular Router Architecture for On-Chip Networks. In Proceedings of the 33rd International Symposium on Computer Architecture (ISCA’06), Boston, MA, USA, 17–21 June 2006; pp. 4–15. [Google Scholar]
- Park, D.; Vaidya, A.; Kumar, A.; Azimi, M. MoDe-X: Microarchitecture of a Layout-Aware Modular Decoupled Crossbar for On-Chip Interconnects. IEEE Trans. Comput. 2014, 63, 622–636. [Google Scholar]
- FallahRad, M.; Patooghy, A.; Ziaeeziabari, H.; Taheri, E. CirKet: A Performance Efficient Hybrid Switching Mechanism for NoC Architectures. In Proceedings of the Euromicro Conference on Digital System Design (DSD), Limassol, Cyprus, 31 August–2 September 2016; pp. 123–130. [Google Scholar]


© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ofori-Attah, E.; Bhebhe, W.; Agyeman, M.O. Architectural Techniques for Improving the Power Consumption of NoC-Based CMPs: A Case Study of Cache and Network Layer. J. Low Power Electron. Appl. 2017, 7, 14. https://doi.org/10.3390/jlpea7020014
Ofori-Attah E, Bhebhe W, Agyeman MO. Architectural Techniques for Improving the Power Consumption of NoC-Based CMPs: A Case Study of Cache and Network Layer. Journal of Low Power Electronics and Applications. 2017; 7(2):14. https://doi.org/10.3390/jlpea7020014
Chicago/Turabian StyleOfori-Attah, Emmanuel, Washington Bhebhe, and Michael Opoku Agyeman. 2017. "Architectural Techniques for Improving the Power Consumption of NoC-Based CMPs: A Case Study of Cache and Network Layer" Journal of Low Power Electronics and Applications 7, no. 2: 14. https://doi.org/10.3390/jlpea7020014
APA StyleOfori-Attah, E., Bhebhe, W., & Agyeman, M. O. (2017). Architectural Techniques for Improving the Power Consumption of NoC-Based CMPs: A Case Study of Cache and Network Layer. Journal of Low Power Electronics and Applications, 7(2), 14. https://doi.org/10.3390/jlpea7020014